

ارزیابی داده های توئیتر با برچسب جغرافیایی برای تجزیه و تحلیل جریان های توریستی در اشتایر، اتریش
خلاصه
این تحقیق بر شناسایی جریانهای توریستی در استان اشتایریا در اتریش بر اساس دادههای جمعسپاری متمرکز است. دادههای توییتر در بازه زمانی 2008 تا آگوست 2018 جمعآوری شدهاند. توییتهای استخراجشده به یک فرآیند فیلترینگ گسترده در پایگاه داده غیرمرتبط MongoDB ارسال شدند. برای بررسی توزیع فضایی توییتهای مربوط به گردشگری تحت تغییرات زمانی، از روشهای آنالیز نقطه داغ و تخمین تراکم هسته استفاده شد.

علاوه بر این، با استفاده از روش VADER یک تحلیل معنایی یکپارچه احساسات توییت های استخراج شده را ارائه می دهد. تجزیه و تحلیل فضایی نشان داد که نقاط حساس شناسایی شده با مناطق معمولی توریستی استایری مطابقت دارد. جدا از تجزیه و تحلیل احساسات عمدتاً موفق، به یک جنبه مشکل ساز کار با داده های چند زبانه نیز اشاره کرد. برای اهداف ارزیابی، داده های رسمی گردشگری از استان اشتایر و اداره آمار فدرال اتریش نقش داده های حقیقت زمین را ایفا کردند. یک ارزیابی با ضریب همبستگی پیرسون به کار گرفته شد که ارتباط آماری معنیداری بین دادههای توییتر و دادههای مرجع را ثابت میکند. به طور خاص، این مقاله نشان میدهد که دادههای جمعسپاری شده در سطح منطقهای میتواند به عنوان شاخص دقیقی برای رفتار و حرکت کاربران باشد.
کلید واژه ها:
توییتر ؛ جمع سپاری ; تحلیل فضایی ; تحلیل احساسات ؛ گردشگری ؛ استایر
1. معرفی
رسانه های اجتماعی مانند توییتر ارتباط کاربر و به اشتراک گذاری وضعیت ذهنی، رفتار یا فعالیت های آنها را امکان پذیر می کند. علاوه بر این، امکان ارائه موقعیت یا مکان فعلی هر توییت نیز وجود دارد. از جنبه جغرافیایی، توییتر برخلاف مجموعههای رسمی دادهها با در دسترس بودن به تعویق افتاده، به راحتی دادههای جغرافیایی بلادرنگ را مستقیماً از کاربران ارائه میکند. تحلیلهای مکانی مختلفی ممکن است با دادههای جغرافیایی جمعآوریشده انجام شود، مانند شناسایی روندهای درون دادهها برای به دست آوردن اطلاعات مکانهایی که اکثر کاربران توییتر دارند یا تجزیه و تحلیل حرکت آنها. دادههای جمعسپاری (جغرافیایی) دادههایی هستند که داوطلبانه و غیرارادی توسط شهروندان ارائه میشوند [ 1 ، 2 ]. علاوه بر این، [ 1] از جمله به این واقعیت اشاره دارد که هر داده از رسانه های اجتماعی به عنوان داده های جمع سپاری در نظر گرفته می شود. در این تحقیق داده های جغرافیایی جمع سپاری شده [ 1 ، 2 ]، از پلت فرم توییتر، برای تجزیه و تحلیل جریان های توریستی در استایرا، ایالتی در این کشور، جمع آوری شده است. اتریش در این مقاله خاص، ما هجوم گردشگران را به عنوان «جریان» در نظر میگیریم و متعاقباً سعی میکنیم توزیع مکانی – زمانی این هجوم گردشگر را تحلیل کنیم. به این ترتیب، برخلاف بسیاری از نشریات که در مقیاس بزرگتر تمرکز دارند [ 3 ، 4]، این مطالعه بر قابلیت اطمینان داده های توییتر در مقیاس منطقه ای تمرکز دارد. بررسی دادههای بهدستآمده بر شناخت الگوهای مکانی و زمانی توریستی و همچنین ارزیابی قابلیت اطمینان و کفایت دادههای توییتر برچسبگذاریشده جغرافیایی در مقایسه با دادههای عمومی اداره آمار اتریش متمرکز بود.
این مقاله در مورد توسعه یک روش برای تجزیه و تحلیل مکانی و معنایی است که در منطقه آزمایشی – استان اشتایر در اتریش استفاده می شود. قابل قبول بودن و دقت نتایج بهدستآمده با دادههای توییتر در مقایسه با آمار رسمی گردشگری [ 2 ، 3 ] ارزیابی میشود. نتایج و ارزیابی ها در قالب نقشه ها، نمودارها و ارزیابی های آماری تفسیر می شوند. سؤالات تحقیق مفصل مقاله به شرح زیر است:
- –
-
آیا دادههای جمعسپاری شده در مقیاس منطقهای به درستی رفتار گردشگری کاربران را نشان میدهند؟
- –
-
آیا دادههای جمعسپاری مرتبط با گردشگری با آمار رسمی گردشگری مرتبط است؟
- –
-
آیا دادههای مرتبط با توریستی در توییتر در سطح منطقهای برای نتیجهگیری در مورد موضوعات تحت پوشش و مربوط به احساسات کافی است؟
مقاله بصورت زیر مرتب شده است. بخش 2 ادبیات مربوطه را مورد بحث قرار می دهد و بخش 3 روش بکار گرفته شده برای داده های آزمون جمع آوری شده را توضیح می دهد. آزمایش انجام شده در بخش 4 شرح داده شده است و نتایج به دست آمده در بخش 5 فهرست شده است . بحث در مورد نتایج و نتیجه گیری در بخش 6 ارائه شده است .
2. ادبیات مرتبط
ادبیاتی در زمینه سنجش اجتماعی برای اهداف گردشگری در زمینه های علمی مختلف منتشر شده است. به ویژه پیشرفتهای علم اطلاعات جغرافیایی بیشترین تأثیر را بر این مقاله دارد. به طور خاص، نشریاتی که با اطلاعات جغرافیایی داوطلبانه، حس اجتماعی و هوش مصنوعی زمین مکانی سروکار دارند، مورد توجه ویژه هستند.
اصطلاح حس اجتماعی رویکردهای یادگیری ماشین و هوش مصنوعی را به طور کلی ترکیب می کند [ 5 ، 6 ، 7 ]. طبق [ 8 ] به عنوان استفاده از داده های تولید شده توسط کاربر برای درک پویایی انسان تعریف شده است. این روشها را میتوان برای درک الگوهای تحرک انسانی، الگوهای شبکههای اجتماعی یا حتی پشتیبانی از برنامهریزی شهری مورد استفاده قرار داد [ 3 ، 9 ، 10 ]. هاولکا و همکاران [ 11] الگوهای تحرک جهانی کشورهای مختلف را در مقایسه با نفوذ بازار توییتر بررسی کرده اند. ارزیابی نتایج آنها با کمک آمار گردشگری نشان داد که بین تعداد کاربران توییتر، رونق اقتصادی و رفتار تحرک یک کشور همبستگی وجود دارد. از این رو، توییتر به عنوان پروکسی برای الگوهای تحرک جهانی در نظر گرفته می شود.
مقالات [ 12 ، 13 ] در مورد الگوهای مهاجرت بر اساس داده های توییتر گزارش می دهند. [ 12 ] الگوهای مهاجرت از خاورمیانه و شمال آفریقا به اروپا را تحلیل می کند. نویسندگان از تحلیلهای مکانی و معنایی (خوشههای موضوعی در طول مسیرهای مهاجرت)، با استفاده از روش OPTICS استفاده میکنند. نویسندگان در [ 13 ] یک برآوردگر برای الگوهای مهاجرت بر اساس داده های توییتر ایجاد کردند. سایر الگوهای حرکتی شامل تشخیص مسیرها با استفاده از تجزیه و تحلیل نقطه داغ و متعاقبا مشخص کردن آنها از طریق تجزیه و تحلیل دریفت [ 14] است.]. این مقاله از تحلیل خوشهای نقطه داغ و تخمین چگالی هسته برای استخراج مسیرهای فضایی استفاده میکند. این روش برای شناسایی مسیر کنسرت یک خواننده پاپ اعمال شده است.
داده های تولید شده توسط کاربر در شرایط اضطراری نیز استفاده شده است. در ادبیات، بمب گذاری ماراتن بوستون به عنوان مثالی استفاده می شود که در آن پیام های رسانه های اجتماعی ممکن است ابزاری برای تشخیص زودهنگام موقعیت های اضطراری باشد [ 15 ]. در [ 16 ]، نویسندگان یک برنامه کاربردی برای تشخیص و اطلاع رسانی زلزله، بر اساس رسانه های اجتماعی ایجاد کردند. این مطالعه به ترتیب از کالمن و فیلتر ذرات برای تخمین مکان و تحلیل معنایی بر اساس کلمات کلیدی، تعداد کلمات و زمینه آنها استفاده می کند.
