1. مقدمه
فضای عمومی شهری ارتباط مستقیمی با کیفیت زندگی ساکنان و جذابیت گردشگری دارد و تصاویر فضاهای عمومی شهری با تصاویر مناطق مرکزی شهرها همخوانی بالایی دارد. فضای عمومی نه تنها محلی برای ارائه فعالیت های عمومی به شهروندان و گردشگران بلکه حامل فرهنگ شهری است [ 1 ]. بسیاری از فضاهای عمومی محبوب مترادف با شهرهای خود شده اند [ 2]، مانند پارک مرکزی، پارک برایانت، و میدان تایمز در نیویورک و ریورفرانت در شیکاگو. در مطالعه فضاهای عمومی اتفاق نظر وجود دارد که زندگی عمومی شهری متنوع مفهوم اصلی ایجاد فضای عمومی است و ادراک بصری بر احساس ذهنی زندگی عمومی شهری حاکم است. موضوعات جامعهشناختی مانند خصوصیسازی فضای عمومی [ 3 ]، اعیانسازی، کنترل اجتماعی [ 4 ]، مشارکت عمومی و عدالت اجتماعی در فضاهای عمومی محبوبترین موضوعات پژوهشی هستند. جین جاکوبز فکر میکند که تنها فضاهای عمومی بهطور دموکراتیک به اشتراک گذاشته شده میتوانند واقعاً زندگی عمومی را ایجاد کنند [ 5 ]. صرف نظر از جهتگیری پژوهشهای مرتبط با فضای عمومی، فضاهای مردممدار و مشارکت عمومی همواره از مهمترین موضوعات بودهاند.6 ، 7 ، 8 ].
بررسی فضای عمومی با هدف بهبود کیفیت فضاهای عمومی و بهبود زندگی عمومی ساکنان و گردشگران انجام می شود. جان گهل با هدف ارتباط بین زندگی شهری و فضای عمومی، به تدریج پس از سال ها تحقیق، یک بررسی فضای عمومی و زندگی عمومی (PSPL) کامل را تشکیل داد [ 9 ]. با این حال، تحقیقات سنتی بر روی تصاویر فضاهای عمومی شهری به دلیل محدودیت بودجه تحقیقاتی و زمان، محققان و سایر شرایط مانع می شود و نمی تواند در دوره های طولانی ادامه یابد.
در سالهای اخیر، پیشنهاد استفاده از دادههای رسانههای اجتماعی برای بررسی و بهینهسازی فضای شهری مورد توجه گسترده محققان قرار گرفته است و روشهای یادگیری عمیق چشمانداز وسیعی در این زمینه دارد. اگرچه تکنیکهای یادگیری عمیق به طور فزایندهای در تحقیقات شهری و منظر مورد استفاده قرار میگیرند، تحقیقات بر روی مقیاسهای طراحی شهری مانند فضای عمومی شهری همچنان باید توسعه یابد. با توسعه هوش مصنوعی و یادگیری عمیق، تحقیقات فضای عمومی شهری به رویکردهای روانشناسی محیطی مرسوم محدود نمی شود. بر اساس پیشرفت فناوری بینایی رایانه ای (CV) و رسانه های اجتماعی مبتنی بر مکان (LBSM) و رواج محصولات خدماتی مربوطه، در صورت وجود، می توان نماهای فضای عمومی شهری توسط افراد محلی و گردشگران در دوره های مختلف را در زمان واقعی آموخت. داده های کافی [10 ]. عملی ترین مزیت فناوری جدید در نقشه برداری تصاویر شهری و سرزندگی فضایی شهری از طریق
داده های داوطلبانه اطلاعات جغرافیایی (VGI) نهفته است [ 11 ]. داده های جغرافیایی می توانند ویژگی های رفتاری و توزیع های فضایی ترجیحات عمومی را منعکس کنند [ 12 ]. از آنجایی که مکانسازی فضای عمومی یک کار مداوم است، میتوان تغییرات جزئی برای بهبود سودمندی فضاهای عمومی شهری در طول زمان انجام داد و تجزیه و تحلیل یادگیری عمیق به فرآیند پویا تغییر زندگی عمومی کمک میکند.
با این حال، مطالعات قبلی با استفاده از یادگیری عمیق برای طبقهبندی تصویر، عمدتاً ادراک بصری را تجزیه و تحلیل کردهاند و به ندرت مکان کاربر، توزیع دادههای جغرافیایی طبقهبندیهای تصویر، و کاربریهای فعلی زمین را برای ارائه پیشنهادهای مکانسازی برای فضاهای عمومی شهری ترکیب کردهاند. برای پر کردن این شکاف و کشف روشی ارزشمند برای درک تصاویر فضاهای عمومی شهری، این مطالعه استفاده از طبقهبندی تصاویر یادگیری عمیق را برای کاوش عمیق تصاویر فضاهای عمومی شهری و ارائه چندین پیشنهاد مکانسازی برای مقاومسازی فضاهای عمومی موجود شهری یا برنامهریزی جدید پیشنهاد کرد. فضاها بر اساس تراکم هسته و نتایج تحلیل کیفی. علاوه بر این، این مطالعه با هدف تجزیه و تحلیل صحنههایی که از طریق تصاویر فلیکر بیشتر مورد توجه قرار میگیرند، چه نوع افرادی تصاویر را ارسال میکنند، انجام شد.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 کار مرتبط با داده های فلیکر در زمینه تحقیقات شهری و روش CV بر اساس یادگیری عمیق را مورد بحث قرار می دهد. در بخش 3 ، منطقه مورد مطالعه را با توسعه تاریخی آن و وضعیت فعلی فضای عمومی شهری رودخانه هایهه در تیانجین معرفی می کنیم. ما همچنین مجموعه دادههای فراداده توصیفی و تصویر را از رابط API Flickr معرفی میکنیم و توضیح میدهیم که چگونه آنها را بهدست آوردیم و آنها را تمیز کردیم. در همین حال، روشهای متاداده رویکرد تحلیلی و تجسم نقشه و روشهای تحلیل تصویر را با استفاده از شبکه گروهی هندسه بصری با عمق 16 لایه (VGG-16) بر اساس یادگیری عمیق شبکه عصبی کانولوشن (CNN) در TensorFlow 2.0 و چارچوب Keras ارائه میکنیم. در بخش 4، نتایج از سه کار اصلی مطالعه ارائه شده است. اولین مورد تجزیه و تحلیل فراداده های فلیکر بود. دوم، طبقه بندی تصاویر فلیکر با استفاده از یادگیری عمیق VGG-16 بهینه شده بود. مولفه نهایی استفاده از چگالی هسته برای شدت و توزیع سرزندگی، همراه با کاربری فعلی زمین برای تجزیه و تحلیل کیفی بود. در بخش 5 ، مزایا و معایب استفاده از دادههای رسانههای اجتماعی برای اندازهگیری تصاویر فضاهای عمومی شهری را مورد بحث قرار میدهیم و سه پیشنهاد مکانسازی طراحی شهری برای فضاهای عمومی شهری هایهه و همچنین راهنمایی نسل شهری برای کارهای آینده ارائه میکنیم. ما در بخش 6 با خلاصهای از روش اصلی خود برای بررسی و تحلیل تصاویر فضاهای عمومی شهری نتیجهگیری میکنیم.

2. کارهای مرتبط
سال های اخیر شاهد توسعه سریع و محبوبیت استفاده از داده های بزرگ برای اندازه گیری جامع رفتار انسان از جمله درک عمومی از فضاهای شهری بوده است [ 13 ]. کاوشگر Wi-Fi و داده های مکان [ 14 ]، ردیابی دستگاه GPS [ 15 ]، داده های تلفن همراه [ 16 ]، و داده های رسانه های اجتماعی [ 17 ]] به تدریج در تحقیقات فضاهای عمومی به کار گرفته می شوند. می توان گفت که داده های بزرگ برای ارضای نیازهای در حال تغییر عمومی به کار گرفته می شوند. در همین حال، داده های پویا جایگزین داده های ایستا می شوند و داده های چند منبع جایگزین داده های تک منبعی می شوند. برای این مطالعه، استفاده از روشهای سنتی طراحی شهری برای اندازهگیری تصاویر فضاهای عمومی شهری تنها میتواند چند روز را برای مشاهده تغییرات در تصاویر شهری انتخاب کند، اما یادگیری عمیق بر اساس تحقیقات کلان دادهها میتواند اطلاعات بیشتری را توضیح دهد و هزینه کمتری نیز داشته باشد. به طور کلی، در حالی که استفاده از داده های رسانه های اجتماعی در تحقیقات مطالعات شهری هنوز در مراحل ابتدایی خود است، پوشش میدانی به تدریج در جهت های مختلف به ویژه در زمینه های CV و پردازش زبان طبیعی در حال افزایش است.
