1. معرفی
تعداد فزاینده ای از مطالعات مربوط به جغرافیای گردشگری در سال های اخیر انجام شده است زیرا صنعت گردشگری سهم قابل توجهی در اقتصاد جهانی دارد: کل هزینه های گردشگری خارج از کشور در سال 2016 به 1.23 تریلیون دلار و تعداد گردشگران بین المللی در سال 2017 به 1.32 رسید. میلیارد دلار با رشد 4 درصد در سال در هشت سال [ 1 ]. در میان این مطالعات، استخراج تصاویری معرف از جاذبه های گردشگری، پژوهشی بی نقص و عملی است. می تواند توضیحات آموزنده ای در مورد جاذبه های گردشگری ارائه دهد [ 2 ]. علاوه بر این، میتوان آن را در ساخت سیستمهای اطلاعات گردشگری [ 3 ] و تولید نقشههای گردشگری [ 4 ] به کار برد.]، و همچنین ارائه محتوای تصویری برای برخی از توصیه های گردشگری مبتنی بر محتوا [ 5 ]. با رواج پلتفرمهای اشتراکگذاری محتوای مبتنی بر تصویر، محققان بیشتر و بیشتر تمایل دارند تا جاذبههای گردشگری را از این پلتفرمها استخراج کنند. از آنجا که عکس های گرفته شده توسط کاربران مختلف می توانند ترجیحات واقعی گردشگران را در مقایسه با نظرات ذهنی معدود کارشناسان به طور مستقیم تری منعکس کنند [ 6 ]. علاوه بر این، به عنوان یک نوع داده رسانه های اجتماعی، آنها می توانند به سرعت جاذبه های توریستی نوظهور را کشف کنند. در میان این پلتفرم ها، فلیکر یکی از محبوب ترین پلتفرم ها است. بیش از 100 میلیون کاربر ثبت شده دارد و بیش از 60 میلیون نفر در ماه از آن بازدید می کنند [ 7 ]]. علاوه بر این، در تحقیقات قبلی مربوط به استخراج مکانهای شهری نیز غالباً استفاده میشود، زیرا دادههای آن برای به دست آوردن راحت است و بیشتر محتوای آن تمایل دارد اطلاعات بیشتری را در مورد مکانهای اطراف در مقایسه با سایر پلت فرمها منعکس کند [ 8 ].
برخلاف مطالعاتی که هدفشان استنباط موقعیت جغرافیایی از تصاویر است [ 9 ، 10 ]، انتخاب تصویر نماینده توجه بیشتری به کاوش ترجیحات بصری کاربران و شباهت بصری به تصاویر داده شده در یک مکان خاص دارد. بنابراین، معمولاً با خوشهبندی شروع میشود: عکسها را بر اساس مختصاتشان خوشهبندی کنید، و سپس با رمزگذاری معکوس جغرافیایی [ 11 ، 12 ] یا انتخاب برچسبهای متمایز با TF-IDF [ 6 ، 13 ] و تغییرات آن، حاشیهنویسی معنایی به دست آورید [ 14 ]]. با این حال، اکثر روشهای خوشهای فقط میتوانند یک نتیجه درشت دانه ایجاد کنند، به عنوان مثال، مناطق مورد علاقه. چنین نتایجی ممکن است دشواری انتخاب تصویر نماینده را افزایش دهد. یکی دیگر از روشهای متمایز استخراج جاذبههای توریستی این است که نامهای استاندارد جاذبههای گردشگری را از وبسایت راهنمای سفر یا روزنامههای خارجی بهعنوان کلمات کلیدی بهدست آوریم و با آنها پرس و جو کنیم تا عکسهایی را بگیریم که دارای این برچسبها هستند [ 15 ، 16 ]. با این وجود، چنین روشی دارای معایبی نیز می باشد. اولاً، نمیتوان تضمین کرد که تمام عکسهای مربوط به جاذبههای گردشگری خاص به نامهای رسمی پیوست شدهاند، زیرا اختصارات، املای متناوب و حتی املای غلط نیز وجود دارد [ 17 ]]. بنابراین، ممکن است هنگام استفاده از یک نام واحد و استاندارد برای بازیابی عکسها، یادآور کم شود. دوم، ممکن است عکسهایی به نام برخی از جاذبههای توریستی پیوست شده باشد، اما به دلیل برچسبگذاری اشتباه یا دلایل دیگر، در مکانهای واقعی قرار نگرفته باشند، که میتواند به عنوان نقاط نویز در نظر گرفته شود [ 18 ]. بنابراین، برای نتایج دقیق انتخاب تصویر نماینده، یک روش خوشهبندی که نتایج ریزدانه ایجاد میکند، مورد نیاز است.
پس از به دست آوردن نتایج خوشه ای، به دلیل ماهیت عکس های گردشگری، چالش همچنان وجود دارد. اولاً، طبق تعریف در [ 19 ]، جاذبه توریستی به مکانی اطلاق میشود که اوقات فراغت و سرگرمی را ارائه میدهد و گردشگران را برای بازدید جذب میکند، که به این معنی است که عکسهای جاذبههای توریستی ممکن است شامل افراد زیادی باشد. علاوه بر این، بسیاری از گردشگران تمایل دارند هنگام سفر در مقابل جاذبه های گردشگری سلفی بگیرند [ 2]. بدیهی است که چنین تصاویری برای نمایش تصاویر یک جاذبه گردشگری مناسب نیستند و بنابراین، فرآیندهای فیلترینگ خاصی مورد نیاز است. با این حال، اجتناب ناپذیر است که برخی از مکان ها، مانند بازار و میدان، جمعیت زیادی داشته باشند. شلوغی ممکن است یکی از اجزای اساسی تصاویر چنین مکان هایی باشد. بنابراین فیلتر غیرمتمایز ممکن است تصویر معرف برخی از انواع جاذبه های گردشگری را پیدا نکند. دوم، وجود عکسهای نامربوط یا نویز در محتوای تولید شده توسط کاربر، یافتن تصاویر رضایتبخش را دشوارتر میکند. برخی از گردشگران ممکن است از اشیاء محلی در داخل جاذبه های گردشگری عکس بگیرند، به عنوان مثال، نمایشگاه های موجود در یک موزه. برخی حتی از چیزهای نامرتبط عکس می گیرند، به عنوان مثال، یک گربه یا یک سیب در موزه.