تحلیل فضایی برای اهداف گردشگری در [ 17 ] پوشش داده شده است ، در حالی که روششناسی برای تحلیل متن معنایی در [ 18 ] منتشر شده است . در [ 19 ] فلیکر به عنوان پایه ای برای الگوهای تحرک فضایی استفاده می شود. برای این مقاله، آثار [ 20 ]، یک پیشبینی موقعیت جغرافیایی بر اساس دادههای توییتر [ 21 ] و همچنین [ 22 ] که با الگوهای تحرک در شهرهای واقع در استرالیا سروکار دارند، هستند. مقالات جدیدتر با توسعه ابزارهای برنامه ریزی سفر بر اساس محتوای تولید شده توسط کاربر [ 23 ]، ردپای دیجیتالی داده های جمع سپاری برای مدیریت مناطق حفاظت شده [ 24] سروکار دارند.]، یا تجزیه و تحلیل الگوهای محتوای تولید شده توسط کاربر با تمرکز بر Flickr و Panoramio [ 25 ]. مقالات [ 26 ، 27 ، 28 ] داده های شبکه های اجتماعی مبتنی بر مکان (توئیتر، فلیکر، و غیره) را برای تحقیق در مورد پدیده های شهری، و فعالیت های انسانی به طور کلی و الگوهای تفریحی توضیح می دهند. در یک جنبه کلی تر [ 29 ] به نقش داده های بزرگ برای استراتژی های نوآوری باز در شرکت های کوچک و متوسط و شرکت های بزرگ توجه کرد که می تواند برای گردشگری نیز ارزشمند باشد. به طور خاص، [ 30 ] در مورد چالش ها و اقدامات آینده برای تحقیقات نوآوری در صنعت گردشگری توضیح دهید. استفاده از رسانه های اجتماعی از امکانات مهمان نوازی لوکس در ترکیه توسط [ 31]. به منظور ایجاد مشارکت کاربران برای رویدادها و مقاصد توریستی [ 32 ]، نویسندگان دو رویداد و رسانه های اجتماعی پلتفرم های مختلف را ارزیابی کردند. یک دستور کار پژوهشی معاصر برای جغرافیاهای گردشگری و کلان داده در جغرافیای گردشگری در [ 33 ، 34 ] ارائه شده است .
3. روش شناسی
این تحقیق از هیچ گردش کار روش شناختی از پیش تعیین شده ای پیروی نکرد. بر اساس ادبیات موجود، مناسبترین روشها را برای انجام تحلیل مکانی-زمانی و معنایی انتخاب کردیم. روششناسی و گردش کار توسعهیافته در این مقاله شامل روشهایی برای جمعآوری، پردازش و فیلتر کردن دادهها، به دنبال آن روشهایی برای تحلیل مکانی و معنایی و همچنین برای تجسم، تفسیر و ارزیابی است. این روش مبتنی بر شش رکن است که در شکل 1 نشان داده شده است که شامل جمع آوری داده ها، پردازش و فیلتر کردن داده ها، تجزیه و تحلیل فضایی، تحلیل متن معنایی، تجسم و تفسیر و ارزیابی است.
اکتساب داده به دنبال جمعآوری دادهها از پلتفرم رسانه اجتماعی توییتر با استفاده از بسته پایتون Twitterscraper [ 35 ] است. مقایسه اولیه با Twitter REST API موجود نشان میدهد که Twitter REST API دارای محدودیتهای خاصی از نظر مقدار جمعآوری داده است (فقط 180 درخواست در هر 15 دقیقه، و حداکثر 100 توییت در هر درخواست بازگردانده میشود) [36 ] . بنابراین، ما از Twitterscraper برای جمعآوری توییتهایی که بین ۱۶ فوریه ۲۰۰۸ و ۲۲ اوت ۲۰۱۸ منتشر شدهاند، استفاده میکنیم.
پیش پردازش داده ها در یک پایگاه داده اسناد غیر رابطه ای (NoSQL) انجام شد. قبل از اینکه دادهها در پایگاه داده وارد شوند، یک روش کدگذاری جغرافیایی انجام میشود، که در آن توییتهایی که مکان دقیق (یعنی مختصات) مرتبط ندارند، در ارتباط با شهرداری آنها تجزیه و تحلیل میشوند – و نام و مرکز شهرداری به عنوان شی به هر داده اضافه میشود. تنظیم. فرآیند فیلتر برای انجام موارد زیر در نظر گرفته شده است:
-
توئیت های سازمان ها را مرتب کنید
-
توییتها را با کلمات کلیدی غیر گردشگری فیلتر کنید
-
توییت هایی را که چندین بار توسط یک کاربر و توسط/برای همان شهرداری منتشر شده است، فیلتر کنید
این فرآیند فیلتر برای دسته بندی توییت های باقی مانده در سه دسته است:
-
اسناد (به عنوان مثال، توییت ها) با ارتباط قوی با گردشگری (با کمک کلمات کلیدی تعریف شده)
-
اسنادی (به عنوان مثال، توییتها) که مکان نویسنده را نشان میدهند – شبیه به “من در … هستم” یا “من در … هستم”.
-
اسناد (یعنی توییتها) که با دستههای 1 یا 2 مطابقت ندارند.
تجزیه و تحلیل متن ارتباط نزدیکی با فرآیند فیلتر کردن توییتها دارد که در بالا ذکر شد. برای انجام مدلسازی موضوع و تحلیل فراوانی کلمه، دادهها باید از قبل پردازش شوند. مرحله پیشپردازش شامل توکنسازی توییتها است که متن را به واحدهای کوچکتر تقسیم میکند (اما ما هشتگها، شکلکها یا نمادهای دیگر را حفظ کردیم). علاوه بر این، کلمات توقف، علائم نگارشی و براکت های انگلیسی و آلمانی را از داده ها حذف کردیم. پس از مرحله پیش پردازش داده ها، ما تمام اطلاعات شخصی (یعنی نام کاربری) مجموعه داده ها را پاک کردیم تا هیچ گونه داده شخصی فاش نشود.
مدل سازی موضوع برای تعیین گروه هایی از موضوعات مطابق با کلمات استفاده شده در متن توییت ها در نظر گرفته شده است [ 37 ]. ما از نمایه سازی معنایی پنهان و تخصیص دیریکله پنهان [ 38 ، 39 ، 40 ] برای این منظور استفاده کردیم. تجزیه و تحلیل فرکانس به منظور شناسایی کلمات کلیدی مرتبط با گردشگری است که می تواند برای فیلتر کردن استفاده شود. تجزیه و تحلیل فرکانس اجرا شده در زبان برنامه نویسی R [ 41 ]. کلمات کلیدی مرتبط با گردشگری بر اساس واژگان موجود است [ 42 ، 43 ، 44 ]. تجزیه و تحلیل احساسات، جهت گیری احساسات را نشان می دهد، که توییت ها را به کلاس های قطبی طبقه بندی می کند، مانند منفی، مثبت یا خنثی [45 ]. به منظور تشخیص احساسات توییتها، از الگوریتم VADER [ 46 ، 47 ] استفاده کردیم. VADER یک رویکرد مبتنی بر ظرفیت برای تجزیه و تحلیل احساسات است که هم خود احساس و هم شدت آن را در نظر می گیرد. در جدول زیر نمونه هایی از کلمات و درجه شدت رتبه بندی احساسات آنها نمایش داده شده است. کلمات مثبت بیشتر دارای امتیاز بالاتر و کلمات منفی بیشتر دارای امتیاز کمتری هستند. در نتیجه، Vader سه معیار را ارائه می دهد که نسبت متن را توضیح می دهد، که در دسته های مثبت، خنثی و منفی قرار می گیرد. چهارمین معیار که امتیاز مرکب نامیده میشود، مجموع تمام رتبهبندیهای واژگان استاندارد شده بین ۱- و ۱ است [ 47] .]. هر چه به 1 نزدیکتر باشد، احساس مثبت تر و به 1- نزدیکتر، احساسات منفی تر است. نمره 0 نشان دهنده یک متن کاملاً خنثی است. ثابت شده است که این رویکرد برای داده های رسانه های اجتماعی مناسب است زیرا شامل مجموعه ای از اصطلاحات مرتبط با رسانه های اجتماعی یا نوشته های غیررسمی مانند احساسات، کلمات اختصاری یا چند علامت نگارشی است. حتی کلمات اختصاری “omg” (اوه خدای من)، یا “smh” (سرم را تکان می دهم) در فرهنگ لغت گنجانده شده است. کلمات اختصاری به تعیین شدت مثبت و منفی کمک می کنند. مقاله [ 46 ] نشان می دهد که ویدر حتی از ارزیاب های فردی انسان نیز بهتر عمل می کند.
