1. معرفی
با شهرنشینی مداوم و گسترش شهرها در سراسر جهان، بسیاری از شهرهای بین المللی در حال افزایش فعالیت های ساخت و ساز هستند. علاوه بر این، بسیاری از شهرهای چین نیاز به ساخت شهرهای هوشمند را ابراز می کنند، از این رو درک هوشمندانه اطلاعات جغرافیایی از حسگرهای مختلف (به عنوان مثال، تصاویر سنجش از راه دور، ابرهای نقاط اسکن لیزری) به یک ضرورت برای بخش های مدیریت شهری تبدیل می شود. استخراج ساختمان نقش مهمی را ایفا می کند و همچنین مبنایی برای تشخیص تغییرات ساختمان، مدل سازی ساختمان سه بعدی (سه بعدی) و برنامه ریزی شهری بیشتر است.
استخراج ساختمان یک موضوع تحقیقاتی محبوب در زمینه فتوگرامتری و بینایی کامپیوتر است. روشهای استخراج خودکار ساختمان به یک موضوع تحقیقاتی داغ برای محققان در سراسر جهان تبدیل شده است. روشهای بسیار متنوعی پیشنهاد شدهاند و به طور کلی میتوان آنها را به دو دسته تقسیم کرد: روشهای بدون نظارت و روشهای نظارت شده.
دسته اول (روش های بدون نظارت) عمدتاً با دانش قبلی ضعیف یا مفروضات اساسی توسعه یافته است. به عنوان مثال، Du et al. یک روش مبتنی بر برش های نمودار را معرفی کرد و آن را در تشخیص نور و محدوده داده ها (LiDAR) استفاده کرد [ 1 ]. عملکرد انرژی آن توسط برخی ویژگی های دست ساز ساخته شده است که به وضوح ممکن است همه انواع موقعیت ها را در صحنه های پیچیده شهری برآورده نکنند. هوانگ و همکاران مفهومی به نام «شاخص مورفولوژیکی ساختمان» (MBI) برای استخراج ساختمان ها در تصاویر با وضوح بالا بیان کرد [ 2 ]]. این شاخص عمدتاً به رابطه بین ویژگی های طیفی-ساختاری ساختمان ها و عملگرهای مورفولوژیکی مربوط می شود. با این حال، این نوع رابطه نمی تواند به اندازه کافی همه انواع تصاویر سنجش از دور را نشان دهد. از آنجایی که تشخیص پوشش گیاهی از ساختمانها دشوار است، روشهایی برای فیلتر کردن سطح پوشش گیاهی و سپس اعمال برخی عملیات مورفولوژیکی طراحی شد [ 3 ، 4 ، 5 ]. بر اساس برخی مطالعات [ 3 ، 4]، استفاده از یک شاخص گیاهی تفاوت نرمال شده (NDVI) برای فیلتر کردن مناطق پوشش گیاهی و به دست آوردن نتایج بهتر استخراج مفید است. با این وجود، NDVI در تصاویر RGB (قرمز، سبز، آبی) قابل استفاده نیست. در حالی که برخی از روشهای شاخص پوشش گیاهی برای مقابله با این مشکل توسعه داده شدند [ 6 ]، این روشها دارای محدودیتهایی هستند و در جاهای دیگر به سختی اعمال میشوند. در مجموع، روشهای بدون نظارت بر اساس دانش قبلی ضعیفی توسعه مییابند که میتواند نوع خاصی از موقعیت یا صحنه شهری را برآورده کند. فرض کنید ساخت و سازها در شهرها پیچیده تر شود، این روش ها کاستی های خود را نشان می دهند.
دسته دوم (روش نظارت شده) می تواند به نتایج رضایت بخش تری به خصوص در کنار روش های یادگیری عمیق دست یابد [ 7 ]. برای به دست آوردن نتایج رضایت بخش، نمونه های آموزشی کافی مورد نیاز است. به خوبی شناخته شده است که آموزش برچسب زدن نمونه ها یک کار وقت گیر است. برای کاهش نیاز به برچسبگذاری دستی، روشهای متعددی دادههای سیستم اطلاعات جغرافیایی (GIS) یا دادههای منبع باز را معرفی میکنند تا برچسبهای آموزشی را بهطور خودکار بدست آورند [ 8 ، 9 ]]. با این حال، دادههای GIS موجود مانند دادههای نمودار خطی دیجیتال تاریخی (DLG) ممکن است حاوی نویز برای تغییر ساختمانها در فاصله زمانی باشد. اطلاعات جغرافیایی داوطلبانه (VGI) مانند داده های OpenStreetMap (OSM) ممکن است شامل خطای موقعیت و خطای ویژگی باشد. اولی عمدتاً ناشی از ناسازگاری بین داده های OSM و داده های سنجش از دور است، در حالی که دومی عمدتاً توسط برچسب های نادرست ارائه شده توسط داوطلبان آماتور هدایت می شود [ 10 ]. برای رسیدگی به این مشکل، روشهای مختلفی برای انتخاب قطعات تمیز در برچسبهای نویزدار پیشنهاد شد. در یک مطالعه قبلی [ 11 ]، یک مرور کلی نسبت به طبقه بندی با برچسب های پر سر و صدا، سه استراتژی اصلی را برای رسیدگی به این موضوع به پایان می رساند. در مطالعه ای توسط Wan و همکاران. [ 10]، برای مثال، یک روش c-means (FCM) فازی برای جلوگیری از خطای احتمالی ناشی از دادههای OSM و خوشهبندی هر کلاس از نمونههای آموزشی ممکن استفاده شد. در مطالعات دیگر [ 8 ، 12 ]، آموزش تکراری در طبقهبندیکننده جنگل تصادفی (RF) برای انتخاب نمونههای تمیز به کار گرفته شد، زیرا طبقهبندیکننده RF ثابت کرده است که برای برچسبگذاری نویز قوی است.