با توجه به چالشهایی که در بالا توضیح داده شد، در این مقاله، ما چارچوبی را پیشنهاد میکنیم که یک روش خوشهای بهبود یافته و مدلهای شبکه عصبی متعدد را برای استخراج تصاویر معرف جاذبههای توریستی از فلیکر ترکیب میکند. ما ابتدا خوشه قابل اتصال چگالی را اصلاح کردیم [ 20] با افزودن محدودیت زمان و آستانه کاربر، که هدف آن شناسایی برچسبهای مربوط به مکان و فیلتر کردن همزمان برخی از برچسبهای مربوط به رویدادهای موقتی است که در یک مکان ثابت رخ داده یا اغلب توسط یک کاربر استفاده میشود. سپس با توجه به وجود املای متناوب نام مکانها، ما این خوشههای مبتنی بر برچسب را با توجه به روابط فضایی بین خوشهها و شباهت معنایی بین برچسبها ادغام و گسترش میدهیم. شباهت معنایی از شباهت کسینوس تعبیههای برچسبها Word2Vec به دست میآید، زیرا Word2Vec میتواند کلمات را در فاصله معنایی نزدیکتر کند و برای محاسبه شباهت دانهبندیهای متن مختلف کاربرد بیشتری داشته باشد [ 21 ].]. بر اساس نتایج خوشه، ما تصاویر پر سر و صدا با اشیاء را با پرسپترون چندلایه (MLP) و تصاویر با انسان را با یک مدل آشکارساز چند جعبه ای تک شات (SSD) فیلتر می کنیم [ 22 ]. سپس شباهت تصاویر فیلتر شده توسط مدل رتبه بندی عمیق رتبه بندی می شود [ 23]، فهرست مکان رتبه بندی شده با تصاویر نماینده را برمی گرداند. ما پکن را به عنوان منطقه مطالعه انتخاب می کنیم. نتایج روشهای خوشهای پیشنهادی و روشهای موجود از نظر تعداد خوشهبندی، دقت خوشهبندی و تمایز معنایی مقایسه شده و نتایج انتخاب تصاویر معرف بهصورت کیفی تحلیل میشوند. علاوه بر این، یک پرسشنامه نیز برای ارزیابی اینکه آیا نتایج کلی رضایت گردشگران را در زندگی واقعی برآورده میکند یا خیر، انجام میشود. مجموعه ای از نتایج به دست آمده اثربخشی چارچوب را نشان می دهد.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 کار مربوط به روش های خوشه بندی برای عکس های دارای برچسب جغرافیایی و انتخاب تصاویر نماینده برای مکان های استخراج شده را بررسی می کند. بخش 3 چارچوب اولیه و کلی استخراج جاذبه های گردشگری و تصاویر معرف آنها را معرفی می کند. بخش 4 منطقه مورد مطالعه را تشریح می کند و نتایج پیاده سازی و ارزیابی را مورد بحث قرار می دهد. بخش 5 این مقاله را خلاصه می کند و به مسیرهای کار آینده اشاره می کند.
2. کارهای مرتبط
2.1. دسته بندی عکس دارای برچسب جغرافیایی
خوشه بندی مقدمه و مبنای انتخاب تصویر نماینده از عکس های دارای برچسب جغرافیایی است. در میان این روشهای خوشهبندی، روشهای خوشهای مبتنی بر چگالی به طور گسترده در خوشهبندی عکسهای دارای برچسب جغرافیایی استفاده میشوند، زیرا نیازی به تعریف از پیش تعداد خوشهها ندارند و میتوانند نقاط نویز را فیلتر کنند [ 11 ، 24 ]. این روشهای خوشهای مبتنی بر چگالی شامل DBSCAN (خوشهبندی فضایی برنامههای کاربردی با نویز مبتنی بر تراکم) [ 6 ، 8 ، 24 ] و DBSCAN اصلاحشدههای مختلف، مانند P-DBSCAN [ 25 ]، روشی که یک شعاع از پیش تنظیم شده را در نظر میگیرد. حداقل تعداد صاحبان عکس [ 11 ، 26]. پس از خوشهبندی، برخی مستقیماً این خوشهها را معکوس میکنند و با استفاده از ابزارهایی مانند Geonames [ 12 ] و Google Places API [ 11 ]، نام مکانهای مربوطه را شناسایی میکنند. با این حال، تنوع نتایج ژئوکدینگ معکوس قضاوت در مورد دقت را دشوار می کند و گاهی اوقات خطاهای موقعیت یابی آن را بدتر می کند [ 27 ، 28 ]. مقالات دیگر استفاده از محتوای متنی پیوست شده به عکس های دارای برچسب جغرافیایی را برای به دست آوردن نام مکان های دقیق تر، عمدتاً با محاسبه TF-IDF یا انواع آن از هر خوشه و یافتن برچسب های نماینده به عنوان نام مکان یا اطلاعات در نظر می گیرند [ 14 ، 29 ]]. با این وجود، اکثر روشهای خوشهای فقط میتوانند یک نتیجه خوشهای درشت ایجاد کنند، بهعنوان مثال، مناطق مورد علاقه، که احتمالاً حاوی بیش از یک جاذبه گردشگری هستند، بهویژه در منطقهای با عکسهای بارگذاری شده با تراکم بالا. چنین نتایجی برای کاربرد بیشتر، مانند توصیههای جاذبه توریستی مفید نیستند.
بخش کوچکی از محققان انتخاب میکنند که عکسهای دارای برچسب جغرافیایی با نامهای استاندارد جاذبههای گردشگری را بازیابی کنند [ 15 ، 30 ]. این ممکن است باعث یادآوری کم و حاوی نویز شود. چند مطالعه تلاش کردند تا برچسبهای مکان را در عکسهای دارای برچسب جغرافیایی بدون مراجعه به هیچ روزنامهای با خوشهبندی عکسها با همان برچسب و تجزیه و تحلیل توزیع فضایی شناسایی کنند [ 18 ]]. همانطور که در بالا ذکر شد، تعداد زیادی اختصار و املای متناوب اسامی مکان های استاندارد در مجموعه برچسب ها وجود دارد که حل آنها بی اهمیت است. با این حال، هنگام ادغام برچسبهای مکان، محققان در مطالعات قبلی عمدتاً شباهت توزیع فضایی بین برچسبها را در نظر میگیرند و تعداد کمی شباهت معنایی برچسبهای مکان را در نظر میگیرند. علاوه بر این، برخی از برچسبهای مربوط به رویدادهایی که در مکانهای ثابت رخ میدهند یا اغلب توسط تعداد کمی از کاربران استفاده میشوند، قابل فیلتر نیستند. بنابراین، در خوشهبندی مکانهایی که عکسهای دارای برچسب جغرافیایی دارند، به بهبود بیشتری نیاز است.
2.2. انتخاب تصویر نماینده
انتخاب تصویر نماینده یک مطالعه پرطرفدار، اما همچنین چالش برانگیز است، به دلیل وجود تصاویر نویزدار در عکس های دارای برچسب جغرافیایی. چند مطالعه از روش های یادگیری نظارت شده برای استخراج تصاویر معرف مکان های خاص استفاده کردند. به عنوان مثال، کراندال و همکاران. [ 31 ] از یک مدل SVM برای تشخیص عکسهای جاذبههای گردشگری از عکسهای منفی بهدستآمده از مکانهای دیگر استفاده کنید. به طور مشابه، سامانی [ 32 ] از یک شبکه اعتقادی عمیق برای طبقهبندی نقاط دیدنی در تهران، ایران استفاده میکند. کیم و همکاران [ 33 ] به دنبال راه دیگری برای طبقه بندی و تجزیه و تحلیل تصویر نماینده اجزای اصلی در هر منطقه مورد علاقه در سئول با مدل Inception v3 است که از قبل با ImageNet آموزش داده شده است. با این حال، برچسب زدن تصاویر برای یادگیری تحت نظارت هزینه کار دستی گسترده ای دارد [34 ]. علاوه بر این، آموزش طبقه بندی کننده برای هر جاذبه گردشگری در جهان به سختی امکان پذیر است [ 30 ]. بنابراین، یک رویکرد رایج تر، مقایسه ویژگی های تصویر و یافتن تصاویر مشابه پس از خوشه بندی یا استخراج مکان ها از برچسب ها و برچسب های جغرافیایی است. در میان آن ویژگی های تصویر، SIFT اغلب استفاده می شود [ 18 ، 31 ]. خصوصیات دیگر نیز استفاده می شود، از جمله GIST [ 29 ، 35 ]، هیستوگرام رنگی [ 36 ]، و غیره. برای نمایش بهتر، برخی مطالعات ممکن است بیش از یک ویژگی تصویر را ترکیب کنند [ 36 ، 37 ]. با این حال، عملکرد ممکن است با نمایش این ویژگی های دست ساز تا حد زیادی محدود شود [ 23]. با توسعه شبکه های عصبی کانولوشنال، محققان به تدریج سعی می کنند از مدل های مبتنی بر کانولوشن برای تکمیل این کار استفاده کنند. برای مثال، دینگ و فن [ 38 ] SURF (الگوریتمی شبیه به SIFT) و LIFT (یک مدل یادگیری عمیق) را برای یافتن تصاویر معرف و تطبیق تصاویر بدون برچسب با آنها ترکیب میکنند.
