1. معرفی
ساینیج دیجیتال یک سیستم صوتی و تصویری چند رسانه ای است که اطلاعات تجاری، مالی و سرگرمی را از طریق دستگاه های نمایش پایانه در مکان های عمومی منتشر می کند [ 1 ، 2 ]. در مقایسه با تبلیغات تلویزیونی و روزنامه های سنتی، ساینیج دیجیتال می تواند برای تبلیغات شخصی و سفارشی بر اساس مخاطبان مختلف استفاده شود [ 3 ، 4 ]. در حال حاضر، تبلیغات دیجیتال ساینیج به تدریج به روند اصلی در توسعه تبلیغات در فضای باز تبدیل شده است و از رشد کلی تبلیغات در فضای باز حمایت می کند [ 5 ]. ساینیج دیجیتال در بیش از 20 سال توسعه یافته است و کاربرد آن در تمام زمینه های زندگی گسترش یافته است [ 6 ، 7 ]]؛ علاوه بر این، کاربرد گسترده آن ارزش کاربردی خاصی را برای جامعه به ارمغان آورده است. در حال حاضر مطالعات انجام شده در زمینه دیجیتال ساینیج به طور عمده به دو دسته تقسیم می شوند. اولین مورد مطالعه رفتار مصرف کنندگان با استفاده از علامت دیجیتال است. ماریون و همکاران [ 8 ] واکنش مصرفکننده به تبلیغات دیجیتال ساینیج در محیط خرید را تجزیه و تحلیل کرد و دریافت که استفاده از تابلوهای دیجیتال در مراکز خرید باعث ایجاد احساسات مثبت برای مشتریان میشود و میتواند خریدهای فوری و وفاداری فروشگاه را افزایش دهد. وجود یک سیستم علامت دیجیتال زمان انتظار درک شده را کاهش داد و در عین حال تجربه انتظار مطلوبی را ایجاد کرد [ 9 ]. به طور خلاصه، ساینیج دیجیتال می تواند فضای خرده فروشی را ترویج کند و رفتار مصرف را تحریک کند [ 10 ، 11 ،12 ، 13 ، 14 ]. تمرکز دوم بر روی توسعه سیستم برای مدیریت علائم دیجیتال و توزیع محتوا است. خو و همکاران [ 15 ] یک سیستم علامت دیجیتال بلادرنگ مقیاسپذیر طراحی کرد که میتواند به طور موثر وظایف بلادرنگ، مانند پیامرسانی فوری/ فوری و نظارت بر وضعیت سیستم را انجام دهد. شپرد و همکاران [ 16] از روشهای ورودی صدا و پردازش زبان طبیعی برای پیادهسازی علامتهای دیجیتال به شکل انتقال صوتی استفاده میکند و کاربران را قادر میسازد اطلاعات را سریعتر از روشهای استاندارد فقط با صفحه لمسی پیدا کنند. علاوه بر این، فناوریهای نوظهور که توسط فناوری دادههای بزرگ ارائه میشوند، توسعه پلتفرمهای هوشمند را برای مدیریت پایانههای علامت دیجیتال، زمانبندی خودکار و توزیع محتوا ارتقا دادهاند [ 17 ، 18 ، 19 ، 20 ]]. به طور خلاصه، تحقیق در مورد ساینیج دیجیتال عمدتاً بر رفتار مصرف و ساخت سیستم اطلاعاتی تمرکز دارد و فاقد انتخاب سایت برای تابلوهای دیجیتال است. با این حال، انتخاب سایت ساینیج دیجیتال تجربی و قرار دادن تبلیغات، همگی به صورت دستی انجام میشوند، و کمبود دادهها و استانداردهای روش وجود دارد، که رفع نیازهای تبلیغکنندگان و فروشندگان رسانه را دشوار میکند. بنابراین، مدلهای مکانیابی دقیق باید برای مدیریت استاندارد شده به دیجیتال ساینیج معرفی شود، که یک مشکل فوری برای شرکتهای علامت دیجیتال است.
مدلهای انتخاب سایت عمدتاً به مدلهای مکانی تجربی و روشهای یادگیری ماشینی تقسیم میشوند. (1) مدلهای مکان تجربی شامل مدل جاذبه [ 21 ]، مدل هاف [ 22 ]، مدل تعامل رقابتی چندگانه (MCI)، مدل تصمیمگیری چند معیاره (MCDM) [ 23 ، 24 ، 25 ] و فرآیند سلسله مراتبی تحلیلی است. (AHP) مدل [ 26 ، 27 ، 28 ]. سوارز وگا و همکاران [ 22 ] مدل هاف را با یک مدل رگرسیون وزندار جغرافیایی ترکیب کرد تا برنامهای را ارائه دهد که در آن پارامترها ناهمگونی فضایی را نشان میدهند و مکان یک فروشگاه جدید را تجزیه و تحلیل میکنند. آمپارو و همکاران [ 29] تجزیه و تحلیل مؤلفه اصلی (PCA) از 16 نوع عامل تأثیرگذار سوپرمارکت، مانند قیمت خانه، مرکزیت حمل و نقل و انواع فروش سوپرمارکت را برای حذف عوامل تأثیرگذار مرتبط انجام داد و سپس از مدل MCI برای به دست آوردن مکان سوپرمارکت استفاده کرد. با این وجود، این مدل ها محدوده انتخاب سایت محدودی دارند و برای انتخاب سایت در مقیاس بزرگ مناسب نیستند. با توجه به اینکه عوامل مختلف تأثیرات متفاوتی بر نتایج مکان دارند، Velasquez et al. [ 25] از ترکیبی از مدل MCDM و مدل AHP برای انتخاب مکانهای فروشگاههای خردهفروشی استفاده کرد و در نتیجه کارایی و دقت نتایج مکان را بهبود بخشید. مدل ریلی و مدل هاف فاصله فضایی بین مخاطب و امکاناتی را که برای انتخاب مکان به کار گرفته میشوند در نظر میگیرند. مدل MCI، MCDM و سایر مدلها اطلاعات اقتصادی و حمل و نقل امکانات را برای انتخاب مکان در نظر میگیرند. مدل مکان یابی تجربی می تواند مشکل مکان یابی را به خوبی در یک منطقه کوچک یا با مقدار کمی داده حل کند. با این حال، در مواجهه با محیط های اجتماعی و جغرافیایی پیچیده، حجم زیادی از داده ها و محاسبات به طور چشمگیری افزایش یافته است، پیچیدگی محاسباتی افزایش یافته است، و انتخاب سایت منبع چندگانه به یک مشکل NP-hard (چند جمله ای غیر قطعی) تبدیل شده است.30 ]. مدل تجربی انتخاب سایت به سختی قابل حل است و مشکلاتی در محدوده و تعداد سایت ها وجود دارد. بنابراین، یادگیری ماشین برای انطباق با محاسبات در مقیاس بزرگ و بهبود هوشمندی و دقت مدل انتخاب سایت تا حدودی معرفی شده است. (2) یادگیری ماشین از روشهای پیشبینی مانند درخت تصمیم و شبکه عصبی برای حل مشکلات مکان استفاده میکند [ 31 ، 32 ، 33 ، 34 ، 35 ، 36 ، 37 ، 38 ]. یانگ و همکاران [ 35] یک برنامه کاربردی HoLSAT (مجموعه ابزارهای انتخاب و تجزیه و تحلیل مکان هتل) با ترکیب WebGIS و الگوریتم های یادگیری ماشین برای به دست آوردن مکان های هتل توسعه داد. لو و همکاران [ 36 ] پیشبینی رگرسیون شبکه عصبی و مدل MCDM را برای پیشبینی مکانهای استقرار هتل بر اساس دادههای GPS تاکسی ترکیب کرد. لیو و همکاران [ 37 ] یک سیستم انتخاب سایت بیلبورد شهری به نام SmartAdP بر اساس داده های مسیر تاکسی ساخت. وانگ و همکاران [ 38] یک الگوریتم شبکه عصبی ترکیبی BP (شبکه عصبی پس انتشار) را بر اساس داده های نقطه مورد علاقه شهری برای انجام انتخاب مکان مغازه ساخت و نتایج مکان را تجسم کرد. مدل تجربی مکانگزینی دارای مزایای در نظر گرفتن جامع فاصله و محیط تجاری منطقه مورد مطالعه است، اما دامنه و کمیت انتخاب مکان آن محدود و ترسیم و تعیین کمیت آن دشوار است. روش های یادگیری ماشینی می توانند با محاسبات در مقیاس بزرگ و پیچیده سازگار شوند. از این رو یادگیری ماشینی برای بهبود کارایی محاسبات کلان داده و گسترش دامنه انتخاب سایت و نتایج انتخاب سایت معرفی شده و به تدریج به کانون تحقیقاتی تبدیل شده است.
