

خلاصه
از طریق داده های داوطلبانه، افراد می توانند به ارزیابی اطلاعات در مورد جنبه های مختلف محیط اطراف خود کمک کنند. به ویژه در مدیریت منابع طبیعی، اطلاعات جغرافیایی داوطلبانه (VGI) به طور فزاینده ای به عنوان یک منبع مهم شناخته می شود، به عنوان مثال، پشتیبانی از تحلیل الگوی بازدید برای ارزیابی ارزش های جمعی و بهبود رفاه طبیعی. با این حال، در سال های اخیر، حفظ حریم خصوصی کاربران به یک موضوع مهم تبدیل شده است. تضادهای بالقوه اغلب از این واقعیت پدید میآیند که VGI میتواند در زمینههایی که در اصل توسط داوطلبان در نظر گرفته نشده است، دوباره استفاده شود. پرداختن به این تضادهای حریم خصوصی به ویژه در مدیریت منابع طبیعی مشکل ساز است، جایی که تجسم ها اغلب اکتشافی هستند، با مجموعه های چند وجهی و گاهی اوقات در ابتدا ناشناخته از نتایج تحلیل. در این صفحه، ما یک رویکرد یکپارچه و مبتنی بر مؤلفه برای تجسم آگاه از حریم خصوصی VGI ارائه میکنیم، که به طور خاص برای کاربرد در مدیریت منابع طبیعی مناسب است. به عنوان یک مؤلفه کلیدی، HyperLogLog (HLL) – یک قالب انتزاعی داده – برای امکان تخمین نتایج به جای اندازه گیری دقیق تر استفاده می شود. در حالی که HLL به تنهایی نمی تواند حریم خصوصی را حفظ کند، می توان آن را با رویکردهای موجود برای بهبود حریم خصوصی ترکیب کرد و در عین حال، انعطاف پذیری تجزیه و تحلیل را حفظ کرد. این مؤلفهها با هم، کاهش تدریجی خطرات حریم خصوصی برای داوطلبان را در مراحل مختلف فرآیند تحلیلی ممکن میسازد. یک نمایش مورد استفاده خاص بر اساس یک مجموعه داده جهانی و در دسترس عموم ارائه شده است که شامل 100 میلیون عکس است که توسط 581099 کاربر تحت مجوزهای Creative Commons به اشتراک گذاشته شده است.
کلید واژه ها:
حریم خصوصی ؛ شبکه های اجتماعی ؛ داده های مکانی ؛ HyperLogLog ; تصمیم گیری ؛ تجسم
چکیده گرافیکی
1. معرفی
مجموعهای از اصطلاحات برای توصیف محتوای تولید شده توسط کاربر (UGC) که در دسترس عموم است و برای زمینههای مختلف کاربرد و حل مسئله استفاده میشود، مانند اطلاعات جغرافیایی داوطلبانه (VGI)، اطلاعات جغرافیایی مشارکتی (CGI) یا اطلاعات جغرافیایی محیطی پدید آمده است. (AGI) (نگاه کنید به [ 1 ]). یکی از دلایل این است که بین اشتراک گذاری داوطلبانه اطلاعات و اطلاعات داوطلبانه تفاوت ظریف وجود دارد. به عنوان مثال، برای یک هدف یا کاربرد خاص مانند VGI [ 2 ]. گرماندی و سینکلر [ 3]، در میان دیگران، اصطلاح «جمع سپاری غیرفعال» را برای مورد خاص UGC ابداع کرد که در آن «[…] اطلاعات به طور داوطلبانه توسط کاربران به اشتراک گذاشته می شود، البته نه برای هدفی که توسط محققان استفاده می شود» (ص. 37).
با این حال، از منظر حفظ حریم خصوصی، به نظر میرسد که این مشکلات در تعریف دقیق دادهها اهمیت چندانی ندارند، زیرا حریم خصوصی داوطلبان میتواند بدون در نظر گرفتن اینکه دادهها داوطلبانه یا داوطلبانه به اشتراک گذاشته شدهاند به خطر بیفتد [ 2 ، 3 ]. به عنوان یک تعریف ساده و در عین حال مفید از حریم خصوصی، Malhotra و همکاران. [ 4] از عبارت نگرانیهای مربوط به حریم خصوصی اطلاعات کاربران اینترنت (IUIPC) برای توصیف «میزان نگرانی یک فرد در مورد میزان دادههای خاص فردی که توسط دیگران نسبت به ارزش مزایای دریافتی در اختیار دارد» (ص. 338) استفاده کنید. چنین تعریفی نشان میدهد که هرگونه ارزیابی از حریم خصوصی و عوامل اخلاقی زمانی که با کاربردهای واقعی دادهها جدا باشد ناقص است، مفهومی که توسط نویسندگان دیگر پشتیبانی میشود (نگاه کنید به [5، 6 ] ) . در اینجا، مدیریت منابع طبیعی نقش ویژه ای ایفا می کند، زیرا کاربردهای داده ها معمولاً در جهت منافع افراد یا جامعه است (نگاه کنید به [ 7 ]؛ همچنین به مدل سیستم ما، شکل 1، در بخش 3 توجه کنید.). در نتیجه، حفاظت از هویت داوطلبان، در عین حال که کیفیت نتایج را نیز حفظ می کند، باید مورد علاقه تصمیم گیرندگان و عموم مردم باشد [ 2 ، 3 ، 5 ].
بسیاری از تکنیکها در حال حاضر وجود دارند که به کاهش حساسیت مجموعه دادههای داوطلبانه یا جمعآوریشده و نتایج مشترک کمک میکنند. این تکنیک ها از مولفه های اساسی، مانند ناشناس سازی شبه یا هش رمزنگاری، تا راه حل های پیچیده تر، مانند القای نویز یا تجمیع داده ها را شامل می شود (به [ 8 ، 9 ] مراجعه کنید). در سطح مدل سیستم، این مؤلفهها را میتوان با در نظر گرفتن مجموعه گستردهتری از پروتکلها و چارچوبهای عملکرد خوب، مانند کمینهسازی دادهها، اصل جداسازی نگرانیها، یا حریم خصوصی با طراحی و حریم خصوصی بهطور پیشفرض (برای تعاریف این موارد) ترکیب کرد. شرایط، [ 8 ، 10 ، 11 ، 12 را ببینید]). معمولاً پذیرفته شده است که افزایش سطوح حریم خصوصی با هزینههای متعددی همراه است، مانند محدودیتها در تنظیم تحقیقات یا کاهش سودمندی نتایج [ 13 ]. به عنوان یک نتیجه اولیه از این بسیاری از ملاحظات، یک بحث مداوم و داغ پیرامون سؤالاتی در مورد اینکه کجا می توان مصالحه کرد، چگونه اجزاء را به بهترین نحو ترکیب کرد و چه سطوحی از خطرات قابل قبول است، پدیدار شد [14 ] .
در جستجوی مکانیسمهای بهبودیافته و قوی برای محافظت از حریم خصوصی، تعجب آور نیست که اجزایی که مزایای مختلفی را ارائه میکنند توجه کمی به خود جلب میکنند، اگر نتوانند بالاترین انتظارات را از حریم خصوصی برآورده کنند [15 ] . یکی از این مؤلفه ها HyperLogLog (HLL) است، یک قالب انتزاعی داده که توسط Flajolet و همکاران پیشنهاد شده است. [ 16 ] برای شمارش مقادیر متمایز در یک مجموعه، به نام تخمین کاردینالیته. HLL ممکن است به طور خاص شکافی را در مراحل میانی فرآیندهای تحلیلی پر کند، جایی که حفظ حریم خصوصی یک الزام مطلق نیست. چنین موقعیت هایی اغلب در سیستم های تصمیم گیری چند معیاره [ 17 ] و علم شهروندی [ 18] رخ می دهد.]، با طیف وسیعی از نیازها برای تنظیم تدریجی معاوضه حریم خصوصی و ابزار در مراحل مختلف پردازش داده ها. HLL دارای چندین ویژگی است که آن را به ویژه به عنوان یک مؤلفه میانی و آگاه از حریم خصوصی برای برنامه های کاربردی آگاه از مکان مانند VGI و اطلاعات جغرافیایی جمع سپاری مناسب می کند [ 19]]. با این حال، از آنجایی که الگوریتم HLL فقط تخمین کاردینالیته را امکان پذیر میکند، کاربرد آن در حوزه فضایی نیاز به در نظر گرفتن اجزای اضافه، روشها و استراتژیهای کاهش ریسک دارد. از آنجایی که اثر حفظ حریم خصوصی HLL به خودی خود تضمین نمی شود، ما از “حریم خصوصی آگاه” برای تاکید بر وابستگی به پیاده سازی، انتخاب های کاربر و ویژگی های داده استفاده می کنیم. علاوه بر این، پردازش دادههای مکانی برای تصمیمگیری چند معیاره شامل مراحل متعددی از بازیابی دادهها تا ذخیرهسازی دادهها و تجسم و انتشار نتایج است. با هدف کاهش تدریجی خطر شناسایی مجدد افراد، معاوضه حریم خصوصی و ابزار در هر یک از این مراحل امکان پذیر است.
در این مقاله، ما یک مثال یکپارچه از استفاده از HLL برای نظارت بر الگوهای بازدید فضایی را نشان میدهیم. ما بحث می کنیم که چگونه چندین تکنیک کاهش خطر را می توان با در نظر گرفتن پارامترهای فردی در ترکیب با سایر مؤلفه ها، از جمله ادغام مفاهیم geoprivacy [ 20] اجرا کرد.]. با در نظر گرفتن شرایط منحصربهفرد دادههای جغرافیایی جمعسپاری عمومی و داوطلبانه، نشان داده میشود که چگونه HLL ممکن است شکاف پردازش آگاهانه از حریم خصوصی دادههای تولید شده توسط کاربر را در مدیریت منابع طبیعی پر کند. با توجه به باز بودن و پیچیدگی مجموعه تحقیقاتی ارائه شده، تأکید می کنیم که هدف ما ارائه مدارک رسمی برای حفظ حریم خصوصی با تکنیک های نشان داده شده در اینجا نیست. ارزیابیهای ریاضی از رابطه مطلوبیت با حریم خصوصی وجود دارد و برای ابزارها و مؤلفههای فردی مورد استفاده در این کار ارجاع داده میشود. در عوض، با نشان دادن یک طرح مدولار آگاه از حریم خصوصی گسترده تر که می تواند بر اساس نیازهای شخصی و زمینه های برنامه تطبیق داده شود، تمرکز ما بر سودمندی است. درجات مختلفی از تناسب برای اهداف خاص وجود دارد، و چندین مثال در این کار مورد بحث قرار گرفته است. به عنوان وسیله ای برای کاهش موانع کاربرد عملی، ما به طور خاص جزئیات پیاده سازی و موانع را برای ادغام HLL در گردش کار موجود در نظر می گیریم. بنابراین، مشارکتهای ما چندوجهی است، اما بر روی یک تنظیم تجسم جدید و ارزیابی متعادل و کاربردیمحور مبادلات بین حریم خصوصی و ابزار تمرکز دارد. با حمایت از پذیرش گسترده و تکرار شفاف نتایج، ابزارهای خود، پردازش خط لوله و داده های معیار را در کنار این کار به طور کامل منتشر می کنیم.
2. کار قبلی
تعاریف مفیدی که به توصیف ابعاد روانی، اجتماعی و سیاسی حریم خصوصی کمک می کند، از دهه 1960 وجود داشته است [ 21 ، 22 ]. با این حال، تنها در دهه اول قرن بیست و یکم بود که مفاهیم رسمی حریم خصوصی در دسترس قرار گرفت و به دانشمندان اجازه داد تضادهای حریم خصوصی را در مجموعه داده ها کمیت و اندازه گیری کنند [ 23 ]. K-anonymity [ 24 ] یکی از اولین روشهای پیشنهادی بود که هدف آن کمی کردن و پیشبینی خطر شناسایی مجدد در یک مجموعه داده است. در اینجا، k آستانه ای را برای تعداد دفعاتی که ویژگی ها ممکن است در یک مجموعه داده رخ دهد برای گنجاندن [ 25 ] توصیف می کند، به عنوان مثال، حداقل پنج به عنوان یک قانون سرانگشتی [ 26]] (ص 14). یک k کمتر معمولاً به معنای خطر بالاتر شناسایی مجدد است، به عنوان مثال، از طریق ارتباط مشترک و ترکیب ویژگی ها با اطلاعات خارجی. برعکس، k بزرگتر منجر به از دست دادن اطلاعات بیشتر می شود، تا جایی که داده ها بی فایده می شوند [ 23 ] (ص. 2754).
برای جبران کاستی های مختلف در موارد استفاده خاص، تعداد زیادی از انواع فرعی، جایگزین ها و پیشرفت ها پیشنهاد شده است [ 25 ، 27 ، 28 ]. با این حال، در حالی که کاهش دانه بندی یا سرکوب داده ها می تواند خطرات را کاهش دهد، ارائه تضمین های دقیق [ 13 ] دشوار است. این یکی از دلایلی بود که Dwork et al. [ 29 ] مسیر متفاوتی را بر اساس سطوح نویز با دقت کالیبره شده اضافه شده به خروجی ها بررسی کرد. بعدها، این مفهوم به عنوان حریم خصوصی متفاوت (DP) شناخته شد و یک مفهوم رسمی دقیق و تضمین های ریاضی برای حفظ حریم خصوصی [ 30 ] ارائه کرد.