برای انتخاب تصاویر معرف بهتر، برخی از پیش پردازش فیلتر نیز در مطالعات قبلی انجام شده است. بیشتر آنها با استفاده از یک کتابخانه پیچیده (مانند OpenCV) [ 8 ] و یا آموزش یک مدل یادگیری عمیق برای طبقه بندی تصاویر [ 5 ]، تصاویر را با انسان فیلتر می کنند. با این حال، همه مطالعات قبلی فرآیند فیلتر غیرمتمایز را انجام دادند، که ممکن است تصویر معرف برخی از جاذبههای گردشگری را پیدا نکند. علاوه بر این، به غیر از تصاویر با انسان، تعداد کمی از انواع دیگر تصاویر نویز، مانند تصاویر مصنوعی (به عنوان مثال، یک آرم) و تصاویر با اشیا (به عنوان مثال، یک سیب) را در نظر می گیرند [ 39 ]]. به طور خلاصه، تلاش بیشتری برای استفاده از پتانسیل مدلهای مبتنی بر کانولوشن برای اعمال در انتخاب تصویر معرف برای جذب توریست مورد نیاز است.
3. چارچوب کلی
3.1. مقدماتی
مجموعه عکس ها در یک منطقه مطالعه خاص را به صورت تعریف می کنیم پ={پ1،پ2،…،پ|پ|}، جایی که ∀پمن∈پمتشکل از چندین صفت است که به صورت نمایش داده می شود پمن=(مندپمن،تیپمن، لپمن،توپمن،ایکسپمن). این ویژگی ها شامل شناسه عکس منحصر به فرد است مندپمن، زمان صرف شده است تیپمن، مکان گرفته شده است لپمن(با عرض جغرافیایی نشان داده شده است لآتیپمنو طول جغرافیایی لonپمن)، کاربری که در این عکس مشارکت دارد توپمن، و لیستی از برچسب ها ایکسپمن=[ایکس1،ایکس2،…،ایکس|ایکسپمن|]. توجه داشته باشید که تعداد تگ ها در ایکسپمنمی تواند صفر یا هر عدد صحیح مثبت و یک تگ باشد ایکسرا می توان به یک یا چند عکس پیوست کرد. ما مجموعه ای از برچسب ها را به عنوان نشان می دهیم ایکس={ایکس1،ایکس2،…،ایکس|ایکس|}، و زیرمجموعه عکس هایی که به یک برچسب خاص پیوست شده اند ایکسمانند پایکس=∪پمن∈پ،ایکس∈ایکسپایکس.
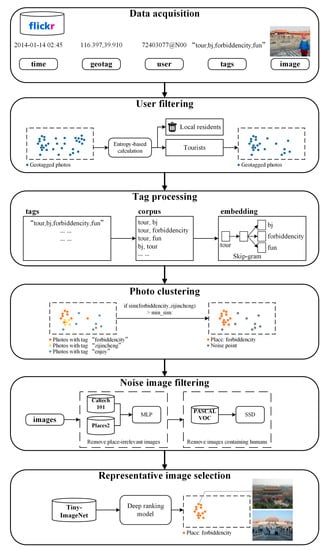
هدف ما شناسایی مجموعه ای از برچسب های مربوط به مکان، و ادغام و گسترش بیشتر این خوشه ها است. بر اساس نتایج خوشه، تصاویر معرف هر جاذبه گردشگری را بیابید. شکل 1 چارچوب کلی را نشان می دهد و هر مرحله به طور مفصل در بخش های زیر نشان داده شده است.
3.2. اکتساب داده ها
برداشت داده ها اولین مرحله از چارچوب است. همانطور که در بالا ذکر شد، مجموعه داده عکس دارای برچسب جغرافیایی فلیکر به دلیل چندین مزیت آن، یک انتخاب بهینه برای این مطالعه است. جدا از APIهای فلیکر، مجموعه دادهها را میتوان به راحتی از یاهو فلیکر کریتیو کامانز 100 میلیون داده (YFCC100M) که در آمازون AWS میزبانی میشود، دریافت کرد. به عنوان بخشی از برنامه Yahoo Webscope [ 40]، تقریباً 100 میلیون عکس فلیکر عمومی را ارائه می دهد که هر کدام شامل شناسه کاربر، طول جغرافیایی، عرض جغرافیایی، برچسب های کاربر، زمان ضبط، دستگاه ضبط، URL صفحه عکس/فیلم، URL مجوز و غیره است. این مقدار داده کافی را تحت یک Creative ارائه می کند. Commons Attribution License و می تواند محققین را از کار دردسرساز خزیدن داده رها کند. ما از عکسهای دارای برچسب جغرافیایی از YFCC100M استفاده میکنیم که مختصات آن در منطقه مورد مطالعه محدود شده و در مدت زمان مشخصی گرفته شدهاند. ویژگی های اصلی که ما در این مقاله استفاده می کنیم شامل: شماره خط (شناسایی منحصر به فرد هر عکس دارای برچسب جغرافیایی)، شناسه کاربر (شناسه منحصر به فرد هر کاربر)، زمان ضبط، برچسب جغرافیایی (طول و عرض جغرافیایی)، برچسب های کاربر و خود تصاویر است.
3.3. فیلتر کردن کاربر
از آنجا که هدف ما استخراج جاذبههای گردشگری در این مطالعه است، عکسهای دارای برچسب جغرافیایی آپلود شده توسط بومیان باید حذف شوند، زیرا بیشتر سوابق ثبت نام آنها در مورد زندگی روزمره و رویدادهای غیرمرتبط با گردشگری است. مشابه مطالعه انجام شده توسط Sun و همکاران. [ 24 ]، ما از یک روش مبتنی بر آنتروپی برای متمایز کردن گردشگران از بومیها در مقصد گردشگری استفاده میکنیم که به صورت معادله (1) فرموله شده است:
در معادله (2) Dمتر(تو)تعداد روزهایی است که کاربر استفاده می کند تودر ماه در منطقه مورد مطالعه اقامت داشته اند متر، و مon(تو)تعداد کل ماه های آن کاربر است تودر این منطقه مطالعاتی اقامت داشته اند. پمتر(تو)نسبت تعداد روزها در ماه است مترو تعداد کل روزهای آن کاربر تودر منطقه مورد مطالعه مانده است. به طور شهودی، ارزش بزرگتر است E(تو)این است که کاربر پراکنده تر است توتوزیع بازدید کنندگان این است که کمتر احتمال دارد که او یک توریست باشد. بنابراین ما یک آستانه تعریف می کنیم Eبرای حذف عکس های دارای برچسب جغرافیایی کاربر تواگر ارزش E(تو)برای کاربر توبزرگتر از E.
