1. مقدمه
ظهور COVID-19 (بیماری کروناویروس 2019) منجر به شوک قابل توجهی در سراسر جهان شده است و ده ها میلیون نفر از بیماری تنفسی ناشی از SARS-CoV-2 (سندرم حاد تنفسی شدید کروناویروس 2) رنج می برند. 1]. در مواجهه با چنین وضعیت اضطراری، دانشمندان در سراسر جهان تحقیقات گستردهای را انجام دادهاند و تعداد زیادی مقاله برای کمک به درک COVID-19 و حمایت از پیشگیری و کنترل همهگیری منتشر کردهاند. این یک سوال را ایجاد می کند که چگونه این مطالعات برای پاسخ به COVID-19 تکامل می یابند؟ این سؤال را می توان با سه سؤال دقیق تر از دیدگاه های مختلف بیشتر مورد بررسی قرار داد: (1) از نظر زمانی، چگونه تعداد مقالات در طول زمان با تکامل همه گیر افزایش یافته است؟ (2) از نظر فضایی، توزیع این مقالات بر اساس کشور نویسنده چگونه است؟ (3) از منظر موضوعی، چگونه موضوعات مربوطه با توسعه اپیدمی تغییر کرده است؟ پاسخ به این سؤالات تنها نمی تواند به درک چگونگی تسهیل تحقیقات علمی در مهار COVID-19 کمک کند. اما همچنین می تواند به دانشمندان کمک کند تا مشکلات و شکاف های علمی بیشتری را برای بهبود وضعیت اپیدمی کنونی یا مقابله با هر گونه مسائل احتمالی مانند مشکلات اجتماعی یا اقتصادی که به طور غیرمستقیم ناشی از این بیماری همه گیر است، شناسایی کنند. بنابراین، برای پاسخ به آنها، باید با استفاده از تکنیکهای متن کاوی، اطلاعات مکانی-زمانی و موضوعی را از مقالات استخراج کنیم و سپس سیر تحول پژوهش در پاسخ به کووید-19 را از سه منظر فوقالذکر تحلیل کنیم.
متن کاوی به فرآیند شناسایی و استخراج اطلاعات ناشناخته، قابل فهم، بالقوه و ارزشمند از متن بدون ساختار با استفاده از پردازش زبان طبیعی (NLP) و تکنیک های یادگیری ماشین اشاره دارد [ 2 ، 3 ]. در سالهای اخیر با توسعه مداوم فناوریهای مرتبط، قابلیت استخراج اطلاعات موضوعی و مکانی-زمانی و تحلیل و درک متن بهبود زیادی یافته است که در مطالعات مربوط به واکنش اضطراری و پشتیبانی تصمیمگیری از رویدادهای غیرمنتظره به خوبی به کار گرفته شده است. (به عنوان مثال، خطرات طبیعی محیطی [ 4 ، 5 ، 6 ] یا بیماری های عفونی [ 7 ، 8]). برای مثال، Cvetojevic و Hochmair از متن کاوی، روشهای اکتشافی و مدلهای رگرسیون برای تجزیه و تحلیل انتشار توییتها در پاسخ به حملات تروریستی نوامبر ۲۰۱۵ پاریس استفاده کردند [ 9 ]. هان و همکاران نظرات عمومی را از دادههای رسانههای اجتماعی با مدل تخصیص نهفته دیریکله (LDA) استخراج کرد و تفاوتهای مکانی-زمانی این نظرات را در مراحل اولیه ظهور COVID-19 تجزیه و تحلیل کرد [ 11 ] . یه و همکاران کلمات موضوعی را از یک میکروبلاگ (یک رسانه اجتماعی مشابه توییتر در چین) مربوط به تب گوردون توسط مدل LDA استخراج کرد و الگوی تکامل تب گوردون در چین را در سال 2014 همراه با اطلاعات مکانی-زمانی تجزیه و تحلیل کرد [ 12 ]]. لیو و همکاران نگرانیهای رسانههای خبری را در مراحل اولیه اضطراری COVID-19 در چین از طریق رویکرد مدلسازی موضوع تحلیل کرد [ 13 ].
برخی از مطالعات همچنین استخراج و تجزیه و تحلیل پیشرفت تحقیقات مرتبط در COVID-19 را انجام داده اند [ 14 ، 15 ، 16 ]. برای مثال، Älgå و همکاران. از مدل LDA برای استخراج موضوعات از مقالات مرتبط با COVID-19 استفاده کردند و بر اساس موضوعات، ضریب تأثیر و زمان انتشار، پیشرفت تحقیقات را در طول اولین عبارت همهگیری COVID-19 از دیدگاه کتابسنجی تحلیل کردند [ 15 ]. ژانگ و همکاران موضوعات تحقیقاتی را از مقالات ویروس کرونا استخراج کرد، که از ژانویه 2009 تا آوریل 2020 منتشر شد، سپس از نظریه تاب آوری برای کشف چگونگی تاثیرگذاری مسیر تحقیقات کروناویروس توسط همه گیری COVID-19 استفاده کرد [ 16 ]]. مطالعات ذکر شده در بالا پایه خوبی برای استخراج و تجزیه و تحلیل موضوع و ویژگی مکانی-زمانی از مقالات مرتبط با COVID-19 در این کار ایجاد می کند.
این مطالعه با هدف تجزیه و تحلیل چگونگی تکامل تحقیقات مرتبط در پاسخ به COVID-19، روشی را برای استخراج اطلاعات موضوعی و مکانی-زمانی طراحی کرد و سپس به تجزیه و تحلیل جامع تکامل تحقیق پرداخت. سهم این مطالعه دو جنبه است: اول، یک فرآیند کلی برای استخراج کشور نویسندگان (اطلاعات مکانی) از اطلاعات سازمانی مقالات با تکنیکهای شناسایی موجودیت نامگذاری شده (NER) و پایگاههای دانش خارجی طراحی و اجرا میشود. عناوین و چکیده مقالات با استفاده از مدل های موضوعی، و دسته بندی موضوعات استخراج شده به دسته های مختلف توسط الگوریتم های یادگیری ماشین. دوم، با استفاده از روش تحلیل همبستگی،
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 مجموعه داده ها و روش های استخراج اطلاعات مکانی، استخراج موضوع و طبقه بندی مورد استفاده در این مقاله را ارائه می دهد. بخش 3 ضرایب همبستگی رتبه اسپیرمن بین مقالات مرتبط و موارد تایید شده COVID-19 را محاسبه می کند و روندهای زمانی، توزیع مکانی و تنوع موضوعی این مقالات را تجزیه و تحلیل می کند. بخش 4 برخی از کمبودهای این مطالعه را مورد بحث قرار می دهد. در نهایت، بخش 5 این مقاله را پایان می دهد و کارهای آینده را مورد بحث قرار می دهد.
2. داده ها و روش ها
2.1. داده ها و پیش پردازش داده ها
در این تحقیق سه مجموعه داده را جمع آوری و استفاده کردیم. اولین مجموعه داده شامل فراداده مقالات مربوط به COVID-19 بود و از مجموعه داده تحقیقاتی باز COVID-19 (CORD-19) ( https://www.semanticscholar.org/cord19 ) به دست آمد.، قابل دسترسی در 1 مارس 2021) توسط Semantic Scholar، یک موتور جستجوی مبتنی بر هوش مصنوعی برای انتشارات دانشگاهی منتشر شده است. CORD-19 به طور مشترک توسط کتابخانه ملی پزشکی ایالات متحده منتشر شده است. موسسه آلن برای هوش مصنوعی، کاگل، دانشگاه جورج تاون؛ و دفتر سیاست علم و فناوری کاخ سفید. CORD-19 به صورت روزانه به روز می شود و از سه بخش متادیتای کاغذی، متن کامل JSON و جاسازی های SPECTER تشکیل شده است. ما این مجموعه داده را با نسخه «cord-19_2021-03-01» دانلود کردیم، که شامل 78125 مقاله مرتبط با کووید-19 بود که از 15 ژانویه 2020 تا 28 فوریه 2021 منتشر شد. از آنجایی که فراداده قبلاً شامل مؤلفههایی بود که موضوع و زمانی را توصیف میکرد. اطلاعاتی مانند عنوان، چکیده و زمان انتشار، نیازی به استخراج آنها از متن کامل نیست. اما فقط با استفاده از “فراداده کاغذی”. چکیده و عنوان مقالات شامل برخی اطلاعات تداخلی مانند علائم نگارشی، نمادهای خاص، آدرس های اینترنتی و لینک ها بود که بر دقت و کارایی استخراج اطلاعات تأثیر می گذاشت. بنابراین، آنها از قبل با استفاده از عبارات منظم حذف شدند.
