

خلاصه
:
اطلاعات دقیق تنظیم کننده های ترافیکی در تقاطع ها برای پیمایش و رانندگی در شهرها مهم است. با این حال، چنین اطلاعاتی اغلب در نقشه های دیجیتال به دلیل هزینه زیاد، به عنوان مثال، زمان و هزینه، برای جمع آوری و به روز رسانی داده ها، ناقص، ناقص یا به روز نیستند. در این مطالعه ما یک روش جمعسپاری را پیشنهاد میکنیم که از مسیرهای GPS سبک وزن از وسایل نقلیه در حال رفت و آمد به عنوان اطلاعات جغرافیایی داوطلبانه (VGI) برای تشخیص تنظیمکننده ترافیک استفاده میکند. ما ایده جدید تشخیص تنظیم کننده های ترافیک را با یادگیری الگوهای حرکت وسایل نقلیه در مکان های تنظیم شده بررسی می کنیم. رفتار حرکتی وسایل نقلیه در قالب مشخصات سرعت کدگذاری شد.چراغ های راهنمایی ، علائم اولویت و تقاطع های کنترل نشده . این روش یک تابع وزنی متوسط و یک طرح رای اکثریت برای تحمل خطاهای دادههای VGI ارائه میکند. چارچوب ترتیب به دنباله نیازی به سربار اضافی برای پردازش داده ندارد، که این روش را برای وظایف تشخیص تنظیم کننده ترافیک در دنیای واقعی قابل اجرا می کند. نتایج نشان داد که طبقهبندیکننده خودکار متغیر شرطی یادگیری عمیق میتواند تنظیمکنندهها را با دقت 90 درصد پیشبینی کند، و از طبقهبندیکننده جنگل تصادفی (دقت 88 درصد) که از آمار خلاصهشده حرکت به عنوان ویژگیها استفاده میکند، بهتر عمل میکند. در کار آینده ما، میتوان از تصاویر و تکنیکهای تقویت برای تعمیم توانایی روش برای طبقهبندی انواع بیشتری از کلاسهای تنظیمکننده ترافیک استفاده کرد.
کلید واژه ها:
تنظیم کننده های ترافیکی ؛ علائم راهنمایی و رانندگی خط سیر ; ازدحام ; جمع سپاری ; آهنگ های GPS ; سرعت-پروفایل ; تقاطع ها ؛ طبقه بندی ; دنباله به دنباله ; مدل مولد شرطی
1. معرفی
تحت چتر مفهوم شهر هوشمند ، توسعه حمل و نقل و تحرک هوشمند در دستور کار بسیاری از ادارات و نهادهای دولتی قرار گرفته است [ 1 ]. امروزه که رشد شهرنشینی [ 2 ] و تراکم ترافیک در شهرهای اروپایی [ 3 ] در حال افزایش است، نیاز به رفت و آمد سریع روزانه بین محل سکونت و محل کار، یا سفرهای دوره ای کمتر، انگیزه زیادی ایجاد کرده است. تحقیق در مورد اینکه چگونه این تقاضا می تواند به طور موثر تسهیل شود [ 4 ، 5]. برای این کار ناوبری، نقشه ها یک پایه ابتدایی هستند. این نقشه ها شامل هندسه و معنایی بخش های مسیر و همچنین اطلاعات اضافی مانند محدودیت ها یا تنظیم کننده های ترافیکی است. اگرچه نقشه برداری با تصاویر هوایی یا تجهیزات نقشه برداری یک روش دقیق و موثر برای جمع آوری ویژگی های یک شهر یا سطح زمین به طور کلی است، این روش بسیار زمان بر و هزینه بر است. این به ویژه مرتبط است، زیرا این داده ها در معرض تغییرات مکرر هستند.
راه حلی برای مشکل فوق از طریق مفهوم شهروندان به عنوان حسگر [ 6 ] ارائه شده است، که در آن اطلاعات جغرافیایی را می توان از طریق افرادی ایجاد کرد و به اشتراک گذاشت که می توانند به عنوان حسگر محیط خود عمل کنند. بر اساس این مفهوم، شهروندان می توانند اندازه گیری ها یا داده های مختلفی از محیط فعالیت خود، مانند مقادیر دما و نویز یا تصاویر را جمع آوری کنند. این دادهها همراه یا برچسبگذاری شده با مختصات جغرافیایی مکانی که از آن گرفته شدهاند، میتوانند به طور جمعی برای استخراج اطلاعات در مورد جنبههای خاصی از یک پدیده در سطح جغرافیایی پردازش شوند. برای این منظور، اطلاعات جغرافیایی داوطلبانه (VGI) تولید شده توسط کاربران فردی تا حد زیادی برای غنیسازی ویژگیهای موجود در نقشهها، به عنوان مثال، OpenStreetMap (OSM) [ 7] استفاده شده است.]. با این حال، اطلاعات تنظیمکنندههای ترافیک به عنوان یک ویژگی نقشه هنوز تا حد زیادی ناقص، ناقص یا قدیمی هستند.
1.1. از GPS-Tracks تا Traffic-Regulator Detection
راه حل کارآمد و “ارزان” برای تشخیص تنظیم کننده ترافیک از طریق “Crowdsourcing” است. این توضیح میدهد که چگونه یک کار بزرگ یا گرانقیمت، به عنوان مثال، غنیسازی تنظیمکنندههای ترافیک برای یک شهر در نقشههای دیجیتال، میتواند توسط گروهی از داوطلبان از طریق برخی از فعالیتهای آنلاین مشارکتی انجام شود [8]، بهعنوان مثال، جمعآوری مسیرهای GPS در هنگام رفتوآمد . از نقاط مختلف شهر این را می توان به راحتی با تجهیزات دستگاه های تلفن همراه مدرن که قادر به انجام وظایف پردازش، ذخیره سازی و سنجش عظیم هستند، انجام داد. برنامه های کاربردی جمع سپاری مبتنی بر مکان متعدد از طریق سنجش جمعیت سیار (MCS) [ 9 ] پدید آمده اند، مانند تولید شبکه جاده ای از مسیرهای GPS [ 10 ، 11 ، 12]]، توصیه مکان پارک [ 13 ]، تشخیص تراکم ترافیک [ 14 ]، نقض محدودیت سرعت [ 15 ]، برنامه های نقشه کارآمد انرژی [ 16 ] و مدیریت خطر سیل با استفاده از داده های جمع سپاری [ 17 ، 18 ، 19 ]. در این مطالعه، ما به ویژه علاقه مند به بررسی پتانسیل استفاده از VGI [ 20 ] بودیم که توسط کاربران جاده های شهری با استفاده از دستگاه های تلفن همراه برای جمع آوری مسیرهای GPS، برای غنی سازی ویژگی تنظیم کننده ترافیک در نقشه ها ایجاد می شود.
نقشه های شهر برای فعال کردن سریع ترین جهت گیری فضایی ممکن در فضای شهری ایجاد شده اند و ویژگی نقشه ارائه کننده اطلاعات تنظیم کننده ترافیک در تقاطع ها برای رفت و آمد موثر، به عنوان مثال، تخمین دقیق زمان سفر بسیار سودمند است. علاوه بر این، خودروهای خودران نیز به چنین اطلاعات مربوط به تقاطع برای ارزیابی خطرات، استنباط اهداف دیگر شرکت کنندگان و به طور کلی برای برنامه ریزی مسیر در امتداد تقاطع ها نیاز دارند. با کمال تعجب، این اطلاعات هنوز تا حد زیادی گم شده است. بنابراین، کار ارائه شده در این مقاله با این مشاهدات انجام شد و در درجه اول با هدف بررسی چگونگی شناسایی و شناسایی تنظیمکنندههای ترافیک با استفاده از دادههای VGI تولید شده توسط مسافران شهری بود.
تصاویر یا مسیرهای GPS معمولاً برای تشخیص و طبقه بندی تنظیم کننده استفاده می شوند [ 21 ]. تشخیص علائم راهنمایی و رانندگی یک موضوع محبوب در جامعه بینایی رایانه است، با برخی از مطالعات بر طبقه بندی علائم ترافیکی مانند [ 22 ] و برخی دیگر بر روی موضوعات مرتبط مانند پیش بینی فازهای سیگنال ترافیک [ 23 ]. از نقطه نظر سنجش جمعی، تصاویر مقدار زیادی داده تولید میکنند که منابع زیادی را مصرف میکند، به عنوان مثال، ذخیرهسازی، پهنای باند، انرژی و مصرف ممکن است بر کیفیت خدمات برنامههایی که بر اساس چنین دادههایی ساخته شدهاند تأثیر بگذارد [24] .]. علاوه بر این، زمانی که افراد یا پلاک ها در تصاویر قابل تشخیص باشند، مسائل مربوط به حریم خصوصی نیز وجود دارد. همچنین، مسیرهای GPS مستقل از انسداد، روشنایی یا سایر موقعیتهایی که دید را بدتر میکنند، کار میکنند. به این دلایل، ما ترجیح دادیم روی داده های سبک وزن تمرکز کنیم : ردیابی GPS به جای تصاویر. مسیرهای GPS همانگونه که در شکل 1 الف نشان داده شده است، سه قلوهای مرتب شده با زمان {طول جغرافیایی، طول جغرافیایی و مُهر زمانی} هستند ، که اغلب به ترتیب زمانی متصل شده و به عنوان مسیرها ذخیره می شوند، همانطور که در شکل 1 ب نشان داده شده است. به طور شماتیک، هدف از پیش بینی تنظیم کننده ترافیک هر بازو در اتصالات از مسیرهای GPS در شکل 1 c,d نشان داده شده است.
