

چکیده
کلید واژه ها:
شکست های شیب ; رانش زمین ؛ تشخیص و محدوده نور ؛ LiDAR ; تجزیه و تحلیل زمین دیجیتال ; یادگیری ماشینی ؛ جنگل تصادفی ; مدل سازی پیش بینی فضایی ; تعمیم
1. مقدمه
2. پس زمینه
2.1. تعمیم مدل
2.2. مدلهای فضایی احتمالی با جنگل تصادفی
2.3. داده های دیجیتالی زمین برای نقشه برداری و مدل سازی زمین لغزش
3. روش ها
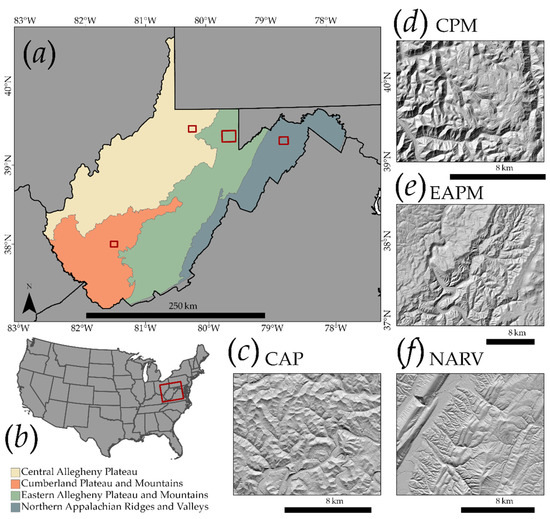
3.1. منطقه مطالعه
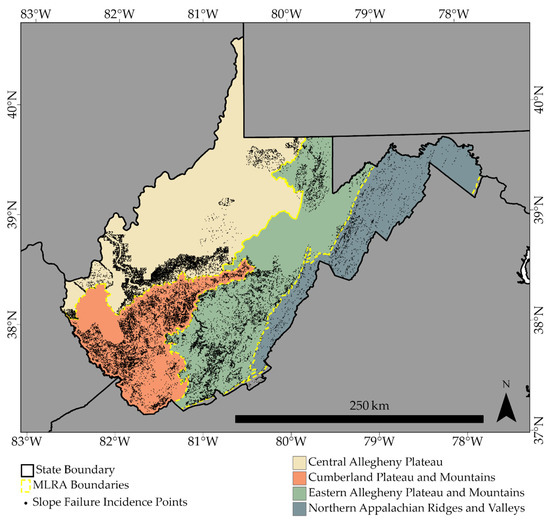
3.2. فهرست زمین لغزش و توسعه داده های آموزشی
3.3. متغیرهای پیش بینی کننده توپوگرافی
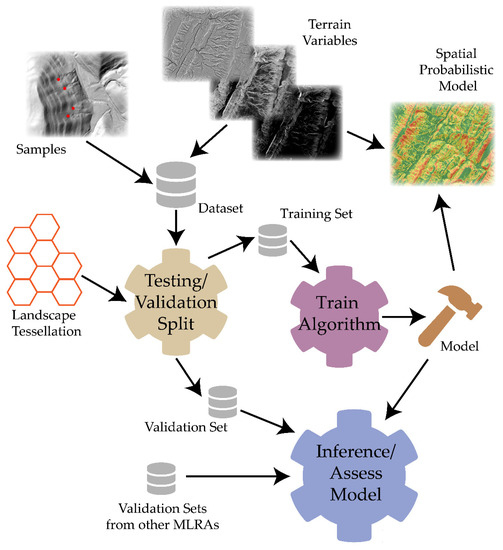
3.4. آموزش مدل و پیش بینی
3.5. اعتبارسنجی مدل و اهمیت متغیر
دقت (معادله (1)) نشان دهنده 1- خطای کمیسیون یا نسبت نمونه هایی است که به درستی در نمونه های پیش بینی شده مثبت طبقه بندی شده اند. یادآوری یا حساسیت (معادله (2)) نشان دهنده 1- خطای حذف یا نسبت داده های مرجع برای کلاس مثبت است که به درستی طبقه بندی شده است. امتیاز F1 (معادله (3)) میانگین هارمونیک دقت و یادآوری است، در حالی که ویژگی (معادله (4)) نشان دهنده نسبت نمونه های مرجع منفی است که به درستی پیش بینی شده اند. دقت کلی (OA) (معادله (5)) نسبت ویژگی های به درستی طبقه بندی شده را نشان می دهد [ 101 ]. آماره کاپا (معادله (6)) OA را برای توافق شانس تصحیح می کند [ 57 ]. تمام معیارهای ارزیابی باینری با استفاده از کارت [ 100 ] محاسبه شد] بسته در R [ 99 ]. این بسته همچنین امکان محاسبه 95% فواصل اطمینان را برای OA بر اساس توزیع دو جمله ای [ 100 ، 102 ] می دهد.