به غیر از برچسب نمونه، ویژگی کلید دیگری است که بر نتیجه طبقه بندی نهایی تأثیر می گذارد. برای افراد معمول است که ویژگی ها را مطابق با برخی دانش قبلی از مشاهده ساده یا فرضیات اساسی طراحی کنند. به عنوان مثال، برخی از انواع ویژگی های دست ساز طراحی شده اند (به عنوان مثال، ویژگی های زمینه، ویژگی های فضایی، و ویژگی های طیفی) [ 1 ، 13 ، 14 ، 15 ]. همانطور که در بالا ذکر شد، ویژگی های دست ساز طراحی شده توسط انسان محدودیت هایی دارد. آنها نمیتوانند موقعیتهای کافی را در صحنههای شهری پیچیدهتر امروزی پوشش دهند و نتایج غیر قابلتوجهی تولید کنند. در سال های اخیر، یادگیری عمیق به حوزه تقسیم بندی و طبقه بندی معنایی تصاویر سنجش از دور معرفی شده است [ 16 ,17 ]. با این حال، آموزش یک شبکه عمیق از ابتدا برای یک کار سنجش از راه دور نیاز به نمونه های مرتبط زیادی دارد. بنابراین، انتقال یادگیری از طریق یادگیری عمیق برای کاهش وابستگی بیش از حد به نمونه آموزشی پیشنهاد شد [ 18 ]. برای حفظ تنوع ویژگی ها، اطلاعات طیفی و اطلاعات ارتفاع باید هر دو به عنوان داده های ورودی یادگیری انتقال در نظر گرفته شوند.
در بین این روشها، نتایج استخراج ساختمان بر اساس دادههای LiDAR یا ترکیبی از تصاویر سنجش از دور و دادههای LiDAR بهتر از اعمال تنها تصاویر است. این به این دلیل است که داده های LiDAR می توانند اطلاعات مفیدی را ارائه دهند که از استخراج ساختمان پشتیبانی می کند [ 19 , 20 , 21]، شامل مختصات سه بعدی دقیق، اطلاعات زمینه و اطلاعات طیفی. متأسفانه، این روش ها را نمی توان به طور گسترده در بسیاری از شهرها اعمال کرد، زیرا داده های LiDAR گران هستند و همیشه در دسترس نیستند. برای پرداختن به این موضوع، برخی از محققان سعی کرده اند از داده های ابر نقطه تطبیق تصویر متراکم (DIM) برای جایگزینی داده های LiDAR استفاده کنند. همراه با توسعه فن آوری سیستم چند نمای (MVS) و سیستم تصویر مایل هوایی، مدل سطح دیجیتال (DSM) را می توان به راحتی به دست آورد که منبع داده جایگزین اطلاعات ارتفاع را فراهم می کند.
مشارکت های این مقاله را می توان به طور عمده در دو جنبه نتیجه گرفت. در مرحله اول، برای کاهش برچسبگذاری دستی، دادههای DLG تاریخی برای به دست آوردن برچسبهای آموزشی کافی بهطور خودکار اعمال میشوند. از آنجایی که DLG های تاریخی به طور مکرر در شهرها به روز می شوند، نویز باید در سطح مشخصی حفظ شود. یک روش تکراری برای حذف خطاهای احتمالی در برچسب اولیه استفاده می شود. ثانیاً، برای به دست آوردن ویژگیهای مؤثر، ویژگیهای عمیق استخراجشده از اطلاعات طیفی بهدستآمده از نقشه دیجیتال ارتوفوتو (DOM) و اطلاعات ارتفاع بهدستآمده از DSM توسط یک شبکه کاملاً متصل از قبل آموزشدیده (FCN) ترکیب میشوند. در این مقاله، ویژگی های عمیق به صورت پیکسل استخراج می شوند. برای اطمینان از کارایی پردازش تکراری و جلوگیری از آسیب احتمالی ناشی از بعد ویژگی بالا،
بقیه این مقاله به شرح زیر سازماندهی شده است: روش پیشنهادی به تفصیل در بخش 2 توضیح داده شده است . مجموعه داده های تجربی و معیارهای ارزیابی مرتبط در بخش 3 معرفی شده اند . نتایج مربوطه و بحث از چهار جنبه در بخش 4 نشان داده شده است. و در نهایت، نتیجه گیری و کار آینده در بخش 5 ارائه شده است.
2. روش ها
2.1. مروری بر روش
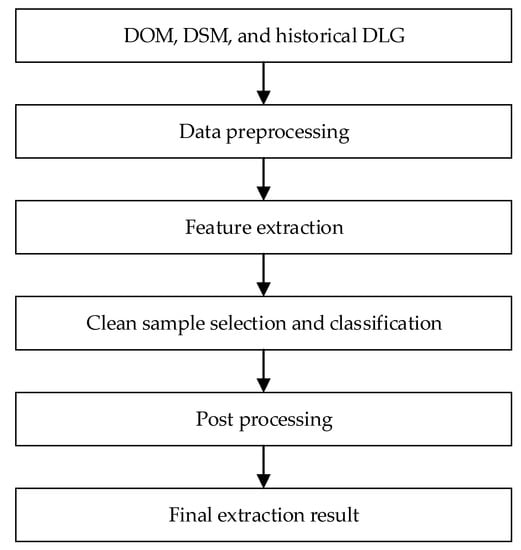
گردش کار کلی روش پیشنهادی ما در شکل 1 نشان داده شده است . این شامل چهار مرحله اصلی است: پیش پردازش داده، استخراج ویژگی، انتخاب و طبقه بندی نمونه تمیز، و پردازش پس از آن. توضیحات کامل هر مرحله در زیر بخش های بعدی توضیح داده خواهد شد.
