


پیادهسازی پایتون از رگرسیون وزندار جغرافیایی چند مقیاسی برای بررسی ناهمگونی و مقیاس فضایی فرآیند
چکیده
1. مقدمه
2. کد منبع و مجموعه داده ها
2.1. کد منبع و نصب
2.2. مجموعه داده ها
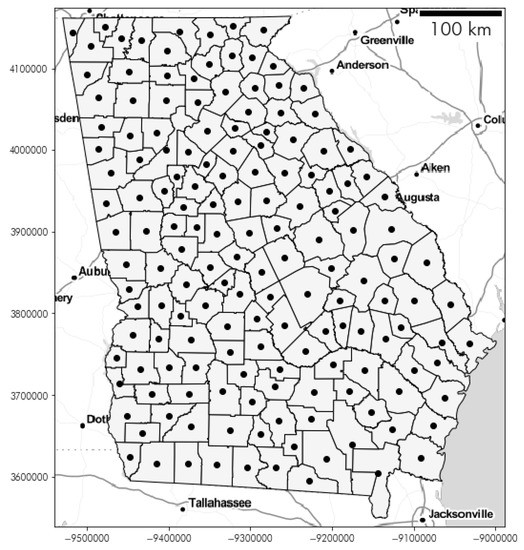
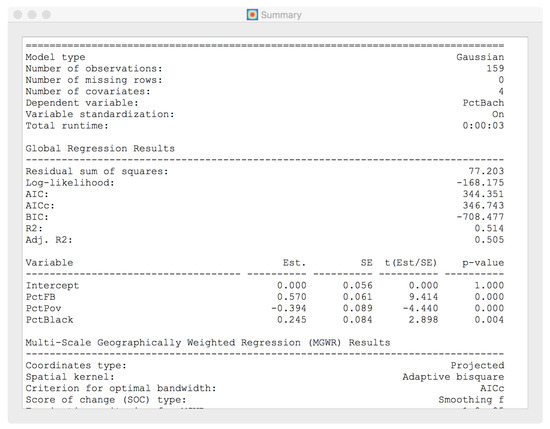
2.2.1. مجموعه داده گرجستان
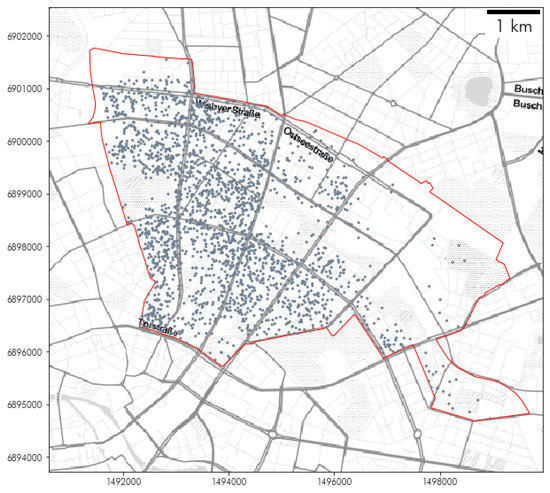
2.2.2. مجموعه داده های Airbnb برلین
3. عملکرد GWR
جایی که yمنمتغیر وابسته در مکان i است، βمن 0ضریب رهگیری در مکان i است، ایکسمنکk- امین متغیر توضیحی در مکان i است، βمن کk- امین ضریب رگرسیون محلی برای k امین متغیر توضیحی در مکان i است، و ϵمنعبارت خطای تصادفی مرتبط با مکان i است. توجه داشته باشید که i معمولاً با مختصات جغرافیایی دو بعدی نمایه می شود. (تومن،vمن)، نشان دهنده محل نقطه رگرسیون است. در شکل ماتریسی، برآوردگر GWR برای تخمین پارامترهای محلی در سایت i است:
جایی که ایکسیک ماتریس n در k از متغیرهای توضیحی است، دبلیو( i ) = دیگ [w1( من ) ، … _wn( من ) ]ماتریس وزن مورب n در n است که هر مشاهده را بر اساس فاصله آن از مکان i وزن می کند ، β^( من )بردار k در 1 ضرایب است و yبردار k در 1 مشاهدات متغیر وابسته است. ورودی های مدل، ایکس، yو مختصات جغرافیایی ( u , v )، برای مجموعه داده های گرجستان و برلین به شرح زیر آماده شده اند:
3.1. طرح فاصله وزنی
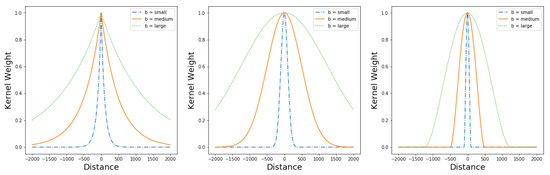
3.1.1. توابع هسته
3.1.2. انواع هسته
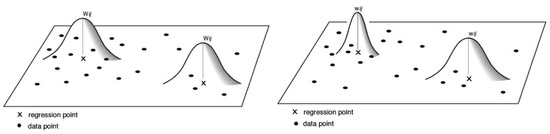
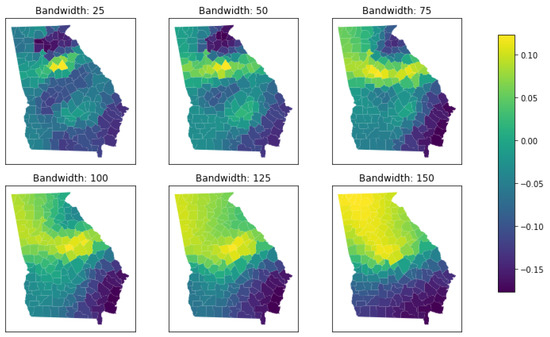
3.2. انتخاب پهنای باند
که در آن n تعداد مشاهدات است، اسماتریس نفوذ یا کلاه است و آر اساسمجموع مربعات باقی مانده است.
3.3. کالیبراسیون مدل
3.4. مدل های احتمال
از spglm.family import Poisson، Binomial
و سپس لازم است که خانواده = Poisson() یا Family = Binomial() را هنگام نمونه سازی یک شی Sel_BW یا GWR تنظیم کنید. به طور کلی، وارد کردن یا مشخص کردن یک شی خانواده گاوسی ضروری نیست زیرا این رفتار پیش فرض در سراسر mgwr است.
