1. مقدمه
توسعه فناوری اطلاعات و اینترنت تلفن همراه و همچنین تقاضای مردم برای زندگی راحت، تعداد زیادی از برنامه های کاربردی سرویس مبتنی بر مکان (LBS) را ایجاد کرده است که اکثر کاربران مشتری تلفن همراه را قادر می سازد از خدمات موقعیت یابی و توصیه با کیفیت بالا لذت ببرند. ، در حالی که تعداد زیادی داده مسیر حرکت اجسام متحرک از جمله وسایل نقلیه را نیز تولید می کند.
داده های مسیر شامل اطلاعات فراوانی از اجسام متحرک در ابعاد زمانی و مکانی است. هنگام ترکیب با دانش مرتبط با این دادهها برای استنتاج و تجزیه و تحلیل تهاجمی، اطلاعات حریم خصوصی گسترده ممکن است به راحتی استخراج شود، که حتی تهدیدی برای ایمنی شخصی است [ 1 ].
بنابراین، به منظور جلوگیری از نشت حریم خصوصی مسیر، حفظ حریم خصوصی مسیر به عنوان یک موضوع مهم مطرح می شود که اخیرا توجه روزافزونی را به خود جلب کرده است. تکنیک حفظ حریم خصوصی مسیر بر اساس روابط اجتماعی و اطلاعات مکان است. از روابط تلفن همراه و صحنه کاربر برای مقابله با رابطه تداعی مکان در مسیر استفاده می کند تا اطلاعات مسیر هدف حفظ شده خاص را تشکیل دهد. هدف اصلی آن هم تضمین خدمات با کیفیت بالا برای اشتراک گذاری داده های مسیر و هم محافظت از حریم خصوصی مسیر افراد است [ 2 ].
اخیراً انواع بسیاری از فناوری های حفظ حریم خصوصی مسیر ارائه شده است. بیشتر فناوریهای موجود نیاز به ایجاد اطلاعات مکان نادرست دارند، که میتواند حریم خصوصی مسیر را تا حدی محافظت کند. با این حال، تعداد زیادی از مسیرهای نادرست منجر به تحریف جدی اطلاعات مسیر می شود و تضمین کیفیت خدمات در ابزار داده را سخت می کند. همچنین تجزیه و تحلیل آماری را بر روی داده های اصلاح شده و تاخیر سرویس به دلیل از دست دادن اطلاعات ترافیک شبکه انجام می دهد [ 3 ]]. به منظور غلبه بر این مشکلات، در این مقاله ما یک روش جدید از ناشناسسازی پویا را بر اساس اختلاط مسیرهای اعوجاج محدود پیشنهاد میکنیم. این روش نیازی به تولید تعداد زیادی مکان و مسیرهای نادرست برای دستیابی به یک ناشناس جهانی ثابت مانند روش های موجود ندارد. درعوض، ناشناسسازی پویا را بر اساس مخلوط کردن بخشهای مسیر واقعی با کمترین نویز اضافه شده بهصورت پیشرونده به روشی محلی انجام میدهد تا مسیرهای مصنوعی برای انتشار را تشکیل دهد.
روش ما برای اختلاط مسیر این است که پنجرههای زمانی و مکانی را تنظیم کنیم و مسیرهای واقعی مناسب را در هر پنجره انتخاب کنیم تا مسیر مصنوعی را در محدودهای از واگرایی جهتگیری ایجاد کنیم. به عنوان مثال، برای سه مسیر A ، B و C در چهار پنجره A=A1�=�1– A2�2– A3�3– A4�4، B=B1�=�1– B2�2– B3�3– B4�4، و C=C1�=�1– C2�2– C3�3– C4�4، اختلاط مسیر ما سه مسیر مصنوعی تولید می کند: A′=B1�′=�1– C2�2– C3�3– B4�4، B′=A1�′=�1– A2�2– C3�3– A4�4، و C′=B1�′=�1– A2�2– A3�3– A4�4، جایی که در هر پنجره، واگرایی جهت بین هر مسیر واقعی و ترکیبی آن در یک حد معین است. θ�. از آنجا که هر مسیر مصنوعی از بخش هایی از مسیرهای منفرد واقعی تشکیل شده است، با هیچ یک از مسیرهای واقعی منطبق نیست، بنابراین تمام مسیرهای واقعی به طور موثر محافظت می شوند. در عین حال، از آنجایی که هر مسیر مصنوعی شامل دنبالهای از بخشهایی از مسیرهای واقعی در یک واگرایی جهتگیری است، دادههای منتشر شده دارای ویژگیهای آماری مشابه با نسخه اصلی هستند و از این رو دارای کاربرد خوبی هستند.
مشارکت های اصلی مقاله عبارتند از:
(1) ما یک روش ناشناس پویا جدید را بر اساس اختلاط مسیر محلی برای رسیدگی به مشکل انتشار دادههای مسیر حفظ حریم خصوصی پیشنهاد میکنیم.
(2) ما یک چارچوب جدید برای نمایش مسیر پیشنهاد میکنیم که شناسایی کارآمد تقاطعها را در مسیرها و یک الگوریتم برای محاسبه تقاطع مسیر و اختلاط فردی تسهیل میکند.
(3) روش ما ضمن حفظ حریم خصوصی داده ها نسبت به روش های موجود با استفاده از تکنیک ناشناس سازی استاتیک جهانی، ابزار داده را بهبود می بخشد.
(4) ما آزمایشهای گستردهای را بر روی دادههای مسیر واقعی خودروهای شهری انجام میدهیم تا اثربخشی روش خود را برای انتشار دادههای مسیر حفظ حریم خصوصی نشان دهیم، و نشان دهیم که روش پیشنهادی ما به سودمندی دادههای بهتری نسبت به روشهای جریان اصلی موجود، بدون مبادله با امنیت دادهها دست مییابد. در برابر حملات
این مقاله به شرح زیر تنظیم شده است. بخش 2 کارهای مرتبط را مورد بحث قرار می دهد. بخش 3 مفاهیم اساسی و مدل حمله را تعریف می کند. بخش 4 مقدمه ای جامع از ایده، چارچوب، الگوریتم و کاربردهای روش پیشنهادی ما ارائه می دهد. بخش 5 یک مدل ارزیابی از روشهای حریم خصوصی مسیر، از جمله شاخص ارزیابی حفاظت از حریم خصوصی و کاربرد داده را پیشنهاد میکند. بخش 6 نتایج تجربی را بر اساس مدل ارزیابی و مقایسه روشهای پیشنهادی ما با سایر روشهای حفاظتی ارائه میکند. بخش 7 مقاله را با نظرات و کارهای آینده به پایان می رساند.
2. کارهای مرتبط
بسیاری از تکنیکهای موجود مبتنی بر نمونهبرداری موقعیت مستقل و توزیع شده (iid)، موقعیتهای نمونهگیری از مسیرهای تصادفی روی شبکهها، شبکههای جادهای یا بین نقاط مورد علاقه هستند، اما الگوریتمها و عملیات خاص متفاوت هستند.
شکری و همکاران [ 4 و 5 ] یک روش توزیع یکسان مستقل یکنواخت را پیشنهاد کرد که هر مکان کاذب را مستقل از توزیع احتمال یکسان ایجاد می کند و باعث می شود توزیع یکسانی داشته باشد. بنابراین، مسیر کاذب یک سری موقعیت های نادرست نامرتبط است.
روش های پیشنهاد شده توسط Chow و همکاران. و کروم و همکاران [ 6 ، 7 ] را می توان به صورت زیر خلاصه کرد: دادن توزیع احتمال p حرکت جمعیت، به طور تصادفی روی یک سری از موقعیت ها با توزیع احتمال p راه بروید ، و در نهایت یک مسیر نادرست با موقعیت های انتخاب شده ایجاد کنید.
کاتو و همکاران [ 8 ] روشی را برای پیشبینی راه رفتن تصادفی در مسیر موبایل کاربر و سپس پیشبینی توزیع احتمال پیشنهاد کرد. p(u)�(�)از مسیر متحرک بعدی کاربر. توزیع احتمال p(u)�(�)برای راه رفتن تصادفی روی یک سری موقعیت استفاده شد. در نهایت، یک مسیر نادرست از موقعیت های انتخاب شده ایجاد شد.
الگوریتم های این روش ها با استفاده از تعداد زیادی از مسیرهای نادرست برای پوشاندن مسیر واقعی مشابه هستند و مشکلات نیز مشابه هستند. داده های ساخته شده توسط احتمال به راحتی می توانند نامعتبر باشند و باعث می شوند که داده های کاربر در آمار کاملاً بی فایده باشند.
