

آمارهای استخدامی مبدا و مقصد دینامیک طولی کارفرما-خانوار (LODES) یک منبع مهم برنامه ریزی شهری در ایالات متحده است. با این حال، نظارت بر این آمار منابع فشرده است، و دقت آنها زمانی که تغییرات در جمعیت و ساختارهای شهری منجر به تغییر در الگوهای رفت و آمد می شود، بدتر می شود. منطقه مورد مطالعه ما منطقه خلیج سانفرانسیسکو است و در سالهای گذشته شاهد رشد سریع جمعیت بوده است که بهروزرسانی مکرر LODES یا در دسترس بودن جایگزین مناسب را مطلوب میکند. در این مقاله، ما جریانهای تحرک را از مجموعهای از بیش از 40 میلیون توییت جغرافیایی مرجع منطقه مورد مطالعه استخراج کرده و آنها را با دادههای LODES مقایسه میکنیم. این توییتها در دسترس عموم هستند و وضوح مکانی و زمانی خوبی ارائه میدهند. بر اساس تجزیه و تحلیل اکتشافی داده های توییتر، ما سؤالات تحقیقی را در مورد جنبه های مختلف ادغام داده های LODES و Twitter مطرح می کنیم. علاوه بر این، ما روشهایی را برای تجزیه و تحلیل مقایسهای آنها در مقیاسهای فضایی مختلف توسعه میدهیم: در شهرستان، مسیر سرشماری، بلوک سرشماری، و سطح بخش خیابان فردی. بدین ترتیب نشان میدهیم که دادههای توییتر را میتوان برای تقریبی LODES در سطح شهرستان و در سطح بخش خیابان استفاده کرد، اما همچنین حاوی اطلاعاتی درباره سفرهای عادی غیرمرتبط با رفت و آمد است. با استفاده از وضوح زمانی بالای توییتر، ما همچنین نشان میدهیم که چگونه عواملی مانند ساعات شلوغی و تعطیلات آخر هفته بر تحرک تأثیر میگذارند. ما مزایا و کاستیهای روشهای مختلف برای استفاده در برنامهریزی شهری را مورد بحث قرار میدهیم و با دستورالعملهایی برای مسیرهای تحقیقاتی آینده میبندیم. ما روشهایی را برای تجزیه و تحلیل مقایسهای آنها در مقیاسهای فضایی مختلف توسعه میدهیم: در شهرستان، مسیر سرشماری، بلوک سرشماری، و سطح بخش خیابان فردی. بدین ترتیب نشان میدهیم که دادههای توییتر را میتوان برای تقریبی LODES در سطح شهرستان و در سطح بخش خیابان استفاده کرد، اما همچنین حاوی اطلاعاتی درباره سفرهای عادی غیرمرتبط با رفت و آمد است. با استفاده از وضوح زمانی بالای توییتر، ما همچنین نشان میدهیم که چگونه عواملی مانند ساعات شلوغی و تعطیلات آخر هفته بر تحرک تأثیر میگذارند. ما مزایا و کاستیهای روشهای مختلف برای استفاده در برنامهریزی شهری را مورد بحث قرار میدهیم و با دستورالعملهایی برای مسیرهای تحقیقاتی آینده میبندیم. ما روشهایی را برای تجزیه و تحلیل مقایسهای آنها در مقیاسهای فضایی مختلف توسعه میدهیم: در شهرستان، مسیر سرشماری، بلوک سرشماری، و سطح بخش خیابان فردی. بدین ترتیب نشان میدهیم که دادههای توییتر را میتوان برای تقریبی LODES در سطح شهرستان و در سطح بخش خیابان استفاده کرد، اما همچنین حاوی اطلاعاتی درباره سفرهای عادی غیرمرتبط با رفت و آمد است. با استفاده از وضوح زمانی بالای توییتر، ما همچنین نشان میدهیم که چگونه عواملی مانند ساعات شلوغی و تعطیلات آخر هفته بر تحرک تأثیر میگذارند. ما مزایا و کاستیهای روشهای مختلف برای استفاده در برنامهریزی شهری را مورد بحث قرار میدهیم و با دستورالعملهایی برای مسیرهای تحقیقاتی آینده میبندیم. بدین ترتیب نشان میدهیم که دادههای توییتر را میتوان برای تقریبی LODES در سطح شهرستان و در سطح بخش خیابان استفاده کرد، اما همچنین حاوی اطلاعاتی درباره سفرهای عادی غیرمرتبط با رفت و آمد است. با استفاده از وضوح زمانی بالای توییتر، ما همچنین نشان میدهیم که چگونه عواملی مانند ساعات شلوغی و تعطیلات آخر هفته بر تحرک تأثیر میگذارند. ما مزایا و کاستیهای روشهای مختلف برای استفاده در برنامهریزی شهری را مورد بحث قرار میدهیم و با دستورالعملهایی برای مسیرهای تحقیقاتی آینده میبندیم. بدین ترتیب نشان میدهیم که دادههای توییتر را میتوان برای تقریبی LODES در سطح شهرستان و در سطح بخش خیابان استفاده کرد، اما همچنین حاوی اطلاعاتی درباره سفرهای عادی غیرمرتبط با رفت و آمد است. با استفاده از وضوح زمانی بالای توییتر، ما همچنین نشان میدهیم که چگونه عواملی مانند ساعات شلوغی و تعطیلات آخر هفته بر تحرک تأثیر میگذارند. ما مزایا و کاستیهای روشهای مختلف برای استفاده در برنامهریزی شهری را مورد بحث قرار میدهیم و با دستورالعملهایی برای مسیرهای تحقیقاتی آینده میبندیم.
کلید واژه ها:
برنامه ریزی شهری ; جابجایی مسافران ؛ تحرک توییتر ؛ جنبش جمعی
1. مقدمه
الگوهای تاریخی استفاده از زمین و توسعه، همراه با سیاست های فدرال، ایالتی و محلی منجر به عدم تعادل شدید بین مشاغل و مسکن در بسیاری از مناطق شهری گسترده شده است [ 1 ]. در اکثر مناطق بزرگ کلان شهر آمریکا، نتایج آشکار است – افزایش هزینه مسکن، زمان طولانی رفت و آمد و ترافیک بد. هدف برنامه ریزی حمل و نقل کاهش اصطکاک مسافت و در نتیجه افزایش تحرک افراد است [ 2 ].
سیاست گذاران با تمرکز بر رفت و آمدهای کاری به جای سفرهای غیر کاری، پیچیدگی های رفتار سفر را ساده و ساده کردند، اگرچه تحقیقات به طور مداوم اهمیت و تأثیر آنها را تأیید کرده است [ 3 ، 4 ]. بسیاری از آنچه در مورد سفر به محل کار نوشته شده است به نظر می رسد بر اساس نگرش های مرسوم/سنتی است که در آن سفر به عنوان سفری است که از یک مکان مسکونی دائمی به یک محل کار دائمی رخ می دهد. برنامه ریزی حمل و نقل و سیاست توسعه یافته در قرن بیستم تلاش می کند تا با ماهیت در حال تغییر و پویایی کار در قرن بیست و یکم همگام شود، زیرا به دست آوردن آماری که تحرک انسان را ثبت می کند بسیار پرهزینه است و با تغییر الگوهای حرکتی موجود و ظهور الگوهای جدید به سرعت خراب می شود [ 5 ].، 6 ]. مشروح ترین نمونه ایالات متحده از چنین آمارهایی که در حال حاضر موجود است، آمارهای استخدامی مبدأ-مقصد دینامیک طولی کارفرما-خانوار (LODES) [ 7 ] است که توسط اداره سرشماری ایالات متحده در دسترس قرار گرفته است. داده های LODES کل ایالات متحده را پوشش می دهد و جریان های رفت و آمد بین بلوک های سرشماری را کمیت می کند. به دلیل دانه بندی فضایی خوب، کیفیت و پوشش بالا، آنها به عنوان ابزار مهمی برای تصمیم گیری در برنامه ریزی منطقه ای و شهری عمل می کنند. یکی از اشکالات مهم داده های LODES این است که آنها به طور انحصاری ترافیک رفت و آمد را پوشش می دهند، به این معنی که آنها انواع سفر مانند خرید یا فعالیت های اجتماعی را پوشش نمی دهند. با این حال، بر اساس داده های نظرسنجی ارائه شده توسط اداره بزرگراه فدرال (FHWA) [ 8]، تنها بخش کوچکی، یعنی 16.6 درصد از کل سفرها، یا 20.8 درصد از مایل های وسیله نقلیه، مربوط به سفر به یا از محل کار انجام شده با وسایل نقلیه خصوصی است. برخی از مقامات حملونقل منطقهای، نظرسنجیهای پرهزینه و در عین حال پراکنده ایجاد کردهاند که تلاش میکنند تحرکی را که LODES پوشش نمیدهد، ثبت کنند، اما آنها کمتر از یک درصد از جمعیت منطقه مورد مطالعه را پوشش میدهند. بنابراین، داده های LODES به عنوان جانشین برای همه اشکال تحرک ایالات متحده استفاده شده است. حدود 86 درصد از آمریکایی ها از ماشین برای رفت و آمد استفاده می کنند. در منطقه مورد مطالعه ما، منطقه خلیج سان فرانسیسکو، این تعداد تقریباً 76٪ است، اگرچه این میانگین توسط تنها 41٪ مسافران ثبت شده در مرکز سانفرانسیسکو منحرف است، در حالی که بقیه منطقه از روند ملی پیروی می کند.6 ].
برای این مطالعه، ما از دادههای شبکه جغرافیایی اجتماعی (GSND) به شکل «توییت» استفاده میکنیم، که از پلتفرم رسانه اجتماعی توییتر گرفته شده است تا الگوهای تحرک را استخراج کنیم، که با دادههای LODES مرتبط میشویم. آنها را می توان به صورت خودکار از طریق رابط برنامه نویسی برنامه کاربردی ارائه شده در پلت فرم برداشت کرد [ 9]. هر یک از توییت های مورد استفاده در این مطالعه دارای یک مهر زمانی و موقعیت منحصر به فرد است، بنابراین ما را قادر می سازد تا داده ها را به صورت زمانی و مکانی در هر مقیاس مورد نیاز جمع آوری کنیم. با شمارش تعداد اتصالات مکرر بین مناطق مختلف، اطلاعات اتصال وزنی را بدست می آوریم. ما به این اتصالات وزنی اشاره می کنیم که توییتر در بقیه مقاله جریان دارد. ساختار داده مبدا-مقصد (OD) جریانهای توییتر با دادههای LODES، که جریانها را نیز نشان میدهند، یکسان است. با پارتیشن بندی و جمع آوری توییت ها، می توانیم آزمایش کنیم که ارتباط بین جریان های توییتر و LODES در زمینه های مختلف چقدر پایدار است. بهترین دانه بندی فضایی موجود داده های LODES، سطح بلوک سرشماری است که سطح بلوک سرشماری را به سطح تجمعی مناسب برای GSND برای انجام مقایسه های مستقیم تبدیل می کند.
