

هدف از این کار، تمایز لکههای جنگل اقیانوس اطلس و همچنین توزیع فضایی آنها از سایر پوششهای درختی که منظره را تشکیل میدهند، با مقایسه سه روش طبقهبندی تصاویر دیجیتال، با استفاده از تکنیکهای ژئوپردازش و سنجش از دور بود. منطقه مورد مطالعه زیرحوضه ای از رودخانه ایپرو، شاخه ای از رودخانه ایپرو-میریم، حوضه رودخانه ساراپوئی، در Ara ç oiaba da Serra، ایالت S ã بود.o پائولو، برزیل. این تحقیق بر روی یک پلت فرم محیطی سیستم اطلاعات جغرافیایی با استفاده از تصاویر با وضوح متوسط از ماهواره Sentinel-2 توسعه یافته است. سه الگوریتم طبقهبندی تصویر: طبقهبندی حداکثر احتمال (MLC)، ماشینهای بردار پشتیبان (SVM) و درخت تصادفی (RT) برای تأیید تفکیکپذیری تکههای جنگل، جنگلداری و سایر کاربردها استفاده شد. نتایج با استفاده از یک ماتریس سردرگمی، دقت و شاخص کاپا مورد تجزیه و تحلیل قرار گرفت، بنابراین نشان داد که سه الگوریتم قادر به تمایز موفقیتآمیز اهداف بودند، با کارایی بالاتر به MLC و کمترین به RT. به طور کلی، سه طبقهبندیکننده خطا ارائه کردند، اما به طور خاص برای تکههای جنگلی، بالاترین دقت از SVM بهدست آمد.
کلید واژه ها
جنگل اقیانوس اطلس ، پوشش زمین ، طبقه بندی تصویر
1. مقدمه
نقشه برداری از بقایای جنگل اقیانوس اطلس برزیل و مراحل جانشینی آنها یک گام اساسی برای اجرای چندین مطالعه، کنترل محیطی و اقدامات مدیریتی است [ 1 ]. بنابراین، طبقهبندی لکههای طبیعی از بیوم جنگل اقیانوس اطلس برای طیف وسیعی از مطالعات اساسی است، با توجه به اینکه اکثر بقایای جنگلهای طبیعی به شکل تکههای کوچک، بسیار آشفته، منزوی، کمتر شناخته شده و محافظت ضعیف هستند [ 2 ]. این لکههای جنگلی طبیعی دائماً توسط پویایی پوشش زمین، مربوط به گسترش و پسرفت کاربریها تحت فشار قرار میگیرند که با تشکیل موزاییکی از لکههای جنگلی با اندازههای مختلف و در چندین مرحله متوالی، که توسط یک ماتریس آنتروپیزه جدا شدهاند، چشمانداز را تغییر میدهند [ 3 ] .
پیشنهاد روشهایی که این موضوع را مورد بررسی قرار میدهند، امکان ارزیابی کمی و کیفی لکههای باقیمانده، و همچنین توزیع فضایی آنها [ 4 ] را فراهم میکند، همچنین برای توصیف این تکههای طبیعی، متشکل از افراد مختلف درختزی که یک تاج پوشش گیاهی پیچیده را تشکیل میدهند، بسیار مهم است. در میان موزاییک هایی با کاربردهای مختلف که اطراف این لکه ها را احاطه کرده اند، مناطق کشت گونه های اکالیپتوس برجسته است. (Myrtaceae)، Pinus spp. (Pinaceae) و گونه های عجیب و غریب با اهداف تجاری، اساسی است که بین این پوشش های درختی مختلف تمایز قائل شویم تا ارزیابی دقیقی از لکه های واقعاً طبیعی از جنگل بومی اقیانوس اطلس بدست آوریم.
به این ترتیب، هدف این تحقیق ارزیابی سه روش طبقهبندی تصویری: طبقهبندی حداکثر احتمال (MLC)، ماشین بردار پشتیبان (SVM) و درخت تصادفی (RT) به منظور تمایز لکههای پوشش گیاهی بومی از تکههای پوشش گیاهی عجیب و غریب بود. از طریق تمایز سایبان آنها. استفاده از طبقه بندی تصاویر توسط سنجش از دور شامل فرآیند پیچیده ای است که عوامل زیادی را در بر می گیرد، از جمله انتخاب روش طبقه بندی، که مستلزم بررسی صحت نتایج است [ 5 ].
