

خلاصه
کلید واژه ها:
حمل و نقل ; GPS ؛ پایگاه داده ; حمل و نقل جاده ای ; ماتریس های OD اقدامات پارکینگ ؛ الگوهای رانندگی ؛ نمودار میل ; الزامات کاربر
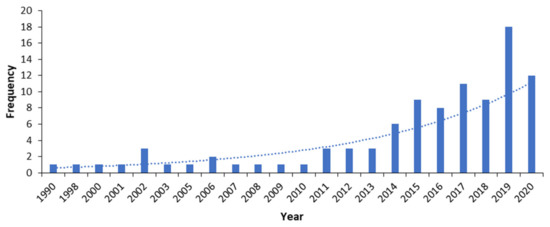
1. معرفی
-
چگونه می توان الزامات DRD (اقدامات ترافیکی) را به طور موثر در مرحله توسعه سیستم پایگاه داده جمع آوری کرد؟
-
انواع مختلف داده های حمل و نقل خام که برای فعال کردن سیستم پردازش برای برآوردن نیازهای DRD مورد نیاز است، چیست؟
-
رویه ها و سیستم هایی برای جمع آوری و تجزیه و تحلیل داده های حمل و نقل مشترک و اطمینان از حفظ حریم خصوصی داده ها چیست؟
-
چه مقدار داده برای ارائه تجزیه و تحلیل داده های حمل و نقل از نظر آماری مهم مورد نیاز است؟
“سازمان های عمومی”، “وزارت حمل و نقل”، “سیاست حمل و نقل”، “بخش عمومی”؛ “مبداء-مقصد”، “لجستیک”، “بار”، “کامیون”، “جی پی اس”، “کامیون”، “داده”.
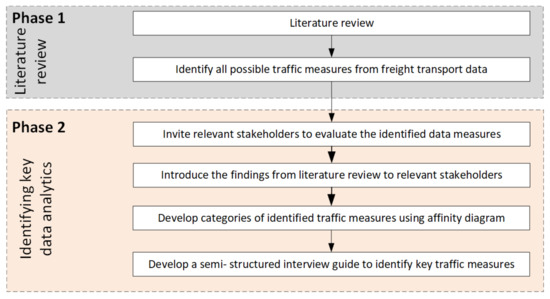
2. شناسایی مهمترین اقدامات ترافیکی از دیدگاه کاربران نهایی
-
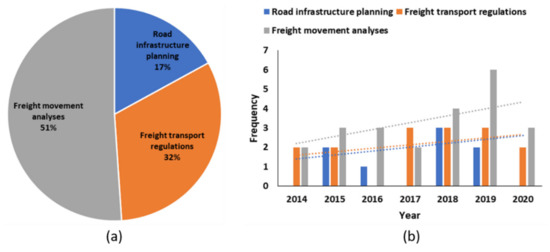
برنامه ریزی زیرساخت جاده: این دسته شامل مطالعاتی است که از داده های حمل و نقل برای تأیید یا بررسی تأثیر جاده های جدید، مناطق پارکینگ برای کامیون ها و پتانسیل های جاده های عوارضی استفاده می کند.
-
مقررات حمل و نقل کالا: این دسته شامل مطالعاتی است که نشان می دهد چگونه می توان از داده های حمل و نقل برای پیشنهاد و تأیید سیاست های ترافیک بار استفاده کرد.
-
تجزیه و تحلیل حرکت بار: این دسته شامل مطالعاتی است که داده های حمل و نقل را به منظور ایجاد درک بهتری از نحوه استفاده از شبکه های جاده ای توسط کامیون های باری تجزیه و تحلیل می کند.
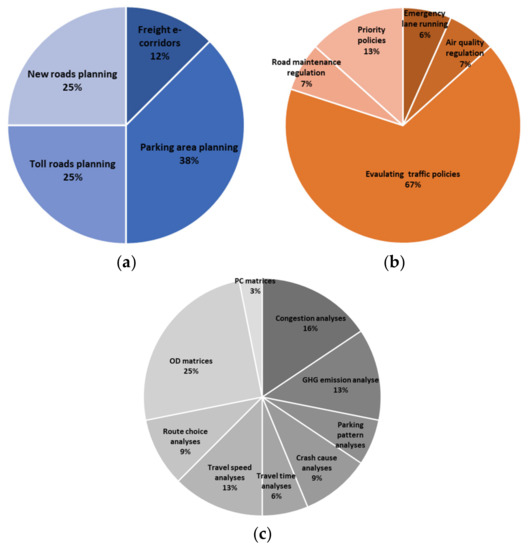
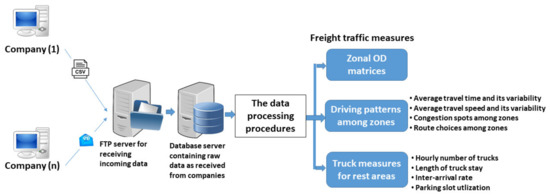
2.1. ماتریس های OD
2.2. الگوهای رانندگی در بین مناطق
2.3. تجزیه و تحلیل الگوی پارکینگ
3. شناسایی مورد نیاز داده های ورودی
4. رویه ها و سیستم برای توسعه اقدامات حمل و نقل کالا
- (آ)
-
جمع آوری و تجزیه و تحلیل داده های خام
- (ب)
-
ذخیره سازی داده ها و توسعه پایگاه داده.
- (ج)
-
پردازش داده های خام؛
- –
-
روش فیلتر کردن داده ها؛
- –
-
روش تعیین اندازه نمونه؛
- –
-
روش تجزیه و تحلیل حمل و نقل کالا
- (د)
-
اعتبار سنجی تحلیل های حمل و نقل کالا
4.1. جمع آوری و تجزیه و تحلیل داده های خام
4.2. ذخیره سازی داده ها و توسعه پایگاه داده
4.3. رویه های پردازش داده ها
4.3.1. فیلتر و تصحیح داده ها
-
هنگامی که ارتباط مؤثر بین دستگاههای GPS و ماهوارههای GPS از دست رفته سیگنالهای GPS ممکن است از بین بروند. چنین انسدادی ممکن است بر شناسایی داده های OD تأثیر منفی بگذارد. در پاسخ به این مشکل از دست دادن سیگنال، سوابق GPS گزارش شده قبل و بعد از از دست دادن سیگنال می تواند برای فرض سوابق GPS از دست رفته استفاده شود. به عنوان مثال، اگر میانگین سرعت سفر برای رکوردهای GPS قبل و بعد از از دست دادن سیگنال کمتر از حد آستانه سرعت باشد، یعنی 8 کیلومتر در ساعت، منطقی است که فرض کنیم یک سفر در منطقه از دست دادن سیگنال به پایان رسیده است. . برعکس، اگر میانگین سرعت سفر برای رکوردهای GPS قبل و بعد از تلف شدن سیگنال بالاتر از این آستانه باشد، فرض می شود که کامیون به طور مداوم با سرعتی برابر با میانگین سرعت سفر در منطقه از دست دادن سیگنال به حرکت خود ادامه می دهد.