در حالی که k-anonymity، DP و سایر رویکردها در حال حاضر طیف گسترده ای از موارد استفاده را پوشش می دهند، چندین چالش همچنان کاربرد گسترده آنها را در عمل محدود می کند [ 12 ، 23 ، 31 ]. برای مثال، در حالی که DP آسیبپذیریهای شناخته شده k-anonymity را حل میکند، تعدادی از عوامل انعطافپذیری و امکانسنجی را در عمل کاهش میدهند [ 23 ] (ص. 2760). [ 31 ]. مشابه K-anonymity، برخی از سوالات تحلیلی به سطوحی از نویز نیاز دارند که برای نتایج مضر است [ 14 ، 27]]. برای القای تصادفی، حداقل برخی از ویژگیهای آماری دادهها باید شناخته شوند، که نیاز به انطباق خاص یا تحمیل محدودیتهایی برای استفاده در برنامههای پخش جریانی، ابزارهای نظارت مستمر و خطوط لوله تجسمهای مستقل دارند [12] (ص. 71 ) . [ 32 ، 33 ]. در حالی که استثنائات اعمال می شود، اکثر رویکردهای موجود نیز به طور خاص بر حفظ حریم خصوصی انتشار نتایج تمرکز می کنند (نگاه کنید به [ 28 ]، ص 16)، با نادیده گرفتن این که هر “عمل جمع آوری داده ها […] نقطه شروع نگرانی های مختلف در مورد حریم خصوصی اطلاعات است” [4 ] ] (ص 338).
از منظر حفظ حریم خصوصی، یک جزء نسبتاً جدید، ساختارهای داده احتمالی (PDS) مانند فیلترهای بلوم، طرحهای شمارش حداقل، یا HyperLogLog (HLL) هستند (برای یک نمای کلی به [ 19 ] مراجعه کنید ). برخلاف k-anonymity – که بر اساس اصول تجمع و حذف در مجموعه دادههای منفرد شکل گرفته است – و DP – که بر اساس اختلال دادههای تصادفی با تمرکز بر حساسیت خروجی ساخته شده است -، الگوریتمهای احتمالی استراتژی متفاوتی را با هدف متفاوت به کار میبرند. با حذف سیستماتیک بخشهای اطلاعات در سطح بنیادیتری از دادهها، دقت با کاهش حیرتانگیز در مصرف حافظه و زمان پردازش معامله میشود، در حالی که محدودیتهای خطای تضمین شده حفظ میشود (همان، ص 1). به طور طبیعی، مورد اصلی استفاده از محاسبات احتمالی، داده های بزرگ و برنامه های کاربردی جریان بود (همان).
اخیراً، چندین نشریه به کاربرد PDS برای حفظ حریم خصوصی، با نتایج دوسویه نگاه کرده اند. فیسیتن و همکاران [ 27 ] طرحهای Count-Min را با k-anonymity ترکیب کرد، بهعنوان وسیلهای برای بهبود عملکرد برای تخمین فرکانسهای پرس و جو برای مجموعههای داده بسیار بزرگ. Bianchi، Bracciale و Loreti [ 34 ]، با بررسی مزایای حفظ حریم خصوصی فیلترهای بلوم، به نتیجهای «بهتر از هیچ» میرسند. به منظور متعادل کردن دقت و حریم خصوصی، یو و وبر [ 35 ] HLL را برای تعداد کل در دادههای بالینی پیشنهاد کردند و آزمایشی را با 100 میلیون بیمار شبیهسازی کردند. دزفونتینز و همکاران [ 36 ] ثابت می کند که HLL حریم خصوصی را حفظ نمی کند، اما چندین استراتژی کاهش خطر را پیشنهاد می کند. اخیراً، رایت و همکاران. [ 37] نشان می دهد که فیلترهای HLL و Bloom را می توان برای ارضای تعریف دقیق DP ترکیب کرد. در دیدگاه خود، سینگ و همکاران. [ 19 ] تأکید می کند که استفاده از PDS در برنامه های کاربردی آگاه از مکان نیاز به کاوش بیشتر دارد (همان، ص 17).
به طور خلاصه، در حالی که حریم خصوصی یک ویژگی اولیه PDS نیست، به عنوان یک عارضه جانبی شناخته می شود. HLL، به عنوان آخرین PDS توسعه یافته، نقش ویژه ای از این منظر حفظ حریم خصوصی به عهده گرفته است. مورد استفاده اولیه HLL شمارش عناصر متمایز در یک مجموعه است که تخمین کاردینالیته نامیده می شود. نمایش داخلی یک مجموعه HLL، طرح نیز نامیده می شود زیرا فقط خلاصه تقریبی کوچکی از داده های اصلی را ذخیره می کند (نگاه کنید به [ 36 ]؛ یک مثال در شکل 2، بخش 4.3 نشان داده شده است ). در نتیجه، یک طرح HLL می تواند 1 میلیارد آیتم متمایز را با نرخ خطای 2٪ با استفاده از تنها 1.5 کیلوبایت حافظه شمارش کند [ 19]] (ص 13). مجموعههای HLL صریحاً از بررسی عضویت عناصر خاص پشتیبانی نمیکنند (همانجا). در نتیجه، حذف آیتم ها امکان پذیر نیست، زیرا پس از اضافه شدن، نمی توان موارد را بدون ابهام شناسایی کرد. از این نظر، مجموعههای HLL بیشتر شبیه دادههای آماری رفتار میکنند، در حالی که عملکرد و کاربرد عملی آنها بیشتر شبیه به مجموعههای معمولی است. به عنوان مثال، چندین مجموعه HLL را می توان ادغام کرد (عملیات اتحاد)، برای محاسبه تعداد ترکیبی عناصر متمایز هر دو مجموعه، بدون از دست دادن دقت. این امکان محاسبات موازی یا ذخیره انفرادی بسیاری از مجموعه های کوچک HLL را فراهم می کند که در نهایت تنها در یک مجموعه واحد ترکیب می شوند. به همین ترتیب، از طریق اصل گنجاندن-خروج [ 38 ]، روابط بین مجموعههای مختلف HLL را میتوان به صورت کمی ارزیابی کرد، همانطور که توسط بیکر و لانگمید [38] پیشنهاد شده است.39 ] برای اندازه گیری شباهت ژنومی. در ادامه، ما بحث و نشان میدهیم که چگونه مجموعههای HLL را میتوان با دادههای فضایی ترکیب کرد تا معیارها و روابط معمولی مورد استفاده در VGI را تقریبی کند.
3. مفهوم
3.1. مدل سیستم
همانطور که در مقدمه به آن اشاره شد، سطح مشارکت برای تولید VGI می تواند تا حد زیادی متفاوت باشد. گومز-بارون و همکاران [ 40 ] ملاحظات کلی را برای طراحی سیستماتیک پروژههای VGI، با در نظر گرفتن زنجیرهای از حالتهای مشارکت احتمالی که از مشارکت غیرفعال به مشارکت فعالتر کشیده میشوند، پیشنهاد کرد (ص. 11). مدل سیستم ما، که در شکل 1 نشان داده شده است ، از این ملاحظات کلی مشتق شده است. هدف این گرافیک ساده شده نشان دادن این ایده کلیدی است که تصمیم گیرندگان و مردم می توانند به شیوه ای مشترک با یکدیگر همکاری کنند تا رفاه کلی را بهبود بخشند و از توسعه سود جمعی محیط اطمینان حاصل کنند [4 ، 41 ] . هایلایت شده در مدل سیستم (رنگ خاکستری،شکل 1 ) اجزایی هستند که برای پردازش داده های HLL، به عنوان بخشی از سرویس Analytics (AS) اضافه شده اند. چنین خدماتی همچنین میتواند به عنوان واحد پردازش جمعسپاری مرکزی [ 40 ] یا متولی داده [ 23 ] (ص 2753) توصیف شود، که در بخش 4.2 (معماری نرمافزار) به طور دقیقتر توضیح داده شده است.
این واقعیت که سطوح مختلف مشارکت ممکن است با دو پیوند ارتباطی ممکن بین کاربران و AS شناخته شده است. اولین و شاید پرکاربردترین رویکرد در حال حاضر، از رسانه های اجتماعی مبتنی بر مکان (LBSM) به عنوان یک سرویس میانی استفاده می کند، که معمولاً منجر به حالت های منفعل تر مشارکت می شود [ 3 ]. برعکس، میتوان با گنجاندن اجزای کلیدی سرویس ارتباطی بهعنوان بخشی از AS، پیوند مستقیمتری با کاربران ایجاد کرد، که نشاندهنده یک حالت مشارکت فعالتر، در زنجیرهای از تعاریف ممکن از VGI است [40 ، 42 ] . در حالی که کیفیت و کمیت داده ها ممکن است به طور قابل توجهی بین این دو رویکرد متفاوت باشد، هر دو ممکن است برای تولید داده هایی با ساختار مشابه استفاده شوند.
این امکان را فراهم میکند تا آسیبپذیریهای مشابه دادههای جمعآوریشده را که با دو مورد یک دشمن داخلی و خارجی در شکل 1 مشخص شدهاند، فرموله کنیم . مورد دشمن داخلی این احتمال را نشان می دهد که سرویس تجزیه و تحلیل توسط شخصی با اطلاعات داخلی یا دسترسی مستقیم به سرویس تجزیه و تحلیل، یا شخصی خارجی که دسترسی مخربی به دست آورده است، به خطر بیفتد. حتی اگر داده ها به طور عمومی در دسترس هستند، به عنوان مثال، از طریق رسانه های اجتماعی، چنین سناریویی تحت شرایط خاصی محتمل به نظر می رسد. به عنوان مثال، هر داده ای که به روش های جدید تجمیع و ترکیب می شود، می تواند بینش هایی ایجاد کند که با داده های اصلی امکان پذیر نیست [ 12]]. برعکس، کاربران رسانههای اجتماعی ممکن است در هر زمانی اطلاعاتی را که قبلاً به اشتراک گذاشته شدهاند حذف کنند و بازتاب به موقع این تغییر در مجموعههای دادههای بعدی را به چالش بکشند [ 6 ]. در مورد دوم یک دشمن خارجی، وضعیت رایجتر مورد بحث کسی که سعی در به خطر انداختن حریم خصوصی در مجموعه دادههای منتشر شده دارد، به تصویر کشیده میشود. نماینده چنین مجموعه داده ای، داده های معیار تولید و به اشتراک گذاشته شده در این کار است ( بخش 6 ). ما به این دو مورد متخاصم در بخش 5 ، با بحث از دو مطالعه موردی باز می گردیم.
3.2. سرویس آنالیز
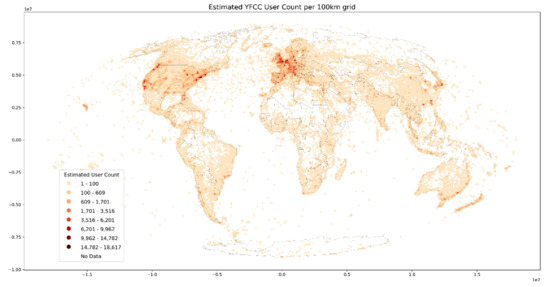
به عنوان ابزاری برای محدود کردن دامنه بحث زیر، ما به طور خاص یک سرویس تحلیلی برای نظارت بر الگوهای بازدید فضایی با توانایی استفاده از نتایج در تعدادی از زمینههای تصمیمگیری در نظر میگیریم. برای مثال ، چن، پارکینز و شرن [ 43 ]، از تعداد عکسهای اینستاگرام برای تجزیه و تحلیل و شناسایی مقادیر مهم چشمانداز اطراف سدهای برق آبی پیشنهادی در کانادا استفاده میکنند. کندی و نعمان [ 44 ] از تعداد کاربران فلیکر که در خوشههای مکان عکس حضور دارند برای کشف نشانههای شاخص استفاده میکنند. چوب، گوری، نقره و لاکایو [ 45] دریافتند که تعداد کاربران Flickr در ماه با نرخ بازدید رسمی از پارک های ملی در ایالات متحده مرتبط است و بنابراین می تواند به عنوان یک پروکسی کافی برای بهبود مدیریت پارک استفاده شود. رویکرد مشابهی توسط Heikinheimo و همکاران اعمال شده است. [ 46 ] برای نرخ بازدید از پارک ملی و فرکانس کاربران مشتق شده از اینستاگرام. دادههای فضایی فلیکر، مشابه نوع مورد استفاده در اینجا، همچنین در یک پروژه بزرگ (naturalcapitalproject.stanford.edu) برای شناسایی و کمی کردن ارزشهای زیباییشناختی، بهعنوان پایهای مهم برای ارزیابی خدمات اکوسیستم استفاده میشود [47 ] .
تکرار در این مثال ها استفاده از چندین نوع شناسه است. برای تمایز بین موارد، شناسههای منحصربهفرد (UID) یک نیاز ذاتی سیستمهای فناوری اطلاعات و تجزیه و تحلیل بصری هستند. به عنوان مثال، مدیریت پارک ملی را در نظر بگیرید که هدف آن نظارت بر تعداد کل بازدیدکنندگان منحصر به فرد کاربر است. این می تواند در محل انجام شود، به عنوان بخشی از جمع آوری هزینه ورودی، و در صورت امکان تعیین شناسه به بازدیدکنندگان، برای جلوگیری از شمارش مضاعف. از طرف دیگر، دادههای رسانههای اجتماعی در دسترس عموم ممکن است به عنوان یک پروکسی در نظر گرفته شوند، مانند مثالی که توسط فیشر و همکاران مورد بحث قرار گرفت. [ 48 ]. در نهایت، یک پروژه متمرکز VGI را می توان تصور کرد که دقیقاً برای پشتیبانی از مدیریت پارک های عمومی ساخته شده است، قابل مقایسه با برنامه هایی که به ارزیابی شیوع بیماری همه گیر کمک می کنند (مثلاً).