تجزیه و تحلیل مکانی و زمانی داده های به دست آمده بر ارزیابی توزیع مکانی و الگوهای زمانی در منطقه آزمایش متمرکز است. هدف ما تجزیه و تحلیل آماری رشد توییتها در مجموعه داده ما در طول سالها و مقایسه آنها با توجه به فصول گردشگری است. همه توییتهایی که به یک شهرداری مربوط میشوند دقیقاً مختصات یکسانی دارند – مرکز شهرداری. برای اینکه بتوانیم تحلیلهای فضایی بیشتری را در سطح شهرداری و ایالت انجام دهیم، توییتها را بهطور تصادفی در هر شهرداری مربوطه توزیع میکنیم. بر اساس این توزیع فضایی، تجزیه و تحلیل های مرتبط با خوشه های بیشتری انجام می شود. بنابراین دقت توزیع توییتها در شهرداری کاملاً صحیح نیست. اما این رویکرد راه حل مناسبی برای تجسم توییت ها و به دست آوردن پاسخ های توزیع نسبی در کل ایالت اشتایر از طریق تحلیل های فضایی بیشتر است. تجزیه و تحلیل نقطه داغ روشی برای شناسایی و تجسم خوشه ای است که ما در تحقیقات خود از آن بهره بردیم. نقطه داغ نشان دهنده خوشه های فضایی معنی دار آماری با مقادیر بالا به عنوان نقاط داغ و مقادیر پایین به عنوان نقاط سرد است. این بر اساس آمار Getis-Ord Gi* و به صورت اختیاری نیز بر روی مجموعه ای از ویژگی های وزنی [ نقطه داغ نشان دهنده خوشه های فضایی معنی دار آماری با مقادیر بالا به عنوان نقاط داغ و مقادیر پایین به عنوان نقاط سرد است. این بر اساس آمار Getis-Ord Gi* و به صورت اختیاری نیز بر روی مجموعه ای از ویژگی های وزنی [ نقطه داغ نشان دهنده خوشه های فضایی معنی دار آماری با مقادیر بالا به عنوان نقاط داغ و مقادیر پایین به عنوان نقاط سرد است. این بر اساس آمار Getis-Ord Gi* و به صورت اختیاری نیز بر روی مجموعه ای از ویژگی های وزنی [48 ، 49 ]. با استفاده از تجزیه و تحلیل Hot Spot برای اهداف اندازهگیری منطقه، میتوان ناحیهای با کمیت یا شدت مقادیر بالای ویژگی مشاهدهشده را شناسایی کرد [ 50 ، 51]. جایگزینی برای تجزیه و تحلیل Hot Spot با تنظیمات دستی، بهینه سازی Hot Spot Analysis است. با استفاده از تجزیه و تحلیل نقطه داغ بهینه، ویژگی های داده های ورودی به طور خودکار ارزیابی می شوند تا پارامترهای مورد نیاز برای نتیجه مطلوب استخراج شوند. پس از تجمیع دادههای حادثه در ویژگیهای وزنی، مقیاس مناسبی از تجزیه و تحلیل تعیین میشود. مقادیر معنی دار آماری نتیجه نهایی چندین بار تنظیم می شوند. تنظیم مقادیر با توجه به آزمایش و وابستگی مکانی با کمک روش تصحیح نرخ کشف نادرست (FDR) [ 52] انجام میشود.]. تجزیه و تحلیل Hot Spot با ابزار Optimized Hot Spot Analysis در دسکتاپ GIS “ArcGIS” پیاده سازی می شود. تخمین چگالی هسته (KDE) دادههای توییتر یک تکنیک امیدوارکننده برای تخمین چگالی است، زیرا متعلق به یک تحلیل ناپارامتریک بدون ساختار ثابت است و به دادههای نقطهای بستگی دارد [3 ] . با KDE، یک ناحیه بزرگی در واحد از ویژگیهای نقطهای محاسبه میشود، بنابراین در این مطالعه از دادههای نقطهای توییتر – به معنای موقعیتهای توییتها است. با محاسبه چگالی، مقادیر ورودی را روی یک سلول شطرنجی پخش می کنیم. با روش KDE به نوبه خود، مقدار کمیت شناخته شده (به عنوان مثال، یک فیلد جمعیت) یک ویژگی از محل نقطه بر اساس یک تابع هسته درجه دوم [ 53 ] که در ابتدا توسط [ 54] توصیف شده بود، پخش می شود.]. نتایج KDE را می توان با یک نقشه حرارتی مشاهده کرد. نقشه حرارتی به تمرکز ویژگی از منظر جغرافیایی، یعنی مکانی، اشاره دارد. از داده های نقطه یا خط یک سطح درون یابی ایجاد می شود تا چگالی وقوع را نشان دهد. این روشی برای تجسم سطح چگالی با گرادیان رنگی به منظور شناسایی آسان مکانهای چگالی بالاتر یا خوشههایی از ویژگیهای جغرافیایی است [ 55 ].
تجزیه و تحلیل زمانی با توجه به تنوع توییت سالانه و فصلی انجام می شود. علاوه بر این، نویسندگان الگوی زمانی فعالیت توییت را در سطح منطقه بررسی میکنند.
این ارزیابی به دنبال پایهریزی نتایج آشکار شده از دادههای رسانههای اجتماعی است. از این رو، مقایسه ای بین توییت های استخراج شده از طریق بسته Twitterscraper و داده های مرجع انجام می شود. داده های مرجع از مقامات رسمی آمار – به عنوان مثال، اداره آمار فدرال اتریش، و آمار استان اشتایر (Styria) سرچشمه می گیرد. رویکرد ارزیابی مبتنی بر تحلیل همبستگی بین دادههای توییتر و دادههای رسمی است که دو متغیر مقیاس را نشان میدهد. اگرچه نمودارها ممکن است رابطه بین رسانه های اجتماعی و داده های مرجع را به صورت بصری نشان دهند، ضریب همبستگی باید تعیین شود تا تأیید شود که آیا همبستگی از نظر آماری معنی دار است یا ناچیز. ما از ضریب پیرسون برای تعیین سطح همبستگی رسانه های اجتماعی و داده های مرجع از سال 2008 تا 2017 در سطح استان و منطقه استفاده کردیم. جنبه فصلی نیز در نظر گرفته شده است. از این رو، ضریب پیرسون مربوط به توییتر و داده های مرجع برای فصل تابستان و زمستان، برای هر منطقه نیز محاسبه می شود.
4. آزمایش کنید
با توجه به سؤالات تحقیق، آزمایش با استفاده از یک منطقه آزمایشی کوچک از نظر جغرافیایی با تعداد کمی توییت (در مقایسه با سایر نقاط توریستی مانند لندن یا نیویورک) انجام شده است. از این رو، منطقه آزمایشی ما استان استایرا، اتریش است. این آزمایش از روش توصیف شده در بخش 3 پیروی می کند و توییت های منتشر شده بین 16 فوریه 2008 و 22 اوت 2018 را تجزیه و تحلیل می کند.
4.1. اکتساب داده ها
فرآیندها با جمعآوری دادهها با کمک بسته پایتون Twitterscraper [ 35 ] آغاز شد. پرس و جو داده ها با کمک نام شهرداری، با بهره برداری از نزدیکی جغرافیایی انجام شد و از 12 کلیدواژه مرتبط با گردشگری (به جدول 1 مراجعه کنید ) بر اساس [ 42 ، 43 ، 44 ] استفاده شد. ما نام هر انجمن را جداگانه جویا شدیم – که در مجموع به 287 پرس و جو منجر شد. طرح پرس و جو مورد استفاده برای به دست آوردن داده ها در شکل 2 نشان داده شده است . در شکل 2 کوئری Twitterscraper برای شهر گراتس نشان داده شده است.
ما در مجموع 35234 توییت از 287 شهرداری برای بازه زمانی 2 فوریه 2008 تا 22 اوت 2018 به دست آوردیم. از 287 پرس و جو، 80 پرس و جو اصلا توییتی برنمی گردانند، در حالی که برای 207 شهرداری اشتایر توییت دریافت کردیم.
4.2. پیش پردازش و فیلتر کردن داده ها
دادههای بهدستآمده در پایگاه داده MongoDB ذخیره میشوند که در آن هر سند (هر توییت) در سیستم مرجع مختصات WGS84 جغرافیایی کدگذاری میشود – یعنی با مختصات شهرداری مربوطه بهروزرسانی میشود. فرآیند فیلتر کردن به 3 گروه مختلف از توییت ها منجر می شود:
-
اسناد (به عنوان مثال، توییت ها) با ارتباط قوی با گردشگری (با کمک کلمات کلیدی تعریف شده)
-
اسنادی (به عنوان مثال، توییتها) که مکان نویسنده را نشان میدهند – شبیه به “من در … هستم” یا “من در … هستم”.
-
اسناد (یعنی توییتها) که با دستههای 1 یا 2 مطابقت ندارند.
بر اساس روشی که در بخش 3 توضیح داده شد ، ما از تجزیه و تحلیل فراوانی اصطلاح برای تعیین متداول ترین اصطلاحات در ارتباط با گردشگری موجود در توییت ها استفاده کردیم. این در بسته R پیاده سازی شده است. برای این منظور، متون به حروف کوچک تبدیل شدند، علائم نگارشی حذف شدند، فضاهای خالی اضافی حذف شدند، اعداد و کلمات توقف (انگلیسی و آلمانی) حذف شدند. در نهایت، URL ها و علائم ASCII نیز حذف می شوند. این مجموعه داده مبنایی برای ماتریس سند-ترم است که برای تعیین بسامد کلمه استفاده می شود. در نتیجه، ما 229 کلمه را به دست آوردیم که برای اهداف فیلتر کردن استفاده می شد – یعنی برای اختصاص توییت به گروه های 1، 2 یا 3.
