1. مقدمه
در سال های اخیر با پیشرفت شهرنشینی، ساختار داخلی ساختمان های شهری پیچیده تر و متغیرتر شده است. خطر پنهان بلایای شهری تا حدی توسط جمعیت شهری و منابع بسیار متمرکز [ 1 ] تشدید می شود.
بلایای شهری پیچیده هستند و به طور ناگهانی رخ می دهند، و ساختار فضایی پیچیده ساختمان های شهری به طور قابل توجهی بر امداد و نجات اضطراری تاثیر می گذارد [ 2 ، 3 ]. از خلاصه و تجزیه و تحلیل بسیاری از موارد اضطراری، احتمال تلفات ناشی از تخلیه نامناسب در حال افزایش است [ 3 ]]. در سناریوهای فاجعه واقعی، بیشتر تلفات ناشی از عدم امداد و نجات به موقع و موثر است. تجزیه و تحلیل علمی و معقول ساختار داخلی محیط داخلی، تعیین سریع تغییرات پویا در موقعیتهای تخلیهشده و تحقق تخلیه سریع و ایمن پرسنل و نجات در مواقع اضطراری از اهمیت بالایی برخوردار است [ 4 ].]. با توجه به فراوانی فزاینده حوادث بلایا و افزایش تقاضا برای پیشگیری و کاهش بلایا، فناوری های جدید و دانش نظری مانند یادگیری عمیق و یادگیری تقویتی باید به صورت علمی و منطقی برای طراحی برنامه ریزی منطقی مسیر تخلیه اضطراری با توجه به محیط داخلی منطقه فاجعه به کار گرفته شود. برنامه ریزی مسیر معقول می تواند انتقال منظم افراد آسیب دیده را ترتیب دهد و به طور موثر زمان تخلیه را کوتاه کند، که یکی از مسائل پیشرو کنونی امنیت عمومی اجتماعی است که به فوریت حل می شود و کانون تحقیقاتی محققان مرتبط در داخل و خارج از کشور است [ 5 ].
از اواسط قرن بیستم، بسیاری از محققان تحقیقات گسترده ای در مورد برنامه ریزی مسیر در موقعیت های نجات اضطراری انجام داده اند [ 6 ]. در حدود دهه 1960، با توسعه سریع علوم کامپیوتر، الگوریتم های مختلف برنامه ریزی مسیر به طور بی پایان ظهور کردند. الگوریتم برنامه ریزی مسیر از الگوریتم سنتی اصلی و الگوریتم گرافیکی به الگوریتم جستجوی بیونیک و الگوریتم
هوش مصنوعی توسعه یافته است. این الگوریتم های برنامه ریزی مسیر در مراحل توسعه ویژگی های متفاوتی دارند و دامنه کاربرد و سناریوهای آن ها متفاوت است. در کاربردهای عملی، مسئله ای که باید حل شود و ویژگی های الگوریتم به طور جامع در نظر گرفته می شود و یک الگوریتم برنامه ریزی مسیر مناسب انتخاب می شود [ 7 ].]. در سالهای اخیر، با توسعه علم هوش و رونق هوش مصنوعی، فناوری برنامهریزی مسیر هوش مصنوعی به سرعت در کانون تحقیقات کارشناسان و محققان قرار گرفته است، در حالی که الگوریتمهای یادگیری تقویتی بیشتر مورد توجه قرار گرفته است [ 8 ]. یادگیری تقویتی می تواند برای حل مشکلات اجتناب از موانع، برنامه ریزی مسیر و سایر مسائل به صورت مشترک بدون ایجاد مدل های ریاضی و نقشه های محیطی برای مسائل برنامه ریزی مسیر استفاده شود. لو و همکاران [ 9 ] یک شبکه عصبی مبتنی بر الگوریتم یادگیری تقویتی پیشنهاد کرد، آزمایشهای برنامهریزی مسیر محلی را انجام داد و نتایج برنامهریزی مسیر را در یک محیط بدون دانش قبلی به دست آورد. او و همکاران [ 10] ترکیبی از فناوری یادگیری Q و منطق فازی را برای دستیابی به خودآموزی ربات های متحرک و برنامه ریزی مسیر در محیط های نامشخص پیشنهاد کرد. هیانسو و همکاران [ 11 ] ترکیبی از یادگیری عمیق Q و CNN را پیشنهاد کرد تا ربات بتواند به طور انعطاف پذیر و کارآمد در محیط های مختلف حرکت کند. ماو و همکاران [ 12 ] یک الگوریتم برنامهریزی مسیر ترکیبی را پیشنهاد کرد که از الگوریتم برنامهریزی مسیر نمودار زمان برای برنامهریزی جهانی و یادگیری تقویت عمیق برای برنامهریزی محلی استفاده میکند تا وسایل نقلیه هوایی بدون سرنشین (UAV) بتوانند در زمان واقعی از برخورد جلوگیری کنند. جونیور و همکاران [ 13] یک الگوریتم یادگیری Q را بر اساس یک ماتریس پاداش برای برآوردن نیازهای برنامه ریزی مسیر ربات های دریایی پیشنهاد کرد. یادگیری تقویتی با توجه به ویژگی های آن به طور گسترده ای برای برنامه ریزی مسیر به ویژه برای برنامه ریزی مسیر محلی در محیط های ناشناخته استفاده شده است. با این حال، یادگیری تقویتی مشکل ذاتی ایجاد تعادل بین اکتشاف و استفاده را دارد. در یادگیری تقویتی، محیط برای عامل ناشناخته است. کاوش بیش از حد محیط توسط عامل باعث کاهش کارایی محلول می شود و استفاده بیش از حد از محیط باعث می شود که عامل راه حل بهینه را از دست بدهد. بنابراین، تعادل اکتشاف و بهرهبرداری از موضوعات مهم پژوهشی در یادگیری تقویتی است. جرادات و همکاران [ 14] الگوریتم یادگیری Q را برای ناوبری ربات های متحرک در یک محیط پویا اعمال کرد و اندازه