با وجود این نیت های خوب، نشان داده شده است که داده ها را می توان در طول عمر خود تغییر کاربری داد. UID ها به طور خاص یک علت اصلی درگیری های حریم خصوصی و سوء استفاده از داده ها هستند (به عنوان مثال، [ 49 ]). بدون جامع بودن، ما سه معیار تکرارشونده را مشاهده میکنیم که بر اساس UIDها در مدیریت منابع طبیعی ایجاد میشوند: تعداد پست (PC)، تعداد کاربر (UC) و پست (یا عکس) روزهای کاربر (PUD) (نگاه کنید به [3، 45 ، 48 ] ) . . دومی توسط وود و همکاران ابداع شده است. [ 45 ] بهعنوان اندازهگیری برای «تعداد کل روزهایی که هر شخص در هر سایت حداقل یک عکس گرفته است» (ص 6) و بهطور فزایندهای به عنوان یک نماینده کمی برای ارزش زیباییشناختی استفاده میشود (مثلاً ، [ 47]). به عنوان چهارمین شبه UID، مختصات پستها یا عکسهای به اشتراک گذاشته شده عمومی معمولاً برای مشاهده رخدادهای فضایی استفاده میشود. با توجه به دقت آنها، چنین مختصاتی معمولاً با حساسیت یکسانی نسبت به UIDها برخورد میشود که پیامدهای ویژهای برای حریم خصوصی جغرافیایی دارد [ 20 ]. فقط یک مثال توسط شی و همکاران ارائه شده است. [ 50 ]، که امکان استخراج مکان های شغلی و مسکن کاربران را از سوابق عمومی ایستگاه اجاره دوچرخه نشان می دهد. به طور خلاصه، در حالی که این معیارها قابل قبول به نظر می رسند، از منظر حریم خصوصی نیز آزاردهنده هستند، حتی در سناریوهای همکاری پیشگیرانه. در حالی که مجموعه بزرگی از راه حل ها برای این مشکل وجود دارد (به بخش 2 مراجعه کنید)، ما به طور خاص قابلیت های HLL را به عنوان یک جزء در ادامه بررسی می کنیم.
4. مواد و روش ها
4.1. مجموعه داده
ما از مجموعه داده 100 میلیونی یاهو فلیکر کریتیو کامانز (YFCC100M) که توسط یاهو در سال 2014 [ 51 ] منتشر شد برای ارائه یک مثال نمایشی استفاده می کنیم. این مجموعه داده به صورت یک فایل مقادیر جدا شده با کاما (CSV) به صورت عمومی در دسترس است و متا دیتا از 100 میلیون عکس و ویدیو به اشتراک گذاشته شده توسط 581099 کاربر تشکیل شده است. 48366323 عکس و 103506 ویدیو در مجموعه داده دارای برچسب جغرافیایی هستند (همان، ص 66). برای شبیه سازی یک برنامه استریم، داده ها ابتدا در یک پایگاه داده به نام “rawdb” خوانده می شوند (به بخش 4.2 مراجعه کنید.) حفظ تمام روابط درونی. این روابط، مانند شناسههای کاربر، شناسههای پست، مُهرهای زمانی یا مختصات و سایر مراجع، معمولاً هنگام دسترسی مستقیم به رابط برنامهنویسی برنامه کاربردی فلیکر (API) نیز در دسترس هستند. منطق انتخاب این مجموعه داده این است که دارای ساختار و محدوده ای است که امکان مقایسه با سایر داده های مورد استفاده در زمینه های مختلف VGI را فراهم می کند (نمونه هایی را در بخش 3 ببینید ).
4.2. معماری نرم افزار
برای ارزیابی شفاف و تکرار سیستم و نتایج ارائه شده در این کار، ما چندین مؤلفه فناوری را ترکیب می کنیم تا یک راه اندازی سرویس تحلیلی معمولی را نشان دهیم. در هسته، چهار داکر کانتینر (docker.com) به عنوان نمایشی از نقش های مختلف در مدل سیستم شرح داده شده در بخش 3 ( شکل 1 ) استفاده می شود. از آنجایی که اکثر کارها در زمینه حفاظت از حریم خصوصی در زمینه پایگاه داده انجام می شود [ 23 ] (ص 2754)، یک انتخاب طبیعی اجرای این نقش ها با PostgreSQL (postgresql.org) بود. اولین کانتینر (“rawdb”) یک سرویس رسانه اجتماعی را شبیه سازی می کند که امکان دسترسی به داده های اصلی و بدون فیلتر را از طریق یک API باز فراهم می کند. یا داده های خام جمع آوری شده مستقیم از کاربران (یعنی حالت مشارکت فعال VGI،شکل 1 ). عملکرد API توسط رابط پرس و جو PostgreSQL منعکس می شود. به طور مشابه، دومین ظرف PostgreSQL (“hlldb”) برای نشان دادن یک متصدی داده آگاه از حریم خصوصی استفاده می شود. این متصدی داده، اجرای Citus HLL (github.com/citusdata/postgresql-hll) را اجرا می کند. با هدف نشان دادن اصل تفکیک نگرانیها، سرویس Aggregation و Sketching با یک کانتینر جداگانه و سوم (“hllworker”) اجرا میشود که فقط برای محاسبات درون حافظه استفاده میشود. در نهایت، کانتینر چهارم که Jupyter Notebook (jupyter.org) را اجرا می کند، نماد بخش تجسم سرویس Analytics (AS) است. مراحل دقیق و کد خط لوله تجسم در چهار نوت بوک ساختار یافته است. این نوت بوک ها در کنار این مقاله در یک مخزن داده منتشر شده اند [ 52] و نسخههای HTML در مواد تکمیلی (S1–S4) گنجانده شدهاند .
هدف برای این نوت بوک ها چندگانه است. اولاً، از طریق معیار عملکرد، میتوان میزان معاوضه بالقوه سودمندی-حریم خصوصی را که متخصصان باید در هنگام تغییر گردش کار در نظر بگیرند، تعیین کرد. ثانیاً، هر مرحله بهطور شفاف مستند شده است، و هم قابلیت تکرارپذیری تحقیق و هم «دیدگاه بینشی» را برای عملکرد AS تصور شده ما فراهم میکند، همانطور که برای سناریوی دشمن داخلی مورد بحث قرار میگیرد (بخش 5 ) . این امکان شناسایی و بحث در مورد نقاط قوت و ضعف در بخش 6.3 (معادل حریم خصوصی) را فراهم می کند. در نهایت، نوتبوکها میتوانند بهعنوان پایهای برای ارزیابی نحوه انجام برخی انتخابها و تنظیمات پارامترها در مراحل اولیه فرآیند عمل کنند (به بخش 4 مراجعه کنید.) ممکن است بر نتایج بعدی تأثیر بگذارد. اولین نوت بوک نحوه وارد کردن داده های YFCC100M را به فرمت های rawdb و hlldb توضیح می دهد. نوت بوک دوم و سوم به ترتیب برای مقایسه پردازش داده ها بر اساس داده های خام و HLL استفاده می شود. در دفترچه چهارم، نشان داده شده است که چگونه می توان از داده های معیار منتشر شده برای تجزیه و تحلیل بیشتر استفاده کرد (به بخش 6.2 مراجعه کنید ). دو نوت بوک اضافی حاوی کدی برای تکرار ارقام و آمار باقی مانده در این مقاله هستند (به مواد تکمیلی، S5-S6 مراجعه کنید ).
4.3. مؤلفه اول: HyperLogLog (HLL)
به عنوان اولین مؤلفه از دو مؤلفه، HLL برای شمارش موارد متمایز برای سه معیار مختلف PC، UC و PUD که در بخش 3.2 معرفی شدهاند، استفاده میشود . حتی اگر پیاده سازی های مختلف HLL وجود داشته باشد، همه تعدادی از مراحل اساسی را به اشتراک می گذارند. در هسته، نسخه باینری هر رشته کاراکتری به «سطلهایی» با اندازه مساوی تقسیم میشود، مثلاً 4 (به تصویر در شکل 2 ، مرحله 4 مراجعه کنید). سطل همچنین به عنوان عرض ثبت نامیده می شود. برای هر سطل، تعداد صفرهای پیشرو شمارش می شود. از آنجایی که هر رشته کاراکتری داده شده ابتدا تصادفی می شود (مرحله 3، شکل 2 )، معمولاً با استفاده از یک تابع هش غیر رمزنگاری، می توان پیش بینی کرد که چند آیتم متمایز باید به مجموعه HLL داده شده اضافه شده باشد.بر اساس حداکثر تعداد صفرهای پیشرو مشاهده شده [ 16 ]. به عبارت دیگر، اگر چندین آیتم به یک مجموعه HLL اضافه شود، تنها بیشترین تعداد صفرهای ابتدایی در هر سطل باید حفظ شود. در نتیجه، تخمین اصلی (یعنی تعداد عناصر متمایز اضافه شده به مجموعه، مرحله 6، شکل 2 ) اعداد اعشاری را تولید می کند که فقط تعداد دقیق را تقریبی می کنند.
به عنوان یک عارضه جانبی، بررسی اینکه آیا یک کاربر یا شناسه خاص به مجموعه HLL اضافه شده است یا خیر، فقط به طور محدود امکان پذیر است. در یک موقعیت خصمانه، Desfontaines و همکاران. [ 36 ] به چنین چکی به عنوان “حمله تقاطع” اشاره می کند. حملات تقاطع ابتدا مستلزم به دست آوردن هش یک شخص یا شناسه مورد نظر و سپس افزودن این هش به مجموعه HLL است. اگر مجموعه HLL تغییر کند، یک طرف مقابل ممکن است بتواند سوء ظن اولیه خود را تا حدی افزایش دهد. چنین افزایشی در دانش قبلی، حتی به میزان کمی، معمولاً با تعاریف دقیق حفظ حریم خصوصی ناسازگار است (به بخش 2 مراجعه کنید ). دزفونتینز و همکاران [ 36] نشان می دهد که اثر حفظ حریم خصوصی HLL مستقیماً به اندازه یک مجموعه مربوط می شود و مجموعه های کوچکتر آسیب پذیری بیشتری دارند. نویسندگان به این نتیجه رسیدند که مجموعههای HLL با 10000 عنصر دارای اثر حفظ حریم خصوصی قوی هستند، مجموعههایی با 1000 عنصر کاهش محسوسی در حفظ حریم خصوصی دارند، و مجموعههایی با کمتر از 1000 عنصر اثر ضعیف حفظ حریم خصوصی را نشان میدهند (همان، ص 14). .
در کنار اندازه مجموعه ها، پارامترهای متعددی بر دقت تخمین کاردینالیته و در نتیجه به طور غیرمستقیم اثر حفظ حریم خصوصی تأثیر می گذارد. به عنوان مثال، تعداد و عرض سطل ها را می توان برای نیازهای مختلف تنظیم کرد. با تنظیم پارامتر log2m = 11 (لگاریتم به پایه 2)، تعداد رجیسترهای استفاده شده 2048 خواهد بود. در این حالت، خطای نسبی تخمین ±1.04/√(2| log 2 m ) = ± خواهد بود. 2.30 درصد در ترکیب با عرض رجیستر پیشفرض 5 ( عرض reg=5 )، پیادهسازی Citus HLL اجازه میدهد حداکثر تعداد 1.6 × 1012 آیتم را به یک مجموعه اضافه کنید – عددی که بیان آن با نمادهای غیر علمی دشوار است. برای مقایسه، با استفاده از aregwidth 4 و log2m 10 در حال حاضر حداکثر تعداد مواردی را که می توان تخمین زد به 12 میلیون کاهش می دهد، با خطای نسبی ±3.25٪ (برای ارجاع به موارد فوق، به مستندات آنلاین مراجعه کنید). از منظر حفظ حریم خصوصی، توصیه می شود از کوچکترین تنظیمات پارامتر ممکن استفاده کنید، که به حداکثر اندازه مورد انتظار مجموعه های HLL بستگی دارد. در مورد ما، مجموعه داده Flickr YFCC100M شامل 100 میلیون شناسه پست است، به همین دلیل است که از تنظیمات پیش فرض log2m = 11 و regwidth = 5 استفاده کردیم . برای بسیاری از مجموعه داده های دیگر، تنظیمات پارامتر کوچکتر امکان پذیر خواهد بود.
کاملاً نامرتبط با عملکرد HLL است، اما از منظر حفظ حریم خصوصی توصیه می شود، یک تابع هش رمزنگاری را می توان در مرحله قبل اضافه کرد (مرحله 2، شکل 2 ). این به طور موثر از حملات معمولی تقاطع جلوگیری می کند زیرا یک دشمن نمی تواند بدون دانستن کلید مخفی، هش را برای شناسه اصلی شناخته شده ایجاد کند. در پیاده سازی ما از تابع Postgres HMAC با استفاده از SHA256 و یک کلید مخفی با طول 160 بیت استفاده می کنیم. پیامدهای مربوط به حریم خصوصی و کاربرد در محیط فضایی ما بعداً در بخش 6.3 (معادل حریم خصوصی) ارزیابی می شود. در نهایت، و به جای پیاده سازی خاص، این است که مجموعه های HLL به طور متوالی به سه “حالت” مختلف عملکرد ارتقا می یابند: صریح ، پراکنده ، وپر . به دلایل عملکرد، حالت صریح و پراکنده دقت بالاتری در کاردینالیتههای پایینتر ارائه میدهد. از آنجایی که حالت صریح هشهای اصلی را به طور کامل ذخیره میکند، بدیهی است که نمیتواند هیچ مزیتی برای حفظ حریم خصوصی داشته باشد و باید غیرفعال شود، که هر مجموعهای را مستقیماً به پراکنده ارتقا میدهد (همانطور که توسط Desfontaines و همکاران [36]، ص 15، که از «sparse» استفاده میکنند پیشنهاد شده است . منظور ما از حالت صریح در اینجا).
در حالی که ذخیره یک مورد واحد در یک مجموعه HLL مورد معمول برنامه نیست، تنها مزایای اولیه ضعیفی را برای حریم خصوصی ارائه میکند، به مشخص کردن برخی از عملکردهای کلیدی کمک میکند. برای نشان دادن، در نظر بگیرید که همه شناسههای کاربر موجود در مجموعه داده YFCC100M را میتوان به مجموعههای تک تک HLL تبدیل کرد. برخلاف دادههای خام، که از 581099 آیتم منحصر به فرد (k = 1) تشکیل شده است، یک شمارش مستقیم ساده از آیتمهای متمایز از این نمایشهای HLL منفرد، تعداد 17358 را به دست میدهد (برای بازتولید این اعداد، به محاسبات در مواد تکمیلی، S5 مراجعه کنید .). بنابراین، بدیهی است که چندین شناسه کاربر به یک نمایش HLL تبدیل می شوند. این گروه بندی از تصادفی سازی ناشی از عملیات هش نشات می گیرد. همه این مجموعههای HLL منفرد را میتوان با هم ادغام کرد (یک عملیات اتحادیه)، برای تولید یک مجموعه HLL منفرد که میتوان از آن برای تخمین کاردینالیتی 589475 استفاده کرد ( جدول 1 را ببینید ).