-
در برخی موارد، سوابق GPS همان کامیون نشان می دهد که کامیون به طور ناگهانی مسیر را ترک کرده و بازگشته است، به عنوان مثال گاهی اوقات اتفاق می افتد که یک نقطه GPS در فاصله دورتر از مسیر ثبت می شود، اما نقاط GPS قبلی و بعدی روی یکسان هستند. مسیر چنین نقاط GPS در تجزیه و تحلیل در نظر گرفته نمی شود.
4.3.2. تعیین حجم نمونه و تحلیل کفایت داده ها
برای توسعه تجزیه و تحلیل های قابل اعتماد حمل و نقل با استفاده از دستگاه های GPS، بررسی نیازهای اندازه نمونه مهم است [ 24 ]. به عنوان مثال، برای تخمین زمان یا سرعت سفر لینک، تجزیه و تحلیل حمل و نقل باید تصمیم بگیرد که چند کامیون منحصر به فرد مورد نیاز است، همچنین به عنوان حداقل حجم نمونه مورد نیاز شناخته می شود [ 19 ]. همیشه یک نمونه بزرگ برای ایجاد اطلاعات دقیق تر در مورد جمعیت توصیه می شود. این به این دلیل است که حجم نمونه بزرگ نشان میدهد که دادههای بهدستآمده بیشتر معرف وضعیت دنیای واقعی هستند و این باعث افزایش اعتماد به نتایج میشود [ 24] .]. با این حال، با افزایش حجم نمونه، هزینه های جمع آوری داده ها افزایش می یابد، زیرا این امر مستلزم گنجاندن شرکت های بیشتری در پروژه است. بنابراین، محاسبه حداقل حجم نمونه نشان دهنده یک مبادله متوازن بین دقت تجزیه و تحلیل و هزینه اکتساب داده است. چو و همکاران (2002) و چن و چین (2000) معادله ای را برای محاسبه حجم نمونه هنگام تخمین سرعت بر اساس داده های GPS به شرح زیر ارائه کردند [ 22 ، 23 ]:
جایی که:
-
n حجم نمونه است که بر حسب تعداد کامیون های مجهز به کاوشگر GPS بیان می شود.
-
zα2= مقدار z جدول بندی شده مربوط به 100 × است 1-α جonfمندهnجهبه عنوان مثال، سطح اطمینان 95٪ به این معنی است که احتمال 95٪ وجود دارد که تخمین های سرعت جمعیت در محدوده مشخص شده مقادیر سرعت شناسایی شده بر اساس نمونه قرار می گیرند.
-
σ = انحراف استاندارد.
-
SE = خطای نمونه برداری، که خطای نسبی مجاز انتخاب شده توسط کاربر در تخمین سرعت متوسط است.
-
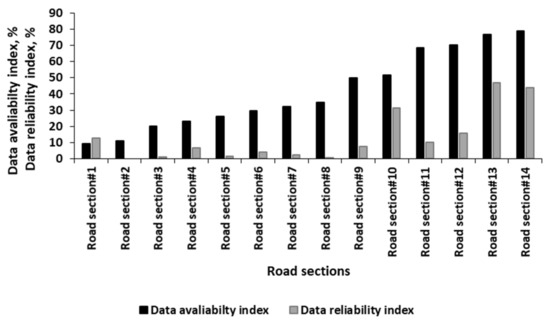
شاخص در دسترس بودن داده ها ( u )، که درصد (%) ساعات روزانه را که حداقل یک کامیون GPS در دسترس است، نشان می دهد. u را می توان به صورت زیر محاسبه کرد:
تو=ل24×100%که در آن l تعداد ساعاتی است که در آن حداقل یک کامیون در دسترس است. l از داده های GPS موجود محاسبه می شود. به عنوان مثال، اگر u برای یک بخش جاده خاص 100٪ باشد، به این معنی است که حداقل یک رکورد داده GPS در هر ساعت برای این بخش در دسترس است.
-
شاخص قابلیت اطمینان داده ها ( d ) درصد (%) ساعات روزانه را نشان می دهد که در آن داده های GPS موجود حداقل مورد نیاز اندازه نمونه را برآورده می کند. d را می توان با این معادله محاسبه کرد:
د=v24×100%که در آن v تعداد ساعاتی است که داده های GPS حداقل مورد نیاز اندازه نمونه را برآورده می کند. به عنوان مثال، اگر d 54.2٪ باشد، به این معنی است که حدود 54.2٪ از 24 ساعت داده های GPS کافی برای ارائه معیارهای سرعت آماری قابل توجهی دارند.
4.3.3. روش تحلیل حمل و نقل بار
-
شناسایی ایستگاه های کامیون:روش DBSCAN شامل دو مرحله اصلی است: (1) شناسایی خوشههایی از نقاط GPS، و (2) اجرای یک محدودیت زمانی برای اطمینان از عدم شناسایی توقفها بر اساس نقاط GPS با شکاف زمانی بزرگ [95 ] .
-
شناسایی هدف از توقف کامیون ها:دادههای کاربری عمومی در دسترس عموم برای شناسایی اهداف توقفها استفاده خواهد شد: توقفهای استراحت، توقفهای بارگیری/تخلیه، و توقفهای سوخترسانی [ 71 ].
-
تعیین مبدا و مقصد برای تولید سفر:توقفگاه های مبدأ و مقصد، توقفگاه هایی خواهند بود که استراحت، سوخت و یا توقف ترافیک نیستند.
-
محاسبه ماتریس OD ناحیه ای:ماتریس OD ناحیه ای مقدار سفرهای منحصر به فرد بین هر منطقه را تعیین می کند [ 19 ].
-
تعیین تنوع انتخاب مسیر بین مناطق:تجزیه و تحلیل انتخاب مسیر، میزان سفرها را در مسیرهای جداگانه در میان مناطق توصیف می کند و مسیرهای اصلی سفر بین مناطق را به عنوان مسیری با بیشترین میزان سفر شناسایی می کند [ 15 ].
-
تعیین زمان و سرعت سفر بین مناطق:زمان و سرعت سفر با استفاده از اطلاعات سفرها در میان مبدا و مقصد محاسبه خواهد شد، به دنبال رویههای معرفیشده در [ 67 ].
-
تشخیص توقف در مناطق استراحت:همانطور که قبلا گفته شد، روش DBSCAN برای شناسایی تمام توقف های احتمالی کامیون ها استفاده خواهد شد. تجزیه و تحلیل پارکینگ فقط توقف های کامیون ها در مناطق مختلف استراحت در دانمارک را در نظر می گیرد.
