

واژههای کلیدی:
بازیابی اطلاعات جغرافیایی. برنامه آنلاین؛ پردازش داده های جغرافیایی از راه دور
چکیده
ابزار جمعبندی و جمعبندی آنلاین سفارشی برای سیستم رسترهای محیطی (COASTER) (www.COASTERdata.net) توسط مرکز تحقیقات زیستمحیطی یلوستون (YERC) (www.yellowstoneresearch.org) در پاسخ به نیازهای اطلاعاتی جوامع کاربر نهایی علاقهمند توسعه داده شد. در حمایت از تصمیم گیری برای مدیریت منابع طبیعی هدف COASTER ساده کردن فرآیند ایجاد مجموعه داده های پیش بینی کننده برای تحقیقاتی است که اثرات زیست محیطی ناشی از تغییرات آب و هوا، فعالیت های کاربری زمین، اختلالات و گسترش تهاجمی را بررسی می کند. COASTER با ارائه یک سیستم مبتنی بر وب برای پردازش مجموعه داده های محیطی (شبکه ای، شطرنجی) با استفاده از مجموعه ای از توابع استاندارد شده، برای ایجاد خروجی سفارشی شده برای برآوردن نیازهای تحلیلی کاربران، به این هدف دست می یابد. در انجام این کار، COASTER به طور موثر مجموعه داده های بزرگ و دست و پا گیر را به اطلاعات مشخص شده توسط کاربر ترجمه می کند که برای پارامترسازی مدل های آماری و برای تجسم الگوهای مکانی و زمانی در مجموعه داده های محیطی مفید است. سیستم COASTER در حال حاضر حاوی بیش از 10 ترابایت داده آب و هوا از چندین منبع است. این مجموعه داده ها دارای وضوح زمانی روزانه، تفکیک مکانی بین 1 کیلومتر تا 330 کیلومتر، و گستره زمانی بین 30 تا 64 سال (1948-2011) هستند. مجموعه داده های COASTER در درجه اول به آمریکای شمالی محدود می شوند، اما مجموعه داده های شبکه بندی شده از مناطق دیگر به راحتی می توانند به سیستم اضافه شوند. متغیرهای موجود در مجموعه دادههای آب و هوایی موجود در COASTER شامل معیارهایی هستند که دما، بارش، تابش موج کوتاه، کمبود فشار بخار، رطوبت و شرایط باد را تعیین میکنند.
1. مقدمه
متغیرهای محیطی که شرایط تغییر زیستگاه را در طول زمان مشخص میکنند، برای ارزیابی نرخ حیاتی گونهها و سلامت جامعه و اکوسیستم، و برای حمایت از تصمیمات مدیریت منابع آگاهانه بسیار ارزشمند هستند. متغیرهای مورد علاقه خاص برای چنین وظایفی شامل مجموعه داده های شطرنجی (به عنوان مثال، مجموعه داده های جغرافیایی شبکه ای، دیوار به دیوار) است که شرایط آب و هوایی، فنولوژی پوشش گیاهی و/یا بهره وری، و اطلاعات رطوبت/آب با وضوح زمانی و مکانی کافی برای تجزیه و تحلیل پدیده ها را به تصویر می کشد. مورد علاقه. استفاده از چنین متغیرهایی چالش برانگیز است، با این حال، به دلایلی از جمله: 1) هزینه بالا و سطح تخصص فن آوری مورد نیاز برای تولید مجموعه داده های اساسی. 2) قابلیت های مدیریت داده های لازم برای به دست آوردن و ذخیره مجموعه داده های موجود؛ و 3) زیرساخت محاسباتی، بسته های نرم افزاری و مهارت های برنامه نویسی کامپیوتری لازم برای استخراج و ترکیب اطلاعات مفید از مجموعه داده های بزرگ. سیستم سفارشیسازی آنلاین و جمعبندی و جمعبندی آنلاین برای رسترهای محیطی (COASTER) برای کاهش یا حذف این چالشها با ارائه موارد زیر طراحی شده است: 1) دسترسی به مجموعه دادههای بسیار جستجو شده، شروع با مجموعه دادههای آب و هوایی درونیابی شده که دارای وضوح زمانی روزانه هستند. 2) مجموعه ای از ابزارها که با پردازش داده ها در یک سرور راه دور، محاسبات و قابلیت های ذخیره سازی داده مورد نیاز کاربران را کاهش می دهد. و 3) ارائه (از طریق وب) محصولات سفارشی شده که به آسانی در یک محیط نرم افزار GIS یا سنجش از دور ادغام، کاوش و تجزیه و تحلیل می شوند. هدف سیستم COASTER تولید خروجی تعریف شده توسط کاربر برای رفع نیازهای تحلیلی خاص به سادگی و آسانی است.
نسخه فعلی (بتا) سیستم COASTER شامل مجموعه داده های شطرنجی آب و هوایی درون یابی شده با وضوح مکانی متنوع (به اندازه 1 کیلومتر)، گستره مکانی (منطقه ای به جهانی)، وضوح زمانی روزانه، و گستره زمانی (30 تا 64 سال در مدت زمان) است. . مجموعه داده های میزبانی شده در COASTER شامل متغیرهایی از سیستم مشاهده و پیش بینی زمینی (TOPS) [1،2] برای ایالات متحده و آلاسکا به هم پیوسته، و داده های TOPOMET برای ایالات متحده به هم پیوسته است که توسط گروه شبیه سازی ترادینامیک عددی دانشگاه مونتانا تولید شده است. . مجموعه دادههای TOPS و TOPOMET با استفاده از الگوریتمهای درونیابی تنظیمشده توپوگرافی مشابه برای برآورد شرایط در مناطق بین ایستگاههای پایه هواشناسی ایجاد شدند. روش های درون یابی زیربنای TOPS و TOPOMET بسیار شبیه به روشی است که در مدل DAYMET استفاده شده است [3 ] و رویکردی مشابه با روشی که در مدل رگرسیون پارامتری شیبهای مستقل (PRISM) استفاده میشود [ 4 ] را دنبال کنید. COASTER همچنین شامل چندین محصول توزیع شده توسط NOAA از جمله متغیرهایی از مجموعه داده NCEP/NCAR [ 5 ]، مرکز پیش بینی آب و هوا (CPC) تجزیه و تحلیل یکپارچه مبتنی بر سنج مجموعه داده های بارش روزانه [ 6 ]، و متغیرهایی از NCEP/NARR (آمریکای شمالی) است. تجزیه و تحلیل مجدد منطقه ای) مجموعه داده [ 7]. در حالی که COASTER در حال حاضر فقط حاوی داده های آب و هوایی است، الگوریتم های زیربنایی برای طیف گسترده ای از مجموعه داده های شطرنجی متغیر موقت از جمله تصاویر ماهواره ای، محصولات تصاویر طبقه بندی شده و معیارهای مدل شده که شرایط و فرآیندهای اکوسیستم را مشخص می کنند (به عنوان مثال، بهره وری، شرایط هیدرولوژیکی، زیست توده و غیره) قابل استفاده هستند. ). برای فهرست کامل مجموعه دادههایی که در حال حاضر در COASTER میزبانی میشوند، شامل متغیرهایی که هر مجموعه داده وجود دارد و ویژگیهای مجموعه، لطفاً به https://www.coasterdata.net/documents/COASTER_metadata.html مراجعه کنید.