توجه داشته باشید که آنچه شمارش می شود کاملاً به تحلیلگر واگذار می شود. در جدول 1 ، خلاصه ای برای معیارهای مورد استفاده در این مقاله، با مقادیر متناظر که بر اساس مجموعه داده YFCC100M جمع آوری شده است، ارائه شده است. برای وضوح، در حالی که تعداد پست و کاربر را می توان بر اساس یک شناسه اعمال کرد ( مندتوسهr، مندپoستی، مختصات متمایز و روزهای کاربر با الحاق رشته ها اندازه گیری می شوند (به عنوان مثال، لآتیمنتیتودهپoستی∥لongمنتیتودهپoستیو مندتوسهr∥مندپoستی-پتوبلمنسساعت-دآتیه، به ترتیب). بنابراین، طول و عرض جغرافیایی، یا تاریخ، به عنوان رشته های کاراکتری در نظر گرفته می شود که به ترکیب با سایر شناسه ها، مانند شناسه های کاربر، اجازه می دهد تا معیارهای ترکیبی را تشکیل دهد. این الحاق قبل از مرحله هش رمزنگاری و تبدیل HLL اعمال می شود (برای فرآیند دقیق، به مواد تکمیلی، S1 مراجعه کنید ).
از آنجایی که HLL فقط امکان شمارش مقادیر متمایز را می دهد، واضح است که برخی اطلاعات به عنوان مرجع برای آنچه شمارش می شود مورد نیاز است. این معمولاً منجر به تنظیم دو جزئی می شود که در آن یک قسمت در متن واضح ذخیره می شود. در یک زمینه فضایی، این جزء متنی واضح، شناسه مکان خواهد بود که با مجموعه HLL مرتبط است. نتیجه این است که هر ارزیابی از خطرات حریم خصوصی مستلزم نگاه کردن به HLL و مؤلفه مکان است.
4.4. جزء دوم: مکان
در سناریویی برای نظارت بر الگوهای بازدید فضایی، همانطور که در بخش 3 تصور میشود، در نقطهای تصمیمگیری میشود که در چه سطحی از جزئیات باید اطلاعات مکانی جمعآوری شود و در چه سطحی باید تجسم شود. فرض کنید، اگرچه بعید اما گویا، هدفی برای نظارت بر الگوهای بازدید در سراسر جهان، با دانه بندی بسیار درشت، مانند شبکه ای از سطل های زباله 100 کیلومتری. در مرحله اولیه پروژه، نمی توان به طور دقیق پیش بینی کرد که آیا 100 کیلومتر کافی است یا خیر. بنابراین، در یک معاوضه حریم خصوصی و ابزار، ممکن است تصمیم گرفته شود که داده ها با دقت کمی بالاتر جمع آوری شوند. اغلب، چنین مبادلاتی باینری نیستند، بلکه تدریجی خواهند بود و میتوانند با استفاده از تعدادی معیار، مانند k-نزدیکترین همسایه، t-closeness، L-تنوع، یا p-sensitive ارزیابی شوند.53 ].
از نظر k-ناشناس بودن، یک مکان (به عنوان مثال، نشان داده شده توسط یک جفت مختصات طول و عرض جغرافیایی) را می توان به عنوان مربوط به هر تعداد از ک≥1افراد (به عنوان مثال، [ 54 ]). ایده کلی این است که اگر یک مکان حداقل به یک مکان اشاره کند، داده ها k-ناشناس هستند ک-1افراد دیگر [ 55 ]. محمول k-anonymity معمولاً در حضور نقاط پرت (مکانی) به خطر می افتد [ 56 ]. برای حذف نقاط پرت، یک راه حل کاهش دانه بندی فضایی است. ما از یک تابع GeoHash ساده برای کاهش دانه بندی مختصات در مراحل گسسته از مثلاً 10 تا 1 استفاده می کنیم، مشابه اینکه Ruppel و Küpper [ 57 ] GeoHashes را با فیلترهای بلوم ترکیب می کنند. تابع GeoHash با نقاط “snapping” به یک شبکه قابل مقایسه است، با 10 و 1 که منجر به میانگین نرخ خطا به ترتیب از 60 سانتی متر تا 2500 کیلومتر می شود (همان، ص 420). بر اساس این تابع، درصد کلی حجم پرت را می توان برای کاهش سطوح دقت فضایی و برای معیارهای مورد استفاده در این مقاله ارزیابی کرد ( شکل 3) .).
منعکس شده در نمودار در شکل 3 یک ویژگی مشترک UGC است که اغلب به طور ناهموار توزیع می شود و دارای الگوهای دم سنگین است. به عنوان مثال، تعداد کل پرت های کاربر، در بالاترین دقت (10)، تقریباً 100٪ است، به این معنی که در هر مختصات فقط یک کاربر مشاهده می شود. در مقابل، حدود 80 درصد از مختصات به حداقل 2 پست اشاره دارد، به این معنی که حجم بیشتری از پستهای متمایز در بالاترین سطح دقت مکان قرار دارند (همچنین به [54 ] مراجعه کنید ). این توزیع نابرابر در دانه بندی های درشت تر قابل توجه تر می شود. در سطح GeoHash 5، با اشاره به میانگین “فاصله گیر” 4 کیلومتر، تقریبا 80٪ از مختصات ” k” را برآورده می کند.− 1» یعنی حداقل 2 نفر حضور دارند. با این حال، ارزیابی های مختلفی از ریسک وجود دارد . روش دیگری که با خط قرمز نشان داده شده است (اشکال برون مختصات کاربر، شکل 3 ) بررسی تعداد کل کاربرانی است که با داشتن حداقل یک مختصات در مجموعه داده کل با k = 1 می تواند به خطر بیفتد. این منحنی فقط به 0% می رسد. با دقت GeoHash 1، که احتمالاً سطح بالایی از حریم خصوصی را نشان می دهد، اما همچنین منجر به اطلاعات مکانی می شود که ممکن است دیگر فایده ای نداشته باشد. بر اساس این ارزیابی، دقت GeoHash 5 ممکن است برای کاهش اولیه دانه بندی فضایی داده های ورودی قابل قبول به نظر برسد. توجه داشته باشید که این عدد کاملاً وابسته به زمینه است. در اینجا فقط برای اهداف نمایشی استفاده می شود.
5. مطالعه موردی: الکس، “ساندی” و “رابرت”
تنها راه برای مهاجم برای به دست آوردن اطلاعات در مورد محتویات یک مجموعه HLL از طریق حمله تقاطع است ( بخش 4.3 ). برای نشان دادن بهتر حملات تقاطع، و اینکه چگونه، و تحت چه شرایطی، حریم خصوصی یک کاربر می تواند در راه اندازی تحقیق دو جزئی ارائه شده به خطر بیفتد، به طور خلاصه دو مثال را معرفی می کنیم. الکس یک کاربر واقعی است که در مجموعه داده YFCC100M گنجانده شده است زیرا او 289 عکس را تحت مجوز Creative Commons بین سالهای 2013 و 2014 در فلیکر منتشر کرده است. 120 مورد از این عکس ها دارای برچسب جغرافیایی هستند. الکس یکی از نویسندگان این مقاله است. با توجه به این اطلاعات، شناسایی مجدد الکس نسبتا آسان خواهد بود. «ساندی» و «رابرت»، در عوض، افراد خیالی هستند.
ما از سندی برای توصیف یک دشمن داخلی استفاده می کنیم. سندی می تواند شخصی باشد که در سرویس تحلیلی کار می کند و دسترسی کامل به پایگاه داده دارد. در مثال اول، اگر سندی بتواند سوء ظن خود را مبنی بر نبود الکس در محل کار خود در برلین در 9 مه 2012 افزایش دهد یا تأیید کند، حریم خصوصی الکس به خطر می افتد. از سوی دیگر، رابرت فردی است که نماینده یک دشمن خارجی است و فقط دسترسی دارد. به مجموعه داده منتشر شده در مثال دوم، حریم خصوصی الکس به خطر می افتد اگر رابرت بتواند سوء ظن خود را افزایش دهد یا تأیید کند که الکس واقعاً حداقل یک بار در یک مکان خاص بوده است، به عنوان مثال، برخلاف آنچه الکس ادعا می کند. در نهایت، الکس میتواند کسی باشد که داوطلبانه تصاویر خود را به AS ارائه میکند، یا عکسهای Creative Commons را نوع دوستانه در فلیکر منتشر میکند.
در نظر بگیرید که در لحظه مشارکت، الکس ممکن است به عواقب حریم خصوصی خود فکر نکرده باشد، اما بعداً متوجه اشتباه خود شده است. با استفاده از دادههای خام، حتی با حذف هر گونه داده به خطر انداخته از Flickr، این تغییر باید در هر مجموعه داده بعدی، مانند مجموعه دادههای AS خیالی یا YFCC100M منعکس شود. این یا غیرعملی است یا غیرممکن. بنابراین، سؤال این است که آیا میتوان جریانهای کاری دادههای خام را با یک خط لوله تجسم آگاه از حریم خصوصی جایگزین کرد، بدون اینکه به طور قابل توجهی از ابزار کاهش یابد. در ادامه، ابتدا با مقایسه فرآیند تجسم به صورت موازی برای دادههای خام و HLL، چگونگی تأثیر انتخاب پارامترهای انجامشده تا کنون بر تجسمسازی و توانایی استفاده از نتایج را مورد بحث و بررسی قرار میدهیم. در بخش 6.3، به دو مثالی که در اینجا نشان داده شده است باز می گردیم و با استفاده از داده های HLL آگاه از حریم خصوصی ارزیابی می کنیم که آیا حریم خصوصی Alex می تواند از طریق یک حمله تقاطع به خطر بیفتد یا خیر.
6. نتایج
6.1. الگوهای بازدید در سراسر جهان
برای تولید گرافیکی از الگوهای بازدید فضایی در سراسر جهان، که در شبکهای از سطلهای 100 کیلومتری پیشبینی شدهاند، به تجمیع فضایی دادهها نیاز است. ما از جستجوی دودویی برای اختصاص مختصات به bin های گسسته استفاده می کنیم. در یک تنظیم داده خام، همه شناسههای متمایز (شناسه کاربر، شناسه پست، تاریخ انتشار پست) ابتدا باید بهطور کامل در هر سطل جمعآوری شوند، تا زمانی که همه دادهها در دسترس باشند. تنها پس از آن، تعداد عناصر متمایز در هر bin را می توان محاسبه کرد. در مقابل، در یک تنظیم داده HLL، تمام مراحل تبدیل (مراحل 1 تا 4، شکل 2 ، بخش 4.3)) را می توان بر اساس یک تکه اطلاعات اعمال کرد. به عبارت دیگر، تبدیل HLL می تواند بلافاصله پس از ورود هر عنصر جدید، به عنوان مثال، در زمینه های جریان اتفاق بیفتد. این همچنین به این معنی است که مجموعههای تک تک HLL برای PC، UC و PUC توسط اتحادیه افزایشی در هر bin ادغام میشوند تا زمانی که همه دادهها پردازش شوند. مواد تکمیلی (S2-S4) شامل کد رویه ای پایتون برای تولید گرافیک زیر به ترتیب از داده های خام و HLL است.
قبل از ارائه نتایج ملموس تر، به طور خلاصه تفاوت های ظاهری در بصری و گردش کار پردازش را خلاصه می کنیم. شکل 4 گرافیک های تولید شده را برای روزهای دقیق و تخمینی کاربر در هر سطل زباله 100 کیلومتری برای بخشی از اروپا مقایسه می کند. برای طبقهبندی، از الگوریتم شکست سر/دم استفاده میشود که طرحی را ارائه میدهد که به طور خاص برای دادههایی با توزیع دم سنگین مناسب است [ 58 ]. Head/tail breaks به طور خودکار تعداد کلاس ها را محاسبه می کند. برای دادههای خام و HLL، شکستهای سر/دم هفت کلاس تولید کردند. نرخ خطای 3 تا 5 درصدی HLL فقط در ورودی های افسانه ای قابل توجه است. در شکل 4، تعداد کل دو سطل سوئیچ کلاس (یعنی تغییر رنگ)، به دلیل موارد لبه در فرآیند طبقه بندی خودکار (برای مقایسه گرافیکی، به مواد تکمیلی، S7 مراجعه کنید ).
همه معیارها برای همه سطل ها را می توان به صورت تعاملی در یک رابط نقشه کاوش کرد ( شکل 5 و مواد تکمیلی، S8 را ببینید ). بدیهی است که مقادیر مشاهده شده در محدوده خطای مورد انتظار تخمین اصلی HLL قرار دارند ( بخش 4.3 ). در مجموع، تفاوتهایی که بر روی تصاویر تأثیر میگذارند تا حد زیادی نامحسوس هستند. علاوه بر این، تلاش مورد نیاز برای اصلاح فرآیند تجسم، برای سازگاری با محاسبات HLL، به استثنای برخی پشتیبانی های دست و پا گیر برای پایتون (مقایسه کنید نوت بوک های خام/HLL، مواد تکمیلی، S2-S3 ) بسیار کم بود.
برای یک مبنای اضافی برای مقایسه مبادلات بین پردازش داده خام و HLL، چندین معیار عملکرد در نوتبوکها جمعآوری شدهاند (خلاصه جدول 2 و کد را در مواد تکمیلی، S2-S3 ببینید ). حجم کل داده هایی که در ابتدا به فرآیند تجسم داده می شود 2.5 گیگابایت (خام) و 134 مگابایت (HLL، حالت پراکنده) است. به منظور مقایسه، تفاوت اندازه برای حالت صریح (281 مگابایت) و حالت کامل (3.3 گیگابایت) آورده شده است ( جدول 2)). اگر هر دو حالت صریح و پراکنده غیرفعال باشند، اندازه کل داده های HLL کمی بزرگتر از داده های خام است زیرا مجموعه های کوچک زیادی وجود دارد. برای دادههای خام، زمان پردازش برای تولید نقشه جهان برای معیارهای مختلف متفاوت است، زیرا محاسبه تعداد موارد متمایز برای معیارهای پیچیدهتر مانند روزهای کاربر گرانتر میشود. در مقابل، زمان پردازش HLL برای اتحاد افزایشی همه مجموعهها به سطلهای 100 کیلومتری خطی باقی میماند. پیک حافظه مشاهده شده برای تجمع خام و HLL تا حد زیادی به تنظیمات پارامتر بستگی دارد. برای اتحاد مجموعههای HLL، از هر chunk_size دلخواه میتوان برای موازی کردن پردازش استفاده کرد. در مقابل، برای محاسبه تعداد آیتمهای مجزا با دادههای خام، ابتدا باید همه شناسهها در هر سطل کاملاً در دسترس باشند و امکانات کاهش بار حافظه را محدود کنند.
