1. معرفی
در سال های اخیر، تغییرات غیرعادی در آب و هوای جهانی باعث بروز بلایای هواشناسی مکرر، به ویژه باران های سیل آسا در مناطق شهری شده است. این امر مشکلات زیادی را برای مدیریت عادی شهری و سفرهای عمومی ایجاد می کند. اگرچه بسیاری از روش های نظارتی مدرن برای کسب به موقع اطلاعات بلایا بسیار مفید هستند، اما محدودیت های زیادی وجود دارد. به عنوان مثال، دوربینهای توزیع شده در مناطق شهری میتوانند اطلاعات دقیق بلایای مناطق محلی را در زمان واقعی ارائه دهند، اما هزینه استفاده از این دستگاهها بالا است و به سختی میتوان آنها را در برخی از مناطق توسعه نیافته رایج کرد. فناوری سنجش از دور راداری پیشرفته می تواند بر تأثیر آب و هوا غلبه کند که برای سنجش از دور نوری سنتی کشنده است [ 1 ، 2 ]]. با این حال، ساختمانهای مواج در محیط شهری تأثیر زیادی بر تصویربرداری از آن میگذارند و مدت زمان طولانیتر بازدید مجدد برای مشاهده مستمر بلایا مساعد نیست.
رسانه های اجتماعی، به عنوان یک منبع داده جدید، به طور گسترده ای برای کاهش بلایا استفاده شده است. این منبع داده توسط عموم به صورت خود به خود آپلود می شود، که مشابه داده های جمع سپاری [ 3 ] و VGI [ 4 ] است.] (اطلاعات جغرافیایی داوطلبانه). رسانههای اجتماعی مزایای بهموقع بودن سریع، ارتباط خوب و هزینههای کم را دارند. اطلاعات غنی مرتبط با فاجعه موجود در آن (مانند زمان، مکان، محتوا و شبکه) برای درک پیشرفت بلایا و کسب آگاهی از وضعیت بلایا بسیار مفید است. با شناخت پتانسیل کاهش بلایا، UNISDR (استراتژی بینالمللی سازمان ملل برای کاهش بلایا) رسانههای اجتماعی را در جریان اصلی ارتباطات اضطراری تحت چارچوب سندای برای کاهش خطر بلایا 2015 تا 2030 در 15 مارس 2015 پذیرفت [ 5 ]]. با این حال، شکل بدون ساختار داده ها، استفاده کارآمد از اطلاعات مربوط به فاجعه را دشوار می کند. بنابراین، بسیاری از محققان سعی کردهاند تا روشها یا چارچوبهای محاسباتی مختلفی را برای پردازش این دادهها از دیدگاههای مختلف بسازند تا در خدمت کاهش بلایا باشند. به عنوان مثال، Chae [ 6 ] یک سیستم متمرکز را پیشنهاد کرد که از اطلاعات مکانی-زمانی موجود در داده های رسانه های اجتماعی برای مطالعه تغییرات مسیر عمومی برای کمک به دولت در اتخاذ تصمیمات کاهش بلایا استفاده می کند. در ترکیب با سایر دادههای چند منبعی، J Fohringer [ 7 ] و Li [ 8 ] روشی را برای نقشهبرداری سریع محدوده سیلها بر اساس اطلاعات مکانی – زمانی رسانههای اجتماعی پیشنهاد کردند. بر اساس یک مدل بیزی، ساکاکی [ 9] چارچوبی را پیشنهاد کرد که میتواند موضوعات مرتبط با فاجعه را از متن رسانههای اجتماعی استخراج کند و سپس آن را با اطلاعات مکانی و زمانی موجود در رسانههای اجتماعی برای تشخیص وقوع بلایا ترکیب کند. برخی دیگر از محققان استخراج اطلاعات عاطفی عمومی موجود در رسانه های اجتماعی را برای مطالعه پیشرفت فاجعه در نظر گرفته اند [ 10 , 11 , 12]. این اطلاعات می تواند بینشی در مورد وضعیت فاجعه، اثر نجات و غیره از احساسات ذهنی مردم ارائه دهد. علاوه بر این، در مقایسه با سایر دادهها، دادههای رسانههای اجتماعی حاوی اطلاعات تعاملی منحصربهفردی هستند که اغلب از طریق عملیاتهایی مانند تمجید و ارسال بیان میشوند. این سوابق و الگوهای تعامل فرصت بزرگی را برای بررسی انتشار اطلاعات، تبادل، به روز رسانی و غیره در عوامل مختلف (به عنوان مثال، کاربران عادی، آژانس های معتبر و رسانه های خبری) فراهم می کند [ 13 ]. بسیاری از محققان این اطلاعات را برای مطالعه بلایای مختلف، مانند سیل [ 14 ]، طوفان [ 15 ] و شورش [ 16 ] استفاده کرده اند.]، که نشان دهنده دانش بیشتر در مورد افراد، گروه ها، پدیده های اجتماعی و غیره است. اگرچه تحقیقات کنونی در مورد استفاده از رسانه های اجتماعی برای کاهش بلایا بسیار جامع است، اما هنوز کاستی هایی وجود دارد، مانند جزئیات درشت اطلاعات کاوی بلایا و تجزیه و تحلیل جامع نادر. اطلاعات چند بعدی مرتبط با بلایا به عنوان مثال، هنگام وقوع طوفانهای شهری، چگونگی استخراج سریع اطلاعات مربوط به بلایا برای کمک به شناسایی مناطق تأثیر ترافیک، نحوه بازخورد شدت مناطق آسیبدیده بر اساس احساسات عمومی، و چگونگی ارزیابی تأثیر مکانی و زمانی بلایا سؤالات مهمی هستند. . بنابراین، در این مقاله، ما یک رویداد طوفان باران در پکن در 16 ژوئیه 2018 را به عنوان موردی برای رسیدگی به این مشکلات از دو جنبه زیر در نظر گرفتیم.
1.1. استخراج اطلاعات چند بعدی مرتبط با بلایا برای کمک به تشخیص مناطق تاثیر ترافیک
بسیاری از محققان از روش های متن کاوی برای به دست آوردن اطلاعات بلایای طبیعی استفاده کرده اند. به عنوان مثال، لیلوی [ 17 ] واژه، فراوانی کلمه و همبستگی رویداد را برای استخراج رویدادهای فاجعه طوفان از داده های رسانه های اجتماعی برای کمک به نظارت بر بلایا انتخاب کرد. فانگ [ 18 ] و وانگ [ 19 ] از یک مدل یادگیری بدون نظارت برای طبقه بندی مضامین بلایای موجود در متن رسانه های اجتماعی برای مطالعه توجه عمومی در بلایای طوفان باران استفاده کردند. از طریق محاسبات مدل، برخی از اطلاعات بلایای مربوط به تأثیر ترافیک را می توان شناسایی کرد. سایر محققان روش های پردازش زبان طبیعی را برای استخراج اطلاعات غرقابی شهری برای کمک به تجزیه و تحلیل اثرات ترافیک در نظر گرفته اند [ 20 , 21 ]]. با این حال، این روش های موجود در استخراج اطلاعات بلایای طبیعی درشت هستند. آنها به ندرت بر روی اطلاعات دقیق وضعیت جاده تمرکز می کردند، که می تواند تأثیر خاص بر ترافیک را منعکس کند. علاوه بر این، روشهای موجود نیز به ندرت اطلاعات احساسی عمومی موجود در رسانههای اجتماعی را برای تجزیه و تحلیل جامع تأثیر ترافیک در نظر گرفتهاند. از یک طرف، اطلاعات عاطفی عمومی منعکس کننده احساسات ذهنی مردم در مورد فاجعه، نیازهای عمومی، اثر نجات و غیره است که جمع آوری آنها از سایر داده های پایش بلایا دشوار است. از سوی دیگر، هر میکرو وبلاگی حاوی اطلاعات واضح وضعیت جاده نیست. بنابراین، احساسات عمومی را می توان اطلاعات تکمیلی موثر در نظر گرفت. در این مقاله، ما الگوریتم های متن کاوی، از جمله پردازش زبان طبیعی، پایگاه دانش معنایی، و یادگیری عمیق، برای استخراج اطلاعات دقیق وضعیت جاده و اطلاعات احساسات عمومی موجود در متون رسانه های اجتماعی. علاوه بر این، ما این اطلاعات را با داده های زمان، مکان و شبکه جاده ترکیب می کنیم تا مناطق تاثیر ترافیک را شناسایی کنیم. نتایج تجزیه و تحلیل اطلاعات موثرتری را برای کاهش بلایا ارائه میکند و کارایی نجات را تا حد زیادی بهبود میبخشد.