جدول مقدار Q را برای افزایش سرعت الگوریتم ناوبری کنترل کرد. وانگ و همکاران [ 15 ] دو الگوریتم را بر اساس عملکرد نهایی بهتر الگوریتم یادگیری Q و همگرایی سریعتر الگوریتم SARSA (State-Action-Reward-State-Action) ترکیب کرد و یک الگوریتم یادگیری Q معکوس را پیشنهاد کرد که باعث بهبود سرعت یادگیری و عملکرد الگوریتم زنگ و همکاران [ 16 ] یک الگوریتم یادگیری تقویتی نظارت شده را بر اساس کنترل اسمی پیشنهاد کرد و نظارت را در الگوریتم یادگیری Q معرفی کرد، در نتیجه همگرایی الگوریتم را تسریع کرد. فانگ و همکاران [ 17] یک الگوریتم یادگیری تقویتی اکتشافی مبتنی بر ردیابی حالت پیشنهاد کرد که استراتژی انتخاب کنش یادگیری تقویتی را بهبود بخشید، مراحل کاوش بی معنی را حذف کرد و نرخ یادگیری را بسیار بهبود بخشید. سونگ و همکاران [ 18 ] یک رابطه نگاشت بین اطلاعات محیطی موجود یا آموخته شده و مقدار اولیه جدول مقدار Q ایجاد کرد و با تنظیم مقدار اولیه در جدول مقدار Q، یادگیری را تسریع کرد [ 19 ، 20 ]. ژانگ و همکاران [ 21 ] از یک استراتژی کاوش پیشرفته برای جایگزینی ε-گریدی در الگوریتم یادگیری Q سنتی استفاده کرد و یک الگوریتم یادگیری تقویتی خودسازگاری (SARE-Q) را برای بهبود کارایی اکتشاف پیشنهاد کرد. ژوانگ و همکاران [22 ] یک الگوریتم برنامه ریزی مسیر جهانی چند مقصدی را بر اساس مقدار بهینه مانع پیشنهاد کرد. با توجه به الگوریتم یادگیری Q، پارامترهای تابع پاداش برای بهبود کارایی برنامه ریزی مسیر یک ربات متحرک که در مقصدهای مختلف رانندگی می کند، بهینه شده است. سونگ و همکاران [ 23 ] مفهوم یادگیری Q جزئی هدایت شده را معرفی کرد و جدول Q را از طریق الگوریتم گرده افشانی گل (FPA) برای سرعت بخشیدن به همگرایی یادگیری Q آغاز کرد. ε- استراتژی حریصانه روشی رایج برای حل مشکل تعادل بین اکتشاف و استفاده است. لی سی و همکاران بر اساس یادگیری Q همراه با ε-گریدی. [ 24] یک استراتژی تنظیم پویا پارامتر و مکانیسم حذف آزمون و خطا را پیشنهاد کرد که نه تنها تعادل بین تنظیم تطبیقی و استفاده در فرآیند یادگیری را متوجه شد، بلکه کارایی اکتشاف عامل را نیز بهبود بخشید. یانگ تی و همکاران [ 25 ] یک استراتژی ε-غریب پیشنهاد کرد که به طور تطبیقی ضریب اکتشاف را تنظیم می کند، که کیفیت استراتژی آموخته شده توسط عامل را بهبود می بخشد و اکتشاف و استفاده را متعادل می کند.
محققان فوق پیشرفت های مفیدی برای بهبود کارایی الگوریتم های یادگیری تقویتی داشته اند. با این حال، در محیط های اضطراری بزرگ و پیچیده، دستیابی به نتایج مطلوب برای الگوریتم های یادگیری تقویتی دشوار است. از آنجایی که هیچ دانش یادگیری قبلی وجود ندارد، عامل فقط میتواند بهطور تصادفی اقداماتی را برای جستجوی کور انتخاب کند، که منجر به معایب راندمان یادگیری پایین و سرعت همگرایی کند در محیط پیچیده میشود. بنابراین، این مقاله یک الگوریتم برنامه ریزی مسیر را بر اساس یک محیط شبکه پیشنهاد می کند و با معرفی محاسبه نرخ تنزیل عامل اکتشافی، الگوریتم یادگیری Q را بهینه می کند. نرخ تنزیل ضریب اکتشاف قبل از اینکه نماینده اقدامات تصادفی را برای حل مشکل جستجوی کور در فرآیند یادگیری انتخاب کند محاسبه می شود.
-
با هدف مسئله برنامهریزی مسیر محیطهای پیچیده داخلی در سناریوهای فاجعه، یک مدل محیط شبکه ایجاد میشود و الگوریتم یادگیری Q برای پیادهسازی مشکل برنامهریزی مسیر محیط شبکه اتخاذ میشود.
-
با هدف مشکلات سرعت همگرایی آهسته و دقت کم الگوریتم یادگیری Q در یک محیط شبکه در مقیاس بزرگ، ضریب اکتشاف در استراتژی ε-گریدی به صورت پویا تنظیم میشود و متغیر نرخ تنزیل عامل اکتشاف معرفی میشود. قبل از انتخاب اقدامات تصادفی، نرخ تنزیل ضریب اکتشاف برای بهینه سازی الگوریتم یادگیری Q در محیط شبکه محاسبه می شود.
-
یک آزمایش برنامه ریزی مسیر اضطراری داخلی بر اساس الگوریتم بهینه سازی یادگیری Q با استفاده از داده های شبیه سازی شده و داده های محیط داخلی واقعی یک ساختمان اداری انجام می شود. نتایج نشان میدهد که الگوریتم بهینهسازی یادگیری Q از هر دو الگوریتم SARSA و الگوریتم یادگیری Q از نظر زمان حل و همگرایی هنگام برنامهریزی کوتاهترین مسیر در یک محیط شبکه بهتر است. الگوریتم بهینه سازی یادگیری Q دارای سرعت همگرایی است که تقریباً پنج برابر سریعتر از الگوریتم کلاسیک یادگیری Q است. در محیط شبکه، الگوریتم بهینهسازی یادگیری Q میتواند با موفقیت کوتاهترین مسیر را برای اجتناب از موانع در مدت زمان کوتاهی برنامهریزی کند.
