1. معرفی
یک منطقه جغرافیایی با ساختمانهایی برای بازدید و خیابانهایی که عابران پیاده میتوانند به راحتی در آن راه بروند، مردم را تشویق میکند تا با پای پیاده سفر کنند [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ]. عابران پیاده معمولاً ترجیح می دهند در امتداد خطوط خطی حرکت کنند که مشخصه آنها حداقل تعداد چرخش است و حرکت توسط درک فضاهای بصری هدایت می شود. این فضاها که توسط هیلیر [ 9 ] به عنوان محیطهای فیزیکی قابل پیادهروی برای عابران پیاده در مراکز شهرها که تراکم ساختمانها بالاست، تعریف شدهاند، از نظر فیزیکی با شبکه خیابان منطبق هستند. 10 ].]. تکنیکهای نحو فضایی (SS) اغلب برای تحلیل رفتار پیادهروی عابر پیاده در یک محیط شهری متشکل از پیکربندیهای خیابان و ساختمان استفاده میشوند. تجزیه و تحلیل محوری (AA) و تجزیه و تحلیل نمودار بصری (VGA) دو مورد از آنها هستند [ 11 ].
در دهه گذشته شاهد افزایش قابل توجهی در مطالعاتی بوده است که رفتارهای راه رفتن را از طریق اقدامات AA بررسی می کنند. به عنوان مثال، لرمن و اومر [ 12 ]، رابطه بین حرکت عابر پیاده در دو منطقه همسایه واقع در تل آویو را بر اساس معیارهای یکپارچه سازی، انتخاب و اتصال تحلیل کردند. Monokrousou و Giannopoulou [ 13 ] ادغام و انتخاب را در یک تحلیل همبستگی برای توضیح حرکت عابر پیاده و پیشبینی وضعیت آتی آتن وارد کردند. احمد و همکاران [ 14 ] تغییرات مورفولوژیکی را که از سال 1947 تا 2007 در شهر داکا، بنگلادش، با استفاده از اقدامات یکپارچهسازی، اتصال و کنترل رخ داد، بررسی کرد. حجرسولیها و لی [ 15] حرکت عابران پیاده در مرکز شهر بوفالو در نیویورک را از طریق معیار اتصال توضیح داد. لیو و همکاران [ 16 ] از کنترل و ادغام به عنوان مبنایی در تعیین رفتارهای پیاده روی گردشگران در کوه خوش منظره Sanqingshan، یکی از مناطق عمده گردشگری چین استفاده کرد. جباری و همکاران [ 17 ] ارتباط بین اتصال و حرکت عابر پیاده را با انجام تحلیلهای چند معیاره در مرکز شهر اوپورتو، پرتغال بررسی کرد. علاوه بر این، برخی از مطالعات اخیر روابط بین اقدامات به دست آمده از VGA و حرکات عابر پیاده را بررسی کرده و آنها را همراه با اقدامات AA ارزیابی می کنند. Dessylas و Duxburry [ 18 ] و Hölscher و همکاران. [ 19] برخی از معیارهای به دست آمده از VGA و AA را برای تعیین همبستگی داده ها با حرکت عابر پیاده مقایسه کرد. هیتور و همکاران [ 20 ] پردیس موسسه فنی لیسبون در پرتغال را با معیارهای اتصال حاصل از ادغام VGA و AA ارزیابی کرد. بندیدیدی و همکاران. [ 21 ] از معیارهای اتصال و ادغام VGA برای بررسی شدت حرکت عابران پیاده در میادین شهر Biskra در الجزایر استفاده کرد. کوتسولامپروس و همکاران [ 22 ] از معیارهای VGA برای تجزیه و تحلیل راه رفتن در داخل خانه استفاده کرد. پاگکراتیدو و همکاران [ 23 ] رفتارهای افراد ناآشنا با محوطه دانشگاه تمپل را با استفاده از معیارهای ادغام، انتخاب و اتصال VGA و AA مورد بررسی قرار داد.
همه این مطالعات ذکر شده در بالا نشان داد که محققان تلاش قابل توجهی برای توضیح حرکات عابر پیاده با استفاده از اقدامات به دست آمده از AA و VGA داشتند. با این حال، قابل توجه بود که این محققان معیار کلی معتبر در مناطق مورد مطالعه خود را برای توضیح حرکت عابر پیاده انتخاب نکردند. تعداد اقداماتی که استفاده می کردند معمولا بیش از یک بود. این وضعیت گیج کننده به نیاز به تعیین معیار مناسبی اشاره می کند که حرکت عابر پیاده را برای هر منطقه مطالعه توضیح دهد. اندازه گیری مناسب باید یک معیار خاص باشد که منعکس کننده ویژگی پیاده روی منطقه مورد نظر باشد، با این تفاوت که یک معیار عمومی معتبر برای همه مناطق مورد مطالعه است. هدف این مقاله تعیین مناسبترین معیار برای تعیین شدت حرکات عابر پیاده در یک منطقه آزمایشی مشخص برای غلبه بر این کمبود ذکر شده در بالا است. برای این منظور، روابط بین حرکات عابر پیاده و اقدامات با استفاده از تحلیل رگرسیون ارزیابی می شود. علاوه بر این، این مطالعه با هدف نشان دادن چگونگی تأثیر تغییرات آتی مطابق با طرح جامع بر تراکم عابر پیاده انجام می شود. ارزیابی کلی از اثرات این تغییرات بر اساس نتایج نمونه زوجی انجام می شودآزمون t ، که معمولا برای مقایسه تفاوت بین دو نمونه استفاده می شود.