پینگلی و همکاران [ 9 ] یک طرح مبتنی بر اغتشاش پرس و جو ارائه کرد که از حریم خصوصی پرس و جو در LBS مداوم حتی زمانی که هویت کاربر آشکار می شود محافظت می کند، و وانگ و همکاران. [ 10 ] یک مشکل حریم خصوصی مکان را معرفی کرد: مشکل حفاظت از حریم خصوصی مکان آگاه از مکان (L2P2) برای یافتن کوچکترین ناحیه پنهان، این روش ها در حفظ حریم خصوصی بسیار ساده هستند. دلیل اصلی این است که آنها از مسیر یک کاربر دیگر به عنوان پوشش داده یا حتی مسیر یک غیر کاربر استفاده می کنند. این روش تغییر انتساب مسیر بسیار آسان است که توسط مهاجمان شکسته می شود و اطلاعات افراد “بی گناه” را مستقیماً افشا می کند. اگرچه روش ها از نظر کاهش مصرف و تلفات ساده و موثر هستند، اما دارای کاستی هایی نیز هستند.
اکثر فنآوریهای انتشار دادههای مسیر حفظ حریم خصوصی موجود، از روشهای تعمیم یا اختلال برای مقابله با مسیر منتشر شده برای مطابقت با مدل k -anonymity استفاده میکنند.
ماچاناوجهالا و همکاران. [ 11 ، 12 ] یک مدل افزایش یافته k -anonymity، مدل l -diversity پیشنهاد کردند . اصل تنوع l مستلزم آن است که هر گروه k -anonymity در یک جدول داده حاوی حداقل 1 مقدار مشخصه حساس متفاوت باشد. مهاجم استنباط می کند که احتمال یک پیام حفظ حریم خصوصی ضبط شده کمتر از 1/l1/�.
ابول و همکاران [ 13 ، 14 ] پیشنهاد شد(k,δ)(�,�)مدل ناشناس بودن بر اساس عدم قطعیت داده های مسیر متحرک. بر اساس مدل، مشکل ناشناس بودن مسیر با خوشه بندی درمان شد. با این حال، با تجزیه و تحلیل درجه حفاظت از (k,δ)(�,�)مدل ناشناس بودن، مدل فقط می تواند k- ناشناس بودن مسیر را فقط در شرایطی که δ=0�=0.
شین و همکاران [ 15 ، 16 ] الگوریتمی را پیشنهاد کرد که یک مسیر را به مجموعهای از بخشها تقسیم میکند تا از حریم خصوصی اطمینان حاصل شود. در این الگوریتم، دادههای مسیر به چندین بخش تقسیم میشوند که برای محافظت از حریم خصوصی مسیر و اطمینان از کاربرد دادهها بالاتر از سطح مطلوب کیفیت خدمات، ناشناس هستند.
در زیر چندین روش پیچیده تر، بالغ و مؤثرتر حفظ حریم خصوصی آورده شده است و همه مزایا و معایب خاص خود را دارند.
درخشان و همکاران. [ 17 ] روش DP-WHERE را معرفی کرد، که پایگاه داده Detailed Records (CDRs) را برای تولید پایگاههای داده ترکیبی خصوصی مختلف، که توزیع آنها نزدیک به CDRهای واقعی است، فراخوانی میکند. با این حال، CDR ها معادل یک مسیر مکانی کامل نیستند، زیرا مکان تنها در صورت فراخوانی شناخته می شود.
گورسوی و همکاران [ 18 ] روش انتشار خصوصی و مفیدی را برای داده های مسیر پیشنهاد کرد. این روش DP-Star را ارائه میکند، یک چارچوب روشمند برای انتشار دادههای مسیر با تضمین حریم خصوصی متفاوت و همچنین حفظ ابزار بالا. از مقایسه ها، DP-Star به طور قابل توجهی از رویکردهای موجود از نظر ابزار و دقت مسیر بهتر عمل می کند.
ژائو و همکاران [ 19 و 20 ] یک روش حفظ حریم خصوصی مسیر بر اساس خوشه بندی با استفاده از حریم خصوصی افتراقی پیشنهاد کرد. در این روش، نویز لاپلاسی محدود با شعاع به داده های مکان مسیر در خوشه اضافه می شود تا از نویز بیش از حد بر اثر خوشه بندی جلوگیری شود، و آنها در نظر گرفتند که مهاجم می تواند مسیر کاربر را با اطلاعات دیگر مرتبط کند تا حمله استدلال مخفی ایجاد کند. یک مدل حمله استدلال مخفی را پیشنهاد کرد.
پروسرپیو و همکاران [ 21 ] روش wPINQ را معرفی کرد که با کالیبره کردن وزن برخی از رکوردهای داده به حریم خصوصی متفاوتی دست می یابد. آنها همچنین روشی را پیشنهاد کردند که مجموعه داده های مصنوعی را با استفاده از روش زنجیره مارکوف-مونته کارلو، با تمرکز بر نمودار اندازه گیری نویز با توجه به تعداد مثلث ها، تولید می کند.
Bindschaedler و همکاران. [ 3 ] معیاری برای ثبت همزمان ویژگیهای جغرافیایی و معنایی مسیر واقعی مکان پیشنهاد کرد. بر اساس این معیارهای آماری، یک مدل تولید حفظ حریم خصوصی برای ترکیب مسیرهای مکان طراحی شده است. این مسیرها ممکن است مسیر برخی از افراد متحرک باشد که سبک زندگی آنها ثابت و معنادار است.
در سال های اخیر، بسیاری از روش های جدید حفظ حریم خصوصی مسیر ارائه شده است.
دای و همکاران [ 22 ] یک روش حفظ حریم خصوصی مسیر مبتنی بر پارتیشن بندی منطقه را پیشنهاد کرد، که عمدتا با ارسال نقاط پرس و جوی شبه، مهاجمان را گیج می کند و با استفاده از روش پارتیشن بندی منطقه که مسیر واقعی کاربران را پوشش می دهد، چندین نقطه پرس و جو را در همان منطقه فرعی پنهان می کند. به طوری که مهاجمان نمی توانند مسیر واقعی کاربران را بازسازی کنند و در نتیجه از حریم خصوصی کاربران محافظت کنند.
سان و همکاران [ 23 ] یک الگوریتم حفظ حریم خصوصی را بر اساس چند ویژگی مسیر پیشنهاد کرد. این الگوریتم عدم قطعیت دادههای مسیر را در نظر میگیرد و تفاوتهای جهت، سرعت، زمان و مکان را به عنوان مبنای مسیرها در مجموعه خوشهای در فرآیند خوشهبندی مسیر و کاربرد دادههای مسیر پس از حفاظت یکپارچه میکند.
ژانگ و همکاران [ 24 ] یک روش حفظ حریم خصوصی مسیر بر اساس چند ناشناس بودن پیشنهاد کرد. این روش n دستگاه ناشناس را بین کاربران و ارائه دهندگان خدمات مکان مستقر می کند. به هر پرس و جو یک نام مستعار داده می شود. با ترکیب با طرح دروازه Shamir، محتوای پرس و جو کاربر به n قسمت تقسیم می شود. n بخش اطلاعات به صورت تصادفی در n دستگاه ناشناس توزیع می شود و پس از پردازش ناشناس برای ارائه دهنده ارسال می شود.
زو و همکاران [ 25 ] یک مدل حفظ حریم خصوصی مسیر LBS را برای گروه های ناشناس بر اساس حریم خصوصی متفاوت ایجاد کرد. این مدل از ایده گروه ناشناس نویز برای غلبه بر ضرر اتکای بیش از حد به بودجه حریم خصوصی الگوریتمهای موجود استفاده میکند. در عین حال کیفیت خدمات کاربران را از طریق ایده پارتیشن مسیر کاربر و موقعیت مکانی تضمین می کند.
لی و همکاران [ 26 و 27 ] یک روش انتشار با حفظ حریم خصوصی برای داده های مسیر بر اساس تقسیم بندی داده ها پیشنهاد کرد. با گذشت زمان، الگوریتم می تواند به طور موثر مسیرهای هر پارتیشن داده را بدون محاسبه مجدد مسیرهای منتشر شده پردازش کند، بنابراین به طور موثر هزینه محاسباتی را کاهش می دهد. دارای عملکردهای اسکن مسیر کارآمد، خوشه بندی و حفظ حریم خصوصی است.
از منظر پیادهسازی فناوری، فناوری حفظ حریم خصوصی مسیر بالا را میتوان به سه نوع خلاصه کرد: فناوری مبتنی بر ناشناس بودن مسیر، فناوری مبتنی بر مسیر کاذب و فناوری مبتنی بر حریم خصوصی متفاوت. مزایا، معایب و فن آوری های اصلی سه نوع معمولی در جدول 1 نشان داده شده است.