3.4. پردازش برچسب
پیش پردازش برچسبها و آموزش Word2Vec قبل از شناسایی برچسبهای مکان و مکانهای خوشهبندی مورد نیاز است، که ابهامات رایج زبانی مانند فضاهای سفید، جداسازی کلمات و حروف بزرگ را برطرف میکند و اصطلاحات را منظم میکند. پس از آن، ما از Word2Vec برای استخراج روابط معنایی استفاده میکنیم، جایی که همه برچسبها در ناحیه مورد مطالعه بدنه را تشکیل میدهند، و برچسبها در هر عکس یک جمله را تشکیل میدهند.
به منظور استخراج معناشناسی مورد نظر، ما آستانه حذف کلمه را به عنوان یک محدودیت کاربر تطبیق می دهیم (یعنی برچسب هایی که توسط کمتر از حداقل تعداد کاربران استفاده می شوند آموزش داده نمی شوند). همچنین، کلمه محله را به گونه ای تعریف می کنیم که تمام عبارات پیوست شده به همان عکس را در خود جای دهد. ما از Skip-gram در Word2Vec برای آموزش مجموعههای برچسب استفاده میکنیم، که عمدتاً هدف آن به حداکثر رساندن احتمال ورود به سیستم کلمه متنی با توجه به کلمه مرکزی است که به عنوان معادله (3) فرموله شده است:
جایی که ایکستینشان دهنده کلمه داده شده است، و سی(ایکستی)نشان دهنده محتویات است ایکستی، و ایکسج∈سی(ایکستی)(جایی که ایکستیاختصاصی است) یک کلمه همسایه را نشان می دهد. Skip-gram تعریف می کند پ(ایکسج|ایکستی)با استفاده از تابع softmax با این حال، هزینه محاسبه معادله (1) در هنگام استفاده از تابع softmax غیر عملی است. بنابراین، تابع softmax سلسله مراتبی و نمونه گیری منفی به عنوان دو الگوریتم تقریب محاسباتی کارآمد در معادله (3) پیشنهاد شده است. در این مقاله، تابع softmax سلسله مراتبی برای بهبود کارایی استفاده می شود، که از یک درخت هافمن باینری برای نمایش لایه خروجی با کلمات استفاده می کند و به صراحت احتمالات نسبی گره های فرزند را برای هر گره نشان می دهد [ 41 ].
3.5. خوشه بندی عکس
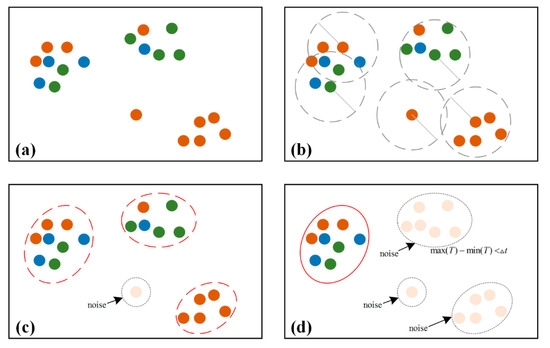
خوشهبندی عکس شامل استخراج برچسب مکان، ادغام و گسترش خوشه است. فرآیند استخراج و ادغام برچسب مکان با تگ دلخواه شروع می شود ایکسکه هنوز پردازش نشده است اگر تعداد عکس های حاوی برچسب ایکس(به عنوان |پایکس|) کمتر از حداقل تعداد عکس است مترمنn_پتیسسپس تگ به عنوان یک تگ نویز علامت گذاری می شود و به پردازش تگ بعدی ادامه می دهد. در غیر این صورت، عکس ها را با TU-DJ-Cluster دسته بندی کنید. این یک روش خوشهای با چگالی اصلاحشده است [ 20 ]، که بیشتر توسط آستانه زمانی محدود میشود. Δتیو حداقل تعداد کاربر و مختص عکس های دارای برچسب جغرافیایی است. فرآیند اصلی TU-DJ-Cluster در شکل 2 نشان داده شده است : (الف) همه نقاط را با همان برچسب مجموعه داده خوشهبندی در هر زمان استخراج کنید، جایی که رنگهای مختلف عکسهای گرفته شده توسط کاربران مختلف را نشان میدهند. ب) همسایگی هر نقطه را در شعاع محاسبه کنید هپس; ج) نقاط بدون همسایگی را به عنوان نقاط نویز علامت گذاری کنید و آن نقاط را با حداقل یک نقطه مشترک به هم بپیوندید. (د) پس از ایجاد یک نتیجه اولیه خوشه، بیشتر قضاوت کنید که آیا هر خوشه شرایط حداقل آستانه زمانی و حداقل کاربران را برآورده می کند یا خیر. اگر نه، آنها را به عنوان نقاط نویز علامت گذاری کنید.
پس از خوشه بندی پایکسبا TU-DJ-Cluster، ما نتایج خوشه را دریافت خواهیم کرد سیایکس. اگر خوشه ای ایجاد نشد، تگ را علامت گذاری کنید ایکسبه عنوان برچسب نویز در غیر این صورت، از میان این خوشه ها حلقه بزنید و مشخص کنید که آیا خوشه ای وجود دارد که تعداد عکس ها تعداد کل عکس ها را محاسبه می کند. |پایکس|بزرگتر از حداقل نسبت است پ_پro. اگر خوشه جایکسمنکه مطابق با شرط بالا وجود دارد، سپس برچسب را علامت بزنید ایکسبه عنوان یک برچسب مکان و بدنه محدب را با نقاط داخل ایجاد کنید جایکسمن.
ما بیشتر برخی از بدنه های محدب را با توجه به روابط فضایی و شباهت معنایی برچسب ها ادغام می کنیم. اگر دو بدنه محدب قسمت همپوشانی داشته باشند و مقدار شباهت تگ های مکان آنها بزرگتر از حداقل آستانه باشد. مترمنn_سمنمتر، سپس آنها را ادغام کنید. همانطور که رابطه (4) نشان می دهد، شباهت کسینوس برای محاسبه شباهت دو تگ استفاده می شود ایکسمنو ایکسj:
جایی که هایکسمنو هایکسjنشان دهنده تعبیه برچسب ها است ایکسمنو ایکسjبه ترتیب که از آموزش Word2Vec فوق به دست آمده اند. پس از پردازش تمام بدنه های محدب، مجموعه ای از بدنه های محدب پردازش شده با معنایی متفاوت به دست می آوریم. سیاچایکس”.
نتایج خوشهای بالا فقط شامل بخش کوچکی از عکسهایی است که با برچسبهای مربوط به مکان پیوست شدهاند، زیرا زیرمجموعهای از عکسهای مربوط به مکان بر این اساس برچسبگذاری نمیشوند. بنابراین، ما به طبقه بندی عکس های پردازش نشده بر اساس روابط فضایی و شباهت معنایی برای بهبود یادآوری ادامه می دهیم. ماهیت عکس گرفتن از مکان های توریستی باعث می شود که چنین عکس هایی در داخل یا نزدیک آن مکان گرفته شود. بنابراین، ما یک بافر با شعاع ایجاد می کنیم rبرای هر بدنه محدب در سیاچایکس”تولید شده توسط مراحل بالا برای استفاده بیشتر. علاوه بر این، مطالعات قبلی نشان میدهد که بین برچسبها و برچسبهای جغرافیایی [ 42 ] همبستگی وجود دارد، بنابراین فرض میکنیم که عکسهای گرفته شده در مکان مجاور تمایل به اختصاص برچسبهای مشابه دارند. ما قضاوت می کنیم که آیا عکس های طبقه بندی نشده در داخل بدنه محدب قرار دارند یا خیر سیاچایکسبو اگر برچسب پیوستی وجود داشته باشد که شباهت آن با نام بدنه محدب بزرگتر از مترمنn_سمنمتر. خروجی نهایی مجموعه ای از خوشه ها است که جاذبه های گردشگری را با معنایی متفاوت نشان می دهد.