همچنین گهگان م [ 39] نشان داد که در استفاده از یادگیری ماشین، که عموماً منجر به مدلهایی میشود که برای انسان قابل درک نیستند یا به نظریه دامنه مربوط نمیشوند، میتوانیم مدلهای تجربی را با روشهای یادگیری ماشین ترکیب کنیم تا کارایی محاسبات و تفسیرپذیری مدل را بهبود بخشیم. مدل هاف یکی از مدلهای نظری بالغ برای انتخاب سایت است و ما بهطور مبتکرانه این مدل را بهبود میدهیم تا آن را با انتخاب سایت ساینیج دیجیتال تطبیق دهیم و آن را با روشهای یادگیری ماشین ترکیب کنیم تا با محاسبات پیچیده در مقیاس بزرگ تطبیق داده شود و کارایی محاسبات و تفسیرپذیری مدل بنابراین، این مقاله با هدف ارائه یک ترکیب مدل انتخاب سایت علامت دیجیتال از یادگیری ماشین و یک رویکرد تجربی مبتنی بر عوامل چند منبعی برای بهبود دقت و تفسیر مدلهای انتخاب سایت علامت دیجیتال است.
منطقه در جاده حلقه ششم در پکن به عنوان منطقه تحقیقاتی و علائم دیجیتال تجاری در فضای باز به عنوان هدف تحقیق در نظر گرفته شد. این مطالعه به طور جامع عوامل تأثیرگذار 19 نوع علامت دیجیتال، مانند جمعیت، قیمت مسکن، و ورود به شبکه اجتماعی را در نظر میگیرد و چگونگی تأثیر مقیاسهای مختلف بر فرآیند انتخاب سایت را از طریق تجزیه و تحلیل شبکه چند مقیاسی بررسی میکند. فرآیند انتخاب سایت شامل سه جنبه است: (1) یک مدل هاف اصلاح شده برای تجزیه و تحلیل و ارزیابی دسترسی به علائم دیجیتال، یعنی فرآیند اولیه انتخاب سایت استفاده می شود. (2) مدل شبکه عصبی BP برای پیشبینی پتانسیل طرحبندی علامت دیجیتال استفاده میشود. (3) تحلیل همپوشانی دسترسی به تابلوهای دیجیتال، مخاطبان، و پتانسیل طرح بندی برای تعیین سایت برای استقرار علائم دیجیتال استفاده می شود. علاوه بر این، نتایج انتخاب سایت با روش های تجربی برای تأیید اعتبار و صحت نتایج انتخاب مکان به دست آمده در این مقاله مقایسه می شود. از یک طرف، ما تعدادی سلول شبکه را ارائه می دهیم که برای طرح علائم دیجیتالی در جاده حلقه ششم پکن مناسب هستند. علاوه بر این، ما یک ایده تحقیقاتی ارائه میکنیم که روشهای تجربی را با روشهای یادگیری ماشین ترکیب میکند و مرجعی برای ادغام ویژگیهای جغرافیایی و عناصر دادهای آنها در الگوریتم انتخاب سایت ارائه میکند، و دقت و تفسیرپذیری مدلهای انتخاب سایت موجود را بهبود میبخشد. در عین حال برای سایر مسائل مکان یابی تاسیسات تجاری می توان از این روش به عنوان مرجع استفاده کرد. بدین ترتیب،
2. منطقه مطالعه و منبع داده
2.1. منطقه مطالعه
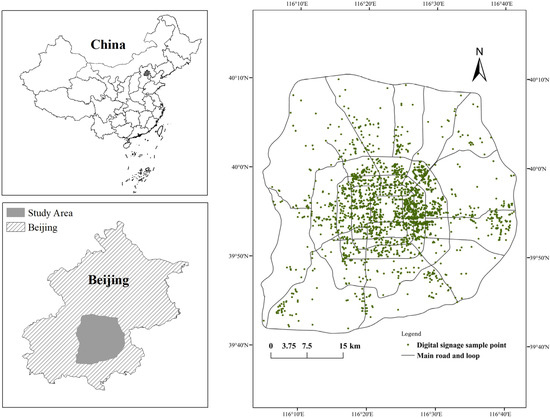
پکن مرکز سیاسی، مرکز فرهنگی، مرکز نوآوری فناوری و مرکز ارتباطات بینالمللی چین است. این یک شهر بین المللی مدرن است. به عنوان یک کلان شهر جامع، توسعه سریع اقتصاد شهری پکن فرصت های جدیدی را برای توسعه صنعت تابلوهای دیجیتال به ارمغان آورده است. پکن شهر مهمی است که صنعت تابلوهای دیجیتال جهانی در آن جمع شده است. در مرکز پکن و حومه آن، تابلوهای دیجیتال 85 درصد از کل تابلوها را در پکن تشکیل می دهند [ 20 ]. گزارش بررسی نمونه جمعیت پکن در سال 2014 نشان داد که 79.5 درصد از جمعیت دائمی پکن در جاده کمربندی ششم متمرکز شده اند [ 40 ]]. داده های ساینیج دیجیتال از پروژه های قبلی به دست آمده و هزینه های عملیاتی، انواع صفحه و آدرس های 5823 علامت دیجیتال در منطقه مورد مطالعه را توصیف می کند ( شکل 1 ). منطقه در داخل جاده حلقه ششم در پکن به عنوان منطقه مورد مطالعه انتخاب شد (همانطور که در شکل 1 نشان داده شده است )، شامل منطقه دونگ چنگ، منطقه شیچنگ، منطقه هایدیان، منطقه چائویانگ، بیشتر منطقه فنگتای، منطقه شیجینگشان، منطقه شونیی، منطقه چانگ پینگ، ناحیه تونگژو، ناحیه داکسینگ، ناحیه فانگشان و بخشهایی از ناحیه منتوگو.
2.2. منبع اطلاعات
به عنوان یک سیستم پیچیده غیرخطی، توزیع علائم دیجیتال نیاز به بررسی جامع تعامل بین عوامل مختلف دارد. جمعیت شناسی، حمل و نقل، رقابت و امکانات، عوامل اصلی موثر بر طرح و مکان تابلوهای دیجیتال هستند [ 20 ، 37 ، 38 ]. بنابراین، ما 19 شاخص را همانطور که در جدول 1 نشان داده شده است، انتخاب می کنیم ، از جمله اطلاعات مکانی و قیمت پخش سیگنال دیجیتال، تعداد امکانات POI، داده های ورود به سیستم Sina Weibo، داده های سرشماری، و داده های شاخص مرکزیت شبکه حمل و نقل (محاسبه شده بر اساس شبکه خیابانی) [ 41 ، 42 ].
تابلوهای دیجیتالی فرض شده در این مطالعه شامل تابلوهای دیجیتال تجاری در فضای باز با پخش ویدئو، انیمیشن، تصاویر یا متن، و همچنین تمام تابلوهای دیجیتال بزرگ تجاری در فضای باز توزیع شده در جاده حلقه ششم در پکن بر اساس پایگاه داده ما که توسط تحقیقات میدانی ایجاد شده است. اطلاعات نمایش داده شده بر روی تابلوی دیجیتال باید حداقل 100 متر دید داشته باشد، یعنی در فاصله 100 متری مخاطب به وضوح دیده شود.