لازم به ذکر است که در روشهای فوق، با اضافه شدن انباشت مسیرهای کاذب، افست مسیر، توزیع مکان تصادفی به دادههای مسیر، اختلاف دادههای مسیر نسبت به اصلی خود به طور مداوم افزایش مییابد و این روشها را سخت میکند. ابزار داده محدود که توسط بسیاری از برنامه های کاربردی واقعی مورد نیاز است.
3. مدل حمله
3.1. نمادها
اصطلاحات اساسی مورد استفاده در این مقاله را در زیر و نمادهای ریاضی را در جدول 2 تعریف می کنیم .
تعریف 1.
مسیر ( t r��). خط سیر مسیری است در فضای سه بعدی (دو بعد مکانی و یک بعد زمانی) که با t r = {پ1،پ2، … ، صمتر}��={�1,�2,…,��}. یک نقطه (موقعیت) از t r�� پک= (ایکسک،yک،تیک)��=(��,��,��)، جایی که ایکسک،yک��,��طول و عرض جغرافیایی هستند، تیک��زمان است، تی1<تی2< ⋯ <تیمتر�1<�2<⋯<��و m تعداد نقاط نمونه برداری است.
یک مسیر با یک شماره منحصر به فرد به نام Identify شناسایی می شود. منD��).
ما استفاده می کنیم D ( t r )�(��)برای نشان دادن پایگاه داده مسیرها: D ( t r ) = { ( Q I، تیrمن) }�(��)={(��,���)}، | D | = n|�|=�، 1 ≤ i ≤ n1≤�≤�. n تعداد افراد مسیر است، Dس( t r ) ⊆ D ( t r )��(��)⊆�(��)پایگاه داده نمونه مسیر است و Dپ( t r )��(��)محافظت شده است D ( t r )�(��)برای انتشار
3.2. تبدیل دو سطحی
اجازه دهید h :Dس( t r ) →Dپ( t r )ℎ:��(��)→��(��)تابعی باشد که پایگاه داده مسیر را تبدیل کند Dس( t r )��(��)به پایگاه داده انتشار مسیر Dپ( t r )��(��)برای دستیابی به انتشار مسیر حفظ حریم خصوصی.
h را می توان به دو سطح تبدیل تجزیه کرد: تبدیل هویت فردی f و تبدیل اطلاعات مکان g ، و h = f⋅ گرمℎ=�·�.
برای محافظت از هویت فردی، اطلاعات هویتی افراد مسیر حرکت را تغییر می دهیم. f:u→v�:�→�، f تابع نگاشت بین u و v است که منتشر نشده است. پس از محافظت از هویت فردی، 4 تاپلی هر نقطه از مسیر تبدیل می شود (u,x,y,t)(�,�,�,�)به (v,x,y,t)(�,�,�,�).
برای حفاظت از اطلاعات مکانی و زمانی، (x,y)(�,�)تبدیل می شود به (x′,y′)(�′,�′)استفاده كردن g:(x,y)→(x′,y′)�:(�,�)→(�′,�′).
فاصله بین مسیرها با فاصله اقلیدسی اندازه گیری می شود. فاصله اقلیدسی بین دو مسیر tr1��1و تیr2��2در زمان t ([ 28 ، 29 ]) برابر است با:
در محدوده زمانی [تیs t a r t،تیe n d][������,����]، فاصله از تیr1��1و تیr2��2است:
تعریف 2.
تقاطع مسیرهای m. در محدوده زمانی [تیs t a r t، تیe n d][������,����]، m مسیرها تیr1��1به تیrمتر���اگر فاصله بین m در هر زمان متقاطع باشند تیک��که در [تیs t a r t، تیe n d][������,����]کمتر از δ است، یعنی D i s t ( tr1[تیک] ، تیrمتر[تیک] ) ≤ δ����(��1[��],���[��])≤�، جایی که δ آستانه تقاطع m مسیرها است.
3.3. مدل حمله
با توجه به سناریوی کاربردی انتشار داده های مسیر، مدل حمله را در انتشار داده های مسیری تجزیه و تحلیل می کنیم.
با تجزیه و تحلیل Dپ( t r )��(��)، مهاجم می تواند پایگاه داده مسیر را بازیابی یا تا حدی بازیابی کند Dس( t r )��(��)، به این حمله حمله حریم خصوصی خط سیر می گویند. عملکرد حمله حریم خصوصی مسیر ساعت“=ساعت– 1:Dپ( t r ) →Dس( t r ) ،ℎ′=ℎ−1:��(��)→��(��),که فرآیند معکوس حفاظت از مسیر است. هدف بازیابی است ( v _ایکس“،y“، تی )(�,�′,�′,�)به ( u ، x ، y، تی )(�,�,�,�)، جایی که تو درست است منD��از t r��، v جعل شده است منD��از t r��.
بر این اساس، حملات حریم خصوصی مسیر را می توان به دو سطح استنتاج اطلاعات مکان و استنتاج هویت فردی تقسیم کرد. ساعت“=g“⋅f“ℎ′=�′·�′.
g“: (ایکس“،y“) → ( x ، y)�′:(�′,�′)→(�,�). با کمک اطلاعات شبکه جادهای، اطلاعات پسزمینه یا سایر روشهای کاهش نویز، مهاجم میتواند اطلاعات مکان را با استفاده از آن استنتاج کند g“�′.
f“: ( x ، y, t ) → u�′:(�,�,�)→�. بر اساس ( v ، x ، y، تی )(�,�,�,�)، مهاجم می تواند شما را از اطلاعات موجود در آن استنتاج کند( x ، y، تی )(�,�,�)و ارتباط بین هویت فردی u و v را ایجاد کنید.
روش های مختلفی برای اجرای تابع استنتاج مکان وجود دارد g“�′در الگوریتم های حفاظتی مختلف
اجرای تابع استنتاج هویت فردی f“�′از چارچوب کلی استنباط ابتدا آدرس فرد و سپس هویت فرد از طریق آدرسی که اطلاعات پس زمینه را ترکیب می کند، پیروی می کند تا رابطه بین هویت فرد و مسیر حرکت فرد برقرار شود.
استنتاج مسیر (TrajInfer) برای تعیین رابطه بین مسیر فردی است ( س I, t r )(��,��)و فردی منD��، جایی که t r = {پ1،پ2، … ، صمتر}��=�1,�2,…,��. اگر استنتاج مسیر موفقیت آمیز باشد، حریم خصوصی مسیر نقض می شود.
حمله استنتاج موقعیت برای استنتاج اطلاعات موقعیت حساس فردی (مانند خانه) بر اساس داده های مسیر است.
مهاجمان ممکن است اطلاعات مسیر کاربر را به روش های زیر پیدا کنند [ 3 ، 30 ، 31 ]:
(1) موقعیت های محبوب
مهاجم سعی می کند با محاسبه موقعیت هایی که اغلب بین خانه و محل کار بازدید شده است، محبوب ترین موقعیت ها را شناسایی کند. این حمله تابع رتبه بندی زیر را انجام می دهد:
جایی که سیo u n t ( ⋅ )�����(·)تعداد موقعیت را محاسبه می کند ( x ، y)(�,�)در تمام مسیرها
(2) مگا خوشه ها
مهاجم سعی می کند دو خوشه بزرگ را که حاوی نقاط داده مسیر هستند شناسایی کند t r��. این حمله عملکرد زیر را انجام می دهد:
واضح است که با در نظر گرفتن سناریوی تجزیه و تحلیل دادهها و استخراج عادات زندگی کاربران، معمولاً فرض میکنیم که بیشتر نقاط مکان کاربر در خانه و محل کار توزیع میشود، زیرا خانه و محل کار محبوبترین موقعیتها برای همه افراد هستند. کاربران، آنها به عنوان مراکز 2 خوشه بزرگ بازگردانده می شوند.
(3) موقعیت های محبوب در یک بازه زمانی
مهاجم سعی می کند موقعیت های محبوبی را که اکثر کاربران در یک بازه زمانی خاص از آنها بازدید کرده اند شناسایی کند (تیs t a r t،تیe n d)(������,����). این مهاجم محاسبات زیر را انجام می دهد:
4. الگوریتم پیشنهادی
برای دستیابی به تحول دو سطحی با تغییر شکل اطلاعات مکان و تبدیل هویت فردی برای حفاظت از حریم خصوصی، الگوریتم حفظ حریم خصوصی مسیر مسیر با ناشناسسازی پویا با اعوجاج محدود (TPP-DABD) را در زیر پیشنهاد میکنیم.