در این مقاله، ما یک مدل یادگیری عمیق دنباله به ترتیب با استفاده از مسیرهای GPS به عنوان یک توالی زمانی برای تحقق هدف ذکر شده در بالا پیشنهاد میکنیم. اکثر کارهای قبلی استفاده از ویژگی های آماری استخراج شده از مسیرهای GPS مانند زمان توقف و مدت زمان توقف [ 5 ، 25 ، 26 ]، رویدادهای کاهش سرعت و توقف [ 27 ، 28 ، 29 ] یا پروفایل های سرعت [ 30 ، 31 ، را پیشنهاد می کنند. 32]. این نوع ویژگی ها پویایی حرکت وسایل نقلیه در اتصالات مربوطه را در طول زمان خلاصه می کنند. با این حال، اطلاعات دقیق در مورد اینکه چگونه یک وسیله نقلیه حرکت خود را از مرحله زمانی قبلی به مرحله بعدی تغییر می دهد، از بین می رود. از سوی دیگر، زمان و مکان وسایل نقلیه نزدیک میتواند منجر به رفتارهای مانور بسیار متفاوت و پروفایلهای سرعت در برابر یک تنظیمکننده ترافیک شود. ویژگی های آماری نیاز به پیش پردازش مسیرهای GPS دارد و ممکن است در یک بازوی تقاطع خاص بیش از حد مناسب باشد. برای این منظور، طبیعیتر است که از مسیرهای GPS بهعنوان توالیهایی برای ثبت دینامیک دقیق رفتارهای رانندگی استفاده کنیم تا تنظیمکنندههای ترافیک را تشخیص دهیم. برای غلبه بر مشکل بیش از حد برازش، ما از موقعیت نسبی GPS به مرکز اتصال و یک پنجره کشویی در امتداد مسیر GPS استفاده می کنیم تا به طور خودکار زمان و مکان وسیله نقلیه نزدیک را یاد بگیریم. تا جایی که می دانیم، ما اولین کسی هستیم که از یک مدل یادگیری عمیق دنباله به ترتیب، همانطور که در این مقاله پیشنهاد و اعمال می شود، برای تشخیص تنظیم کننده ترافیک استفاده می کنیم.
1.2. کار مرتبط
اخیراً، زورلیدو و سستر [ 21 ] یک مرور ادبیات سیستماتیک در مورد تشخیص کنترل ترافیک از مسیرهای GPS انجام دادند، که (1) اهمیت خود موضوع، (2) نیاز به داده های باز (ردهای GPS و نقشه حقیقت زمینی) را برجسته کردند. محققان میتوانند برای آزمایش روشهای خود و مقایسه نتایج خود با سایرین، (3) تنوع پایین کلاسهای پیشبینیشده در هر مطالعه و (4) درصد پایین مطالعاتی که کاربرد بین شهری روشهای پیشنهادی خود را بررسی میکنند (یعنی، در شهر A آموزش دیده و در شهر B آزمایش شده است). در این بخش به طور مختصر روش های مبتنی بر GPS برای تشخیص و شناسایی تنظیم کننده ترافیک را شرح می دهیم. تمام مطالعات، همراه با کلاس های تنظیم کننده ای که بررسی می کنند، در جدول 1 فهرست شده اند .
دسته اول روش ها، مطالعاتی هستند که از ویژگی های استخراج شده از نقشه استفاده می کنند. چنین ویژگی های مربوط به تقاطع را می توان از نقشه های باز، به عنوان مثال، OSM استخراج کرد. مطالعه صارمی و عبدالظاهر در این زمینه بی نظیر است [ 33 ]. آنها ویژگی هایی مانند رتبه بندی سرعت بخش های جاده، فاصله یک تقاطع تا نزدیک ترین، فاصله سرتاسر جاده ای که یک تقاطع به آن تعلق دارد، نیمه فواصل یک تقاطع به دو سر جاده که به آن تعلق دارد صادر می کنند. و دسته بندی بخش های خیابان. آنها همچنین ترکیبی از ویژگیهای مبتنی بر نقشه را با ویژگیهای مشتق از ردیابی (تعداد توقف، سرعت پیمایش و مدت توقف) آزمایش میکنند و به بهبود دقت طبقهبندی 97 درصد دست مییابند.
دسته دوم شامل رویکردهایی است که از ویژگی های مختلفی استفاده می کنند که عمدتاً مربوط به رویدادهای توقف یا کاهش سرعت است. در اینجا ما اولین مطالعه منتشر شده در مورد این موضوع را می یابیم که توسط پرایب و راجرز [ 25 ] ارائه شده است. یک شبکه عصبی (NN) برای یادگیری ارتباط دادن رفتار راننده با دو نوع قوانین راهنمایی و رانندگی، چراغ راهنمایی و علائم توقف، آموزش دیده است. به عنوان دادههای ورودی، آنها از میانگین و انحراف استاندارد ویژگیهای مرتبط با رویداد توقف استفاده میکنند: تعداد دفعاتی که وسیله نقلیه قبل از عبور از یک تقاطع توقف میکند، مدت زمان کل تمام توقفها و سه توقف آخر که نزدیکترین نقطه به تقاطع هستند. یک ویژگی افزودنی درصد پیمایش است که شامل حداقل یک توقف برای هر بخش جاده است. رویکرد مشابهی توسط هو و همکاران پیشنهاد شده است. [ 5]. آنها از دو نوع ویژگی یعنی فیزیکی و آماری استفاده می کنند . به عنوان ویژگیهای فیزیکی، مدت توقف نهایی، حداقل سرعت عبور، تعداد دفعاتی که خودرو سرعت میگیرد، تعداد توقفها و فاصله آخرین توقف از تقاطع را محاسبه میکنند. با محاسبه حداقل، حداکثر، میانگین و واریانس ویژگی های فیزیکی، چهار ویژگی آماری جدید برای هر ویژگی فیزیکی تعریف می شود. آنها یک طبقهبندی تصادفی جنگل و همچنین خوشهبندی طیفی را برای یک مشکل طبقهبندی سه کلاسه (علامت توقف، چراغ راهنمایی و اتصالات کنترلنشده) آزمایش میکنند. روش آنها دقت بیش از 90 درصد را برای ویژگی های مختلف مورد استفاده برای آموزش و آزمایش گزارش می دهد. کاریسی و همکاران [ 29] یک روش اکتشافی ساده برای یک مسئله طبقه بندی باینری (علائم توقف و علائم ترافیک) با استفاده از رویدادهای کاهش سرعت و توقف مشاهده شده در ردیابی ها پیشنهاد می کند. آنها توضیح می دهند که چگونه می توان نقشه های دیجیتال را با مکان و زمان تنظیم کننده های فوق الذکر غنی کرد. روش آنها بیش از 90٪ دقت را برای مسئله طبقه بندی باینری در یک مجموعه داده کوچک به دست می آورد. کوی و همکاران [ 27] علائم توقف را بر اساس یک ویژگی رایج توقف در یک علامت توقف تشخیص می دهد: کاهش سرعت و به دنبال آن یک شتاب. علاوه بر این، آنها از برخی قوانین اکتشافی در مسیرهای GPS جمعسپاری برای تمایز بین علائم توقف چهار طرفه و دو طرفه و بین علائم توقف و چراغهای راهنمایی استفاده میکنند. اگر تنها یک قطعه توقف در یک تقاطع در یک ردیابی واحد تشخیص داده شود، علامت توقف وجود ندارد، در حالی که سایر ردیابی ها چنین بخش هایی ندارند. منروکس و همکاران [ 35] یک الگوریتم یادگیری نظارت شده (جنگل های تصادفی و رگرسیون) برای تشخیص و بومی سازی سیگنال های ترافیکی بر اساس توزیع فضایی نقاط توقف خودرو در طول جاده ارائه می کند. ردیابی GPS یک ماهه جمع آوری شده از شهری در ژاپن برای آموزش الگوریتم مورد استفاده قرار می گیرد و روش آنها تا 85 درصد در امتیاز تشخیص و دقت موقعیتی تقریباً 5 متر می رسد. روش مشابهی برای استخراج موقعیت تقاطع و توقف در [ 34 ] پیشنهاد شده است. علی و بسلامه [ 28 ] مسیرهای عابران پیاده را برای تشخیص علائم ایست و چراغ های راهنمایی مهار می کنند. آنها مکانهایی را تشخیص میدهند که عابران پیاده بیش از یک آستانه زمانی (زمان اقامت) میمانند و تنظیمکنندهها را بر این اساس به دو دسته دستهبندی میکنند. مشابه مطالعه [ 5]، جدیدترین اثر گلزه و همکاران. [ 26 ] از آمار مربوط به سرعت (به عنوان مثال، میانگین و حداکثر سرعت عبور) استخراج شده از مسیرهای GPS برای طبقه بندی تنظیم کننده ترافیک استفاده می کند.