باقی مانده از مقاله به شرح زیر سازماندهی شده است. بخش 2 به طور خلاصه منطقه مورد مطالعه و مجموعه داده های مورد استفاده در این مطالعه را توصیف می کند. بخش 3 استفاده از تکنیک های SS و روش های آماری را برای تعیین مناسب ترین معیار مربوط به تراکم عابر پیاده معرفی می کند و بخش 4 نتایج را ارائه می دهد. بخش 5 مقاله را با نکات پایانی پایان می دهد.
2. منطقه مطالعه
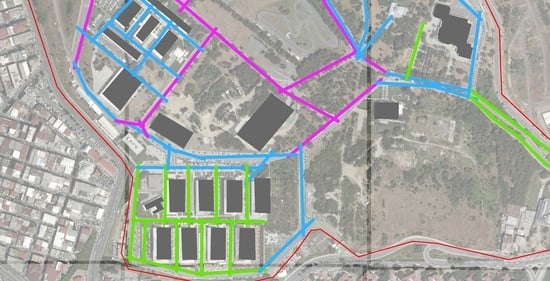
پردیس های دانشگاهی با جمعیت دانشجویی بالا، سکونتگاه های قابل توجهی با ویژگی های مشابه مناطق شهری هستند. چندین پردیس دانشگاهی را می توان در بیشتر کلان شهرهای پرجمعیت اروپا یافت. یکی از این شهرها استانبول است که بیش از 15 میلیون نفر جمعیت دارد و موسسات آموزش عالی پیشرو ترکیه را در خود جای داده است. در میان این مؤسسات، دانشگاه فنی یلدیز چهارمین دانشگاه قدیمی است که در سال 1911 تأسیس شد. این دانشگاه بیشتر خدمات آموزشی خود را در پردیس داووتپاشا ارائه می دهد که مساحتی حدود 124 هکتار را اشغال می کند و بزرگترین وسعت آموزشی در استانبول است. این پردیس در پایان سال 1398 دارای هشت دانشکده، دو مؤسسه و واحدهای اداری مختلف بود.شکل 1 ).
بنای تاریخی در مرکز پردیس در سال 1832 ساخته شده است. طبق اسناد موجودی، بقیه ساختمان ها بعد از سال 2001 ساخته شده اند. طرح جامعی که مدیریت دانشگاه در نظر دارد بعد از سال 2019 اجرا کند، کل مساحت ساختمان و شبکه راه را توسعه می دهد. طول به ترتیب تقریباً 1 هکتار و 4.2 کیلومتر (مناطق نارنجی در شکل 1 ). ساختمان های جدید در فضاهای باز در ضلع شمال غربی و جنوب شرقی پردیس ساخته می شوند و جاده های پیش بینی شده دسترسی به این ساختمان ها را فراهم می کند. برخی مسیرهای پیاده روی منتهی به فضاهای باز در مرکز پردیس نیز ساخته خواهد شد. تغییرات مورفولوژیکی رخ داده از سال 2001 تا 2019، همراه با داده های طرح جامع، ساختار پویای منطقه مورد مطالعه را منعکس می کند.
3. مواد و روشها
مجموعه دادههای مورد نیاز برای استخراج اندازههای AA و VGA در منطقه مورد مطالعه با دیجیتالسازی از عکسهای ارتوفتو موجود در منطقه بهدست آمد. نقشه محوری و ردپای ساختمان به ترتیب داده های پایه مورد استفاده در AA و VGA هستند. نقشه محوری مورد استفاده برای AA از حداقل تعداد خطوط محوری تشکیل شده است. هر خط محوری در این نقشه جهت بین دو نقطه ای را که حرکت عابر پیاده شروع و پایان می یابد نشان می دهد [ 24 ، 25 ]. همه آنها باید با پیکربندی های شبکه خیابانی سازگار باشند [ 24 ، 26 ، 27 ]. VGA بسته به پیکربندی ساختمان فضا اجرا می شود [ 28 , 29 , 30]. این تکنیک مستلزم تقسیم مناطق جغرافیایی به سلولهای شبکهای و متعاقباً محاسبه معیارها از طریق بررسی سلولهای خالی، همراه با همسایههای مجاور است که عابران پیاده میتوانند حرکت کنند. در این مطالعه، در مجموع 15 معیار، که در زیر توضیح داده شده است، با استفاده از هر دو تجزیه و تحلیل به دست آمد.
3.1. اندازه گیری های AA و VGA
ابزار منبع باز برای محاسبه معیارهای به دست آمده از AA و VGA استفاده شد. یکی از اینها جعبه ابزار SS، نرم افزار سیستم اطلاعات جغرافیایی (GIS) Quantum GIS (QGIS) بود که برای به دست آوردن اندازه های AA از یک نقشه محوری استفاده می شد. این یک ابزار تجزیه و تحلیل شبکه فضایی چند پلتفرمی است که تکنیک های SS را با تجزیه و تحلیل داده های GIS و ویژگی های تجسم [ 31 ] ادغام می کند. یکی دیگر از ابزارهای منبع باز مورد استفاده در این مطالعه DepthMap بود که به عنوان پلت فرمی برای تحلیل دید طرح های شهری و معماری توسعه یافت [ 30 ]. هم کیت ابزار SS و هم DepthMap به محققان اجازه می دهد تا از چندین معیار استفاده کنند ( شکل 2 ).
