

ارزیابی کیفیت هوای شهری با ترکیب دادههای مکانی و زمانی از منابع مطالعاتی متعدد با استفاده از روشهای برآورد تصفیه شده



1
مرکز توسعه و تحقیقات سازمان زمین شناسی چین، پکن 100037، چین
2
دانشکده علوم و منابع زمین، دانشگاه علوم زمین چین، پکن 100083، چین
3
Cloud and Smart Industries Group, Tencent Technology (Shenzhen) Co., Ltd., Shenzhen 518057, China
4
دانشکده علوم زمین و مهندسی نقشه برداری، دانشگاه معدن و فناوری چین، پکن 100083، چین
5
کالج علوم انسانی و اجتماعی، دانشگاه ملی Kangwon، Samcheok 25913، کره
*
نویسنده ای که مسئول است باید ذکر شود.
دریافت: 4 آوریل 2022/تجدید نظر: 24 مه 2022/پذیرش: 27 مه 2022/تاریخ انتشار: 31 مه 2022
چکیده
:
در مدیریت زیست محیطی شهری و تلاشهای ارزیابی سلامت عمومی، نیاز فوری به پایش دقیق کیفیت هوای شهری وجود دارد. با این حال، قیمت بالا و توزیع پراکنده تجهیزات پایش کیفیت هوا، توسعه نظارت موثر و جامع در مقیاس ریز در مقیاس شهر را دشوار می کند. این همچنین منجر به روشهای تخمین کیفیت هوا بر اساس دادههای نظارتی ناقص شده است که فاقد توانایی تشخیص تفاوتهای کیفیت هوای شهری در یک محله است. برای پرداختن به این مشکل، این مطالعه یک روش برآورد کیفیت هوای شهری تصفیه شده را پیشنهاد میکند که دادههای مکانی-زمانی چند منبعی را ترکیب میکند. بر اساس این واقعیت که کیفیت هوای شهری به راحتی تحت تأثیر فعالیتهای اجتماعی قرار میگیرد، این روش دادههای هواشناسی را با دادههای فعالیت اجتماعی شهری یکپارچه میکند تا مجموعه دادههای محیطی جامعی را تشکیل دهد. از مدل استخراج ویژگی مکانی-زمانی برای استخراج ویژگی های مکانی-زمانی چند منبعی مجموعه داده های محیطی جامع استفاده می کند. در نهایت، الگوریتم جنگل آبشاری بهبودیافته برای برازش رابطه بین ویژگیهای مکانی-زمانی چندمنبعی و شاخص کیفیت هوا (AQI) برای ساخت یک مدل تخمین کیفیت هوا استفاده میشود و این مدل برای تخمین شاخص ساعتی PM2.5 در پکن در یک شبکه 1 کیلومتر × 1 کیلومتر. نتایج نشان میدهد که مدل تخمین عملکرد عالی و برازش خوبی دارد (R الگوریتم جنگل آبشاری بهبودیافته برای برازش رابطه بین ویژگیهای مکانی-زمانی چندمنبعی و شاخص کیفیت هوا (AQI) برای ساخت یک مدل تخمین کیفیت هوا استفاده میشود، و این مدل برای تخمین شاخص ساعتی PM2.5 در پکن استفاده میشود. یک شبکه 1 کیلومتر × 1 کیلومتر. نتایج نشان میدهد که مدل تخمین عملکرد عالی و برازش خوبی دارد (R الگوریتم جنگل آبشاری بهبودیافته برای برازش رابطه بین ویژگیهای مکانی-زمانی چندمنبعی و شاخص کیفیت هوا (AQI) برای ساخت یک مدل تخمین کیفیت هوا استفاده میشود، و این مدل برای تخمین شاخص ساعتی PM2.5 در پکن استفاده میشود. یک شبکه 1 کیلومتر × 1 کیلومتر. نتایج نشان میدهد که مدل تخمین عملکرد عالی و برازش خوبی دارد (R2 ) و ریشه میانگین مربعات خطا (RMSE) به ترتیب به 0.961 و 17.47 می رسد. این روش به طور موثری به ارزیابی تفاوتهای کیفیت هوای شهری در یک محله دست مییابد و یک استراتژی جدید برای جلوگیری از پراکندگی اطلاعات و بهبود اثربخشی نمایش اطلاعات در فرآیند تلفیق دادهها ارائه میکند.
کلید واژه ها:
تخمین کیفیت هوا ; جنگل آبشاری ; ترکیب داده های چند منبعی ; استخراج ویژگی یکپارچه
1. مقدمه
با شتاب شهرنشینی، بسیاری از مشکلات شهری ناشی از آن باید حل شود که در میان آنها شرایط کیفیت هوای شهری از مهمترین آنها است [ 1 ، 2 ، 3 ]. در حال حاضر، اکثر شهرها دارای ایستگاه های پایش کیفیت هوا با دقت بالا و به روز شده در زمان واقعی هستند تا بر محتوای گازهای مضر مانند NO 2 ، SO 2 و CO و ذرات ریز قابل تنفس (مانند PM2.5، PM10 و غیره) نظارت کنند. ) در ترکیب هوای بلادرنگ [ 4 ، 5 ، 6 ، 7 ، 8]. با این حال، به دلیل تأثیر منابع آلودگی محلی، حمل و نقل جوی و اثرات رقیقسازی، و تفاوتها در فعالیتهای فضایی اجتماعی، کیفیت هوای شهری در مناطق شهری محلی بسیار متفاوت است [ 9 ، 10 ]. به طور کلی، تعداد ایستگاههای زمینی برای پایش کیفیت هوا در شهرهای بزرگ کم است و این ایستگاهها از نظر فضایی نابرابر با فاصله زیاد بین ایستگاهها توزیع شدهاند که منجر به تفاوتهای محلی در اندازهگیریهای کیفیت هوا در مناطق بدون ایستگاه میشود که نمیتوان آنها را پایش کرد. توزیع محدود ایستگاه های پایش کیفیت هوا، انعکاس شرایط کیفیت هوای شهری را به صورت پویا، جامع و در زمان واقعی دشوار می کند [ 11 ، 12 ]]، به این معنی که ساکنان شهری نمی توانند به طور موثر داده های پایش آلودگی هوا را در مناطقی که مجهز به ایستگاه های پایش آلودگی هوا نیستند به دست آورند. بنابراین، در مرحله فعلی، نیاز فوری به یک روش تخمین پالایش کیفیت هوا وجود دارد که بتواند تفاوتهای فضایی در مقیاس کوچک را در زمان واقعی تشخیص دهد، که میتواند پشتیبانی تصمیمگیری برای ادارات دولتی و راهنمایی سفر برای ساکنان شهری را فراهم کند.
در حال حاضر، توسعه سیستم اطلاعات جغرافیایی (GIS) و فنآوریهای سنجش از دور، بسیاری از رویکردهای جدید را برای تخمین کیفیت هوای تصفیهشده ارائه میکنند [ 13 ]. در میان آنها، متداول ترین روش های فنی مورد استفاده، درون یابی زمین آماری، مانند درون یابی کریجینگ [ 14 ]، و رگرسیون با وزن جغرافیایی [ 15 ، 16 ] است.]. در مقایسه با روشهای رگرسیون آماری پارامتریک سنتی، روشهای درونیابی جغرافیایی بهتر میتوانند خودهمبستگی فضایی محیط طبیعی را در نظر بگیرند و بنابراین میتوانند کیفیت هوای لحظهای را در مکانهای فضایی همسایه بر اساس مشاهدات برخی ایستگاهها به دست آورند، اما دشوار است. ناپیوستگی ها در سطح زمانی و اثرات جفت بین عوامل متعدد را در نظر بگیرید (اثر جفت به تعامل و تأثیر کیفیت هوا، تراکم جمعیت، تراکم ترافیک و سایر عوامل اشاره دارد). به طور مشابه، پردازش تصویر سنجش از دور نیز یک روش بسیار پرکاربرد برای تخمین کیفیت هوا است، مانند تجزیه و تحلیل مخلوط طیفی [ 17 ]، وارونگی شاخص آئروسل [ 18 ، 19 ]]، و وارونگی شاخص گیاهی تفاوت نرمال شده (NDVI) [ 20]. این روشها میتوانند منظم بودن تغییرات بین کیفیت هوا و محیط طبیعی را منعکس کنند، اما انعکاس فعل و انفعالات پیچیده بین عوامل تأثیرگذار متعدد دشوار است (عامل شامل یک یا چند ویژگی است. برای مثال، آب و هوا شامل دما، رطوبت و غیره است. ). در پاسخ به این مشکلات، برخی از محققان نیز تحقیقات و کاوش های عمیق تری انجام داده اند. به عنوان مثال، برای کشف ارتباط بین پوشش گیاهی سطحی و کیفیت هوای محلی، Xiang و همکاران. رابطه خطی بین شاخص PM2.5 و عوامل مختلف را با استفاده از مدلهای رگرسیون از طریق تجزیه و تحلیل مخلوط طیفی و تحلیل شاخص سنجش از دور با استفاده از تصاویر سنجش از دور و دادههای هواشناسی مورد بررسی قرار داد [ 21 ]]. با در نظر گرفتن اثرات جفت بین عوامل زمانی و مکانی، هوانگ و همکاران. از یک مدل رگرسیون وزندار جغرافیایی (GTWR) برای کشف رابطه نگاشت بین PM10 و PM2.5 استفاده کرد که میتواند شاخص PM2.5 را از دادههای PM10 در غیاب اطلاعات معتبر استنتاج کند [ 22 ، 23 ]. در مطالعه بعدی توسط این تیم، دادههای ویژگیهای هواشناسی، ذرات معلق در هوا و تصاویر سنجش از دور نیز برای شبیهسازی توزیع PM2.5 در منطقه چین به مدل GTWR معرفی شدند [ 24 ]. علاوه بر این، زو و همکاران. همچنین ویژگیهای هواشناسی، دادههای آئروسل و دادههای طبقهبندی کاربری زمین را جمعآوری کرد و از مدل رگرسیون کاربری زمین (LUR) برای تشخیص اثرات عوامل متعدد بر کیفیت هوا استفاده کرد [ 25 ، 26 ]] و به دقت برازش عالی و نقشه برداری PM2.5 در وضوح بالا دست یافت. با این حال، این روشها هنوز در طبیعت روشهای رگرسیون خطی هستند و بررسی کامل ارتباط غیرخطی بین عوامل تأثیرگذار متعدد و کیفیت هوا و برآوردن نیاز تفکیک مکانی و زمانی بالا برای برآورد زمان واقعی در دانهبندی دقیق مکانی و زمانی دشوار است. . به عنوان مثال کیفیت هوا تحت تأثیر میزان پوشش گیاهی است اما با افزایش سطح پوشش گیاهی به طور یکنواخت تغییر نمی کند زیرا تحت تأثیر عوامل دیگری مانند تراکم جمعیت، هواشناسی و غیره نیز قرار می گیرد. علاوه بر این، فعالیتهای اجتماعی پیچیده شهری نیز ارتباط نزدیکی با کیفیت هوای شهری دارند. با توسعه سریع تکنیک های یادگیری ماشینی،27 ، 28 ، 29 ، 30 ، 31 ، 32 ]. ژنگ و همکاران از منابع متعدد دادههای مکانی-زمانی شهری برای مدلسازی دادههای زمانی و مکانی به طور جداگانه استفاده کرد و سپس آنها را برای ساخت یک مدل تخمین کیفیت هوای شهری در زمان واقعی به روشی آموزشی مشترک برای انجام تخمین کیفیت هوای شهری ایستگاههای پایش ریزدانه جفت کرد. مجموعه ای از مقالات [ 11 ، 33 ، 34 ، 35] یک چارچوب کامل برای تخمین کیفیت هوا در زمان واقعی ایجاد کرد که از توانایی یادگیری برتر مدلهای یادگیری ماشین و محاسبات شهری برای بهرهبرداری کامل از اطلاعات مکانی-زمانی غنی موجود در مجموعه داده شهری به خوبی استفاده کرد، اما کاستیها شامل جداسازی زمانی بود. و ویژگیهای فضایی (ویژگی به برخی از شیهای نظارتی مانند دما، سرعت و غیره اشاره دارد)، و رویکرد مدلسازی جداگانه مستعد انباشتگی خطاها بوده و با پدیدههای جغرافیایی مطابقت ندارد. همه این مشکلات بر روش تخمین کیفیت هوا برای تشخیص تفاوت کیفیت هوای شهری در یک منطقه کوچک تأثیر میگذارد و نمیتواند برآورد کیفیت هوای لحظهای واحدهای فضایی شهری را در مقیاس میکروسکوپی (1 کیلومتر × 1 کیلومتر) برآورده کند.