دسته سوم شامل رویکردهایی است که از پروفایل های سرعت به عنوان ویژگی های طبقه بندی استفاده می کنند. برای مثال زورلیدو و همکاران. [ 31 ] و کونتزش و همکاران. [ 30 ] اثر پروفیلهای سرعت با کیفیت بالا به دست آمده از CAN-Bus را برای آموزش طبقهبندی درخت برای تشخیص تقاطعهای کنترلشده با چراغ راهنمایی از تقاطعهای اولویتدار و کنترلشده بازده بررسی میکند. مطالعه [ 31 ] اولین مطالعه ای است که از پروفایل های سرعت برای تشخیص تنظیم کننده استفاده می کند. یادآوری بالا اما دقت پایین و اندازه گیری F را برای پیش بینی تنظیم کننده چراغ راهنمایی گزارش می کند. به طور مشابه، Méneroux و همکاران. [ 32] سیگنال های ترافیکی را با استفاده از نمایه های سرعت تشخیص دهید. آنها سه روش مختلف برای استخراج ویژگی ها را آزمایش می کنند: تجزیه و تحلیل عملکردی گزارش های سرعت، اندازه گیری سرعت خام و تکنیک تشخیص تصویر. آنها توصیف عملکردی پروفیل های سرعت را با تبدیل موجک نشان می دهند. در بین طبقهبندیکنندههای مختلف، جنگلهای تصادفی بهترین دقت (95 درصد) را کسب کردند. آخرین، Munoz-Organero و همکاران. [ 36] با طبقهبندی سریهای زمانی سرعت و شتاب با رویکرد یادگیری عمیق، عناصر زیرساختی مختلف خیابان، مانند چراغهای راهنمایی، تقاطع خیابانها و دوربرگردانها را در زمان واقعی شناسایی میکند. اگرچه دقت ترکیبی و فراخوانی نسبتاً بالا است، در مقایسه با دو کلاس دیگر، امتیاز عملکرد تنظیم کننده چراغ راهنمایی یک محدودیت واضح در تمام تنظیمات طبقه بندی آزمایش شده نشان می دهد.
این مقاله مکانیسم جدیدی را برای دستکاری توانایی توصیفی پروفایل های سرعت پیشنهاد می کند که رفتار حرکتی وسایل نقلیه را در مکان های تنظیم شده نشان می دهد. متفاوت از تمام رویکردهای ذکر شده، ما یک طبقهبندیکننده مولد شرطی دنباله به دنباله برای تشخیص منظم ترافیک با استفاده از مسیرهای GPS جمعآوریشده از وسایل نقلیه در قالب سریهای زمانی با طولهای توالی متفاوت ارائه میکنیم.
2. مواد و روشها
2.1. مجموعه داده
مسیرهای GPS با استفاده از برنامه تلفن همراه Geo Tracker که در سیستم عامل اندروید توسعه یافته است جمع آوری شده است. مدت زمان جمعآوری دادهها از دسامبر 2017 شروع شد و در مارس 2019 به پایان رسید. دادهها طبیعی بودند، به این معنا که هیچ دستورالعملی از طرف یک فرد خارجی در حین رانندگی در مورد مکان رفتن یا نحوه رانندگی به راننده داده نمیشد. تمام مسیرها/سفرها بخشی از سفر روزانه رانندگان بود، به عنوان مثال، از خانه تا محل کار یا مرکز خرید، و بالعکس. در مجموع، 1204 مسیری که از 1064 اتصال عبور می کنند ( شکل 2 ) تنظیم شده توسط 3538 تنظیم کننده بازوی اتصال انباشته شدند. برای کار طبقه بندی، یک تنظیم کننده برای هر بازوی اتصال در نظر گرفتیم. جدول 2توصیفی از مجموعه داده ای را ارائه می دهد که برای آزمایش روش پیشنهادی استفاده کردیم.
بیشتر مسیرها بین 1 تا 12 کیلومتر طول دارند ( پیوست A شکل A1 a)، مدت سفر عمدتاً بین 0 تا 28 دقیقه طول می کشد ( پیوست A شکل A1 b) و رایج ترین انواع اتصالات سه طرفه و چهار طرفه هستند. ضمیمه A شکل A1 د). با توجه به تعداد مسیرهای هر نوع تنظیم کننده، چراغ های راهنمایی، علائم اولویت و قوانین کنترل نشده بیشترین تعداد عبور را دارند ( پیوست A شکل A1)ه) با توجه به محدودیت دادهها که بعداً در بخش بعدی مورد بحث قرار گرفت، علائم تسلیم، علائم توقف و دوربرگردانها در واقع از طبقهبندی نادیده گرفته میشوند. در آخر، اکثر اتصالات (689 از 1064) از 1 تا 10 مسیر نمونه برداری می شوند، به دنبال آن 141 اتصال بین 11 تا 20 مسیر و تنها دو اتصال دارای بین 421 تا 460 مسیر هستند ( پیوست A شکل A1 f).
2.2. روش شناسی
2.2.1. فرمول مسأله
وظیفه تشخیص تنظیم کننده ترافیک به عنوان یک مشکل طبقه بندی تعریف شده است. برای بازوی اتصال داده شده، وظیفه تشخیص به صورت ریاضی به صورت فرموله شده است Yn= f(ایکس( تی)n)��=�(��(�))، جایی که Yn��تنظیم کننده ترافیک (یکی از کلاس های علائم اولویت ، چراغ راهنمایی و کنترل نشده ) است که مسیر GPS داده شده را تنظیم می کند. ایکسn��، و n به N تعلق دارد که نشان دهنده تعداد کل مسیرهای GPS ثبت شده در بازوی اتصال داده شده است. مسیر GPS سیگنالهای مشاهدهشده بهموقع را ذخیره میکند ایکسn= {ایکس1, … ,ایکستی}��={�1,…,��}، ایکسمن∈آرد��∈��و d نشان دهنده بعد بردار ویژگی است که حاوی اطلاعات مکان و سرعت در هر نقطه سیگنال است.
طبق تعریف فوق، f(.)�(.)یک طبقه بندی کننده دنباله به یک است. ما کمی فرم را تغییر می دهیم Yn��به Yn=∑تیi = 1λ (Yتیمن)��=∑�=1��(���)، جایی که λ (.)�(.)تابع وزن دهی است که پیش بینی سیگنال به پیش بینی ترتیبی برای تنظیم کننده ترافیک برای مسیر GPS داده را خلاصه می کند. از این رو، طبقه بندی دنباله به یک اکنون به طبقه بندی دنباله به دنباله تبدیل می شود.
در بیشتر موارد برای بازوی اتصال داده شده، ن≥ 1�≥1مسیرهای GPS در دسترس هستند. تنظیم کننده بازو اکثریت رای تمام مسیرهای GPS است که به تنهایی از بازوی داده شده عبور می کند. معادلات ( 1 ) و ( 2 ) فرآیند پیشبینی را با استفاده از مسیرهای پیمایش شده GPS نشان میدهند. توجه داشته باشید که طبقهبندی از نظر سیگنال، بازخورد دقیقی را در هر نقطه سیگنال برای یک مسیر واحد ارائه میکند، در حالی که نتیجه طبقهبندی بازوی تنظیمکننده بازخورد جمعسپاری از همه مسیرهای GPS است.
Y = حداکثر ارگ1ن∑n = 1نYn،�=arg max1�∑�=1���,
جایی که
Yn=∑i = 1تیλ ( f(ایکس( تی )n) ) .��=∑�=1��(�(��(�))).
