

خلاصه
کلید واژه ها:
توصیه مکان ؛ شبکه های اجتماعی مبتنی بر مکان ؛ مدل سازی جغرافیایی ; مدل سازی اجتماعی ; تخمین چگالی هسته ; فیلتر مشارکتی
1. معرفی
2. کارهای مرتبط
3. روش ها
3.1. بیان مسأله
تعریف 1 (مکان).
تعریف 2 (توصیه مکان).
تعریف 3 (مختصات جغرافیایی).
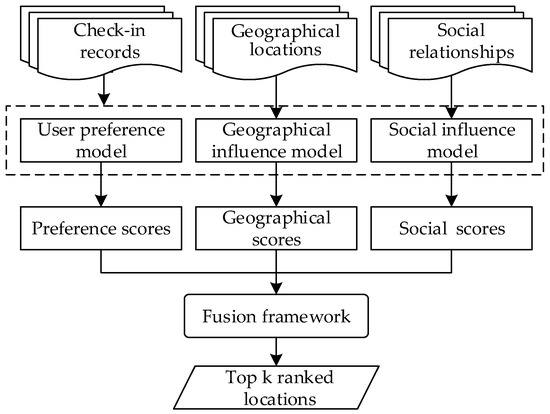
3.2. مدل تأثیرات اجتماعی جغرافیایی و ترکیبی (GeSso).
3.2.1. مدل ترجیحی کاربر
همانطور که در کارهای قبلی نشان داده شده است، ترجیح کاربر اطلاعات قابل توجهی در افزایش کیفیت توصیه مکان است [ 15 ، 16 ]. بنابراین، ترجیح کاربر را پیش بینی می کنیم پپ�ه(لمتر|�تو)بر اساس فناوری UCG [ 44 ]، ارائه شده توسط
با هم
جایی که سی�ساسمنمتر(تو،تو”)شباهت بین کاربر u و u است. در مطالعه ما از شباهت کسینوس برای اندازه گیری شباهت کاربر استفاده می کنیم.
3.2.2. مدل نفوذ جغرافیایی
مرحله 1: محاسبه پهنای باند پیش فرض . یک کاربر داده شده است توو مجموعه ای از مکان های بازدید شده �تو. هر مکان لمن={ایکسمن،�من}از طول جغرافیایی تشکیل شده است ایکسمنو عرض جغرافیایی �من. پهنای باند (یعنی شعاع جستجو) به صورت زیر محاسبه می شود:
جایی که اس�فاصله استاندارد وزنی است. �مفاصله متوسط وزنی است. �منتعداد دفعات ورود کاربر را نشان می دهد تودر محل لمن. min(⋅) حداقل مقدار در بین لیستی از اعداد است. به طور مشخص، اس�منعکس کننده پراکندگی مکان های دیگر نسبت به مرکز است. محاسبه فاصله استاندارد بر اساس یک سیستم مختصات کروی با یک نقطه مرجع فضایی است، بنابراین، ما فاصله استاندارد نسبی را از انحراف استاندارد محاسبه میکنیم. ��=(�ایکس،��)به مبدأ ل�(0،0)، داده شده توسط
با هم
جایی که �ایکسو ��به ترتیب انحراف استاندارد وزنی طول و عرض جغرافیایی را نشان می دهد. علاوه بر این، �ممیانگین فاصله بین لمن∈�توو لسی، داده شده توسط
جایی که دمنس(لمن،،لسی)نشان دهنده فاصله بین لمن∈�توو لسی. لسی=(ایکس¯سی،�¯سی)مرکز میانگین وزنی مکان های مکان در آن است �تو، و ایکس¯سیو �¯سیمیانگین وزنی طول و عرض جغرافیایی را به ترتیب نشان می دهد.
