

کلید واژه ها:
بلاک چین ؛ شاخص مکانی – زمانی ; Verkle AR*-tree ; پرس و جو تطبیقی
1. مقدمه
2. کارهای مرتبط
2.1. شاخص مکانی- زمانی
2.2. بلاک چین
2.2.1. معماری بلاک چین
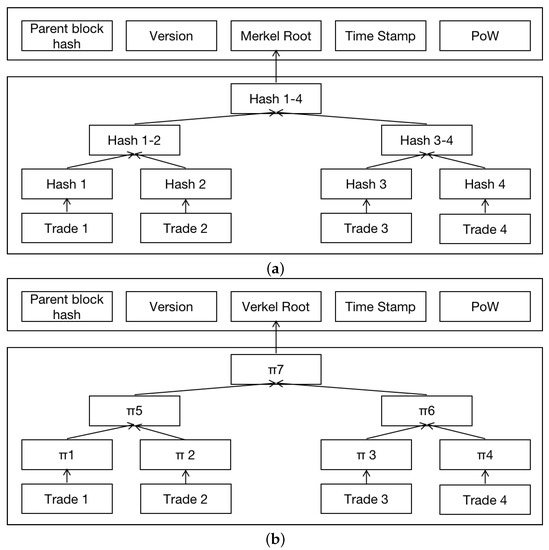
2.2.2. درختان مرکل و درختان ورکل
2.2.3. شاخص فضایی-زمانی در بلاک چین
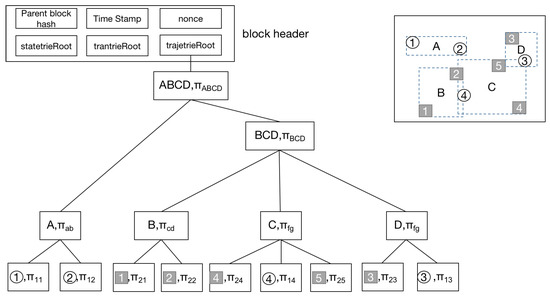
3. Verkle AR*-Tree در بلاک چین فضایی-زمانی
3.1. مقدماتی
3.2. Verkle AR*-Tree
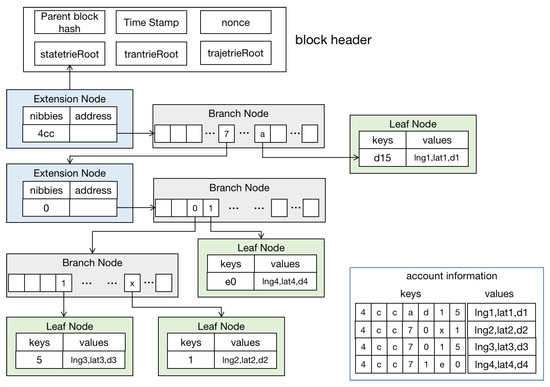
3.2.1. فهرست حساب با آخرین مکان
| الگوریتم 1 به روز رسانی الگوریتم VPT. |
| ورودی: |
| vpt: سعی کنید Verkle patricia |
| گره: گره فعلی در VPT |
| acc (کلیدها، مقادیر): اطلاعات حساب که باید به روز شود |
| خروجی: |
| vpt: VPT به روز شده |
| 1: اگر گره صفر باشد پس |
| 2: گره ← createLeafNode ( acc ) |
| 3: vpt.root ← گره |
| 4: دیگری |
| 5: اگر node.type LeftNode باشد، پس |
| 6: p ← maxLengthPrefix ( acc.keys ، node.keys ) |
| 7: newe ، newb ← createExtensionNode ( p )، createBranchNode () |
| 8: newb.children [ node.keys [ len ( p )]] ← node |
| 9: newb.children [ acc.keys ( len ( p ))] ← createLeftNode ( acc ) |
| 10: newb.parent ، newe.parent ← newe ، node.parent |
| 11: other if node.type ExtensionNode است پس |
| 12: p ← maxLengthPrefix ( acc.keys ، node.nibbs ) |
| 13: اگر p == node.nibbs پس |
| 14: acc.keys = acc.keys[len(p):] |
| 15: به روز رسانی (vpt، node.next، acc) |
| 16: else if node.nibbs.startWith(p) سپس |
| 17: newe ، newb ← createExtensionNode ( p )، createBranchNode () |
| 18: newb.children [ node.nibbs [ len ( p )]] getsnode |
| 19: newb.children [ acc.keys ( len ( p ))] ← createLeftNode ( acc ) |
| 20: newb.parent ، newe.parent ← newe ، node.parent |
| 21: دیگری |
| 22: newb ← createBranchNode () |
| 23: newb.parent ← node.parent |
| 24: newb.children [ acc.keys [0]] ← createLeftNode ( acc ) |
| 25: newb.children [ node.nibbs [0]] ← node |
| 26: node.nibbs ← node.nibbs [1:] |
| 27: پایان اگر |
| 28: else اگر node.type BranchNode است، پس |