1.2. ارزیابی تأثیر مکانی و زمانی بلایا
رسانههای اجتماعی شامل الگوهای تعاملی متعددی هستند که بر اساس آنها بسیاری از محققان دانش بیشتری در مورد فاجعه استخراج کردهاند. با این حال، تعداد کمی از نویسندگان به معرفی اطلاعات موقعیت جغرافیایی در این الگوهای تعامل فکر کرده اند. این به این دلیل است که عملیات تعامل رایج در رسانه های اجتماعی، از جمله فوروارد، لایک و غیره، معمولاً برچسب جغرافیایی ندارند. برخی از محققان [ 22 ، 23] سعی کرده اند با استفاده از مکان های نمایه کاربران رسانه های اجتماعی برای جایگزینی مکان واقعی کاربر، بر این محدودیت رسانه های اجتماعی غلبه کنند، که برای درک انتشار فضایی اطلاعات و تأثیر فضایی حوادث فاجعه بسیار کاربردی است. با این حال، این روش ها هنوز هم دارای معایبی هستند. از یک طرف، درک بیشتر توزیع تأثیر فضایی رویدادهای فاجعه در مقیاس فضایی کوچک دشوار است (مکان های پروفایل کاربر بیشتر در سطح شهر هستند). از سوی دیگر، تحقیقات تعامل اطلاعات موجود به ندرت اطلاعات عاطفی عمومی را در نظر گرفته است، و اطلاعات احساسی مختلف نشان دهنده درجه تأثیر متفاوت رویدادهای فاجعه است. در این مقاله، ما میخواهیم بزرگی و توزیع تأثیر فضایی مناطق تأثیر ترافیک را بیشتر درک کنیم. بنابراین، ما یک مدل ارزیابی تأثیر فضایی بر اساس رابطه مرجع مشترک این مناطق ایجاد کردیم. یعنی وقتی میکرو وبلاگ ها در مکان های مختلف در مورد یک منطقه تاثیر ترافیک خاص صحبت می کنند، با این منطقه تعامل خواهند داشت. علاوه بر این، ما به روش مدل سازی شبکه های پیچیده [24 ، 25 ، 26 ] و ترکیب آن با اطلاعات عاطفی عمومی برای ایجاد شاخص های ارزیابی، از جمله درجه توجه، درجه تعامل، و درجه وزن، برای تعیین کمیت تأثیر فضایی مناطق تأثیر ترافیک. این شاخصها نه تنها به تعداد میکرو وبلاگهای مرتبط، بلکه به اطلاعات احساسی موجود در وبلاگهای کوچک مرتبط هستند. از آنجایی که دستههای هیجانی مختلف واکنشهای متفاوت مردم را نسبت به فاجعه منعکس میکنند، مناطقی که احساسات منفی بیشتری دارند ممکن است تأثیرات بیشتری را نشان دهند.
2. روش شناسی
در این مقاله، ما چارچوبی را پیشنهاد میکنیم که میتواند بهطور خودکار دادههای رسانههای اجتماعی را جمعآوری، تجزیه و پردازش کند و سپس به طور هوشمند اطلاعات مربوط به فاجعه موجود در آن، از جمله زمان، مکان، اطلاعات دقیق وضعیت جاده، و اطلاعات احساسی عمومی را استخراج کند. در نهایت، این چارچوب اطلاعات مؤثری را برای کاهش بلایا از طریق شناسایی مناطق تأثیر ترافیک و ارزیابی تأثیر مکانی و زمانی بلایا فراهم میکند. ساختار کلی چارچوب در شکل 1 نشان داده شده است .
2.1. جمع آوری، تجزیه و پردازش داده های رسانه های اجتماعی
ما یک فاجعه طوفان باران در پکن، چین، در سال 2018 را به عنوان مطالعه موردی برای تأیید نقش چارچوب کاهش بلایا پیشنهاد شده در این مقاله بررسی کردیم. دوره اصلی این رگبار از شب 24 تیرماه تا شب 26 تیرماه بود که 26 تیرماه شدیدترین آن بود. طوفان باعث تجمع جدی آب در بسیاری از جاده ها و حتی ریزش جاده شد. بسیاری از خودروها نیز بر اثر آب ایستاده آسیب دیدند. این طوفان باران “7.16” نام گرفت که به یکی از شدیدترین رویدادهای بارانی در این شهر در هشت سال گذشته تبدیل شده است.
2.1.1. اکتساب و تجزیه داده ها
داده های مربوط به این مقاله از میکرو بلاگ سینا که یکی از فعال ترین پلتفرم های رسانه های اجتماعی در چین است به دست آمده است. این پلتفرم رابط های API (Application Programming Interface) را برای عموم فراهم می کند تا داده های خود را به دست آورند. با این حال، این روش دارای محدودیت هایی است. به عنوان مثال، داده های به دست آمده فاقد اطلاعات مکان هستند و اطلاعات بی ربط زیادی وجود دارد. بنابراین، در این مقاله، ما از برنامهنویسی کامپیوتری برای توسعه ابزار جمعآوری دادهها استفاده کردیم. این ابزار بر اساس پلت فرم جستجوی پیشرفته میکرو بلاگ سینا ساخته شده است. با تنظیم پارامترهای مشخص شده مانند دوره زمانی، محدوده منطقه ای و کلمات کلیدی، داده های مربوط به فاجعه مورد نظر را به دست آوردیم. داده های اصلی رسانه های اجتماعی به شکل HTML بودند. از طریق تجزیه داده ها، اطلاعات مشخص شده از جمله زمان را جدا کردیم،
در مورد این مقاله، کل منطقه پکن را به عنوان منطقه مورد مطالعه قرار دادیم و محدوده زمانی از 20:00 روز 15 جولای تا ساعت 12:00 در 18 جولای بود. کلیدواژهها بهعنوان «طوفان باران»، «باران شدید» و «سیل» تنظیم شدند تا میزان دادههای بازیابی شده بهبود یابد.
2.1.2. پردازش داده ها
داده های رسانه های اجتماعی به صورت خودجوش توسط عموم آپلود می شوند. این افراد معمولاً هیچ پیشینه حرفه ای در مورد بلایا ندارند و عادات استفاده از زبان آنها نیز متفاوت است. بنابراین، داده های اصلی رسانه های اجتماعی اغلب دارای معایب استانداردهای ویرایش ناسازگار و افزونگی بالا هستند که قبل از استفاده نیاز به تمیز کردن و پردازش بیشتری دارند. در این مطالعه، ما عمدتا داده های متنی و داده های مکان را پردازش کردیم.
دادههای موقعیت مکانی موجود در دادههای رسانههای اجتماعی معمولاً در قالب یک توضیح آدرس وجود دارد، مانند «ایستگاه مترو Xierqi» و «جاده Houchangcun». داده ها در این فرم را نمی توان به طور مستقیم تجزیه و تحلیل و استفاده کرد. بنابراین، در این مقاله، ما از ابزار کدگذاری جغرافیایی Amap ( https://lbs.amap.com/api/javascript-api/guide/services/geocoder ) استفاده کردیم تا این توضیحات آدرس را به مختصات طول و عرض جغرافیایی تبدیل کنیم. در میان آنها، برای دادههای نقطهای، مختصات نقطه مرکزی (مانند «پارک نرمافزاری Zhongguancun»)، و برای دادههای خط، مختصات نقطه میانی (مانند «جاده Houchangcun») را گرفتیم.
پردازش دادههای متنی عمدتاً شامل سازگاری دادهها، پاک کردن غیرعادی دادهها و حذف مجدد دادههای اضافی بود. سازگاری داده تضمین میکند که قالب دادههای متنی سازگار است، از جمله تبدیل کاراکترهای تمام عرض به نویسههای نیمهعرض، چینی سنتی به چینی سادهشده، و غیره. این میتواند کارایی الگوریتم متن کاوی را به طور موثر بهبود بخشد. پاکسازی غیرعادی داده ها عمدتاً برای حذف داده هایی استفاده می شود که در زمان و مکان مشخص شده نیستند. این به دلیل خطاهای جستجو در پلت فرم جستجوی پیشرفته میکرو بلاگ سینا است. در نهایت، پس از حذف موارد تکراری، بیش از 24779 داده رسانه های اجتماعی را با زمان، محدوده منطقه ای و موضوع مشخص به دست آوردیم.
2.2. استخراج اطلاعات تاثیر ترافیک از متن رسانه های اجتماعی
در این مقاله، ما اطلاعات مربوط به فاجعه را از متن رسانههای اجتماعی از دو جنبه مختلف استخراج کردیم، از جمله اطلاعات دقیق وضعیت جاده و اطلاعات احساسی عمومی، که منعکسکننده تاثیر ترافیک از دیدگاههای توصیف عینی عمومی و احساسات ذهنی است.
2.2.1. استخراج اطلاعات وضعیت جاده ریزدانه
در متن رسانه های اجتماعی اطلاعات دقیق زیادی از وضعیت جاده وجود دارد. به عنوان مثال، یک وبلاگ کوچک گفت: “پس از یک باران شدید، جاده Houchangcun مستقیماً دچار آب گرفتگی شد و بسیاری از وسایل نقلیه نیز دچار آبگرفتگی شدند”. در این جمله عبارات «جاده هوشانگجون – آبگرفته» و «وسایل نقلیه – آبگرفته» به وضوح وضعیت فاجعه را توصیف می کند. بنابراین، ما به یک روش خودکار برای استخراج این اطلاعات نیاز داریم. با این حال، استفاده از روش سنتی یادگیری با نظارت دو نقطه ضعف دارد. (1) متن رسانههای اجتماعی معمولاً کوتاهتر و شبیهتر به زبان گفتاری است و یک متن معمولاً حاوی دستههای مختلف اطلاعات وضعیت جاده است. به راحتی می توان ویژگی متن را پراکنده و اطلاعات معنایی را تکه تکه کرد. (2) فقدان یک مجموعه حاشیه نویسی در دسترس، به کارگیری یک روش یادگیری نظارت شده را دشوار می کند، و ساخت چنین مجموعه حاشیه نویسی به صورت دستی زمان بر و زمان بر است. در مطالعات قبلی، ما به این مسائل پی بردیم و با در نظر گرفتن قواعد معنایی و دستور زبان چینی، روشی را پیشنهاد کردیم که پردازش زبان طبیعی و یک پایگاه دانش معنایی اطلاعات آسیب های خطر را ترکیب می کند.27]. این روش یک الگوی قاعدهای از همآمیزی کلمات مشخصه از ریزدانگی سطح کلمه میسازد. سپس از این الگو برای استخراج کلمات نامزد استفاده می شود که ممکن است اطلاعات آسیب خطر موجود در داده های رسانه های اجتماعی را نشان دهند. این کلمات نامزد با پایگاه دانش معنایی آسیب خطر تطبیق داده می شوند تا مشخص شود که آیا آنها به یک دسته آسیب خطر خاص تعلق دارند یا خیر. این پایگاه دانش با استفاده از پایگاه های دانش شخص ثالث (مانند اصطلاحنامه Synonymy ارائه شده توسط موسسه فناوری هاربین) و مجموعه عظیم مرتبط با بلایا تکمیل و غنی می شود. آزمایشات مربوطه نشان داده است که این روش عملکرد خوبی در استخراج اطلاعات خسارت خطر در بلایای طوفان دارد. بر اساس مورد در این مقاله، ما از این روش برای استخراج اطلاعات وضعیت جاده از داده های رسانه های اجتماعی استفاده کردیم.