-
تعیین زمان ورود و اقامت:از آنجایی که هر توقف مجموعه ای از رکوردهای GPS است، برای هر توقف، رکوردهای GPS آن بر اساس مهر زمانی مرتب می شوند. سپس زمان ورود و خروج هر کامیون به عنوان اولین و آخرین مهر زمانی در محل استراحت در نظر گرفته می شود. این می تواند امکان تجزیه و تحلیل در مورد کل زمان اقامت در هر منطقه پارکینگ را فراهم کند [ 96 ]. این می تواند در هر ساعت، روز، هفته یا ماه، بسته به نیازهای شناسایی شده DRD در نظر گرفته شود.
-
محاسبه بهره برداری از جایگاه های پارکینگ:با اطلاعات مربوط به زمان ورود و خروج کامیون ها، میانگین بهره برداری از جایگاه پارکینگ را می توان به عنوان نسبت تعداد کامیون های پارک شده به طور همزمان به حداکثر ظرفیت فضای استراحت تخمین زد.
4.4. اعتبار سنجی تحلیل های حمل و نقل بار
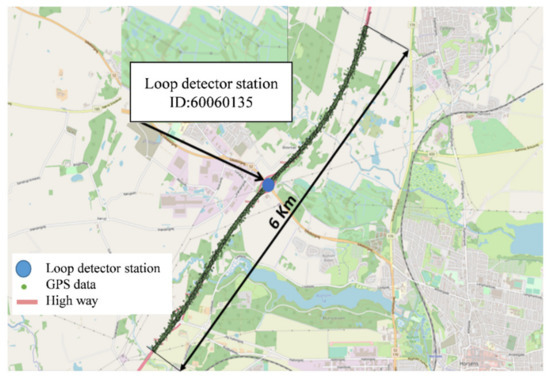
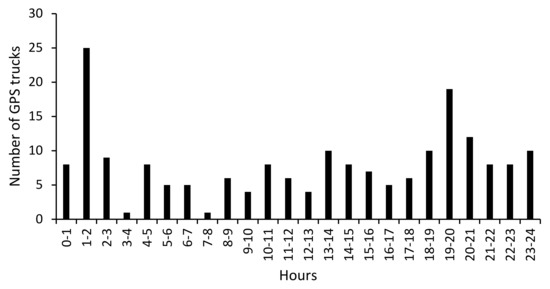
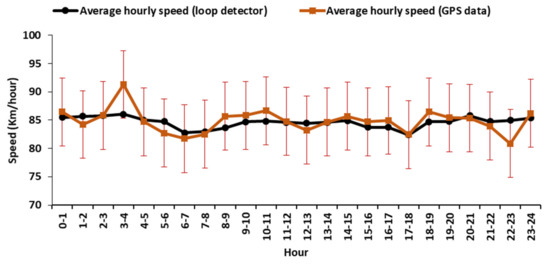
5. یک پرونده کاربردی
6. نتیجه گیری و تحقیقات آتی
-
تقاضای حمل و نقل آینده: استفاده از داده ها برای تجزیه و تحلیل تغییراتی که می تواند بر تقاضای حمل و نقل بار در آینده تأثیر بگذارد و احتمالات را برای شکل دادن به نسل بعدی سیاست های حمل و نقل نشان دهد. این شامل تجزیه و تحلیل تغییرات در الگوهای خرید سنتی به سمت خریدهای بیشتر مبتنی بر وب، تغییر در الگوهای سفر، محدودیتهای سیاستی در مورد انتشار گازهای گلخانهای در شهرها یا تغییر به سمت وسایل نقلیه الکتریکی است که نیازمند ملاحظات زیرساخت شارژ و توزیع شبکه برق است.
-
کاهش ازدحام: یک سوال جالب که میتوان در تحقیقات آینده به آن پرداخت این است که «آیا هزینههای عوارض متمایز شده با زمان میتواند زمان تحویل را تغییر دهد و در نتیجه بر نرخ تراکم، با دور کردن زمان رانندگی کامیونها از دورههای شلوغی تأثیر بگذارد؟». علاوه بر این، عوامل مؤثر بر این امر باید بیشتر مورد بررسی قرار گیرند، به عنوان مثال، قیمت حمل و نقل و پذیرش مصرف کننده از زمان تحویل متغیر. تجزیه و تحلیل انتخاب مسیر ممکن است نشان دهد که کدام بخش جاده در صورت ترافیک کامیون های سنگین یا عدم وجود مسیرهای جایگزین آسیب پذیر است. استفاده از این دانش احتمالاً میتواند فرصتهایی را برای گسترش جادهها یا ساخت جادههای جدید نشان دهد.
-
حمایت از سیاست: «آیا دادههای حمل و نقل میتوانند از مقامات دولتی در زمینههای دیگری غیر از برنامهریزی حملونقل یا پشتیبانی از متخصصان حملونقل در بخشهای خصوصی حمایت کنند؟» سوال جالبی است که می توان با تحقیقات آتی به آن پرداخت. دادههای جمعآوریشده عمدتاً بر توسعه حملونقل کالا و سیاستهای مرتبط تمرکز دارد، ممکن است در حمایت از سیاستهای توسعه مفید باشد، بهعنوان مثال، مناطق شهری، مناطقی که جابهجایی در آنها رخ میدهد، و غیره. انتشار گازهای گلخانه ای، سر و صدا و جاده های دسترسی ممکن است بهبود و بهبود یابد.
-
داده های نسل بعدی: یک سوال مرتبط این است که “پیشرفت های فناوری بعدی که ابعاد بیشتری را به داده های موجود ارائه می دهد و امکان تغییر گام در درک تحولات سیاست را فراهم می کند، چیست؟”. استفاده از داده های خصوصی در سازمان های دولتی تأثیر مستقیمی بر جمع آوری داده های بیشتر توسط شرکت های خصوصی دارد. این نمونهگیری طبیعی، سازمانهای عمومی را قادر میسازد تا دادههای ارزان قیمت را بدون نیاز به نصب تجهیزات گران قیمت به دست آورند. با کاستی هایی همراه است، به عنوان مثال، داده ها برای هدف خاصی جمع آوری نشده اند. تحقیقات آینده باید بر چگونگی توسعه روشهای جدید یا تنظیم روشهای موجود تمرکز کند.
-
روشهای جمعآوری دادهها: ابزار جمعآوری دانش در مورد انواع توقف و علل توقف، برای بهبود مدلهای حملونقل در آینده را در نظر بگیرید. تحقیق در مورد اینکه کدام روشهای جمعآوری دادهها بهترین هستند، جنبه مهمی از چندین مطالعه است. از آنجایی که دادههای ضروری مورد نیاز برای ایجاد ماتریسهای OD هنوز مورد بحث است، بررسی اینکه چه دادههایی مورد نیاز است و کدام روشها میتوانند به بهترین وجه از این دادهها پشتیبانی کنند، اهمیت دارد، به ویژه با توجه به هزینه و زمان برای جمعآوری دادههای لازم.
-
تجزیه و تحلیل فراداده: با در نظر گرفتن ماتریس OD و تجزیه و تحلیل الگوهای محرک، درک گسترش مورد نیاز داده ها اهمیت دارد. برای تعیین یک مجموعه انتخاب مسیر بیطرفانه برای جفتهای OD، لازم است تا گسترش زمانی دادهها را بیشتر تجزیه و تحلیل کنیم، یا تجزیه و تحلیل دادهها را تنظیم کنیم تا به این نتیجه برسیم که چند سفر کافی است [63 ] .
