

چکیده
کلید واژه ها:
بازیابی تصویر ; وزن برجسته ; تجمع ویژگی های کانولوشنال
1. مقدمه
-
ما یک روش ادغام ویژگی جدید به نام R-MAC تعمیم یافته معرفی می کنیم که می تواند اطلاعات موجود در تمام نقاط ویژگی در هر ناحیه از R-MAC [ 25 ] را به جای در نظر گرفتن حداکثر مقدار نقاط مشخصه در هر منطقه، جمع آوری کند.
-
ما رویکردی را برای تجمیع ویژگیهای کانولوشنی ارائه میکنیم، از جمله وزندهی برجستگی ناپارامتری و مراحل ادغام. بدون از دست دادن اطلاعات کل ساختمان (منطقه هدف) توجه بیشتری را بر روی ویژگی های کانولوشنال منطقه برجسته متمرکز می کند.
-
ما آزمایشهای جامعی را روی چندین مجموعه داده محبوب انجام دادیم، و نتایج نشان میدهد که روش ما نتایج پیشرفتهای را بدون هیچ گونه تنظیم دقیق ارائه میدهد.
2. کارهای مرتبط
2.1. روش های تجمیع
2.2. عادی سازی و سفید کردن
عادی سازی یک مرحله بسیار مهم در بازیابی تصویر است [ 30 ]. نرمال سازی می تواند داده ها را برای مقایسه به یک محدوده یکنواخت تبدیل کند. نرمال سازی L2 [ 30 ] داده ها را به محدوده ای بین 0 و 1 تبدیل می کند. محدوده مقدار خروجی ویژگی توسط شبکه عصبی کانولوشن معمولاً بسیار بزرگ است. بر این اساس، نرمال سازی L2 می تواند برای متعادل کردن تأثیر اندازه و ارزش استفاده شود. محاسبه اختصاصی به شرح زیر است:
جایی که ایکسبردار بتنی است و “مقدار 2-نرمی این بردار است.
نرمال سازی توان [ 30 ] بردار را با توجه به توان توان کاهش می دهد. فرمول محاسبه خاص به شرح زیر است:
جایی که ξیک فراپارامتر قابل تنظیم است که از 0 تا 1 متغیر است. ایکسیک بردار بتنی است. برای جلوگیری از تبدیل علامت مقدار پس از نرمال سازی توان، استفاده می کنیم سgn(ایکس)، تابع علامت نامیده می شود که به صورت تعریف شده است سgn(ایکس)= 1 برای ایکس>0و سgn(ایکس)= -1 برای ایکس≤0.
در قسمت اول ماتریس کوواریانس را بدست می آوریم سیاساز تصاویر درون کلاسی با استفاده از رابطه (3) و ماتریس کوواریانس سیDاز تصاویر بین کلاسی (جفت تصویر غیر همسان) با استفاده از معادله (4)، که در آن
جایی که منو jدو تصویر مجزا در مجموعه داده را نشان می دهد، ایکسمنو ایکسjتوصیفگرهای ویژگی را پس از ادغام تصویر نشان دهید، و لآبهلمن=لآبهلj( لآبهلمن≠لآبهلj) یعنی تصاویر منو jبا یک کلاس (متفاوت) مرتبط هستند.
در قسمت دوم پروجکشن را بدست می آوریم پدر فضای سفید شده (بردار ویژه ماتریس کوواریانس سیاس-12سیDسیاس-12) و آن را در توصیفگرهای تصاویر اعمال کنید:
جایی که همنg(.)بردار ویژه ماتریس خاص است، μمیانگین بردار ادغام (بردار میانگین توصیفگرهای همه تصاویر در مجموعه داده های آزمایشی پس از ادغام) برای انجام مرکز، و ایکسمنwساعتمنتیهnنتیجه سفید شده است ایکسمن. شایان ذکر است که معادله (5) تنها بردارهای ویژه را بیشتر از یک آستانه خاص برای کاهش ویژگی نمی گیرد.