2.2.2. استخراج اطلاعات احساسات عمومی
بسیاری از محققان نحوه استخراج اطلاعات عاطفی عمومی از داده های رسانه های اجتماعی را مطالعه کرده اند. روش های مرتبط را می توان به روش های مبتنی بر فرهنگ لغت عاطفی [ 28 ، 29 ] و روش های یادگیری ماشین سنتی [ 30 ، 31 ] تقسیم کرد.]. اولی فرهنگ لغت احساسات را برای مطابقت با کلمات احساسی در متن می گیرد و سپس وزن هر کلمه احساسی را برای محاسبه ارزش احساسی کل متن می گیرد. این روش معمولاً ساده و مؤثر است، مخصوصاً برای متن هایی با قوانین بیان زبانی سختگیرانه، مانند اخبار. با این حال، این روش برای داده های رسانه های اجتماعی با محاوره جدی مناسب نیست. این به این دلیل است که متن رسانه های اجتماعی اغلب حاوی کلمات شبکه ای با گرایش عاطفی است، مانند “凉凉 (انجام شد)”، که نشان دهنده احساسات منفی است. بارگذاری این کلمات در فرهنگ لغت عاطفی دشوار است. دومی این است که مدل را با پیکره حاشیه نویسی دسته بندی های مختلف احساسات آموزش دهد و سپس مدل آموزش دیده می تواند به طور خودکار تمایل عاطفی داده های متنی را محاسبه کند. این روش تحت تأثیر کلمات شبکه قرار نمی گیرد.32 ، Naive Bayes [ 33 ] و غیره با توسعه فناوری داده کاوی و محاسبات با کارایی بالا، محققان به طور فزاینده ای بر روی مدل های یادگیری عمیق برای استخراج اطلاعات احساسی از متن تمرکز کرده اند [ 34 ]. در مقایسه با روشهای یادگیری ماشین سنتی، الگوریتمهای یادگیری عمیق میتوانند اطلاعات معنایی متن را در نظر بگیرند و به نتایج کارآمدتری دست یابند [ 35 ]]. این به این دلیل است که (1) مدلهای یادگیری ماشین سنتی بر اساس استخراج دستی کلمات ویژگی (کلماتی که میتوانند مقولههای احساسی را نشان دهند) هستند، و کیفیت استخراج کلمات ویژگی مستقیماً بر دقت طبقهبندی مدل تأثیر میگذارد. (2) مدلهای یادگیری ماشینی سنتی از یک مدل مجموعهای از کلمات استفاده میکنند تا این کلمات ویژگی استخراجشده دستی را مدیریت کنند. این روش اطلاعات زمینه را در متن نادیده می گیرد. بنابراین، استفاده از متن زمانی که کلمات مشخصه واضح نیستند یا مقوله احساسات به زمینه بستگی دارد دشوار است. در عوض، الگوریتم یادگیری عمیق، مدل بردار کلمه را به جای مدل کیسه کلمات می گیرد. مدل کلمه برداری با آموزش مجموعه های متنی مرتبط با مقیاس بزرگ به دست می آید و مدل آموزش دیده می تواند هر کلمه در متن را به یک بردار با ابعاد بالا تبدیل کند. این بردارها حاوی اطلاعات معنایی با زمینه غنی هستند. از طریق محاسبه تکراری مدل های یادگیری عمیق، برخی از کلمات ویژگی که می توانند گرایش عاطفی متن را تعیین کنند می توانند به طور خودکار استخراج شوند. اینها برای بهبود دقت تشخیص و کارایی مدل مفید هستند. بنابراین، در این مقاله، ما از یک شبکه عصبی کانولوشن برای استخراج اطلاعات احساسی از متن بر اساس اسناد استفاده کردیم.12 ].
2.3. روش تشخیص مناطق تأثیر ترافیک بر اساس دادههای چند منبع مرتبط با بلایا
پکن یکی از بزرگترین شهرهای چین با جمعیت بسیار زیاد است. طبق آمار، تا سال 2018، جمعیت دائمی پکن به 21.542 میلیون نفر رسیده بود [ 36 ]. هر روز تعداد زیادی از سفرهای انسانی در شهر اتفاق می افتد که فشار زیادی را بر ترافیک وارد می کند. هنگام وقوع بلایای باران، غرقابی شهری برای شرایط ترافیکی بسیار مضر است. بنابراین، ما یک فرآیند تحلیل را با استفاده از اطلاعات فاجعه چند بعدی استخراجشده از رسانههای اجتماعی برای تجزیه و تحلیل ویژگیهای مکانی و زمانی اثرات ترافیک در طول طوفان باران پیشنهاد کردیم. جریان کلی در شکل 2 نشان داده شده است .
(1) ورودی داده:
دادههایی که ما وارد کردیم عمدتاً شامل دادههای رسانههای اجتماعی و دادههای شبکه جادهای از پکن بود. در میان آنها، دادههای رسانههای اجتماعی شامل زمان، مختصات مکان، محتوا و اطلاعات استخراجشده مربوط به بلایا (اطلاعات احساسی عمومی و اطلاعات دقیق وضعیت جاده) بود. دادههای شبکه جادهای پکن از «سرویس کاتالوگ ملی برای اطلاعات جغرافیایی» ( https://www.webmap.cn/commres.do?method=dataDownload ) آمده است.
(2) ساختن یک تور ماهی عاطفی:
اطلاعات عاطفی بیان شده توسط کاربران رسانه های اجتماعی نیز ممکن است منعکس کننده تمایلات عاطفی همسایگان یا کل جامعه باشد، حتی اگر این همسایگان یا جوامع از رسانه های اجتماعی استفاده نکرده باشند [ 10 ]. بنابراین، ما به روشی برای تخصیص احساسات به یک ناحیه اندازه معین در اطراف مکان کاربر نیاز داریم، یعنی تبدیل داده های نقطه گسسته به داده های چندضلعی با مقادیر مشخصه مشخص. هدف این مقاله دستیابی به این هدف با ساخت یک تور ماهی هیجانی بود. ما کل منطقه تحقیقاتی را به چند شبکه کوچک تقسیم کردیم. سپس، ارزشهای احساسی تمام نقاط هر شبکه کوچک را جمعبندی کردیم و مقدار متوسط را به این شبکهها اختصاص دادیم. فرمول محاسبه میانگین مقدار هر شبکه به شرح زیر است:
در این فرمول، Ejارزش عاطفی یک تور ماهی کوچک است، nتعداد نقاط تور ماهی را نشان می دهد و همنارزش احساسی هر نقطه در تور ماهی را نشان می دهد. ما عاطفه مثبت را 1، عاطفه منفی را 1- و احساس خنثی را 0 تعریف کردیم.
(3) استخراج کلمه کلیدی:
اطلاعات عاطفی احساسات ذهنی مردم در مورد یک فاجعه است. این یک مکمل موثر برای اطلاعات وضعیت جاده است و شدت مناطق آسیب دیده را منعکس می کند. استخراج کلمه کلیدی می تواند دلایلی برای بیان احساسات عمومی منعکس کند زیرا هر قطعه از داده های میکرو وبلاگ حاوی اطلاعات وضعیت جاده نیست. در این مقاله، ابزاری ( https://www.picdata.cn/picdata/ ) برای استخراج کلمات کلیدی از ریزوبلاگهایی که حاوی اطلاعات احساسی مرتبط هستند، گرفتیم.
(4) تشخیص منطقه تاثیر ترافیک همراه با اطلاعات زمان:
ما اطلاعات مربوط به فاجعه را در فضا قرار دادیم و سپس ویژگی های فاجعه را در مناطق مختلف مورد علاقه تجزیه و تحلیل کردیم. این به میزان زیادی دقت تشخیص مناطق آسیب دیده را بهبود می بخشد.
2.4. ساخت مدل ارزیابی تأثیر مکانی و زمانی بلایا
روش شرح داده شده در بخش 2.3 می تواند به شناسایی برخی از مناطق آسیب دیده جدی کمک کند. با این حال، اگر بتوانیم ویژگیهای تأثیر مکانی و زمانی این مناطق آسیبدیده را ارزیابی کنیم، به ما کمک میکند تا برنامههای استقرار و نجات کاهش بلایا را بهینه کنیم. بنابراین، در این مقاله، ما یک مدل ارزیابی تأثیر فضایی را با ترکیب زمان، مکان مکانی و اطلاعات فاجعه (اطلاعات عاطفی عمومی) پیشنهاد کردیم و یک نمودار تعاملی برای ارزیابی تأثیر مکانی – زمانی فاجعه در مناطق مختلف ساختیم.