| 29: اگر node.children[acc.keys[0]] صفر باشد، پس |
| 30: node.children [ acc.keys [0]] ← createLeftNode ( acc ) |
| 31: دیگری |
| 32: acc.keys ← acc.keys [1:] |
| 33: بهروزرسانی (vpt,node.children[acc.keys[0]],acc) |
| 34: پایان اگر |
| 35: پایان اگر |
| 36: پایان اگر |
3.2.2. فهرست اطلاعات معاملات
با توجه به پنجره پرس و جو W (wx,wy) و شی فضایی O (rx,ry)، که در آن wx,wy و rx,ry به ترتیب مقادیر نرمال شده عرض و ارتفاع W و O هستند، سپس احتمال تقاطع پنجره پرس و جو با شیء این است:
با توجه به R*-tree کامل با گرههای M، اگر توزیع پرس و جو یکنواخت باشد، [ 33 ] میانگین تعداد گرههای قابل دسترسی را به صورت زیر نشان میدهد:
فرض کنید یک درخت R* کامل وجود دارد که توسط N شی فضایی ساخته شده است، تعداد گره ها در لایه i برابر است.متر( من)�(�)، 1 ≤ I≤ اچ1≤�≤�، که در آن H ارتفاع درخت و M حداکثر تعداد گره های فرزند گره است. با توجه به یک پنجره پرس و جو W(wx,wy)، احتمال تقاطع بین مستطیل فضایی آرمن ج( r x ، r y)���(��,��)از هر گره R-tree و W به عنوان نشان داده می شود پآرمن ج����، i تعداد لایه و j تعداد گره لایه i است. سپس میانگین تعداد دسترسی به گره لایه k برابر است با:
میانگین تعداد گرههایی که در درخت R به آنها دسترسی دارند، مجموع گرههای دسترسی به هر لایه است (گره ریشه همیشه قابل دسترسی است).
| الگوریتم 2 ایجاد مجدد. |
| ورودی: |
| درخت: R*-tree |
| خروجی: |
| درخت: درخت R* بازسازی شده |
| 1: ورودیها ← tree.allentries () |
| 2: گره ها ← گوشواره ها ( ورودی ها ) |
| 3: در حالی که True do |
| 4: نتایج ← rearragenodes ( گره ها ) |
| 5: والدین ← [ createNode ( فرزندان = r ) برای نتایج ] |
| 6: اگر parent.length ≤ context.maxchildrennum سپس |
| 7: tree.root ← createNode ( فرزندان = والدین ) |
| 8: بازگشت |
| 9: پایان اگر |
| 10: نتایج ، گرهها ← []، والدین |
| 10: پایان در حالی که |
| الگوریتم 3 Rearragenodes. |
| ورودی: |
| درخت: R*-tree |
| گره ها: تمام گره های یک لایه |
| خروجی: |
| گروه ها: گروه های گره |
| 1: برای گره ∈ گره ها انجام می دهند |
| 2: برای d = 0 به node.dimension انجام دهید |