یکپارچه سازی، دسترسی از یک مکان به تمام مکان های دیگر را توصیف می کند [ 32 ]. دسترسی یکی از مهم ترین عواملی است که حرکت عابران پیاده را افزایش یا کاهش می دهد [ 33 ، 34 ، 35 ]. هر دو تحلیل می توانند ادغام را بر اساس داده های منبع تعیین کنند. ادغام هیلیر و هانسون [ 24 ] ( منnتیاچاچآآ) یک اندازه گیری جهانی است که از AA [ 11 ] به دست می آید. همچنین نزدیکی توپولوژیکی یک خط محوری به خطوط دیگر در یک نقشه محوری را نشان می دهد. هنگامی که یکپارچه سازی برای خطوط محوری که با یک مقدار شعاع محدود شده اند محاسبه می شود، به آن ادغام محلی می گویند. منnتیrایکسآآ. عمق متوسط ( متردآآ) معکوس یکپارچگی جهانی است و میانگین عمق کل یک خط محوری متصل به خطوط محوری دیگر را ارائه می دهد. ادغام VGA ( منnتیاچاچVجیآ) توسعه یافته توسط هیلیر و هانسون [ 24 ] نسبت دید هر سلول شبکه ای در فضا را به دید سلول های دیگر به دست می دهد. Teklenburg [ 36 ] عادی سازی ادغام VGA را پیشنهاد کرد ( منnتیتیVجیآ) برای ایجاد فرصتی برای مقایسه ادغام به دست آمده از تجزیه و تحلیل های انجام شده در زمینه های مختلف. به طور مشابه، کامپوس و فونگ [ 37 ] ادغام را با استفاده از مقدار p ( منnتیپvآلVجیآ). میانگین عمق VGA ( متردVجیآ) میانگین مقدار عمق محاسبه شده از یک سلول به سلول های شبکه دیگر است. قابلیت اتصال معیار دیگری است که می توان از AA و VGA بدست آورد. اتصال AA ( جonآآ) تعداد کل خطوط محوری متصل به یک خط محوری است، در حالی که اتصال VGA ( جonVجیآ) به تعداد کل شبکه های مجاور متصل به یک سلول شبکه در فضا اشاره دارد. AA می تواند برای استخراج معیار دیگری به نام انتخاب استفاده شود ( جساعتآآ) که فاصله کل یک خط محوری را تا خطوط محوری دیگر منعکس می کند. تعداد کوتاه ترین مسیرهایی را که یک خط محوری را به خطوط محوری دیگر متصل می کند، ارائه می دهد. فاصله بین دو خط محوری کوتاهترین مسیر محاسبه شده توپولوژیکی است [ 38 ].
سایر معیارهای ارزیابی شده در این مطالعه از طریق VGA به دست آمد. اندازه گیری کنترل هیلیر و هانسون [ 24 ] (جnتیVجیآ) و قابلیت کنترل ترنر [ 30 ] ( جبلVجیآ) دو معیار هستند. کنترل شامل انتخاب بصری مناطق غالب است، در حالی که قابلیت کنترل، مناطقی را که به راحتی در طول پیاده روی نظارت می شوند، تعیین می کند. آنتروپی بصری ( هnتیVجیآ) در بررسی مقادیر عمق یک سلول شبکه و سایر سلول های مجاور اتخاذ می شود. اگر مقدار عمق سلول های همسایه تقریباً برابر با یک سلول مورد بررسی باشد، آنتروپی زیاد است. اگر مقادیر عمق بین سلول های مجاور با یکدیگر متفاوت باشد، آنتروپی کم است. آنتروپی نسبی شده ( rهnتیVجیآ) محاسبه توزیع مورد انتظار مقدار میانگین عمق است. ضریب خوشه بندی ( ججVجیآ) برای تعیین چگونگی تغییر درک فضای عابر پیاده در صورت دور شدن از مکان فعلی استفاده می شود. از دست دادن اطلاعات بصری به دلیل حرکت عابر پیاده، مقدار ضریب خوشه بندی را کاهش می دهد [ 30 ].
3.2. تعیین مناسب ترین معیار
در این پژوهش از تحلیل رگرسیون برای تبیین روابط بین معیارهای فوق با تراکم عابر پیاده استفاده شد. با ارزیابی نتایج مدلهای تحلیل آن، مناسبترین معیار تعیین شد. تحلیل رگرسیون یک رویکرد آماری است که برای تحلیل رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل اجرا می شود. در این مطالعه، داده های تراکم عابر پیاده محاسبه شده با توجه به تعداد افراد شمارش شده در 22 دروازه در محوطه دانشگاه (علامت های آبی در شکل 1 ) به عنوان متغیر وابسته پذیرفته شد. شمارش افراد، که به عنوان روش شمارش دروازه نیز شناخته می شود [ 39 ] شناخته می شود، ساده ترین رویکرد برای تعیین حساس حرکت عابر پیاده در مکانی است که نمی توان از روش جمع آوری داده های خودکار استفاده کرد.40 ]. انتخاب مناسب مکانهایی که افراد از آنجا شمارش میشوند، در بازتاب مؤثر تحرک عابران پیاده بسیار مهم است. نقاط کافی با ویژگی های مختلف که فراوانی استفاده عابران پیاده در یک منطقه را نشان می دهد نیز مورد نیاز است [ 41]. شمارش در دروازه 22 در روزهای هفته به مدت دو هفته ادامه داشت. هر دروازه حداقل یک بار در چهار دوره مختلف (08.30-10:30، 10.30-12:30، 12:30-14:30، 14:30-16:30) سعی شد به مدت 15 دقیقه شمارش کند. علاوه بر این، دو بار دیگر در دوره های تصادفی شمارش شد. تعداد 15 دقیقه برای مجموع 22 دروازه 132 بار بود. سپس، نویسندگان تمام عناصر داده را در سه کلاس دسته بندی کردند که نشان دهنده گروه های چگالی مرتب (کم، متوسط و زیاد) هستند. سه گروه برای 132 داده شمارش دروازه در این مطالعه کافی بود. از سوی دیگر، اگر محققین به شمارش های تکراری بیشتری در دروازه های بیشتر برای منطقه مطالعاتی گسترده تر دست یابند، می توانند تعداد گروه های تراکم را نیز افزایش دهند.
