

انتخاب مدل مقیاس پذیر برای مدل سازی ترکیبی افزودنی فضایی: کاربرد در تجزیه و تحلیل جرم
خلاصه

کلید واژه ها:
انتخاب مدل ؛ رگرسیون فضایی ; جرم و جنایت ؛ محاسبه سریع ؛ مدلسازی ضریب متغیر مکانی
1. معرفی
2. مدل ترکیبی افزودنی فضایی
2.1. مدل
ما مدل ترکیبی افزودنی فضایی زیر را در نظر می گیریم:
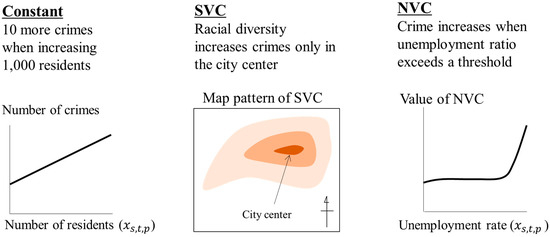
جایی که درجهاپراتور محصول از نظر عنصر است، yبردار متغیرهای پاسخ است ( ن×1)، N حجم نمونه است، ایکسپبردار متغیر کمکی p است ، εبردار اختلالات با واریانس است σ2، 0 بردار صفر است و I یک ماتریس هویت است. fپبردار ضرایبی است که تأثیر متغیر کمکی p را توصیف می کند .
یکی از ایده های کلیدی مورد استفاده در این مطالعه، مشخص کردن است fپSVC ها به عنوان مثال، [ 21 ] مشخصات زیر را اتخاذ کرد:
E(س)هست یک (ن×Lپ)ماتریس از Lپبردارهای ویژه مربوط به مقادیر ویژه مثبت که بردارهای ویژه موران (ME) نامیده می شوند. آنها از یک ماتریس مجاورت فضایی با مرکز دوگانه استخراج می شوند [ 22 ]. Λهست یک Lپ×Lپماتریس مورب که عناصر آن مقادیر ویژه مثبت هستند. توپ(س)هست یک (Lپ×1)بردار متغیرهای تصادفی که قبل از تثبیت تخمین SVC به عنوان گاوسی عمل می کند. این αپو τپ(س)پارامترها مقیاس و خطای استاندارد فرآیند فضایی را تعیین می کنند. یک مزیت مشخصه رویکرد ME این است که SVC حاصل ( fپ) از طریق ضریب موران قابل تفسیر است که یک آمار مورب وابستگی مکانی است و مقدار آن در صورت وجود وابستگی فضایی مثبت (منفی) می تواند مثبت (منفی) باشد. به طور خاص، هنگام در نظر گرفتن تمام ME هایی که دارای مقادیر ویژه مثبت هستند، τپ(س)σE(س)Λαپتوپیک الگوی نقشه وابسته مثبت را توصیف می کند. به عبارت دیگر، معادله (2) یک فرآیند فضایی وابسته مثبت را ارائه میکند، که در بسیاری از موارد دنیای واقعی [ 23 ] به طور کارآمد غالب است. مقدار ضریب موران افزایش می یابد αپرشد می کند.
این fپتابع را می توان بر حسب یک ضریب متغیر غیر مکانی (NVC) نیز تعیین کرد. این مشخصات تأثیر متفاوت را با توجه به متغیر کمکی نشان می دهد ایکسپبه شرح زیر است:
جایی که Eپ(n)هست یک ن×Lپماتریس از Lپ،و تابع پایه تولید شده از ایکسپ. τپ(n)واریانس اثرات غیر فضایی را نشان می دهد.
مشخصات زیر که ضرایب متغیر مکانی و غیر مکانی (S&NVC) را در همه متغیرهای کمکی فرض می کند نیز امکان پذیر است:
به طور خلاصه، fپ، ثابت با یک ضریب ثابت داده می شود ( بپ)، در حالی که SVC، NVC و S&NVC با مجموع (ترکیبات خطی) اثرات ثابت و تصادفی مشخص می شوند. با جایگزینی این مقادیر، معادله مدل (1) به صورت زیر فرموله می شود:
ایکس=[ایکس1،…،ایکسپ]، ب=[ب1،…،بپ]”، U=[تو1،…،توپ]”، و Θ∈{θ1،…،θپ}،جایی که ” ” نشان دهنده جابجایی ماتریس است. E˜(Θ)=[ایکس1درجهE1V1(θ1)،…،ایکسپدرجهEپVپ(θپ)]، جایی که ” آدرجهب” یک عملگر است که یک بردار ستون را ضرب می کند آاز نظر عنصر با هر ستون از ب. ماتریس ها Eپ، Vپ(θپ)، و پارامتر θپدر جدول 1 تعریف شده اند . معادله (5) نشان می دهد که مدل ما به عنوان یک مدل خطی با اثرات مختلط [ 26 ] با اثرات ثابت فرموله شده است.ایکسب، اثرات تصادفی، E˜(Θ)U،و ε.