ما به برخی از شاخص های مدل سازی در شبکه های پیچیده مانند درجه گره، درجه تعامل و درجه وزن اشاره می کنیم. این شاخص ها در حوزه گردشگری برای مطالعه محبوبیت نقاط دیدنی اعمال شده و نتایج خوبی به دست آمده است [ 37 ]. در میان آنها، درجه گره نشان دهنده اهمیت گره ها در شبکه، درجه تعامل نشان دهنده فرکانس تعامل بین دو گره، و درجه وزنی نشان دهنده درجه تعامل یک گره در کل شبکه است. در این مقاله، ما رابطه مرجع مشترک رویدادها را برای نشان دادن تعاملات بین گره ها در نظر گرفتیم. به عنوان مثال، زمانی که یک منطقه خاص vمنتحت تأثیر یک طوفان باران و منطقه دیگری قرار گرفته است vjمیکرو وبلاگ هایی دارد که در مورد آن صحبت می کنند vمن، سپس vمنو vjیک رابطه تعاملی برقرار کنید علاوه بر این، در مورد این مقاله، ما شاخصها را در [ 37 ] بهینهسازی کردیم و درجه توجه، درجه تعامل و درجه وزندهی را برای ترکیب اطلاعات احساسی و ارزیابی تأثیر فضایی و زمانی ناحیه آسیبدیده پیشنهاد کردیم.
(1) درجه توجه:
در مدل ساخته شده در این مقاله، ما میکرو بلاگ ها را با موقعیت جغرافیایی یکسان در یک گره ادغام کردیم. مکانی که رویداد فاجعه رخ داده است به عنوان گره رویداد استفاده می شود و مکانی که به این گره رویداد اشاره می کند، گره فرزند نشان داده می شود. برای مثال، رویداد جدی انباشت آب در “Xierqi” را به عنوان گره رویداد در نظر گرفتیم vمنو «پارک نرمافزاری Zhongguancun»، جایی که وبلاگهای کوچک زیادی در مورد این رویداد تجمع آب، به عنوان گره کودک بحث میکردند. vj. هر میکرو وبلاگ در گره کودک (“پارک نرم افزاری Zhongguancun”) به گره رویداد (“Xierqi”) اشاره می کند. ما از نشانگر استفاده کردیم Dبرای نشان دادن درجه توجه این گره ها. این نشانگر به عنوان یک مقدار مشخصه یک گره در نظر گرفته می شود که به تعداد ریز وبلاگ ها در این گره مربوط می شود که در مورد رویداد فاجعه ای خاص بحث می کنند. این نشان دهنده تأثیر یک رویداد فاجعه بار تعیین شده در منطقه ای است که گره در آن قرار دارد. به طور کلی اعتقاد بر این است که وبلاگ های کوچک با احساسات منفی نشان می دهد که رویداد تأثیر بیشتری داشته است یا مردم توجه بیشتری به این رویداد داشته اند. بنابراین، ما اطلاعات عاطفی عمومی را به فرمول محاسبه درجه توجه وارد کردیم:
اینجا، Dمندرجه توجه هر گره، از جمله گره رویداد و گره های فرزند آن است، nتعداد میکرو بلاگ های موجود در هر گره است و Eکارزش عاطفی عمومی هر میکرو وبلاگ موجود در گره است vک.
(2) درجه تعامل و درجه وزن:
درجه تعامل عموماً به فراوانی تعامل بین دو گره اشاره دارد که نشان دهنده درجه فعال جریان اطلاعات بین گره ها است. وقتی گره vjبه گره اشاره می کند vمن، تعداد میکرو وبلاگ ها در گره vjدرجه تعامل است. در نمودار تعامل ساخته شده از مدل، درجه تعامل در ضخامت اتصال خط بین دو گره منعکس می شود. درجه وزنی منعکس کننده مجموع فرکانس هایی است که گره ها به آنها متصل هستند [ 38 ]. به عنوان مثال، درجه وزن گره vمنمجموع درجات تعامل همه گره ها است vjبا اشاره به آن بر اساس سناریوی فاجعه در این مقاله، ما اطلاعات احساسی ریزوبلاگ ها را برای بهینه سازی فرمول محاسبه درجه وزنی ترکیب کردیم. ما در نظر گرفتیم که احساسات منفی می توانند این درجه وزنی را افزایش دهند. فرمول محاسبه درجه تعامل و درجه وزنی به شرح زیر است:
اینجا، نمنمجموعه ای از نقاط مجاور گره است vمن، و دبلیومنjدرجه تعامل بین گره است vمنو گره vj. اگر هیچ تعاملی بین گره وجود نداشته باشد vمنو گره vj، یعنی گره vمنربطی به گره نداره vj، سپس دبلیومنj= 0. Ejارزش احساسی هر میکرو وبلاگ موجود در گره است vj، و ما احساسات منفی را به عنوان مقدار 1.5 تعریف کردیم. هم عواطف مثبت و هم عاطفه خنثی مقدار 1 را گرفتند. یعنی وقتی گره های بیشتری حاوی احساسات منفی باشند، درجه وزن گره ( vمن) به بالاتر اشاره می کنند.
3. نتایج
بر اساس روشهای بخش 2.1 و بخش 2.2 ، دادههای رسانههای اجتماعی مربوط به فاجعه طوفان باران “7.16” پکن را بهدست آوردیم و پردازش کردیم و اطلاعات تأثیر ترافیک ساختاریافته موجود در آن را استخراج کردیم. علاوه بر این، با ترکیب روشهای ارائهشده در بخش 2.3 و بخش 2.4 ، مناطق تأثیر ترافیک را شناسایی کردیم، ویژگیهای مکانی-زمانی آن را تجزیه و تحلیل کردیم و به طور مؤثر تأثیر مکانی-زمانی مناطق آسیبدیده مرتبط را ارزیابی کردیم.
3.1. نتایج استخراج اطلاعات تأثیر ترافیک
3.1.1. پردازش پیکره تجربی
در آزمایش استخراج اطلاعات ریزدانه وضعیت جاده، دادههای رسانههای اجتماعی را در مورد طوفان باران در پکن در سال ۲۰۱۸ و طوفانی که از سرزمین اصلی در سال ۲۰۱۷ میگذرد [ 39 ] ترکیب کردیم تا پایگاه دانش معنایی را در این مقاله گسترش دهیم و غنی کنیم. ما طبقهبندی اطلاعات خسارت بلایا را که در [ 12 ] پیشنهاد شده بود، بهینهسازی کردیم و آن را با توجه به شرایط جادهای که اغلب در مجموعه ظاهر میشوند، به طور مفصل به چهار دسته تقسیم کردیم، همانطور که در جدول 1 نشان داده شده است.. ما تقریباً 80 متن را برای هر دسته به عنوان مجموعه آزمایشی با نزدیک به 320 متن برچسب گذاری کردیم. علاوه بر این، ما تعریف کردیم که سطح 4 نشان دهنده جدی ترین تأثیر در جاده است و سطح 1 برعکس است. در برخی جملات، ممکن است چندین سطح تأثیر ترافیک وجود داشته باشد، مانند «暴雨过后، 该处路段积水严重، 造成了整条路封闭. (بعد از رگبار باران، تجمع آب در این قسمت جاده به طور جدی صورت گرفت و در نتیجه کل جاده بسته شد). این جمله شامل سطوح 1 و 2 بود و ما سطح 2 را برای نشان دادن وضعیت فاجعه این متن انتخاب کردیم.
در آزمایش طبقهبندی هیجان، اطلاعات عواطف عمومی را به سه دسته تقسیم کردیم: هیجان مثبت، هیجان منفی و هیجان خنثی. در این میان، عاطفه منفی بیانگر شکایات مردم از طوفان باران، خسارت خطر و غیره بود. عاطفه مثبت بیشتر برای ابراز خوشحالی افراد به دلیل اجتناب از وقوع یک فاجعه، قدردانی از کاهش بلایا، برخی شوخیها و غیره بود. احساس خنثی به توصیف عینی مربوط میشد. و گزارش یک فاجعه ما به صورت دستی نزدیک به 1700 متن را برای هر دسته برچسب گذاری کردیم که 1400 مورد از آنها به عنوان آموزش مدل و 300 متن به عنوان آزمایش مدل استفاده شد.
3.1.2. محیط تجربی
کل جریان الگوریتم با استفاده از زبان پایتون محقق شد. ابزار پردازش زبان طبیعی “Hanlp” ( https://www.hanlp.com/ )، که یک جعبه ابزار متن باز است و می تواند تقسیم بندی کلمات و بخشی از عملکردهای برچسب گذاری گفتار را ارائه دهد، استفاده شد. برای محاسبه شباهت معنایی و بردار سازی کلمات در داده های متنی از مدل Word2vec استفاده شد. یک شبکه عصبی کانولوشنال با استفاده از چارچوب TensorFlow [ 40 ] ساخته شد و ما پارامترهای مدل را برای دستیابی به نتایج بهتر بهینه کردیم.
3.1.3. نتایج تجربی
ما دقت الگوریتم را بر اساس شاخصهای دقت (P)، فراخوان (R) و ارزیابی جامع (F-1) تأیید کردیم. فرمول ها در زیر نشان داده شده است:
ن_سیorrهجتینشان دهنده تعداد متن هایی است که به درستی در یک دسته طبقه بندی شده اند، ن_افآلسهنشان دهنده تعداد متن هایی است که به اشتباه در این دسته طبقه بندی شده اند، و ن_سیآتیهgoryتعداد متون متعلق به این دسته را در مجموعه تست نشان می دهد.