در نهایت، شکل 6 همان شبکه را برای اروپا، برای تعداد پست ها و با پارامتر تغییر یافته grid_size = 50 (km) نشان می دهد. برای اینکه چنین تغییری در خط لوله تجسم در زمان بعدی امکان پذیر شود، لازم است که یک دانه بندی اولیه دقیق به اندازه کافی از اطلاعات مکانی در دسترس باشد. در حالی که مجموعههای HLL را میتوان به صورت یکپارچه به روشی از پایین به بالا ادغام کرد، آستانه پایینتری که در زمان جمعآوری دادهها تعریف میشود، بر توانایی کاهش بعدی پارامتر اندازه شبکه تأثیر میگذارد. در نمایش ما، یک GeoHash از 5 (4 کیلومتر) شاید یک مبادله نسبتا محافظه کارانه، به سمت انعطاف پذیری تحلیلی بیشتر، اما خدمات کمتر – حفظ حریم جغرافیایی داخلی را نشان می دهد.
6.2. کاربرد داده های معیار منتشر شده
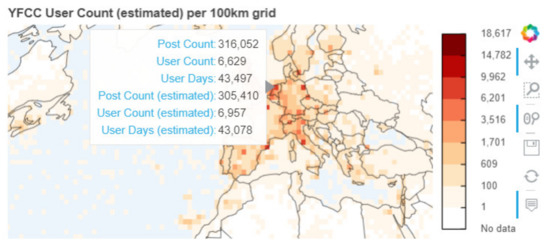
دادههای معیار حاوی تمام مجموعههای HLL برای سطلهای شبکه با تعداد کاربر ≥ 100 بهعنوان مواد تکمیلی (S9) در دسترس قرار میگیرند ، که به همان اندازه منعکسکننده یک مبادله نسبتا محافظه کارانه به سمت آزادی تحلیلی بیشتر است. در مدل سیستم ما ( بخش 3.1 )، تصمیم گیرندگان می توانند از این داده ها برای مطالعه بیشتر الگوهای داده، به روشی محدود، از طریق قابلیت اتحاد و تقاطع HLL استفاده کنند. برای نشان دادن این استفاده بیشتر از داده های معیار HLL منتشر شده، به طور خلاصه یک مثال را در اینجا نشان می دهیم. اولاً، در نظر بگیرید که برای دو مجموعه A و B، اتحاد مجموعه ها به مجموع همه عناصری که در یکی از دو مجموعه ظاهر می شوند اشاره دارد. این عملیات اتحادیه را می توان به صورت بیان کرد آ∪ب. تقاطع، در مقابل، مجموع همه عناصری است که در هر دو مجموعه ظاهر می شوند و می توانند به صورت بیان شوند آ∩ب.بر اساس نظریه مجموعه ها [ 38 ]، اتحادیه ها می توانند برای محاسبه تقاطع استفاده شوند. با پیروی از اصل شمول – طرد (همان، ص 120)، رابطه بین تقاطع و اتحاد را می توان به طور رسمی به صورت بیان کرد. آ∪ب = آ + ب – آ ∩ ب، که می تواند به آ∩ب = آ + ب – آ ∪ ب. برای سه مجموعه A، B و C، فرمول را می توان به صورت نوشتاری نوشت آ ∩ ب ∩ سی = آ ∪ ب ∪ سی – آ – ب – سی + آ ∩ ب + آ ∩ سی + ب ∩ سی(همانجا). هر دو اتحاد و تقاطع امکان ارزیابی کمی روابط بین مجموعه های مختلف HLL مانند تعداد بازدید کاربر مشترک بین مناطق مختلف را فراهم می کنند.
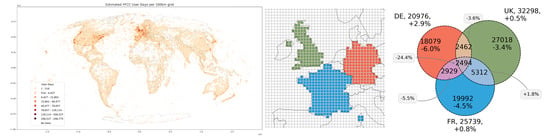
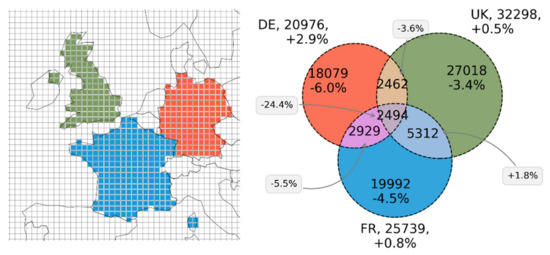
در شکل 7 ، سلول های شبکه ابتدا بر اساس تقاطع مرکز-کشور برای فرانسه، آلمان و بریتانیا انتخاب شده و برای تولید سه مجموعه (تعداد کاربر) برای سه کشور ادغام شده اند. بر اساس اصل گنجاندن – حذف، تعداد کاربران مشترک برای چندین گروه مختلف تخمین زده می شود. میزان خطای نسبی در مقایسه با پردازش داده های خام به صورت درصدی ارائه شده است. کیفیت تقاطع خیلی قابل اعتماد نیست اگر مجموعه ها همپوشانی های بسیار کمی داشته باشند یا تفاوت زیادی در اندازه داشته باشند [ 59]]. در مثال ما، همه مجموعهها تقریباً اندازه یکسانی دارند، با تعداد کل کاربران 24318 (DE)، 24947 (FR)، 31290 (بریتانیا) کاربر متمایز حداقل یک عکس از این کشورها را به اشتراک گذاشتهاند. تنها تعداد کمی از 2778 کاربر تخمین زده شده یک عکس از هر سه کشور به اشتراک گذاشته اند.
بدیهی است که یک عامل محدودیت برای سودمندی قابلیت تقاطع، میزان خطای نسبی است. در شکل 7 ، میزان خطای بالایی تا 16 درصد مشاهده شده است. این اعداد حاصل ترکیب دو عامل است. اولاً، تقاطع مجموعه های HLL ممکن است به طور قابل توجهی مرزهای خطای مجموعه های HLL اصلی را تقویت کند (همان). ثانیا، دانه بندی داده های معیار با یک شبکه 100 کیلومتری فقط به طور محدود برای تلاقی با مرزهای دقیق کشور مناسب است. این نتیجه کار با داده های از پیش انباشته شده است و معمولاً به عنوان مسئله واحد منطقه ای قابل اصلاح نامیده می شود (MAUP، [ 60] را ببینید.]). MAUP، برای مثال، نرخ خطای بزرگ 12.6% بیش برآورد را برای آلمان توضیح می دهد، و همچنین برای فرانسه، جایی که هیچ سطلی برای کورس بر اساس تقاطع کشور-مرکز انتخاب نشده است، واضح است. در شکل A2 ، شکل 7 بر اساس یک پارامتر اندازه شبکه کاهش یافته 50 کیلومتری تولید شده است که به طور قابل توجهی نرخ خطا را از MAUP کاهش می دهد.
6.3. حریم خصوصی معامله کردن
قابلیت اتحاد-تقاطع HLL یک ابزار افزایش یافته از داده ها را باز می کند، اما در عین حال احتمال حملات تقاطع را معرفی می کند (به بخش 4.3 مراجعه کنید ). برای موفقیت آمیز بودن حملات تقاطع، عوامل متعددی باید همزمان باشند. اولا، یک طرف مقابل باید به مجموعه های HLL دسترسی داشته باشد. در مدل سیستم ما، این می تواند یک دشمن داخلی (“Sandy”)، با دسترسی مستقیم به پایگاه داده، یا یک دشمن خارجی (“Robert”) باشد که فقط به داده های معیار منتشر شده دسترسی داشته باشد (به بخش 5 مراجعه کنید) .). علاوه بر این، یک حریف باید بتواند یا هش را برای یک کاربر هدف مشخص محاسبه کند، یا به نحوی به مجموعه HLL محاسبه شده برای کاربر معین دسترسی پیدا کند. مورد اول تنها در صورتی امکان پذیر است که کلید مخفی به خطر بیفتد. در مثال ما، اگر حریف اطلاعات قبلی در مورد مکانهای دیگر بازدید شده توسط کاربر هدف داشته باشد، و اگر مجموعههای HLL این مکانها به طور ایدهآل فقط شامل کاربر هدف یا چند کاربر دیگر باشد، مورد دوم قابل تصور است. در ادامه، ما این بدترین سناریو را بررسی میکنیم، جایی که هر دو «Sandy» و «Robert» (به مطالعات موردی، بخش 5 مراجعه کنید ) بهنوعی مجموعهای از HLL را که فقط حاوی هشهای محاسبهشده الکس است، در اختیار گرفتند.
برای “Sandy”، این بدان معناست که برای آزمایش اینکه آیا الکس در 9 مه 2012 در برلین نبوده است، او یا به شناسه کاربر اصلی الکس و کلید مخفی برای ساخت روز-هش کاربر نیاز دارد یا مکان دیگری (مثلاً یک شبکه) پیدا کند. bin) که فقط در این تاریخ توسط الکس بازدید شده است. در این سناریوی بعید، نتیجه یک حمله تقاطع برای تمام سلول های شبکه در شکل 8 نشان داده شده است.. در شکل قابل مشاهده است که تعداد زیادی از سلولهای شبکه دیگر برای تست تقاطع مثبت کاذب نشان میدهند، یعنی این مجموعههای HLL تغییری نکردهاند، حتی زمانی که با روز هش کاربر خاص برای Alex بهروزرسانی میشوند. از آنجایی که HLL از وقوع منفی های کاذب جلوگیری می کند و سانفرانسیسکو واقعاً در میان این مکان ها قرار دارد، نتیجه شامل مکان واقعی الکس در 9 مه 2012 می شود. بسته به اندازه مجموعه هدفمند HLL، سندی ممکن است شک خود را تا حدودی افزایش دهد. در مورد سلول شبکه برای سانفرانسیسکو، با 209581 روز کاربر، این افزایش در دانش قبلی ممکن است ناچیز باشد. به عبارت دیگر، حتی اگر هیچ پستی از الکس در 9 مه 2012 وجود نداشته باشد، حمله تقاطع ممکن است همان نتیجه را ایجاد کرده باشد و یک موقعیت خصوصی متفاوت را ارائه دهد. در نتیجه، حتی در بدترین سناریو، سندی با داشتن دسترسی مستقیم به پایگاه داده و یک کلید مخفی به خطر افتاده، نمیتوانست تأیید بیشتری به دست آورد. به طور مشابه، و به طور اتفاقی، سلول شبکه مثبت برای برلین واقعاً به دروغ نشان می دهد که الکس در برلین بوده است. با توجه به اینکه مجموعه های HLL بزرگتر احتمال بیشتری برای نشان دادن مثبت کاذب دارند، تعجب آور نیست و برلین مکانی بسیار پر رفت و آمد است. به عبارت دیگر، الکس از اثر حفظ حریم خصوصی HLL با “پنهان شدن در میان جمعیت” سود می برد.27 ] (ص 2).
در سناریوی دوم، موقعیتی را در نظر بگیرید که در آن «رابرت» ممکن است پیش از پیش مشکوک شود که الکس به کابو ورد رفته است. از سوی دیگر، الکس نمی خواهد رابرت بداند که بدون او موج سواری کرده است. رابرت میداند که الکس در طرح AS شرکت میکند و به نوعی به مجموعه HLL که حاوی تنها یک شناسه کاربر هش شده از Alex است، دسترسی پیدا میکند. نتایج حمله تقاطع برای تمام سلول های شبکه در شکل 9 نشان داده شده است. از آنجایی که تنها 56 کاربر در مجموعه داده YFCC100M به Cabo Verde رفتهاند، سطل خاص در دادههای معیار منتشر شده، که با حداقل آستانه 100 کاربر محدود شده است، گنجانده نشده است. با این حال، با دسترسی مستقیم به پایگاه داده، رابرت می تواند مشاهده کند که کابو ورد در میان مکان های فاش شده است. در این مورد، رابرت ممکن است به دلیل سوء ظن خود مبنی بر اینکه الکس در کابو ورد بوده است، تأیید شود. در عین حال، با توجه به تقریب غیرقابل برگشت ساختار HLL، پاسخ قطعی ممکن نخواهد بود. برای مثال، برای همان حمله تقاطع، برای اندازههای مجموعه زیر 56 کاربر، 14 سلول شبکه دیگر وجود دارد که مثبت کاذب را نشان میدهند، تا هشت کاربر (برای مقایسه این اعداد، به مواد تکمیلی، S6 مراجعه کنید .). به عبارت دیگر، حتی اگر این مجموعههای HLL هنگام آزمایش تغییر نمیکنند، Alex هرگز به این مکانها نرفته است و نویز بیشتری به نتایج اضافه میکند.
