

وظیفه استخراج سطح جاده معمولاً از طریق تقسیم بندی معنایی بر روی تصاویر سنجش از راه دور انجام می شود. با این حال، این کار یادگیری نظارت شده اغلب پرهزینه است، زیرا به تصاویر سنجش از راه دور برچسب گذاری شده در سطح پیکسل نیاز دارد، و نتایج همیشه رضایت بخش نیستند (وجود ناپیوستگی، نقاط اتصال نادیده گرفته شده، یا بخش های جدا شده جاده). از سوی دیگر، یادگیری بدون نظارت نیازی به داده های برچسب دار ندارد و می تواند برای پس پردازش هندسه اشیاء مکانی استخراج شده از طریق تقسیم بندی معنایی استفاده شود. در این کار، ما یک شبکه متخاصم مولد مشروط را برای بازسازی هندسههای جاده از طریق روشهای رنگ آمیزی عمیق بر روی یک مجموعه داده جدید شامل نمونههای جاده بدون برچسب از مناطق چالش برانگیز موجود در پشتیبانی نقشهبرداری رسمی از اسپانیا پیادهسازی میکنیم. هدف این است که بازنماییهای جاده اولیه بهدستآمده با مدلهای تقسیمبندی معنایی از طریق یادگیری مولد را بهبود بخشد. عملکرد مدل بر روی دادههای دیده نشده با انجام یک مقایسه متریک ارزیابی شد که در آن حداکثر بهبود امتیاز تقاطع بیش از اتحادیه (IoU) 1.3٪ در مقایسه با نتیجه تقسیمبندی معنایی اولیه مشاهده شد. در مرحله بعد، ما مناسب بودن استفاده از یادگیری مولد بدون نظارت را با استفاده از اعتبار سنجی ادراکی کیفی برای شناسایی نقاط قوت و ضعف روش پیشنهادی در سناریوهای بسیار پیچیده و به دست آوردن شهود بهتری از رفتار مدل در هنگام انجام پس پردازش در مقیاس بزرگ با یادگیری مولد ارزیابی کردیم. و رویههای نقاشی عمیق و بهبودهای مهمی در دادههای تولید شده مشاهده شد. عملکرد مدل بر روی دادههای دیده نشده با انجام یک مقایسه متریک ارزیابی شد که در آن حداکثر بهبود امتیاز تقاطع بیش از اتحادیه (IoU) 1.3٪ در مقایسه با نتیجه تقسیمبندی معنایی اولیه مشاهده شد. در مرحله بعد، ما مناسب بودن استفاده از یادگیری مولد بدون نظارت را با استفاده از اعتبار سنجی ادراکی کیفی برای شناسایی نقاط قوت و ضعف روش پیشنهادی در سناریوهای بسیار پیچیده و به دست آوردن شهود بهتری از رفتار مدل در هنگام انجام پس پردازش در مقیاس بزرگ با یادگیری مولد ارزیابی کردیم. و رویههای نقاشی عمیق و بهبودهای مهمی در دادههای تولید شده مشاهده شد. عملکرد مدل بر روی دادههای دیده نشده با انجام یک مقایسه متریک ارزیابی شد که در آن حداکثر بهبود امتیاز تقاطع بیش از اتحادیه (IoU) 1.3٪ در مقایسه با نتیجه تقسیمبندی معنایی اولیه مشاهده شد. در مرحله بعد، ما مناسب بودن استفاده از یادگیری مولد بدون نظارت را با استفاده از اعتبار سنجی ادراکی کیفی برای شناسایی نقاط قوت و ضعف روش پیشنهادی در سناریوهای بسیار پیچیده و به دست آوردن شهود بهتری از رفتار مدل در هنگام انجام پس پردازش در مقیاس بزرگ با یادگیری مولد ارزیابی کردیم. و رویههای نقاشی عمیق و بهبودهای مهمی در دادههای تولید شده مشاهده شد. 3٪ در مقایسه با نتیجه تقسیم بندی معنایی اولیه مشاهده شد. در مرحله بعد، ما مناسب بودن استفاده از یادگیری مولد بدون نظارت را با استفاده از اعتبار سنجی ادراکی کیفی برای شناسایی نقاط قوت و ضعف روش پیشنهادی در سناریوهای بسیار پیچیده و به دست آوردن شهود بهتری از رفتار مدل در هنگام انجام پس پردازش در مقیاس بزرگ با یادگیری مولد ارزیابی کردیم. و رویههای نقاشی عمیق و بهبودهای مهمی در دادههای تولید شده مشاهده شد. 3٪ در مقایسه با نتیجه تقسیم بندی معنایی اولیه مشاهده شد. در مرحله بعد، ما مناسب بودن استفاده از یادگیری مولد بدون نظارت را با استفاده از اعتبار سنجی ادراکی کیفی برای شناسایی نقاط قوت و ضعف روش پیشنهادی در سناریوهای بسیار پیچیده و به دست آوردن شهود بهتری از رفتار مدل در هنگام انجام پس پردازش در مقیاس بزرگ با یادگیری مولد ارزیابی کردیم. و رویههای نقاشی عمیق و بهبودهای مهمی در دادههای تولید شده مشاهده شد.
کلید واژه ها:
یادگیری مشروط ; شبکه متخاصم مولد ; یادگیری مولد ; نقاشی درون تصویر ; پس پردازش تصویر ؛ استخراج جاده ; یادگیری بدون نظارت
1. مقدمه
در یکی از کارهای قبلی ما [ 1] مربوط به استخراج جادهها با استفاده از پیشرفتهترین مدلهای تقسیمبندی معنایی برای اهداف نقشهبرداری خودکار، ما مشکل استخراج نادرست هندسه جادهها را مشاهده کردیم، حتی هنگام کار با مجموعه دادهای در مقیاس بزرگ حاوی اطلاعات مناطق مختلف اسپانیا (ساختهشده) برای بهبود ظرفیت تعمیم مدل های حاصل). در این مطالعه، ناپیوستگیهای مکرر در ماسکهای تقسیمبندی استخراجشده (شکافها و نقاط اتصال از دست رفته) مشاهده شد که منجر به ایجاد بخشهای جادهای غیرمرتبط شد. پیشبینیها نرخهای بالاتری از مثبتهای کاذب (FP) را در مناطقی که اشیاء جغرافیایی اطراف دارای نشانههای طیفی مشابهی با جادهها هستند، و نرخهای بالاتری از منفیهای کاذب (FN) در مناطقی که انسداد در صحنهها وجود دارد، نشان دادند. ما به این نتیجه رسیدیم که این نواقص به دلیل ماهیت پیچیده شی زمینفضایی (جادهها تغییرات انحنای زیادی دارند، مواد مختلف در روسازی استفاده میشوند، عرضهای متفاوت، بسته به اهمیت مسیر، و اغلب مرزهای مشخصی ندارند) ایجاد میشوند. وجود انسداد در صحنه ها، و با محدودیت الگوریتم های تقسیم بندی معنایی موجود. این نواقص و خطاها در راستای مسائلی است که توسط تحقیقات دیگر مطرح شده است، زیرا مشکلات مشابهی در کارهای دیگر شناسایی شده است که وظیفه استخراج جاده را از تصاویر سنجش از دور با وضوح بالا انجام می دهند. و با محدودیت الگوریتم های تقسیم بندی معنایی موجود. این نواقص و خطاها در راستای مسائلی است که توسط تحقیقات دیگر مطرح شده است، زیرا مشکلات مشابهی در کارهای دیگر شناسایی شده است که وظیفه استخراج جاده را از تصاویر سنجش از دور با وضوح بالا انجام می دهند. و با محدودیت الگوریتم های تقسیم بندی معنایی موجود. این نواقص و خطاها در راستای مسائلی است که توسط تحقیقات دیگر مطرح شده است، زیرا مشکلات مشابهی در کارهای دیگر شناسایی شده است که وظیفه استخراج جاده را از تصاویر سنجش از دور با وضوح بالا انجام می دهند.2 ، 3 ، 4 ، 5 ]، و هنگام پیگیری عملیات استخراج جاده در مقیاس بزرگ برای اهداف نقشه برداری خودکار بسیار مشکل ساز هستند. در نتیجه، ما در نظر می گیریم که افزودن یک عملیات پس از پردازش برای بهبود پیش بینی های تقسیم بندی اولیه برای استخراج موفقیت آمیز جاده ضروری است. در این کار، هدف عملیات پس از پردازش این است که بخشهای جاده را روانتر به هم پیوند دهد، بخشهای کوچک جاده گمشده را استنتاج کند، و بخشهای جاده جدا شده (که تداوم ندارند) را حذف کند.
همانطور که قبلاً ذکر شد، یکی از رایجترین مشکلاتی که با آن مواجه میشد مربوط به نادیده گرفتن نقاط اتصال بود که منجر به عدم اتصال بخشهای جاده میشد (یک مثال در شکل 1 مشاهده میشود ). به طور سنتی، عملیات پس از پردازش با استفاده از فیلدهای تصادفی شرطی [ 6 ] یا فیلتر شکل [ 7 ، 8 ] انجام می شود. با این حال، امروزه رویکردهای مبتنی بر عملیات رنگ آمیزی بیشتر مورد استفاده قرار می گیرند. Inpainting یک عملیات بینایی کامپیوتری محبوب است که توسط Bertalmío و همکاران معرفی شده است. که در [ 9] برای بازسازی قسمت های تصویر گم شده و با هدف بازیابی مناطق تخریب شده در تصاویر. برای یک آزمایش اولیه پس از پردازش، ما یک الگوریتم نقاشی داخلی حاوی یک هسته با اندازه 4 × 4 پیکسل برای اعمال عملیات مورفولوژیکی بر روی نقشههای تقسیمبندی اولیه (پردازش بر اساس اشکال) ایجاد کردیم. این الگوریتم قادر است یک عملیات فرعی اولیه فرسایش مرزهای جاده را برای کاهش ویژگی ها و حذف نویز انجام دهد و به دنبال آن یک عملیات فرعی اتساع برای افزایش سطح جسم و برجسته کردن ویژگی ها انجام شود. با استفاده از همان هسته، اشیاء به اندازه اصلی خود باز می گردند. این دو عملیات با هم به جداسازی عناصر منفرد و اتصال کارآمدتر عناصر کمی جدا شده میرسند.
با این حال، ما معتقدیم که برای مقابله با موفقیت در مقیاس بزرگ پس پردازش اهداف چالش برانگیز جغرافیایی (مانند شبکه جاده)، پیاده سازی های پیچیده تری پس پردازش مبتنی بر یادگیری عمیق (DL) مورد نیاز است. ثابت شد که مدلهای DL برای برنامههای فشرده داده مناسبتر هستند، الگوریتمهای یادگیری ماشین سنتی (ML) که قابلیت تعمیم محدودتری دارند [ 10 ]. پاتاک و همکاران [ 11] جزو اولین کسانی بودند که از یادگیری بدون نظارت برای درک زمینه یک تصویر و تولید پیشبینیهای پیکسلی قابل قبول برای قسمتهای از دست رفته استفاده کردند. آنها مدلی مبتنی بر یادگیری مولد و شبکههای عصبی کانولوشنال (CNN) برای تولید محتوای تصویر گمشده قابل قبول در سطح پیکسل، مشروط به محیط اطراف، پیشنهاد کردند.