یکی از مشکلات باقی مانده که مدل دنباله به دنباله باید با آن مقابله کند، طول توالی متغیر است. به عبارت دیگر، T به دلیل مدت زمان متفاوت مسیرها و در دسترس بودن سیگنال های GPS ثابت نیست. ما پیشنهاد می کنیم از یک پنجره کشویی با اندازه پنجره ثابت ( w ) برای طول توالی های مختلف استفاده کنیم [ 37]]. اول، یک دنباله به زیر دنبالههای کوچکی تقسیم میشود، که هم وابستگیهای طولانی و هم کوتاه را ثبت میکنند و مشکل طولهای دنبالههای مختلف در مسیرهای مختلف GPS را دور میزنند. دوم، همانطور که در بخش قبل بحث کردیم، مکان و زمان بندی یک مسیر در مورد کنترل ترافیک مهم است. با این حال، مشخص نیست که کجا و چه زمانی مسیر ممکن است دقیقاً توسط کنترل ترافیک تنظیم شود. علاوه بر این، مکان و زمان دقیق ممکن است از یک مسیر به آهنگ دیگر متفاوت باشد. پنجره کشویی از هر مرحله زمانی خارج می شود و به طور خودکار مکان و زمان تحت تاثیر کنترل ترافیک را یاد می گیرد. در مقایسه با یک مکان یا زمان ثابت، این روش ( w ≪ T�≪�) کمتر به یک اتصال خاص اضافه شده است. معادله ( 3 ) روش پنجره کشویی را با اندازه یک گام به اندازه اندازه بیوه کشویی نشان می دهد. همپوشانی بین دو پنجره متوالی زمانی مجاز است که گام کوچکتر از w تنظیم شود (بخش چپ شکل 3 را ببینید ).
ایکس( تی)n= {ایکسw 1, … ,ایکسw m} ، جایی کهm =تیw.��(�)={��1,…,���},where�=��.
2.2.2. مدل مولد شرطی
ما پیشنهاد می کنیم از یک مدل مولد شرطی که توسط شبکه های عصبی برای تابع طبقه بندی پارامتربندی شده است استفاده کنیم f(.)�(.)، یعنی رمزگذار خودکار متغیر شرطی (CVAE) [ 38 ، 39 ]. ثابت شده است که چارچوب CVAE برای حل بسیاری از مسائل پیچیده، به عنوان مثال، طبقه بندی و تولید تصویر [ 39 ، 40 ] و پیش بینی مسیر [ 41] بسیار موفق است.]. انتخاب این مدل با در نظر گرفتن جنبه های زیر انجام می شود: مسیرهای GPS در برابر تنظیم کننده های ترافیک به دلیل (1) رفتار رانندگی نامشخص رانندگان خودرو و (2) مکان و زمان عبور در امتداد بازوی اتصال داده شده تصادفی هستند. CVAE یک مدل تشخیص را می آموزد که ورودی را در برخی از متغیرهای تصادفی، به اصطلاح متغیرهای تصادفی پنهان، به دنبال برخی توزیع های قبلی مانند توزیع گاوسی رمزگذاری می کند. سپس، یک مدل تولیدی را می آموزد که بر روی متغیرهای تصادفی برای کار پیش بینی احتمالی شرطی شده است [ 39 ].
در ادامه به طور خلاصه چارچوب CVAE را بررسی می کنیم. با توجه به ورودی ایکس�و خروجی Y�مدل CVAE به صورت زیر تعریف می شود:
p ( Y | X ) = N( ف( z ، X ) ،σ2* من) .�(�|�)=�(�(�,�),�2*�).
احتمال مشروط خروجی یک توزیع گاوسی همسانگرد است که میانگین آن است μ = f( z ، X )�=�(�,�)، تابعی از ورودی است ایکس�و متغیرهای پنهان z�و ماتریس کوواریانس Σ =σ2* منΣ=�2*�، یک ماتریس هویت است که من در مقداری اسکالر ضرب کردم σ2�2.
با توجه به خلفی واقعی غیرقابل حل qθ( z | X , Y )��(�|�,�)، معادله را نمی توان به صورت تحلیلی حل کرد. خلفی متغیر qϕ( z | X , Y )��(�|�,�)برای تقریب خلفی واقعی معرفی شده است. سپس این مدل را می توان با استفاده از بیزهای متغیر گرادیان تصادفی (SGVB) [ 38 ] با رسیدن به یک کران پایینی متغیر، که با معادله ( 5 ) نشان داده شده است، آموزش داد.
ورود به سیستمپθ( Y | X ) ≥ – K L (qϕ( z | X , Y ) | |پθ( z ) ) +Eqϕ( z | X , Y )[ ورودپθ( Y | ( X , Z ) ) ] ,log��(�|�)≥−KL(��(�|�,�)||��(�))+���(�|�,�)[log��(�|(�,�))],
جایی که پθ( ز )��(�)قبلی است که می تواند مستقل از ورودی ساخته شود ایکس�[ 40 ] و از ن∼ ( 0 ، I)�∼(0,�). برای اشتقاق کامل کران پایین، به خوانندگان توصیه می کنیم نگاهی به [ 38 ، 39 ] بیاندازند .
شکل معادله ( 5 ) به عنوان یک رمزگذار خودکار تفسیر می شود، زیرا عبارت اول در سمت راست هر دو ورودی و خروجی را در متغیرهای پنهان «کد می کند» و عبارت دوم خروجی را از ورودی و خروجی «رمزگشایی» می کند. متغیرهای پنهان رمزگشا را مدل مولد نیز می نامند. توجه داشته باشید که در مقایسه با یک رمزگذار خودکار سنتی، در اینجا مدل CVAE خروجی را پیشبینی میکند Y�، به جای بازسازی ورودی ایکس�.
واگرایی کولبک-لیبر K L (.)KL(.)بین توزیع های خلفی و قبلی تقریبی (هر دو گاوسی) را می توان به صورت تحلیلی حل کرد. ضرر بازسازی Eqϕ( z | X , Y )(،)���(�|�,�)(,)می توان با نمونه گیری مونت کارلو [ 38 ] تقریب زد. توابع نگاشت غیرخطی هر دو θ�و ϕ�توسط شبکه های عصبی پارامتر می شوند. به منظور فعال کردن گرادیان در فرآیند نمونهبرداری، یک ترفند پارامترسازی مجدد [ 42 ] برای انتشار پساز استفاده میشود، جایی که
z( ل )=gϕ( X , Y ,ϵ( ل )) =μ( ل )+σ( ل )⊙ϵ( ل )،وϵ( ل )= ن~ ( 0 , 1 ) .�(�)=��(�,�,�(�))=�(�)+�(�)⊙�(�),and�(�)=�∼(0,1).
سپس از دست دادن مدل CVAE از طریق نزول گرادیان تصادفی بهینه می شود. معادله ( 5 ) فرآیند بهینه سازی را نشان می دهد.
LCVAE( X , Y ؛ θ , φ ) = – K L (qϕ( z | X , Y ) | |پθ( z ) ) +1L∑l = 1Lورود به سیستمپθ( Y∣∣( X ,z( ل )) ) .�CVAE(�,�;�,�)=−KL(��(�|�,�)||��(�))+1�∑�=1�log��(�|(�,�(�))).
2.2.3. خط لوله چارچوب و ویژگی های ورودی
در این بخش فرعی، خط لوله کلی مدل CVAE را برای کار طبقهبندی ترتیب به دنباله با استفاده از مسیرهای GPS با پنجره کشویی و عملکرد وزن، که در شکل 3 نشان داده شده است، معرفی میکنیم .
مدل CVAE به ترتیب دارای دو جریان اطلاعات متفاوت در آموزش و استنتاج/پیشبینی است. در فرآیند آموزش، هم سیگنال های GPS و هم تنظیم کننده بازوی مربوطه در دسترس هستند. ابتدا برچسب رگولاتور بازو کپی می شود تا با مراحل زمان سیگنال هماهنگ شود. سپس یک پنجره کشویی اعمال می شود تا سیگنال GPS و دنباله های تنظیم کننده بازو را به صورت موازی تخلیه کند. پس از آن هر دو دنباله به عنوان یک ورودی کامل برای آموزش یک رمزگذار متغیر برای متغیرهای پنهان به هم متصل می شوند. در پایان، رمزگشا با استفاده از اطلاعات مسیر GPS و متغیرهای پنهان برای پیشبینی رگولاتورهای بازویی سیگنالی آموزش داده میشود که بعداً توسط تابع وزن برای دستیابی به پیشبینی مسیر خلاصه میشود. در فرآیند استنتاج، فقط سیگنال های GPS در دسترس هستند. به منظور پیشبینی تنظیمکننده بازو، سیگنالهای GPS با متغیرهای پنهان که مستقیماً از توزیع گاوسی نمونهبرداری شدهاند، الحاق میشوند. ما از حافظه های کوتاه مدت (LSTM) استفاده کردیم [43 ] هم برای رمزگذار و هم برای رمزگشا.