قبل از طبقهبندی، یک فرآیند پیشبررسی برای تعیین اینکه آیا در میان دادههای شمارش دروازه وجود دارد یا خیر، استفاده شد. یکی از روشهای ضروری برای آشکار کردن نقاط پرت بالقوه در آمار، انتخاب یک مقدار معیار شناخته شده به عنوان z -score است. عناصر داده با مقدار بیشتر یا کمتر از z -score به عنوان نقاط پرت بررسی می شوند. در این مطالعه، z – score هر عنصر داده در مجموعه داده با استفاده از رابطه (1) [ 42 ] محاسبه می شود.
جایی که x مقدار عنصر داده را نشان می دهد، μو σبه ترتیب مقادیر میانگین و انحراف استاندارد مجموعه داده است. مقادیر آستانه پیش فرض در این مطالعه 2.5± انتخاب شد. نقاط پرت بالقوه شناسایی شده به عنوان عناصر داده ناچیز در نظر گرفته نشد که باید حذف شوند. بررسی شد که آیا آنها مقادیر حدی طبقات را تحریف می کنند یا خیر.
در این مطالعه، الگوریتم شکست طبیعی جنکس (JNB) که بهترین گروههایی را که مقادیر مشابهی دارند شناسایی میکند، برای دستهبندی دادهها به سه کلاس ترتیبی استفاده شد. JNB یک تکنیک بهینه سازی است که تفاوت بین کلاس ها را به حداکثر می رساند. این مسئله به چگونگی تقسیم طیفی از اعداد به کلاس های پیوسته برای به حداقل رساندن انحراف مربع در هر کلاس می پردازد [ 43 ]. این الگوریتم به صورت مکرر داده ها را پردازش می کند و آنها را به کلاس هایی که نام آنها توسط کاربر مشخص شده است اختصاص می دهد. سپس مجموع مربعات انحرافات (SSD) عناصر داده را از میانگین نمونه (معادله (2)) در هر کلاس برمی گرداند و مقدار کل را برای همه کلاس ها محاسبه می کند. طبقه بندی که حداقل مقدار کل را در بین فرآیندهای تکراری می دهد، بهینه است [ 44].
خوب بودن تناسب واریانس (GVF) برای عناصر کلاس مشخص، قدرت فرآیند طبقه بندی را نشان می دهد (معادله (3)). GVF مقداری بین 0 و 1 می گیرد. هر چه GVF به 1 نزدیکتر باشد، تناسب بهتری دارد.
جایی که SSDمترمنnحداقل مقدار کل SDD برای طبقه بندی بهینه است و SSDدیاسانحراف مجذور همه عناصر در مجموعه داده است.
اولین متغیر مستقل مورد استفاده برای ایجاد یک مدل رگرسیونی، معیارهایی است که رابطه آن با تراکم عابر پیاده بررسی شده است. آنها مقادیر پیوسته محاسبه شده با نرم افزار را می گیرند. از آنجایی که معیارهای بهدستآمده از AA و VGA معمولاً به هم مرتبط هستند، یک مشکل همخطی چندگانه زمانی رخ میدهد که همه معیارها به عنوان دادههای ورودی در مدل رگرسیونی داده شوند. بنابراین برای هر معیار مدل جداگانه ای ایجاد شد و به صورت جداگانه مورد ارزیابی قرار گرفتند. دومین متغیر مستقل برای مدل رگرسیون دوره های شمارش عابر پیاده بود. از آنجایی که معیارها در چهار دوره مختلف جمعآوری میشوند، این متغیر مستقل مقادیر طبقهبندی شدهای از اسمی 1 تا 4 را میگیرد.