مجموعه دادههای موجود در COASTER به این دلیل انتخاب شدند که معمولاً باید خلاصه شوند (یعنی از مقادیر روزانه به مقداری از تجمع زمانی تبدیل شوند) برای استفاده در تجزیه و تحلیل محیطی و برنامههای مدیریت منابع. وضوح زمانی روزانه مجموعه داده های موجود نیز برای نشان دادن قدرت و انعطاف پذیری سیستم COASTER مناسب است. همه مجموعههای داده در COASTER توسط سازمانهایی که آنها را تولید کردهاند تأیید شدهاند، اما مانند همه مجموعههای داده مدلسازیشده، محدودیتهایی وجود دارد که کاربران باید در نظر بگیرند. با این حال، توجه به این نکته مهم است که محدودیتهای ذاتی در مجموعه دادههای فردی فراتر از محدوده این مقاله است.
2. پس زمینه
ایجاد و/یا توزیع مجموعه داده های آب و هوایی شطرنجی چالشی است که توسط چندین گروه مختلف انجام می شود. آزمایشگاه تحقیقاتی سیستم زمین NOAA، بخش علوم فیزیکی (www.esrl.noaa.gov/psd/) مجموعهای متنوع و مفید از مجموعه دادههای هواشناسی شبکهبندیشده را با تفکیکپذیری مکانی بالا زمانی اما پایین (یعنی 25 کیلومتر و بالاتر) توزیع میکند. پروژههای قابل توجهی که دادهها را با وضوحهای قابل مقایسه یا دقیقتر تولید و/یا توزیع میکنند عبارتند از DAYMET (daymet.ornl.gov)، PRISM (www.prism.oregonstate.edu) [ 4 ]، آب و هوای غربی آمریکای شمالی (www.genetics.forestry.ubc) .ca/cfcg/ClimateWNA/ClimateWNA.html) [8،9]، واحد تحقیقات آب و هوا (CRU) (www.cru.uea.ac.uk/) [ 10 ]، WorldClim (www.worldclim.org/) [ 11 ]، کلیموند (www.climond.org) [ 12]، و RIMS قطب شمال (rims.unh.edu). این پروژهها با مجموعه دادههایی که در خود دارند، مدلهای اساسی مورد استفاده برای ایجاد دادهها و روشهای توزیع دادههایی که به کار میبرند، متمایز میشوند.
چیزی که COASTER را از این منابع داده ارزشمند متمایز می کند این است که COASTER فراتر از توزیع محصولات مدل شده با اجازه دادن به کاربران برای ایجاد محصولات سفارشی مشخص شده برای رفع نیازهای تحلیلی خود است. COASTER این کار را از طریق ترکیبی از دادههای موجود و عملکرد پردازش دادهاش انجام میدهد، که انعطافپذیری فوقالعادهای را برای ایجاد مجموعههای داده مشخص شده توسط کاربر ارائه میکند در حالی که قابلیتهای پردازش و ظرفیت ذخیرهسازی داده مورد نیاز کاربران نهایی را به حداقل میرساند. یکی دیگر از نقاط قوت COASTER در کاربرد آن در مجموعه گسترده ای از مجموعه داده های محیطی است، زیرا تقریباً هر مجموعه داده شطرنجی با وضوح زمانی بالا را می توان با سهولت نسبی به سیستم اضافه کرد. COASTER همچنین از این نظر منحصر به فرد است که به یک سازمان تولید کننده داده متصل نیست و شامل نمونه های متعددی از متغیرها (از منابع مختلف) است که برای ثبت پدیده های محیطی یکسان یا مشابه طراحی شده اند. COASTER با ارائه ابزاری برای اعمال عملکرد پردازش یکسان برای مجموعه داده های به ظاهر زائد، مکانیزم بسیار ساده شده ای را برای مقایسه مستقیم مجموعه داده ها در اختیار کاربران قرار می دهد. به عبارت دیگر، کاربران می توانند محصولات منطبق را از مجموعه داده های مختلف بسازند و نتایج را در ترکیب با ابرداده های همراه بررسی کنند تا تعیین کنند کدام مجموعه داده برای پاسخگویی به نیازهای آنها مناسب تر است.
3. روش ها
3.1. رابط کاربری COASTER
رابط آنلاین سیستم COASTER ( شکل 1) را می توان در www.COASTERdata.net یافت. برای اینکه سیستم COASTER را تا حد ممکن ساده و قوی نگه داریم (مثلاً در همه مرورگرهای وب به یک اندازه کارایی داشته باشد) ما یک رابط وب نسبتاً ساده را انتخاب کردیم که در آن از یک صفحه وب واحد برای جمع آوری تمام اطلاعات کاربر لازم برای ایجاد خروجی های COASTER استفاده می کنیم. یک اثر جانبی مثبت این تصمیم، سهولت ایجاد یک ابزار مبتنی بر GIS برای جمعآوری مشخصات کاربر است، در نتیجه در صورت تمایل، یک رابط COASTER گرافیکیتر ارائه میکند. ما همچنین تصمیم گرفتیم که فقط مختصات طول و عرض جغرافیایی را برای تعریف منطقه مورد نظر جمع آوری کنیم (یعنی زیرمجموعه فضایی گستره فضایی کامل مجموعه داده تحویل داده شده در فایل خروجی). دلیل این تصمیم نارضایتی مکرر گذشته ما از سیستم های توزیع داده موجود بود

که از رابط های نقشه برداری تعاملی استفاده می کنند (به عنوان مثال، آنهایی که کاربران یک کادر محدود را روی نقشه می کشند تا منطقه مورد علاقه خود را مشخص کنند).
3.2. ساختار محاسباتی
عناصر پردازش دادههای سیستم COASTER به عنوان یک سری از اسکریپتهای IDL که برای استفاده با نرمافزار پردازش تصویر ENVI نوشته شدهاند، ایجاد شدهاند. برای اینکه سیستم COASTER مستقل شود، و برای جلوگیری از مشکلات مربوط به مجوز، کد پردازش داده COASTER را در سی شارپ بازنویسی کردیم و از کتابخانه رایگان GDAL برای پردازش مجموعه داده های مکانی استفاده کردیم. کارهای مشخص شده توسط کاربر که از طریق رابط آنلاین وارد می شوند، ابتدا به یک صف کار فرستاده می شوند تا زمانی که یک سرور پردازشی حاوی مجموعه داده انتخابی آنها را انتخاب کند. تمام دادهها و جزئیات سرور پردازش و پیوندها با استفاده از کنسولهای مدیریتی مبتنی بر وب مدیریت میشوند، در نتیجه فرآیند افزودن یا ویرایش مجموعههای داده موجود در COASTER تسهیل میشود. چالش های کلیدی معماری آدرس های COASTER شامل 1) ایجاد یک رابط کاربری ساده و در عین حال موثر مبتنی بر وب. 2) طراحی سیستمی که نیازهای محاسباتی کمی را بر روی ماشینهای کاربر اعمال میکند، زیرا تولید خروجیهای COASTER مانند به صورت محلی میتواند بازدارنده باشد. 3) محدود کردن زمان جستجوی فایل و ورودی/خروجی (ورودی و خروجی – خواندن و نوشتن فایلها بر روی هارد دیسک) به کندی عملکرد COASTER نیاز دارد. 4) ایجاد یک سیستم مقیاس پذیر که به طور بالقوه میزبان بسیاری از مجموعه داده های بزرگ (مثلاً تا چند ترابایت اندازه) باشد. و 5) ارائه خروجی هایی که نیاز به حداقل پردازش اضافی قبل از استفاده توسط محققان دارند. 4) ایجاد یک سیستم مقیاس پذیر که به طور بالقوه میزبان بسیاری از مجموعه داده های بزرگ (مثلاً تا چند ترابایت اندازه) باشد. و 5) ارائه خروجی هایی که نیاز به حداقل پردازش اضافی قبل از استفاده توسط محققان دارند. 4) ایجاد یک سیستم مقیاس پذیر که به طور بالقوه میزبان بسیاری از مجموعه داده های بزرگ (مثلاً تا چند ترابایت اندازه) باشد. و 5) ارائه خروجی هایی که نیاز به حداقل پردازش اضافی قبل از استفاده توسط محققان دارند.