2.2. پیش پردازش داده ها
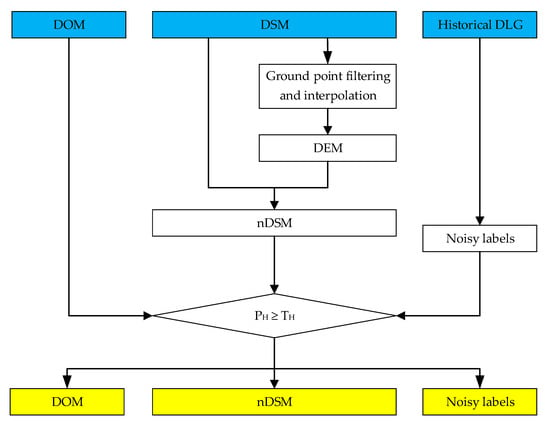
گردش کار پیش پردازش در شکل 2 نشان داده شده است (که در آن داده های ورودی با رنگ آبی و نتیجه خروجی با رنگ زرد مشخص شده اند). DSM، DOM و DLG مربوطه همگی به خوبی تراز شده اند و اندازه آنها همگی یکسان است. ابتدا، DSM با استفاده از فیلتر شبیه سازی پارچه ای (CSF) [ 22 ] پیاده سازی شده در CloudCompare [ 22] به نقاط زمین و نقاط غیر زمین فیلتر می شود. 23 ] به نقاط زمین و نقاط غیر زمین فیلتر می شود.]. سپس از این نقاط زمین برای درون یابی مدل رقومی ارتفاع (DEM) با استفاده از روش کریجینگ استفاده می شود. در نهایت، DEM از DSM کم می شود تا تصویر نرمال شده DSM (nDSM) تولید شود که نشان دهنده ارتفاع واقعی اشیا است. در این مقاله، تصویر nDSM یک تصویر سه کاناله است که نیاز برای استخراج ویژگی های بعدی را برآورده می کند. برای هر پیکسل در تصویر nDSM، مقادیر در سه کانال یکسان است.
DSM و DOM جدید بهخوبی با دادههای DLG تاریخی ثبت میشوند. داده های DLG را می توان برای پشتیبانی از استخراج مساحت ساختمان بر روی داده های تازه به دست آمده استفاده کرد. با این وجود، با تغییرات مکرر در شهرهای مدرن، برخی از ساختمانها در دادههای DLG ممکن است در DSM و DOM تازه بهدستآمده تخریب شوند، در حالی که ساختمانهای دیگر ممکن است در DSM و DOM تازه بهدستآمده ظاهر شوند. در این حالت، مساحت ساختمان به دست آمده از DLG دارای درجه خاصی از نویز است.
همانطور که DEM به دست می آید، کار استخراج منطقه ساختمان را می توان ساده کرد تا ساختمان را از سایر اشیاء بالای زمین متمایز کند. بنابراین، یک ماسک ناحیه غیر ساختمانی بر اساس nDSM تولید میشود و برای شناسایی مستقیم برخی از پیکسلهای متعلق به منطقه غیرساختمانی استفاده میشود. این با یک فرض ساده همراه است که ارتفاع ساختمان ها باید بیشتر از یک آستانه باشد تیاچدر صحنه های شهری همانطور که در شکل 2 نشان داده شده است ، این فرض را با ارتفاع پیکسل فعلی بیان می کنیم پاچکه کمتر از یک آستانه معین نیست تیاچ( پاچ≥تیاچ). ارزش تیاچباید با توجه به موقعیت ها در مناطق مختلف شهری تنظیم شود. پس از استخراج ماسک غیر ساختمانی، برای نگهداری پیکسلهای DOM، nDSM، و برچسبهای اولیه فقط در ناحیه ساختمان ممکن (موارد زرد در شکل 2 ) برای پردازش بعدی اعمال میشود.
2.3. استخراج ویژگی
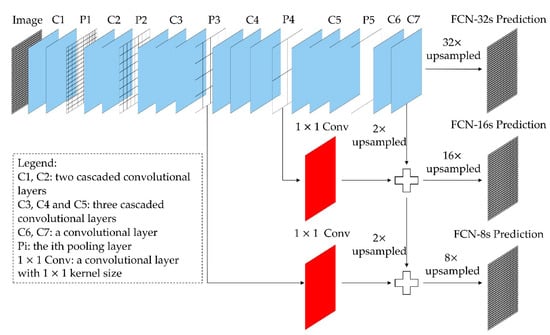
در این مقاله، ویژگیهای عمیق به صورت پیکسلی از هر دو تصویر DOM و تصویر nDSM استخراج میشوند. FCN ها می توانند تصاویر را بدون محدودیت اندازه بپذیرند و خروجی های فضایی دوبعدی با اندازه متناظر تولید کنند که اطلاعات مکانی در تصاویر ورودی را در برابر گم شدن یا تغییر ایمن می کند [ 24 ]. FCN-8 های از پیش آموزش داده شده بر روی مجموعه داده PASCAL VOC برای تقسیم بندی اشیاء معنایی برای استخراج ویژگی های عمیق در این مقاله [ 25 ] استفاده شد. ساختار FCN به کار گرفته شده در شکل 3 نشان داده شده است .
با در نظر گرفتن اطلاعات ارتفاع و اطلاعات طیفی، محاسبه رو به جلو FCN-8 ها به طور مستقیم بر روی تصویر DOM و تصویر nDSM برای استخراج ویژگی های عمیق انجام می شود. سپس، نقشه ویژگی از اولین لایه کانولوشن پس از P1 پذیرفته می شود، زیرا احتمال بیشتری دارد که به لبه جسم پاسخ دهد. پس از آن، یک پردازش نمونهبرداری دوخطی انجام میشود تا بردار ویژگی 128 بعدی (128 بعد) برای هر پیکسل از تصویر ورودی به دست آید. در روش پیشنهادی، تصویر DOM و تصویر nDSM برای استخراج ویژگیهای عمقی ۱۲۸ بعدی توسط FCN-8 به طور جداگانه استفاده میشوند.
برای کنترل هزینه محاسبات و جلوگیری از آسیب احتمالی ناشی از ابعاد بالای ویژگی های به دست آمده، از الگوریتم PCA برای کاهش ابعاد ویژگی و کاهش افزونگی ویژگی استفاده می شود [ 26 ]. ابعاد ویژگی عمیق nDSM و DOM به ترتیب به 7-d (7 بعد) و 12-d (12 بعد) کاهش می یابد.