4. نتایج
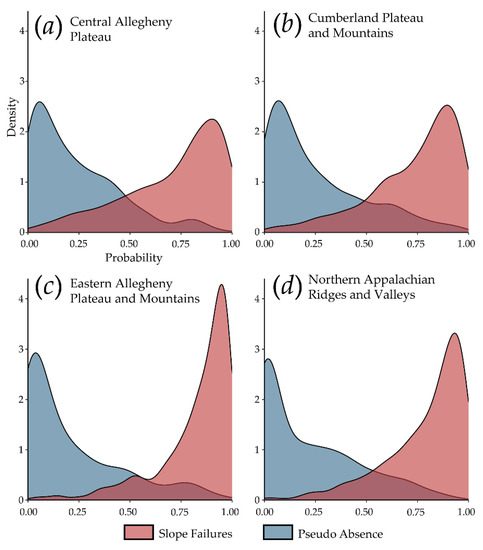
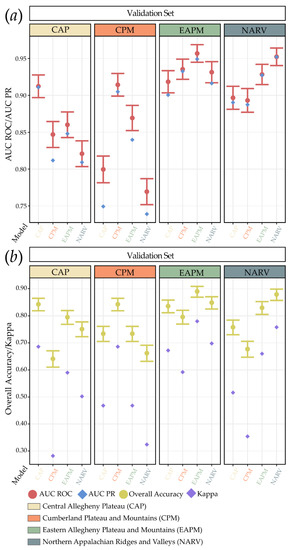
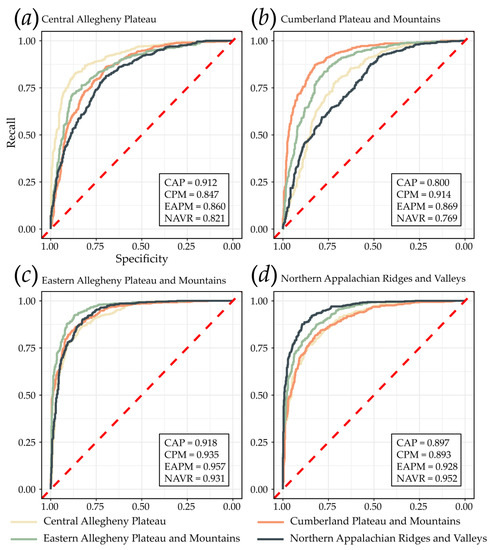
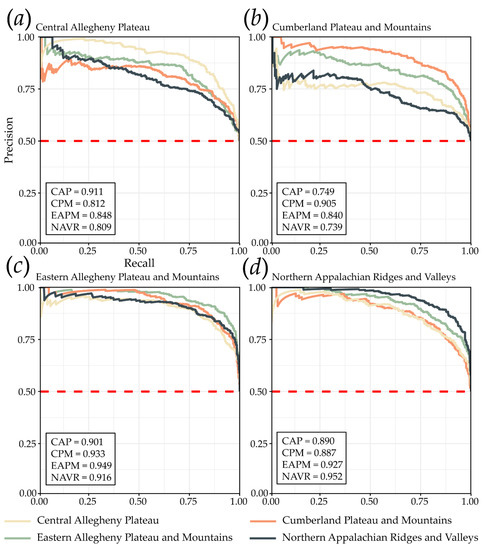
4.1. عملکرد مدل در همان MLRA
4.2. تعمیم مدل به MLRA های مختلف
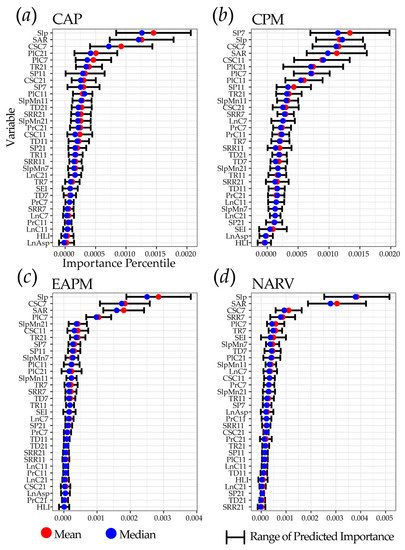
4.3. مقایسه اهمیت متغیر بین MLRA
5. بحث
6. نتیجه گیری
منابع
- پتلی، دی. الگوهای جهانی از دست دادن زندگی در اثر زمین لغزش. زمین شناسی 2012 ، 40 ، 927-930. [ Google Scholar ] [ CrossRef ]
- ترنر، AK اثرات اجتماعی و زیست محیطی زمین لغزش. نوآوری. زیرساخت. حلال. 2018 ، 3 ، 70. [ Google Scholar ] [ CrossRef ]
- هایلند، LM؛ Bobrowsky, P. The Landslide Handbook—A Guide to Understanding Landslides ; گرد؛ سازمان زمین شناسی ایالات متحده: Reston، VA، ایالات متحده آمریکا، 2008; پ. 147. [ Google Scholar ]
- کاساگلی، ن. سیگنا، اف. بیانچینی، اس. هلبلینگ، دی. فوردر، پی. ریگینی، جی. دل کونته، اس. فریدل، بی. اشنایدرباوئر، اس. ایاسیو، سی. و همکاران نقشه برداری و پایش زمین لغزش با استفاده از رادار و سنجش از دور نوری: نمونه هایی از پروژه EC-FP7 SAFER. Remote Sens. Appl. Soc. محیط زیست 2016 ، 4 ، 92-108. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- قربانزاده، ا. بلاشکه، تی. غلام نیا، ک. مینا، اس آر. تاید، دی. Aryal, J. ارزیابی روشهای مختلف یادگیری ماشین و شبکههای عصبی کانولوشنال یادگیری عمیق برای تشخیص زمین لغزش. Remote Sens. 2019 , 11 , 196. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- قربانزاده، ا. مینا، اس آر. بلاشکه، تی. تشخیص شکست شیب مبتنی بر پهپاد Aryal، J. با استفاده از شبکههای عصبی کانولوشنال یادگیری عمیق. Remote Sens. 2019 ، 11 ، 2046. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لی، تی. ژانگ، ی. Lv، Z. لی، اس. لیو، اس. Nandi، AK نگاشت فهرست زمین لغزش از تصاویر Bitemporal با استفاده از شبکه های عصبی پیچیده عمیق. IEEE Geosci. سنسور از راه دور Lett. 2019 ، 16 ، 982-986. [ Google Scholar ] [ CrossRef ]
- لو، پی. استامف، ا. کرل، ن. Casagli، N. تشخیص تغییر شی گرا برای نقشه برداری سریع زمین لغزش. IEEE Geosci. سنسور از راه دور Lett. 2011 ، 8 ، 701-705. [ Google Scholar ] [ CrossRef ]
- استامف، ا. Kerle، N. ترکیب جنگل های تصادفی و تجزیه و تحلیل شی گرا برای نقشه برداری زمین لغزش از تصاویر با وضوح بسیار بالا. Procedia Environ. علمی 2011 ، 3 ، 123-129. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بالابیو، سی. Sterlacchini، S. ماشینهای بردار پشتیبانی برای نقشهبرداری حساسیت زمین لغزش: مطالعه موردی حوضه رودخانه استافورا، ایتالیا. ریاضی. Geosci. 2012 ، 44 ، 47-70. [ Google Scholar ] [ CrossRef ]
- هوانگ، ی. ژائو، ال. بررسی نقشهبرداری حساسیت زمین لغزش با استفاده از ماشینهای بردار پشتیبان. CATENA 2018 ، 165 ، 520–529. [ Google Scholar ] [ CrossRef ]
- کیم، جی. سی. لی، اس. یونگ، اچ.-اس. لی، اس. نقشهبرداری حساسیت زمین لغزش با استفاده از مدلهای جنگل تصادفی و درخت تقویتشده در پیونگ چانگ، کره. Geocarto Int. 2018 ، 33 ، 1000-1015. [ Google Scholar ] [ CrossRef ]
- مریانوویچ، م. کوواچویچ، م. باجات، بی. Voženílek، V. ارزیابی حساسیت زمین لغزش با استفاده از الگوریتم یادگیری ماشین SVM. مهندس جئول 2011 ، 123 ، 225-234. [ Google Scholar ] [ CrossRef ]
- طلب، ک. چنگ، تی. Zhang, Y. نقشه برداری حساسیت زمین لغزش و انواع با استفاده از جنگل تصادفی. داده های بزرگ زمین 2018 ، 2 ، 159-178. [ Google Scholar ] [ CrossRef ]