سیگنال های GPS از موقعیت های نسبی x و y مختصات UTM (Universal Transverse Mercator) در رابطه با مرکز اتصال داده شده استخراج می شوند. ابتدا از یک فاصله از پیش تعریف شده برای انتخاب مسیرهای GPS مربوطه استفاده کردیم. فقط آهنگ های داخل آستانه مورد توجه هستند. زیرا مسافت زیاد ممکن است باعث شود که یک مسیر از چندین اتصال مختلف عبور کند. علاوه بر این، با توجه به اینکه سیگنال های بعد از تقاطع به اندازه سیگنال های قبل از تقاطع مهم نیستند، هنگام خروج وسیله نقلیه، آستانه دیگری (حداکثر یک اندازه پنجره) برای سیگنال های GPS بعد از مرکز اتصال تعیین می کنیم. شکل 4نمونه ای از مسیرهای GPS استخراج شده از برخی از اتصالات است که به ترتیب با علائم اولویت، چراغ های راهنمایی و کنترل نشده تنظیم می شوند.
دوم، پس از استخراج، سیگنالهای GPS را با محاسبه فاصله d ، افست x و y غنیسازی کردیم.Δ x��و Δ y��، سرعت v نسبت به مرکز اتصال. توجه داشته باشید که چون سیگنالهای GPS خام در طول زمان به طور مساوی توزیع نمیشوند، فاصله زمانی دو سیگنال GPS متوالی را نیز اضافه کردیم. Δ t��به عنوان یک ویژگی ورودی بردار ویژگی GPS غنی شده به صورت مشخص شده است ایکس( تی)={ x ، y، د, Δ x , Δ y, v , Δ t }نوع گره ناشناخته: فونتتینوع گره ناشناخته: فونتنوع گره ناشناخته: فونت�(�)={�,�,�,��,��,�,��}�Unknown node type: fontUnknown node type: fontUnknown node type: font.
2.2.4. تنظیمات آزمایشی
مدل CVAE را چندین بار با استفاده از پارامترهای مختلف اجرا کردیم و مقادیر را بر اساس بهترین عملکرد تنظیم کردیم. مهمترین پارامترهای تعریف شده پس از این فرآیند به شرح زیر فهرست شده اند:
-
برای استخراج مسیرهای GPS، آستانه فاصله برای انتخاب مسیرهای GPS مربوطه با توجه به اتصال داده شده روی 65 متر، اندازه پنجره کشویی روی 8 و گام به 2 تنظیم شده است.
-
برای پارتیشن بندی داده ها، مسیرهای GPS به ترتیب برای آموزش و آزمایش به طور تصادفی به 70:30 تقسیم می شوند.
-
برای شبکه های عصبی مدل CVAE، بعد متغیرهای پنهان نوع گره ناشناخته: فونتUnknown node type: fontروی 2 تنظیم شده است، بعد برای حالت پنهان LSTM برای هر دو رمزگذار و رمزگشا به 128 تنظیم شده است.
-
برای هایپرپارامترهای آموزشی، اندازه دسته روی 256، تعداد دوره های تمرینی 500 و توقف زودهنگام با 50 دوره صبر تنظیم شده است. نرخ یادگیری تنظیم شده است نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontبا استفاده از بهینه ساز Adam [ 44 ] با نرخ فروپاشی نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: font;
-
ما از تابع وزن متوسط برای خلاصه کردن پیش بینی سیگنال به پیش بینی مسیر استفاده می کنیم.
جزئیات بیشتر تنظیمات و کد مدل CVAE را میتوانید در مخزن ( https://github.com/haohao11/Traffic_Control_Recognition ) بیابید.
2.2.5. مدل مقایسه
مدل CVAE پیشنهادی با عملکرد یک مدل جنگل تصادفی [ 26 ] با استفاده از همان مجموعه داده (1328 در مجموع تنظیمکنندهها) مشابه در [ 26 ]، که توسط 1609 تنظیمکننده اضافی از همان شهر/شبکه جاده (در مجموع 2937 نفر) بزرگتر شد، مقایسه شد. تنظیم کننده). متفاوت از ویژگی های متوالی ذکر شده در بالا، مدل جنگل تصادفی از دو نوع ویژگی خلاصه شده از مسیرهای GPS استفاده می کند: ویژگی های فیزیکی و آماری. ویژگی های فیزیکی، به عنوان مثال، تعداد، درصد، مدت و فاصله فازهای سکون است. مدت و فاصله آخرین فاز سکون نسبت به اتصالات داده شده، میانگین و حداکثر سرعت هر مسیر GPS. ویژگی های آماری عبارتند از آمار، مانند حداقل ، حداکثر، میانگین و واریانس کلیه ویژگی های فیزیکی فوق الذکر. استراتژیهای مختلف برای تقویت عملکرد مدل جنگل تصادفی، مانند نمونهبرداری بیش از حد تصادفی و کیسهبندی یا AdaBoost [ 26 ] مورد استفاده قرار گرفت.
3. نتایج
در این بخش، نتایج تجربی را برای مدل CVAE و مدل جنگل تصادفی با استراتژیهای تقویت مختلف ارائه میکنیم. عملکرد با دقت برای طبقه بندی سه تنظیم کننده ترافیک اکثریت، به عنوان مثال، علائم اولویت، چراغ های راهنمایی و کنترل نشده در مجموعه داده آزمایش اندازه گیری شد. جدول 3 نتایج ارزیابی را برای مدل جنگل تصادفی و مدل CVAE نشان می دهد.
طبقهبندیکننده جنگل تصادفی اولیه، دقت 0.83 را برای مسیرهای آزمایشی GPS، شامل مسیرهای بدون چرخش و چرخش، به دست آورد. عملکرد با حذف مسیرهای چرخشی که طبقه بندی آنها دشوارتر بود، بهبود یافت. با این حال، حذف اندازه مجموعه داده را کاهش می دهد. نمونه گیری تصادفی بیش از حد برای افزایش نمونه های طبقه اقلیت به کار گرفته شد و از این طریق افزایش عملکرد حاصل شد. بهترین عملکرد (دقت 0.88) توسط طبقه بندی کننده با استفاده از نمونه برداری بیش از حد و استراتژی AdaBoost انجام شد.
مدل CVAE برای طبقهبندی تمام مسیرهای GPS، از جمله مسیرهای بدون چرخش و چرخش برای مجموعه داده کامل، آموزش داده شد. مدل CVAE ابتدا تنظیم کننده های ترافیک را برای هر سیگنال GPS پیش بینی می کند و سپس پیش بینی های وزنی سیگنال را به پیش بینی مسیر برای هر مسیر GPS خلاصه می کند (به بخش 2.2.1 مراجعه کنید ). اکثریت رای از نتایج طبقه بندی شده برای مسیرهای طی شده در امتداد بازوی اتصال داده شده طبقه بندی نهایی است. به طور کلی، مدل CVAE از مدل جنگل تصادفی با استفاده از تمام مسیرها (0.90 در مقابل 0.83) و همچنین مدل جنگل تصادفی با استفاده از مسیرهای بدون چرخش با بیش نمونه برداری و استراتژی AdaBoost (0.90 در مقابل 0.88) بهتر عمل کرد.
شکل 5 ماتریس های سردرگمی را برای بهترین طبقه بندی جنگل تصادفی با نمونه برداری بیش از حد و AdaBoost ( شکل 5 الف) و مدل CVAE ( شکل 5 ب) برای طبقه بندی تنظیم کننده ترافیک نشان می دهد. ماتریسهای سردرگمی نشان میدهند که در مقایسه با طبقهبندیکننده جنگل تصادفی، مدل CVAE به ترتیب کمی بهتر (0.87 در مقابل 0.86) و دقت برتر (0.91 در مقابل 0.88) برای پیشبینی تنظیمکنندههای علائم کنترلنشده و اولویتدار به دست آورد. برای پیشبینی تنظیمکنندههای چراغ راهنمایی، با اختلاف زیادی (0.90 در مقابل 0.80) از طبقهبندیکننده جنگل تصادفی بهتر عمل کرد.
از نتایج فوق، در مقایسه با مدل جنگل تصادفی، مدل CVAE دقت بهتری برای پیشبینی قاعده بازوی اتصال ایجاد کرد. علاوه بر این، مدل CVAE به هر دو مسیر بدون چرخش و چرخش تعمیم داده شد و در یک مجموعه داده بزرگتر اعتبار سنجی شد. علاوه بر این، مدل CVAE از هیچ استراتژی تقویت پیشرفته ای استفاده نکرد. نتایج تجربی تایید میکنند که چارچوب پیشنهادی، یک طبقهبندیکننده دنباله به دنباله با یک پنجره کشویی و یک تابع وزن متوسط، برای برخورد با مسیرهای GPS خطی و غیرخطی با طول توالیهای مختلف برای طبقهبندی تنظیمکننده ترافیک مناسب است.