-
الگوهای جریان رفت و آمد شناسایی شده در GSND تا چه حد با دادههای رسمی رفت و آمد LODES مرتبط هستند؟
-
کدام اطلاعات جریان ترافیک فراتر از رفت و آمد در GSND موجود است؟
-
تأثیر مقیاس فضایی بر همبستگی بین جریانهای استخراجشده از جریانهای رفتوآمد GSND و LODES چقدر قوی است؟
ما جریانهای توییتر و LODES را با دو رویکرد متفاوت برای رسیدگی به سؤالات تحقیق مقایسه میکنیم. رویکرد اول شامل یک بخش اکتشافی است که در آن ویژگیهای مکانی-زمانی متفاوتی مانند تغییرات در بزرگی و توزیع جریان در طول زمان و نحوه تأثیرگذاری جریانها توسط پدیدههای زمانی دورهای مانند زمان روز را نشان میدهیم. علاوه بر این، ما دادههای کاربری زمین را در سطح قطعه در تجزیه و تحلیل ادغام میکنیم تا اتصال جریان بین جفت کلاسهای کاربری زمین را نشان دهیم. برای رویکرد دوم، ما دادههای OD را برای ارزیابی اینکه چگونه جریانهای توییتر و LODES مرتبط هستند، مرتبط میکنیم. ما این مقایسه را در یک رویکرد مبتنی بر منطقه در سه مقیاس فضایی و همچنین بر اساس بخشهای جداگانه خیابان انجام میدهیم.
2. کارهای مرتبط
توییتر و سایر منابع GSND در تعدادی از مطالعات دیگر مربوط به تحرک انسان، به عنوان مثال در تشخیص و تجسم الگوهای تحرک [ 10 ]، رویدادها و اختلالات ترافیکی [ 11 ]، و طیف وسیعی از کاربردهای دیگر در مورد برنامه ریزی شهری و فعالیت و تحرک به طور کلی [ 12 ]. در یک مطالعه که در منطقه شهر نیویورک انجام شد، محققان الگوهای تحرک و فعالیت انسانی را در سطح شهرستان بر اساس دادههای توییتر تخمین زدند و به این نتیجه رسیدند که دادهها برای این هدف مناسب هستند [ 13 ]. به طور مشابه، دادههای توییتر به عنوان پیشبینیکنندههای مناسبی برای تحرک انسان در انواع تنظیمات شهری نشان داده شد. [ 14 ، 15]. بسته به مورد استفاده، استخراج اطلاعات حرکت در قالب ماتریس های OD از GSND می تواند مفید باشد، همانطور که در این مطالعه وجود دارد. یک رویکرد برای انجام این کار، منطقهبندی GSND و سپس استخراج سفرها از توالی مناطق بازدید شده است. اینها سپس می توانند برای تشکیل یک ماتریس OD [ 16 ] جمع شوند. منطقهبندی توییتها در این مطالعه مشابه عمل میکند، اگرچه ما فقط از مناطقی استفاده میکنیم که دارای یک خوشه توییت هستند تا ماتریس OD را به سمت سفرهای منظم تغییر دهیم.
مشکلات پیرامون شناسایی فعالیت و تحرک مرتبط با کار در دادههای توییتر نیز با استفاده از همبستگی خودکار مکانی و روشهای تحلیل متن معنایی در سطلهای زمانی مورد بررسی قرار گرفته است [ 17 ].
با این حال، استفاده از GSND به عنوان یک منبع داده جدید در برنامه ریزی شهری به طرح های مطالعاتی سنتی محدود نمی شود. وضوح زمانی بالای داده ها به ما این امکان را می دهد که تقریباً در هر مقیاس زمانی مطالعاتی را انجام دهیم [ 18 ]. این پتانسیل برای وضوح زمانی بالای داده های تحرک عاملی است که انگیزه این مطالعه را فراهم می کند، زیرا اگر با داده های دیگر مرتبط شود، به محققان این امکان را می دهد که تعداد بی شماری از اثرات وابسته زمانی مانند حجم ترافیک، ترافیک یا تصادفات و نقشی که فصلی، روز یا شرایط آب و هوایی در آنها بازی می کند.
برای تفسیر نتایج مطالعه، ماهیت ناهمگن زمانی و مکانی داده های ورودی [ 19 ، 20 ] باید در نظر گرفته شود. جنبه زمانی نه تنها ماهیت خطی دارد، بلکه دارای جنبه های چرخه ای مانند روز و روز هفته نیز می باشد [ 21 ]. در این مطالعه، ما این اثرات را از طریق مهندسی ویژگی قبل از فرآیند خوشهبندی زمانی بررسی میکنیم.
یک سوال تحقیقاتی مطرح شده در بالا مربوط به ترافیکی است که در سفرهای رفت و آمد ایجاد نمی شود. این عدد تا حد زیادی ناشناخته است، زیرا هزینه های بالایی برای به دست آوردن داده های مربوطه وجود دارد. گذشته از یک مطالعه کوچک مبتنی بر شهرداری [ 22 ] و یک مطالعه کوچک ملی [ 23 ]، ما تنها چند نمونه از کارهای مرتبط در این زمینه موضوعی را شناسایی می کنیم. در یک نمونه، GSND در ترکیب با مجموعه ای از نقاط مورد علاقه برای توسعه یک مدل گرانشی برای شهر شیکاگو استفاده شد [ 24 ]. مطالعه ای که در شهر نیویورک انجام شد، آموزش یک مدل شبکه عصبی بر اساس GSND را برای تقویت یک مدل گرانشی توصیف می کند [ 25 ]. مدل جاذبه فوق الذکر [ 26] همچنین اصولی را تعریف می کند که بر اساس آنها داده های جریان را از GSND در این مطالعه استخراج می کنیم.
GSND [ 27 ، 28 ] همچنین با مدل های شبیه سازی برای تعیین تقاضای سفر ادغام شده است [ 29 ]. یکی از راههای برآورد تقاضای سفر و الگوهای رفتوآمد بسیار شبیه به رویکرد ما، استخراج آنها از توییتهای جغرافیایی بر اساس مکانهایی است که به طور منظم بازدید میشوند [ 30 ]. نویسندگان نتایج مشابهی را هنگام استفاده از GSND برای تخمین تعداد مسافران رسمی به دست آوردند. با این حال، آنها به سفرهای غیر مسافربری نمی پردازند. ما با بررسی تبادلپذیری بین دادههای توییتر و LODES به این مجموعه دانش کمک میکنیم. کمک دیگر به کار ذکر شده در بالا، برجسته کردن اهمیت مقیاس و تفاوت بین OD و مقایسههای مبتنی بر نمودار نتایج است.
3. مواد
3.1. شرح منطقه مطالعه
منطقه مورد مطالعه ما در منطقه خلیج سانفرانسیسکو واقع شده است که در شکل 1 نشان داده شده است. در طول دو دهه گذشته، این منطقه شاهد رشد سریع جمعیت بوده است. در سال 2020، 7.75 میلیون نفر در 101 شهرداری زندگی می کردند. برآوردی برای سال 2040، 2.1 میلیون نفر دیگر و 1.1 میلیون شغل را برای این منطقه پیش بینی می کند [ 31 ]. افزایش تقاضا برای مسکن که از این روند پیروی می کند، در ترکیب با محدودیت های نظارتی و توپوگرافی موجود، منجر به تغییرات کاربری زمین و تشدید ترافیک و مشکلات زیست محیطی شده است [ 32 ، 33 ].
نه شهرستانی که این منطقه را تشکیل می دهند الگوهای رشد بسیار متفاوتی را نشان می دهند. این، در ترکیب با الگوهای سکونتگاه موجود، منجر به اختلافات زیادی بین تقاضا برای مسکن و در دسترس بودن مشاغل شده است [ 34 ]. از آنجا که سیستم ترافیک توسط توپوگرافی منطقه که نیاز به عبور از پل را ایجاب می کند، محدود شده است، تقاضای سفر در نتیجه سیستم جاده را بیش از حد بارگذاری می کند [ 35 ].
3.2. شرح داده ها و پیش پردازش
داده های LODES محصولی است که از آمار اشتغال، نظرسنجی ها و داده های اداری به دست می آید. در حالی که بیشتر حرفه ها در LODES پوشش داده می شوند، برخی از آنها مانند نظامی، مرتبط با امنیت یا خوداشتغالی نمایندگی ندارند. این داده ها همچنین فقط یک جفت OD را به ازای هر کارگر و سایت استخدام فهرست می کند، که منجر به ارائه اشتباه احتمالی سفرهای کاری از سوی افرادی می شود که در چندین مکان کار می کنند. کیفیت اطلاعات جغرافیایی موجود در داده ها کاملاً سازگار نیست. در حالی که بیشتر محلهای کار و مکانهای خانه با دقت زیر شهرستان گزارش میشوند، سه درصد از محلهای کار و چهار درصد از مکانهای خانه یا در سطح شهرستان گزارش شدهاند یا آدرس معتبری ندارند. اطلاعات بیشتر در مورد مشخصات LODES در مواد تکمیلی موجود است [ 36]. دادهها به صورت فایلهای متنی ارائه میشوند که یک ماتریس پراکنده را در قالب طولانی کدگذاری میکنند.
کالیفرنیا 710485 بلوک سرشماری دارد. داده های LODES مربوطه در مجموع 15327971 جریان بین بلوک ها را به عنوان اتصالات خانه-کار فهرست می کند. این داده ها همچنین شامل تعداد مشاغل مبتنی بر هر بلوک جداگانه است که در مجموع 16566140 شغل است. با این حال، داده های LODES حاوی هیچ اطلاعاتی در مورد تقسیم مودال نیستند. با این حال، داده های سرشماری در سطح دستگاه [ 37 ]، بینش هایی را در مورد وسایل حمل و نقل ارائه می دهد. داده های LODES در مجموع شامل 3252286 ارتباط رفت و آمد فردی بین 109228 بلوک سرشماری در منطقه مورد مطالعه نه شهرستان است. برخی از این اتصالات بین یک جفت بلوک سرشماری اتفاق میافتد و جمع کردن تمام دادههای LODES منجر به 2,972,821 جریان میشود.
دادههای خام توییتر شامل 44،812،476 توییت از زمان بین 8 اکتبر 2010 تا 19 آوریل 2020 است که همه آنها در منطقه مورد مطالعه قرار گرفتهاند. در میان ویژگیهای دیگر، هر کدام شامل یک مهر زمانی، متن توییتی است که توسط کاربر ارسال شده است و همچنین یک مکان نقطه به شکل مختصات جغرافیایی. شکل 2توزیع زمانی توییت ها را نشان می دهد. واریانس بالای مشاهده شده در منحنی ها را می توان با تغییر رفتار کاربر، نمونه برداری نامنظم یا تغییر در سیاست اشتراک گذاری داده توییتر توضیح داد. در طول سالها، شرکت توییتر (سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا) چندین بار سیاست اشتراکگذاری دادههای خود را تغییر داد که بر روی دسترسی به دادهها تأثیر میگذارد. تا تاریخ 09/2012، تنها بخش بسیار کوچکی از توییتها در دسترس ما بود، که تحلیلهای قبل از آن تاریخ را کمتر قابل اعتماد میکرد. توییت ها نه تنها توسط کاربران انسانی ارسال می شوند، بلکه به طور خودکار توسط ربات ها تولید می شوند. با این حال، طراحی مطالعه ما فرض می کند که توییت ها به صورت دستی نوشته شده اند. بنابراین، بخشی از دادههای خام را بر اساس محتوایی که به نظر میرسید بهطور خودکار تولید میشد، حذف کردیم، مانند بهروزرسانیهای ایستگاههای هواشناسی یا تبلیغات [ 38 ]]. ما فرآیند فیلتر را با شناسایی دستی کاربران توییتر که توییتهایی شامل تبلیغات بسیار تکراری، مقالات خبری یا ایستگاههای هواشناسی را در زیرمجموعهای بهطور تصادفی انتخاب شده و حذف همه توییتهای تولید شده توسط آن کاربر، اجرا کردیم. ما این روش را به طور مکرر تکرار کردیم تا زمانی که دیگر توییت های توهین آمیز را شناسایی نکردیم. به کارگیری معیارها منجر به در مجموع 33755914 توییت شد که در نهایت از آنها در مطالعه استفاده کردیم.