-
کالیبراسیون مدل: کالیبراسیون مدلها با ماتریسهای OD، با استفاده از دادههای حقیقت زمین یا دادههای شبیهسازی شده، به انواع ورودی دادههای بیشتری نیاز دارد. اینکه از کدام نوع داده ها برای کالیبراسیون استفاده شود و چگونه از این داده ها استفاده شود، موضوعی است که نیاز به بررسی بیشتر دارد.
منابع
- لاوی، دی. بنیاد، جی. Solomon, C. اثر سرمایه گذاری در زیرساخت های حمل و نقل بر نسبت بدهی به تولید ناخالص داخلی. ترانسپ Rev. 2011 , 1647 . [ Google Scholar ] [ CrossRef ]
- آمار دانمارک تعداد شرکت ها در بخش حمل و نقل در دانمارک بر اساس حالت. در دسترس آنلاین: https://www.statista.com/statistics/448383/number-of-enterprises-in-the-transport-sector-in-denmark-by-mode/ (دسترسی در 10 اکتبر 2019).
- آمار دانمارک تعداد کارمندان در بخش حمل و نقل در دانمارک بر اساس حالت. در دسترس آنلاین: https://www.statista.com/statistics/448130/number-of-employees-in-the-transport-sector-in-denmark-by-mode/ (دسترسی در 10 اکتبر 2019).
- Danmarks Statistik دانمارک حجم گردش مالی در بخش حمل و نقل بر اساس حالت. در دسترس آنلاین: https://www.statista.com/statistics/448688/denmark-turnover-volume-in-the-transport-sector-by-mode/ (دسترسی در 10 اکتبر 2019).
- Danmarks Statistik حمل و نقل بار از طریق درآمد جاده ای در دانمارک. در دسترس آنلاین: https://www.statista.com/forecasts/390721/freight-transport-by-road-revenue-in-denmark (در 10 اکتبر 2019 قابل دسترسی است).
- کویبورگ، او. Fosgerau, M. تجزیه جداسازی رشد ترافیک حمل و نقل جاده ای دانمارکی و رشد اقتصادی. ترانسپ سیاست 2007 ، 14 ، 39-48. [ Google Scholar ] [ CrossRef ]
- هوانگ، مدلسازی تقاضای حمل و نقل TS و برنامه ریزی لجستیک برای ارزیابی اثرات زیست محیطی سیستم های حمل و نقل. Ph.D. پایان نامه، دانشگاه ایلینوی در Urbana-Champaign، Urbana، IL، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- Vejdirektoratet Statsvejnettet. 2019. در دسترس آنلاین: https://www.vejdirektoratet.dk/api/drupal/sites/default/files/2019-07/WEB_Statsvejnettet%202019.pdf (دسترسی در 10 ژوئیه 2019).
- جمع آوری و مدل سازی داده های حمل و نقل پان، QS: روش ها و عمل. ترانسپ طرح. تکنولوژی 2006 ، 29 ، 43-74. [ Google Scholar ] [ CrossRef ]
- مک کورمک، ای. دستگاههای Hallenbeck، ME ITS برای جمعآوری دادههای کامیون برای معیارهای عملکرد استفاده میشوند. Natl. اطلاعات حمل و نقل ایالتی مدیریت دارایی. 2006 ، 1957 ، 43-50. [ Google Scholar ] [ CrossRef ]
- گریوز، SP; Figliozzi، MA جمع آوری داده های تور خودروهای تجاری با فناوری سیستم موقعیت یابی غیرفعال جهانی: مسائل و کاربردهای بالقوه. ترانسپ Res. ضبط J. Transp. Res. هیئت 2008 ، 2049 ، 158-166. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عذاب، ع. کرم، ع. Eltawil، A. یک رویکرد بهینهسازی مبتنی بر شبیهسازی برای زمانبندی قرار ملاقات کامیونهای خارجی در پایانههای کانتینری. بین المللی جی مدل. شبیه سازی 2020 ، 40 ، 321-338. [ Google Scholar ] [ CrossRef ]
- چانکائو، ن. سومالی، ع. سیریپیروت، تی. تریپاک، تی. هو، HW; لام، تجزیه و تحلیل ترافیک حمل و نقل WHK از داده های GPS کامیون ملی در تایلند. ترانسپ Res. Procedia 2018 ، 34 ، 123-130. [ Google Scholar ] [ CrossRef ]
- والر، MA; Fawcett، SE برای یک دانشمند داده اینجا را کلیک کنید: داده های بزرگ، تجزیه و تحلیل پیش بینی، و توسعه نظریه در عصر زنجیره تامین جنبش سازندگان. اتوبوس جی. تدارکات. 2013 ، 34 ، 249-252. [ Google Scholar ] [ CrossRef ]
- کمالی، م. ارماگون، ا. ویسواناتان، ک. پینجاری، انتخاب مسیر کامیون AR از جریانهای داده بزرگ GPS. ترانسپ Res. ضبط J. Transp. Res. هیئت 2016 ، 2563 ، 62-70. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زنجانی، ع. پینجاری، ع. کمالی، م. تاکور، ا. کوتاه، جی. میسور، وی. طباطبایی، برآورد SF جریانهای کامیون مبدأ-مقصد سراسر ایالت از جریانهای بزرگ داده GPS برای مدل ایالتی فلوریدا. ترانسپ Res. ضبط 2015 ، 87-96. [ Google Scholar ] [ CrossRef ]
- هیون، ک. مدل تصمیم گیری مکان سنسور ریچی، SG برای اندازه گیری جریان کامیون. ترانسپ Res. ضبط J. Transp. Res. هیئت 2017 ، 2644 ، 1-10. [ Google Scholar ] [ CrossRef ]
- لیائو، سی.-ف. ایجاد معیارهای قابل اعتماد عملکرد حمل و نقل با داده های GPS کامیون. ترانسپ Res. ضبط 2014 ، 2410 ، 21-30. [ Google Scholar ] [ CrossRef ]
- ما، ایکس. Mccormack، ED; Wang, Y. پردازش دادههای سیستم موقعیتیابی جهانی تجاری برای توسعه یک برنامه اندازهگیری عملکرد کامیون مبتنی بر وب. ترانسپ Res. ضبط J. Transp. Res. هیئت 2011 ، 2246 ، 92-100. [ Google Scholar ] [ CrossRef ]
- پارکر، سی. رویکردی به تحلیل نیازمندی ها برای سیستم های پشتیبانی تصمیم. بین المللی جی. هوم. محاسبه کنید. گل میخ. 2001 ، 55 ، 423-433. [ Google Scholar ] [ CrossRef ]
- Illemann, TM; کرم، ع. Reinau، KH به سمت اشتراک گذاری داده های شرکت های حمل و نقل خصوصی با سیاست گذاران عمومی: چارچوب پیشنهادی برای شناسایی استفاده از داده های مشترک. در مجموعه مقالات هفتمین کنفرانس بین المللی IEEE 2020 در زمینه مهندسی صنایع و کاربردها (ICIEA)، بانکوک، تایلند، 16 تا 21 آوریل 2020. [ Google Scholar ]