2.2. برآورد کردن
در میان الگوریتمهای تخمین برای مدلهای ترکیبی افزودنی فضایی، ما بر تخمین حداکثر احتمال محدود سریع (REML) [ 19 ] تمرکز میکنیم که هم برای اندازه نمونه N و هم برای تعداد اثرات P مقیاسپذیر است . گلوگاه محاسباتی در اینجا یک ارزیابی تکراری از احتمال ورود به سیستم محدود است لogلمنکآر(Θ)از معادله (1) (یا معادله (5)) برای تخمین عددی پارامترهای واریانس Θ∈{θ1،⋯θپ}( به پیوست A مراجعه کنید ). برای کاهش هزینه، [ 19 ] یک تخمین متوالی از {θ1،⋯θپ}پارامترها با اعمال رابطه (6) تا همگرایی.
در حالی که حداکثر کردن مستقیم معادله (6) هنوز هم بار محاسباتی یکسانی دارد، [ 19 ] روش زیر را برای REML سریع توسعه داد:
- (من)
-
جایگزینی ماتریس های داده { y،ایکس،E1،…،Eپ} که ابعاد آن به N وابسته است ، با محصولات درونی آنها که ابعاد آن مستقل از N است.
- (II)
-
با استفاده از محصولات داخلی، محاسبات زیر را به ترتیب تکرار کنید پ∈{1،…،پ}:
- (II-1)
-
تخمین زدن θ^پبا به حداکثر رساندن لogلمنک(θپ|Θ^-پ)با Θ-پ∈{θ1،⋯θپ-1،θپ+1،⋯θپ}.
- (II-2)
-
اگر مقدار احتمال همگرا شد به (III) بروید. در غیر این صورت، به (II-1) بازگردید.
- (III)
-
خروجی مدل نهایی
3. انتخاب مدل
3.1. معرفی
-
این رایج ترین مشخصات برای مدل های اثرات مختلط خطی [ 30 ]، از جمله مدل های ترکیبی افزودنی فضایی است.
-
عملکرد ضعیف انتخاب مدل مشروط مبتنی بر AIC/BIC هنگام در نظر گرفتن دو یا چند اثر تصادفی گزارش شد (نگاه کنید به [ 31 ، 32 ])، در حالی که [ 33 ] نشان داد که AIC/BIC شرطی هنگام مقایسه مدلهای با یا بدون یک اثر تصادفی بهتر عمل میکند.
-
اگرچه مشخصات حاشیه ای از یک سوگیری نظری رنج می برد، [ 32 ] نشان داد که تأثیر سوگیری بر نتیجه انتخاب مدل بسیار کم است.
3.2. مراحل انتخاب مدل
3.2.1. روش انتخاب ساده
- (آ)
-
جایگزینی ماتریس های داده { y،ایکس،E1،…،Eپ} با محصولات داخلی همانطور که در مرحله (II) در بخش 2.2 پردازش شده است .
- (ب)
-
محاسبه زیر را به ترتیب برای هر کدام انجام دهید پ∈{1،…،پ}:
- (b-1)
-
SVC p -ام را با حداکثر کردن تخمین بزنیدلogلمنک(θپ(س)|Θ^-پ(س))با توجه به θپ(س)، که زیر مجموعه ای از θپمشخص کردن SVC، و Θ^-پ(س)مجموعه ای از پارامترهای واریانس را نشان می دهد θ^پاز جانب Θ^.
- (b-2)
-
اگر مقدار تابع هزینه را بهبود می بخشد، SVC را انتخاب کنید (به عنوان مثال، BIC). در غیر این صورت، آن را با یک ثابت جایگزین کنید.
- (b-3)
-
p -th NVC را با حداکثر کردن تخمین بزنیدلogلمنک(θپ(n)|Θ^-پ(n))با توجه به θپ(n)، که زیر مجموعه ای از θپمشخص کردن NVC، و Θ^-پ(س)مجموعه ای از پارامترهای واریانس را نشان می دهد θ^پ(n)از جانب Θ^.
- (b-4)
-
NVC در صورتی انتخاب می شود که مقدار تابع هزینه را بهبود بخشد (به عنوان مثال، BIC). در غیر این صورت، با یک ثابت جایگزین می شود.
- (ج)
-
اگر تابع هزینه همگرا شد به (d) بروید. در غیر این صورت به (ب) برگردید.
- (د)
-
خروجی مدل نهایی
3.2.2. روش انتخاب مونت کارلو (MC).
- (آ)
-
جایگزینی ماتریس های داده { y،ایکس،E1،…،Eپ} با محصولات داخلی.
- (ب)
-
با استفاده از حاصلضرب های داخلی، محاسبه زیر را G بار تکرار کنید:
- (B-1)
-
به صورت تصادفی از دنباله g- ام نمونه برداری کنید{1g،…،پg}بدون تعویض
- (B-2)
-
محاسبه زیر را به ترتیب برای هر کدام انجام دهید پg∈{1g،…،پg}:
- (B–2a)
-
را برآورد کنید پg-ام SVC با به حداکثر رساندن لogلمنک(θپg(س)|Θ^-پg(س))، کجا { θپg(س)،Θ^-پg(س)}به طور مشابه تعریف می شوند {θپ(س)،Θ^-پ(س)}.