با توجه به کمبود اطلاعات سازمانی در بخش فراداده CORD-19 که برای استخراج کشور نویسندگان ضروری است، این اطلاعات را با خزیدن در وب سایت دانشگاهی مایکروسافت ( https://academic.microsoft.com/home ، قابل دسترسی در 1 مارس 2021) با عنوان مقالات با استفاده از فناوری خزنده وب. از آنجایی که بسیاری از مقالات حاوی بیش از یک قطعه اطلاعات سازمانی بودند، ما از عبارات منظم استفاده کردیم تا آنها را به یک تکه اطلاعات سازمانی جدا کنیم تا استخراج نام کشور و تجزیه و تحلیل دادهها راحتتر شود.
دومین مجموعه داده، داده های جهانی موارد کووید-19 ( https://covid19.who.int/table ، قابل دسترسی در 1 مارس 2021) بود که توسط سازمان بهداشت جهانی (WHO) منتشر شد، که به روز رسانی روزانه تعداد موارد تایید شده جدید را ارائه می کند. موارد و مرگ و میر بر اساس کشور، قلمرو، یا منطقه، و وضعیت جهانی همه گیری COVID-19 را نشان می دهد.
سومین مجموعه داده، علاقه جستجوی چندین کلمه کلیدی مرتبط با COVID-19 از Google Trends است ( https://trends.google.com ، در 1 مارس 2021 قابل دسترسی است). Google Trends یک ابزار تحلیلی است که با تجزیه و تحلیل میلیاردها نتیجه جستجوی گوگل در سراسر جهان می تواند فرکانس جستجو و آمار مربوط به یک کلمه کلیدی جستجو را در دوره های مختلف به کاربران بگوید [ 17 ] و به طور گسترده در تحقیقات علمی مختلف استفاده شده است [ 18 ، 19 ] ، 20 ].
2.2. مواد و روش ها
اطلاعات زمانی را می توان مستقیماً از مجموعه داده های مورد استفاده، یعنی زمان انتشار مقالات در بخش فراداده مجموعه داده CORD-19 به دست آورد، در حالی که اطلاعات مکانی و موضوعی لازم است از سایر اجزای مرتبط مقالات استخراج شود. در این قسمت به ترتیب روش های استخراج اطلاعات مکانی و استخراج موضوع و طبقه بندی را ارائه می کنیم. ما همچنین روش محاسبه همبستگی مورد استفاده در این مقاله را معرفی می کنیم.
2.2.1. استخراج اطلاعات مکانی
اطلاعات سازمانی را می توان به طور تقریبی به سه دسته تقسیم کرد: دسته اول اطلاعات کامل سازمانی را ارائه می دهد که از نام موسسه، نام کشور، نام شهر و غیره تشکیل شده است. به عنوان مثال، اطلاعات سازمانی “دانشگاه Tsinghua، پکن، چین» که در آن «دانشگاه تسینگهوا» نام مؤسسه است و «پکن» و «چین» به ترتیب شهر و کشوری هستند که دانشگاه تسینگهوا در آن واقع شده است. دسته دوم فقط شامل نام موسسه می شود، اما نامی در آن وجود دارد. به عنوان مثال، اطلاعات سازمانی “دانشگاه ووهان”، که در آن “ووهان” یک نام است. دسته سوم نیز فقط شامل نام موسسه است. اما هیچ نامی مانند اطلاعات سازمانی “دانشگاه هاروارد” در آن وجود ندارد.
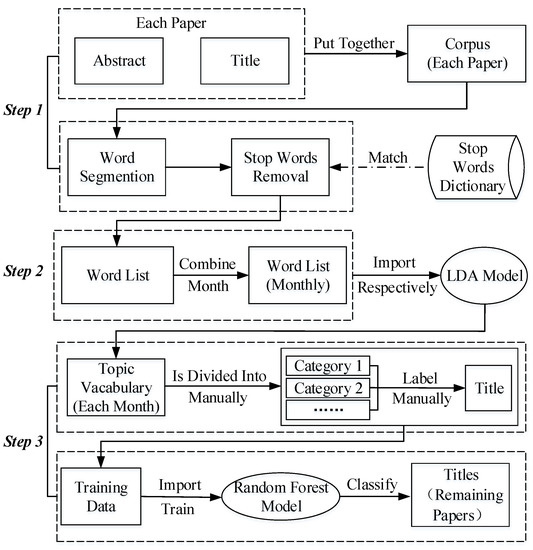
در پاسخ به موقعیتهای مختلف سه دسته اطلاعات سازمانی ذکر شده در بالا، ما یک فرآیند خودکار برای به دست آوردن کشور نویسندگان پیشنهاد میکنیم که تکنیکهای NER و برخی پایگاههای دانش خارجی مانند روزنامه و کتابخانه دانشنامه را ترکیب میکند. این فرآیند از دو مرحله تشکیل شده است: (1) طبقه بندی اطلاعات نهادی، که اطلاعات نهادی ورودی را به یکی از سه دسته فوق الذکر طبقه بندی می کند، و (2) استخراج اطلاعات کشور، که بر اساس آن اطلاعات سازمانی به آن دسته تعلق دارد، متفاوت است. روش هایی برای استخراج اطلاعات کشور استفاده خواهد شد. فرآیند دقیق در شکل 1 نشان داده شده است .
مرحله اول با استفاده از تکنیک های NER و تطبیق روزنامه اجرا می شود. به طور خاص، ما از ابزار spaCy NER و GAMD ( https://gadm.org/ ، در تاریخ 1 مارس 2021) به عنوان روزنامه برای مطابقت استفاده می کنیم. در برخی از مطالعات قبلی ثابت شده است که spaCy از بسیاری جهات (مانند کارایی برچسبگذاری و تجزیه POS) نسبت به سایر کیتها برتری دارد [ 21]. این مدل از شناسایی نهاد از انواع مختلف پشتیبانی می کند، که در میان آنها دسته بندی های مربوط به اطلاعات سازمانی شامل GPE (به عنوان مثال، کشورها، شهرها، یا ایالت ها) و ORG (به عنوان مثال، شرکت ها، آژانس ها، یا موسسات) است. بنابراین، ما ابتدا از ابزار spaCy NER بر روی اطلاعات سازمانی برای شناسایی موجودیتهای احتمالاً حاوی نام استفاده میکنیم، زیرا موجودیتهای شناسایی شده از دسته اول اطلاعات سازمانی به دو دسته طبقهبندی میشوند: ORG و GPE. با این حال، دو نوع دیگر از اطلاعات سازمانی تنها یک دسته در خروجی خود دارند، یعنی ORG. بنابراین با توجه به تعداد دسته های موجود در خروجی می توان تشخیص داد که اطلاعات نهادی ورودی متعلق به دسته اول است یا خیر. اگر اطلاعات نهادی ورودی متعلق به دسته اول نباشد، ما به تفکیک اینکه آیا به دسته دوم یا سوم تعلق دارد با تطبیق روزنامه ادامه خواهیم داد. ابتدا اطلاعات ورودی را با تقسیم بندی کلمه پردازش می کنیم و حذف کلمات را متوقف می کنیم و سپس نتایج پردازش شده را با ورودی های GAMD مطابقت می دهیم. اگر بتوان اطلاعات پردازش شده را با یک ورودی از روزنامه تطبیق داد، این اطلاعات سازمانی در دسته دوم طبقه بندی می شود. در غیر این صورت جزو دسته سوم خواهد بود. این اطلاعات سازمانی در دسته دوم طبقه بندی می شود. در غیر این صورت جزو دسته سوم خواهد بود. این اطلاعات سازمانی در دسته دوم طبقه بندی می شود. در غیر این صورت جزو دسته سوم خواهد بود.