یکی از ویژگی های اصلی طراحی COASTER مقیاس پذیری است که از طریق معماری سیستمی که برای توزیع داده ها و نیازهای پردازش در بسیاری از سرورها طراحی شده است که به طور بالقوه در مکان های مختلف قرار دارند، به دست می آید. رابط COASTER از یک برنامه وب واحد تشکیل شده است که درخواست های کاربر را برای نتایج خلاصه شده به دست آمده از مجموعه داده های موجود در سیستم می پذیرد. موازی با رابط وب، دو جدول پایگاه داده وجود دارد که 1) مجموعه داده های خاصی را با سرور(های) پردازش مرتبط می کند و حاوی جزئیات مربوط به مجموعه داده ها است (به عنوان مثال، مسیر داده آنها در سرور میزبان و قراردادهای نامگذاری فایل)، و 2) پردازش ارسال شده توسط کاربر را ذخیره می کند. درخواست ها (یعنی صف کار). صف کار به عنوان پیوند بین رابط وب و سرورهای پردازش عمل می کند. و درخواستهای کاربر در نهایت تنها زمانی اجرا میشوند که یک سرور پردازشی یک کار را از این صف درخواست کند. صف برای تمام پردازش های COASTER به دلیل I/O فشرده مورد نیاز برای بسیاری از کارهای COASTER اجرا شد، که سرعت دسترسی به داده ها و بنابراین کارایی پردازش را تا حد زیادی کاهش می دهد، اگر/زمانی که یک سرور پردازش تلاش می کند چندین کار را برای یک مجموعه داده مشابه اجرا کند. به عبارت دیگر، برای به حداقل رساندن زمان اجرا، سرورهای پردازشی در سیستم COASTER تنها یک کار را در یک زمان پردازش میکنند و درخواستهای کاربر بعدی فقط زمانی از صف کار درخواست میشوند که سرور پردازشگر برای انجام این کار آزاد باشد. اگر/زمانی که یک سرور پردازش تلاش می کند چندین کار را برای یک مجموعه داده اجرا کند. به عبارت دیگر، برای به حداقل رساندن زمان اجرا، سرورهای پردازشی در سیستم COASTER تنها یک کار را در یک زمان پردازش میکنند و درخواستهای کاربر بعدی فقط زمانی از صف کار درخواست میشوند که سرور پردازشگر برای انجام این کار آزاد باشد. اگر/وقتی یک سرور پردازش تلاش می کند چندین کار را برای یک مجموعه داده اجرا کند. به عبارت دیگر، برای به حداقل رساندن زمان اجرا، سرورهای پردازشی در سیستم COASTER تنها یک کار را در یک زمان پردازش میکنند و درخواستهای کاربر بعدی فقط زمانی از صف کار درخواست میشوند که سرور پردازشگر برای انجام این کار آزاد باشد.شکل 2 اجزای کلیدی سیستم COASTER و نحوه پیوند آنها را نشان می دهد.

هنگامی که یک سرور پردازش COASTER یک کار را تکمیل میکند، فایلهای بهدستآمده در یک سرور FTP آپلود میشوند و به کاربر درخواستکننده ایمیلی ارسال میشود که حاوی لینک URL به خروجی پردازششدهاش است. نتایج COASTER شامل 1) یک تصویر GeoTIFF در پیشبینی دادههای بومی است (یعنی پیشبینی مرتبط با هر مجموعه داده موجود در COASTER، بدون تغییر نسبت به پیشبینی تعریفشده هنگام ایجاد مجموعه داده اصلی). 2) اطلاعات لازم برای بازپخش داده ها در صورت نیاز؛ و 3) یک فایل متنی که تمام آرگومان های مشخص شده توسط کاربر وارد شده در رابط وب را مستند می کند. توجه داشته باشید که COASTER به طور خاص بدون ابزار بازپرداخت داخلی طراحی شده است تا 1) پیچیدگی سیستم را کاهش دهد. 2) از مشکلات پردازش جعبه سیاه اجتناب کنید (یعنی مواردی که کاربر هیچ کنترلی یا دانشی بر رویه تبدیل ندارد). و 3) حفظ یکپارچگی مجموعه داده اصلی از طریق تحویل به کاربر نهایی (به عنوان مثال، تمام رویه های آماری در COASTER تحت تأثیر تغییرات تصویر قرار نمی گیرند). در نتیجه، بر عهده کاربران نهایی است که خروجی COASTER را برای مطابقت با مجموعه دادههای موجود خود (یا برعکس) مجدداً طراحی کنند، اما اعتقاد ما این است که این روش به بهترین وجه با نظارت مستقیم انجام میشود.
معماری پردازش درون خطی COASTER به طور بالقوه محدود می شود اگر تعداد درخواست های کار پردازش نشده ذخیره شده در صف کار بسیار زیاد شود و/یا اگر بسیاری از کارها از مجموعه داده های با وضوح مکانی بالاترین درخواست شوند (یعنی آنهایی که بیشترین اندازه فایل را دارند) . COASTER از دو مکانیسم اصلی برای کاهش احتمال کند شدن سیستم در این موارد استفاده می کند. اولین مکانیسم مربوط به مقیاس پذیری سیستم است، زیرا سرورهای پردازشی اضافی را می توان به COASTER اضافه کرد تا تقاضای کاربر را برآورده کند. علاوه بر این، COASTER از روابط یک تن، یک به چند، و چند به چند بین مجموعه داده ها و سرورهای پردازشی پشتیبانی می کند، که اجازه می دهد 1) مجموعه داده های با تقاضای بالا در چندین سرور و/یا 2) مجموعه داده های بسیار بزرگ منعکس شوند. بر روی سرورهای اختصاصی میزبانی شود، در نتیجه سرورهای پردازشی دیگر را از مسئولیت اجرای کارهای بسیار وقت گیر رها می کند. مکانیسم دوم برای کاهش بار در سیستم COASTER با محدود کردن دسترسی به مجموعه دادههای با وضوح مکانی بالاتر است. اکثر مجموعههای داده در COASTER به صورت رایگان در دسترس عموم هستند و کارهایی که از این مجموعه دادهها استفاده میکنند زمان اجرای معمولی چند دقیقه دارند. در مقابل، کارهای مربوط به مجموعه دادههای با وضوح فضایی بالاتر (مثلاً 1 کیلومتر) ممکن است ساعتها طول بکشد و بنابراین دسترسی به این مجموعه دادهها را محدود میکنیم. هنگامی که کاربران خروجی مشتق شده از مجموعه داده دسترسی محدود را درخواست می کنند، ایمیلی برای آنها ارسال می شود که جزئیات مربوط به درخواست پردازش، مانند هدف خروجی درخواستی و وابستگی سازمانی کاربر را درخواست می کند. بر اساس پاسخ به این سوالات، کار توسط یک کارمند YERC با استفاده از کنسول تایید تایید یا رد می شود. برای کاربران مرتبط با سازمانهایی که به بودجه توسعه COASTER کمک کردهاند، تأیید اساساً خودکار است.