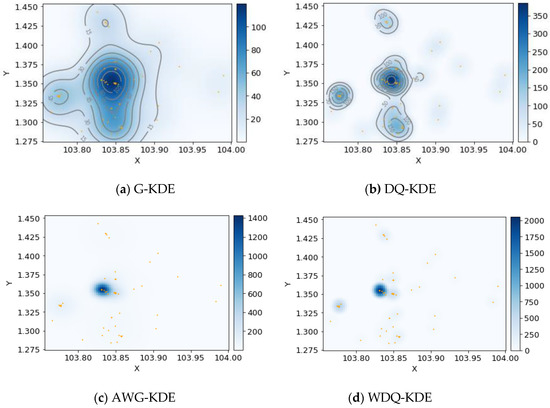
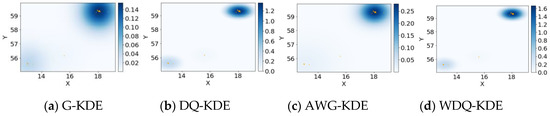
مرحله 2: تخمین هسته برای امتیاز ارتباط جغرافیایی . با پهنای باند جهانی ساعتدر معادله (3)، احتمال جغرافیایی آن کاربر تواز یک مکان بازدید نشده بازدید می کند لمتر∉�تواز رابطه زیر بدست می آید:
با هم
و
جایی که د(لمتر،لمن)نشان دهنده فاصله بین لمن∈�توو لمتر∉�تو. ک(·)تابع هسته است و نتعداد دفعات ورود کاربر به کل است توکه در �تو. این مقاله تابع هسته quartic [ 45 ] را اعمال می کند که در تخمین هسته دو بعدی مفید است. همانطور که در رابطه (8) نشان داده شده است، زمانی که فاصله بین لمنو لمتربزرگتر از ساعت، محل لمنتاثیری ندارد لمتر.
3.2.3. مدل نفوذ اجتماعی
به طور خلاصه، ما شباهت جامع کاربران را بر اساس اطلاعات اجتماعی محاسبه میکنیم که نزدیکی اجتماعی و ارتباطات را برای ارائه توصیهها ترکیب میکند. ما شباهت اجتماعی بین را تعریف می کنیم توو تو”به شرح زیر است:
جایی که �یک پارامتر تنظیم در محدوده است [0،1]. سیل�اسمنمتر(تو،تو”)و سی��اسمنمتر(تو،تو”)نشان دهنده نزدیکی و ارتباط اجتماعی بین کاربران است توو تو”و توسط
معادله (11) از یک روش ساده و موثر یعنی شباهت جاکارد استفاده می کند. در نهایت، برای استفاده کامل از روابط اجتماعی، یک مدل اجتماعی مصنوعی (SSo) بر اساس فناوری SCF ساخته شده است، رتبه اجتماعی توبرای یک مکان بازدید نشده l m را می توان به صورت زیر تخمین زد:
3.2.4. Fusion Framework
قوانین واضح [ 7 ، 16 ، 26 ]، قوانین فازی [ 47 ، 48 ، 49 ]، یادگیری ماشین و رویکردهای یادگیری عمیق [ 22 ، 50 ] و رویکردهای ترکیبی [ 51 ] چهار رویکرد اصلی برای محاسبه امتیاز نهایی بر اساس ویژگی های متنی ورودی مختلف قانون جمع متعلق به قوانین واضح است، این یک روش همجوشی ساده و مرسوم است. بنابراین، ما قانون همجوشی مجموع [ 15 ] را برای ترکیب سه نتیجه ذکر شده در نمره نهایی اعمال می کنیم. اجازه دهید استو،لمترنشان دهنده امتیاز احتمال کاربر است توبرای یک مکان بازدید نشده لمتر. استو،لمترپ�ه، استو،لمترجیه�و استو،لمتراس�جبه ترتیب نمرات احتمال عادی شده ترجیح کاربر، نفوذ جغرافیایی و نفوذ اجتماعی را نشان می دهد. مدل فیوژن به صورت تعریف شده است
با هم
جایی که �و �پارامترهای وزنی هستند (0≤�+�≤1). آنها اهمیت نسبی نفوذ جغرافیایی و اجتماعی را در مقایسه با اولویت کاربر نشان می دهند. ما قصد داریم پارامترهای α و β را تغییر دهیم تا تنظیمات بهینه آنها را پیدا کنیم. پارامترها وزن ترجیح کاربر، تأثیر جغرافیایی و اجتماعی را در به دست آوردن توصیههای بهینه نشان میدهند.