یک تحلیلگر باید بسته به نوع داده متغیرهای وابسته و مستقلی که وارد مدل می شوند از یک مدل رگرسیون مناسب استفاده کند. متغیر وابسته مورد استفاده در این تحقیق شامل داده های عددی است که در سه کلاس مرتب شده گروه بندی شده اند. هنگامی که داده های مرتب شده که متغیر وابسته را تشکیل می دهند دارای حداقل سه گروه در یک نظم طبیعی باشند، با استفاده از رگرسیون لجستیک ترتیبی مدل می شوند [ 45 ]. مدل رگرسیون لجستیک ترتیبی مبتنی بر وجود یک متغیر نهفته تصادفی پیوسته و مشاهده نشده Y* تحت متغیر کاملاً وابسته Y است. دسته بندی های این متغیر به صورت فواصل متوالی در یک صفحه پیوسته به نام مقدار آستانه پیش بینی می شوند [ 46 , 47]. چهار آزمون جداگانه استحکام مدل رگرسیون لجستیک ترتیبی را بررسی میکنند. این تست ها عبارتند از (1) برازش مدل، (2) خوب بودن برازش، (3) شبه R2 و (4) خطوط موازی . برازش مدل، احتمال ورود -2 را بررسی می کند. یک تغییر قابل توجه (0.05 < p) در آمار log-likelihood 2- بین مدل پایه و مدل نهایی نشان می دهد که پیش بینی کننده ها بر اساس این آزمون ها معنی دار بودند [ 48 ]]. دو نوع آزمون خوب بودن برازش به نامهای کایدو پیرسون و آمار انحراف، اختلاف بین مدل فعلی و مدل کامل را ارزیابی میکنند. با این حال، این تست ها به سلول های خالی حساس هستند. اگر تعداد زیادی سلول خالی در مدل وجود داشته باشد، احتمال log-2- شاخص قوی تری نسبت به آماره کای دو و انحراف پیرسون در نظر گرفته می شود [ 49 ، 50 ]. مقادیر شبه R2 برای تخمین واریانس توضیح داده شده توسط متغیر مستقل استفاده می شود. هنگامی که این مقادیر به صفر نزدیکتر شوند، برازش مدل کاهش می یابد. R 2 پایین ترمقادیر از تفسیر پارامترها جلوگیری نمی کنند. یکی از مفروضات زیربنایی رگرسیون لجستیک ترتیبی مبتنی بر این است که رابطه بین هر جفت از نتایج یکسان است. به عبارت دیگر، رگرسیون لجستیک ترتیبی فرض میکند که ضرایبی که رابطه بین پایینترین و همه دستههای بالاتر متغیر پاسخ را تعریف میکنند، همان ضرایبی هستند که رابطه بین پایینترین دسته بعدی و همه دستههای بالاتر را توصیف میکنند. این فرض خطوط موازی نامیده می شود و از آزمون کای دو برای آزمون اعتبار فرض موازی استفاده می شود. در پایان فرآیند تحلیل رگرسیون، حساسیت های آزمون هر مدل رگرسیون لجستیک ترتیبی ایجاد شده در این مطالعه بررسی شد.
3.3. تحلیل اثر طرح جامع
در این مرحله بر آن شد تا مشخص شود مسیرهای پیادهروی جدیدی که قرار است در آینده اضافه شوند، طبق طرح جامع چگونه میتوانند بر تراکم عابر پیاده در محدوده مورد مطالعه تأثیر بگذارند. تراکم عابر پیاده با توجه به معیار مرجع تعیین شده توسط تحلیل رگرسیون در مرحله قبل مورد بررسی قرار گرفت. ارزیابیها با تحلیل مقادیر اندازهگیری ویژگیهای یکسان در وضعیت فعلی و طرح جامع انجام شد.
تعداد ویژگیها در مجموعه داده طرح اصلی به دلیل مسیرهای پیادهروی جدید اضافه شده، بیشتر از مجموعه داده فعلی است. مقادیر اندازه گیری مرجع ویژگی ها در هر دو مجموعه داده نرمال شد تا یک مقایسه منطقی بین مسیرهای پیاده روی جدید اضافه شده و فعلی ایجاد شود. در این تحقیق فرآیند نرمال سازی با استفاده از فاصله بین صفر و یک انجام شد (معادل (4)).
جایی که ایکسمنمقادیر اندازه گیری را نشان می دهد و ایکسمترآایکسو ایکسمترمنnبه ترتیب به حداکثر و حداقل مقادیر در مجموعه داده ها مربوط می شود.
تفاوت بین مجموعه دادههای طرح اصلی و فعلی با استفاده از آزمون t نمونه زوجی مقایسه شد ، که یک روش استنتاجی پارامتری است که برای ارزیابی دو میانگین محاسبهشده از دو نمونه مرتبط طراحی شده است. سه فرضی که در آزمون t نمونه زوجی مورد استفاده قرار می گیرد ، همان فرضیاتی است که در آزمون t نمونه مستقل اتخاذ شده است. فرض اول نشان می دهد که متغیر وابسته دارای مقیاس یا مقیاس نسبت است و به طور نرمال توزیع می شود. فرض دوم حاکی از آن است که واریانس در نمرات خام معادل جمعیت های برآورد شده توسط سایکس2. فرض سوم که جمعیت های ارائه شده را نشان می دهد واریانس های همگن را نشان می دهد. تعداد نمونه ها در دو گروه برای موقعیت های قبل و بعد باید برابر باشد تا از نمونه های مربوطه جفت امتیاز ایجاد شود. نمونه های جفت شده بر اساس H 0 و H a هستند. در ارزیابی آماری آزمون از مقدار t استفاده می شود . مقدار t محاسبه شده با مقدار مربوطه از جدول توزیع t برای سطح اطمینان انتخاب شده مقایسه می شود. اگر مقدار t محاسبه شده بالاتر از مقدار بحرانی باشد، H 0 رد می شود. رد نشان می دهد که میانگین ها از نظر آماری با یکدیگر تفاوت دارند [ 42 ].
4. نتایج
4.1. مقادیر محاسبه شده برای اندازه گیری ها
در این مطالعه مقادیر AA و VGA محاسبه شده برای 22 گیت به ترتیب در جدول 1 و جدول 2 آورده شده است. از آنجایی که ادغام های محلی AA برای دو شعاع مختلف (r = 3 و r = 6) محاسبه شد، تعداد کل اندازه گیری ها در دو جدول 16 بود. علاوه بر این، فاصله شبکه به عنوان 10 متر در هنگام محاسبه معیارهای VGA استفاده شد.