3. روش ها
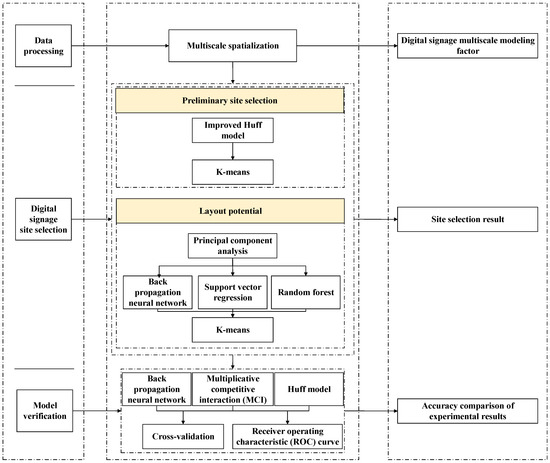
انتخاب سایت ساینیج دیجیتال فرآیند شناسایی مکان های جدید برای استقرار ساینیج دیجیتال با ترکیب داده های دیجیتال ساینیج و عوامل تاثیرگذار است. مدل بهبود یافته هاف یک رویکرد تجربی است که میتواند فاصله بین مخاطبان و تابلوهای دیجیتال را محاسبه کند و سپس شبکههایی را با دسترسی فضایی کم انتخاب کند. روشهای یادگیری ماشینی، تعداد خروجیهای تجاری، امکانات POI و سایر عوامل تأثیرگذار در شبکه را تجزیه و تحلیل میکنند تا پتانسیل طرحبندی علامتهای دیجیتال را به دست آورند و سپس شبکههایی با پتانسیل استقرار بالا را بهعنوان مکان مستقر انتخاب کنند. در مقایسه با مطالعات قبلی، با ترکیب این دو روش، ویژگیهای فضایی و پتانسیل تجاری مکان در روش انتخاب سایت مبتنی بر محتوا ادغام میشوند. این نه تنها کارایی محاسبات را بهبود می بخشد، بلکه قابلیت تفسیر مدل را نیز بهبود می بخشد. این فرآیند عمدتاً شامل سه بخش است: فضایی سازی داده ها، انتخاب سایت و تأیید مدل (شکل 2 ).
ابتدا، دادهها در مقیاسهای چندگانه توسط ESRI ® ArcGIS TM 10.3 پردازش و فضاسازی میشوند. سپس، مدل بهبود یافته هاف برای محاسبه دسترسی فضایی علائم دیجیتال و روشهای یادگیری ماشینی مانند شبکه عصبی BP برای محاسبه پتانسیل طرحبندی علامت دیجیتال در جاده حلقه ششم در پکن استفاده میشود. در نهایت، مدل MCI، مدل شبکه عصبی BP و مدل هاف برای تضاد با مدل ما استفاده میشوند. اعتبار و دقت مدل انتخاب سایت علامت دیجیتال ارائه شده در این مقاله با اعتبار متقاطع و منحنیهای ROC تأیید میشود.
3.1. پردازش داده ها
با توجه به ناهمگونی چندمنبعی عوامل تأثیرگذار دیجیتال ساینیج، برای به دست آوردن ویژگی های فضایی ساینیج دیجیتال و عوامل تأثیرگذار، لازم است یک شبکه استاندارد و مقیاس های مناسب برای به دست آوردن فاکتورهای مدل سازی دیجیتال ساینیج ساخته شود. عوامل مدلسازی دیجیتال ساینیج مبتنی بر شبکه نه تنها میتوانند اطلاعات ویژگیهای فضایی را به صورت واقعیتر و شهودی منعکس کنند، بلکه میتوانند یک مرجع فضایی واحد برای تلفیق دادهها و تجزیه و تحلیل بعدی فراهم کنند.
در فرآیند فضایی سازی، در نظر گرفته می شود که نتایج تجربی متفاوتی به دلیل مقیاس های فضایی متفاوت رخ خواهد داد (یعنی یک مشکل واحد منطقه ای قابل اصلاح [ 43 ، 44 ، 45 ، 46 ، 47 ، 48 ، 49 ] (MAUP) وجود دارد). به گفته وانگ و همکاران. [ 38 ]، تقسیم منطقه مورد مطالعه به مقیاس شبکه ای 100 متر تا 1000 متر، نیازهای آزمایش های انتخاب مکان را برآورده می کند. بنابراین، برای ارزیابی دقیق پتانسیل سیگنال دیجیتال در جاده کمربندی ششم در پکن و یافتن مقیاس فضایی مناسبتر، این مقاله 100 متر تا 1000 متر را برای آزمایشهای تقسیم مقیاس فضایی انتخاب میکند.
فرآیند آزمایشی خاص در شکل 3 نشان داده شده است . ابتدا پردازش دادهها بر روی دادههای عامل تأثیرگذار علامتهای دیجیتال انجام میشود و سپس درونیابی منطقهای چند مقیاسی انجام میشود، یعنی شبکههای استاندارد 100 متر تا 1000 متر برای ویژگیها با استفاده از ESRI® ArcGIS TM 10.3 استفاده میشود. تعداد شبکه های استاندارد در 10 مقیاس مختلف در جدول 2 نشان داده شده است ، به طوری که 10 عامل مدل سازی مکان مقیاس به دست می آید.
3.2. مدل مکان
فرآیند انتخاب سایت عمدتاً به دو مرحله تقسیم می شود. اولین گام استفاده از مدل اصلاح شده هاف برای محاسبه دسترسی فضایی ساینیج دیجیتال و استفاده از الگوریتم خوشه بندی K-means برای طبقه بندی نتایج محاسباتی در 3 سطح بالا، متوسط و پایین است تا دسترسی مکانی به ساینیج دیجیتال را بدست آوریم. ده مقیاس (از 100 متر تا 1000 متر). مرحله دوم محاسبه پتانسیل طرحبندی سیگنال دیجیتال در منطقه توسط شبکه عصبی BP، جنگل تصادفی و الگوریتمهای رگرسیون ماشین برداری پشتیبانی و استفاده از الگوریتم خوشهبندی برای طبقهبندی نتایج محاسباتی به بالا، متوسط و پایین است. در نهایت، تجزیه و تحلیل پوشش برای به دست آوردن نتایج انتخاب سایت استفاده می شود.
3.2.1. انتخاب اولیه سایت
انتخاب اولیه سایت به محاسبه دسترسی فضایی تابلوهای دیجیتال در منطقه اشاره دارد و نتایج انتخاب اولیه بر اساس قیمت پخش، تعداد بازدیدها (نوع داده نشان دهنده مخاطب) و فاصله بین دیجیتال است. تابلوها و مخاطبان مدل هاف، به عنوان یک مدل تجربی انتخاب سایت تجاری، فاصله بین فروشگاه خرده فروشی و مشتری و منطقه خود فروشگاه خرده فروشی را در نظر می گیرد. بنابراین، یک مدل هاف اصلاحشده با محوریت دادههای ورود به Weibo برای محاسبه دسترسی فضایی علائم دیجیتال استفاده میشود. سپس، از الگوریتم خوشهبندی K-means برای طبقهبندی نتایج محاسبه دسترسی فضایی استفاده میشود و خوشههایی از سطوح مختلف دسترسی فضایی علامت دیجیتال بهدست میآیند.
مدل هاف
مدل هاف یک مدل تجربی مکان کسب و کار است [ 50 ]. این مدل از فاصله و مساحت منطقه فروش برای محاسبه جذابیت یک فروشگاه خرده فروشی برای مصرف کنندگان استفاده می کند، یعنی احتمال انتخاب یک فروشگاه توسط مشتری. متغیر P ij نشان دهنده این احتمال است که مصرف کننده در مکان i در فروشگاه j هزینه کند . فرمول را می توان به صورت نوشتاری
که در آن T ij زمان رسیدن به فروشگاه را نشان می دهد (این به محاسبه فاصله تا فروشگاه اشاره دارد). S ij مساحت منطقه فروش فروشگاه را نشان می دهد. و β پارامتری است که از تجربه تخمین زده می شود که تأثیر زمان مورد نیاز برای مصرف کنندگان برای ایجاد رفتارهای مختلف را نشان می دهد که معمولاً به صورت 2 تنظیم می شود.