- تین بوی، دی. پرادان، بی. لوفمن، او. Revhaug، I. ارزیابی حساسیت زمین لغزش در ویتنام با استفاده از ماشینهای بردار پشتیبان، درخت تصمیم، و مدلهای ساده بیز. ریاضی. مشکل مهندس 2012 ، 2012 ، 1-26. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یائو، ایکس. تام، ال جی؛ نقشهبرداری حساسیت زمین لغزش Dai، FC بر اساس ماشین بردار پشتیبان: مطالعه موردی در دامنههای طبیعی هنگ کنگ، چین. ژئومورفولوژی 2008 ، 101 ، 572-582. [ Google Scholar ] [ CrossRef ]
- ماکسول، AE; شارما، م. بادبادک، JS; دونالدسون، کالیفرنیا؛ تامپسون، جی. بل، ام ال. پیشبینی شکست شیب مینارد، SM با استفاده از یادگیری ماشین جنگل تصادفی و LiDAR در یک کمربند کوهپیچ خورده فرسایش یافته. Remote Sens. 2020 , 12 , 486. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- محلینگم، ر. اولسن، ام جی; O’Banion، MS ارزیابی تکنیک های نقشه برداری حساسیت زمین لغزش با استفاده از عوامل شرطی سازی مشتق از لیدار (مطالعه موردی اورگان). Geomat. نات. خطر خطرات 2016 ، 7 ، 1884-1907. [ Google Scholar ] [ CrossRef ]
- دوو، جی. یونس، AP; تین بوی، دی. ساهانا، م. چن، سی.-و. زو، ز. وانگ، دبلیو. Thai Pham، B. ارزیابی مدلهای آماری چندگانه مبتنی بر GIS و دادهکاوی برای حساسیت زمین لغزش ناشی از زلزله و بارندگی با استفاده از LiDAR DEM. Remote Sens. 2019 , 11 , 638. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوفل، بی. Rutzinger، M. توپوگرافی هوابرد LiDAR در ژئومورفولوژی: یک دیدگاه تکنولوژیکی. Z. fur Geomorphol. تامین 2011 ، 55 ، 1-29. [ Google Scholar ] [ CrossRef ]
- جابویدوف، م. اوپیکوفر، تی. آبلان، ا. درون، M.-H. لویه، ا. متزگر، آر. Pedrazzini، A. استفاده از LIDAR در بررسی زمین لغزش: بررسی. نات. خطرات 2012 ، 61 ، 5-28. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مور، شناسه; گریسون، RB; Ladson، مدلسازی زمین دیجیتال AR: مروری بر کاربردهای هیدرولوژیکی، ژئومورفولوژیکی و بیولوژیکی. هیدرول. روند. 1991 ، 5 ، 3-30. [ Google Scholar ] [ CrossRef ]
- آروندل، ST; فیلیپس، لس آنجلس؛ لو، ای جی. بوبین مایر، جی. Mantey، KS; دان، کالیفرنیا؛ کنستانس، EW; Usery، EL در حال تهیه نقشه ملی برای برنامه ارتفاع سه بعدی – محصولات، فرآیند و تحقیقات. کارتوگر. Geogr. Inf. علمی 2015 ، 42 ، 40-53. [ Google Scholar ] [ CrossRef ]
- استوکر، جی.ام. عبدالله، ق. نایگاندی، ع. واینهاوس، جی. ارزیابی تک فوتون و لیدار حالت گایگر برای برنامه ارتفاع سه بعدی. Remote Sens. 2016 , 8 , 767. [ Google Scholar ] [ CrossRef ][ Green Version ]
- بابروفسکی، پ. Highland, L. The Landslide Handbook-راهنمای درک زمین لغزش: انتشارات برجسته برای آموزش و آمادگی زمین لغزش. در زمین لغزش ها: آمادگی جهانی برای خطر . Sassa, K., Rouhban, B., Briceño, S., McSaveney, M., He, B., Eds.; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 75-84. شابک 978-3-642-22087-6. [ Google Scholar ]
- کاواگوچی، ک. Kaelbling، LP; Bengio، Y. تعمیم در یادگیری عمیق. arXiv 2020 ، arXiv:1710.05468. [ Google Scholar ]
- ماکسول، AE; پورمحمدی، پ. پوینر، جی دی نقشه برداری از ویژگی های توپوگرافی پرهای دره مرتبط با معدن با استفاده از ماسک R-CNN Deep Learning و داده های ارتفاعی دیجیتال. Remote Sens. 2020 , 12 , 547. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ماکسول، AE; وارنر، TA; Strager، MP پیشبینی احتمال تالاب Palustrine با استفاده از یادگیری ماشین تصادفی جنگل و متغیرهای زمین مشتق از دادههای ارتفاعی دیجیتال. فتوگرام مهندس Remote Sens. 2016 , 82 , 437–447. [ Google Scholar ] [ CrossRef ]