| 3: برای j = 0 تا 1 انجام دهید |
| 4: g 1, g 2 ← split ( گره ها , d , node , j ) |
| 5: plans.add(g1,g2) |
| 6: پایان برای |
| 7: پایان برای |
| 8: پایان برای |
| 9: طرحها ← مرتبشده ( طرحها ، ‘ cov ‘، معکوس شده ) |
| 10: maxcov ← برنامهها [0]. cov |
| 11: برنامه ها ← طرح ها [ cov == maxcov ] |
| 12: طرحها ← مرتبشده ( طرح ، « همپوشانی ») |
| 13: برنامه های بازگشت[0] |
| الگوریتم 4 تقسیم. |
| ورودی: |
| ورودی ها: ورودی هایی که باید تقسیم شوند |
| خروجی: |
| گره ها: مجموعه گره های تقسیم شده |
| 1: برای ورود ∈ ورودی انجام دهید |
| 2: برای d = 0 به enter.dimension انجام دهید |
| 3: برای j = 0 تا 1 انجام دهید |
| 4: g 1, g 2 ← تقسیم ( ورودی ها , d , ورودی , j ) |
| 5: plans.add(g1,g2) |
| 6: پایان برای |
| 7: پایان برای |
| 8: پایان برای |
| 9: طرحها ← مرتبشده ( طرحها ، ‘ cov ‘، معکوس شده ) |
| 10: maxcov ← برنامهها [0]. cov |
| 11: برنامه ها ← طرح ها [ cov == maxcov ] |
| 12: طرحها ← مرتب شده ( طرحها ، ‘ minarea ‘) |
| 13: minarea ← پلان [0]. حوزه |
| 14: plans ← plans.trim ( minarea , 0.) |
| 15: پلانها مرتبشده ( طرحها ، ‘ همپوشانی ‘ ) |
| 16: Optima ← plans [0] |
| 17: بازگشت اپتیما |
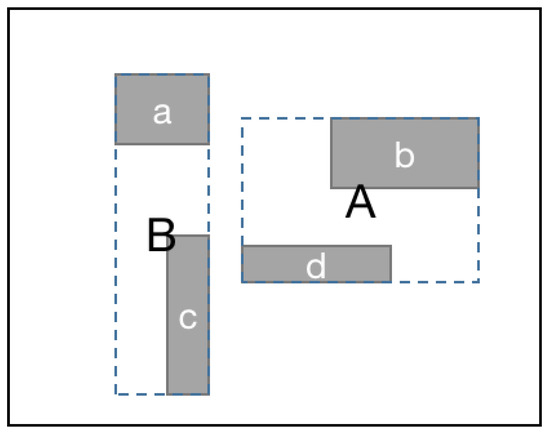
3.2.3. شاخص مسیر
4. آزمایش کنید
4.1. راه اندازی آزمایشی
-
اینکه آیا عملکرد پرس و جوی مکانی-زمانی Verkle AR*-tree پیشنهاد شده در کار ما بهتر از معیار در [ 9 ] است که گزارش می دهد عملکرد پرس و جو مکانی-زمانی تا حد زیادی تحت تأثیر اندازه بلوک قرار می گیرد، بنابراین از اندازه های مختلف بلوک استفاده می کنیم. عملکرد پرس و جو را مقایسه کنید
-
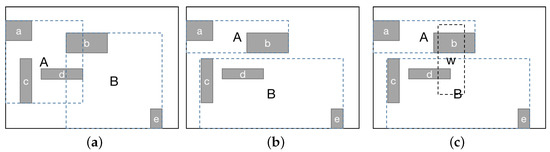
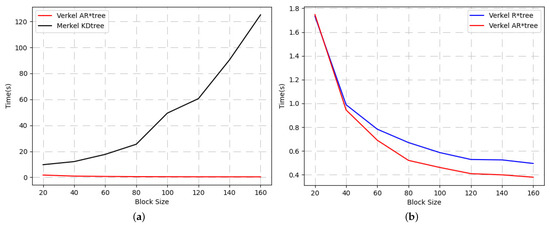
مقایسه عملکرد بین AR*-tree و R*-tree تطبیقی در بلاک چین.
-
طول تعهد بردار ارائه شده توسط درخت Verkle به عمق درخت مربوط است، اما مستقل از عرض درخت است. بنابراین باید از نظر عملکرد بهتر از درخت مرکل باشد. با این حال، تفاوت در اثبات عملکرد درختان Verkle AR* در اندازههای مختلف مشخص نیست، که نیاز به مقایسه بیشتر در آزمایشها دارد.