2.4. انتخاب و طبقه بندی نمونه پاک
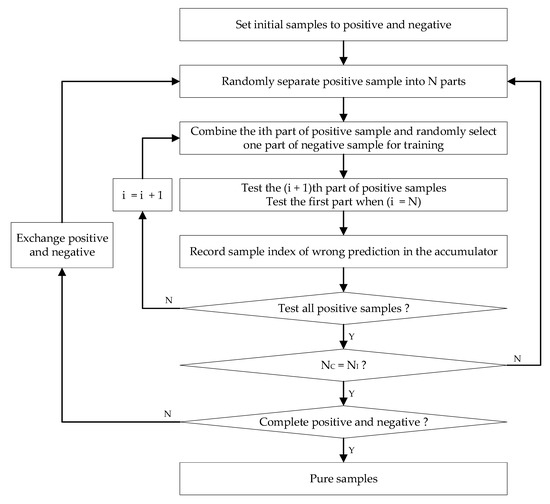
برای خالصسازی برچسبهای نویز بهدستآمده در مرحله پیشپردازش، یک روش تکراری با الهام از آثار [ 8 ، 12 ] پیشنهاد شد. گردش کار در شکل 4 ارائه شده است. از برچسب های نویز اولیه از مرحله پیش پردازش داده ها شروع می شود. پردازش تکراری به عنوان یک رویکرد اعتبارسنجی متقاطع ترک یکاون انجام میشود. میتوان فرض کرد که طبقهبندیکننده آموزشدیده بر اساس برچسبهای اولیه بهتر از حدس تصادفی عمل میکند، بنابراین آن نمونههای نادرست احتمالاً با برچسبهایی متفاوت از برچسبهای داده شده پیشبینی میشوند. با تقسیم تصادفی نمونه های آموزشی و نمونه های آزمایشی، هر تکرار می تواند به عنوان تست مستقل در نظر گرفته شود. بنابراین، زمانی که برچسب اولیه آن بارها با نتیجه پیشبینیشده مطابقت داشته باشد، به احتمال زیاد تمیز میشود.
در ابتدا، پیکسل هایی که به عنوان “ساختمان” برچسب گذاری شده اند، نمونه های مثبت در نظر گرفته می شوند و پیکسل هایی که به عنوان “غیر ساختمانی” برچسب گذاری شده اند، نمونه های منفی در نظر گرفته می شوند. برای متعادل کردن مقدار نمونه های مثبت و منفی، هر دو نمونه به چند قسمت تقسیم می شوند. اگر تعداد نمونه های مثبت را به نپو تعداد نمونه های منفی را بر روی تنظیم کنید نن، نسبت نپو ننبا استفاده از رابطه (1) محاسبه می شود. اگر نپو ننبه وضوح متفاوت است ( نسبت≥2، نمونه های مثبت به دو دسته تقسیم می شوند نقطعات و نمونه های منفی به دو دسته تقسیم می شوند مقطعات ( ن≠م). در هر قسمت از نمونه های مثبت یا نمونه های منفی، تعداد نمونه ها بزرگترین مقسوم علیه مشترک است نپو نن. اگر نسبت<2هر دو نمونه مثبت و نمونه منفی به دو قسمت تقسیم می شوند ( ن، م=2) به طوری که تعداد نمونه های مثبت و نمونه های منفی تقریباً برابر باشد.
پس از آن نمونه های تمیز در دو مرحله انتخاب می شوند. جنبه مثبت در ابتدا پردازش می شود. را منتیساعتبخشی از نمونه های مثبت (پمن، من= 1:ن)و یک بخش به طور تصادفی انتخاب شده از نمونه های منفی برای آموزش یک طبقه بندی کننده RF ترکیب شده و سپس تست (من+1)تیساعتبخشی از نمونه های مثبت (پمن+1).به طور خاص، زمانی که آن را تبدیل به نتیساعتبخشی از نمونه های مثبت (پن)،بخش اول نمونه های مثبت (پ1)مورد آزمایش قرار می گیرد. بعد از تمرین نبارها، تمام نمونه های مثبت یک بار آزمایش می شوند و اولین تکرار کامل می شود. پس از تکرار نمنبارها، جنبه مثبت به پایان می رسد. این امر جنبه منفی را به دنبال دارد. روش های مشابهی اعمال می شود و تفاوت در آموزش است مبار در یک تکرار در فرآیند اول، یک انباشته که از این به بعد به عنوان ACC در نظر گرفته می شود، در ابتدا به صفر تبدیل می شود. اگر برخی از نمونه ها به اشتباه در هر تکرار پیش بینی شوند، یک ACC یک نمونه را در موقعیت مربوطه اضافه می کند. پس از پردازش هر دو طرف، ACC برای تعیین اینکه آیا یک نمونه درست است یا نه استفاده می شود. به دنبال رابطه (2)، اگر نسبت زمان های پیش بینی اشتباه کمتر از θتی،پیکسل مربوطه به عنوان یک نمونه با برچسب سمت راست گرفته می شود، سپس برچسب L(P) روی 1 تنظیم می شود که مخفف یک نمونه تمیز است. در غیر این صورت، روی 0 تنظیم می شود که مخفف یک نمونه ناخالص است.
جایی که ندبلیوعددی است که در ACC ثبت شده است.
بر اساس نمونههای تمیز انتخاب شده، یک طبقهبندیکننده نهایی RF برای پیشبینی نمونههای سردرگم باقیمانده برای به دست آوردن نتیجه اولیه استخراج منطقه ساختمان آموزش داده میشود.