در حالی که این دو سناریو پایهای برای درک اینکه چگونه حملات تقاطع ممکن است در یک محیط فضایی اجرا شوند، فراهم میکنند، یک سوال معتبر این است که احتمال موفقیت حملات تقاطع در کل چقدر است. این امر تا حدی به مسائل امنیتی مانند حفاظت از کلید مخفی یا مدیریت دسترسی به پایگاه داده بستگی دارد که نمی توان به طور کامل در این کار پوشش داد. بخش دیگر به طور مستقیم به توزیع داده های جمع آوری شده و تعداد موارد پرت که در هر مرحله از پردازش داده ها وجود دارد، مرتبط است (به بخش 4.4 مراجعه کنید.). اگر دادهها خوشهبندیتر باشند، کاربران عموماً مزایای بیشتری از اثرات حفظ حریم خصوصی HLL دریافت خواهند کرد. این را می توان به طور کمی با مجموعه داده داده شده اثبات کرد. به عنوان مثال، در زمان جمعآوری دادهها، با Geohash 5، 226025 مکان وجود دارد که فقط یک شناسه کاربری دارند. در مقایسه با داده های خام، این تنها 1.77٪ از کل مکان های متمایز موجود در مجموعه داده YFCC100M را نشان می دهد. علاوه بر این، تنها 50358 کاربر (8.43 درصد) حداقل یک بار از یکی از این مکانها بازدید کردهاند، که بر اساس یک پایگاه داده کاملاً در معرض خطر، حد بالایی برای احتمال حملات تقاطع ارائه میکند. خطرات حریم خصوصی با داده های جمع آوری شده در سطل های 100 کیلومتری کاهش می یابد. در مجموع 3354 سطل شبکه (26.64٪ از کل سطل های شبکه با داده) دارای یک کاردینالیته کاربر هستند. این سطل های شبکه فقط 1833 کاربر دارند، منعکس کننده اقلیت کوچکی از کاربران “ماجراجو” هستند که حداقل از یک سطل بازدید کرده اند که هیچ کاربر دیگری در آن حضور نداشته است. در موقعیت خصمانه یک پایگاه داده کاملاً در معرض خطر، این ماجراجویان مزایای کمی از اثرات حفظ حریم خصوصی HLL دریافت خواهند کرد. با این حال، این گروه همچنین تنها 0.31٪ از کل کاربران را در مجموعه داده YFCC100M نشان می دهد و مجموعه نتایج احتمالی که می توان از یک حمله موفقیت آمیز تقاطع گرفت به شدت محدود است. در نهایت، 41,582,251 پست در مجموعههای HLL سطلها (100 کیلومتر) با تعداد پستهای ≥ 10,000 گنجانده شدهاند که دارای یک اثر قوی حفظ حریم خصوصی با توجه به [ این ماجراجویان مزایای کمی از اثرات حفظ حریم خصوصی HLL دریافت خواهند کرد. با این حال، این گروه همچنین تنها 0.31٪ از کل کاربران را در مجموعه داده YFCC100M نشان می دهد و مجموعه نتایج احتمالی که می توان از یک حمله موفقیت آمیز تقاطع گرفت به شدت محدود است. در نهایت، 41,582,251 پست در مجموعههای HLL سطلها (100 کیلومتر) با تعداد پستهای ≥ 10,000 گنجانده شدهاند که دارای یک اثر قوی حفظ حریم خصوصی با توجه به [ این ماجراجویان مزایای کمی از اثرات حفظ حریم خصوصی HLL دریافت خواهند کرد. با این حال، این گروه همچنین تنها 0.31٪ از کل کاربران را در مجموعه داده YFCC100M نشان می دهد و مجموعه نتایج احتمالی که می توان از یک حمله موفقیت آمیز تقاطع گرفت به شدت محدود است. در نهایت، 41,582,251 پست در مجموعههای HLL سطلها (100 کیلومتر) با تعداد پستهای ≥ 10,000 گنجانده شدهاند که دارای یک اثر قوی حفظ حریم خصوصی با توجه به [36 ]. این نشان دهنده 85.79٪ از تمام پست های دارای برچسب جغرافیایی در مجموعه داده YFCC100M است (برای محاسبات اعداد بالا، به مواد تکمیلی، S5 مراجعه کنید ).
7. بحث
در قطعه پازل مؤلفههای آگاه از حریم خصوصی و حفظ حریم خصوصی، موانع عملی پیادهسازی و هزینه سازگار کردن گردشهای کاری موجود با حریم خصوصی همچنان مانع پذیرش گستردهتر میشوند [31 ] . این به ویژه در مناطقی که حفظ حریم خصوصی کاربر، اگرچه به عنوان مفید شناخته می شود، یک الزام اساسی نیست، مشکل ساز است. در اینجا، HLL ممکن است یک شکاف را با قابلیتهای ad-hoc پر کند که میتواند به طور کلی جریان کار را بهبود بخشد، در حالی که هنوز هم امکان انعطاف پذیری تجزیه و تحلیل را فراهم میکند. با این حال، همانطور که توسط دیگران نشان داده شده است، اثر جانبی حفظ حریم خصوصی HLL می تواند در شرایط خاص ضعیف باشد. پزشکان می توانند به طور منطقی به نتایج متضادی در مورد اینکه آیا مزایا بر هزینه ها در زمینه های خاص برتری دارد یا خیر، برسند.
نتایج در این مقاله طیف وسیعی از معیارها را ارائه میکند، که به طور خاص برای ارزیابی معاوضه حریم خصوصی و ابزار مرتبط با استفاده از HLL در زمینه پردازش دادههای مکانی مناسب است. در زمینه برنامههای پخش جریانی برای VGI و اطلاعات جغرافیایی جمعسپاری شده، یک مزیت بارز این است که دادههای خام را میتوان بلافاصله به قطعات اتمی آن، با ورود هر عنصر جدید تقسیم کرد. این اجازه می دهد تا ردپای کلی داده های تجزیه و تحلیل بصری در زمان جمع آوری داده ها کاهش یابد. به همین ترتیب، روابط مستقیم بین دادهها، مانند شناسههای کاربر، شناسههای پست یا روزهای کاربر، که از نظر حریم خصوصی یکی از مشکلسازترین ویژگیها هستند، میتوانند قبل از ذخیره دادهها منحل شوند. این تا حد زیادی احتمال استفاده مجدد از داده ها را فراتر از زمینه اصلی در نظر گرفته کاهش می دهد. در این صفحه، این برای محبوبترین معیارها، تعداد کاربر، تعداد پستها و روزهای کاربر، که در حال حاضر در تصمیمگیری برای تجزیه و تحلیل فعالیتهای فضایی استفاده میشوند، نشان داده شده است. برخلاف دادههای خام، ردیابی یک کاربر در چندین مکان با قطعیت مطلق با توجه به دادههای HLL غیرممکن است.
در همان زمان، برخی از انعطافپذیریها برای کاوش بیشتر دادهها همچنان باز است. با استفاده از اصل طرد-شمول، الگوهای داده ها و روابط را می توان به صورت کمی ارزیابی کرد، همانطور که با شناسایی تعداد بازدیدکنندگان رایج برای آلمان، فرانسه و بریتانیا نشان داده شد ( بخش 6.2 ). اطلاعاتی مانند این ممکن است در تصمیمگیری، بهعنوان یک نماینده آگاه از حریم خصوصی، برای تجزیه و تحلیل رفتار گردشگری یا ارتباطات فرهنگی مهم بین گروههایی از افراد مختلف استفاده شود. اطلاعات مشابه به عنوان یک مبنای مهم برای ارزیابی نابرابری اجتماعی- فضایی [ 61] در نظر گرفته می شود.]. در مدیریت منابع طبیعی، به ویژه مکانهای پر رفت و آمد ممکن است با استفاده از ساختار دادهای که در اینجا ارائه شده است، نظارت شوند و بینشهایی را در مورد رفتار کاربر بدون به خطر انداختن حریم خصوصی کاربر ارائه میدهد. تنها یک مثال کاربردی می تواند نظارت و کاهش تأثیر منفی بر نقاط برتری باشد که توسط فالوورهای اینستاگرام تحت تأثیر قرار می گیرند، در نتیجه تأثیرگذاران و گسترش جهانی اطلاعات [ 62 ]. از دیدگاه وسیعتر، رویکرد ارائهشده در اینجا میتواند برای سایر زمینههای حل مسئله فضایی، به عنوان مثال برای دلفی فضایی [63 ] ، به عنوان وسیلهای برای جستجوی همگرایی نظرات متخصصان ناشناس استفاده شود.
ما به طور خاص و عمداً به رویکردی که در اینجا نشان داده شده است، به جای حفظ حریم خصوصی، به عنوان “آگاه از حریم خصوصی” اشاره می کنیم، زیرا ملاحظات اضافی و استراتژی های کاهش خطر برای دشوارتر کردن حملات تقاطع و کارایی کمتر در عمل مورد نیاز است. در میان موارد مورد بحث، محافظت از کلید مخفی که برای ایجاد هش استفاده می شود، شاید مهم ترین باشد. حفاظت از یک کلید مخفی با قابلیت موازی سازی و محاسبات محاسباتی مجموعه های HLL ساده می شود و به این دلیل که تحلیلگران برای اینکه بتوانند با داده ها کار کنند نیازی به دانستن کلید ندارند. به عنوان مثال، یک سرویس Sketching جداگانه می تواند برای ایجاد هش استفاده شود ( شکل 1 ، بخش 3.1 را ببینید.) که می تواند به طور جداگانه از سرویس تحلیلی مورد استفاده قرار گیرد. در سناریوهای همکاری فعال (به شکل 1 ، بخش 3.1 مراجعه کنید)، به نظر میرسد که بهبودهای بیشتر، مانند امضای هشها در دستگاههای کاربر، با کلیدهایی که فقط برای خود کاربران شناخته میشوند، ممکن است. اقدامی برای جلوگیری موثر از حملات تقاطع، همانطور که توسط Desfontaines و همکاران پیشنهاد شده است. [ 36] (ص 15)، استفاده از کلیدهای مختلف برای مجموعه های مختلف HLL است. در مورد ما، هشها برای هر Grid bin را میتوان با یک کلید متفاوت ایجاد کرد، که حملات تقاطع را بسیار دشوارتر میکند. با این حال، این همچنین هرگونه توانایی برای استفاده از دادههای فراتر از تخمین اصلی را حذف میکند. در نهایت، یک اقدام مهم برای کاهش تدریجی آسیبپذیری، بهویژه هنگام انتشار مجموعههای داده، محدود کردن مجموعههای HLL با یک آستانه پایینتر است. آستانه های بالاتر میانگین حریم خصوصی کاربران را افزایش می دهد، اما همچنین برنامه را به مجموعه داده های نسبتاً بزرگ محدود می کند.
از این منظر، HLL ممکن است به ویژه به عنوان اولین گام به سمت حفظ حریم خصوصی بیشتر کاربر مناسب باشد، که تأثیر مخربی بر کیفیت و سودمندی نتایج ندارد، از جمله وعده بهبود عملکرد. بر اساس این مزایا، HLL پتانسیل تا حد زیادی استفاده نشده را برای جایگزینی بسیاری از خطوط لوله پردازش داده که در حال حاضر هنوز از داده های خام استفاده می کنند، ارائه می دهد. معیارهای عملکرد جمعآوریشده در بخش 6 و کد نمونه منتشر شده ممکن است زیربنای این توسعه برای تجسمهای فضایی باشد. در نهایت، تمام اقداماتی که در بالا توضیح داده شد مکمل یکدیگر هستند. آنها را می توان با راه حل های قوی تر، مانند اضافه کردن سر و صدا، برای ارضای مفاهیم سختگیرانه تر از حریم خصوصی تکمیل کرد.
علیرغم راههای زیادی که میتوان از طریق آن تنظیمات تجسم ارائه شده را مورد استفاده و اعمال قرار داد، روشی که در اینجا توضیح داده شد یک رویکرد یکپارچه با در نظر گرفتن محدود روشهای تجسم فضایی مرتبط است و تنها بر روی یک مجموعه داده خاص آزمایش شد. برخی از تکنیکهای تجسم فضایی، مانند تکنیک ارائه شده در اینجا، ممکن است برای ترکیب با HLL مناسبتر از سایرین باشند. برای مثال، طبقه بندی تکنیک های تجسم بر اساس توانایی آنها در ترکیب با PDS جالب خواهد بود. جهت دیگر می تواند استفاده از روش های پیشرفته تر برای طبقه بندی خودکار حساسیت مجموعه های HLL در مراحل مختلف باشد، مانند آنچه توسط Reviriego و همکاران ارائه شده است. [ 64]، یا به طور رسمی تر، معاوضه حریم خصوصی- سودمندی را ارزیابی می کند، مانند موارد ارائه شده توسط Feyisetan و همکاران. [ 27 ] یا Desfontaines و همکاران. [ 36 ]. از منظر برنامه گرا، استفاده از تنظیمات HLL دو جزئی ارائه شده برای داده های فراتر از مکان ها، مانند اطلاعات موضعی و زمانی (به عنوان مثال، برچسب ها، تاریخ ها)، با توانایی مطالعه مجموعه گسترده تری از روابط، جالب خواهد بود. تقاطع.
8. نتیجه گیری
HLL و سایر PDS مسیر نسبتا جدیدی را برای تجزیه و تحلیل بصری باز می کنند، که به طور خاص برای کاوش در ترکیب با تکنیک های تجسم مناسب است که بر شناسایی الگوهای داده ها و زمینه هایی که در آن پاسخ های قطعی الزامی نیست تمرکز می کنند. این امر باعث میشود HLL برای مجموعههای دادههای بزرگ، مانند آنهایی که اغلب با VGI و اطلاعات جغرافیایی جمعسپاری شده عمومی مواجه میشوند، مناسب باشد. به عنوان یک عارضه جانبی، HLL امکان افزایش حریم خصوصی داوطلبان را در زمان جمعآوری دادهها، با قابلیت تنظیم بیشتر و تدریجی خطرات در طول فرآیندهای تصمیمگیری چند مرحلهای و چند معیاره فراهم میکند. در یک سناریوی کاربردی محدود، این برای تجزیه و تحلیل فعالیت فضایی در مطالعه حاضر نشان داده شده است. از دیدگاه سودمندی، نتایج نشان میدهد که برای انتقال جریانهای کاری، سازشهای کمی یا بدون هیچ مصالحهای لازم است. علاوه بر این، HLL مزایایی فراتر از افزایش حریم خصوصی کاربر مانند بهبود عملکرد، کاهش نیاز به ذخیره سازی، یا محصورسازی بهبود یافته خطوط لوله پردازش را فراهم می کند. نتایج نشاندادهشده در این مقاله، پایهای برای ارزیابی تعدادی از معاوضههای ابزار اضافی هنگام انتقال جریانهای کاری، بهویژه برای تکنیکهای پردازش دادههای مکانی، فراهم میکند. دفترچه های ارائه شده می تواند به عنوان مبنایی برای سازگاری با سایر زمینه ها باشد. نتایج نشاندادهشده در این مقاله، پایهای برای ارزیابی تعدادی از معاوضههای ابزار اضافی هنگام انتقال جریانهای کاری، بهویژه برای تکنیکهای پردازش دادههای مکانی، فراهم میکند. دفترچه های ارائه شده می تواند به عنوان مبنایی برای سازگاری با سایر زمینه ها باشد. نتایج نشاندادهشده در این مقاله، پایهای برای ارزیابی تعدادی از معاوضههای ابزار اضافی هنگام انتقال جریانهای کاری، بهویژه برای تکنیکهای پردازش دادههای مکانی، فراهم میکند. دفترچه های ارائه شده می تواند به عنوان مبنایی برای سازگاری با سایر زمینه ها باشد.