4.2. نتیجه
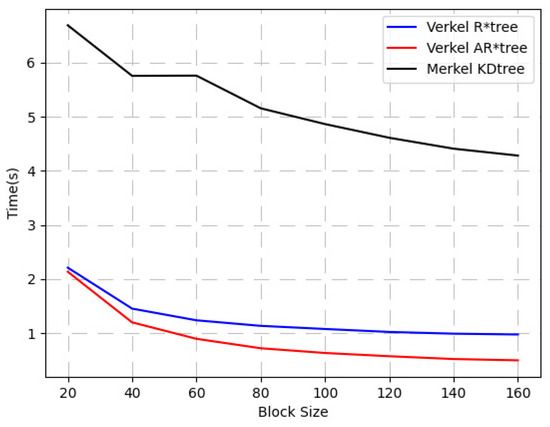
4.2.1. عملکرد جستجوی فضایی-زمانی Verkle AR*-Tree
ما حداکثر عرض درخت Verkle AR* را روی 8 قرار دادیم. ما از مراکز منطقه پرس و جو از مدل گاوسی مختلط زیر در یک منطقه عادی متشکل از عرض جغرافیایی، طول جغرافیایی و مهر زمانی نمونه برداری کردیم. عرض هر مکعب پرس و جو بر روی یک توزیع گاوسی با مرکز 0.05 و واریانس 0.1 نمونه برداری می شود.
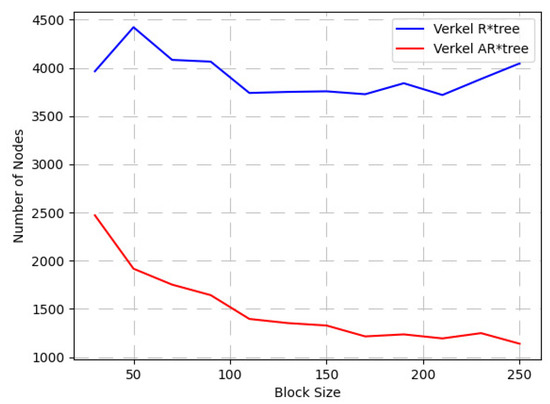
جایی که تومنتومنهشت نقطه انتهایی مکعب است که با <0.33،0.33،0.33> و <0.66،0.66،0.66> احاطه شده اند. اندازه بلوک را از 20 تا 160 با فاصله 20 تنظیم می کنیم. برای هر اندازه بلوک، به طور تصادفی از 200 مکعب پرس و جو نمونه برداری می کنیم و پرس و جوها را روی Verkle R*-tree (عدم تطبیق)، Verkle AR*-tree (تطبیقی شامل) اجرا می کنیم. و Merkle KD tree [ 9 ] به ترتیب. آزمایش پنج بار اجرا شد و میانگین تمام آزمایشها به عنوان نتیجه در نظر گرفته شد، همانطور که در شکل 7 نشان داده شده است.
4.2.2. تجزیه و تحلیل عملکرد تطبیقی
-
نمونه گیری مرکزی مرکز تمام پنجره های پرس و جو در مرکز کل منطقه فضا-زمان ثابت است. عرض هر بعد از پنجره پرس و جو با نمونه برداری از توزیع گاوسی N(0.3,0.05) بدست می آید. استثنا این است که عرض بعد زمانی پنجره پرس و جو (بعد سوم) روی 0.5 ثابت شده است تا بلاک های بیشتری به طور موثر پرس و جو شوند.
-
نمونه گیری گاوسی توزیع پرس و جو یک تابع گاوسی است (تعداد نقاط مرکزی 9 است و عرض پنجره پرس و جو از توزیع نرمال با مقدار مرکزی 0.1 و واریانس 0.05 پیروی می کند).
-
نمونه گیری دیریکله هم موقعیت مرکزی و هم عرض پنجره پرس و جو از توزیع دیریکله با آلفا = 3 و k = 4 پیروی می کنند.
-
نمونه گیری نمایی: نقطه مرکز پرس و جو از توزیع نمایی چند متغیره با مقیاس = 2 پیروی می کند و عرض پنجره پرس و جو از توزیع نرمال با مقدار مرکزی 0.1 و واریانس 0.05 پیروی می کند.