- چن، ام. Chien، SIJ تعیین تعداد وسایل نقلیه کاوشگر برای تخمین زمان سفر آزادراه با شبیه سازی میکروسکوپی. ترانسپ Res. ضبط J. Transp. Res. هیئت 2000 ، 1719 ، 61-68. [ Google Scholar ] [ CrossRef ]
- چو، آر. زی، سی. لی، دی. جمعیت وسیله نقلیه کاوشگر و اندازه نمونه برای تخمین سرعت شریانی. محاسبه کنید. مدنی زیرساخت. مهندس 2002 ، 17 ، 53-60. [ Google Scholar ] [ CrossRef ]
- لی، اس. زو، ک. ون گلدر، BHW; ناگل، جی. تاتل، سی. بررسی مجدد الزامات اندازه نمونه برای جمعآوری دادههای ترافیک میدانی با دستگاههای سیستم موقعیتیابی جهانی. ترانسپ Res. ضبط 2002 ، 1804 ، 17-22. [ Google Scholar ] [ CrossRef ]
- Hsiao، CT; چو، FCC؛ Hsieh, CC; چانگ، ال سی. Hsu، CM توسعه یک سیستم یادگیری و ارزیابی مبتنی بر شایستگی برای آموزش اقامت: مطالعه تحلیلی نیازهای کاربر و پذیرش. جی. مد. Internet Res. 2020 ، 22 ، e15655. [ Google Scholar ] [ CrossRef ]
- نیکلسون، اف. Laursen، RK; کسیدی، آر. فارو، ال. تندلر، ال. ویلیامز، جی. سوردیک، ن. Velthof، G. چگونه ابزارهای پشتیبانی تصمیم می توانند به کاهش آلودگی نیترات و آفت کش ها در کشاورزی کمک کنند؟ بررسی ادبیات و بینش عملی از پروژه اتحادیه اروپا FAIRWAY. Water 2020 , 12 , 768. [ Google Scholar ] [ CrossRef ]
- سعیده، ح. دونگ، جی. وانگ، ی. Abid, MA چارچوب پیشنهادی برای بهبود فرآیند استخراج نیازمندیهای نرمافزار در SCRUM: پیادهسازی توسط یک پروژه فناوری اطلاعات مبتنی بر نروژ در زندگی واقعی. جی. سافتو. تکامل. فرآیند 2020 ، 32 ، 1-24. [ Google Scholar ] [ CrossRef ]
- آواستی، ع. Chauhan، SS یک رویکرد ترکیبی با ادغام نمودار میل ترکیبی، AHP و TOPSIS فازی برای برنامه ریزی لجستیک شهری پایدار. Appl. ریاضی. مدل. 2012 ، 36 ، 573-584. [ Google Scholar ] [ CrossRef ]
- چو، اس. Koo, Y. پیشنهاد سناریوی رابط کاربری یک خودروی هوشمند بر اساس روش تحقیق متنی. قوس. دس Res. 2020 ، 33 ، 113-133. [ Google Scholar ] [ CrossRef ]
- اسلام، MN; کریم، م. اینان، TT; اسلام، AKMN بررسی قابلیت استفاده از برنامه های کاربردی سلامت تلفن همراه در بنگلادش. BMC Med. آگاه کردن. تصمیم می گیرد. ماک 2020 ، 20 ، 19. [ Google Scholar ] [ CrossRef ]
- بابر، س. بهارا، ر. White, E. قابلیت استفاده محصول نقشه برداری. بین المللی جی. اوپر. تولید مدیریت 2002 ، 22 ، 19. [ Google Scholar ] [ CrossRef ]
- پافومی، ای. دی جنارو، ام. مارتینی، جی. مطالعه در سراسر اروپا در مورد کلان داده ها برای حمایت از سیاست حمل و نقل جاده ای. مورد مطالعه. ترانسپ سیاست 2018 ، 6 ، 785–802. [ Google Scholar ] [ CrossRef ]
- پرز، BO تعیین و توجیه عملکرد مناطق پارکینگ رویکرد معیار مبتنی بر داده در واشنگتن، دی سی Transp. Res. ضبط 2015 ، 2537 ، 148-157. [ Google Scholar ] [ CrossRef ]
- ملو، اس. مکدو، جی. Baptista، P. اشتراک ظرفیت در راه حل های لجستیک: مسیری جدید به سمت پایداری. ترانسپ سیاست 2019 ، 73 ، 143-151. [ Google Scholar ] [ CrossRef ]
- Alho، AR; شما، ال. لو، اف. چیه، ال. ژائو، اف. Ben-Akiva، M. نسل بعدی بررسی وسایل نقلیه باری: تکمیل ردیابی GPS کامیون با بررسی فعالیت راننده. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی 2018 در مورد سیستم های حمل و نقل هوشمند (ITSC)، مائوئی، HI، ایالات متحده آمریکا، 4 تا 7 نوامبر 2018. [ Google Scholar ]
- Vegelien، AGJ; Dugundji، ER یک مدل زمان ترجیحی روز برای زمان عزیمت کامیونهای تحویل در هلند. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی 2018 در مورد سیستم های حمل و نقل هوشمند (ITSC)، مائوئی، HI، ایالات متحده آمریکا، 4 تا 7 نوامبر 2018. [ Google Scholar ]
- گومز، جی. Vassallo، JMM تکامل در طول زمان حجم وسایل نقلیه سنگین در جادههای عوارضی: دادههای پانل پویا برای شناسایی متغیرهای توضیحی کلیدی در اسپانیا. ترانسپ Res. بخش A خط مشی Pr. 2015 ، 74 ، 282-297. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بوشنر، BS; کرانس، KM; داک، SP; کلیفتون، کی جی. گیبسون، PA; هاردی، DK; هوپر، KG; کیم، ال.-جی. مک کورت، آر اس؛ سامدال، DR; و همکاران پیشرفت در تخمین تولید سفرهای شهری ITE J. 2016 ، 86 ، 17-19. [ Google Scholar ]
- ملاندر، ال. دوبوا، ا. هدوال، ک. Lind, F. حمل و نقل کالاهای آینده در سوئد 2050: با استفاده از تحلیل سناریویی مبتنی بر دلفی. تکنولوژی پیش بینی. Soc. چانگ. 2019 ، 138 ، 178-189. [ Google Scholar ] [ CrossRef ]
- دوتا، ن. بواتنگ، RA؛ Fontaine, MD ایمنی و اثرات عملیاتی سیستم مدیریت ترافیک فعال بین ایالتی 66. J. Transp. مهندس بخش A سیستم. 2019 , 145 . [ Google Scholar ] [ CrossRef ]
- گرانت مولر، اس. هاجسون، اف. مالسون، ن. Snowball, R. Enhancing Energy, Health and Security Policy by استخراج، غنی سازی و واسط داده های نسل بعدی در حوزه حمل و نقل (مطالعه ای در مورد استفاده از داده های بزرگ در توسعه سیاست های بین بخشی). در مجموعه مقالات ششمین کنگره بین المللی IEEE 2017 در مورد داده های بزرگ، هونولولو، HI، ایالات متحده آمریکا، 25 تا 30 ژوئن 2017. [ Google Scholar ]
- هادوی، س. ورلینده، اس. وربکه، دبلیو. ماچاریس، سی. Guns, T. نظارت بر حمل و نقل شهری-باری بر اساس مسیرهای GPS وسایل نقلیه سنگین کالا. IEEE Trans. هوشمند ترانسپ سیستم 2019 ، 20 ، 3747–3758. [ Google Scholar ] [ CrossRef ]