در مطالعات شهری با استفاده از دادههای CV و LBSM، اصلیترین پلتفرمهای رسانههای اجتماعی مورد مطالعه عبارتند از توییتر، فیسبوک، فلیکر، فورسکوئر و سینا ویبو که محبوبترین پلتفرمهای رسانههای اجتماعی مبتنی بر وب ۲.۰ هستند. در میان آنها، توییتر و فلیکر اغلب پلتفرم های مورد مطالعه هستند [ 18 ، 19 ]. در تحقیقات رسانه های اجتماعی در مطالعات شهری، داده های فلیکر دومین داده پرکاربرد پس از توییتر است [ 20 ]. تحقیقات داده های فلیکر بر روی ابرداده ها و داده های تصویری تمرکز دارد. ابرداده های فلیکر می توانند الگوهای بازدید فضایی و ویژگی های آنها [ 21 ]، منشأ بازدیدکننده و الگوهای تفریح [ 22 ]، فراوانی بازدید [ 23 ]، توزیع های فضایی [ 24 ] را منعکس کنند.]، زیبایی شناسی منظر [ 25 ] و مناطق شهری مورد علاقه [ 26 ]. تحقیقات فراداده به شدت به تعداد و دقت اطلاعات جغرافیایی و تصاویر دارای برچسب جغرافیایی وابسته است که بر اساس حجم داده های 100000 سطحی هستند. عکسهای رسانههای اجتماعی شامل عکسهایی با انسانها و صحنهها است که اولی منعکسکننده فعالیتهای انسانی است و دومی قدردانی کاربران از فضاها یا عناصر را ثبت میکند [ 27 ].
در تحقیقات CV با استفاده از دادههای فلیکر، خوشهبندی، یادگیری ماشین سنتی و یادگیری عمیق روشهای اصلی برای استخراج تصاویر، طبقهبندی تصاویر و تجزیه و تحلیل اطلاعات بالقوه هستند. گوسال [ 28 ] و وارتمن [ 29 ] و همکاران. از API های Cloud Vision گوگل و برنامه نویسی پایتون برای بازیابی عکس و تجزیه و تحلیل محتوا استفاده کرد که ثابت کرد Cloud Vision یک ابزار تجزیه و تحلیل تصویر موثر است. اشکذری طوسی [ 30] ساختار عاطفی شهر را از طریق بیان انسان ها در تصاویر رسانه های اجتماعی تحلیل کرد. علاوه بر این، مطالعات متعددی برای تجزیه و تحلیل زیباییشناسی تصویر شهری یا منظر با استفاده از مدلهای آموزش عمیق مبتنی بر مجموعه دادههای ImageNet و Places365 انجام شده است. کیم قصد داشت با تجزیه و تحلیل عکسهای فلیکر سئول با استفاده از مدل Inception v3 در مجموعه داده ImageNet، تصاویر شهری را نشان دهد. کانگ [ 31 ] با مدل Inception v3 به تجزیه و تحلیل مناطق جذاب و تصویر شهری گردشگران در سئول با استفاده از یادگیری انتقالی ادامه داد و دقت اول را به 85.77٪ و دقت بالای 5 را به 95.69٪ ارتقا داد. برخی از مطالعات به وضوح به مشکل نرخ موفقیت طبقه بندی پایین اشاره کردند [ 32]. بنابراین، یافتن معماری طبقهبندی تصویر مناسب برای رودخانه Haihe میتواند میزان دقت دادههای Flickr مانند ResNet،
GoogLeNet و VGG-16 را بر اساس CNN بهبود بخشد.
3. مواد و روشها
3.1. منطقه مطالعه
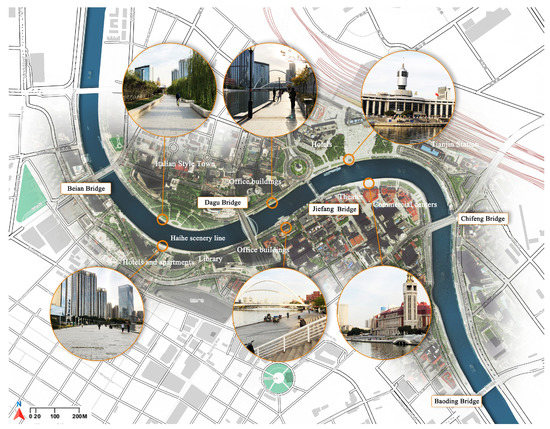
طول رودخانه هایهه 73 کیلومتر است. این بزرگترین رودخانه در شمال چین است. رودخانه هایهه نه تنها نماد فرهنگ شهری در تیانجین بلکه جذاب ترین فضای شهری برای ساکنان و گردشگران است. منطقه اصلی فضای عمومی جامع رودخانه هیهه تیانجین در نزدیکی ایستگاه تیانجین قرار دارد که منبع تاریخی و فرهنگی لامپ ها و مرکز تجاری در منطقه مرکزی شهری تیانجین است ( شکل 1).). در ناحیه مرکزی رودخانه هایهه، در سمت شمالی رودخانه، شهر تیانجین ایتالیایی، ساختمان های اداری، هتل ها و ایستگاه تیانجین قرار دارند و در سمت جنوبی رودخانه هتل ها و آپارتمان ها، کتابخانه، ساختمان های اداری، تئاتر و مرکز تجاری: جینوان پلازا. در این منطقه، مسیرهای پیاده روی رودخانه در نزدیکی هایهه، یک میدان ساحلی، پارک های متعدد و طرح های چشم انداز وجود دارد تا یک کمربند منظره دوستدار آب را تشکیل دهد.
تیانجین طراحی شهری دو طرف رودخانه هایهه را در دهه 1990 آغاز کرد و به طور رسمی توسعه مجدد جامع رودخانه را در سال 2002 با مشارکت عمومی آغاز کرد [ 33 ]. طراحی شهری علاوه بر تجدید رودخانه هایهه در دو سوی رودخانه ها، شامل تصفیه کارگاه های صنعتی و فاضلاب رودخانه در حاشیه رودخانه، حفاظت و استفاده مجدد از ساختمان های با ارزش فرهنگی بالا در حاشیه رودخانه و نوسازی شهری مسکونی است. مناطق و صنعت خدمات در امتداد رودخانه [ 34 ]. در عین حال، رودخانه هایهه نه تنها بر سرزندگی فضایی در امتداد رودخانه تأثیر می گذارد، بلکه سرزندگی کل شهر را نیز تسریع می کند.
درست مانند رودخانه سن در پاریس [ 35 ]، رودخانه تیمز در لندن، و رودخانه یارا در ملبورن، رودخانه هایهه زندگی روزمره ساکنان را حمل می کند و مرکز فرهنگ شهری و زندگی عمومی است. شهروندان برای حفظ نشاط تولید کارآمدتر، انسجام و شمول اجتماعی، خودشناسی مدنی و کیفیت زندگی خود به فضای عمومی نیاز دارند. پژوهش ما بر درک تصاویر رودخانه هایهه متمرکز است که میتواند وضعیت زندگی جامعه محله و ترجیح گردشگری را منعکس کند.
3.2. جمع آوری داده ها
فلیکر که در سال 2004 در کانادا تأسیس شد، یک پلتفرم رسانه اجتماعی میزبان تصویر و ویدیو با بیش از 112 میلیون عضو در سراسر جهان است. در مقایسه با نظرات متنی متعادل و اشتراکگذاری تصاویر در پلتفرمهای رسانههای اجتماعی، فلیکر یک پلتفرم رسانه اجتماعی است که عمدتاً مبتنی بر اشتراکگذاری تصویر است. برخی از تصاویر فلیکر دارای مختصات جغرافیایی هستند که تجزیه و تحلیل فضایی را بر اساس فراداده تصویر فراهم می کند. عکسهای فلیکر جغرافیایی به طور مؤثری برای تعیین کمیت گردشگری و تفریحات مبتنی بر طبیعت در سراسر جهان استفاده شده است [ 36 ]. در تحقیقات مطالعات شهری، توییتر و فلیکر هر دو منابع داده غالب هستند، در حالی که تعداد فزاینده ای از مطالعات از چین بر روی Sina Weibo تمرکز می کنند [ 20 ]]. برخی از مطالعات نشان میدهند که فلیکر عمدتاً در آمریکای شمالی و اروپا استفاده میشود و در میان کاربران چینی محبوبیت خاصی ندارد [ 37 ، 38 ]. بنابراین، از نظر کاربردی، به نظر می رسد Weibo بستر رسانه اجتماعی مناسب تری نسبت به Flickr برای مطالعه شهرهای چین باشد. از آنجایی که سرویس اطلاعات موقعیت مکانی Weibo در حال حاضر توسط API تجاری قابل دسترسی است، Flickr هنوز برای این مطالعه مناسب تر است.