مدل هاف اصلاح شده
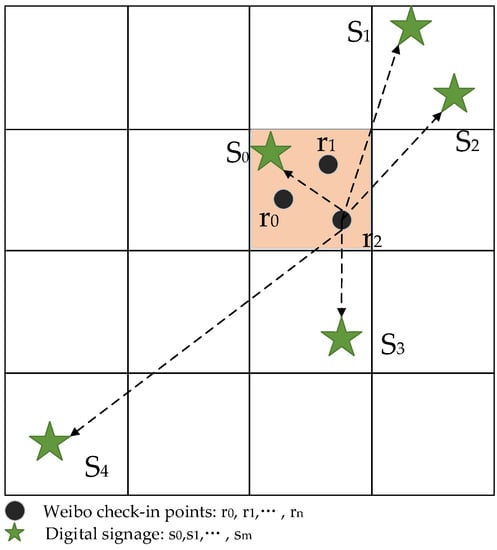
بر اساس چارچوب محاسباتی مدل هاف، همراه با نیازهای تجربی انتخاب سایت ساینیج دیجیتال، این مدل برای تمرکز بر روی نقطه ورود به Weibo در شبکه استاندارد بهبود یافت تا جذابیت ساینیج دیجیتال برای مخاطبان در واحد محاسبه شود. منطقه ( شکل 4 ) و برای مشخص کردن قابلیت دسترسی فضایی تابلوهای دیجیتال، همانطور که در فرمول (2) نشان داده شده است:
جایی که i نشان دهنده داده های نقطه ورود به Weibo است. j نشان دهنده داده های نقطه علامت دیجیتال است. num i تعداد دفعات ورود به نقطه ورود را نشان می دهد. p j نشان دهنده قیمت پخش دیجیتال ساینیج است. d ij نشان دهنده فاصله بین نقطه ورود و علامت دیجیتال است. و a i مجموع یکی از نقاط ورود (مخاطب را نشان می دهد) در یک شبکه و تمام نقاط داده علامت دیجیتال را نشان می دهد ( nتومترمن∗پjدمنj2) که نشان دهنده توانایی نقطه ورود به علامت دیجیتال است. A G میانگین توانایی یک شبکه برای رسیدن به یک علامت دیجیتال را مشخص می کند و n تعداد نقاط ورود در یک شبکه است.
K-Means Clustering
مدل K-means [ 51 ] یک روش خوشه بندی بر اساس تقسیم فاصله است. فرآیند خوشهبندی به شرح زیر است: ابتدا باید مرکز K را تعیین کرد، یعنی تعداد خوشههایی که میخواهیم تجمیع شوند. دوم، فاصله اقلیدسی هر شاخص محاسبه می شود و فواصل بین اشیاء محاسبه شده ادغام می شوند. در نهایت، برنامه به طور مداوم اجرا می شود و هر گروه به طور تصادفی مرکز را انتخاب می کند تا مجموع مجذور خطاها کوچکترین باشد [ 52 ].
لازم است مناطقی با قابلیت دسترسی و چیدمان فضایی متفاوت از هم متمایز شوند. از آنجایی که داده ها داده های عددی هستند، سطوح مختلف مناطق باید بر اساس فاصله اقلیدسی تقسیم شوند. بنابراین، الگوریتم K-means برای به دست آوردن خوشه های سطوح مختلف مورد نیاز است.
شاخص Calinski–Harabasz (شاخص CH )
شاخص CH یک شاخص اندازه گیری آماری برای تشخیص اثر توزیع است. فرمول خاص در فرمول (3) نشان داده شده است تیr(بک)و تیr(دبلیوک)به ترتیب فاصله بین دسته ها و درون دسته ها هستند. شاخص CH نشان می دهد که تفاوت بین دسته های اندازه گیری بیشتر از تفاوت در دسته ها است. یعنی زمانی که نتیجه خوشه بندی بهینه باشد، CH حداکثر مقدار [ 53 ] را دارد.
جایی که بکماتریس واگرایی درون طبقاتی است، دبلیوکماتریس واگرایی بین طبقاتی و محاسبه است دبلیوکو بکبه شرح زیر است:
که در آن n تعداد نقاط داده است، سیqمجموعه نقاط در خوشه q است، جمرکز نقطه نمونه است و nqتعداد امتیازات کلاس q است.
شاخص CH برای ارزیابی اثر خوشه بندی پارامترهای مختلف در الگوریتم فوق استفاده می شود. هر چه مقدار شاخص بالاتر باشد، اثر خوشه بندی بهتر است و سپس پارامترهای موجود در الگوریتم تعیین می شوند.
3.2.2. محاسبه پتانسیل طرح بندی تابلوهای دیجیتال
پتانسیل طرحبندی دیجیتال ساینیج به معنای انتخاب عوامل مدلسازی چند مقیاسی به عنوان متغیرهای مستقل و قیمتهای تبلیغاتی ساینیج دیجیتال بهعنوان متغیرهای وابسته برای پیشبینی پتانسیل در یک منطقه است. الگوریتمهای پیشبینی معمولی شامل شبکه عصبی BP، رگرسیون ماشین بردار پشتیبان و جنگل تصادفی است. با توجه به تفاوت بین مجموعه داده و ویژگی های داده، هیچ روش پیش بینی جهانی قابل اجرا برای همه مجموعه داده ها وجود ندارد. بنابراین، آزمایشهای مقایسهای را انجام میدهیم و ریشه میانگین مربعات خطا ( RMSE ) را به عنوان شاخص ارزیابی در نظر میگیریم و الگوریتم مناسب و مقیاس مناسب را برای پیشبینی پتانسیل طرحبندی علامت دیجیتال در منطقه انتخاب میکنیم.
شبکه عصبی BP
شبکه های عصبی BP [ 54 ] از لایه های ورودی، پنهان و خروجی تشکیل شده اند. روند آموزش به شرح زیر است: ابتدا وزن سیناپسی و ماتریس آستانه شبکه مقداردهی اولیه شده و نمونه های آموزشی ارائه می شود. دوم، انتشار رو به جلو و انتشار خطا به عقب محاسبه می شود، سپس وزن به روز می شود. و در آخر، تکرار انجام می شود، با استفاده از نمونه های جدید برای انجام محاسبات انتشار به جلو و محاسبات انتشار خطا تا زمانی که معیار توقف برآورده شود.
رگرسیون ماشین برداری پشتیبان (SVR)
رگرسیون SVR، به عبارت ساده، صفحه رگرسیونی را پیدا می کند که فاصله تمام داده های یک مجموعه را تا صفحه نزدیک ترین می کند [ 55 ]. متفاوت از مدل رگرسیون تجربی، رگرسیون بردار پشتیبان فرض میکند که تا زمانی که f(x) و y خیلی انحراف نداشته باشند، میتوان پیشبینی را درست در نظر گرفت و ضرر محاسبه نمیشود. به طور خاص، آستانه α تنظیم شده است، و فقط | f(x) – y |> α به عنوان مقدار تلفات نقطه داده محاسبه می شود. توابع کرنل که معمولاً مورد استفاده قرار می گیرند عبارتند از RBF (تابع پایه شعاعی)، خطی و پلی.
جنگل تصادفی (RF)
جنگل تصادفی یک روش یادگیری ساختاریافته با نظارت است. فرآیند محاسبه با استفاده از پیشبینی رگرسیون به شرح زیر است: ابتدا N واحد نمونه را از دادههای اصلی به طور تصادفی استخراج کنید و یک درخت رگرسیون ایجاد کنید. دوم، به طور تصادفی m را در هر گره استخراج کنید. در نهایت، نتیجه هر درخت رگرسیون را ادغام کنید و مقادیر پیش بینی شده را تولید کنید [ 56 ].