2. منطقه مطالعه
به عنوان منطقه مورد مطالعه، زیرحوضه ای از رودخانه ایپرو، که در شهرداری Araçoiaba da Serra، در جنوب شرقی ایالت سائوپائولو، برزیل قرار دارد، انتخاب شد ( شکل 1 ). به دلیل وجود بقایای جنگلهای متعلق به بیوم جنگل اقیانوس اطلس [ 6 ]، که یک کانون تنوع زیستی است [ 7 ] که دارای یک پایگاه داده ارجاعشده جغرافیایی است، انتخاب شد که توسط مرکز مطالعات بومشناسی منظر و حفاظت (UFSCar-Sorocaba) توسعه یافته است. . رودخانه ایپرو شاخه ای از رودخانه ایپرو-میریم است که بخشی از حوضه رودخانه ساپاپوئی است. مساحت آن 4933.23 هکتار است و 295 کانال چندساله در 88638.19 متر پراکنده شده است [ 8 ].
3. مواد و روشها
در طول توسعه تحقیق، مراحل زیر انجام شد: 1) انتخاب منطقه مورد مطالعه، که یک زیرحوضه از رودخانه Iperó را اتخاذ کرد، با توجه به اینکه این منطقه دارای لکه های جنگلی (لکه های جنگلی طبیعی اقیانوس اطلس است).
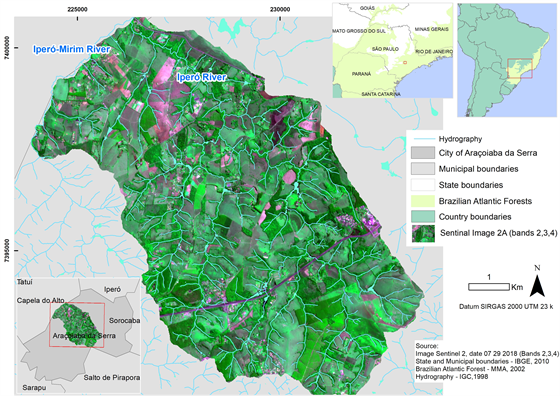
شکل 1 . منطقه مطالعه: حوضه آبریز رودخانه ایپرو در Araçoiaba da Serra – ایالت سائوپائولو، برزیل.
جنگل) و مناطق جنگلی (Eucalyptus spp. (Myrtaceae) یا Pinus spp. (Pinaceae)؛ 2) یک تصویر به دست آمده از ماهواره Sentinel-2 از برنامه GMES، با باندهای 02 تا 12 به عنوان ماده استفاده شد. 3) سپس انتخاب نمونه برای طبقات: لکه های جنگلی، جنگلداری و سایر عناصر منظر انجام شد. 4) این نمونه ها در طبقه بندی حداکثر احتمال (MLC)، ماشین بردار پشتیبان (SVM) و درختان تصادفی (RT) استفاده شدند. 5) آزمون صحت طبقهبندیکنندهها از روی صحت زمینی جمعآوریشده و استفاده از شاخصهای آماری انجام شد. 6) نتیجه یک نقشه پوشش زمین از هر الگوریتم طبقهبندی، با توجه به دستههای «لکههای جنگلی»، «جنگلداری» و «سایر کاربریها» است.
3.1. اکتساب داده ها
تصاویر از ماهواره Sentinel 2a و 2b سال 2018، ماموریت تصویربرداری چند طیفی GMES انتخاب شدند. در این تحقیق از دوازده باند چند طیفی B02 (آبی)، B03 (سبز)، B04 (قرمز) و B08 (نزدیک به فروسرخ) با تفکیک مکانی 10 متر و باندهای 05 تا 08A (لبه قرمز و مادون قرمز) استفاده شد. امواج کوتاه)، با وضوح فضایی 20 متر، اندازه آن به 10 متر تغییر یافته است.