- ماکسول، AE; بهتر، ام اس; گیلن، لس آنجلس; رمضان، کالیفرنیا; کارپینلو، دی جی; فن، ی. هارتلی، اف.ام. مینارد، اس ام. Pyron، JL Semantic Segmentation Deep Learning برای استخراج گستره معادن سطحی از نقشه های توپوگرافی تاریخی. Remote Sens. 2020 , 12 , 4145. [ Google Scholar ] [ CrossRef ]
- نیشابور، ب. بوجاناپالی، س. مک آلستر، دی. سربرو، ن. بررسی تعمیم در یادگیری عمیق. arXiv 2017 , arXiv:1706.08947. [ Google Scholar ]
- هوزر، تی. باکوفر، اف. کوئنزر، سی. تشخیص شی و تقسیمبندی تصویر با یادگیری عمیق در دادههای رصد زمین: بررسی – بخش دوم: کاربردها. Remote Sens. 2020 , 12 , 3053. [ Google Scholar ] [ CrossRef ]
- هوزر، تی. کوئنزر، سی. تشخیص اشیاء و تقسیمبندی تصویر با یادگیری عمیق در دادههای رصد زمین: مروری – بخش اول: تکامل و روندهای اخیر. Remote Sens. 2020 , 12 , 1667. [ Google Scholar ] [ CrossRef ]
- ماگیوری، ای. تارابالکا، ی. چارپیات، جی. آیا روشهای برچسبگذاری معنایی به هر شهری تعمیم مییابد؟ معیار برچسب گذاری تصویر هوایی اینریا. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2017 (IGARSS)، فورت ورث، تگزاس، ایالات متحده آمریکا، 23 تا 28 ژوئیه 2017؛ صص 3226–3229. [ Google Scholar ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بلژیک، م. Drăguţ، L. جنگل تصادفی در سنجش از دور: مروری بر کاربردها و مسیرهای آینده. ISPRS J. Photogramm. Remote Sens. 2016 ، 114 ، 24–31. [ Google Scholar ] [ CrossRef ]
- Gislason، PO; بندیکتسون، جی. Sveinsson، JR طبقه بندی جنگل تصادفی سنجش از دور چند منبعی و داده های جغرافیایی. در مجموعه مقالات IGARSS 2004، 2004 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، انکوریج، AK، ایالات متحده آمریکا، 20-24 سپتامبر 2004. جلد 2، ص 1049–1052. [ Google Scholar ]
- ماکسول، AE; وارنر، TA; Fang, F. پیادهسازی طبقهبندی یادگیری ماشینی در سنجش از دور: یک بررسی کاربردی. بین المللی J. Remote Sens. 2018 , 39 , 2784–2817. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ماکسول، AE; غریبه، نماینده مجلس؛ وارنر، TA; رمضان، کالیفرنیا; مورگان، AN; Pauley، CE نقشهبرداری پوشش زمین با وضوح فضایی بالا با استفاده از جنگلهای تصادفی، GEOBIA و NAIP Orthophotography: یافتهها و توصیهها. Remote Sens. 2019 ، 11 ، 1409. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Gislason، PO; بندیکتسون، جی. Sveinsson، JR جنگل های تصادفی برای طبقه بندی پوشش زمین. تشخیص الگو Lett. 2006 ، 27 ، 294-300. [ Google Scholar ] [ CrossRef ]
- ایوانز، جی اس. کوشمن، SA مدلسازی گرادیان گونههای مخروطی با استفاده از جنگلهای تصادفی. Landsc. Ecol. 2009 ، 24 ، 673-683. [ Google Scholar ] [ CrossRef ]
- غریبه، نماینده مجلس؛ استراگر، جی.ام. ایوانز، جی اس. Dunscomb، JK; کرپس، بیجی؛ Maxwell، AE ترکیب یک مدل فضایی و پیشبینی تقاضا برای نقشهبرداری از معادن سطحی زغال سنگ در آپالاشیا. PLoS ONE 2015 ، 10 ، e0128813. [ Google Scholar ] [ CrossRef ]
- رایت، سی. گالانت، الف. سنجش از دور تالاب در پارک ملی یلوستون با استفاده از درختان طبقهبندی برای ترکیب تصاویر TM و دادههای محیطی جانبی. سنسور از راه دور محیط. 2007 ، 107 ، 582-605. [ Google Scholar ] [ CrossRef ]