4. ارزیابی آزمایش
4.1. توضیحات مجموعه داده
4.2. روشهای پیشنهادی ارزیابی شده
-
USG. USG یک چارچوب توصیه مکان یکپارچه است که ترجیحات کاربر و تأثیرات جغرافیایی و اجتماعی را برای توصیه مکان بررسی می کند. از یک قانون جمع برای ادغام ترجیحات کاربر و تأثیرات جغرافیایی و اجتماعی استفاده می کند [ 15 ].
-
لور. این روش تأثیرات متوالی، جغرافیایی و اجتماعی را برای توصیه مکان مدل میکند. از یک مدل KDE دو بعدی بدون وزن برای مدلسازی جغرافیایی استفاده میکند [ 11 ]. شباهت بین دوستان بر اساس فاصله بین محل سکونت محاسبه می شود. از آنجایی که مکانهای اقامت در دسترس نیستند، مکانهای پربازدید کاربران را بهعنوان محل اقامت آنها تعریف میکنیم. از یک قانون ترکیب محصول برای ادغام عوامل مختلف استفاده می کند.
-
GeoSoCa. این روش سه نوع اطلاعات زمینه ای یعنی اطلاعات جغرافیایی، اجتماعی و طبقه بندی را مدل می کند. از یک مدل وزنی دو بعدی KDE تطبیقی برای مدلسازی جغرافیایی استفاده میکند [ 18 ].
-
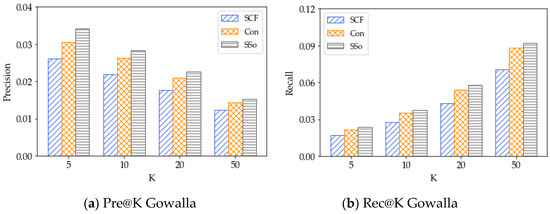
SCF. SCF یک روش فیلتر مشارکتی مبتنی بر اجتماعی است که توصیه های مکان را بر اساس شباهت جاکارد بین دوستان ارائه می دهد. شباهت بین دوستان بر اساس دوستان مشترک محاسبه می شود. [ 37 ]
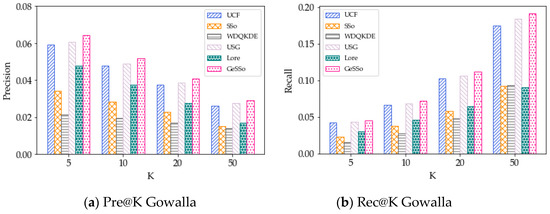
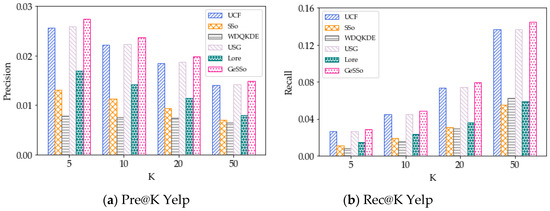
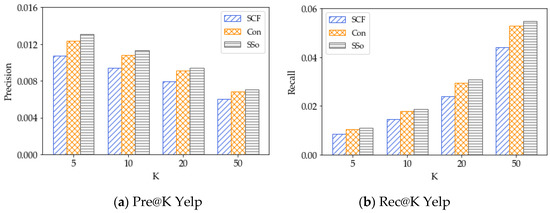
4.3. معیارهای عملکرد
دو معیار استاندارد پرکاربرد، یعنی دقت ( Pre@K ) و فراخوان ( Rec@K )، برای ارزیابی کیفیت مدلهای پیشنهاد مکان استفاده میشوند. برای هر کاربر، دقت، نسبت مکانهای بازیابی شده را به K مکانهای توصیهشده منعکس میکند، و فراخوانی نسبت مکانهای بازیابی شده را به مکانهایی که واقعاً در مجموعه دادههای آزمایشی بازدید شدهاند، منعکس میکند. میانگین دقت و فراخوانی همه کاربران به ترتیب در معادلات (17) و (19) گزارش شده است که توسط
جایی که، پ�هتو@کو آرهجتو@کنشان دهنده دقت و فراخوانی کاربر است تو، به ترتیب. �کمجموعه ای از مکان های توصیه شده است. �توتیهستیمجموعه مکان هایی است که توسط آنها بازدید شده است تودر مجموعه داده آزمایشی در آزمایش ما، عملکرد را زمانی آزمایش میکنیم که K = 5، 10، 20، 50 باشد. میانگین دقت و مقادیر یادآوری همه کاربران گزارش شده است.