در این کار، ما عملیات پس از پردازش را به عنوان یک کار نقاشی عمیق (با توجه به ماهیت عیوب و خطاهای شناسایی شده) مطرح می کنیم و یک شبکه متخاصم مولد مشروط (cGAN) را برای مقابله با آن پیشنهاد می کنیم. آموزش cGAN از طریق تکنیکهای یادگیری مولد بدون نظارت بر روی یک مجموعه داده جدید با هدف یادگیری توزیع جادههای موجود در نقشهبرداری رسمی و کاهش تأثیر مشکلات پیشبینیشده بر روی پیشبینیهای اولیه انجام میشود. عملکرد مدل بر اساس دادههای دیده نشده مورد ارزیابی قرار گرفت و حداکثر پیشرفتها در مرتبه 1.3 درصد از نظر امتیاز تقاطع بیش از اتحادیه (IoU)، ، مشاهده شدند. مشخص است که امتیاز IoU بسیار حساس است، به خصوص در سناریوهای سنجش از راه دور که در آن کلاسها معمولاً موارد بسیار نامتعادل هستند (پیکسلهای جاده معمولاً حدود 10٪ پیکسلهای تصویر را اشغال میکنند)، زیرا در محاسبه منفی واقعی را در نظر نمیگیرد. معیارهای عملکرد، و حتی افزایش های کوچک می تواند به عنوان قابل توجه [ 12 ] منجر شود. به همین دلیل، ما همچنین یک ارزیابی کیفی از نتایج را برای شناسایی برخی از نقاط قوت و ضعف روش پیشنهادی در سناریوهای بسیار پیچیده و تعیین جهتهای تحقیقاتی آتی انجام میدهیم. تا آنجا که ما می دانیم، این اولین نمونه از پس پردازش جاده در مقیاس بزرگ با استفاده از چنین رویکردی است.
مشارکت های این مقاله به شرح زیر خلاصه می شود:
-
ما یک مدل cGAN را برای وظیفه نقاشی عمیق برای بهبود پیشبینیهای تقسیمبندی معنایی اولیه جادهها پیادهسازی کردیم. ما ژنراتور را پیشنهاد کردیم، و تبعیض، ، معماری ها را برای اینکه آموزش را برای هدف یادگیری ما مناسب تر کنیم. یک شبکه U-Net [ 13 ] است که به شدت برای کارایی محاسباتی اصلاح شده است، در حالی که یک PatchGAN اصلاح شده [ 14 ] است که برای پردازش تصاویر 256 × 256 پیکسل سازگار شده است.
-
ما مدل را بر روی یک مجموعه داده جدید متشکل از آموزش دادیم نقشههای تقسیمبندی واقعی جادههای موجود در نقشهبرداری رسمی در اینجا، ما تصادفی را به شکل شکاف های مصنوعی به ورودی برای آموزش اعمال کردیم (که منجر به بسیاری از تصاویر خراب احتمالی می شود [ 15 ]). این منبع تصادفی اعمال شده برای اطلاعات شرطی اجازه می دهد برای تولید تصاویر واقعی ما مدل را در یک مجموعه آزمایشی جدید متشکل از اعتبارسنجی کردیم پیشبینیهای تقسیمبندی معنایی واقعی بهدستآمده توسط یک شبکه تقسیمبندی معنایی پیشرفته (با U-Net به عنوان معماری پایه و SEResNeXt50 [ 16 ] به عنوان ستون فقرات تقسیمبندی). ما این عملیات را در مقیاس بزرگ انجام دادیم، با هدف به دست آوردن یک مدل تولید که قادر به کاهش موفقیت آمیز مشارکت انسان در کار استخراج جاده باشد.
-
ما با ارزیابی توانایی مدل در تولید نمونههای جدید از حوزه آموختهشده و انجام مقایسههای متریک و عملیات اعتبار سنجی ادراکی، مناسب بودن بهکارگیری یادگیری مولد با عملیات رنگآمیزی را برای کار پسپردازش جاده مورد مطالعه قرار دادیم. cGAN پیشنهادی به حداکثر افزایش 1.28٪ نسبت به امتیاز IoU به دست آمده توسط مدل تقسیم بندی معنایی دست یافت.
به صورت زیر عمل می کنیم. در بخش 2 ، ما کارهای مربوط به استخراج جاده و پس پردازش را مورد بحث قرار می دهیم. در بخش 3 ، پیشینه شبکههای متخاصم مولد مشروط و روش آموزش آنها را ارائه میدهیم. داده های مورد استفاده در مطالعه در بخش 4 توضیح داده شده است . جزئیات مربوط به اجرای cGAN ما در بخش 5 ارائه شده است. نتایج تجربی پس پردازش از طریق رنگ آمیزی عمیق در بخش 6 از دیدگاه کمی و کیفی تجزیه و تحلیل شده است. بخش 7 نتیجه گیری را ارائه می کند.
2. کارهای مرتبط
به طور مشابه عبداللهی و همکاران. [ 17 ]، ما معتقدیم که کارهای موجود برای مقابله با استخراج جاده با DL را می توان بر اساس نوع شبکه عصبی (NN) اعمال شده طبقه بندی کرد. اول، ما رویکردهای مبتنی بر CNN ها را داریم. در اینجا، برچسبهای جادهها در سطح پچ با استفاده از CNN پیشبینی میشوند و پیشبینی نهایی با مونتاژ وصلههای برچسبدار به دست میآید. به عنوان مثال، لی و همکاران. [ 18 ] یک رویکرد مبتنی بر CNN را بر اساس پیشبینی احتمال تعلق هر پیکسل به یک بخش جاده پیشنهاد کرد. آنها همچنین یک تکنیک استخراج خط مرکزی جاده را بر اساس پردازش تصویر ساده با اپراتورهای مورفولوژیکی پیشنهاد کردند و امتیاز IoU حداکثر 0.78 را به دست آوردند.
با این حال، اکثر کارهای مربوط به استخراج جاده با تکنیکهای DL از رویکرد تقسیمبندی معنایی پیروی میکنند، جایی که لایههای کاملاً متصل (FC) با لایههای درونیابی جایگزین میشوند که نقشههای ویژگی را از آخرین لایه تا اندازه ورودی برای پیشبینی برچسبها نمونهبرداری میکنند. . بوسلایف و همکاران [ 19 ] مدلی را به دنبال ساختار رمزگذار-رمزگشا بر اساس U-Net [ 13 ] و ResNet [ 20 ] برای استخراج جاده ها از تصاویر سنجش از دور توسعه داد و یک تابع از دست دادن را پیشنهاد کرد که ترکیب آنتروپی متقاطع باینری و امتیاز ژاکارد را کاهش می دهد. هزینه. این مدل امتیاز IoU 0.64 را در داده های دیده نشده به دست آورد. به طور مشابه، Xu و همکاران. [ 21] M-Res-U-Net را معرفی کرد، مدلی مبتنی بر ResNet و U-Net، که در آن فیلتر گاوسی در هنگام پیش پردازش اعمال می شود تا نویز در تصاویر کاهش یابد. نویسندگان دادههای نقشه برداری جادهای بردار موجود را شطرنجی کردند، اما این رویکرد در مناطقی که سایر اجسام جغرافیایی رنگهای مشابهی با توزیع جاده داشتند، عملکرد ضعیفی داشت. چنگ و همکاران CasNet [ 22 ] را معرفی کرد که شامل دو شبکه آبشاری – یکی برای شناسایی مناطق جادهای و دیگری برای استخراج خطوط مرکزی جادهها – در حالی که از نقشههای ویژگی آموخته شده توسط شبکه اول بهره میبرد، معرفی کرد. این مدل بر روی مجموعه داده ای متشکل از 224 تصویر Google Earth آموزش و آزمایش شد [ 23] و امتیاز IoU حداکثر 0.88 به دست آورد. با این حال، نویسندگان نامناسب بودن شبکه را برای پردازش مناطقی که انسداد درختان وجود دارد، تشخیص دادند.
اخیراً رویکردهای مبتنی بر شبکههای متخاصم مولد (GANs) [ 24 ] پدیدار شدهاند. این نوع NN توسط Goodfellow و همکاران معرفی شد. در سال 2014. آنها مدل های مولد DL بر اساس یادگیری بدون نظارت هستند (الگوی یادگیری که در آن مدل فقط متغیرهای ورودی داده می شود و متغیرهای خروجی وجود ندارد)، که در آن دو شبکه (به نام مولد، و تبعیض، ) به طور همزمان در یک محیط خصمانه با هدف یافتن تابع احتمالی که نمونه های آموزشی را به بهترین شکل توصیف می کند، آموزش می بینند. GAN ها در طول سال های بعد تکامل یافته اند [ 25 ]. Deep Convolutional GANs (DCGANs) [ 26 ] دارای CNN های عمیق در و و سودمندی خود را در وظایف بینایی ماشین بدون نظارت ثابت کرده اند. شبکه مشروط Generative Adversarial Network (cGAN) [ 27 ] به عنوان یک برنامه افزودنی پدید آمد که اطلاعات اضافی را هم به مولد و هم به تمایزکننده ارائه می دهد (به عنوان مثال، استفاده از برچسب های کلاس به عنوان ورودی قبل از اعمال توزیع نویز).
در زمینه نقاشی عمیق تصویر، ایزوکا و همکاران. GLCIC پیشنهاد شده [ 28 ]، که شامل پردازشگر تمایزکننده جهانی در سطح تصویر و تشخیص دهنده محلی است که مرکز مناطق را برای رنگ آمیزی پردازش می کند. به این ترتیب، مناطق پر شده به ثبات جهانی و محلی بالاتری دست می یابند. لیو و همکاران کانولوشن جزئی (Pconv) [ 29 ] (شامل عملیات پیچیدگی پوشانده شده و عادی سازی شده و به دنبال راه اندازی به روز رسانی ماسک) را به عنوان روشی برای رنگ آمیزی حفره های نامنظم متعدد با استفاده از یادگیری مولد عمیق معرفی کرد و به نتایج با کیفیت بالا بر روی تصاویر ماسک دار نامنظم دست یافت. بر اساس DeepFill v1 [ 30 ] (آموزش داده شده برای مطابقت و ترکیب ویژگی های تولید شده در داخل و خارج از سوراخ گمشده)، Yu et al. DeepFill نسخه 2 [ 31]، شامل Gated Convolution (یک Pconv که در آن یک لایه کانولوشن استاندارد اضافی به دنبال تابع سیگموئید اضافه می شود). این مدل نشاندهنده آخرین هنر در زمینه نقاشی عمیق تصویر است.
این پیشرفتها اجازه میدهد تا کار استخراج جاده از دیدگاه یادگیری بدون نظارت مورد بررسی قرار گیرد. در [ 32 ]، de la Fuente Castillo و همکاران. با موفقیت از یادگیری بدون نظارت بر اساس برنامهریزی ژنتیکی هدایتشده گرامر برای به دست آوردن معماریهای شبکه عصبی جدید متخصص در تشخیص جاده در تصاویر هوایی استفاده کرد. واریا و همکاران [ 33 ] از نوع FCN-32 [ 34 ] و Pix2pix [ 14 ] برای استخراج جاده ها از مجموعه داده های وسیله نقلیه هوایی بدون سرنشین حاوی 189 تصویر آموزشی و 23 تصویر آزمایشی استفاده کرد، اما نرخ بالایی از پیش بینی FN را مشاهده کرد. شی و همکاران [ 35 ] یک معماری cGAN را با استفاده از SegNet [ 36 ] (بر اساس معماری رمزگذار-رمزگشا) توسعه داد. به بخش بندی جاده ها در تصاویر هوایی با وضوح بالا و به امتیاز F1 0.8831 (3.6٪ بهبود در مقایسه با امتیاز F1 0.8472 که توسط SegNet در زمانی که در شرایط خصمانه آموزش نمی بیند) به دست آورد. یانگ و همکاران [ 37 ] جریمه فاصله Wasserstein را به GAN اضافه کرد تا به امتیاز IoU 0.73 هنگام استخراج هندسه راه از مناطق روستایی در چین دست یابد.