-
نمونه گیری Weibull: موقعیت مرکز پرس و جو از توزیع Weibull با شکل = 5 پیروی می کند و عرض پنجره query از توزیع نرمال با مقدار مرکزی 0.1 و واریانس 0.05 پیروی می کند.
-
نمونه گیری یکنواخت نمونه گیری یکنواخت مرکز پرس و جو را با توزیع یکنواخت در کل منطقه مکانی-زمانی ایجاد می کند و عرض هر بعد از پنجره پرس و جو 0.05 است.
-
نمونه گیری شبکه ای تعداد کل پرسوجوها را برطرف میکنیم و سپس کل فضا را با توجه به تعداد کوئریها به شبکههایی تقسیم میکنیم. هر شبکه فقط مربوط به یک پنجره پرس و جو است. این یک نمونه گیری یکنواخت مطلق است، که در آن نمونه گیری یکنواخت نمونه برداری با توزیع احتمال است.
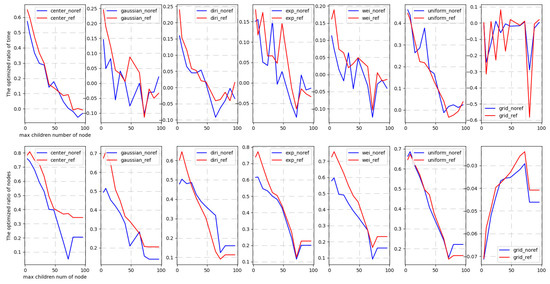
برای هر یک از روش های نمونه گیری فوق، الگوریتم بازسازی تطبیقی را دو بار اجرا می کنیم. اولی (به نام غیر ref) از فرکانس پرس و جوی تاریخی استفاده نمی کند، اما دومی (به نام ref) از فرکانس پرس و جو استفاده می کند. برای اولی، خطوط 10-11 در الگوریتم realragenodes اجرا نمی شوند. برای هر نمونه برداری، 6000 پنجره پرس و جو دریافت می کنیم تا کل زمان پرس و جو و تعداد گره های قابل دسترسی را ثبت کنیم. ما به ترتیب نسبت بهینه شده زمان دسترسی و تعداد گره های دسترسی را محاسبه می کنیم. نسبت بهینه سازی با فرمول زیر تعریف می شود، که در آن ORT نسبت بهینه سازی شده زمان است، TBR زمان پرس و جو قبل از بازسازی، TAR زمان پرس و جو پس از بازسازی، و ORN نسبت بهینه شده گره ها، NBR تعداد گره هایی است که قبل از بازسازی به آن دسترسی پیدا کرده اند. بازسازی، NAR تعداد گره هایی است که پس از بازسازی به آنها دسترسی پیدا می کنند.
هدف از آزمایش بررسی بهبود عملکرد نسبی الگوریتم بازسازی بر اساس فرکانس توزیع پرس و جو است. شماره گره معماری را برای [4,8,16,24,32,40,48,64,72,80,88,96] تنظیم می کنیم و آزمایشات فوق را انجام می دهیم. نتایج تجربی در شکل 10 نشان داده شده است.