4.1. طرح کلی الگوریتم
الگوریتم TPP-DABD ما شامل چهار مرحله کلیدی زیر است:
-
یک پنجره زمانی را محاسبه کنید و منطقه را برای ناشناس کردن تقسیم کنید.
-
جفت های مسیر (که با P نشان داده می شوند ) با زاویه متقاطع بیشتر از θ�.
-
برای جفت کردن بخشهای مسیر باقیمانده در درجه واگرایی جهتگیری، کمترین بخش ساختگی را معرفی کنید. θ�، حاصل می شود پ˜�˜جفت
-
قطعات را در هر جفت تعویض کنید پ∪پ˜�∪�˜.
این الگوریتم می تواند به صورت آنلاین و آفلاین در صورت نیاز اجرا شود. برای اجرای آنلاین، چهار مرحله بالا را با پیشرفت تمام مسیرها تکرار می کند، جایی که پنجره زمانی در هر اجرا به صورت پویا با توجه به نیازهای برنامه و جهت گیری مسیرها محاسبه می شود. برای اجرای آفلاین، چون اطلاعات کامل همه مسیرها مشخص است، تمام پنجره های زمانی محاسبه شده در مرحله 1 را خواهد داشت و سپس مراحل 2 تا 3 را برای هر پنجره زمانی انجام می دهد.
برای مراحل 2 و 3، به منظور کارایی الگوریتم، ما از یک رویکرد حریصانه برای محاسبه یک عدد رضایت بخش به جای یک عدد بهینه استفاده می کنیم که از نظر محاسباتی برای دستیابی به آن بسیار گران است.
4.2. توضیحات الگوریتم
برای پیاده سازی طرح کلی الگوریتم بالا، ایده اصلی ما این است که مسیر را به پنجره ها تقسیم کنیم و مخلوط کردن آنها را انجام دهیم. Q I��در یک اعوجاج محدود ابتدا بر اساس بخشهای مسیر در داخل هر پنجره و سپس با معرفی حداقل بخشهای ساختگی، به طوری که مهاجم از شناسایی مسیرهای منفرد جلوگیری میکند.
چهار مرحله الگوریتم ما با در نظر گرفتن الگوهای تقاطع بخش های مسیر به شرح زیر پیاده سازی می شود:
-
مرحله 1: یک پنجره زمانی را محاسبه کنید [تیs t a r t،تیe n d)[������,����)و منطقه را برای ناشناس کردن تقسیم کنید. برای تعیین سریع تقاطع، روش شبکه بندی را برای تقسیم تقریبی منطقه (شبکه مسیرها) به صورت زیر اعمال می کنیم. اصل این مرحله تقسیم کل منطقه به دو مجموعه شبکه است. gمن d _1����1و gمن d _2����2، جایی که هر مجموعه شامل د× d�×�مربع، gمن d _1����1و gمن d _2����2همپوشانی دارند، مرکز gمن d _1����1یک راس از gمن d _2����2. فاصله بین دو نقطه که در یک شبکه قرار می گیرند تقریباً d در نظر گرفته می شود . از طریق این مرحله، منطقه را شبکهبندی میکنیم، سپس میتوانیم از روشی سادهتر برای قضاوت در مورد تلاقی قطعات مسیر با محاسبه اینکه آیا نقاط مسیر آنها در یک شبکه هستند استفاده کنیم.
-
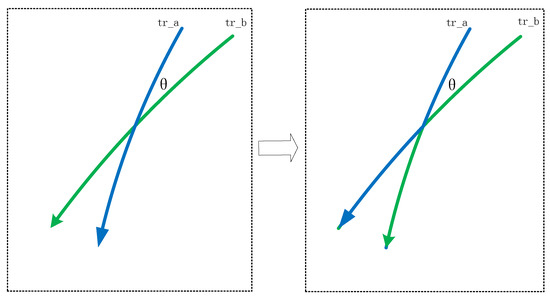
مرحله 2: جفت های مسیر (که با P نشان داده می شوند ) با زاویه متقاطع بیشتر از θ�. به منظور بهبود کاربرد هر داده مسیر پس از تعویض، ابتدا حداکثر تعداد جفت قطعه مسیر را شناسایی می کنیم که زوایای متقاطع آنها زیر آستانه است. θ�، و سپس دو بخش را در هر جفت به ترتیب در داخل قرار دهید L e fتیپ�����و R i gساعتتیپ���ℎ��. همانطور که در شکل 1 نشان داده شده است ، اصل این مرحله یافتن بخش های مسیر متقاطع و واگرا در پنجره زمانی و محدود کردن درجه واگرایی هر جفت از بخش های مسیر به یک آستانه خاص است. θ�. در این صورت، اگر درجه واگرایی بین تیrآ���و تیrب���بزرگتر است از θ�، ورودی ( تیrآ، تیrب���,���) در ماتریس مبادله به بی نهایت تنظیم شده است، به طوری که احتمال تبادل بین تیrآ���و تیrب���0 است. از طریق این مرحله، ما می توانیم از جهت یک مسیر از واگرایی زاویه بزرگ جلوگیری کنیم، به طوری که پس از اختلاط، کاربرد داده های مسیر بهبود یابد.
-
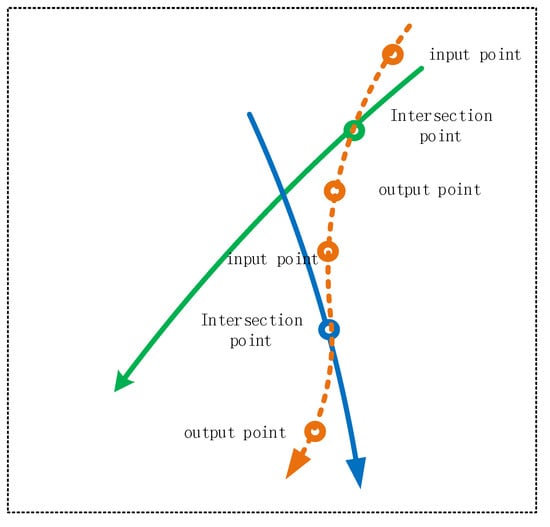
مرحله 3: معرفی کمترین قطعه ساختگی برای جفت کردن بخش های مسیر باقی مانده در درجه واگرایی جهت گیری θ�. برای تمام بخشهای چپ به تنهایی (جفت نشده)، ما از خوشهبندی k-means استفاده میکنیم تا کوچکترین مرکزهای k را پیدا کنیم که همه بخشها را در خوشههای شعاع قرار میدهند. θ�، و نتیجه پ˜�˜جفت هدف اصلی این مرحله ایجاد یک جفت از بخش های مسیر باقی مانده است. اصل این مرحله معرفی بخشهای مجازی است که با بخشهای مسیر باقیمانده ترکیب میشوند تا یک جفت مسیر با واگرایی جهت (زاویه متقاطع) را تشکیل دهند. θ�. همانطور که در شکل 2 نشان داده شده است ، برای ساخت بخش مجازی، ابتدا باید نقطه تقاطع بخش مجازی و قطعه مسیر تعیین شود و سپس نقطه ورودی و خروجی قطعه مجازی با تقاطع به عنوان مرکز ساخته شود. . به منظور کاهش هر چه بیشتر تعداد بخش های مجازی، بخش های مجازی مجاور را می توان با اتصال صاف در یک بخش ادغام کرد.
-
مرحله 4: هر جفت بخش را با هم عوض کنید پ∪پ˜�∪�˜. ما تقاطع را به عنوان مرز با توجه به احتمال داده شده برای جایگزینی جلو و عقب در نظر می گیریم Q I��، و مبادله بخش مسیر را درک کنید. جایگزین نیز باید تفاوت و تعادل را در نظر بگیرد. بخش های مسیر به طور تصادفی با توجه به یک احتمال مشخص، که از طریق ماتریس مبادله محقق می شود، مبادله می شوند. اصل این مرحله جایگزینی است منD��قطعه مسیر بعد از نقطه تقاطع مسیر طبق یک احتمال مشخص. از طریق این مرحله می توان تبادل شناسه مسیر را تکمیل کرد.