در مدلهای پیشبینی فوق، شبکههای بدون علامت دیجیتال به عنوان مجموعه آموزشی مدل و شبکههای دارای علامت دیجیتال به عنوان مجموعه آزمایشی مدل استفاده میشوند.
ریشه میانگین مربعات خطا ( RMSE )
ریشه میانگین مربعات خطا برای اندازه گیری انحراف بین مقدار پیش بینی شده و مقدار واقعی استفاده می شود. هر چه مقدار RMSE کوچکتر باشد، خطای الگوریتم کمتر است. فرمول این است
برای حذف همبستگی احتمالی بین ویژگیهای چند بعدی، روش تحلیل مؤلفه اصلی برای کاهش ابعاد دادههای ویژگی چند بعدی معرفی شد و از نتایج کاهش ابعاد به عنوان ورودیهای مدل استفاده شد.
تجزیه و تحلیل اجزای اصلی (PCA)
PCA یک الگوریتم فشرده سازی داده است [ 57 ]. هنگامی که با داده های چند بعدی سروکار داریم، از PCA برای فیلتر کردن ویژگی های داده با شباهت بالاتر استفاده می شود، در نتیجه به هدف کاهش ابعاد و سرعت بخشیدن به پردازش داده ها می رسد. فرآیند محاسباتی خاص حذف مقدار متوسط، محاسبه ماتریس کوواریانس، محاسبه مقادیر ویژه و بردارهای ویژه ماتریس کوواریانس، مرتبسازی مقادیر ویژه، حفظ بردارهای ویژه مربوط به اولین N بزرگترین مقادیر ویژه و تبدیل دادهها به فضای جدید است. بردارهای ویژگی N به دست آمده در بالا.
3.3. تایید مدل
در راستیآزمایی مدل، روش انتخاب سایت علامت دیجیتال همراه با مدل اصلاحشده هاف و مدل شبکه عصبی BP با مدل تجربی هاف، مدل شبکه عصبی BP و مدل مکانیابی MCI مقایسه میشود. منحنی مشخصه عملکرد گیرنده (منحنی ROC) به عنوان استاندارد ارزیابی برای تأیید اثربخشی و دقت روش انتخاب سایت علامت دیجیتال پیشنهاد شده در این مقاله استفاده میشود.
منحنی ROC می تواند حساسیت و دقت مدل را هنگام انتخاب آستانه های مختلف منعکس کند. هنگامی که توزیع نمونههای مثبت و منفی تغییر میکند، شکل منحنی را میتوان اساساً بدون تغییر نگه داشت، بنابراین این شاخص ارزیابی میتواند تداخل ایجاد شده توسط مجموعههای آزمایشی مختلف را کاهش دهد و به طور عینیتر عملکرد خود مدل را اندازهگیری کند [ 58 ].
محور افقی منحنی نرخ مثبت کاذب ( FPR ) است. نرخ مثبت کاذب نشان می دهد که چند نمونه منفی در نمونه به عنوان نمونه مثبت پیش بینی شده است. برای این مورد دو احتمال وجود دارد. یکی تغییر مقدار منفی اصلی – کلاس به عنوان یک کلاس مثبت پیش بینی می شود (مثبت نادرست، FP ) – و دیگری پیش بینی کلاس منفی اصلی به عنوان یک کلاس منفی (منفی واقعی، TN )، یعنی
محور عمودی منحنی نرخ مثبت واقعی ( TPR ) است. نرخ مثبت واقعی نشان دهنده نسبت نمونه هایی است که پیش بینی می شود مثبت باشند نسبت به تعداد کل نمونه های مثبت. دو احتمال برای پیش بینی نتایج مثبت وجود دارد. یکی کلاس مثبت (مثبت واقعی، TP ) و دیگری پیش بینی کلاس منفی به عنوان کلاس مثبت (مثبت کاذب، FP ) است، یعنی
در این مقاله، نرخ مثبت کاذب ( FPR ) نشاندهنده نسبت نمونههای بدون علامت دیجیتالی است که بهعنوان نمونههایی برای استقرار انتخاب شدهاند، و نرخ مثبت واقعی ( TPR ) به معنای نسبت نمونههای دارای علامت دیجیتالی است که به عنوان نمونههایی برای استقرار انتخاب شدهاند. هر چه منحنی ROC به سمت چپ بالا نزدیکتر باشد، نرخ کلاس واقعی بالاتر، نرخ کلاس منفی کمتر و اثر مدل بهتر است.
در مدل هاف، فاکتورهای مدلسازی ساینیج دیجیتال چند مقیاسی به عنوان دادههای ورودی برای به دست آوردن جذابیت مرکز محاسبات برای شبکههای اطراف استفاده میشوند که مشخصهی امکان ساینیج دیجیتال در این شبکه است. پس از محاسبه دقت مدل از طریق منحنی ROC، احتمال به آستانه های چندگانه 0-1 با اندازه گام 0.1 تقسیم می شود و در نهایت دقت مدل هاف به دست می آید.
در شبکه عصبی BP، فاکتورهای مدلسازی ساینیج دیجیتال چندمقیاسی بهعنوان داده ورودی استفاده میشود و قیمت پخش سیگنال دیجیتال نرمال شده به عنوان خروجی برای پیشبینی پتانسیل طرحبندی ساینیج دیجیتال در حلقه ششم پکن استفاده میشود. شبکه ای که در آن پتانسیل بالا باشد به عنوان واحدی که قرار است مستقر شود انتخاب می شود. پس از محاسبه دقت مدل از طریق منحنی ROC، پتانسیل چیدمان به آستانه های چندگانه 0-1 با اندازه گام 0.1 تقسیم می شود و در نهایت دقت مدل شبکه عصبی BP به دست می آید.
در مدل انتخاب سایت MCI، فاکتورهای مدلسازی ساینیج دیجیتال چند مقیاسی به عنوان داده ورودی استفاده میشود، احتمال طرحبندی دیجیتال ساینیج شبکه خروجی است و مقدار احتمال به عنوان آستانه منحنی ROC با اندازه گام 0.1 تنظیم میشود. در نهایت یک آستانه با میزان دقت بالا انتخاب می شود. شبکههایی با احتمال طرحبندی بیشتر از آستانه انتخابشده به عنوان واحدهایی برای استقرار استفاده میشوند.
اعتبار سنجی متقابل
روش اعتبارسنجی متقاطع برای بهبود دقت سه مدل پیشبینی رگرسیون، مانند شبکه عصبی BP، از طریق نمونهگیری و فرآیندهای آموزشی متعدد استفاده میشود. در مدل، مجموعه دادههای آموزشی و اعتبارسنجی بهطور تصادفی انتخاب میشوند، بنابراین کیفیت دادههای آموزش و اعتبارسنجی ممکن است ناهموار باشد. برای کاهش از دست دادن دقت در طول تقسیمبندی دادهها، این آزمایش از اعتبارسنجی متقاطع ده برابری استفاده میکند و مجموعه دادهها را بهطور تصادفی به چهار تقسیم میکند. در این فرآیند تقسیم داده ها 10 بار تکرار شد. بنابراین، کل فرآیند آموزش – تأیید 40 بار انجام شد. خطای نهایی میانگین خطای 40 تکرار است.