محدودیتهایی برای زمینههای کاربردی اعمال میشود که به تضمینهای دقیق برای حفظ حریم خصوصی نیاز دارند. در سناریوهای فضایی، مانند آنچه در اینجا ارائه شده است، اثر حفظ حریم خصوصی HLL می تواند در حضور پرت ضعیف باشد. در حالی که میتوان با تکنیکهای مختلف مقادیر پرت را کاهش داد، استراتژیهای کاهش خطر اضافی برای سازگار کردن رویکرد با مفاهیم سختگیرانهتر حریم خصوصی، مانند اضافه کردن نویز یا حذف دادهها، مورد نیاز است. چندین مورد از این استراتژی ها در این مقاله مورد بحث قرار گرفته است. اینکه آیا مزایا بر هزینهها بیشتر است، به زمینه بستگی دارد و شاغلین تشویق میشوند تا ترکیبی از تکنیکها را در نظر بگیرند، به جای تمرکز بر یک راهحل خاص، همانطور که برای اهداف جداسازی در این مقاله ارائه شده است.
پیوست اول
شکل A1. نقشه جهانی تعداد تخمینی کاربر (YFCC) در سطل شبکه 100 کیلومتری.
شکل A2. شکل 7 با پارامتر اندازه شبکه 50 کیلومتر و نرخ خطای مربوطه ایجاد شده است.
منابع
- ببینید، L. مونی، پی. فودی، جی. باستین، ال. کامبر، ا. استیما، ج. Rutzinger، M. Crowdsourcing، دانش شهروندی یا اطلاعات جغرافیایی داوطلبانه؟ وضعیت فعلی اطلاعات جغرافیایی جمع سپاری شده. ISPRS Int. J. Geo Inf. 2016 ، 5 ، 55. [ Google Scholar ] [ CrossRef ]
- هاروی، اف. داوطلب شدن یا ارائه اطلاعات مکانی؟ به سوی حقیقت در برچسبگذاری برای اطلاعات جغرافیایی جمعسپاری شده. در جمع سپاری دانش جغرافیایی: اطلاعات جغرافیایی داوطلبانه (VGI) در تئوری و عمل . Sui، DZ، Elwood، S.، Goodchild، MF، Eds. Springer: Dordrecht، هلند، 2013; صص 31-42. [ Google Scholar ]
- آلمانی، ع. سینکلر، ام. جمع سپاری غیرفعال رسانه های اجتماعی در تحقیقات محیطی: یک نقشه سیستماتیک. گلوب. محیط زیست چانگ. 2019 ، 55 ، 36-47. [ Google Scholar ] [ CrossRef ]
- مالهوترا، NK; کیم، اس اس؛ آگاروال، جی. نگرانیهای مربوط به حریم خصوصی اطلاعات کاربران اینترنت (IUIPC): ساختار، مقیاس و یک مدل علی. Inf. سیستم Res. 2004 ، 15 ، 336-355. [ Google Scholar ] [ CrossRef ]
- لین، جی. استودن، وی. بندر، اس. Nissenbaum, H. Privacy, Big Data, and the Public Good: Frameworks for Engagement ; انتشارات دانشگاه کمبریج: کمبریج، بریتانیا، 2015. [ Google Scholar ] [ CrossRef ]
- متکالف، جی. کرافورد، ک. سوژه های انسانی در تحقیقات کلان داده کجا هستند؟ اخلاق در حال ظهور شکاف می کند. Big Data Soc. 2016 ، 3 ، 205395171665021. [ Google Scholar ] [ CrossRef ]
- دی گروت، آر.اس. آلکماد، آر. برات، ال. هاین، ال. چالش ها در ادغام مفهوم خدمات و ارزش های اکوسیستم در برنامه ریزی، مدیریت و تصمیم گیری منظر. Ecol. مجتمع. 2010 ، 7 ، 260-272. [ Google Scholar ]
- Hon، WK; میلارد، سی. والدن، آی. مشکل “داده های شخصی” در رایانش ابری: چه اطلاعاتی تنظیم می شود؟ – ابر نادانسته. بین المللی داده خصوصی قانون 2011 ، 1 ، 211-228. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، کیو. ژانگ، ی. لو، ایکس. وانگ، ز. Qin، Z. Ren, K. انتشار دادههای شبکه اجتماعی بهمنبع جمعیت در زمان واقعی و فضایی-زمانی با حریم خصوصی متفاوت. IEEE Trans. ایمن قابل اعتماد محاسبه کنید. 2018 ، 15 ، 591-606. [ Google Scholar ] [ CrossRef ]
- دوستدار، س. روزنبرگ، اف. نظرسنجی در مورد سیستم های آگاه از زمینه. Inf. سیستم 2007 ، 2 ، 263-277. [ Google Scholar ]
- پولیتو، ای. الپس، ای. پاتساکیس، سی. فراموش کردن داده های شخصی و لغو رضایت تحت GDPR: چالش ها و راه حل های پیشنهادی. J. Cybersecur. 2018 ، 1-20. [ Google Scholar ] [ CrossRef ]
- ویکتور، ن. لوپز، دی. Abawajy، JH مدلهای حریم خصوصی برای دادههای بزرگ: یک نظرسنجی. بین المللی J. هوش کلان داده. 2016 ، 3 ، 61. [ Google Scholar ] [ CrossRef ]
- D’Orazio، V. هوناکر، جی. کینگ، جی. حریم خصوصی متفاوت برای استنتاج علوم اجتماعی. الکترون SSRN. J. 2015 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اوبرسکی، دی.ال. کروتر، اف. حریم خصوصی و علوم اجتماعی متفاوت: یک معمای فوری. هارو. اطلاعات علمی Rev. 2020 , 2 , 1-22. [ Google Scholar ] [ CrossRef ]
- Solove، DJ مقدمه: خود مدیریتی حریم خصوصی و معضل رضایت. هارو. Law Rev. 2013 , 126 , 1880-1903. [ Google Scholar ]
- فلاژولت، پی. Fusy، É. Gandouet، O. HyperLogLog: تجزیه و تحلیل یک الگوریتم تخمین کاردینالیتی نزدیک به بهینه. در مجموعه مقالات کنفرانس تحلیل الگوریتم ها، AofA 07، نیس، فرانسه، 17-22 ژوئن 2007. 2007; جلد 7، ص 127–146. [ Google Scholar ]
- عطایی، م. دگبلو، ا. کری، سی. سانتوس، وی. پیروی از قانون حفظ حریم خصوصی: از متن قانونی تا اجرای خدمات مبتنی بر مکان آگاه از حریم خصوصی. ISPRS Int. J. Geo Inf. 2018 ، 7 ، 442. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مارتینز-بالست، آ. پرز مارتینز، پ. سولاناس، A. پیگیری حریم خصوصی شهروندان: یک شهر هوشمند آگاه از حریم خصوصی ممکن است. IEEE Commun. Mag. 2013 ، 51 ، 136-141. [ Google Scholar ] [ CrossRef ]
- سینگ، آ. گارگ، اس. کائور، آر. باترا، اس. کومار، ن. Zomaya، AY ساختارهای داده احتمالی برای تجزیه و تحلیل داده های بزرگ: یک بررسی جامع. بدانید. سیستم مبتنی بر 2020 , 188 . [ Google Scholar ] [ CrossRef ]
- کسلر، سی. McKenzie, G. مانیفست geoprivacy. ترانس. GIS 2018 ، 22 ، 3-19. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Westin, AF Privacy and Freedom ; Atheneum: نیویورک، نیویورک، ایالات متحده آمریکا، 1967. [ Google Scholar ]
- آلتمن، I. محیط و رفتار اجتماعی: حریم خصوصی، فضای شخصی، قلمرو، ازدحام . بروکس / میخانه کول. شرکت: Monterey, CA, USA, 1975. [ Google Scholar ]
- یو، اس. حریم خصوصی بزرگ: چالش ها و فرصت های مطالعه حریم خصوصی در عصر داده های بزرگ. IEEE Access 2016 ، 4 ، 2751-2763. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سامراتی، پ. Sweeney, L. حفاظت از حریم خصوصی هنگام افشای اطلاعات: K-Anonymity و اجرای آن از طریق تعمیم و سرکوب . گزارش فنی SRI-CSL-98-04; آزمایشگاه علوم کامپیوتر، SRI International: Menlo Park، CA، USA، 1998. [ Google Scholar ]
- آگاروال، سی سی در مورد k-ناشناس بودن و نفرین ابعاد. در مجموعه مقالات سی و یکمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، تروندهایم، نروژ، 30 اوت تا 2 سپتامبر 2005. صفحات 901–909، VLDB Endowment. [ Google Scholar ]
- کمپ، ام. کوپ، سی. ماک، م. بولی، ام. مه، M. حفظ حریم خصوصی نظارت بر تحرک با استفاده از طرحهایی از قرائتهای حسگر ثابت. در یادگیری ماشین و کشف دانش در پایگاه های داده. ECML PKDD 2013. نکات سخنرانی در علوم کامپیوتر ; Springer: برلین/هایدلبرگ، آلمان، 2013. [ Google Scholar ]
- فییستان، او. دریک، تی. باله، بی. Diethe، T. یادگیری فعال حفظ حریم خصوصی در مورد داده های حساس برای طبقه بندی قصد کاربر. CEUR Workshop Proc. 2019 ، 2335 ، 3-12. [ Google Scholar ]
- جین، پی. گیانچندانی، م. Khare, N. حریم خصوصی داده های بزرگ: دیدگاه و بررسی تکنولوژیکی. J. Big Data 2016 , 3 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیورک، سی. مک شری، اف. نیسیم، ک. اسمیت، A. کالیبره کردن نویز به حساسیت در تجزیه و تحلیل داده های خصوصی. کنفرانس تئوری رمزنگاری ; Springer: برلین/هایدلبرگ، آلمان، 2006; صص 265-284. [ Google Scholar ]
- Dwork، C. حریم خصوصی متفاوت: بررسی نتایج. در نظریه و کاربردهای مدلهای محاسبات: مجموعه مقالات پنجمین کنفرانس بینالمللی، TAMC 2008، شیان، چین، 25-29 آوریل 2008 . یادداشت های سخنرانی Springer در علوم کامپیوتر; Springer: برلین/هایدلبرگ، آلمان، 2008; جلد 4978، ص 1-19. [ Google Scholar ]
- ماچاناواجهالا، ع. او، X. Hay, M. Differential privacy in the wild: آموزشی در مورد شیوه های فعلی و چالش های باز. قسمت F127746. Proc. ACM SIGMOD Int. Conf. مدیریت داده 2017 ، 1727-1730. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فن، ال. Xiong، L. نظارت بر کل زمان واقعی با حریم خصوصی دیفرانسیل. ACM Int. Conf. Proc. سر. 2012 ، 2169-2173. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیورک، سی. ناور، م. پیتاسی، تی. Rothblum، GN Differential Privacy تحت نظارت مستمر. در مجموعه مقالات چهل و دومین سمپوزیوم ACM در تئوری محاسبات، STOC’10، کمبریج، MA، ایالات متحده آمریکا، 6-8 ژوئن 2010. ص 715-724. [ Google Scholar ]
- بیانچی، جی. براشیاله، ال. لورتی، ص. حریم خصوصی “بهتر از هیچ” با فیلترهای شکوفه: تا چه حد؟ در مجموعه مقالات کنفرانس بینالمللی حریم خصوصی در پایگاههای داده آماری 2012، پالرمو، ایتالیا، 26-28 سپتامبر 2012. Springer: برلین/هایدلبرگ، آلمان، 2012; صص 348-363. [ Google Scholar ] [ CrossRef ]