هارتمن و همکاران [ 38 ] یک معماری GAN را برای ترکیب اطلاعات جاده در مناطقی که استخراج پیچیده است (مثلاً جایی که ناپیوستگی وجود دارد) آموزش داد. کوستئا و همکاران [ 39 ] یک روش استخراج جاده متشکل از یک مرحله تشخیص لبه با یک GAN، و مرحله بعدی هموارسازی برای پس پردازش نتایج و بهبود پیشبینیهای تقسیمبندی اولیه را پیشنهاد کرد. در نهایت، ژانگ و همکاران. یک GAN چند شرطی (McGAN) اجرا کرد [ 40] برای اصلاح توپولوژی جاده و به دست آوردن نمودارهای شبکه جاده ای کامل تر. متفاوت از این کارها، ما میخواستیم از تمرکز بر مناطق کوچک و ایدهآل خودداری کنیم و تصمیم گرفتیم مجموعه داده جدیدی شامل 8480 کاشی 256 × 256 پیکسلی حاوی جادهها از نقشهبرداری رسمی و ماسکهای تقسیمبندی متناظر آنها بسازیم تا پیچیدگی دنیای واقعی را به کار تولیدی اضافه کنیم. و آزمایشات را در مقیاس وسیع انجام دهید.
اگرچه کارهای زیادی برای مقابله با استخراج سطح جاده وجود دارد، پس پردازش پیشبینیهای بخشبندی هنوز یک حوزه فعال تحقیقاتی است. در [ 41 ]، ما پس پردازش پیشبینیهای تقسیمبندی معنایی را از طریق عملیات ترجمه تصویر به تصویر مطالعه کردیم و روشی را بر اساس Pix2pix [ 14 ] پیشنهاد کردیم و نتایج چشمگیری را مشاهده کردیم. ما معتقدیم که یکی دیگر از کاربردهای مهم پس پردازش، که مستقیماً برای سنجش از دور و تشخیص عناصر جغرافیایی قابل استفاده است، عملیات رنگآمیزی است که میتواند برای بازسازی بخشهای گمشده با پر کردن قسمتهای گمشده ماسک تقسیمبندی معنایی اولیه استفاده شود. به دنبال این خط، چن و همکاران. [ 15 ، 42] روشی را پیشنهاد کرد که یادگیری مخالف را با یادگیری تقویتی ترکیب میکند (یک جزء گرادیان سیاست [ 43 ]، که در آن یک رویکرد یادگیری تقویتی مبتنی بر الگوریتم REINFORCE [ 44 ] به یک تمایزکننده جهانی اضافه میشود) برای بازیابی شکافها از ساختارهای نازک در تصاویر بزرگ، مدلی که عملکرد خود را بر روی مجموعه دادههای کاهش یافته حاوی ساختارهایی مانند عروق شبکیه، جادهها یا ریشههای گیاه اثبات میکند. شایان ذکر است که بسیاری از مدلهای پیشنهادی برای نقاشی عمیق تصویر از طراحی تفکیککننده چند مقیاسی پیروی میکنند، که در آن یک تشخیصدهنده جهانی در سطح تصویر و یک تشخیصدهنده محلی در سطح منطقه خراب استفاده میشود.
در این مقاله، ما به کار پس پردازش جاده از طریق یادگیری مولد نزدیک میشویم و یک مدل GAN شرطی برای تولید پیشبینیهای تقسیمبندی معنایی جادهها پیشنهاد میکنیم. این مدل با خراب کردن تصاویر آموزشی با حفرههای تصادفی کار میکند و متعاقباً با استفاده از یک cGAN آموزشدیده برای عملیات نقاشی داخلی، تصاویر مخرب حاصل را بازسازی میکند. در نهایت، ماسک های تقسیم بندی اولیه، که در طول تمرین دیده نمی شوند، عبور داده می شوند برای محاسبه معیارهای عملکرد مدل و انجام یک اعتبار سنجی ادراکی از نتایج.
3. شرح مشکل
هدف Inpainting [ 9 ] بازیابی اطلاعات از دست رفته از تصاویر با پر کردن مناطق تخریب شده است. در این کار، ما یک رویکرد مبتنی بر مدل را در نظر میگیریم و یک cGAN را با استفاده از تکنیکهای یادگیری بدون نظارت (که در آن به دادههای برچسبگذاری شده نیاز نیست) برای یک کار نقاشی عمیق آموزش میدهیم. در اینجا، ما یک دامنه داریم، ، با توزیع، ، حاوی بازنمایی های متعلق به حوزه نقشه برداری رسمی جاده ها است. با این حال، ما فقط به تعداد محدودی از نمونه ها دسترسی داریم، . هدف این است یک نقشه برداری قابل قبول را می آموزد ، با توجه به یک مشاهده (شرط)، و یک متغیر تصادفی، (در نتیجه یک بازسازی واقع بینانه، ) [ 45 ]. زیرا تصادفی است، نقشه برداری یاد می گیرد از بسیاری از تصاویر احتمالی خراب شده است.
برای تولید خروجی آموزش دیده است، ( متعلق به حوزه بازسازی هاست ) که نمی توان آن را از تصاویر “واقعی” تشخیص داد، (متعلق به دامنه )، توسط یک تبعیض آمیز آموزش دیده، ، که برای تشخیص “جعلی” ژنراتور آموزش دیده است. بدین ترتیب، تولید نمونه های مصنوعی را یاد خواهد گرفت، ، تا حد امکان به نمونه های واقعی که از آن می آیند نزدیک است . برای جلوگیری از اشباع شیب در اوایل (زمانی که در تولید داده ها خوب عمل نمی کند)، به جای اتخاذ رویکرد سنتی برای به حداقل رساندن احتمال ورود به سیستم اشتباه بودن، ما یک هدف حداقلی اصلاح شده را اعمال می کنیم، ، و آموزش دهید برای به حداکثر رساندن احتمال ورود به سیستم تشخیص دهنده در اشتباه بودن، . این تشویق می کند برای تولید نمونه هایی با احتمال کم “جعلی” بودن. از طریق صعود شیب تصادفی آموزش داده می شود، .
شبکه ژنراتور در یک محیط بدون نظارت آموزش داده می شود. نمونه می گیرد، ، از داده های آموزشی استفاده می کند و تصادفی را اعمال می کند، ، به آن (شکاف های تصادفی) برای فعال کردن خروجی بسیاری از تصاویر بازسازی شده مختلف، به جای تنها یک. با اعمال تابع مولد، یک نمونه جدید به دست می آوریم، . طوری آموزش داده شده است که مشاهده جعلی، ، توزیعی شبیه به مشاهدات واقعی دارد، ( ). ما همچنین باید این را در نظر بگیریم که آموزش GAN ها ناپایدار است و همیشه همگرا نمی شود زیرا هر یک از دو بازیکن مختلف تابع هزینه خود را به حداقل می رساند [ 46 ].
4. داده ها
در این کار، ما از یک نسخه باینریزه شده از مجموعه داده معرفی شده در [ 1 ] استفاده خواهیم کرد، که از نقشه ملی توپوگرافی آشکارا موجود، در مقیاس 1:50000 [ 47 ] به دست آمده است، که مساحت زمینی به وسعت تقریبی 181 کیلومتر مربع از مناطق معرف را پوشش می دهد. اسپانیا. این مجموعه داده حقیقت زمینی بر اساس دادههای جادهای است که بهطور آشکار در دسترس است، که توسط یک آژانس عمومی توزیع شده است (موسسه ملی جغرافیایی اسپانیا (به اسپانیایی: “Instituto Geográfico Nacional”). طبق گفته سازنده آن، نمونهها به صورت دستی توسط یک اپراتور برچسبگذاری شدهاند. مجموعه داده شامل 8480 کاشی با معیارهای تقسیم 80:20٪، که منجر به استفاده از 6784 کاشی برای آموزش (80٪) و 1696 کاشی برای آزمایش (20٪) شد [ 48 ]]. در این مجموعه داده، مقادیر پیکسل 0 به پیکسل های متعلق به کلاس “بدون جاده” و مقادیر پیکسل 1 به پیکسل های متعلق به کلاس “جاده وجود دارد” اختصاص داده می شود.
مدل تقسیمبندی معنایی با بهترین عملکرد آموزشدیده بر روی این مجموعه داده، حداکثر امتیاز IoU 0.6726 را در مجموعه آزمایشی حاوی دادههای دیده نشده به دست آورد (نمره IoU بالاتر از 0.5 پیشبینی خوبی در نظر گرفته میشود [ 49 ]). این مقدار ارزش عملکرد اولیه ما را نشان می دهد و در ارزیابی متریک مدل استفاده می شود. اگرچه ما هیچ نوع نظارتی نداریم، ماسک های تقسیم بندی به دست آمده از ارزیابی مجموعه آزمون با بهترین عملکرد مدل تقسیم بندی معنایی (U-Net [ 13 ] — SEResNeXt50 [ 16 ]]) در قالب PNG بدون تلفات (گرافیک شبکه قابل حمل) ذخیره شدند و به عنوان پیش بینی های تقسیم بندی اولیه در نظر گرفته شدند که برای ارزیابی و مطالعه عملکرد cGAN پیشنهادی استفاده می شود. لطفاً توجه داشته باشید که تنها حداکثر نتایج ارائه شده در نظر گرفته می شوند (که به نقطه شروع یا مقادیر پایه ما تبدیل می شوند)، زیرا ما به دنبال بهبود استخراج جاده از طریق عملیات رنگ آمیزی عمیق هستیم. در شکل 2 ، میتوانیم نمونههایی را بیابیم که مطابقت بین تصویر ارتوی هوایی، ماسک تقسیمبندی حقیقت زمینی دوتایی شده (برای آموزش) و پیشبینی تقسیمبندی اولیه (برای آزمایش) را از ده کاشی تصادفی توصیف میکنند.
ما می خواهیم مدل ما توزیع جاده های موجود در پشتیبانی نقشه برداری رسمی را بیاموزد. بنابراین در طول آموزش از تصاویر ردیف دوم به عنوان اطلاعات شرطی استفاده خواهیم کرد. پس از آن، ماسک های تقسیم بندی اولیه (ردیف سوم) را با استفاده از ژنراتور آموزش دیده برای به دست آوردن نتایج عملیات رنگ آمیزی عمیق مولد ارزیابی می کنیم. پیشبینیها برای محاسبه معیارهای عملکرد مدل پیشنهادی و انجام یک تجزیه و تحلیل جامع از نتایج نقاشی داخلی ذخیره میشوند.
5. cGAN برای پیشبینیهای جاده پس از پردازش از طریق عملیات Inpainting عمیق
عملیات رنگ آمیزی عمیق با استفاده از یک شبکه متخاصم مولد شرطی انجام می شود که در آن برچسب حقیقت زمین به عنوان شرط به ورودی اضافه می شود. مدل های مولد قادر به تولید نمونه های داده جدید هستند و هدف آموزش این است یاد می گیرد که چگونه داده ها را از یک توزیع ترکیب کند، (تشریح شبکه راه های موجود در کارتوگرافی رسمی)، با استفاده از نمونه های آموزشی، به نحوی که دیگر قادر به تمایز بین داده های حاصل از توزیع واقعی جاده نیست، و داده های تولید شده از توزیع مصنوعی، ما این کار را با محدود کردن انجام می دهیم نزدیک بودن از طریق یک ضرر خصمانه تعریف شده
5.1. ژنراتور
کاشیهای 256 × 256 پیکسلی را که با شکافهای تصادفی در اندازههای مختلف خراب شدهاند، ورودی میگیرد و برای بازسازی صحیح کاشیهای خراب آموزش دیده است. مکان شکاف های معرفی شده را نمی داند و مجبور است یاد بگیرد که به طور خودکار شکاف ها را با استفاده از بازخورد دریافتی از شبکه تفکیک کننده شناسایی و رنگ آمیزی کند. با اعمال تابع مولد، یک کاشی بازسازی شده را تولید خواهد کرد، . این نمونه جدید، ، باید به طور منطقی مشابه توزیع داده های آموزشی باشد، .