4.4. تنظیمات آزمایش
5. نتایج و بحث
5.1. نتایج کلی عملکرد
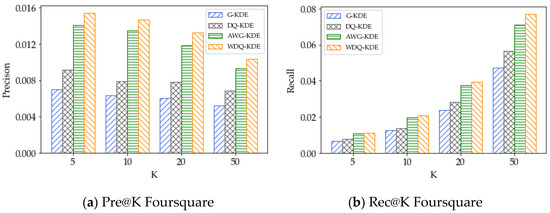
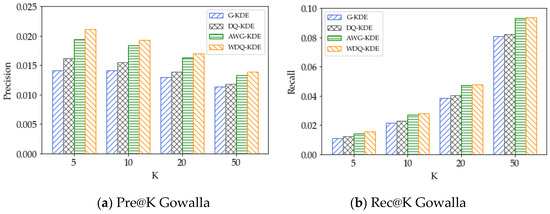
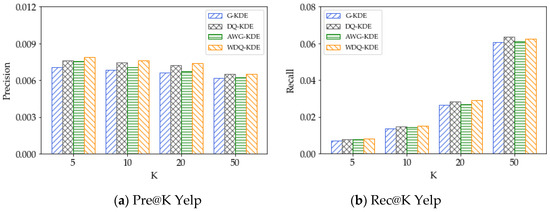
5.2. نتایج روشهای نفوذ جغرافیایی
5.3. نتایج برای روشهای تأثیر اجتماعی
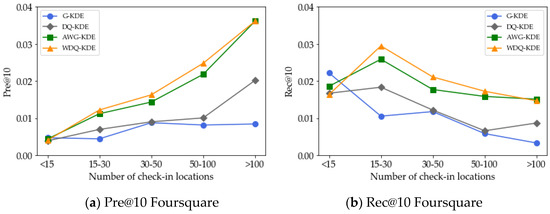
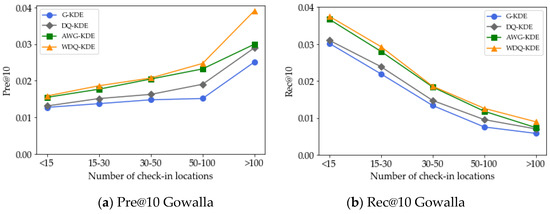
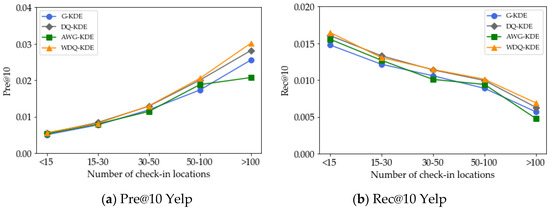
5.4. تأثیر تعداد مکان های ورود
5.5. اثر مدل تخمین چگالی هسته
6. نتیجه گیری و کار آینده
منابع
- کای، ال. خو، جی. لیو، جی. Pei, T. ادغام زمینه های مکانی و زمانی در یک مدل فاکتورسازی برای توصیه POI. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 524-546. [ Google Scholar ] [ CrossRef ]
- بائو، جی. ژنگ، ی. ویلکی، دی. موکبل، ام. توصیههایی در شبکههای اجتماعی مبتنی بر مکان: یک نظرسنجی. Geoinformatica 2015 ، 19 ، 525-565. [ Google Scholar ] [ CrossRef ]
- لو، ز. وانگ، اچ. مامولیس، ن. تو، دبلیو. Cheung, D. توصیه مکان شخصی شده با جمع آوری چندین توصیه کننده در تنوع. GeoInformatica 2017 ، 21 ، 1-26. [ Google Scholar ] [ CrossRef ]
- علیان نژادی، م. Crestani, F. شخصی سازی شده زمینه آگاه از نقطه مورد علاقه توصیه. ACM Trans. Inf. سیستم (TOIS) 2018 ، 36 ، 1-28. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. فام، T.-AN; کنگ، جی. یوان، س. ارزیابی تجربی توصیههای نقطهنظر در شبکههای اجتماعی مبتنی بر مکان. Proc. VLDB Enddow. 2017 ، 10 ، 1010-1021. [ Google Scholar ] [ CrossRef ]
- وانگ، اف. منگ، ایکس. ژانگ، ی. ژانگ، سی. اولویتهای کاربر استخراج مکانهای جدید در شبکههای اجتماعی مبتنی بر مکان: رویکرد مدل ابری چند بعدی. سیم. شبکه 2018 ، 24 ، 113-125. [ Google Scholar ] [ CrossRef ]
- اوگاندل، تی جی؛ Chow, C.-Y.; ژانگ، J.-D. SoCaST: بهره برداری از اولویت های اجتماعی، طبقه ای و مکانی-زمانی برای توصیه های رویداد شخصی. در مجموعه مقالات چهاردهمین سمپوزیوم بین المللی سیستم های فراگیر، الگوریتم ها و شبکه ها در سال 2017 و یازدهمین کنفرانس بین المللی مرزهای علوم و فناوری رایانه و 2017 سومین سمپوزیوم بین المللی محاسبات خلاق (ISAN-FCST-ISCC)، اکستر، انگلستان، 2232 ژوئن 2017; صص 38-45. [ Google Scholar ]
- یو، ایکس. پان، ا. تانگ، L.-A. لی، ز. Han, J. Geo-Friends Recommendation در شبکه اجتماعی سایبری فیزیکی مبتنی بر GPS. در مجموعه مقالات کنفرانس بین المللی 2011 در مورد پیشرفت در تجزیه و تحلیل شبکه های اجتماعی و استخراج، Kaohsiung، تایوان، 25-27 ژوئیه 2011; صص 361-368. [ Google Scholar ]
- شوکین، جی. رعنا، سی. بررسی ویژگیهای سیستمهای توصیهگر اجتماعی. آرتیف. هوشمند Rev. 2020 , 53 , 965–988. [ Google Scholar ] [ CrossRef ]