2.3. روش اندازه گیری شباهت
پس از به دست آوردن توصیفگرهای ویژگی تصویر، باید شباهت بین توصیفگرهای ویژگی تصویر پرس و جو و توصیفگرهای ویژگی همه تصاویر مجموعه آزمایشی را اندازه گیری کنیم. یک روش متداول برای محاسبه شباهت دو بردار مبتنی بر معکوس فاصله اقلیدسی آنها است. فرمول به شرح زیر است:
جایی که آ∈آرnو ب∈آرnدو بردار نمونه هستند و آمنو بمنهستند منمولفه های بردار آو ب، به ترتیب. با نشان می دهیم L(آ،ب)فاصله اقلیدسی بین آو ب.
از تشابه کسینوس برای اندازه گیری تشابه نیز استفاده می شود که از زاویه بین دو بردار بتن برای محاسبه مقدار کسینوس برای نشان دادن شباهت دو بردار استفاده می کند. هر چه مقدار کسینوس به 1 نزدیکتر باشد، این دو بردار به هم شباهت بیشتری دارند. هر چه مقدار کسینوس به 1- نزدیکتر باشد، این دو بردار ناهمگون تر هستند. فرمول محاسبه خاص به شرح زیر است:
جایی که اس(آ،ب)شباهت کسینوس بین است آو ب.
2.4. گسترش پرس و جو
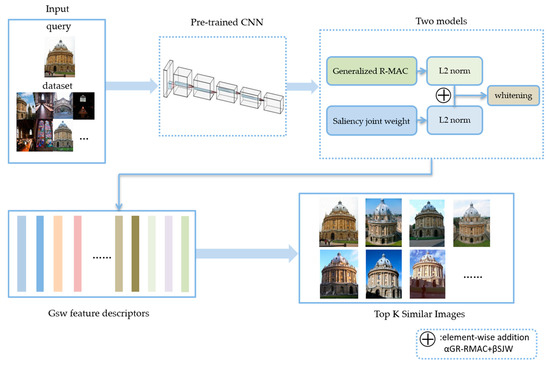
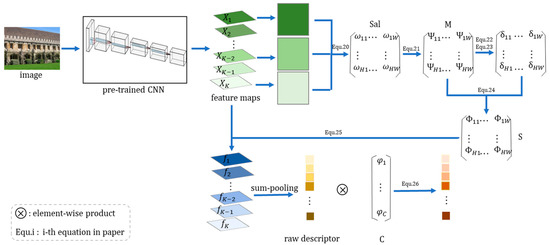
3. روش پیشنهادی
3.1. پس زمینه الگوریتم
ما توصیفگر ویژگی نهایی را با ادغام توصیفگرهای ویژگی به دست آمده توسط دو ماژول به دست می آوریم.
جایی که جیrاز بخش 3.2 آمده است، اسjwاز بخش 3.3 می آید و αو βفاکتورهای همجوشی با مقادیری از 0 تا 1 هستند.
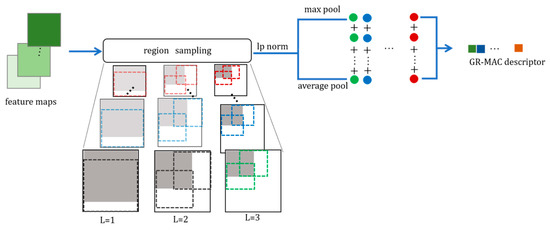
3.2. R-MAC تعمیم یافته
جزئیات عملیات خاص به شرح زیر است: با در نظر گرفتن نقشه ویژگی یک کانال به عنوان مثال، نقشه ویژگی به تقسیم می شود آرمناطق و منطقه نتیجه به شرح زیر است:
جایی که ایکسکrr-مترآجمنطقه r از است کنقشه ویژگی.
R-MAC [ 25 ] حداکثر مقدار را در هر منطقه تقطیر می کند، اما این اطلاعات ویژگی کلی منطقه را از دست می دهد. از این رو، همانطور که در رابطه (12) نشان داده شده است، از استراتژی دیگری برای محاسبه مقادیر ویژگی منطقه ای استفاده می کنیم. روش خاص شامل استفاده از لپهنجار به فیوز حداکثر ادغام و ادغام مجموع برای به دست آوردن ویژگی های منطقه ای نماینده تر. فرمول محاسبه خاص به شرح زیر است:
جایی که fکrمقدار محاسبه شده توسط است لپهنجار از rمنطقه ام از کنقشه ویژگی هفتم، کجا پ=3.