3.5. تشخیص مدل
3.5.1. مدل مناسب
3.5.2. استنتاج بر برآورد پارامترهای فردی
جایی که سه( من ، ج )خطای استاندارد مرتبط با منjتی ساعتتخمین پارامتر با این حال، ماهیت طرح وزندهی فاصله به طور بالقوه میتواند باعث شود که نمونههای فرعی محلی وابسته باشند و اصلاحی برای محاسبه آزمونهای فرضیههای وابسته چندگانه ایجاد شده است [ 12 ]. به جای استفاده از معمولی α = 0.05ارزشی که به الف مربوط می شود 95 درصدفاصله اطمینان، جایگزین اصلاح شد αاز رابطه زیر بدست می آید:
جایی که Eنپتعداد مؤثر پارامترهایی است که با گرفتن ردی از ماتریس کلاه GWR به دست میآید (نشان داده شده با اس، p تعداد متغیرهای توضیحی است و ξمیزان خطای مورد نظر نوع I در مجموعه آزمایشات است. نسبت Eنپپ( Eنپ> ص) معرف تعداد تست های متعدد است و اگر په= صسپس ξ= αو تعداد تست های انجام شده توسط GWR و یک رگرسیون جهانی معادل هستند.
3.5.3. استنتاج بر روی سطح تخمین پارامترها
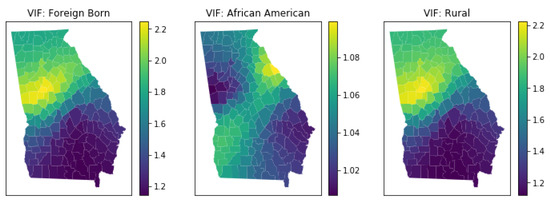
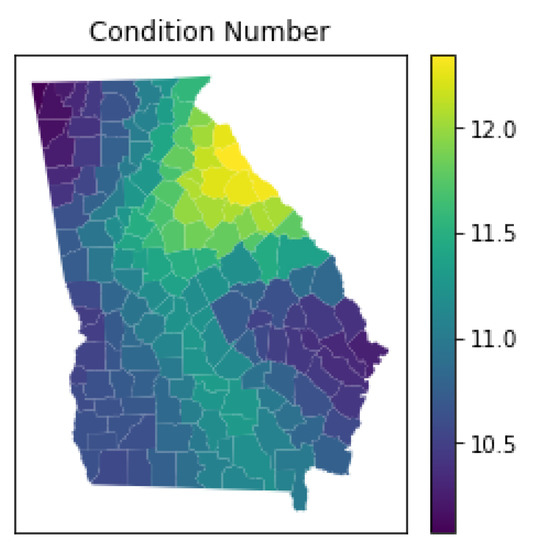
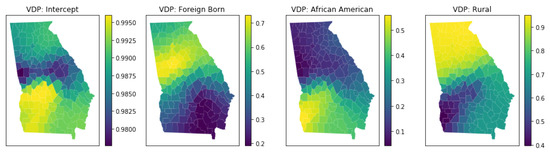
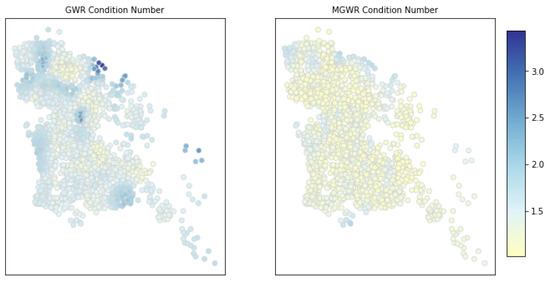
3.5.4. چند خطی محلی
3.6. پیشبینی فضایی خارج از نمونه
4. قابلیت MGWR
جایی که fjیک تابع هموارسازی (به عنوان مثال، طرح استقراض داده) است که به آن اعمال می شود jتی ساعتمتغیر توضیحی که ممکن است با پارامتر پهنای باند مجزا مشخص شود [ 3 ]. در این بخش، مفاهیم و عملکرد جدید لازم برای کالیبراسیون و ارزیابی یک مدل MGWR با توجه ویژه به جزئیاتی که با عملکرد GWR قبلا معرفی شده متفاوت است، معرفی میشوند.
4.1. استانداردسازی متغیرها
4.2. انتخاب پهنای باند و کالیبراسیون مدل
4.3. تنظیم دستی پهنای باند خاص متغیر کمکی
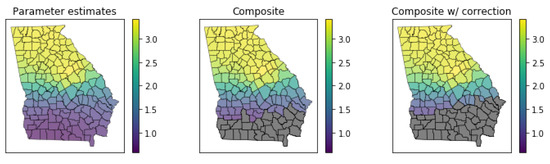
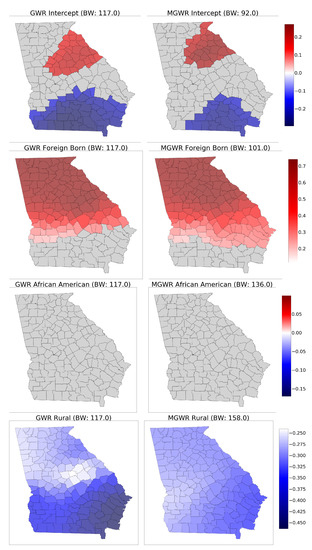
4.4. مدل مناسب
4.5. استنباط بر برآورد پارامترها