بقیه مقاله به صورت زیر سازماندهی شده است: بخش 1 برنامه ریزی مسیر اضطراری داخلی را بر اساس الگوریتم بهینه سازی یادگیری Q پیشنهادی در محیط شبکه معرفی می کند. بخش 2 آزمایش شبیه سازی الگوریتم و آزمایش برنامه ریزی مسیر اضطراری داخلی را بر اساس الگوریتم بهینه سازی یادگیری Q پیشنهادی معرفی می کند. بخش 3 این مقاله را به پایان می رساند و کار آینده جالب مربوط به مطالعات ما را نشان می دهد.
2. روش برنامه ریزی مسیر اضطراری داخلی
بر اساس این مزیت که یادگیری Q در یادگیری تقویتی می تواند اجتناب از موانع، برنامه ریزی مسیر و سایر مسائل را به روشی یکپارچه بدون ایجاد یک مدل ریاضی و نقشه محیطی حل کند، این مقاله یک روش برنامه ریزی مسیر اضطراری داخلی را بر اساس یادگیری Q پیشنهاد می کند. ابتدا از روش گراف شبکه ای برای مدل سازی محیط شبکه استفاده می شود. در مرحله بعد، استراتژی برنامه ریزی مسیر الگوریتم یادگیری Q بر اساس محیط شبکه طراحی می شود و سپس الگوریتم یادگیری Q بر اساس محیط شبکه با تنظیم پویا عوامل اکتشافی بهینه می شود.
2.1. مدلسازی محیط شبکه
مسئله مدلسازی محیطی به نحوه بیان موثر اطلاعات محیطی از طریق مدلهای خاص اشاره دارد. انجام مدلسازی محیطی قبل از برنامهریزی مسیر ضروری است. قبل از برنامه ریزی مسیر جهانی، مدل سازی محیطی که پرسنل اورژانس در آن مستقر هستند و به دست آوردن اطلاعات محیطی پیچیده ضروری است. این امر به پرسنل اورژانس اجازه می دهد تا از قبل مکان موانع ثابت در محیط را بدانند که این یک گام اساسی در برنامه ریزی مسیر است.
روشهای رایج مورد استفاده در مدلسازی محیطی شامل روش قابل مشاهده [ 26 ]، روش درخت سلولی [ 27 ]، روش نمودار پیوند [ 28 ]، روش گراف شبکه [ 29 ] و غیره است. مزایا و معایب این چهار روش در جدول 1 نشان داده شده است. :
با توجه به ویژگیهای محیط اضطراری و مقایسه مزایا و معایب روشهای مدلسازی، این مقاله روش گراف شبکهای را برای مدلسازی محیطی اتخاذ میکند. اصل این است که اطلاعات محیطی را شطرنجی کنیم و از ویژگی های رنگی مختلف برای نمایش اطلاعات مختلف محیطی استفاده کنیم. همانطور که در شکل 1 نشان داده شده است ، شبکه سیاه نشان دهنده منطقه غیر قابل عبور است که با “1” نشان داده شده است. شبکه سفید نشان دهنده مناطق آزاد است که می توان به آنها دسترسی داشت که با “0” نشان داده شده است.
پس از یادگیری موقعیت اولیه و موقعیت هدف، عامل در یک محیط شبکه سیاه و سفید به کاوش و یادگیری می پردازد تا کوتاه ترین طرح مسیر اجتناب از مانع را به دست آورد. دانش نظری روش گراف شبکه ای مختصر و قابل درک است که برای نوشتن و عملیات کد برنامه راحت است.
اطلاعات گراف شبکه ای را می توان با یک ماتریس نشان داد. ماتریس مربوط به گراف شبکه ای در شکل 1 معادله (1) است:
2.2. الگوریتم Q-Learning Optimization
یادگیری تقویتی یک روش یادگیری ماشینی است که ماهیت آن یافتن یک تصمیم بهینه از طریق تعامل مستمر با محیط است [ 30 ]. ایده یادگیری تقویتی به شرح زیر است: عامل با انجام اعمال بر محیط تأثیر می گذارد. محیط یک عمل جدید دریافت می کند، حالت جدیدی ایجاد می کند و به اقدامات عامل بازخورد پاداش می دهد. در نهایت، عامل اقدام بعدی را برای انجام با توجه به وضعیت جدید و بازخورد پاداش انتخاب می کند. مدل یادگیری تقویتی در شکل 2 نشان داده شده است .
یادگیری Q که توسط واتکینز در سال 1989 پیشنهاد شد، یک کشف برجسته در توسعه یادگیری تقویتی است. یادگیری Q با برآورد مداوم تابع مقدار حالت و بهینه سازی تابع Q، استراتژی بهینه را به دست می آورد [ 31 ، 32 ]. یادگیری Q تا حدی با روش متداول اختلاف زمانی (TD) متفاوت است. تصویب می کند تابع جفت حالت-عمل برای انجام محاسبات تکراری. در فرآیند یادگیری عامل، لازم است بررسی شود که آیا رفتار متناظر معقول است تا از همگرایی نتیجه نهایی اطمینان حاصل شود [ 33 ، 34 ].
2.2.1. الگوریتم Q-Learning
Q-learning یک الگوریتم یادگیری تقویتی است که بر اساس فرآیند تصمیم گیری مارکوف محدود است که عمدتاً از عامل، حالت، عمل و محیط تشکیل شده است. حالت در یک لحظه معین با نشان داده می شود ، و عملی که باید توسط عامل انجام شود با نشان داده می شود . Q-learning تابع را مقداردهی اولیه می کند و ارزش دولتی ، و یک عمل را انتخاب می کند با توجه به یک استراتژی، مانند ε-greedy [ 35 ]، برای به دست آوردن حالت بعدی و بازگشت فوری . سپس، مقدار Q طبق قوانین به روز رسانی [ 34 ] به روز می شود. هنگامی که عامل در طول حرکت به مقصد می رسد، الگوریتم یک تکرار را کامل می کند. عامل به گره اولیه باز می گردد تا چرخه تکرار را تا تکمیل فرآیند یادگیری تکراری ادامه دهد [ 36 ، 37 ].