2.5. پردازش پست
از آنجایی که نتیجه اولیه از نظر پیکسلی به دست می آید، برخی از پیکسل ها را می توان به اشتباه پیش بینی کرد (به عنوان مثال، مساحت ساختمان به عنوان مساحت غیرساختمانی پیش بینی می شود، و منطقه غیر ساختمانی به عنوان منطقه ساختمان پیش بینی می شود). برای معقولتر کردن نتایج، دو روش برای پس پردازش اتخاذ میشود: تجزیه و تحلیل مؤلفههای متصل (CCA) و عملیات بسته در پردازش مورفولوژیکی. از آنجایی که یک ساختمان منطقه ای را در nDSM اشغال می کند، یک عملیات CCA بر روی نتیجه طبقه بندی اولیه انجام می شود. سپس، برخی از مؤلفهها با کمتر از یک آستانه معین متصل میشوند تیاساز نتیجه استخراج ساختمان حذف می شوند. این فرآیند می تواند برخی از خطاهای ارائه شده به شکل نویز نمک را حذف کند. عملیات بسته عمدتاً برای پر کردن سوراخهای خالی در یک منطقه متصل به منظور اطمینان از کامل بودن نتیجه استخراج ساختمان استفاده میشود. نتایج تصفیه شده به عنوان نتایج استخراج نهایی روش پیشنهادی در نظر گرفته می شوند.
3. مجموعه داده ها و معیارهای ارزیابی
روش پیشنهادی با استفاده از زبان پایتون پیادهسازی شد، با این تفاوت که فیلتر نقاط زمین در مرحله پیش پردازش با استفاده از CloudCompare انجام شد. یک کامپیوتر رومیزی با CPU Inter Core i7-8700 در فرکانس 3.19 گیگاهرتز برای انجام آزمایش ها استفاده شد.
3.1. توضیحات مجموعه داده ها
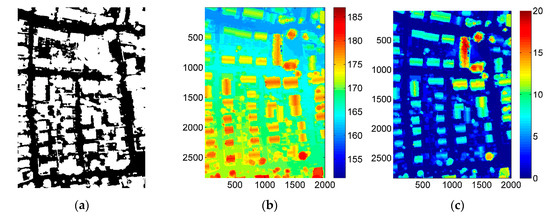
برای ارزیابی روش پیشنهادی، از مجموعه دادههایی که دو حوزه مختلف را پوشش میدهند، استفاده شد. شکل 5 داده های اولین منطقه ارائه شده توسط پروژه آزمایشی ISPRS در طبقه بندی شهری و بازسازی ساختمان های سه بعدی را نشان می دهد که در شهر Vaihingen، آلمان واقع شده است. از این پس به عنوان Area1 در نظر گرفته می شود. حقیقت زمینی نقشه ساختمان به صورت دستی ویرایش شد تا DLG تاریخی را شبیه سازی کند (که بعداً با استفاده از DLG_M نمایش داده می شود؛ شکل 5 الف). وضوح فضایی DOM، DSM و DLG_M همگی 0.09 متر و اندازه این داده ها 2002 × 2842 پیکسل بود. DOM یک تصویر مادون قرمز رنگی (CIR) است. برای نشان دادن جزئیات بیشتر از اولین مجموعه داده، سه تصویر در جهت عقربه های ساعت چرخانده شدند، همانطور که در شکل 5 ج نشان داده شده است.
مجموعه داده های منطقه دوم، واقع در شهر شنژن، چین، در شکل 6 و شکل 7 نشان داده شده است. در مقایسه با Area1، ساختمان های زیادی در شنژن در حال ساخت هستند و شکل ساختمان ها تا حدودی نامنظم است. از این پس به عنوان Area2 در نظر گرفته می شود. DOM و DSM فتوگرامتری از تصاویر مایل موجود در هوا به دست آمده در سال 2016 و با استفاده از ContextCapture تولید شدند و وضوح به 0.5 متر کاهش یافت. اولین داده های تاریخی DLG در سال 2008 به دست آمد ( شکل 6 الف)، و دومین داده تاریخی DLG در سال 2014 به دست آمد ( شکل 7)آ). از آنجایی که دو DLG تاریخی در قالب یک بردار ارائه شده بودند، برای مطابقت با وضوح فضایی DOM و DSM به تصاویر شطرنجی منتقل شدند. پس از یکسان سازی رزولوشن، تصاویر شطرنجی مشتق شده از DLGها به همان اندازه DSM و DOM برش داده شدند. اندازه 1503 × 1539 پیکسل بود. تصویر شطرنجی برشخورده مشتقشده از DLG (بهدستآمده در سال 2008) از این به بعد با استفاده از DLG2008 نشان داده میشود، در حالی که تصویر مشتقشده دیگر با استفاده از DLG2014 نشان داده میشود.
برای نشان دادن واضح دادههای آزمایش، DLG اصلی بر روی nDSM با مرزهای آبی مانند شکل 5c ، شکل 6c ، و شکل 7c روی هم قرار داده شد . سطح نویز DLG_M، DLG2008 و DLG2014 به ترتیب حدود 15%، 65% و 25% بود. از تصویر، می توان دریافت که نسبت تغییر بین DLG2008 و DSM جدید در مقایسه با نسبت بین DLG2014 و DSM جدید بسیار واضح بود. به دلیل گذشت زمان طولانی، انتخاب خودکار نمونه ها از داده های DLG دشوار است.
3.2. معیارهای ارزیابی
سه معیار پیشنهادی در [ 27 ] برای ارزیابی کمی نتایج اتخاذ شد. آنها به عنوان معادلات (3) – (5) تعریف می شوند:
که در آن TP ، FN و FP به ترتیب به معنای مثبت واقعی، منفی کاذب و مثبت کاذب هستند. در اینجا، TP مخفف ناحیه ساختمانی است که به عنوان یک منطقه ساختمانی تشخیص داده می شود، FN مخفف منطقه ساختمانی است که به عنوان یک منطقه غیر ساختمانی شناسایی می شود، و FP مخفف یک منطقه غیر ساختمانی است که به عنوان یک منطقه ساختمانی شناسایی می شود. در بخشهای بعدی، تمام نتایج استخراج با این سه معیار در هر دو جنبه مبتنی بر پیکسل و جنبه مبتنی بر شی ارزیابی میشوند. فرض کنید حداقل 50 درصد از یک ساختمان شناسایی شود، این ساختمان در ارزیابی مبتنی بر شی به درستی طبقه بندی می شود.