4. نتایج و بحث
4.1. نتایج اولیه انتخاب سایت
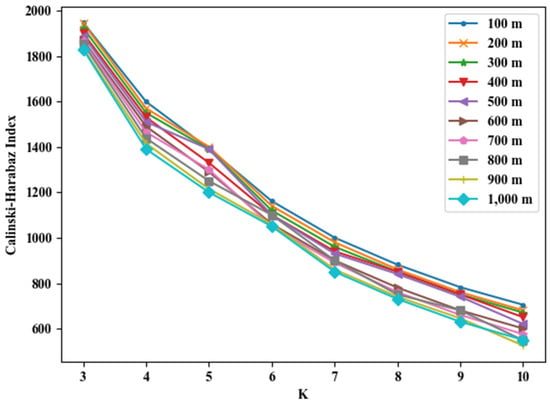
روشی که در بخش 3.2.1 توضیح داده شده است برای محاسبه دسترسی فضایی تابلوهای دیجیتال در واحدهای شبکه استاندارد 100-1000 متر استفاده می شود. علاوه بر این، الگوریتم خوشهبندی K-means برای خوشهبندی نتایج دسترسی فضایی و تنظیم پارامترهای ( مقدار K ) الگوریتم برای آزمایشهای متعدد برای به دست آوردن نتایج خوشهبندی دقیق استفاده میشود. شاخص CH یک شاخص اندازهگیری آماری برای تشخیص اثرات خوشهبندی است که معمولاً برای ارزیابی تأثیر الگوریتم خوشهبندی استفاده میشود. بنابراین، ما از شاخص CH توضیح داده شده در بخش 3.2.1 به عنوان شاخص ارزیابی استفاده می کنیم. کیفیت خوشه بندی الگوریتم با پارامترهای مختلف در شکل 5 نشان داده شده است . مانندKافزایش می یابد، شاخص CH همچنان به سقوط خود ادامه می دهد. وقتی مقدار K 3 باشد، شاخص CH نسبتاً بالاست. بنابراین، الگوریتم K-means برای تقسیم دسترسی به سه دسته کم، متوسط و زیاد استفاده می شود ( شکل 5 ).
آزمایش ها در 10 مقیاس از 100 متر تا 1000 متر انجام می شود، بنابراین نتایج دسترسی مکانی نیز در هر مقیاس به دست می آید. در همان زمان، ما از ESRI ® ArcGIS TM 10.3 برای انجام یک پرس و جو فضایی برای به دست آوردن تعداد بررسی های Weibo در شبکه استاندارد در جاده حلقه ششم پکن استفاده می کنیم. تعداد ورود نشانگر قابل مشاهده بودن تابلوهای دیجیتال است. واحد شبکه بسیار قابل مشاهده مجهز به ساینیج دیجیتال است که بیشتر برای مخاطبان دیده می شود.
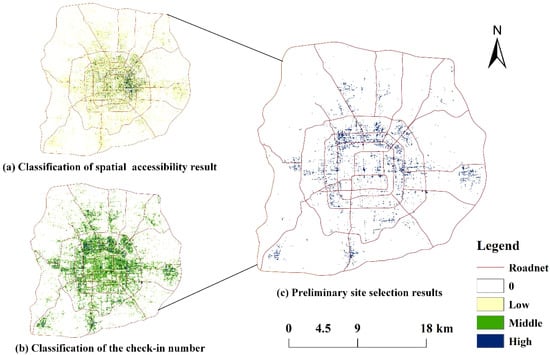
با در نظر گرفتن یک واحد شبکه 100 متری به عنوان مثال، شکل 6 a نتیجه دسترسی مکانی را نشان می دهد. شبکه زرد در شکل نشان می دهد که دسترسی کم است و به علائم دیجیتال نیاز فوری است. شبکه سبز نشان می دهد که دسترسی متوسط است، و هنوز هم می توان از علائم دیجیتال استفاده کرد. شبکه آبی نشان می دهد که دسترسی بالا است و نیازی به استقرار علامت دیجیتال نیست. شکل 6 ب توزیع تعداد ورودهای Weibo را در شبکه نشان می دهد. شبکه زرد در شکل 6b نشان دهنده این است که منطقه دارای تعداد کم ورود است، که نشان می دهد این منطقه تعداد نسبتاً کمی دارد. اگر ساینیج دیجیتال در اینجا قرار داده شود، دید نسبتاً کم است و شبکه آبی نشان میدهد که تعداد ورودها زیاد است، به این معنی که مخاطبان بیشتری در اینجا وجود دارند. اگر ساینیج دیجیتال در اینجا نصب شده باشد، دید زیاد است و ارزش استقرار بسیار بالایی دارد. پوشاندن دو لایه شکل 6 a,b، واحدهای شبکه با دسترسی فضایی متوسط و کم و تعداد زیاد بررسیهای Weibo نتایج اولیه موقعیتهایی هستند که علائم دیجیتال در آن مستقر خواهند شد ( شکل 6 ج).
دسترسی مکانی به ساینیج دیجیتال عمدتاً متاثر از فاصله بین تابلو و مخاطب، تعداد مراجعه و قیمت و مقدار تابلوی دیجیتال است. بنابراین، نتایج اولیه عمدتاً در نزدیکی روستای Weigong، Wangfujing، Xidan و خطوط اصلی حمل و نقل توزیع شد. به طور کلی، مناطق تجاری مختلف و جاذبه های گردشگری جذابیت بیشتری برای مخاطبان دارند. به دلیل تعداد ورود بیشتر، دید بیشتر و دسترسی فضایی نسبتاً کمتر، علائم دیجیتال مورد نیاز است. همانطور که در شکل 6 نشان داده شده استج، مناطق اطراف Weigongcun، بازار مصالح ساختمانی Sihui، Wangfujing، Xidan، و بازار عمده فروشی Huilongguan اساسا فرهنگ، حق امتیاز، مرکز خرید و منطقه تجاری جامع را پوشش می دهند. جذابیت و گستره تاثیرگذاری این مناطق گسترده و مناسب برای چیدمان تابلوهای دیجیتال است. با جابجایی دولت و دانشگاه ها، مخاطبان در برخی مناطق مانند فانگشان، داکسینگ و تونگژو به تدریج افزایش یافته اند و تابلوهای دیجیتال در اینجا نیز مزایای بیشتری خواهند داشت.
4.2. نتایج بالقوه چیدمان
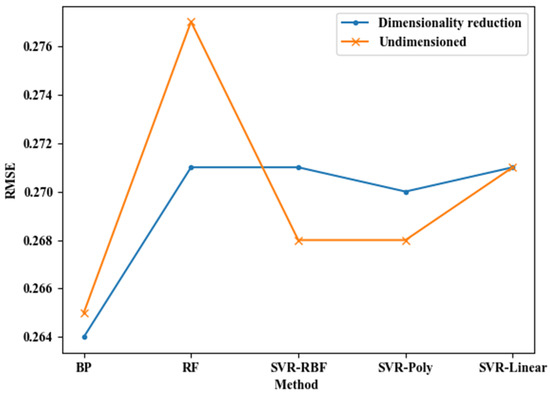
پتانسیل طرح ساینیج دیجیتال با روشی که در بخش 3.2.2 توضیح داده شده محاسبه می شود . RMSE شرح داده شده در بخش 3.2.2 به طور کلی به عنوان یک شاخص ارزیابی برای الگوریتم های پیش بینی استفاده می شود. این مقاله از آن برای ارزیابی اثرات پیشبینی پنج الگوریتم پیشبینی رگرسیون استفاده میکند. نتایج در جدول 3 و شکل 7 نشان داده شده است. با افزایش مقیاس شبکه، مقادیر RMSE پنج الگوریتم به طور کلی به تدریج افزایش یافت. هنگامی که مقیاس ها 100 متر هستند، خطاها نسبتا کوچک هستند و مقادیر RMSE پنج الگوریتم 0.277، 0.265، 0.268، 0.271 و 0.268 است. RMSE نسبتا کوچکمقدار 0.265 است و الگوریتم با خطای نسبتاً کوچک شبکه عصبی BP است ( شکل 7 ). بنابراین، فاکتورهای مدلسازی علامت دیجیتال در مقیاس شبکه 100 متر و الگوریتم شبکه عصبی BP برای محاسبه پتانسیل طرحبندی علامت دیجیتال در جاده حلقه ششم در پکن انتخاب شدهاند.
برای حذف همبستگی بین 19 نوع فاکتور مدلسازی علامت دیجیتال از آزمایش، PCA برای انجام تجزیه و تحلیل ویژگیهای فوق برای دستیابی به هدف کاهش ابعاد ویژگی، در نتیجه کاهش مقدار RMSE و بهبود دقت تحلیل رگرسیون دیجیتال معرفی شده است. پتانسیل علامت گذاری از نتایج پس از استفاده از PCA ( جدول 4 ، شکل 8 ) مشاهده می شود که حداقل مقدار RMSE در این زمان 0.264 است که نسبتاً کوچکتر از قبل از کاهش ابعاد است. پس از استخراج مولفههای اصلی دنباله فاکتور مدلسازی، خطای محاسباتی پتانسیل ساینیج دیجیتال به طور نسبی کاهش مییابد.