داده های فلیکر از API فلیکر ( https://www.flickr.com/services/api/ ) به دست آمده است(9 فوریه 2022)) پس از درخواست برای کلید OAuth API. تابع API مورد استفاده در این تحقیق تابع “flickr.photos.search” است که با ارسال یک درخواست REST به نقطه پایانی قابل دسترسی است. سه راه برای جستجوی تصاویر فلیکر وجود دارد: اولی بر اساس شناسه مکان ها، دومی جستجوی شعاع و bbox (مستطیل) بر اساس یک مختصات خاص، و سومی جستجوی کلیدواژه است. در این مطالعه از جستجوی کلیدواژه استفاده شده است که می تواند ثبت تصاویر به اشتراک گذاشته شده را بدون برچسب های جغرافیایی به حداکثر برساند. کلمه کلیدی انگلیسی “Haihe” و چینی “Haihe” است. داده ها به دو دسته «دارای جغرافیا» و «بدون جغرافیا» تقسیم می شوند. پس از پاکسازی دادههایی مانند «Hai River» یا «Haihe» در شهرهای دیگر به وقت محلی (GMT+8، پکن سنگاپور) و حذف تصاویر تکراری و تصاویر غیر مرتبط با رودخانه Haihe، 1940 تصویر فلیکر وجود داشت. شامل 440 تصویر با ابرداده با اطلاعات جغرافیایی و 1500 تصویر بدون ابرداده. این پاسخ در فراداده های خاص با فرمت CSV و داده های تصویر با فرمت JPG برگردانده شد. برای پیروی از شرایط و خطمشیهای حریم خصوصی Flickr API، همه مجموعههای دادههای مالک عکس و فراداده ناشناس شدند و دادههای اطلاعات شخصی غیرضروری پاک شدند.
از آنجایی که تنها 18.9 درصد از تصاویر فلیکر دارای داده های جغرافیایی با دقت بالا هستند، این مطالعه از چشم انداز فیدهای تصویر فلیکر به عنوان منبع داده های برچسب گذاری شده جغرافیایی استفاده کرد. نتایج تجسم نیز نشان دهنده توزیع فضایی توجه عمومی در امتداد رودخانه هایهه است. جدول 1 نمونه هایی از داده های فلیکر را با اطلاعات جغرافیایی و فراداده ها و تصاویر بدون داده های جغرافیایی نشان می دهد. برای محافظت از حریم خصوصی تصاویر کاربر، پنج رقم آخر شناسه تصویر پنهان می شود. حق چاپ هر تصویر فلیکر متعلق به عکاس است.
3.3. تحلیل داده ها
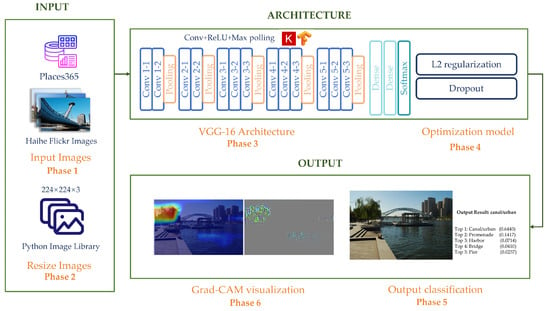
نمودار جریان روش در شکل 2 نشان داده شده است . بر اساس فراداده و تصاویر داده های فلیکر، این مطالعه به سه مرحله برای تجزیه و تحلیل داده های فلیکر نیاز داشت. فاز 1 تجزیه و تحلیل گروه بندی فلیکر شامل گردشگران و افراد محلی، سن و جنسیت و برچسب های ماشینی بود. فاز 2 طبقهبندی تصویر فلیکر بود، از جمله ایجاد معماری VGG-16، استفاده از ابزارهای منظمسازی و تنظیم حذف L2 پس از استفاده از معماری VGG-16 و تجسم Grad-CAM (نگاشت فعالسازی کلاس با وزن گرادیان) پس از خروجی نتیجه طبقهبندی. . فاز 3 تجزیه و تحلیل بصری قدرت فضایی و توزیع فضایی فضاهای عمومی شهری بود. این مرحله شامل تجزیه و تحلیل تراکم هسته فضاهای عمومی دو بعدی بر اساس
ArcGIS Pro بود.
نتایج فاز 1 منعکس کننده تغییرات در تاریخ های ارسال و مکان های کاربر برای زمانی که تصاویر فلیکر به اشتراک گذاشته شده اند. این امکان وجود داشت که بر اساس موقعیت مکانی کاربر، توریست یا ساکن بودن کاربر را تحلیل کرد. فاز 2 هسته اصلی تحقیق بود و طبقه بندی تصویر می تواند تصویر کلی رودخانه هایهه را منعکس کند. همچنین می تواند به عنوان منعکس کننده ترجیحات صحنه عمومی تفسیر شود. فاز 3 تفسیر دیگری از تصاویر فضای عمومی شهری بود که میتوانست توزیعهای فضایی قصد فضای عمومی را به دست آورد.
بر اساس نتایج چگالی هسته، چندین تحلیل کیفی برای پیشنهادات فضای عمومی شهری وجود دارد، از جمله کشف مناطق داغ در رودخانه هایهه، مقایسه نتایج طبقهبندی تصویر دادههای جغرافیایی با توسعه زمین فعلی، و مقایسه نتایج طبقهبندی تصویر. بین تصاویر geodata و غیر geodata. این تحقیق یک روش برای درک تصاویر ترجیحی از فضاهای عمومی شهری بر اساس دادههای تصویر رسانههای اجتماعی و فراداده است. نتایج تجزیه و تحلیل همچنین به سه پیشنهاد مکانسازی فضای عمومی شهری برای رودخانه هایهه منجر میشود.
3.3.1. آمار گروه بندی
علاوه بر برچسبهای جغرافیایی، ابردادههایی مانند نام، شهر و زمان اشتراکگذاری هر اشتراکگذار تصویر فلیکر را میتوان از API فلیکر دریافت کرد. در اینجا، تاریخ گرفته شده از تصویر فلیکر و مکان کاربر را شمارش کردیم. ما برشهای زمانی آمار تصویر Take_date را بر حسب سال گروهبندی کردیم و آمار مکان کاربر را بر اساس منطقه گروهبندی کردیم. ما از روش های آماری برای تجزیه و تحلیل ابرداده اصلی استفاده کردیم، بنابراین نتایج کارآمد و واضح هستند. ابرداده ها به اطلاعات جغرافیایی (ژئوداده) با کلمات کلیدی انگلیسی “Haihe” و چینی “Haihe” یا بدون اطلاعات جغرافیایی (غیر geodata) با کلمات کلیدی انگلیسی “Haihe” و چینی “Haihe” تقسیم می شوند.
3.3.2. چارچوب طبقه بندی تصویر فلیکر
در تحقیقات قبلی، تشخیص و طبقهبندی تصویر بر اساس دادههای رسانههای اجتماعی بیشتر در مقیاس برنامهریزی شهری و منطقهای مورد استفاده قرار میگرفت، در حالی که آموزش و آزمایش مجموعه دادهها با یادگیری ماشینی، فضاهای عمومی شهری به دلیل مقادیر کم دادههای تصویر، دشوار بود. 1940 تصاویر فلیکر از رودخانه هایهه به اشتراک گذاشته شد که مجموعه داده های کوچکی است. استفاده از پایگاه داده Places برای آموزش یک مدل طبقه بندی تصویر مناسب برای تشخیص صحنه فضای عمومی می تواند مشکل دقت پایین در داده های کوچک را حل کند. مجموعه داده Places365 مناسب ترین مجموعه داده برای این تحقیق بود که توسط آزمایشگاه علوم کامپیوتر و هوش مصنوعی MIT طراحی شد. مجموعه داده شامل 5000 تصویر آموزشی در هر کلاس در مجموع 365 کلاس است [ 39]. ImageNet یک پایگاه داده شیمحور است که استخراج برچسبهای صحنه فضای عمومی از آن دشوار است، بنابراین لازم است در Places365 نیز آموزش داده شود [ 32 ]. با استفاده از چارچوب یادگیری عمیق CNN، این دادههای تصویری برای این هدف تحقیقاتی با توجه به کلاسهای پایه Places365 به چندین کلاس تقسیم شدند.
چندین مطالعه ثابت کرده اند که VGG-16 در دقت بالای 1 برای وظایف طبقه بندی تصویر قابل اعتماد است [ 40 ، 41 ، 42 ]، و بالاترین دقت بالای 1 را برای پایگاه داده Places365 نشان می دهد. مزیت برجسته مدل VGG16 این است که عملکرد CNN ها را بدون نیاز به آموزش عمیق تر با تعداد بالای لایه های کانولوشنال افزایش می دهد [ 43 ]. این مطالعه مدل VGG-16 را در چارچوب Keras TensorFlow ساخت. ساختارهای اصلی CNN مانند لایههای کانولوشن، لایههای ترکیبی و لایههای کاملاً متصل توسط توابع مربوطه Keras ارائه میشوند. این فرآیند را می توان به شش مرحله اصلی تقسیم کرد ( شکل 3 ).
1. مجموعه داده پایه Places365 را دانلود کنید، شامل مجموعه آموزشی (5000 در هر کلاس، 1825000 در مجموع)، مجموعه اعتبارسنجی (100 در هر کلاس، در مجموع 36500) و مجموعه آزمایشی (900 در هر کلاس، در کل 328500).
2. اندازه تصویر مجموعه داده استاندارد Places365 را روی 224 × 224 × 3 تنظیم کنید و از آن برای آموزش، ارزیابی و آزمایش بر روی مدل بهینه سازی شده VGG-16 برای به دست آوردن یک طبقه بندی استفاده کنید.