3.6. فیلتر نویز تصویر
تصاویری که به مکان بی ربط هستند یا توسط بخش بزرگی از انسان ها اشغال شده اند با چندین مدل از پیش آموزش دیده حذف می شوند. با الهام از مطالعه انجام شده توسط Zhang و همکاران. [ 39 ]، ما همچنین از مجموعه داده Caltech 101 (یک مجموعه داده تصویر شی) [ 43 ]، و مجموعه داده Places2 (یک مجموعه داده تصویر صحنه با اکثر انواع مکان) استفاده می کنیم [ 44 ]] برای آموزش یک طبقه بندی کننده باینری از تصاویر مربوط به مکان و تصاویر بی ربط به مکان. هر دو مجموعه داده مکمل یکدیگر برای طبقه بندی باینری هدف هستند: Caltech 101 اشیاء منفرد و ساخته دست بشر را به تصویر می کشد، در حالی که Places2 به صراحت مناظر جغرافیایی قابل مکان یابی را نشان می دهد. برای آموزش، ما به طور تصادفی حدود 4000 تصویر از هر مجموعه داده را انتخاب می کنیم تا به ویژگی های بعدی 2048 تبدیل شده و به پرسپترون چندلایه (MLP) و حدود 2000 تصویر برای ارزیابی دقت تغذیه شود. دقت طبقه بندی نهایی به 98.68 درصد می رسد.
در مرحله بعد، یک مدل آشکارساز چند جعبه ای تک شات (SSD) [ 22 ] را برای شناسایی افراد در تصاویر اعمال می کنیم. این یک مدل تشخیص شی مبتنی بر کانولوشن است که از قبل بر روی مجموعه دادههای کلاسهای شی بصری PASCAL (VOC) آموزش دیده است. ما فرض می کنیم که اگر بخش قابل توجهی از یک تصویر توسط حداقل یک نفر اشغال شده باشد، به احتمال زیاد سلفی یک گردشگر در مقابل یک جاذبه گردشگری است. نمونه هایی در شکل 3 نشان داده شده است. اگرچه هر دو تصویر جاذبه توریستی یکسانی را نشان میدهند (دیوار بزرگ در پکن، چین) و هر دو دارای دو نفر هستند، به نظر میرسد شکل 3 a بیشتر از شکل 3 نماینده این جاذبه گردشگری باشد.ب با توجه به این فرض، اگر فردی وجود داشته باشد که حداقل مساحت مستطیل مرزی او بیش از 10٪ از این تصویر را پوشش می دهد، هر تصویر را شناسایی کرده و آن را فیلتر می کنیم.
3.7. انتخاب تصویر نماینده
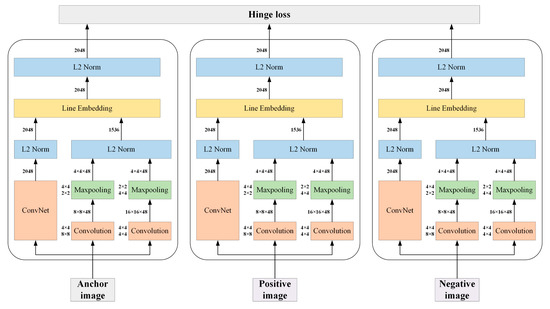
پس از حذف عکسهای نویز، مدل رتبهبندی عمیق را آموزش میدهیم و نمایندهترین تصاویر هر جاذبه گردشگری را پیدا میکنیم. مدل رتبهبندی عمیق یک مدل کانولوشنی است که بر شباهت بصری ریز تمرکز دارد، که با اکثر مدلهای موجود که فقط بر شباهت در سطح دسته تمرکز میکنند، متفاوت است [ 23 ]. همانطور که در شکل 4 نشان داده شده است ، مدل می تواند یک شبکه کانولوشنال رایج (ConvNet)، مانند شبکه های VGG [ 45 ] و ResNet [ 46 ] را ادغام کند.] با مسیرهای با وضوح پایین و عادی سازی ویژگی های خروجی آنها. سهگانههای تصویر، شامل تصویر لنگر، تصویر مثبت و تصویر منفی، به طور مستقل به سه شبکه با معماری یکسان و پارامترهای مشترک تغذیه میشوند. این خروجیهای تعبیهشده ورودیها برای ارزیابی تلفات لولا، با انتشار مجدد گرادیانها به لایههای پایینتر برای بهینهسازی پارامترهای آنها و به حداقل رساندن تلفات لولا، استفاده میشوند.
در مطالعه خود، از ResNet به عنوان ConvNet در مدل و Tiny-ImageNet [ 47 ] به عنوان مجموعه داده آموزشی استفاده میکنیم. برای هر تصویر در مجموعه داده آموزشی، به طور تصادفی یک تصویر در همان دسته با تصویر مثبت و یک تصویر در هر دسته دیگر به عنوان تصویر منفی انتخاب می کنیم تا ورودی سه گانه ایجاد شود. برای تسریع روند آموزش، بخش ConvNet مدل را با وزن های ImageNet مقداردهی اولیه می کنیم. پس از آموزش، وزن های مدل را به دست آورده و به مجموعه داده خود منتقل می کنیم.
4. نتایج تجربی
4.1. منطقه مطالعه
ما پکن را به عنوان منطقه مطالعه انتخاب می کنیم تا چارچوب را تأیید کنیم. پکن پایتخت چین و همچنین دومین شهر بزرگ چین است. منابع گردشگری فراوانی دارد و هر ساله گردشگران زیادی را در داخل و خارج از کشور جذب کرده است [ 48 ]. تعداد تصاویر خام محدود شده در پکن 145,397 و تعداد کاربران 2,846 است. پس از فیلتر کردن کاربران، همانطور که در بخش 3.3 توضیح داده شد، تعداد تصاویر به 140891 و تعداد کاربران 2750 کاهش یافته است. شکل 5 توزیع عکس در پکن را نشان می دهد.
4.2. نتیجه تشخیص برچسب مربوط به مکان
قبل از اعمال Word2Vec در مجموعه برچسبها، توزیع فراوانی برچسبهای مورد استفاده در مطالعه ( شکل 6 a)، و همچنین تعداد کاربرانی که از این برچسبها استفاده میکنند ( شکل 6 ب) را تجزیه و تحلیل کردهایم و آنها را به صورت نمودارهای log-log نشان میدهیم. نمودارها نشان میدهند که هر دو تقریباً از یک توزیع قانون قدرت مشابه با توزیع فرکانس کلمه در زبان طبیعی پیروی میکنند، که نشان میدهد برای استفاده از Word2Vec برای جاسازی این برچسبها با شرایط محدودیت تعداد کاربران قابل استفاده است. ما حداقل تعداد کاربر را سه نفر و اندازه جاسازی را 200 تنظیم کرده ایم. پس از فیلتر کردن برچسب ها، تعداد برچسب ها از 19469 به 2845 کاهش می یابد.