بنابراین، این مطالعه یک روش تخمین کیفیت هوای شهری ریزدانه را با ترکیب منابع متعدد دادههای مکانی-زمانی پیشنهاد میکند. این روش شامل چندین مرحله است. (1) با ادغام دادههای مکانی-زمانی ویژگیهای مختلف مربوط به کیفیت هوای شهری برای جلوگیری از تکهتکه شدن زمانی و ویژگیها، ارتباط بین مهرهای زمانی و مقادیر مشخصههای چند لایه مشخصه را ایجاد کنید. (2) از مدل استخراج ویژگی برای اسکن هر شبکه مکانی با ویژگیهای مکانی-زمانی متناظر برای ایجاد رابطه ارتباط بین مهرهای زمانی و اطلاعات مکانی برای جلوگیری از تکه تکه شدن زمانی و مکانی استفاده کنید. از روش شبکه عصبی آبشاری برای ساخت یک مدل تخمین کیفیت هوا و ایجاد یک رابطه نگاشت بین ویژگیهای شبکههای فضایی و مقادیر تخمینی (شاخص کیفیت هوا PM2.5) استفاده میشود و مدل تخمین با آموزش و کالیبرهسازی میشود. مجموعه داده نمونه (3) مقادیر تخمینی کیفیت هوا به دست آمده از مدل تخمین به صورت سه بعدی تجسم شده است. این روش با موفقیت یک مدل برآورد کیفیت هوای شهری را ایجاد کرد که ویژگیهای مکانی-زمانی را ادغام میکرد، و برآورد کیفیت هوای لحظهای واحدهای فضایی شهری را در مقیاس خوب (1 کیلومتر × 1 کیلومتر) تحقق بخشید. این یک راه حل برای تخمین کیفیت هوا در دانه بندی زمانی و مکانی خوب تحت محدودیت های توزیع پراکنده سایت و توانایی نظارت محدود ارائه می دهد. و مدل تخمین با مجموعه داده نمونه آموزش و کالیبره شده است. (3) مقادیر تخمینی کیفیت هوا به دست آمده از مدل تخمین به صورت سه بعدی تجسم شده است. این روش با موفقیت یک مدل برآورد کیفیت هوای شهری را ایجاد کرد که ویژگیهای مکانی-زمانی را ادغام میکرد، و برآورد کیفیت هوای لحظهای واحدهای فضایی شهری را در مقیاس خوب (1 کیلومتر × 1 کیلومتر) تحقق بخشید. این یک راه حل برای تخمین کیفیت هوا در دانه بندی زمانی و مکانی خوب تحت محدودیت های توزیع پراکنده سایت و توانایی نظارت محدود ارائه می دهد. و مدل تخمین با مجموعه داده نمونه آموزش و کالیبره شده است. (3) مقادیر تخمینی کیفیت هوا به دست آمده از مدل تخمین به صورت سه بعدی تجسم شده است. این روش با موفقیت یک مدل برآورد کیفیت هوای شهری را ایجاد کرد که ویژگیهای مکانی-زمانی را ادغام میکرد، و برآورد کیفیت هوای لحظهای واحدهای فضایی شهری را در مقیاس خوب (1 کیلومتر × 1 کیلومتر) تحقق بخشید. این یک راه حل برای تخمین کیفیت هوا در دانه بندی زمانی و مکانی خوب تحت محدودیت های توزیع پراکنده سایت و توانایی نظارت محدود ارائه می دهد. و برآورد کیفیت هوا در زمان واقعی واحدهای فضایی شهری در مقیاس خوب (1 کیلومتر × 1 کیلومتر) را تحقق بخشید. این یک راه حل برای تخمین کیفیت هوا در دانه بندی زمانی و مکانی خوب تحت محدودیت های توزیع پراکنده سایت و توانایی نظارت محدود ارائه می دهد. و برآورد کیفیت هوا در زمان واقعی واحدهای فضایی شهری در مقیاس خوب (1 کیلومتر × 1 کیلومتر) را تحقق بخشید. این یک راه حل برای تخمین کیفیت هوا در دانه بندی زمانی و مکانی خوب تحت محدودیت های توزیع پراکنده سایت و توانایی نظارت محدود ارائه می دهد.
2. مواد و روشها
2.1. داده ها
هواشناسی، تراکم ساختمان شهری، دسته بندی های عملکردی مناطق شهری، جریان ترافیک و انواع پوشش گیاهی سطحی می توانند بر کیفیت هوای شهری تأثیر بگذارند. برای برآورد دقیق کیفیت هوا، این مطالعه از دادههای زیر استفاده کرد: دادههای پایش کیفیت هوای پکن، دادههای پایش هواشناسی، مسیرهای کابین، شبکههای جادهای، نقاط مورد علاقه (POI)، انواع کاربری زمین، و دادههای NDVI.
-
دادههای پایش کیفیت هوا، که از 28 فوریه 2013 تا 28 فوریه 2014 با جزئیات زمانی یک ساعت را شامل میشود، توسط ایستگاههای پایش کیفیت هوا در پکن جمعآوری شد. داده ها شامل شناسه ایستگاه پایش، نام ایستگاه پایش، طول و عرض جغرافیایی، زمان جمع آوری، شاخص PM2.5، شاخص PM10، شاخص NO 2 و غیره است که PM2.5 هدف برآورد این مدل مطالعه است (همانطور که نشان داده شده است. در شکل 1 ). و شاخص PM2.5، شاخص PM10 و شاخص NO 2 با مقادیر میانگین ساعتی محاسبه می شود.
-
برای دادههای پایش هواشناسی، دادهها از 28 فوریه 2013 تا 28 فوریه 2014 با جزئیات زمانی یک ساعت را شامل میشود. داده ها شامل اطلاعات دما (درجه سانتیگراد)، فشار (hPa)، رطوبت (%)، سرعت باد (کیلومتر در ساعت)، جهت باد (درجه)، و توصیف شرایط آب و هوایی (باران، برف، هوای صاف و غیره) است. . دما، فشار، رطوبت و سرعت باد با مقادیر میانگین ساعتی محاسبه می شود. زیرا اداره حفاظت محیط زیست شهری در ساخت ایستگاه های پایش کیفیت هوا، مجهز به تجهیزات پایش مشخصات هواشناسی خواهد بود. بنابراین، سایت پایش هواشناسی با سایت پایش کیفیت هوا سازگار است.
-
دادههای مسیر خودرو، که دادههای مکان ثبت شده توسط GPS خودروی کابین هستند، از 1 می 2013 تا 31 ژوئیه 2013 با جزئیات زمانی 10 ثانیه باز میشوند. داده ها شامل شماره وسیله نقلیه، زمان UTC، مختصات جغرافیایی (طول و عرض جغرافیایی)، جهت (واحد: درجه)، سرعت (واحد: متر بر ثانیه)، وضعیت مسافر (0/1)، و سایر اطلاعات، شامل 3500 سفر تاکسی است. مسیرهایی که پکن را پوشش می دهند. اطلاعات برای تمام مناطق پکن در دسترس بود. هرچه سطح تراکم ترافیک بالاتر بود، انتشار گازهای گلخانه ای بیشتر بود [ 36 ، 37]. ما سطح تراکم ترافیک را برای تخمین تاثیر انتشار گازهای گلخانه ای بر کیفیت هوا محاسبه کردیم. محاسبه ضریب تراکم ترافیک بر اساس روش ارزیابی تراکم ترافیک است که توسط اداره شهرداری پکن در سال 2011 نظارت فنی و کیفیت در سال 2009 [ 38 ] اتخاذ شد.
-
شبکه راه های شهری، شامل لایه های برداری راه های ملی، جاده های استانی، جاده های شهری، رمپ های شهری، جاده های خطی و جاده های روستایی در پکن.