3. از چارچوب Keras TensorFlow برای ساخت اجزای ساختاری متناظر مدل VGG16، از جمله لایههای کانولوشن، لایههای تجمع حداکثر و لایههای کاملاً متصل استفاده کنید.
4. برای جلوگیری از برازش بیش از حد، L2 و استفاده از تنظیم انصراف بر اساس مدل اصلی VGG-16.
5. از مدل بهینه سازی شده VGG-16 به عنوان طبقه بندی کننده برای طبقه بندی تصاویر فلیکر استفاده کنید که هر تصویر مربوط به 365 احتمال برچسب پیش بینی شده است. احتمالات برچسب های پیش بینی شده را به ترتیب نزولی مرتب کنید و پنج احتمال برتر را به عنوان نتایج خروجی تصویر برتر 1 تا 5 انتخاب کنید.
6. از Grad-CAM برای تفسیر بصری تصاویر فلیکر و شناسایی و مکان یابی مناطق تصویر مربوطه استفاده کنید.
Grad-CAM از گرادیان پس انتشار شبکه برای محاسبه وزن هر کانال از نقشه ویژگی استفاده می کند تا نقشه حرارتی مربوطه را بدست آورد [ 44 ]. Grad-CAM را می توان برای انواع مختلف وظایف تصویری اعمال کرد.
مدل معماری میتواند عملکرد طبقهبندیکننده تشخیص صحنه را با دقت بالا و نرخ فراخوان بالا درک کند، میتواند برچسبهای ویژگی صحنه متناظر را برای هر تصویر فلیکر ارائه کند و میتواند دستهها و وزنهای پیشبینیشده از ۱ تا ۵ بالا را محاسبه کند. در میان نتایج خروجی، نتایج پیشبینی برای دقت بالای 1 تا 5 از اهمیت ویژهای برخوردار است. دقت Top-N معیاری است که نشان می دهد چند بار کلاس پیش بینی شده در مقادیر بالای N توزیع SOFTMAX قرار می گیرد. در ImageNet، نرخ خطا اغلب برای توضیح احتمال تشخیص تصویر استفاده می شود [ 45 ، 46 ]]. دقت بالای 1 دقت معمولی است: پاسخ مدل باید دقیقاً پاسخ مورد انتظار باشد. دقت بالای 5 به این معنی است که هر یک از پنج نتیجه با بالاترین احتمال باید با پاسخ مورد انتظار مطابقت داشته باشد.
3.3.3. VGG-16 Architecture و Grad-CAM
در مقایسه با مدل یادگیری عمیق، مدل طبقهبندی تصویر یادگیری ماشین سنتی از تشخیص کمتری برخوردار است. CNN ها می توانند دقت طبقه بندی تصویر بهتری را در مجموعه داده های مقیاس بزرگ به دست آورند [ 47 ، 48 ]. مدلهای یادگیری عمیق را میتوان به طور کلی تا بیش از ۷۰ درصد دقت بالای ۱ بهبود بخشید. به عنوان مثال، تیم آمازون دقت اعتبار سنجی برتر ResNet-50 را از 75.3 درصد به 79.29 درصد در ImageNet در سال 2019 افزایش داد [ 49 ]، که برای به دست آوردن اطلاعات طبقه بندی تصاویر بیشتر از داده های تصویر مفید خواهد بود. علاوه بر این، ماشینهای بردار پشتیبانی نیز طبقهبندیکنندههای موثری برای کارهای طبقهبندی صحنه هستند [ 50 ].
در مطالعه ما، VGGnet یک مدل بهینهسازی مبتنی بر شبکه CNN است که توسط کارن سیمونیان و اندرو زیسرمن از دانشگاه آکسفورد در سال 2014 پیشنهاد شد. در تحقیق خود، ما از معماری VGG-16 برای طبقهبندیکنندههای تصویر استفاده کردیم [ 48 ]]. VGG-16 دارای 16 لایه وزنی (مخفف ’16’ یا ’19’ برای تعداد لایه های وزن در شبکه)، شامل 13 لایه کانولوشن، 3 لایه کاملاً متصل و 5 لایه ادغام کننده است. هر دو نوع، VGG-16 و VGG-19، از دو لایه کاملاً متصل تشکیل شده اند. تمام هسته های تبدیل 3 × 3 هستند. و هسته های maxpool 2 × 2 (کوچکتر از هسته 3×3 الکس نت) با گام دو، هر کدام با 4096 کانال، و به دنبال آن یک لایه کاملا متصل دیگر هستند. هسته کانولوشن بر گسترش تعداد کانال ها تمرکز دارد و ادغام بر کاهش عرض و ارتفاع تمرکز دارد. معماری مدل عمیق تر و گسترده تر است. متأسفانه VGGNet دو اشکال عمده دارد که عبارتند از سرعت کم تمرین و وزنه های معماری بزرگ (وزن 16 یا 19). VGG-16 در لایه های Keras TensorFlow ساخته شد. اگرچه شبکههای کارآمدتری مانند معماری ResNet و SENet در ILSVRC برای طبقهبندی تصاویر وجود داشت، VGG-16 همگرا میشود و سپس به عنوان مقداردهی اولیه برای شبکههای بزرگتر و عمیقتر استفاده میشود، فرآیندی به نام پیشآموزش. به طور خلاصه، ما معتقدیم که VGG معماری مناسب تری بر اساس میزان داده در تحقیقات فضای عمومی شهری برای مقیاس های شهری کوچک و متوسط بود.
برازش بیش از حد یک مشکل رایج در رویکردهای شبکه عصبی است. برای کاهش مشکل اضافه برازش VGG-16 در فرآیند آموزش، این مطالعه منظمسازی L2 و تنظیم ترک تحصیل را بر اساس معماری اصلی VGG-16 در TensorFlow Keras اعمال کرد. تنظیم L2 کاهش وزن نیز نامیده می شود. اصل این است که مدت تنظیم L2 را بر اساس تابع از دست دادن اصلی افزایش دهیم، در نتیجه عملکرد از دست دادن اصلی را محدود کنیم و بیش از حد برازش ناشی از وزن بیش از حد را سرکوب کنیم [ 51 ].
با استفاده از روش منظم سازی L2 شی Keras Regularizers، با کمک آرگومان کلمه کلیدی Kernel_regularizer لایه کانولوشن، تنظیم L2 را با ضریب تنظیم 0.0002 به لایه کانولوشن اضافه کردیم.
تابع تنظیم L2 که برای تابع ضرر اصلی اعمال می شود:
در فرمول: m نشان دهنده تعداد داده های دسته ای ورودی است، y^منهست منارزش پیش بینی شده، yمنهست منمقدار هدف، و Ly^من،yمنارزش زیان است منداده ها فرض کنید مشتق تابع ضرر اصلی مربوط به wاست:
للایه شبکه عصبی را نشان می دهد. سپس فرمول به روز رسانی وزن به صورت زیر است:
پس از اضافه کردن عبارت منظم سازی، تابع ضرر به:
در فرمول: λضریب منظم شدن است. تابع ضرر جدید مشتق از w:
این بدان معناست که فرمول جدید به روز رسانی وزن به صورت زیر بدست می آید:
از فرمول (7) می توان دریافت که 1-αλمترعددی است که کمتر از 1 است که کاهش می یابد w، کاهش نفوذ wدر شبکه عصبی، و مشکل بیش از حد برازش را کاهش دهید.
Dropout تکنیکی برای بهبود شبکه های عصبی با کاهش بیش از حد برازش است [ 52 ]. حذف به طور تصادفی نورون ها در شبکه عصبی حذف می شود تا شبکه دارای درجه خاصی از پراکندگی باشد و به طور موثر اثر هم افزایی ویژگی های مختلف را کاهش دهد. سازگاری مشترک بین گره های عصبی را تضعیف می کند، توانایی تعمیم را افزایش می دهد و به طور موثری وقوع بیش از حد برازش را کاهش می دهد. فرمول محاسبه انتشار رو به جلو شبکه عصبی بدون ریزش به صورت زیر است:
فرمول محاسبه انتشار شبکه عصبی به سمت جلو پس از اضافه کردن قاعده ریزش به صورت زیر است:
تابع برنولی در فرمول (10) برای تولید تصادفی بردار 0 و 1 با احتمال p استفاده شد. در این مطالعه، انصراف به شبکه دو لایه کاملا متصل در مدل VGG16 معرفی شد و احتمال انصراف روی 0.5 تنظیم شد، زیرا انصراف به طور تصادفی بیشترین شبکه ها را زمانی که احتمال انصراف 0.5 است ایجاد می کند [ 53 ]. در این مرحله، ما یک معماری بهینه سازی شده VGG-16 برای پیش بینی طبقه بندی تصاویر به دست آورده بودیم. طبقهبندیکننده تصویر بهینهشده شامل VGG-16، منظمسازی L2 که پس از 13 لایه کانولوشن عمل میکند، و منظمسازی حذف برای 2 لایه متراکم است.