- (B-2b)
-
اگر مقدار تابع هزینه را بهبود می بخشد، SVC را انتخاب کنید (به عنوان مثال، BIC). در غیر این صورت، آن را با یک ثابت جایگزین کنید.
- (B-2c)
-
را برآورد کنید پg-ام NVC با به حداکثر رساندن لogلمنک(θپg(n)|Θ^-پg(n))، کجا { θپg(n)،Θ^-پg(n)}به طور مشابه تعریف می شوند {θپ(n)،Θ^-پ(n)}.
- (B–2d)
-
NVC در صورتی انتخاب می شود که مقدار تابع هزینه را بهبود بخشد (به عنوان مثال، BIC). در غیر این صورت، با یک ثابت جایگزین می شود.
- (B-3)
-
اگر تابع هزینه همگرا شد به (B-4) بروید. در غیر این صورت به (B-2) برگردید.
- (B-4)
-
مقدار تابع هزینه مدل انتخاب شده را محاسبه کنید.
- (C)
-
خروجی بهترین مدل در مدل های انتخابی G از نظر تابع کمترین هزینه.
4. آزمایش های عددی
4.1. جزئیات محاسباتی
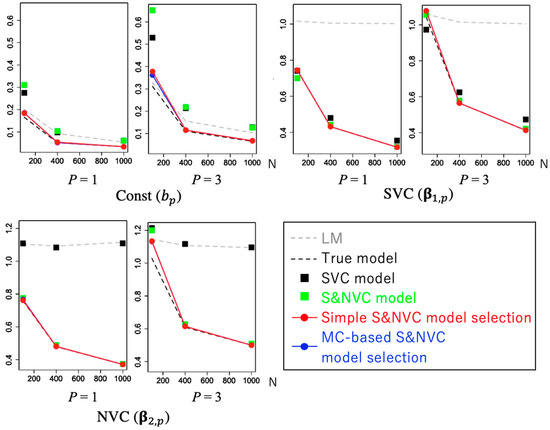
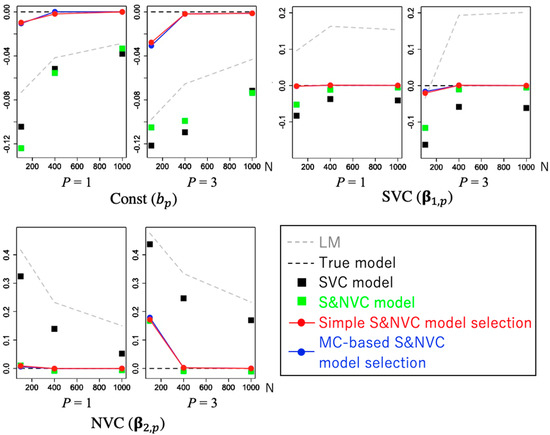
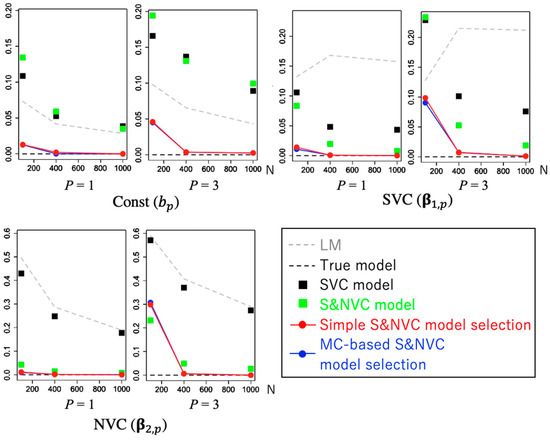
در اینجا، بررسی می کنیم که آیا این روش انتخاب ساده به طور دقیق به مدل واقعی تقریب می زند، یعنی مدلی که همه انواع ضرایب (به عنوان مثال، ثابت، SVC، NVC، یا S&NVC) به درستی تعریف شده اند، یا اینکه برای دستیابی به روش انتخاب MC نیاز است. انتخاب دقیق مدل از طریق آزمایش های مقایسه ای مونت کارلو ما با / بدون مدل انتخاب اثرات با برازش این مدلها با دادههای مصنوعی تولید شده از آن مقایسه میکنیم
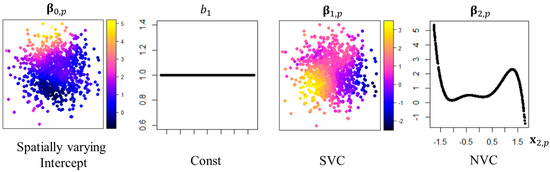
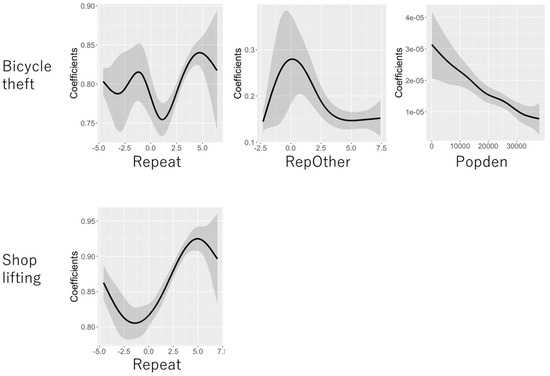
جایی که متغیرهای کمکی {ایکس1،…،ایکس1}،{ایکس1،پ،…،ایکس1،پ}،{ایکس2،پ،…،ایکس2،پ}از توزیع های نرمال استاندارد مستقل تولید می شوند. ماتریکس سی˜از استانداردسازی ردیف ماتریس اتصال فضایی ساخته شده است سی، که عنصر ( i , j ) -امین آن برابر است انقضا(-دمن،j)، جایی که دمن،jفاصله اقلیدسی بین سایت های نمونه i و j است . سایت های نمونه از دو توزیع نرمال استاندارد مستقل تولید شدند. SVC ها β0و β1،پتوسط فرآیندهای میانگین متحرک فضایی تعریف می شوند. β2،پیک NVC است که با توجه به آن متفاوت است ایکس2،پ، که در آن E2،پماتریسی از 10 تابع پایه چند جمله ای است که از آن تولید می شود ایکس2،پ. شکل 2 ضرایب به دست آمده از این فرآیندهای تولید را نشان می دهد.