- لیو، بی. فو، ی. یائو، ز. Xiong, H. یادگیری ترجیحات جغرافیایی برای توصیه نقطه مورد علاقه. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، شیکاگو، IL، ایالات متحده، 11-14 اوت 2013. ص 1043-1051. [ Google Scholar ]
- ژانگ، J.-D. Chow, C.-Y.; Li, Y. LORE: بهرهبرداری از تأثیر متوالی برای توصیههای مکان. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، 4-7 نوامبر 2014. صص 103-112. [ Google Scholar ]
- سان، ی. یین، اچ. Ren, X. توصیه در محیط غنی از زمینه: رویکرد تحلیل شبکه اطلاعات. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی در مورد همنشین وب جهانی، پرت، استرالیا، 3 تا 7 آوریل 2017؛ ص 941-945. [ Google Scholar ]
- رن، ایکس. آهنگ، م. Song, J. Context-Aware Point-of-Interest Recommendation در شبکه های اجتماعی مبتنی بر مکان. جیسوانجی خوئبائو چین. جی. کامپیوتر. 2017 ، 40 ، 824-841. [ Google Scholar ]
- کوی، کیو. تانگ، ی. وو، اس. وانگ، L. Distance2Pre: ترجیح فضایی شخصی برای پیشبینی نقطهی علاقه بعدی. در کنفرانس اقیانوس آرام-آسیا در مورد کشف دانش و داده کاوی ؛ Springer: Cham، سوئیس، 2019; صص 289-301. [ Google Scholar ]
- بله، م. یین، پی. لی، دبلیو.-سی. لی، دی.-ال. بهرهبرداری از نفوذ جغرافیایی برای توصیه مشترک نقطهای از علاقه. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، پکن، چین، 25-29 ژوئیه 2011. صص 325-334. [ Google Scholar ]
- ژانگ، J.-D. چاو، سی.-ای. iGSLR: توصیه موقعیت جغرافیایی اجتماعی شخصی شده: یک رویکرد تخمین چگالی هسته. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، اورلاندو، فلوریدا، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013. صص 334-343. [ Google Scholar ]
- لیان، دی. ژائو، سی. Xie، X. سان، جی. چن، ای. Rui, Y. GeoMF: مدلسازی جغرافیایی مشترک و فاکتورسازی ماتریسی برای توصیه نقطهنظر. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 24 تا 27 اوت 2014. صص 831-840. [ Google Scholar ]
- ژانگ، J.-D. چاو، سی.-ای. GeoSoCa: بهرهبرداری از همبستگیهای جغرافیایی، اجتماعی و طبقهبندی برای توصیههای نقطهنظر. در مجموعه مقالات سی و هشتمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، سانتیاگو، شیلی، 9 تا 13 اوت 2015. صص 443-452. [ Google Scholar ]
- ژانگ، J.-D. Chow, C.-Y.; Li, Y. iGeoRec: یک چارچوب توصیه موقعیت جغرافیایی شخصی و کارآمد. IEEE Trans. خدمت محاسبه کنید. 2015 ، 8 ، 701-714. [ Google Scholar ] [ CrossRef ]
- گوا، اچ. لی، ایکس. او، م. ژائو، ایکس. لیو، جی. Xu، G. CoSoLoRec: مدل عامل مشترک با محتوا، اجتماعی، مکان برای توصیه نقطهای ناهمگن. در کنفرانس بین المللی دانش، مهندسی و مدیریت ؛ Springer: Cham, Switzerland, 2016; صص 613-627. [ Google Scholar ]