با توجه به مقادیر چندگانه ویژگی منطقه ای به دست آمده توسط هر کانال، مقادیر ویژگی منطقه ای کانال برای تولید توصیفگر بردار ویژگی نهایی جمع می شود. جیr، به شرح زیر است:
جایی که gکمجموع مقادیر به دست آمده توسط همه مناطق است fکاز ککانال ام و جیrتوصیفگر نابالغ تصویر با استفاده از R-MAC تعمیم یافته است.
3.3. روش وزن گیری مفاصل برجسته
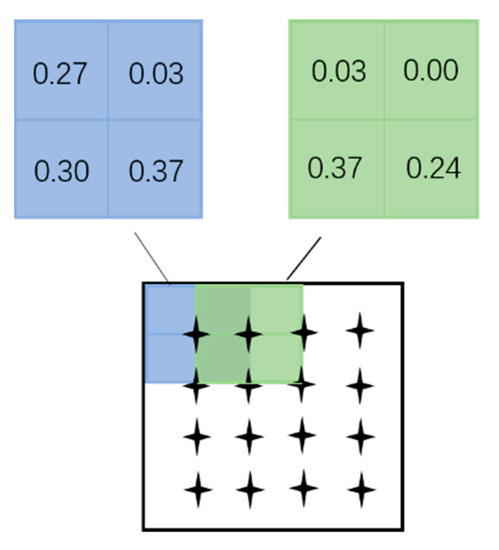
سپس، مشابه کرو [ 26 ]، عملیات وزن دهی فضایی و وزن دهی کانال را نیز بر روی ویژگی های کانولوشن به دست آمده انجام دادیم. برای ماتریس وزن کانال ما، بر خلاف کرو [ 26 ]، که فقط تعداد کمیت های غیر صفر را برای هر کانال در نظر می گیرد، واریانس هر کانال را نیز به عنوان بخشی از ملاحظاتی در نظر گرفتیم که بر مقدار ماتریس وزن کانال تأثیر می گذارد. همانند کرو [ 26 ]، برای هر بعد از نقشه ویژگی، نسبت مقدار مجموع آن مربوط به تعداد مقادیر صفر در هر نقشه مشخصه محاسبه شد و عبارت بدست آمده به صورت زیر است:
جایی که ج1کنسبت کل مکان فضایی در است کنگاشت ویژگی به مقدار صفر. ما می توانیم مقدار اطلاعات موجود در یک نقشه ویژگی را با شمارش تعداد مقادیر غیر صفر قضاوت کنیم، که برای بهبود ویژگی هایی استفاده می شود که اغلب دیده نمی شوند اما معنی دار هستند.
بر اساس ج1ک، ما پیشنهاد اضافه کردن یک عبارت واریانس برای بهینه سازی ماتریس وزن کانال را پیشنهاد کردیم، همانطور که در رابطه (15) نشان داده شده است. برای اینکه نقشه ویژگی هر کانال انحراف معیار خود را پیدا کند، عبارت به دست آمده به صورت زیر است:
جایی که ایکس¯منjکمیانگین است ایکسمنjکو ج2کواریانس است ککانال ام
سپس نسبت های آن را محاسبه کردیم ج1کو ج2ک. پس از آن، آنها را جمع کردیم و عبارت حاصل به صورت زیر است:
هنگام جمعآوری ویژگیهای کانولوشن عمیق، از آنجایی که متعاقباً کانال هدف و منطقه هدف را بر اساس واریانس و مقدار پاسخ به شدت تقویت کردیم، ممکن است کانال با اطلاعات کمتر نادیده گرفته شود. با این حال، چنین کانال هایی ممکن است حاوی اطلاعات بسیار مهمی نیز باشند و کانال هایی با واریانس کوچک نیز می توانند نویز را سرکوب کنند. بنابراین، ما باید وزن بیشتری را به کانال ویژگی با تعداد صفر زیاد و واریانس کوچک اختصاص دهیم. در نهایت، مشابه کرو [ 26 ]، عملیات وارونگی از طریق تابع log انجام شد. فرمول خاص برای به دست آوردن بردار وزن کانال نهایی سیک با استفاده از تبدیل لگاریتمی به شرح زیر است:
جایی که سیکوزن کانال است و εیک ثابت به شدت کوچک است که برای جلوگیری از صفر بودن مخرج اضافه می شود.