الگوریتم تفصیلی شامل چهار مرحله در الگوریتم 1 توضیح داده شده است.
| الگوریتم 1: حفظ حریم خصوصی مسیر با ناشناس سازی پویا با اعوجاج محدود |
| 1 ورودی: د ( t r ) : [ ( u , x , y، تی ) ]�(��):[(�,�,�,�)] |
| 2 خروجی: برگردانید D“( t r ) : [ ( v ,ایکس“،y“،تی“) ]�′(��):[(�,�′,�′,�′)] |
| 3 // ایجاد پنجره زمانی تصادفی سازی [تیs t a r t،تیe n d)[تیستیآ�تی،تیه�د)، عرض پنجره زمانی یک عدد تصادفی از تصادفی(). |
| 4 برای ( t =تیm i n; t <تیm a x; t + = r a n do m ( ) )(تی=تیمترمن�;تی<تیمترآایکس;تی+=�آ�د�متر()){ |
| 5 تیs t a r t= t ;تیe n d= m i n ( t + r a n do m ( ) ,تیm a x)تیستیآ�تی=تی;تیه�د=مترمن�(تی+�آ�د�متر()،تیمترآایکس); |
| 6 // برای تشکیل جفت قطعات مسیر (P) با درجه واگرایی جهت گیری که بیشتر از θ�. |
| 7 P = الگوریتم-2( D ( t r )�(تی�)، تیs t a r tتیستیآ�تی، تیe n dتیه�د) |
| 8 // معرفی کمترین بخش ساختگی برای جفت کردن بخش های باقی مانده در درجه واگرایی جهت گیری θ�. |
| 9 پ˜پ˜=الگوریتم-3( D ( t r )�(تی�)، تیs t a r tتیستیآ�تی، تیe n dتیه�د، P )؛ |
| 10 //تغییر هر جفت از بخش ها در پ∪پ˜پ∪پ˜ |
| 11 D“( t r )�”(تی�)=الگوریتم-4( D ( t r )�(تی�), P , پ˜پ˜) |
| 12 } |
مرحله 2 توسط الگوریتم 2 (تقسیم بخش های مسیر) پیاده سازی می شود، که جفت قطعات مسیر ( P ) را با درجه واگرایی جهت گیری که بیشتر از θ�.
در الگوریتم 2، فرآیند جستجوی بخش های مسیر متقاطع با درجه واگرایی جهت گیری بیشتر از θ�و جفت قرار دادن آنها که توسط الگوریتم 4 رد و بدل خواهد شد، در شکل 1 نشان داده شده است .
| الگوریتم 2: جفت کردن بخش های مسیر |
| 1 ورودی: د ( t r ) : [ ( u , x , y، تی ) ]�(تی�):[(�,�,�,�)]، tstart,tend������,���� |
| 2 خروجی: برگردانید pair(P)����(�)با درجه واگرایی جهت گیری بیشتر از θ� |
| 3 مقداردهی اولیه grid1����1، grid2����2 |
| 4 //اسکن هر نقطه مسیر ص |
| 5 برای هر امتیاز p(x,y,t)�(�,�,�)که در D(tr)�(��) |
| 6 اگر ( t>=tstart�>=������&& t<tend�<����){ |
| 7 tstart=t;tend=min(t+random(),tmax)������=�;����=���(�+������(),����); |
| 8 //ایجاد پنجره زمانی تصادفی سازی [tstart,tend)[������,����)، عرض پنجره زمانی عدد تصادفی تصادفی است() |
| 9 برای (t=tmin;t<tmax;t+=random())(�=����;�<����;�+=������()){ |
| 10 برای هر p in gمن d _1����1 |
| 11 نقطه جفت شدن آن را پیدا کنید پ“�′که در gمن d _1����1، جایی که pپ“�′متعلق به یک قطعه هستند و زاویه تقاطع آنها کمتر از θ� |
| 12 اگر چنین نیست پ“�′را می توان یافت |
| 13 حرکت p را از g1�1و نقشه آن را به gمن d _2����2بر اساس ( ص . ایکس�.�، ص . y�.�). |
| 14 اضافه کردن نقاط ساختگی به gمن d _2����2برای جفت کردن هر p in gمن d _2����2. |
| 15 } |
| 16 // نقاط مسیر را با آدمک های لازم جفت کنید به طوری که درجه واگرایی جهت آنها بیشتر از θ�. |
| 17 } |
همانطور که در شکل 1 نشان داده شده است ، جفت های دو مسیر متقاطع به صورت زیر تشکیل می شوند:
(1) پنجره زمانی [ تیs t a r t،تیe n d������,����، و شبکه grid1 و grid2 را مقداردهی اولیه کنید.
(2) در grid1 و grid2، بخش های مسیر متقاطع محاسبه می شوند و زاویه بین مسیرهای متقاطع در همان زمان محاسبه می شود.
(3) از طریق محاسبه، بخش های مسیری که زاویه تقاطع آنها تجاوز نمی کند θ�پیدا می شوند و جفت تشکیل می دهند و درجه واگرایی هر جفت بخش مسیر در یک آستانه معین محدود می شود. θ�.
(4) در این صورت، اگر درجه واگرایی بین تیrآ���و تیrب���بزرگتر است از θ�، مقدار ماتریس مبادله ( تیrآ، تیrب���,���) روی بی نهایت تنظیم شده است، به طوری که احتمال تبادل بین تیrآ���و تیrب���0 است.
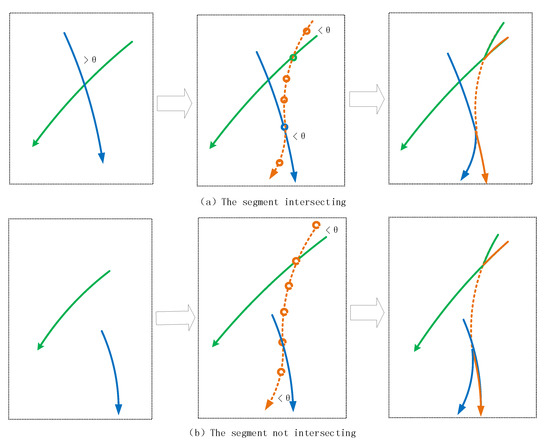
مرحله 3 توسط الگوریتم 3 پیاده سازی می شود: جفت کردن بخش های مسیر باقی مانده ( پ˜�˜( پ˜�˜) با درجه واگرایی جهت گیری بیشتر از θ�.
| الگوریتم 3: جفت کردن بخش های مسیر باقی مانده ( پ˜�˜) |
| 1 ورودی: د ( t r ) : [ ( u , x , y، تی ) ]�(��):[(�,�,�,�)]، تیs t a r t،تیe n d������,����، p a i r ( P)����(�) |
| 2 خروجی: برگردانید p a i r (پ˜)����(�˜)با درجه واگرایی جهت گیری بیشتر از θ� |
| 3 برای هر بخش در D ( t r )�(��)– P { |
| 4 نقطه تقاطع بخش ساختگی را با استفاده از k – m e a n s�����الگوریتم |
| 5 نقاط ورودی و خروجی تصادفی بخش ساختگی را تنظیم کنید در حالی که اطمینان حاصل کنید که زاویه متقاطع بیشتر از θ�. |
| 6 } |
| 7 //استفاده از الگوریتم Greedy برای ساختن بخش ساختگی. |
| 8 برای هر بخش A در D ( t r )�(��)– پ |
| 9 اگر قطعه A جفت نباشد { |
| 10 بخش ساختگی را با پیوند دادن نقاط ورودی، متقاطع و خروجی بسازید |
| 11 بخش باقیمانده B را جستجو کنید که می تواند قطعه ساختگی را با زاویه ای بیشتر از آن قطع کند θ�. |
| 12 اگر از این بخش B خارج شوید ، B و قطعه ساختگی را یک جفت بسازید و بخش ساختگی موجود قطعه B را حذف کنید . |
| 13 در غیر این صورت، بخش ساختگی را تا نقطه ورودی قطعه ساختگی B گسترش دهید . |
| 14 } |
| 15 تمام بخش های ساختگی را در آن قرار دهید D ( t r )�(��). |
| 16 بازگشت D ( t r )�(��); |
| 17 } |
الگوریتم 3 مشکل بخش های مسیر باقی مانده را حل می کند.
پس از فرآیند الگوریتم 2، بخش های مسیر باقی مانده به دو نوع زیر تقسیم می شوند، یکی شامل بخش های متقاطع است (واگرایی جهت گیری بیشتر از θ�، دیگری شامل بخش های غیر متقاطع است. هر دو نوع را می توان با معرفی بخش های ساختگی پردازش کرد، به طوری که واگرایی بخش ساختگی و بخش باقی مانده در داخل است. θ�.
همانطور که در شکل 2 نشان داده شده است، این جفت ها توسط الگوریتم 4 مبادله خواهند شد .