برای خوشهبندی دادهها بر اساس مهرهای زمانی آنها، از مقادیر مطلق مهرهای زمانی استفاده نکردیم، بلکه از زمان روز بدون توجه به تاریخ توییت استفاده کردیم. روشهای خوشهبندی مرسوم ماهیت چرخهای مهرهای زمانی را در نظر نمیگیرند، بنابراین یک شکاف به ظاهر بزرگ بین انتهای مقیاس، در این مورد کمی قبل و بعد از نیمهشب ایجاد میکنند. برای کاهش این اثر، ما هر مهر زمان t را در فضای دو بعدی با مختصات تطبیق دادیم. و با ساعت قبل از خوشه بندی
هندسه های مرتبط با توییت ها به صورت مختصات نقطه ای با طول و عرض جغرافیایی ارائه می شوند. برای برآورده کردن مفروضات روشهای تحلیل فضایی، ما دادهها را بر روی یک سیستم مختصات دکارتی پیشبینی کردیم.
هندسه دادههای کلی شهرستانها، بخشهای سرشماری و بلوکهای سرشماری که در طول مطالعه استفاده میکنیم از وبسایت اداره سرشماری ایالات متحده [ 39 ] گرفته شده است. به عنوان یک نمای کلی، ویژگی های انتخاب شده هندسه طرح کلی و داده های توییتر موجود در جدول 1 نشان داده شده است. هم تعداد توییتها و هم اندازه منطقهها در مناطق کوچکتر، تغییرات بیشتری دارند، همانطور که با انحراف استاندارد و ضرایب تنوع (CV) نشان داده میشود.
یک بعد اضافی از جریان ها، مربوط به سوال تحقیق 2، هدف سفر است. با ترکیب دادههای کاربری زمین در سطح قطعه از راهحلهای مرزی [ 40 ] و طرحهای بلوک سرشماری، میتوانیم بفهمیم که چه چیزی باعث سفرهای خاص میشود. با این حال، هندسه دو مجموعه داده مطابقت دقیقی ندارند. تعداد زیادی از بلوک های سرشماری شامل بیش از یک قطعه کاربری زمین است. برای هماهنگ کردن آنها، ما کلاس کاربری زمین را به یک بلوک سرشماری اختصاص دادیم که اکثریت مساحت آن را تشکیل می دهد.
ما همچنین آزمایشاتی را در سطح شبکه خیابان انجام دادیم که برای آن به نمودار جاده نیاز داشتیم. ما از داده های نمودار ارائه شده توسط OpenStreetMap [ 41 ] استفاده کردیم. عملیات دانلود و پیش پردازش داده ها با استفاده از ماژول پایتون OSMnx [ 42 ] انجام شد. ما از تمام دادههای خیابانهای عمومی قابل رانندگی در شعاع 250 کیلومتری اطراف مرکز منطقه مورد مطالعه استفاده کردیم. دلیل گسترش دادهها به این روش این بود که بتوانیم نتایج فرآیند مسیریابی را ضبط کنیم، حتی اگر آنها شامل بخشهای خیابان از خارج از منطقه اصلی مطالعه باشند، که به راحتی میتوانست در نزدیکی لبهها رخ دهد. ما از پیادهسازی NetworkX [ 43 ] از الگوریتم معروف Dijkstra برای مسیریابی، با وزنههای لبهای که هدفشان نمایش سفر با ماشین است، استفاده کردیم.
جدای از کتابخانه های فوق، ما از پایگاه داده های PostgreSQL [ 44 ] با PostGIS [ 45 ] برای مدیریت و تجزیه و تحلیل داده های مکانی استفاده کردیم. برای پردازش و تجسم بیشتر، از Python [ 46 ]، R [ 47 ] و QGIS [ 48 ] استفاده کردیم.
4. روش ها
این بخش روش های مورد استفاده برای انجام تحقیقات ما را شرح می دهد. سپس نتایج حاصل از گردش کار ما در بخش 5 ارائه شده است. شکل 3 گردش کار روش شناختی کلی تحقیق ارائه شده در این مقاله را نشان می دهد. در سمت چپ بالا، مراحل پیش پردازش و تجزیه و تحلیل داده های خام توییتر و LODES را به دو ماتریس OD متناظر تبدیل می کند. کادر سمت راست ادغام شبکه خیابان و دادههای کاربری زمین را برای تولید خروجیهای میانی، یعنی مجموعه دادههای هدف سفر و نمودارهای جریان توصیف میکند. در پایین شکل، این خروجیهای میانی و OD با هم ترکیب میشوند تا همبستگیها و تجسمهای نهایی را ایجاد کنند، که هر کدام با سؤالات پژوهشی که پاسخ میدهند مشخص شدهاند.
4.1. محاسبه مسیرها و جریان ها در داده های توییتر
4.1.1. شناسایی خوشه های مکان های کاربر
تأکید تحقیق ما بر مدلسازی جریان سفرهای منظم است، و از بازدیدهای یکباره از مکانهای تصادفی حذف میشود. برای این کار، مکانهایی را شناسایی میکنیم که توسط یک کاربر چندین بار و در زمانهای مشابهی از روز بازدید شده است. فقط توییتهایی که توسط کاربر در یکی از مکانهای بازدید شدهشان پست شده است، برای محاسبه جریانها استفاده میشوند. ما از الگوریتم خوشهبندی DBSCAN [ 49 ] برای تعیین خوشههای مکانی و زمانی در توییتهای هر فرد استفاده میکنیم و از این رو مبدا یا مقصدهای بالقوه سفرهای معمولی را شناسایی میکنیم. این الگوریتم به تعیین حداقل تعداد نقاط در هر خوشه نیاز دارد ( ) و شعاع جستجو ( ). با استفاده از روش “آرنج” [ 50 ]، یک آستانه زمانی از دقیقه و حداقل پنج نقطه و شعاع جستجو 100 متر برای بعد فضایی مشخص شده است. پس از شناسایی توییتهای گروهبندیشده، بلوک سرشماری که حاوی مرکز توییتها است، بهعنوان یک مکان مرتباً بازدید شده از آن کاربر شناسایی میشود.
4.1.2. شناسایی مسیرهای کاربر فردی
بر اساس لیست کاربر از بلوک های بازدید شده معمول، اکنون می توانیم حرکات آنها را بین آنها تعیین کنیم. اگر کاربر توییت هایی را از دو بلوک مختلف در یک بازه زمانی سه ساعته ارسال کند، ارتباط حاصله بین بلوک ها را یک سفر در نظر می گیریم. حداکثر سه ساعت انتخاب شد زیرا نشان دهنده حداکثر زمان مورد نیاز برای حرکت بین دورترین انتهای منطقه مطالعه ما است. همچنین فضایی برای این فرض باقی میگذارد که کاربر ممکن است بلافاصله پس از شروع یا پایان سفر خود، توییتی ارسال نکند. از آنجایی که هدف ما شناسایی سفرهای مستقیم معمولی است، میخواهیم از بازههای زمانی طولانیتری که ممکن است شامل توقفهای میانی باشد، اجتناب کنیم. ما بهصراحت بین مبدا و مقصد تمایز قائل نمیشویم، به جز شناسایی توالی که در آن دو مکان بازدید میشود. با اعمال این منطق، 1060 را شناسایی کردیم،
4.1.3. شناسایی جریان های جهت دار در مقیاس های مختلف
با فهرست همه سفرها، اکنون میتوانیم مجموع همه جابجاییها را بین هر دو بلوک سرشماری ایجاد کنیم و عناصر غیر صفر چنین ماتریس مجاورتی را بهعنوان جریانهای بین مکانهایی که مرتباً پرتردد میشوند، برچسبگذاری کنیم. از نظر ساختاری، ماتریس های LODES و Twitter یکسان هستند، که به ما امکان می دهد آنها را با یکدیگر مقایسه کنیم. مزیت اضافی این تجمیع این است که دادههای سطح فردی را پنهان میکند و امکان انطباق با بهترین شیوههای حفاظت از حریم خصوصی را فراهم میکند [ 51 ، 52 ].
یکی از سؤالات تحقیقاتی ما این است که ببینیم آیا پارتیشنهای زمانی مختلف توییتر ممکن است برای شناسایی سفرهای غیر رفت و آمد و متمایز کردن آنها از رفتوآمدهایی که توسط دادههای LODES گرفته میشوند استفاده شوند یا خیر. علاوه بر این، برنامه ریزان از یادگیری در مورد نوسانات در طول زمان سود خواهند برد. برای تحلیلهای روند بلندمدت، دادهها به بخشهای دو ساله تقسیم شدند که به مقابله با تغییرات بزرگ در دادههای جغرافیایی توئیتر کمک کرد. جمعیت سفرهای رفتوآمد را میتوان با دادههای جریان در ساعات شلوغی معمولی (6:00-8:00 صبح یا 3:00-5:00 بعد از ظهر) در منطقه خلیج مرتبط کرد. برای این منطقه خاص، ساعات شلوغی نسبتاً زود است، زیرا بسیاری از شرکتها ساعات کاری خود را طوری تنظیم کردهاند که با شرکای تجاری خود در ساحل شرقی ایالات متحده هماهنگ باشند.
ما همچنین دادههای جریان را در واحدهای سطح سرشماری سطح بالاتر تجمیع کردیم تا استحکام دادههای توییتر را در مقیاسهای فضایی مختلف تعیین کنیم. سلسله مراتب فضایی اداره سرشماری ایالات متحده یک نمونه کامل از این است .
4.2. جریان بین مناطق فضایی و طبقات کاربری زمین
در بخش فرعی قبلی دیدیم که از نظر ساختاری و عملکردی، ماتریسهای مجاورت دادههای LODES و Twitter یکسان هستند، که به ما امکان میدهد هر جفت OD را با هم مقایسه کنیم و تفاوتها را کمی کنیم. از آنجایی که هر مسافر در طول رفت و آمد توییت نمیکند، تعداد مطلق جریانها بین بلوکهای سرشماری بسیار کمتر است و باید متناسب با دادههای LODES مقیاس شوند. مقایسه ما بر اساس ضرایب همبستگی است. هر داده از جفت های LODES و Twitter OD نشان دهنده حرکت انبوه بین یک جفت بلوک سرشماری است. ما این جفتهای LODES را با دادههای جریان توییتر مقایسه میکنیم و تفاوتهای بین دو مجموعه داده را کمیت میکنیم. این مقایسه امکان پذیر است، زیرا اگرچه داده های LODES و توییتر از منابع مختلف هستند، اما حاوی اطلاعات مشترک بین آنها هستند. . همانطور که داده ها را در مناطق سرشماری و شهرستان ها جمع آوری کردیم، محاسبات را در هر سه مقیاس فضایی انجام دادیم.
راه دیگر برای تشخیص سفرهای رفت و آمد از دیگر جریانهای معمولی، بررسی کاربری زمین مقصدهای جریان است. پس از تجمیع دادههای کاربری زمین در سطح قطعه به سطح بلوک سرشماری (و متعاقباً سطح منطقه و شهرستان) میتوانیم جفتهای OD دو ماتریس مجاورت را با استفاده از زمین مقصد مقایسه کنیم، که راه دیگری را برای متمایز کردن دو جمعیت آماری باز میکند.