3.3. تنظیمات پارامترها
آستانه ارتفاع تیاچاز Area1 و Area2 به طور تجربی به ترتیب 1 متر و 3 متر تنظیم شده است. تعداد تکرارها نمنبه طور تجربی روی 10 تنظیم شده است و میزان تحمل θتیبه صورت تجربی روی 0.1 تنظیم شده است. این بدان معنی است که فقط پیکسل هایی که هر بار اشتباه پیش بینی نمی شوند ( ندبلیو=0) به عنوان نمونه های تمیز در نظر گرفته می شوند. آستانه مساحت تیاساز Area1 و Area2 به صورت تجربی به ترتیب 10 متر مربع و 25 متر مربع تنظیم شده است.
4. نتایج و بحث
4.1. نتایج
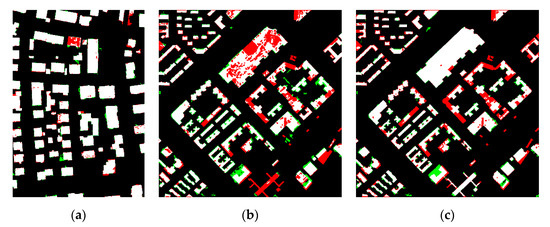
نتایج پیش پردازش داده ها در شکل 8 ارائه شده است. نتایج استخراج ساختمان در شکل 9 ارائه شده است. نتایج ارزیابی دقت مربوطه در جدول 1 ارائه شده است. در شکل 8 a,d، قسمتهای سیاه برای مناطق غیرساختمانی هستند، در حالی که قسمتهای سفید نشاندهنده مناطق ساختمانی احتمالی هستند که در انتخاب نمونه تمیز شرکت میکنند. علاوه بر این، اثرات کنتراست مختلف بین DSM و nDSM قابل مشاهده است. اولی ( شکل 8 b,e) ارتفاع زمین را در نظر می گیرد، در حالی که دومی ارتفاع واقعی اشیاء را در صحنه های شهری توصیف می کند ( شکل 8)ج، ج). در شکلهای زیر که نتایج استخراج ساختمان را نشان میدهند، رنگ سفید مخفف طبقهبندی صحیح (TP )، مخفف قرمز برای طبقهبندی گمشده ( FN )، و سبز مخفف اشتباه طبقهبندی شده ( FP ) است.
جدول 1 ارزیابی های دقت نتایج استخراج ساختمان را در سه مجموعه داده ارائه می کند. ارزیابی همه موارد در Area1 با DLG_M بالای 90٪ است. در Area2 با DLG2008، صحت در هر دو جنبه پیکسل و شی به 87٪ می رسد، در حالی که ارزیابی کامل بودن مبتنی بر پیکسل حدود 70٪ است. وقتی در Area2 به DLG2014 تبدیل میشود، ارزیابی صحت در هر دو جنبه پیکسل و شی بیش از 92٪ است، اما ارزیابی پیکسلی کامل بودن زیر 80٪ است. به طور کلی، دستیابی به کیفیت بالای 90 درصد در Area1 با DLG نویز 15 درصد آسان است. در Area2، 78٪ از ارزیابی کیفیت در جنبه شی با استفاده از DLG با نویز 65٪ به دست می آید، در حالی که ارزیابی کیفیت مبتنی بر شی می تواند در هنگام استفاده از 25٪ نویز DLG به 81٪ برسد.
4.2. بحث
4.2.1. انتخاب برچسب
سه استراتژی در مورد انتخاب برچسب مقایسه و تجزیه و تحلیل شد: (1) با استفاده از داده های حقیقت زمین به عنوان برچسب. (2) استفاده از داده های DLG تاریخی به عنوان برچسب. و (3) با استفاده از برچسب های انتخاب شده از نمونه های تمیز (پیشنهاد شده). در این مقاله می توان تعداد معینی از نمونه ها را انتخاب و به عنوان تمیز در نظر گرفت. همین تعداد از داده های حقیقت زمینی نیز به طور تصادفی برای تکمیل استراتژی (1) انتخاب می شود تا روش ما منطقی تر ارزیابی شود. در جدول 2 ، جدول 3 و جدول 4 ، این سه استراتژی به ترتیب به صورت استراتژی (1)، (2) و (3) نشان داده شده است. اگر نمونه های انتخاب شده به اندازه کافی تمیز باشند، ارزیابی دقت نتایج بر اساس استراتژی (3) باید بین ارزیابی متناظر استراتژی (1) و استراتژی (2) باشد.
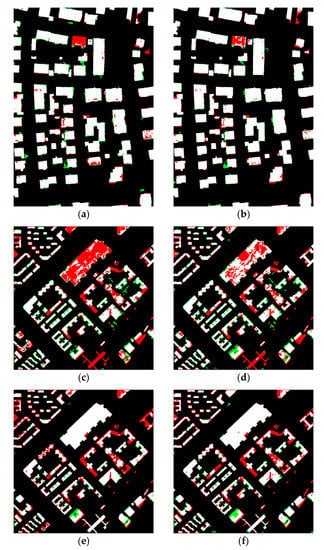
شکل 10 نتایج سه استراتژی را در Area1 با DLG_M نشان می دهد و جدول 2 ارزیابی های دقت مربوطه را نشان می دهد. توجه داشته باشید که در استراتژی (1)، 2618281 نمونه به طور تصادفی (در مجموع 3047394 نمونه، حدود 86 درصد نمونه ها انتخاب شدند) از داده های حقیقت زمینی و به همین تعداد نمونه تمیز از DLG_M در استراتژی (3) انتخاب شدند. .