- ژانگ، J.-D. چاو، سی.-ای. TICRec: یک چارچوب احتمالی برای استفاده از همبستگیهای تأثیر زمانی برای توصیههای مکان آگاه به زمان. IEEE Trans. خدمت محاسبه کنید. 2016 ، 9 ، 633-646. [ Google Scholar ] [ CrossRef ]
- گائو، آر. لی، جی. لی، ایکس. آهنگ، سی. ژو، ی. یک مدل توصیهای شخصیشده نقطهای از علاقه از طریق ادغام اطلاعات جغرافیایی-اجتماعی. کامپیوترهای عصبی 2018 ، 273 ، 159-170. [ Google Scholar ] [ CrossRef ]
- چنگ، سی. یانگ، اچ. کینگ، آی. لیو، MR فاکتورسازی ماتریس ذوب شده با نفوذ جغرافیایی و اجتماعی در شبکه های اجتماعی مبتنی بر مکان. Proc. Natl. Conf. آرتیف. هوشمند 2012 ، 1 ، 17-23. [ Google Scholar ]
- یوان، Q. کنگ، جی. ما، ز. سان، ا. Thalmann، NM توصیه نقطه مورد علاقه آگاه از زمان. در مجموعه مقالات سی و ششمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، دوبلین، ایرلند، 28 ژوئیه تا 1 اوت 2013. صص 363-372. [ Google Scholar ]
- یین، اچ. سان، ی. کوی، بی. هو، ز. Chen, L. LCARS: یک سیستم توصیهکننده آگاه از محتوا. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، شیکاگو، IL، ایالات متحده آمریکا، 11 تا 14 اوت 2013. [ Google Scholar ]
- ژانگ، J.-D. چاو، سی.-ای. CoRe: بهرهبرداری از تأثیر شخصی مختصات جغرافیایی دو بعدی برای توصیههای مکان. Inf. علمی 2015 ، 293 ، 163-181. [ Google Scholar ] [ CrossRef ]
- لیو، ی. وی، دبلیو. سان، ا. میائو، سی. بهرهبرداری از ویژگیهای همسایگی جغرافیایی برای توصیه مکان. در مجموعه مقالات بیست و سومین کنفرانس بین المللی ACM در کنفرانس مدیریت اطلاعات و دانش، شانگهای، چین، 13 تا 14 ژوئیه 2017؛ صص 739-748. [ Google Scholar ]
- لی، ایکس. کنگ، جی. لی، X.-L. فام، T.-AN; کریشناسوامی، S. Rank-GeoFM: یک روش فاکتورسازی جغرافیایی مبتنی بر رتبه بندی برای توصیه نقطه مورد علاقه. در مجموعه مقالات سی و هشتمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، سانتیاگو، شیلی، 9 تا 13 اوت 2015. صص 433-442. [ Google Scholar ]
- دینگ، آر. Chen, Z. RecNet: یک شبکه عصبی عمیق برای توصیه های شخصی شده POI در شبکه های اجتماعی مبتنی بر مکان. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 1631-1648. [ Google Scholar ] [ CrossRef ]
- ژائو، پی. زو، اچ. لیو، ی. خو، جی. لی، ز. ژوانگ، اف. شنگ، وی. ژو، ایکس. بعد کجا برویم: یک شبکه فضایی-زمانی برای توصیه POI بعدی. Proc. AAAI Conf. آرتیف. هوشمند 2019 ، 33 ، 5877-5884. [ Google Scholar ] [ CrossRef ]
- لیو، کیو. وو، اس. وانگ، ال. Tan, T. پیشبینی مکان بعدی: یک مدل تکرارشونده با زمینههای مکانی و زمانی. در مجموعه مقالات سیامین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016. [ Google Scholar ]