در فرآیند یادگیری Q، تابع مقدار بهینه با محاسبه تکراری بهینه تعیین و تقریب میشود. تابع. قوانین به روز رسانی تابع در معادلات (2) و (3) نشان داده شده است:
جایی که نشان دهنده ضریب تخفیف است، نشان دهنده میزان یادگیری است و عمل بعدی را نشان می دهد.
فرآیند یادگیری Q شامل قسمت های زیادی است و همه قسمت ها روند محاسبه زیر را تکرار می کنند. زمانی که نماینده در زمان خود است :
-
وضعیت را رعایت کنید در این زمان؛
-
اقدام را انتخاب کنید برای اجرای بعدی؛
-
به مشاهده مرحله بعدی ادامه دهید ;
-
دریافت پاداش فوری ;
-
-
به لحظه بعد می رود
تابع Q توسط یک جدول جستجو و شبکه عصبی نمایش و پیاده سازی می شود.
هنگام استفاده از جدول جستجو، تعداد عناصر موجود در حاصلضرب دکارتی از اندازه جدول را نشان می دهد. هنگامی که دولت تنظیم شده است و مجموعه عملیات احتمالی محیط نسبتا بزرگ هستند، فضای ذخیره سازی بزرگی اشغال خواهد شد و راندمان یادگیری بسیار کاهش می یابد. این کمبودهای خاصی برای کاربردهای روزانه دارد.
هنگام استفاده از شبکه عصبی، بردار حالت متناظر ورودی شبکه است. نتایج خروجی هر شبکه با مقدار Q یک عمل مطابقت دارد. شبکه های عصبی مکاتبات ورودی-خروجی را ذخیره می کنند [ 33 ]. تعریف تابع Q در رابطه (5) نشان داده شده است:
رابطه (5) تنها زمانی مؤثر است که استراتژی بهینه به دست آید. در فرآیند عملیات یادگیری، معادله (6) به صورت زیر است:
جایی که نشان دهنده مقدار Q متناظر حالت بعدی است. هدف از کاهش خطا است. محاسبه تنظیم وزن در رابطه (7) نشان داده شده است:
الگوریتم خاص به شرح زیر است:
-
مقدار Q را مقداردهی کنید.
-
وضعیت را انتخاب کنید در زمان ;
-
به روز رسانی ;
-
بعدی را انتخاب کنید اقدام با توجه به به روز رسانی ;
-
اقدامی انجام دهد ، وضعیت جدید را بدست آورید و ارزش پاداش فوری ;
-
محاسبه ;
-
وزن شبکه Q را برای به حداقل رساندن خطا تنظیم کنید همانطور که در رابطه (8) نشان داده شده است:
-
به 2 بروید.
2.2.2. استراتژی برنامه ریزی مسیر
هنگامی که عامل از الگوریتم یادگیری Q برای برنامه ریزی یک مسیر در یک محیط مانع ناشناخته استفاده می کند، تجربه باید با کاوش مداوم محیط جمع شود. عامل از استراتژی ε-greedy برای انتخاب کنش استفاده میکند و هنگام انجام انتقال حالت، پاداشهای فوری دریافت میکند. در طول هر تکرار، زمانی که عامل به مکان مورد نظر می رسد، جدول مقدار Q به روز می شود. موقعیت عامل فوراً به نقطه شروع برای تکرار حلقه منتقل می شود تا زمانی که تابع مقدار تمایل به همگرا شدن داشته باشد، به این معنی که فرآیند یادگیری به پایان رسیده است. برای بهبود کارایی اکتشاف و سرعت همگرایی تابع ارزش افزوده، در صورت مواجه شدن با مانع در طول فرآیند یادگیری، به عامل پاداش منفی داده می شود. سپس، عامل می تواند جهت کاوش در موقعیت های دیگر را تغییر دهد،
- 1.
-
عمل و وضعیت عامل
اگر عامل بهعنوان ذرهای در نظر گرفته شود که نیازی به در نظر گرفتن مساحت ندارد، لازم نیست اندازه عامل در هنگام انجام آنالیز تجربی در نظر گرفته شود. شبکه اشغال شده توسط ذره موقعیت فعلی عامل و مختصات است برای نشان دادن اطلاعات وضعیت مربوطه استفاده می شود. در محیط گرید، عامل برای هر مرحله یک شبکه حرکت می دهد. عامل می تواند در چهار جهت حرکت کند: بالا، پایین، چپ و راست. فضای عمل مربوط به چهار جهت حرکت است.
- 2.
-
تابع پاداش را تنظیم کنید
تابع پاداش بازخورد ارزشی است که عامل هنگام کاوش در محیط دریافت می کند. اگر عامل عمل بهینه را انجام دهد، پاداش بزرگتری به دست می آید. اگر عامل عمل ضعیفی انجام دهد، پاداش کمتری دریافت می شود. اقدامات با ارزش پاداش بالا شانس انتخاب شدن بیشتری دارند، در حالی که اقدامات با ارزش پاداش پایین شانس انتخاب شدن کمتری خواهند داشت. در این بخش، استراتژی برنامه ریزی مسیر در محیط شبکه، انتخاب مسیری است که در طول آن عامل بیشترین پاداش تجمعی را در فرآیند یادگیری به دست می آورد. تابع پاداش خاص با یک تابع تکه ای غیر خطی، همانطور که در رابطه (9) نشان داده شده است، تعریف می شود:
در فرآیند یادگیری، زمانی که عامل در حین کاوش در محیط به مکان مورد نظر می رسد، مقدار پاداشی از به دست می آید و آموزش تا طرح بعدی ادامه می یابد. هنگامی که عامل در منطقه آزاد حرکت می کند، ارزش پاداش بازخورد است هنگامی که یک نماینده با یک منطقه مانع روبرو می شود، پاداش است .