با توجه به دسته بندی های مختلف اطلاعات سازمانی شناسایی شده در مرحله قبل، مرحله دوم از روش های مربوطه برای تکمیل استخراج نام کشور استفاده می کند. برای دسته اول اطلاعات سازمانی، ما مستقیماً موجودیت GPE شناسایی شده توسط مدل spaCy را در آخرین مرحله با روزنامه GAMD مطابقت دادیم. GAMD نام مکان ها را برای مناطق اداری همه کشورها در تمام سطوح زیربخش ارائه می کند. دادهها را بر اساس ردیفها سازماندهی میکند و هر ردیف در این مجموعه شامل چندین ستون است، مانند «NAME_0» که نشاندهنده نام کشوری است که منطقه اداری کنونی در آن قرار دارد، و «NAME_1»، «NAME_2»، یا «NAME_3»، نشان دهنده نام مکان های مناطق اداری چند سطحی است. بنابراین، هنگامی که موجودیت GPE با یک ردیف از این مجموعه داده تطبیق داده می شود، مقدار ستون “NAME_0” در این ردیف، نام کشور مورد نظر ما است. با توجه به دسته دوم اطلاعات سازمانی، از آنجایی که میتواند با یک ردیف روزنامه بعد از تقسیمبندی کلمه مطابقت داشته باشد و کلمات را متوقف کند، میتوان نام کشور را از این دسته از اطلاعات با همان روشی که در دسته اول استفاده میکرد به دست آورد. با توجه به دسته سوم، نمی تواند با هیچ ردیفی از روزنامه مطابقت داشته باشد، زیرا در این دسته از اطلاعات نامی وجود ندارد. بنابراین، ما از روش دیگری برای به دست آوردن نام کشور استفاده می کنیم، یعنی استفاده از فناوری خزنده وب برای جستجوی خودکار نام موسسه در یک وب سایت دایره المعارف ( از آنجایی که میتواند با یک ردیف از روزنامه بعد از تقسیمبندی کلمه مطابقت داشته باشد و حذف کلمات را متوقف کند، میتوانیم نام کشور را از این دسته اطلاعات با همان روشی که در دسته اول استفاده میشود به دست آوریم. با توجه به دسته سوم، نمی تواند با هیچ ردیفی از روزنامه مطابقت داشته باشد، زیرا در این دسته از اطلاعات نامی وجود ندارد. بنابراین، ما از روش دیگری برای به دست آوردن نام کشور استفاده می کنیم، یعنی استفاده از فناوری خزنده وب برای جستجوی خودکار نام موسسه در یک وب سایت دایره المعارف ( از آنجایی که میتواند با یک ردیف از روزنامه بعد از تقسیمبندی کلمه مطابقت داشته باشد و حذف کلمات را متوقف کند، میتوانیم نام کشور را از این دسته اطلاعات با همان روشی که در دسته اول استفاده میشود به دست آوریم. با توجه به دسته سوم، نمی تواند با هیچ ردیفی از روزنامه مطابقت داشته باشد، زیرا در این دسته از اطلاعات نامی وجود ندارد. بنابراین، ما از روش دیگری برای به دست آوردن نام کشور استفاده می کنیم، یعنی استفاده از فناوری خزنده وب برای جستجوی خودکار نام موسسه در یک وب سایت دایره المعارف (https://www.thefreedictionary.com/dictionary.htm ، قابل دسترسی در 1 مارس 2021). از آنجایی که این وبسایت اطلاعات کشور مؤسسات را با یک برچسب html منحصر به فرد (مثلاً «<span class = ‘country-name’> چین </span>» حاشیهنویسی میکند)، میتوانیم به سادگی نام کشور را با استخراج مقدار متن مربوط به آن به دست آوریم. این برچسب در صفحه وب
یک راه سادهتر برای استخراج نام کشور همه دستههای اطلاعات مؤسسه، تطبیق نام مؤسسه با صفحه وب مربوطه وبسایت دانشنامه است. با این حال، ما این کار را انجام نمی دهیم زیرا بسیاری از موسسات در وب سایت مذکور گنجانده نشده اند. در چنین مواردی نمی توان نام کشوری برای این موسسات به دست آورد. بنابراین، برای به دست آوردن نام کشور نویسندگان برای هر چه بیشتر مقالات، مانند دسته اول و دوم اطلاعات سازمانی، نام کشور را با تطبیق آن با روزنامه استخراج می کنیم، زیرا تقریباً همه مکان را در بر می گیرد. نام برای همه کشورها نام کشور دسته سوم اطلاعات سازمانی به دلیل نداشتن نام نامی تنها با استفاده از وب سایت دایره المعارف قابل دریافت است.
2.2.2. استخراج و طبقه بندی موضوع
از آنجایی که چکیده و عنوان معمولاً آموزندهترین بخشهایی هستند که ایده اصلی یک مقاله را توصیف میکنند و به دلیل تعداد کلمات بسیار کمتری نسبت به متن کامل مقاله، استخراج اطلاعات از آنها آسانتر است، ما موضوع را از آنها استخراج میکنیم. در این مطالعه. پس از اتمام استخراج موضوع، موضوعات استخراج شده را بیشتر در دسته بندی های مختلف دسته بندی می کنیم. دو کار فوق به ترتیب با استفاده از مدل LDA و الگوریتم جنگل تصادفی انجام شده است. جنگل تصادفی یک الگوریتم یادگیری مجموعه ای است که چندین درخت تصمیم را ترکیب می کند [ 22 ]، که عملکرد عالی را در وظایف طبقه بندی متن، رگرسیون و غیره نشان می دهد [ 23 ، 24 ، 25 ]]. کل فرآیند شامل سه مرحله است: (1) تقسیم بندی کلمات و حذف کلمات توقف، (2) استخراج موضوع، و (3) طبقه بندی موضوع، همانطور که در شکل 2 نشان داده شده است.
مرحله 1. تقسیم بندی کلمات و توقف حذف کلمات. ابتدا برای هر مقاله با کنار هم قرار دادن عنوان و چکیده آن یک پیکره می سازیم. سپس بر روی پیکره ساخته شده از تقسیم بندی کلمات استفاده می شود و کلمات توقف از آن حذف می شوند. در نهایت، پیکره پردازش شده به عنوان یک لیست کلمات سازماندهی شده است.
مرحله 2. استخراج موضوع. این مطالعه استخراج موضوع را با فراخوانی مدل LDA اجرا می کند (LDA یک مدل مبحثی است که می تواند موضوعات یک سند ورودی را با توجه به توزیع احتمال کلمات در سند [ 10 ] خروجی دهد) با استفاده از Gensim ( https:// radimrehurek.com/gensim/، در 1 مارس 2021 قابل دسترسی است) بسته در پایتون، که یک لیست کلمات تودرتو را به عنوان ورودی می گیرد، که در آن هر فهرست فرعی نشان دهنده لیست کلمات یک سند است. به طور مشخص، هر زیر فهرست شامل فهرست کلمات عنوان و چکیده یک مقاله در این پژوهش است. همانطور که ما تغییر موضوعات تحقیق را به تفکیک ماه تجزیه و تحلیل خواهیم کرد، فهرست کلمات مجموعه ها (هر مجموعه شامل عنوان و چکیده یک مقاله است) مقالات منتشر شده در همان ماه را در یک لیست تودرتو ترکیب می کنیم (به عنوان مثال، [[“nCov -19، «ویروس»، «…»]، [«…»، «…»]])، و سپس آن را به مدل LDA برای استخراج موضوع وارد کنید. سه پارامتر مهم در مدل LDA وجود دارد: num_topics ، alpha و بتا ، که در میان آنها num_topicsنشان دهنده تعداد موضوعاتی است که باید استخراج شوند، آلفا بر پراکندگی موضوعات و بتا بر پراکندگی کلمات تأثیر می گذارد. در این تحقیق از مقادیر مختلف پارامتر num_topics برای استخراج موضوع در ماه های مختلف استفاده شده است. به طور خاص، ما این پارامتر را به عنوان 5 برای ژانویه 2020، 10 برای فوریه 2020، 15 برای مارس 2020، و 20 برای بقیه ماه ها تا فوریه 2021 برای اجرای مدل اختصاص دادیم. ما آلفا را به عنوان 1/num_topics و بتا را به عنوان 1/(10*num_topics) اختصاص دادیم، که از ادبیات قبلی گریفیث و استیورز [ 26 ] یاد گرفتیم.
مرحله 3. طبقه بندی موضوع. با توجه به واژگان موضوعی استخراج شده در مرحله قبل، چندین دسته برای مقالات مرتبط با COVID-19 تعریف کردیم و عناوین 20000 مقاله از 78125 مقاله را با دسته بندی های تعریف شده برچسب گذاری کردیم. از داده های برچسب گذاری شده، 14000 به عنوان داده های آموزشی و 6000 باقی مانده به عنوان داده های آزمایشی برای مدل جنگل های تصادفی استفاده می شود. ویژگی رگرسیون جنگل تصادفی در کتابخانه اسکیت یادگیری پایتون برای پیادهسازی مدل جنگلهای تصادفی در این مقاله، که در آن n_estimators (تعداد درختهای تصمیم) و max_features استفاده میشود.(تعداد ویژگی) دو پارامتر مهم هستند. ما با تنظیم پارامتر آنها را به ترتیب به عنوان 197 و 240 اختصاص دادیم. مقالات باقی مانده به طور خودکار در دسته های از پیش تعریف شده بر اساس عناوین آنها با استفاده از مدل آموزش دیده طبقه بندی می شوند.