3.2. طبقه بندی تصویر نظارت شده و انتخاب نمونه های آموزشی
طبقهبندی نظارت شده فرآیند استخراج اطلاعات از تصاویر برای شناسایی الگوها و اشیاء همگن است که برای نقشهبرداری مناطق روی سطح زمین مطابق با موضوعات مورد علاقه، با مرتبط کردن هر پیکسل از تصویر با یک “برچسب” که یک شی واقعی را توصیف میکند، استفاده میشود. نتیجه یک نقشه موضوعی است که توزیع جغرافیایی یک موضوع، به عنوان مثال، پوشش گیاهی را ارائه می دهد. در طبقه بندی نظارت شده، دانش منطقه مورد مطالعه لازم است تا امکان جمع آوری نمونه برای آموزش طبقه بندی کننده ها فراهم شود. این با تفسیر تصاویر صفحه کامپیوتر، انتخاب مناطق شناخته شده برای تشکیل مجموعه آموزشی با حقایق زمینی برای طبقه بندی تحت نظارت بعدی ساخته می شود. نتیجه به صورت کلاس های طیفی (مناطقی که ویژگی های طیفی مشابهی دارند) ارائه می شود. از آنجایی که یک هدف به سختی با یک امضای طیفی مشخص می شود. این شامل نقشهای از «پیکسلهای» درجهبندیشده است که با نمادها یا رنگهای گرافیکی نشان داده میشود. فرآیند طبقهبندی دیجیتال تعداد زیادی از سطوح خاکستری را، از هر باند طیفی، به تعداد کمی از کلاسها به یک تصویر واحد تبدیل میکند.9 ] [ 10 ] [ 11 ] [ 12 ] [ 13 ].
ساخت مجموعه نمونه ها بر اساس انتخاب مناطق تعریف شده به عنوان “لکه های جنگلی” ( شکل 2 (A))، “جنگلداری” ( شکل 2 (B)) و “سایر کاربری ها” ( شکل 2 (C)) بود. . این گروه ها با استفاده از مفروضات نظری تفسیر عکس [ 14 ]، از تعیین حدود توسط آموزش بردارهای چند ضلعی بر روی تصویر Sentinel 2 ایجاد شدند. در این روش، ما سعی کردیم الگوهایی را با بیشترین تنوع در بین پیکسل ها برای هر مجموعه از کلاس ها شناسایی کنیم. برای مجموعه راستیآزمایی میدانی، 40 نمونه بهطور تصادفی برای هر کلاس بهدست آمد و از تصاویر Google Earth طبقهبندی شد ( شکل 2 (D)).
3.3. طبقه بندی تصویر
طبقه بندی تصاویر با استفاده از الگوریتم پارامتری MLC و SVM و DT ناپارامتریک انجام شد. در بخش های فرعی زیر توضیح مختصری در مورد سه الگوریتم ارائه شده است.
3.3.1. طبقه بندی حداکثر احتمال (MLC)
الگوریتم طبقهبندی حداکثر احتمال یکی از طبقهبندیکنندههای پارامتری معروف است که برای طبقهبندی نظارت شده استفاده میشود. پیکسل به پیکسل در نظر گرفته می شود، زیرا از وزن کردن فاصله بین میانگین مقادیر پیکسل برای هر کلاس، با استفاده از پارامترهای آماری و با فرض اینکه همه باندها کار می کند.

شکل 2 . ساخت مجموعه نمونه: (الف) تکه های جنگلی. (ب) جنگلداری؛ (ج) کاربردهای دیگر؛ د) حقایق پایه.
دارای طبقه بندی عادی بنابراین، احتمال تعلق یک پیکسل تعیین شده به یک کلاس تعیین شده تخمین زده می شود [ 15 ]. استفاده عالی از آن به کارایی آن محدود می شود، زیرا کلاس های آموزشی برای تخمین شکل توزیع پیکسل ها برای هر کلاس در فضای n باند و همچنین مکان مرکز هر کلاس استفاده می شوند [ 16 ].
3.3.2. ماشینهای بردار پشتیبانی (SVM)
ماشینهای بردار پشتیبان (SVM) مجموعهای از الگوریتمهای یادگیری هستند که برای طبقهبندی و رگرسیون استفاده میشوند و طبقهبندیکنندههای ناپارامتریک هستند. تئوری یادگیری آماری در اواخر دهه 1960 معرفی شد و تا دهه 1990، یک تحلیل نظری صرف از مسئله برآورد عملکرد یک مجموعه داده معین بود. در اواسط دهه 1990، انواع جدیدی از الگوریتم های یادگیری (موسوم به ماشین های بردار پشتیبان)، بر اساس نظریه توسعه یافته، پیشنهاد شد. این امر باعث شده است که نظریه یادگیری آماری نه تنها ابزاری برای تجزیه و تحلیل نظری، بلکه ابزاری برای ایجاد الگوریتمهای عملی برای تخمین توابع چند بعدی باشد [ 17 ].]. موفقیت SVM بستگی به این دارد که فرآیند چقدر خوب آموزش داده شده است. سادهترین راه برای آموزش SVM با استفاده از کلاسهای قابل جداسازی خطی است، عملکرد آن بر اساس آموزش یافتن ابر صفحه بهینه، با به حداقل رساندن حد بالای خطای طبقهبندی است [ 18 ].