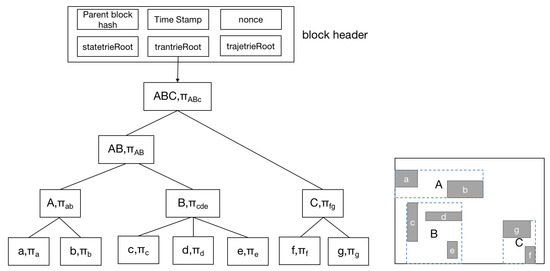
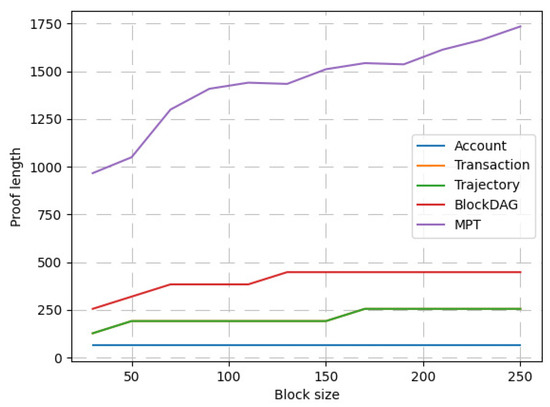
4.2.3. تحلیل عملکرد تعهد برداری
5. بحث
6. نتیجه گیری و کار آینده
منابع
- خو، ام. چن، ایکس. Kou, G. بررسی سیستماتیک بلاک چین. مالی نوآوری. 2019 ، 5 ، 27. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کازینو، اف. داساکلیس، TK; پاتساکیس، سی. بررسی ادبیات سیستماتیک برنامه های کاربردی مبتنی بر بلاک چین: وضعیت فعلی، طبقه بندی و مسائل باز. Telemat. به اطلاع رساندن. 2019 ، 36 ، 55–81. [ Google Scholar ] [ CrossRef ]
- ورلی، سی. Skjellum، A. معاوضه ها و چالش های بلاک چین برای کاربردهای فعلی و در حال ظهور: تعمیم، تکه تکه شدن، زنجیره های جانبی و مقیاس پذیری. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در مورد اینترنت اشیا (iThings) و محاسبات سبز و ارتباطات IEEE (GreenCom) و IEEE Cyber, Physical and Social Computing (CPSCom) و IEEE Smart Data (SmartData)، هالیفاکس، NS، کانادا، 30 جولای–3 اوت 2018; صص 1582-1587. [ Google Scholar ] [ CrossRef ]
- Nakamoto، S. Bitcoin: یک سیستم نقدی الکترونیکی همتا به همتا. در دسترس آنلاین: https://bitcoin.org/bitcoin.pdf (در 22 مه 2022 قابل دسترسی است).
- برگشت، A.; کورالو، ام. دشجر، ل. فریدنباخ، م. ماکسول، جی. میلر، آ. پولسترا، ا. تیمون، جی. Wuille, P. فعال کردن نوآوری های بلاک چین با زنجیره های جانبی متصل. در دسترس آنلاین: https://blockstream.com/sidechains.pdf (در 22 مه 2022 قابل دسترسی است).
- ووجیچیچ، دی. یاگودیچ، دی. Ranđić، S. فناوری بلاک چین، بیت کوین و اتریوم: مروری کوتاه. در مجموعه مقالات 2018 هفدهمین سمپوزیوم بین المللی Infoteh-Jahorina (INFOTEH)، سارایوو شرقی، بوسنی و هرزگوین، 21–23 مارس 2018؛ صص 1-6. [ Google Scholar ] [ CrossRef ]
- هلمر، اس. روگیا، م. ال یوینی، ن. Pahl, C. EthernityDB – ادغام عملکرد پایگاه داده در یک بلاک چین. در مجموعه مقالات کنفرانس اروپایی پیشرفت در پایگاه های داده و سیستم های اطلاعاتی، بوداپست، مجارستان، 2 تا 5 سپتامبر 2018؛ Springer: برلین/هایدلبرگ، آلمان، 2018; صص 37-44. [ Google Scholar ] [ CrossRef ]
- سومپلینسکی، ی. ویبورسکی، اس. Zohar, A. PHANTOM GHOSTDAG: A Scalable Generalization of Nakamoto Consensus: 2 سپتامبر 2021. در مجموعه مقالات سومین کنفرانس ACM در مورد پیشرفت در فناوری های مالی، آرلینگتون، VA، ایالات متحده آمریکا، 26-28 سپتامبر 2021. صص 57-70. [ Google Scholar ]
- نورگلیف، آی. مزمل، م. Qu, Q. فعال کردن بلاک چین برای پردازش پرس و جوی مکانی-زمانی کارآمد. در مجموعه مقالات کنفرانس بین المللی مهندسی سیستم های اطلاعات وب، ملبورن، VIC، استرالیا، 20 تا 24 اکتبر 2018؛ Springer: برلین/هایدلبرگ، آلمان، 2018; صص 36-51. [ Google Scholar ]
- درختان Kuszmaul، J. Verkle. در دسترس آنلاین: https://math.mit.edu/research/highschool/primes/materials/2018/Kuszmaul.pdf (در 22 مه 2022 قابل دسترسی است).