- یو، یو.و. وبر، GM فدرال پرس و جو از مخازن داده های بالینی: تعادل دقت و حریم خصوصی. BioRxiv 2019 ، 841072. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- دزفونتینز، دی. لوچبیهلر، ا. Basin, D. Cardinality برآوردگرها حریم خصوصی را حفظ نمی کنند. Proc. خصوصی تقویت فناوری 2019 ، 2 ، 26–46. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رایت، سی. اسکورتسوف، ای. کروتر، بی. Wang, Y. حفظ حریم خصوصی کاردینالیته ایمن و تخمین فرکانس . Google LLC: Mountain View، CA، USA، 2020؛ صص 1-20. [ Google Scholar ]
- آندریسکو، تی. Feng, Z. اصل شمول-حذف. در مسیری به ترکیبیات برای دانشجویان لیسانس ; Birkhäuser: بوستون، MA، ایالات متحده آمریکا، 2004. [ Google Scholar ]
- Baker, DN; Langmead، B. Dashing: فواصل ژنومی سریع و دقیق با HyperLogLog. ژنوم بیول. 2019 ، 20 ، 1-12. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- گومز-بارون، جی پی. Manso-Callejo، M.Á. آلکاریا، آر. Iturrioz, T. طراحی سیستم اطلاعات جغرافیایی داوطلبانه: دستورالعمل های پروژه و مشارکت. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 108. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مانیکس، EA؛ نیل، MA; Northcraft، GB Equity، Equality یا Need؟ تأثیر فرهنگ سازمانی بر تخصیص مزایا و بارها. عضو. رفتار هوم تصمیم می گیرد. روند. 1995 , 63 , 276. [ Google Scholar ] [ CrossRef ]
- دوان، ا. راماکریشنان، ر. سیستم های جمع سپاری Halevy، AY در وب جهانی. اشتراک. ACM 2011 ، 54 ، 86. [ Google Scholar ] [ CrossRef ]
- چن، ی. پارکینز، جی آر. شررن، ک. استفاده از پستهای اینستاگرام با برچسب جغرافیایی برای آشکار کردن ارزشهای چشمانداز اطراف سدهای برق آبی فعلی و پیشنهادی و مخازن آنها. Landsc. طرح شهری. 2017 170 . _ [ Google Scholar ] [ CrossRef ]
- کندی، ال. Naaman, M. ایجاد نتایج جستجوی تصویری متنوع و معرف برای مکانهای دیدنی. در مجموعه مقالات هفدهمین کنفرانس بین المللی وب جهانی، WWW’08، پکن، چین، 21-25 آوریل 2008; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2008; صص 297-306. [ Google Scholar ]
- چوب، SA; Guerry، AD; نقره، JM; Lacayo, M. استفاده از رسانه های اجتماعی برای تعیین کمیت گردشگری و تفریحات مبتنی بر طبیعت. علمی Rep. 2013 , 3 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هایکینهایمو، وی. مینین ای دی تنکانن، اچ. هاسمن، ا. ارکونن، جی. Toivonen، T. اطلاعات جغرافیایی تولید شده توسط کاربر برای نظارت بر بازدیدکنندگان در پارک ملی: مقایسه داده های رسانه های اجتماعی و نظرسنجی بازدیدکنندگان. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 85. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کیم، ی. کیم، سی. لی، DK; لی، اچ. آندرادا، RIT کمی کردن گردشگری مبتنی بر طبیعت در مناطق حفاظت شده در کشورهای در حال توسعه با استفاده از داده های بزرگ اجتماعی. تور. مدیریت 2019 ، 72 ، 249-256. [ Google Scholar ] [ CrossRef ]
- فیشر، دی.م. چوب، SA; سفید، EM; بلانا، دی جی; لانگ، اس. واینبرگ، ا. لیا، ای. استفاده تفریحی در زمینهای عمومی پراکنده با استفاده از دادههای رسانههای اجتماعی و شمارش در محل اندازهگیری شد. جی. محیط زیست. مدیریت 2018 ، 222 ، 465-474. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- شفر، م. شارتنر، پی. Rass, S. شناسههای منحصربهفرد جهانی: چگونه از منحصربهفرد بودن در حین محافظت از حریم خصوصی صادرکننده اطمینان حاصل کنیم. در مجموعه مقالات کنفرانس بین المللی امنیت و مدیریت 2007، SAM’07، لاس وگاس، NV، ایالات متحده آمریکا، 25-28 ژوئن 2007. ص 198-204. [ Google Scholar ]
- شی، ایکس. یو، ز. نیش، Q. ژو، کیو. یک رویکرد تحلیل بصری برای استنباط موقعیتهای شغلی شخصی و مسکن بر اساس دادههای عمومی دوچرخه. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 205. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تومی، بی. Shamma، DA; فریدلند، جی. الیزالد، بی. نی، ک. لهستان، دی. بورث، دی. لی، L. YFCC100M: داده های جدید در تحقیقات چند رسانه ای. اشتراک. ACM 2016 ، 59 ، 64-73. [ Google Scholar ] [ CrossRef ]
- دانکل، ا. لوشنر، ام. Burghardt, D. مواد تکمیلی (نسخه نسخه 0.1.0) برای تجسم اطلاعات جغرافیایی داوطلبانه (VGI) با آگاهی از حریم خصوصی برای تجزیه و تحلیل فعالیت فضایی: اجرای معیار. مخازن داده 2020 . [ Google Scholar ] [ CrossRef ]
- پریا، وی. ایلاواراسی، آ.ک. باما، اس. یک رویکرد داده کاوی حفظ حریم خصوصی برای مدیریت داده ها با موارد دور از دسترس. Adv. نات. Appl. علمی 2017 ، 11 ، 585-591. [ Google Scholar ]
- ژو، بی. پی، جی. رویکردهای k-anonymity و l-diversity برای حفظ حریم خصوصی در شبکه های اجتماعی در برابر حملات محله. بدانید. Inf. سیستم 2011 ، 28 ، 47-77. [ Google Scholar ] [ CrossRef ]
- گروتسر، م. Grunwald، D. استفاده ناشناس از خدمات مبتنی بر مکان از طریق پنهان کاری مکانی و زمانی. در مجموعه مقالات اولین کنفرانس بین المللی سیستم های تلفن همراه، برنامه ها و خدمات (MobiSys)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 5 تا 8 مه 2003. [ Google Scholar ]
- وانگ، اچ. لیو، آر. پنهان کردن موارد پرت در میان جمعیت: انتشار دادههای حفظ حریم خصوصی با موارد پرت. دانستن داده ها مهندس 2015 ، 100 ، 94-115. [ Google Scholar ] [ CrossRef ]
- روپل، پی. Küpper، A. Geocookie: یک نمایش فضای کارآمد از مجموعه موقعیت جغرافیایی. J. Inf. روند. 2014 ، 22 ، 418-424. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Jiang, B. Head/Tail Breaks: یک طرح طبقه بندی جدید برای داده ها با توزیع دم سنگین. پروفسور Geogr. 2013 ، 65 ، 482-494. [ Google Scholar ] [ CrossRef ]
- روش و سیستم Ertl، O. برای تخمین کاردینالیته مجموعه ها و مجموعه نتایج عملیات از طرح های HyperLogLog منفرد و چندگانه. درخواست ثبت اختراع ایالات متحده شماره 15/950,632، 11 آوریل 2018. [ Google Scholar ]
- De Andrade، SC; رسترپو-استرادا، سی. Nunes، LH; رودریگز، CAM; استرلا، جی سی. دلبم، ACB؛ پورتو دو آلبوکرک، جی. چارچوب بهینهسازی چند معیاره برای تعریف دانهبندی فضایی تحلیل رسانههای اجتماعی شهری. بین المللی جی. جئوگر. Inf. علمی 2020 ، 1-20. [ Google Scholar ] [ CrossRef ]
- شلتون، تی. پورتویس، ا. Zook, M. رسانه های اجتماعی و شهر: بازاندیشی نابرابری اجتماعی- فضایی شهری با استفاده از اطلاعات جغرافیایی تولید شده توسط کاربر. Landsc. طرح شهری. 2015 ، 142 ، 198-211. [ Google Scholar ] [ CrossRef ]
- اویان، اچ. فردمن، پی. سندل، ک. Sæþórsdóttir، AD; Tyrväinen، L. جنسن، FS گردشگری، طبیعت و پایداری: مروری بر ابزارهای سیاست در کشورهای شمال اروپا . شورای وزیران شمال اروپا: کپنهاگ، دانمارک، 2018. [ Google Scholar ] [ CrossRef ]
- دی زیو، اس. کاستیلو روزاس، جی.دی. Lamelza, L. Real Time Spatial Delphi: همگرایی سریع نظرات کارشناسان در مورد قلمرو. تکنولوژی پیش بینی. Soc. تغییر 2017 ، 115 ، 143-154. [ Google Scholar ] [ CrossRef ]
- Reviriego، P. Ting، D. امنیت HyperLogLog (HLL) برآورد کاردینالیتی: آسیبپذیریها و حفاظت. IEEE Commun. Lett. 2020 ، 1 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
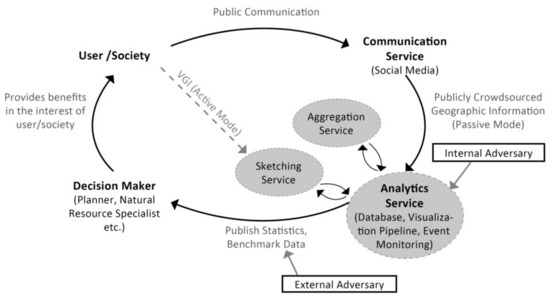
شکل 1. تصویری از مدل سیستم و دو مورد از دشمنان احتمالی مورد بحث در این کار.
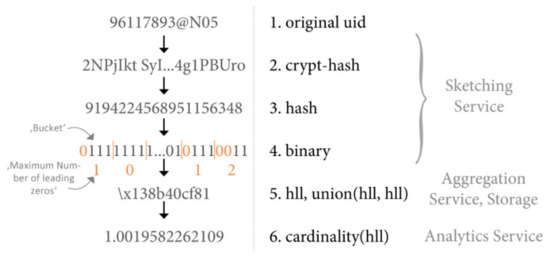
شکل 2. مراحل تبدیل اعمال شده بر روی یک رشته کاراکتر منفرد، مانند شناسه کاربر، برای تولید مجموعه HyperLogLog (HLL) و تخمین نهایی کاردینالیته (مقادیر مثال با داده های واقعی تولید شده اند، اما مقادیر متفاوتی ممکن است بر اساس تنظیمات پارامترهای مختلف).
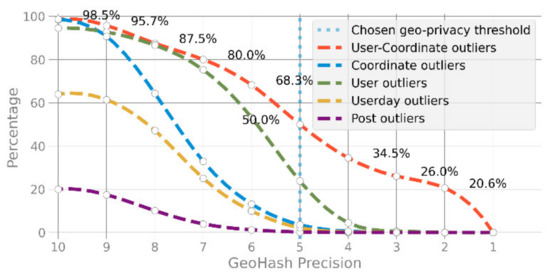
شکل 3. درصد حجم پرت فضایی جهانی (k = 1) در مجموعه داده 100 میلیونی یاهو فلیکر کریتیو کامانز (YFCC100M)، برای کاهش سطوح دقت (GeoHash) و معیارهای مختلف استفاده شده در این مقاله (برای بازتولید این گرافیک، به مواد تکمیلی مراجعه کنید . ، S5 ).
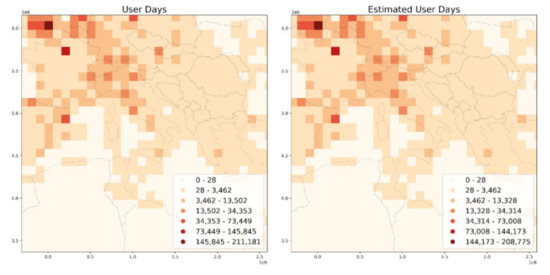
شکل 4. مقایسه طبقه بندی خودکار روزهای کاربر خام و HLL برای اروپا (شبکه 100 کیلومتر).
شکل 5. تصویری از نقشه برای تعداد کاربران در سطل شبکه 100 کیلومتری، که امکان مقایسه تعاملی مقادیر تخمینی (HLL) و شمارش دقیق (خام) را فراهم می کند ( شکل A1 را برای نمای ایستا و سراسری از نقشه، و مواد تکمیلی S8 را ببینید. نسخه تعاملی).
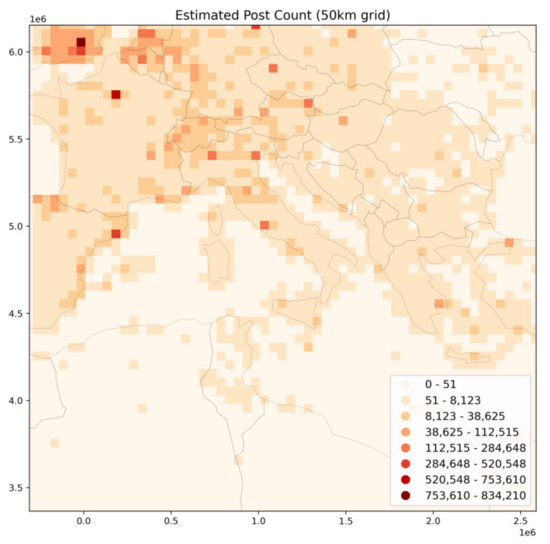
شکل 6. تعداد پست تخمینی با اندازه شبکه کاهش یافته 50 کیلومتر برای اروپا.
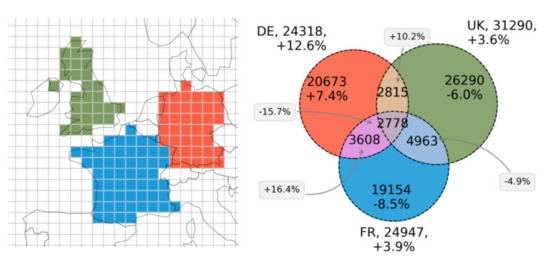
شکل 7. تجزیه و تحلیل روابط فضایی با تقاطع HLL، بر اساس اتحاد افزایشی مجموعههای کاربر از دادههای معیار (شبکه 100 کیلومتر) برای فرانسه، آلمان و بریتانیا (سمت چپ ). نمودار ون ( سمت راست ) تخمین تعداد کاربران رایج برای گروههای مختلف و درصد خطا را در مقایسه با دادههای خام نشان میدهد. همین گرافیک که برای اندازه شبکه 50 کیلومتری ایجاد شده است، در شکل A2 موجود است .
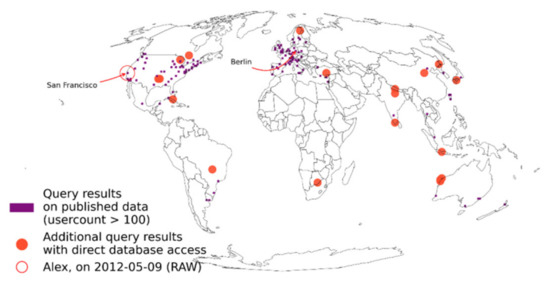
شکل 8. مطالعه موردی الکس، ارزیابی سناریوی سندی.
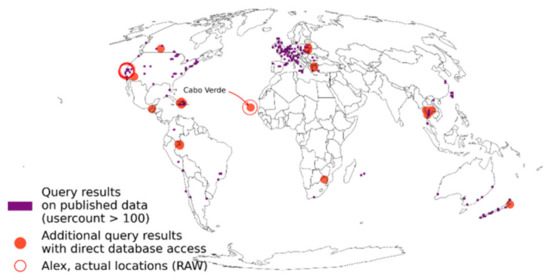
شکل 9. مطالعه موردی الکس، ارزیابی سناریوی “رابرت”.


بدون دیدگاه