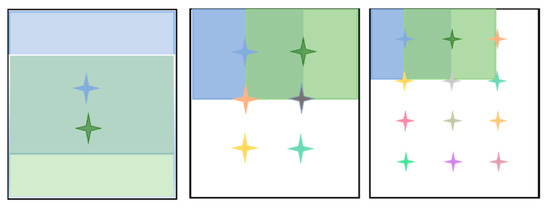
ماتریس وزن دهی فضایی ما با کرو [ 26 ] متفاوت است، که فقط تمام نقشه های ویژگی کانال را جمع و نرمال می کند و سپس به عنوان ماتریس وزن بندی فضایی نهایی S عمل می کند. ما ابتدا کانالهای ویژگی k بالا را فیلتر کردیم که برای متمایز کردن منطقه هدف از ناحیه نویز پسزمینه از طریق واریانس برای جمع ماتریس وزن اولیه S مفیدتر هستند. آلو سپس ماتریس وزنی را نرمال کرد م، که شبیه کلاغ [ 26 ] است. با توجه به فاکتور انتخاب کانال بدست آمده ج2، ما کانالی را با واریانس زیاد انتخاب کردیم تا ماتریس وزنی فضا را روی هم قرار دهیم زیرا کانال با واریانس بزرگ برای تمایز بین منطقه هدف و منطقه پس زمینه مساعدتر است. فرمول محاسبه خاص به شرح زیر است:
سپس ماتریس وزن دهی فضایی به دست آمده است اسآلبرای به دست آوردن ماتریس وزنی نرمال شده، نرمال و توان مقیاس شده است م.
ما از الگوریتم محاسباتی خطی (LC) [ 34 ] برای تشخیص برجسته بودن ماتریس وزن استفاده کردیم. م. ابتدا، مقدار ماتریس M به دست آمده را بین 0 تا 255 مقیاس کردیم تا برای الگوریتم LC قابل اجرا باشد [ 34 ]. سپس، مقدار آن را ترسیم کردیم مبه فضای پیکسلی از 0 تا 255 برای محاسبه ماتریس برجستگی بعدی. فرمول نقشه برداری به شرح زیر است:
جایی که مجییک ماتریس وزنی است که مقدار را عادی می کند مبه محدوده بین 0 تا 255.
در مورد ایده الگوریتم LC [ 34 ]، ما مجموع فواصل اقلیدسی بین هر نقطه در ماتریس وزن فضایی و تمام نقاط دیگر را به عنوان مقدار پاسخ نقطه محاسبه کردیم. پس از آن، ماتریس وزن برجستگی فضایی را به دست آوردیم. فرمول محاسبه خاص به شرح زیر است:
جایی که اسwمنjمقدار ویژگی ماتریس وزن دهی برجسته در است من، j.
سپس، ماتریس وزن برجستگی به دست آمده را ذوب کردیم اسwبه ماتریس وزنی اصلی م با یک ضریب مقیاس معین، به طوری که ماتریس وزندهی فضایی نهایی وزن بیشتری را به منطقه کلیدی با ضریب همجوشی خاص اختصاص میدهد، در حالی که اطلاعات پاسخ ناحیه هدف و ناحیه نویز پسزمینه در ویژگی پیچیدگی اصلی حفظ میشود. برای ماتریس وزن فضایی به دست آمده اسw، از ضریب مقیاس خاصی استفاده کردیم ρبرای ادغام آن در ماتریس وزن دهی فضایی به دست آمده با انتخاب کانال قبلی به طوری که ماتریس وزن نهایی اسبهتر می تواند منطقه هدف نقشه ویژگی را برجسته کند.
جایی که ρعامل ذوب شده است و اسماتریس وزن فضایی پس از وزن دهی مفصل برجسته است.
در نهایت، ما توصیفگر وزن مشترک برجسته (SJW) را از طریق ماتریس وزن دهی فضایی نهایی به دست آوردیم. اسو ماتریس وزن کانال سی. ماتریس وزنی فضایی نهایی بدست آمده را ضرب کردیم اسبا نقشه ویژگی های سه بعدی که توسط کانولوشن به دست آمد و سپس نقشه های ویژگی هر کانال را برای به دست آوردن یک توصیفگر تصویر یک بعدی جمع کرد. اف.