دقت تخمین ضریب با استفاده از ریشه میانگین مربعات خطا (RMSE) ارزیابی می شود که به صورت تعریف می شود.
جایی که iter نشان دهنده عدد تکرار است، βمن،پعنصر i- امین استβپ، و β^من،پ(منتیهr)تخمین داده شده در تکرار تکراری است . سوگیری برآوردها با استفاده از ارزیابی می شود
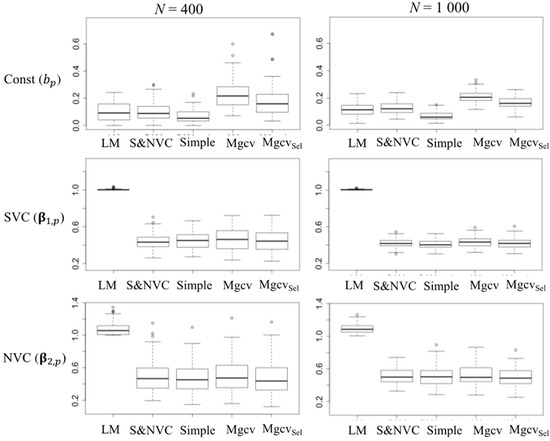
4.2. عملکرد انتخاب مدل
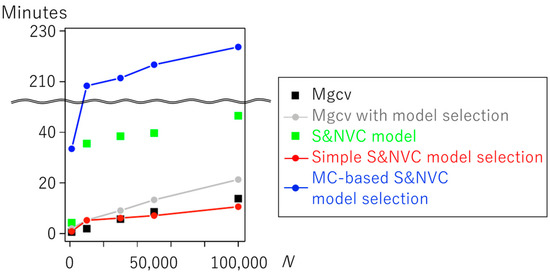
4.3. مقایسه معیار روشهای انتخاب مدل
5. کاربرد در مدل سازی جرم
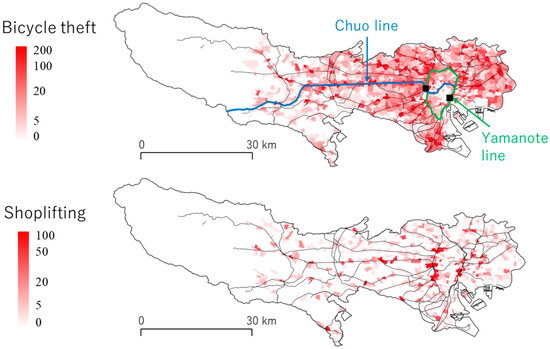
5.1. طرح کلی
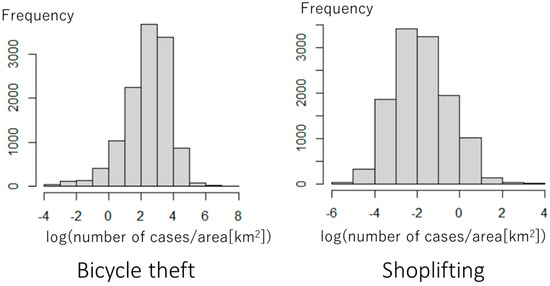
ما تعداد ثبتشده سرقت دوچرخه و موارد دزدی از مغازه را در هر منطقه بر اساس منطقه بهترتیب مدل میکنیم. بر اساس شکل 9 ، که هیستوگرام تراکم جرم را نشان می دهد، توزیع داده ها تقریباً گوسی است. یک مدل خطی (گاوسی) در مورد ما قابل قبول خواهد بود. این مطالعه از مدل خطی زیر استفاده می کند:
جایی که yمن،تیجتعداد ج -مین جرم در هر منطقه در ناحیه یکم در سه ماهه t (مقیاس ورود) است.