2.2.3. محاسبه همبستگی
معیارهای زیادی برای تحلیل همبستگی وجود دارد که در میان آنها معمولاً از ضریب همبستگی پیرسون، ضریب همبستگی رتبه تاو کندال و ضریب همبستگی رتبه اسپیرمن استفاده می شود. همانطور که روش اول مستلزم توزیع نرمال یا خطی متغیرها است [ 27 ] و روش دوم شاخصی است که همبستگی بین متغیرهای طبقهای را منعکس میکند [ 28 ]]، هیچ یک از آنها برای مورد مطالعه ما مناسب نیستند. ضریب همبستگی رتبه اسپیرمن، همبستگی را با رتبه بندی عناصر در دو بردار یا مجموعه محاسبه می کند، که می تواند به طور موثر جهت و درجه تمایل تغییرات بین دو متغیر را نشان دهد. بنابراین، ما از این روش برای تجزیه و تحلیل همبستگی بالقوه بین توسعه همهگیری COVID-19 و مطالعات مرتبط استفاده میکنیم. ضریب همبستگی رتبه اسپیرمن ( R S ) به عنوان معادله (1) محاسبه می شود، که در آن R ( Xi ) و R ( Y i )) رتبه بندی هر عنصر را در بردارها یا مجموعه های مربوطه نشان می دهد (به عنوان مثال، اگر دو مجموعه وجود دارد: X = [170,150,210,180,160]، Y = [180,160,190,169,172]، پس مجموعه رتبه بندی عناصر هر دو R(X) = [3,X) است. 1،5،4،2] و R(Y) = [4،1،5،2،3] R ( Xi ) و R ( Yi ) عنصر i در R ( X ) و R ( Y ) هستند. به ترتیب و N تعداد عناصر موجود در بردارها یا مجموعه ها است.
در این مطالعه، ما ضریب همبستگی رتبه اسپیرمن را با فراخوانی بسته Numpy در پایتون محاسبه کردیم. علاوه بر ضرایب Rs ، نتایج محاسبات شامل سطح معنی داری ( p) نیز خواهد بود که با آزمون t زوجی به دست می آید و برای تصمیم گیری در مورد همبستگی دو معیار استفاده می شود. هنگامی که p کمتر از 0.01 باشد، این دو معیار از نظر آماری همبستگی معنیداری در نظر گرفته میشوند.
2.2.4. ارزیابی نتایج
ما از Precision ( P )، Recall ( R ) و F1-Measure ( F1 ) [ 29 ] استفاده کردیم.] برای ارزیابی دقت استخراج و طبقه بندی اطلاعات در این کار، که معیارهایی هستند که معمولا در زمینه بازیابی اطلاعات مورد استفاده قرار می گیرند. دقت به نسبت اقلام به درستی استخراج شده (طبقه بندی شده) در همه موارد استخراج شده (طبقه بندی شده) اشاره دارد. یادآوری نسبت اقلام به درستی استخراج شده (طبقه بندی شده) در همه موارد است. بین دقت و فراخوانی یک معامله وجود دارد. بنابراین، لازم بود میانگین وزنی هارمونیک دقت و یادآوری، یعنی اندازه گیری F1 در نظر گرفته شود. هرچه اندازه F1 بالاتر باشد، روش های استخراج (طبقه بندی) موثرتر است. این سه معیار با معادلات (2) – (4)، که در آن تعریف شده است تیپنشان دهنده تعداد نام کشورها است که به درستی از اطلاعات سازمانی استخراج شده است، یا تعداد مقالاتی که به درستی طبقه بندی شده اند. افپنشان دهنده تعداد نام کشورها است که به اشتباه از اطلاعات سازمانی استخراج شده است، یا تعداد مقالاتی که به اشتباه طبقه بندی شده اند. و افnنشان دهنده تعداد کل نام کشورها است که به اشتباه و ناموفق استخراج شده اند، یا تعداد کل مقالاتی که به اشتباه و ناموفق طبقه بندی شده اند.
3. نتایج و تجزیه و تحلیل
در این بخش، ابتدا نتایج استخراج و طبقهبندی اطلاعات را ارزیابی میکنیم و سپس تحلیل جامعی از همبستگیهای چند سطحی بین مقالات تحقیقاتی منتشر شده مرتبط با COVID-19 و توسعه این همهگیری انجام میدهیم.
3.1. نتایج
برای ارزیابی روش استخراج اطلاعات مکانی خود، ما به طور تصادفی 6000 قطعه از اطلاعات سازمانی را انتخاب کردیم و آنها را با نام صحیح شهرستان به عنوان حقیقت پایه برچسب گذاری کردیم. عملکردها در جدول 1 نشان داده شده است. ارزش های تیپ، افپ، و افnبه ترتیب 5599، 167 و 401 هستند. بنابراین، دقت محاسبهشده، یادآوری، و اندازهگیری F1 با استفاده از معادلات (2) – (4) به ترتیب 97.1٪، 93.3٪ و 95.2٪ است. در مورد طبقه بندی موضوع، عملکرد مدل جنگل های تصادفی بر روی داده های آزمایشی در جدول 2 نشان داده شده است . تیپ4883 است، افپ1117 است و افnهمچنین 1117 است، یعنی تعداد مقالات طبقه بندی شده ناموفق 0 است. بنابراین، معیارهای ارزیابی محاسبه شده همه 81.3٪ است. نتایج فوق نشان میدهد که روش پیشنهادی دقیق و امکانپذیر بوده است، بنابراین میتوان از آنها برای استخراج اطلاعات مکانی و استخراج اطلاعات موضوعی و طبقهبندی بر روی مقالات باقیمانده استفاده کرد و در نتیجه پایهای برای تحلیل بیشتر در بخشهای فرعی زیر ایجاد کرد.
3.2. تحلیل زمانی
به منظور تجزیه و تحلیل و درک بهتر همبستگی زمانی بین همهگیری COVID-19 و تکامل تحقیقات مرتبط، ما ضرایب همبستگی رتبه اسپیرمن بین تعداد موارد تایید شده و تعداد مقالات منتشر شده را محاسبه میکنیم و روند آنها را در طول زمان به طور کلی تجزیه و تحلیل میکنیم. ، به ترتیب سطح ماهانه و روزانه.
3.2.1. تحلیل زمانی در سطح کلی
ضریب همبستگی رتبه اسپیرمن بین تعداد تجمعی موارد تایید شده و تعداد تجمعی مقالات منتشر شده به تفکیک ماه در جدول 3 نشان داده شده است . سطح معنی داری که برابر با 0 و کمتر از 0.01 است، نشان می دهد که این دو متغیر از نظر آماری بسیار معنادار هستند. ضریب Rs برابر با 1 است که نشان می دهد همبستگی مثبت بسیار قوی بین این دو متغیر وجود دارد.
همانطور که در شکل 3 و جدول 3 نشان داده شده است ، تعداد تجمعی موارد تایید شده به سرعت از 9906 به 113,432,271 افزایش یافت، در حالی که تعداد تجمعی مقالات منتشر شده نیز از 37 به 78,125 در 14 ماه گذشته افزایش یافت. این دو منحنی روند بسیار مشابهی را نشان می دهند. با این حال، از نقطه نظر عملی، درجه خاصی از انحراف بین تعداد تجمعی مقالات و موارد تایید شده وجود دارد. به این دلیل که انتشار مقالات زمان معینی را می طلبد، در حالی که تعداد موارد تایید شده به دلیل پیشگیری و کنترل نابهنگام می تواند در مدت زمان کوتاهی به سرعت افزایش یابد.
3.2.2. تجزیه و تحلیل زمانی در سطح ماهانه
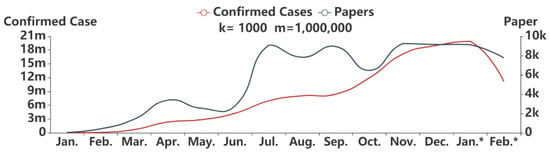
ضریب همبستگی محاسبه شده بین تعداد موارد تایید شده جدید و تعداد مقالات جدید منتشر شده در سطح ماهانه در جدول 4 نشان داده شده است . همانطور که مشاهده می شود، سطح معنی داری ( p = 2.5× 10-5 ) که کوچکتر از 0.01 است، نشان می دهد که همبستگی بین این دو متغیر از نظر آماری معنادار است. ضریب Rs 0.89 بسیار بزرگتر از 0 و حتی بسیار بزرگتر از 0.5 است که نشان می دهد این دو متغیر دارای درجه بالایی از همبستگی هستند.