برای ارزیابی توانایی فیلتر کردن برچسبهای نامرتبط با مکان TU-DJ-Cluster، آن را با یک خوشه قابل اتصال با چگالی بدون محدودیت زمان و کاربر مقایسه میکنیم که میتواند به عنوان DBSCAN در نظر گرفته شود. ممنnپتیستا حدودی 1 است. TU-DJ-Cluster را در چارچوب خوشه بندی عکس با آن جایگزین می کنیم. جدول 1 مقادیر پارامترها را برای همه روش های این آزمایش نشان می دهد. در همین حال، روش پایه DBSCAN هر دو را تنظیم کرد مترمنn_توسهrسو Δتیبه عنوان صفر، نشان می دهد که هیچ محدودیتی در تعداد کاربران و زمان برای خوشه بندی وجود ندارد.
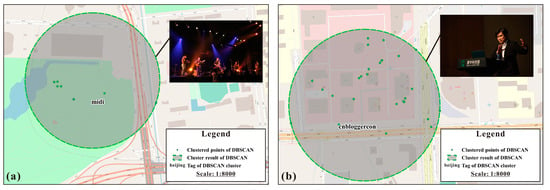
جدول 2نتایج تشخیص هر دو روش را فهرست می کند. TU-DJ-Cluster 131 برچسب مربوط به مکان را شناسایی کرده است، در حالی که DBSCAN 385 را بدون محدودیت زمان و کاربر شناسایی کرده است. برای اعتبارسنجی بهتر دقت تشخیص برچسب مربوط به مکان، از داوطلبانی که با پکن آشنا هستند دعوت میکنیم تا برچسبهای مربوط به مکان را به صورت دستی علامتگذاری کنند و برای محاسبه فراخوانی TU-DJ-Cluster و DBSCAN، که به عنوان نسبت تعداد تگ های واقعی مربوط به مکان و تعداد تگ های شناسایی شده، یا می توانیم آن را به عنوان نسبت ضربه در نظر بگیریم. ما می توانیم ببینیم که نسبت ضربه TU-DJ-Cluster بسیار بزرگتر از DBSCAN است، که بیش از 85٪ از برچسب های شناسایی شده مقادیر مثبت واقعی هستند. اگرچه TU-DJ-Cluster برخی از برچسب های مربوط به مکان واقعی را از دست داده است (52 کمتر از DBSCAN)، بسیاری از آنها را می توان با برچسب های شناسایی شده در پسوند خوشه ای ادغام کرد، زیرا اکثر آنها املای متناوب یا غلط املایی برچسب های شناسایی شده هستند که توسط تعداد کمی از کاربران استفاده می شود. برعکس، مقادیر مثبت کاذب شناسایی شده توسط DBSCAN، خوشه های بی اهمیت زیادی را ایجاد کرده اند.شکل 7 برخی از نتایج شناسایی نادرست DBSCAN را هنگام شناسایی برچسب های مربوط به مکان نشان می دهد. «midi» ( شکل 7 الف، یک جشنواره موسیقی معروف که در پارک هایدیان، پکن برگزار میشود) و «cnbloggercon» ( شکل 7 ب، کنفرانس مربوط به بلاگر چین) را بهعنوان یک برچسب مرتبط با مکان شناسایی کرده است، و همچنین برچسبهای مربوط به مکان های شخصی مانند “دفتر” و “خانه” که ما در این شکل نشان نمی دهیم. الگوریتم ترجیحی ما TU-DJ-Cluster، به طور طبیعی آن تگ های معنایی نامربوط را فیلتر می کند (به مواد تکمیلی مراجعه کنید ).
برای اثبات اثربخشی استفاده از Word2Vec در پردازش برچسب و محاسبه شباهت، ما همچنین برخی از نتایج شباهت زیاد بین برچسبهای مربوط به مکان را فهرست میکنیم، در حالی که بدنههای محدب معنایی را ادغام میکنیم و در جدول 3 نشان میدهیم.. تجزیه و تحلیل نشان میدهد که پردازش برچسبهای مترادف مرتبط با مکان را شناسایی و ادغام میکند، زیرا برچسبهای مترادف به احتمال زیاد شباهت بالایی دارند، از جمله نام انگلیسی و “Pinyin” یک جاذبه گردشگری خاص (به عنوان مثال، “altarofheaven” و “tiantanpark)، “oldsummerpalace” و “yuanmingyuan” و غیره)، اختصارات (به عنوان مثال، “nationalcentrefortheperformingarts” و “ncpa” می توانند نشان دهنده مرکز ملی هنرهای نمایشی باشند.) و نام های جایگزین (به عنوان مثال، “birdsnest” و “nationalstadium” می تواند نماینده ورزشگاه ملی پکن باشد).
4.3. نتیجه خوشه بندی عکس
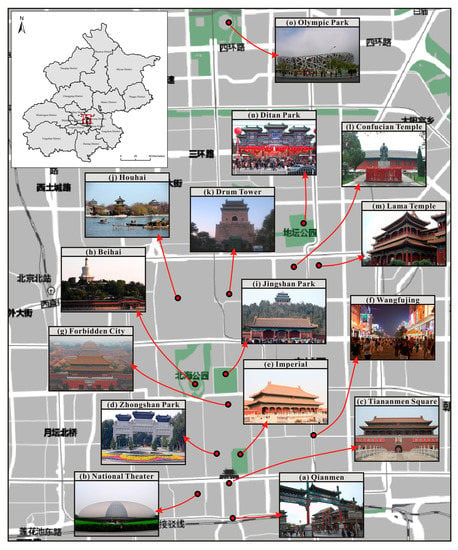
با پیروی از پارامترها و فرآیند بالا، نتیجه خوشه بندی کلی چارچوب خود را به دست می آوریم. نتیجه شامل تعداد کل 30 خوشه است که بیشتر آنها در ناحیه دونگ چنگ و ناحیه شیچنگ از جمله تیان آنمن، شهر ممنوعه، وانگ فوجینگ، پارک جینگشان، برج درام و غیره قرار دارند و در شکل 8 نشان داده شده است.
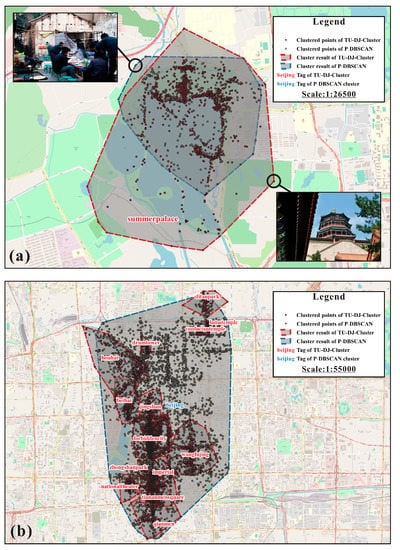
برای نشان دادن بهتر، ما چارچوب خود را با P-DBSCAN و TF-IDF-UF مقایسه می کنیم، که فرآیند را در مطالعات کندی و همکاران دنبال می کنیم. [ 14 ] و Vu و همکاران. [ 26 ]. همانطور که انتظار می رفت، نتایج P-DBSCAN خوشه های کمتری (16 خوشه) را با تمایز کمتر نسبت به TU-DJ-Clustering استخراج می کند که به صورت کیفی در گرافیک OpenStreetMap در شکل 9 ارائه شده است. هم P-DBSCAN و هم روش ما با موفقیت مکان های دیدنی یکسانی را شناسایی کرده اند، از جمله کاخ تابستانی قدیمی (همچنین به عنوان “یوآنمینیوان” شناخته می شود)، منطقه هنری “798” و کاخ تابستانی (همچنین به عنوان “Yiheyuan” شناخته می شود؛ شکل 9. آ). با این حال، به دلیل توزیع نامتعادل چگالی نقطه در این مکان ها، نتیجه P-DBSCAN در شکل 9a شامل بخش جنوب غربی آن نمی شود که بخشی از کاخ تابستانی است که در OSM نشان داده شده است. علاوه بر این، از آنجایی که این نقاط واقع در قسمت شمال غربی نتیجه P-DBSCAN به ناحیه با چگالی بالا نزدیکتر میشوند، در این خوشه قرار میگیرند، جایی که به طور تصادفی محتوای برخی از عکسها را بررسی میکنیم و متوجه میشویم که از نظر معنایی مرتبط با آن نیستند. کاخ تابستانی در نتیجه، اگرچه هر دوی آنها با موفقیت مکان مورد علاقه یکسانی را شناسایی میکنند، یک نتیجه خوشهبندی که تفاوت معنایی عکسها را در نظر گرفته است، بدون شک میتواند نتیجه خوشهبندی ریزدانهای را به دست آورد و کاربرد بیشتری را به همراه داشته باشد.