در حالی که یادگیری عمیق دقت بیسابقهای را در طبقهبندی تصاویر تسهیل کرده است، یکی از بزرگترین مشکلات، تفسیرپذیری مدل است که یک جزء اصلی در درک مدل و اشکالزدایی مدل است. برای قابل تفسیر کردن نتایج طبقهبندی تصویر، از روش تجسم Grad-CAM [ 54 ] در این مطالعه برای به دست آوردن نقشههای حرارتی استفاده شد که طبقهبندی تصویر را مشخص میکند. Grad-CAM با پیدا کردن لایه کانولوشن در شبکه VGG-16 و بررسی اطلاعات گرادیان جریان یافته به آن لایه پس از نتایج خروجی کار می کند. Grad-CAM یک نسخه ارتقا یافته از CAM [ 54 ] (نقشه فعال سازی کلاس) است که نیازی به اصلاح شبکه عصبی و آموزش مجدد آن ندارد.
3.3.4. نقشه برداری از فضای عمومی شهری با Geodata
در بین روشهای تجسم، چگالی هسته یکی از محبوبترین و شناختهشدهترین تکنیکها است و بیشترین استفاده را در تحقیقات فضایی شهری جریان اصلی دارد زیرا ArcGIS pro. تجزیه و تحلیل تراکم هسته (Spatial Analyst) مقادیر کمی و توانایی تجسم غلظت نقاط یا خطوط را فراهم می کند. طبق گفته سیلورمن [ 55 ]، چگالی هسته چگالی ویژگی های نقطه ای را در اطراف هر سلول شطرنجی خروجی محاسبه می کند [ 56 ]. چگالی هسته، توزیع استفاده را در هر پیکسل از شبکه ای که بر روی مکان های اشتراک گذاری داده های یک فرد قرار دارد، تخمین زد [ 57 ].
در مطالعات مرتبط، تجزیه و تحلیل تراکم هسته به طور گسترده ای برای تشخیص الگوهای تداوم و ناپیوستگی در فعالیت های رسانه های اجتماعی استفاده شده است [ 58 ]. نتیجه نقشهبرداری در اینجا، ویژگیهای تجمع و توزیع فضایی فراداده فلیکر را با اطلاعات جغرافیایی نشان داد. در تحقیق ما، تجزیه و تحلیل چگالی هسته سطوح پیوسته را با استفاده از فراداده های فلیکر برای تجسم مکان مجموعه داده های نقطه ای ایجاد کرد. اکثر تحقیقات تراکم هسته از مقیاس های شهری و منطقه ای با شعاع 500 متر، 1000 متر یا 5000 متر استفاده می کنند. در مورد مقیاس طراحی شهری، این روش تحت تأثیر کارهای اساسی در مناطق پیاده [ 59 ] و فضاهای باز عمومی [ 60 ] قرار گرفت.]. مقادیر از پیش تعیین شده کوچکتر یک شطرنجی (اندازه سلول خروجی) تولید می کند که جزئیات بیشتری از سرزندگی فضایی را نشان می دهد، به این معنی که تنها نقشه برداری چگالی هسته با دقت بالا برای تحقیقات مقیاس فضای عمومی مناسب است [ 61 ] که با استفاده از فرمول زیر انجام می شود:
برای اندازه گیری چگالی نقاط فراداده فلیکر در نقطه ایکس، جایی که ایکسمنمجموعه داده فلیکر شامل مختصات X (طول جغرافیایی) و Y (طول جغرافیایی) و ایکسمن= (Xi، Yi)T، و من= 1،2،3،… n . h پهنای باند است که به عنوان پارامتر هموارسازی نیز شناخته می شود. تا زمانی که پهنای باند تعیین می شود، تأثیر توابع هسته در اشکال مختلف ریاضی بر تراکم هسته اندک است [ 62 ].
4. نتایج
4.1. آمار فراداده
طبق آمار API فلیکر، فراداده از مجموع 1940 تصویر به دست آمده است. پس از تمیز کردن تصاویر تکراری فلیکر، ماژول Take_date به ویژه قابل توجه بود که ترجیحات افراد را در دوره های مختلف منعکس می کند. متأسفانه، به دلیل مقیاس کوچک فضای عمومی، مقادیر فراداده کم بود و برش های زمانی را فقط می توان برای سال های 2017، 2013 و 2009 تنظیم کرد. اینها اوج فراداده هایه فلیکر بودند ( شکل 4). این قله ها ممکن است به این دلیل باشد که برگزاری بازی های المپیک 2008 و مجمع جهانی اقتصاد داووس در تیانجین (2010، 2012، 2018) گردشگران بیشتری را به رودخانه هایهه جذب کرد. مهمتر از آن، این از پروژه طراحی شهری در رودخانه هایهه که از سال 2008 در حال ساخت و ساز مداوم بوده است جدا نیست. از مقایسه تصاویر داده های جغرافیایی و غیر داده های جغرافیایی، تصاویر داده های جغرافیایی بسیار نادرتر از تصاویر بدون مختصات جغرافیایی هستند.
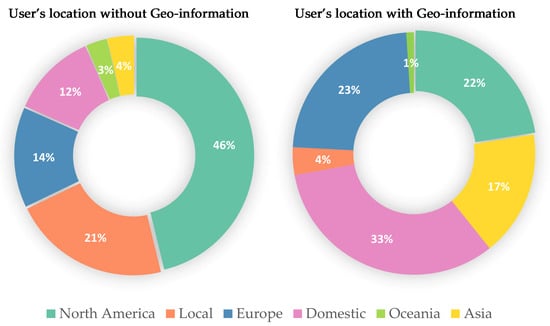
فراداده همچنین شامل اطلاعات کاربر از جمله داده های 1393 با موقعیت مکانی کاربر و 547 داده دیگر با داده های موقعیت مکانی کاربر ناشناخته است. از نظر آماری ( شکل 5)، کاربران در آمریکای شمالی بیشترین تصاویر فلیکر را به اشتراک گذاشتند، با داده هایی با مختصات جغرافیایی 22٪ و مختصات بدون اطلاعات جغرافیایی 46٪ از کل داده ها را تشکیل می دهند. داده های به اشتراک گذاشته شده توسط کاربران محلی 4 درصد با اطلاعات جغرافیایی و 21 درصد بدون اطلاعات جغرافیایی کل داده ها را تشکیل می دهد. دادههای فلیکر که توسط بازدیدکنندگان داخلی به اشتراک گذاشته شده بود نیز برجسته بود، با اطلاعات جغرافیایی 33 درصد از کل دادهها و بدون اطلاعات جغرافیایی 12 درصد از کل دادهها. علاوه بر این، کاربران آسیا و اروپا نیز علاقه زیادی به عکاسی از رودخانه هایهه داشتند. در مجموع، درصد بالایی از تصاویر فلیکر مربوط به گردشگران داخلی و خارجی بوده است و اکثر تصاویر فلیکر توسط ساکنان به اشتراک گذاشته شده اند که حاوی داده های جغرافیایی نیستند. متقابلا، توزیع فضایی دادههای جغرافیایی ترجیحات تصویری گردشگران را برای فضاهای عمومی شهری، به ویژه گردشگران خارج از کشور، بهتر منعکس میکند، و نسبت پایین دادههای جغرافیایی از ساکنان بر قضاوت توزیع برای گروههای محلی تأثیر میگذارد. اگرچه نسبت ساکنان محلی نسبتاً اندک است، اما این مطالعه هنوز هم می تواند ادراک ساکنان و گردشگران را منعکس کند.
4.2. نتیجه طبقه بندی تصویر
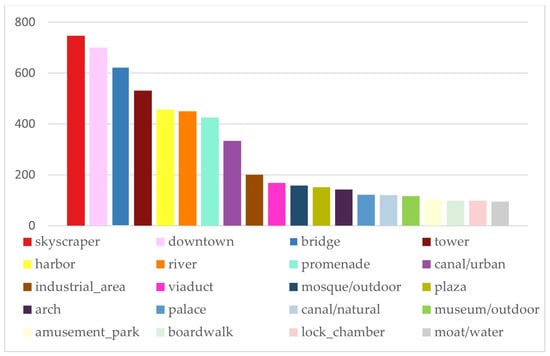
قبل از آموزش معماری یادگیری عمیق VGG-16، ما نوع صحنه تصویر را در تصاویر 1940 با استفاده از طبقه بندی دستی پیش بینی کردیم. ما معتقدیم که باید حداقل هشت نوع صحنه در Places365 وجود داشته باشد، که بیشترین نسبتها بر روی فضاهای عمومی کنار رودخانه مانند رودخانه هایهه متمرکز شده است، یعنی: پل، کانال/شهری، مرکز شهر، شناور یخ، پارک/پارک آبی، میدان، تفرجگاه ، و آسمان خراش ( شکل 6 ).