شکل 4 تغییرات تعداد موارد تایید شده جدید و تعداد مقالات جدید منتشر شده را به تفکیک ماه از ژانویه 2020 تا فوریه 2021 نشان می دهد. به طور کلی، هر دو متغیر یک روند صعودی همزمان آشکار و پیوسته را نشان می دهند که باز هم همبستگی بالای این دو را ثابت می کند. متغیرها اگرچه یک انحراف بزرگ در چند گره زمانی رخ می دهد (دلیل آن ممکن است مشابه موارد ذکر شده در بخش 3.2.1 باشد.)، همچنین در اکثر قسمتهای منحنیها، هماهنگی خوبی بین آنها وجود دارد، که نشان میدهد تکامل تحقیقات ناشی از گسترش اپیدمی است. به طور خاص، تنها 37 مقاله مرتبط در ژانویه، زمان اضطراری COVID-19 منتشر شد. در فوریه، این تعداد شروع به افزایش کرد و به 404 رسید. تعداد مقالات با مجموع 1411 مقاله منتشر شده در ماه مارس، زمانی که COVID-19 شروع به گسترش در سراسر جهان کرد، همچنان افزایش یافت. در 11 مارس، WHO وضعیت اضطراری ویروس کرونا را به عنوان یک بیماری همه گیر اعلام کرد. پس از این، یک اوج کوچک 3375 در ماه آوریل رخ داد. در اردیبهشت و خرداد این روند ثابت ماند و تعداد مقالات (به ترتیب 2533 و 2788) تفاوت چندانی نداشت. در ماه جولای، تعداد مقالات به شدت افزایش یافت و با 9065 مقاله به بالاترین حد در هفت ماه گذشته رسید. 7829، 8935، 6467، 9244، 9147 وجود داشت،
3.2.3. تحلیل زمانی در سطح روزانه
ضریب همبستگی رتبه اسپیرمن بین تعداد موارد تایید شده جدید و تعداد مقالات جدید منتشر شده در سطح روزانه محاسبه شده است، همانطور که در جدول 5 نشان داده شده است. مقدار p بسیار کوچک نزدیک به 0 نشان می دهد که همبستگی بین این دو متغیر از نظر آماری بسیار معنادار است. این دو متغیر نیز با مقدار Rs 0.67 همبستگی مثبت معناداری دارند. در مقایسه با همبستگی این دو متغیر در سطح ماهانه، همبستگی در سطح روزانه کمتر مثبت است.
این همبستگی را می توان با نشان دادن تعداد موارد تایید شده جدید و تعداد مقالات جدید منتشر شده در سطح روزانه به عنوان منحنی پیدا کرد، همانطور که در شکل 5 نشان داده شده است.. در آغاز وضعیت اضطراری COVID-19، اولین مقاله دیرتر از زمانی که اولین مورد COVID-19 تأیید شد منتشر شد. در 24 ژانویه، نوسان تعداد مقالات به طور قابل توجهی بیشتر از موارد تایید شده بود، که ممکن است به دلیل تاخیر زمانی ناشی از انجام تحقیقات، نگارش مقالات، بررسی همتایان و غیره یک عدد تجمعی باشد. تعداد روزنامه ها همچنان رو به افزایش بود، اما در مقایسه با روند مشابه این دو متغیر در دی ماه، تفاوت زیادی بین آنها در بهمن ماه مشاهده شد. این به این دلیل است که اکثر موارد تایید شده در چین در این مدت گزارش شده است و برخی اقدامات پیشگیرانه به موقع و سختگیرانه توسط دولت انجام شده است (مانند ساخت بیمارستان کوهستانی هوشن و بیمارستان کوهستان ریتون، تحویل بسیاری از اعضای کادر پزشکی و تعداد زیادی تجهیزات پزشکی به ووهان و مسدود کردن ترافیک) و در نتیجه تعداد موارد تایید شده با سرعت پایین افزایش می یابد. این امر حاکی از اهمیت تخصیص منطقی منابع پزشکی و اقدامات پیشگیرانه به موقع برای مهار اپیدمی در مدت زمان کوتاه است. در همین حال، اپیدمی مورد توجه بسیاری از دانشمندان قرار گرفت. بنابراین، تعداد مقالات شروع به افزایش کرد. اپیدمی مورد توجه بسیاری از دانشمندان قرار گرفت. بنابراین، تعداد مقالات شروع به افزایش کرد. اپیدمی مورد توجه بسیاری از دانشمندان قرار گرفت. بنابراین، تعداد مقالات شروع به افزایش کرد.
متعاقباً، COVID-19 در ماه مارس در سراسر جهان گسترش یافت. دانشمندان بیشتری از کشورهای مختلف به طور متوالی تحقیقات مرتبط را انجام دادند و تعداد مقالات نیز به سرعت افزایش یافت. منحنی های این دو متغیر روند مشابهی را نشان دادند. از آوریل، اکثر کشورها به طور فعال اقدامات پیشگیری و کنترل را اجرا کردند، روند رشد تعداد موارد تایید شده روزانه جدید در چند ماه بعد نسبتاً ثابت به نظر می رسید. با این حال، این تعداد بیشتر و بیشتر شد. در این ماهها، تعداد نشریات روزانه بیشتر از ماههای گذشته بود، زیرا پژوهشگران زمان بیشتری برای انتشار مقالات خود داشتند. یک نکته جالب که از این منحنی ها مشاهده می شود، کاهش دوره ای در هفته است، زیرا مقالات معمولاً در روزهای هفته منتشر می شوند و در نتیجه منجر به کاهش تعداد در آخر هفته می شود.
3.3. تحلیل فضایی
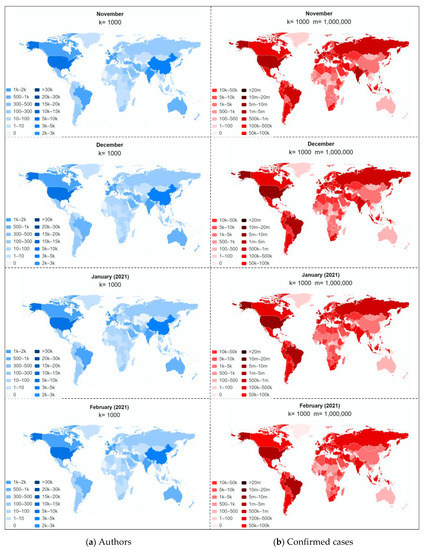
در این بخش ابتدا به تحلیل همبستگی و توزیع فضایی تعداد تجمعی موارد تایید شده و تعداد تجمعی نویسندگان بر اساس کشور می پردازیم و سپس توزیع فضایی تعداد موارد تایید شده جدید و تعداد نویسندگان را برای مقالات منتشر شده جدید ارائه می کنیم. در سطح ماهانه
3.3.1. تحلیل فضایی در سطح کلی
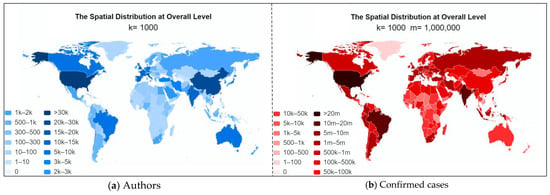
این مطالعه می تواند توزیع فضایی را به دو صورت تجزیه و تحلیل کند: روش اول شمارش تعداد نویسندگان مشترک هر مقاله بر اساس کشور است، این به ما کمک می کند تا متوجه شویم که دانشمندان در سراسر جهان تا چه اندازه به COVID-19 توجه می کنند و در آن مشارکت دارند. تحقیق مرتبط راه دوم این است که وزنهای متفاوتی را برای نویسندگان مشترک در مقاله تعیین کنیم تا مشارکتهای تحقیقاتی علمی کشورهای مختلف در مبارزه با کووید-19 را تحلیل کنیم. با این حال، راه دوم نه تنها دشوار است، زیرا سهم هر نویسنده در یک تحقیق متفاوت است، بلکه هدف کار ما نیز نیست. بنابراین، ما اولین راه را برای تجزیه و تحلیل توزیع فضایی انتخاب کردیم. در جدول 6، نتیجه محاسبه شده برای ضریب همبستگی بین تعداد تجمعی نویسندگان و موارد تایید شده فهرست شده است. همانطور که مشاهده می شود، Rs = 0.76 و p = 1.52 × 10-43 ( p <0.01)، که نشان دهنده همبستگی مثبت قوی بین این دو متغیر است. این با نتایج تحلیل شده از منظر زمانی سازگار است.