- 3.
-
انتخاب استراتژی اقدام
الگوریتم ε-greedy برای انتخاب استراتژی اقدام استفاده می شود. احتمال برای انتخاب عمل با حداکثر مقدار اقدام حالت استفاده می شود. احتمالی برای انتخاب عمل تصادفی استفاده می شود. در نهایت، استراتژی با بیشترین ارزش پاداش تجمعی انتخاب می شود. محاسبه استراتژی ε-گریدی در معادله (10) نشان داده شده است:
که در آن prob ( a ( t )) انتخاب استراتژی اقدام عامل را نشان می دهد.
- 4.
-
جدول ارزش Q
عامل توالی عمل با حداکثر مقدار پاداش را به عنوان مسیر بهینه در جدول ارزش Q نهایی انتخاب می کند. در یک محیط شبکه، اطلاعات وضعیت موقعیت ها را نشان می دهد. هر موقعیت می تواند در چهار جهت حرکت کند: بالا، پایین، چپ و راست، بنابراین وجود دارد مقادیر ذخیره شده در جدول مقدار Q در ابتدا، تمام مقادیر جدول مقدار Q روی 0 تنظیم می شوند. هنگام یادگیری، بررسی کنید که آیا عملکرد حالت در جدول وجود دارد یا خیر. اگر نه، مقدار Q را به موقعیت مربوطه اضافه کنید. اگر عمل حالت وجود دارد، مقدار Q را در جدول تغییر دهید.
2.2.3. تنظیم پویا عوامل اکتشاف
الگوریتم یادگیری Q استراتژی اکتشاف ε-غریب را اتخاذ می کند، که تصمیمی را که عامل هر بار می گیرد، تعیین می کند. عامل اکتشاف است که از 0 تا 1 متغیر است با رویکرد 1، عامل تمایل بیشتری به کاوش در محیط دارد، به عنوان مثال، اقدامات تصادفی را امتحان می کند. با این حال، اگر عامل همیشه تمایل به کشف محیط داشته باشد، اقدامات تصادفی برای یافتن هدف نهایی مناسب نیستند [ 35 ]. مانند با نزدیک شدن به 0، عامل تمایل دارد از محیط خارجی استفاده کند و اقدامی را با بزرگترین تابع ارزش عمل انتخاب کند. در این حالت، تابع مقدار ممکن است به طور موثر همگرا نشود و نتیجه تحت تأثیر محیط قرار گیرد. بنابراین، راه حل بهینه را می توان به راحتی از دست داد و ممکن است راه حل نهایی به دست نیاید. این ارزش ارتباط نزدیکی با استراتژی اکتشاف عامل دارد که دقت و کارایی راه حل نهایی را تعیین می کند. بنابراین، انتخاب از ارزش حیاتی است [ 38 ].
این مقاله الگوریتم یادگیری Q را با تنظیم پویا ضریب اکتشاف در استراتژی ε-گریدی بهینه میکند، نرخ تنزیل عامل اکتشاف را معرفی میکند و نرخ تنزیل عامل اکتشاف را قبل از انتخاب اقدامات تصادفی محاسبه میکند، همانطور که در رابطه (11) نشان داده شده است. ):
جایی که قسمت (تعداد تکرار) است. زمانی که مقدار اولیه از 0 است، مقدار اولیه طبق فرمول 1 است و نرخ در حداکثر مقدار است. بسیاری از کاوشها با انتخاب تصادفی اقدامات و آموزش مداوم تابع Q انجام شدهاند و عامل به طور فزایندهای نسبت به مقدار تخمینی Q اطمینان پیدا کرده است. در عین حال، با افزایش تعداد تکرارها، نسبت ضریب اکتشاف به تدریج کاهش می یابد به طوری که عامل استفاده بیشتری از محیط خارجی برای بهبود سرعت همگرایی در هنگام انتخاب بعدی می کند.
2.3. جریان الگوریتم
ابتدا پارامترهای مربوطه را مقداردهی اولیه کرده و تنظیم کنید به 0. قبل از انتخاب یک اقدام تصادفی، نرخ تنزیل ضریب اکتشاف محاسبه می شود. سپس عمل را مطابق با استراتژی اقدام ε-greedy انجام دهید و به موقعیت بعدی بروید تا حالت مربوطه را بدست آورید و پاداش فوری . مقدار Q طبق قوانین به روز رسانی فرمول محاسبه تابع مقدار به روز می شود. زمانی که زمانهای آموزش با مقدار تنظیم اولیه مطابقت ندارند، چرخه تکرار میشود. پس از برآورده شدن الزامات، مقادیر Q مربوط به همه حالت ها خروجی می شود و یادگیری الگوریتم به پایان می رسد.
یک نمودار جریان بر اساس الگوریتم بهینه سازی یادگیری Q در محیط شبکه در شکل 3 نشان داده شده است :
3. آزمایش و تجزیه و تحلیل
در آزمایش شبیهسازی الگوریتم، الگوریتم یادگیری Q، الگوریتم SARSA و الگوریتم بهینهسازی یادگیری Q پیشنهادی برای برنامهریزی مسیر اضطراری استفاده میشود و نتایج تجربی با هم مقایسه و تحلیل میشوند. با هدف قرار دادن صحنه شبیهسازی، با توجه به یک محیط داخلی واقعی، تحلیل برنامهریزی مسیر اضطراری داخلی بر اساس الگوریتم بهینهسازی یادگیری Q پیشنهادی انجام میشود.
3.1. تنظیمات پارامتر
پس از آزمایشهای فراوان، پارامترهای الگوریتم بهینهسازی یادگیری Q پیشنهادی به صورت زیر تنظیم میشوند: نرخ یادگیری ، احتمال اکتشاف و فاکتور تخفیف . در آزمایش شبیهسازی الگوریتم، تعداد قسمتهای آموزشی روی 5000 قسمت تنظیم شده است. الگوریتم یادگیری Q و پارامترهای الگوریتم SARSA تنظیم شدهاند تا با تنظیمات پارامتر الگوریتم بهینهسازی یادگیری Q سازگار باشند. در آزمایش صحنه شبیه سازی، به دلیل افزایش اندازه شبکه، تعداد سناریوهای آموزشی به 10000 افزایش یافته است.