-
دادههای POI توزیع موجودیتهای جغرافیایی در فضای شهری را ثبت میکنند و میتوانند به طور دقیق عملکردهای فضایی شهری محلی و ویژگیهای فعالیت اجتماعی را منعکس کنند. دادهها از Baidu Map API مشتق شدهاند که در مجموع 380000 نقطه POI در پکن شامل مختصات جغرافیایی (طول و عرض جغرافیایی)، نامها، آدرسهای دقیق خیابانها و اطلاعات دیگر میشود. داده ها بر اساس چگالی ارائه شد تا یک نقشه توزیع چگالی POI از پکن ایجاد شود. دادههای POI شهری توزیع انواع مختلف موجودیتهای جغرافیایی در فضای شهری را ارائه میدهند که به شدت با فعالیتهای اجتماعی همبستگی دارد و میتواند توزیع فعالیتهای مردم و الگوی عملکردهای فضایی شهری را منعکس کند.
-
دادههای نوع کاربری زمین از تصویر شطرنجی جهانی کاربری زمین FROM-GLC-seg (در دسترس آنلاین: https://data.ess.tsinghua.edu.cn/ (دسترسی در 1 دسامبر 2019)) که توسط Earth System تهیه شده است ، مشتق شده است. مرکز تحقیقات علمی دانشگاه Tsinghua با وضوح 30 متر × 30 متر، شامل زمین های کشاورزی، جنگل، علفزار، درختچه، بدنه آبی، سطح ساخته شده توسط انسان، زمین برهنه، و انواع دیگر. داده های کاربری اراضی جنگل، درختچه و سایر انواع پوشش گیاهی را منعکس می کند. این اطلاعات تاثیر مهمی بر کیفیت هوا دارد.
-
دادههای تصویر سنجش از دور از تصاویر ماهوارهای سنجش از دور Google Maps استخراج شدهاند. داده ها از تصویر سنجش از دور پکن در سال 2013 و وضوح 30 × 30 متر است. داده های سنجش از دور می توانند پوشش گیاهی جنگل، درختچه و دیگر پوشش گیاهی را منعکس کنند. این اطلاعات تاثیر مهمی بر کیفیت هوا دارد.
علاوه بر این، منطقه مورد مطالعه در شمال چین واقع شده است، تغییرات آب و هوایی در منطقه ویژگی های زمانی متمایز را نشان می دهد، و محیط هواشناسی ماهیت چرخه ای را نشان می دهد. فعالیت های اجتماعی شهری دارای نظم زمانی بالایی هستند. برای تعیین تأثیر تناوب و منظم بر کیفیت هوا، فصل (1-4)، هفته (1-7) و دوره زمانی (0-23) را که هر نقطه در آزمایش به آن تعلق دارد، برچسب گذاری کردیم و آنها را به عنوان تأثیرگذار در نظر گرفتیم. عوامل موجود در مدل
2.2. پیش پردازش داده های مکانی-زمانی
دادههای چند منبعی درگیر در این مطالعه دارای ساختارهای سازماندهی فضایی مختلف (دادههای نقطهای، دادههای خطی و دادههای سطحی)، حالتهای مکانی-زمانی مختلف (دادههای استاتیک و دادههای دینامیکی)، انواع لایههای مختلف (دادههای شطرنجی و دادههای برداری) و غیره هستند. اگر این داده ها نیاز به ادغام و استخراج داشته باشند تا همان پدیده و ویژگی های مکانی-زمانی جامع را منعکس کنند، یک سری کار پیش پردازش باید تکمیل شود: (1) تنظیم واحد فضایی، تنظیم روش تقسیم واحدهای مکانی و مقیاس تقسیم. با توجه به تقاضا برای اصلاح محتوای تحقیق؛ (2) پردازش نرمالسازی دادههای مکانی-زمانی، یکپارچهسازی فضای مکانی دادههای برداری، دادههای شطرنجی، و دادههای پویا، و عملیات پیشپردازش مانند عادیسازی و استانداردسازی دادهها.
- (1)
-
تنظیم واحد فضایی
تقسیم واحدهای فضایی معمولاً به تقسیمات شبکه ای همگن یا تقسیمات ناحیه عملکردی همگن (مانند بسته ها و مناطق ترافیکی) تقسیم می شود. با توجه به اینکه تقسیم شبکه می تواند تغییرات دینامیکی در مرز را در نظر بگیرد، این مقاله از روش تقسیم شبکه همگن استفاده می کند. برای کیفیت هوای شهری، مقیاس شبکه روی 1 کیلومتر × 1 کیلومتر تنظیم شده است که می تواند تأثیر ناهمگونی فضایی را جبران کند و الزامات نظارت دقیق را برآورده کند. بنابراین، مقیاس انتخاب شده در این مقاله 1 کیلومتر × 1 کیلومتر است. منطقه مورد مطالعه را به یک شبکه همگن تقسیم می کنیم و پس از تقسیم، یک شبکه دو بعدی به ابعاد 45 × 48 به دست می آوریم که در مجموع 2160 سلول شبکه را شامل می شود که هر کدام نشان دهنده یک واحد تجزیه و تحلیل اولیه است، یعنی مکان هدفی که باید پیش بینی شود.
- (2)
-
نرمال سازی داده های مکانی-زمانی
عملیات عادی سازی داده های مکانی-زمانی عمدتاً شامل 6 مورد است: (1) درونیابی داده های نقطه ای، که در آن داده های هواشناسی از ایستگاه های نظارت هواشناسی به عنوان داده های نقطه گسسته جمع آوری می شوند. (2) ما از وزن دهی معکوس فاصله (IDW) استفاده می کنیم که نوعی روش درونیابی فضایی برای به دست آوردن داده ها برای کل منطقه مورد مطالعه است. (3) نمونهبرداری مجدد از دادههای شطرنجی، زیرا وضوحهای مکانی متفاوت دادههای شطرنجی (دادههای نوع کاربری زمین) میتواند برای یکسان کردن وضوح استفاده شود. (4) ادغام مکانی-زمانی دادههای دینامیکی (دادههای مسیر خودرو)، برای هر لحظه برای ایجاد مجموعه دادههای مکانی، نقشهبرداری اطلاعات مکان هر وسیله نقلیه در آن لحظه به مجموعه دادههای مکانی. (5) عادی سازی داده های پیوسته (داده های انتشار گازهای آلاینده،
- (3)
-
مدل اسکن ویژگی مکانی-زمانی
بسیاری از روشهای برآورد کیفیت هوای موجود استخراج ویژگیهای مکانی-زمانی با استخراج ویژگیهای زمانی و ویژگیهای مکانی به طور جداگانه است. با این حال، این روش ارتباط بین ویژگی های زمانی و مکانی را قطع می کند. برای پرداختن به این مشکل، این مقاله یک مدل استخراج ویژگی مبتنی بر یکپارچگی مکانی-زمانی را پیشنهاد میکند، که در آن ابتدا ویژگیهای زمانی و مکانی به طور جداگانه استخراج میشوند و سپس ترکیب ویژگیها برای ایجاد اتصالات مکانی-زمانی (همانطور که در شکل 2 نشان داده شده است ) انجام میشود. اطمینان حاصل کنید که هیچ اطلاعات مکانی-زمانی از بین نمی رود. اول، در طول زمان استخراج ویژگی، ویژگی های زمانی لحظه فعلی و اولین کگشتاورها توسط یک پنجره کشویی زمانی استخراج می شوند تا سری های زمانی بدست آید ( شکل 2 A):
تی�هآتیتو�ه=آ1……آک–1،آک
آکارزش یک موقعیت است ( متر،�) در زمان ک.
ثانیاً، بر اساس نظریه خودهمبستگی فضایی، ویژگیهای فضایی استخراج میشوند و در موقعیتی از زمان ( کویژگی های فضایی واحد و همسایگی آن با اسکن اطلاعات مکان و دامنه آن به دست می آید ( شکل 2 ب):
س�هآتیتو�ه=آمتر–1،�–1،آمتر–1،�،آمتر–1،�+1آمتر،�–1،آمتر،�،آمتر،�+1 آمتر+1،�–1،آمتر+1،�،آمتر+1،�+1
در نهایت، ترکیب ویژگی های زمانی و مکانی ( شکل 2 C).
افتوسمن��ک،متر،�=آمتر–1،�–1،آمتر–1،�،آمتر–1،�+1آمتر،�–1،آمتر،�،آمتر،�+1 آمتر+1،�–1،آمتر+1،�،آمتر+1،�+11……آمتر–1،�–1،آمتر–1،�،آمتر–1،�+1آمتر،�–1،آمتر،�،آمتر،�+1 آمتر+1،�–1،آمتر+1،�،آمتر+1،�+1ک
موارد فوق عمدتاً بر روی دادههای پویا تمرکز دارند، در حالی که برای دادههای استاتیک، به عنوان مثال، دادههای بدون ویژگیهای زمانی، تنها استخراج ویژگی مکانی در این مقاله انجام میشود.
علاوه بر این، اندازه پنجره کشویی زمانی بهعنوان لحظات t و ( t + 1) انتخاب میشود که دلیل آن قویترین همبستگی بین لحظههای مجاورت است. اندازه پنجره کشویی محله 3 کیلومتر × 3 کیلومتر است، زیرا شبکه 1 کیلومتر × 1 کیلومتر حداقل دانه بندی مورد نیاز توسط برآورد تصفیه شده فعلی است. لازم به ذکر است که اندازه پنجره در اینجا ثابت نیست و می توان بر اساس نیاز به صورت انعطاف پذیر انتخاب کرد.
ما از مدل اسکن ویژگی مکانی-زمانی برای اسکن ویژگیهای منطقه مورد مطالعه استفاده کردیم. مجموع 129 ویژگی مکانی-زمانی بدست آمده پس از اسکن در جدول 1 نشان داده شده است. پس از استخراج تمامی ویژگی های مکانی-زمانی، یک مجموعه داده نمونه بین ویژگی های مکانی- زمانی و شاخص های PM2.5 ساختیم و پس از پاکسازی داده ها، در مجموع بیش از 86000 نقطه داده معتبر به دست آوردیم و سپس مجموعه آموزشی و مجموعه تست را تقسیم کردیم. بر اساس نسبت 7:3.