جایی که fکمقدار ویژگی است که از کنقشه ویژگی بعد از وزن دهی فضایی و افبردار همه است fک.
برای توصیفگر یک بعدی به دست آمده افبرای وزن از بردار وزن کانال به دست آمده از رابطه فوق (17) استفاده کردیم تا توصیفگر به کانال های ویژگی مهم توجه بیشتری داشته باشد و توصیفگر وزن برجستگی فضایی نهایی را تشکیل دهد. اسjw.
جایی که gکمقدار ویژگی است که از کنقشه ویژگی بعد از وزن دهی کانال و اسjwبردار همه است gک.
4. آزمایش ها و ارزیابی
4.1. مجموعه داده ها
-
مجموعه داده Oxford5k [ 33 ]: این مجموعه داده توسط فلیکر ارائه شده است و شامل 11 نشانه در مجموعه داده آکسفورد و در مجموع 5063 تصویر است.
-
مجموعه داده Paris6k [ 35 ]: Paris6k نیز توسط فلیکر ارائه شده است. 11 دسته از ساختمان های پاریس وجود دارد که شامل 6412 تصویر و 5 منطقه جستجو در مجموع برای هر کلاس است.
-
مجموعه داده تعطیلات [ 36 ]: مجموعه داده تعطیلات از 500 گروه از تصاویر مشابه تشکیل شده است. هر گروه دارای یک تصویر پرس و جو برای مجموع 1491 تصویر است.
-
بازبینی آکسفورد و پاریس [ 37 ]: مجموعه داده های بازبینی شده-آکسفورد (راکسفورد) و بازبینی شده-پاریس (Rparis) به ترتیب از 4993 و 6322 تصویر تشکیل شده است. هر مجموعه داده دارای 70 تصویر پرس و جو است. آنها مجموعه داده های oxford5k و paris6k را با حذف نظرات و افزودن تصاویر دوباره بررسی می کنند. سه سطح دشواری پروتکل ارزیابی وجود دارد: آسان، متوسط و سخت.
4.2. محیط تست و جزئیات
دقت متوسط ( آپ) کیفیت مدل آموخته شده را در هر دسته می سنجد. مترآپکیفیت مدل آموخته شده را در همه دسته ها اندازه گیری می کند. پس از آپبه دست آمد، مقدار متوسط در نظر گرفته شد. محدوده از مترآپمقادیر بین 0 و 1 بود آپ، مترآپفرمول محاسبه به شرح زیر است:
جایی که کتصاویر حاصله که مربوط به تصویر پرس و جو هستند، برگردانده شده است، بحجم تصاویر برگشتی در حین بازیابی است و مترحجم تصاویر در مجموعه داده های آزمایشی است که به تصویر پرس و جو مربوط می شود.
جایی که سمقدار تصاویر پرس و جو در یک مجموعه داده است.
4.3. تست دو ماژول به طور جداگانه
4.4. مقایسه روش تجمیع ویژگی ها
4.5. بحث
4.6. تجزیه و تحلیل پارامتر
5. نتیجه گیری ها
منابع
- الذوبی، ع. امیره، ع. Ramzan, N. بازیابی تصویر مبتنی بر محتوا با ویژگی های فشرده عمیق کانولوشن. محاسبات عصبی 2017 ، 249 ، 95-105. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسمولدرز، AWM; نگران، م. سانتینی، اس. گوپتا، ا. جین، R. بازیابی تصویر مبتنی بر محتوا در پایان اوایل. IEEE Trans. الگوی مقعدی ماخ هوشمند 2001 ، 22 ، 1349-1380. [ Google Scholar ] [ CrossRef ]
- یو-هی نگ، جی. یانگ، اف. دیویس، LS بهره برداری از ویژگی های محلی از شبکه های عمیق برای بازیابی تصویر. در مجموعه مقالات 2015 مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، نیویورک، نیویورک، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 53-61. [ Google Scholar ]