ما فاکتور مدلسازی دیجیتال ساینیج را در مقیاس شبکه 100 متری پس از کاهش ابعاد به عنوان ورودی و قیمت پخش سیگنال دیجیتال نرمال شده را به عنوان خروجی در نظر میگیریم. این مدل برای پتانسیل طرح بندی تابلوهای دیجیتال آموزش دیده است. الگوریتم خوشه بندی K-means نتیجه را به سه سطح کم، متوسط و زیاد تقسیم می کند که در شکل 9 نشان داده شده است.. در میان شبکهها، منطقه آبی منطقه با پتانسیل بالایی برای استقرار علائم دیجیتال است که عمدتاً در CBD، پارک المپیک و سایر مناطق تجاری و مناطق گردشگری توزیع شده است. نتیجه با تابلوهای دیجیتالی که باید در تعداد زیادی از مکانهای اعلام حضور مستقر شوند، سازگار است، که احتمالاً با احتمال بیشتری توسط مخاطبان دیده میشود. منطقه سبز نشان داده شده در شکل، سطح متوسطی از پتانسیل چیدمان است که عمدتاً در فانگشان چانگ یانگ، تونگژو بالیکیائو، داکسینگ زائویوان و جاهای دیگر توزیع شده است. این مناطق تجاری در حال توسعه با جمعیت زیاد و امکانات تجاری کمتر مشخص می شوند، بنابراین باید علائم دیجیتال بیشتری به کار گرفته شود. نواحی زرد نشان داده شده در شکل، نواحی با پتانسیل کم برای استقرار هستند. اساساً هیچ مرکز خرید یا منطقه تجاری در مقیاس بزرگ وجود ندارد، و مناطق برای ساکنان مجاور جذابیت کمتری دارند. امکان توجه مخاطبان به دیجیتال ساینیج کم است که منجر به پایین بودن پتانسیل چیدمان دیجیتال ساینیج در این مکان می شود و استقرار آن توصیه نمی شود.
4.3. نتایج و تحلیل مکان یابی دیجیتال ساینیج
برای تأیید صحت روش انتخاب سایت ساینیج دیجیتال فوق، روش خود را با مدل شبکه عصبی BP در روش یادگیری ماشینی و مدل تجربی هاف و MCI در جغرافیای تجاری مقایسه میکنیم. منحنی ROC (شرح شده در بخش 3.3 ) دقت نتایج انتخاب سایت را مشخص می کند. نرخ مثبت کاذب کمتر و نرخ مثبت واقعی بالاتر، یعنی هر چه منحنی ROC به سمت چپ بالا نزدیکتر باشد، نشان میدهد که مدل دقت بالاتر و اثر انتخاب سایت بهتری دارد.
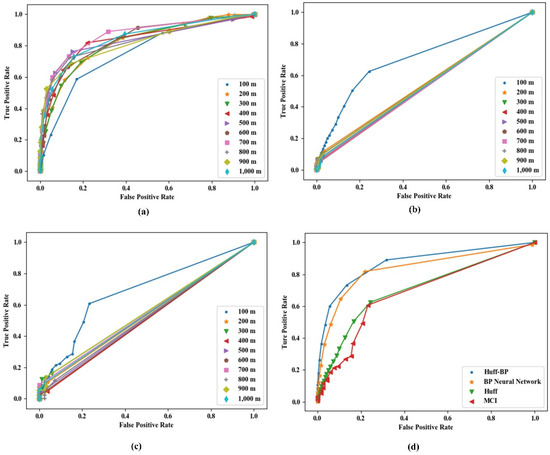
نتایج مکان هر مدل در شکل 10 نشان داده شده است. نتیجه مدل شبکه عصبی BP در شکل 10 الف نشان داده شده است. با استفاده از فاکتورهای مدلسازی 100-1000 متری به عنوان ورودی مدل شبکه عصبی BP، با افزایش مقیاس مدلسازی، منحنی ROC به تدریج به سمت چپ بالای مختصات نزدیک میشود. در 700 متر، اثر آزمایشی بهترین است و به تدریج پس از 800 متر کاهش می یابد. بنابراین، با استفاده از مدل شبکه عصبی BP برای پیشبینی مکان ساینیج دیجیتال، اثر پیشبینی در مقیاس 700 متر بهترین است.
مدل هاف یکی از روش های اصلی انتخاب سایت تجاری است و متغیرهای آن مساحت فروشگاه و فاصله فروشگاه از محله است. مدل هاف برای انطباق با آزمایش انتخاب سایت علامت دیجیتال اصلاح شد. هنگامی که مقیاس مدل سازی 100 متر است، اثر مدل بهتر است. با افزایش مقیاس مدل سازی، اثر مدل به تدریج کاهش می یابد و به همگرایی خاصی می رسد ( شکل 10 ب).
مدل MCI احتمال انتخاب مخاطب این منطقه را برای مصرف تحت تأثیر جمعیت، اقتصاد و سایر محیطهای جغرافیایی مشخص میکند [ 29 ]. فاکتورهای چند مقیاسی ذکر شده در مدل آورده شده و مکانهای با احتمال بالاتر به عنوان مکانهای جدید ساینیج دیجیتال پیشنهاد میشوند. در هر مقیاس مدل سازی، با افزایش آستانه، اثر مدل به تدریج همگرا می شود. هنگامی که مقیاس مدل سازی 100 متر است، نتایج مکان مدل بهتر است. با افزایش مقیاس مدلسازی، اثر مکان مدل MCI به تدریج کاهش مییابد ( شکل 10 ج).
منحنی ROC مدل Huff-BP پیشنهاد شده در این مقاله منحنی آبی است که در آن نشان داده شده است شکل 10 است.د بر اساس انتخاب منحنی های ROC مدل های انتخاب سایت فوق (شبکه عصبی BP، مدل هاف و مدل MCI) با مقیاس های بهتر، می توان دریافت که نرخ مثبت واقعی Huff–BP نسبتا بالا و مثبت کاذب آن است. نرخ نسبتاً پایین است – منحنی نزدیکترین منحنی به سمت چپ بالا است، که نشان میدهد اثر مکان این آزمایش نسبتاً خوب است و به دنبال آن مدل شبکه عصبی BP قرار دارد. هر دو مدل هاف و مدل MCI مدلهای احتمالی هستند و اثرات مکان این دو مشابه هستند، بنابراین صحت و قابلیت اطمینان این آزمایش را تأیید میکنند. به طور خلاصه، روشها و پارامترهای فعلی و نتایج انتخاب سایت نسبتاً خوب است و اگر روششناسی را تغییر دهیم، ممکن است نتایج رضایتبخشتر باشد.
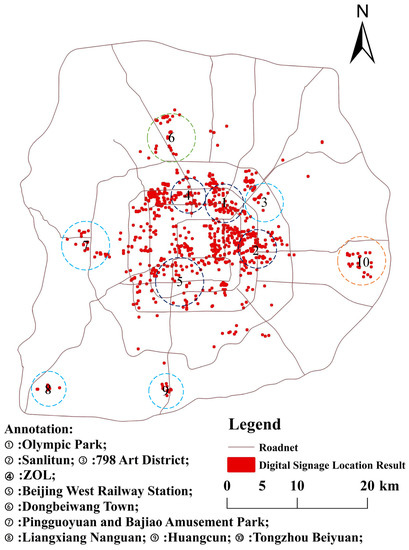
نتایج اولیه انتخاب سایت علامت گذاری فوق الذکر و نتایج بالقوه طرح ساینیج دیجیتال برای تجزیه و تحلیل مناطقی که به طور همزمان دسترسی فضایی کم، تعداد ورود بالا و پتانسیل طرح بندی بالا را برآورده می کنند (مناطق برای علامت دیجیتالی که باید انتخاب شوند) روی هم قرار می گیرند . 11 .