- کنگ، دی. Wu, F. HST-LSTM: یک شبکه حافظه بلند مدت کوتاه مدت مکانی-زمانی سلسله مراتبی برای پیش بینی مکان. در مجموعه مقالات بیست و هفتمین کنفرانس مشترک بین المللی هوش مصنوعی و بیست و سومین کنفرانس اروپایی هوش مصنوعی، استکهلم، سوئد، 13 تا 19 ژوئیه 2018؛ صص 2341–2347. [ Google Scholar ]
- لیان، دی. ژنگ، ک. Ge، Y. کائو، ال. چن، ای. Xie, X. GeoMF++: توصیه مکان مقیاس پذیر از طریق مدل سازی مشترک جغرافیایی و فاکتورسازی ماتریس. ACM Trans. Inf. سیستم 2018 ، 36 ، 1-29. [ Google Scholar ] [ CrossRef ]
- Guo, Q. توصیه نقطه مورد علاقه مبتنی بر نمودار در شبکه های اجتماعی مبتنی بر مکان. دکتری پایان نامه، دانشگاه فنی نانیانگ، سنگاپور، 2019. [ Google Scholar ]
- آناگنوستوپولوس، آ. کومار، آر. مهدیان، م. تأثیر و همبستگی در شبکه های اجتماعی. در مجموعه مقالات چهاردهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، لاس وگاس، NV، ایالات متحده، 24-27 اوت 2008. صص 7-15. [ Google Scholar ]
- کیو، جی. تانگ، جی. ما، اچ. دونگ، ی. وانگ، ک. Tang, J. DeepInf: مدلسازی مکان تأثیرگذاری در شبکههای اجتماعی بزرگ. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، لندن، بریتانیا، 19 تا 23 اوت 2018. [ Google Scholar ]
- ما، اچ. کینگ، آی. لیو، ام آر آموزش توصیه با گروه اعتماد اجتماعی. در مجموعه مقالات سی و دومین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، بوستون، MA، ایالات متحده، 19-23 ژوئیه 2009. ص 203-210. [ Google Scholar ]
- ما، اچ. ژو، TC; لیو، ام آر؛ King, I. بهبود سیستمهای توصیهکننده با ترکیب اطلاعات زمینهای اجتماعی. ACM Trans. Inf. سیستم 2011 ، 29 ، 1-23. [ Google Scholar ] [ CrossRef ]
- Lak, P. یک رویکرد جدید برای تعریف و مدلسازی ویژگیهای متنی در سیستمهای توصیهکننده. در مجموعه مقالات سی و نهمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، پیزا، ایتالیا، 17 تا 21 ژوئیه 2016. پ. 1161. [ Google Scholar ]
- کنستاس، آی. استاتوپولوس، وی. Jose, JM در شبکه های اجتماعی و توصیه مشترک. در مجموعه مقالات سی و دومین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، بوستون، MA، ایالات متحده، 19-23 ژوئیه 2009. صص 195-202. [ Google Scholar ]
- چانی، ای جی؛ Blei، DM; الیاسی راد، تی. یک مدل احتمالی برای استفاده از شبکه های اجتماعی در توصیه آیتم های شخصی. در مجموعه مقالات نهمین کنفرانس ACM در سیستم های توصیه کننده، وین، اتریش، 16-20 سپتامبر 2015. صص 43-50. [ Google Scholar ]
- وانگ، ام. ژنگ، ایکس. یانگ، ی. ژانگ، ک. فیلتر کردن مشارکتی با قرار گرفتن در معرض اجتماعی: یک رویکرد مدولار به توصیه اجتماعی. در مجموعه مقالات سی و دومین کنفرانس AAAI در مورد هوش مصنوعی، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 2 تا 7 فوریه 2018. [ Google Scholar ]