جدول 2 نمونه ای از تناقضات بین برچسب های دستی و نتایج پیش بینی را نشان می دهد. تصاویر نادرست تشخیص داده شده عمدتا دارای نوردهی کم یا بیش از حد نوردهی بودند. این VGG-16 بهینه سازی شده به دقت آزمون برتر 5 برابر 96.75 درصد دست یافت. با توجه به برخی ابهامات بین دستههای صحنه فضای عمومی، و ویژگیهای صحنههای متعددی که در یک تصویر ظاهر میشوند، دقت بالای 5 استاندارد برای اندازهگیری عملکرد مدل طبقهبندی تصویر است [ 39 ، 49 ].
برای تأیید صحت بالای 1 و 5 برتر، دو محقق با تجربه به طور تصادفی 400 تصویر فلیکر از رودخانه هایهه را برای طبقه بندی دستی انتخاب کردند. نتایج نشان میدهد که برچسبهای دستهبندی دستی مطابق با نتایج پیشبینی برتر ۱، ۸۱.۷۵ درصد از کل ۴۰۰ تصویر را تشکیل میدهند، و تصاویر فلیکر که با نتایج پیشبینی برتر ۵ مطابقت دارند، ۹۶.۷۵ درصد از کل ۴۰۰ تصویر را تشکیل میدهند.
شکل 7نتیجه خروجی مثال را درست نشان می دهد. به عنوان مثال، تصویر A کانال/شهری است و نتایج برتر از 1 تا 5 پیش بینی شده کانال/شهری، آسمان خراش، مرکز شهر، منطقه صنعتی و بندر بود. تصویر E پل است و نتایج برتر از 1 تا 5 پیش بینی شده عبارتند از: پل، آسمان خراش، مرکز شهر، برج و رودخانه. نتیجه پیش بینی همچنین احتمال برچسب طبقه بندی تصویر را نشان می دهد. از آنجایی که مجموعه داده Places365 دارای 365 دسته است، 365 مقدار احتمال برای هر تصویر پیش بینی شده است. از منظر احتمال پیشبینی، احتمال پیشبینی برتر تصویر A تا تصویر F به ترتیب 12.99٪، 16.23٪، 23.74٪، 35.78٪، 33.6٪، 64.4٪ است. نتیجه پیشبینیشده بسیار با دسته برچسب واقعی: کانال/شهری سازگار است. در مقابل، نتیجه پیشبینیشده ممکن است همیشه با برچسب واقعی مطابقت نداشته باشد، حتی در حد امکان عملکرد top-1–top-5. ما چنین مواردی مانند تصویر B را به عنوان خطا تعریف کردیم. بر خلاف سایر مطالعات در مقیاس شهری، تصویر فضاهای عمومی شهری در هایهه دارای درجه بالایی از شباهت است که دشواری تشخیص این تصویر را افزایش می دهد. دقت بالای 5 کمک عالی شد.
اصل Grad-CAM این است که مشتقات جزئی همه نقشه های ویژگی آخرین لایه کانولوشن را با توجه به احتمال گره با بزرگترین مقدار SOFTMAX بدست آوریم و سپس میانگین گرادیان هر نقشه ویژگی را به عنوان وزن انتخاب کنیم تا بردار وزن به دست آید. [ 63 ]. بردار وزن و نقشه ویژگی را به ترتیب ضرب کرده و آنها را با هم جمع کنید تا یک ماتریس دو بعدی بدست آورید. سپس ماتریس دو بعدی برای فعال سازی به ReLU فرستاده می شود [ 64 ]، و اعداد منفی در ماتریس دو بعدی به 0 تغییر می کنند. در نهایت، نمونه برداری برای به دست آوردن نقشه حرارتی Grad-CAM و ترکیب Grad-CAM با پس انتشار هدایت شده ( شکل 8 ).
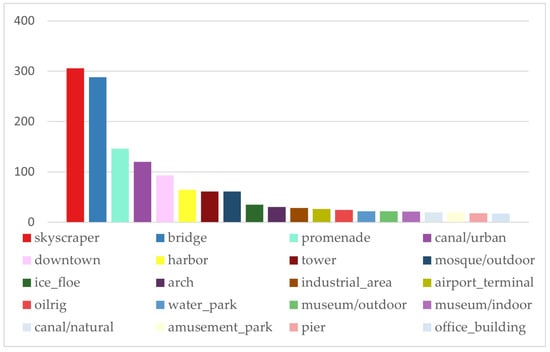
به طور کلی، پس از شمارش نتایج پیشبینی برتر 1 (پیشبینی صحیح)، بیشترین تصاویر در آسمانخراش (321)، پل (299)، تفرجگاه (155)، کانال/شهر (120)، مرکز شهر (107)، بندر بوده است. (66)، برج (64)، مسجد/فضای باز (61)، و دسته یخ (35) ( شکل 9)). نتایج پیشبینی با نتایج حدس قبل از آزمایش طبقهبندی یادگیری عمیق مطابقت دارد. آسمان خراش ها در هسته مرکزی رودخانه هایهه و 30 پل روی رودخانه هایهه محبوب ترین سوژه های تصاویر فضای عمومی شهری بودند. آسمان خراش ها عمدتاً در ضلع جنوبی ایستگاه تیانجین و دو طرف میدان فرهنگ هایهه متمرکز شده اند، در حالی که پل ها به طور مساوی در تقاطع جاده های اصلی با رودخانه هایهه توزیع شده اند. در میان نتایج، پیشبینیها برای صحنههای برج و مسجد/ فضای باز شگفتانگیز بود. پس از مرتبسازی دادهها، متوجه شدیم که بیشتر تصاویر طبقهبندی شده به عنوان مسجد/خارج از تصاویر اصلی فلیکر، نماهای ایستگاه تیانجین بودند و برج طبقهبندی شده برج ساعت جینوان پلازا بود. شکل 10نتایج پیشبینیشده از top-1 تا top-5 را نشان میدهد، به این معنی که هر تصویر دارای پنج برچسب طبقهبندی است: پرشمارترین دستههای تصویر عبارتند از: آسمانخراش (747)، مرکز شهر (700)، پل (624)، برج (531)، بندر. (456)، رودخانه (450)، تفرجگاه (425)، ساختمان اداری (376)، و کانال / شهری (334). نتایج 5 برتر با نتایج برتر 1 سازگارتر است. صحنه های مرکز شهر، برج، رودخانه و … شباهت زیادی به برچسب های آسمان خراش ها و کانال دارد. به طور کلی، نتایج پیشبینی برتر ۱ قابل اعتماد هستند. طبقهبندی تصویر به نتایج زیر منجر شد: ساختمانهای مرتفع در منطقه مرکزی رودخانه هایهه، پلها و تفرجگاههای کنار کانال برای عموم جالبترینها هستند.
4.3. تجسم ژئوداده فلیکر مبتنی بر مکان
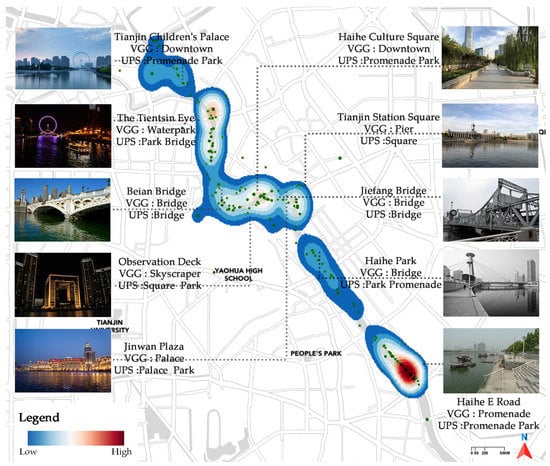
برای مقایسه توزیعهای فضایی نتایج طبقهبندی تصویر از معماری VGG-16، تجزیه و تحلیل چگالی هسته را برای تصاویر با مختصات جغرافیایی انجام دادیم. مناطقی که در شکل 11 به رنگ قرمز سایه زده شده اند ، تراکم جمعیت بالاتر، فراوانی فعالیت بیشتر و تمرکز بالاتر استفاده از رسانه های اجتماعی را نشان می دهد [ 65 ]. برخی از ویژگیها از نگاشت دادههای جغرافیایی فلیکر در شکل 11 بسیار محبوب هستندمانند عرشه مشاهده، پل بیان، پل جیفانگ، میدان ایستگاه تیانجین، میدان فرهنگ هایهه و پلازا جینوان در منطقه مرکزی رودخانه هایهه. این منطقه مجموعه ای از رویدادهای عمومی را برای گردشگران خارجی، گردشگران ملی و ساکنان فراهم می کند. چشم Tientsin به عنوان یک نقطه عطف مهم در امتداد رودخانه Haihe، تعداد زیادی از بازدیدکنندگان را به خود جذب می کند. همچنین منجر به ساخت مجتمعهای مسکونی، تجاری، پارکها و کاخ کودکان تیانجین شده است که در حال ساخت است. علاوه بر این، نتیجه نگاشت چگالی هسته همچنین نشان می دهد که بسیاری از تصاویر در امتداد جاده Haihe E متمرکز شده اند (یعنی منطقه قرمز در شکل). این ممکن است بسیار به پارک هایهه و پلت فرم آبدوست در اینجا مرتبط باشد. با این حال، ما همچنان تمرکز تصاویر فضاهای عمومی شهری در امتداد جاده Haihe E را غیرعادی میدانیم زیرا یک کاربر در 22 ژوئیه 2010 52 تصویر متوالی گرفت. با ترکیب نتایج بخش قبل، ما ترجیح میدهیم که Haihe E Road را در تصاویر کلی به اشتراک گذاشته شده در رتبه سوم قرار دهیم، درست زیر ناحیه مرکزی رودخانه Haihe و چشم Tientsin.