3.3.3. درختان تصمیم (DT)
طبقهبندیکننده درختهای تصادفی را میتوان به عنوان مجموعهای از درختهای تصمیم فردی تعریف کرد که از نمونهها و زیر مجموعههای مختلف دادههای آموزشی تولید میشوند. ایده اصلی این نوع طبقه بندی کننده این است که برای هر پیکسل طبقه بندی شده، تعدادی تصمیم گرفته شود، بر اساس ترتیب اهمیت، ایجاد درخت تصمیم [ 19 ]. ساختار اصلی درخت تصمیم، از یک گره ریشه، تعدادی گره داخلی و در نهایت، مجموعه ای از گره های پایانی تشکیل شده است. داده ها به صورت بازگشتی به درخت تصمیم تقسیم می شوند، طبق چارچوب طبقه بندی تعریف شده [ 20 ].
3.4. ماتریس سردرگمی
ماتریس سردرگمی تمام موارد یک مدل مطالعه شده را در دسته بندی طبقه بندی می کند. برای این منظور، یک ماتریس طبقه بندی ایجاد می شود تا تعیین کند آیا یک مقدار پیش بینی شده با مقدار واقعی مطابقت دارد یا خیر. در هر دسته، داده ها شمارش می شوند و مجموع ها در آرایه نمایش داده می شوند [ 21 ]. این طبقه بندی یک ابزار استاندارد برای همه مدل های آماری است [ 22 ].
در این تحقیق داده های ارائه شده توسط سه الگوریتم با مجموعه حقیقت زمین مقایسه شده است. نتایج در یک جدول دو ستونی مرتب شدند که با نشان دادن تعداد طبقهبندی صحیح در مقابل طبقهبندیهای پیشبینیشده برای هر کلاس، در مجموعهای از مثالها، معیار مؤثری از مدل طبقهبندی را ارائه میدهد.
3.5. ارزیابی دقت
ارزیابی دقت طبقهبندیکننده، احتمال اینکه یک نمونه تصادفی انتخاب شده به درستی طبقهبندی شود را نشان میدهد (معادله (1)) [ 15 ]:
∑k = 1جایکسk kn∑k=1cxkkn(1)
جایی که:
C = مورب طبقه بندی و مرجع.
N = کل ستون های طبقه بندی و مرجع.
X kk = تعداد کل امتیازهای طبقه بندی شده به درستی در کلاس.
دو ارزیابی دیگر را نیز می توان از ماتریس سردرگمی استخراج کرد. دقت مرجع، که ارزیابی می کند که چه مقدار از یک کلاس خاص توسط طبقه بندی کننده شناسایی شده است (معادله (2)) و دقت طبقه بندی کننده، که ارزیابی می کند که چه مقدار از یک کلاس طبقه بندی شده خاص واقعاً به این کلاس تعلق دارد، همچنین به عنوان خطاهای مربوط به حذف و انجام آنها (معادله (3)) [ 15 ].
ک1=ایکسk kایکس+ kK1=xkkx+k(2)
ک2=ایکسk kایکسk +K2=xkkxk+(3)
جایی که:
K 1 = کلاسی که باید طبقه بندی شود.
K 2 = کلاسی که باید طبقه بندی شود.
X kk = تعداد کل نقاط به درستی طبقه بندی شده کلاس k.
X + k = مقدار طبقه بندی شده به عنوان k;
X k + = مقدار متعلق به k;
3.6. شاخص کاپا
شاخص کاپا یک معیار ارتباطی برای آزمایش است و درجه قابلیت اطمینان و دقت یک طبقه بندی را توصیف می کند (معادله (4)). این شاخص دقت نتایج را بر اساس ماتریس سردرگمی تصویر مرتب شده و تصویر مرجع اندازه گیری می کند. مقادیر آنها از 0 تا 1 متغیر است، جایی که مقادیر نزدیک به 0 یک طبقه بندی ناکارآمد و در کنار 1، بسیار کارآمد را نشان می دهد [ 23 ].
ک=ن∑ri = 1ایکسمن من–∑ri = 1(ایکسمن +∗ایکس+ من)ن2–∑ri = 1(ایکسمن +∗ایکس+ من)K=N∑i=1rXii−∑i=1r(Xi+∗X+i)N2−∑i=1r(Xi+∗X+i)(4)
جایی که:
K = شاخص دقت کاپا. r = تعداد سطرها در آرایه.