- لیندهولم، MEE; Blinge، M. ارزیابی دانش و آگاهی از حمل و نقل بار شهری پایدار در میان برنامه ریزان سیاست مقامات محلی سوئد. ترانسپ سیاست 2014 ، 32 ، 124-131. [ Google Scholar ] [ CrossRef ]
- مینیس، پی. بیرنباوم، ال. مورتنسن، S. پاسخ حادثه راه آهن ترانزیت قبل و بعد از استقرار ICM: استراتژی ها و محدودیت ها. در مجموعه مقالات بیست و یکمین کنگره جهانی سیستم های حمل و نقل هوشمند: اختراع مجدد حمل و نقل در جهان متصل ما (ITSWC 2014)، دیترویت، MI، ایالات متحده، 7-11 سپتامبر 2014. انجمن حمل و نقل هوشمند آمریکا: واشنگتن، دی سی، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- بولدیو رای، اچ. ون لیر، تی. میرس، دی. Macharis، C. بهبود پایداری حمل و نقل بار شهری: چارچوب ارزیابی سیاست و مطالعه موردی. Res. ترانسپ اقتصاد 2017 ، 64 ، 26-35. [ Google Scholar ] [ CrossRef ]
- سانچز-دیاز، I. مدلسازی تولید بار شهری: مطالعه نیازهای باری مؤسسات تجاری. ترانسپ Res. بخش A خط مشی Pr. 2017 ، 102 ، 3-17. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسماعیل، ع. اینتان سوهانا، MR; مصری، کالیفرنیا؛ Rapar، NH اکتشاف در شرایط سطح روسازی منتسب به حمل و نقل مواد معدنی و عملیات لجستیک در شبکه جاده Kuantan. در سری کنفرانس های IOP: علم و مهندسی مواد ; IOP Publishing Ltd.: بریستول، بریتانیا، 2020؛ جلد 712. [ Google Scholar ]
- هرناندز، اس. هیون، کی. ترکیب داده های وزن در حرکت و سیستم موقعیت یابی جهانی برای تخمین توزیع وزن کامیون در سایت های شمارش ترافیک. جی. اینتل. ترانسپ سیستم تکنولوژی طرح. اپراتور 2020 ، 24 ، 201-215. [ Google Scholar ] [ CrossRef ]
- مقیمی، ب. کامگا، سی. زمانی پور، م. کنترل اولویت سیگنال ترانزیت نگاه به آینده با منطق خودسازماندهی. J. Transp. مهندس بخش A سیستم. 2020 , 146 . [ Google Scholar ] [ CrossRef ]
- Topilin, IV; Volodina، MV شبیه سازی ترافیک شبکه جاده های تنظیم شده با استفاده از سیستم های ناوبری. ماتر علمی انجمن 2018 ، 931 ، 661–666. [ Google Scholar ] [ CrossRef ]
- آدو-گیامفی، یو. شارما، ا. نیکربوکر، اس. هاوکینز، ن. جکسون، ام. چارچوب برای ارزیابی قابلیت اطمینان داده های کاوشگر پهناور. ترانسپ Res. ضبط J. Transp. Res. هیئت 2017 ، 2643 ، 93-104. [ Google Scholar ] [ CrossRef ]
- شارما، اس. اسنلدر، ام. Lint، HV استخراج انتخاب مسیر در سفر رانندگان کامیون با استفاده از دادههای بلوتوث، دادههای آشکارساز حلقه و دادههای علامت پیام متغیر. در مجموعه مقالات ششمین کنفرانس بینالمللی مدلها و فناوریها برای سیستم حملونقل هوشمند (MT-ITS 2019)، کراکوف، لهستان، 5 تا 7 ژوئن 2019. [ Google Scholar ]
- کاترکازاس، سی. آنتونیو، سی. وازکز، NS; تروکیدیس، آی. Arampatzis، S. داده های بزرگ و چالش های حمل و نقل در حال ظهور: یافته های پروژه noesis. در مجموعه مقالات ششمین کنفرانس بین المللی مدل ها و فناوری ها برای سیستم های حمل و نقل هوشمند (MT-ITS 2019)، کراکوف، لهستان، 5 تا 7 ژوئن 2019. [ Google Scholar ]
- دی جنارو، ام. پافومی، ای. مارتینی، جی. داده های بزرگ برای حمایت از سیاست های حمل و نقل جاده ای کم کربن در اروپا: برنامه ها، چالش ها و فرصت ها. بیگ دیتا Res. 2016 ، 6 ، 11-25. [ Google Scholar ] [ CrossRef ]
- فریدل، ای. بکستروم، اس. استریپل، اچ. در نظر گرفتن زیرساخت هنگام محاسبه انتشار گازهای گلخانه ای برای حمل و نقل کالا. ترانسپ Res. قسمت D Transp. محیط زیست 2019 ، 69 ، 346-363. [ Google Scholar ] [ CrossRef ]
- گوچمن، ای. ارول، آر. مشکل حمل و نقل میان وجهی پایدار: مطالعه موردی یک شرکت لجستیک بین المللی، ترکیه. Sustainability 2018 , 10 , 4268. [ Google Scholar ] [ CrossRef ][ Green Version ]
- هاک، ک. میشا، س. پالتی، ر. گلیاس، م.م. سارکر، AA; Pujats، K. تحلیل استفاده از پارکینگ کامیون با استفاده از داده های GPS. J. Transp. مهندس بخش A سیستم. 2017 ، 143 ، 1-12. [ Google Scholar ] [ CrossRef ]
- پاز، ا. ویرامیستی، ن. Fuente-Mella، HDLDL پیشبینی معیارهای عملکرد برای ایمنی ترافیک با استفاده از مدلهای قطعی و تصادفی. در مجموعه مقالات هجدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند (ITSC 2015)، لاس پالماس، اسپانیا، 15 تا 18 سپتامبر 2015. [ Google Scholar ]
- چنس اسکات، ام. سن روی، اس. Prasad، S. الگوهای فضایی تصادفات ترافیکی خارج از سیستم در شهرستان میامی-دید، فلوریدا، طی سالهای 2005-2010. Traffic Inj. قبلی 2016 ، 17 ، 729-735. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- خو، X. Duan, L. پیشبینی نرخ تصادف با استفاده از رگرسیون چندکی لجستیک با نتایج محدود. IEEE Access 2017 ، 5 ، 27036–27042. [ Google Scholar ] [ CrossRef ]
- سیریپیروت، تی. سومالی، ع. Ho, HW برآورد آماری تجزیه و تحلیل فعالیت حمل و نقل از داده های سیستم موقعیت یابی جهانی کامیون ها. ترانسپ Res. بخش E Logist. ترانسپ Rev. 2020 , 140 . [ Google Scholar ] [ CrossRef ]
- ژانگ، اس. لیو، ایکس. تانگ، جی. چنگ، اس. چی، ی. وانگ، ی. مدلسازی فضایی-زمانی رفتار انتخاب مقصد از طریق رویکرد سلسله مراتبی بیزی. فیزیک یک آمار مکانیک. برنامه آن است. 2018 ، 512 ، 537-551. [ Google Scholar ] [ CrossRef ]
- تهلیان، د. Pinjari، AR ارزیابی عملکرد الگوریتمهای تولید مجموعه انتخاب برای تجزیه و تحلیل انتخاب مسیر کامیون: بینشهایی از تجمع فضایی برای الگوریتم حذف پیوند اول جستجوی وسعت (BFS-LE). ترانسپ ترانسپ. علمی 2020 ، 16 ، 1030-1061. [ Google Scholar ] [ CrossRef ]