جدول 7تعداد تجمعی نویسندگان بیش از 500 نفر را بر اساس کشور نشان می دهد. همانطور که مشاهده می شود، ایالات متحده با 58146 نویسنده بیشترین تعداد نویسنده را دارد. کشور دیگری که بیش از 20000 نویسنده در تحقیقات مرتبط شرکت کرده است، چین با مجموع 29011 نویسنده است. کشورهای زیر ایتالیا، بریتانیا، اسپانیا، هند و فرانسه به ترتیب با 18348، 17880، 11214، 11132 و 11130 نویسنده هستند. کشورهایی که بین 5000 تا 10000 نویسنده دارند آلمان، کانادا، ژاپن، برزیل و استرالیا هستند. این در حالی است که تقریباً 23 کشور بین 1000 تا 5000 نویسنده در تحقیقات مرتبط شرکت کرده اند و تعداد نویسندگان در کشورهای باقی مانده کمتر از 1000 است. ما نمیتوانیم به سادگی نتیجه بگیریم که این کشورها دارای درجه بالاتری از نگرانیها و مشارکت بیشتری در غلبه بر این ویروس هستند، زیرا همه کشورها دارای سطوح توسعه، مقیاس و ظرفیتهای تحقیقاتی بسیار متفاوتی هستند. هر چه یک کشور توسعه یافته یا بزرگتر باشد، ظرفیت و توانایی بیشتری برای اختصاص منابع بیشتر به مطالعات مرتبط دارد. به همین دلیل است که بیشتر کشورهایی که در ده کشور اول قرار دارند، کشورهای توسعه یافته هستند، به جز چین و هند که دو کشور پرجمعیت هستند. ترکیب شده با که دو کشور پرجمعیت هستند. ترکیب شده با که دو کشور پرجمعیت هستند. ترکیب شده باشکل 6که توزیع فضایی تعداد تجمعی موارد تایید شده و تعداد تجمعی نویسندگان را نشان داد، میتوان همبستگی خوبی بین این دو متغیر مشاهده کرد. این بدان معناست که سطح سرمایهگذاری تحقیقات علمی در COVID-19 نیز در واقع با شدت همهگیری برای هر کشور مرتبط است. با این حال، از آنجایی که کشورهای مختلف تحمل خطر متفاوتی دارند، این امر منجر به پاسخ تحقیقات علمی نامتناسب خواهد شد، مشروط بر اینکه تعداد موارد تایید شده در این کشورها مشابه باشد. به عنوان مثال، تفاوت کمی بین تعداد موارد تایید شده در چین (101878) و کنیا (105648) وجود دارد، اما تحمل خطر در چین قویتر از کنیا است که منجر به تعداد نویسندگانی میشود که در تحقیقات مرتبط در چین شرکت میکنند. 29011) بسیار بیشتر از کنیا (<
3.3.2. تحلیل فضایی در سطح ماهانه
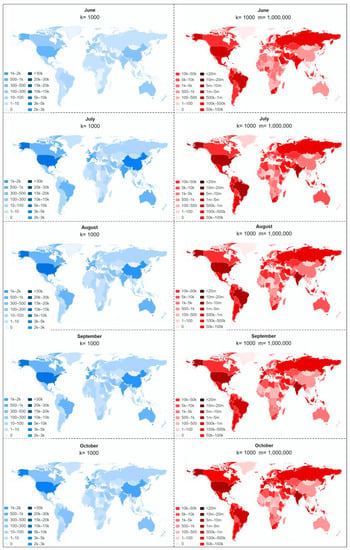
شکل 7توزیع فضایی تعداد موارد تایید شده جدید و تعداد نویسندگان مقالات منتشر شده جدید را از ژانویه 2020 تا فوریه 2021 نشان می دهد. فقط تعداد کمی از دانشمندان از چندین کشور در تحقیقات مرتبط شرکت کردند، از جمله چین، ایالات متحده، بریتانیا، فرانسه، هلند، استرالیا، بلژیک، برزیل، کانادا، سوئیس، ایتالیا و کره جنوبی. همانطور که مشاهده می شود، در ماه های ژانویه و فوریه، چین بیشترین تعداد را از نظر نویسندگان و موارد تایید شده داشت، در حالی که موارد ایالات متحده، ایتالیا و بریتانیا کمی کمتر از چین بودند. این با این واقعیت مطابقت دارد که اپیدمی در این دوره در چین متمرکز شده است. از ماه مارس، ویروس شروع به گسترش در سراسر جهان کرد. تعداد موارد تایید شده جدید در ایالات متحده از چین پیشی گرفت. و به طور فزاینده ای کشورهای بیشتری شروع به مشارکت در تحقیقات مرتبط کردند. با این حال، کشوری که بیشترین تعداد نویسندگان را دارد تا ماه آوریل چین باقی مانده است، که ممکن است به این دلیل باشد که انتشار مقالات زمان بیشتری می برد. در ماه آوریل، تعداد نویسندگان از ایالات متحده شروع به پیشی گرفتن از چین شد. در ده ماه آینده، ایالات متحده به طور مداوم کشوری بود که بیشترین تعداد نویسنده را داشت و همچنین بیشترین تعداد موارد تایید شده را داشت. تعداد نویسندگانی از چین، ایتالیا و بریتانیا به دنبال نویسندگان ایالات متحده است. به طور کلی، توزیع فضایی این دو متغیر در طول زمان به تدریج در سراسر جهان گسترش یافت. این نه تنها نشان دهنده همبستگی فضایی بین آنهاست،
3.4. تحلیل موضوع
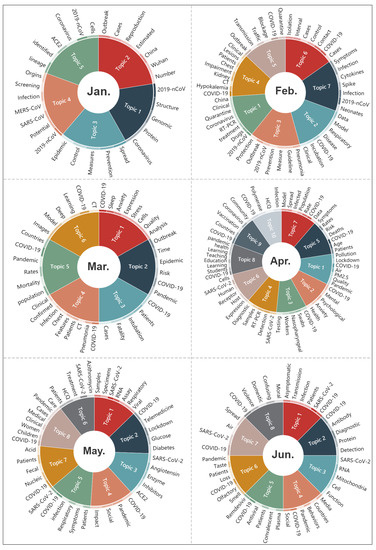
3.4.1. تجزیه و تحلیل موضوعات استخراج شده به تفکیک ماه
شکل 8 موضوعات و واژگان مربوطه استخراج شده از عناوین و چکیده مقالات را به تفکیک ماه با استفاده از مدل موضوعی LDA نشان می دهد. همانطور که مشاهده می شود دایره های هر ماه با توجه به تعداد موضوعات استخراج شده به تعداد قسمت های مختلف با رنگ های مختلف تقسیم می شوند. متن خارج از دایره به واژگان استخراج شده مربوط به هر موضوع اشاره دارد. به عنوان مثال، هنگام استفاده از مدل LDA، پارامتر تعداد موضوعات در ژانویه به پنج اختصاص داده شد (که در بخش 2.2.3 قابل مشاهده است.) و متن عناوین و چکیده مقالات در دی ماه با استفاده از مدل LDA در پنج موضوع خلاصه شده است. بنابراین، دایره ژانویه نیز به پنج بخش تقسیم شد و واژگان مربوطه در خارج از دایره فهرست شده است. توجه داشته باشید که به دلیل محدودیت فضا، فقط برخی از موضوعات و واژگان ذکر شده است. به عنوان مثال، مدل LDA 20 موضوع را برای آوریل خروجی می دهد، اما تنها 10 مورد از آنها در شکل نشان داده شده است. از این شکل به وضوح می توان تغییر کانون های تحقیقاتی را با گسترش بیماری همه گیر مشاهده کرد. در ابتدای این اورژانس، COVID-19 برای دانشمندان ناشناخته بود. بنابراین، تحقیقات عمدتاً بر روی اکتشاف منشا، اصل و نسب و ساختار ژنومی این ویروس در ژانویه متمرکز شده است. از فوریه تعداد موارد تایید شده به تدریج افزایش یافت. و به منظور کنترل و تثبیت اپیدمی و نجات بیماران مبتلا، دانشمندان نه تنها به تجزیه و تحلیل وضعیت اپیدمی پرداختند و در مورد دستورالعمل ها و اقداماتی برای پیشگیری و کنترل همه گیر مانند انسداد ترافیک و قرنطینه بحث کردند، بلکه شروع به بررسی کردند. بررسی ویژگی های بالینی، روش درمانی و توصیه های دارویی. یک بیماری همه گیر جهانی توسط WHO در ماه مارس اعلام شد. در چهار ماه آینده علاوه بر برخی مطالعات رایج مرتبط با پزشکی مانند تشخیص و شناسایی این بیماری، پاتوژنز و واکنش های دارویی، بیماران بدون علامت، تحقیق و توسعه واکسن و اثرات درمانی داروهای موجود، برخی مطالعات در سایر زمینههای حاصل از COVID-19 مانند رفتار رسانههای اجتماعی، کیفیت هوا، سلامت روان، درگیری های خشونت آمیز، پزشکی از راه دور، مشکلات اجتماعی و غیره. موضوعات تحقیق از ژوئیه 2020 تا فوریه 2021 اساساً مشابه ماه های قبل است، با این تفاوت که از نوامبر سال گذشته، چند موضوع بیشتر ظاهر شده است، مانند موضوعات مرتبط. تحقیق در مورد واکسن و سلامت روان بنابراین، به طور کلی، موضوعات تحقیق از ژانویه تا آوریل بسیار تغییر کرد و تقریباً اکثر موضوعات را در طول 14 ماه کامل پوشش داد. از ماه می، تغییرات موضوع بسیار اندک بوده است. موضوعات تحقیق از ژانویه تا آوریل به شدت تغییر کرد و تقریباً اکثر موضوعات را در طول 14 ماه کامل پوشش داد. از ماه می، تغییرات موضوع بسیار اندک بوده است. موضوعات تحقیق از ژانویه تا آوریل به شدت تغییر کرد و تقریباً اکثر موضوعات را در طول 14 ماه کامل پوشش داد. از ماه می، تغییرات موضوع بسیار اندک بوده است.