شکل 11 نتایج سه استراتژی را در Area2 با DLG2008 نشان میدهد و جدول 3 ارزیابیهای دقت مربوطه را نشان میدهد. توجه داشته باشید که در استراتژی (1)، 555318 نمونه (در مجموع 1056178 نمونه، حدود 52 درصد نمونه ها انتخاب شدند) به طور تصادفی از داده های حقیقت زمینی و همین تعداد نمونه تمیز از DLG2008 در استراتژی (3) انتخاب شدند.
شکل 12 نتایج سه استراتژی را در Area2 با DLG2014 نشان می دهد و جدول 4 ارزیابی های دقت مربوطه را نشان می دهد. توجه داشته باشید که در استراتژی (1)، 732214 نمونه به طور تصادفی (در مجموع 1056178 نمونه، حدود 69 درصد نمونه ها انتخاب شدند) از داده های حقیقت زمین و به همین تعداد نمونه تمیز از DLG2014 در استراتژی (3) انتخاب شدند.
به طور کلی، شکل های ( شکل 10 ، شکل 11 و شکل 12 ) و جداول ( جدول 2 ، جدول 3 و جدول 4 ) به وضوح نشان می دهند که دقت بر اساس نمونه های تمیز انتخاب شده (استراتژی (3)) بین دقت بر اساس زمین است. داده های حقیقت (استراتژی (1)) و دقت بر اساس داده های DLG داده شده (استراتژی (2)). این بدان معناست که نمونه های تمیز بیشتری را می توان در روش ما با کمی نویز در برچسب ها انتخاب کرد.
4.2.2. انتخاب ویژگی
برای مقایسه راهبردهای مختلف انتخاب ویژگی، سه روش دیگر اجرا شد. مورد اول فقط سه نوع ویژگی دست ساز پیشنهاد شده در [ 1 را اعمال می کند]، از جمله صافی، واریانس جهت طبیعی، و همگنی ماتریس هموقوع سطح خاکستری (GLCM) تصویر nDSM. با توجه به ویژگی اول، بر اساس یک فرض ساده است که یک ساختمان عمدتاً از سطوح مسطح تشکیل شده است، در حالی که پوشش گیاهی ممکن است شامل سطوحی نامنظم باشد. ویژگی دوم نیز مطابق با یک فرض طراحی شده است (یعنی تغییر جهت نرمال سطح ساختمان باید در مقایسه با این مقدار سطح پوشش گیاهی کمتر باشد). ویژگی سوم با این ایده طراحی شده است که بافت پوشش گیاهی از نظر ارتفاع از ساختمان غنی تر است. قابل ذکر است، مورد دوم فقط از ویژگی های عمیق تصویر nDSM استفاده می کند. مورد سوم فقط از ویژگی های عمیق تصویر DOM استفاده می کند و چهارمی از ویژگی های عمیق تصویر nDSM و تصویر DOM (پیشنهاد شده) استفاده می کند. که درجدول 5 ، این چهار استراتژی به ترتیب با استفاده از استراتژی (1) تا (4) نشان داده شده است. شکل 13 نتایج چهار راهبرد را نشان می دهد و جدول 5 ارزیابی های دقت مربوطه را نشان می دهد. بهترین نتیجه هر مورد ارزیابی در جدول 5 با فونت پررنگ مشخص شده است.
شکل 13 و جدول 5 نشان می دهد که ویژگی های دست ساز ناکارآمد هستند. از این رو، آنها برای DSM فتوگرامتری مناسب نیستند. با مقایسه استراتژی (2) با استراتژی (4)، محدودیت صرفاً اتخاذ ویژگی های عمیق از یک جنبه قابل مشاهده است. در حالی که نتایج استراتژی (2) همیشه در مورد ارزیابی کامل بودن هر دو جنبه مبتنی بر پیکسل و جنبه مبتنی بر شی در رتبه اول قرار دارند، آنها در ارزیابی صحت به نتایج امیدوارکننده ای دست پیدا نمی کنند. با توجه به ارزیابی صحت و کیفیت، استراتژی (4) در هر دو ارزیابی مبتنی بر پیکسل و مبتنی بر شی رتبه اول را دارد. به طور کلی، روش ما که ویژگی های عمیق استخراج شده از هر دو تصویر nDSM و تصویر DOM را ترکیب می کند، امیدوارکننده ترین نتیجه را به دست می آورد.
4.2.3. کاهش ابعاد ویژگی
برای کاهش ابعاد ویژگی، نتایج استخراج ساختمان از دو استراتژی مقایسه شد: (1) با استفاده از ویژگیهای ترکیبی بدون پردازش PCA، و (2) استفاده از ویژگیهای ترکیبی با پردازش PCA (پیشنهاد شده). در جدول 6 و جدول 7 ، این دو استراتژی به ترتیب با استفاده از استراتژی (1) تا (2) نشان داده شده اند.
شکل 14 نتایج دو استراتژی را در سه مجموعه داده نشان می دهد و جدول 6 ارزیابی های دقت مربوطه را ارائه می دهد. بهترین نتیجه هر مورد ارزیابی در جدول 6 با فونت پررنگ مشخص شده است.
از شکل 14 و جدول 6 ، بدیهی است که ارزیابی دقت استراتژی (1) همیشه خوب نیست و می تواند بدتر از نتیجه استراتژی (2) باشد. این پدیده نشان می دهد که استفاده از الگوریتم PCA اطلاعات مفید را در ویژگی های عمیق نگه می دارد و شاید اطلاعات مضر را حذف می کند.
با توجه به ارزیابی هزینه های محاسباتی، چهار استراتژی با هم مقایسه شدند: (1) تنها با استفاده از ویژگی های عمیق از تصویر nDSM. (2) فقط با استفاده از ویژگی های عمیق از تصویر DOM. (3) استفاده از ویژگی های ترکیبی بدون پردازش PCA. و (4) استفاده از ویژگی های ترکیبی با پردازش PCA (پیشنهاد شده). جدول 7 زمان انتخاب نمونه ها و آموزش این استراتژی ها را نشان می دهد و به ترتیب به صورت استراتژی (1) تا (4) نشان داده شده است. ابعاد ویژگی برای هر استراتژی به ترتیب 7، 12، 256 و 19 است. این هزینههای محاسباتی نیز با استفاده از تنظیمات آزمایشی ذکر شده در ابتدای بخش 3 محاسبه میشوند .