همانطور که در شکل 2 نشان داده شده است ، فرآیند ساخت یک قطعه مسیر مجازی برای تشکیل یک قطعه مسیر با واگرایی جهتی بیشتر از θ�به شرح زیر است:
(1) با توجه به بخش های مسیر باقی مانده، نقطه تقاطع بین هر بخش مسیر باقی مانده و بخش مسیر مجازی، نقطه ورودی و خروجی بخش مجازی ساخته می شود.
(2) در grid1 و grid2، بخش های مسیر متقاطع محاسبه می شوند و واگرایی مسیرهای متقاطع در همان زمان محاسبه می شود.
(3) از طریق محاسبه، بخش های مسیری که واگرایی آنها تجاوز نمی کند θ�پیدا می شوند و جفت تشکیل می دهند و درجه واگرایی هر جفت بخش مسیر در یک آستانه معین محدود می شود. θ�.
(4) در این صورت، اگر درجه واگرایی بین تیrآ���و تیrب���بزرگتر است از θ�، مقدار ماتریس مبادله ( تیrآ، تیrب���,���) روی بی نهایت تنظیم شده است، به طوری که احتمال تبادل بین تیrآ���و تیrب���0 است.
در ساخت قطعه مجازی ابتدا باید محل تلاقی قطعه ساختگی و قطعه واقعی مشخص شود و سپس نقطه ورودی و نقطه خروجی قطعه ساختگی با تقاطع به عنوان مرکز ساخته شود. به منظور کاهش تعداد قطعات ساختگی تا حد ممکن، قطعات ساختگی مجاور را می توان از طریق اتصال صاف در یک قطعه ترکیب کرد، همانطور که در شکل 3 نشان داده شده است.
مرحله 4 توسط الگوریتم 4 پیاده سازی می شود: مبادله هر جفت از بخش ها پ∪پ˜�∪�˜.
| الگوریتم 4: جابجایی هر جفت از بخش ها پ∪پ˜�∪�˜ |
| 1 ورودی: د ( t r ) : [ ( u , x , y، تی ) ]�(��):[(�,�,�,�)], P , پ˜�˜ |
| 2 خروجی: برگردانید D“( t r ) : [ ( v ,ایکس“،y“،تی“) ]�′(��):[(�,�′,�′,�′)] |
| 3 //تبادل کردن Q I��پس از تقاطع با توجه به یک احتمال خاص |
| 4 // احتمال توسط ماتریس مبادله M تعیین می شود . |
| برای هر 5 عدد ( tra,trb���,���) { |
| 6 v را به طور تصادفی انتخاب کنید و v را به آن مبادلهv′�′ |
| 7 با احتمال در ورودی ( tra,trb���,���) در M موارد زیر را کامل کنید: |
| 8 برای هر امتیاز در tra���و هر نقطه در trb���{ |
| 9 تعویض کنید IDs���بین آنها |
| 10 } |
| 11 به روز رسانی M برای تبادل بعدی. |
| 12 } |
5. معیارهای ارزیابی عملکرد
در حال حاضر، در تحقیق و تمرین فناوری انتشار دادههای حفظ حریم مسیر برای سناریوهای کاربردی تحلیل آماری دادههای مسیر، معمولاً از دو نوع معیار برای ارزیابی عملکرد الگوریتمها استفاده میشود: انکار قابل قبول و عدم تشابه آماری.
معیار انکار قابل قبول برای ارزیابی درجه حفظ حریم خصوصی مسیر استفاده می شود. در این مقاله، انکار پذیرفتنی به درجهای اشاره دارد که مهاجم میتواند حداقل یک مسیر سنتز را با اعتباری مشابه با مسیر واقعی اصلی استنتاج کند، زمانی که او مسیر را پس از اختلاط استنباط میکند.
معیار عدم تشابه آماری برای ارزیابی سودمندی داده های مسیر استفاده می شود. در این مقاله، عدم تشابه آماری به تفاوت آماری بین مجموعه داده های مسیر تولید شده توسط روش حفظ حریم خصوصی مسیر و مجموعه داده های مسیر اصلی اشاره دارد.
معیارهای مورد استفاده در این مقاله در جدول 3 نشان داده شده است.
5.1. درجه حفظ حریم خصوصی
در این مقاله، نرخ خطای استنتاج (IER) به عنوان معیاری برای ارزیابی درجه حفظ حریم خصوصی مسیر استفاده شده است. IER به نسبت تعداد استنتاج های مسیر اشتباه به تعداد کل استنتاج ها اشاره دارد که می تواند به صورت زیر بیان شود:
هر چه IER به 1 نزدیکتر باشد، حریم خصوصی مسیر بهتر محافظت می شود.
با توجه به الگوریتم TPP-DABD، انتظارات ریاضی IER به تعداد مبادلات ( n ) در مسیر سنتز شده بستگی دارد. k مسیرهای داده شده در گروه اختلاط:
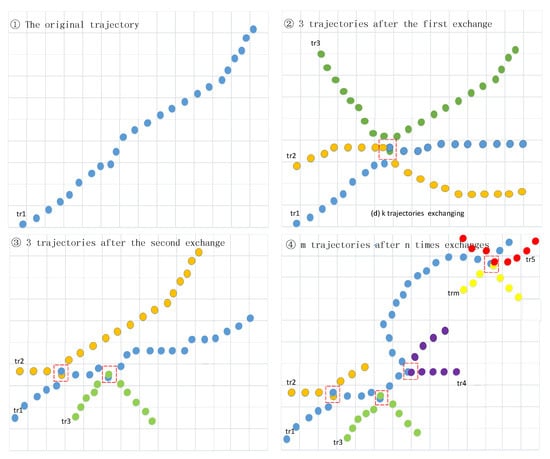
همانطور که در شکل 4 نشان داده شده است ، زمانی که تعداد مبادلات مسیر 0 باشد، مسیر اصلی مطابق با QI��یکی یکی. اگر مهاجم بتواند آن را پیدا کند ID��از فرد مربوط به QI��از طریق حمله استنتاج مسیر، اطلاعات مسیر اصلی فرد را می توان به درستی شناسایی کرد، یعنی E(IER)=0�(���)=0.
هنگامی که تعداد مبادلات مسیر 1 باشد، دو مسیر در یک گره تقاطع درگیر می شوند. اگر مهاجم بتواند شناسایی کند ID��از طریق حمله استنتاج مسیر، هنوز وجود دارد 1212احتمال اینکه اطلاعات مسیر اصلی فرد به درستی شناسایی شود، یعنی E(IER)=1−12=12�(���)=1−12=12.
وقتی تعداد مبادلات مسیر n باشد، k مسیر روی n گره درگیر در اختلاط وجود دارد. اگر مهاجم بتواند متوجه شود ID��از طریق حمله استنتاج مسیر، هنوز وجود دارد 1kn1��احتمال اینکه اطلاعات مسیر اصلی فرد به درستی شناسایی شود، یعنی E(IER)=1−1kn�(���)=1−1��.
هنگامی که داده های مسیر کاربر با روش TPP-DABD پردازش می شود، مسیر ترکیبی دیگر نمی تواند به طور کامل با اطلاعات مسیر هر کاربر در داده های مسیر اصلی مطابقت داشته باشد.
با این حال، مجموعه داده های مسیر جدید مبتنی بر TPP-DABD با مجموعه داده های مسیر اصلی در توزیع اطلاعات مکان مطابقت دارد، و همچنین با توزیع واقعی اطلاعات مکان کاربران مختلف در شبکه جاده مطابقت دارد، که داده های مسیر را ایجاد می کند. مجموعه تشکیل شده پس از سنتز هنوز قابل استفاده است. علاوه بر این، با افزایش تعداد اختلاط فردی در هر دوره زمانی، دشواری مهاجمان برای بازگرداندن مسیر سنتز شده به مسیر اصلی نیز افزایش مییابد.
انتظارات ریاضی IER با n متفاوت در جدول 4 فهرست شده است. چه زمانی n>=7�>=7، IER مورد انتظار بیشتر از 99%99%، که به معنای درجه بالایی از حفظ حریم خصوصی است.
5.2. کاربرد داده های مسیر
در برخی از سناریوهای کاربردی، روش ارزیابی ابزار داده، تفاوت بین داده های منتشر شده و داده های اصلی را مقایسه می کند. در این روش، کاربرد داده و حفظ حریم خصوصی داده ها یک جفت تناقض هستند. استفاده زیاد از داده ها در حفظ حریم خصوصی مسیر، حفاظت از حریم خصوصی مسیر را به سطح پایینی محدود می کند، به ویژه در انتشار داده ها با حفظ حریم خصوصی مسیر طولانی مدت.