3.2. شبیه سازی الگوریتم تحلیل تجربی
TD را می توان به دو نوع تقسیم کرد: الگوریتم کنترل آنلاین SARSA و الگوریتم کنترل آفلاین Q-learning. بزرگترین تفاوت بین Q-learning و الگوریتم SARSA روش به روز رسانی مقدار Q است. الگوریتم یادگیری Q در انتخاب اقدامات جسورتر است و بیشتر تمایل دارد رفتاری را انتخاب کند که به استراتژی مربوط به وضعیت فعلی مربوط نیست، اما رفتاری که حداکثر مقدار عمل را نشان می دهد. الگوریتم SARSA در انتخاب خود محافظه کارتر است و مقدار Q را مطابق با ریتم یادگیری خود به روز می کند [ 39]. موارد زیر بر اساس الگوریتم یادگیری Q، الگوریتم SARSA و الگوریتم بهینهسازی یادگیری Q پیشنهادی برای تعیین کوتاهترین مسیر تحت مدل محیط شبکه و مقایسه و تجزیه و تحلیل نتایج تجربی است.
3.2.1. مدلسازی فضایی محیطی
در این آزمایش، از جعبه ابزار Tkinter [ 40 ] برای ساخت یک مدل محیطی استفاده شد. در آزمایش شبیهسازی الگوریتم، یک محیط شبکهای با 20 پیکسل و تعداد کل شبکههای 25×25 به عنوان نقشه موانع ساخته شده است. عامل اعمال را تحت این مدل محیطی انتخاب و اجرا می کند. تعداد کل شبکه ها در محیط، تعداد حالت های فعالیت عامل است. همانطور که در شکل 4 نشان داده شده است ، در مجموع 625 حالت وجود دارد. عامل با یک دایره قرمز نشان داده شده است. عامل هر بار که اقدامی را انجام می دهد، یک شبکه را روی نقشه حرکت می دهد. نکته اولیه برای این آزمایش این است و نقطه هدف شبکه آبی رنگ در گوشه پایین سمت راست است . شبکه سفید نمایانگر ناحیه قابل عبور و شبکه سیاه نمایانگر ناحیه مانع است. در Tkinter، موقعیت مستطیل با مختصات دو نقطه مورب نشان داده می شود و دایره ای که عامل را نشان می دهد، دایره محاطی مستطیل است. این امر راحتی قابل توجهی برای نشان دادن مکان دارد. در برنامه با تنظیم مختصات گرید می توان محیط نقشه و مکان عامل را طراحی کرد. با مشاهده رابط عملیات در شکل 4 ، موقعیت بلادرنگ عامل در هر لحظه مشخص می شود تا بتوانیم مشاهده کنیم که چه زمانی عامل می تواند کوتاه ترین مسیر را برنامه ریزی کند، که مرجعی برای تنظیم و تنظیم پارامترها ارائه می دهد.
3.2.2. مقایسه و تحلیل نتایج تجربی
نتیجه شبیه سازی برنامه ریزی مسیر برای عامل از موقعیت شروع تا موقعیت هدف با استفاده از الگوریتم SARSA در یک محیط شبکه در شکل 5 الف نشان داده شده است. کوتاه ترین مسیر 102 پله و طولانی ترین مسیر 3682 پله بود. نتایج شبیه سازی برنامه ریزی مسیر با استفاده از استراتژی الگوریتم یادگیری Q در شکل 5 ب نشان داده شده است. کوتاه ترین مسیر 42 پله و طولانی ترین مسیر 1340 پله بوده است. نتیجه الگوریتم بهینه سازی یادگیری Q پیشنهادی در شکل 5 نشان داده شده استج. کوتاه ترین مسیر نیز 42 پله و طولانی ترین مسیر 1227 پله بوده است. تفاوت کمی بین نتایج برنامه ریزی مسیر الگوریتم یادگیری Q و الگوریتم بهینه سازی یادگیری Q پیشنهادی وجود دارد، اما نتایج به طور قابل توجهی بهتر از نتایج با استفاده از الگوریتم SARSA هستند.
در فرآیند آموزش، از آنجایی که هیچ سیگنالی در مراحل اولیه یادگیری وجود ندارد، زمان زیادی برای یافتن مسیر در ابتدا صرف می شود که در طی آن به طور مداوم با موانع مواجه می شود. با این حال، با یادگیری مستمر، دانش انباشته شده توسط عامل همچنان افزایش می یابد و تعداد مراحل مورد نیاز در فرآیند مسیریابی به تدریج کاهش می یابد. شکل 6 الف نشان می دهد که الگوریتم SARSA روند همگرایی آشکاری در فرآیند 5000 تکرار یادگیری ندارد. شکل 6 ب نشان می دهد که الگوریتم یادگیری Q از طریق اکتشاف مداوم محیط و انباشت دانش در حول و حوش مرحله 2500 همگرا می شود. شکل 6c نشان میدهد که سرعت همگرایی الگوریتم بهینهسازی یادگیری Q پیشنهادی به طور قابلتوجهی سریعتر است زمانی که ضریب اکتشاف بهینه میشود. اساساً در حدود گام 500 همگرا شده است که تقریباً 2000 پله کمتر از نرخ همگرایی قبل از بهینه سازی است. در همین محیط، کل زمان سپری شده الگوریتم SASRA 164.86 ثانیه، کل زمان سپری شده الگوریتم Q-learning 68.692 ثانیه و کل زمان سپری شده الگوریتم بهینه سازی یادگیری Q پیشنهادی 13.738 ثانیه است.