2.3. یک روش برآورد کیفیت هوای شهری تصفیه شده با یکپارچه سازی داده های مکانی-زمانی چندمنبعی
روش تخمین پالایش کیفیت هوای شهری با ادغام دادههای مکانی-زمانی چند منبعی، روشی برای انجام رابطه کاوی عمیق بین ویژگیهای مکانی-زمانی شهری و شاخصهای PM2.5 برای تخمین کیفیت هوای شهری با استفاده از یک الگوریتم جنگلهای آبشاری چند دانهای است.
برای تحقق موثر داده کاوی مکانی-زمانی، ما یک فرآیند برآورد کیفیت هوای شهری تصفیه شده را با ترکیب داده های مکانی-زمانی چندمنبعی طراحی می کنیم. ابتدا، ما از مدل اسکن ویژگی مبتنی بر ادغام مکانی-زمانی برای اسکن لایههای ویژگی مختلف که نقشهبرداری مکانی-زمانی را کامل کردهاند، تکمیل ادغام و ارتباط ویژگیهای زمانی-مکانی، استخراج عوامل تأثیر کیفیت هوا، تکمیل غربالگری ضربه استفاده میکنیم. عوامل با توجه به رتبهبندی اهمیت ویژگی، عوامل تأثیر غربالشده را با شاخصهای کیفیت هوا که باید تخمین زده شوند مرتبط میکنند و یک مجموعه داده نمونه ایجاد میکنند، مجموعه آموزشی و مجموعه آزمایشی را بر اساس مجموعه دادههای نمونه انجام میدهند. در نهایت، از مدل جنگل آبشاری برای تکمیل آموزش مدل تخمین استفاده می شود (همانطور که در شکل 3 نشان داده شده است.).
- (1)
-
غربالگری ویژگی
در فرآیند آموزش مدل، افزونگی اطلاعات بر دقت آموزش مدل تأثیر می گذارد. بنابراین، غربالگری ویژگی یک بخش ضروری است. انتخاب تعداد معقولی از ویژگی ها به اهمیت هر یک از ویژگی ها در مدل بستگی دارد و اندازه گیری اهمیت به نوبه خود به بزرگی سهم ویژگی بستگی دارد. در جنگلهای تصادفی، هنگام حل مسائل رگرسیون، روش رتبهبندی اهمیت ویژگیها معمولاً از MSE (میانگین مربعات خطا) استفاده میکند [ 39 ، 40]. بنابراین، در این مقاله، استفاده از MSE را به عنوان یک شاخص قضاوت برای رتبهبندی ویژگیهای مکانی-زمانی بهدستآمده از مدل اسکن ویژگی انتخاب میکنیم و نتایج نشان میدهد که عامل زمانی و عامل هواشناسی بسیار مهمتر از عامل تراکم ترافیک هستند. دسته POI و نوع پوشش گیاهی سطحی. چنین نتایج رتبهبندی نیز اساساً با انتظارات ما مطابقت دارد که کیفیت هوا به شدت به تأثیر نظم زمانی و شرایط هواشناسی وابسته است. از سوی دیگر، سه ویژگی با رتبه پایینتر نیز به دلیل افزایش تعداد ویژگیها پس از پیمایش پنجره کشویی فضایی، مقدار اطلاعاتی را که در خود دارند ضعیف میکنند. بنابراین، در این مقاله، سه ویژگی با رتبه پایین تر، همانطور که در جدول 2 نشان داده شده است، پردازش می شوند. 9 ویژگی اصلی محله میانگین میشوند و تعداد ویژگیها از 9 اصلی به 1 کاهش مییابد. این نه تنها اطلاعات ویژگیهای این دسته را حفظ میکند، بلکه تعداد ویژگیها را کاهش میدهد تا از پراکندگی اطلاعات جلوگیری شود، و نتایج آموزشی بعدی همچنین ثابت می کند که چنین روش پردازشی بهتر از رد مستقیم یا پردازش نشده است.
مجموعه داده نمونه با فیلتر کردن ویژگی پردازش می شود و تعداد نمونه ها در مجموعه داده نمونه جدید بدون تغییر باقی می ماند، با این تفاوت که تعداد 129 ویژگی مکانی-زمانی به 25 کاهش می یابد تا افزونگی اطلاعات کاهش یابد. به طور مشابه، ویژگیهای مکانی-زمانی در مجموعههای آموزشی و آزمایشی نیز بر این اساس تغییر میکنند، و مجموعه داده آموزشی جدید که پس از فیلتر کردن ویژگیها تشکیل میشود، در مدل جنگل آبشاری بعدی برای آموزش و کالیبراسیون قرار میگیرد و سپس تخمین و تجسم مدل انجام میشود. تکمیل شد.
- (2)
-
الگوریتم جنگل آبشاری چند دانه ای
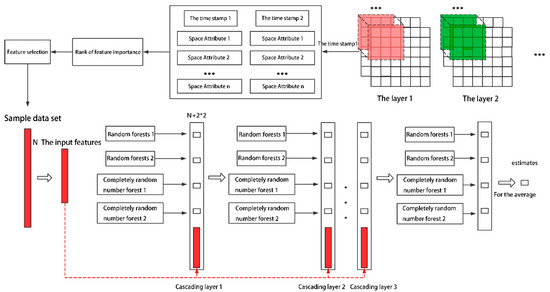
رویکرد جنگل آبشاری چند دانه ای [ 41 ] یک روش یادگیری ماشینی بر اساس یک جنگل تصادفی است [ 42 ]. مهمترین ویژگی این روش این است که می تواند بدون تکیه بر تجربه انسانی به پارامترهای مدل تطبیقی دست یابد، دشواری آموزش کم است و می تواند به طور موثر اطلاعات ترتیبی داده های توالی و اطلاعات همبستگی مکانی داده های مکانی را کشف کند.
مدل جنگل آبشاری چند دانه ای عمدتاً از دو بخش تشکیل شده است: ساختار اسکن چند دانه ای و ساختار جنگل آبشاری. ساختار اسکن چند دانه ای از پنجره های متعدد با عرض های مختلف برای نمونه برداری اسلاید برای به دست آوردن نمونه های فرعی به هم پیوسته و متمایز استفاده می کند. نمونههای فرعی با طبقهبندیکننده جنگل تصادفی معمولی و طبقهبندیکننده جنگل تصادفی کامل آموزش داده میشوند و بردارهای احتمال دسته خروجی برای به دست آوردن ویژگیهای تبدیل نهایی، همانطور که در شکل 4 نشان داده شده است، بخیه میشوند .
کل فرآیند تبدیل اسکن ویژگی با استفاده از یک پنجره کشویی با ابعاد k به عنوان مثال معرفی شده است. هنگامی که بردار ویژه ورودی اولیه d -dimension است، و گام لغزشی s است ، تعداد نمونه ها m = ( d – k )/ s + 1 است. مجموعه نمونه با فرمول (4)-(6) به دست می آید.
�آتیآ=آ1،آ2،……آد;
دبلیومن�د��=ب1،ب2،……بمتر=1، 0، 0……01،1،0……0……0،0،0……1 ;
اسآمترپله=�آتیآ��من�من�آل×دبلیومن�د��=آ1،آ2،……آدب1،آ1،آ2،……آدب2،……آ1،آ2،……آدبمتر;
جایی که تعداد 1 ثانیه اینچ است بk است و عدد 0 s قبل از 1 s است .
نمونه ها با دو طبقه بندی (جنگل تصادفی معمولی (ORF) و جنگل کاملا تصادفی (CRF)) آموزش داده می شوند. پس از آموزش، هر طبقهبندی کننده یک بردار احتمال c بعدی دریافت میکند ( c تعداد دستههایی است که از قبل تنظیم شدهاند)، که نشاندهنده احتمال قرار گرفتن نمونه در هر دسته است. در نهایت، دو طبقهبندی کننده در مجموع بردارهای احتمالی 2× m را خروجی میدهند. بردارهای ویژگی تبدیل شده با ابعاد 2× m × c با دوخت همه بردارهای احتمال دسته به دست آمده (فرمول (7)) به دست می آیند.
افهآتیتو�ه2×متر×�=�توتی�آرافمتر×�،�توتیسیآرافمتر×�;
مدل جنگل آبشاری چند دانه ای از ساختار سلسله مراتبی استفاده می کند، یعنی خروجی جنگل های قبلی به عنوان ورودی جنگل های بعدی عمل می کند، همانطور که در شکل 5 نشان داده شده است. خروجی آخرین لایه جنگل (بردارهای احتمالی 2 متر) برای به دست آوردن یک بردار احتمال میانگین می شود. در نهایت از کوچکترین مقدار بردار به عنوان مقدار پیش بینی شده استفاده می شود.
دو طبقهبندیکننده جنگلی مختلف در هر لایه، تنوع ادغام مدل را افزایش میدهند. طبقهبندیکنندههای جنگلی متعدد میتوانند از تفاوتهای ویژگیها استفاده کامل کنند، که به استخراج اطلاعات ویژگیها کمک میکند. برای جلوگیری از وقوع بیشبرازش، اعتبارسنجی متقاطع k -fold در فرآیند آموزش هر طبقهبندی جنگل در هر لایه از ساختار جنگل آبشاری استفاده میشود.
- (3)
-
کالیبراسیون و پیاده سازی مدل
- آ.
-
کالیبراسیون پارامتر مدل
پس از آموزش مدل برآورد کیفیت هوای شهری، کالیبراسیون بیشتر مدل برای بهبود بیشتر دقت برآورد مورد نیاز است. پارامترهایی که می توان در جنگل آبشاری تنظیم کرد شامل موارد زیر است: (1) حداکثر تعداد ویژگی های درگیر در طبقه بندی ویژگی ها. در حالی که درخت تصمیم سنتی بهترین ویژگی را در مجموعه ویژگی گره فعلی (با فرض وجود n ویژگی) برای طبقه بندی ویژگی انتخاب می کند، جنگل تصادفی با انتخاب تصادفی k زیر ویژگی از مجموعه n بهترین ویژگی را در مجموعه ویژگی تصادفی انتخاب می کند. ویژگی های؛ پارامتر kدرجه تصادفی بودن پارتیشن بندی صفت را کنترل می کند. (2) تعداد یادگیرندگان پایه و تعداد درختان تصمیم موجود در جنگل آبشاری. تعداد جنگل ها و تعداد درختان موجود در جنگل به طور مشترک پیچیدگی و اثر آموزشی مدل را تعیین می کند. و (3) تعداد لایههای آبشاری، که اثر آموزشی و پیچیدگی زمانی مدل را نیز تعیین میکند. ما پارامترهای مدل را از طریق آزمایش و آزمایش بهینه کردیم.