X ii = تعداد مشاهدات در ردیف i و ستون j.
X i + و X +i = مجموع حاشیه ای ردیف i و ستون j.
N = تعداد کل مشاهدات.
4. نتایج
طبقه بندی الگوریتم MLC شاخص کاپا 0.85 را نشان داد ( شکل 3 (A))، که طبق طبقه بندی Landis و Koch [ 23 ]، یک توافق تقریباً کامل در نظر گرفته می شود. دقت کلی 90 درصد به دست آمد، به این معنی که در مجموع 150 نمونه، اگر یک نمونه به طور تصادفی انتخاب شود، احتمال 90 درصد طبقه بندی صحیح آن خواهد بود ( جدول 1 ).
با توجه به اینکه چه مقدار از کلاس توسط طبقهبندیکننده (دقت مرجع) شناسایی شد، کلاس «سایر کاربردها» بهترین عملکرد را به دست آورد و پس از آن «جنگلکاری» و «تکههای جنگلی» قرار گرفتند. از نقطه نظر تعداد پیکسلهایی که واقعاً در کلاس صحیح طبقهبندی شدهاند (دقت طبقهبندی)، «سایر کاربردها» بهترین دقت را به دست آوردند و پس از آن «تکههای جنگلی» و «جنگلسازی» ( جدول 2 ) قرار دارند.
شکل 3 (B) نقشه طبقه بندی SVM و جدول 3 ماتریس سردرگمی این طبقه بندی کننده را نشان می دهد. با توجه به Landis و Koch [ 23 ] ، شاخص کاپا 0.84 بود که به عنوان یک توافق تقریباً کامل در نظر گرفته شد . با توجه به دقت طبقهبندیکننده، SVM به 89.3 درصد رسید، تنها 0.7 تفاوت از طبقهبندی MLC.
محاسبه دقت بهترین عملکرد را برای “جنگلداری” و به دنبال آن “لکههای جنگلی” و “سایر کاربردها” نشان داد. با توجه به عملکرد طبقهبندی، محاسبه دقت بهترین عملکرد را برای «سایر کاربریها» و پس از آن «لکههای جنگلی» نشان داد. برای “جنگلداری”، عملکرد 30٪ از

شکل 3 . تصاویر طبقه بندی شده: (الف) طبقه بندی حداکثر احتمال (MLC); (ب) ماشین بردار پشتیبانی (SVM)؛ (C) درختان تصادفی (RT).
خطای کمیسیون، به این معنی که یک سردرگمی قابل توجه در رابطه با این کلاس وجود دارد ( جدول 4 ).
شکل 3 (C) ترتیب کلاس ها را بر اساس درختان تصادفی و شاخص کاپا برای طبقه بندی کننده RT نشان می دهد که 0.49 بود. این نتیجه با توجه به کیفیت طبقه بندی ( جدول 5 )، مطابق با Landis و Koch [ 23 ] به عنوان توافق متوسط در نظر گرفته می شود.
با توجه به اینکه چه مقدار از کلاس توسط طبقهبندیکننده (دقت مرجع) شناسایی شده است، کلاسهای «سایر کاربردها» و «جنگلداری» بهترین عملکرد را به دست آوردند و پس از آن کلاس «تکههای جنگلی» قرار گرفتند. از نقطه نظر تعداد پیکسلهایی که در واقع در کلاس صحیح طبقهبندی شدهاند (دقت طبقهبندی)، کلاس «سایر کاربردها» بهترین دقت را به دست آورد و پس از آن «تکههای جنگلی» و «جنگلسازی» قرار دارند. کلاس «جنگلداری» عملکرد طبقهبندیکننده پایینی با خطای کمیسیون 48 به دست آورد ( جدول 6 ).
5. بحث
نتایج نشان داد که طبقهبندی MLC منجر به بهترین عملکرد تفکیکپذیری در بین همه کلاسها میشود، اگرچه هنگام ارزیابی اهداف بهصورت جداگانه، مشخص شد که الگوریتم SVM منجر به بالاترین دقت برای کلاس «لکههای جنگلی» در رابطه با سایر طبقهبندیکنندههای در نظر گرفته شده در این میشود. پژوهش.