- گولر، اچ. چارچوب مدلسازی تجربی برای پیش بینی حمل و نقل بار. حمل و نقل 2014 ، 29 ، 185-194. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Joubert, JW; Meintjes، S. تکرارپذیری و تکرارپذیری: پیامدهای استفاده از داده های GPS برای زنجیره های فعالیت حمل و نقل. ترانسپ Res. روش قسمت B. 2015 ، 76 ، 81-92. [ Google Scholar ] [ CrossRef ]
- بن آکیوا، من؛ تولدو، تی. سانتوس، جی. کاکس، ن. ژائو، اف. لی، YJ; Marzano، V. جمع آوری داده های حمل و نقل با استفاده از GPS و نظرسنجی های مبتنی بر وب: بینش از نظرسنجی رانندگان کامیون ایالات متحده و دیدگاه های حمل و نقل شهری. مورد مطالعه. ترانسپ سیاست 2016 ، 4 ، 38-44. [ Google Scholar ] [ CrossRef ]
- Luong، TD; تهلیان، د. پینجاری، تحلیل اکتشافی جامع AR از تنوع انتخاب مسیر کامیون در فلوریدا. ترانسپ Res. ضبط 2018 ، 2672 ، 152-163. [ Google Scholar ] [ CrossRef ]
- ممتاز، SU; الورو، ن. انور، س. کیا، ن. دی، ب.ک. پینجاری، ع. طباطبایی، چارچوب تجزیه و تحلیل محموله SF Fusing و داده های ترانسفر: رویکرد تلفیق داده های اقتصادسنجی با کاربرد در فلوریدا. J. Transp. مهندس بخش A سیستم. 2020 , 146 . [ Google Scholar ] [ CrossRef ]
- کریشناکوماری، پ. ون لینت، اچ. جوکیچ، تی. Cats, O. یک روش مبتنی بر داده برای تخمین ماتریس OD. ترانسپ Res. قسمت C Emerg. تکنولوژی 2019 ، 1-19. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Hansen, CO مستندات از Godsmodel. در دسترس آنلاین: https://www.landstrafikmodellen.dk/-/media/Sites/Landstrafikmodellen/Dokumentation-1-1/Notat-Godstrafikmodel.ashx?la=da&hash=A02446304C683ABB573CC76AA5207E60D54B .
- تقوی، م. ایران نژاد، ا. Prato، CG شناسایی کامیون از جریان بزرگی از داده های GPS از طریق یک مدل زنجیره مارکوف پنهان متوقف می شود. در مجموعه مقالات کنفرانس سیستم های حمل و نقل هوشمند IEEE 2019 (ITSC)، اوکلند، نیوزیلند، 27 تا 30 اکتبر 2019؛ صص 2265-2271. [ Google Scholar ]
- سامبو، اف. سالتی، س. براوی، ال. سیمونچینی، ام. تاکاری، ال. لری، ع. یکپارچه سازی GPS و تصاویر ماهواره ای برای تشخیص و طبقه بندی نقاط حساس ناوگان. در مجموعه مقالات بیستمین کنفرانس بین المللی IEEE 2017 در مورد سیستم های حمل و نقل هوشمند (ITSC)، یوکوهاما، ژاپن، 16 تا 19 اکتبر 2017. [ Google Scholar ] [ CrossRef ]
- اشبروک، دی. Starner, T. استفاده از GPS برای یادگیری مکانهای مهم و پیشبینی حرکت بین کاربران متعدد. پارس همه جا. محاسبه کنید. 2003 ، 7 ، 275-286. [ Google Scholar ] [ CrossRef ]
- هولگوین-وراس، جی. Encarnación، T. پرز-گوزمان، اس. یانگ، X. شناسایی مکانیکی توقف فعالیت های حمل و نقل از داده های سیستم موقعیت یابی جهانی. ترانسپ Res. ضبط 2020 ، 2674 ، 235-246. [ Google Scholar ] [ CrossRef ]
- برناردین، وی.ال. تروینو، اس. کوتاه، JA در حال گسترش دادههای مبدأ-مقصد غیرفعال مبتنی بر GPS کامیون در آیووا و تنسی. در مجموعه مقالات نود و چهارمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن دی سی، ایالات متحده آمریکا، 11 تا 15 ژانویه 2015. [ Google Scholar ]
- بوته، دبلیو. Maat، K. استخراج و اعتبارسنجی اهداف سفر و حالتهای سفر برای بررسیهای سفر چند روزه مبتنی بر GPS: یک برنامه کاربردی در مقیاس بزرگ در هلند. ترانسپ Res. قسمت C Emerg. تکنولوژی 2009 ، 17 ، 285-297. [ Google Scholar ] [ CrossRef ]
- مک کورمک، ای. Bassok، A. ارزیابی دو روش کم هزینه برای جمع آوری داده های تولید کامیون با استفاده از فروشگاه های مواد غذایی. ITE J. 2011 ، 81 ، 34-38. [ Google Scholar ]
- مونوزوری، جی. کورتس، پی. اونیوا، ال. Guadix, J. برآورد جریان روزانه خودرو برای تحویل بار شهری. ج. طرح شهری. توسعه دهنده 2012 ، 138 ، 43-52. [ Google Scholar ] [ CrossRef ]
- مسا آرانگو، ر. اوکوسوری، اس. Sarmiento، I. روش شناسی جریان شبکه برای تخمین سفرهای خالی در مدل های حمل و نقل کالا. ترانسپ Res. ضبط J. Transp. Res. هیئت 2013 ، 2378 ، 110-119. [ Google Scholar ] [ CrossRef ]
- پاتیره، AD; رایت، ام. پرودهوم، بی. Bayen، AM به چه مقدار داده GPS نیاز داریم؟ ترانسپ Res. قسمت C Emerg. تکنولوژی 2015 ، 58 ، 325-342. [ Google Scholar ] [ CrossRef ]
- گراهام، ای. راجرز، جی. ارزیابی روشهای جمعآوری دادههای بهرهوری حملونقل کالا و قابلیت اطمینان. در مجموعه مقالات کنفرانس تحقیقات مهندسی صنعتی 2012، اورلاندو، فلوریدا، ایالات متحده آمریکا، 19 تا 23 مه 2012. [ Google Scholar ]
- ایبارا-اسپینوزا، اس. ینو، آر. جیانوتی، ام. راپکینز، ک. de Freitas، ED تولید جریان ترافیک و سرعت دادههای مدل منطقهای با استفاده از سوابق وسایل نقلیه اینترنتی GPS. MethodsX 2019 ، 6 ، 2065–2075. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- شن، ال. Stopher، PR بررسی روشهای بررسی سفر GPS و روشهای پردازش دادههای GPS. ترانسپ Rev. 2014 , 34 , 316-334. [ Google Scholar ] [ CrossRef ]
- Danmarks Statistik Bestanden af køretøjer pr 1. Januar efter køretøjstype, tid og område. در دسترس آنلاین: https://www.dst.dk/da/Statistik/emner/erhvervslivets-sektorer/transport/transportmidler (در 5 اکتبر 2019 قابل دسترسی است).