- Ahn، HK; مامولیس، ن. وانگ، اچ. بررسی روشهای دسترسی چند بعدی. در دسترس آنلاین: https://dspace.library.uu.nl/bitstream/handle/1874/2491/2001-14.pdf (در تاریخ 22 مه 2022 قابل دسترسی است).
- سامت، اچ. چهار درخت و ساختارهای داده سلسله مراتبی مرتبط. کامپیوتر ACM. Surv. 1984 ، 16 ، 187-260. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اوی، بی. مکدونل، ک. Sacks-davis, R. فضایی kd-tree: مکانیزم نمایه سازی برای پایگاه های داده فضایی. در مجموعه مقالات کنفرانس بین المللی نرم افزار کامپیوتر و برنامه های کاربردی IEEE، توکیو، ژاپن، 5 تا 6 اکتبر 1987. ص 433-438. [ Google Scholar ]
- اوهساوا، ی. Sakauchi, M. The BD-Tree – ساختار دادههای N بعدی با ویژگیهای دینامیکی بسیار کارآمد. در مجموعه مقالات نهمین کنگره جهانی کامپیوتر IFIP، پاریس، فرانسه، 19 تا 23 سپتامبر 1983. صص 539-544. [ Google Scholar ]
- تائو، ز. چنگ، سی. پان، ز. Shi, J. تولید و کاربردهای درخت BSP با وضوح چندگانه. جی. سافتو. 2001 ، 12 ، 117-125. [ Google Scholar ]
- لی، سی. وو، زی. وو، پی. Zhao, Z. یک روش ساخت تطبیقی از شاخص مکانی-زمانی سلسله مراتبی برای داده های برداری تحت شبکه های همتا به همتا. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 512. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بکمن، ن. کریگل، اچ پی؛ اشنایدر، آر. Seeger, B. R*-tree: یک روش دسترسی کارآمد و قوی برای نقاط و مستطیل ها. ACM SIGMOD 1990 ، 19 ، 322-331. [ Google Scholar ] [ CrossRef ]
- شوماک، م. Gurský, P. R ++ -Tree: یک روش دسترسی فضایی کارآمد برای دادههای نقطهای بسیار زائد. در روندهای جدید در پایگاه های داده و سیستم های اطلاعاتی ; Springer: برلین/هایدلبرگ، آلمان، 2014; صص 37-44. [ Google Scholar ]
- شکر، س. شیونگ، اچ. Zhou، X. (ویرایش) R-Tree. در دایره المعارف GIS ; Springer: برلین/هایدلبرگ، آلمان، 2017; پ. 1805. [ Google Scholar ] [ CrossRef ]
- Gunther, O. طراحی درخت سلولی: ساختار شاخص شی گرا برای پایگاه های داده هندسی. در مجموعه مقالات پنجمین کنفرانس بین المللی مهندسی داده، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 6-10 فوریه 1989; صص 598-605. [ Google Scholar ] [ CrossRef ]
- کامل، من. Faloutsos، C. Hilbert R-Tree: An Improved R-Tree با استفاده از فراکتال ها. در مجموعه مقالات بیستمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ (VLDB ’94)، سانتیاگو دی شیلی، شیلی، 12 تا 15 سپتامبر 1994. صص 500–509. [ Google Scholar ]
- الطراونه، ع. هرشبرگ، تی. مدوری، اس. کنده، ف. Skjellum، A. Buterin’s Scalability Trilemma از طریق یک طبقه بندی مبتنی بر تغییر حالت برای الگوریتم های اجماع مشترک مشاهده شده است. در مجموعه مقالات دهمین کارگاه و کنفرانس سالانه محاسبات و ارتباطات (CCWC) 2020، لاس وگاس، NV، ایالات متحده، 6 تا 8 ژانویه 2020؛ صص 727-736. [ Google Scholar ] [ CrossRef ]