با توجه به اینکه دادههای LODES طبق تعریف فقط شامل سفرهای کاری هستند، در حالی که دادههای توییتر چنین محدودیتهایی ندارند، میتوانیم هم از بعد زمانی و هم از بعد کاربری زمین برای شناسایی قطعی تفاوتهای بین دو مجموعه داده استفاده کنیم. سفرهای رفت و آمد و غیر رفت و آمد، البته، متقابلاً منحصر به فرد نیستند، و ممکن است انتظار داشته باشیم که هر دو را در ساعات شلوغی داشته باشیم، همانطور که ممکن است مقاصد رفت و آمد را در بلوکهای سرشماری مشاهده کنیم که در اکثریت آنها (اما نه منحصرا) بوده است. طبقه بندی شده به عنوان کمتر احتمال دارد که مکان های شغلی را در خود جای دهد. اما منصفانه است که فرض کنیم سفرهای رفت و آمد بر زمان شلوغی و استفاده از زمین مقصد مانند ادارات، تجاری یا صنعتی غالب خواهد بود. ما از نمودارهای سانکی که اتصالات کلاس کاربری زمین را تجسم میکند برای نشان دادن مقادیر جریان بین کلاسهای کاربری زمین برای هر دو منبع داده استفاده میکنیم. این به دنبال استفاده های مشابه از این تکنیک برای تجسم دینامیک پوشش زمین [53 ].
4.3. نگاشت جریان ها به بخش های خیابان
به استثنای شهر سانفرانسیسکو، اکثر مسافران در منطقه مورد مطالعه با ماشین سفر می کنند [ 6 ]. به همین دلیل است که ما مسیرهای سفر را برای جفت های OD خود در یک شبکه خیابانی با وزن برای استفاده از ماشین ترسیم کرده ایم. برای مسیریابی بین جفت بلوکهای سرشماری، نزدیکترین گره نمودار به مرکز هر بلوک را انتخاب کردیم. روال مسیریابی مجموعهای از بخشهای خیابان استفاده شده توسط هر جفت OD را برمیگرداند که ضرب در تعداد سفر برای هر جفت، تقاضای کل در هر بخش خیابان را که توسط دادههای جریان LODES و Twitter اعمال میشود به ما میدهد و امکان مقایسه مستقیم بین این دو داده را فراهم میکند. بر اساس لبه به لبه تنظیم می شود. ما از امتیازات استاندارد برای محاسبه تفاوت در حجم جریان استفاده کردیم.
برای اطلاع از انتخاب اندازه گیری مقایسه، سپس همبستگی بین بارهای بخش LODES و جریان های توییتر را همانطور که در شکل 4 نشان داده شده است محاسبه کردیم . در مقیاس کل منطقه مورد مطالعه، و با ترکیب تمام مسیرهای مشتق شده از توییتر با مسیرهای مبتنی بر LODES، ما نتوانستیم هیچ تفاوت آماری قابل تشخیصی بین دو مجموعه داده پیدا کنیم (نرخ های همبستگی فراتر از بالاترین امتیاز Z هستند).
با توجه به اینکه جریانهای توییتر و LODES باید جنبههای مختلف تحرک را نشان دهند، چنین نرخ همبستگی بالایی مشکوک است، و ما تصمیم گرفتیم یک رگرسیون فضایی را روی دو مجموعه داده اعمال کنیم. این نیاز به ترجمه از یک نمودار به یک ساختار نقطه ای نامنظم توزیع شده داشت، و نقاط میانی بیش از 3.1 میلیون بخش خیابان (طول متوسط: 92 متر) را در نظر گرفت و مقادیر تقاضای سفر مربوطه را به آنها اختصاص داد. همانطور که می دانیم هر سفر اصلی چگونه به استفاده از بخش خیابان کمک می کند، می توانیم تقاضای کل برای هر یک از پارتیشن های موقت داده های توییتر را محاسبه کنیم.
4.3.1. همبستگی جریان های توییتر و جریان های لود
همبستگی فوقالعاده بالا بین تقریباً 3 میلیون سفر LODES و تقریباً 1 میلیون سفر حاصل از توییتر را میتوان به قانون اعداد بزرگ نسبت داد: این دو نمونه عمدتاً از یک جمعیت، ساکنان منطقه خلیج، گرفته شدهاند. با توجه به حجم نمونه به اندازه کافی بزرگ، این دو نمونه بیشتر و بیشتر به یکدیگر شباهت خواهند داشت. این نشان میدهد که مقایسه دادههای LODES از یک سو و پارتیشنهای زمانی متفاوت دادههای توییتر از سوی دیگر معنادارتر است. بنابراین، ما روابط بین زیرمجموعههای مختلف دادههای توییتر و همچنین بین آنها و دادههای LODES را بررسی کردیم تا ببینیم آیا دادههای Twitter ممکن است برای ارائه بهروزرسانیهای کوتاهمدت دادههای LODES که ممکن است نشاندهنده تغییرات رفتاری باشد، استفاده شوند یا خیر. جدول 2یک نمای کلی از تعداد بخش های خیابانی که اساس مقایسه را تشکیل می دهند، ارائه می دهد.
سپس مدلهای رگرسیون فضایی را بر روی تمام ترکیبهای ممکن از ورودیهای جدول 2 اجرا کردیم . قضاوت بر اساس آنها مقادیر نشان داده شده در جدول 3 و جدول 4 ، مدل خطای مکانی کمی بهتر از مدل تاخیر مکانی [ 54 ، 55 ] عمل می کند.
نتایج به نتایج زیر اجازه می دهد. زیر مجموعههای زمانی دو ساله برای جایگزینی استفاده از بخش خیابان مبتنی بر LODES کافی نیستند، اما برای استفاده کلی از بخش خیابان مبتنی بر توییتر نشاندهنده هستند. این اولین مدرکی است که نشان می دهد داده های توییتر در واقع جمعیت های متفاوتی را نسبت به داده های LODES نشان می دهد.
4.3.2. تعیین استفاده از بخش خیابان ناشی از توییتر غیر مرتبط با کار
راه دیگر برای شناسایی انواع مختلف سفر، گنجاندن هدف سفر است. امن ترین (اما سخت ترین) راه برای انجام این کار، تحلیل معنایی محتوای توییت است [ 17 ]. در اینجا، ما در عوض به متغیرهای غیرمستقیمتر اما کاملتر از نوع کاربری زمین و همچنین نقطه مورد علاقه شناخته شده در مقصد سفر و زمان روز و روز هفته برای استخراج اهداف سفر تکیه میکنیم. تخصیص بخش خیابان شرح داده شده در بخش قبل اکنون برای ایجاد نقشه هایی مانند نقشه های نشان داده شده در شکل 5 استفاده می شود.. نقشه (الف) نشان می دهد که در منطقه مورد مطالعه، نقشه های دقیق (b) و (c) که سفرهای غیر رفت و آمد را نشان می دهند، در کجا قرار دارند. خطوط سبز در نقشه (ب) نشاندهنده استفاده از بخشهای جاده در تعطیلات آخر هفته است، در حالی که خطوط قرمز در نقشه (c) بخشهای جادهای را نشان میدهند که در روزهای هفته اما خارج از ساعات شلوغی استفاده میشوند. علاوه بر تفاوتهای مورد انتظار در الگوهای سفر، این دو نقشه همچنین با اهداف سفر به دست آمده از تجزیه و تحلیل کاربریهای سرزمین مقصد مطابقت دارند (به عنوان مثال، سفرهای کوتاه مسکونی به مسکونی در ساعات غیر شلوغی روزهای هفته و مقصدهای خرید و رستوران در تعطیلات آخر هفته. .
5. نتایج
5.1. جریان بین مناطق فضایی و طبقات کاربری زمین
تجزیه و تحلیل داده های اکتشافی یک نمای کلی از تفاوت های مبتنی بر منطقه بین داده های توییتر و LODES ارائه می دهد. جدول 5 مقایسهای از جریانهای توییتر و LODES درون منطقهای و درون منطقهای را نشان میدهد، بنابراین تعداد جریانهایی که در یک منطقه فضایی معین روی میدهند در مقابل جریانهایی که بین مناطق رخ میدهند. توجه داشته باشید که تعداد جریانهای توییتر در یک بلوک طبق تعریف صفر است، زیرا ما فقط حرکتهایی را میشماریم که بین دو بلوک سرشماری مجزا اتفاق میافتد.
در سطح توصیفی صرف، تفاوت های قابل توجهی بین LODES و داده های توییتر وجود دارد. اکثریت قریب به اتفاق جریان های توییتر در بخش سرشماری و شهرستان آنها اتفاق می افتد، در حالی که بیش از 40٪ از اتصالات LODES از مرزهای شهرستان عبور می کنند. این تفاوت به ویژه در سطح سرشماری شدید است، جایی که 42.7٪ از جریان های توییتر در یک تراکت اتفاق می افتد، در حالی که همین امر برای تنها 3.4٪ از جریان های LODES صادق است. این با آمار توصیفی طول سفر و زمان تخمینی سفر با ماشین ارائه شده در جدول 6 مطابقت دارد .
علاوه بر مقایسه های درون منطقه ای و درون منطقه ای جریان های توییتر و LODES، ما ضریب همبستگی رتبه اسپیرمن را محاسبه کردیم. از بزرگی جریان بین مناطق برای سه سطح مقیاس فضایی و تقسیم زمانی. نتایج در شکل 6 نشان داده شده است. وابستگی مقیاس همبستگی ها برجسته است، مقایسه سطوح تجمع کوچکتر به طور مداوم منجر به ضرایب همبستگی پایین تر می شود. نتایج در ساعات شلوغی و خارج از آن بسیار مشابه است، اگرچه همبستگی ها در ساعات شلوغی کمی بیشتر است.
شکل 7 یک تجزیه و تحلیل در سطح شهرستان از جریان های توییتر در ساعات شلوغی (a)، جریان های توییتر در روزهای هفته خارج از ساعات شلوغی (b) و داده های LODES (c) است. فلش های کد رنگی این نمودار وتر هم جهت و هم اندازه جریان بین هر یک از نه شهرستان را به تصویر می کشد. تعداد اتصالات، بزرگی جریان مطلق بالاتر داده های LODES را نشان می دهد. علاوه بر این، اتصالات LODES بین شهرستانی بسیار بیشتری نسبت به جریان های توییتر وجود دارد. به عنوان مثال، حدود نیمی از اتصالات خروجی شهرستان Alameda به سایر شهرستان ها در داده های LODES متصل می شوند، در حالی که تنها حدود 15٪ از اتصالات توییتر خروجی هستند. نمودارهای وتر همچنین ماهیت استثنایی سانفرانسیسکو را نشان می دهد، جایی که جریان های توییتر در مقایسه با سایر شهرستان ها بسیار قوی تر است.
نمودارهای سانکی شکل 8ارتباط بین کلاسهای کاربری زمین برای جریانهای توییتر در ساعات شلوغی (a)، خارج از ساعات شلوغی (b) و دادههای LODES (c) را نشان میدهد. در مقایسه با (c)، دو نمودار جریان توییتر در نگاه اول کاملاً مشابه به نظر می رسند، اما تفاوت های قابل توجهی بین آنها وجود دارد. همانطور که قبلاً فرض کردیم، ارتباطات کمتری بین مناطق مسکونی در ساعات شلوغی وجود دارد و این بازه زمانی خاص تحت سلطه اتصالات بین مناطق مسکونی و طبقات کاربری زمین مرتبط با کار است. توزیع کلاسهای کاربری زمین برای مناطق مبدا و مقصد جریان توییتر در مقایسه با دادههای LODES نشانه دیگری برای تفکیک واضح مکان خانه و محل کار در دومی است. چیزی که نمی توان از داده های توییتر انتظار داشت، که طیف عملکردی وسیع تری از سفرها را نشان می دهد.