- ژنگ، ال. یانگ، ی. Tian، Q. SIFT با CNN ملاقات می کند: یک دهه بررسی بازیابی نمونه. IEEE Trans. الگوی مقعدی ماخ هوشمند 2018 ، 40 ، 1224-1244. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- چام، او. فیلبین، جی. سیویک، جی. ایسارد، م. Zisserman، A. فراخوان کل: گسترش خودکار پرس و جو با یک مدل ویژگی مولد برای بازیابی شی. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE در سال 2007 در بینایی کامپیوتر، ریودوژانیرو، برزیل، 14 تا 21 اکتبر 2007. صص 1-8. [ Google Scholar ]
- چام، او. میکولیک، ا. پردوچ، م. Matas, J. فراخوان کل II: بسط پرس و جو مجدداً بازبینی شد. در مجموعه مقالات کنفرانس IEEE 2011 در مورد بینایی کامپیوتری و تشخیص الگو، کلرادو اسپرینگز، CO، ایالات متحده آمریکا، 20-25 ژوئن 2011. صص 889-896. [ Google Scholar ]
- فیلیپ، آر. جورجوس، تی. Ondrej, C. تنظیم دقیق بازیابی تصویر CNN بدون حاشیه نویسی انسانی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 41 ، 1655-1668. [ Google Scholar ]
- جگو، اچ. Chum, O. شواهد منفی و اتفاقات همزمان در بازیابی تصویر: مزایای PCA و سفید کردن. در مجموعه مقالات کنفرانس اروپایی 2012 در بینایی کامپیوتر، فلورانس، ایتالیا، 7 تا 13 اکتبر 2012. صص 774-787. [ Google Scholar ]
- اولیوا، ا. Torralba، A. مدل سازی شکل صحنه: بازنمایی کل نگر از پوشش فضایی. بین المللی جی. کامپیوتر. چشم انداز 2001 ، 42 ، 145-175. [ Google Scholar ] [ CrossRef ]
- اولیوا، ا. Torralba، A. توصیف صحنه محور از ویژگی های پوشش فضایی. در مجموعه مقالات کارگاه بین المللی 2002 در مورد بینایی کامپیوتری با انگیزه بیولوژیکی، توبینگن، آلمان، 22-24 نوامبر 2002. صص 263-272. [ Google Scholar ]
- جین، AK; Vailaya، A. بازیابی تصویر با استفاده از رنگ و شکل. تشخیص الگو 1996 ، 29 ، 1233-1244. [ Google Scholar ] [ CrossRef ]
- ویژگی های تصویر متمایز Lowe، DG از نقاط کلیدی Scale-Invariant. بین المللی جی. کامپیوتر. چشم انداز 2004 ، 60 ، 91-110. [ Google Scholar ] [ CrossRef ]
- تولیاس، جی. فورون، تی. Jégou، H. تجمع کوواریانس جهت گیری توصیفگرهای محلی با جاسازی. در مجموعه مقالات کنفرانس اروپایی 2014 در بینایی کامپیوتر، زوریخ، سوئیس، 6 تا 12 سپتامبر 2014. صص 382-397. [ Google Scholar ]
- بی، اچ. تویتلارس، تی. Van Gool، L. Surf: سرعت بخشیدن به ویژگی های قوی. در مجموعه مقالات کنفرانس اروپایی 2006 در بینایی کامپیوتر، گراتس، اتریش، 7 تا 13 مه 2006. ص 404-417. [ Google Scholar ]
- سیویک، جی. Zisserman, A. Video Google: رویکرد بازیابی متن برای تطبیق اشیا در ویدیوها. در مجموعه مقالات 2003 Computer Vision، کنفرانس بین المللی IEEE در، نیس، فرانسه، 13-16 اکتبر 2003. پ. 1470. [ Google Scholar ]
- جگو، اچ. پرونین، اف. دوز، م. سانچز، جی. پرز، پی. اشمید، سی. تجمیع توصیفگرهای تصویر محلی در کدهای فشرده. IEEE Trans. الگوی مقعدی ماخ هوشمند 2011 ، 34 ، 1704-1716. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- پرونین، اف. رقص، C. Fisher هسته در واژگان بصری برای طبقه بندی تصویر. در مجموعه مقالات کنفرانس IEEE 2007 در مورد بینایی کامپیوتری و تشخیص الگو، مینیاپولیس، MN، ایالات متحده، 17-22 ژوئن 2007. صص 1-8. [ Google Scholar ]
- پرونین، اف. سانچز، جی. Mensink, T. بهبود هسته فیشر برای طبقه بندی تصاویر در مقیاس بزرگ. در مجموعه مقالات کنفرانس اروپایی 2010 در بینایی کامپیوتر، هراکلیون، کرت، یونان، 5 تا 11 سپتامبر 2010. صص 143-156. [ Google Scholar ]