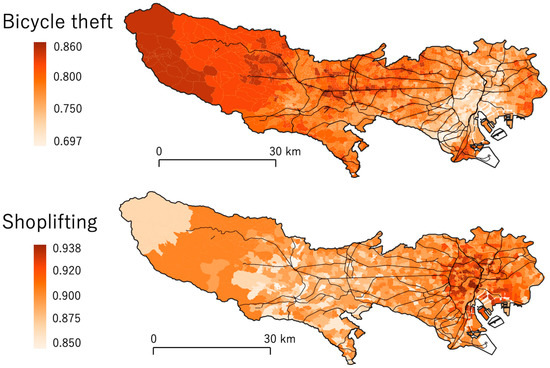
5.2. نتایج تخمین ضریب
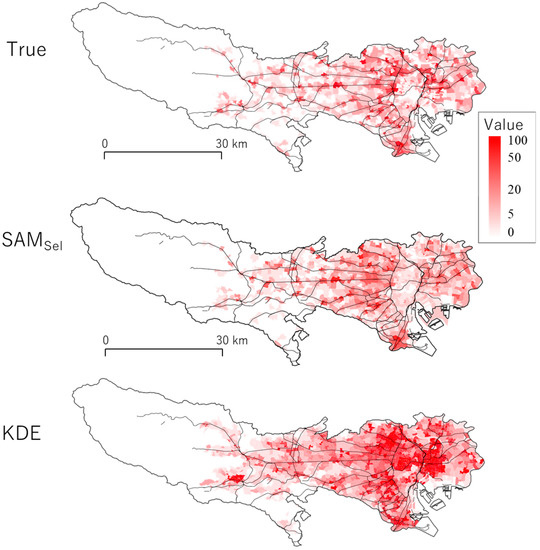
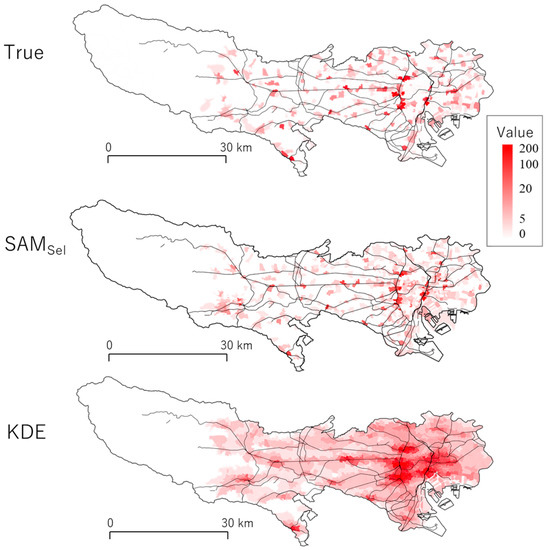
5.3. کاربرد در پیش بینی جرم
6. نکات پایانی
پیوست A. تابع Log-Likelihood محدود مدل ترکیبی افزودنی فضایی
REML سریع احتمال نهایی را به حداکثر می رساند لogلمنکآر(Θ)تعریف شده با ادغام { ب،U}از احتمال کامل، که به صورت فرموله شده است
جایی که E˜(Θ)=[ایکس1درجهE1V1(θ1)،…،ایکسپدرجهEپVپ(θپ)]. در ترم دوم معادله (6)، د(Θ)=ε^”ε^+∑پ=1پتو^”پتو^پواریانس نویز و واریانس اثرات تصادفی را متعادل می کند
ضمیمه B. جزئیات رویکردهای انتخاب مدل
احتمال ورود محدود حداکثر شده در مرحله (ب) (به بخش 3.2.1 مراجعه کنید) با جایگزین کردن این محصولات داخلی در معادله (A1) [ 19 ] بازنویسی می شود :
جایی که
تکرار P- امین مرحله (ب) را به عنوان مثال در نظر بگیرید . در مرحله (b-1) از تکرار P- امین، لogلمنکآر(θپ(س)|Θ^-پ(س))با توجه به به حداکثر می رسد θپ(س). حداکثر سازی شامل ارزیابی تکراری است |پ| و پ-1که پیچیدگی محاسباتی آن برابر است O((∑پ=1پLپ)3)، که در هنگام در نظر گرفتن بسیاری از اثرات می تواند کند باشد، همانطور که در مورد ما وجود دارد. برای کاهش هزینه، معادله (A7)، از جمله پ-1، به شرح زیر گسترش می یابد:
جایی که V˜-پ=[من⬚⬚V1⬚⬚⬚⬚⬚⬚⬚⬚⋱⬚⬚Vپ-1]، جایی که Vپ=Vپ(θ^پ). Θ^-پ(س)∈{θ^1،…،θ^پ-1،θ^پ(n)} که در این مرحله رفع شده است برای سادگی حذف شده است. س=[م˜-پ،-پ+V˜-پ-2م˜-پ،پم˜پ،-پمپ،پ]، جایی که م˜-پ،-پ=[م0،0م0،1م1،0م1،1+V1-2⋯م0،پ-1⋯م1،پ-1⋮⋮مپ-1،0مپ-1،1⋱⋮⋯مپ-1،پ-1+Vپ-1-2]و م˜-پ،پ=[مپ،0مپ،1⋯مپ،پ-1]”، و [س-پ،-پ*س-پ،پ*سپ،-پ*سپ،پ*]=س-1.