جدول 2 و جدول 3 به ترتیب دقت استخراج اطلاعات وضعیت جاده و اطلاعات عاطفی عمومی را نشان می دهد. در این میان، شاخص ارزیابی جامع دستههای مختلف اطلاعات وضعیت جادهها بالای 72 درصد و اطلاعات عاطفی عمومی بیش از 78 درصد است. این دقت ها الزامات آزمایش در این مقاله را برآورده می کند.
3.2. شناسایی مناطق تاثیرگذار بر ترافیک شهری
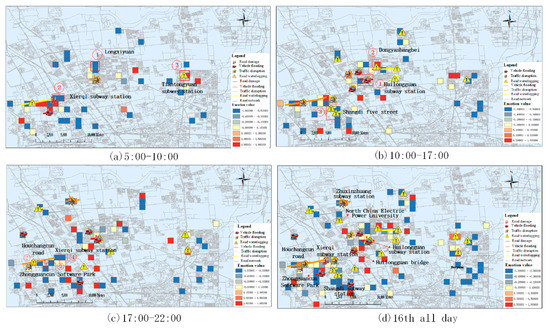
گزارش شده است که 16 جولای جدی ترین روز در طول فاجعه باران بود. بنابراین، ما این روز را برای بررسی تأثیر طوفان باران بر شرایط ترافیک شهری انتخاب کردیم. ما تمام دادههای ریزوبلاگ را از تاریخ شانزدهم روی نقشه تجسم کردیم و دادههایی را که شامل دستههای مختلف وضعیت جاده و دستههای احساسات عمومی بودند، نمادی کردیم، همانطور که در شکل 3 نشان داده شده است.. تاثیر در منطقه a در طول این فاجعه باران بسیار زیاد بود. بلایای اصلی در این منطقه شامل «سیل وسایل نقلیه»، «اختلال در ترافیک»، «آبگرفتگی جاده» و غیره بود. اطلاعات احساسی در اینجا عمدتا منفی بود، که نشان می دهد مردم بیشتر از طوفان باران شکایت کرده اند. بنابراین، ما این منطقه را به عنوان مثال در نظر گرفتیم و اطلاعات زمانی را برای تجزیه و تحلیل مناطق به شدت آسیب دیده ترکیب کردیم. ما شانزدهم را به سه دوره تقسیم کردیم: 5:00-10:00 (اوج صبح)، 10:00-17:00 (سایر دوره ها) و 17:00-22:00 (اوج عصر). علاوه بر این، ما جاده ها را با توضیحات دقیق بر اساس تأثیر ترافیک نمادین کردیم. به عنوان مثال، خیابان هفت شانگدیبعد از باران پر از گودال های آب شد، لطفا با احتیاط رانندگی کنید!». نتایج نهایی در شکل 4 نشان داده شده است
روز شانزدهم بارندگی تاثیر زیادی در ترافیک داشت و محدود به اوج صبح و عصر نبود. در شکل 4 ، برخی از مناطق مورد علاقه را انتخاب کرده و فاجعه را از میان کلمات کلیدی استخراج شده، احساسات عمومی، شرایط جاده و دسته بندی منطقه ای تجزیه و تحلیل کردیم. نتایج مقایسه در جدول 4 نشان داده شده است. در شکل 4a، منطقه 2 و منطقه 3 فقط ایستگاه های ترافیکی را شامل می شوند، اما آنها به طور متفاوتی تحت تأثیر قرار گرفتند. از طریق کلمات کلیدی، ما بیشتر متوجه شدیم که فاجعه در منطقه 3 جدی نبوده و مقوله احساسی اصلی در این منطقه مثبت است. در مقابل، وضعیت فاجعه در منطقه 2 نسبتاً جدی بود و مردم عموماً نگران بودند که وضعیت ترافیک فعلی باعث ایجاد مشکلات اساسی در کار و زندگی آنها شود. بنابراین، منطقه 2 باید توجه بیشتری برای کاهش بلایا می داشت. علاوه بر این، اگرچه هیچ فاجعه آشکاری در منطقه 1 رخ نداده است، اما این منطقه نشان دهنده یک منطقه مسکونی با جمعیت بالاتر است. نسبت عواطف منفی و اطلاعات کلیدواژه نشان می دهد که این منطقه نیز بیشتر تحت تأثیر طوفان باران قرار گرفته است. همانطور که در نشان داده شده است، با ادامه زمان، تأثیر شرایط جاده بیشتر شدشکل 4 ب. با این حال، در این دوره زمانی، احساسات مثبت بیشتری وجود داشت. ما سه منطقه کوچک را در این شکل برای تجزیه و تحلیل بیشتر انتخاب کردیم. جدول 4نتایج تحلیل این مناطق را نشان می دهد. می بینیم که منطقه 1 و منطقه 2 در “Huilongguan”، Changping District قرار داشتند. در میان آنها، منطقه 1 در نزدیکی “ایستگاه مترو Huilongguan” قرار داشت. حجم زیادی آب در جاده وجود داشت که باعث آبگرفتگی بسیاری از خودروها شد. بیشتر مردم نسبت به خودروهای آب گرفتگی غمگین و نگران ایمنی سفر بودند. منطقه 2 یک منطقه مسکونی در نزدیکی “ایستگاه مترو Huilongguan” بود. این منطقه نیز به شدت تحت تاثیر رگبار باران قرار گرفت. جاده نزدیک به شدت آبگرفته بود. با این حال، از کلمات کلیدی و محتوای متن متناظر می توان دریافت که وضعیت بلایای مربوطه به درستی کاهش یافته است (برخی از امدادگران در حال پاکسازی بودند و حتی برخی از ساکنان نیز به طور خودجوش به آن ملحق شدند). عموم مردم از این امر بسیار راضی بودند و احساسات مثبت بیشتری ابراز کردند. منطقه 3 در نزدیکی «شانگدی» قرار داشت و همچنین به شدت تحت تأثیر بارندگی قرار گرفت. می بینیم که «خیابان هفت شنگدی» و «خیابان پنج شنگدی» دچار آبگرفتگی شد و مردم احساسات منفی بیشتری نسبت به این وضعیت ابراز کردند. در طول دوره اوج عصر، اگرچه اطلاعات فاجعه زیادی در کل منطقه وجود نداشت، مردم احساسات منفی بیشتری را ابراز کردند، همانطور که در نشان داده شده است.شکل 4ج ما سه منطقه را انتخاب کردیم که همگی متعلق به منطقه “زیرقی” بودند (منطقه 2 ارتباط نزدیکی با منطقه 1 و منطقه 3 داشت). در میان آنها، منطقه 1 نزدیک “ایستگاه مترو Xierqi” و منطقه 3 “جاده Houchangcun” بود. منطقه 2 منطقه اداری مجاور، یعنی «پارک نرم افزاری Zhongguancun» بود. هر روز تعداد زیادی از کارکنان برای کار به “پارک نرم افزاری Zhongguancun” می روند و از طریق “ایستگاه مترو Xierqi” و “جاده Houchangcun” سفر می کنند. بنابراین، اگرچه اطلاعات چندانی از وضعیت جادهها در این سه منطقه وجود نداشت، اما همه آنها احساسات منفی آشکاری داشتند و کلیدواژههای میکرو وبلاگهای این مناطق مشابه بودند. مردم نگران بودند که به دلیل بارندگی نتوانند به موقع به خانه برگردند (از ساعت 17:00 گزارش شد که بارش باران در این منطقه شروع شد) به ویژه در منطقه 1 و منطقه 3.شکل 4 d شرایط آسیب دیده کل منطقه را در 16 نشان می دهد. با ترکیب نتایج تجزیه و تحلیل سه دوره زمانی دیگر، متوجه شدیم که فاجعه در نزدیکی «ایستگاه مترو Xierqi» و «ایستگاه مترو Huilongguan» شدید بود و مردم احساسات منفی بیشتری را ابراز کردند. بسیاری از وسایل نقلیه آب گرفتگی، به ویژه در نزدیکی “ایستگاه مترو Huilongguan” وجود داشت. فاجعه نزدیک «ایستگاه مترو شانگدی» نیز جدی بود. برخی از جاده های مجاور دچار آبگرفتگی شد که تأثیر زیادی بر جریان ترافیک داشت.
3.3. ارزیابی تأثیر مکانی و زمانی بلایا
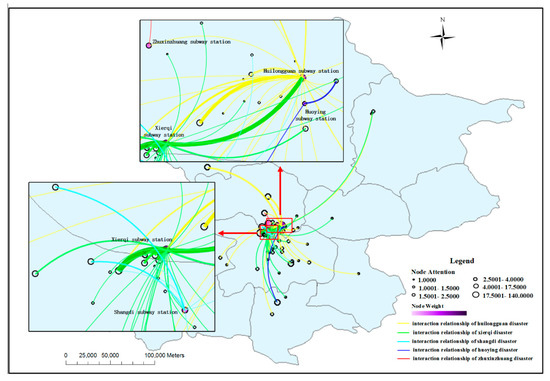
گزارش شده است که در این فاجعه باران (در تاریخ شانزدهم) بسیاری از مناطق به ویژه برخی از ایستگاه های حمل و نقل مانند “ایستگاه مترو Xierqi”، “ایستگاه مترو Huilongguan” و “Shangdi مترو” آسیب جدی دیده اند. در این مناطق آب گرفتگی جاده ها جدی بود و بسیاری از وسایل نقلیه دچار آبگرفتگی شدند که تاثیر زیادی در رفت و آمد انسان ها داشت. نتایج تجزیه و تحلیل در بخش 3.1 نیز این سناریو را نشان داد. در این بخش، پنج منطقه را انتخاب کردیم که در شکل 4 د به شدت تحت تأثیر طوفان باران قرار گرفتند ، از جمله «ایستگاه مترو Xierqi»، «ایستگاه مترو Huilongguan»، «ایستگاه مترو Huoying»، «ایستگاه مترو Shangdi» و «ایستگاه مترو Zhuxinzhuang». “، و ما مدل ارزیابی تاثیر فضایی پیشنهاد شده در بخش 2.3 را به کار بردیمبرای تجزیه و تحلیل بیشتر آنها. همانطور که در شکل 5 نشان داده شده است، ما از یک نمودار تعامل برای تجسم نتایج تحلیل مدل استفاده کردیم .