شکل 9b نتایج خوشه ای TU-DJ-Cluster و P-DBSCAN را در اطراف منطقه شهر ممنوعه مقایسه می کند. روش ما مکان های دیدنی مختلفی را در این منطقه شناسایی کرده است، در حالی که P-DBSCAN چنین طیف وسیعی از مناطق را در یک خوشه خوشه بندی کرده است. حتی اگر چندین ترکیب از پارامترهای P-DBSCAN را در طول آزمایش آزمایش کرده باشیم، اکثر آنها تمایل دارند این مکانهای مختلف مورد علاقه را در یک خوشه خوشهبندی کنند. یکی از دلایل احتمالی این است که این جاذبه های توریستی محبوب پکن به طور متراکم در منطقه اطراف شهر ممنوعه قرار گرفته اند که باعث تراکم نسبتاً بالایی از عکس های دارای برچسب جغرافیایی می شود و تشخیص P-DBSCAN را دشوار می کند. همچنین، با روش TF-IDF-UF، “beijing” را انتخاب می کند که یک برچسب نسبتاً غیرنماینده برای این خوشه است. چنین نتیجه خوشه ای ممکن است تأثیر بدی بر کاربردهای بعدی داشته باشد، مانند توصیه جاذبه توریستی. مقایسه برتری روش ما را در تشخیص مکان های دیدنی ریز دانه و استخراج برچسب های دقیق و معرف به این مکان های دیدنی نسبت به روش سنتی P-DBSCAN نشان می دهد.
4.4. نتیجه انتخاب تصویر نماینده
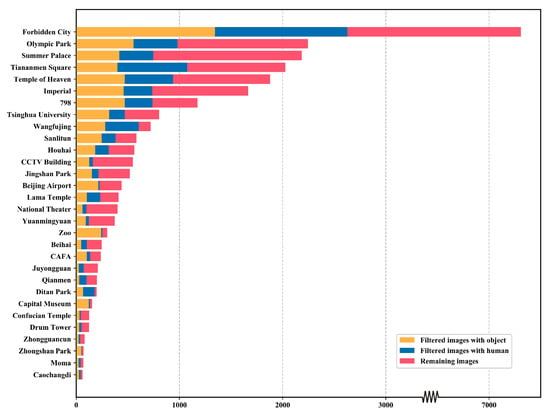
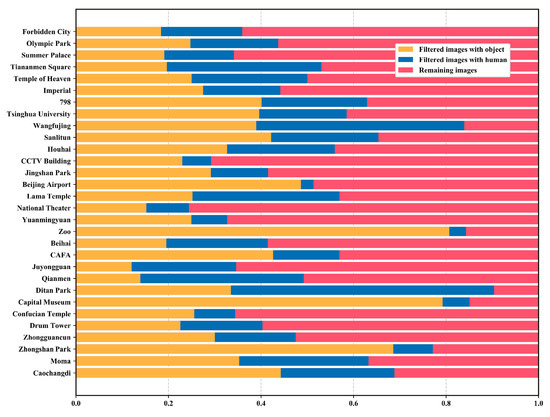
بر اساس نتایج خوشه فوق از TU-DJ-Cluster، ما تصاویر مربوطه را در هر خوشه جمع آوری می کنیم تا تصاویر معرف را فیلتر و پیدا کنیم. ما نتیجه کلی فیلتر کردن هر خوشه را با نمودار میله ای انباشته در شکل 10 و شکل 11 نشان می دهیم . شکل 10 تعداد مطلق تصاویر است و این جاذبه های گردشگری بر اساس تعداد کل تصاویر مرتب شده اند که نشان دهنده محبوبیت هر جاذبه گردشگری تا حدی است. همانطور که شکل 10 نشان می دهد، شهر ممنوعه محبوب ترین جاذبه گردشگری است، زیرا تعداد تصاویر بسیار بیشتر از سایرین است. پارک المپیک، کاخ تابستانی و میدان تیانآنمن از موارد زیر است. شکل 11نسبت انواع مختلف محتوای تصویر را نشان می دهد. موزه پایتخت، باغ وحش و پارک ژونگشان به ترتیب با آثار تاریخی، پانداها و لاله ها گردشگران را جذب می کنند. جاذبه های گردشگری مانند آنها نسبت نسبتاً بالایی از تصاویر مربوط به اشیاء را دارند. این نتیجه نشان می دهد که گردشگران در هنگام بازدید از این نوع جاذبه های گردشگری علاقه بیشتری به عکس گرفتن از اشیا دارند. برعکس، تصاویر با انسان در جاذبه های گردشگری مانند وانگ فوجینگ و پارک دیتان غالب است. در مورد Wangfujing، توضیح آن آسان است زیرا یک منطقه خرید با جریان عظیم مردم است. پارک دیتان به همان اندازه با نمایشگاههای پر جنب و جوش معابد خود گردشگران را به خود جذب میکند و بنابراین، تصاویر بسیاری از انسانها را در خود جای داده است. علاوه بر این، این نمودار نشان میدهد که جاذبههای گردشگری با ظاهری باشکوه میتوانند گردشگران را برای گرفتن عکسهای کلیتر از آنها جذب کنند، زیرا تصاویر مربوط به صحنهها بیش از 60 درصد از جاذبههای گردشگری مانند ساختمان دوربین مدار بسته، تئاتر ملی و یوانمینگیوان را تشکیل میدهند. به طور خلاصه، گردشگران هنگام عکس گرفتن از انواع مختلف جاذبه های گردشگری ترجیحات متفاوتی از خود نشان می دهند و دشواری انتخاب تصویر نماینده نیز از انواع مختلف جاذبه های گردشگری متفاوت است.