- کاتانی، اف. لاگومارسینو، دی. سگونی، س. طوفانی، وی. برآورد حساسیت زمین لغزش با تکنیک جنگلهای تصادفی: مسائل مربوط به حساسیت و مقیاسپذیری. نات. سیستم خطرات زمین. علمی 2013 ، 13 ، 2815-2831. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گوتز، JN; برنینگ، آ. پتچکو، اچ. Leopold, P. ارزیابی تکنیکهای یادگیری ماشین و پیشبینی آماری برای مدلسازی حساسیت زمین لغزش. محاسبه کنید. Geosci. 2015 ، 81 ، 1-11. [ Google Scholar ] [ CrossRef ]
- هونگ، اچ. لیو، جی. Bui، DT; پرادان، بی. آچاریا، تی دی. فام، بی تی؛ زو، A.-X. چن، دبلیو. احمد، BB نقشهبرداری حساسیت زمین لغزش با استفاده از درخت تصمیم J48 با مجموعههای جنگلی AdaBoost، Bagging و Rotation Forest در منطقه Guangchang (چین). CATENA 2018 ، 163 ، 399–413. [ Google Scholar ] [ CrossRef ]
- تریگیلا، ا. ایدانزا، سی. اسپوزیتو، سی. Scarascia-Mugnozza، G. مقایسه تکنیک های رگرسیون لجستیک و جنگل های تصادفی برای ارزیابی حساسیت زمین لغزش کم عمق در Giampilieri (NE سیسیل، ایتالیا). ژئومورفولوژی 2015 ، 249 ، 119-136. [ Google Scholar ] [ CrossRef ]
- یوسف، ع.م. پورقاسمی، HR; پورتقی، ز.س. الکثیری، MM نقشهبرداری حساسیت زمین لغزش با استفاده از جنگل تصادفی، درخت رگرسیون تقویتشده، طبقهبندی و درخت رگرسیون، و مدلهای خطی عمومی و مقایسه عملکرد آنها در حوضه وادی طیه، منطقه عسیر، عربستان سعودی. زمین لغزش 2016 ، 13 ، 839-856. [ Google Scholar ] [ CrossRef ]
- چن، دبلیو. Xie، X. پنگ، جی. شهابی، ح. هونگ، اچ. Bui، DT; دوان، ز. لی، اس. زو، A.-X. ارزیابی حساسیت زمین لغزش مبتنی بر GIS با استفاده از یک رویکرد ترکیبی ترکیبی جدید از روش جنگل تصادفی مبتنی بر آماری دو متغیره. CATENA 2018 ، 164 ، 135-149. [ Google Scholar ] [ CrossRef ]
- پورقاسمی، HR; Kerle، N. جنگلهای تصادفی و ارزیابی حساسیت زمین لغزش مبتنی بر تابع باور شواهدی در استان مازندران غربی، ایران. محیط زیست علوم زمین 2016 ، 75 ، 185. [ Google Scholar ] [ CrossRef ]
- گوتز، JN; گاتری، RH; برنینگ، الف. ادغام مدل های فیزیکی و تجربی حساسیت زمین لغزش با استفاده از مدل های افزایشی تعمیم یافته. ژئومورفولوژی 2011 ، 129 ، 376-386. [ Google Scholar ] [ CrossRef ]
- نیکول، جی. Wong، MS ماهواره سنجش از راه دور برای فهرست دقیق زمین لغزش با استفاده از تشخیص تغییر و ترکیب تصویر. بین المللی J. Remote Sens. 2005 ، 26 ، 1913-1926. [ Google Scholar ] [ CrossRef ]
- استامف، ا. Kerle، N. نقشه برداری شی گرا زمین لغزش با استفاده از جنگل های تصادفی. سنسور از راه دور محیط. 2011 ، 115 ، 2564-2577. [ Google Scholar ] [ CrossRef ]
- لی، تی. ژانگ، Q. ژو، دی. چن، تی. منگ، اچ. Nandi، AK تشخیص تغییر سرتاسر با استفاده از یک شبکه کاملاً پیچیده متقارن برای نقشه برداری زمین لغزش. در مجموعه مقالات کنفرانس بین المللی ICASSP 2019-2019 IEEE در مورد آکوستیک، پردازش گفتار و سیگنال (ICASSP)، برایتون، انگلستان، 12 تا 17 مه 2019؛ ص 3027–3031. [ Google Scholar ]
- لیو، ی. Wu, L. تشخیص فاجعه زمین شناسی بر روی تصاویر سنجش از دور نوری با استفاده از یادگیری عمیق. Procedia Comput. علمی 2016 ، 91 ، 566-575. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، ی. وانگ، ایکس. ژیان، جی. تشخیص زمین لغزش سنجش از دور بر اساس شبکه عصبی کانولوشنال. در دسترس آنلاین: https://www.hindawi.com/journals/mpe/2019/8389368/ (در 24 ژانویه 2020 قابل دسترسی است).