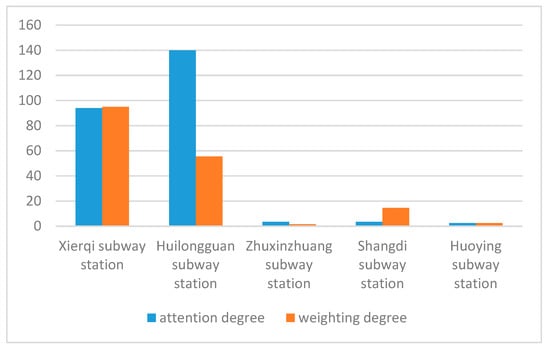
در شکل 5 ، ضخامت خطی که دو گره را به هم متصل می کند، درجه برهمکنش آنها را نشان می دهد. هرچه خط ضخیم تر باشد، تعامل بین دو گره آشکارتر است. اندازه گره نشان دهنده درجه توجه گره است. هر چه مقدار بزرگتر باشد، تأثیر فاجعه بر محل گره بیشتر است. درجه توجه گره رویداد نشان دهنده تأثیر محلی رویداد بر مکان آن است. زمانی که دو گره vjو vکبا یک گره رویداد متصل می شوند vمنو دارای درجه تعامل یکسانی با این گره رویداد هستند، گره با درجه توجه بالا به میزان بیشتری تحت تاثیر رویداد قرار می گیرد، یعنی حاوی ریزوبلاگ های بیشتری با احساسات منفی است. در کل شبکه، تنها پنج گره رویداد انتخاب شده دارای درجه وزنی هستند. این به این دلیل است که گره های فرزند هیچ گره دیگری ندارند که به آنها اشاره کند. گره رویداد با درجه وزنی بالا نشان می دهد که این رویداد تأثیر فضایی بیشتری دارد و رنگ این گره در نمودار تعامل تیره تر است. شکل 6مقایسه دقیق پنج گره رویداد انتخاب شده در درجه توجه و درجه وزن را در 16 نشان می دهد. ما میتوانیم ببینیم که رویدادهای فاجعهآمیز در «ایستگاه مترو Xierqi» و «ایستگاه مترو Huilongguan» دارای درجه توجه و درجه وزن بالایی هستند. در میان آنها، گره در “ایستگاه مترو Huilongguan” تأثیر بیشتری بر منطقه محلی داشت، در حالی که گره در “ایستگاه مترو Xierqi” تأثیر بیشتری بر سایر مناطق داشت. این امر نشان داد که تأثیر فضایی حادثه فاجعه در «ایستگاه مترو زییرقی» چشمگیرتر بوده و بسیاری از مردم در نقاط دیگر توجه بیشتری به وضعیت فاجعه در این منطقه داشتند. “ایستگاه مترو ژوکین ژوانگ” یک مرکز حمل و نقل مهم است و گردش روزانه مسافران زیادی دارد. با این حال، درجه توجه و درجه وزنی این گره زیاد نبود. این نشان داد که وضعیت فاجعه در این گره جدی نبوده و تأثیر محدودی داشته است. وضعیت فاجعه در اطراف “ایستگاه مترو هویینگ” مشابه “ایستگاه مترو ژوکین ژوانگ” بود. اگرچه درجه توجه و درجه وزن گره در “ایستگاه مترو Shangdi” به مراتب کمتر از گره های “ایستگاه مترو Xierqi” و “ایستگاه مترو Huilongguan” بود، اما درجه وزنی به مراتب بیشتر از درجه توجه بود. این نتیجه نشان داد که تأثیر فضایی فاجعه در این گره زیاد بود. اگرچه درجه توجه و درجه وزن گره در “ایستگاه مترو Shangdi” به مراتب کمتر از گره های “ایستگاه مترو Xierqi” و “ایستگاه مترو Huilongguan” بود، اما درجه وزنی به مراتب بیشتر از درجه توجه بود. این نتیجه نشان داد که تأثیر فضایی فاجعه در این گره زیاد بود. اگرچه درجه توجه و درجه وزن گره در “ایستگاه مترو Shangdi” به مراتب کمتر از گره های “ایستگاه مترو Xierqi” و “ایستگاه مترو Huilongguan” بود، اما درجه وزنی به مراتب بیشتر از درجه توجه بود. این نتیجه نشان داد که تأثیر فضایی فاجعه در این گره زیاد بود.
بر اساس نتایج تجزیه و تحلیل فوق، ما دو گره واقع در “ایستگاه مترو Xierqi” و “ایستگاه مترو Huilongguan” را به عنوان اهداف تحقیق برای تجزیه و تحلیل دقیق تر انتخاب کردیم. ما متغیر “زمان” را برای مطالعه تاثیر فضای زمانی این دو گره اضافه کردیم. ما شانزدهم را انتخاب کردیم، زمانی که طوفان باران بدترین بود، و طبق بخش 3.1 آن را به سه دوره تقسیم کردیم . نتیجه نهایی در شکل 7 نشان داده شده است .
در شکل 7 a، میتوانیم ببینیم که تعداد بسیار کمی از گرههای دیگر متصل به گره A (نماینده «ایستگاه مترو Huilongguan») وجود دارد. ما دو گره (گره 1 و گره 2) متصل به گره A را برای تجزیه و تحلیل دقیق انتخاب کردیم. گره 1 و گره 2 دارای درجه تعامل یکسان با گره A بودند، یعنی ضخامت خطوط اتصال بین آنها یکسان بود. با این حال، درجه توجه گره 1 بزرگتر بود، که نشان داد گره A تأثیر بیشتری بر گره 1 دارد. ما محتوای میکرو وبلاگ مربوطه را برای تأیید این موضوع بررسی کردیم و متوجه شدیم که مردم نگران هستند که وضعیت فاجعه در گره A تأثیر بگذارد. سفر آنها در مقایسه با گره A، گره B دارای گره های خارجی زیادی مانند ناحیه a در شکل 7 بود.آ. ما متوجه شدیم که منطقه a عمدتاً یک منطقه اداری است (“پارک نرم افزاری Zhongguancun”)، که در آن بسیاری از شرکت ها مانند “Baidu” و “Lenovo” قرار داشتند. درجه توجه گره ها در این منطقه نسبتاً زیاد بود. با بررسی میکرو وبلاگهای مربوطه، متوجه شدیم که عموم مردم عمدتاً بیزاری خود را نسبت به فاجعه در گره B ابراز میکنند، زیرا بر روی کار عادی آنها تأثیر میگذارد، و همچنین نگران هستند که همکارانشان از این منطقه عبور نکنند. شکل 7 ب نشان می دهد که دوره زمانی از ساعت 10:00 تا 17:00 بوده است. در این دوره، نواحی نفوذ اصلی گره A و گره B با آنچه در شکل 7 نشان داده شده است کاملاً متفاوت بود.آ. این اثرات شروع به گسترش به کل شهر، به ویژه در جنوب (شهر خاص) کرد. به عبارت دیگر، تأثیر این دو گره از تأثیرات محلی به تأثیرات خارجی گسترش یافت. ما چهار گره فرزند شامل گره 1، گره 2، گره 3 و گره 4 را برای تجزیه و تحلیل انتخاب کردیم. گره 1 و گره 2 در نزدیکی گره A و گره B قرار دارند و گره های مربوطه دارای درجه توجه و درجات تعامل بیشتری بودند. این نتیجه نشان داد که مردم در مورد فجایع رخ داده در گره های A و B، به ویژه در گره 1، که در اطراف “پل Huilongguan” واقع شده بود، بسیار نگران بودند. ما میکرو وبلاگ های مربوطه را بررسی کردیم و متوجه شدیم که گره 1 نیز به شدت تحت تأثیر رویداد طوفان باران قرار گرفته است و بلایای گره های 1 و A باعث ناراحتی زیادی برای سفر ساکنان محلی شده است. درجات تعامل و درجات توجه گره 3 و گره 4 زیاد نبودند، اما از گره های رویداد A و B بسیار دور بودند. این نتیجه نشان داد که گره A و گره B تأثیر فضایی بیشتری در این دوره داشتند. در اوج عصر که از ساعت 17:00 تا 22:00 بود، همانطور که در نشان داده شده استدر شکل 7 ج، می بینیم که تعداد گره هایی که به گره A و گره B اشاره می کنند کمتر از شکل 7 است.b، اما آنها به طور یکنواخت در اطراف منطقه پخش می شوند و نشان می دهد که توجه گسترده ای به این دو گره وجود دارد. ما چند منطقه و گره جالب را انتخاب کردیم، از جمله منطقه a، گره 1، و گره 2. در میان آنها، منطقه a در “پارک نرم افزار Zhongguancun” قرار داشت. مردم در این گره نگران بودند که نتوانند به موقع به خانه بروند زیرا گره های A و B تحت تأثیر طوفان باران قرار گرفتند. گره 1 در شهر نانشائو قرار داشت و مردم آنجا با دیدن فاجعه شدید در گره A و گره B نگران وقوع طوفان باران در آینده به خانههایشان بودند. نفوذ اطلاعات نادرست Node 2 در داخل شهر پکن واقع شده بود و همچنین حوادث سیل شدیدی در اینجا رخ داده بود.شکل 7 d وسعت مکانی و توزیع تأثیر فاجعه گره A و گره B را در کل روز شانزدهم نشان می دهد. می بینیم که در طول این فاجعه بارانی، تأثیر فضایی بلایا در گره A و گره B، به ویژه برای منطقه مسکونی و منطقه اداری اطراف، نسبتاً زیاد بود.