در بسیاری از سناریوهای کاربردی، کاربرد داده های مسیر بیشتر به ویژگی های آماری مسیر واقعی بستگی دارد. ویژگی های آماری اصلی را می توان پس از محافظت از داده های مسیر حفظ کرد. برخلاف روش ارزیابی تفاوت بین دادههای اصلی و منتشر شده، حفظ بالای ویژگیهای آماری لزوماً به معنای سطح پایین حفاظت از حریم خصوصی نیست، بنابراین معیار قابل اعتمادتری برای ابزار داده است.
در این مقاله، ما سودمندی داده ها را بر اساس تجزیه و تحلیل آماری اندازه گیری می کنیم، با هدف اعمال داده ها در سناریوهایی مانند استخراج نقطه بهره، حاشیه نویسی معنایی مکان، استنتاج نقشه، مکان یابی کسب و کار و غیره.
ما از نرخ حفظ ویژگی آماری ( SFRR ) برای ارزیابی سودمندی داده های مسیر استفاده می کنیم. SFRR به صورت زیر تعریف می شود:
که در آن FoST����ویژگی های مسیر مصنوعی هستند، FoOT����از ویژگی های مسیر اصلی هستند. محدوده SFRR است [0,1][0,1]. هر چه به عدد 1 نزدیکتر شود، کاربرد داده های مسیر بالاتر است.
به طور خاص، معیارهای آماری زیر را می توان استفاده کرد [ 3 ، 31 ]:
(1) توزیع بازدیدها یا تعداد بازدیدکنندگان در هر مکان.
(2) توزیع بازدیدکنندگان در 10 مکان برتر مورد علاقه.
(3) موقعیت های برتر در منطقه.
(4) تخصیص زمان کاربر.
در ارزیابی ابزار، همان متریک را می توان به ترتیب بر روی داده های مسیر مصنوعی و اصلی محاسبه کرد و برای تجزیه و تحلیل حفظ ویژگی های آماری مقایسه کرد.
پس از پردازش داده های مسیر توسط الگوریتم TPP-DABD، مختصات و زمان هر موقعیت در مجموعه داده های مسیر تغییر نمی کند. بنابراین، از نظر تجزیه و تحلیل آماری در مورد توزیع بازدید و تخصیص زمان کاربر، ویژگیهای خط سیر مصنوعی و اصلی سازگار است، به این معنی که SFRR 1 است.
در بخش 6 ، ارزیابی فوق را از طریق آزمایشات تحلیل و اثبات خواهیم کرد.
6. آزمایش ها و ارزیابی ها
در این بخش از این معیارها برای مقایسه الگوریتم خود با برخی از الگوریتمهای کلاسیک، از طریق نتایج تجربی و تحلیل مزایا و معایب این الگوریتمها استفاده میکنیم.
6.1. مجموعه داده ها و روش های تجربی
مجموعه دادههای مسیر مورد استفاده در آزمایشهای ما بر اساس دادههای GPS از تاکسیهای شهر گوانگژو، چین، از جمله دادههای مسیر حدود 2000 تاکسی برای یک روز و 340000 نقطه موقعیت مسیر بود. حجم کل داده ها 3 گیگابایت بود و مسیرها در محدوده 112 تا 114 درجه طول شرقی و 22 تا 23 درجه عرض شمالی متمرکز شدند.
روند اصلی آزمایشها به شرح زیر بود: ابتدا همان مجموعه دادههای مسیر اصلی انتخاب شد و الگوریتمهای مختلفی روی مجموعه دادههای مسیر اجرا شد تا مجموعه دادههای مسیر منتشر شده تشکیل شود. سپس اعتبار الگوریتمهای مختلف در حفاظت از حریم خصوصی بر اساس نرخ خطای استنتاج (IER) و اعتبار الگوریتمهای مختلف در کاربرد دادهها بر اساس نرخ حفظ ویژگیهای آماری (SFRR) مقایسه شد.
الگوریتمهای حفظ حریم خصوصی مسیر کلاسیک زیر با الگوریتم ما مقایسه شد:
(1) روش نمونه گیری iid یکنواخت (UIIDSM) [ 4 ]. با توجه به توزیع احتمال یکنواخت، هر موقعیت نادرست به طور مستقل و یکسان ایجاد می شود.
(2) روش نمونه گیری iid جمع آوری شده (AIIDSM) [ 4 ]. با توجه به توزیع پواسون موبایل، هر مکان نادرست به طور مستقل و یکسان ایجاد می شود.
(3) روش حرکت تصادفی جمع شده (ARMM) [ 6 ، 30 ]. مسیرهای کاذب با حرکت تصادفی بر روی مجموعه ای از موقعیت ها پس از توزیع پواسون ایجاد می شوند.
(4) روش حرکت تصادفی احتمال کاربر (RMMUP) [ 8 ]. بر اساس توزیع احتمال p(u)�(�)در صورت وقوع کاربر، گروهی از مکان ها تشکیل می شود و حرکت تصادفی برای ایجاد مسیرهای نادرست انجام می شود.
(5) سنتز روش مسیر بر اساس معناشناسی موقعیت (STMPS) [ 3 ]. مسیرهای کاذب بر اساس معناشناسی موقعیت تولید می شوند.
(6) انتشار داده های مسیر بر اساس تقسیم بندی داده ها (DPCP) [ 27 ]. انتشار داده های مسیر تحت ( k,δ�,�) محدودیت های امنیتی بر اساس پارتیشن بندی داده ها.
6.2. تجزیه و تحلیل درجه حفظ حریم خصوصی
هدف از حفظ حریم خصوصی مسیر، محافظت از ردیابی یک فرد است، یعنی جلوگیری از شناسایی هویت و مسیر مربوطه او.
برای استنباط صحیح مسیر یک فرد، مهاجم باید مسیر خود و همچنین هویت خود را شناسایی کند. در صورتی که احتمالات این دو نوع شناسایی به ترتیب باشد π1�1) و π2�2، انتظار ریاضی از نرخ خطای استنتاج مسیر (ERoTI) است:
(1) احتمال شناسایی صحیح مسیرهای فردی ( π1�1)
با توجه به الگوریتم اختلاط فردی ما، فرض کنید n بار اختلاط وجود دارد، تعداد مسیرهای درگیر در اختلاط m- امین است.km��، و مهاجم هویت فردی را برای برخی از مسیرها پیدا کرده است، پس احتمال اینکه این مسیر بتواند به درستی توسط مهاجم شناسایی شود این است:
همانطور که در شکل 4 ، در پنجره اول نشان داده شده استn=0�=0، مسیر و QI��می توان به راحتی پیدا کرد، سپس ردیابی را می توان به درستی شناسایی کرد، یعنی π1=1�1=1. در پنجره دوم n=1�=1، سه مسیر درگیر در اختلاط وجود دارد. اگر هویت فردی توسط مهاجم پیدا شود، این احتمال وجود دارد 1313برای اینکه مسیر صحیح شناسایی شود، یعنی π1=13�1=13. در پنجره سوم، n = 2�=2در اختلاط اول سه مسیر و در اختلاط دوم چهار مسیر درگیر است. در این زمان، پس از کشف هویت فرد، احتمال می رود 112112برای شناسایی مسیر، یعنی π1= 8.3 ٪�1=8.3%.
وقتی تعداد مبادلات مسیر n باشد، در هر زمان اختلاط k مسیر وجود دارد ، سپسπ1=1کn�1=1��. همانطور که در جدول 5 نشان داده شده است ، با افزایش k و n ، π1�1به 0 همگرا می شود.
(2) احتمال شناسایی صحیح هویت فردی ( π2�2)
بر اساس مدل مهاجم، احتمال شناسایی صحیح هویت فردی، π2�2، عمدتاً به توزیع تجمع نقاط مکان بستگی دارد. مهاجم می تواند به درستی هویت فرد را در مسیر اصلی شناسایی کند، اما نه لزوماً در مسیر سنتز شده.
مسیر اصلی را فرض کنید t r = {پ1،پ2, … ,پمتر}��={�1,�2,…,��}، و خط سیر سنتز شده است تیr“��′. اگر اختلاط از نقطه m in شروع شودتیr“��′، سپس تیr“= {π1،π2, … ,πمتر،π“m + 1،π“m + 2, … ,π“n}��′={�1,�2,…,��,��+1′,��+2′,…,��′}. به راحتی می توان فهمید که:
بنابراین هنگام استفاده از روش های حمله مانند سیl u s t e r i n g( t r )����������(��)یا سیo u n t ( t r )�����(��)در مسیر سنتز شده، نتایج نهایی با نتایج موجود در مسیر اصلی ناسازگار است، یعنی هویت فردی را نمی توان به درستی در مسیر سنتز شده شناسایی کرد.