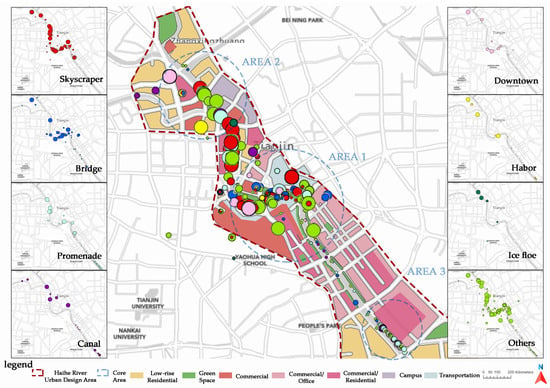
بر اساس نتیجه تراکم هسته، نتایج طبقه بندی را می توان به سه ناحیه تقسیم کرد که در آن تصاویر فضای عمومی شهری بسیار متمرکز است. شکل 12روابط بین نتایج طبقه بندی تصویر برای داده های جغرافیایی و کاربری های فعلی زمین در رودخانه هایهه را نشان می دهد. با قضاوت از کاربری فعلی زمین، عملکردهای شهری منطقه 1 عمدتا تجاری، تجاری/اداری و حمل و نقل است. منطقه 2، عمدتاً مسکونی، تجاری/مسکونی و پردیس. و از منطقه 3، عمدتا تجاری / اداری، تجاری / مسکونی، و مسکونی. از منظر ویژگی های عملکردی فضای عمومی شهری، منطقه 1 فضاهای باز بزرگ همراه با مراکز تجاری و حمل و نقل است، منطقه 2 پارک های اجتماعی و امکانات تفریحی را ترجیح می دهد و منطقه 3 به پارک های اجتماعی، پارک های جیبی و مسیرهای کنار رودخانه تمایل دارد.
دستههایی که بیشترین تعداد نتایج طبقهبندی تصاویر برتر را داشتند، آسمانخراش، پل، تفرجگاه، کانال، مرکز شهر و شناور یخ بودند. با استفاده از ابزار Graduated Symbols for Mapping، اندازه نماد تفاوت های کمی را نشان داد [ 66 ]. آسمان خراش ها و مرکز شهر پیش بینی شده توسط VGG-16 در منطقه 1 و منطقه 2 متمرکز شده اند. دسته بندی تصاویر پیش بینی شده که در هر سه منطقه ظاهر می شوند شامل پل ها، تفرجگاه ها، کانال ها و بندر هستند. در مورد فلوت یخ برچسب، عمدتاً در منطقه 2 قرار دارد. این نشان می دهد که فعالیت های یخی در زمستان عمدتاً در منطقه 2 متمرکز است.
به طور خلاصه، منطقه 1 در شعاع یک کیلومتری ساعت قرن (نزدیک پل جیفانگ) واقع شده است، تصاویر معرف فضاهای عمومی شهری بر اساس نتایج طبقه بندی تصاویر VGG-16 عبارتند از آسمان خراش، پل، تفرجگاه، مرکز شهر و برج. نتیجه نشان میدهد که جینوان پلازا، ساختمانهای اداری و فضاهای عمومی شهری وابسته به آنها جذابترین صحنهها با ساختار ترکیبی ازدحام هستند. منطقه 2 در شعاع 300 متری چشم Tientsin واقع شده است و 3 پل در نزدیکی آن وجود دارد که توجه زیادی را به خود جلب کرده اند. داده های فلیکر در این منطقه بیشتر از بازدیدکنندگان داخلی است. پارک آبی، بندرگاه و شهربازی صحنه هایی هستند که مردم به آن توجه می کنند. منطقه 3 بین پل ژیگو و پل دانگ شینگ قرار دارد و نتایج عبارتند از تفرجگاه، پل، کانال/شهری، بندر، و منطقه صنعتی علاوه بر این، منطقه 3 پرجمعیت ترین است، با اقامتگاه هایی در امتداد هر دو طرف رودخانه در ارتباط با چندین پارک اجتماعی که بیشتر توسط مردم محلی استفاده می شود.جدول 3 ).
پس از شمارش نتایج طبقهبندی تصاویر برای دادههای جغرافیایی و تصاویر بدون دادههای جغرافیایی در شکل 13نتایج نسبت نشان می دهد که تصاویر آسمان خراش ها، تفرجگاه ها و ترمینال فرودگاه بندر به طور کاذب بالا هستند. در میان آنها، ترمینال فرودگاه باید نادیده گرفته شود، زیرا فرودگاه های تیانجین در دو طرف رودخانه هایهه قرار ندارند. در عین حال، آمار نسبت نیز نشان میدهد که تصاویر پل، کانال/شهر، مرکز شهر و برج در دادههای جغرافیایی کمتر از نسبت کل است. در مقایسه با نتایج طبقهبندی برای دادههای جغرافیایی، نسبت نتایج طبقهبندی برای تصاویر بدون دادههای جغرافیایی به نسبت کل نزدیکتر است. اگرچه دادههای جغرافیایی نقش بزرگی در تجزیه و تحلیل فضایی بازی میکنند، بینشهای بهدستآمده از این بخش ممکن است به محققان آینده در مورد تصاویر غیرژئوداده کمک کند.
5. بحث
از آنجایی که تحقیقات در مورد اشتراکگذاری تصاویر در پلتفرمهای رسانههای اجتماعی اخیراً به طور گسترده در برنامهریزی شهری، طراحی شهری و طراحی منظر مورد استفاده قرار گرفته است، استفاده از فناوری یادگیری عمیق برای تجزیه و تحلیل تصاویر چشمانداز وسیعی برای مطالعات شهری و جغرافیای فیزیکی دارد. وظایف CV مانند طبقه بندی تصویر، تقسیم بندی تصویر، و تشخیص اشیا می توانند ادراکات عمومی و تمایلات بصری را منعکس کنند. در عین حال، تحقیقات LBSM بر روی اطلاعات جغرافیایی می تواند منعکس کننده ویژگی های پویای سرزندگی شهری و فعالیت های شلوغ باشد و اطلاعات کاربر در ابرداده می تواند تصاویر فضایی گروه های مختلف را منعکس کند. با این حال، در مطالعات قبلی، ابردادههای مبتنی بر LBSM و دادههای تصویری مبتنی بر تحقیقات CV نسبتاً مستقل هستند و بسیاری از مطالعات تحلیل فضایی مبتنی بر دادههای جغرافیایی، محتوای تصویر تصاویر غیرژئوداده را در نظر نمیگیرند.
نتایج طبقهبندی تصاویر برای دادههای جغرافیایی و تصاویر بدون دادههای جغرافیایی، هر دو ترجیح عمومی قوی برای صحنههای آسمانخراش، پل، تفرجگاه و کانال را نشان میدهند. ژئوداده نقش مهمی در تحلیل فضایی دارد. از آنجایی که تنها 18.9 درصد از تصاویر فلیکر دارای مختصات جغرافیایی هستند، توزیع این غلظتها از تصویر فضای عمومی شهری به سادگی احتمال بالایی را نشان میدهد که این منطقه ترجیح عمومی سطح بالایی دارد. در همین حال، نتایج بدون دادههای جغرافیایی ترجیحی را برای مقولههایی مانند مرکز شهر، بندر و پارک آبی نشان میدهند، که نتایج تجزیه و تحلیل فضایی geodata را تکمیل میکند و نقش تصاویر غیر geodata را در درک تصاویر فضاهای عمومی شهری نشان میدهد. قابل ذکر است که وزن گردشگران در این یافته بیشتر از ساکنان است.
در پاسخ به نتایج پیشبینی VGG-16، نتایج نقشهبرداری چگالی هسته و کاربری فعلی رودخانه هایهه، ما سه پیشنهاد مکانسازی برای فضای عمومی شهری در رودخانه هایهه پیشنهاد میکنیم:
فرآیند مکانسازی را میتوان هم در مقاومسازی فضای موجود یا برنامهریزی یک فضای جدید مورد استفاده قرار داد. پیشنهاد ما این است که با ارزش ترین فضا برای افزایش سرزندگی منطقه 1 است. برای بهبود سرزندگی در منطقه 1، فضای موجود نیاز به مقاوم سازی دارد، به خصوص میدان فرهنگی هایهه که باید پویاترین منطقه باشد. در حال حاضر، این منطقه به اندازه کافی جوان نیست، سرزندگی شهری به طور جدی ناکافی است، و عناصر چشم انداز نسبتا کمی هستند. علاوه بر این، میدان روبروی ایستگاه راهآهن تیانجین و سکوی آبدوست عملکردهای تجاری را به طور مؤثر ترکیب نمیکنند و تنوع فضای عمومی شهری در این منطقه کم است. یک بازسازی بسیار خوب شهری اوزاکا استیشن پلازا و اومکیتا پلازا در ژاپن است.