عملکرد پردازش داده زیربنایی COASTER بسیار پیچیده نیست، زیرا گزینه های خلاصه سازی در دسترس کاربران نه از نظر محاسباتی فشرده و نه از نظر ریاضی پیچیده هستند. با این حال، طراحی سیستمی که قادر به باز کردن و خواندن کارآمد، زیرمجموعه فضایی، و انجام توابع ریاضی بر روی همه سلولها (به عنوان مثال، تعداد بالقوه در میلیونها)، از هزاران فایل شطرنجی (به عنوان مثال، رکورد روزانه برای یک پارامتر اقلیمی منفرد در محدوده 60 باشد. + سال به بیش از 20000 فایل، از مجموعه دادههایی با ویژگیهای متنوع (به عنوان مثال، پیشبینیهای مختلف و گسترههای مکانی و زمانی) یک چالش محاسباتی مهم بود. میراث سیستم COASTER به عنوان مجموعه ای از ابزارهای دسکتاپ، طراحی شده برای عملکرد علی رغم محدودیت های پردازش و حافظه، برای پایین نگه داشتن نیازهای زیرساخت محاسباتی COASTER نسبتاً پایین مفید بود. نتیجه سیستمی است که حداکثر دو آرایه موقت (هر یک به اندازه یک فایل شطرنجی برای یک روز) را به عنوان “جدول های کاری” لازم برای عملکرد خلاصه سازی داده های انتخاب شده توسط کاربر ذخیره می کند. هنگام پردازش، هر فایل شطرنجی روزانه مورد نیاز تابع منتخب کاربران، قبل از انتقال به فایل بعدی، باز، پردازش و سپس بسته میشود. به این ترتیب COASTER نیازی به بارگذاری همزمان تمام داده های ضروری در حافظه ندارد، در نتیجه آن را قادر می سازد تا روی سرورهای نسبتا ارزان قیمت کار کند. نتیجه سیستمی است که حداکثر دو آرایه موقت (هر یک به اندازه یک فایل شطرنجی برای یک روز) را به عنوان “جدول های کاری” لازم برای عملکرد خلاصه سازی داده های انتخاب شده توسط کاربر ذخیره می کند. هنگام پردازش، هر فایل شطرنجی روزانه مورد نیاز تابع منتخب کاربران، قبل از انتقال به فایل بعدی، باز، پردازش و سپس بسته میشود. به این ترتیب COASTER نیازی به بارگذاری همزمان تمام داده های ضروری در حافظه ندارد، در نتیجه آن را قادر می سازد تا روی سرورهای نسبتا ارزان قیمت کار کند. نتیجه سیستمی است که حداکثر دو آرایه موقت (هر یک به اندازه یک فایل شطرنجی برای یک روز) را به عنوان “جدول های کاری” لازم برای عملکرد خلاصه سازی داده های انتخاب شده توسط کاربر ذخیره می کند. هنگام پردازش، هر فایل شطرنجی روزانه مورد نیاز تابع منتخب کاربران، قبل از انتقال به فایل بعدی، باز، پردازش و سپس بسته میشود. به این ترتیب COASTER نیازی به بارگذاری همزمان تمام داده های ضروری در حافظه ندارد، در نتیجه آن را قادر می سازد تا روی سرورهای نسبتا ارزان قیمت کار کند.
علاوه بر ابزار آنلاین، سیستم COASTER ممکن است به عنوان نرم افزار به عنوان سرویس (SaaS) نیز مورد استفاده قرار گیرد که با استفاده از پروتکل دسترسی به اشیاء ساده (SOAP) یا انتقال وضعیت نمایندگی (REST) مبتنی بر خدمات وب قابل دسترسی است. این قابلیت به COASTER اجازه می دهد تا با استفاده از یک تماس خودکار به URL دسترسی داشته باشید که به موجب آن پارامترهای تعریف شده توسط کاربر مستقیماً به یک وب سرویس ارسال می شوند. نمونههایی از ابزارهایی که میتوانند از این قابلیت بهره ببرند شامل برنامههای کاربردی سفارشی ساخته شده در محیطهای GIS و همچنین ابزارهای تصویرسازی و نقشهبرداری دادههای آنلاین موجود است. توضیحات زبان توصیف خدمات وب (WSDL) به عنوان بخشی از وب سرویس ارائه می شود تا نحوه فراخوانی و پارامترهای مورد انتظار آن را توضیح دهد. ما در حال حاضر COASTER در فهرست رجیستری Universal Description Discovery and Integration (UDDI) نداریم،
3.3. افزودن مجموعه داده ها و سرورهای پردازش
افزودن مجموعه داده ها و سرورهای پردازشی جدید به COASTER از طریق کنسول اداری آنلاین انجام می شود. برای افزودن یک مجموعه داده به سرور پردازشی که قبلاً نرمافزار COASTER را اجرا میکند، این روش شامل 1) ایجاد یک رکورد مجموعه داده جدید حاوی جزئیات لازم در پایگاه داده SQL، و 2) کپی کردن مجموعه داده بر روی سرور(های) پردازش مناسب است. برای افزودن یک سرور پردازشی جدید به COASTER، ابتدا باید نرم افزار پردازش داده روی آن سرور نصب شود و سرور باید به طور مناسب پیکربندی شود (به عنوان مثال، راه اندازی به عنوان یک وب سرور در حال اجرا IIS، تنظیم مجوزها برای اجازه دادن به COASTER برای فراخوانی زیر روال های ضروری، و نصب پردازنده صف ویندوز سرویس). هنگامی که سرور پردازش پیکربندی شد، با استفاده از کنسول مدیریت آنلاین به سیستم COASTER اضافه می شود.
3.4. کارکرد
توابع موجود در COASTER به سه دسته تقسیم می شوند: خلاصه سازی ( جدول 1 )، آستانه ( جدول 2 )، و تشخیص ناهنجاری و روند ( جدول 3 ). هر یک از این دستهها مربوط به یک بخش (که با یک کادر خاکستری مشخص شده است) از رابط کاربر است که در آن پارامترهای تابع تعریف میشوند. هر درخواست کاربر همچنین با 1) پارامترهای زمانی مشخص شده در بخش “فریم زمانی” رابط همراه است، و 2) وسعت مکانی خروجی (یعنی بخش زیرمجموعه فضایی COASTER) همانطور که در سمت چپ بالا تعریف شده است. و مختصات گوشه سمت راست پایین. با کلیک بر روی دکمه ارسال، تمام اطلاعات مشخص شده توسط کاربر به عنوان یک رکورد جدید در صف کار ذخیره می شود.
تعاریف متغیر:
Y = مقدار به دست آمده (توجه داشته باشید که تمام معادلات برای سلول های جداگانه اعمال می شود).
X = مقدار یک سلول شبکه در یک روز.
d1 = روز شروع دوره درون سالی.
dn = روز پایان دوره درون سالیانه.
dx = روزی که در حال حاضر در یک معادله خارجی (حلقه) پردازش می شود.
y1 = سال شروع دوره بین سالی.
yn = سال پایانی دوره بین سالانه.
3.5. نکات عملکردی و هشدارها
• تمام محاسباتی که به صورت سالیانه انجام می شود، تصویری با یک یا چند باند (تا تعداد سال های موجود در مجموعه داده) تولید می کند که هر باند نشان دهنده نتایج یک سال است.