این بهترین عملکرد از الگوریتم SVM ناپارامتریک در طبقهبندی لکههای جنگلی با تحقیق Kavzogluand Colkesen [ 24 ] مطابقت دارد که کاربرد SVM را برای طبقهبندی پوشش اراضی ناحیه Gebze در ترکیه با استفاده از آن مورد مطالعه قرار داد. تصاویر Landsat ETM + و Terra ASTER. نتایج آنها نشان داد که SVM از طبقهبندیکننده حداکثر احتمال، از نظر دقت کلی و کلاس فردی، بهتر عمل میکند. Oommen [ 25 ] مطالعه ای بر روی عملکرد SVM برای تصاویر Landsat انجام داد و دو ناحیه را مقایسه کرد: Cuprite، نوادا، و خلیج Goodnews، در جنوب غربی آلاسکا، و به این نتیجه رسید که SVM از دقت بالاتری نسبت به MLC برخوردار است.
طبقهبندی SVM در رابطه با قابلیت تفکیکپذیری کلاسهای «جنگلداری» و «لکههای جنگلی» کارآمدتر از MLC در نظر گرفته شد. اگرچه این طبقهبندیکننده ناپارامتریک است و اطلاعات بافتی پیکسلها را در نظر میگیرد، که نشاندهنده تمایز بهتر بین طبقات پوشش گیاهی [ 26 ] است، پتانسیل آن برای تفکیکپذیری طبقات تأیید نشده است. در کار حاضر، طبقهبندیکننده خطای نویز کوچکتری را ارائه کرد (اثر نمک و فلفل، کمتر مستعد خطا بودن، اما همچنین طبقهبندی مناطق به اشتباه جدا شده).
از سوی دیگر، MLC مشکلات رایج مربوط به طبقهبندی پیکسل به پیکسل، مانند اثر نمک و فلفل، که به نویز و خطاهای طبقهبندی مربوط میشود، به ویژه زمانی که اطلاعات زمینهای مکانی در نظر گرفته نمیشود، ارائه کرد [ 27 ]. چلوتی [ 28 ] معتقد است که عملکرد طبقهبندیکنندهها تحت تأثیر تعداد کلاسها قرار میگیرد. بنابراین، چند کلاس منتخب مرتبط با آمار پارامتری MLC ممکن است نشاندهنده اثربخشی طبقهبندیکننده بهتر باشد.
تفکیک پذیری “لکه های جنگلی” و “جنگلداری” زمانی که از الگوریتم RT استفاده شد کمتر معنی دار بود. طبق آدام [ 18 ]، فرضیه اصلی چنین نتیجه ای ممکن است مربوط به ناکارآمدی الگوریتم طبقه بندی درخت تصمیم در پلت فرم های GIS باشد که با نتایج حاصل از مطالعات نشان دهنده پتانسیل بزرگ طبقه بندی تصاویر بر اساس الگوریتم RT [ 29 ] تایید می شود. ] [ 30 ] [ 31 ] [ 32 ].
همانطور که توسط جنسن [ 33 ] بیان شده است، استفاده از تصاویر ماهواره ای با وضوح بالا نیز باید دقت طبقه بندی کننده را بهبود بخشد . وضوح رادیومتریک بالا احتمال ارزیابی پدیده ها توسط سنجش از دور را با دقت بیشتری افزایش می دهد و امکان شناسایی چندین قطعه جنگل را در میان تکه های جنگلی فراهم می کند. این نتایج افزایش یافته فقط برای طبقه بندی کننده های MLC و SVM به دست آمد.
6. نتیجه گیری
نقشهبرداری و طبقهبندی لکههای جنگل اقیانوس اطلس برزیل برای اقداماتی با هدف حفاظت و مدیریت این بیوم مهم اهمیت اساسی دارد. به این ترتیب، این تحقیق به دانش در مورد کاربرد طبقهبندیکننده تصویر برای تفکیک پذیری اهداف، مانند تکههای جنگل بومی کمک میکند. بنابراین، نتایج حاصل از کار حاضر نشان میدهد که سه طبقهبندیکننده مورد مطالعه اجازه میدهند تا تکههای باقیمانده را از جنگل بومی اقیانوس اطلس جدا کنند، با بیشترین کارایی مشاهدهشده برای SVM. علاوه بر این، اصلاح مداوم الگوریتمهای طبقهبندی تصاویر ماهوارهای یک کار مهم است، زیرا بهبود چنین روشهایی به شناسایی بهتر جنگلهای بومی در امتداد محیطهای تکه تکهشده، افزایش دانش و حمایت از تصمیمگیریها و همچنین سیاستهای حفاظتی کمک میکند.


بدون دیدگاه