- 2.
-
استراتژی تنوع معقول فضای عمومی شهری
نتایج پیشبینی فلیکر نیز عناصر چشمانداز نسبتاً همگنی را نشان میدهد: یعنی مرکز ثقل توجه مردم آسمانخراشها، پلها، تفرجگاهها و شهری/کانالها است و تصاویر فضاهای عمومی شهری که مردم بیشتر به آن توجه میکنند، بر روی آسمانخراشها، پل، و مرکز شهر در منطقه 1. ما پیشنهاد میکنیم زمینهای بازی و پارکهای موضوعی بیشتری در منطقه 2 ایجاد کنیم و خیابانهای عابر پیاده تجاری بیشتری را در امتداد خیابانهای ساحلی در منطقه 3 توسعه دهیم. به ویژه، منطقه 3 به دلیل توسعه، پتانسیل و تقاضای داخلی بیشتری دارد. از اقامتگاه های ساحلی
- 3.
-
استراتژی توسعه پایدار فضای عمومی شهری
از منظر بهبود محیط زندگی ساکنان، بازآفرینی فضای عمومی شهری در منطقه 3 ارزشمندترین است. پارک های اجتماعی متراکم تر و سکوهای آب دوست می توانند این منطقه را به یک جامعه آینده تبدیل کنند. از منظر توسعه گردشگری، منطقه 1 و منطقه 2 دارای پتانسیل تجاری قوی و نیاز به فضای عمومی شهری هستند. این منطقه می تواند برای فضای عمومی شهری مصرف گراتر برنامه ریزی شود.
در این مطالعه، دستاوردهای اصلی، از جمله کمک به حوزه طراحی شهری را می توان به شرح زیر خلاصه کرد:
1. این مطالعه سهم برجسته دادههای تصویر رسانههای اجتماعی و همچنین فرادادهها را در درک تصاویر فضاهای عمومی شهری نشان میدهد در حالی که اثربخشی یک مدل طبقهبندی تصویر منظم VGG-16، Grad-CAM و تراکم هسته را نشان میدهد.
2. نتایج نشاندهنده اهمیت ژئوداده فلیکر برای تحلیل فضایی فضاهای عمومی شهری است و همچنین محدودیتهای مطالعه تصاویر فضاهای عمومی شهری را تنها با نتایج حاصل از چگالی هسته نشان میدهد. این یافتهها با تحقیقاتی که نشان میدهد نتایج طبقهبندی تصاویر برتر ۱ تا ۵ برای تصاویر بدون دادههای جغرافیایی اهمیت ویژهای دارد، سازگار است.
3. این روش تحقیق چندین پیشنهاد مکانسازی برای بازسازی فضای عمومی شهری در اطراف رودخانه هایهه در تیانجین ارائه میکند. امیدواریم این تحقیق تجربی به عنوان بازخورد مفیدی برای بهبود سرزندگی و تنوع فضاهای عمومی شهری باشد.
6. نتیجه گیری
نتایج حاضر تایید میکنند که معماری بهینهسازی شده VGG-16 ما برای طبقهبندی صحنه تصویر فلیکر، از جمله دقت 81.75% بالا و 96.75% دقت بالای 5، مهم است و یک روش تجسم Grad-CAM موثر است. این یک جایگزین موثر برای طبقه بندی دستی است، زمانی که داده های تصویر پیچیده و تشخیص آنها دشوار است. بر این اساس، نتیجه میگیریم که تصاویر کلی فضاهای عمومی شهری تحت سلطه آسمانخراشها، پلها، تفرجگاهها، کانالهای شهری، بندرها و پارکهای روی رودخانه هایهه است.
سه فضای عمومی فعالیت تصویر متمرکز بر اساس دادههای فلیکر را با مختصات جغرافیایی نشان میدهند: منطقه با مرکز میدان فرهنگ هایه، منطقه با مرکز چشم تینتسین، و رودخانه در امتداد جاده هایهه ای. وزن این نتایج به ترتیب برای ساکنان 5 درصد، برای گردشگران داخلی 15 درصد و برای گردشگران خارج از کشور 80 درصد است. با این حال، تکمیل اطلاعات جغرافیایی با تصاویر فلیکر بدون داده جغرافیایی با شناسایی محتوای تصویر دشوار است. با وجود این محدودیتها، این نتایج برای طبقهبندی تصاویر غیرجغرافیایی و توزیع فضایی تصاویر با دادههای جغرافیایی ارزشمند هستند. یافتههای این مطالعه را میتوان به عنوان انتقادی از استفاده از تصاویر با دادههای جغرافیایی بهعنوان دادههای تحقیق درک کرد. تصاویر بدون داده جغرافیایی باید بیشتر مورد توجه قرار گیرند.
در روش تحقیق و نتایج این تحقیق محدودیت های متعددی وجود دارد:
1. فراداده فلیکر ناقص، شامل اطلاعات ناقص کاربر (سن و جنسیت) و داده های جغرافیایی ناقص. در این تحقیق داده های دارای مختصات جغرافیایی تنها 9/18 درصد از کل داده ها را تشکیل می دهند و در برخی شرایط خاص انحرافاتی در صحت مختصات جغرافیایی وجود داشت. این گونه انحرافات در مقیاس برنامه ریزی شهری یا منطقه ای برجسته نیستند، اما در مقیاس طراحی شهری، نتایج نقشه برداری را به طور جدی تحت تأثیر قرار می دهند. در مقایسه با کاربران فلیکر در شهرهای آمریکای شمالی، تعداد کاربران فلیکر در شهرهای چین نیز ناکافی است. علاوه بر این، موقعیت جغرافیایی تصاویر قادر به نمایش دقیق مکانهای ترجیحات ذهنی عموم نیست. به عنوان مثال، مردم ممکن است در مقابل بایستند تا از فضای عمومی مورد علاقه خود برای روابط بصری بهتر عکس بگیرند. این منجر به نادرست بودن مختصات جغرافیایی محل عکس گرفته شده می شود. ما معتقدیم که روش تحقیقی که فقط از ابرداده مانند اطلاعات جغرافیایی یا اطلاعات کاربر به عنوان منبع اصلی داده استفاده می کند، برای رودخانه هایهه مناسب نیست.
2. دقت طبقهبندی تصویر VGG-16 کمتر از فریمورکهای جدید مانند ResNet-101 (در بالای 5 دقت 95.6%) [ 67 ] یا CoCa [ 68 ] است.] (بالاترین دقت 91.0%). با این حال، بهبود دقت آموزش، جهت توسعه آینده این تحقیق در زمینه طراحی شهری نیست. کلید حل مشکل، تفسیر نتایج یادگیری عمیق و استفاده از آنها برای هدایت مکانسازی است. به عنوان مثال، منطقه رودخانه در هایهه یک منطقه حفاظت از میراث تاریخی است. نه تنها بسیاری از بناهای تاریخی به سبک ایتالیایی، انگلیسی و فرانسوی وجود دارد، بلکه ساختمانهای مدرنی نیز وجود دارند که به تازگی ساخته شدهاند و در عین حال فرم معماری یکپارچه را تضمین میکنند. این امر در این واقعیت منعکس می شود که بسیاری از ویلاهای به سبک غربی به عنوان کلیساها، موزه ها و ساختمان های دیگر فهرست شده اند. همچنین انحرافاتی در طبقه بندی تصاویر وجود دارد که با روش های یادگیری عمیق نمی توان آنها را به دقت شناسایی کرد. ترکیب با گونه شناسی معماری نیز ضروری است.
3. پایگاه داده Places365 دارای 1.8 میلیون تصویر آموزشی است. اندازه حجم آموزش مستقیماً دقت پیشبینی را تعیین میکند، اما نقطه ضعف آن این است که زمان آموزش طولانی است و نیاز به حافظه گرافیکی زیاد است. اگر بتوان نتایج را به مجموعه دادههای مربوط به منظره و مکان شهری ساده کرد، در آموزش مدل و بهینهسازی مدل به میزان زیادی در زمان صرفهجویی میشود.
تحقیقات آینده در مورد تصاویر فضاهای عمومی شهری ممکن است توضیحاتی را در مورد رابطه بین ترجیحات مردم برای صحنه های فضای عمومی و احساسات مردم در مورد این فضاها گسترش دهد. به طور خلاصه، این مقاله استدلال می کند که طبقه بندی تصاویر بر اساس شبکه CNN می تواند تجزیه و تحلیل موثری از تصاویر فضاهای عمومی شهری ارائه دهد و پیشنهادهایی برای مکان سازی یا بازسازی فضای عمومی ارائه دهد. به طور کلی، نتایج ما اثرات تکنیکهای بینایی کامپیوتری را در طراحی شهری نشان میدهد.











بدون دیدگاه