4.2. تحلیل رگرسیون لجستیک ترتیبی
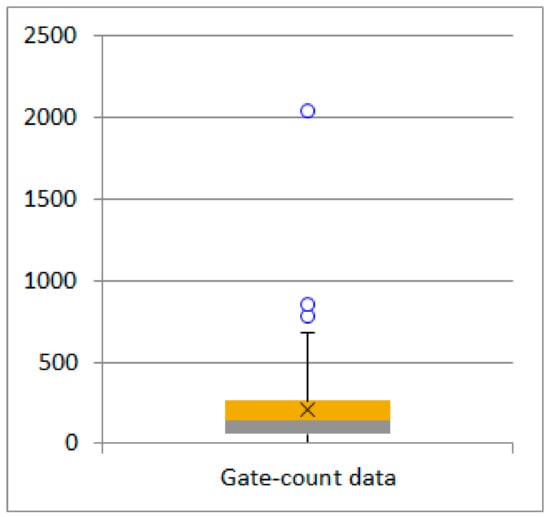
متغیر وابسته فرآیند رگرسیون لجستیک ترتیبی بر اساس دادههای شمارش دروازه در این مطالعه است. میانگین و مقادیر انحراف معیار در مجموع 132 عنصر داده به ترتیب 16/189 و 97/228 محاسبه شد. بسته به این مقادیر، z -score با استفاده از معادله 1 برای هر عنصر ایجاد شد و آنهایی که میتوانستند پرت باشند تعیین شدند. شکل 3 محدوده توزیع داده های شمارش دروازه را نشان می دهد. در این نمودار، سه عنصر داده با مقادیر z -score خارج از آستانه پیشفرض 2.5± را میتوان به عنوان نقاط پرت بالقوه (با حلقههای آبی نشان داده شده) در نظر گرفت. در یک فرآیند طبقه بندی با استفاده از الگوریتم JNB باید به این عناصر توجه شود.
طبق اولین طبقه بندی JNB با 132 عنصر داده، 106 داده به پایین، 25 داده به متوسط و تنها یک داده به کلاس های بالا اختصاص داده شد ( جدول 3 ). مقدار GVF برای این طبقه بندی 0.823 محاسبه می شود. اختصاص دادن تنها یک عنصر به کلاس بالا و مقدار GVF کمتر از 0.850، نویسندگان را بر آن داشت تا موارد پرت را در اولین طبقهبندی JNB حذف کنند. طبق طبقه بندی دوم با 129 عنصر داده، 75 داده به کلاس های کم، 44 داده به متوسط و 10 داده به کلاس های بالا اختصاص داده شد ( جدول 3).). مقدار GVF برای این طبقه بندی 0.870 است. توزیع موفقتر دادهها به کلاسها و مقدار GVF بالاتر از 0.850 نشان داد که این روش قابل اجرا است. علاوه بر این، سه نقطه پرت به کلاس بالا اضافه شد و تعداد داده های این کلاس 13 بود.
اطلاعات توصیفی در مورد متغیرهای وابسته و مستقل مورد استفاده در این پژوهش در جدول 4 ارائه شده است . در مجموع 16 مدل مختلف ساخته شد. در هر مدل از متغیر وابسته تراکم عابر پیاده و دوره های متغیر مستقل استفاده شده است. معیارهای متغیر مستقل در هر مدل یک به یک گنجانده شد.
اهمیت مدل های ایجاد شده در این مطالعه با آزمون برازش مدل و خطوط موازی مورد بررسی قرار گرفت ( جدول 5 ). خوب بودن برازش و شبه آزمون R2 ارزیابی نشد زیرا داده ها حاوی تعداد زیادی سلول خالی بود و مرتب سازی مدل ها غیر ضروری بود. همه 16 مدل فرض خطوط موازی را به دلیل p > 0.05 ارائه کردند. هنگامی که مقادیر برازش که اهمیت مدل را توضیح میدهند مورد ارزیابی قرار گرفتند، چهار مدل که در جدول 5 با رنگ خاکستری مشخص شدهاند به دلیل P <0.05 از نظر آماری معنیدار شدند .
اثرات متغیرهای مستقل (دورهها و معیارها) بر متغیر وابسته (تراکم عابر پیاده) با آمار تخمین پارامتر برای چهار مدل معنیدار شناساییشده در بالا مورد تجزیه و تحلیل قرار گرفت. تخمین پارامتر از جدولی از آمار برای توضیح جهت، قدرت و اهمیت آماری روابط بین متغیرها استفاده می کند.