الگوریتم یادگیری Q به طور مداوم در طول فرآیند یادگیری پاداش ها را جمع آوری می کند و ارزش پاداش تجمعی را به عنوان هدف یادگیری به حداکثر می رساند. در ابتدای یادگیری، عامل به صورت تصادفی انتخاب می شود و به راحتی به موانع برخورد می کند. هنگام برخورد با مانع، مقدار پاداش 1- است، بنابراین مقدار پاداش اولیه منفی یا تقریباً 0 است. با افزایش تعداد جلسات آموزشی، تعداد دفعاتی که مامور به موانع برخورد می کند کم می شود و پاداش های انباشته به تدریج افزایش می یابد. از شکل 7 الف، با افزایش تعداد تکرارهای آموزشی، پاداش تجمعی الگوریتم SARSA تقریباً 0 افزایش می یابد و روند تغییر آشکاری در طول فرآیند آموزش وجود ندارد. از شکل 7ب، پاداش تجمعی الگوریتم یادگیری Q به تدریج با افزایش زمان آموزش افزایش می یابد و در نهایت به عدد 10 نزدیک می شود. از شکل 7 ج، تغییر پاداش تجمعی الگوریتم پیشنهادی بهینه سازی یادگیری Q پایدارتر از الگوریتم قبلی است در حدود 3000 قدم به 10 نزدیک می شود.
نتایج تجربی فوق در جدول 2 ادغام شده است. بر اساس نتایج تجربی نشان داده شده در جدول 2 ، الگوریتم یادگیری Q از نظر انتخاب مسیر و همگرایی بهتر از الگوریتم SARSA عمل می کند. در مقایسه با الگوریتم SARSA، الگوریتم یادگیری Q برای برنامه ریزی مسیر اضطراری در محیط شبکه مناسب تر است. در عین حال، در مقایسه با الگوریتم کلاسیک یادگیری Q، الگوریتم بهینه سازی یادگیری Q پیشنهادی به طور قابل توجهی کارایی راه حل را بهبود بخشیده است و سرعت همگرایی نیز به طور قابل توجهی سریعتر است. این ثابت می کند که الگوریتم بهینه سازی یادگیری Q پیشنهادی در محیط شبکه موثر است.
3.3. تجزیه و تحلیل صحنه شبیه سازی
برای تأیید اثربخشی الگوریتم پیشنهادی، یک آزمایش شبیهسازی با یک ساختمان اداری در پکن به عنوان محیط انجام شد. هنگامی که آتش سوزی در یک طبقه از یک ساختمان اداری رخ می دهد، تهدیدی جدی برای ایمنی شخصی و اموال مردم محلی است. برای اطلاعات موانع آتش که در حال تغییر هستند، از یک الگوریتم بهینه سازی یادگیری Q در محیط شبکه برای برنامه ریزی مسیر نجات به منظور تخلیه افراد گرفتار استفاده می شود.
3.3.1. داده های تجربی و ساخت صحنه
محیط شبیه سازی صحنه داخلی یک ساختمان اداری در پکن است. برای نمایش بصری موقعیت حرکت امدادگران در طول فرآیند تخلیه، از نرم افزار Glodon برای ساخت نقشه محیط مجازی سه بعدی صحنه استفاده می شود. محیط ساختمان اداری در صورت آتش سوزی را می توان مطابق شکل 8 مدل سازی کرد. مستطیل آبی نشان دهنده افرادی است که نیاز به نجات دارند و دایره های متحدالمرکز قرمز و زرد نشان می دهد که آتش کجا رخ می دهد. این طبقه از ساختمان اداری تنها یک خروجی در گوشه بالا سمت چپ دارد. امدادگران در موقعیتی هستند که توسط سیلندر در گوشه سمت چپ بالا نشان داده شده است و برای نجات به سمت نقطه هدف حرکت می کنند. اگر امدادگران بخواهند در اسرع وقت محل را تخلیه کنند، باید تاثیر مسافت و همچنین تاثیر بخش های مختلف مسیر و اطلاعات خروجی را در زمان تخلیه در نظر بگیرند. بنابراین، محتوای تحقیق این بخش را می توان از طریق مدل صحنه سه بعدی، همانطور که در شکل 8 نشان داده شده است، تأیید کرد .
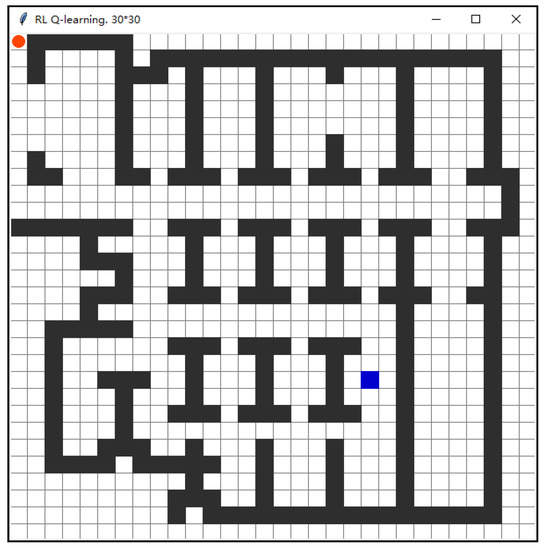
بر اساس ویژگیهای ساختاری ساختمانهای دیوار داخلی با توزیع یکنواخت، از روش گراف شبکهای برای ساخت نقشه شبکه داخلی استفاده میشود، همانطور که در شکل 9 نشان داده شده است. با توجه به صحنه ساختمان اداری، نقشه شبکه ای به ابعاد 30×30 ساخته شده است. در طول ساختن نقشه شبکه، شبکه واحد به صورت مستطیلی با طول و عرض مساوی تنظیم می شود. با ترکیب یکنواختی و فشردگی طول و عرض ساختمان، یک محیط شبکه داخلی ساخته شده است، همانطور که در شکل 10 نشان داده شده است.