- پاسالاکوا، پ. بلمونت، پی. استالی، دی.م. سیملی، جی دی. Arrowsmith، JR; بود، کالیفرنیا؛ کراسبی، سی. دلانگ، اس بی؛ گلن، NF; کلی، SA; و همکاران تجزیه و تحلیل توپوگرافی با وضوح بالا برای پیشرفت درک انتقال جرم و انرژی از طریق مناظر: مروری. علوم زمین Rev. 2015 , 148 , 174-193. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وارنر، TA; فودی، جنرال موتورز; Nellis, MD The SAGE Handbook of Remote Sensing ; انتشارات SAGE: Thousand Oaks, CA, USA, 2009; شابک 978-1-4129-3616-3. [ Google Scholar ]
- روزیکا، م. میگون، پی. Michniewicz، A. شاخص رطوبت توپوگرافی و شاخص ناهمواری زمین در ویژگی های ژئومورفیک زمین لغزش، در نمونه هایی از Sudetes، SW لهستان. در دسترس آنلاین: https://www.ingentaconnect.com/content/schweiz/zfgs/2017/00000061/00000002/art00005 (در 13 نوامبر 2019 قابل دسترسی است).
- پایک، RJ; ویلسون، نسبت SE Elevation-Relief، Hypsometric Integral و Geomorphic Area-Alttitude Analysis. گاو GSA. 1971 ، 82 ، 1079-1084. [ Google Scholar ] [ CrossRef ]
- مورنو، ام. لواچکین، اس. تورس، ام. Quintero، R. تجزیه و تحلیل ژئومورفومتریک داده های تصویر شطرنجی برای تشخیص ناهمواری زمین و تراکم زهکشی. در مجموعه مقالات پیشرفت در تشخیص الگو، گفتار و تحلیل تصویر، هاوانا، کوبا، 26-29 نوامبر 2003. Sanfeliu, A., Ruiz-Shulcloper, J., Eds. Springer: برلین/هایدلبرگ، آلمان، 2003; صص 643-650. [ Google Scholar ]
- هویسمن، او. اصول سیستم های اطلاعات جغرافیایی – کتاب درسی مقدماتی. 540. در دسترس آنلاین: https://webapps.itc.utwente.nl/librarywww/papers_2009/general/principlesgis.pdf (در 2 مه 2021 قابل دسترسی است).
- Gessler، PE; مور (متوفی)، شناسه; مک کنزی، نیوجرسی؛ رایان، PJ مدلسازی خاک-منظر و پیشبینی فضایی ویژگیهای خاک. بین المللی جی. جئوگر. Inf. سیستم 1995 ، 9 ، 421-432. [ Google Scholar ] [ CrossRef ]
- Zevenbergen، LW; Thorne، CR تجزیه و تحلیل کمی توپوگرافی سطح زمین. زمین گشت و گذار. روند. Landf. 1987 ، 12 ، 47-56. [ Google Scholar ] [ CrossRef ]
- آلبانی*، م. کلینکنبرگ، بی. اندیسون، DW; Kimmins, JP انتخاب اندازه پنجره در تقریب سطوح توپوگرافی از مدلهای ارتفاعی دیجیتال. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 577-593. [ Google Scholar ] [ CrossRef ]
- فرانکلین، SE تفسیر و استفاده از ژئومورفومتری در سنجش از دور: راهنما و بررسی برنامه های کاربردی یکپارچه. بین المللی J. Remote Sens. 2020 , 41 , 7700–7733. [ Google Scholar ] [ CrossRef ]
- منطقه اصلی منابع زمین (MLRA) | خاک های NRCS در دسترس به صورت آنلاین: https://www.nrcs.usda.gov/wps/portal/nrcs/detail/soils/survey/geo/?cid=nrcs142p2_053624 (در 28 فوریه 2021 قابل دسترسی است).
- Strausbaugh, PD; کور، EL فلور ویرجینیای غربی ; بولتن دانشگاه ویرجینیای غربی؛ دانشگاه ویرجینیای غربی: مورگان تاون، WV، ایالات متحده آمریکا، 1952. [ Google Scholar ]
- Hooke, RL توزیع فضایی فعالیت ژئومورفیک انسانی در ایالات متحده: مقایسه با رودخانه ها. زمین گشت و گذار. روند. Landf. 1999 ، 24 ، 687-692. [ Google Scholar ] [ CrossRef ]
- هوک، RL درباره تاریخچه انسان ها به عنوان عوامل ژئومورفیک. زمین شناسی 2000 ، 28 ، 843-846. [ Google Scholar ] [ CrossRef ]
- WVGES. WV استان های فیزیوگرافی. در دسترس آنلاین: https://www.wvgs.wvnet.edu/www/maps/pprovinces.htm (در 14 نوامبر 2019 قابل دسترسی است).