از نظر معماری، ژنراتور یک شبکه U-Net مانند است و دارای یک سری لایه های کانولوشن با اندازه هسته 3×3 و لایه صفر اضافه شده (برای جلوگیری از کوچک شدن کاشی در طول پردازش) است که به تدریج کاشی ورودی را کاهش می دهد. پیرو توصیههای [ 26 ]، در بلوکهای نمونهبرداری پایین رمزگذار، لایههای کانولوشن با نرمالسازی دستهای [ 50 ] دنبال میشوند تا از آموزش سریعتر و فعالسازی واحد خطی اصلاحشده (ReLU) [ 51 ] اطمینان حاصل شود.
در رمزگشا، فرآیند معکوس می شود و نمایش های آموخته شده به 256 × 256 پیکسل ارتقا داده می شوند. نقشههای ویژگی از طریق استفاده از پیچیدگیهای جابجا شده به اندازه اصلی گسترش مییابند (با استفاده از پیچیدگیهای گامهای کسری، به جای ادغام لایهها – به دنبال توصیههای [ 26 ]). در این بلوکهای نمونهبرداری رمزگشا، لایههای پیچشی (همانطور که در [ 52 ] پیشنهاد شد)، عادیسازی دستهای، و فعالسازیهای Leaky ReLU [ 53 ] دنبال میشوند (زیرا این تابع فعالسازی به تثبیت آموزش cGAN کمک میکند [ 54 ] ).
اطلاعات از تمام لایه های شبکه مولد عبور می کند. مشابه U-Net [ 13 ]، ما اتصالات پرش را اضافه کردیم که به اشتراک گذاری اطلاعات سطح پایین بین رمزگذار و رمزگشا را امکان پذیر می کند تا ویژگی های آموخته شده در لایه های اول حفظ شود و جریان گرادیان بهتری ارائه شود. فعال سازی SoftMax به آخرین لایه اعمال می شود برای حفظ argmax برای هر کانال و خروجی یک کاشی مصنوعی تک کاناله 256 × 256 پیکسل (نقشه احتمال). یک نمایش گرافیکی از شبکه ژنراتور پیشنهادی در شکل 3 ارائه شده است .
ما همچنین بر افزایش کارایی محاسباتی شبکه ژنراتور خود تمرکز کردیم. را معماری توصیف شده در شکل 4 دارای 2,006,974 پارامتر است که در مقایسه با تعداد پارامترهای مشخص شده توسط معماری اصلی U-Net برای همان اندازه ورودی (31,031,685 پارامتر) 93.53% کاهش دارد.
5.2. تبعیض کننده
شبکه تبعیض، ، یک PatchGAN اصلاح شده است [ 14 ] که برای طبقه بندی کاشی های ورودی و اختصاص توزیع صحیح ورودی از کجا آموزش دیده است (توزیع جاده موجود در کارتوگرافی رسمی، ، یا توزیع جاده بازسازی شده، ). کاشی های ورودی 256 × 256 پیکسل به چهار تکه 128 × 128 (به جای 32 × 32، همانطور که در اجرای اصلی پیشنهاد شد) تقسیم می شوند تا احتمال لکه هایی که حاوی هیچ عنصر جاده نیستند کاهش یابد. هر یک از آنها ارزیابی می شود و تصمیم نهایی میانگین امتیاز به دست آمده در هر یک از چهار وصله است (همانطور که در شکل 5 از [ 41 ] توضیح داده شده است).
از دیدگاه معماری، از هفت بلوک کانولوشن تشکیل شده است. اولین بلوک کانولوشن دارای یک لایه کانولوشن با اندازه هسته 3 × 3 و گام 1 است. ما نرمال سازی طیفی را در هر بلوک کانولوشن اضافه کردیم تا ناپایداری آموزش تمایزکننده را کاهش دهیم [ 55 ]. پنج بلوک کانولوشن بعدی از لایه های کانولوشن با اندازه هسته 4×4 و گام 2 تشکیل شده است و به دنبال آن نرمال سازی دسته ای قرار می گیرد. به دنبال توصیه [ 26 ]، ما فعالسازی Leaky ReLU (با شیب منفی 0.2) را بر روی تمام لایههای تشخیصدهنده اعمال کردیم و همچنین لایههای جمعکننده را با پیچشهای گامبهگام جایگزین کردیم، زیرا ثابت شد که رفتار آموزشی پایدارتر را تضمین میکند [ 14 ]]. آخرین بلوک تشخیصگر از یک لایه کانولوشن با هسته 4 × 4 و گام 1 تشکیل شده است که با یک تابع فعال سازی سیگموئید ختم می شود که نقشه های ویژگی را در یک امتیاز طبقه بندی اسکالر برای هر پچ 128 × 128 پیکسل ترسیم می کند.
یک نمایش ساده از شبکه تشخیص دهنده پیاده سازی شده را می توان در شکل 4 یافت . تعداد کل پارامترهای 2,791,009 است که در مقایسه با PatchGAN اصلی (که دارای 6,968,257 پارامتر) 85.61% کاهش است. لطفاً توجه داشته باشید که ما شبکههای مولد و تفکیککننده خود را با استفاده از مفاهیم معرفیشده توسط U-Net و PatchGAN (مثلاً ساختارهای رمزگذار-رمزگشا با اتصالات پرش یا مدلسازی یک تصویر بهعنوان یک فیلد تصادفی مارکوف در یک اندازه وصله تعیینشده) ساختهایم، اما بر روی آن تمرکز کردیم. کاهش ردپای محاسباتی شبکه ها برای استفاده از بودجه محاسباتی موجود.
گرادیان خروجی شبکه تفکیک کننده با توجه به داده های بازسازی شده مجبور خواهد شد برای تولید داده های واقعی تر (نزدیک تر به توزیع داده های واقعی جاده موجود در کارتوگرافی رسمی). در یک حالت ایده آل، داده های مصنوعی آنقدر به توزیع واقعی داده نزدیک است که قادر به تشخیص تفاوت بین دو توزیع داده نیست.
5.3. فرآیند یادگیری
هر نمونه مشروط ورودی، ، به طور مصنوعی با معرفی تصادفی خراب می شود، ، متشکل از شکاف هایی با اشکال و اندازه های مختلف (شکاف های مربعی و دایره ای [ 52 ]، شکاف های قلم مو [ 31 ]، و حتی بیشتر شکاف های لکه ای بدون ساختار [ 56 ]، یا ترکیبی از همه آنها)، همانطور که در [ 15 ] نیز پیشنهاد شده است. . این شکاف های مصنوعی به طور تصادفی به اندازه های مختلف تغییر مقیاس داده می شوند و به صورت آنلاین اضافه می شوند و منبع تصادفی در داده های آموزشی را نشان می دهند که اجازه می دهد برای خروجی بسیاری از نتایج مصنوعی مختلف. شکاف ها بدون مکان مشخصی به داده های شرطی اضافه می شوند. ; هدف آموزش این است که یاد بگیریم چگونه آنها را نقاشی کنیم بدون اینکه از موقعیت آنها در تصویر اطلاع داشته باشیم (موقعیت مناطق برای رنگ آمیزی ارائه نشده است ). ما همچنین افزایش دادهها شامل چرخشهای تصادفی 90 درجه را اضافه کردیم تا مدل را در معرض جنبههای بیشتری از دادههای آموزشی قرار دهیم و رفتار بیش از حد برازش را کاهش دهیم.
ژنراتور، ، یک کاشی خراب با ابعاد 256 × 256 پیکسل را به عنوان ورودی می گیرد و یک نسخه نقاشی شده ارائه می دهد که در آن شکاف ها پر می شود. بعد، چهار وصله تصویر تولید شده و چهار وصله نمونه اصلی را ارزیابی می کند (حاوی یک نمایش جاده از نقشهبرداری رسمی جاده، بدون شکاف) برای محاسبه آنتروپی متقاطع بین جفتهای مربوط به تکههای 128 × 128. سپس خطا در مدل منتشر میشود. یک نمایش ساده که روش یادگیری مدل cGAN پیاده سازی شده را توصیف می کند را می توان در شکل 5 یافت .
در شکل 5 مشاهده می شود که شبکه تفکیک کننده با مجموعه هایی از نمونه های جعلی و واقعی آموزش داده شده است. سعی می کند تشخیص دهد کدام تصاویر واقعی هستند ( ) و که توسط ( )، در حالی که هدف این شرکت تولید کاشی های مصنوعی است که از کاشی های واقعی قابل تشخیص نیستند. شبکه تشخیص دهنده نمونه واقعی را به عنوان ورودی می گیرد، ( نزدیک به 1 باشد) و نمونه جعلی، تجزیه و تحلیل توزیع برای تصمیم گیری در مورد اینکه آیا داده ها تولید شده اند یا از مجموعه داده های نمونه واقعی می آیند. سعی می کند تفاوت بین خروجی خود را در کاشی های واقعی و خروجی آن در کاشی های بازسازی شده را به حداکثر برساند (تلاش برای ایجاد نزدیک به 0، به این معنی که ورودی جعلی است)، while سعی می کند بسازد نزدیک به 1 (یعنی ورودی واقعی است).
در این مورد، تمایز دهنده با استفاده از یادگیری نظارت شده از طریق صعود گرادیان تصادفی با حداقل مربعات افت تولید (LSGAN) پیشنهاد شده در [ 57 ] آموزش می بیند. . مانند یک طبقه بندی کننده باینری عمل می کند که برای تمایز بین تولید شده آموزش دیده است [ 58 ] و نمونه واقعی، و دارای یک تابع سیگموئید برای ارزیابی اینکه آیا شکاف ها به درستی پر شده اند (اگر نمونه واقعی است یا نه)، هر ورودی احتمال واقعی بودن 0.5 و جعلی بودن 0.5. هر جفت ورودی/هدف را در سطح وصله مقایسه می کند و آنتروپی متقاطع بین اطلاعات شرطی را تخمین می زند، (قبل از معرفی شکاف ها)، و بازسازی شد با فرمول سپس یک امتیاز احتمال در سطح وصله در مورد اینکه چقدر واقعی به نظر می رسند را ارائه می دهد و میانگین نتایج را برای ارائه میانگین تصویر کلی (برای تابع ضرر مدل استفاده می شود) ارائه می دهد. بر اساس خطای طبقهبندی متمایزکننده، وزنها سپس برای به حداکثر رساندن عملکرد آن تنظیم میشوند (احتمال را به حداکثر میرساند. درست بودن) با فرمول زیر: .
شبکه ژنراتور برای تعمیر کاشی های خراب، گرفتن یک پچ خراب به عنوان ورودی، و ارائه یک نسخه نقاشی شده که در آن شکاف های تصادفی پر شده است، آموزش دیده است. یک نقشه احتمال را پیش بینی می کند، ، که نشان دهنده احتمال “جاده” یا “پس زمینه” بودن یک پیکسل است و هدف آموزشی آن تولید کاشی های مصنوعی است که از کاشی های واقعی قابل تشخیص نیستند. بر خلاف ، به توزیع واقعی دسترسی ندارد، ، و استفاده می کند برای مشاهده اینکه کاشی های بازسازی شده برای به روز رسانی وزن آن ها چقدر واقعی هستند. همانطور که در بخش 3 توضیح داده شد ، وزن ژنراتور بر اساس خروجی تفکیک کننده تنظیم می شود تا تلفات پیش بینی شده توسط برای تصاویر تولید شده که به عنوان “واقعی” مشخص شده اند. هزینه خصمانه است . بدین ترتیب، وزنها که نشان میدهند تصاویر تولید شده واقعی بودند، بهروزرسانیهای وزن زیادی را مجبور میکنند به سمت تولید تصاویر واقعی تر
تابع تلفات ترکیبی مدل توسط ، جایی که و . در حین تمرین وزنه بالاتری به آن می زنیم برای از دست دادن بازسازی به شدت مدل را به سمت ایجاد بازسازی های قابل قبول از تصویر ورودی (تصاویر واقعی تر) تشویق می کند زیرا عملکرد مولد را بهبود می بخشد [ 11 ]. در طول زمان، داده های واقعی تری ایجاد خواهد کرد، در حالی که در تمایز آن از توزیع داده واقعی بهتر خواهد شد، [ 25 ]. چه زمانی نمیتوان تعیین کرد که دادهها از مجموعه داده واقعی میآیند یا از مولد (دیگر تصاویر واقعی را از تقلبی متمایز نمیکند)، به حالت بهینه میرسد.