ابر کلمه 150 کلمه پرتکرار اول در شکل 3 نشان داده شده است . در طول فیلتر کردن، متن کاوی را برای انتخاب گزینه نهایی کلمات مرتبط با گردشگری اعمال کردیم و سپس به فیلترینگ بازگشتیم تا مجموعه داده نهایی توییتهای خود را استخراج کنیم. در مجموعه داده نهایی 6953 سند/توییت وجود دارد. تعداد توییت ها و گروه های مربوط به آنها (1-3) در جدول 2 نشان داده شده است .
4.3. تحلیل احساسات
تحلیل احساسات و تحلیل مدلسازی موضوع با استفاده از نرمافزار داده کاوی Orange [ 38 ، 56 ] انجام شد . نرم افزار Orange Data Mining یک نرم افزار متن باز است. برای ایجاد تحلیل احساسات، از الگوریتم VADER استفاده کردیم. احساسات بر اساس نتیجه تجزیه و تحلیل ترکیبی با بیش از 0 و تا 1 طبقه بندی شده به عنوان مثبت، 0 به عنوان خنثی و بین کمتر از 0 و -1 به عنوان احساسات منفی طبقه بندی شد. هر گونه تحلیل فضایی و تجسم جغرافیایی نتایج در ArcGIS انجام می شود.
4.4. تخمین چگالی هسته و تجزیه و تحلیل نقطه داغ
تجزیه و تحلیل Hot Spot با استفاده از ابزار Optimized Hot Spot Analysis ارائه شده توسط ArcGIS پیاده سازی می شود. برای اهداف تجمع، اندازه سلول تور ماهی 1 کیلومتر است. تخمین تراکم هسته با شعاع جستجوی 5 کیلومتر و اندازه سلول 500 متر استفاده شد. چنین شعاع جستجو و اندازه سلول خروجی پس از تجزیه و تحلیل نتایج تنظیمات مختلف از 1 تا 10 کیلومتر شعاع جستجو و اندازه سلول خروجی 100 تا 5000 متر تعیین شد. مقادیر انتخاب شده مناسب تعیین شدند زیرا این تنظیمات امکان ایجاد یک تجسم قانع کننده با مقادیر معنی دار را فراهم می کند. به دلیل تفاوتهای زیاد در چگالیهای حاصل، از روش طبقهبندی Jenks Natural Breaks استفاده کردیم که مقادیر را در کلاسهای مختلف مرتب میکند، تفاوت را در یک کلاس به حداقل میرساند و آن را بین کلاسها به حداکثر میرساند.
4.5. تحلیل و ارزیابی زمانی
تجزیه و تحلیل زمانی در آزمایش تغییرات کلاسیک سالانه و همچنین تغییرات فصلی را در نظر می گیرد. مشابه داده های مرجع، از فصل گردشگری تابستان و زمستان استفاده کردیم. توییتها از 1 می تا 31 اکتبر به فصل تابستان اختصاص داده میشوند، در حالی که توییتها از 1 نوامبر تا 30 آوریل سال بعد به فصل زمستان اختصاص داده میشوند. برای اهداف ارزیابی ما از نرم افزار SPSS به منظور انجام تحلیل همبستگی بین داده های توییتر و داده های مرجع استفاده کردیم.
5. نتایج
این بخش شامل نتایج به دست آمده با آزمایش و روش توصیف شده در بخش های قبلی است. بخش نتایج ارزیابی نتایج را نیز پوشش می دهد.
اساساً، مجموعه توییتهای مرتبط با گردشگری که از بین همه توییتها در بازه زمانی بین 16 فوریه 2008 تا 22 اوت 2018 انتخاب شدهاند، شامل 6953 توییت است. تعداد توییتهای مرتبط با توریست در سطح منطقه در شکل 4 آورده شده است . بدیهی است که شهر گراتس – به عنوان پایتخت اشتایریا – بیشترین توئیت ها را دارد و پس از آن ناحیه لیزن و هارتبرگ/فورستنفلد قرار دارند. در شکل 5، توزیع فضایی توییتهای مرتبط با گردشگری را بر اساس مناطق استان اشتایریا نشان میدهیم.
شکل 6 توزیع توییت ها را بر اساس سه دسته که در بخش 4.2 توضیح داده شده است نشان می دهد . علاوه بر این، تجزیه و تحلیل نقطه داغ (نگاه کنید به شکل 7 ) در ارتباط با شکل 6شش نقطه داغ واضح و آشکار را با اطمینان 99٪ نشان می دهد. به عنوان یک نتیجه واضح و مورد انتظار، میتوانیم نقطهای داغ از شهر گراتس، پایتخت ایالت و اطراف آن را در بخش مرکزی جنوب شرقی اشتایریا مشاهده کنیم. یکی دیگر از نقاط داغ مرتبط با گردشگری شهری، تراکم شهری شهرداریهای Leoben، Bruck an der Mur و Kapfenberg است. یک نقطه داغ به شکل یک نیم دایره در شمال غربی متعلق به شهرداری های گردشگری باد آوسی و رامسائو آم داخشتاین است که مجموعه ای از فعالیت های گردشگری مرتبط با طبیعت و کوهستان، مانند پیاده روی، اسکی یا حمام کردن در دریاچه های طبیعی را ارائه می دهد. سه نقطه مهم آخر با اطمینان 99 درصد متعلق به شهرداری های گردشگری حرارتی بهداشت و زیبایی، یعنی باد رادکرزبورگ در منتهی الیه جنوب شرقی است. Bad Gleichenberg در شمال و Loipersdorf bei Fürstenfeld در شرق. نقاط سرد از نظر آماری معنیدار مناطقی را نشان میدهند که با بازدید کم گردشگران مواجه هستند و به استثنای کل ناحیه دویچلندزبرگ در لبههای مناطق پرجمعیتتر مانند کوهها یا حومه شهر قرار دارند. خوشههای لکههای سرد با اطمینان 99 درصد در بخشهای کوهستانی غربی و شمالی ایالت، عمدتاً در مناطق Liezen و Bruck-Mürzzuschlag قرار دارند. با این حال، نقاط سرد قابل توجهی نیز در لبه های محیطی سایر مناطق (به جز لایبنیتس) قرار دارند. به استثنای کل ناحیه Deutschlandsberg که در حاشیه مناطق پرجمعیت تر مانند کوهستان یا حومه شهر قرار دارد. خوشههای لکههای سرد با اطمینان 99 درصد در بخشهای کوهستانی غربی و شمالی ایالت، عمدتاً در مناطق Liezen و Bruck-Mürzzuschlag قرار دارند. با این حال، نقاط سرد قابل توجهی نیز در لبه های محیطی سایر مناطق (به جز لایبنیتس) قرار دارند. به استثنای کل ناحیه Deutschlandsberg که در حاشیه مناطق پرجمعیت تر مانند کوهستان یا حومه شهر قرار دارد. خوشههای لکههای سرد با اطمینان 99 درصد در بخشهای کوهستانی غربی و شمالی ایالت، عمدتاً در مناطق Liezen و Bruck-Mürzzuschlag قرار دارند. با این حال، نقاط سرد قابل توجهی نیز در لبه های محیطی سایر مناطق (به جز لایبنیتس) قرار دارند.
نتایج تخمین تراکم هسته تغییرات قابل توجهی را در مقادیر، به ویژه بین مرکز ایالت گراتس و سایر مناطق روستایی تر، همانطور که در بالا ذکر شد، تأیید می کند ( شکل 8 را ببینید ). بیشتر منطقه مورد مطالعه با تراکم کمتر از 1 توییت در هر شعاع جستجو مطابقت دارد. مقادیر سفید مکان هایی با چگالی هسته 0 هستند و از تجسم حذف شدند تا تفاوت را در مناطق دیگر تحت فشار قرار دهند.
الگوهای فضایی احساسات مثبت، منفی و خنثی در نقشه در شکل 9 نشان داده شده است . با این حال، توجه به این نکته مهم است که برخی از شهرداریها وجود دارند که در نام خود کلمه “بد” را دارند، مانند Bad Radkersburg یا Bad Aussee. در این موارد، اگرچه کاربر به نام شهرداری اشاره می کرد، اما به دلیل کلمه “Bad” که به مناطق گرمایی یا شنا در آلمانی اشاره دارد، این توییت به عنوان منفی دسته بندی شد، اما توسط الگوریتم به عنوان کلمه انگلیسی اشاره می شود. به چیزی منفی همانطور که در شکل 10 ، شش شهرداری با یک الگوی هچ متقاطع مشخص شده اند تا به بی ربط بودن آنها با مقوله درصد احساسات منفی بسیار بالا اشاره شود.
همانطور که در شکل 11 مشاهده می شود ، یک رابطه قوی بین داده های جمع سپاری و داده های مرجع از سال 2011 به بعد وجود دارد. به منظور دستیابی به نتایج مرتبط، ما تجزیه و تحلیل همبستگی را در دو مجموعه داده جداگانه اعمال کردیم – یکی برای کل مجموعه داده از سال 2008 تا 2018 (نگاه کنید به شکل 12 )، در حالی که در سال 2018 فقط داده های نیمه سال اول (و همچنین تنها نیمه سال اول داده های مرجع) استفاده شد. همبستگی معنی داری در سطح 05/0 با ضریب پیرسون 650/0 وجود دارد. مقدار Sig (2-tailed) زیر 0.05 اهمیت آماری همبستگی را تأیید می کند. از سوی دیگر، تنها با در نظر گرفتن سال های کامل بین 2011 و 2017 ( شکل 13 را ببینیدضریب پیرسون به 0.772 افزایش می یابد، که طبق تعاریف در بخش نظری ما، در حال حاضر یک همبستگی قوی است. همبستگی بین سالهای 2011 و 2017 نیز در سطح 05/0 معنادار است.