همانطور که در شکل 11 نشان داده شده استسایتها عمدتاً در Sanlitun، 798 Art District، ایستگاه راهآهن غرب پکن و مکانهای دیگر قرار دارند. این مکان ها به سه دسته تقسیم می شوند: (1) پارک المپیک، سانلیتون، منطقه هنری 798، و مکان های دیگر در شکل که برای حمل و نقل مناسب هستند، دارای امکانات پذیرایی و سرگرمی کامل هستند و بخشی از فرهنگ و سرگرمی های معروف هستند. منطقه صنعتی در پکن این منطقه دارای تعداد زیادی چکاین و پتانسیل بالایی برای استقرار است. استفاده از تابلوهای دیجیتال بیشتر توصیه می شود. (2) Fangshan Liangxiang، Daxing Huangcun، Tongzhou Beiyuan و غیره به دلیل ساخت مراکز فرعی پکن و جابجایی برخی از دانشگاه ها به تدریج توسعه تجاری خود را افزایش داده اند. این منطقه دارای ارزش تجاری و پتانسیل طرح بندی بالایی است و تابلوهای دیجیتال توصیه می شود. (3) ایستگاه راهآهن پکن، ایستگاه راهآهن غرب پکن، ایستگاه راهآهن جنوبی پکن، Siyuanqiao و غیره، مکانهای تجمع لجستیک مسافران هستند. این مکان ها دارای تحرک جمعیت بالایی در طول سال هستند و مراکز تجاری زیادی در نزدیکی آن وجود دارد، بنابراین تابلوهای دیجیتال نیز توصیه می شود.
هنگامی که ما مدل را آموزش دادیم، از دادههای نقطه علامت دیجیتال و فاکتورهای مدلسازی علامت دیجیتال در شش جاده کمربندی پکن استفاده کردیم و پارامترها را بر اساس نتایج آموزش تنظیم کردیم، بنابراین مدل برای آزمایش انتخاب مکان تابلوی دیجیتال در محدوده مناسبتر است. شش جاده کمربندی پکن، یعنی نتایج با این منطقه مورد مطالعه خاص سازگار است.
به طور خلاصه، ما برخی از شبکهها را از یک مقیاس نسبتاً کلان انتخاب کردیم که برای طرحبندی تابلوهای دیجیتالی در جاده حلقهای ششگانه پکن مناسب هستند و یک روش انتخاب سایت علامت دیجیتال ارائه میدهند. علاوه بر این، ما یک ایده تحقیقاتی ارائه کردیم که روشهای انتخاب سایت تجربی را با روشهای یادگیری ماشین ترکیب میکند تا تفسیرپذیری، کارایی محاسبات را بهبود بخشد. منطقه مطالعه ما در پکن است، مدل آموزشی با داده های پکن، بنابراین به احتمال زیاد برای شهرهای جهان وطنی با تعداد زیادی از چک-این ها و رفاه بالا مناسب تر است. برای سایر مسائل مکان یابی تسهیلات تجاری، روش انتخاب مکان پیشنهادی در این مقاله نیز می تواند به عنوان مرجع استفاده شود.
5. نتیجه گیری ها
با استفاده گسترده از دیجیتال ساینیج، مکان دقیق ساینیج دیجیتال یک مسئله فوری برای شرکت های ساینیج دیجیتال و آژانس های مدیریتی است. ما یک مدل شبکه عصبی هیبریدی Huff و BP را پیشنهاد کردیم که به طور جامع جمعیت، اقتصاد، حمل و نقل و سایر عواملی را که بر مکان ساینیج دیجیتال تأثیر میگذارند در نظر میگیرد و پردازش شبکه استاندارد را برای تشکیل عوامل مدلسازی چند مقیاسی انجام میدهد. ما مدل هاف را برای محاسبه دسترسی فضایی ساینیج دیجیتال اصلاح کردیم و پتانسیل طرحبندی علامت دیجیتال را با استفاده از چندین روش یادگیری ماشین مانند شبکههای عصبی BP محاسبه کردیم. مدلهای شبکه عصبی Huff–BP، MCI، Huff و BP مقایسه شدند. نتیجه گیری به شرح زیر است:
(1) مجموعه ای از فاکتورهای مدل سازی علامت دیجیتال چند عاملی و چند مقیاسی ساخته شد. بر اساس عوامل تأثیرگذار علامت دیجیتال، مانند قیمت پخش، امکانات POI، سرشماری، شاخص مرکزیت شبکه حمل و نقل و بررسی شبکه های اجتماعی، ما مقیاس فضایی را با پردازش شبکه چند مقیاسی 100 متر تا 1000 متر یکسان کردیم.
(2) یک روش انتخاب سایت علامت دیجیتال که یک الگوریتم یادگیری ماشین را با یک مدل هاف اصلاح شده ترکیب میکند، پیشنهاد شد. بر اساس مکان و قیمت ساینیج دیجیتال، مدل هاف برای محاسبه دسترسی فضایی ساینیج دیجیتال بهبود یافت و انتخاب اولیه برای واحد انجام شد. با استفاده از الگوریتمهای پیشبینی مختلف برای محاسبه پتانسیل استقرار سیگنال دیجیتال، نتایج نشان میدهد که مقیاس 100 متر و الگوریتم شبکه عصبی BP عملکرد بهتری نسبت به الگوریتم RF و SVR در مقیاسهای دیگر دارد. نتایج انتخاب سایت با همپوشانی نتایج انتخاب اولیه و نتایج بالقوه چیدمان به دست آمد.
(3) نتایج انتخاب مکان نشان داد که مناطق مناسب برای علائم دیجیتال عمدتاً در Sanlitun، Wangfujing، Financial Street، ایستگاه راهآهن غرب پکن، و مناطقی در امتداد شبکه جاده اصلی توزیع شدهاند. این مناطق عمدتاً مناطق معروف صنعتی فرهنگی و سرگرمی و مکانهای تجمع لجستیک مسافران در پکن هستند. آنها دارای خروجی های تجاری نسبتا بهتر، جمعیت بالاتر و حمل و نقل راحت هستند که می تواند مزایای علامت دیجیتال را به حداکثر برساند.
تحقیق ما مرجعی برای ادغام ویژگیهای جغرافیایی و دادههای محتوا در الگوریتم انتخاب سایت برای علائم دیجیتال ارائه میدهد. علاوه بر این، ما برخی از شبکهها را از مقیاس نسبتاً کلان ارائه میکنیم که برای طرحبندی تابلوهای دیجیتال در جادهی حلقهای ششگانه پکن مناسب هستند و یک روش انتخاب سایت علامت دیجیتال ارائه میدهند. این روش می تواند به طور موثر دقت و ماهیت علمی استقرار علائم دیجیتال را بهبود بخشد، مزایای استقرار را به حداکثر برساند و تخصیص منابع دیجیتال ساینیج را بهینه کند. علاوه بر این، این مقاله یک ایده تحقیقاتی ارائه میکند که روشهای تجربی را با روشهای یادگیری ماشین ترکیب میکند تا تفسیرپذیری و کارایی محاسباتی مدل را بهبود بخشد. برای سایر مسائل مکان یابی تأسیسات تجاری، روش مکان یابی پیشنهادی در این مقاله نیز می تواند به عنوان مرجع استفاده شود. با این حال، یکی از مهمترین عوامل برای مکان یابی سایت تابلوهای دیجیتال، دید از خیابان ها است. بنابراین، تحقیقات آینده ما مکان یابی تابلوهای دیجیتال در امتداد شبکه خیابان ها را هدف قرار خواهد داد. بر اساس تئوری میکرو مکان، معرفی عواملی مانند موقعیت و جهت گیری دیجیتال ساینیج در آزمایش های مکان یابی دقیق تر، و گنجاندن محدودیت هایی در مدل، مانند نیازهای کاربر و هزینه های استقرار، به چیدمان بهینه ساینیج دیجیتال دست خواهد یافت.







بدون دیدگاه