با مقایسه زمان محاسبه استراتژی (4) و استراتژی (3)، اثربخشی الگوریتم PCA در کنترل هزینه محاسبات تأیید می شود. علاوه بر این، زمان محاسبه استراتژی (4) کمی بیشتر از استراتژی (1) و (2) است که قابل قبول است. برای Area2 با DLG2014، زمان محاسبه هر استراتژی کمی بیشتر از زمان مربوطه در Area2 با DLG2008 است. این به دلیل سطوح مختلف نویز در DLG های شرکت کننده در انتخاب و تعداد متفاوت نمونه های تمیز درگیر در آموزش است. همانطور که قبلا ذکر شد، DLG2014 دارای نویز کمتری نسبت به DLG2008 است، و بنابراین شامل نمونه های تمیز بیشتری در روش پیشنهادی است.
4.2.4. محدودیت روش پیشنهادی
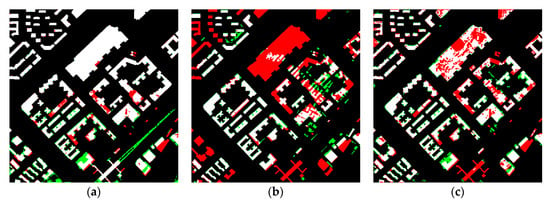
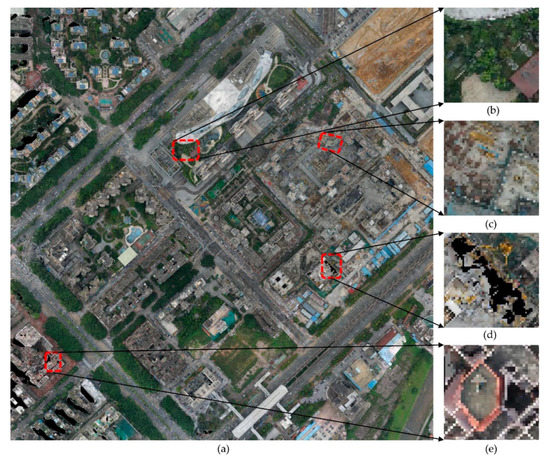
در حالی که آزمایش ما کارایی روش پیشنهادی را تایید کرد، دارای محدودیتهایی است. با توجه به ارزیابی کامل، در Area2 دو داده DLG تاریخی نسبتاً کمتر از ارزیابی مربوط به صحت است. موقعیت های اصلی ممکن که باعث استخراج اشتباه یا اشتباه می شوند از شکل 15 b–e نشان داده شده است.
همانطور که در شکل 15 ب نشان داده شده است، طبیعی است که پوشش گیاهی روی پشت بام یک ساختمان به عنوان “غیر ساختمانی” در یک کار استخراج پیکسلی شناسایی شود. به طور مشابه، مصالح ساختمانی (همانطور که در شکل 15 ج نشان داده شده است) به راحتی قابل پیش بینی اشتباه هستند. همانطور که در شکل 15 d، این پیکسل ها حاوی اطلاعات طیفی نیستند و باعث ایجاد ویژگی های ناقص می شوند که می تواند منجر به پیش بینی نادرست شود. در نهایت، در شکل 15e، پیشبینی صحیح بالای ساختمان ناتمام نیز دشوار است، زیرا ویژگیهای ساختاری آن واقعاً با سایر قسمتهای نهایی ساختمان متفاوت است. با توجه به این شرایط، به نظر ما، غلبه بر آن در کار استخراج در سطح پیکسل چالش برانگیز نیست و برای پرداختن به این موضوع به تحقیقات بیشتری نیاز است.
5. نتیجه گیری و کار آینده
در این مقاله، ما یک روش استخراج خودکار ساختمان در شهرها را با کمک دادههای DLG تاریخی پیشنهاد میکنیم. این DLG ها می توانند برچسب های آموزشی کافی را ارائه دهند که به معنای الزامات کمتری برای برچسب زدن دستی است. نمونه های تمیز را می توان با روش تکراری پیشنهادی از طریق طبقه بندی کننده RF با در نظر گرفتن نمونه های نامتعادل انتخاب کرد. قابلیت اطمینان این روش در فیلتر کردن برچسب های نویزدار و حفظ پیکسل های بدون تغییر در تصاویر تایید شد. با مقایسه نتایج بر اساس چهار استراتژی مختلف در انتخاب ویژگی، اهمیت ویژگیهای عمیق و لزوم ترکیب اطلاعات ارتفاع و اطلاعات طیفی قابل مشاهده است. استفاده از الگوریتم PCA می تواند اطلاعات مفید را حفظ کند و حتی از آسیب احتمالی ناشی از ابعاد بالا در ویژگی های عمیق جلوگیری کند. علاوه بر این، الگوریتم PCA می تواند به کنترل هزینه محاسبات در سطح نسبتاً پایین کمک کند. آزمایشها در دو منطقه با سه DLG حاوی سطوح مختلف نویز، اثربخشی و استحکام این روش را نشان داد.
در حالی که کارهای ما ثابت کرد که دادههای DLG تاریخی موجود در ساخت وظایف استخراج مفید هستند، مطالعات بیشتری مورد نیاز است. به عنوان مثال، پردازش استخراج می تواند در قالب سوپر پیکسل برای بهبود کارایی و کاهش نویز احتمالی در نتیجه نهایی انجام شود. علاوه بر این، میتواند تعداد نمونههایی را که در انتخاب نمونه تمیز شرکت میکنند کاهش دهد و هزینه محاسبات را بیشتر کاهش دهد.











بدون دیدگاه