همبستگیهای بیشتر در سطح منطقه برای دوره زمانی 2011 تا 2017 تعیین شد، زیرا ما معتقدیم که تعداد کم توییتها در سالهای 2008، 2009 و 2010 نشاندهنده چنین بازدیدکنندگان کم گردشگر نیست، بلکه تعداد کم کاربران توییتر را نشان میدهد. به طور کلی همانطور که در جدول 3 مشاهده می شود5 ناحیه با همبستگی مثبت بالای 8/0 و از نظر آماری در سطح 001/0 معنی دار هستند. Murau، Liezen و Graz Umgebung همبستگی قوی بالای 0.85 و Graz و Südoststeiermark حتی همبستگی بسیار قوی بالای 0.9 دارند. با 0.694 نیز Leoben با همبستگی معنی دار در سطح 0.001 وجود دارد. با این حال، در نیمی از ولسوالی ها همبستگی معنی داری بین داده های ما و مرجع وجود ندارد. یک منطقه، Voitsberg، حتی با همبستگی منفی در سطح معناداری 0.005 مواجه است. علاوه بر این، جدول 3ضرایب پیرسون را برای فصل تابستان و زمستان نشان می دهد. نواحی بر اساس قدرت همبستگی در فصل تابستان مرتب شده اند. مشاهده می شود که همبستگی ها به طور کلی در تابستان نسبت به زمستان بیشتر است. Graz، Südoststeiermark، Graz Umgebung و Liezen با بالاترین مقادیر برای هر دو فصل در صدر قرار دارند. سایر مناطق دارای نوسان هستند – برای مثال در موراو یک همبستگی مثبت معنیدار در تابستان وجود دارد اما یک رابطه منفی بسیار ضعیف بدون همبستگی معنیدار در زمستان وجود دارد. در Bruck-Mürzzuschlag، Deutschlandberg، Hartberg-Fürstenfeld و Voitsberg روابط مثبت در یک فصل و روابط منفی در فصل دیگر وجود دارد.
6. بحث و نتیجه گیری
این مقاله دادههای جمعسپاری شده پلتفرم توییتر را در چندین «بُعد» ارزیابی میکند تا مناسب بودن برای عمل به عنوان نماینده برای سؤالات مربوط به گردشگران و جریانهای توریستی را تجزیه و تحلیل کند. به طور خاص، ما به اعتبار نتایج بهدستآمده از مجموعه دادههای جمعسپاری کوچک – در سطح منطقهای علاقهمندیم. بنابراین، ما یک روش برای تجزیه و تحلیل توییت ها در بعد مکانی- زمانی و معنایی ایجاد کردیم و سعی کردیم یافته ها را با کمک داده های رسمی گردشگری ارزیابی کنیم. این روش برای دوره زمانی 2008 تا 2018 در استان استایرا در اتریش اعمال شد.
اول، تعداد مطلق سالانه توییتهای مرتبط با توریست به منظور کمی کردن اندازه کاربر مورد توجه است. از سال 2008 تا 2010 عدد مطلق برای هر فصل زمستان و تابستان بسیار کمتر از 100 است. از این رو، هر گونه ارزیابی آماری از چنین عدد پایینی به دلیل حجم نمونه پایین مورد تردید است. بنابراین، تصمیم گرفتیم نگاهی دقیق به سالهای 2011 تا 2018 داشته باشیم، زیرا صدها توییت مرتبط با توریست وجود دارد که باید برای هر فصل تجزیه و تحلیل شوند. مقایسه مجموعه دادههای جمعسپاری با آمار رسمی گردشگری با کمک ضریب همبستگی پیرسون، نشان میدهد که نیمی از مناطق به طور معنیداری همبستگی دارند. همین امر در مورد ارزیابی فصلی نیز صدق می کند، جایی که نیمی از مناطق در تابستان نسبت به زمستان با داده های مرجع بهتر ارتباط دارند.
علیرغم اندازه کوچک مجموعه داده های مرتبط با گردشگری جمع سپاری شده، قابل مشاهده است که توزیع مکانی و زمانی توییت ها مشابه داده های رسمی گردشگری است. خوشههای فضایی دادههای جمعسپاری با شهرداریهایی که صنعت گردشگری قوی دارند (یعنی تعداد بالای اقامتهای شبانه) همسو است. این مناطق توریستی در شمال غربی (به عنوان مثال، Bad Aussee، Ramsau am Dachstein) و در منطقه حرارتی در جنوب شرقی (به عنوان مثال، Bad Radkersburg، Bad Gleichenberg، Loipersdorf) و منطقه مرکزی (Graz, Bruck/) واقع شده اند. مور، لئوبن). مدلسازی موضوع برای چنین مجموعه دادههای کوچکی با استفاده از تخصیص دیتریکله نهفته منجر به موضوعاتی میشود که بیفایده هستند، در حالی که اصطلاح تحلیل فرکانس منجر به ابر کلمه دقیقی شد که موضوعات توریستی در اشتایر را نشان میدهد. رویکردهای متن کاوی برای تجزیه و تحلیل احساسات که در دادههای توییتر اعمال میشود، از اهمیت بالایی برخوردار هستند، زیرا متن در رسانههای اجتماعی خاص است و بدون هیچ قاعدهای کلی نوشته میشود – عمدتاً به زبانی روزمره از جمله اختصارات، اشتباهات تایپی، هشتگها و تگهای احساسات. به دلیل مجموعه داده های چند زبانه، ممکن است در مراحل ترجمه اشتباهاتی رخ دهد. در مقاله، نمونه شهرداریها را با نام «بد» برجسته کردیم. این داده های رسانه های اجتماعی به دلیل ترجمه نام مکان “بد” دارای احساسات منفی در نظر گرفته می شوند. از این رو، بهبود در تجزیه و تحلیل با داده های چند زبانه می تواند به بهبود دقت نتایج کمک کند. اشتباهات تایپ، هشتگ ها و تگ های احساسات. به دلیل مجموعه داده های چند زبانه، ممکن است در مراحل ترجمه اشتباهاتی رخ دهد. در مقاله، نمونه شهرداریها را با نام «بد» برجسته کردیم. این داده های رسانه های اجتماعی به دلیل ترجمه نام مکان “بد” دارای احساسات منفی در نظر گرفته می شوند. از این رو، بهبود در تجزیه و تحلیل با داده های چند زبانه می تواند به بهبود دقت نتایج کمک کند. اشتباهات تایپ، هشتگ ها و تگ های احساسات. به دلیل مجموعه داده های چند زبانه، ممکن است در مراحل ترجمه اشتباهاتی رخ دهد. در مقاله، نمونه شهرداریها را با نام «بد» برجسته کردیم. این داده های رسانه های اجتماعی به دلیل ترجمه نام مکان “بد” دارای احساسات منفی در نظر گرفته می شوند. از این رو، بهبود در تجزیه و تحلیل با داده های چند زبانه می تواند به بهبود دقت نتایج کمک کند.
علاوه بر این، فیلتر کردن داده ها برای این نوع تجزیه و تحلیل بسیار مهم است – زیرا تنها مجموعه داده های تمیز منجر به نتایج و اطلاعات واضح و عینی می شود. رویکرد اتخاذ شده در این مقاله ترکیبی از تعیین خودکار و دستی توییتهای مرتبط با گردشگری است که بر اساس محتوای آنها است. ما قویاً معتقدیم که یک رویکرد یادگیری ماشینی می تواند کیفیت رویکرد فیلتر را افزایش دهد و بنابراین می تواند یکی از مراحل بعدی در این موضوع تحقیقاتی باشد. رویکردهای متن کاوی و تجزیه و تحلیل احساسات مجموعه داده های جمع سپاری می تواند به تعیین و ردیابی نظرات کاربران کمک کند. از این رو، این داده ها می تواند نماینده ارزشمندی برای نظر گردشگران باشد. به طور خاص، در مقاله ما، توییتها – بهویژه از سالهای 2011 تا 2018 – میتوانند به عنوان نماینده برای تعیین تقاضا و اشغال در صنعت گردشگری استفاده شوند.