- مور، AM سناریوهای نوآورانه برای مدل سازی حمل و نقل بار درون شهری. ترانسپ Res. بین رشته ای. چشم انداز 2019 ، 3 . [ Google Scholar ] [ CrossRef ]
- پیررا، م. کربنی، ا. Deflorio، F. نظارت بر دسترسی شهری برای خدمات تحویل بار از ردیابی وسایل نقلیه و مدلسازی شبکه. ترانسپ Res. Procedia 2019 ، 41 ، 410-413. [ Google Scholar ] [ CrossRef ]
- گان، م. لیو، ایکس. چن، اس. یان، ی. لی، دی. شناسایی انتشار گازهای گلخانه ای مرتبط با کامیون و عوامل تاثیر حیاتی در یک شبکه لجستیک شهری. جی. پاک. تولید 2018 ، 178 ، 561-571. [ Google Scholar ] [ CrossRef ]
- کامارگو، پ. هونگ، اس. Livshits, V. گسترش استفاده از داده های GPS کامیون در فعالیت های مدل سازی و برنامه ریزی حمل و نقل. ترانسپ Res. ضبط 2017 ، 2646 ، 68-76. [ Google Scholar ] [ CrossRef ]
- جینگریچ، ک. مائو، اچ. Anderson, W. طبقه بندی هدف رویدادهای کامیون متوقف شده: کاربرد آنتروپی در داده های GPS. ترانسپ Res. قسمت C Emerg. تکنولوژی 2016 ، 64 ، 17-27. [ Google Scholar ] [ CrossRef ]
- Joubert, JW; Meintjes، S. تولید زنجیره فعالیت حمل و نقل با استفاده از شبکه های پیچیده اتصال. ترانسپ Res. Procedia 2016 ، 12 ، 425-435. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سانچز-دیاز، آی. هولگوین-وراس، جی. Ban، X. مدل ترکیبی تور باربری وابسته به زمان. ترانسپ Res. روش قسمت B. 2015 ، 78 ، 144-168. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
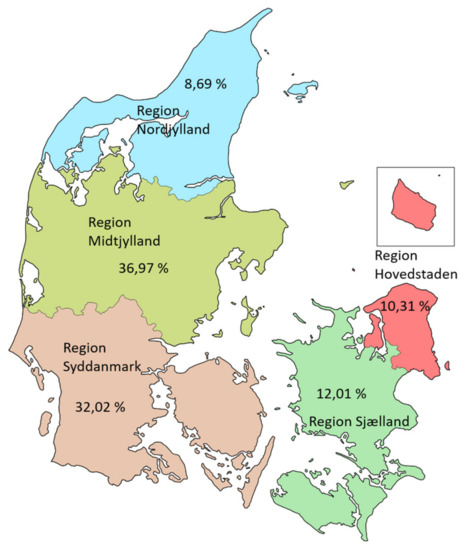
- مناطق دانمارک در دسترس آنلاین: https://commons.wikimedia.org/wiki/File:Denmark_regions.svg (در 24 اکتبر 2019 قابل دسترسی است).
- بخور، س. لوتان، تی. گیتلمن، وی. موریک، اس. تحلیل و پایش سرعت سفر جریان آزاد در سطح ملی با استفاده از اندازهگیریهای سیستم موقعیتیابی جهانی. J. Transp. مهندس 2013 ، 139 ، 1235-1243. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژنگ، جی. وانگ، ی. نیهان، NL ارزیابی کمی عملکرد GPS در زیر سایبان های جنگلی. در مجموعه مقالات IEEE 2005 Networking, Sensing and Control, Tucson, AZ, USA, 19-22 مارس 2005; صص 777-782. [ Google Scholar ]
- گونگ، ال. ساتو، اچ. یاماموتو، تی. میوا، تی. موریکاوا، تی. شناسایی مکانهای توقف فعالیت در مسیرهای GPS با روش خوشهبندی مبتنی بر چگالی همراه با ماشینهای بردار پشتیبان. J. Mod. ترانسپ 2015 ، 23 ، 202-213. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وزارت حمل و نقل آمریکا نتایج بررسی پارکینگ کامیون قانون جیسون اداره بزرگراه فدرال و تجزیه و تحلیل مقایسه ای. در دسترس آنلاین: https://ops.fhwa.dot.gov/freight/infrastructure/truck_parking/jasons_law/truckparkingsurvey/index.htm (در 25 ژوئن 2020 قابل دسترسی است).
- هان، جی. پولاک، جی دبلیو. باریا، جی. کریشنان، آر. در مورد تخمین میانگین سرعت فضا از دادههای آشکارساز حلقه القایی. ترانسپ طرح. تکنولوژی 2010 ، 33 ، 91-104. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ترنر، اس ام. آیزل، WL; بنز، RJ; Holdener, DJ Travel Time Data Collection Handbook ; اداره بزرگراه فدرال ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 1998.
- می، مبانی جریان ترافیک AD ; Prentice Hall: Englewood Cliffs، NJ، USA، 1990; شابک 0-13-926072-2. [ Google Scholar ]
|
توجه ناشر: MDPI با توجه به ادعاهای قضایی در نقشه های منتشر شده و وابستگی های سازمانی بی طرف می ماند.
|


بدون دیدگاه