5.1.1. مقایسه Lodes با استفاده از بخش خیابان مشتق شده از توییتر
یک نتیجه شگفت انگیز از مدل خطای مکانی در جدول 3این است که سفرهای ساعت شلوغی نسبت به سفرهای خارج از ساعت شلوغی و در تعطیلات آخر هفته پیش بینی ضعیف تری برای سفرهای LODES هستند. این را می توان با این واقعیت توضیح داد که سفرهای واقعی مرتبط با کار کمتر با توئیت همراه هستند تا سفرهای غیر رفت و آمد. این واقعیت که تعداد قابلتوجهی از جریانهای توییتر دارای مبدا و مقصد مسکونی هستند، از این مفهوم حمایت میکند و به خوبی با نتایج بررسیهای ملی FHWA مقایسه میشود. ما قبلاً ظرفیت پیشبینی نسبتاً ضعیف زیرمجموعههای دو ساله را مشاهده کردهایم، اما میخواهیم در اینجا اضافه کنیم که کاهش محدودیتهای شدید مبتنی بر بخش جادهای ممکن است نتایج را بهبود بخشد. ما تلاش می کنیم مطالعات خود را در جهت تعیین آستانه های مقیاس مناسب برای چنین پیش بینی هایی ادامه دهیم.
با نزدیک شدن به این سوال که آیا میتوان از وضوح زمانی دقیقتر دادههای توییتر برای بهروزرسانی مجموعه دادههای موجود سرشماری ایالات متحده استفاده کرد، ما زیرمجموعه 2018/19 را با دادههای بسیار حجیمتر توییتر از سالهای گذشته مقایسه کردیم، دوباره با استفاده از مدلهای رگرسیون فضایی. به استثنای سفرهای عجله ای، نتایج جدول 7 همبستگی های رضایت بخشی را به ما می دهد.
5.1.2. تعیین استفاده از بخش خیابان برگرفته از توییتر در ساعت شلوغی
همانطور که در بالا گزارش شد، هدف ما برای استفاده از دادههای ساعت شلوغی توییتر برای پیشبینی رفتوآمدهای ارائهشده توسط LODES، دست نیافتنی بود. این فرض که دادههای حرکت از زمانهای مشابه روز باید ماهیت مشابهی داشته باشند، هم با تعداد زیاد سفرهای مسکونی به مسکونی و هم با تفاوتهای قابل توجه در طول سفر در تناقض است. اکنون فرض میکنیم که توییتهای قبل یا بعد از سفر به محل کار نسبتاً نادر هستند و حرکاتی که در ساعات شلوغی مشاهده میکنیم در واقع نشان دهنده سفرهای غیر کاری هستند – علیرغم ساعات روز.
5.1.3. تعیین استفاده از بخش خیابان ناشی از توییتر غیر مرتبط با کار
بینش اصلی بهدستآمده از نقشه در شکل 9 ، که سفرهایی را نشان میدهد که توسط دادههای LODES بهطور سنتی ثبت نشدهاند، این است که افرادی که توییت میکنند، در وهله اول افرادی هستند که مانند بقیه در اطراف حرکت میکنند. تلاش برای تشخیص تفاوتهای بین حرکات مبتنی بر LODES و آنهایی که از دادههای آخر هفته توییتر به دست میآیند منجر به حداکثر همبستگی میشود. – یک تفاوت واقعاً کوچک علاوه بر این، نواحی تفاوت هیچ خودهمبستگی فضایی را نشان نمی دهند، به این معنی که آنها به طور تصادفی توزیع شده اند. بیشتر این تفاوتهای کوچک در مناطق مسکونی (با تعداد کمی دیگر در مناطق دورافتاده) رخ میدهد و هیچ کدام با نقاط مورد علاقه شناخته شده مانند مراکز خرید یا مکانهای ورزشی مطابقت ندارند. برعکس، برای نقاط خفه کننده ترافیک شناخته شده، بارهای بخش خیابان آنچه را که از داده های LODES می دانیم تأیید می کند. با تکمیل بینش ما از دادههای ساعت شلوغی و بررسیهای ملی FHWA، فراگیر بودن جریانهای حاصل از دادههای توییتر ما به پتانسیل آن به عنوان منبع جدیدی از اطلاعات در مورد سفرهای خارج از حوزه رفت و آمد اشاره میکند که تاکنون در دسترس نبوده است. با این حال، در این زمینه، مهم است
6. بحث و محدودیت
6.1. بحث و بررسی سوالات تحقیق
برای پرداختن به سوال تحقیق 1، تا چه حد الگوهای جریان رفت و آمد شناسایی شده در GSND با دادههای رفت و آمد رسمی LODES همبستگی دارند، ما همبستگی بین جفتهای OD هر دو منبع داده را در مقیاسهای فضایی چندگانه تحلیل کردیم. همانطور که توسط دیگر تجزیه و تحلیل های سطح شهرستان از داده های جریان مبتنی بر توییتر تأیید شد، ما دریافتیم که یک همبستگی قوی در مقیاس های فضایی کوچکتر وجود دارد. در مقابل، زمانی که ما جریانها را در سطوح بسیار محلی در سطح خیابان ترسیم کردیم، نشانههایی پیدا کردیم که بخش بزرگی از جریانهای توییتر با سفرهای کاری مستقیم متفاوت است. آنها به طور قابل توجهی کوتاهتر هستند، حتی اگر در ساعات شلوغی رخ دهند.
برای پرداختن به سوال تحقیق 2، که اطلاعات جریان ترافیک فراتر از رفت و آمد در GSND موجود است، ما از هر دو کلاس کاربری زمین مقصد و همچنین مهرهای زمانی خارج از ساعات شلوغی معمولی برای استخراج جمعیت های مختلف سفر استفاده کردیم. هر دو روش به الگوهای حرکتی به وضوح قابل تشخیص منجر می شوند. فرض ما مبنی بر اینکه سفرهای LODES پیوند قویتری بین کاربریهای مسکونی و زمین مرتبط با کار نسبت به جابجاییهای غیر مسافربری نشان میدهد، با مقایسه بخشهای (a) و (b) در نمودارهای Sankey در شکل 8 تأیید میشود .
برای پرداختن به سوال تحقیق 3، تأثیر مقیاس فضایی بر همبستگیهای بین جریانهای استخراجشده از جریانهای رفتوآمد GSND و LODES چقدر قوی است، ما دوباره به ضرایب همبستگی جریانهای توییتر و LODES در زمانهای مختلف و در مقیاسهای فضایی مختلف اشاره میکنیم. ضرایب همبستگی نشان می دهد که برای تحرک در سطح شهرستان، توییتر و LODES همبستگی قوی و بالایی از خود نشان می دهند. این با تعدادی از مطالعات قطعنامه در سطح کشور در سطح کشور مطابقت دارد.
6.2. بحث روشها
برای هدف این مطالعه، ما بر روی حرکات در محدوده مطالعه خود تمرکز کردیم که کاربر به طور مکرر از آنها بازدید می کند. ما این فرض را تنها با گنجاندن مناطق ریزدانه (بزرگتر از یک بلوک سرشماری) اجرا کردیم که در آن خوشههای فضایی-زمانی توییتهای یک کاربر مشخص را شناسایی کردیم. ما این محدودیت را اجرا کردیم تا مطمئن شویم که رفتار معمول سفر را ثبت میکنیم، به این معنی که مکانهایی که به ندرت بازدید میشوند به طور هدفمند از این تحلیل حذف شدهاند. یک فرض داخلی در اینجا این است که بازدیدهای مکرر از یک مکان منجر به توییت های مکرر می شود. این محدودیتی است که از هیچ مدل مفهومی خاصی ناشی نمی شود، بلکه بر اساس ماهیت داده ها است. یکی دیگر از محدودیتهای کار ما این است که زنجیرهای بین خانه و محل کار، که در آن کاربر به طور منظم در مکانهای میانی توقف میکند، میتواند بهعنوان سفرهای معمولی که دادههای OD توییتر را از دادههای LODES منحرف میکند، انتخاب شود. با این حال، اگر الگوهای واقعی استفاده از جاده ایجاد شده توسط مسافران مورد توجه باشد، این تأثیر نیز می تواند مفید باشد.
برای رویکردهای مبتنی بر منطقه ما، بر بزرگی جریان، و همچنین مناطق مبدا و مقصد تأکید میکنیم. مقایسه مستقیم ضرایب همبستگی منجر به آمار خلاصه ساده می شود که فشرده و قابل مقایسه است، اما بینش عمیق تری در مورد ویژگی های فضایی نتایج ارائه نمی دهد. این با ماهیت باینری ذاتا مقایسههای جفت OD ترکیب میشود: دو جفت OD یا یکسان هستند یا نیستند. این واقعیت را تحریف می کند که هر جفت OD یک نمایش ساده از آنچه در واقع یک مسیر در امتداد یک شبکه خیابانی است. دو جفت OD با نقاط شروع یا پایان در مجاورت فضایی نزدیک اما در واحدهای منطقه متفاوت، احتمالاً برخی از بخشهای خیابان را در مسیرهای خود به اشتراک میگذارند. با این حال، آنها یکسان نیستند و بنابراین، از منظر منطقه محور ناهماهنگی هستند. این آمار همبستگی را به سمت مقادیر پایین، به ویژه برای مناطق کوچکتر، منحرف می کند. روشهای استدلال مبتنی بر نمودار برای گرفتن چنین ارتباطات فضایی مشابه اما غیر یکسان مناسبتر هستند. این تأثیر را می توان هنگام مقایسه نتایج مبتنی بر منطقه مشاهده کردشکل 6 با نمودارهای مبتنی بر نمودار از جدول 3 . اگرچه متوسط طول بخش خیابان از مقیاسی دقیق تر از سطح بلوک سرشماری را تشکیل می دهند، قدرت پیش بینی به طور قابل توجهی بالاتر است. با این حال، شایان ذکر است که استفاده از یک الگوریتم مسیر کمهزینه برای استخراج استفاده از بخش جاده از جفتهای OD، رفتار سفر بسیار کارآمد را فرض میکند، که ممکن است ارائه نشود.
جدای از نمودارهای جاده، بهترین واحد منطقه برای مقایسه مستقیم دادههای LODES و توییتر مورد استفاده در این مطالعه بلوک سرشماری است. اطلاعات جغرافیایی توئیتر معمولاً مکان خود را از سنسور سیستم موقعیت یابی جهانی (GPS) دستگاه تلفن همراه استخراج می کند. استفاده از مکانهای GPS به طور بالقوه امکان مقایسه در مقیاس فضایی حتی دقیقتر را فراهم میکند، با این حال این نیز به دادههای مرجع مناسب نیاز دارد. در مورد این مطالعه، ما مقیاس بلوک سرشماری داده های LODES را به عنوان حد انتخاب کردیم.
بخش قابل توجهی از اتصالات طبقه کاربری زمین، سفرهای مسکونی به مسکونی است. این یک نتیجه شگفتانگیز برای جریانهای توییتر نیست، زیرا ما انتظار حرکت بین اقامتگاههای خصوصی مختلف را به عنوان بخشی از تعاملات اجتماعی روزمره داشتیم. با این حال، در داده های LODES، این غیرمنتظره بود، زیرا ما انتظار نداشتیم بسیاری از مناطق مسکونی به عنوان محل کار عمل کنند. ما دلایل احتمالی این اختلاف را شناسایی کردیم. مناطقی که در دادههای کاربری زمین ما به عنوان مناطق مسکونی طبقهبندی میشوند، در واقع میتوانند مناطق مرکب از طبقات مختلف کاربری زمین باشند. همچنین، با ادغام دادههای کاربری زمین در سطح بلوک سرشماری، میتوان مناطق مرکب را به غالبترین طبقه کاربری اراضی تجمیع کرد و در نتیجه برخی از قطعات طبقه کاربری تجاری را پنهان کرد.