- جگو، اچ. زیسرمن، الف. جاسازی مثلث و تجمیع دموکراتیک برای جستجوی تصویر. در مجموعه مقالات کنفرانس IEEE 2014 در مورد دید رایانه و تشخیص الگو، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 23 تا 28 ژوئن 2014. صص 3310–3317. [ Google Scholar ]
- سیمپوی، م. مجی، س. ودالدی، A. بانک های فیلتر عمیق برای تشخیص بافت و تقسیم بندی. در مجموعه مقالات کنفرانس IEEE 2015 در مورد دید رایانه و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 3828–3836. [ Google Scholar ]
- قدرتی، ع. دیبا، ع. پدرسولی، م. تویتلارس، تی. Van Gool, L. Deep Proposals: Hunting Objects and Actions by Cascading Deep Convolutional Layers. بین المللی جی. کامپیوتر. چشم انداز 2017 ، 124 ، 115-131. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بابنکو، آ. اسلسارف، آ. چیگورین، آ. Lempitsky، V. کدهای عصبی برای بازیابی تصویر. مجموعه مقالات کنفرانس اروپایی 2014 بینایی کامپیوتر، زوریخ، سوئیس، 6 تا 12 سپتامبر 2014. صص 584-599. [ Google Scholar ]
- بابنکو، آ. Lempitsky، V. جمع آوری ویژگی های عمیق محلی برای بازیابی تصویر. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2015 در بینایی کامپیوتر، شمال غربی واشنگتن، دی سی، ایالات متحده آمریکا، 7 تا 13 دسامبر 2015. ص 1269-1277. [ Google Scholar ]
- رضویان، ع. سالیوان، جی. کارلسون، اس. ماکی، الف. بازیابی نمونه بصری با شبکه های کانولوشن عمیق. ترانس. فناوری رسانه Appl. 2016 ، 4 ، 251-258. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تولیاس، جی. سیکر، آر. Jégou, H. بازیابی شی خاص با حداکثر ادغام یکپارچه فعالسازیهای CNN. arXiv 2015 ، arXiv:1511.05879. [ Google Scholar ]
- کالانتیدیس، ی. ملینا، سی. Osindero، S. وزندهی متقاطع بعدی برای ویژگیهای پیچیده پیچیده عمیق. در مجموعه مقالات کنفرانس اروپایی 2016 در بینایی کامپیوتر، آمستردام، هلند، 11 تا 14 اکتبر 2016؛ صص 685-701. [ Google Scholar ]
- هائو، جی. وانگ، دبلیو. دونگ، جی. Tan, T. MFC: یک رویکرد کاملاً پیچیده چند مقیاسی برای بازیابی نمونه های بصری. در مجموعه مقالات کنفرانس بین المللی IEEE 2017 در کارگاه های چند رسانه ای و نمایشگاهی (ICMEW)، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 23 تا 27 ژوئیه 2018؛ صص 513-518. [ Google Scholar ]
- شریف رضویان، ع. عزیزپور، ح. سالیوان، جی. Carlsson، S. CNN ویژگیهای خارج از قفسه: یک خط پایه شگفتانگیز برای شناسایی. در مجموعه مقالات کنفرانس IEEE 2014 در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، کلمبوس، OH، ایالات متحده آمریکا، 24 تا 27 ژوئن 2014. ص 806-813. [ Google Scholar ]
- خو، جی. وانگ، سی. چی، سی. شی، سی. Xiao، B. تجمع بدون نظارت بر اساس معنایی ویژگیهای پیچیده پیچیده. IEEE Trans. فرآیند تصویر 2019 ، 28 ، 601–611. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- سگدی، سی. لیو، دبلیو. جیا، ی. سرمانت، پ. رید، اس. آنگلوف، دی. ایرهان، د. ونهوک، وی. رابینوویچ، الف. با پیچیدگی ها عمیق تر می رویم. در مجموعه مقالات کنفرانس IEEE 2015 در مورد دید رایانه و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صفحات 1-9. [ Google Scholar ]