جایی که p حذف می شود زیرا برای هر رابطه p = 1. رفتار پیش فرض در mgwr استفاده است αjبرای محاسبه یک مقدار t بحرانی ویژه متغیر کمکی برای آزمون فرضیه. امکان بازرسی هر کدام وجود دارد Eنپj، αjو مقادیر t تنظیم شده به صورت زیر است:
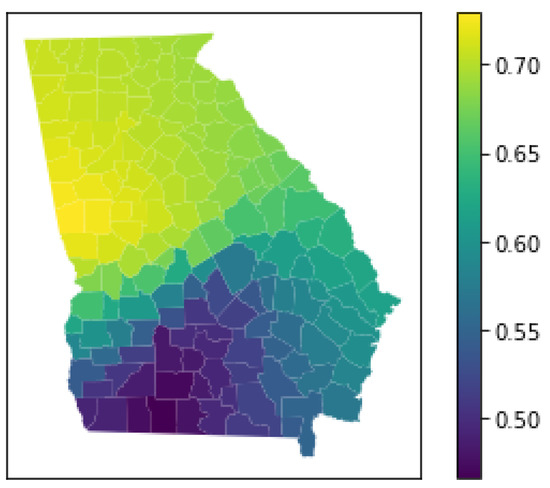
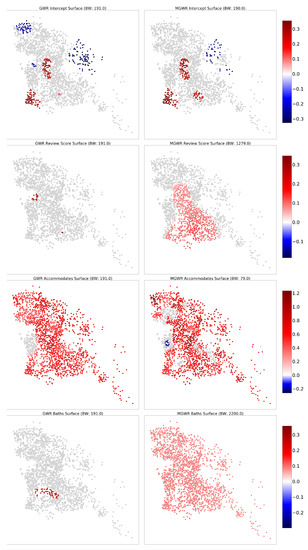
4.5.1. مجموعه داده جورجیا
4.5.2. مجموعه داده برلین
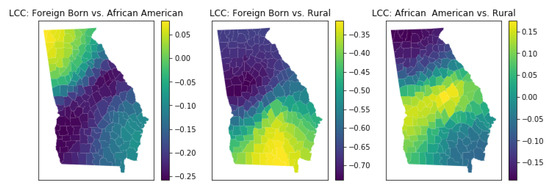
4.6. چند خطی محلی
5. ویژگی های اضافی
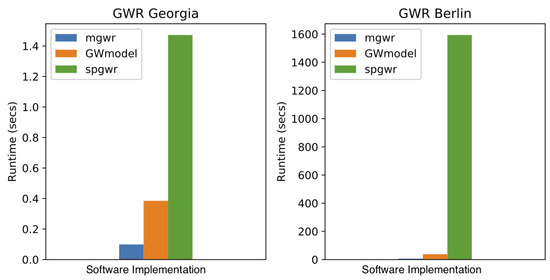
5.1. کارایی محاسباتی
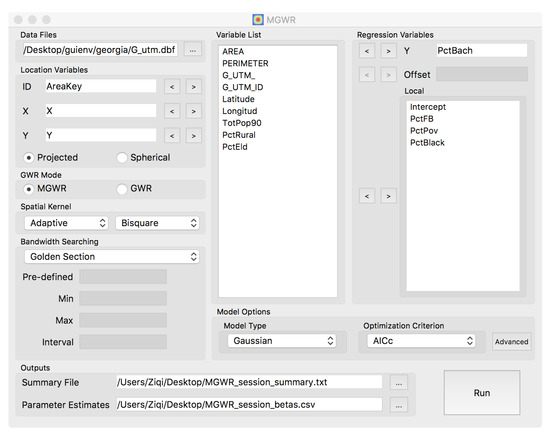
5.2. دسترسی
6. نتیجه گیری
مشارکت های نویسنده
منابع مالی
تضاد علاقه
منابع
- Tobler, WR یک فیلم کامپیوتری شبیه سازی رشد شهری در منطقه دیترویت. اقتصاد Geogr. 1970 , 46 , 234. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; براندون، سی. چارلتون، ام. رگرسیون وزندار جغرافیایی: تحلیل روابط متغیر فضایی . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2002. [ Google Scholar ]
- Fotheringham، AS; یانگ، دبلیو. کانگ، دبلیو. رگرسیون وزنی جغرافیایی چند مقیاسی. ان صبح. دانشیار Geogr. 2017 ، 107 ، 1247-1265. [ Google Scholar ]
- موسسه تحقیقات سیستم های محیطی (ESRI). جعبه ابزار تحلیل فضایی ArcMap 10.3 . ESRI: Redlands، CA، USA، 2018. [ Google Scholar ]
- بیوند، ر. یو، دی. ناکایا، تی. گارسیا-لوپز، MA spgwr : رگرسیون وزندار جغرافیایی ، بسته R نسخه 0.6-32. 2017. [ Google Scholar ]
- Wheeler، D. gwrr : متناسب با مدلهای رگرسیون دارای وزن جغرافیایی با ابزارهای تشخیصی ، بسته R نسخه 0.2-1. 2013. [ Google Scholar ]
- یو، اچ. Fotheringham، AS; لی، ز. اوشان، تی. کانگ، دبلیو. استنتاج Wolf، LJ در رگرسیون وزندار جغرافیایی چند مقیاسی. Geogr. مقعدی 2019 . [ Google Scholar ] [ CrossRef ]
- لو، بی. هریس، پی. چارلتون، ام. بروندسون، سی. نایاکا، تی. Gollini ، I. GWmodel : Geographically-Weighted Models ، بسته R نسخه 2.0-5. 2018. [ Google Scholar ]