منابع
- ببینید، L. مونی، پی. فودی، جی. باستین، ال. کامبر، ا. استیما، ج. فریتز، اس. کرل، ن. جیانگ، بی. لااکسو، ام. و همکاران جمع سپاری، دانش شهروندی یا اطلاعات جغرافیایی داوطلبانه؟ وضعیت فعلی اطلاعات جغرافیایی جمع سپاری شده. ISPRS Int. J. Geo Inf. 2016 ، 5 ، 55. [ Google Scholar ] [ CrossRef ]
- پاپاپسیوس، ن. ایلول، سی. شاکر، ع. هارت، جی. بررسی استفاده از اطلاعات جغرافیایی جمعسپاری شده در دفاع: چالشها و فرصتها. جی. جئوگر. سیستم 2019 ، 21 ، 133-160. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کواچ-گیوری، آ. کابررا-بارونا، پ. ریستئا، ع. هاواس، سی. Resch, B. # London2012: Towards towards Citizen Urban Planning Through Analysis Sentiment of Twitter Data. طرح شهری. 2018 ، 3 ، 75-99. [ Google Scholar ]
- کاپینری، سی. هاکلی، م. هوانگ، اچ. آنتونیو، وی. کتونن، جی. اوسترمن، اف. Purves, R. European Handbook of Crowdsourced Geographic Information ; Ubiquity Press: لندن، انگلستان، 2016; ISBN 9781909188792. [ Google Scholar ]
- آگاروال، سی سی; عبدالظاهر، ت. حس اجتماعی. در مدیریت و استخراج داده های حسگر ; Springer: Boston, MA, US, 2013; صص 237-297. ISBN 9781461463092. [ Google Scholar ]
- یانوویچ، ک. مک کنزی، جی. هو، ی. زو، آر. گائو، اس. استفاده از امضاهای معنایی برای سنجش اجتماعی در محیط های شهری. در الگوهای تحرک، داده های بزرگ و تجزیه و تحلیل حمل و نقل ؛ الزویر: آمستردام، هلند، 2019؛ صص 31-54. [ Google Scholar ]
- لیو، ی. لیو، ایکس. گائو، اس. گونگ، ال. کانگ، سی. ژی، ی. چی، جی. شی، ال. حس اجتماعی: رویکردی جدید برای درک محیط های اجتماعی-اقتصادی ما. ان دانشیار صبح. Geogr. 2015 ، 105 ، 512-530. [ Google Scholar ] [ CrossRef ]
- یانوویچ، ک. گائو، اس. مک کنزی، جی. هو، ی. Bhaduri، B. GeoAI: تکنیکهای هوش مصنوعی صریح فضایی برای کشف دانش جغرافیایی و فراتر از آن. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 625-636. [ Google Scholar ] [ CrossRef ]
- زیل، پ. Resch, B. ترکیب فناوری حسگر زیستی و محیط های مجازی برای برنامه ریزی شهری بهبود یافته. GI_Forum 2018 ، 1 ، 344–357. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژنگ، ی. لیو، تی. وانگ، ی. زو، ی. لیو، ی. چانگ، ای. تشخیص صداهای شهر نیویورک با داده های همه جا حاضر. در مجموعه مقالات کنفرانس مشترک بین المللی UbiComp 2014 ACM در مورد محاسبات فراگیر و همه جا ؛ Association for Computing Machinery, Inc.: New York, NY, USA, 2014; صص 715-725. [ Google Scholar ]
- هاولکا، بی. سیتکو، آی. بینات، ای. سوبولفسکی، اس. کازاکوپولوس، پ. Ratti, C. توئیتر را به عنوان نماینده الگوهای تحرک جهانی در موقعیت جغرافیایی قرار داد. کارتوگر. Geogr. Inf. علمی 2014 ، 41 ، 260-271. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوبل، ف. Cvetojevic، S. هوچمیر، اچ. پاولوس، جی. تجزیه و تحلیل الگوهای مهاجرت پناهندگان با استفاده از توییت های دارای برچسب جغرافیایی. ISPRS Int. J. Geo Inf. 2017 ، 6 ، 302-325. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زاغنی، ا. Garimella، VRK؛ وبر، I. استنتاج الگوهای مهاجرت بین المللی و داخلی از داده های توییتر. در مجموعه مقالات بیست و سومین کنفرانس بین المللی وب جهانی، سئول، کره، 7 تا 11 آوریل 2014; ص 439-444. [ Google Scholar ]
- سناراتنه، اچ. برورینگ، آ. شرک، تی. Lehle, D. Moving on Twitter: استفاده از تجزیه و تحلیل نقطه داغ و رانش اپیزودیک برای شناسایی و مشخص کردن مسیرهای فضایی. در مجموعه مقالات هفتمین کارگاه بین المللی ACM Sigspatial در مورد شبکه های اجتماعی مبتنی بر مکان—LBSN ’14 ; ACM Press: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. ص 23-30. [ Google Scholar ]
- کاسا، کالیفرنیا؛ چونارا، ر. ماندل، ک. براونشتاین، جی اس توییتر به عنوان نگهبان در شرایط اضطراری: درس هایی از انفجارهای ماراتن بوستون. PLoS Curr. 2013 ، 5. [ Google Scholar ] [ CrossRef ]
- ساکاکی، ت. اوکازاکی، م. Matsuo, Y. زلزله کاربران توییتر را می لرزاند: تشخیص رویداد در زمان واقعی توسط حسگرهای اجتماعی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010; صص 851-860. [ Google Scholar ]
- هال، CM تحلیل فضایی: ابزاری حیاتی برای جغرافیاهای گردشگری. روتلج هندب. تور. Geogr. 2012 ، 1 ، 163-173. [ Google Scholar ]
- کلاستر، دبلیو. پاردو، پ. کوپر، ام. تاجالدینی، ک. گردشگری، سفر و توییتها: روشهای تحلیل الگوریتمی متن در گردشگری. خاورمیانه J. Manag. 2013 ، 1 ، 81-99. [ Google Scholar ] [ CrossRef ]
- بیرو، ام جی; پانیسون، آ. تیزونی، م. کاتتوتو، سی. پیش بینی تحرک انسان از طریق جذب ردپای رسانه های اجتماعی در مدل های تحرک. EPJ Data Sci. 2016 ، 5 ، 30. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- باسولاس، ا. لنورمند، م. توگورس، آ. گونسالوز، بی. راماسکو، جی جی جذابیت سایت توریستی از طریق توییتر دیده می شود. EPJ Data Sci. 2016 ، 5 ، 12. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هان، بی. کوک، پی. بالدوین، تی. پیشبینی موقعیت جغرافیایی کاربر توییتر مبتنی بر متن. جی آرتیف. هوشمند Res. 2014 ، 49 ، 451-500. [ Google Scholar ] [ CrossRef ]
- خان، اس.اف. برگمان، ن. جوردک، ر. کوسی، بی. کامرون، ام. تحرک در شهرها: تحلیل مقایسه ای مدل های تحرک با استفاده از توییت های دارای برچسب جغرافیایی در استرالیا. در مجموعه مقالات دومین کنفرانس بین المللی IEEE در سال 2017 در مورد تجزیه و تحلیل داده های بزرگ (ICBDA)، پکن، چین، 10 تا 12 مارس 2017؛ صص 816-822. [ Google Scholar ]
- ژو، ایکس. وانگ، ام. لی، دی. از اقامت تا بازی – یک ابزار برنامه ریزی سفر بر اساس جمع سپاری محتوای تولید شده توسط کاربر. Appl. Geogr. 2017 ، 78 ، 1-11. [ Google Scholar ] [ CrossRef ]
- والدن-شراینر، سی. لئونگ، Y.-F. Tateosian, L. ردپای دیجیتال: ترکیب اطلاعات جغرافیایی جمعسپاری شده برای مدیریت مناطق حفاظتشده. Appl. Geogr. 2018 ، 90 ، 44-54. [ Google Scholar ] [ CrossRef ]
- علیوند، م. Hochmair، HH تجزیه و تحلیل فضایی-زمانی الگوهای مشارکت عکس در Panoramio و Flickr. کارتوگر. Geogr. Inf. علمی 2017 ، 44 ، 170-184. [ Google Scholar ] [ CrossRef ]
- مارتی، پی. سرانو-استرادا، ال. Nolasco-Cirugeda، A. داده های رسانه های اجتماعی: چالش ها، فرصت ها و محدودیت ها در مطالعات شهری. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 74 ، 161-174. [ Google Scholar ] [ CrossRef ]
- جیانگ، بی. Ren, Z. فضای جغرافیایی به عنوان یک ساختار زنده برای پیش بینی فعالیت های انسانی با استفاده از داده های بزرگ. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 764-779. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سینکلر، ام. مایر، ام. ولترینگ، م. Ghermandi، A. استفاده از رسانه های اجتماعی برای برآورد منشأ بازدیدکنندگان و الگوهای تفریح در پارک های ملی آلمان. جی. محیط زیست. مدیریت 2020 ، 263. [ Google Scholar ] [ CrossRef ]
- دل وکیو، پی. دی مینین، ا. پتروزلی، AM; Panniello، U. پیری، اس. داده های بزرگ برای نوآوری باز در شرکت های کوچک و متوسط و شرکت های بزرگ: روندها، فرصت ها و چالش ها. ایجاد کنید. نوآوری. مدیریت 2018 ، 27 ، 6-22. [ Google Scholar ] [ CrossRef ]
- پیکمات، بی. پیترز، ام. Bichler، BF تحقیقات نوآوری در گردشگری: جریان های تحقیقاتی و اقدامات برای آینده. جی. هاسپ. تور. مدیریت 2019 ، 41 ، 184-196. [ Google Scholar ] [ CrossRef ]
- آیدین، جی. تعامل رسانههای اجتماعی و اثربخشی پست ارگانیک: نقشه راه برای افزایش اثربخشی استفاده از رسانههای اجتماعی در صنعت مهماننوازی. جی. هاسپ. علامت گذاری. مدیریت 2020 ، 29 ، 1-21. [ Google Scholar ] [ CrossRef ]
- پینو، جی. پلوسو، AM؛ دل وکیو، پی. ندو، وی. پاسیانته، جی. Guido, G. چارچوب روش شناختی برای ارزیابی استراتژی های رسانه های اجتماعی سازمان های مدیریت رویداد و مقصد. جی. هاسپ. علامت گذاری. مدیریت 2019 ، 28 ، 189–216. [ Google Scholar ] [ CrossRef ]
- مولر، دی. یک دستور کار تحقیقاتی برای جغرافیاهای گردشگری . انتشارات ادوارد الگار: چلتنهام، انگلستان; نورث همپتون، MA، ایالات متحده آمریکا، 2019؛ ISBN 9781786439314. [ Google Scholar ]
- بادر، ام. درگیر! دستور کار تحقیقاتی برای داده های بزرگ در جغرافیای گردشگری در یک دستور کار تحقیقاتی برای جغرافیاهای گردشگری ; انتشارات ادوارد الگار: چلتنهام، انگلستان; نورث همپتون، MA، ایالات متحده آمریکا، 2019؛ صص 149-158. [ Google Scholar ]
- تاسپینار، ا. توییتر اسکراپر. در دسترس آنلاین: https://github.com/taspinar/twitterscraper (در 16 ژوئن 2020 قابل دسترسی است).