از سوی دیگر، | P | که یکی دیگر از بخش های خسته کننده است، عبارت زیر را دارد:
در مرحله انتخاب مدل (b-2)، باید تابع هزینه (به عنوان مثال، BIC) مدل را با P – th SVC که در مرحله (b-1) تخمین زده شده است، با مدل بدون P مقایسه کنیم. -ام SVC. برای این کار، ما همچنین باید احتمال مدل اخیر را با استفاده از معادله (A4) ارزیابی کنیم. احتمال را می توان با جایگزینی معادلات (A8) و (A9) با معادلات (A10) و (A11) ارزیابی کرد.
منابع
- تجزیه و تحلیل رگرسیون مبتنی بر Osgood، DW Poisson از میزان جرم کل. جی. کوانت. Criminol. 2000 ، 16 ، 21-43. [ Google Scholar ] [ CrossRef ]
- کیهیل، م. مولیگان، جی. استفاده از رگرسیون وزندار جغرافیایی برای کشف الگوهای جرم محلی. Soc. علمی محاسبه کنید. Rev. 2007 , 25 , 174-193. [ Google Scholar ] [ CrossRef ]
- برناسکو، دبلیو. بلوک، R. Robbery در شیکاگو: تجزیه و تحلیل سطح بلوک از تأثیر عوامل جنایت، مجذوبان جرم، و نقاط لنگر مجرم. J. Res. جنایت دلینق. 2011 ، 48 ، 33-57. [ Google Scholar ] [ CrossRef ]
- مگوایر، ام. McVie, S. داده های جرم و آمار جنایی: بازتاب انتقادی. در کتاب راهنمای جرم شناسی آکسفورد ؛ Maruna, S., McAra, L., Eds. انتشارات دانشگاه آکسفورد: آکسفورد، انگلستان، 2017; صص 163-189. [ Google Scholar ]
- LeSage، JP; Pace, RK مقدمه ای بر اقتصاد سنجی فضایی ; CRC Press: Boca Raton، FL، USA، 2009. [ Google Scholar ]
- کرسی، ن. Wikle، آمار CK برای داده های مکانی-زمانی ; جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- براندون، سی. فاثرینگهام، اس. چارلتون، ام. رگرسیون وزنی جغرافیایی. JR Stat. Soc. سر. D (آمار) 1998 ، 47 ، 431-443. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; براندون، سی. چارلتون، ام. رگرسیون وزندار جغرافیایی: تجزیه و تحلیل روابط متغیر فضایی . جان وایلی و پسران: وست ساسکس، انگلستان، 2002. [ Google Scholar ]
- لی، اس. کانگ، دی. کیم، ام. عوامل تعیین کننده وقوع جرم در کره: یک رویکرد GWR مخلوط. در مجموعه مقالات کنفرانس جهانی انجمن اقتصاد سنجی فضایی، بارسلون، اسپانیا، 8 تا 10 ژوئیه 2009. صص 8-10. [ Google Scholar ]
- آرنیو، AN; باومر، جمعیت شناسی EP، سلب حق اقامه دعوی، و جرم: ارزیابی ناهمگونی فضایی در مدل های معاصر نرخ جرم محله. Demogr. Res. 2012 ، 26 ، 449-486. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- املاوف، ن. آدلر، دی. کنیب، تی. لانگ، اس. Zeileis، A. مدلهای رگرسیون افزودنی ساختاریافته: رابط R برای BayesX. J. Stat. نرم افزار 2015 ، 21 ، 63. [ Google Scholar ]
- ناکایا، تی. فاثرینگهام، اس. چارلتون، ام. Brunsdon، C. مدلسازی خطی تعمیم یافته با وزن جغرافیایی نیمه پارامتریک در GWR 4.0. در مجموعه مقالات دهمین کنفرانس بین المللی محاسبات جغرافیایی، سیدنی، استرالیا، 30 نوامبر تا 2 دسامبر 2009. [ Google Scholar ]
- ویلر، DC جریمه ضریب همزمان و انتخاب مدل در رگرسیون وزندار جغرافیایی: کمند وزندار جغرافیایی. محیط زیست طرح. A 2009 , 41 , 722-742. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کامبر، ا. براندون، سی. چارلتون، ام. دونگ، جی. هریس، آر. لو، بی. لو، ی. موراکامی، دی. ناکایا، تی. وانگ، ی. و همکاران نقشه مسیر GWR: راهنمای کاربرد آگاهانه رگرسیون وزندار جغرافیایی. arXiv 2020 ، arXiv:2004.06070. [ Google Scholar ]
- هوانگ، جی. هوروویتز، جی ال. Wei, F. انتخاب متغیر در مدلهای افزودنی ناپارامتریک. ان آمار 2010 ، 38 ، 2282. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- آماتو، U. آنتونیادیس، ا. De Feis، I. انتخاب مدل افزودنی. آمار Methods Appl. 2016 ، 25 ، 519-654. [ Google Scholar ] [ CrossRef ]
- Mei، CL; او، SY; نیش، KT یادداشتی در مورد مدل رگرسیون ترکیبی وزندار جغرافیایی. J. Reg. علمی 2004 ، 44 ، 143-157. [ Google Scholar ] [ CrossRef ]