- یانگ، بی. لی، ی. لیو، جی. لی، دبلیو. فیلتر مشارکتی اجتماعی توسط اعتماد. IEEE Trans. الگوی مقعدی ماخ هوشمند 2016 ، 39 ، 1633-1647. [ Google Scholar ] [ CrossRef ]
- هرلوکر، جی ال. کنستان، ج.ا. بورچرز، ا. Riedl, J. چارچوب الگوریتمی برای انجام فیلتر مشترک. در مجموعه مقالات بیست و دومین کنفرانس بین المللی سالانه ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، برکلی، کالیفرنیا، ایالات متحده آمریکا، 15-19 اوت 1999. ص 230-237. [ Google Scholar ]
- سیلورمن، تخمین چگالی BW برای آمار و تجزیه و تحلیل داده ها . CRC Press: Boca Raton، FL، USA، 1986. [ Google Scholar ]
- ما، اچ. یانگ، اچ. لیو، ام آر؛ King, I. SoRec: توصیه اجتماعی با استفاده از فاکتورسازی ماتریس احتمالی. در مجموعه مقالات هفدهمین کنفرانس ACM در مدیریت اطلاعات و دانش، دره ناپا، کالیفرنیا، ایالات متحده آمریکا، 26 تا 30 اکتبر 2008. ص 931-940. [ Google Scholar ]
- کائو، ی. Li, Y. یک سیستم توصیه مبتنی بر فازی هوشمند برای محصولات الکترونیکی مصرفی. سیستم خبره Appl. 2007 ، 33 ، 230-240. [ Google Scholar ] [ CrossRef ]
- یان، ی. فنگ، سی.-سی. وانگ، Y.-C. استفاده از نظریه مجموعه های فازی برای اطمینان از کیفیت اطلاعات جغرافیایی داوطلبانه جئوژورنال 2017 ، 82 ، 517–532. [ Google Scholar ] [ CrossRef ]
- وحیدی، ح. کلینکنبرگ، بی. Yan, W. Trust به عنوان شاخصی برای کیفیت ذاتی اطلاعات جغرافیایی داوطلبانه در برنامه های نظارت بر تنوع زیستی. GISci. Remote Sens. 2018 , 55 , 502–538. [ Google Scholar ] [ CrossRef ]
- یین، اچ. وانگ، دبلیو. وانگ، اچ. چن، ال. ژو، X. یادگیری عمیق مشارکتی سلسله مراتبی آگاه به فضایی برای توصیه POI. IEEE Trans. بدانید. مهندسی داده 2017 ، 29 ، 2537–2551. [ Google Scholar ] [ CrossRef ]
- ژانگ، اف. یوان، نیوجرسی؛ لیان، دی. Xie، X. ما، W.-Y. جاسازی پایگاه دانش مشترک برای سیستم های توصیه گر در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGKDD در زمینه کشف دانش و داده کاوی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 13 تا 17 اوت 2016؛ صص 353-362. [ Google Scholar ]
- ما، اچ. ژو، دی. لیو، سی. لیو، ام آر؛ King, I. سیستمهای توصیهکننده با نظمدهی اجتماعی. در مجموعه مقالات چهارمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، هنگ کنگ، چین، 9 تا 12 فوریه 2011. ص 287-296. [ Google Scholar ]
- حسینی، س. یین، اچ. ژو، ایکس. صادق، س. کنگاوری، محمدرضا; چونگ، ن.-ام. اعمال نفوذ چند جنبه ای مرتبط با زمان در توصیه مکان. وب جهانی 2019 ، 22 ، 1001–1028. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]


بدون دیدگاه