- لو، بی. براندون، سی. چارلتون، ام. هریس، پی. رگرسیون وزندار جغرافیایی با معیارهای فاصله خاص پارامتر. بین المللی جی. جئوگر. Inf. علمی 2017 ، 31 ، 982-998. [ Google Scholar ] [ CrossRef ]
- لی، ز. Fotheringham، AS; لی، دبلیو. اوشان، تی. رگرسیون وزندار جغرافیایی سریع (FastGWR): یک الگوریتم مقیاسپذیر برای بررسی ناهمگونی فرآیند فضایی در میلیونها مشاهده. بین المللی جی. جئوگر. Inf. علمی 2018 . [ Google Scholar ] [ CrossRef ]
- گریفیث، DA مشارکتهای مبتنی بر فیلتر فضایی در نقد رگرسیون وزندار جغرافیایی (GWR). محیط زیست طرح. A 2008 , 40 , 2751-2769. [ Google Scholar ] [ CrossRef ]
- داسیلوا، آر. Fotheringham، AS مسئله آزمایش چندگانه در رگرسیون وزندار جغرافیایی: مسئله آزمایش چندگانه در GWR. Geogr. مقعدی 2015 . [ Google Scholar ] [ CrossRef ]
- ویلر، دی. Tiefelsdorf، M. چند خطی و همبستگی بین ضرایب رگرسیون محلی در رگرسیون وزنی جغرافیایی. جی. جئوگر. سیستم 2005 ، 7 ، 161-187. [ Google Scholar ] [ CrossRef ]
- بلزی، دی. کوه، ای. Welsch، RE Regression Diagnostics: شناسایی دادههای تأثیرگذار و منابع همخطی . Wiley: نیویورک، نیویورک، ایالات متحده آمریکا، 1980. [ Google Scholar ]
- اوبرین، RM یک احتیاط در مورد قوانین سرانگشتی برای عوامل تورم واریانس. کیفیت مقدار. 2007 ، 41 ، 673-690. [ Google Scholar ] [ CrossRef ]
- Wheeler، ابزارهای تشخیصی DC و یک روش اصلاحی برای هم خطی در رگرسیون وزندار جغرافیایی. محیط زیست طرح. A 2007 , 39 , 2464-2481. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; اوشان، TM رگرسیون وزنی جغرافیایی و چند خطی: رد اسطوره. جی. جئوگر. سیستم 2016 ، 18 ، 303-329. [ Google Scholar ] [ CrossRef ]
- اوشان، TM; Fotheringham، AS مقایسه تخمینهای ضریب رگرسیون فضایی با استفاده از تکنیکهای وزندار جغرافیایی و مبتنی بر فیلتر فضایی: مقایسه رگرسیون متغیر فضایی. Geogr. مقعدی 2017 . [ Google Scholar ] [ CrossRef ]