- فاکس، جی. حذف قله کوه در ویرجینیای غربی: یک منطقه قربانی محیطی. عضو. محیط زیست 1999 ، 12 ، 163-183. [ Google Scholar ] [ CrossRef ]
- فریتز، KM; فولتون، اس. جانسون، BR; بارتون، سی دی; جک، جی دی. Word، DA; بورک، RA ویژگیهای ساختاری و عملکردی کانالهای طبیعی و ساختهشده در حال تخلیه یک معدن زغالسنگ برداشتهشده از بالای کوه و پر کردن دره. JN Am. بنتول. Soc. 2010 ، 29 ، 673-689. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیندبرگ، تی تی; برنهارت، ES; بیر، آر. هلتون، AM; مرولا، RB; ونگوش، ع. Giulio، RTD اثرات تجمعی معدن کوهستانی در حوضه آبخیز آپالاچی. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2011 ، 108 ، 20929–20934. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میلر، ای جی; Zégre، NP کوهستان حذف معدن و هیدرولوژی حوضه. آب 2014 ، 6 ، 472-499. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پالمر، MA; برنهارت، ES; شلزینگر، WH; اشلمان، KN; فوفولا-جورجیو، ای. هندریکس، ام اس؛ لملی، AD; Likens، GE; Loucks، OL; قدرت، من. و همکاران عواقب معدن در بالای کوه. علوم 2010 ، 327 ، 148-149. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- ویکهام، جی دی. Riitters، KH; وید، تی جی؛ کوان، ام. هومر، سی. اثر معدنکاری قله کوه آپالاچی بر جنگل داخلی. Landsc. Ecol. 2007 ، 22 ، 179-187. [ Google Scholar ] [ CrossRef ]
- ویکهام، جی. چوب، PB; نیکلسون، ام سی؛ جنکینز، دبلیو. دراکنبرود، دی. سوتر، GW; غریبه، نماینده مجلس؛ مازارلا، سی. گالووی، دبلیو. آموس، جی. تأثیرات زمینی نادیده گرفته شده استخراج در بالای کوه. BioScience 2013 ، 63 ، 335-348. [ Google Scholar ] [ CrossRef ]
- ماکسول، AE; Strager، MP در حال ارزیابی تغییرات شکل زمین ناشی از استخراج کوهستانی. نات. علمی 2013 ، 5 ، 229-237. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- راس، MRV؛ مک گلین، BL; برنهارت، ES Deep Impact: اثرات استخراج در بالای کوه بر توپوگرافی سطح، ساختار سنگ بستر و آبهای پایین دست. محیط زیست علمی تکنولوژی 2016 ، 50 ، 2064–2074. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چانگ، K.-T. سیستم اطلاعات جغرافیایی. در دایره المعارف بین المللی جغرافیا ; انجمن سرطان آمریکا: آتلانتا، GA، ایالات متحده آمریکا، 2017؛ صفحات 1-9. شابک 978-1-118-78635-2. [ Google Scholar ]
- ماکسول، AE; وارنر، TA آیا داده های DEM با وضوح فضایی بالا برای نقشه برداری تالاب های پالسترین ضروری است؟ بین المللی J. Remote Sens. 2019 ، 40 ، 118-137. [ Google Scholar ] [ CrossRef ]
- ArcGIS Pro 2.2 ; ESRI: Redlands, CA, USA, 2018. موجود آنلاین: https://www.esri.com/arcgis-blog/products/arcgis-pro/uncategorized/arcgis-pro-2-2-now-available/ (دسترسی در 2 مه 2021).
- ایوانز، JS Jeffreyevans/GradientMetrics. 2020. در دسترس آنلاین: https://evansmurphy.wixsite.com/evan (در 2 مه 2021 قابل دسترسی است).
- مرحله، AR بیانی برای تأثیر جنبه، شیب، و نوع زیستگاه بر رشد درخت. برای. علمی 1976 ، 22 ، 457-460. [ Google Scholar ] [ CrossRef ]
- لوپز، م. Berry، JK از مساحت سطح برای محاسبات واقعی استفاده می کنند. GeoWorld 2002 , 15 , 25. [ Google Scholar ]
- ریلی، اس جی. دی گلوریا، SD؛ الیوت، RA شاخص ناهمواری زمین که ناهمگونی توپوگرافی را کمی می کند. Intermt. J. Sci. 1999 ، 5 ، 23. [ Google Scholar ]
- Jacek، S. مشخصه سازی شکل زمین با سیستم های اطلاعات جغرافیایی. فتوگرام مهندس Remote Sens. 1997 , 63 , 183-191. [ Google Scholar ]
- ایوانز، ژئومورفومتری عمومی IS، مشتقات ارتفاع، و آمار توصیفی. در تحلیل فضایی در ژئومورفولوژی ; Methuen & Co.: لندن، انگلستان، 1972; صص 17-90. [ Google Scholar ]
- پایک، RJ; ایوانز، IS; Hengl, T. فصل 1 ژئومورفومتری: راهنمای مختصر. در تحولات علوم خاک ; Hengl, T., Reuter, HI, Eds. ژئومورفومتری; الزویر: آمستردام، هلند، 2009; جلد 33، ص 3-30. [ Google Scholar ]
- آیرونساید، KE; ماتسون، دی جی؛ آروندل، تی. تیمر، تی. هولتون، بی. پیترز، ام. ادواردز، TC; هانسن، جی. ژئومورفومتری در اکولوژی منظر: مسائل مقیاس، فیزیوگرافی و کاربرد. محیط زیست Ecol. Res. 2018 ، 6 ، 397-412. [ Google Scholar ] [ CrossRef ]
- مک کیون، بی. معادلات کئون، دی. J. Veg. علمی 2002 ، 13 ، 603-606. [ Google Scholar ] [ CrossRef ]
- Wood, J. Chapter 14 Geomorphometry in LandSerf. در تحولات علوم خاک ; Hengl, T., Reuter, HI, Eds. ژئومورفومتری; الزویر: آمستردام، هلند، 2009; جلد 33، ص 333-349. [ Google Scholar ]
- وود، ج. خصوصیات ژئومورفولوژیکی مدلهای ارتفاعی دیجیتال. Ph.D. پایان نامه، دانشگاه لستر، لستر، انگلستان، 1996. [ Google Scholar ]
- ویژگی های مورفومتریک ماژول/ مستندات کتابخانه ماژول SAGA-GIS (v2.2.5). در دسترس آنلاین: https://www.saga-gis.org/saga_tool_doc/2.2.5/ta_morphometry_23.html (دسترسی در 14 نوامبر 2019).