• تمام عملکردهای موجود در COASTER فقط برای پارامترهای اقلیمی منفرد قابل اجرا هستند. عملکردهایی که قادر به پردازش پارامترهای متعدد هستند مطلوب هستند (مثلاً میزان بارندگی که در دمای زیر 0 درجه سانتیگراد کاهش می یابد) و ممکن است در آینده اضافه شوند.
• اکثر توابع COASTER به یک گذر از داده ها محدود می شوند، به این معنی که توابعی که می توانند داده های قبلاً خلاصه شده را خلاصه کنند هنوز در COASTER در دسترس نیستند. نمونهای از چنین مجموعه دادههایی میتواند سردترین میانگین دمای ماه آوریل را از تمام سالهای دوره اندازهگیری شناسایی کند. برای تولید این مجموعه داده ابتدا باید یک محصول متوسط در سال محاسبه شود و سپس آن نتیجه میانی با استفاده از تابع حداقل پردازش شود.
• انحراف استاندارد و اختلاف میانگین مربعات ریشه از نرمال (RMSDN) توابع مرتبط هستند، اما پدیده های اساساً متفاوتی را ثبت می کنند. نتایج شطرنجی انحراف استاندارد معیاری از اینکه یک دوره معین نسبت به مقدار میانگین آن دوره چقدر متغیر است را ارائه می دهد. به عنوان مثال، نتایج سالانه برای انحراف استاندارد، هر روز را با مقدار میانگین سال مربوطه مقایسه میکند تا اندازهگیری از متغیر بودن شرایط در طول یک سال منفرد را نشان دهد. در مقابل، نتایج RMSDN بر میزان غیرعادی بودن روزهای در یک بازه زمانی نسبت به مقادیر عادی روزانه (بر اساس میانگین تاریخ خاص) تمرکز میکند.




مقادیر از همه سال ها در مجموعه داده) برای همان دوره. نمونه ای از مقایسه مستقیم بین انحراف استاندارد سالانه و RMSDN را می توان با مشاهده حداقل دما برای یک دوره 8 روزه که در طی آن یک توده هوای به شدت سرد برای منطقه مورد نظر وجود داشت، ایجاد کرد. در طول آن زمان، انحراف استاندارد سالانه ممکن است به دلیل دمای نسبتاً ثابت روزانه بسیار کم باشد، اما اگر شرایط روزانه بسیار کمتر از مقادیر نرمال روزانه متناظر باشد، RMSDN بسیار بالا خواهد بود.
• تجزیه و تحلیل روند و توابع تشخیص ناهنجاری به بهترین وجه تجربی در نظر گرفته میشوند، زیرا ممکن است به شدت تحت تأثیر شرایط متغیر مدلسازی برای مجموعه داده زیربنایی قرار گیرند (به عنوان مثال، افزودن ایستگاههای هواشناسی جدید و/یا ابزارهای تغییر که بر مجموعه دادههای آب و هوایی درونیابی شده مانند TOPS تأثیر میگذارد. ). روند COASTER و خروجی های ناهنجاری روندهای قابل تفسیر را در مقیاس های منطقه ای نشان می دهد، اما تجزیه و تحلیل مقیاس خوب (یعنی تجزیه و تحلیل یک پیکسل) باید با احتیاط انجام شود.
4. نتایج
COASTER در حال حاضر حاوی بیش از 10 ترابایت داده محیطی در بیش از 700000 فایل شطرنجی روزانه است. اکثریت قریب به اتفاق این داده ها در ژوئیه 2012 با رونمایی نسخه 2 سیستم اضافه شد. علیرغم عدم انتشار گسترده COASTER و تعداد محدودی از داده های میزبانی شده در سیستم در اکثر موارد موجود، از زمانی که برای اولین بار در مارس 2011 عملیاتی شد، www.COASTERdata.net توسط بیش از 500 کاربر منحصر به فرد از 40 کشور جهان بازدید شده است، که بسیاری از آنها بسیاری از آنها هستند. بارها به سایت بازگشت. در حالی که استفاده از COASTER تا کنون کم بوده است، ما انتظار داریم (و برای آن آماده شده ایم) افزایش قابل توجهی در تعداد بازدیدهای سایت به دلیل اضافه شدن اخیر تعداد زیادی مجموعه داده جدید و همچنین افزایش تلاش برای عمومی کردن سیستم.
زمان پردازش و تحویل برای خروجیهای COASTER برای همه محصولات به جز بالاترین وضوح مکانی (یعنی 1 کیلومتر، مجموعه دادههای دسترسی محدود)، حتی زمانی که فشردهترین توابع محاسباتی را برای طولانیترین دورههای زمانی ممکن اعمال میکنند، معمولاً کمتر از یک ساعت است. در مقابل، کارهای کوچکتر اغلب در عرض چند دقیقه تکمیل و تحویل می شوند. زمان تحویل به طور قابل توجهی افزایش می یابد زمانی که بسیاری از درخواست های کاربر در صف کار وجود دارند، اما تاکنون COASTER در بدترین حالت تحویل روز بعد همه خروجی های درخواستی، از جمله خروجی های حاصل از مجموعه داده های دسترسی محدود را ارائه کرده است.
بزرگترین نقطه قوت سیستم COASTER در توانایی آن برای تبدیل موثر مقادیر عظیم و دست و پا گیر داده به اطلاعات مفید برای تحقیق، آموزش و تصمیم گیری آگاهانه نهفته است. حجم عظیم داده ها و تعداد فایل هایی که ممکن است در هنگام برخورد با مجموعه داده های با وضوح زمانی بالا نیاز به پردازش داشته باشند، این قابلیت را نشان می دهد. در حالی که مجموعه دادههای موجود در COASTER میتوانند از نظر دامنه کاری دلهرهآور باشند، محصولات خلاصهشده تولید شده از آنها نیازی به چنین کاری ندارند، و در واقع، کاربران احتمالاً از قبل با محصولاتی که میتوان با استفاده از COASTER تولید کرد کاملاً آشنا هستند. برای مثال، یک خروجی COASTER که میانگین دمای بالا را برای یک روز کمیت میکند، از نظر مفهومی مشابه دمای بالا «عادی» آن روز است که در اخبار محلی گزارش شده است. یکی دیگر از نقاط قوت COASTER در توانایی آن برای تولید نتایج خاص مکانی است، با مقادیر منحصر به فرد محاسبه شده برای هر سلول شبکه در یک منطقه مطالعه مشخص شده توسط کاربر، در نتیجه امکان بررسی الگوهای فضایی در متغیرهای جدید ساخته شده به صورت بصری و آماری را فراهم می کند. شکلهای 3-6 خروجیهای COASTER را نشان میدهند که در یک GIS (در این مورد توسط یک لایه مرزی ایالت ایالات متحده پوشانده شدهاند) نمایش داده میشوند. توجه داشته باشید که نقشههای مثال نشان داده شده تنها بخشی از قابلیتهای COASTER را نشان میدهد، زیرا تعداد توابع بیشتری نسبت به آنچه نشان داده شده است وجود دارد.
یک مثال توصیفی از یک کاربرد از

شکل 3 . نمونه خروجی تولید شده با استفاده از یک تابع خلاصه COASTER. در این نقشه، هر مقدار سلول حاوی مجموع بارش روزانه برای تمام روزهای بین 1 اکتبر 2010 تا 31 مارس 2011 است.

شکل 4 . نمونه خروجی تولید شده با استفاده از تابع آستانه COASTER. در این نقشه هر سلول حاوی تاریخ ژولیان اولین روز در سال 2000 است که حداقل مقادیر دمای روزانه بالای 0 درجه سانتیگراد بود.