-
- ب
-
پیاده سازی الگوریتم
آزمایشهای ما بر اساس کد منبع جنگل آبشاری (در دسترس آنلاین: https://github.com/kingfengji/gcForest (در 1 فوریه 2021 قابل دسترسی است) است. برای فیلتر کردن ویژگیها، روشهای تصحیح مدل، و پیادهسازی مدل مرتبط، از کتابخانههای Numpy، Pandas، و Scikit-learn بر اساس کتابخانههای Python 3.5 (در دسترس آنلاین: https://www.python.org/ (دسترسی در 5 ) استفاده میکنیم. سپتامبر 2020)) که در ابتدا توسط Guido van Rossum در اواخر دهه هشتاد و اوایل دهه نود در موسسه تحقیقات ملی ریاضیات و علوم کامپیوتر در هلند توسعه یافت.
3. نتایج
3.1. نتایج بهینه سازی پارامتر
پس از چندین آزمایش و آزمایش مدل، پارامترهای مدل زیر در این مقاله تصحیح میشوند.
- (1)
-
حداکثر تعداد ویژگی هایی که در قضاوت در هنگام تقسیم صفات دخالت دارند ( m )
در تنظیمات مدل جنگل تصادفی معمولی، با فرض اینکه مجموعه کامل ویژگی ها شامل مجموع ویژگی های s باشد، تنظیم پیش فرض m به طور کلی s یا س. برای قضاوت بهتر در مورد رابطه بین این پارامتر و اثر آموزشی، رابطه بین مقدار m و دقت را چندین بار آزمایش کردیم. نتایج آزمایش در سمت چپ شکل 6 نشان داده شده است ، که در آن محور افقی حداکثر تعداد ویژگیهای m را نشان میدهد که در قضاوت هنگام تقسیم ویژگیها نقش دارند و محور عمودی نشاندهنده دقت برازش است. از نتایج آزمایش، میتوانیم ببینیم که دقت برازش زمانی به نقطه بحرانی میرسد که m به عنوان شش در نظر گرفته شود. بنابراین، ما این پارامتر را به عنوان شش تنظیم می کنیم.
- (2)
-
تعداد یادگیرندگان پایه و تعداد درخت تصمیم آنها ( k )
تعداد پیشفرض یادگیرندههای پایه برای مدل جنگلهای آبشاری چهار است که شامل دو جنگل تصادفی و دو جنگل درختی کاملاً تصادفی است. پس از تست، این ساختار پیش فرض برای تعداد زبان آموزان پایه حفظ می شود. تعداد درخت های موجود در هر یادگیرنده پایه هنوز با پارامترهای مختلف در این مقاله آزمایش می شود. همانطور که در شکل 6 نشان داده شده است ، محور افقی نشان دهنده تعداد درختان و محور عمودی نشان دهنده دقت اتصال است. نتایج نشان میدهد که دقت برازش مدل زمانی که k برابر با 100 در بالا گرفته میشود پایدار است و در حدود 300 به بالاترین مقدار میرسد. اما با توجه به اینکه مقدار kمی تواند تأثیر جدی بر پیچیدگی زمانی آموزش مدل داشته باشد، همچنان 100 به عنوان مقدار نهایی این پارامتر در این مقاله انتخاب شده است.
- (3)
-
تعداد لایه های آبشاری ( n )
به طور کلی، تنظیم تعداد لایههای آبشاری ( n ) به بازده تمرینی مدل بستگی دارد و زمانی که دقت تمرین چهار لایه متوالی دیگر بهبود نیابد، آبشار متوقف میشود و ساختار نتیجه تمرین بهینه فعلی به عنوان مدل آموزش دیده ذخیره می شود. به طور مشابه، چنین استراتژی در آزمایش های شرح داده شده در این مقاله اتخاذ شده است و مقدار n در نهایت به عنوان چهار لایه تعیین می شود.
3.2. ارزیابی عملکرد مدل
در این مقاله، نتایج آموزش مدل مورد ارزیابی و مقایسه قرار گرفت، روش ارزیابی اتخاذ شده اعتبار سنجی متقاطع 10 برابری بود و معیار ارزیابی به عنوان برازش مناسب (R2 ) انتخاب شد. نتایج ارزیابی نشان می دهد که نتایج متریک ارزیابی R2 نزدیک به یک است، به طوری که نتایج آموزش نشان می دهد که مدل اطلاعات موجود در ویژگی های ورودی را یاد می گیرد. برای تأیید توانایی تعمیم مدل، از مجموعه داده آزمایشی برای اعتبارسنجی مدل آموزشدیده استفاده میکنیم. معیارهای ارزیابی به عنوان خوبی برازش (R 2 ) و ریشه میانگین مربعات خطا (RMSE) انتخاب شده اند و نتایج آزمون به ترتیب 0.961 و 17.47 است.
این آزمایش همچنین با سایر الگوریتمهای یادگیری ماشین بر اساس دادههای مشابه مقایسه شد و الگوریتمهای مقایسه انتخابشده شبکه عصبی پرکاربردتر (ANN) و جنگل تصادفی (RF) بودند. ساختار شبکه عصبی به صورت سه لایه انتخاب شده است که شامل یک لایه پنهان است. ساختار نورون هر لایه 25 × 40 × 1 است، تابع فعال سازی لایه پنهان به عنوان تابع ReLU، تابع فعال سازی لایه خروجی تابع خطی، الگوریتم آموزشی Rmsprop و تابع از دست دادن است. تابع اختلاف مجذور میانگین پارامترهای جنگل تصادفی به گونه ای انتخاب شده اند که با یادگیرنده پایه مورد استفاده در بخش تجربی این مقاله سازگار باشد. این دو الگوریتم از نظر نتایج آموزشی با مدل مورد استفاده در این مقاله (CF) مقایسه شدهاند. نتایج آزمایش و میانگین مجذور انحراف. نتایج مقایسه در نشان داده شده استجدول 3 ، و مشاهده می شود که مدل توصیف شده در این مقاله با توجه به انواع شاخص های ارزیابی عملکرد بهتری را نشان می دهد که طراحی علمی منطقی چارچوب الگوریتم گزارش شده در این مقاله را تایید می کند.
این آزمایش علاوه بر مقایسه الگوریتم های مشابه، دقت مدل تخمین PM2.5 (FFA) پیشنهاد شده توسط دکتر ژنگ یو از تحقیقات مایکروسافت [ 34 ] را نیز مقایسه می کند. مدل FFA ویژگیهای زمانی و مکانی را به روشهای مختلف مدلسازی میکند و این دو را به شیوهای آموزشی مشترک برای ساخت یک مدل تخمین PM2.5 جفت میکند. در این مقاله، دقت مدل مورد استفاده با مدل FFA در همان مجموعه داده مقایسه شده و شاخصهای دقت p (معادله (8)) و خطا e (معادله (9)) مورد استفاده در مدل FFA انتخاب شدهاند. برای مقایسه. نتایج مقایسه در جدول 4 نشان داده شده است. نتایج تجربی این مقاله در معیارهای مختلف از مدل FFA بهتر عمل میکند، که برتری روش اسکن ویژگی و روش آموزش مدل مورد استفاده در این مقاله را نیز تأیید میکند.
پ=1–∑من�من^–�من∑من�من
ه=∑من�من^–�من�
که در آن p نشان دهنده دقت تخمین است، e نشان دهنده خطای تخمین است، n نشان دهنده تعداد مجموعه داده هایی است که باید تخمین زده شوند، �منمقدار واقعی برچسب از i مین داده است و �منمقدار تخمینی داده های i است.
علاوه بر این، به دلیل عدم وجود داده های واقعی PM2.5 برای مناطقی غیر از یک ایستگاه نظارتی هنگام انجام تخمین های جهانی برای منطقه مورد مطالعه، اعتبار سنجی تخمین های مدل دشوار است. به همین دلیل، بهطور تصادفی دادهها را برای چند هفته (هفت روز × 24 ساعت) انتخاب کردیم، بهطور تصادفی دو ایستگاه پایش کیفیت هوا را در هر دوره تخمینی حذف کردیم و 20 ایستگاه پایش کیفیت هوای باقیمانده را درونیابی کردیم تا دادههای هواشناسی سایر موارد غیر پایش را به دست آوریم. ایستگاه ها در شبکه فضایی سپس از مدل آموزشدیده برای تخمین مقادیر PM2.5 برای کل منطقه مورد مطالعه در دوره زمانی فعلی استفاده شد و نتایج شبکهای که ایستگاههای حذف شده در آن قرار داشتند برای هر دوره زمانی استخراج و با مقادیر واقعی برای اندازهگیری مقایسه شد. عملکرد تعمیم مدل
همانطور که در شکل 7 نشان داده شده استداده های سه هفته به صورت تصادفی در این مقاله استخراج شد و در مجموع 590 بازه زمانی معتبر بدون احتساب چند لحظه از دست رفته به دست آمد. با حذف تصادفی دو ایستگاه، شناسه ایستگاه ها 1012 (قرمز) و 1014 (آبی) انتخاب شد. برای هر دوره زمانی، دادههای 20 ایستگاه غیر از ایستگاههای حذف شده برای به دست آوردن دادههای هواشناسی سایر مکانها درونیابی شدند و سپس از مدل آموزشدیده برای برآورد آنها استفاده شد. پس از مقایسه مقادیر برآورد شده با مقادیر واقعی شبکه حذف شده در هر زمان، نتایج برازش در زمان استخراج به ترتیب 826/0 و 936/0 بود. در میان آنها، نتایج نصب شده برای ایستگاه 1012 کمی پایین تر بود. پس از تجزیه و تحلیل بیشتر، مشخص شد که ایستگاه 1014 (آبی) در مرکز منطقه درون یابی قرار دارد.شکل 7 . این به دلیل میزان پوشش دادههای هواشناسی و تأثیر مرزی روش درونیابی بود که در آن دقت نتایج تخمین از مرکز به مرز نوسان داشت، که اشکالی است که اجتناب از آن در مطالعه کنونی دشوار است [ 43 ]. ]. با این حال، این نیز پایداری مدل برآورد در این مقاله را ثابت می کند. حتی با وجود اثر مرزی ناشی از درون یابی، مدل همچنان می تواند به دقت برازش بالایی دست یابد.