جدول 6 نتایج مدل اندازه گیری یکپارچه سازی به دست آمده از AA را نشان می دهد. از آنجایی که نویسندگان خواستار تجزیه و تحلیل متغیرهایی بودند که تراکم عابر پیاده را افزایش میدهند، گروه تراکم عابر پیاده بالا را به عنوان مرجع در این مطالعه انتخاب کردند. این ترجیح باعث می شود که مقدار ß متغیرهای مستقلی که تراکم عابر پیاده را افزایش می دهند مثبت شود. مقدار p کمتر از 0.05 برای منnتیاچاچآآاطلاع می دهد که یکپارچه سازی تأثیر قابل توجهی بر مدل ایجاد شده دارد. با توجه به متغیر دوره، T2 از نظر آماری معنی دار بود ( P <0.05). زمانی که T4 به عنوان مرجع انتخاب شد، T1 و T3 معنی دار نبودند ( 05/0p >). اثرات غیر قابل توجه برای T1 و T3 توضیح می دهد که تراکم عابر پیاده در این دوره ها تفاوت معنی داری با T4 نداشت. ß ضریبی است که چگونگی تأثیر متغیرها بر متغیر وابسته را به طور متناسب بیان می کند. متغیری با مقدار ß بالا تأثیر بیشتری در مدل نسبت به بقیه دارد. در این مطالعه، از آنجایی که منnتیاچاچآآمقدار ß بیشتری نسبت به بقیه دارد، ادغام به عنوان مهم ترین متغیر در توضیح تراکم عابر پیاده پذیرفته شد. از سوی دیگر، مقادیر ß دورهها از نظر آماری به اندازه ادغام در توضیح تراکم عابر پیاده مؤثر نیستند. e β و w -values برای تفسیر اثرات متغیرهایی مانند ß -values استفاده می شوند. e β- value وقتی مقدار ß منفی است مقادیر کمتر از یک و وقتی مثبت است بیشتر از یک می گیرد. ß بالاضریب برای یک متغیر نشان می دهد که تأثیر آن بر متغیر وابسته قابل توجه است. به طور خلاصه، ادغام AA در این مدل نسبت به دورهها در توضیح تراکم عابر پیاده مؤثرتر بود.
جدول 7 نتایج مدل اندازه گیری عمق متوسط به دست آمده از AA را نشان می دهد. مقدار p کمتر از 0.05 برای متردآآنشان می دهد که عمق متوسط تأثیر قابل توجهی دارد. نتایج برای متغیر دوره مشابه مدل ایجاد شده با است منnتیاچاچآآ. زیرا متردآآمعکوس است منnتیاچاچآآ، مقدار ß آن منفی است و بنابراین مقدار e β آن کمتر از یک است. ß -value، e β -value و w -value for متردآآکمتر از مقادیر بودند منnتیاچاچآآدارد. این نتایج آماری نشان می دهد که متردآآتراکم عابر پیاده را به اندازه موفقیت منعکس نمی کند منnتیاچاچآآمیکند.
جدول 8 نتایج مدل اندازه گیری انتخابی به دست آمده از AA را نشان می دهد. مقدار p بالاتر از 0.05 برای جساعتآآاعلام می کند که انتخاب تأثیر قابل توجهی بر تراکم عابر پیاده ندارد. بنابراین نویسندگان نمی توانند ß -value، e β -value و w -value را برای انتخاب ارزیابی کنند. نتایج برای متغیر دوره مشابه مدل های ایجاد شده با منnتیاچاچآآو متردآآ.
جدول 9 نتایج مدل اندازه گیری کنترل به دست آمده از VGA را نشان می دهد. مقدار p بالاتر از 0.05 برای جnتیVجیآبه اطلاع می رساند که کنترل اثر قابل توجهی بر تراکم عابر پیاده ندارد. بنابراین نویسندگان نتوانستند ß -value، e β -value و w -value را برای کنترل ارزیابی کنند. نتایج برای متغیر دوره مشابه مدل های ایجاد شده با منnتیاچاچآآ، متردآآو جساعتآآ.
چهار جدول تهیهشده برای تخمین پارامترهای تحلیلهای رگرسیون لجستیک ترتیبی تأیید میکند که ادغام مؤثرترین معیار برای پیشبینی تراکم عابر پیاده در این منطقه مورد مطالعه بود. از آنجا که ص-مقادیر گروههای T1 و T3 که جزو دورههای مورد استفاده در همه مدلها بودند، بالاتر از 05/0 بود، شمارشهای انجامشده در این دورهها تفاوت معنیداری با T4 مرجع در تعیین تراکم عابر پیاده نداشت. تأثیر گروه T2 که در هر مدل از نظر آماری معنیدار بود، در مقایسه با گروه مرجع T4 منفی بود. اثر قابل توجه برای T2 نشان می دهد که حجم عابر پیاده در T2 به طور قابل توجهی کمتر از T4 مرجع بود. اگر هدف آن تعیین تراکم پایین عابر پیاده در منطقه مورد مطالعه بود، شمارش در دوره مربوط به گروه T2 مناسب بود.
4.3. ارزیابی مجموعه داده های فعلی و طرح جامع
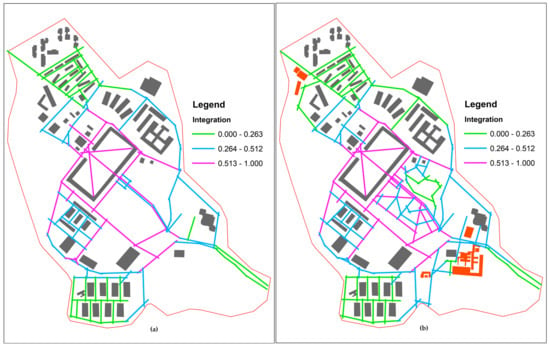
شکل 4 a,b نقشه های محوری پردیس داوودپاشا را نشان می دهد که به ترتیب بر اساس مقادیر یکپارچه سازی نرمال شده AA ایجاد شده است. کلاسها (کم: سبز، متوسط: آبی و زیاد: صورتی) که مقادیر یکپارچهسازی با رنگها را نشان میدهند با استفاده از الگوریتم طبقهبندی JNB طراحی شدند. محدودیت کلاس استاندارد در هر دو نقشه برای تسهیل مقایسه بصری استفاده شد.