4. بحث
در این بخش، ابتدا عملکرد مدل CVAE ترتیب به دنباله را از نظر پیشبینی سیگنال و اهمیت ویژگیهای مورد استفاده برای کار طبقهبندی تحلیل میکنیم، سپس کاربرد مدل بر اساس سیگنالهای GPS را مورد بحث قرار میدهیم. تشخیص تنظیم کننده ترافیک در دنیای واقعی
نتایج دقیق برای پیش بینی های سیگنال در جدول 4 فهرست شده است . به طور کلی، دقت در سطح سیگنال برای یک کار طبقه بندی سه کلاسه 0.73 است. این نشان میدهد که پیشبینی تنظیمکنندههای ترافیک برای هر سیگنال GPS بسیار چالش برانگیز است، زیرا حرکت وسایل نقلیه در طول زمان تغییر میکند، به عنوان مثال، کاهش سرعت، توقف و شتاب زمانی که به تقاطعها نزدیک میشوند. با این حال، دقت بسیار بالاتر از حدس تصادفی است که طبقه بندی کلی قانون بازوی اتصال را روشن می کند. پیشبینیهای انباشتهشده از نظر سیگنال توسط تابع وزنی متوسط و پیشبینیهای مسیری توسط طرح رأی اکثریت منجر به طبقهبندی قوانین بازوی اتصال بسیار دقیق میشود (دقت 0.90، جدول 3 را ببینید .). این ثابت میکند که عملکرد وزندهی و طرح رأیگیری میتواند خطاهای سطح پایین (طبقهبندی اشتباه سیگنالهای GPS) را تحمل کند، و مهمتر از همه، دقت اطلاعات فردی را میتوان با اطلاعات جمعآوریشده (سیگنالها و مسیرهای GPS متعدد) افزایش داد. با نگاهی دقیق به نتایج برای هر کلاس، دقت دقیق و اندازه گیری F نشان می دهد که پیش بینی تنظیم کننده ها برای علائم اولویت و کنترل نشده در سطح سیگنال دشوارتر از پیش بینی تنظیم کننده برای چراغ های راهنمایی است. اولاً، حجم نمونه مربوطه (پشتیبانی) کلاس های اولویت و کنترل نشده کوچکتر از اندازه نمونه کلاس چراغ راهنمایی است. توجه داشته باشید که ما از هیچ استراتژی تقویتی برای افزایش نمونه ها در کلاس اقلیت استفاده نکردیم. کلاس های علامت اولویت و کنترل نشده ممکن است به خوبی کلاس های دیگر آموزش دیده نباشند. ثانیاً، ضابطان علائم اولویت و کنترل نشده از نظر اجرا مشابه هستند; رانندگان باید ادب خود را که به شدت به فردی وابسته است، تمرین کنند. از سوی دیگر، تنظیم کننده چراغ راهنمایی به وضوح تعریف شده است و تأثیر قوی تری نسبت به دو تنظیم کننده دیگر بر رفتار رانندگان دارد که باعث می شود طبقه بندی دقیق تر شود.
مدل CVAE با استفاده از ترکیبهای ویژگیهای مختلف آموزش داده شد تا اینکه چگونه این ویژگیها به عملکرد طبقهبندی کمک میکنند. به عبارت دیگر، ویژگی های مشخص شده در بخش 2.2.3 مختصات نسبی x و y و فاصله d تا مرکز اتصال هستند، افست x – و y که به صورت نشان داده شده است. Δ x��و Δ y��بین دو سیگنال GPS متوالی با فاصله زمانی Δ t��و سرعت v . جدول 5 نتایج دقیق را فهرست می کند. از جدول می بینیم که مدل CVAE (A) با استفاده از مختصات x و y در مقایسه با مدل های دیگر با استفاده از ویژگی های متفاوت یا بیشتر، عملکرد بسیار محدودی دارد. این به این دلیل است که مختصات در طول زمان به طور یکنواخت توزیع نمی شوند و هیچ اطلاعات دینامیکی دقیقی (مثلاً سرعت) برای نشان دادن نحوه نزدیک شدن وسایل نقلیه به تقاطع ها ارائه نمی شود. مدل (B) تنها با افزودن ویژگی فاصله d عملکرد کمی بهتر داشت . اما به همین دلیل، عملکرد آن نسبتاً محدود بود. از سوی دیگر، مدل (C) با استفاده از افست Δ x��و Δ y��در مقایسه با دو مدل قبلی، عملکرد بسیار بهتری را که توسط تمام معیارهای ارزیابی اندازهگیری شده بود، به دست آوردند. این به این دلیل است که ویژگی افست نشان می دهد که خودرویی که از تقاطع عبور می کند با چه سرعتی موقعیت خود را بین دو سیگنال GPS متوالی تغییر می دهد. هنگامی که مختصات، فاصله و ویژگیهای آفست مورد استفاده قرار گرفتند، مدل (D) به عملکرد بهتری دست یافت. جالب اینجاست که افزودن ویژگی سرعت v سهم مثبتی ندارد، یعنی مدل (E) در مقابل مدل (D). اما ویژگی زمان Δ t��به عملکرد کمی بهبود یافته، یعنی مدل (F) در مقابل مدل (D) کمک کرد. هنگامی که تمام ویژگی های ذکر شده استفاده شد، مدل (G) به بهترین نتایج اندازه گیری شده توسط تمام معیارهای ارزیابی دست یافت.
از تحلیلهای بالا مشخص میشود که مدل CVAE ترتیب به دنباله، تنظیمکنندههای ترافیک را با یادگیری اطلاعات حرکت (پروفایلهای سرعت) از وسایل نقلیه در حال حرکت از طریق اتصالات شناسایی میکند. اطلاعات حرکتی گرفته شده توسط مسیرهای GPS را می توان به راحتی توسط یک برنامه کاربردی تلفن همراه به دست آورد، که نسبتاً ارزان تر از به دست آوردن تصاویری است که به عنوان مثال به فضای ذخیره سازی بزرگتر و پهنای باند ارتباطی نیاز دارند. علاوه بر این، سیگنال های GPS به عنوان دنباله استفاده می شود. هیچ سربار محاسباتی اضافی برای پیش پردازش سیگنال های GPS برای استخراج ویژگی به صورت محلی روی تلفن همراه یا از راه دور در سمت سرور وجود ندارد [ 5]]. این مزایا باعث می شود که مدل سبک وزن باشد و برای کارهای تشخیص تنظیم کننده ترافیک در دنیای واقعی قابل استفاده باشد. مهمتر از همه، همانطور که در بالا تحلیل کردیم، این مدل راه حلی برای تحمل خطاهای VGI – ردیابیهای GPS جمعسپاری – ایجاد شده توسط مسافران ارائه میکند. یک سیگنال GPS ممکن است به درستی تنظیم کننده ترافیک را نشان ندهد. اما دنبالهای از سیگنالهای GPS و ردیابیهای GPS جمعآوری شده از طریق طرح رای اکثریت، تشخیص بسیار دقیقی را برای تنظیمکننده ترافیک نشان میدهد.
5. نتیجه گیری و کار آینده
در این مقاله، ما یک چارچوب مولد مشروط برای تشخیص کنترل ترافیک با استفاده از دادههای مسیرهای GPS جمعسپاری شده پیشنهاد میکنیم. ابتدا، مزایای استفاده از داده های GPS سبک وزن در مقایسه با داده های مبتنی بر تصویر را مورد بحث قرار می دهیم. دوم، توضیح میدهیم که چگونه چارچوب جدید پیشنهادی ما با روشهای پیشنهادی قبلی که معمولاً از ویژگیهای آماری خلاصهشده از مسیرهای GPS استفاده میکنند، متفاوت است. ما پیشنهاد میکنیم از سیگنالهای GPS ریز دانه بهعنوان توالی استفاده کنیم و یک طبقهبندیکننده ترتیب به دنباله را بر اساس رمزگذار خودکار متغیر شرطی (CVAE) آموزش دهیم. یک مکانیسم پنجره کشویی برای توالی های پردازش با طول های مختلف و یک تابع وزن متوسط برای خلاصه کردن پیش بینی سطح سیگنال به پیش بینی مسیر استفاده شد. مدل پیشنهادی CVAE از مدل جنگل تصادفی بهتر عمل کرد و به 0 رسید. دقت 90 تست شده بر روی داده های GPS تلفن همراه جمع آوری شده در شهر آلمانی هانوفر برای اتصالات بدون گردش و چرخش. روش توالی به ترتیب با تابع وزن میانگین و طرح رای اکثریت راه حلی برای تحمل خطاهای ایجاد شده توسط تک تک کاربران ارائه می دهد. استفاده از سیگنالهای GPS بهعنوان توالی، مدل ما را به راحتی برای کارهای تشخیص تنظیمکننده ترافیک در دنیای واقعی قابل استفاده میکند.