3.3. برآورد زمان واقعی اثرات
تخمین PM2.5 و تجسم نتایج برای تمام دوره های زمانی (1:00 صبح تا اواخر شب در ساعت 12:00 بعد از ظهر) در روز 1 مه 2013 (نشان داده شده در شکل 8) انجام شد.). از نتایج تخمین، میتوان دید که مدل تخمین کیفیت هوای شهری در زمان واقعی مبتنی بر جنگلهای آبشاری با دانهبندی زمانی و مکانی ریز پیشنهاد شده در این بخش از آزمایش، تأثیر تخمین خوبی داشت و نتایج تجسم انتقال آرامی داشتند. و می تواند به وضوح تفاوت های هوا را در ریزمنطقه ها نشان دهد. از نتایج برآورد روز می توان دریافت که کیفیت هوا در ساعات بعد از ظهر تا عصر بهتر از ساعات اولیه صبح تا صبح بوده و وضعیت آلودگی هوا مطابق با یافته های تحقیقات قبلی بوده و آلودگی شدید را نشان می دهد. الگو [ 17]. مناطق آلودگی شدید در نیمه اول روز عمدتاً در چونگ ونمن، ژوان وومن، هایدیان، داکسینگ، ییژوانگ، شیجینگشان و سایر مناطق مشاهده شد، در حالی که کیفیت هوا در نیمه دوم روز، منطقه اوج آلودگی را در Fengtai تشکیل داد. ناحیه.
از نظر الگوی توزیع آلودگی هوا، کیفیت کلی هوای پکن در جنوب بالا و در شمال پایین و در شرق بالا و در غرب پایین در 1 ژانویه 2013 بود. کیفیت هوای کل روز در رتبهبندی مشابه در منطقه آلودگی جدی قرار داشت و این مناطق شامل منطقه Fengtai و منطقه Fangshan بودند. بخش مرکزی شهر به طور کلی دارای سطح متوسطی از آلودگی بود، اما با توجه به جمعیت زیادی که در شهر زندگی میکردند، سطح آلودگی متوسط بود، اما AQI همچنان بین 100 تا 200 در هشدار نارنجی “ناسالم برای” بالا بود. افراد حساس» و «ناسالم». این امر در درازمدت آسیب زیادی به سلامت ساکنان وارد می کند. بخش شمالی کشور به دلیل پوشش گیاهی متراکم و مجاورت با موجودات طبیعی مانند پارک های جنگلی و آب انبارها، در مجموع از نظر کیفیت هوا در وضعیت بهتری قرار دارد. بنابراین، به طور کلی، روز کارگر در سال 2013 یک تعطیلات محبوب بود و تعداد زیادی از ساکنان مسافر و گردشگران خارجی در آن حضور داشتند. با این حال، وضعیت کلی کیفیت هوا در پکن هنوز خوش بینانه نیست و در سطحی است که سلامت انسان را تهدید می کند.
دولت و بخشهای مرتبط در سال 2013 بهینهسازی صنعتی، انرژی پاک، محدودیتهای سفر و سایر پروژههای صرفهجویی در مصرف انرژی و کاهش انتشار را ترویج کردند که هدف آن بهبود تدریجی محیط کیفیت کلی هوا در پکن است. مدل تخمین کیفیت هوا ارائه شده در این مقاله بر اساس عملکرد عالی و اثر تخمینی آن به مدیریت محیطی هوا کمک می کند.
4. بحث
در این مطالعه، با ادغام دادههای فضایی-زمانی چندمنبعی شهری، ما شکافها را در اطلاعات کیفیت هوای شهری در مقیاس ریز مکانی-زمانی پر میکنیم و برآورد کیفیت هوا در مقیاس ریز را در مقیاس خرد محقق میکنیم. این روش از یک مدل اسکن ویژگی یکپارچه مکانی-زمانی استفاده می کند تا به طور موثر ویژگی های مکانی-زمانی داده های بزرگ شهری را استخراج کند و سپس با استفاده از الگوریتم جنگل آبشاری از طریق تست های ارزیابی مدل، مدل تخمین از نظر توانایی تعمیم و دقت عملکرد خوبی دارد و عملکرد مدل در مقایسه با سایر روش های یادگیری ماشین بهتر است.
مطالعات قبلی [ 44 ، 45 ] بر روی تخمین کیفیت هوا بر اساس همجوشی دادهها نشان دادهاند که تخمین مکانی-زمانی با وضوح بالا را میتوان از طریق همجوشی دادهها به دست آورد و میانگین تناسب آن (R2 ) تقریباً 0.9 بود. در این مطالعه، خوب بودن برازش (R2 ) و ریشه میانگین مربعات خطا (RMSE) مدل برآورد کیفیت هوا 0.961 با ترکیب دادههای چند منبع شهری است که میتواند فعالیتهای اجتماعی را منعکس کند.
این مطالعه با ادغام دادههای چندمنبعی شهری حاوی اطلاعات فعالیت اجتماعی و استخراج اطلاعات فعالیت اجتماعی مرتبط با کیفیت هوا، اطلاعات کیفیت هوا را در مناطق خالی از سایت تکمیل میکند تا کمبود ظرفیت نظارت بر کیفیت هوای شهری را جبران کند. با ساخت یک مدل برآورد کیفیت هوای شهری تصفیه شده با ویژگیهای زمانی، مکانی و ویژگیهای یکپارچه، دانهبندی تفاوتهای فضایی درک شده در کیفیت هوای شهری بهبود مییابد. علاوه بر این، این مطالعه بیشتر اثربخشی روشهای همجوشی دادهها را برای تخمین کیفیت هوا تأیید میکند و ایدههایی برای انتخاب دادههای موثر در فرآیند همجوشی دادهها ارائه میدهد.
کاستی هایی نیز در این مطالعه وجود دارد. داده های هواشناسی مناطق بدون ایستگاه های پایش با روش های درون یابی به دست می آیند که بر دقت برازش مدل برآورد تأثیر می گذارد. با این حال، در مرحله فعلی، راه حل های خوبی برای این مشکل وجود ندارد. اگر دستگاههای پایش هواشناسی به طور گسترده در دسترس باشند و شبکههای حسگر میتوانند منطقه وسیعی را پوشش دهند، این راهحل بهتری برای بهبود دقت اتصالات به ما ارائه میدهد [ 46 ، 47 ، 48 ، 49 ].
در تحقیقات آینده خود، ما تخمین کیفیت هوای تصفیه شده را بیشتر مطالعه خواهیم کرد، از جمله تمرکز بر تخمین کیفیت هوا در سطح خیابان، تشخیص تغییرات کیفیت هوا در فضای شهری محلی، و انجام تحقیقاتی در مورد ارتباط بین کیفیت هوای شهری، فعالیتهای اجتماعی مردم. و عملکردهای داخلی شهری برای ارائه بهتر اطلاعات مرجع و راهنمایی قابل اعتماد برای تصمیم گیری و مدیریت زیست محیطی شهری.
5. نتیجه گیری ها
با توسعه فناوری یادگیری ماشین و تجزیه و تحلیل داده های بزرگ، روند استفاده از فناوری همجوشی داده ها برای دستیابی به تخمین کیفیت هوای شهری تصفیه شده وجود دارد. روش همجوشی دادههای کنونی همچنان از تقسیمبندی سه بعد زمان، مکان و ویژگیها رنج میبرد که میتواند منجر به انباشته شدن خطاها در فرآیند مدلسازی شود و نتایج برآورد با پدیدهها و الگوهای جغرافیایی مطابقت ندارد. در عین حال، ادغام داده ها عمدتاً بر ادغام داده های مشخصه یکسان در وضوح های مختلف متمرکز است و این رویکرد تأثیر فعالیت های اجتماعی بر کیفیت هوا را در نظر نمی گیرد، که منجر به ناتوانی در تشخیص تفاوت های کیفیت هوا در یک منطقه کوچک می شود. .
بر اساس مشکلات فوق، این مطالعه یک روش تخمین کیفیت هوای شهری در مقیاس ریز را پیشنهاد میکند که دادههای مکانی-زمانی چند منبعی را ادغام میکند. این روش استخراج ویژگی های جامع سه بعدی از زمان، مکان و ویژگی ها را محقق می کند. یک مدل تخمین کیفیت هوای شهری در مقیاس خوب با استفاده از الگوریتم جنگل آبشاری برای دستیابی به تخمین کیفیت هوای شهری با وضوح مکانی و زمانی بالا ساخته شده است. در عین حال، این روش دادههای فعالیت اجتماعی را برای بهبود اثر تخمین کیفیت هوا معرفی میکند که ایده جدیدی برای بهبود توانایی اطلاعات کاوی ارائه میکند.
در آینده همچنین رابطه بین گردش هوا، سرعت باد و فعالیت های اجتماعی مردم و عملکردهای شهری را در نظر خواهیم گرفت. از آنجایی که این روابط اطلاعاتی را در مورد انتشار و جریان گازهای مضر منعکس میکنند، این اطلاعات میتواند به ردیابی منابع و مسیرهای جریان انتشار گازهای مضر کمک کند، که بیشتر به اصلاح تخمین و پیشبینی کیفیت فضایی کمک میکند.
مشارکت های نویسنده
مفهوم سازی، لیرونگ چن. روش، لیرونگ چن و جونی وانگ. نرم افزار، Hui Wang و Junyi Wang. اعتبارسنجی، لیرونگ چن، جونی وانگ و هوی وانگ؛ نوشتن – آماده سازی پیش نویس اصلی، لیرونگ چن. نوشتن-بررسی و ویرایش، هوی وانگ و تیانچنگ جین. تجسم، لیرونگ چن، هوی وانگ و تیانچنگ جین. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق توسط پروژه زمین شناسی سازمان زمین شناسی چین (شماره DD20190392) پشتیبانی شد.