4. بحث
4.1. بحث در مورد دقت استخراج اطلاعات مربوط به بلایا
استخراج اطلاعات وضعیت جاده با دانه بندی ریز نقش مهمی در شناسایی و تجزیه و تحلیل موثر مناطق تاثیر ترافیک دارد. نتایج استخراج مربوطه پشتیبانی داده قدرتمندی را برای امدادرسانی هدفمند در بلایای طبیعی فراهم میکند. با این حال، کاستیهای تقسیم معنایی و ویژگی گسسته این اطلاعات، کاربرد بسیاری از روشهای یادگیری ماشین سنتی را دشوار میکند. اگرچه دقت استخراج روش در این مقاله الزامات آزمایش را برآورده می کند، اما این روش هنوز هم جای بهینه سازی دارد. ما به دقت برخی از دادههای متنی طبقهبندیشده اشتباه را تجزیه و تحلیل کردیم و دو پیشرفت زیر را خلاصه کردیم: (1) برخی جملات، مانند “滴滴大厦附近被水淹了 (سیل در نزدیکی ساختمان دیدی)” را نمیتوان به طور موثر شناسایی کرد. این به این دلیل است که ما نمیتوانیم همه موجودیتهای نامگذاری شده مرتبط با جغرافیا را به طور کامل فهرست کنیم، مانند “滴滴大厦 (ساختمان دیدی)”. بنابراین، روشی که می تواند به طور خودکار این کلمات را تشخیص دهد [41 ] باید برای بهبود کارایی تشخیص الگوریتم در آینده معرفی شود. (2) این روش نمی تواند برخی از متن های حاوی اطلاعات معنایی ضمنی را پردازش کند، مانند “我在西二旗看海 (من دریا را در Xierqi تماشا می کنم). کلمه “看海 (مواظب دریا)” نشان دهنده این است که جاده در این زمینه آب گرفته است. بنابراین، ما باید مجموعه مرتبطتری را در نظر بگیریم و از الگوریتمهای خوشهبندی، مانند مدل LDA (تخصیص دیریکله نهفته) [ 42 ] برای به دست آوردن کلمات مشابه برای تکمیل پایگاه دانش خود در مورد فاجعه استفاده کنیم.
احساسات عمومی را می توان به عنوان یک اطلاعات مکمل موثر برای شرایط جاده ریز در نظر گرفت و به تشخیص و تجزیه و تحلیل مناطق تأثیر ترافیک کمک می کند. در این مقاله، با تحلیل ویژگیهای متن رسانههای اجتماعی مرتبط با فاجعه، از یک مدل شبکه عصبی کانولوشن برای استخراج این اطلاعات استفاده کردیم. دقت نهایی الزامات آزمایش را برآورده می کند. با این حال، برخی از شاخص ها هنوز نیاز به بهبود دارند، به ویژه دقت احساسات خنثی و یادآوری احساسات منفی. ما دادههای متنی طبقهبندیشده اشتباه را تجزیه و تحلیل کردیم و متوجه شدیم که یک عامل اصلی احتمالی، تعداد متون مشابه است که به دستههای احساسی مختلف تعلق دارند، و آنها را با برخی از کلمات مشخصه انتزاعی دشوار، مانند علائم نگارشی و شکلکها، به عنوان مثال، متن، متمایز میکنند. «پکن، باران شدید» و «پکن،

…”. این دو متن ساختارهای مشابهی دارند، اما اولی متعلق به مقوله خنثی و دومی متعلق به طبقه منفی است. بنابراین، در مطالعه بعدی خود، معرفی مهندسی ویژگی های مصنوعی را برای بهبود توانایی طبقه بندی مدل در نظر خواهیم گرفت، مانند استخراج دسته های مختلف ایموجی ها از داده های متن آموزشی و برچسب گذاری آنها با وزن های احساسی برای هدایت مدل برای محاسبات طبقه بندی.
4.2. بحث در مورد نتایج تحلیل مکانی و زمانی بلایا
در بخش 3.2 ، ما اطلاعات مختلف مرتبط با بلایا، از جمله زمان، مکان، شرایط جاده، احساسات عمومی، شبکه جادهها و غیره را برای مطالعه نقش رسانههای اجتماعی در شناسایی مناطق تأثیر ترافیک ترکیب کردیم. این منابع اطلاعاتی مکمل یکدیگر بودند و به ما در درک بهتر وضعیت فاجعه کمک کردند. بر اساس نتایج در بخش 3.2 ، ما دانش زیر را به دست آوردیم: (1) در منطقه مورد مطالعه نشان داده شده در شکل 4، می بینیم که مناطق ایستگاه های حمل و نقل به طور جدی تحت تأثیر قرار گرفتند، مانند «ایستگاه مترو Huilongguan»، «ایستگاه مترو Xierqi» و «ایستگاه مترو Shangdi». این به این دلیل است که نه تنها اطلاعات مربوط به وضعیت جاده در این مکان ها بیشتر بود، بلکه احساسات منفی بیشتری نیز وجود داشت که نشان دهنده شدت فاجعه بود. علاوه بر این، برخی از مناطق مسکونی و اداری در نزدیکی این ایستگاه های حمل و نقل نیز به شدت تحت تاثیر قرار گرفتند، مانند “Zhongguancun Software Park” و “Dongyashangbei”. این مناطق حاوی احساسات منفی بیشتری به خصوص در اوج صبح و عصر بودند. این به این دلیل است که در این بازههای زمانی، افراد معمولاً فعالیتهای مسافرتی بیشتری دارند و شرایط بد ترافیکی آنها را بیشتر تحت تأثیر قرار میدهد. بدین ترتیب، برخی از کارهای پیشگیری از بلایا که برای اطمینان از ترافیک روان طراحی شدهاند، باید بر اساس ویژگیهای توزیع مکانی و زمانی موقعیتهای فاجعه مرتبط طراحی شوند، بهویژه برای مناطقی که اطلاعات تاثیر ترافیک قابل توجهی دارند. در طول دوره زمانی که درشکل 4 ب، مقداری «سیلاب خودرو» در منطقه مورد مطالعه ظاهر شد. این بلایا عمدتاً در نزدیکی «ایستگاه مترو Huilongguan» و «Huilongguan Bridge» واقع شدهاند که ممکن است ناشی از تخمین نادرست عمق آب توسط برخی رانندگان باشد. هنگامی که چنین حوادث فاجعه ای رخ می دهد، بخش کاهش بلایا می تواند تلاش های نجات را به موقع آغاز کند و اطلاعات مربوط به بلایا را از طریق کانال های مختلف از جمله رسانه های اجتماعی منتشر کند تا از حوادث بیشتر جلوگیری کند، که می تواند کارایی کاهش بلایا و نجات را تا حد زیادی بهبود بخشد. (2) احساسات عمومی، به عنوان یک اطلاعات تکمیلی مهم، برای کاهش بلایا بسیار مهم است. در شکل 4 ، بسیاری از مناطق حاوی اطلاعات خاصی از وضعیت جاده نیستند، به ویژه برخی از مناطق مسکونی، مانند منطقه 1 در شکل 4.آ. این مناطق معمولاً پرجمعیت بودند و احساسات منفی بیشتری داشتند. آنها همچنین باید بیشتر مورد توجه قرار گیرند زیرا طوفان باران بیش از سفرهای عمومی تأثیر گذاشته است. علاوه بر این، برخی از مطالعات روانشناختی نشان دادهاند که احساسات منفی ممکن است افراد را در برابر القا و فریب اطلاعات بد، مانند شایعات، در هنگام بلایا آسیبپذیر کند [ 43 ]. به عنوان مثال، شایعهای حاکی از آن بود که ساکنان پکن باید به دلیل طوفان بیسابقهی باران از کار بمانند ( https://www.cma.gov.cn/2011xwzx/2011xqxxw/2011xqxyw/201706/t20170623_426973.html ). این تأثیر زیادی بر روی آن دسته از افرادی که نگران دیر رسیدن به سر کار بودند و مضطرب بودند و ممکن است برخی اقدامات ناگوار را برای از بین بردن این روانشناسی متناقض انتخاب کنند [ 44 ] خواهد داشت.]، مانند انتشار این شایعات یا به راحتی شایعات دیگر را باور کنید. این امر خطر بروز بلایای ثانویه را تا حد زیادی افزایش می دهد. بنابراین باید به موقع اقدامات لازم برای کاهش بلایا از جمله شفاف سازی این شایعات و انتشار به موقع وضعیت بلایا آغاز شود. به طور کلی، تجزیه و تحلیل جامع اطلاعات چند بعدی مرتبط با بلایا، درک جامع تری از پیشرفت بلایا به ما می دهد، که برای بهبود کارایی کاهش بلایا از اهمیت زیادی برخوردار است.