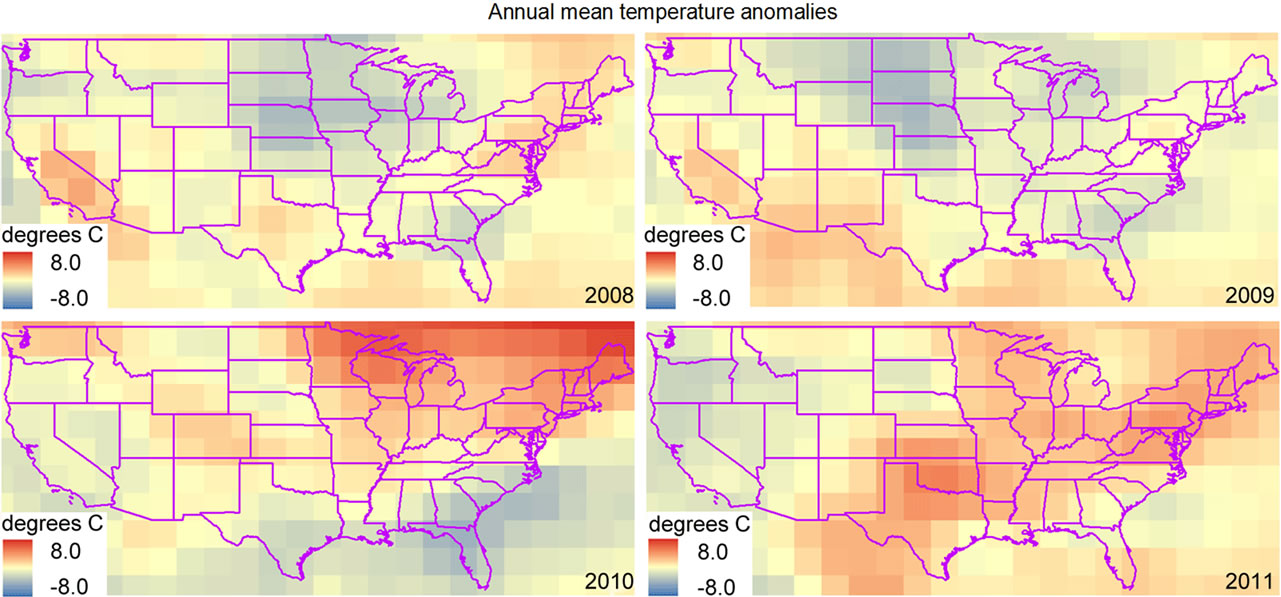
شکل 5 . نمونه خروجی تولید شده با استفاده از تابع ناهنجاری COASTER. هر نقشه تفاوت بین میانگین دمای سالانه (در هر سلول) برای یک سال خاص و میانگین دمای میانگین سالانه حاصل از تمام سالهای مجموعه داده (1948-2011) را نشان میدهد.

شکل 6 . نمونه خروجی تولید شده با استفاده از تابع روند COASTER. در این نقشه، هر سلول شیب روند میانگین دمای 64 ساله (1948-2011) را در مجموعه داده NCEP/NCAR نشان می دهد.
سیستم COASTER یک تحلیل فرضی از پویایی جمعیت پرندگان آبزی است. چنین تحلیلی ممکن است به متغیرهایی نیاز داشته باشد که شرایط آب و هوایی را قبل از زمان تخمینی رسیدن گونه های کانونی در مناطق لانه گزینی تابستانی آن کمیت می کند، زیرا این متغیرها به نوع، فراوانی و الگوی فضایی منابع غذایی موجود در چشم انداز مربوط می شود. با استفاده از COASTER، استخراج میانگین دما (حداقل و حداکثر)، دما (حداقل و حداکثر)، ناهنجاریهای بارندگی کل، و ناهنجاریهای بارش برای چندین پنجره زمانی درونسالی بسیار ساده است. چنین مجموعه دادههایی محققان را قادر میسازد تا به سرعت بسیاری از فرضیههای مرتبط با مشاهدات پرندگان آبی (مثلاً استفاده از زیستگاه یا موفقیت در لانهسازی) را با شرایط آب و هوایی با استفاده از طیف گستردهای از رویکردهای آماری آزمایش کنند.
5. بحث
تازگی COASTER در توانایی آن در ترکیب ویژگی ها در یک سیستم آنلاین واحد است که معمولاً برای تولید به بسته های نرم افزاری متعدد و زمان و تخصص قابل توجهی نیاز دارد. به طور خاص، COASTER عملکردهای زیر را برای کاهش یا حذف بسیاری از خواسته های کاربرانی که نیاز به خروجی های شطرنجی سفارشی دارند، ترکیب می کند:
1) توزیع داده – فایل های خروجی نسبتاً کوچک از طریق یک پیوند FTP ساده قابل دانلود هستند.
2) ذخیرهسازی از راه دور – نیاز کاربران به دستیابی به دادههای خام را از بین میبرد، در نتیجه ذخیرهسازی دادههای کاربر و نیازهای پهنای باند را تا حد زیادی کاهش میدهد.
3) قابلیت های پردازش – عملکرد پردازش COASTER همراه با توانایی تعریف مناطق و پنجره های زمانی مورد علاقه به کاربران اجازه می دهد تا تعداد نامحدودی از محصولات خروجی را بدون نیاز به توسعه الگوریتم های سفارشی و نوشتن اسکریپت های سفارشی ایجاد کنند. علاوه بر این، یک تفاوت مهم بین COASTER و سایر منابع توزیع دادههای شطرنجی محیطی این است که COASTER کاربران را به پنجرههای خلاصهسازی موقت از پیش تعریفشده (مثلا، خلاصههای ماهانه یا سالانه) که ممکن است با نیازهای تحلیلی آنها مطابقت نداشته باشد، محدود نمیکند.
1) پردازش از راه دور – تمام پردازش ها از راه دور در سیستم COASTER انجام می شود و کاربران را از نیاز به قابلیت محاسباتی برای تولید خروجی های معادل رها می کند.
2) قالببندی دادهها – همه خروجیهای COASTER بهعنوان GEOtiffهایی که GIS آماده هستند، تحویل داده میشوند (یعنی در قالبی باطنی که نیاز به چندین مرحله قبل از تجسم دارد، تحویل داده نمیشوند).