- لی، ز. Fotheringham، AS; لی، دبلیو. Oshan, T. Fast Geographically Weighted Regression (FastGWR): یک الگوریتم مقیاس پذیر برای بررسی ناهمگونی فرآیند فضایی در میلیون ها مشاهده. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 155-175. [ Google Scholar ] [ CrossRef ]
- موراکامی، دی. گریفیث، DA مدلسازی ضریب متغیر فضایی برای مجموعه دادههای بزرگ: حذف N از رگرسیونهای فضایی. تف کردن آمار 2019 ، 30 ، 39–64. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- موراکامی، دی. گریفیث، DA یک مدلسازی ترکیبی افزودنی فضایی بدون حافظه برای دادههای فضایی بزرگ. Jpn. J. Stat. اطلاعات علمی 2020 ، 3 ، 215-241. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- موراکامی، دی. یوشیدا، تی. سیا، ح. گریفیث، دی. یاماگاتا، ی. رویکرد اثرات مختلط مبتنی بر ضریب موران برای بررسی روابط متغیر فضایی. تف کردن آمار 2017 ، 19 ، 68-89. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گریفیث، DA خودهمبستگی فضایی و فیلتر فضایی: به دست آوردن درک از طریق تئوری و تجسم علمی . Springer Science & Business Media: برلین، آلمان، 2003. [ Google Scholar ]
- تیفلسدورف، ام. گریفیث، DA فیلتر نیمه پارامتریک همبستگی فضایی: رویکرد بردار ویژه. محیط زیست طرح. A 2007 , 39 , 1193-1221. [ Google Scholar ] [ CrossRef ]
- موراکامی، دی. گریفیث، DA متوازن کردن تغییرات فضایی و غیر فضایی در مدلسازی ضرایب متغیر: درمانی برای همبستگی جعلی. arXiv 2020 ، arXiv:2005.09981. [ Google Scholar ]
- ویلر، دی. Tiefelsdorf، M. چند خطی و همبستگی بین ضرایب رگرسیون محلی در رگرسیون وزنی جغرافیایی. جی. جئوگر. سیستم 2005 ، 7 ، 161-187. [ Google Scholar ] [ CrossRef ]
- بیتس، دی. ماچلر، ام. بولکر، بی. واکر، اس. برازش مدلهای خطی با جلوههای مختلط با استفاده از lme4. arXiv 2014 ، arXiv:1406.5823. [ Google Scholar ]
- زمستان، بی. Wieling، M. چگونگی تجزیه و تحلیل تغییر زبانی با استفاده از مدل های ترکیبی: تجزیه و تحلیل منحنی رشد و مدل سازی افزایشی تعمیم یافته. جی. لانگ. تکامل. 2016 ، 1 ، 7-18. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بااین، ح. واسیشت، س. کلیگل، آر. بیتس، دی. غار سایه ها: پرداختن به عامل انسانی با مدل های ترکیبی افزودنی تعمیم یافته. جی. مم. لنگ 2017 ، 94 ، 206-234. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Gurka, MJ انتخاب بهترین مدل خطی مختلط تحت REML. صبح. آمار 2006 ، 60 ، 19-26. [ Google Scholar ] [ CrossRef ]
- مولر، اس. Scealy، JL; انتخاب مدل ولز، AH در مدل های مختلط خطی. آمار علمی 2013 ، 28 ، 135-167. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیمووا، RB; مارکاتو، م. روشهای اطلاعاتی طلال، AH برای انتخاب مدل در مدلهای اثرات مختلط خطی با کاربرد در دادههای HCV. محاسبه کنید. آمار داده آنال. 2011 ، 55 ، 2677-2697. [ Google Scholar ] [ CrossRef ]
- Sakamoto، W. Bias معیارهای اطلاعات حاشیه ای Akaike را بر اساس روش مونت کارلو برای مدل های خطی اثرات مختلط کاهش داد. Scand. J. Stat. 2019 ، 46 ، 87-115. [ Google Scholar ] [ CrossRef ]
- گریون، اس. Kneib, T. در مورد رفتار AIC حاشیه ای و شرطی در مدل های خطی مختلط. Biometrika 2010 ، 97 ، 773-789. [ Google Scholar ] [ CrossRef ]
- بلیتز، سی. Lang, S. انتخاب همزمان متغیرها و پارامترهای هموارسازی در مدل های رگرسیون افزودنی ساختاریافته. محاسبه کنید. آمار داده آنال. 2008 ، 53 ، 61-81. [ Google Scholar ] [ CrossRef ]
- ریس، PT; Todd Ogden, R. انتخاب پارامتر هموارسازی برای کلاسی از مدل های خطی نیمه پارامتریک. JR Stat. Soc. سر. B (Stat. Methodol.) 2009 ، 71 ، 505-523. [ Google Scholar ] [ CrossRef ]