خطوط محوری جدیدی که قرار بود به محورهای طبقهبندی شده در نقشه محوری فعلی متصل شوند، عموماً در کلاس بالا دستهبندی شدند. این خطوط محوری اغلب در قسمت مرکزی پردیس در طرح جامع ظاهر میشوند. با این حال، محورهای جدید دیگری که قرار بود در اطراف مرزهای پردیس اضافه شود، در طبقات متوسط و پایین بود. آنها با کمک به گسترش مرکزیت به لبه ها، دسترسی کلی را افزایش دادند.
جدول 10 نتایج آزمون t نمونه جفتی را برای مجموعه داده های فعلی و طرح اصلی نشان می دهد. 96 خط محوری در مجموعه داده فعلی وجود دارد و میانگین مقدار ادغام آنها 0.388 است. بر اساس طرح جامع، زمانی که 41 راهرو جدید به محوطه دانشگاه اضافه شد، میانگین مقدار ادغام به 0.356 کاهش یافت. آزمون t نمونه جفتی برای 96 راهروی مشترک در هر دو مجموعه داده انجام شد. میانگین مقدار ادغام این 96 مسیر در طرح جامع 0.370 محاسبه شد. این تفاوت بین مقادیر میانگین نشان داد که مسیرهای جدیدی که باید اضافه شوند، مقدار میانگین مسیرهای فعلی را کاهش میدهند. علاوه بر این، مقادیر میانگین مسیرهای جدید کمتر از مسیرهای فعلی بود. راصمقدار 002/0 نشان داد که تغییرات میانگین های ذکر شده در بالا از نظر آماری معنی دار است. ارزش ثابت کرد که طرح جامع مورفولوژی پردیس را برای عابران پیاده تغییر خواهد داد.
5. نتیجه گیری ها
این مطالعه رابطه بین تراکم عابر پیاده و معیارهای بهدستآمده از AA و VGA را بررسی کرد. این دو روش تجزیه و تحلیل اشتقاق 15 معیار مختلف را امکان پذیر کرد. رابطه هر معیار با تراکم عابر پیاده با استفاده از رگرسیون لجستیک ترتیبی تحلیل شد. ادغام و میانگین عمق AA نتایج آماری قابل توجهی را برای توضیح تراکم عابر پیاده به همراه داشت. با این حال، مقادیر ضرایب تحلیل رگرسیون نشان داد که ادغام موثرتر از عمق متوسط است. به همین دلیل، ادغام به عنوان مؤثرترین ابزار برای توضیح حرکت عابر پیاده در منطقه مورد مطالعه پذیرفته شد.
با توجه به نتایج تحلیل رگرسیون در مورد پردیس داوودپاشا، مقدار یکپارچه سازی AA یک خط محوری منعکس کننده شدت استفاده از مسیر پیاده روی است که از نظر فیزیکی با این خط منطبق است. این خط محوری با ارزش ادغام بالا امکان شناسایی مسیر پیاده روی با تراکم عابر پیاده بالا را فراهم می کند. علاوه بر این، نتایج تجزیه و تحلیل ثابت می کند که AA، به عنوان یک تکنیک SS، تراکم عابر پیاده را بهتر از VGA توضیح می دهد. این ارزیابی بر اهمیت ادغام AA به دست آمده از یک نقشه محوری دو بعدی تأکید می کند. با این حال، برخی از ویژگیهای محیطی مانند توپوگرافی منطقه و ویژگیهای کاربری اراضی از دیگر عوامل مؤثر بر پیادهروی و تراکم عابر پیاده در مسیرها هستند. از آنجایی که پردیس داوودپاشا نسبت به یک منطقه شهری بزرگ ارتباط خیابانی بسیار کمتری دارد. ویژگی های محیطی مسیرهای پیاده روی را می توان به راحتی مشاهده کرد. با توجه به ویژگی های محیطی، مسیرهای پیاده روی که بر اساس معیار ادغام تراکم عابر پیاده بالایی دارند، برای پیاده روی در محوطه دانشگاه نیز مناسب هستند. با این حال، اثرات آنها از نظر آماری در این مطالعه بررسی نشده است. در آینده، نویسندگان قصد دارند این روابط بین مسیرهای پیادهروی با ارزشهای یکپارچهسازی بالا و عوامل محیطی را در یک منطقه مطالعه وسیعتر که دارای اتصالات خیابانی زیادی است، بررسی کنند.
افزایش دسترسی و تحرک عابر پیاده به حداکثر با افزودن حداقل تعداد پیاده روهای جدید بهینه ترین راه حل برای برنامه ریزان است. تجزیه و تحلیل آماری اثرات مسیرهای جدید بر مسیرهای موجود، بسته به طرح های جایگزین، به تصمیم گیری در مورد مناسب ترین راه حل کمک می کند. در بخش دوم این مطالعه، تغییرات مقادیر یکپارچه سازی خطوط محوری در مجموعه داده های فعلی و طرح اصلی با استفاده از آزمون t نمونه جفتی مورد تجزیه و تحلیل قرار گرفت. این مقایسه تنها تعیین می کند که آیا طرح جامع به طور قابل توجهی بر پیاده روهای موجود تأثیر می گذارد یا خیر. در مورد بیش از یک طرح جایگزین، اهمیت تغییرات ایجاد شده توسط هر طرح در مسیرهای پیادهروی موجود برای مقایسه طرحها باید بررسی شود.






بدون دیدگاه