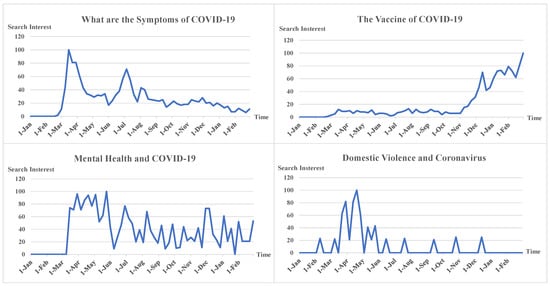
علاوه بر این، از گرایشهای Google، تمایل برخی از موضوعات پرطرفدار مرتبط با COVID-19 را در عرض 14 ماه به دست آوردیم، مانند “علائم COVID-19 چیست” (موضوع 1)، “واکسن COVID-19” (موضوع) 2) “خشونت خانگی و کرونا” (مبحث 3) و “سلامت روان و COVID-19” (مبحث 4) که در شکل 9 نشان داده شده است.. در مقایسه، میتوانیم متوجه شویم که علاقه جستجوی مبحث 1 در شش ماه اول اضطراری COVID-19 زیاد بوده و سپس از بین رفته است. علاقه جستجوی موضوع 2 در مرحله اولیه اضطراری COVID-19 کم بود و از نوامبر به طور قابل توجهی افزایش یافت. روند توسعه این دو موضوع اساساً با تکامل تحقیقاتی COVID-19 سازگار است. علایق جستجوی مبحث 3 و مبحث 4 با این همه گیری آغاز شد. اگرچه در ماه های بعد کاهش یافت، اما به طور کامل از بین نرفت. مشاهده میشود که ممکن است تعداد معینی از موارد بهداشت روانی و خشونت خانگی در دنیای واقعی وجود داشته باشد، که این یافتههای فوق را ثابت میکند که مقالات بیشتری در رابطه با سلامت روان و خشونت خانگی در مراحل بعدی کووید-۱۹ منتشر شده است. 19 همه گیری.
3.4.2. تحلیل فضایی موضوعات
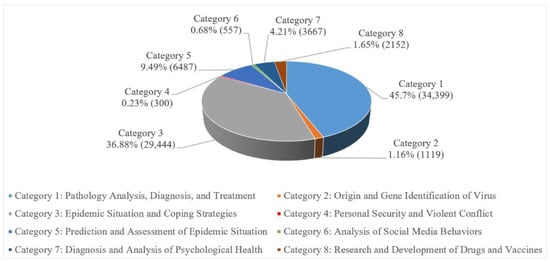
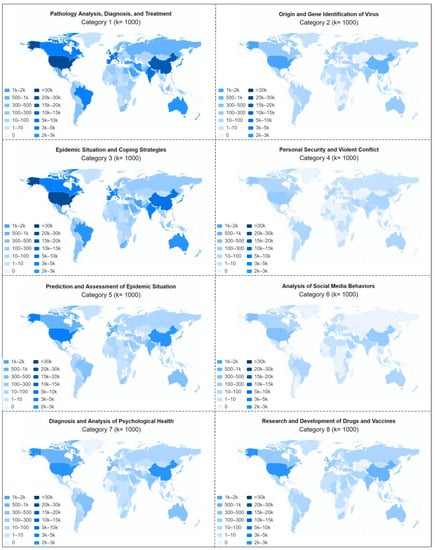
با توجه به واژگان موضوع استخراج شده، ما هشت دسته را تعریف کردیم: تجزیه و تحلیل آسیب شناسی، تشخیص و درمان (دسته 1). شناسایی منشا و ژن ویروس (دسته 2)؛ وضعیت اپیدمی و راهبردهای مقابله ای (دسته 3)؛ امنیت شخصی و درگیری خشونت آمیز (دسته 4)؛ پیش بینی و ارزیابی وضعیت اپیدمی (دسته 5)؛ تجزیه و تحلیل رفتارهای رسانه های اجتماعی (دسته 6)؛ تشخیص و تجزیه و تحلیل سلامت روانی (دسته 7)؛ و تحقیق و توسعه داروها و واکسن ها (دسته 8). با استفاده از مدل جنگلهای تصادفی آموزشدیده با دادههای برچسبگذاری شده، مقالات به دستههای از پیش تعریفشده طبقهبندی شدند. شکل 10 تعداد و نسبت هر دسته از مقالات و شکل 11 را نشان می دهدتوزیع فضایی تعداد نویسندگان شرکت کننده در هر موضوع را ارائه می دهد که از بین تعداد شرکت کنندگان برای هر موضوع به ترتیب 127686، 4602، 89695، 756، 18217، 1436، 12904 و 7187 نفر می باشد.
همانطور که مشاهده می شود، تعداد کل مقالات متعلق به دسته های 1، 3 و 5 بیش از 90 درصد از کل مقالات را به خود اختصاص داده است و این سه دسته نیز بیشترین توزیع فضایی را نسبت به سایر دسته ها دارند. این نشان می دهد که این دسته از موضوعات تحقیقاتی بیشترین توجه دانشمندان را در سراسر جهان به خود جلب کرده است. این از نقطه نظر عملی قابل درک است زیرا این موضوعات بیشترین ارتباط را با اپیدمی واقعی دارند. قبل از واکسیناسیون عموم مردم، تجزیه و تحلیل پاتولوژیک، درمان بیماران، پیشگیری از بیماری همه گیر و اقدامات کنترلی همچنان از مهمترین نگرانی ها خواهد بود و نشریات مرتبط همچنان مفیدترین مطالعات در مبارزه با همه گیری خواهند بود. توزیع فضایی دسته های 2 و 8 نیز بسیار گسترده بود.30 ، 31]. راه اول تعیین منشاء این ویروس و مسدود کردن آن از منبع است که مستلزم بررسی های دسته 2 است. راه دوم مطالعه و تولید دارو یا واکسن علیه این ویروس است که تمرکز تحقیقاتی گروه 8 است. رده های 4 و 7 مربوط به دو نوع مطالعه به دست آمده از همه گیری کووید-19 است که به دو دلیل احتمالی توجه دانشمندان کشورهای مختلف را به خود جلب کرده است. اولاً، به دلیل شدت همه گیری، بسیاری از مردم مجبورند برای مدت طولانی در خانه بمانند، که ممکن است منجر به افسردگی، تحریک پذیری و حتی مشکلات روانی جدی شود که به طور بالقوه منجر به خشونت خانگی می شود. دوم، کادر پزشکی خط اول نزدیکترین گروه به COVID-19 هستند، که ممکن است به دلیل خطر بالاتر عفونت، مانند ترس و اضطراب، مشکلات روانی ایجاد کند. این دو موضوع نه تنها بر اثر پیشگیری و کنترل بیماری همه گیر تأثیر می گذارد، بلکه در صورت نادیده گرفته شدن در طول همه گیری ممکن است به تهدیدی برای ثبات اجتماعی منجر شود. علاوه بر این، اگرچه تعداد مقالات در دسته 6 بسیار کم است و پوشش فضایی آن نیز کم بود، رسانه های اجتماعی (مانند توییتر، فیس بوک و Weibo) بستر ارزشمندی را برای عموم مردم فراهم می کند تا به روز رسانی های مربوط به همه گیری و همه گیری را دریافت کنند. آزادانه نظرات خود را بیان کنند. رسانه های اجتماعی همچنین گاهی اوقات می توانند اطلاعات بسیار مهمی را برای پیشگیری و کنترل همه گیر ارائه دهند. بنابراین، دسته 6 نیز قابل توجه است. از منظر کشور ( و پوشش فضایی آن نیز کم بود، رسانههای اجتماعی (مانند توییتر، فیسبوک و ویبو) بستر ارزشمندی را برای عموم مردم فراهم میکند تا بهروزرسانیهای مربوط به همهگیری را دریافت کنند و آزادانه نظرات خود را بیان کنند. رسانه های اجتماعی همچنین گاهی اوقات می توانند اطلاعات بسیار مهمی را برای پیشگیری و کنترل همه گیر ارائه دهند. بنابراین، دسته 6 نیز قابل توجه است. از منظر کشور ( و پوشش فضایی آن نیز کم بود، رسانههای اجتماعی (مانند توییتر، فیسبوک و ویبو) بستر ارزشمندی را برای عموم مردم فراهم میکند تا بهروزرسانیهای مربوط به همهگیری را دریافت کنند و آزادانه نظرات خود را بیان کنند. رسانه های اجتماعی همچنین گاهی اوقات می توانند اطلاعات بسیار مهمی را برای پیشگیری و کنترل همه گیر ارائه دهند. بنابراین، دسته 6 نیز قابل توجه است. از منظر کشور (شکل 11 )، ایالات متحده، برزیل، چین، استرالیا و برخی از کشورهای اروپایی در مطالعات هر دسته شرکت کردند که نشان می دهد این کشورها قابلیت های تحقیقاتی قوی تری دارند.