- موراکامی، دی. لو، بی. هریس، پی. براندون، سی. چارلتون، ام. ناکایا، تی. گریفیث، DA اهمیت مقیاس در مدلسازی ضریب متغیر فضایی. arXivt 2017 , arXiv:1709.08764. [ Google Scholar ] [ CrossRef ]
- هریس، پی. Fotheringham، AS; کرسپو، آر. چارلتون، ام. استفاده از رگرسیون دارای وزن جغرافیایی برای پیش بینی فضایی: ارزیابی مدل ها با استفاده از مجموعه داده های شبیه سازی شده. ریاضی. Geosci. 2010 ، 42 ، 657-680. [ Google Scholar ] [ CrossRef ]
- لو، بی. یانگ، دبلیو. Ge، Y. Harris, P. بهبودهایی در کالیبراسیون یک رگرسیون وزندار جغرافیایی با معیارهای فاصله و پهنای باند خاص پارامتر. محاسبه کنید. محیط زیست سیستم شهری 2018 . [ Google Scholar ] [ CrossRef ]
- کامبر، ا. چی، ک. کوانگ هوی، ام. نگوین، کیو. لو، بی. هوو فه، اچ. هریس، P. انتخاب متریک فاصله میتواند هم خطی بودن را در رگرسیون وزندار جغرافیایی کاهش دهد و هم القا کند. محیط زیست طرح. ب مقعد شهری. علوم شهر 2018 . [ Google Scholar ] [ CrossRef ]


Fatal error: Uncaught TypeError: ltrim(): Argument #1 ($string) must be of type string, WP_Error given in /home/gisland/public_html/wp-includes/formatting.php:4486 Stack trace: #0 /home/gisland/public_html/wp-includes/formatting.php(4486): ltrim(Object(WP_Error)) #1 /home/gisland/public_html/wp-content/themes/xtra/functions.php(3349): esc_url(Object(WP_Error)) #2 /home/gisland/public_html/wp-content/themes/xtra/single.php(19): Codevz_Core_Theme::generate_page('single') #3 /home/gisland/public_html/wp-includes/template-loader.php(113): include('/home/gisland/p...') #4 /home/gisland/public_html/wp-blog-header.php(19): require_once('/home/gisland/p...') #5 /home/gisland/public_html/index.php(17): require('/home/gisland/p...') #6 {main} thrown in /home/gisland/public_html/wp-includes/formatting.php on line 4486