استفاده از توییتر بر اساس بافت جمعیتی و جغرافیایی منحرف می شود. جمعیت برخی از مناطق و تحرکات اعضای آنها با قدرت بیشتری نسبت به مناطق دیگر نمایش داده خواهد شد. برای مثال، ممکن است مناطق مسکونی با تعداد کمی از کاربران فعال توییتر، اما جمعیت شاغل زیادی وجود داشته باشد. یا ممکن است مکان هایی با تعداد کمی از ساکنان دائمی وجود داشته باشند که تعداد زیادی از بازدیدکنندگان را به خود جذب کنند، مانند مکان های ورزشی یا مراکز خرید. هنگام تفسیر نتایج مطالعه ای مانند مطالعه ما، گنجاندن دانش چنین مکان هایی مهم است. یکی دیگر از عواملی که بر در دسترس بودن داده های توئیتر جغرافیایی ارجاع داده شده تأثیر می گذارد زمان است. ممکن است دلایل متعددی برای تغییر در دسترس بودن داده ها در طول زمان وجود داشته باشد، به عنوان مثال تغییر در شماره کاربران، سیاست های اشتراک گذاری داده توسط توییتر یا تفاوت در فعالیت کاربر در طول زمان.
در حالی که LODES به تحرک خانه به محل کار محدود می شود، جریان های توییتر اهداف دیگر سفر را نیز نشان می دهند. در حالت ایده آل، تفاوت بین دو مجموعه داده باید فقط بر اساس تحرک غیر رفت و آمد باشد. با این حال، در واقعیت، بین سفرهای رفت و آمد و غیر رفت و آمد در ساعات شلوغی همپوشانی وجود دارد و همچنین تعداد ناچیز سفرهای رفتوآمد خارج از ساعات شلوغی سنتی وجود دارد که تفکیک جمعیتهای جابهجایی را دشوار میکند.
از منظر تحلیل خطای آماری، میتوان توزیعهای کلاس کاربری زمین مبدا توییتر را به گونهای که توزیعهای LODES را شبیهسازی کرد و طبقات کاربری زمین مقصد توییتر را بر این اساس تنظیم کرد. این به قیمت معرفی یک عبارت خطای اضافی، توزیع جریانهای توییتر را به سمت LODES منحرف میکند. موضوع دیگر در مورد استفاده از داده های LODES به عنوان مرجع برای جریان های توییتر، تاخیر زمانی بین دو منبع داده است. داده های LODES مورد استفاده در این مطالعه مربوط به سال 2019 است و بنابراین جدیدتر از بسیاری از داده های توییتر است. تشخیص اثرات این تاخیر بر نتایج مشکل ساز است، زیرا میزان داده های توییتر، جمعیت شناسی کاربر و در دسترس بودن داده ها نیز ممکن است در طول زمان متفاوت باشد. بنابراین نتایج با تاخیر زمانی بالا باید به دقت تفسیر شوند و
دادههای LODES حاوی اطلاعاتی درباره ویژگیهای سفر موقت مانند زمان روز یا روزهای هفته نیست. داشتن این اطلاعات اضافی برای کیفیت تجزیه و تحلیل حساس به زمان و برای مشخص کردن فرضیات در مورد فرآیند رفت و آمد مفید خواهد بود.
داده های حرکتی یک فرد ممکن است بینش های صمیمی را در مورد زندگی آنها نشان دهد. با پیروی از رهنمودهای طراحی حریم خصوصی جغرافیایی توسط [ 51 ، 52 ]، ما اصل اقتصاد داده را در کل گردش کار اعمال می کنیم و تنها در جایی نتایج را افشا می کنیم که تجمع مکانی و زمانی مانع از شناسایی افراد شود. بنابراین بسیار مهم است که محققانی که از روشها و منابع داده مشابه استفاده میکنند، اصول حریم خصوصی اطلاعات را رعایت کنند و در حالت ایدهآل، روشهایی را توسعه دهند که اطلاعات شخصی در GSND را بهاندازه کافی بدون به خطر انداختن نتایج مطالعه مبهم میسازد.
6.3. بحث در مورد نتایج و ارتباط برای برنامه ریزی شهری
مقایسه ما از دو داده جریان با منبع متفاوت از روشهایی استفاده کرد که برای برجسته کردن جنبههای مختلف دادهها طراحی شدهاند. با تمرکز بر بزرگی جریان، متوجه شدیم که مقیاس فضایی تاثیرگذارترین عامل است. در مقیاسهای کوچک مانند سطح شهرستان، میتوانیم نسبت جریانها را به خوبی مدلسازی کنیم، در حالی که در مقیاسهای بزرگتر، تفاوتهای قابلتوجهی بین جریانهای توییتر و LODES مشاهده میکنیم. با توجه به تفاوتهای مشاهدهشده بین سه مقیاس فضایی، توصیه میکنیم سطوح مقیاس بیشتری را برای کسب اطلاعات بیشتر در مورد این جنبه از دادهها بررسی کنید. از طرف دیگر، میتوان استفاده از مرزهای اداری را به کلی کنار گذاشت و از سلولهای شبکهای با فاصله منظم برای کشف تأثیر مقیاسهای فضایی استفاده کرد.
انتقال به تجزیه و تحلیل شبکه جاده با مقایسه بارهای بخش خیابان به ما اجازه می دهد تا جمعیت های جریان مختلف را با دانه بندی بسیار بالاتر مقایسه کنیم. ما دریافتیم که در ساعات شلوغی، منابع داده به طور قابل توجهی منحرف میشوند، که نشان میدهد جریانهای توییتر سفرهای منظم با اهدافی غیر از رفت و آمد را ثبت میکنند. تجزیه و تحلیل مبتنی بر نمودار همچنین نشان میدهد که سفرهای توییتر معمولاً بسیار کوتاهتر از رفتوآمدهای LODES هستند، که از اهداف سفر به غیر از سفر مستقیم به محل کار نیز پشتیبانی میکند، حتی اگر بسیاری از آنها در ساعات شلوغی قرار بگیرند. این تفسیر همچنین توسط تجزیه و تحلیل اتصالات کلاس کاربری زمین پشتیبانی می شود، که دوباره تفاوت های قابل توجهی را بین LODES و Twitter نشان می دهد. یک فرضیه که در مدل مبتنی بر شبکه خیابان تعبیه شده است این است که نحوه حمل و نقل با ماشین است. که از طریق طرح وزن دهی گراف پیاده سازی می شود. این نتایج را به سمت زیرساختهای خاص خودرو مانند بزرگراهها منحرف میکند که باید هنگام تفسیر آنها در نظر گرفته شود. همانطور که از سفرها به محل کار انتظار می رود، داده های LODES در مقایسه با جریان های توییتر حاوی ارتباطات کمتری بین مناطق مسکونی است. در نهایت، نسبت طبقات کاربری زمین باقیمانده دوباره به تفاوت در هدف سفر اشاره می کند.
استفاده بالقوه در برنامه ریزی شهری
برنامه ریزی حمل و نقل و سیاست گذاری نیاز به برنامه ریزی طولانی مدت دارد که از پیش بینی جمعیتی و مدل سازی تقاضای سفر برای هدایت سرمایه گذاری های زیرساختی استفاده می کند. منابع داده موجود مانند سرشماری ده ساله و محصولات داده مشتق از آن مانند LODES برای پشتیبانی از این تحلیل ها مناسب هستند. در سالهای اخیر، شیوع اطلاعات جغرافیایی داوطلبانه و منابع دادهای مشابه که توسط ارائهدهندگان تجاری مانند SeeClickFix [ 56 ]، Waze [ 57 ] در دسترس است.]، یا در مورد این مطالعه، توییتر، به برنامه ریزان و مدیران کمک کرده اند تا برنامه ریزی به موقع را انجام دهند و در پاسخ به درخواست های عمومی برای مداخله، تنظیماتی را انجام دهند. ما استدلال میکنیم که GSND از توییتر میتواند برای پشتیبانی از برنامهریزی در بازه زمانی سه تا پنج ساله، برای انجام بهبودهای سرمایهای اندک و سایر برنامهریزیها و مداخلات سیاستی که احتمالاً به نفع عموم باشد، استفاده شود، زیرا دادهها قابل اعتماد هستند و بلافاصله برای برنامهریزان قابل استفاده هستند. . با توجه به اینکه در دسترس بودن دادههای توییتر در طول زمان به طور قابلتوجهی متفاوت است و حجم آن در پایان دوره مطالعه کاهش مییابد، منابع داده جایگزین و پایدارتر از ساختار دادههای قابل مقایسه هنگام استفاده از این روشها در برنامهریزی شهری سودمند خواهند بود.
با توجه به اینکه تنها 16.6 درصد از سفرهای وسایل نقلیه در خیابان های ایالات متحده مربوط به کار است [ 8]، 83.4 درصد باقی مانده از سفرها توسط داده های LODES بررسی نمی شود. همانطور که میتوانیم در مقایسههای منطقهای خود در مقیاس بزرگ نشان دهیم، سفرهای مشتق شده از توییتر از نظر ویژگیهای مکانی-زمانی با سفرهای مربوط به کار متفاوت است، که سؤالاتی را در مورد اعتبار مدلهای حملونقل صرفاً بر اساس دادههای LODES ایجاد میکند. نیاز آشکاری به دادههایی وجود دارد که LODES را تکمیل کرده و جریانهای باقیمانده را در مقیاس فضایی قابل مقایسه ثبت کند. پیشنهاد می کنیم که روش های ارائه شده در این مقاله گامی به سوی توسعه چنین مجموعه داده ای باشد. با این حال، یکی دیگر از یافته های مهم، همبستگی بالا بین جریان های توییتر و LODES در سطح بخش خیابان است. با توجه به اینکه جریانهای عمومی توییتر و جریانهای LODES مبتنی بر مسافران در این مقیاس مشابه هستند، میتوان نتیجه گرفت که جریانهای LODES تنها نشاندهنده سفر مسافران نیستند،
7. نتیجه گیری و چشم انداز
اگرچه تجزیه و تحلیل ما در منطقه خلیج که به خوبی تحقیق شده است، قرار دارد، دو مجموعه داده، LODES و Twitter برای کل ایالات متحده در دسترس هستند. الگوهای استفاده از توییتر ممکن است بر ارزش توضیحی نتایج تأثیر بگذارد. در خارج از ایالات متحده، داده های LODES وجود ندارد، اما بسیاری از کشورها آمار مشابهی دارند. در سایر نقاط جهان، سایر پلتفرمهای GSND ممکن است برای این کار مناسبتر باشند. جستجو برای جایگزینهای توییتر حتی ممکن است در ایالات متحده مفید باشد، اگر دادههای توئیتر جغرافیایی به دلیل کاهش تعداد کاربران یا محدودیتهای Twitter، Inc در دسترس نباشد.
دلیل دیگری که مشتاقانه منتظر بکارگیری روش های ما در خارج از منطقه خلیج هستیم، تعداد غیرعادی بالای افراد با سواد فناوری اطلاعات در منطقه است. درصد افرادی که نمیخواهند یا نمیتوانند در رسانههای اجتماعی شرکت کنند و اطلاعات جغرافیایی خصوصی را به اشتراک بگذارند، احتمالاً در منطقه خلیج کوچکتر است و مهم است که ببینیم نتایج در مناطقی که GSND کمتر ارائه میشود چگونه است. محدودیتهای مشابهی برای حوزههایی اعمال میشود که استفاده از GSND را برای حفاظت از حریم خصوصی مکان به شدت محدود میکنند. در چنین مواردی، جایگزینهای نظارتی فراگیرتر مانند ایستگاههای شمارش ترافیک ممکن است منبع داده مناسبتری برای ارزیابی ترافیک مسافران باشد.