- Wood, SN برآورد حداکثر احتمال محدود شده با ثبات سریع و احتمال حاشیه ای مدل های خطی تعمیم یافته نیمه پارامتری. JR Stat. Soc. سر. B (Stat. Methodol.) 2011 ، 73 ، 3-36. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مارا، جی. Wood, SN انتخاب متغیر عملی برای مدل های افزودنی تعمیم یافته. محاسبه کنید. آمار داده آنال. 2011 ، 55 ، 2372-2387. [ Google Scholar ] [ CrossRef ]
- چوب، SN; لی، ز. شادیک، جی. آگوستین، NH مدلهای افزودنی تعمیمیافته برای گیگاداده: مدلسازی دادههای روزانه شبکه دود سیاه بریتانیا. مربا. آمار دانشیار 2017 ، 112 ، 1199-1210. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Felson, M. Crime and Everyday Life: Insights and Implications for Society (The Pine Forge Press Library Science Social Science) ; Pine Forge: Berks، PA، USA، 1994. [ Google Scholar ]
- فارل، جی. جلوگیری از تکرار قربانی شدن. عدالت جنایی 1995 ، 19 ، 469-534. [ Google Scholar ] [ CrossRef ]
- جانسون، SD تکرار قربانی سرقت: داستانی از دو نظریه. J. Exp. Criminol. 2008 ، 4 ، 215-240. [ Google Scholar ] [ CrossRef ]
- Caplan، JM; کندی، LW; میلر، جی. مدلسازی زمین ریسک: نظریه جرمشناسی و روشهای GIS برای پیشبینی جرم. عدالت Q. 2011 ، 28 ، 360-381. [ Google Scholar ] [ CrossRef ]
- رانسون، ام. جنایت، آب و هوا و تغییرات آب و هوایی. جی. محیط زیست. اقتصاد مدیریت 2014 ، 67 ، 274-302. [ Google Scholar ] [ CrossRef ]
- هارادا، ی. شیمادا، تی. بررسی تأثیر دقت کدگذاری جغرافیایی آدرس بر تراکم تخمینی مکانهای جرم. محاسبه کنید. Geosci. 2006 ، 32 ، 1096-1107. [ Google Scholar ] [ CrossRef ]
- عصا، نماینده مجلس؛ Jones، MC Multivariate پلاگین انتخاب پهنای باند. محاسبه کنید. آمار 1994 ، 9 ، 97-116. [ Google Scholar ]
- یو، او. ژانگ، ال. ثبت کم جرم توسط پلیس در چین: مطالعه موردی. پلیس بین المللی J. 1999 , 22 , 252-264. [ Google Scholar ] [ CrossRef ]
- تباروک، ع. هیتون، پی. هلند، E. معیار رذیلت و گناه: مروری بر کاربردها، محدودیتها و پیامدهای دادههای جرم. هندب اقتصاد جنایت 2010 ، 3 ، 53-81. [ Google Scholar ]
- فارل، جی. فیلیپس، سی. Pease, K. مانند خوردن آب نبات – چرا قربانی تکرار اتفاق می افتد. برادر J. Criminol. 1995 ، 35 ، 384-399. [ Google Scholar ] [ CrossRef ]
- فارل، جی. Pease, K. Repeat Victimization ; مطبوعات عدالت کیفری: نیویورک، نیویورک، ایالات متحده آمریکا، 2001. [ Google Scholar ]
- گلفاند، AE; کیم، اچ جی. سیرمنز، سی اف. Banerjee, S. مدلسازی فضایی با فرآیندهای ضریب متغیر مکانی. مربا. آمار دانشیار 2003 ، 98 ، 387-396. [ Google Scholar ] [ CrossRef ]
- هوانگ، بی. وو، بی. Barry, M. رگرسیون وزندار جغرافیایی و زمانی برای مدلسازی تغییرات مکانی-زمانی قیمت مسکن. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 383-401. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; کرسپو، آر. یائو، جی. رگرسیون وزنی جغرافیایی و زمانی (GTWR). Geogr. مقعدی 2015 ، 47 ، 431-452. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Mohler, G. مدلسازی و برآورد خوشهبندی چند منبعی در دادههای جرم و امنیت. ان Appl. آمار 2013 ، 7 ، 1525-1539. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاجیتا، م. کاجیتا، اس. پیشبینی جرم با روش تابع گرین مبتنی بر داده. بین المللی J. پیش بینی. 2020 ، 36 ، 480-488. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هستی، تی. طبشیرانی، ر. Wainwright, M. Statistical Learning with Sparity: The Lasso and Generalizations ; CRC Press: نیویورک، نیویورک، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- فن، جی. Li, R. انتخاب متغیر از طریق احتمال جریمه شده غیر مقعر و خواص اوراکل آن. مربا. آمار دانشیار 2001 ، 96 ، 1348-1360. [ Google Scholar ] [ CrossRef ]
- کولی، دی. تحلیل ارزش افراطی و مطالعه تغییرات آب و هوا. صعود چانگ. 2009 ، 97 ، 77. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه