

چکیده
:
تشخیص نقاط کانونی شهری موضوع مهمی است که برای برنامه ریزی شهری و مدیریت ترافیک باید مورد بررسی قرار گیرد. استخراج نقاط داغ از داده های مسیر تاکسی، که منعکس کننده ویژگی های سفر ساکنان و وضعیت عملیاتی ترافیک شهری است، اهمیت زیادی دارد. روشهای خوشهبندی موجود عمدتاً بر تعداد اشیاء موجود در یک منطقه در اندازه مشخص تمرکز میکنند و از تأثیر چگالی محلی و تنگی بین اجسام غفلت میکنند. از این رو، یک الگوریتم جدید برای تشخیص نقاط داغ شهری از دادههای مسیر تاکسی بر اساس تکنیکهای خوشهبندی کیفیت مرتبط با نزدیکترین محله پیشنهاد شدهاست. الگوریتم خوشهبندی فضایی پیشنهادی نه تنها حداکثر خوشهبندی را در یک محدوده محدود در نظر میگیرد، بلکه رابطه بین هر مرکز خوشهای و نزدیکترین همسایگی آن را نیز در نظر میگیرد و به طور موثر به موضوع خوشهبندی مجموعه دادههای توزیع نابرابر میپردازد. در نتیجه، الگوریتم پیشنهادی نتایج خوشهبندی با کیفیت بالا را به دست میآورد. نمایش بصری و نتایج تجربی شبیهسازیشده روی مجموعه دادههای مسیر کابین واقعی نشان میدهد که الگوریتم پیشنهادی برای استنباط مناطق کانونی شهری مناسب است و دقت بهتری نسبت به روشهای سنتی مبتنی بر تراکم به دست میآورد.
کلید واژه ها:
مسیر سفر مسافر ; انجمن محله ; تشخیص منطقه هات اسپات شهری ; نزدیکترین خوشه بندی کیفیت مرتبط با محله
1. مقدمه
کانون های شهری مظهر فعالیت های مکرر ساکنان شهری هستند. مکانها و مسیرهایی که اغلب ساکنان سفر میکنند میتوانند به طور مستقیم شرایط ترافیکی شهر و الگوهای حرکت کاربر را منعکس کنند. تشخیص نقاط کانونی شهری موضوع مهمی است که باید در برنامه ریزی شهری و مدیریت ترافیک مورد بررسی قرار گیرد. مناطق کانونی شناسایی شده می توانند به عنوان اطلاعات مرجع موثر برای راهنمایی ترافیک و چیدمان امکانات عمومی شهری استفاده شوند. به عنوان مثال، نتایج شناسایی نقاط مهم در همان زمان در روزهای مختلف می تواند به طور موثر راهنمایی کند که در کجا تبلیغات خدمات عمومی قرار داده شود. تبلیغاتی که در مناطق کانونی قرار می گیرند بیشتر مورد توجه قرار می گیرند. با انتشار نقاط حساسی که در زمانهای خاص اتفاق میافتد، میتوان به رانندگان راهنمایی کرد که از این مناطق پرحادثه دوری کنند و در نتیجه تراکم ترافیک را کاهش دهند. همانطور که مشخص است، شرایط ترافیک شهری تحت تأثیر تراکم وسایل نقلیه در جاده ها است. تاکسی ها یکی از راحت ترین وسایل حمل و نقل عمومی برای ساکنان شهر هستند که خدمات مسافرتی شخصی را ارائه می دهند. به این ترتیب، دادههای مسیر تاکسی، دادههای بزرگ مکانی-زمانی هستند که حاوی رفتار سفر ساکنان هستند. اطلاعات مربوط به زمان سفر ساکنان، مسیرها و مسافت طی شده ارتباط نزدیکی با فعالیت های سفر ساکنان دارد. از این رو، کسب تراکم مکان تاکسی را می توان برای تحلیل شرایط ترافیک شهری استفاده کرد. در نتیجه، استخراج نقاط داغ از دادههای مسیر تاکسی، که منعکسکننده ویژگیهای سفر ساکنان شهری و وضعیت عملیاتی ترافیک شهری است، مهم است. تاکسی ها یکی از راحت ترین وسایل حمل و نقل عمومی برای ساکنان شهر هستند که خدمات مسافرتی شخصی را ارائه می دهند. به این ترتیب، دادههای مسیر تاکسی، دادههای بزرگ مکانی-زمانی هستند که حاوی رفتار سفر ساکنان هستند. اطلاعات مربوط به زمان سفر ساکنان، مسیرها و مسافت طی شده ارتباط نزدیکی با فعالیت های سفر ساکنان دارد. از این رو، کسب تراکم مکان تاکسی را می توان برای تحلیل شرایط ترافیک شهری استفاده کرد. در نتیجه، استخراج نقاط داغ از دادههای مسیر تاکسی، که منعکسکننده ویژگیهای سفر ساکنان شهری و وضعیت عملیاتی ترافیک شهری است، مهم است. تاکسی ها یکی از راحت ترین وسایل حمل و نقل عمومی برای ساکنان شهر هستند که خدمات مسافرتی شخصی را ارائه می دهند. به این ترتیب، دادههای مسیر تاکسی، دادههای بزرگ مکانی-زمانی هستند که حاوی رفتار سفر ساکنان هستند. اطلاعات مربوط به زمان سفر ساکنان، مسیرها و مسافت طی شده ارتباط نزدیکی با فعالیت های سفر ساکنان دارد. از این رو، کسب تراکم مکان تاکسی را می توان برای تحلیل شرایط ترافیک شهری استفاده کرد. در نتیجه، استخراج نقاط داغ از دادههای مسیر تاکسی، که منعکسکننده ویژگیهای سفر ساکنان شهری و وضعیت عملیاتی ترافیک شهری است، مهم است. اطلاعات مربوط به زمان سفر ساکنان، مسیرها و مسافت طی شده ارتباط نزدیکی با فعالیت های سفر ساکنان دارد. از این رو، کسب تراکم مکان تاکسی را می توان برای تحلیل شرایط ترافیک شهری استفاده کرد. در نتیجه، استخراج نقاط داغ از دادههای مسیر تاکسی، که منعکسکننده ویژگیهای سفر ساکنان شهری و وضعیت عملیاتی ترافیک شهری است، مهم است. اطلاعات مربوط به زمان سفر ساکنان، مسیرها و مسافت طی شده ارتباط نزدیکی با فعالیت های سفر ساکنان دارد. از این رو، کسب تراکم مکان تاکسی را می توان برای تحلیل شرایط ترافیک شهری استفاده کرد. در نتیجه، استخراج نقاط داغ از دادههای مسیر تاکسی، که منعکسکننده ویژگیهای سفر ساکنان شهری و وضعیت عملیاتی ترافیک شهری است، مهم است.1 ].
بسیاری از محققان از داده های بزرگ برای انجام تحقیقات در مورد شناسایی مناطق کانونی فضایی شهری استفاده کرده اند و به نتایج غنی دست یافته اند. برای مثال، اشبروک و همکاران. [ 2 ] یک روش دو مرحلهای برای استنتاج مکانهای کانونی پیشنهاد کرد و یک مدل مارکوف برای پیشبینی مکانهای آینده ساخت. ژو و همکاران [ 3 ] یک الگوریتم خوشه بندی (DJ-Cluster) بر اساس تراکم و اتصال برای استنتاج مکان های دسترسی به هات اسپات پیشنهاد کرد. کائو و همکاران [ 4 ] یک الگوریتم خوشهبندی پیشرفته معنایی (SEM-CLS) را برای استخراج مکانهای معنیدار و رتبهبندی مکانها از طریق یک مدل احتمال یکپارچه پیشنهاد کرد. شیا و همکاران [ 5] مسیر اصلی را به یک سری از مسیرهای فرعی با استفاده از نقاط ماندن و تقاطع های جاده به عنوان نقاط مشخصه تقسیم کرد، مسیرهای فرعی را خوشه بندی کرد و سپس وزن مسیرهای فرعی را برای بدست آوردن مسیرهای داغ تجزیه و تحلیل کرد. گی و همکاران [ 6] یک الگوریتم موازی توزیع شده برای استخراج نقاط داغ ترافیک از مسیرهای تاکسی پیشنهاد کرد. ابتدا اطلاعات ایستگاههای تاکسی استخراج شد و سپس از روش خوشهبندی مبتنی بر تراکم (DBSCAN، خوشهبندی فضایی مبتنی بر چگالی برنامهها با نویز) برای خوشهبندی دادههای بلوک برای کشف مناطق هات اسپات در دورههای زمانی مختلف استفاده شد. متفاوت از روشهای پارتیشنبندی و خوشهبندی سلسله مراتبی، DBSCAN خوشهها را به عنوان بزرگترین مجموعهای از نقاط متصل به چگالی تعریف میکند. این می تواند مناطق با چگالی به اندازه کافی بالا را به خوشه ها تقسیم کند و می تواند خوشه هایی از اشکال دلخواه را در یک پایگاه داده فضایی پر سر و صدا پیدا کند. ما و همکاران [ 7] یک الگوریتم خوشهبندی سلسله مراتبی تجمعی و روش تجزیه و تحلیل GIS (سیستم اطلاعات جغرافیایی) بر اساس دادههای مسیر تاکسی را برای استخراج مناطق کانونی و ویژگیهای مکانی-زمانی ساکنانی که با استفاده از تاکسی سفر میکنند، اعمال کرد. ساویج و همکاران [ 8 ] یک الگوریتم خوشهبندی مسیر مبتنی بر شبکه برای یافتن نقاط داغ پیشنهاد کرد، که میتواند جهت مسیر را تشخیص دهد و بخشهای فرعی مسیر را تجزیه و تحلیل کند. با این حال، نقاط داده غیرعادی موجود در مجموعه داده را نمی توان حذف کرد، که بر اثر خوشه بندی تأثیر می گذارد. فریرا و همکاران [ 9] یک روش احتمالی مبتنی بر مدل شناسایی نقطه اتصال را بر اساس داده های تقاطع شبیه سازی شده پیشنهاد کرد. اعمال این روش آسان است، اما برای تعیین نقاط حساس نیاز به در نظر گرفتن عوامل خطر دارد و فقط برای داده های تقاطع مناسب است. شولز [ 10 ] دادههای مسیر GPS 536 تاکسی در سانفرانسیسکو را در طی 22 روز تجزیه و تحلیل کرد و روشی برای مدلسازی الگوهای فعالیت جمعی برای تعیین مکان و زمان کانونهای فعالیت در کلان شهر سانفرانسیسکو پیشنهاد کرد. با این حال، فاصله زمانی مجموعه داده مورد استفاده یک ساعت بود که جهانی نیست.
روش خوشهبندی فضایی عمدتاً بر اساس دادههای مسیر [ 11 ، 12 ، 13 ، 14 ] در کاوی نقطه داغ به کار گرفته شده است. از منظر خوشهبندی اشیا، تحقیقات موجود عمدتاً به سه دسته تقسیم میشوند:
- (1)
-
مطالعاتی که به طور مستقیم خوشه بندی مبتنی بر چگالی را بر روی مکان های داده های مسیر انجام می دهند [ 15 ، 16 ]. این روش برای خوشه بندی داده های مکانی پر سر و صدا مناسب است. می تواند به طور موثر با داده های غیرعادی مقابله کند و می تواند خوشه هایی با اشکال دلخواه را با اتصال مناطق مجاور با چگالی کافی پیدا کند. با این حال، زمانی که چگالی خوشه بندی فضایی ناهموار است و فاصله خوشه ها بسیار متفاوت است، کیفیت خوشه بندی ضعیف است.
- (2)
-
مطالعاتی که توالی مکانها را به دنبالهای از بخشهای مسیر تبدیل میکنند و مسیرها و مناطق داغ را با خوشهبندی بخشهای مسیر پیدا میکنند [ 17 ]. این روش میتواند شباهتهای محلی را در مسیرهای پیچیده مکانی-زمانی پیدا کند. نقاط ویژگی استخراج شده مختصر و موثر هستند، اما نتایج خوشهبندی عمدتاً به کیفیت تقسیم بخشهای مسیر بستگی دارد.
- (3)
به منظور بهبود سازگاری، برخی از مطالعات از روش های ذکر شده [ 20 ] نیز استفاده کرده اند که نتایج خوشه بندی آن ها را می توان در تجزیه و تحلیل مناطق هات اسپات استفاده کرد. در طول دوره زمانی مشخص شده، k ناحیه بالایی که با بیشترین تراکم مکانها شناسایی شدهاند، نقاط داغی هستند که ممکن است تراکم ترافیک یا معضلات پارکینگ در آنها رخ دهد. بنابراین، تجزیه و تحلیل و شناسایی نقاط حساس می تواند در خدمت مدیریت برنامه ریزی شهری یا ادارات کنترل ترافیک باشد.
اکثر تحقیقات موجود، خوشهبندی مبتنی بر چگالی را مستقیماً در مکانهای مسیرها انجام میدهند. این نوع روش میتواند خوشههایی با اشکال دلخواه را در یک پایگاه داده فضایی حاوی نویز پیدا کند و میتواند مناطق مجاور را با چگالی کافی برای پردازش مؤثر دادههای غیرعادی به هم متصل کند، اما کیفیت خوشه زمانی که چگالی خوشههای فضایی ناهموار است و فواصل بین خوشهای ناهموار است، ضعیف است. بزرگ هستند [ 15 ، 16 ]. ژنگ و همکاران [ 21 ] یک الگوریتم خوشهبندی مبتنی بر تراکم شبکه را برای کشف مناطق سفر ترجیحی ساکنان در دورههای مختلف روز پیشنهاد کرد. لیو و همکاران [ 22 ] مناطق بسیار مستعد ازدحام را با استفاده از روش خوشه بندی DBSCAN شناسایی کرد.
مطالعات فوق در درجه اول برای فضاهای داده با چگالی یکنواخت قابل استفاده است. آنها تأثیر چگالی محلی و سفتی بین اجسام را نادیده می گیرند. با این حال، در یک شبکه ترافیک واقعی، مکان ها در مسیرهای تاکسی به طور مساوی توزیع نشده اند. به منظور حل این مشکل، این مقاله یک الگوریتم خوشهبندی آستانه کیفیت بهبود یافته را بر اساس ارتباط محلهای – که به عنوان QTNA مشخص میشود – پیشنهاد میکند که برای شناسایی نقاط داغ سفر ساکنان شهری از دادههای مسیر تاکسی استفاده میشود. الگوریتم رابطه بین هر مرکز خوشه و همسایگی آن را برای به دست آوردن نتایج خوشه بندی با کیفیت بالا در نظر می گیرد که برای تجزیه و تحلیل مناطق هات اسپات قابل توجه است.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 مفاهیم اولیه و تعریف مسئله را معرفی می کند. روش خوشهبندی فضایی جدید برای تشخیص منطقه کانونی شهری نیز ارائه شده است. نتایج تجربی و تجزیه و تحلیل در بخش 3 و بخش 4 مورد بحث قرار گرفته است. بخش 5 نتیجه گیری و همچنین محدودیت ها و مفاهیم این تحقیق را ارائه می کند.
2. روش ها
2.1. مدل نزدیکترین محله
تعریف 1.
(نزدیکترین محله): یک مجموعه داده DS با n شی در نظر بگیرید. برای هر شی Oمن∈Dاس(من=1،…،n)، نزدیکترین محله از Oمنبه مجموعه ای متشکل از هر شی (به استثنای Oمنخود) با فاصله از Oمنکه کمتر از θr، نشان داده شده با نن(Oمن). به صورت زیر تعریف می شود:
نن(Oمن)={پ|دمنستی(پ،Oمن)≤θr، پ∈Dاس\{Oمن}}،
جایی که θrیک آستانه رادوئیس است، هر p in نن(Oمن)a نامیده می شود θr-همسایه شی Oمن، و دمنستی(ایکس،y)نشان دهنده فاصله بین اشیاء x و y است. یعنی برای هر q∈Dاس–نن(Oمن)، دمنستی(q،Oمن)>θr، q≠Oمن. هر شی در نزدیکترین همسایگی Oمنa نامیده می شود θr-همسایه Oمن.
تعریف 2.
(نزدیکترین فاصله محله): برای هر شی Oمن∈Dاس(من=1،…،n)، نزدیکترین فاصله محله از Oمنبه میانگین فاصله بین آنها اشاره دارد Oمنو تمام اشیاء در نن(Oمن)، نشان داده شده با نندمنستی(Oمن). به عنوان تعریف شده است
نندمنستی(Oمن)=∑پ∈نن(Oمن)دمنستی(پ،Oمن)|نن(Oمن)|.
در معادله (2) |نن(Oمن)|اندازه است نن(Oمن)، که باید با آستانه اندازه مقایسه شود θn.
در الگوریتم خوشهبندی کیفیت مرتبط با نزدیکترین محله پیشنهادی، مکانهای دادههای مسیر تاکسی، اشیاء تحقیقاتی اساسی هستند.
2.2. مدل مسیر سفر مسافر
با توجه به توضیحات خودروهای خالی و سنگین در مجموعه داده اصلی مسیر تاکسی (0 خالی است، بقیه سنگین هستند)، موقعیت مسافران در تمام مسیرهای تاکسی قابل استخراج است. برای نمایش حالت های خالی و سنگین به ترتیب از 0 و 1 استفاده کردیم. داده های مسیر یک تاکسی خاص در یک روز خاص را می توان به یک توالی حالت حمل مسافر تبدیل کرد: 001111110001111…000. همانطور که در شکل 1 نشان داده شده است، می توان دنباله بخش حالت مربوط به مسیر را بدست آورد . دنباله پیوسته “1” بخش سفر مسافر را نشان می دهد و دنباله “0” پیوسته بخش سفر بدون بار را نشان می دهد.
تعریف 3.
(موقعیت تحویل): مکانی که وضعیت آن از صفر به غیرصفر در مجموعه داده مسیر تاکسی منتقل می شود، به عنوان مکان تحویل تعریف می شود. مجموعه همه مکانهای دریافت به صورت PL نشان داده میشود.
تعریف 4.
(موقعیت خروج): مکانی که وضعیت آن از غیرصفر به صفر در مجموعه داده مسیر تاکسی منتقل میشود، به عنوان مکان تخلیه تعریف میشود. مجموعه تمام مکان های رها شده به عنوان DL نشان داده می شود.
همه مکانهای موجود در PL ∪ DL مکانهای اصلی و مقصد هستند.
تعریف 5.
(مسیر سفر مسافر): مسیری متشکل از مجموعهای از مکانهای مرتببندی شده با زمان با محل تحویل به عنوان نقطه شروع و مکان تخلیه به عنوان نقطه پایان، مسیر سفر مسافر نامیده میشود.
همانطور که در شکل 1 نشان داده شده است ، نقاط دایره دوتایی مکان شروع و پایان تاکسی را در آن روز، نقاط دایره سیاه و سفید نشان دهنده مکان سوار شدن و نقاط دایره توخالی مکان های تخلیه را نشان می دهد. بخش خالی تاکسی با Ed (رانندگی خالی) و بخش سفر مسافر با Cp (حمل مسافر) نشان داده می شود. مسیر نشان داده شده در شکل 1 شامل m بخش سفر مسافر است.
2.3. الگوریتم تشخیص منطقه هات اسپات شهری
بر اساس روشهای تحلیل مکانی-زمانی، استخراج الگوهای حرکتی مسیرهای تاکسی و توزیع منطقهای مکانهای حمل و نقل برای تحلیل عمیق ویژگیهای رفتار سفر ساکنان شهری و حرکات مفید است و میتواند دادههای قدرتمندی ارائه دهد. مرجع بخش برنامه ریزی حمل و نقل شهری
2.3.1. چارچوب الگوریتم
بر اساس روش خوشهبندی آستانه کیفیت (QT) [ 23 ]، در این مقاله، ما یک الگوریتم خوشهبندی کیفیت مرتبط با محله را برای تشخیص مناطق کانونی شهری از دادههای مسیر تاکسی پیشنهاد میکنیم. الگوریتم QT در ابتدا برای خوشهبندی ژنی پیشنهاد شد و بعداً در خوشهبندی سریهای زمانی مورد استفاده قرار گرفت. کیفیت خوشهبندی را با یافتن خوشههای متراکم تضمین میکند که قطر آنها از آستانه قطر تعیینشده توسط کاربر تجاوز نمیکند [ 23 ]. با در نظر گرفتن رابطه همسایگی و کیفیت خوشهبندی، الگوریتم پیشنهادی میتواند نتایج خوشهبندی دقیقتری را به دست آورد و مناطق کانونی با تراکم بالا را شناسایی کند.
هات اسپات شهری به مناطقی اطلاق می شود که مسافران در آن به شدت متمرکز هستند. با در نظر گرفتن دادههای مسیر تاکسی بهعنوان هدف تحقیق، بزرگترین خوشه مکانهای حمل و نقل متراکمترین منطقه را نشان میدهد. هدف از الگوریتم ما یافتن یک خوشه بهینه است که هر بار نزدیکترین ویژگی همسایگی را در نظر بگیرد. الگوریتم شامل دو فاز اصلی است. ابتدا، هر نقطه مکان و نزدیکترین همسایگان آن در یک خوشه گروه بندی می شوند. دوم، بزرگترین خوشه ای که نیاز اندازه را برآورده می کند به عنوان یک خوشه نامزد انتخاب می شود و ویژگی همسایگی آن برای به دست آوردن خوشه بهینه فعلی تجزیه و تحلیل می شود. چارچوب الگوریتم پیشنهادی در شکل 2 نشان داده شده است .
2.3.2. توضیحات الگوریتم
بر اساس مجموعه دادههای PL و DL ، از روش خوشهبندی کیفیت مرتبط با نزدیکترین محله برای استخراج نقاط داغ شهری ساکنان در هر دوره، از جمله مناطق جمعآوری و رهاسازی گرم استفاده شد.
ورودی الگوریتم مجموعه ای از مکان های مورد تجزیه و تحلیل بود که از مجموعه داده های خط سیر خام استخراج شد و توسط DS نشان داده شد . هر تکرار از الگوریتم پیشنهادی به گونه ای طراحی شده است که شامل سه بخش خاص به شرح زیر باشد:
- (من)
-
پیدا کن θr-همسایگان برای هر مکان به شکل | DS | خوشه ها
- (II)
-
حداکثر خوشه ای را انتخاب کنید که مطابق با الزامات اندازه باشد.
- (iii)
-
ویژگی همسایگی خوشه نامزد را تجزیه و تحلیل کنید تا خوشه بهینه فعلی را فیلتر کنید.
مراحل الگوریتم پیشنهادی به شرح زیر است:
مرحله 1. برای هر مکان Oمن∈Dاس، فاصله دمنستیمنjبین Oمنو Oj( Oj∈Dاس\{Oمن}) محاسبه می شود.
مرحله 2. برای هر مکان Oمنو Oj، اگر دمنستیمنj≤θr، قرار دادن Ojبه خوشه ای که مرکز آن است Oمن.
مرحله 3. مرتب سازی مجموعه همه | DS | خوشه ها بر اساس اندازه های مربوطه خود به ترتیب نزولی و حداکثر خوشه Clus را پیدا کنید .
مرحله 4. اجازه دهید C مرکز خوشه نامزد، Clus باشد. اگر تعداد اشیاء در Clus بیشتر یا مساوی آستانه اندازه خوشه باشد θn، فاصله درون خوشه ای NNdist ( C ) Clus را محاسبه کنید (یعنی میانگین فاصله بین نقطه مرکزی C و سایر نقاط در Clus ) و فاصله درون خوشه ای NNdist ( q ) را بر روی تمام نقاط دیگر به جز نقطه C محاسبه کنید. در کلوس ، جایی که q∈نن(سی); در غیر این صورت، به روز رسانی کنید θr، DS را ریست کرده و به مرحله 2 بروید.
مرحله 5. محاسبه مقدار NNdist ( C ) – میانه ({ NNdist ( q )| q ∈NN ( C )}). اگر کمتر یا مساوی 0 باشد، Clus را به عنوان حداکثر خوشه انتخاب کنید و تمام اشیاء موجود در Clus را از DS حذف کنید و به مرحله 1 بروید. در غیر این صورت، خوشه حداکثر بعدی (در صورت وجود) را از مجموعه مرتب شده به عنوان Clus انتخاب کنید و به مرحله 4 بروید.
مرحله 6. مراحل 1 تا 5 را تکرار کنید تا زمانی که DS خالی شود یا تعداد تکرارها برسد θج.
الگوریتم خوشه بندی مکان مسیر به عنوان QTNA نشان داده شد. از آن برای تشخیص موثر مناطق کانونی شهری استفاده شد. در این مقاله، الگوریتم QTNA، الگوریتم خوشه بندی کیفیت مرتبط با نزدیکترین محله نیز نامیده می شود. شبه کد الگوریتم به صورت زیر ارائه شده است:
الگوریتم زمانی به پایان می رسد که مجموعه داده مکان خالی باشد، یا تعداد تکرارها به آستانه برسد. θج. روش به روز شده از θrبه شرح زیر است:
θr=θr×(1+∝)
جایی که ∝یک پارامتر تنظیم برای است θr.
پیچیدگی زمانی هر تکرار الگوریتم 1 به موارد زیر بستگی دارد: (الف) زمان محاسبه فاصله دمنستیمنjبین هر دو مکان Oمنو Oj، که پیچیدگی زمانی آن O( n 2 ) است (خطوط 5-16). (ب) زمان مرتبسازی مجموعهای از n خوشه بر اساس اندازه هر خوشه، که پیچیدگی زمانی آن O( n2 ) است (خط 17 ). (ج) زمان اسکن هر خوشه از بزرگ به کوچک برای تعیین اینکه آیا نزدیکترین فاصله همسایگی هر مرکز الزامات را برآورده می کند، که پیچیدگی زمانی آن O( n ) است (خطوط 19-33). حداکثر تعداد تکرار است θج، جایی که θج≪n2. بنابراین، پیچیدگی زمانی الگوریتم 1 O( n2 ) است.
| الگوریتم 1: QTNA (خوشه بندی آستانه کیفیت بر اساس همسایگی) |
| ورودی: DS(={O1،…،On}، مجموعه ای از مکان های حمل و نقل / تحویل در مجموعه داده مسیر تاکسی)، θr(آستانه شعاع)، θn(آستانه اندازه خوشه)، θج(آستانه عدد تکرار) خروجی: CS (نتایج خوشه بندی) 1: منتیهrجnتی←0; ک←0; oldDS ←DS ; 2: سیاس←∅; سیهnتیهrس←∅; 3: تکرار: 4: منتیهrجnتی←منتیهrجnتی+1; 5: برای من ←1 تا | DS | انجام 6: تیهمترپسیاسمن←{Oمن}; 7: برای j ←1 تا | DS | 8 را انجام دهید : اگر ( j == i ) سپس 9: ادامه دهید. 10: پایان اگر 11: فاصله را محاسبه کنید دمنستیمنjبین Oمنو Oj; 12: اگر دمنستیمنj≤θr سپس 13: تیهمترپسیاسمن←تیهمترپسیاسمن∪{Oj}; 14: پایان اگر 15: پایان برای 16: پایان برای 17: مرتب سازی tempCS بر اساس |تیهمترپسیاسمن|به ترتیب نزولی؛ 18: مآایکسمن←1 19: در حالی که ( مآایکسمن≤| tempCS |) 20 را انجام دهید : اگر |تیهمترپسیاسمآایکسمن|≥θn سپس 21: سی←را مرکز از تیهمترپسیاسمآایکسمن; 22: اگر نندمنستی(سی)≤مترهدمنآn({نندمنستی(q)|q∈نن(سی)}) سپس 23: ک←ک+1; 24: سیاسک←تیهمترپسیاسمآایکسمن; 25: سیهnتیهrسک←سی; 26: Dاس←Dاس–تیهمترپسیاسمآایکسمن; 27: شکستن 28: دیگر 29: مآایکسمن←مآایکسمن+1; 30: پایان اگر 31: else break; 32: پایان اگر 33: پایان در حالی که 34: تا زمانی که خالی باشد( DS ) یا منتیهrجnتی==θجیا isequal ( oldDS , DS ); 35: بازگشت CS ; |
3. نتایج
در این بخش، یک مطالعه موردی بر اساس شهر پکن در چین ارائه میکنیم. پکن یک منطقه اداری در سطح استان، شهرداری است که مستقیماً تحت کنترل دولت مرکزی است و مرکز سیاسی، اقتصادی، فرهنگی و حمل و نقل چین است. به عنوان پایتخت چین، ساخت و توسعه شبکه های جاده ای شهری در پکن نشان دهنده وضعیت آن است. پکن دارای یک سیستم شبکه جاده ای به خوبی توسعه یافته، مسیرهای تاکسی فراوان، حالت های متنوع سفر کاربر و منابع گسترده داده های مسیر است. بنابراین، پکن اولین انتخاب برای این مطالعه بود. داده های مسیر تاکسی در پکن دارای ویژگی های آشکار داده های نمونه بزرگ و اهمیت نماینده معمولی است. آنها برای توسعه تشخیص منطقه هات اسپات شهری بر اساس داده کاوی مسیر مناسب هستند. نتایج تشخیص نقطه اتصال میتواند پشتیبانی دادهها را برای بخشهای مدیریت ترافیک فراهم کند، کاربران را برای سفر معقول راهنمایی کند، در زمان سفر صرفهجویی کند و ازدحام ترافیک در شهرهای بزرگ را کاهش دهد. ما مجموعهای از آزمایشها را برای ارزیابی عملکرد الگوریتم پیشنهادی انجام دادیم. ابتدا تنظیمات آزمایشی، از جمله معرفی محیط آزمایشی و چندین پارامتر انتخاب شده در آزمایشها را ارائه میکنیم. سپس مجموعه داده ها و معیارهای ارزیابی مورد استفاده در آزمایش ها معرفی می شوند. در نهایت، نتایج تجسم آزمایشها نشان داده میشود، و دقت روش پیشنهادی با استفاده از متریک silhouette ارزیابی میشود. ما مجموعهای از آزمایشها را برای ارزیابی عملکرد الگوریتم پیشنهادی انجام دادیم. ابتدا تنظیمات آزمایشی، از جمله معرفی محیط آزمایشی و چندین پارامتر انتخاب شده در آزمایشها را ارائه میکنیم. سپس مجموعه داده ها و معیارهای ارزیابی مورد استفاده در آزمایش ها معرفی می شوند. در نهایت، نتایج تجسم آزمایشها نشان داده میشود، و دقت روش پیشنهادی با استفاده از متریک silhouette ارزیابی میشود. ما مجموعهای از آزمایشها را برای ارزیابی عملکرد الگوریتم پیشنهادی انجام دادیم. ابتدا تنظیمات آزمایشی، از جمله معرفی محیط آزمایشی و چندین پارامتر انتخاب شده در آزمایشها را ارائه میکنیم. سپس مجموعه داده ها و معیارهای ارزیابی مورد استفاده در آزمایش ها معرفی می شوند. در نهایت، نتایج تجسم آزمایشها نشان داده میشود، و دقت روش پیشنهادی با استفاده از متریک silhouette ارزیابی میشود.
فرآیند آزمایشی ما به طور خاص به شرح زیر ترتیب داده شد: (1) پیش پردازش مجموعه داده های تجربی بر اساس مدل پیشنهادی مسیر سفر مسافری. (2) مناطق کانونی شهری را از دادههای مسیر تاکسی بر اساس الگوریتم QTNA شناسایی کنید. (3) نتایج تجربی و تجزیه و تحلیل مربوطه را بدست آورید.
3.1. محیط آزمایشی و انتخاب پارامتر
آزمایشها با MATLAB 8.3 روی رایانه شخصی با پردازنده Intel Core 2 Duo 3.60 گیگاهرتز و رم 32 گیگابایتی انجام شد. سیستم عامل مایکروسافت ویندوز 10 بود.
به منظور ارزیابی اثر و دقت تشخیص ناحیه هات اسپات، دو مجموعه آزمایش در این بخش انجام می شود (یک مجموعه بر اساس داده های دوره های زمانی مختلف در یک روز و دیگری بر اساس داده های همان روز است. دوره زمانی در روزهای مختلف). الگوریتم QTNA پیشنهادی از نظر تأثیر و دقت با روشهای خوشهبندی DBSCAN و QT مقایسه میشود. دلایل انتخاب این دو الگوریتم برای آزمایش های مقایسه ای به شرح زیر است. اول، QTNA یک روش خوشهبندی مبتنی بر چگالی است. DBSCAN کلاسیکترین الگوریتم مبتنی بر چگالی است و همچنین پرکاربردترین الگوریتم خوشهبندی مبتنی بر چگالی برای تشخیص نقاط داغ است. دوم، ایده انتخاب خوشه بهینه برای هر تکرار موجود در الگوریتم QT اساس الگوریتم پیشنهادی ما است. θr، آستانه اندازه θn، و آستانه شماره تکرار θج. به طور خاص، بر اساس الزامات مقیاس واقعی و نتایج تجربی پیش پردازش ما، θrبه عنوان 0.005 اختصاص داده شده است، θn30 تنظیم شده است و θج100 تنظیم شده است.
3.2. مجموعه داده
همانطور که قبلا ذکر شد، ما از پکن به عنوان محل مطالعه موردی استفاده کردیم. دادههای آزمایشی مسیر GPS تقریباً 20000 تاکسی در پکن در مارس 2017 از شرکت فناوری هوشمند Datatang (پکن، چین) (خیابان Zhongguancun، منطقه Haidian، پکن، چین) که شامل سازنده تجهیزات اصلی تاکسیها (OEM) میشد. ) کد شناسایی، رمزگذاری شماره تلفن پایانه، زمان هماهنگ شده جهانی (UTC)، طول پیام، عرض جغرافیایی، طول جغرافیایی، زاویه رانندگی، سرعت رانندگی، مسافت پیموده شده، شرح موقعیت، توضیحات خودروی خالی و بارگذاری شده، وضعیت، شرح وضعیت، و اطلاعات دیگر. دادههای روزانه در قالب فایل txt ذخیره میشد – مانند «20170301.txt» که دادههای موقعیت مکانی GPS همه تاکسیهای پکن را در 1 مارس 2017 ثبت کرد. میانگین داده های مسیر روزانه شامل تقریباً 25.05 میلیون مکان است. به دلیل خرابی تجهیزات یا ارتباطات و دلایل دیگر، برخی از داده های نمونه برداری ناگزیر اشتباه خواهند بود. بنابراین، مجموعه دادهها باید پاک میشد تا رکوردهایی با دادههای گمشده یا آشکارا غیرعادی حذف شوند. داده های مسیر تاکسی مورد استفاده در موارد زیر همگی از پیش پردازش شده بودند. این مجموعه داده به عنوان TaxiDS نشان داده می شود.
در آزمایشهای زیر، مجموعاً 12 زیر مجموعه داده را از TaxiDS استخراج کردیم که بهطور خاص شامل دادههای مکانهای تحویل و رها کردن مسیرهای سفر مسافر در طول سه دوره یکسان (8:00-9:00، 13) بود. :00–14:00 و 18:00–19:00—در 1 مارس 2017 و 4 مارس 2017. در سه دوره زمانی 1 مارس، تعداد نقاط تحویل به ترتیب 17675، 18835 و 15403 است. و تعداد امتیازات ریزش به ترتیب 16517، 17573 و 16431 می باشد. در سه بازه زمانی 4 اسفند تعداد نقاط وانت به ترتیب 11466، 14011 و 11381 و تعداد نقاط اسقاط به ترتیب 10490، 13710 و 12422 بوده است. حجم کل 12 زیر مجموعه داده 3.38 مگابایت است.
3.3. معیارهای ارزیابی
بگذارید Tcluster ها مجموعه ای متشکل از خوشه های مسیر و nتومترجتعداد خوشه های مسیر در Tcluster باشد. مقدار شاخص silhouette [ 24 ] مسیر تیایکسمی توان برای اندازه گیری میزان انسجام بین تیایکسو خوشه مسیر سیمنکه به آن تعلق دارد و میزان جدایی بین تیایکسو سایر خوشه های مسیر ( سیj، j≠من). به عنوان مشخص می شود اس(تیایکس)و معادله آن به صورت زیر است:
اس(تیایکس)=ب(تیایکس)–آ(تیایکس)مترآایکس{آ(تیایکس)، ب(تیایکس)}،
جایی که آ(تیایکس)میانگین فاصله است تیایکسبه همه تیy( تیایکس،تیy∈سیمن،تیy≠تیایکس) و ب(تیایکس)حداقل فاصله روی همه خوشه ها است سیj( j≠من) از میانگین فاصله تا تیy∈سیj. آ(تیایکس)و ب(تیایکس)را می توان به صورت زیر محاسبه کرد:
آ(تیایکس)=1|سیمن|–1∑تیایکس،تیy∈سیمن، تیایکس≠تیyدمنستی(تیایکس،تیy)،
ب(تیایکس)=مترمنnسیمن،سیj∈تیسیلتوسهrس، j≠من{1|سیj|∑تیy∈سیjدمنستی(تیایکس،تیy)}.
ارزش شبح اس(تیایکس)محدوده از -1 تا 1، که در آن یک مقدار بالا نشان می دهد که مسیر تیایکسبه خوبی با خوشه خود و با خوشه های همسایه تطابق ضعیفی دارد. اگر بیشتر مسیرها مقادیر بالایی داشته باشند، نتیجه خوشه بندی مسیر مناسب است.
سپس میتوانیم اعتبار خوشهبندی مسیر را با استفاده از شاخص silhouette ( SI )، که به صورت زیر تعریف میشود، کمی کنیم:
اسمن=1nتومترج∑من=1nتومترج{1|سیمن|∑تیایکس∈سیمناس(تیایکس)}.
SI برای ارزیابی عملکرد الگوریتم خوشه بندی مناسب است و نتیجه آن نماینده ارزیابی اثر خوشه بندی است.
3.4. نتایج مطالعه موردی
در این بخش، هم نتایج تجربی و هم تحلیل مربوط به این مطالعه موردی ارائه شده است. مجموعه ای از آزمایش های مقایسه ای ابتدا برای ارزیابی عملکرد رویکرد پیشنهادی انجام می شود. سپس، مناطق کانونی شهری شناسایی شده به صورت بصری نمایش داده می شوند.
3.4.1. دوره های زمانی مختلف در یک روز
ابتدا مجموعهای از آزمایشها برای استنباط مناطق کانونی در بازههای زمانی مختلف در یک روز انجام شد. مجموعه داده شامل مکانهای تحویل و تحویل مسیرهای مسافرتی در سه دوره معمولی (8:00-9:00، 13:00-14:00، و 18:00-19:00) در 1 مارس 2017 بود. .
همانطور که در شکل 3 نشان داده شده است ، 10 ناحیه انتخاب داغ توسط الگوریتم های QTNA و DBSCAN در سه بازه زمانی روز با سه نماد مختلف مشخص شده اند. شکل 3 a نتایج تشخیص QTNA را نشان می دهد و شکل 3 b نتایج تشخیص DBSCAN را نشان می دهد. منطقه هات اسپات شناسایی شده توسط DBSCAN تقریبا نیمی از مرکز شهر را پوشش می دهد که برای مدیریت ترافیک یا برنامه ریزی شهری بی معنی است. نتایج شناسایی شده نشان میدهد که الگوریتم QTNA پیشنهادی برای تشخیص نقطههای مهم مناسبتر است.
از شکل 3 قابل مشاهده استاین که مناطق وانت گرم شناسایی شده عمدتاً در نواحی چائویانگ، دونگچنگ، شیچنگ، فنگتای، شونیی، هایدیان و تونگژو توزیع شدهاند و برخی مناطق در دورههای مختلف مناطق وانت گرم هستند. به عبارت دیگر، مناطق همپوشانی وجود دارد که با نمادهای مختلف مشخص شدهاند، مانند منطقه نزدیک تقاطع جاده گوانگهوا و خیابان جنوبی جینگهوا در منطقه چائویانگ، که اتفاقاً خروجی ایستگاه مترو Jintaixizhao با جریان زیادی مسافر است. برخی از مناطق فقط در یک بازه زمانی خاص مناطقی هستند که برای دریافت گرما استفاده می شوند. به عنوان مثال، منطقه نزدیک به خروجی ایستگاه مترو Taoranting در خیابان Baizhifang شرقی در منطقه Xicheng یک منطقه گرم بین ساعت 8:00 تا 9:00 است. منطقه نزدیک تقاطع بزرگراه Jingtong و جاده Xidawang در منطقه Chaoyang بین ساعت 13:00 تا 14:00 یک منطقه گرم است. و منطقه نزدیک تقاطع جاده میانی بینه و خیابان یودایه شرقی در منطقه تونگژو، بین ساعت 18:00 تا 19:00 یک منطقه گرم برای وانت است. چنین کشف نقطهای برای بسیاری از کاربردها ارزشمند است. می تواند راهنمایی برای تصمیم گیری های مدیریت ترافیک در دوره های زمانی خاص ارائه دهد.
همانطور که در شکل 4 نشان داده شده است ، 10 ناحیه افت داغ بالا که توسط الگوریتم های QTNA و DBSCAN در سه بازه زمانی روز شناسایی شده اند با سه نماد مختلف مشخص شده اند. شکل 4 a نتایج تشخیص الگوریتم QTNA و شکل 4 b نتایج تشخیص الگوریتم DBSCAN را نشان می دهد. مشابه نتیجه در شکل 3 ب، ناحیه هات اسپات در شکل 4 شناسایی شده استb همچنین تقریبا نیمی از مرکز شهر را پوشش می دهد که نشان می دهد الگوریتم DBSCAN برای استنتاج نقاط حساس مناسب نیست. مناطق ریزش داغ شناسایی شده عمدتاً در نواحی چائویانگ، دونگچنگ، هایدیان، شیچنگ، فنگتای و شونی توزیع شدهاند. همچنین میتوان مشاهده کرد که برخی از مناطق در دورههای زمانی مختلف، مناطق پرتابکننده گرم هستند، مانند پایانههای T1، T2، و T3 فرودگاه بینالمللی پایتخت پکن واقع در منطقه Shunyi و منطقه داخلی چائویانگ آن. برخی از مناطق فقط مناطق تخلیه گرم در یک دوره زمانی خاص هستند. به عنوان مثال، منطقه نزدیک به تقاطع جاده Xiaoyun و جاده Dongsanhuan شمالی در منطقه Chaoyang یک منطقه تخلیه گرم در بازه زمانی 8:00 تا 9:00 است. منطقه نزدیک به جاده شرقی Zhongguancun، جاده Chengfu، و جاده Heqing در منطقه Haidian، منطقهای گرم در طول دوره زمانی ۱۸ است:
الگوریتم DBSCAN اساساً فرآیندی برای یافتن نمونههای هسته با چگالی بالا و گسترش خوشهها از آنها است. برای هر نقطه p ، اگر نقطه هسته باشد، می توان یک خوشه C با p به عنوان مرکز و r به عنوان شعاع تشکیل داد. فرآیند گسترش برای عبور از نقاط در خوشه انجام می شود. اگر نقطه q متعلق به r- همسایگی p نقطه مرکزی باشد، نقاط موجود در همسایگی r – q نیز در خوشه C طبقه بندی می شوند . این فرآیند به صورت بازگشتی تا C اجرا می شوددیگر قابل گسترش نیست DBSCAN برای داده هایی که دارای خوشه هایی با چگالی مشابه هستند خوب است. با این حال، در یک شبکه ترافیک واقعی، مکان ها در مسیرهای تاکسی به طور مساوی توزیع نشده اند. در مقابل، الگوریتم QTNA میتواند مناطق با تراکم بالا را بر روی هر نقطه شناسایی کند و رابطه بین هر مرکز خوشه و همسایگی آن را برای به دست آوردن نتایج خوشهبندی با کیفیت بالا در نظر میگیرد که برای تحلیل نقاط داغ شهری قابل توجه است.
بر اساس نتایج تشخیص 10 منطقه برتر انتقال و رهاسازی گرم در طول سه دوره زمانی مختلف در یک روز، مشخص شد که (1) نواحی برداشت و رها کردن گرم به طور نابرابر توزیع و متمرکز شدهاند. در ناحیه هسته عملکردی پایتخت و منطقه توسعه عملکرد شهری؛ (2) برخی از مناطق حمل و نقل گرم نیز مناطق تخلیه گرم بودند که عموماً در بخشهای جادهای با جریان مسافر زیاد، مانند ورودیهای مترو و ایستگاههای اتوبوس متمرکز شدهاند. و (iii) در مقایسه با مناطق برداشت گرم، توزیع مناطق تخلیه گرم در دورههای زمانی مختلف در همان روز متمرکزتر بود. نقاط داغ در یک بازه زمانی معین منعکس کننده ویژگی های تجمع سفر ساکنان شهری است و کشف نقاط کانونی برای مدیریت علمی ترافیک و برنامه ریزی شهری مفید است.
به منظور تأیید صحت تشخیص الگوریتم پیشنهادی، SI معرفی شده در بخش 3.3 برای ارزیابی کمی انتخاب شد. مکانهای تحویل و رهاسازی در طول سه دوره زمانی برای یافتن مناطق حمل و نقل و رها کردن داغ دستهبندی شدند. شکل 5 مقایسه مقادیر شبح الگوریتم های QTNA، DBSCAN و QT را در سه مجموعه داده با دوره های زمانی مختلف نشان می دهد. شکل 5 a نتایج خوشهبندی را بر اساس مجموعه دادههای مکان برداشت برای دورههای زمانی مختلف نشان میدهد و شکل 5 b نتایج خوشهبندی را بر اساس مجموعه دادههای مکان رهاسازی برای دورههای زمانی مختلف نشان میدهد. همانطور که از شکل 5 مشخص استدقت الگوریتم QTNA پیشنهادی نسبت به دو الگوریتم دیگر برتری داشت. با قضاوت از نتایج تجسم و ارزیابی دقت، الگوریتم پیشنهادی برای تشخیص نقطههای مهم مناسبتر است.
3.4.2. بازه زمانی یکسان در روزهای مختلف
دوم، مجموعهای از آزمایشها برای استنتاج منطقه کانونی در طول یک دوره زمانی مشابه در روزهای مختلف انجام شد. مجموعه داده شامل مکانهای تحویل و تحویل مسیرهای مسافرتی در سه دوره یکسان (8:00-9:00، 13:00-14:00، و 18:00-19:00) در 1 مارس 2017 بود. و 4 مارس 2017. شکل 6 10 منطقه بالا و پایین رفتن داغ را نشان می دهد که توسط الگوریتم QTNA در دو روز بین ساعت 8:00 تا 9:00 شناسایی شده است که با نمادهایی از چهار رنگ و شکل مختلف مشخص شده اند. شکل 6 a توزیع نقاط حساس را بر روی نقشه جهانی پکن نشان می دهد و شکل 6 b نمای بزرگ شده ای از ناحیه قاب شده توسط کادر قرمز در شکل 6 است.آ. مشاهده می شود که برخی از مناطق پر تراکم با نمادهای مختلفی مشخص شده اند که نشان می دهد این مناطق در این بازه زمانی در دو روز کانون هستند.
از نتایج تشخیص 10 منطقه برتر حمل و نقل و رها کردن گرم در یک دوره زمانی مشابه در تاریخ های مختلف، موارد زیر را دریافتیم: (1) در بازه زمانی بین ساعت 8:00 و 9:00 روز کاری (1 مارس) و روز استراحت (4 مارس)، مناطق وانت گرم عمدتاً در نواحی چائویانگ، دانگ چنگ، شیچنگ، فنگتای و هوایرو توزیع شدند. مناطق تخلیه گرم عمدتاً در نواحی چائویانگ، دونگچنگ، شیچنگ، هایدیان، فنگتای و شونی توزیع شدهاند. (ii) تفاوتهای مشخصی بین مناطق جمعآوری گرم در روزهای استراحت و مناطق در روزهای هفته وجود داشت. به عنوان مثال، منطقه Huairou یک منطقه توسعه حفاظت از محیط زیست است، با تراکم جمعیت دائمی تنها 185 نفر در هر کیلومتر مربع .. 10 منطقه حمل و نقل داغ که در طی چندین دوره زمانی در روزهای کاری شناسایی شدهاند، در منطقه هوایرو توزیع نشدهاند، و مناطق حمل و نقل گرم در نزدیکی خیابان نانهوا در سمت غربی میدان Yingbin در بخش جنوبی هوایرو توزیع نشدهاند. منطقه در روزهای استراحت شناسایی شد. با توجه به تنوع اهداف سفر و مسافت سفر در روزهای استراحت، تغییرات خاصی در مناطق وانت گرم ایجاد شد. (iii) در میان 10 منطقه ریزش گرم بالا که در بازه زمانی 8:00 تا 9:00 در دو روز شناسایی شده است، یک منطقه تخلیه گرم واقع در منطقه شونیی در ناحیه چائویانگ وجود دارد، همانطور که نشان داده شده است. در شکل 6– مکان مشخص در فرودگاه بین المللی پایتخت پکن (ترمینال های T1 و T2) بود. یکی دیگر از مناطق تخلیه گرم ترمینال T3 واقع در منطقه Shunyi بود که نشان می دهد مناطق تخلیه گرم برای مسیرهای سفر مسافر اغلب مقاصد مسافرتی محبوب برای ساکنان شهری هستند. (iv) در دوره 8:00 تا 9:00 این دو روز، مناطقی وجود داشت که هم مکان های حمل و نقل گرم و هم مکان های تخلیه گرم بودند، مانند مناطق واقع در خروجی های متروی ایستگاه راه آهن پکن. ایستگاه، همانطور که در شکل 7 نشان داده شده است.
برای تأیید صحت تشخیص الگوریتم پیشنهادی، علاوه بر دادهها در بازه زمانی 8:00-9:00، دادهها در بازههای زمانی 13:00-14:00 و 18:00-19:00 نیز بود. برای آزمایش های مقایسه انتخاب شده است. جدول 1 مقایسه مقادیر شبح نتایج خوشهبندی الگوریتمهای QTNA، DBSCAN و QT را بر اساس مکانهای برداشت در یک دوره زمانی مشابه در تاریخهای مختلف نشان میدهد. جدول 2 مقایسه مقادیر شبح نتایج خوشهبندی این سه الگوریتم را بر اساس مکانهای رها کردن در یک دوره زمانی مشابه در تاریخهای مختلف نشان میدهد.
به طور خلاصه، همانطور که در شکل 5 نشان داده شده است ، بر اساس مجموعه داده های مکان سوار تاکسی و مکان تحویل در دوره های زمانی مختلف یک روز، مقادیر شبح نتایج خوشه بندی به دست آمده بر اساس الگوریتم QTNA بیشتر از الگوریتم های DBSCAN و QT همانطور که در جدول 1 و جدول 2 نشان داده شده است، بر اساس داده های یک دوره زمانی در تاریخ های مختلف، نتایج یکسانی به دست آمد. بنابراین، با توجه به نتایج خوشهبندی در مجموعه دادههای مکان سوار و رها کردن تاکسی، تراکم مکانهای دریافت و تحویل تاکسی را میتوان به وضوح تشخیص داد و مناطق کانون مربوطه را میتوان استنباط کرد. چگالی نسبی بر اساس تداعی همسایگی، صحت نتایج خوشهبندی را تضمین میکند. علاوه بر این، آستانههای شعاع و اندازه را میتوان مقادیر متفاوتی برای انطباق با موقعیتهای واقعی مختلف نسبت داد. نتایج مقایسه تجربی نشان میدهد که الگوریتم پیشنهادی از نظر کاربرد و دقت از الگوریتمهای سنتی خوشهبندی DBSCAN و QT بهتر عمل میکند.
4. بحث
کاوش نقاط مورد علاقه از داده های مسیر تاکسی برای مدیریت ترافیک شهری، برنامه ریزی جاده و خدمات مبتنی بر مکان مفید است. مناطق کانونی پنهان در دادههای مسیر، اطلاعاتی هستند که باید هنگام مطالعه ویژگیهای سفر چند کاربر تسلط داشته باشند و میتوانند برای ایجاد یک مدل پیشبینی از رفتار کاربر آینده استفاده شوند. تشخیص ناحیه هات اسپات یک موضوع علمی مهم در تحلیل داده های مسیر است. مکانها و مسیرهایی که ساکنان اغلب از طریق آنها سفر میکنند، میتوانند به طور مستقیم شرایط ترافیک شهری و الگوهای حرکت کاربر را منعکس کنند. مکانهای دریافت و تحویل گرم که در دورههای مختلف روز شناسایی میشوند، میتوانند به طور موثری سفر کاربر را راهنمایی کنند و از ازدحام ترافیک جلوگیری کنند.25 ]. پکن به عنوان پایتخت چین، دارای سیستم شبکه جاده ای توسعه یافته، مسیرهای تاکسی فراوان و منابع گسترده داده های مسیر است. این مقاله دادههای مسیر GPS حدود 20000 تاکسی در پکن را در مارس 2017 مورد مطالعه قرار داد و توزیع مناطق کانونی شهری را با توجه به زمان تجزیه و تحلیل کرد. ابتدا، مکانهای سوار و رها کردن از دادههای مسیر تاکسی بر اساس مدل مسیر سفر مسافر ساخته شده استخراج شد. سپس یک الگوریتم خوشهبندی کیفیت مرتبط با نزدیکترین محله برای خوشهبندی مکانهای حمل و نقل پیشنهاد شد. از یک طرف، ما مناطق کانونی را در بازه های زمانی مختلف در همان روز شناسایی و تجزیه و تحلیل کردیم. از سوی دیگر، ما بر روی نتایج تشخیص در همان بازه زمانی در روزهای مختلف تمرکز کردیم.
به طور خلاصه، در مقایسه با تحقیقات قبلی، تفاوت ها و مزایای این مطالعه به شرح زیر است:
- (1)
-
ساخت مدل نزدیکترین محله. با یادگیری از کار قبلی خود [ 26 ]، ما یک مدل نزدیکترین محله را پیشنهاد کردیم، که در خوشه بندی مکان پذیرفته شد و می تواند به شناسایی خوشه های بهینه کمک کند.
- (2)
-
تشخیص منطقه کانونی شهری با استفاده از الگوریتم خوشهبندی آستانه کیفیت بهبودیافته بر اساس تداعی محله. یک الگوریتم خوشهبندی آستانه کیفیت بهبود یافته پیشنهاد شد که ارتباط همسایگی را به منظور بهبود دقت خوشهبندی فضایی در نظر میگیرد. الگوریتم پیشنهادی برای شناسایی مناطق کانونی شهری بر اساس دادههای مسیر تاکسی استفاده شد. تجزیه و تحلیل تراکم نسبی برای خوشه بندی فضایی مکان های تاکسی مهم است.
- (3)
-
مطالعه موردی. الگوریتم پیشنهادی بر روی مجموعه دادههای مسیر زندگی واقعی تاکسیها در پکن آزمایش شد. ارائه بصری و نتایج تجربی نشان میدهد که الگوریتم ما مناطق کانونی شهری را با دقت بالا شناسایی میکند و به طور موثر پشتیبانی دادهها را برای راهنمایی ترافیک فراهم میکند.
نتایج این مطالعه برای راهنمایی ترافیک و برنامه ریزی تسهیلات شهری با مفاهیم کاربردی زیر مفید است:
- (1)
-
انتشار نقاط حساس شناسایی شده در یک بازه زمانی خاص می تواند به کاهش تراکم ترافیک و بهبود کیفیت تجربه سفر ساکنان کمک کند.
- (2)
-
نتایج تشخیص هات اسپات در بازه زمانی یکسان در روزهای مختلف می تواند به طور موثری مکان تاسیسات عمومی شهری را راهنمایی کند و اتلاف منابع را کاهش دهد.
- (3)
-
مناطق کانونی شناسایی شده از مجموعه داده های مسیر تاکسی می توانند راهنمایی هایی را برای دپارتمان های برنامه ریزی شهری برای راه اندازی مکان های پارک تاکسی ارائه دهند.
5. نتیجه گیری ها
نتایج استخراج عمیق دادههای مسیر تاکسی برای تحلیل ویژگیهای فضایی سفر ساکنان شهری مفید است. این مقاله با استفاده از یک الگوریتم خوشهبندی آستانه کیفیت بهبودیافته بر اساس تداعی محله، به موضوع تشخیص منطقه کانونی شهری پرداخته است. هر تکرار از الگوریتم پیشنهادی دارای سه مرحله خاص است. اول، θrهمسایگان برای هر مکان یافت می شوند تا چندین خوشه را تشکیل دهند. سپس، حداکثر خوشه ای که اندازه مورد نیاز را برآورده می کند انتخاب می شود. در نهایت، ویژگی های همسایگی خوشه نامزد برای فیلتر کردن خوشه بهینه فعلی تجزیه و تحلیل می شود. روش پیشنهادی نه تنها حداکثر خوشهبندی را در یک محدوده محدود در نظر میگیرد، بلکه چگالی محلی خوشهها و تنگی بین اشیاء را از طریق تجزیه و تحلیل همسایگی در نظر میگیرد و به طور موثر به موضوع خوشهبندی مجموعه دادههای توزیع نابرابر میپردازد. نمایش بصری و نتایج تجربی شبیهسازیشده نشان میدهد که الگوریتم پیشنهادی میتواند نقاط حساس شهری موثر و معقول را از دادههای مسیر تاکسی بهدست آورد و اطلاعات ارزشمندی را برای سیستمهای مدیریت ترافیک ارائه دهد. این دستاورد به اندازه کافی کاربردی است تا در توصیه های سفر و برنامه ریزی جاده ها به کار رود و همچنین ممکن است در تجزیه و تحلیل منطقه هات اسپات شهری بر اساس سایر اجسام متحرک در شهر استفاده شود. این مقاله خوشهبندی را بر اساس مکانهای برداشت و رها کردن، بدون خوشهبندی بخشهای مسیر مورد مطالعه قرار داد. در آینده، ما قصد داریم مسیرهای پرطرفدار را در دورههای زمانی مختلف استنتاج کنیم و توصیههای شخصیسازی شده مسیر را انجام دهیم.
مشارکت های نویسنده
مفهوم سازی، Qingying یو. سرپرستی داده ها، چوانمینگ چن. تامین مالی، Qingying یو، Liping Sun و Xiaoyao Zheng. روش، Qingying یو. نظارت، چوانمینگ چن. اعتبار سنجی، چوانمینگ چن. تجسم، Qingying یو. نوشتن-پیش نویس اصلی، Qingying Yu; نوشتن-بررسی و ویرایش، Liping Sun و Xiaoyao Zheng. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق توسط بنیاد ملی علوم طبیعی چین، شماره های کمک مالی 61702010، 61972439، و 61672039، بنیاد علوم طبیعی استان آنهویی، شماره کمک مالی 1808085MF172، و برنامه کلیدی در طرح حمایت از نخبگان جوانان در دانشگاه های Anhui2040D (Anhui2040D) تامین شد. ).
بیانیه هیئت بررسی نهادی
قابل اجرا نیست.
بیانیه رضایت آگاهانه
قابل اجرا نیست.
قدردانی
نویسندگان مایلند از نظرات و پیشنهادات مفید داوران برای این مقاله تشکر کنند. این کار توسط بنیاد ملی علوم طبیعی چین (گرنت شماره های 61702010، 61972439، و 61672039)، بنیاد علوم طبیعی استان آنهویی (گرنت شماره 1808085MF172) و برنامه کلیدی در طرح حمایت از نخبگان جوانان در دانشگاه ها حمایت شده است. استان آنهویی (Grant No. gxyqZD2020004).
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- گونگ، اس. کارتلیج، جی. روبین، بی. یو، ی. لی، کیو. کیو، جی. کالیبراسیون مدل هاف جغرافیایی و زمانی با استفاده از داده های مسیر تاکسی. GeoInformatica 2020 ، 4 ، 1-28. [ Google Scholar ] [ CrossRef ]
- اشبروک، دی. Starner, T. استفاده از GPS برای یادگیری مکانهای مهم و پیشبینی حرکت بین کاربران متعدد. پارس محاسبات همه جا حاضر. 2003 ، 7 ، 275-286. [ Google Scholar ] [ CrossRef ]
- ژو، سی. فرانکوفسکی، دی. لودفورد، پی. شکر، س. تروین، ال. کشف روزنامههای شخصی: رویکرد خوشهبندی تعاملی. در مجموعه مقالات دوازدهمین کارگاه بین المللی سالانه ACM در سیستم های اطلاعات جغرافیایی (GIS)، آرلینگتون، VA، ایالات متحده آمریکا، 12-13 نوامبر 2004. صص 266-273. [ Google Scholar ]
- کائو، ایکس. کنگ، جی. جنسن، CS استخراج مکان های معنایی قابل توجه از داده های GPS. Proc. VLDB Enddow. 2010 ، 3 ، 1009-1020. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شیا، ی. ون، اچ. Zhang, X. روش تجزیه و تحلیل مسیر داغ بر اساس خوشه بندی مسیر. J. دانشگاه چونگ کینگ. پست های مخابراتی. (Nat. Sci.) 2011 , 23 , 602-606. [ Google Scholar ]
- گی، ز. شیانگ، ی. لی، ی. کشف موازی نقطه داغ شهر بر اساس مسیرهای تاکسی. J. Huazhong Univ. علمی تکنولوژی (Nat. Sci.) 2012 ، 40 ، 187-190. [ Google Scholar ]
- Ma, Y. تحقیق در مورد رفتار ساکنان مناطق جذاب و ویژگی های مکانی-زمانی بر اساس داده های مسیر تاکسی . دانشگاه عادی نانجینگ: نانجینگ، چین، 2014. [ Google Scholar ]
- وحشی، NS; نیشیمورا، اس. چاوز، NE; Yan, X. استخراج مسیر مکرر در داده های GPS. در مجموعه مقالات سومین کارگاه بین المللی مکان و وب، توکیو، ژاپن، 29 نوامبر 2010. جلد 2010، صص 8-11. [ Google Scholar ]
- فریرا، اس. Couto، A. شناسایی نقطه داغ: رویکرد مدل باینری طبقه بندی شده. ترانسپ Res. ضبط 2013 ، 2386 ، 1-6. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Scholz، RW مدلسازی فضا-زمان الگوهای سفر-فعالیت روزانه جمعیت شهری با استفاده از دادههای مسیر GPS . دانشگاه ایالتی تگزاس: سن مارکوس، تگزاس، ایالات متحده آمریکا، 2018. [ Google Scholar ]
- هنگ، ز. چن، ی. محمسنی، HS شناسایی الگوهای سفر به شبکه با استفاده از الگوریتم خوشهبندی مسیر خودرو مکانی-زمانی. IEEE Trans. هوشمند ترانسپ سیستم 2018 ، 19 ، 2548-2557. [ Google Scholar ] [ CrossRef ]
- ژائو، پی. Qin، K. بله، X. وانگ، ی. Chen, Y. یک رویکرد خوشهبندی مسیر مبتنی بر نمودار تصمیمگیری و میدان داده برای شناسایی نقاط داغ. بین المللی جی. جئوگر. Inf. علمی 2017 ، 31 ، 1101-1127. [ Google Scholar ] [ CrossRef ]
- لی، اف. شی، دبلیو. ژانگ، اچ. یک رویکرد خوشهبندی دو فازی برای تشخیص نقاط داغ شهری با محدودیتهای فضایی و زمانی شبکه. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2021 , 14 , 3695–3705. [ Google Scholar ] [ CrossRef ]
- وو، بی. Wilamowski، BM یک روش خوشهبندی مبتنی بر شبکه و چگالی سریع برای دادهها با اشکال و نویز دلخواه. IEEE Trans. Ind. اطلاع رسانی. 2017 ، 13 ، 1620-1628. [ Google Scholar ] [ CrossRef ]
- جیانگ، ز. وانگ، ام. Chen, Y. توصیه مسیر بر اساس مختصات جغرافیایی و داده های مسیر. J. Commun. 2017 ، 38 ، 165-171. [ Google Scholar ]
- کیائو، اس. هان، ن. دینگ، ز. جین، سی. سان، دبلیو. شو، اچ. مدل پیشبینی مسیر با الگوی حرکت چندگانه برای اجسام متحرک نامشخص. Acta Autom. گناه 2018 ، 44 ، 608-618. [ Google Scholar ]
- ژانگ، دی. تره فرنگی.؛ لی، I. خوشهبندی مسیر سلسله مراتبی برای الگوبرداری دورهای مکانی-زمانی. سیستم خبره Appl. 2018 ، 92 ، 1-11. [ Google Scholar ] [ CrossRef ]
- یوان، جی. سان، پ. ژائو، جی. لی، دی. وانگ، سی. مروری بر الگوریتمهای خوشهبندی مسیر جسم متحرک. آرتیف. هوشمند Rev. 2017 , 47 , 123-144. [ Google Scholar ] [ CrossRef ]
- دونگ، اس. لیو، جی. لیو، ی. زنگ، ال. خو، سی. ژو، تی. خوشه بندی بر اساس شبکه و چگالی محلی با بسط مبتنی بر اولویت برای داده های چند چگالی. Inf. علمی (NY) 2018 ، 468 ، 103-116. [ Google Scholar ] [ CrossRef ]
- مائو، ی. ژونگ، اچ. چی، اچ. پینگ، پی. Li، X. یک روش خوشهبندی مسیر تطبیقی بر اساس شبکه و چگالی در تحلیل الگوی موبایل. Sensors 2017 , 17 , 2013. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژنگ، ال. شیا، دی. ژائو، ایکس. تان، ال. لی، اچ. الگوی سفر مکانی-زمانی کاوی با استفاده از داده های عظیم مسیر تاکسی. فیزیک یک آمار مکانیک. Appl. 2018 ، 501 ، 24-41. [ Google Scholar ] [ CrossRef ]
- لیو، سی. Qin، K. کانگ، سی. بررسی الگوهای تراکم ترافیک وابسته به زمان از دادههای مسیر تاکسی. در مجموعه مقالات دومین کنفرانس بین المللی IEEE در مورد داده کاوی مکانی و خدمات دانش جغرافیایی (ICSDM)، فوژو، چین، 8 تا 10 ژوئیه 2015. صص 39-44. [ Google Scholar ]
- پراویلوویچ، اس. آپیس، ا. لانزا، ا. Malerba، D. پیشبینی توان باد با استفاده از تحلیل خوشهای سری زمانی. در علم کشف ; انتشارات بین المللی Springer: چم، سوئیس، 2014; ص 276-287. [ Google Scholar ]
- De Amorim، RC; Hennig، C. بازیابی تعداد خوشهها در مجموعههای داده با ویژگیهای نویز با استفاده از عوامل تغییر مقیاس ویژگی. Inf. علمی (NY) 2015 ، 324 ، 126-145. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کیائو، ی. چنگ، ی. یانگ، جی. لیو، جی. کاتو، ن. چارچوب تحلیلی تحرک برای داده های بزرگ تلفن همراه در مناطق پرجمعیت. IEEE Trans. وه تکنولوژی 2017 ، 66 ، 1443-1455. [ Google Scholar ] [ CrossRef ]
- یو، کیو. لو، ی. چن، سی. Bian، W. روش تشخیص پرت مربوطه محله بر اساس آنتروپی اطلاعات. هوشمند داده آنال. 2016 ، 20 ، 1247-1265. [ Google Scholar ] [ CrossRef ]

شکل 1. دنباله ای از بخش های حالت مسیر یک روزه یک تاکسی. m بخش مسافرتی وجود دارد.
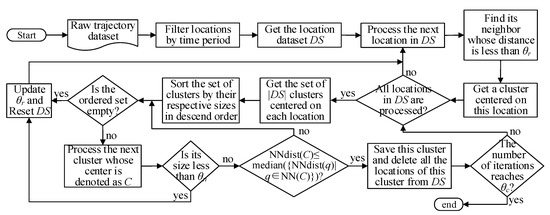
شکل 2. نمودار شماتیک روش پیشنهادی.
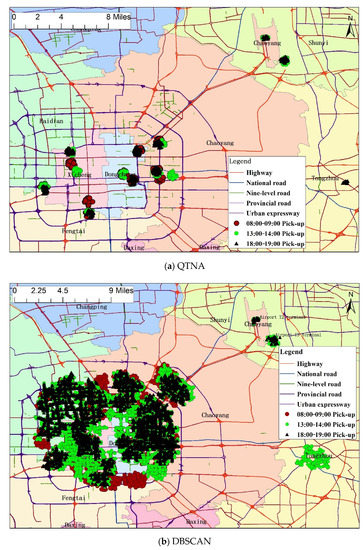
شکل 3. 10 منطقه انتخابی داغ در دوره های مختلف در همان روز. برخی از مناطق همپوشانی که با نمادهای مختلف مشخص شده اند، مناطق برداشت داغ در دوره های مختلف هستند. ( a ) نتایج تشخیص الگوریتم QTNA را نشان می دهد. ( ب ) نتایج تشخیص الگوریتم DBSCAN را نشان می دهد.
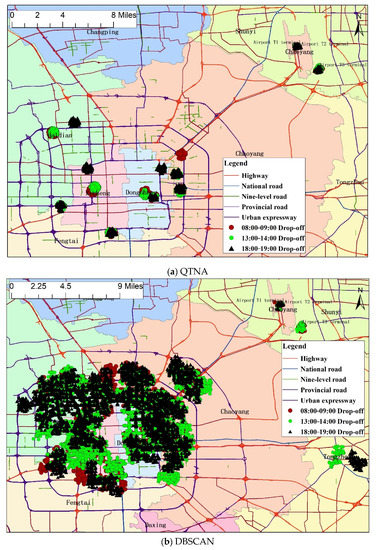
شکل 4. 10 منطقه پرتاب داغ در دوره های زمانی مختلف در یک روز. برخی از مناطق در بازه های زمانی مختلف مناطقی هستند که به صورت گرم تخلیه می شوند. ( a ) نتایج تشخیص الگوریتم QTNA را نشان می دهد. ( ب ) نتایج تشخیص الگوریتم DBSCAN را نشان می دهد.
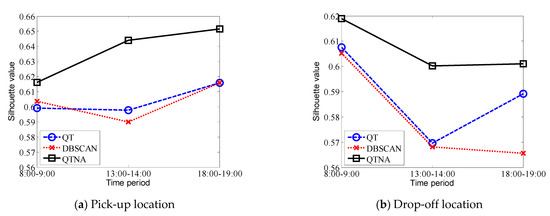
شکل 5. مقایسه عملکرد الگوریتم های خوشه بندی. ( الف ) نتایج خوشهبندی را بر اساس مکانهای برداشت در دورههای زمانی مختلف در همان روز نشان میدهد. ( ب ) نتایج خوشهبندی را بر اساس مکانهای ریزش در دورههای زمانی مختلف در همان روز نشان میدهد.
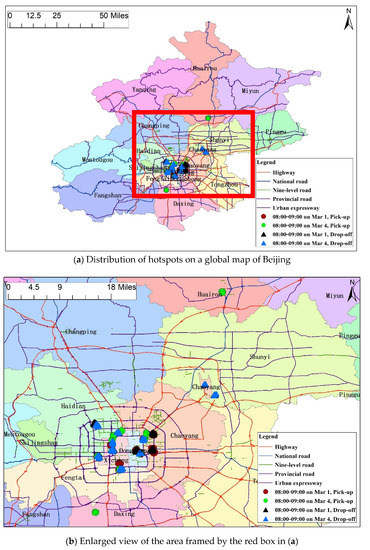
شکل 6. 10 منطقه بالا برای برداشت و رها کردن گرم در یک دوره زمانی در روزهای مختلف. ( الف ) توزیع نقاط حساس را در نقشه جهانی پکن نشان می دهد. ( ب ) نمای بزرگ شده ناحیه قاب شده توسط کادر قرمز در ( a ) را نشان می دهد.
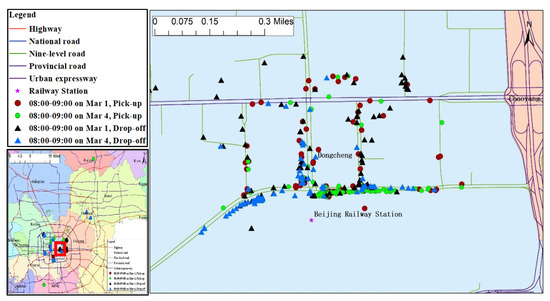
شکل 7. نمونه ای از یک منطقه حمل و نقل گرم در یک دوره زمانی در روزهای مختلف.


بدون دیدگاه