در آینده، استراتژیهای مختلفی برای افزایش بیشتر دقت پیشبینی مورد بررسی قرار خواهند گرفت، به عنوان مثال، استفاده از تکنیکهای تقویت برای افزایش تعداد مسیرهای GPS و تکنیکهای درونیابی برای هموارسازی سیگنالهای GPS. علاوه بر این، تصاویر جادهای استخراجشده از نقشهها یا تصاویر ماهوارهای را میتوان به چارچوب CVAE برای حل دقیقتر وظیفه تشخیص تنظیمکننده ترافیک تغذیه کرد. ما مدل خود را نه تنها برای تشخیص رایجترین کلاسهای تنظیمکننده ترافیک، بلکه برای کلاسهای عمومیتر نیز گسترش خواهیم داد.
مشارکت های نویسنده
همه نویسندگان در مفهومسازی، روششناسی، نگارش-بازبینی و ویرایش و مدیریت پروژه مشارکت داشتند. هائو چنگ در نرمافزار، اعتبارسنجی، تجزیه و تحلیل رسمی، مدیریت دادهها، تجسم و نوشتن – آمادهسازی پیشنویس اصلی مشارکت داشت. استفانیا زورلیدو در منابع داده و قالببندی، تحقیق، تجسم و نوشتن – تهیه پیشنویس اصلی مشارکت داشت. مونیکا سستر در نظارت و تامین مالی مشارکت داشت. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق توسط بنیاد تحقیقات آلمان (Deutsche Forschungsgemeinschaft (DFG)) با شماره کمک مالی 227198829/GRK1931 تامین شده است.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند. تامین کنندگان مالی هیچ نقشی در طراحی مطالعه نداشتند. در جمع آوری، تجزیه و تحلیل یا تفسیر داده ها؛ در نوشتن دستنوشته یا تصمیم به انتشار نتایج.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| CVAE | رمزگذار خودکار متغیر مشروط |
| MCS | سنجش جمعیت موبایل |
| OSM | نقشه خیابان باز |
| روابط عمومی | نشانه های اولویت |
| RW | قانون حق تقدم |
| اس اس | علائم توقف |
| TL | چراغ های راهنمایی و رانندگی |
| UC | کنترل نشده |
| YS | بازده-نشانه ها |
پیوست اول


شکل A1. آماری که مجموعه داده مورد استفاده برای آزمایش روش پیشنهادی را توصیف می کند. ( الف ) توزیع مسیرهای داده بر اساس طول آنها (کیلومتر). ( ب ) توزیع مسیرهای داده بر اساس مدت سفر (دقیقه). (ج) توزیع رگولاتورهای مجموعه داده بر اساس نوع آنها (بازوهای اتصال دارای حداقل یک تقاطع). ( د ) توزیع تقاطع های مجموعه داده ها بر اساس نوع شکل آنها. ( ه ) توزیع مسیرهای داده بر اساس نوع تنظیم کننده اتصالاتی که از آنها عبور می کنند. ( f ) توزیع تقاطع های مجموعه داده ها بر اساس تعداد مسیرهایی که از هر یک از آنها عبور می کنند.
منابع
- نام، تی. پاردو، TA مفهوم شهر هوشمند با ابعاد فناوری، مردم و نهادها. در مجموعه مقالات دوازدهمین کنفرانس بینالمللی پژوهشی سالانه دولت دیجیتال: نوآوری دولت دیجیتال در زمانهای چالش برانگیز، کالج پارک، MD، ایالات متحده آمریکا، 12 تا 15 ژوئن 2011. صص 282-291. [ Google Scholar ]
- Antrop, M. تغییر منظر و فرآیند شهرنشینی در اروپا. Landsc. طرح شهری. 2004 ، 67 ، 9-26. [ Google Scholar ] [ CrossRef ]
- لینک، اچ. Dodgson، JS; میباخ، م. هری، ام. هزینههای زیرساخت جادهای و ازدحام در اروپا . Springer: برلین/هایدلبرگ، آلمان، 2012. [ Google Scholar ]
- دورنبوش، س. Joshi, A. StreetSmart ترافیک: کشف و انتشار تراکم خودرو با استفاده از VANET. در مجموعه مقالات شصت و پنجمین کنفرانس فناوری خودرو IEEE 2007-VTC2007-Spring، دوبلین، ایرلند، 22-25 آوریل 2007. صص 11-15. [ Google Scholar ]
- هو، اس. سو، ال. لیو، اچ. وانگ، اچ. عبدالظاهر، TF SmartRoad: سنجش جمعیت مبتنی بر گوشی هوشمند برای تشخیص و شناسایی تنظیم کننده ترافیک. ACM Trans. Sens. Netw. 2015 ، 11 ، 1-27. [ Google Scholar ] [ CrossRef ]
- Goodchild، M. شهروندان به عنوان حسگرها: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مشارکت کنندگان OpenStreetMap. تخلیه سیاره. 2019. در دسترس آنلاین: https://planet.osm.org;https://www.openstreetmap.org (در 11 مه 2015 قابل دسترسی است).
- استلس-آرولاس، ای. د گوارا، FGL به سوی یک تعریف جمع سپاری یکپارچه. J. Inf. علمی 2012 ، 38 ، 189-200. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Boubiche، DE; عمران، م. مقصود، ع. شعیب، ام. سنجش جمعیت موبایل – طبقه بندی، برنامه ها، چالش ها و راه حل ها. محاسبه کنید. هوم رفتار 2019 ، 101 ، 352-370. [ Google Scholar ] [ CrossRef ]
- ژانگ، سی. شیانگ، ال. لی، اس. وانگ، دی. یک تقاطع-اولین رویکرد برای تولید شبکه جادهای از مسیرهای وسایل نقلیه با منبع جمعیت. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 473. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، ی. لیو، جی. کیان، ایکس. کیو، ا. Zhang, F. روش ساخت شبکه جاده ای خودکار با استفاده از داده های عظیم مسیر GPS. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 400. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، ال. Sester, M. اکتساب اطلاعات افزایشی از Gps-traces. در آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی-ISPRS Archives 38 ; انجمن بین المللی فتوگرامتری و سنجش از دور: لندن، بریتانیا، 2010. [ Google Scholar ]
- نی، ی. خو، ک. چن، اچ. Peng, L. Crowd-parking: ایده جدیدی از راهنمایی پارکینگ بر اساس جمع سپاری اطلاعات مکان پارکینگ از خودروها. در مجموعه مقالات IECON 2019—چهل و پنجمین کنفرانس سالانه انجمن الکترونیک صنعتی IEEE، لیسبون، پرتغال، 14 تا 17 سپتامبر 2019؛ جلد 1، ص 2779–2784. [ Google Scholar ] [ CrossRef ]
- دیمری، ع. سینگ، اچ. آگاروال، ن. رامان، بی. راماکریشنان، ک.ک. Bansal، D. BaroSense: استفاده از فشارسنج برای تشخیص تراکم ترافیک جادهای و تخمین مسیر با Crowdsourcing. ACM Trans. Sens. Netw. 2019 , 16 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Mozas-Calvache، AT تجزیه و تحلیل رفتار وسایل نقلیه با استفاده از داده های VGI. بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 1-20. [ Google Scholar ] [ CrossRef ]
- گانتی، RK; فام، ن. احمدی، ح. نانگیا، اس. عبدالظاهر، TF GreenGPS: یک برنامه کاربردی نقشههای سنجش سوخت کارآمد. در مجموعه مقالات هشتمین کنفرانس بین المللی سیستم های تلفن همراه، برنامه ها و خدمات، MobiSys ’10، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 15-18 ژوئن 2010. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2010; صص 151-164. [ Google Scholar ] [ CrossRef ]
- هولدرنس، تی. Turpin، E. از رسانه های اجتماعی تا هوش جغرافیایی اجتماعی: مدیریت مشترک مدنی جمع سپاری برای واکنش به سیل در جاکارتا، اندونزی. در رسانه های اجتماعی برای خدمات دولتی ; Nepal, S., Paris, C., Georgakopoulos, D., Eds. Springer: Cham, Switzerland, 2015; صص 115-133. [ Google Scholar ] [ CrossRef ]
- موریرا، آر. دگروسی، ال. De Albuquerque, J. ارزیابی تجربی یک رویکرد مبتنی بر جمع سپاری برای مدیریت خطر سیل. در مجموعه مقالات دوازدهمین کارگاه مهندسی نرم افزار تجربی (ESELAW)، لیما، پرو، 22 تا 24 آوریل 2015. [ Google Scholar ]
- فنگ، ی. برنر، سی. Sester، M. نقشهبرداری شدت سیل از اطلاعات جغرافیایی داوطلبانه با تفسیر سطح آب از تصاویر حاوی افراد: مطالعه موردی طوفان هاروی. ISPRS J. Photogramm. Remote Sens. 2020 , 169 , 301–319. [ Google Scholar ] [ CrossRef ]