- Steinert-Threlkeld، ZC Twitter as Data ; Steinert-Threlkeld، ZC، Ed. انتشارات دانشگاه کمبریج: لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 2018؛ ISBN 9781108529327. [ Google Scholar ]
- ون کسل، پی. مقدمهای بر مدلهای موضوعی برای تحلیل متن. در دسترس آنلاین: https://medium.com/pew-research-center-decoded/an-intro-to-topic-models-for-text-analysis-de5aa3e72bdb (در 16 ژوئن 2020 قابل دسترسی است).
- نارنجی، مدل سازی موضوع LBU. در دسترس آنلاین: https://orange3-text.readthedocs.io/en/latest/widgets/topicmodelling.html (در 5 مه 2020 قابل دسترسی است).
- Blei، DM; Ng، AY؛ جردن، MI نهفته دیریکله تخصیص. جی. ماخ. فرا گرفتن. Res. 2003 ، 3 ، 993-1022. [ Google Scholar ]
- دومایس، تی. تحلیل معنایی پنهان. آنو. Rev. Inf. علمی تکنولوژی 2005 ، 38 ، 188-230. [ Google Scholar ] [ CrossRef ]
- ویکهام، اچ. Grolemund، G. R برای علم داده: واردات، مرتب، تبدیل، تجسم و مدل سازی داده ها . O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016; ISBN 9781491910399. [ Google Scholar ]
- دیکشنری ایده های دو کلمه ای. در دسترس آنلاین: https://www.twinword.com/ideas/graph/dictionary/ (در 5 مه 2020 قابل دسترسی است).
- Beaver, A. (Ed.) A Dictionary of Travel and Tourism ; انتشارات دانشگاه آکسفورد: هارلو، بریتانیا، 2012. [ Google Scholar ]
- توریسم. در دسترس آنلاین: https://webterm.term-portal.de/DEUTERM/tourismus/tourismus_e.htm (دسترسی در 5 مه 2020).
- گوپتا، وی. Rattikorn، H. استفاده از قدرت هشتگ ها در تجزیه و تحلیل توییت. در مجموعه مقالات کنفرانس بینالمللی IEEE 2017 درباره دادههای بزرگ، بوستون، MA، ایالات متحده آمریکا، 11 تا 14 دسامبر 2017. [ Google Scholar ]
- هوتو، سی جی; گیلبرت، ای. ویدر: یک مدل قاعدهمحور برای تحلیل احساسات متن رسانههای اجتماعی. در مجموعه مقالات هشتمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، ان آربور، MI، ایالات متحده آمریکا، 1 تا 4 ژوئن 2014. [ Google Scholar ]
- Burchell, J. استفاده از VADER برای مدیریت تحلیل احساسات با متن رسانه های اجتماعی. 2017. در دسترس آنلاین: https://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf (در 13 نوامبر 2020 قابل دسترسی است).
- ESRI. استفاده از نمادهای متناسب در دسترس آنلاین: https://desktop.arcgis.com/en/arcmap/10.3/map/working-with-layers/using-proportional-symbols.htm (دسترسی در 5 مه 2020).
- ArcGIS Pro. مروری بر مجموعه ابزار خوشه های نقشه برداری. در دسترس آنلاین: https://pro.arcgis.com/en/pro-app/tool-reference/spatial-statistics/an-overview-of-the-spatial-statistics-toolbox.htm (دسترسی در 5 مه 2020).
- Lu, Y. تجزیه و تحلیل خوشه فضایی برای داده های نقطه ای: ضرایب مکان در مقابل تراکم هسته. در مجموعه مقالات کنسرسیوم دانشگاه علوم اطلاعات جغرافیایی مجمع تابستانی، پورتلند، اورگان، 21 ژوئن 2000. [ Google Scholar ]
- Attaway، D. GIS کارگاه تجزیه و تحلیل. در مجموعه مقالات GIS 2016 برای کنفرانس جهانی پایدار ؛ ESRI، اد. ESRI: ژنو، سوئیس، 2016; پ. 51. [ Google Scholar ]
- ESRI. تجزیه و تحلیل Hotspot بهینه شده در دسترس آنلاین: https://desktop.arcgis.com/en/arcmap/10.3/tools/spatial-statistics-toolbox/optimized-hot-spot-analysis.htm (دسترسی در 5 مه 2020).
- ESRI. تفاوت بین نقطه، خط و تراکم هسته. در دسترس آنلاین: https://pro.arcgis.com/en/pro-app/tool-reference/spatial-analyst/differences-between-point-line-and-kernel-density.htm (در 5 مه 2020 قابل دسترسی است).
- Silverman، BW (Ed.) تخمین چگالی برای آمار و تجزیه و تحلیل داده ها ; دانشگاه باث: لندن، انگلستان؛ چپمن و هال/CRC: نیویورک، نیویورک، ایالات متحده آمریکا، 1986. [ Google Scholar ]
- Dempsey, C. Heat Maps در GIS. در دسترس آنلاین: https://www.gislounge.com/heat-maps-in-gis/ (دسترسی در 5 مه 2020).
- نارنجی 3. متن پیش پردازش متن کاوی. در دسترس آنلاین: https://orange3-text.readthedocs.io/en/latest/widgets/preprocesstext.html (در 5 مه 2020 قابل دسترسی است).

شکل 1. روش شناسی کلی که در این مقاله دنبال می شود. این فرآیند با جمعآوری دادهها با استفاده از Twitterscraper [ 35 ]، بر اساس مکان و کلمات کلیدی مرتبط با گردشگری در سطح شهرداری آغاز میشود. پردازش و فیلتر داده ها با استفاده از پایگاه داده سند NoSQL انجام می شود. دادههای توییتر از نظر ویژگیهای فضایی تحلیل میشوند، در حالی که متن توییتها با تحلیل متن معنایی تحلیل میشوند. یک ارزیابی به دنبال تجزیه و تحلیل همبستگی بین دادههای توییتر و دادههای آماری رسمی در مورد گردشگری است.

شکل 2. نحو پرس و جو برای شهرداری اشتایر، گراتس.
شکل 3. ابر کلمه از 150 کلمه رایج در مجموعه داده توییتر.
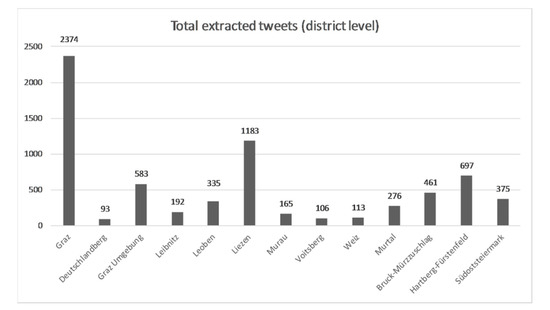
شکل 4. تعداد توییت های استخراج شده برای هر ناحیه از استان اشتایریا. در محور y تعداد کل توییت ها و در محور x نواحی نشان داده شده است.
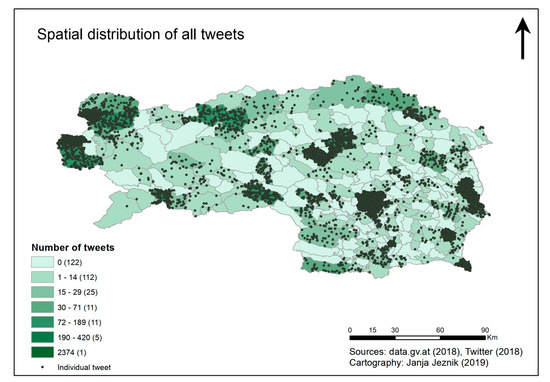
شکل 5. توزیع فضایی توییت های مرتبط با گردشگری بر اساس مناطق استان اشتایریا. هر منطقه با توجه به تعداد مطلق توییت ها در دوره ارزیابی رنگ می شود و هر توییت جداگانه با یک نقطه سبز در نقشه نشان داده می شود.