- SAGA – سیستمی برای تجزیه و تحلیل خودکار زمینشناسی. در دسترس آنلاین: https://www.saga-gis.org/en/index.html (در 14 نوامبر 2019 قابل دسترسی است).
- فلورینسکی، چهارم، مقدمه ای مصور بر ژئومورفومتری عمومی. Prog. فیزیک Geogr. محیط زمین. 2017 ، 41 ، 723-752. [ Google Scholar ] [ CrossRef ]
- اسپیرمن، سی. اثبات و سنجش ارتباط بین دو چیز. بین المللی J. Epidemiol. 2010 ، 39 ، 1137-1150. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیاو، ا. وینر، ام. طبقه بندی و رگرسیون توسط RandomForest. R News 2002 , 2 , 18-22. [ Google Scholar ]
- تیم اصلی R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری: وین، اتریش، 2018. [ Google Scholar ]
- کوهن، ام. ساخت مدل های پیش بینی در R با استفاده از بسته کارت. J. Stat. نرم افزار 2008 ، 28 ، 1-26. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Tharwat، A. طبقه بندی روش های ارزیابی. Appl. محاسبه کنید. به اطلاع رساندن. 2020 . [ Google Scholar ] [ CrossRef ]
- کلپر، سی جی; پیرسون، ES استفاده از اطمینان یا محدودیت های واهی نشان داده شده در مورد دو جمله ای. Biometrika 1934 ، 26 ، 404-413. [ Google Scholar ] [ CrossRef ]
- بک، جی آر. Shultz، EK استفاده از منحنی های مشخصه عملیاتی نسبی (ROC) در ارزیابی عملکرد آزمون. قوس. پاتول. آزمایشگاه. پزشکی 1986 ، 110 ، 13-20. [ Google Scholar ]
- بردلی، AP استفاده از ناحیه زیر منحنی ROC در ارزیابی الگوریتمهای یادگیری ماشین. تشخیص الگو 1997 ، 30 ، 1145-1159. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دلانگ، ای آر. DeLong، DM; Clarke-Pearson، DL مقایسه نواحی زیر دو یا چند منحنی مشخصه عملکرد گیرنده همبسته: یک رویکرد ناپارامتریک. بیومتریک 1988 ، 44 ، 837-845. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- رابین، ایکس. تورک، ن. هاینارد، ا. تیبرتی، ن. لیزاچک، اف. سانچز، جی.-سی. Müller, M. PROC: یک بسته منبع باز برای R و S+ برای تجزیه و تحلیل و مقایسه منحنی های ROC. BMC Bioinform. 2011 ، 12 ، 77. [ Google Scholar ] [ CrossRef ]
- سایتو، تی. Rehmsmeier، M. نمودار یادآوری دقیق هنگام ارزیابی طبقهبندیکنندههای باینری در مجموعه دادههای نامتعادل، آموزندهتر از نمودار ROC است. PLoS ONE 2015 ، 10 ، e0118432. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- گراو، جی. گروس، آی. Keilwagen, J. PRROC: Computing and Visualizing Precision-Recall and Receiver Operating Characteristic Curves in R. Bioinformatics 2015 , 31 , 2595-2597. [ Google Scholar ] [ CrossRef ]
- کوهن، م. وان، دی. RStudio. معیار: خصوصیات مرتب عملکرد مدل . 2020. در دسترس آنلاین: https://cran.r-project.org/web/packages/yardstick/index.html (در 2 مه 2021 قابل دسترسی است).
- استروبل، سی. هاثورن، تی. Zeileis، A. حزب در! یک معیار اهمیت متغیر مشروط جدید در بسته مهمانی موجود است. R J. 2009 ، 1 ، 14-17. [ Google Scholar ] [ CrossRef ]
- استروبل، سی. Boulesteix، A.-L.; کنیب، تی. آگوستین، تی. Zeileis، A. اهمیت متغیر شرطی برای جنگل های تصادفی. BMC Bioinform. 2008 ، 9 ، 1-11. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- خطرات زمین لغزش – نقشه ها. در دسترس آنلاین: https://www.usgs.gov/natural-hazards/landslide-hazards/maps (در 4 مارس 2021 قابل دسترسی است).



بدون دیدگاه