3.3.2. تجزیه و تحلیل نتایج تجربی
الگوریتم بهینه سازی یادگیری Q برای انجام آزمایش برنامه ریزی کوتاه ترین مسیر برای یک محیط داخلی بدون آتش سوزی و موانع در هنگام وقوع آتش سوزی استفاده می شود. نتایج تجربی در شکل 11 و شکل 12 نشان داده شده است.
در طول فرآیند آموزش، همانطور که در شکل 13 الف نشان داده شده است، الگوریتم بهینه سازی یادگیری Q در سناریوی غیر آتش به تدریج دانش را در طول فرآیند یادگیری جمع می کند و تعداد مراحل مورد نیاز از نقطه اولیه تا نقطه هدف به تدریج کاهش می یابد و تمایل پیدا می کند. در اطراف گام 4000 همگرا شوند. از شکل 13ب، الگوریتم بهینهسازی یادگیری Q در سناریوی آتشسوزی زمانی که تعداد مراحل تقریباً 6600 مرحله باشد، همزمان با پیشرفت فرآیند یادگیری، تمایل دارد. با افزایش پیچیدگی محیط داخلی، کارایی عامل کاوش در مسیر تا حدی کاهش می یابد. با این حال، تفاوت کمی بین این دو وجود دارد و هنوز هم می توان کوتاه ترین مسیر را در مدت زمان کوتاهی برای رسیدن به همگرایی به دست آورد.
در فرآیند آموزش، همانطور که عامل به طور مداوم یاد میگیرد، پاداش تجمعی الگوریتم بهینهسازی یادگیری Q در سناریوی بدون آتش همچنان جمع میشود که با تغییر تعداد مراحل هماهنگ میشود. همانطور که در شکل 14 الف نشان داده شده است، زمانی که تعداد مراحل تقریباً 4000 است، پاداش تجمعی شروع به افزایش قابل توجهی می کند و در نهایت به 10 نزدیک می شود. با این حال، همانطور که فرآیند یادگیری در سناریوی آتش ادامه می یابد، مقدار پاداش تجمعی بهینه سازی یادگیری Q-Q همانطور که در شکل 14 نشان داده شده است، الگوریتم زمانی شروع به افزایش می کند که تعداد مراحل تقریباً 6600 باشد و در نهایت به 10 نزدیک شود .ب اگرچه راندمان پاداش تجمعی در محیط های پیچیده تر کمتر است، نتایج همگرایی تحت تأثیر قرار نمی گیرند.
نتایج تجربی نشان میدهد که الگوریتم به برنامهریزی مسیر معقول برای هر دو محیط دست مییابد و کوتاهترین مسیر را بدون برخورد از نقطه شروع تا نقطه پایان در مدت زمان کوتاهی تعیین میکند. شکل 11 بر اساس کوتاه ترین مسیر برنامه ریزی شده در شکل 10 بازآموزی و یاد می گیرد تا مسیر برنامه ریزی شده در محیط آتش به طور کامل از قسمت های مانع در منطقه آتش دوری کند. نشان داده شده است که الگوریتم سازگاری خوبی با محیط مانع دارد، می تواند موانع را در زمان کوتاهی شناسایی کند و به طور منطقی از موانع برای برنامه ریزی مسیر و رسیدن به مقصد اجتناب کند. این امکان سنجی الگوریتم برای برنامه ریزی مسیر در یک محیط مانع داخلی را نشان می دهد.
4. نتیجه گیری
این مقاله با هدف مشکل برنامهریزی مسیر داخلی در یک محیط امداد رسانی بلایای اضطراری، از الگوریتم یادگیری Q برای ارائه یک روش برنامهریزی مسیر اضطراری بر اساس محیط شبکه استفاده میکند. با توجه به عدم آگاهی قبلی از محیط های بلایای داخلی، از جعبه ابزار Tkinter برای ساخت محیط نقشه شبکه استفاده می شود. عامل اکتشاف در استراتژی ε-گریدی به صورت پویا تنظیم می شود. قبل از انتخاب یک اقدام تصادفی، الگوریتم یادگیری Q با افزودن محاسبه نرخ تنزیل ضریب اکتشاف بهینه می شود که سرعت همگرایی الگوریتم یادگیری Q را بهبود می بخشد. الگوریتم SARSA، الگوریتم یادگیری Q و الگوریتم بهینه سازی یادگیری Q در آزمایش شبیه سازی الگوریتم مقایسه و تجزیه و تحلیل می شوند. الگوریتم یادگیری Q در انتخاب مسیر و همگرایی از الگوریتم SARSA بهتر عمل می کند و الگوریتم یادگیری Q برای برنامه ریزی مسیر در مدل محیط شبکه ای مناسب تر است. در مقایسه با الگوریتم SARSA و الگوریتم یادگیری Q، الگوریتم بهینهسازی یادگیری Q ارائه شده در این مقاله کارایی حل را تا حد زیادی بهبود میبخشد و نرخ همگرایی را تسریع میکند. در نهایت، با استفاده از آتش سوزی در یک ساختمان اداری در پکن و نیاز به پرسنل مربوطه برای نجات به عنوان نمونه ای از شرایط اضطراری، آزمایش برنامه ریزی مسیر اضطراری داخلی مورد تجزیه و تحلیل قرار گرفت. با توجه به محیط داخلی واقعی ساختمان اداری، یک محیط مانع شبکه پیچیده تر به عنوان صحنه آزمایش داخلی ایجاد شد.
با توسعه هوش مصنوعی، الگوریتم های برنامه ریزی مسیر مبتنی بر یادگیری تقویتی به طور مداوم به روز و بهینه می شوند. محیط داخلی که در این مقاله به آن پرداخته شده است ایستا است و پیچیدگی و تنوع محیط داخلی واقعی و سایر عوامل را می توان در مطالعات بعدی در نظر گرفت. هنگامی که بلایا رخ می دهد، منطقه فاجعه ممکن است به گسترش خود ادامه دهد و راه حل برنامه ریزی مسیر در محیط های داخلی پویا و پیچیده ممکن است به تحقیقات بیشتری نیاز داشته باشد.



















بدون دیدگاه