6. آزمایشات و تجزیه و تحلیل نتایج
ما مدل شرطی را با استفاده از کتابخانه یادگیری عمیق PyTorch v1 [ 59 ] برای Python [ 60 ] تعریف کردیم و آن را بر روی یک سرور لینوکس Ubuntu [ 61 ] با یک پردازنده 20 هسته ای Intel Xeon و یک کارت گرافیک Nvidia Tesla V100 با 16 گیگابایت آموزش دادیم. VRAM. ما مدل cGAN را با آن آموزش دادیم نمونههای واقعی کاشیهای بهدستآمده از پشتیبانی نقشهبرداری رسمی که در آن بخشهای جاده به هم متصل هستند (با اندازه ۲۵۶×۲۵۶ پیکسل، همانطور که در بخش ۴ توضیح داده شد ).
برای تمرین ما از بهینه ساز Adam [ 62 ] با نرخ یادگیری 0.001 و نرخ فروپاشی اولیه استفاده کردیم. و . از همان بهینه ساز استفاده شد آموزش، اما با نرخ یادگیری 0.002 و نرخ پوسیدگی اولیه و . ما نرخ یادگیری دو برابر بیشتر را برای برای بهبود همگرایی GAN ها و نرخ های مختلف یادگیری برای و برای جلوگیری از آسیب رساندن به بازنمایی های آموخته شده [ 63 ]. هر مرحله آموزشی شامل انتخاب تصادفی یک دسته از نمونه های واقعی و تولید دسته ای از نمونه های مصنوعی بر اساس کاشی های واقعی است (به دنبال روش آموزشی شرح داده شده در شکل 5 ). اندازه دسته انتخابی 32 تصویر (حداکثر مجاز توسط GPU) بود. در طول آموزش، گرادیان تابع تلفات با توجه به وزنهای شبکه برای یک نمونه ورودی-خروجی منفرد منتشر شد.
ما آزمایشها را پنج بار با استفاده از مقداردهی اولیه تصادفی تکرار کردیم تا بتوانیم تفسیر آماری نتایج عملکرد را فعال کنیم. هر بار، مقدار اولیه 40 دوره انتخاب شد، اما از دست دادن مدل نظارت شد، آموزش متوقف شد زمانی که ارزش هزینه آن در پنج دوره قبلی کاهش نیافته بود. به دلایل مقایسه، ما همچنین پیشرفته ترین مدل رنگ آمیزی ساختار نازک را آموزش دادیم [ 15 ]] برای همان تعداد تکرار در مجموعه داده آموزشی یکسان. ما اجرای یک GAN مشروط با U-Net استاندارد به عنوان مولد و PatchGAN استاندارد به عنوان متمایزکننده را به دلیل تعداد قابل توجهی از پارامترهای قابل آموزش بیشتر و هزینه محاسباتی مورد نیاز برای آموزش چنین شرطی برای مطالعه آینده ترک می کنیم. GAN.
پس از آن، ماسکهای تقسیمبندی اولیه از آزمون با ژنراتورهای شبکههای آموزشدیده ارزیابی شدند و پیشبینیها در قالب PNG بدون تلفات ذخیره شدند. مجموعه تست شامل پیشبینیهای تقسیمبندی اولیه توسط U-Net [ 13 ]—SEResNeXt50 [ 16 ] به دست آمد و امتیاز IoU 0.6726 را به دست آورد (همانطور که در بخش 2 توضیح داده شد.). اگر مدلها توزیع جادههای موجود در نقشهبرداری رسمی را به درستی یاد بگیرند، کیفیت دادههای تولید شده ثابت میشود و برای ارزیابی عملکرد شبکهها استفاده میشود. سپس، داده های تولید شده با داده های حقیقت زمینی از مجموعه آزمون (داده های دیده نشده، برای آزمایش ظرفیت تعمیم مدل) برای محاسبه معیارهای عملکرد زیر مقایسه شد: امتیاز IoU، امتیاز F1، دقت، و دقت و یادآوری، با هم. با مقادیر مربوطه محاسبه شده برای طبقات مثبت و منفی. وظیفه استخراج جاده شامل کلاس های بسیار نامتعادل است (جاده ها بخش کوچکی از تصویر را اشغال می کنند، معمولاً کمتر از 10٪) و معیارهای وزنی محاسبه نشده اند. نتایج گزارش شده را می توان در جدول 1 یافت .
همانطور که در جدول 1 نشان داده شده است ، پیاده سازی ما از روش های دیگر بهتر عمل می کند و بالاترین امتیاز عملکرد را به دست می آورد. در رابطه با معیارهای عملکرد انتخاب شده، ما در نظر میگیریم که امتیاز IoU مناسبترین امتیاز برای ارزیابی عملکرد یک مدل آموزشدیده برای عملیات باینری عناصر مکانی (به عنوان مثال، جاده و غیر جاده) است. دلیل این امر این است که کلاسها در چنین سناریوهایی بسیار نامتعادل هستند (در مجموعه دادههای ما، پیکسلهای جادهها به طور کلی حدود 10 درصد پیکسلها را اشغال میکنند)، و معیارهای سنتی ML میتوانند عملکرد یک مدل را گمراه کنند [ 12 ]. امتیاز IoU با فرمول محاسبه می شود ، برای هر دو مجموعه، و (به عنوان مثال، مجموعه حقیقت زمین و مجموعه بازسازی شده تولید شده توسط ).
مدل cGAN پیشنهادی به میانگین امتیاز IoU 0.004 ± 0.6801 دست یافت که نشان دهنده بهبود متوسط 0.75٪ نسبت به نتایج تقسیم بندی معنایی اولیه است. اجرای cGAN با بهترین عملکرد، حداکثر بهبود امتیاز IoU 1.28٪ را به دست آورد (مقدار عملکرد 0.6854، افزایش از 0.6726 به دست آمده توسط U-Net [ 13 ]—SEResNeXt50 [ 16 ]). هنگام مقایسه نتایج امتیاز IoU با نتایج بدست آمده توسط Thin-structure-inpainting [ 15 ] که برای کار مشابه در مجموعه آموزشی مشابه آموزش داده شده است، می توان مشاهده کرد که پیاده سازی ما از مدل پیشرفته با حداکثر عملکرد بهتر عمل کرده است. تفاوت 1.04٪. با این وجود، رنگ آمیزی ساختار نازک [ 15] همچنین میانگین بهبود نمره IoU 0.15٪ با توجه به مقدار IoU اولیه به دست آمده توسط مدل تقسیم بندی معنایی به دست آورد.
با توجه به سایر معیارهای عملکرد محاسبهشده، سناریوی بازپرداخت دقیق فراخوان [ 64] در هر دو مدل رنگ آمیزی عمیق وجود دارد – هر دو مدل cGAN که برای عملیات رنگ آمیزی عمیق آموزش دیده اند، نرخ FP را کاهش می دهند تا مقادیر دقت خود را افزایش دهند (دقت بالاتر شامل به حداقل رساندن نرخ FP است) به قیمت کاهش معیارهای فراخوانی (یک فراخوان بیشتر شامل می شود به حداقل رساندن نرخ FN). اجرای cGAN ما به طور متوسط 4.95٪ از مقادیر فراخوان را قربانی کرد (که از 0.9438 در مورد بهترین مدل تقسیم بندی به 0.021 ± 0.8943 کاهش یافت) تا میانگین سود در دقت 1.62٪ (افزایش از 0.93979 ± 0.9393 به 0.9379 به 0.021) برسد. نسبت به مدل اصلی این سناریوی مبادله با توجه به اینکه مجموعه داده حقیقت زمینی حاوی کلاسهای نامتعادل با نمونههای مثبت کمتر به دلیل ماهیت شی زمینفضایی مورد مطالعه است، قابل انتظار است.شکل 2 b,c) و بنابراین، احتمال اینکه آنها حاوی پیکسل های بیشتری باشند که به درستی با برچسب “جاده” در حقیقت زمین (نمونه های مثبت) برچسب گذاری شده اند، بیشتر بود. در نتیجه، تفاوت های قابل توجهی را می توان در یادآوری و دقت مشاهده کرد. مدلهای رنگآمیزی عمیق، یادآوری را قربانی افزایش دقت خود با افزایش نسبتهای TN و FN کردند. با این حال، نمرات دقت و یادآوری را نباید به صورت جداگانه مورد بحث قرار داد و به همین دلیل، امتیاز F1 نیز محاسبه شد. اجرای ما به افزایش میانگین 0.46% (0.0040 ± 0.7713) نسبت به مقدار امتیاز اولیه F1 0.7667 دست یافت. در جدول 1 می توان مشاهده کرد که اگرچه معیارهای عملکرد از طبقات مثبت به طور کلی کمتر است، اما نمرات عملکرد کلی افزایش یافته است.
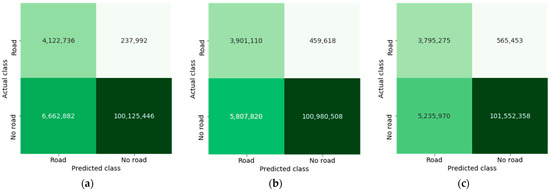
به منظور مطالعه رابطه بین نرخ خطای بهدستآمده توسط شبکههای عصبی آموزشدیده در این کار و اهمیت معیارهای عملکرد، در شکل 6 ماتریسهای سردرگمی بهدستآمده توسط مدلها هنگام ارزیابی مجموعه آزمایشی حاوی دادههای دیده نشده را نشان میدهیم. کاشی). در ماتریس سردرگمی به دست آمده توسط پیاده سازی ما (ارائه شده در شکل 6ج)، می توان دریافت که مدل ما به درستی 3,795,275/4,360,728 پیکسل متعلق به کلاس “جاده” (نسبت TP 0.87) و 101,552,358/106,788,328 نمونه “بدون جاده” (نسبت TN به نسبت labeling/rec59,25) را به درستی تشخیص داده است. 106,788,328 پیکسل از رده “بدون جاده” (نسبت FP 0.049) و 565,453/4,360,728 نمونه از کلاس “جاده” موجود نیست (نسبت FN 0.130). در ماتریس سردرگمی، FN و FP نمونه هایی هستند که به اشتباه طبقه بندی شده اند و نشان دهنده 5.22٪ از پیش بینی ها هستند، در حالی که TN و TP نمونه هایی هستند که به درستی طبقه بندی شده اند و 94.78٪ از پیش بینی ها را نشان می دهند. در مقایسه، مدل تقسیمبندی که پیشبینیهای اولیه را به درستی 93.79 درصد از پیکسلها را طبقهبندی کرد، در حالی که بهترین نسخه Thin-structure [ 15 ]مدل ] که برای رنگ آمیزی عمیق آموزش داده شده است، 94.36 درصد از پیکسل ها را به درستی طبقه بندی کرده است. نتایج حاصل از ماتریس های سردرگمی با نتایج ارائه شده در جدول 1 همراستا هستند .
می توان مشاهده کرد که مطابق با معیارهای عملکرد جدول 1GAN های مشروط آموزش دیده، TP و FP را کاهش دادند و نرخ های FN و TN را افزایش دادند تا عملکرد کلی خود را بهینه کنند و شکاف ها را در نمایش های خط جاده اولیه رنگ آمیزی کنند. می توان اشاره کرد که اگرچه نرخ های TP در مقایسه با ماسک های تقسیم بندی اولیه کمتر است، اما مدل ها به طور قابل توجهی پیش بینی های TN را بهبود بخشیدند و میانگین نمرات IoU خود را افزایش دادند. به طور کلی، پیشبینیهای صحیح در هر دو سناریو رنگآمیزی عمیق نسبت به ماسکهای تقسیمبندی اولیه دارای نسبت بالاتری هستند – رنگآمیزی ساختار نازک به دقت متوسط 0.001 ± 0.9437 دست یافت، در حالی که اجرای ما به دقت متوسط 0.9475 0.9475 ± 0.003 بهبود یافت. به ترتیب +0.58٪ و +0.96٪، بیش از مقدار دقت اولیه 0.9379 به دست آمده توسط بهترین مدل تقسیم بندی با عملکرد.