در بخش 3.3 ، ما تأثیر مکانی-زمانی مناطق مختلف آسیبدیده از بلایا را با استفاده از روشهای پیشرفته مدلسازی شبکه پیچیده سنتی ارزیابی کردیم. شکل 5 و شکل 6 تأثیر فضایی این مناطق را با تجسم برخی شاخص های کمی از جمله درجه توجه، درجه تعامل و درجه وزن نشان می دهد. می بینیم که «ایستگاه مترو Xierqi» و «ایستگاه مترو Huilongguan» بیشترین آسیب را از این فاجعه گرفتند. این اطلاعات مکمل معتبری برای نتایج تجزیه و تحلیل در بخش 3.2 استو همچنین دامنه تأثیر این مناطق فاجعهبار را با جزئیات بیشتری نشان میدهد. تجزیه و تحلیل دقیق تر برای دو منطقه انتخاب شده (“ایستگاه مترو Xierqi” و “ایستگاه مترو Huilongguan”) از بعد زمانی انجام شد. شکل 7نتایج 3 دوره زمانی (دوره اوج صبح، سایر دوره ها و دوره اوج عصر) را ارائه می دهد و دریافتیم که (1) در دوره اوج صبح و عصر، این دو گره (دو ناحیه انتخاب شده) تأثیر بیشتری بر روی گره ها (سایر مناطق) اطراف آنها، به ویژه مناطق مسکونی و مناطق اداری. علاوه بر این، شاخصهای درجه گره و درجه تعامل نشان میدهند که این مناطق چقدر تحت تأثیر قرار گرفتهاند. اگر چه دو گره انتخاب شده نیز بر گره های دور تأثیر داشتند، اما این تأثیر محدود بود. همراه با محتوای میکرو بلاگ، میتوانیم به طور منطقی منابع نجات را برای این مناطق آسیب دیده اختصاص دهیم. (2) در طول دوره های دیگر، مناطق تحت تاثیر دو گره انتخاب شده افزایش یافته است. با این حال، وسعت نفوذ منظم نبود. ما روی مناطقی متمرکز شدیم که گره های زیادی به آنها اشاره می کنند. این مناطق ممکن است به شدت تحت تأثیر گره های A (“ایستگاه مترو Huilongguan”) و B (“ایستگاه مترو Xierqi”) قرار گیرند. بخشهای کاهش بلایا میتوانند با گنجاندن محتوای ریزوبلاگها در این مناطق، مانند پیشبرد شرایط ترافیکی فعلی و توصیه مسیرهای معقول سفر، برخی از برنامههای واکنش را به طور مؤثری تدوین کنند. به طور کلی، مدل پیشنهادی در این مطالعه در ارزیابی تأثیر مکانی و زمانی بلایا مؤثر بود. نتایج تجزیه و تحلیل بصری یک مرجع اطلاعاتی مهم برای بهینه سازی تصمیمات کاهش بلایا و استقرار کارآمد منابع امدادی ارائه کرد. مانند فشار به شرایط فعلی ترافیک و توصیه مسیرهای معقول سفر. به طور کلی، مدل پیشنهادی در این مطالعه در ارزیابی تأثیر مکانی و زمانی بلایا مؤثر بود. نتایج تجزیه و تحلیل بصری یک مرجع اطلاعاتی مهم برای بهینه سازی تصمیمات کاهش بلایا و استقرار کارآمد منابع امدادی ارائه کرد. مانند فشار به شرایط فعلی ترافیک و توصیه مسیرهای معقول سفر. به طور کلی، مدل پیشنهادی در این مطالعه در ارزیابی تأثیر مکانی و زمانی بلایا مؤثر بود. نتایج تجزیه و تحلیل بصری یک مرجع اطلاعاتی مهم برای بهینه سازی تصمیمات کاهش بلایا و استقرار کارآمد منابع امدادی ارائه کرد.
5. نتیجه گیری و کار آینده
رسانههای اجتماعی در سالهای اخیر نقش مهمی در تحقیقات بلایا مانند طوفانهای شهری داشتهاند. اطلاعات فراوان مربوط به فاجعه موجود در آن، پشتیبانی داده های مهمی را برای کاهش بلایا فراهم می کند. با این حال، این اطلاعات مربوط به فاجعه اغلب به شکل بدون ساختار وجود دارد، که استفاده کارآمد از اطلاعات را دشوار می کند. بنابراین، در این مقاله، ما چارچوبی ایجاد کردیم که الگوریتمهایی از جمله پردازش زبان طبیعی و یادگیری عمیق را برای استخراج این اطلاعات چند بعدی مرتبط با فاجعه، از جمله زمان، مکان، اطلاعات دقیق وضعیت جاده، و اطلاعات عاطفی عمومی، یکپارچه ساخت. علاوه بر این، ما به طور جامع این اطلاعات استخراج شده مرتبط با فاجعه را برای شناسایی مناطق تأثیر ترافیک تجزیه و تحلیل کردیم و به نتایج خوبی دست یافتیم. علاوه بر این، بر اساس الگوهای تعامل غنی در رسانه های اجتماعی، ما یک مدل ارزیابی نفوذ فضایی را پیشنهاد کردیم. از طریق تجسم چندین شاخص کمی، میتوانیم در مورد میزان و توزیع تأثیر فضایی مناطق آسیبدیده مختلف بیشتر بیاموزیم، که کمک بزرگی در بهینهسازی تصمیمهای کاهش بلایا بود. فاجعه طوفان باران در پکن در 16 ژوئیه 2018، به عنوان مطالعه موردی برای تأیید اثربخشی روش پیشنهادی در این مقاله استفاده شد.
به طور کلی، چارچوب در این مقاله در تشخیص منطقه تأثیر ترافیک و ارزیابی تأثیر مکانی – زمانی فاجعه انتخاب شده به خوبی عمل کرد. با این حال، در کارهای آینده، هنوز برخی از جنبه ها وجود دارد که نیاز به بهبود بیشتر دارد. ابتدا، استخراج کلمات موجودیت نامگذاری شده مرتبط با جغرافیا از متن رسانههای اجتماعی را در نظر خواهیم گرفت. از یک طرف، این می تواند دقت تشخیص اطلاعات وضعیت جاده را بهبود بخشد (که در بخش 3.1 ذکر شد.). از سوی دیگر، همه داده های رسانه های اجتماعی حاوی اطلاعات مکان نیستند. هنگام ارسال داده های مربوط به فاجعه، افراد ممکن است مکان فعلی خود را به دلیل عادات شخصی و دلایل دیگر آپلود نکنند. این به میزان زیادی استفاده از داده ها را محدود می کند زیرا اکثر روش های تجزیه و تحلیل بلایا بر اطلاعات مکان تکیه می کنند. با این حال، برخی از مطالعات [ 45 ، 46 ، 47] دریافتهاند که واژههای موجود با نام مرتبط با جغرافیای موجود در متن رسانههای اجتماعی میتوانند مکان بارگذاری دادهها را نشان دهند. دوم، چارچوب در این مقاله استفاده از دادههای جغرافیایی سنتی، مانند شبکههای جادهای را برای کمک به تحلیل در نظر گرفته است. این داده ها مکمل موثری برای رسانه های اجتماعی بود و نتایج تجزیه و تحلیل خوبی به دست آورد. بنابراین، در مطالعه بعدی ما، داده های مرتبط تری معرفی خواهند شد. به عنوان مثال، دادههای توزیع جمعیت میتواند به درک تأثیر منطقهای بلایا کمک کند و دادههای مسیر اتوبوس میتواند به تحلیل تأثیر بر سفر مردم کمک کند.


 …”. این دو متن ساختارهای مشابهی دارند، اما اولی متعلق به مقوله خنثی و دومی متعلق به طبقه منفی است. بنابراین، در مطالعه بعدی خود، معرفی مهندسی ویژگی های مصنوعی را برای بهبود توانایی طبقه بندی مدل در نظر خواهیم گرفت، مانند استخراج دسته های مختلف ایموجی ها از داده های متن آموزشی و برچسب گذاری آنها با وزن های احساسی برای هدایت مدل برای محاسبات طبقه بندی.
…”. این دو متن ساختارهای مشابهی دارند، اما اولی متعلق به مقوله خنثی و دومی متعلق به طبقه منفی است. بنابراین، در مطالعه بعدی خود، معرفی مهندسی ویژگی های مصنوعی را برای بهبود توانایی طبقه بندی مدل در نظر خواهیم گرفت، مانند استخراج دسته های مختلف ایموجی ها از داده های متن آموزشی و برچسب گذاری آنها با وزن های احساسی برای هدایت مدل برای محاسبات طبقه بندی.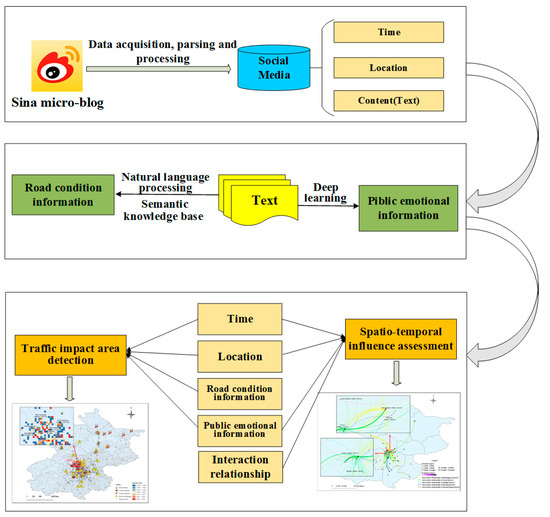





بدون دیدگاه