از اوایل سال 2020، همهگیری کووید-19 آمریکا را درنوردید و متعاقباً، بخش بزرگی از تحرک روزمره تحت تأثیر اقدامات قرنطینهای قرار گرفت که برای مهار این بیماری طراحی شده بود. توییتر، بهعنوان منبع داده، وضوح زمانی بالایی ارائه میدهد و با موفقیت به عنوان پیشبینیکننده شیوع کووید-19 [ 58 ] در یک تحلیل مبتنی بر متن، البته در سطح ایالت ایالات متحده، استفاده شده است. روشهای ارائهشده در این مقاله میتوانند به طور بالقوه به ما اجازه دهند تا تأثیر اقدامات قرنطینه را بر الگوهای تحرک در سطح شهرستان یا پایینتر دریافت کنیم.
منابع
- Ihlanfeldt، KR; Sjoquist، DL فرضیه عدم تطابق فضایی: مروری بر مطالعات اخیر و پیامدهای آنها برای اصلاح رفاه. خانه بحث سیاست 1998 ، 9 ، 849-892. [ Google Scholar ] [ CrossRef ]
- Rodrigue, JP The Geography of Transport Systems , 5th ed.; روتلج: ابینگدون، انگلستان؛ نیویورک، نیویورک، ایالات متحده آمریکا، 2020. [ Google Scholar ] [ CrossRef ]
- جولیانو، جی. کوچک، KA آیا سفر به کار با ساختار شهری توضیح داده شده است؟ مطالعه شهری. 1993 ، 30 ، 1485-1500. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کوکلمن، رفتار سفر KM به عنوان تابع دسترسی، ترکیب کاربری زمین، و تعادل کاربری زمین: شواهدی از منطقه خلیج سانفرانسیسکو. ترانسپ Res. ضبط J. Transp. Res. هیئت 1997 ، 1607 ، 116-125. [ Google Scholar ] [ CrossRef ]
- شلیت، دی. وایدنر، ام. کیم، سی. بررسی تعادل شغل-مسکن دستههای مختلف کارگران در 26 منطقه شهری. J. Transp. Geogr. 2016 ، 57 ، 145-160. [ Google Scholar ] [ CrossRef ]
- McKenzie, B. چه کسی به سمت کار رانندگی می کند؟ رفت و آمد با خودرو در ایالات متحده: 2013 ; گزارش های نظرسنجی جامعه آمریکایی اداره سرشماری ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 2015.
- اداره سرشماری ایالات متحده فهرست اطلاعات LODES. 2019. در دسترس آنلاین: https://lehd.ces.census.gov/data/lodes/ (در 13 نوامبر 2020 قابل دسترسی است).
- بررسی ملی سفر خانوار ; اداره بزرگراه فدرال، وزارت حمل و نقل ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 2017. در دسترس آنلاین: https://nhts.ornl.gov (در 23 فوریه 2020 قابل دسترسی است).
- Twitter, Inc. Twitter Developer API v1.1. 2020. در دسترس آنلاین: https://developer.twitter.com/en/docs/twitter-api/v1 (در 13 نوامبر 2020 قابل دسترسی است).
- گائو، S. تجزیه و تحلیل مکانی-زمانی برای کاوش الگوهای تحرک انسانی و پویایی شهری در عصر موبایل. تف کردن شناخت. محاسبه کنید. 2015 ، 15 ، 86-114. [ Google Scholar ] [ CrossRef ]
- استایگر، ای. رسچ، بی. د آلبوکرک، JP; Zipf، A. استخراج و مرتبط کردن رویدادهای ترافیکی از مشاهدات حسگر انسانی با داده های حمل و نقل رسمی با استفاده از نقشه های خودسازماندهی. ترانسپ Res. قسمت ظهور. تکنولوژی 2016 ، 73 ، 91-104. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مارتی، پی. سرانو-استرادا، ال. Nolasco-Cirugeda، A. داده های رسانه های اجتماعی: چالش ها، فرصت ها و محدودیت ها در مطالعات شهری. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 74 ، 161-174. [ Google Scholar ] [ CrossRef ]
- کورکچو، ا. اوزبای، ک. Morgul، EF ارزیابی قابلیت استفاده توئیتر با موقعیت جغرافیایی به عنوان ابزاری برای فعالیت های انسانی و الگوهای تحرک: مطالعه موردی برای nyc. در مجموعه مقالات نود و پنجمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن دی سی، ایالات متحده آمریکا، 10 تا 14 ژانویه 2016. ص 1-20. [ Google Scholar ]
- جوردک، ر. ژائو، ک. لیو، جی. ابوجاود، م. کامرون، ام. نیوث، دی. درک تحرک انسان از توییتر. PLoS ONE 2015 ، 10 ، e0131469. [ Google Scholar ] [ CrossRef ]
- اوسوریو-آرجونا، جی. García-Palomares, JC رسانه های اجتماعی و تحرک شهری: استفاده از توییتر برای محاسبه ماتریس های سفر خانه-کار. شهرها 2019 ، 89 ، 268–280. [ Google Scholar ] [ CrossRef ]
- گائو، اس. یانگ، جی. یان، بی. هو، ی. یانوویچ، ک. مککنزی، جی. تشخیص جریانهای تحرک مبدا-مقصد از توییتهای دارای برچسب جغرافیایی در منطقه بزرگ لس آنجلس. در مجموعه مقالات هشتمین کنفرانس بین المللی علم اطلاعات جغرافیایی، وین، اتریش، 24-26 سپتامبر 2014; صص 1-4. [ Google Scholar ]
- استایگر، ای. وسترهولت، آر. رسچ، بی. Zipf، A. توییتر به عنوان شاخصی برای مکان افراد؟ ارتباط توییتر با دادههای سرشماری بریتانیا. محاسبه کنید. محیط زیست سیستم شهری 2015 ، 54 ، 255-265. [ Google Scholar ] [ CrossRef ]
- باتی، ام. داده های بزرگ، شهرهای هوشمند و برنامه ریزی شهری. دیالوگ هام Geogr. 2013 ، 3 ، 274-279. [ Google Scholar ] [ CrossRef ]
- لی، ال. Goodchild، MF; Xu، B. الگوهای مکانی، زمانی و اجتماعی-اقتصادی در استفاده از توییتر و فلیکر. کارتوگر. Geogr. Inf. علمی 2013 ، 40 ، 61-77. [ Google Scholar ] [ CrossRef ]
- پتوچنیگ، ا. رسچ، بی. لانگ، اس. هاواس، سی. ارزیابی نمایندگی متغیرهای اجتماعی- جمعیتی در طول زمان برای داده های رسانه های جغرافیایی-اجتماعی. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 323. [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. Zhu، AX نمایندگی و سوگیری فضایی اطلاعات جغرافیایی داوطلبانه: یک بررسی. ان GIS 2018 ، 24 ، 151-162. [ Google Scholar ] [ CrossRef ]
- شهر وانوت کریک. بازاندیشی در تحرک 2020. در دسترس آنلاین: https://www.rethinkingmobilitywc.com/ (در 13 نوامبر 2020 قابل دسترسی است).
- Convery، S. ویلیامز، ب. عوامل تعیین کننده انتخاب حالت حمل و نقل برای سفرهای بدون رفت و آمد: نقش های حمل و نقل، کاربری زمین و ویژگی های اجتماعی – جمعیتی. علوم شهری 2019 ، 3 ، 82. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یانگ، اف. جین، پی جی؛ چنگ، ی. ژانگ، جی. Ran, B. برآورد مبدا-مقصد برای سفرهای غیر رفت و آمد با استفاده از داده های شبکه اجتماعی مبتنی بر مکان. بین المللی J. Sustain. ترانسپ 2015 ، 9 ، 551-564. [ Google Scholar ] [ CrossRef ]
- پورابراهیم، ن. کشمش.؛ تیل، JC; Mohanty، S. افزایش پیشبینی توزیع سفر با دادههای توییتر: مقایسه مدلهای شبکه عصبی و گرانش. در مجموعه مقالات دومین کارگاه بین المللی ACM Sigspatial درباره هوش مصنوعی برای کشف دانش جغرافیایی، GeoAI 2018، سیاتل، WA، ایالات متحده آمریکا، 6 نوامبر 2018؛ صص 33-42. [ Google Scholar ] [ CrossRef ]
- ویلسون، AG تئوری آماری مدلهای توزیع فضایی. ترانسپ Res. 1967 ، 1 ، 253-269. [ Google Scholar ] [ CrossRef ]
- لی، جی اچ. دیویس، AW; یون، سی. گولیاس، KG تخمین فضای فعالیت با مشاهدات طولی داده های رسانه های اجتماعی. حمل و نقل 2016 ، 43 ، 955-977. [ Google Scholar ] [ CrossRef ]
- لیائو، ی. بله، اس. Gil, J. امکان سنجی برآورد تقاضای سفر با استفاده از موقعیت جغرافیایی داده های رسانه های اجتماعی. حمل و نقل 2021 . [ Google Scholar ] [ CrossRef ]
- Waddell, P. برنامه ریزی و مدل سازی یکپارچه استفاده از زمین و حمل و نقل: پرداختن به چالش ها در تحقیق و عمل. ترانسپ Rev. 2011 , 31 , 209-229. [ Google Scholar ] [ CrossRef ]
- مک نیل، جی. برایت، جی. Hale, SA برآورد الگوهای رفت و آمد محلی از دادههای جغرافیایی توئیتر. EPJ Data Sci. 2017 ، 6 ، 24. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مکنزی، جی. آزومبرادو، تی. کانولی، دی. دوترا-ورناچی، سی. Halsted، AW; شاف، ال. اسلوکام، دبلیو. ارزش، AR؛ پیرس، سی جی; Gibbons، ML; و همکاران Plan Bay Area 2040 ; کمیسیون حمل و نقل شهری: سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 2017.
- Cervero، R. Jobs-Housing Balance بازبینی شده: روندها و تأثیرات در منطقه خلیج سانفرانسیسکو. مربا. طرح. دانشیار 1996 ، 62 ، 492-511. [ Google Scholar ] [ CrossRef ]
- سرورو، آر. دانکن، ام. کدام یک سفر خودرو را بیشتر کاهش میدهد: تعادل شغل و مسکن یا خردهفروشی و اختلاط مسکن؟ مربا. طرح. دانشیار 2006 ، 72 ، 475-490. [ Google Scholar ] [ CrossRef ]
- چاپل، ک. Zuk, M. مطالعات موردی در مورد جنسیت سازی و جابجایی در منطقه خلیج سانفرانسیسکو . گزارش فنی؛ دانشگاه کالیفرنیا برکلی: برکلی، کالیفرنیا، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- نگوین، وی بی. استیورز، ای. حرکت سیلیکون ولی به جلو . گزارش فنی؛ زیستگاه شهری: اوکلند، کالیفرنیا، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- گراهام، MR; کوتزباخ، ام جی; McKenzie, B. طراحی مقایسه محصولات داده های رفت و آمد LODES و ACS ; مقالات کاری 14-38; مرکز مطالعات اقتصادی، اداره سرشماری ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 2014.
- اداره سرشماری ایالات متحده وسیله حمل و نقل به محل کار بر اساس ویژگی های انتخاب شده. 2019. در دسترس آنلاین: https://data.census.gov/cedsci/table?q=S0802&tid=ACSST1Y2019.S0802 (در 13 نوامبر 2020 قابل دسترسی است).
- پتوچنیگ، ا. Havas، CR; رسچ، بی. کریگر، وی. فرنر، سی. تحلیل زبان فضایی-زمانی اکتشافی دادههای شبکههای ژئو اجتماعی برای شناسایی جابجاییهای پناهندگان. GI_Forum 2020 ، 1 ، 137–152. [ Google Scholar ] [ CrossRef ]
- اداره سرشماری ایالات متحده داده های کلی منطقه جغرافیایی 2019. در دسترس آنلاین: https://www.census.gov/cgi-bin/geo/shapefiles/index.php?year=2019 (در 13 نوامبر 2020 قابل دسترسی است).