6.3. ارزیابی درجه حفظ حریم خصوصی
در آزمایشهای الگوریتم TPP-DABD ما، تعداد مبادلات مسیر منفرد بین 5 تا 12 تنظیم شده است، با مقدار متوسط 7.57.5. تعداد مسیرهای درگیر در هر مبادله 2 تا 6 با مقدار متوسط 2.6 است. بنابراین، نرخ خطای استنتاج مسیر را محاسبه می کنیم ER o Tمن= ( 1 –12.67.5) × 100 % = 99.92 %�����=(1−12.67.5)×100%=99.92%.
میزان خطای استنتاج مسیر هر الگوریتم حفظ حریم خصوصی مسیر در جدول 6 نشان داده شده است .
در جدول 6 ، میزان خطای روش TPP-DABD ما مشابه روش STMPS است و از روشهای دیگر بیشتر است.
6.4. ارزیابی ابزار داده
ما کاربرد داده های مسیر را عمدتاً با تفاوت بین مسیرهای اصلی و منتشر شده در توزیع مکانی و زمانی ارزیابی کردیم.
بسیاری از روشهای موجود برای محافظت از حریم خصوصی دادههای مسیر، مسیر کاذب، افست مسیر، توزیع مکان تصادفی و غیره را اضافه میکنند. با این وجود، در روش ما، تمام دادههای مسیر از مسیرهای واقعی به دست آمدند و ویژگیهای آماری دادههای مسیر اصلی را تا حد زیادی حفظ کردند. تقریباً هیچ انحرافی در تجزیه و تحلیل آماری بین نتایج روش ما و نتایج استفاده از دادههای اصلی وجود نداشت.
با در نظر گرفتن ” ن مکان برتر در منطقه” به عنوان مثال، ما روش خود را با الگوریتم های حفظ حریم خصوصی مسیر کلاسیک با معیار نرخ حفظ ویژگی های آماری (SFRR) مقایسه کردیم.
SFRR هر الگوریتم در جدول 7 نشان داده شده است .
از طریق تجزیه و تحلیل و مقایسه های فوق، می توان نتیجه گرفت که الگوریتم TPP-DABD ما توانایی قوی تری برای حفظ ویژگی های آماری داده های مسیر دارد. این به ویژه برای سناریوهایی که داده های مسیر به صورت آماری تجزیه و تحلیل شدند، مناسب بود.
6.5. ارزیابی پیچیدگی زمانی
محیط آزمایشی ما شامل 1 سرور پیکربندی شده با 2 CPU (Intel Xeon، E5-2620، 6 هسته)، حافظه 128 گیگابایتی، SSD 2 ترابایتی و سیe n t O S6.7( 64 b i t )������6.7(64���). الگوریتم ها توسط n o dه . j s����.��.
مجموعه های مختلفی از نقاط مسیر را انتخاب می کنیم و زمان عملکرد الگوریتم ها را با هم مقایسه می کنیم. اندازه نقاط مسیر به ترتیب 50000، 100000، 200000، 400000، 800000 می باشد. زمان عملیات هفت الگوریتم فوق در شکل 5 نشان داده شده است ، محور x زمان عملیات و محور y تعداد نقاط مکان مسیر است.
از نتایج آزمایش بالا، میتوان دریافت که عملکرد این الگوریتمها را میتوان به سه درجه تقسیم کرد:
(1) درجه اول DPCP، UIIDSM بود که کمترین هزینه زمانی را داشت. از آنجایی که الگوریتم فقط نیاز به در نظر گرفتن یک نقطه مسیر داشت، الگوریتم ساده بود.
(2) درجه دوم AIIDSM، ARMM، RMMUP و TPP-DABD بود. هزینه های زمانی آنها متوسط بود، و آنها نیاز داشتند که توزیع نقاط مسیر (به طور کلی یا محلی) را محاسبه کنند.
(3) درجه سوم STMPS بود. به دلیل پیچیدگی زیاد محاسبات معنایی، الگوریتم بیشترین زمان را گرفت.
6.6. تجزیه و تحلیل عملکرد TPP-DABD
از تجزیه و تحلیل بالا در مورد درجه حفظ حریم خصوصی، ابزار داده و عملکرد الگوریتم، میتوانیم ببینیم که TPP-DABD برای انتشار دادههای مسیری با حفظ حریم خصوصی امکانپذیر است.
(1) اثربخشی TPP-DABD:
TPP-DABD عمدتاً بر اساس اختلاط ثانویه است Q I��، به طوری که هویت فردی و Q I��دیگر در رابطه نقشه برداری یک به یک نیستند. نقشه واقعی را نمی توان از منطقه کلی بازیابی کرد، به طوری که مسیر نمی تواند با فرد مرتبط شود.
کلید TPP-DABD این است که مسیر اصلی را به مسیرهای مختلف تجزیه کند Q I��بخش ها هرچه به بخش های بیشتری تقسیم شود، حریم خصوصی بهتری به دست خواهد آمد. در نتایج تجربی این مقاله، هر مسیر به دو دسته تقسیم شد 7.57.5بخش ها به طور متوسط و میزان خطای استنباطی بود 99.92 %99.92%. TPP-DABD نسبت به الگوریتم های کلاسیک درجه بالاتری از حفاظت از حریم خصوصی داشت.
در عین حال، TPP-DABD مختصات جغرافیایی اصلی را در نقاط مسیر منتشر شده تغییر نمی دهد. اطلاعات آماری جغرافیایی بر اساس مسیر اصلی می تواند حفظ شود 100 %100%سازگاری با نقاط مسیر نمونه برداری، و ابزار داده بسیار بالا است.
(2) کارایی TPP-DABD
برخلاف سایر الگوریتمهای حفظ حریم خصوصی، ابزار بالای داده و درجه حفاظت از حریم خصوصی در TPP-DABD ما بدون پرداخت هزینههای زمانی زیاد به دست آمد. پیچیدگی زمانی TPP-DABD هنوز برای کاربردهای عملی قابل قبول بود.
مهمتر از آن، TPP-DABD از پردازش داده ها توسط برش های زمانی پشتیبانی می کند. هنگامی که مقدار داده افزایش می یابد، زمان عملکرد الگوریتم به صورت خطی افزایش می یابد. در همان زمان، TPP-DABD از پردازش موازی پشتیبانی می کند. در کاربردهای عملی، کل زمان عملیات را می توان با گسترش منابع سخت افزاری کاهش داد.
7. نتیجه گیری
این مقاله یک الگوریتم جدید از حفظ حریم خصوصی مسیر با ناشناسسازی پویا با اعوجاج محدود (TPP-DABD) پیشنهاد میکند. با در نظر گرفتن الزامات سناریوهای کاربردی دادههای مسیر، معیارهای ارزیابی را برای اندازهگیری عملکرد الگوریتم تعریف میکنیم و عملکرد الگوریتم را بر اساس دادههای واقعی مسیر تاکسی شهر گوانگژو ارزیابی میکنیم.
سهم عمده این مقاله روش جدید ناشناسسازی پویا پیشنهادی بر اساس اختلاط مسیر محلی است. مزیت اصلی این تکنیک این است که تمام داده های مسیر منتشر شده با اختلاط مسیرهای واقعی به صورت محلی تحت تزریق حداقل نویز و نه در سطح جهانی مانند اکثر روش های موجود شکل می گیرند. این به طور موثر یک اعوجاج محدود را تضمین میکند و امکان حفظ بهتر ویژگیهای آماری دادهها را فراهم میکند، و در نتیجه ابزار داده بهتری بدون قربانی کردن حریم خصوصی ایجاد میشود.
ارزیابی عملکرد تجربی و مقایسههای ما با روشهای موجود نشان میدهد که الگوریتم TPP-DABD ما با روش حفظ حریممسیر مبتنی بر معنایی مکان و بهتر از روشهای موجود مبتنی بر ناشناسسازی ایستا (جهانی) مانند نمونهگیری iid و تصادفی عمل میکند. جنبش. علاوه بر کاربرد داده مسیرهای فردی، روش ما همچنین تحریف ویژگی های آماری داده های مسیر را به حداقل می رساند تا کاربرد بالایی از داده های منتشر شده به طور جمعی برای تجزیه و تحلیل آماری ارائه دهد.
ما متوجه شدیم که کیفیت عملکرد TPP-DABD به توزیع داده ها و دانش پس زمینه مهاجم نیز بستگی دارد. در آینده، تکنیک حریم خصوصی دیفرانسیل را برای حفاظت از حریم خصوصی مسیر در برابر حملات با دانش پس زمینه دلخواه در نتایج پرس و جوی آماری اعمال خواهیم کرد.





بدون دیدگاه