برای پایین نگه داشتن هزینه های محاسباتی و نگهداری COASTER برای اجرا بر روی ماشین های رومیزی طراحی شده است و در نتیجه، سیستم COASTER فعلی به طور موثر فقط بر روی چند سرور اجرا می شود. اگر تقاضا برای COASTER کم بماند، سیستم فعلی ممکن است خانه منطقی COASTER در آینده باشد. با این حال، اگر استفاده از سیستم COASTER به طور چشمگیری افزایش یابد، زمان تحویل برای خروجی های تکمیل شده احتمالا افزایش خواهد یافت و ممکن است یک استراتژی جدید مورد نیاز باشد. از آنجایی که COASTER دادهها را رایگان ارائه میکند، ما احساس میکنیم زمانهای تحویل داده چند ساعته غیرمنطقی نیست، به ویژه با توجه به زمان و تلاشی که برای ایجاد نتایج قابل مقایسه بدون COASTER نیاز است. با این حال، اگر زمان تحویل داده ها به طور معمول بیش از 24 ساعت شروع شود، یک یا چند گزینه زیر را دنبال خواهیم کرد (در انتظار در دسترس بودن بودجه): 1) خرید سرورهای بیشتری برای منعکس کردن مجموعه داده های موجود برای توزیع بهتر نیازهای پردازش COASTER در گره های بیشتر. 2) به سمت معماری پردازش چند رشته ای حرکت می کنیم که به موجب آن از چندین گره برای اجرای سریعتر کارهای تک استفاده می کنیم. 3) ایجاد روابط مشارکتی که در آن نرم افزار COASTER، از جمله دسترسی به رابط آنلاین خود، به سایر موسسات (به عنوان مثال، دانشگاه ها یا سازمان های دولتی) برای میزبانی مجموعه داده های خاص بر روی سرورهای آنها ارائه می کنیم. یا 4) COASTER را به محیط محاسبات ابری منتقل کنید. همه این گزینهها جذاب هستند، زیرا از دیدگاه کاربر، تجربه استفاده از COASTER بدون تغییر خواهد بود زیرا سرورهای پردازشگر، هر کجا که باشند، صرفاً رکوردهایی را از صف کار درخواست میکنند. از نظر زمان و تلاش، تغییر به معماری رایانش ابری پرهزینه ترین این گزینه ها خواهد بود. با این حال، اگر ما COASTER را در یک مرکز تجاری رایانش ابری، مانند Google، Microsoft Azure، یا خدمات وب آمازون میزبانی کنیم، برخی از چالشهای چنین انتقالی کاهش خواهند یافت. در حال حاضر بهترین تناسب برای سرویسهای ابری ضروری آمازون است، زیرا گوگل نوع میزبانی مورد نیاز را ارائه نمیکند و Azure مایکروسافت نیاز به پرداخت برای یک نمونه سرور کامل دارد و سپس تنها تا 2 ترابایت فضای ذخیرهسازی ارائه میکند، در حالی که الزامات COASTER در حال حاضر بیش از 10 ترابایت خدمات وب آمازون به COASTER اجازه می دهد تا ذخیره سازی داده های مورد نیاز را از طریق سرویس ذخیره سازی ساده خود (S3) اجاره کند و هزینه زمان پردازش را بر اساس نیاز از طریق سرویس محاسبات الاستیک خود بپردازد.
کیفیت و تداوم دادهها نگرانیهایی برای پروژه COASTER هستند زیرا به طور مستقیم بر کاربرد COASTER برای تحقیقات علمی و تصمیمگیری تأثیر میگذارند. در حالی که ما تلاش می کنیم مجموعه داده هایی با کیفیت بالا ارائه کنیم و این داده ها اغلب بهترین یا تنها مجموعه داده های موجود در نوع خود هستند، هیچ مجموعه داده ای که در COASTER میزبانی می شود بدون خطا نیست و بسیار مهم است که کاربران این خطاها را در تحقیقات خود درک کرده و تصدیق کنند. برای دریافت حس کیفیت داده، کاربران COASTER تشویق میشوند تا قبل از ایجاد و استفاده از خروجیهای خلاصهشده، تمام ابردادهها را بررسی کنند و ادبیات علمی مرتبط با مجموعه دادههای ورودی را که انتخاب میکنند، مطالعه کنند. تداوم داده ها یکی دیگر از مسائل چالش برانگیز پروژه COASTER است زیرا ما مجموعه داده های میزبانی شده در سیستم را تولید نمی کنیم. و بنابراین فقط می توانند مجموعه داده ها را به روز کنند اگر/زمانی که چنین به روز رسانی هایی توسط ارائه دهندگان داده اولیه انجام شود. خوشبختانه تعدادی از مجموعه داده های موجود در COASTER (به عنوان مثال، مجموعه داده های بارش NOAA CPC و محصولات 2.5 درجه جهانی NCEP/NCAR) تقریباً در زمان واقعی به روز می شوند و استراتژی ما این است که COASTER را با داده های اضافی چندین بار در سال به روز کنیم. برای سادهسازی فرآیند بهروزرسانی مجموعههای داده در COASTER، مجموعهای از ابزارها و رویهها را برای ادغام سریع دادههای جدید، از جمله رویکردهایی برای 1) پیش پردازش (به عنوان مثال، تبدیل انواع فایل و/یا استخراج رسترهای تاریخ تک از مجموعه دادههای چند باندی) ایجاد کردهایم. ; 2) تولید توابع ترجمه طرح ریزی جدید (یعنی برای تبدیل مقادیر طول و عرض جغرافیایی وارد شده در رابط مبتنی بر وب به واحدهای نقشه). 3) تغییر جزئیات ذخیره شده در پایگاه داده SQL به منظور منعکس کردن گستره زمانی جدید مجموعه داده به روز شده. و 4) تغییر رابط COASTER برای منعکس کردن حضور سالهای توسعه یافته موجود.
به عنوان یک سیستم بتا، چندین چالش برای سیستم COASTER حل نشده باقی مانده است. یکی از این مسائل تولید خودکار ابرداده هایی است که استانداردهای پذیرفته شده را برآورده می کند. از آنجایی که سیستم COASTER مستقل از فرآیند ایجاد داده است، ما فقط به ارائه ابردادههای مرتبط با مجموعه دادههای خام که توسط تولیدکنندگان آن مجموعه دادهها تولید شدهاند، محدود میشویم. روش اولیه ما برای پرداختن به این مشکل، ارائه یک فایل متنی کوچک است که گزینه های خلاصه سازی انتخاب شده توسط کاربر (موجود در پیوند FTP همراه با فایل .tif) را با تمام خروجی های COASTER توصیف می کند. در حال حاضر این یک محدودیت تایید شده COASTER است که ما قصد داریم تا زمانی که منابع اجازه می دهند آن را برطرف کنیم.
ارزش نهایی COASTER تنها زمانی قابل ارزیابی است که سیستم به طور کامل عملیاتی شود و جزئیات بیشتری برای مستندسازی و ارزیابی استفاده و عملکرد سیستم جمع آوری شود. از ابتدا سیستم COASTER با در نظر گرفتن قابلیت زنده ماندن طولانی مدت طراحی شد. به این ترتیب، ما تلاش کردهایم سیستمی بسازیم که بر چالشهای واقعی هزینه، پردازش و زمان تحویل برای خروجی، مقیاسپذیری، سهولت بهروزرسانی یا افزودن مجموعه دادههای جدید، استحکام سیستم و قابلیت کاربرد برای استفاده فراتر از جامعه تحقیقاتی غلبه کند. یکی از عناصر اصلی این تفکر بلندمدت این است که COASTER را تا حد امکان کوچک و ساده نگه داشته و در عین حال ماموریت خود را برای ارائه محصولات داده مورد نیاز انجام می دهد. منطق پشت این تصمیم تمایل ما به ایجاد سیستمی بود که کارکرد آن ارزان بوده و به ابزارهایی مانند ابزارهای ارائه شده در یک محیط ArcGIS یا Google Maps وابسته نباشد (یعنی به طور بالقوه نیاز به هزینه های نگهداری بیشتر در پاسخ به تغییر پروتکل های نرم افزاری COASTER بستگی دارد). با این حال، نتیجه تصمیم برای ساده نگه داشتن COASTER این است که COASTER فاقد ابزارهای تجسم داده پروژه های بلندپروازانه تر مانند سیستم آنلاین کشف و بازیابی اطلاعات آب است.13 ]. بسته به بازخورد و بودجه کاربر، ممکن است تلاش کنیم COASTER را با ادغام مجموعه دادههای خروجی در یک سیستم نقشهبرداری وب که کاربران را قادر میسازد تا با دادهها تنها با استفاده از یک مرورگر وب تعامل داشته باشند، تقویت کنیم. یک پلتفرم احتمالی برای این قابلیت ClimateScape (www.ClimateScape.net) است، ابزار آنلاین دیگری که توسط NSF تامین می شود و توسط YERC و سازمان خواهرش HyPerspectives, Inc توسعه یافته است. در حالی که بعید است مجموعه کامل توابع COASTER به ClimateScape منتقل شود، یک ابزار گسترده انواع خلاصه داده ها (به عنوان مثال، شرایط میانگین روزانه) را می توان از قبل تهیه کرد و در صورت نیاز برای استفاده در ClimateScape ذخیره کرد.
6. نتیجه گیری
COASTER به دلیل توانایی آن در تولید سریع و آسان خلاصه های سفارشی از داده های با وضوح زمانی بالا، پیشرفت مهمی را در میان سیستم هایی که مجموعه داده های شطرنجی محیطی را توزیع می کنند، نشان می دهد. عملکرد و دادههایی که بهطور رایگان توسط COASTER در دسترس قرار میگیرد، بهطور قابلتوجهی مانع ورود کسانی را که با مجموعه دادههایی مانند دادههای آب و هوای روزانه کار میکنند، کاهش میدهد، زیرا محققانی را با تخصص محدود GIS یا سنجش از دور قادر میسازد تا دادههای متناسب با نیازهای خود را ایجاد کنند. ساختار سیستم COASTER به اندازه کافی منعطف است تا انواع مختلفی از مجموعه داده های شطرنجی محیطی را با سهولت نسبی در خود جای دهد. طراحی بسیار مقیاس پذیر سیستم COASTER احتمال تداوم آن در آینده (با هزینه نسبتاً کم) را افزایش می دهد و در عین حال عملکرد اصلی را حفظ می کند که آن را برای محققان مفید می کند. در مجموع،
منابع
- R. Nemani، H. Hashimoto، P. Votava، F. Melton، W. Wang، A. Michaelis، L. Mutch، C. Milesi، S. Hiatt و M. White، “پایش و پیش بینی دینامیک اکوسیستم با استفاده از مشاهده زمینی و سیستم پیشبینی (TOPS)،” Remote Sensing of Environment, Vol. 113، شماره 7، 1388، صص 1497-1509. doi:10.1016/j.rse.2008.06.017
- R. Nemani، P. Votava، A. Michaelis، M. White، F. Melton، J. Coughlan، K. Golden، H. Hashimoto، K. Ichii، L. Johnson، M. Jolly، C. Milesi، R Myneni، L. Pierce، S. Running، C. Tague و W. Pang، “سیستم مشاهده و پیش بینی زمینی (TOPS): توسعه پیش بینی ها و پیش بینی های زیست محیطی با ادغام داده های سطح، ماهواره و آب و هوا با مدل های شبیه سازی، تحقیقات و کاربردهای اقتصادی محصولات داده سنجش از دور، اتحادیه ژئوفیزیک آمریکا، 2005. https://c3.nasa.gov/nex/resources/1/ https://c3.nasa.gov/nex/static/media/publication/TOPS_AGU. pdf
- PE Thornton، SW Running و MA White، “تولید سطوح متغیرهای هواشناسی روزانه در مناطق وسیعی از زمین پیچیده”، مجله هیدرولوژی، جلد. 190، 1997، صص 214-251. doi:10.1016/S0022-1694(96)03128-9 [زمان(های استناد): 1]
- سی. دالی، RP نیلسون و دی. 33، شماره 2، 1373، صص 140-158. doi:10.1175/1520-0450(1994)033<0140:ASTMFM>2.0.CO;2 [زمان(های استناد): 2]
- E. Kalnay، M. Kanamitsu، R. Kistler، W. Collins، D. Deaven، L. Gandin، M. Iredell، S. Saha، G. White، J. Woollen، Y. Zhu، A. Leetmaa، R. رینولدز، ام. چلیا، دبلیو. ابیسوزاکی، دبلیو هیگینز، جی. جانوویاک، کی سی مو، سی. روپلوسکی، جی. وانگ، آر. جن و دی. جوزف، “پروژه تحلیل مجدد 40 ساله NCEP/NCAR”، بولتن از انجمن هواشناسی آمریکا، جلد. 77، شماره 3، 1375، صص 437-471. doi:10.1175/1520-0477(1996)077<0437:TNYRP>2.0.CO;2 [زمان(های استناد): 1]
- RW Higgins، JE Janowiack و Y.-P. یائو، “پایگاه داده های بارش ساعتی شبکه ای برای ایالات متحده (1963-1993)،” NCEP / مرکز پیش بینی آب و هوا اطلس 1، مراکز ملی پیش بینی محیطی، 1996، 46 ص. [زمان(های استناد): 1]
- F. Mesinger، G. DiMego، E. Kalnay، K. Mitchell، PC Shafran، W. Ebisuzaki، D. Jović، J. Woollen، E. Rogers، EH Berbery، MB Ek، Y. Fan، R. Grumbine، W. هیگینز، H. Li، Y. Lin، G. Manikin، D. Parrish و W. Shi، “تحلیل مجدد منطقه ای آمریکای شمالی”، بولتن انجمن هواشناسی آمریکا، جلد. 87، شماره 3، 2006، صفحات 343- 360. doi:10.1175/BAMS-87-3-343 [زمان(های استناد): 1]
- T. Wang، A. Hamann، DL Spittlehouse و SN Aitken، “توسعه داده های آب و هوایی بدون مقیاس برای غرب کانادا برای استفاده در مدیریت منابع”، مجله بین المللی اقلیم شناسی، جلد. 26، شماره 3، 1385، صص 383-397. doi:10.1002/joc.1247
- MS Mbogga، A. Hamann و T. Wang، “داده های اقلیمی تاریخی و پیش بینی شده برای مدیریت منابع طبیعی در غرب کانادا”، هواشناسی کشاورزی و جنگل، جلد. 149، شماره 5، 1388، صص 881-890. doi:10.1016/j.agrformet.2008.11.009
- TD Mitchell و PD Jones، “روش بهبود یافته برای ایجاد پایگاه داده مشاهدات ماهانه آب و هوا و شبکه های مرتبط با وضوح بالا”، مجله بین المللی اقلیم شناسی، جلد. 25، شماره 6، 1384، صص 693-712. doi:10.1002/joc.1181 [زمان(های استناد): 1]
- RJ Hijmans، SE Cameron، JL Parra، PG Jones and A. Jarvis، “سطوح آب و هوای درون یابی شده با وضوح بسیار بالا برای مناطق زمینی جهانی”، مجله بین المللی اقلیم شناسی، جلد. 25، شماره 15، 2005، صص 1965-1978. doi:10.1002/joc.1276 [Citation Time(s):1]
- DJ Kriticos, BL Webber, A. Leriche, N. Ota, I. Macadam, J. Bathhols and JK Scott, “CliMond: Global Resolution High Resolution Historical and Future Climate Surfaces for Bioclimatic Modelling” Methods in Ecology and Evolution، جلد. 3، شماره 1، 1391، صص 53-64. doi:10.1111/j.2041-210X.2011.00134.x [زمان(های) نقل قول: 1]
- M. Huang، DR Maidment و Y. Tian، “استفاده از SOA و RIA برای کشف و بازیابی دادههای آب،” Environmental Modeling & Software، جلد. 26، شماره 11، 1390، صص 1309-1324. doi:10.1016/j.envsoft.2011.05.008 [Citation Time(s):1]


بدون دیدگاه