- راهنمای کاربر Boundary Solutions, Inc. ParcelAtlas. 2020. در دسترس آنلاین: https://www.boundarysolutions.com/ParcelAtlas/ParcelAtlasUserManual.pdf (در 13 نوامبر 2020 قابل دسترسی است).
- OpenStreetMap Foundation. مشارکت کنندگان OpenStreetMap. 2020. در دسترس آنلاین: https://www.openstreetmap.org (در 13 نوامبر 2020 قابل دسترسی است).
- بوئینگ، G. OSMnx: روشهای جدید برای دستیابی، ساخت، تجزیه و تحلیل و تجسم شبکههای خیابانی پیچیده. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 65 ، 126-139. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هاگبرگ، AA; شولت، دی. Swart، PJ کاوش ساختار، دینامیک و عملکرد شبکه با استفاده از NetworkX. در مجموعه مقالات هفتمین کنفرانس علمی پایتون (SciPy 2008)، پاسادنا، کالیفرنیا، ایالات متحده آمریکا، 19 تا 24 اوت 2008. صص 11-15. [ Google Scholar ]
- گروه توسعه جهانی PostgreSQL. PostgreSQL. 2020. در دسترس آنلاین: https://www.postgresql.org (در 13 نوامبر 2020 قابل دسترسی است).
- PostGIS. PostGIS. 2020. در دسترس آنلاین: https://www.postgis.net (در 13 نوامبر 2020 قابل دسترسی است).
- بنیاد نرم افزار پایتون پایتون. 2020. در دسترس آنلاین: https://www.python.org (در 13 نوامبر 2020 قابل دسترسی است).
- تیم اصلی R. پروژه R برای محاسبات آماری. 2020. در دسترس آنلاین: https://www.r-project.org (در 13 نوامبر 2020 قابل دسترسی است).
- تیم توسعه QGIS. QGIS. 2020. در دسترس آنلاین: https://www.qgis.org (در 13 نوامبر 2020 قابل دسترسی است).
- استر، ام. کریگل، اچ پی؛ ساندر، جی. Xu, X. الگوریتم مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز. در مجموعه مقالات دومین کنفرانس بین المللی کشف دانش و داده کاوی، پورتلند، OR، ایالات متحده آمریکا، 2 تا 4 اوت 1996. صص 226-231. [ Google Scholar ]
- شوبرت، ای. ساندر، جی. استر، ام. کریگل، اچ پی؛ Xu، X. DBSCAN بازبینی شد، بازبینی شد: چرا و چگونه باید (هنوز) از DBSCAN استفاده کنید. ACM Trans. سیستم پایگاه داده 2017 ، 42 ، 1-21. [ Google Scholar ] [ CrossRef ]
- کوندی، ا. Resch, B. راهنمای طراحی حریم خصوصی جغرافیایی برای کمپین های تحقیقاتی که از داده های سنجش مشارکتی استفاده می کنند. جی امپایر. Res. هوم Res. اخلاق 2018 ، 13 ، 203-222. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کوندی، ا. رسچ، بی. Petutschnig، A. تهدیدات حریم خصوصی و توصیه های حفاظتی برای استفاده از داده های شبکه های جغرافیایی اجتماعی در تحقیقات. Soc. علمی 2018 ، 7 ، 191. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کوبا، N. یادداشت تحقیقاتی: نمودارهای سانکی برای تجسم دینامیک پوشش زمین. Landsc. طرح شهری. 2015 ، 139 ، 163-167. [ Google Scholar ] [ CrossRef ]
- Anselin, L. اقتصاد سنجی فضایی: روش ها و مدل ها . جلد 4، مطالعات علوم عملیاتی منطقه ای; Springer: Dordrecht, The Netherlands, 1988. [ Google Scholar ] [ CrossRef ][ Green Version ]
- بخش، MD; مدلهای رگرسیون فضایی گلدیچ، KS ; انتشارات Sage: Thousand Oaks، CA، USA، 2008. [ Google Scholar ] [ CrossRef ][ Green Version ]
- SeeClickFix, Inc. SeeClickFix. 2020. در دسترس آنلاین: https://seeclickfix.com/ (در 13 نوامبر 2020 قابل دسترسی است).
- Waze Online. ویز. 2020. در دسترس آنلاین: https://www.waze.com/ (در 13 نوامبر 2020 قابل دسترسی است).
- کوگان، NE; کلمنته، ال. لیوتو، پی. کاشوک، جی. لینک، NB; نگوین، AT; Lu، FS; هایبرز، پی. رسچ، بی. هاواس، سی. و همکاران یک رویکرد هشدار اولیه برای نظارت بر فعالیت COVID-19 با چندین ردیابی دیجیتال در زمان واقعی. علمی Adv. 2021 ، 7 ، eabd6989. [ Google Scholar ] [ CrossRef ] [ PubMed ]
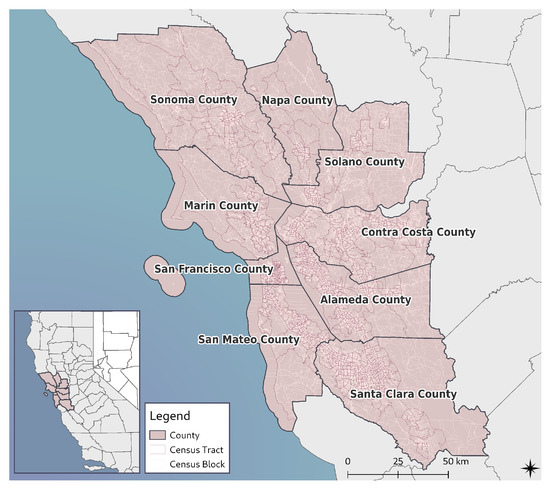
شکل 1. نمای کلی منطقه مطالعه.
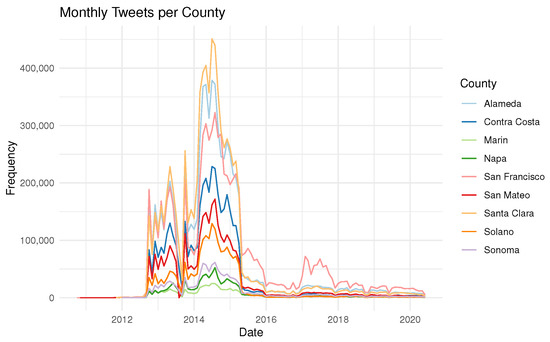
شکل 2. توییت ها در ماه و شهرستان برای کل دوره مشاهده.
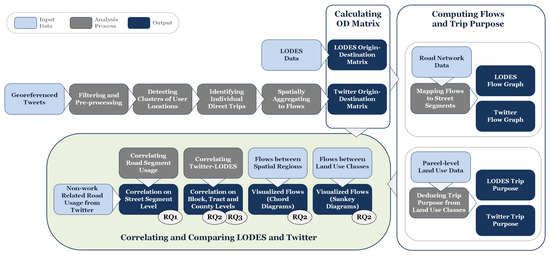
شکل 3. گردش کار شماتیک که داده های ورودی، مراحل تجزیه و تحلیل و خروجی ها را نشان می دهد.
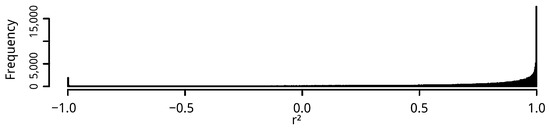
شکل 4. توزیع فرکانس از مقادیر برای مقایسه LODES با تمام داده های توییتر.
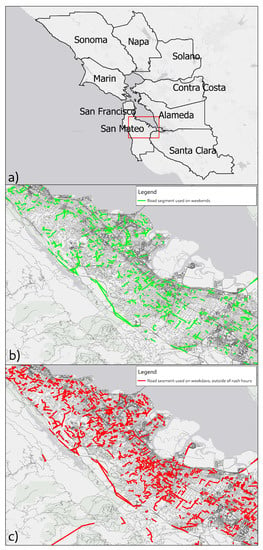
شکل 5. مقایسه استفاده از بخش جاده برای زیر مجموعه های زمانی مختلف داده های توییتر. نقشه ( a ) موقعیت نقشه های تفصیلی را در محدوده مورد مطالعه نشان می دهد. نقشهها ( b ، c ) استفاده از بخش جاده را برای زیر مجموعههای زمانی مختلف نشان میدهند.
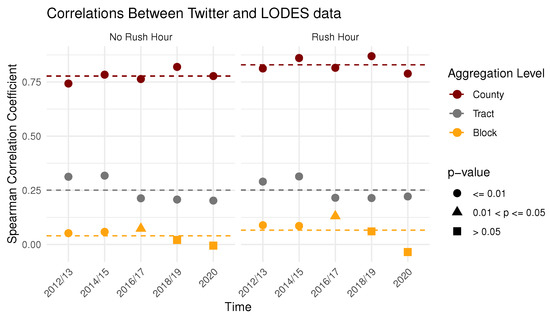
شکل 6. ضرایب همبستگی بین توییتر و جریان LODES بین مناطق. میانگین ضرایب همبستگی برای سطوح مقیاس فضایی با خط چین نشان داده شده است.
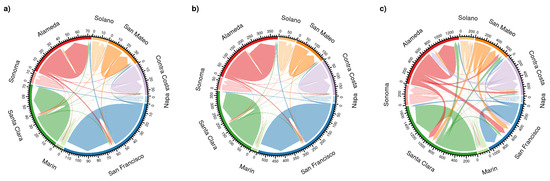
شکل 7. نمودارهای آکورد برای اتصالات سطح شهرستان ( الف ) جریان توییتر در ساعات شلوغ، ( ب ) جریان توییتر در خارج از ساعات شلوغی و ( ج ) داده های LODES (قدر × 1000).
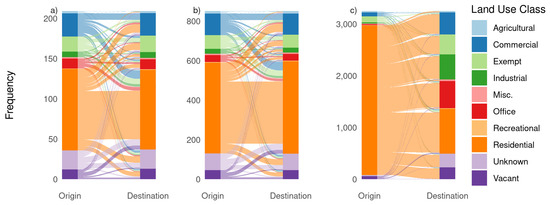
شکل 8. نمودارهای سانکی از جفت استفاده از زمین از ( الف ) جریان توییتر در ساعات شلوغی، ( ب ) جریان توییتر در خارج از ساعات شلوغی و ( ج ) داده های LODES (قدر × 1000).
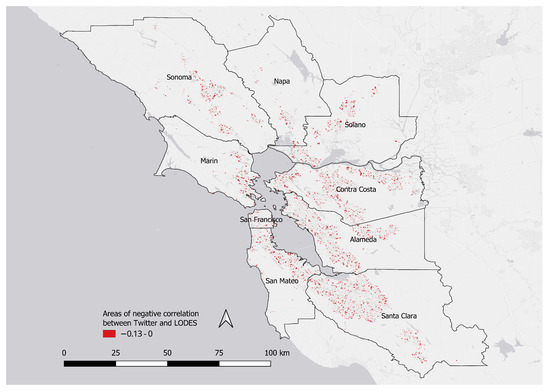
شکل 9. مناطق با (خفیف، تا ) منفی برای داده های توییتر که استفاده از بخش خیابان LODES را پیش بینی می کند. نواحی قرمز رنگ تنها مناطقی هستند که برای همه توییت هایی که به منظور شبیه سازی داده های LODES فیلتر شده اند، تفاوت قابل توجهی وجود دارد. مجموع مجموع این نواحی کوچک است و از نظر مکانی همبستگی خودکار ندارد.


بدون دیدگاه