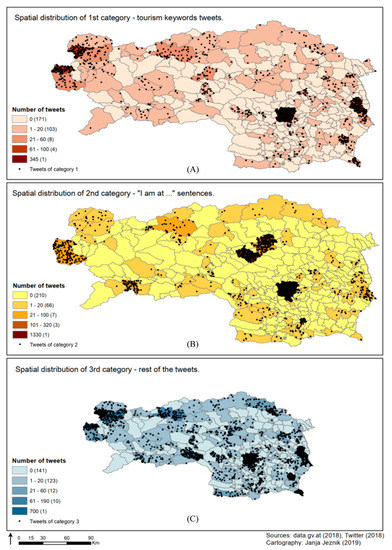
شکل 6. توزیع فضایی توییت های مرتبط با گردشگری بر اساس زیر گروه های آنها. نقشه ( A ) تعداد توییتهای دسته 1 را با کلمات کلیدی مرتبط با توریست نشان میدهد. نقشه ( B ) توییتهای دسته 2 را نشان میدهد — توییتهایی که به شکل «من در…» هستند. نقشه ( C ) بقیه توییتهای مرتبط با توریست را نشان میدهد – یعنی دسته 3.
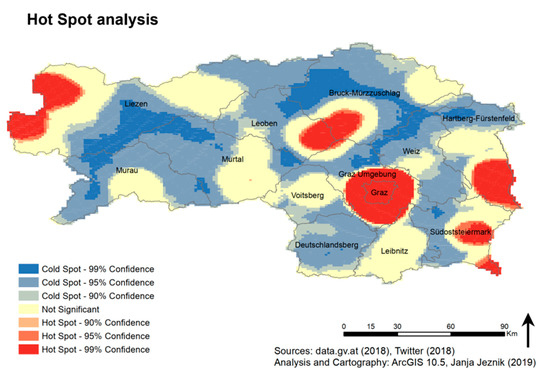
شکل 7. تجزیه و تحلیل نقطه داغ بهینه شده توییت ها و مناطق استان اشتایریا. توییتها بر اساس یک شبکه ماهی با اندازه سلول 1 کیلومتری جمعآوری شدهاند. مناطقی که رنگ قرمز دارند نشان دهنده یک نقطه داغ هستند، در حالی که مناطقی که به رنگ آبی رنگ شده اند به عنوان نقاط سرد در نظر گرفته می شوند.
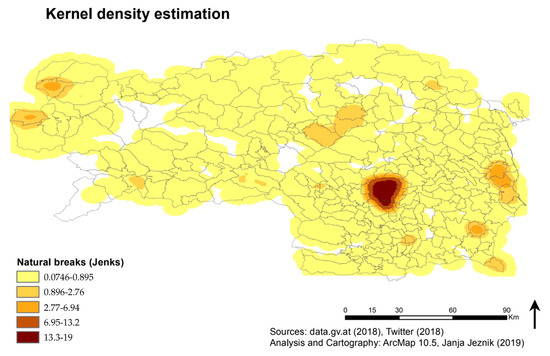
شکل 8. نتایج تخمین چگالی هسته با شعاع جستجوی 5 کیلومتر و اندازه سلول خروجی 500 متر. چگالی های به دست آمده با استفاده از روش Jenk’s Natural Breaks طبقه بندی می شوند. حضور بیش از حد شهر گراتس در مقایسه با مناطق عمدتاً روستایی قابل مشاهده است.
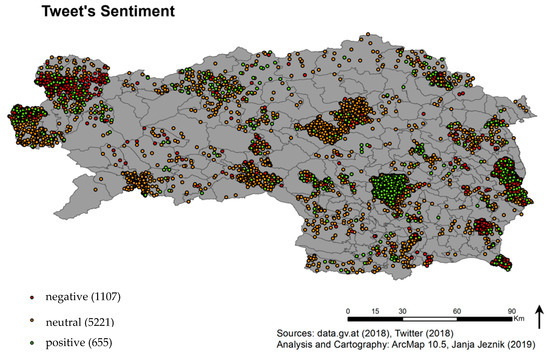
شکل 9. نتایج تحلیل احساسات. اساساً 1107 توییت منفی (که با نقاط قرمز مشخص شده اند)، 5221 توییت خنثی (نقاط نارنجی) و 655 توییت مثبت (نقاط سبز) وجود دارد. توییتهایی که دارای احساسات منفی هستند نیز نتیجه نام مکانهای آلمانی است که با «بد…» شروع میشود که به شهرهای آبگرم اشاره دارد. الگوریتم آلمانی “Bad…” را با معنی کلمه انگلیسی “bad” علامت گذاری می کند.
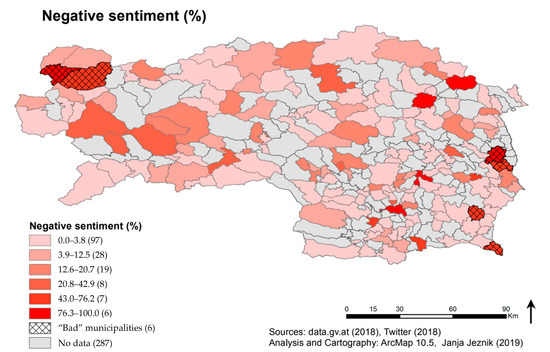
شکل 10. نتایج تحلیل احساسات. درصد توییت های منفی در این نقشه در کلاس های مختلف نشان داده شده است. توییتهایی که دارای احساسات منفی هستند نیز نتیجه نام مکانهای آلمانی است که با «بد…» شروع میشود که به شهرهای آبگرم اشاره دارد. الگوریتم آلمانی “Bad…” را با معنی کلمه انگلیسی “bad” علامت گذاری می کند. این شش شهر با الگوی دریچه متقاطع مشخص شده اند.
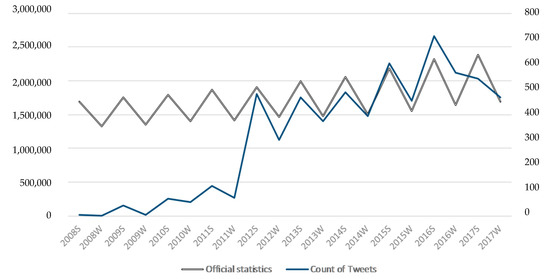
شکل 11. مقایسه اعداد مطلق ورودی ها (از آمار رسمی) و توییت های جمع آوری شده برای دوره ارزیابی – برای فصل زمستان و تابستان. فصل تابستان با پسوند “S” و فصل زمستان با پسوند “W” نشان داده می شود. تعداد ورودی ها با خط خاکستری نشان داده می شود، در حالی که تعداد مطلق توییت ها به صورت خط آبی نشان داده می شود. محور x در سمت چپ تعداد ورودیها را از آمار رسمی نشان میدهد، در حالی که محور x سمت راست تعداد مطلق توییتها را نشان میدهد.
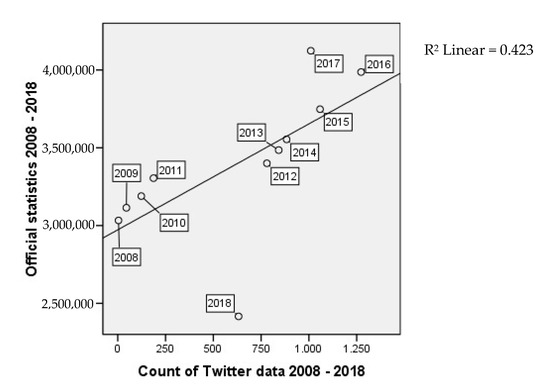
شکل 12. نمودار پراکندگی گردشگری رسمی و توزیع داده های توییتر برای دوره 2008-2018. محور x تعداد مطلق دادههای توییتر و محور y تعداد مطلق ورودیها از آمار رسمی را نشان میدهد. R 2 ضریب تعیین خط رگرسیون است.
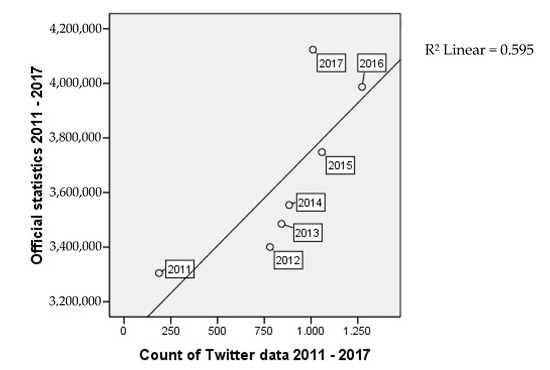
شکل 13. نمودار پراکندگی گردشگری رسمی و توزیع داده های توییتر برای دوره 2011-2017. محور x تعداد مطلق دادههای توییتر و محور y تعداد مطلق ورودیها از آمار رسمی را نشان میدهد. R 2 ضریب تعیین خط رگرسیون است.


بدون دیدگاه