برای به دست آوردن درک بهتری از معنای این بهبودها در معیارهای عملکرد، ما یک تفسیر کیفی غیر عددی از نتایج را از طریق اعتبار سنجی ادراکی انجام دادیم. ما ده تصویر از مجموعه آزمایشی (شامل دادههای دیده نشده توسط مدلها در طول آموزش) نمونهبرداری کردیم و یک بازرسی بصری از تصاویر تولید شده برای مقایسه نتایج بهدستآمده از اجرای خود و نتایج بهدستآمده توسط مدلهای دیگر انجام دادیم. این عملیات به ما امکان می دهد تا الگوهایی را در شی مورد مطالعه شناسایی کنیم که ممکن است مشاهده آنها با روش کمی غیرممکن باشد (به عنوان مثال، سناریوهایی با غلظت های بالاتر FP و FN). نتایج در شکل 7 آمده است.
در شکل 7مشاهده میشود که اجرای ما سازگارترین بازسازیها را ایجاد میکند، نتایج ارائهشده در مقایسه با ماسکهای تقسیمبندی اولیه بیشتر شبیه به ماسکهای حقیقت زمین است. ما همچنین میتوانیم دلیل سناریوی مبادله با فراخوان دقیق را شناسایی کنیم – اگرچه بازنماییهای جادهها از نقشهبرداری رسمی فاقد شکاف هستند، اما سطح واقعی جاده را پوشش نمیدهند (خطوط مورد استفاده برای ترسیم بخشهای جاده فقط دارای اهمیت نقشهبرداری هستند و بر اساس اهمیت جاده انتخاب شدند). اگرچه نرخهای FP پایینتر است، اما مدلها همچنان نرخهای FP بالاتری را در مقایسه با دادههای حقیقت زمینی به دلیل خطاهای نمایشی از پشتیبانی نقشهبرداری رسمی موجود ارائه میدهند. با این حال،
ما همچنین به تأثیر تصادفی بودن اعمال شده روی دادههای شرطی اشاره کردیم، زیرا دادههای تولید شده ما اغلب مصنوعات شکاف کوچکی را ارائه میدهند. با این حال، مجموعه دادههای دنیای واقعی ما حاوی شکافهای بسیار بیشتری است و پیشبینیهای ماشینی بهدستآمده با اجرای مشروط ما میتواند به طور قابل توجهی بهبود یافته در نظر گرفته شود. علاوه بر این، ما یک اثر نازک شدن را بر روی خطوط جاده پس از پردازش مشاهده کردیم، که به شبکههای آموزش دیده کمک کرد تا معیارهای عملکردی بالاتری داشته باشند، زیرا نمایش جاده از نقشهبرداری رسمی دارای عرض دلخواه است که کل سطح جاده را پوشش نمیدهد. .
اگرچه نتایج پس از پردازش کامل نیستند، اما مناسب بودن استفاده از یادگیری مولد را برای وظیفه پس پردازش قطعهبندی معنایی جاده تأیید میکنند، و ما قویاً معتقدیم که این تکنیک میتواند برای استخراج بهتر عناصر جغرافیایی از تصاویر هوایی استفاده شود. ما در نظر میگیریم که هدف آموزشی این مطالعه (بهدست آوردن نمایش جاده نزدیکتر به موارد موجود در نقشهبرداری رسمی) با موفقیت به دست آمد، زیرا نتایج تولید شده به وضوح نشاندهنده بهبودی نسبت به پیشبینیهای تقسیمبندی اولیه است.
7. نتیجه گیری
برای غلبه بر کاستیهای ناشی از استخراج جادهها از طریق تقسیمبندی معنایی، ما یک GAN مشروط آموزشدیده برای یادگیری توزیع جادههای موجود در نقشهبرداری رسمی در یک محیط بدون نظارت پیادهسازی کردیم. تا جایی که ما می دانیم، این یکی از اولین تلاش ها برای پس پردازش در مقیاس بزرگ قطعه بندی اولیه جاده با عملیات رنگ آمیزی عمیق مبتنی بر یادگیری مولد برای کاهش نواقص موجود در پیش بینی های اولیه (به عنوان مثال، ناپیوستگی ها و شکاف ها) بود. به صورت خصمانه
مدل cGAN پیشنهادی در مقایسه با نتایج ماسک تقسیمبندی اولیه، حداکثر بهبود 1.28 درصدی را در امتیاز IoU در دادههای آزمایشی دیده نشده به دست آورد و از سایر مدلهای پیشرفته برتری داشت. ارزیابی کیفی انجامشده بر روی چندین سناریو، ارتباط رویکرد بازسازی را نشان داد و بهبود عملکرد مشاهدهشده در مقایسه متریک را تأیید کرد – کاشیهای تولید شده دارای نمایشهایی از جاده هستند که بیشتر شبیه به حوزه هدف هستند (توزیع جاده موجود در پشتیبانی نقشهبرداری رسمی).
با این حال، مانند بیشتر مدلهای یادگیری عمیق، کیفیت پیشبینیهای ماشین تولید شده به شدت به کیفیت دادههای آموزشی مشروط وابسته بود و مدل ما به تعداد حفرهها در دادهها، مهمترین منبع، حساس است. خطای عیوب موجود در کارتوگرافی رسمی است. لازم به ذکر است که در کارهای مربوط به استخراج طبقات نامتعادل (مانند استخراج جاده)، حتی افزایش اندک در معیارهای عملکرد می تواند قابل توجه باشد و ارزیابی کیفی اضافی در مناطق دیده نشده مورد نیاز است.
این نتایج اثربخشی استفاده از یادگیری مولد مشروط را برای ماسکهای قطعهبندی تصویر پس از پردازش جادههای استخراجشده از تصاویر ارتوی هوایی نشان میدهد. اگرچه فضایی برای بهبود وجود دارد، پیشنهاد ما مزایای عملیات نقاشی عمیق با یادگیری مولد را به عنوان تکنیکی که برای بازسازی شکاف ها در اشیاء سنجش از دور استخراج شده ناشی از انسداد در مناظر به کار می رود، نشان می دهد. مدل cGAN پیشنهادی برای نتایج تقسیمبندی باینری جادهها که توسط هر مدل تقسیمبندی ارائه میشود (جایی که ناپیوستگیها وجود دارد) قابل استفاده است و ما انتظار داریم پیشرفتهای مشابهی نسبت به نتایج داشته باشیم.
ما بر این باوریم که در جهانی که وسایل نقلیه خودران اهمیت بیشتری پیدا میکنند، شیوه مدیریت دولتی نقشهبرداری جادهها باید تکامل یابد و از نمادسازی ساده نقشهبرداری جادهها به داشتن نقشهبرداری کامل و در دسترس سطح جاده تغییر کند. ما قصد داریم به بهبود این نتایج استخراج جاده با سایر رویکردهای بدون نظارت، مانند ترجمه تصویر به تصویر، ادامه دهیم. هدف نهایی طراحی یک راه حل سرتاسری است که بتواند با موفقیت جاده ها را از مناطق گسترده استخراج کند، در حالی که به درستی خواص توپولوژیکی عنصر جغرافیایی را حفظ کند.
منابع
- Cira, C.-I.; آلکاریا، آر. Manso-Callejo، M.-Á.; Serradilla, F. A Deep Learning-based Solution for Larg-scale Extraction of the Second Road Road Network from High Resolution Aerial Orthoimagery. Appl. علمی 2020 ، 10 ، 7272. [ Google Scholar ] [ CrossRef ]
- هو، اف. Xia، G.-S. هو، جی. Zhang، L. انتقال شبکه های عصبی پیچیده عمیق برای طبقه بندی صحنه تصاویر سنجش از دور با وضوح بالا. Remote Sens. 2015 ، 7 ، 14680–14707. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سنتیلناث، جی. واریا، ن. دوکانیا، ع. آناند، جی. Benediktsson، JA Deep TEC: Deep Transfer Learning با Ensemble Classifier برای استخراج جاده از تصاویر پهپاد. Remote Sens. 2020 , 12 , 245. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شان، بی. Fang, Y. مدل شبکه عصبی عمیق مبتنی بر آنتروپی متقاطع برای استخراج جاده از تصاویر ماهوارهای. Entropy 2020 , 22 , 535. [ Google Scholar ] [ CrossRef ]
- لین، ی. خو، دی. وانگ، ن. شی، ز. Chen, Q. استخراج جاده از تصاویر سنجش از دور با وضوح بسیار بالا از طریق مدل Nested SE-Deeplab. Remote Sens. 2020 , 12 , 2985. [ Google Scholar ] [ CrossRef ]
- دونگ، آر. لی، دبلیو. فو، اچ. گان، ال. یو، ال. ژنگ، جی. Xia، M. نقشه برداری از درختکاری نخل روغنی از تصاویر سنجش از دور با وضوح بالا با استفاده از یادگیری عمیق. بین المللی J. Remote Sens. 2020 ، 41 ، 2022–2046. [ Google Scholar ] [ CrossRef ]
- ژانگ، ز. ژانگ، ایکس. سان، ی. Zhang، P. استخراج خط مرکزی جاده از تصویر هوایی با وضوح بسیار بالا و داده های LiDAR بر اساس اتصال جاده. Remote Sens. 2018 , 10 , 1284. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، جی. Qin، Q. لی، جی. Li, Y. استخراج جاده روستایی از تصاویر سنجش از دور با وضوح بالا بر اساس استنتاج ویژگی های هندسی. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 314. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- برتالمیو، ام. ساپیرو، جی. کاسلس، وی. Ballester, C. Inpainting تصویر. در مجموعه مجموعه مقالات بیست و هفتمین کنفرانس سالانه گرافیک کامپیوتری و تکنیک های تعاملی، SIGGRAPH 2000، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 23-28 ژوئیه 2000; Brown, JR, Akeley, K., Eds. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2000; صص 417-424. [ Google Scholar ]
- ژانگ، سی. بنژیو، اس. هاردت، ام. رشت، بی. Vinyals، O. درک یادگیری عمیق نیاز به تعمیم مجدد دارد. در مجموعه مقالات پنجمین کنفرانس بین المللی در مورد بازنمایی های یادگیری، ICLR 2017، تولون، فرانسه، 24–26 آوریل 2017. مجموعه مقالات پیگیری کنفرانس; OpenReview.net، 2017. [ Google Scholar ]
- پاتاک، د. کراهنبول، پ. دوناهو، جی. دارل، تی. Efros، AA Context Encoders: Feature Learning توسط Inpainting. در مجموعه مقالات کنفرانس IEEE 2016 در مورد دید رایانه و تشخیص الگو، CVPR 2016، لاس وگاس، NV، ایالات متحده آمریکا، 27 تا 30 ژوئن 2016. [ Google Scholar ]
- بنجدیرا، بی. عمار، ع. کوبا، ع. Ouni، K. انطباق دامنه کارآمد داده برای تقسیم بندی معنایی تصاویر هوایی با استفاده از شبکه های متخاصم مولد. Appl. علمی 2020 ، 10 ، 1092. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکه های کانولوشن برای تقسیم بندی تصویر زیست پزشکی. در محاسبات تصویر پزشکی و مداخله به کمک کامپیوتر – MICCAI 2015 ; یادداشت های سخنرانی در علوم کامپیوتر; نواب، ن.، هورنگر، ج.، ولز، دبلیو.، فرانگی، ا.، ویرایش. Springer: Cham, Switzerland, 2015; جلد 9351. [ Google Scholar ]