بیانیه در دسترس بودن داده ها
قابل اجرا نیست.
قدردانی
ما صمیمانه از بازبینان ناشناس برای نظرات و پیشنهادات سازنده تشکر می کنیم.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- گرین باوم، دی اس؛ باخمن، دی. کروسکی، دی. Samet, JM; وایت، آر. Wyzga، استانداردهای آلودگی هوا ذرات RE و عوارض و مرگ و میر: مطالعه موردی. صبح. اپیدمیول اورنا. 2001 ، 154 (Suppl. S12)، S78–S90. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- جیمنز-گوئررو، پ. پرز، سی. جربا، او. Baldasano، JM سهم گرد و غبار صحرا در یک سیستم یکپارچه کیفیت هوا و ارزیابی آنلاین آن. ژئوفیز. Res. Lett. 2008 ، 35 ، 183-199. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میلمن، ا. تانگ، دی. Perera، FP آلودگی هوا سلامت کودکان را در چین تهدید می کند. Pediatrics 2008 , 122 , 620-628. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آرنولد، آر. دنیس، RL تست حساسیت های شیمیایی CMAQ در مورد پایه و کنترل انتشار در سایت های سطحی SEARCH و SOS99 در جنوب شرقی ایالات متحده اجرا می شود. اتمس. محیط زیست 2006 ، 40 ، 5027-5040. [ Google Scholar ] [ CrossRef ]
- مارتین، RV ماهواره سنجش از راه دور کیفیت هوای سطحی. اتمس. محیط زیست 2008 ، 42 ، 7823-7843. [ Google Scholar ] [ CrossRef ]
- وو، ال. Bocquet, M. توزیع مجدد بهینه ایستگاه های نظارت بر ازن پس زمینه در فرانسه. اتمس. محیط زیست 2011 ، 45 ، 772-783. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آستین، ای. کول، کارشناسی; زانوبتی، ا. کوتراکیس، P. چارچوبی برای خوشه بندی فضایی سایت های پایش آلودگی هوا در ایالات متحده بر اساس ترکیب PM2.5. محیط زیست بین المللی 2013 ، 59 ، 244-254. [ Google Scholar ] [ CrossRef ]
- Goodsite, ME; هرتل، او. جانسون، ام اس؛ Jørgensen، NR کیفیت هوای شهری: منابع و غلظت. آلودگی هوا منابع آمار Health Eff. 2021 ، 193-214. [ Google Scholar ] [ CrossRef ]
- جورکرا، اچ. مونتویا، LD; روخاس، نیویورک آلودگی هوای شهری در اقلیم شهری در آمریکای لاتین ; Springer: Cham، سوئیس، 2019; صص 137-165. [ Google Scholar ]
- سئو، جی. پارک، D.-SR; کیم، جی. Youn, D. اثرات هواشناسی و انتشار بر کیفیت هوای شهری: یک رویکرد آماری کمی به سوابق بلند مدت (1999-2016) در سئول، کره جنوبی. اتمس. شیمی. فیزیک 2018 ، 18 ، 16121-16137. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هسیه، اچ پی; Lin، SD; ژنگ، ی. استنباط کیفیت هوا برای توصیه مکان ایستگاه بر اساس داده های بزرگ شهری. در مجموعه مقالات بیست و یکمین کنفرانس SIGKDD در مورد کشف دانش و داده کاوی، سیدنی، استرالیا، 10 تا 13 اوت 2015. صص 437-446. [ Google Scholar ]
- لی، تی. شن، اچ. زنگ، سی. یوان، Q. ژانگ، L. همجوشی سطح نقطه ای اندازه گیری های ایستگاه و مشاهدات ماهواره ای برای نقشه برداری توزیع PM2.5 در چین: روش ها و ارزیابی. اتمس. محیط زیست 2017 ، 152 ، 477-489. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گورم، س. استوارت، آل. پینجاری، مدلسازی مبتنی بر عامل AR برای تخمین قرار گرفتن در معرض آلودگی هوای شهری ناشی از حملونقل: تفاوتهای مواجهه و اثرات دادههای با وضوح بالا. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 75 ، 22-34. [ Google Scholar ] [ CrossRef ]
- شاد، ر. مسگری، ام اس; آبکار، ع. شاد، الف. پیش بینی آلودگی هوا با استفاده از کریجینگ عضویت خطی ژنتیکی فازی در GIS. محاسبه کنید. محیط زیست سیستم شهری 2009 ، 33 ، 472-481. [ Google Scholar ] [ CrossRef ]
- زو، بی. Pu، Q. بلال، م. ونگ، کیو. ژای، ال. Nichol, JE نقشهبرداری ماهوارهای با وضوح بالا از ذرات ریز بر اساس رگرسیون وزندار جغرافیایی. در IEEE Geoscience & Remote Sensing Letters ; IEEE: Piscataway, NJ, USA, 2016; جلد 13، ص 495–499. [ Google Scholar ]
- تو، دبلیو. زنگ، ز. ژانگ، ال. لی، ی. پان، X. Wang، W. برآوردهای مقیاس ملی غلظت PM2.5 سطح زمین در چین با استفاده از رگرسیون وزندار جغرافیایی بر اساس وضوح 3 کیلومتری MODIS AOD. Remote Sens. 2016 ، 8 ، 184. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- فیضی زاده، ب. Blaschke، T. بررسی روابط جزیره گرمایی شهری با کاربری زمین و آلودگی هوا: تجزیه و تحلیل مخلوط طیفی چند عضو انتهایی برای سنجش از راه دور حرارتی. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2013 ، 6 ، 1749–1756. [ Google Scholar ] [ CrossRef ]
- هو، ایکس. والر، لس آنجلس; لیاپوستین، آ. وانگ، ی. الحمدان، م.ز. کراسون، WL; استس، ام جی، جونیور؛ استس، اس ام; Quattrochi، DA; پوتاسوامی، اس جی. و همکاران تخمین غلظت PM2.5 سطح زمین در جنوب شرقی ایالات متحده با استفاده از بازیابی MAIAC AOD و یک مدل دو مرحله ای. سنسور از راه دور محیط. 2014 ، 140 ، 220-232. [ Google Scholar ] [ CrossRef ]
- لی، اچ جی; لیو، ی. کول، کارشناسی; شوارتز، جی. کوتراکیس، پی. یک رویکرد کالیبراسیون جدید داده های MODIS AOD برای پیش بینی غلظت PM2.5. اتمس. شیمی. فیزیک 2011 ، 11 ، 9769-9795. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هان، دبلیو. لینگ، تی. Chen, Y. یک الگوریتم جدید برای بازیابی آئروسل با استفاده از داده های H-1 CCD و MODIS NDVI در مناطق شهری. در مجموعه مقالات سمپوزیوم علوم زمین و سنجش از دور، پکن، چین، 10 تا 15 ژوئیه 2016. [ Google Scholar ]
- شیانگ، جی. لی، آر. وانگ، جی. کی، جی. وانگ، کیو. خو، ال. ژانگ، ام. تانگ، ام. مدلسازی غلظت PM2.5 شهری با ترکیب مدلهای رگرسیون و تحلیل اختلاط طیفی در منطقهای از چین شرقی. آلودگی خاک هوای آب 2017 ، 228 ، 250. [ Google Scholar ] [ CrossRef ]
- هوانگ، بی. وو، بی. Barry, M. رگرسیون وزندار جغرافیایی و زمانی برای مدلسازی تغییرات مکانی-زمانی در قیمتهای خانه . Taylor & Francis, Inc.: Oxfordshire, UK, 2010; جلد 24، ص 383–401. [ Google Scholar ]
- چو، اچ جی; هوانگ، بی. Lin, CY مدلسازی ناهمگنی مکانی-زمانی در رابطه PM10-PM2.5. اتمس. محیط زیست 2015 ، 102 ، 176-182. [ Google Scholar ] [ CrossRef ]
- او، س. Bo, H. نقشه برداری ماهواره ای از PM2.5 زمینی با وضوح بالا روزانه در چین از طریق مدل سازی رگرسیون فضا-زمان. سنسور از راه دور محیط. 2018 ، 206 ، 72-83. [ Google Scholar ] [ CrossRef ]
- زو، بی. چن، جی. ژای، ال. نیش، ایکس. Zheng, Z. نقشه برداری ماهواره ای از غلظت PM2.5 زمینی با استفاده از مدل سازی افزایشی تعمیم یافته. Remote Sens. 2016 , 9 , 1. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زو، بی. ژنگ، ز. وان، ن. کیو، ی. Wilson, JG یک مدل مجاورت فضایی بهینه برای ارزیابی قرار گرفتن در معرض آلودگی هوا ذرات ریز در مناطق نظارت پراکنده. بین المللی Ournal Geogr. Inf. علمی 2015 ، 30 ، 727-747. [ Google Scholar ] [ CrossRef ]
- کواچ، آ. Leelőssy، Á. تتامانتی، تی. Esztergár-Kiss، D.; Mészáros، R.; Lagzi، I. ترافیک جفتی منشا برآورد آلودگی هوای شهری با یک مدل شیمی جوی است. اقلیم شهری. 2021 ، 37 ، 100868. [ Google Scholar ] [ CrossRef ]
- هریسون، آر.ام. ون وو، تی. جعفر، ح. Shi, Z. مسافت پیموده شده بیشتر در کاهش آلودگی هوای شهری ناشی از ترافیک جاده ای. محیط زیست بین المللی 2021 ، 149 ، 106329. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بورک، آر. Schrauth، P. تراکم جمعیت و کیفیت هوای شهری. Reg. علمی اقتصاد شهری 2021 ، 86 ، 103596. [ Google Scholar ] [ CrossRef ]
- ممکن است.؛ لی، جی. Guo, R. کاربرد ادغام داده ها بر اساس شبکه باور عمیق در پایش کیفیت هوا. Procedia Comput. علمی 2021 ، 183 ، 254-260. [ Google Scholar ] [ CrossRef ]
- یو، زی. متدولوژی ها برای ترکیب داده های متقابل دامنه: یک مرور کلی. IEEE Trans. کلان داده 2015 ، 1 ، 16-34. [ Google Scholar ]
- لیو، جی. لی، تی. زی، پی. دو، اس. تنگ، اف. یانگ، ایکس. تلفیق کلان داده شهری مبتنی بر یادگیری عمیق: یک مرور کلی. Inf. فیوژن 2020 ، 53 ، 123-133. [ Google Scholar ] [ CrossRef ]
- ژنگ، ی. یی، ایکس. لی، ام. لی، آر. شان، ز. تغییر دادن.؛ لی، تی. پیش بینی کیفیت هوای ریز دانه بر اساس داده های بزرگ: کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، سیدنی، استرالیا، 10 تا 13 اوت 2015. [ Google Scholar ]
- ژنگ، ی. چن، ایکس. جین، Q. چن، ی. Qu، X. لیو، ایکس. تغییر دادن.؛ ما، دبلیو. روی، ی. Sun, W. یک سیستم کشف دانش مبتنی بر ابر برای نظارت بر کیفیت هوای ریز دانه . MSR-TR-2014-40. فنی Rep.. 2014، جلد 1، ص. 40. در دسترس آنلاین: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/UAir20Demo.pdf (در 3 آوریل 2022 قابل دسترسی است).