- Wan, L. یک روش بهینه سازی پرس و جو در تراکنش الکترونیکی بلاک چین بر اساس حساب گروهی. در مجموعه مقالات کنفرانس بین المللی تجزیه و تحلیل داده های بزرگ برای سیستم های سایبری-فیزیکی، شانگهای، چین، 28-29 دسامبر 2021؛ Springer: برلین/هایدلبرگ، آلمان، 2021؛ صص 1358–1364. [ Google Scholar ] [ CrossRef ]
- سومپلینسکی، ی. Zohar, A. PHANTOM: A Scalable BlockDAG Protocol. در مجموعه مقالات سومین کنفرانس ACM در مورد پیشرفتها در فناوریهای مالی، آرلینگتون، VA، ایالات متحده آمریکا، 26 تا 28 سپتامبر 2021. [ Google Scholar ]
- Szydlo، M. Merkle Tree Traversal in Log Space and Time. در کنفرانس بین المللی تئوری و کاربرد تکنیک های رمزنگاری ; Springer: برلین/هایدلبرگ، آلمان، 2004; صص 541-554. [ Google Scholar ]
- کامل بولوس، MN; ویلسون، جی تی; Clauson، KA Geospatial blockchain: وعده ها، چالش ها و سناریوها در سلامت و مراقبت های بهداشتی. بین المللی J. Health Geogr. 2018 ، 17 ، 25. [ Google Scholar ]
- لیو، اچ. تای، دبلیو. وانگ، ی. وانگ، اس. چارچوب تجارت داده های فضایی مبتنی بر بلاک چین. پیش چاپ. 2021. در دسترس آنلاین: https://www.researchgate.net/publication/348709925_A_Blockchain-Based_Spatial_Data_Trading_Framework (در 22 مه 2022 قابل دسترسی است).
- سان، ی. ژانگ، ال. فنگ، جی. یانگ، بی. کائو، بی. عمران، ام. تجزیه و تحلیل عملکرد برای سیستمهای اینترنت اشیاء بیسیم مبتنی بر بلاک چین مبتنی بر مدل تمپو-مکانی. در مجموعه مقالات کنفرانس بین المللی 2019 در زمینه محاسبات توزیع شده مبتنی بر سایبری و کشف دانش (CyberC)، گویلین، چین، 17 تا 19 اکتبر 2019؛ صص 348-353. [ Google Scholar ] [ CrossRef ]
- دمنکوف، م. دمنکوا، ای. Shishmanova, S. کاربرد فناوری بلاک چین برای ذخیره سازی اطلاعات روی اشیاء فضایی. وستن فناوری دولتی آستاراخان دانشگاه سر. مدیریت محاسبه کنید. علمی به اطلاع رساندن. 2019 ، 1 ، 61–72. [ Google Scholar ] [ CrossRef ]
- Qu، Q. نورگلیف، آی. مزمل، م. جنسن، CS; Fan, J. در مورد پردازش پرس و جو بلاک چین مکانی-زمانی. ژنرال آینده. محاسبه کنید. سیستم 2019 ، 98 ، 208-218. [ Google Scholar ] [ CrossRef ]
- موراتیدیس، ک. ساچاریدیس، دی. Pang، HH طرح هضم جزئی تحقق یافته: یک روش تأیید کارآمد برای پایگاه های داده برون سپاری شده. VLDB J. 2009 ، 18 ، 363-381. [ Google Scholar ] [ CrossRef ]
- کریگل، اچ پی؛ کونات، پ. Renz، M. R*-Tree. در دایره المعارف GIS ; Shekhar, S., Xiong, H., Eds. Springer: برلین/هایدلبرگ، آلمان، 2008; ص 987-992. [ Google Scholar ] [ CrossRef ]
- Pagel، BU; شش، HW; توبن، اچ. Widmayer, P. Towards an Analysis of Range Query Performance in Spatial Data Structures. در مجموعه مقالات دوازدهمین سمپوزیوم ACM SIGACT-SIGMOD-SIGART در اصول سیستم های پایگاه داده، واشنگتن، دی سی، ایالات متحده آمریکا، 25-28 مه 1993. صص 214-221. [ Google Scholar ] [ CrossRef ]
- گرین، دی. پیاده سازی و تجزیه و تحلیل عملکرد روش های دسترسی به داده های مکانی. در مجموعه مقالات پنجمین کنفرانس بین المللی مهندسی داده، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 6-10 فوریه 1989; ص 606-615. [ Google Scholar ] [ CrossRef ]


4 نظرات