- ایزولا، پی. ژو، جی.-ی. ژو، تی. Efros، ترجمه تصویر به تصویر AA با شبکه های خصمانه مشروط. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو، CVPR 2017، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017. [ Google Scholar ]
- چن، اچ. Giuffrida، MV; دورنر، پی. رنگ آمیزی کور ماسک های سازه های نازک در مقیاس بزرگ با آموزش خصمانه و تقویتی تسفتریس، SA. arXiv 2019 ، arXiv:1912.02470. [ Google Scholar ]
- هو، جی. شن، ال. Sun، G. شبکه های فشار و برانگیختگی. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در مورد دید رایانه و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 23 ژوئن 2018؛ صص 7132–7141. [ Google Scholar ]
- عبدالهی، ع. پرادان، بی. شوکلا، ن. چاکرابورتی، اس. Alamri، A. رویکردهای یادگیری عمیق به کار گرفته شده در مجموعه داده های سنجش از راه دور برای استخراج جاده: یک بررسی پیشرفته. Remote Sens. 2020 , 12 , 1444. [ Google Scholar ] [ CrossRef ]
- لی، پی. زنگ، ی. وانگ، سی. لی، جی. چنگ، م. لو، ال. Yu, Y. استخراج شبکه جاده از طریق یادگیری عمیق و پیچیدگی انتگرال خط. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2016، IGARSS 2016، پکن، چین، 10 تا 15 ژوئیه 2016. [ Google Scholar ]
- بوسلایف، آ. سفربکوف، اس.اس. ایگلوویکوف، وی. Shvets، A. شبکه کاملاً پیچیده برای استخراج خودکار جاده از تصاویر ماهواره ای. در مجموعه مقالات کنفرانس IEEE 2018 در کارگاههای بینایی رایانه و تشخیص الگو، کارگاههای CVPR 2018، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun، J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE 2016 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لاس وگاس، NV، ایالات متحده آمریکا، 27 تا 30 ژوئن 2016؛ صص 770-778. [ Google Scholar ]
- خو، ی. فنگ، ی. زی، ز. هو، ا. Zhang, X. تحقیقی در مورد استخراج شبکه جاده از تصاویر سنجش از دور با وضوح بالا. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی ژئوانفورماتیک، ژئوانفورماتیک 2018، کونمینگ، چین، 28 تا 30 ژوئن 2018؛ Hu, S., Ye, X., Yang, K., Fan, H., Eds. IEEE: Piscataway، نیوجرسی، ایالات متحده آمریکا، 2018؛ صص 1-4. [ Google Scholar ]
- چنگ، جی. وانگ، ی. خو، اس. وانگ، اچ. شیانگ، اس. Pan، C. تشخیص خودکار جاده و استخراج خط مرکزی از طریق شبکه عصبی کانولوشنال انتها به انتها آبشاری. IEEE Trans. Geosci. از راه دور. Sens. 2017 , 55 , 3322–3337. [ Google Scholar ] [ CrossRef ]
- وی، ی. وانگ، ز. Xu, M. Road Structure CNN اصلاح شده برای استخراج جاده در تصویر هوایی. IEEE Geosci. از راه دور. سنس لت. 2017 ، 14 ، 709-713. [ Google Scholar ] [ CrossRef ]
- Goodfellow، IJ; پوگت ابادی، ج. میرزا، م. خو، بی. وارد-فارلی، دی. اوزایر، س. کورویل، AC; Bengio، Y. شبکه های متخاصم مولد. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی 27: کنفرانس سالانه سیستمهای پردازش اطلاعات عصبی 2014، مونترال، QC، کانادا، 8 تا 13 دسامبر 2014. [ Google Scholar ]
- پان، ز. یو، دبلیو. یی، ایکس. خان، ا. یوان، اف. ژنگ، ی. پیشرفت اخیر در مورد شبکه های متخاصم مولد (GANs): یک بررسی. دسترسی IEEE 2019 ، 7 ، 36322–36333. [ Google Scholar ] [ CrossRef ]
- رادفورد، ای. متز، ال. چینتالا، اس. آموزش نمایندگی بدون نظارت با شبکههای متخاصم مولد عمیق. در مجموعه مقالات چهارمین کنفرانس بین المللی در مورد بازنمایی یادگیری، ICLR 2016، سان خوان، پورتوریکو، 2 تا 4 مه 2016. [ Google Scholar ]
- میرزا، م. شبکه های متخاصم مولد مشروط اوسیندرو، اس. arXiv 2014 ، arXiv:1411.1784. [ Google Scholar ]
- ایزوکا، اس. سیمو سرا، ای. ایشیکاوا، اچ. تکمیل تصویر سازگار جهانی و محلی. ACM Trans. نمودار 2017 ، 36 ، 107:1–107:14. [ Google Scholar ] [ CrossRef ]
- لیو، جی. ردا، FA; Shih، KJ; وانگ، T.-C. تائو، آ. Catanzaro، B. نقاشی تصویر برای سوراخ های نامنظم با استفاده از پیچش جزئی. در مجموعه مقالات چشم انداز کامپیوتر-ECCV 2018- پانزدهمین کنفرانس اروپایی، مونیخ، آلمان، 8 تا 14 سپتامبر 2018. [ Google Scholar ]
- یو، جی. لین، ز. یانگ، جی. شن، ایکس. لو، ایکس. Huang، TS تصویر مولد نقاشی با توجه متنی. در مجموعه مقالات کنفرانس IEEE 2018 در مورد بینایی کامپیوتری و تشخیص الگو، CVPR 2018، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018. [ Google Scholar ]
- یو، جی. لین، ز. یانگ، جی. شن، ایکس. لو، ایکس. Huang، TS تصویر آزاد در نقاشی با پیچش دردار. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF 2019 در بینایی کامپیوتر، ICCV 2019، سئول، کره، 27 اکتبر تا 2 نوامبر 2019. [ Google Scholar ]
- de la Fuente Castillo، V. دیاز آلوارز، آ. Manso-Callejo، M.-Á.; Serradilla García، F. Grammar Guided Programming Genetic for Search Architecture Network and Detection Road on Aerial Orthophotography. Appl. علمی 2020 ، 10 ، 3953. [ Google Scholar ] [ CrossRef ]
- واریا، ن. دوکانیا، ع. Jayavelu، S. DeepExt: یک شبکه عصبی پیچشی برای استخراج جاده با استفاده از تصاویر RGB گرفته شده توسط پهپاد. در مجموعه مقالات مجموعه سمپوزیوم IEEE در مورد هوش محاسباتی، SSCI 2018، بنگلور، هند، 18 تا 21 نوامبر 2018. [ Google Scholar ]
- لانگ، جی. شلهامر، ای. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE 2015 در مورد دید رایانه و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. [ Google Scholar ]
- شی، س. لیو، ایکس. لی، ایکس. تشخیص جاده از تصاویر سنجش از دور توسط شبکههای متخاصم مولد. دسترسی IEEE 2018 ، 6 ، 25486–25494. [ Google Scholar ] [ CrossRef ]
- بدرینارایانان، وی. کندال، ا. Cipolla، R. SegNet: معماری رمزگذار-رمزگشای پیچیده پیچیده برای تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 2481-2495. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- یانگ، سی. Wang, Z. Ansemble Wasserstein Generative Adversarial Method برای استخراج جاده از تصاویر سنجش از دور با وضوح بالا در مناطق روستایی. دسترسی IEEE 2020 ، 8 ، 174317–174324. [ Google Scholar ] [ CrossRef ]
- هارتمن، اس. واینمن، ام. وسل، آر. کلاین، R. StreetGAN: به سوی سنتز شبکه جاده با شبکه های متخاصم مولد. در مجموعه مقالات کنفرانس بین المللی گرافیک کامپیوتری، تجسم و همکاری بینایی کامپیوتری با انجمن EUROGRAPHICS، پلزن، جمهوری چک، 29 مه تا 2 ژوئن 2017. [ Google Scholar ]
- کوستئا، دی. مارکو، ا. لئوردئانو، ام. Slusanschi، E. ایجاد نقشههای راه در تصاویر هوایی با شبکههای دشمن مولد و بهینهسازی مبتنی بر هموارسازی. در مجموعه مقالات کنفرانس بینالمللی IEEE 2017 در کارگاههای بینایی رایانه (ICCVW)، ونیز، ایتالیا، 22 تا 29 اکتبر 2017. [ Google Scholar ]
- ژانگ، ی. لی، ایکس. Zhang، Q. اصلاح توپولوژی جاده از طریق یک شبکه متخاصم مولد چند شرطی. Sensors 2019 , 19 , 1162. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Cira, C.-I.; Manso-Callejo، M.-Á.; آلکاریا، آر. فرناندز پارجا، تی. بوردل سانچز، بی. Serradilla، F. یادگیری مولد برای پس پردازش پیشبینیهای تقسیمبندی معنایی: یک شبکه متخاصم مولد شرطی سبک وزن مبتنی بر Pix2pix برای بهبود استخراج مناطق سطح جاده. Land 2021 , 10 , 79. [ Google Scholar ] [ CrossRef ]
- چن، اچ. والریو جوفریدا، م. دورنر، پی. تسفتریس، SA Adversarial Larg-Scale Root Gap Inpainting. در مجموعه مقالات کنفرانس IEEE/CVF در کارگاههای آموزشی بینایی رایانه و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 21 ژوئن 2019. [ Google Scholar ]
- ساتون، آر اس؛ مک آلستر، DA; سینگ، اس پی؛ منصور، ی. روشهای گرادیان خط مشی برای یادگیری تقویتی با تقریب تابع. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی 12، کنفرانس NIPS، دنور، CO، ایالات متحده آمریکا، 29 نوامبر تا 4 دسامبر 1999. [ Google Scholar ]
- ویلیامز، RJ الگوریتمهای ساده آماری پیروی از گرادیان برای یادگیری تقویتی پیوندگرا. ماخ فرا گرفتن. 1992 ، 8 ، 229-256. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پاژوت، ع. د بزناک، ای. Gallinari، P. Inpainting تصویر خصمانه بدون نظارت. arXiv 2019 ، arXiv:1912.12164. [ Google Scholar ]
- کدالی، ن. آبرنتی، جی. هیز، جی. Kira، Z. در مورد همگرایی و پایداری GANs. arXiv 2017 , arXiv:1705.07215. [ Google Scholar ]
- Instituto Geográfico Nacional Centro descargas del CNIG (IGN). در دسترس آنلاین: https://centrodedescargas.cnig.es (در 3 فوریه 2020 قابل دسترسی است).