- گوردو، آ. Larlus، D. فراتر از بازیابی تصویر در سطح نمونه: استفاده از شرحها برای یادگیری یک نمایش تصویری جهانی برای بازیابی معنایی. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 6589–6598. [ Google Scholar ]
- میکولایچیک، ک. Matas, J. بهبود توصیفگرها برای تطبیق سریع درخت با طرح ریزی خطی بهینه. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE در سال 2007 در بینایی کامپیوتر، ریودوژانیرو، برزیل، 14 تا 21 اکتبر 2007. صص 1-8. [ Google Scholar ]
- فیلبین، جی. چام، او. ایسارد، م. سیویک، جی. Zisserman، A. بازیابی اشیاء با واژگان بزرگ و تطابق سریع فضایی. در مجموعه مقالات کنفرانس IEEE 2007 در مورد بینایی کامپیوتری و تشخیص الگو، مینیاپولیس، MN، ایالات متحده، 17-22 ژوئن 2007. صص 1-8. [ Google Scholar ]
- ژای، ی. شاه، ام. تشخیص توجه بصری در سکانسهای ویدیویی با استفاده از نشانههای فضایی و زمانی. در مجموعه مقالات چهاردهمین کنفرانس بین المللی ACM در چند رسانه ای، سانتا باربارا، کالیفرنیا، ایالات متحده آمریکا، 23 تا 27 اکتبر 2006. صص 815-824. [ Google Scholar ]
- فیلبین، جی. چام، او. ایسارد، م. سیویک، جی. زیسرمن، A. گمشده در کوانتیزاسیون: بهبود بازیابی اشیاء خاص در پایگاه داده های تصویر در مقیاس بزرگ. در مجموعه مقالات کنفرانس IEEE 2008 در مورد بینایی کامپیوتری و تشخیص الگو، انکوریج، AK، ایالات متحده آمریکا، 23 تا 28 ژوئن 2008. صص 1-8. [ Google Scholar ]
- جگو، اچ. دوز، م. Schmid, C. Hamming جاسازی و سازگاری هندسی ضعیف برای جستجوی تصویر در مقیاس بزرگ. در مجموعه مقالات کنفرانس اروپایی 2008 در بینایی کامپیوتر، مارسی، فرانسه، 12 تا 18 اکتبر 2008. صص 304-317. [ Google Scholar ]
- رادنوویچ، اف. ایسن، ا. تولیاس، جی. Avrithis، Y. Chum, O. بازدید مجدد از آکسفورد و پاریس: معیار بازیابی تصویر در مقیاس بزرگ. در مجموعه مقالات کنفرانس IEEE 2018 در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 5706–5715. [ Google Scholar ]
- دنگ، ج. دونگ، دبلیو. سوچر، آر. لی، ال.-جی. لی، ک. Fei-Fei, L. Imagenet: پایگاه داده تصویر سلسله مراتبی در مقیاس بزرگ. در مجموعه مقالات کنفرانس IEEE 2009 در مورد بینایی کامپیوتری و تشخیص الگو، میامی، FL، ایالات متحده آمریکا، 20-25 ژوئن 2009. ص 248-255. [ Google Scholar ]
- لیو، پی. گو، جی. گوا، اچ. ژانگ، دی. ژو، Q. ترکیب آنتروپی توزیع ویژگی با ویژگی های R-MAC در بازیابی تصویر. Entropy 2019 ، 21 ، 1037. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- موهدانو، ای. مک گینس، ک. O’Connor، NE; سالوادور، آ. مارکز، اف. Giró-i-Nieto، X. کیسه هایی از ویژگی های کانولوشنال محلی برای جستجوی نمونه مقیاس پذیر. در مجموعه مقالات ACM 2016 در کنفرانس بین المللی بازیابی چند رسانه ای، ونکوور، BC، کانادا، 6-9 ژوئن 2016؛ صص 327-331. [ Google Scholar ]
- Maaten، LVD شتاب دهنده t-SNE با استفاده از الگوریتم های مبتنی بر درخت. جی. ماخ. فرا گرفتن. Res. 2014 ، 15 ، 3221-3245. [ Google Scholar ]





بدون دیدگاه