4. بحث
در این تحقیق روشی را برای استخراج اطلاعات موضوعی و مکانی پیشنهاد و اجرا کردیم و سیر تحول پژوهش را تحلیل کردیم، اما محدودیت هایی وجود دارد. از منظر روش شناختی، اولاً، اگرچه دقت استخراج اطلاعات مکانی (نام کشور) از اطلاعات سازمانی نسبتاً بالا است، اما همچنان برخی خطاها وجود دارد. یکی از انواع اصلی خطاها به دلیل تطبیق نادرست با روزنامه زمانی است که یک نام یا نام مشابه در بیش از یک کشور وجود دارد. به عنوان مثال، «دانشگاه آکسفورد» نام مؤسسهای است که «آکسفورد» در آن یک نام نامی است، اما «آکسفورد» را میتوان با نامهای متعدد متعلق به کشورهای مختلف در روزنامه GAMD، مانند بریتانیا، ایالات متحده، تطبیق داد. ایالات و نیوزلند. ما سعی خواهیم کرد این مشکل را با استفاده از تکنیک های تفکیک نام مکان حل کنیم که می تواند به رفع ابهام نام مکان ها کمک کند و در نتیجه عملکرد استخراج اطلاعات مکانی را بهبود بخشد. دوم، استخراج موضوع از برخی منظرها قابل بهبود است. به عنوان مثال، ممکن است لازم باشد متن کامل مقالات را اضافه کنیم تا اندازه مجموعه مورد استفاده را افزایش دهیم، در نتیجه اطمینان حاصل کنیم که موضوعات استخراج شده کاملاً ایده کلیدی مقالات را منعکس میکنند، یا سعی کنیم مدلهای پیشرفتهتری مانند مبتنی بر تعبیه کلمه را معرفی کنیم. مدل های موضوعی و تکنیک موازی سازی، به منظور بهبود دقت و کارایی استخراج موضوع. سوم، مقالات پزشکی بخش بزرگی از تمام مقالات در مجموعه داده مورد استفاده را تشکیل می دهند. با این حال، ما در زمینه پزشکی متخصص نیستیم و دقیقاً دانش این حوزه را درک نمی کنیم. این ممکن است منجر به مشکلاتی در طبقه بندی ذهنی موضوعات استخراج شده در این مقاله شود، از جمله این طبقه بندی ممکن است بیش از حد کلی باشد. شاید لازم باشد به استانداردهای طبقه بندی موجود رشته های پزشکی مراجعه کنیم یا از متخصصان پزشکی کمک بخواهیم تا طبقه بندی دقیق تری انجام دهیم.
از نقطه نظر تجزیه و تحلیل داده ها، موقعیت های همه گیر می تواند تحت تأثیر عوامل متعددی از جمله اقدامات پیشگیری و کنترل اتخاذ شده، میزان تمرکز جمعیت، سطح توسعه اقتصادی منطقه ای و اقلیم منطقه باشد. تکامل پژوهش نیز با عوامل بسیاری مانند سطح تحصیلات و سطح توسعه اقتصادی ارتباط تنگاتنگی دارد. این عوامل ممکن است بر همبستگی بین توسعه همهگیری و مطالعات مربوط به COVID-19 تأثیر بگذارد. بنابراین، ما نیاز به بررسی بیشتر همبستگی های زمانی و مکانی با در نظر گرفتن عوامل بیشتر داریم. به عنوان مثال، به جای تجزیه و تحلیل همبستگی های زمانی و مکانی به سادگی با استفاده از تعداد مقالات و تعداد موارد تایید شده، می توانیم اقدامات بیشتری را محاسبه کنیم. مانند مقدار نرمال شده آن اعداد بر اساس جمعیت هر کشور. این ممکن است منجر به نتایج همبستگی متفاوتی شود. دوم، در این مقاله، ما فقط تعداد نویسندگان مشترک هر مقاله را بر اساس کشور شمارش کردیم، که به تجزیه و تحلیل توجه دانشمندان سراسر جهان به COVID-19 کمک می کند. ما میتوانیم وزنهای مختلفی را با توجه به ترتیب تألیف در مقاله برای نویسندگان مشترک تعیین کنیم و سپس مشارکتهای تحقیقاتی علمی کشورهای مختلف در مبارزه با COVID-19 را تجزیه و تحلیل کنیم.
5. نتیجه گیری ها
در این تحقیق ابتدا روشی را برای استخراج اطلاعات موضوعی و مکانی از مقالات مرتبط با کووید-19 پیشنهاد و پیاده سازی کردیم، سپس بر اساس اطلاعات استخراج شده، سیر تحول پژوهش در پاسخ به کووید-19 را به طور جامع مورد تجزیه و تحلیل قرار دادیم و به نتایج زیر رسیدیم.
از منظر زمانی، در سه ماه پس از وضعیت اضطراری COVID-19، تعداد مقالات منتشر شده روند رشد آشکاری را نشان میدهد و روند چرخهای نسبتاً پایداری را در دوره بعدی نشان میدهد که اساساً با توسعه COVID-19 سازگار است. -19. از نظر دیدگاه فضایی، بیشتر نویسندگانی که در تحقیقات مرتبط شرکت کردند در ایالات متحده، چین، ایتالیا، بریتانیا، اسپانیا، هند و فرانسه متمرکز هستند. در عین حال، با گسترش مداوم COVID-19 در سراسر جهان، توزیع تعداد نویسندگان به تدریج افزایش یافته است، که نشان می دهد تعداد نویسندگان با شدت COVID-19 در مقیاس فضایی همبستگی مثبت دارد. از منظر موضوع، مطالعات مربوط به COVID-19 را می توان به هشت دسته تقسیم کرد. در مراحل اولیه اورژانس COVID-19، تحقیقات مرتبط عمدتاً بر منشاء و شناسایی ژنی ویروس متمرکز بود. پس از اعلام وضعیت اضطراری بیماری همه گیر، برخی مطالعات مشتق شده مانند تشخیص و تجزیه و تحلیل سلامت روانی، امنیت شخصی و درگیری خشونت آمیز اضافه شد. این دو مقوله برای ارتقای قابلیت های پیشگیری و کنترل بسیار مهم هستند که پیشنهاد می شود به این موضوعات پژوهشی توجه بیشتری شود. از آنجا که برخی از مقوله ها بیشترین ارتباط را با کنترل و پیشگیری از اپیدمی دارند، مانند تجزیه و تحلیل پاتولوژی، تشخیص و درمان. وضعیت اپیدمی و راهبردهای مقابله؛ و پیش بینی و ارزیابی وضعیت اپیدمی. از این رو، در اکثر دوره های زمانی، اکثریت مطالعات بر روی این سه مقوله متمرکز بوده است.
در ادامه کار، از تکنیک های پیشرفته تری برای حل مشکلات موجود در روش خود استفاده خواهیم کرد، مانند ابهام زدایی از نام ها، استخراج موضوع با دقت و کارایی بالاتر و طبقه بندی موضوعات با دانه بندی دقیق تر. علاوه بر این، مجموعه دادههای جدیدی را اضافه خواهیم کرد تا رابطه بین تکامل تحقیقات مرتبط و همهگیری را بیشتر بررسی کنیم.










بدون دیدگاه