- Cira, C.-I.; آلکاریا، آر. Manso-Callejo، M.-Á.; Serradilla, F. چارچوبی بر اساس تودرتو شبکه های عصبی کانولوشن برای طبقه بندی جاده های ثانویه در تصاویر ارتوی هوایی با وضوح بالا. Remote Sens. 2020 , 12 , 765. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Forczmański، P. ارزیابی عملکرد منتخب آشکارسازهای صورت انسان مبتنی بر تصویربرداری حرارتی. در مجموعه مقالات دهمین کنفرانس بینالمللی سیستمهای تشخیص رایانه CORES 2017، Polanica Zdroj، لهستان، 22 تا 24 مه 2017. [ Google Scholar ]
- آیوف، اس. Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. در مجموعه مقالات سی و دومین کنفرانس بین المللی یادگیری ماشین، لیل، فرانسه، 6 تا 11 ژوئیه 2015؛ جلد 37، ص 448-456. [ Google Scholar ]
- نیر، وی. واحدهای خطی اصلاحشده هینتون، جنرال الکتریک ماشینهای محدود بولتزمن را بهبود میبخشند. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی یادگیری ماشین (ICML-10)، حیفا، اسرائیل، 21 تا 24 ژوئن 2010. Fürnkranz, J., Joachims, T., Eds. Omnipress: مدیسون، WI، ایالات متحده آمریکا، 2010؛ ص 807-814. [ Google Scholar ]
- ساساکی، ک. ایزوکا، اس. سیمو سرا، ای. ایشیکاوا، اچ. تشخیص شکاف مشترک و رنگ آمیزی نقاشی های خطی. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو، CVPR 2017، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017. [ Google Scholar ]
- ماس، آل. هانون، AY; Ng، AY یکسو کننده غیرخطی مدل های صوتی شبکه عصبی را بهبود می بخشد. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین (ICML)، آتلانتا، GA، ایالات متحده آمریکا، 16-21 ژوئن 2013. [ Google Scholar ]
- گلرجانی، ط. احمد، ف. آریوفسکی، م. دومولن، وی. Courville، AC بهبود آموزش GAN های Wasserstein. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی 30: کنفرانس سالانه سیستمهای پردازش اطلاعات عصبی 2017، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017. [ Google Scholar ]
- میاتو، تی. کاتائوکا، تی. کویاما، م. یوشیدا، Y. عادی سازی طیفی برای شبکه های متخاصم مولد. در مجموعه مقالات ششمین کنفرانس بینالمللی بازنماییهای یادگیری، ICLR 2018، ونکوور، BC، کانادا، 30 آوریل تا 3 مه 2018. [ Google Scholar ]
- دوپون، ای. Suresha، S. رنگ آمیزی معنایی احتمالی با CNN های محدود شده پیکسل. در مجموعه مقالات بیست و دومین کنفرانس بین المللی هوش مصنوعی و آمار، AISTATS 2019، ناها، ژاپن، 16-18 آوریل 2019. [ Google Scholar ]
- مائو، ایکس. لی، کیو. زی، اچ. لاو، RYK؛ وانگ، ز. Smoley، SP حداقل مربعات مولد شبکه های متخاصم. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ICCV 2017، ونیز، ایتالیا، 22 تا 29 اکتبر 2017. [ Google Scholar ]
- کوهلر، آر. شولر، سی جی; شولکوپف، بی. Harmeling، S. Mask-Specific Inpainting با شبکه های عصبی عمیق. در مجموعه مقالات تشخیص الگو – سی و ششمین کنفرانس آلمان، GCPR 2014، مونستر، آلمان، 2 تا 5 سپتامبر 2014. [ Google Scholar ]
- پاسسکه، آ. گراس، اس. ماسا، اف. لرر، ا. بردبری، جی. چانان، جی. کیلین، تی. لین، ز. گیملشاین، ن. آنتیگا، ال. و همکاران PyTorch: یک سبک ضروری، کتابخانه یادگیری عمیق با کارایی بالا. در پیشرفت در سیستم های پردازش اطلاعات عصبی 32 ; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., de Fox, E., Garnett, R., Eds. Curran Associates, Inc.: Red Hook, NY, USA, 2019; صفحات 8024–8035. [ Google Scholar ]
- ون روسوم، جی. Drake, FL Python 3 Reference Manual ; CreateSpace: Scotts Valley, CA, USA, 2009; شابک 1-4414-1269-7. [ Google Scholar ]
- Sobell, MG راهنمای عملی لینوکس اوبونتو . تحصیلات پیرسون: لندن، بریتانیا، 2015. [ Google Scholar ]
- Kingma، DP; با، جی. آدام: روشی برای بهینه سازی تصادفی. در مجموعه مقالات سومین کنفرانس بین المللی در مورد بازنمایی های یادگیری، ICLR 2015، مجموعه مقالات پیگیری کنفرانس، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015. [ Google Scholar ]
- هوسل، م. رامساور، اچ. Unterthiner، T. نسلر، بی. Hochreiter، S. GAN های آموزش دیده توسط قانون به روز رسانی دو مقیاس زمانی به یک تعادل نش محلی همگرا می شوند. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017. [ Google Scholar ]
- قدرت ها، تجسم DMW از تجارت در ارزیابی: از Recall-Recall و PN تا LIFT، ROC و BIRD. arXiv 2015 ، arXiv:1505.00401. [ Google Scholar ]
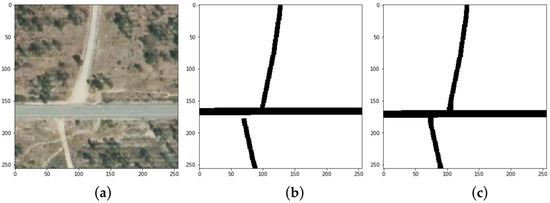
شکل 1. نمونه ای از رنگ آمیزی پس پردازش با عملگرهای مورفولوژی بر اساس اشکال برای پر کردن قسمت های گمشده ( c ) از پیش بینی های ماسک تقسیم بندی اولیه ( b ) ارائه شده توسط مدل تقسیم بندی معنایی پس از ارزیابی یک تصویر ارتومی هوایی نادیده ( a ).

شکل 2. رابطه بین تصویر ارتوی هوایی (ردیف اول، ( a1 – a10 ))، ماسک تقسیمبندی شطرنجی (زمین-حقیقت یا نمونه واقعی، مشاهده شده در ردیف دوم، ( b1 – b10 ) که به عنوان اطلاعات شرطی برای آموزش استفاده میشود. و پیشبینیهای تقسیمبندی معنایی (که در ردیف سوم مشاهده میشود، ( c1 – c10 )، که برای آزمایش عملکرد مدل استفاده میشود). توجه: مجموعه آموزشی شامل کاشی هایی با نمایش جاده در کارتوگرافی رسمی وجود دارد، در حالی که مجموعه آزمایشی شامل کاشیهایی با پیشبینی تقسیمبندی اولیه از ارزیابی تصاویر هوایی با مدل تقسیمبندی به دست آمدند. در این شکل، رنگ سفید برای نشان دادن پیکسل هایی با برچسب “بدون جاده” یا “پس زمینه” و رنگ سیاه برای نشان دادن پیکسل های متعلق به کلاس “جاده” استفاده می شود.
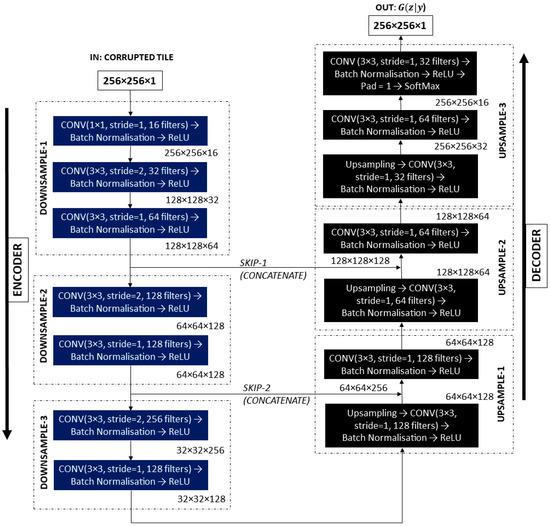
شکل 3. معماری ژنراتور پیشنهادی برای عملیات رنگ آمیزی عمیق.
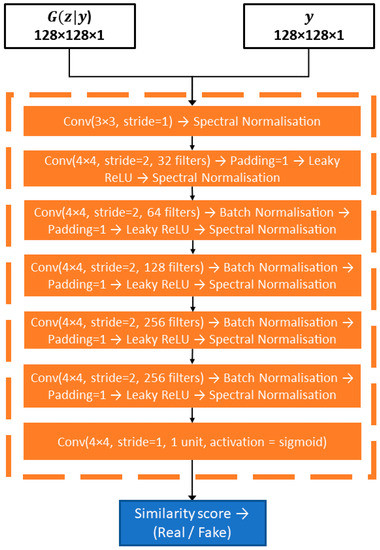
شکل 4. معماری تفکیک کننده پیشنهاد شده برای کار نقاشی عمیق.
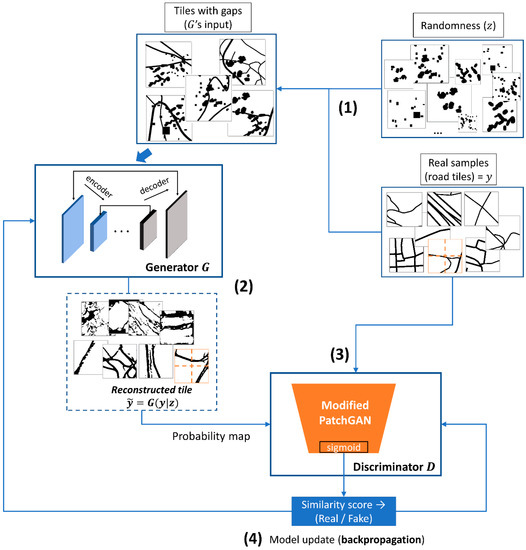
شکل 5. مروری بر فرآیند یادگیری مدل cGAN آموزش دیده برای نقاشی عمیق. ( 1 ) ابتدا شکاف های تصادفی به داده های شرطی وارد می شوند. ، برای تولید ورودی های خراب برای . ( 2 ) ژنراتور (شبکه U-Net مانند با اتصالات پرش) سپس برای پر کردن شکاف ها و رنگ آمیزی کاشی های خراب آموزش داده می شود. ( به نمونه های واقعی دسترسی ندارد، از توزیع واقعی داده ها، .) ( 3 ) تمایز کننده یک PatchGAN اصلاح شده است که وصله ها را از جفت های y و طبقه بندی می کند. و تصمیم می گیرد که آیا آنها از توزیع واقعی داده ها می آیند، ، یا از توزیع داده های مصنوعی، . ( 4 ) بازخورد دریافت می کند و به طور مکرر مولد داده مصنوعی را بهبود می بخشد تا شبکه تفکیک کننده را “گول بزند”. یادداشت ها: (الف) داده های واقعی به هر دو داده می شود (پس از اضافه کردن z ) و به . در کار نقاشی عمیق ما، یک تصویر نمونه برداری شده، ، با تصادفی خراب می شود، (در این مورد، شکاف های تصادفی در اندازه های مختلف). این تصویر خراب را بازسازی و تولید خواهد کرد . نتایج مصنوعی، به طور مکرر به عنوان بهبود خواهد یافت بازخورد دریافت می کند . (ب) گرافیک باید در سطح مرحله تفسیر شود و با استفاده از کاشیهای تصادفی ایجاد شده است تا بینشهایی ارائه کند و درک بهتری از روند آموزشی ارائهشده در بخش 5.3 ایجاد کند.
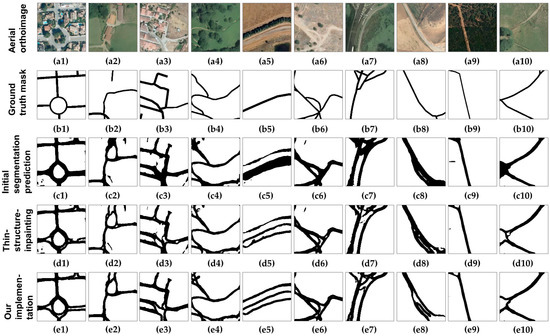
شکل 7. تفسیر کیفی بر روی ده نمونه از مجموعه آزمایش انجام شده است. در سطر اول ( a1 – a10 )، تصوير هوايي را داريم. ردیف دوم ( b1 – b10 ) نمونههایی را از مجموعه حقیقت زمینی شطرنجی شده یا توزیع دادههای مشروط (نمایشهای جاده موجود در نقشهبرداری رسمی) ارائه میکند. ردیف سوم ( c1 – c10 ) پیشبینی تقسیمبندی اولیه را نشان میدهد که با استفاده از یک مدل تقسیمبندی معنایی پیشرفته به دست آمده است. ردیف چهارم ( d1 – d10 ) پیشبینیهای تولید شده با مدل Thin-Structure-Inpainting [ 15 ] را ارائه میکند.] برای عملیات رنگ آمیزی عمیق آموزش داده شده است، در حالی که ردیف پنجم ( e1 – e10 ) ماسک های جاده بازسازی شده تولید شده با مدل مولد شرطی ارائه شده در این مقاله را ارائه می دهد.


بدون دیدگاه