- ژنگ، ی. لیو، اف. Hsieh، HP U-Air: هنگامی که استنتاج کیفیت هوای شهری با داده های بزرگ روبرو می شود: کنفرانس بین المللی ACM SIGKDD در زمینه کشف دانش و داده کاوی. در مجموعه مقالات نوزدهمین کنفرانس SIGKDD در مورد کشف دانش و داده کاوی (KDD 2013)، شیکاگو، IL، ایالات متحده آمریکا، 11-14 اوت 2013. [ Google Scholar ]
- ماسیول، م. هریسون، انتشارات اگزوز موتور هواپیمای RM و سایر مشارکتهای مرتبط با فرودگاه در آلودگی هوای محیط: بررسی. اتمس. محیط زیست 2014 ، 95 ، 409-455. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بور، ام. کرانی، جی. دیویس، بی. هولمز، بی. ویلیامز، ک. اثرات کاهش آلودگی هوا از انتشار اگزوز خودرو بر سلامت تنفسی. اشغال کنید. محیط زیست پزشکی 2004 ، 61 ، 212. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- سو، اف. دونگ، اچ. جیا، ال. Sun, X. سیستم و روش ارزیابی وضعیت ترافیک جاده شهری. مد. فیزیک Lett. B 2017 , 31 , 1650428. [ Google Scholar ] [ CrossRef ]
- گنور، آر. پوگی، جی.-م. Tuleau-Malot، C. VSURF: یک بسته R برای انتخاب متغیر با استفاده از جنگل های تصادفی. R J. 2015 ، 7 ، 19-33. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kuras، MB استحکام روشهای انتخاب ژن تصادفی مبتنی بر جنگل. BMC Bioinform. 2014 ، 15 ، 8. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Podgorelec، V. کوکول، پ. استیگلیک، بی. Rozman, I. Decision Trees: An Overview and Use their in Medicine. جی. مد. سیستم 2002 ، 26 ، 445-463. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژو، ژ. Feng, J. Deep Forest: Towards a Alternative to Deep Neural Networks. در مجموعه مقالات کنفرانس مشترک بین المللی هوش مصنوعی، ملبورن، استرالیا، 19 تا 25 اوت 2017؛ صص 3553-3559. [ Google Scholar ]
- فیشر، MM; وانگ، جی. تجزیه و تحلیل داده های فضایی. آنو. Rev. Public Health 2013 , 37 , 47. [ Google Scholar ]
- زنگ، س. چن، ال. زو، اچ. وانگ، ز. وانگ، ایکس. ژانگ، ال. گو، تی. زو، جی. Zhang، Y. برآورد مبتنی بر ماهواره غلظت PM2.5 ساعتی با استفاده از روش تصحیح رطوبت عمودی از Himawari-AOD در هبی. Sensors 2018 , 18 , 3456. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- گرسنت، ا. مالهرب، ال. کولت، ا. رولین، اچ. Scimia، R. ادغام داده ها برای نقشه برداری کیفیت هوا با استفاده از مشاهدات حسگر کم هزینه: امکان سنجی و ارزش افزوده. محیط زیست بین المللی 2020 , 143 , 105965. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هاسنفراتز، دی. ساوخ، او. استورزنگر، اس. Thiele, L. نظارت مشارکتی آلودگی هوا با استفاده از تلفن های هوشمند. اوباش Sens. 2012 ، 1 ، 1-5. [ Google Scholar ]
- ژانگ، ی. بوکت، م. مالت، وی. سیگنور، سی. باکلانوف، آ. پیشبینی کیفیت هوا در زمان واقعی، بخش دوم: وضعیت علم، نیازهای تحقیقاتی فعلی و چشماندازهای آینده. اتمس. محیط زیست 2012 ، 60 ، 656-676. [ Google Scholar ] [ CrossRef ]
- تونو، بی. شیلدز، KN; لیوی، پی. چو، ن. Kadane، JB; پارمانتو، بی. پرامانا، جی. زورا، ج. دیویدسون، سی. هولگوین، اف. و همکاران درک الگوهای درون همسایگی در PM2.5 و PM10 با استفاده از نظارت تلفن همراه در Braddock، PA. محیط زیست Health A Glob. Access Sci. منبع 2012 ، 11 ، 76. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- جیانگ، ی. لی، ک. تیان، ال. پیدراهیتا، ر. یون، ایکس. منسات، او. Lv، Q. دیک، RP; هانیگان، ام. Shang, L. MAQS: یک سیستم حسگر موبایل شخصی برای پایش کیفیت هوای داخل ساختمان. در مجموعه مقالات سیزدهمین کنفرانس بین المللی محاسبات همه جا حاضر (UBICOMP 2011)، پکن، چین، 17-21 سپتامبر 2011. صص 271-280. [ Google Scholar ]
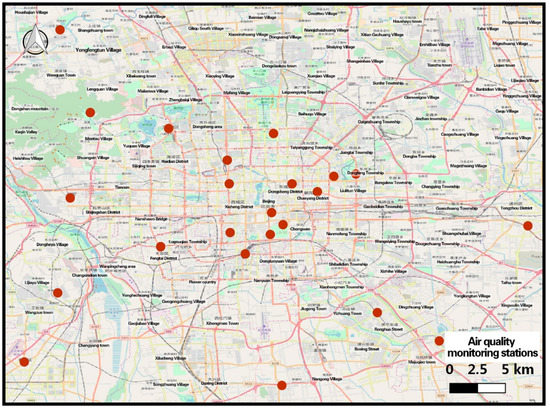
شکل 1. محدوده مطالعه بر روی برآورد کیفیت هوا در زمان واقعی (شامل تمام 22 ایستگاه پایش کیفیت هوا که قبل از سال 2013 در پکن ساخته شده بودند). نقاط قرمز نشان دهنده ایستگاه های نظارت بر کیفیت هوا است.
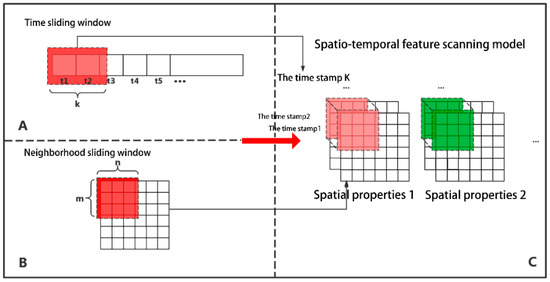
شکل 2. مدل استخراج ویژگی ادغام مکانی-زمانی. ( A ) نشان دهنده استخراج ویژگی زمانی، ( B ) نشان دهنده استخراج ویژگی های مکانی، و ( C ) نشان دهنده ادغام ویژگی های زمانی و مکانی است. مربع قرمز در ( A ) نشان دهنده پنجره کشویی زمان، مربع قرمز در ( B ) نشان دهنده پنجره کشویی فضا است. مربع های صورتی و سبز در ( C ) به ترتیب پنجره های مکانی-زمانی کشویی را برای دو ویژگی نشان می دهند.
شکل 3. فرآیند تخمین کیفیت هوای شهری ریزدانه با ادغام داده های مکانی-زمانی چند منبعی. در شکل، مربعهای قرمز و سبز نمایانگر پنجرههای استخراج ویژگیهای مکانی-زمانی با ویژگیهای مختلف هستند، نوارهای قرمز نشاندهنده مجموعههای ویژگیها هستند.

شکل 4. ساختار اسکن چند دانه ای. مربع های آبی تیره نشان دهنده ویژگی ها و مربع های آبی روشن نشان دهنده نمونه ها هستند. در نمودار ساختار اسکن، مدل جنگل تصادفی از درخت تصمیم به عنوان طبقهبندیکننده پایه الگوریتم کیسهبندی استفاده میکند که برای کاهش خطای تعمیم مدل با کاهش واریانس طبقهبندیکننده پایه استفاده میشود [ 42 ]. جنگل کاملا تصادفی جنگلی تصادفی است که مرحله هرس را حذف می کند. این مرحله، گرههای فرعی را که تأثیر کمی بر تابع هدف دارند، حفظ میکند، بنابراین از حذف اطلاعات جلوگیری میکند.

شکل 5. ساختار جنگلی آبشاری. فلش سیاه رو به پایین جهت جریان داده را نشان می دهد. فلش های اشاره شده به سمت راست خروجی های متعلق به مدل های جنگلی در یک سطح خاص را نشان می دهد. نوارهای آبی تیره نشان دهنده مجموعه داده ها هستند. مربع های آبی روشن خروجی ها را نشان می دهند.

شکل 6. نتایج بهینه سازی پارامتر جنگل آبشاری. نقطه قرمز نشان دهنده مقدار صحیح پارامترها (یعنی Max_features و Estimators) است.

شکل 7. ارزیابی عملکرد تعمیم. مربع های قرمز و آبی ایستگاه هایی هستند که تخمین زده می شوند.

شکل 8. اثر برآورد زمان واقعی (به عنوان مثال با لحظه جزئی از 1 مه 2013). شخصیت های سیاه نام اصلی مکان ها هستند.


8 نظرات