ما پنج جاذبه توریستی برتر را که بیشترین تعداد عکس را دارند انتخاب می کنیم و نتایج آنها را از انتخاب تصویر نماینده تجزیه و تحلیل می کنیم. ما نتیجه چارچوب انتخاب تصویر نماینده خود را با انتخاب تصادفی (بدون فرآیند فیلتر کردن تصویر نویز)، که در شکل 12 نشان داده شده است، مقایسه می کنیم . ما میتوانیم از نتیجه انتخاب تصادفی استنباط کنیم که مجموعه تصویر پرسپکتیوهای عکس مغرضانه یا غیرنماینده (به عنوان مثال 2-a و 5-c در شکل 12 )، بخشهای محلی این جاذبه گردشگری (1-b و 3-b در شکل 12 ) و حتی برخی از تصاویر نویزدار (1-a و 5-b در شکل 12)). علاوه بر این، اگرچه فرآیند فیلتر کردن تصویر نویز انجام شده است، اما برخی از تصاویر نامرتبط هنوز وجود دارند که دشواری رتبهبندی و انتخاب برای مدل رتبهبندی عمیق را افزایش میدهد. چارچوب ما همچنان میتواند تصاویر گرفته شده از رایجترین و معرفترین زوایای دید را با نمای کلی یک جاذبه گردشگری خاص انتخاب کند. اگرچه برخی از تصاویر معرف تنوع بصری را نشان می دهند، اما تا حدی ترجیحات بصری متنوع کاربران مختلف را منعکس می کنند. برای مثال، 1-f و 3-f در شکل 12 ، متفاوت از سایر تصاویر معرف، به ترتیب یکی از کاخهای شهر ممنوعه و قایق مرمری را در کاخ تابستانی نشان میدهند.
4.5. نتیجه رضایت کاربران
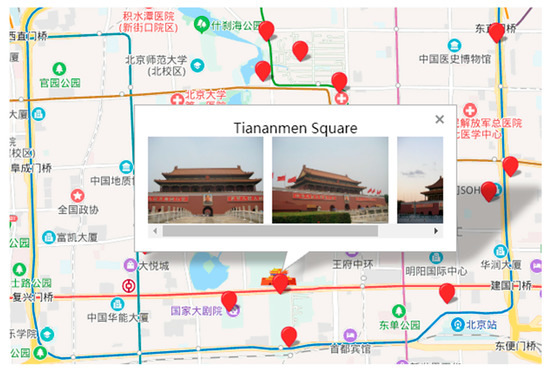
برای ارزیابی بهتر نتایج چارچوب کلی، ما یک پرسشنامه بر اساس نقشه گردشگری ساده ای که ایجاد کردیم، که در آن نقشه بایدو نقشه پایه و مکان های جاذبه های گردشگری استخراج شده است، و تصاویر نماینده نشان داده شده است، انجام دادیم ( شکل 13).). 80 داوطلب در این نظرسنجی شرکت کردند، از جمله افرادی که در پکن زندگی می کردند، قبلاً از پکن بازدید کرده اند یا در آینده توریست های بالقوه پکن هستند (توجه داشته باشید که بیشتر جاذبه های توریستی در پکن به اندازه کافی معروف هستند، و بنابراین، اکثر مردم چین با آن آشنا هستند. آنها را به درجات مختلف). با توجه به نقشه توریستی، هر داوطلب بر اساس مقیاس لیکرت از 1 (کاملاً مخالفم) تا 5 (کاملاً موافقم) سه مورد را رتبهبندی کرد، از جمله: (1) صداقت: به نظر شما نتایج استخراجشده تا چه اندازه میتواند گردشگر معروف پکن را پوشش دهد. جاذبه ها (Q1)؛ (2) نمایندگی: به نظر شما تا چه حد تصاویر انتخاب شده نشان دهنده جاذبه های گردشگری هستند (Q2)؛ (3) جذابیت: فکر می کنید تا چه حد افزودن تصاویر معرف می تواند شما را برای بازدید از جاذبه های گردشگری جذب کند (Q3).
نتایج آماری پرسشنامه در جدول 4 نشان داده شده است ، جایی که عدد صحیح نشان دهنده تعداد رتبه بندی افراد برای هر گزینه است. از بین هر سه معیار، اکثر داوطلبان “موافق” را انتخاب کردند و موارد زیر “خنثی” یا “قوی موافقم” هستند. میانگین امتیازات بالا حاکی از رضایت بالای کاربران به ویژه در معیارهای بازنمایی (حدود 3.88 از 5) است که نشان می دهد چارچوب انتخاب تصویر نماینده موثر است. با توجه به آنچه در بالا مورد تجزیه و تحلیل قرار گرفت، چارچوب کلی این پتانسیل را دارد که در کاربردهای گردشگری کاربرد داشته باشد و رضایت گردشگران را در زندگی واقعی برآورده کند.
5. نتیجه گیری ها
در این مقاله، ما چارچوبی حاوی یک روش خوشهای بهبودیافته و مدلهای شبکه عصبی متعدد برای استخراج تصاویر معرف جاذبههای توریستی پیشنهاد میکنیم. با استفاده از مجموعه داده 100 میلیونی کریتیو کامانز فلیکر، پکن را به عنوان منطقه مورد مطالعه برای ارزیابی چارچوب خود انتخاب می کنیم. سپس مجموعه داده را با روشی مبتنی بر آنتروپی فیلتر میکنیم تا برخی عکسهای آپلود شده توسط افراد بومی را حذف کنیم. ما یک خوشه مبتنی بر چگالی را با اضافه کردن محدودیت زمان و آستانه شماره کاربر (TU-DJ-Cluster) برای استخراج برچسبهای مربوط به مکان بهبود میدهیم و آنها را مطابق با رابطه فضایی بین بدنههای محدب ایجاد شده توسط این مکانها ادغام و گسترش میدهیم. برچسبهای مرتبط و شباهت معنایی بین تعبیههای برچسب بهدستآمده از آموزش Word2Vec. با مقایسه نتیجه استخراج DBSCAN، TU-DJ-Cluster برچسب های مربوط به مکان را استخراج می کند و به طور همزمان برچسب های بی اهمیت و غیر مرتبط با جاذبه های گردشگری را فیلتر می کند. علاوه بر این، نتایج خوشهبندی چارچوب ما نسبت به P-DBSCAN برتر است، چه در تعداد خوشهها و چه در دقت مرزهای خوشهبندی. پس از آن، با فیلتر کردن تصاویر نویز با مدل MLP و SSD از پیش آموزش داده شده و سپس رتبه بندی تصاویر باقیمانده با مدل رتبه بندی عمیق، تصاویر نماینده هر جاذبه گردشگری را انتخاب می کنیم. تجزیه و تحلیل مقایسه ای بیشتر اثربخشی فیلتر کردن تصاویر نامربوط و انتخاب تصاویر نماینده این چارچوب را نشان می دهد. همچنین یک پرسشنامه برای ارزیابی رضایت کاربران از نتایج کلی انجام شده است.
اگرچه نتایج رضایت بخش است، اما هنوز باید تلاش هایی برای بهبود چارچوب ما انجام شود. به عنوان مثال، حتی اگر تصاویر نویز قبل از رتبه بندی اهمیت خود فیلتر می شوند، برخی از تصاویر غیر مرتبط با موضوع باقی می مانند. این به دلیل ترجیحات بصری متنوع کاربران مختلف بر نتایج رتبه بندی تأثیر می گذارد. علاوه بر این، مدل رتبهبندی عمیق مورد استفاده در این مقاله شباهت را از تعبیههای کل تصاویر محاسبه میکند، در حالی که استفاده از مدلهای کانولوشن مبتنی بر آشکارساز نقطه و توصیفگر ممکن است نتیجه انتخاب دقیقتری ارائه دهد، به دلیل دشواری انتخاب تصاویر صحنه عمدتاً در فضای باز از نویزدار. تصاویر دارای برچسب جغرافیایی در کار آینده، ما سعی خواهیم کرد مکان های دیدنی را مستقیماً از عکس ها یا فیلم ها با روش های یادگیری عمیق بدون نظارت یا نیمه نظارت استخراج کنیم.








بدون دیدگاه