- بورگاردت، دی. نجدل، و. شیوه، جی. Sester، M. داوطلبانه اطلاعات جغرافیایی: تفسیر، تجسم و محاسبات اجتماعی (VGIscience). Proc. بین المللی کارتوگر. دانشیار 2018 ، 1 ، 1-5. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زورلیدو، س. Sester, M. Traffic Regulator Detection and Identification from Crowdsourced Data-A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 491. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تیان، ی. گلرنتر، جی. وانگ، ایکس. لی، جی. Yu, Y. تشخیص علائم ترافیکی با استفاده از شبکه توجه تکراری چند مقیاسی. IEEE Trans. هوشمند ترانسپ سیستم 2019 ، 20 ، 4466-4475. [ Google Scholar ] [ CrossRef ]
- پروتچکی، وی. روهمر، سی. Feit، S. یادگیری پارامترهای چراغ راهنمایی با داده های شناور خودرو. در مجموعه مقالات 2015 IEEE هجدهمین کنفرانس بین المللی سیستم های حمل و نقل هوشمند، لاس پالماس، اسپانیا، 15-18 سپتامبر 2015. ص 2438-2443. [ Google Scholar ] [ CrossRef ]
- لیو، جی. شن، اچ. نارمان، اچ اس. چانگ، دبلیو. لین، زی. بررسی تکنیکهای سنجش جمعیت موبایل: مؤلفهای حیاتی برای اینترنت اشیا. ACM Trans. Cyber-Phys. سیستم 2018 ، 2 . [ Google Scholar ] [ CrossRef ]
- پرایب، کالیفرنیا؛ راجرز، بنابراین یادگیری ارتباط رفتار مشاهده شده راننده با کنترل های ترافیک. ترانسپ Res. ضبط J. Transp. Res. هیئت 1999 ، 1679 ، 95-100. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گلزه، ج. زورلیدو، س. Sester، M. تشخیص تنظیم کننده ترافیک با استفاده از مسیرهای GPS. KN J. Cartogr. Geogr. Inf. 2020 . [ Google Scholar ] [ CrossRef ]
- کیو، اچ. چن، جی. جین، اس. جیانگ، ی. مک کارتنی، ام. کار، جی. بای، اف. گریم، DK; گروتسر، م. Govindan، R. Towards Vehicular Context Sensing. IEEE Trans. وه تکنولوژی 2018 ، 67 ، 1909-1922. [ Google Scholar ] [ CrossRef ]
- علی، اچ. بسلامه، ع. یوسف، م. شناسایی معنایی نقشه غنی خودکار از طریق سنجش جمعیت مبتنی بر تلفن هوشمند. IEEE Trans. اوباش محاسبه کنید. 2017 ، 16 ، 2712-2725. [ Google Scholar ] [ CrossRef ]
- کاریسی، ر. جووردانو، ای. پائو، جی. Gerla، M. افزایش در نقشه های دیجیتال خودرو از طریق جمع سپاری GPS. در مجموعه مقالات هشتمین کنفرانس بینالمللی 2011 در مورد سیستمها و خدمات شبکه بیسیم بر اساس تقاضا، باردونکیا، ایتالیا، 26-28 ژانویه 2011. ص 27-34. [ Google Scholar ] [ CrossRef ]
- کونتزش، سی. زورلیدو، س. Feuerhake، U. یادگیری زمینه مقررات ترافیکی تقاطع ها از داده های مشخصات سرعت. در مجموعه مقالات مقالات کوتاه پذیرفته شده از کارگاه GIScience 2016 در مورد تجزیه و تحلیل داده های حرکت (AMD’16)، مونترال، QC، کانادا، 27 سپتامبر 2016. [ Google Scholar ]
- زورلیدو، س. فیشر، سی. Sester, M. طبقه بندی تقاطع های خیابان با توجه به تنظیم کننده های ترافیک. در مجموعه مقالات مقالات و پوسترهای کوتاه پذیرفته شده از بیست و دومین کنفرانس AGILE در علم اطلاعات جغرافیایی، دانشگاه صنعتی قبرس، لیماسول، قبرس، 17 تا 20 ژوئن 2019. [ Google Scholar ]
- منروکس، ی. گیلچر، آ. سنت پیر، جی. حامد، م. موستیره، اس. Orfila, O. تشخیص سیگنال ترافیک از پروفایل های سرعت GPS داخل خودرو با استفاده از تجزیه و تحلیل داده های عملکردی و یادگیری ماشین. بین المللی J. Data Sci. مقعدی 2020 ، 10 ، 101-119. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- صارمی، ف. عبدالظاهر، TF ترکیب استنتاج مبتنی بر نقشه و سنجش جمعیت برای تشخیص تنظیم کننده های ترافیک. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE 2015 در مورد سیستم های حسگر و Ad Hoc موبایل، دالاس، TX، ایالات متحده، 19 تا 22 اکتبر 2015؛ صص 145-153. [ Google Scholar ]
- وانگ، سی. هائو، پی. وو، جی. Qi، X. لیو، تی. Barth، M. تقاطع و استخراج موقعیت نوار توقف از مسیرهای GPS Crowdsourced. در مجموعه مقالات نشست سالانه 96 هیئت تحقیقات حمل و نقل، واشنگتن دی سی، ایالات متحده آمریکا، 8 تا 12 ژانویه 2017. [ Google Scholar ]
- منروکس، ی. کاناسوجی، اچ. پیر، جی اس. Guilcher، AL; موستییر، اس. شیباساکی، آر. Kato، Y. تشخیص و محلی سازی سیگنال های ترافیکی با داده های خودرو شناور GPS و جنگل تصادفی. در مجموعه مقالات دهمین کنفرانس بین المللی علم اطلاعات جغرافیایی (GIScience 2018)، مجموعه مقالات بین المللی لایبنیتس در انفورماتیک (LIPIcs، ملبورن، استرالیا، 28 تا 31 اوت 2018؛ Winter, S., Griffin, A., Sester, M., Eds .؛ Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl، آلمان، 2018؛ جلد 114، صفحات 11:1–11:15. [ Google Scholar ] [ CrossRef ]
- مونوز-اورگانرو، م. رویز-بلاکز، آر. Sánchez-Fernández, L. تشخیص خودکار چراغهای راهنمایی، تقاطع خیابانها و دوربرگردانهای شهری که ترکیبی از تکنیکهای تشخیص بیرونی و طبقهبندی یادگیری عمیق بر اساس ردیابی GPS هنگام رانندگی است. محاسبه کنید. محیط زیست سیستم شهری 2018 ، 68 ، 1-8. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چنگ، اچ. لیو، اچ. هیرایاما، تی. شینمورا، اف. آکای، ن. Murase، H. تشخیص تعامل خودکار بین وسایل نقلیه و کاربران آسیبپذیر جاده در حین چرخش در یک تقاطع. در مجموعه مقالات سی و یکمین سمپوزیوم وسایل نقلیه هوشمند IEEE، لاس وگاس، NV، ایالات متحده آمریکا، 19 اکتبر تا 13 نوامبر 2020. [ Google Scholar ]
- Kingma، DP; Welling, M. Auto-Encoding Variational Bayes. در مجموعه مقالات دومین کنفرانس بین المللی بازنمایی یادگیری، ICLR 2014، مجموعه مقالات پیگیری کنفرانس، Banff، AB، کانادا، 14-16 آوریل 2014. [ Google Scholar ]
- سون، ک. لی، اچ. Yan, X. یادگیری نمایش خروجی ساختاریافته با استفاده از مدلهای مولد شرطی عمیق. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 7 تا 12 دسامبر 2015. صص 3483-3491. [ Google Scholar ]
- Kingma، DP; محمد، س. رزنده، دی جی; Welling, M. یادگیری نیمه نظارتی با مدل های مولد عمیق. در مجموعه مقالات NIPS، مونترال، QC، کانادا، 8 تا 13 دسامبر 2014. صص 3581-3589. [ Google Scholar ]
- چنگ، اچ. لیائو، دبلیو. یانگ، م. روزنهان، بی. Sester، M. MCENET: شبکه رمزگذار چند متنی برای پیشبینی مسیر عامل همگن در ترافیک مختلط. در مجموعه مقالات بیست و سومین کنفرانس بین المللی سیستم های حمل و نقل هوشمند (ITSC)، رودس، یونان، 20 تا 23 سپتامبر 2020. [ Google Scholar ]
- رزنده، دی جی; محمد، س. Wierstra، D. پس انتشار تصادفی و استنتاج تقریبی در مدلهای مولد عمیق. در مجموعه مقالات سی و یکمین کنفرانس بین المللی کنفرانس بین المللی یادگیری ماشین، پکن، چین، 22 تا 24 ژوئن 2014. جلد 32; ص 1278-1286. [ Google Scholar ]
- هوکرایتر، اس. Schmidhuber, J. حافظه کوتاه مدت طولانی. محاسبات عصبی 1997 ، 9 ، 1735-1780. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kingma، DP; Ba, J. Adam: روشی برای بهینه سازی تصادفی. در مجموعه مقالات ICLR، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015. [ Google Scholar ]
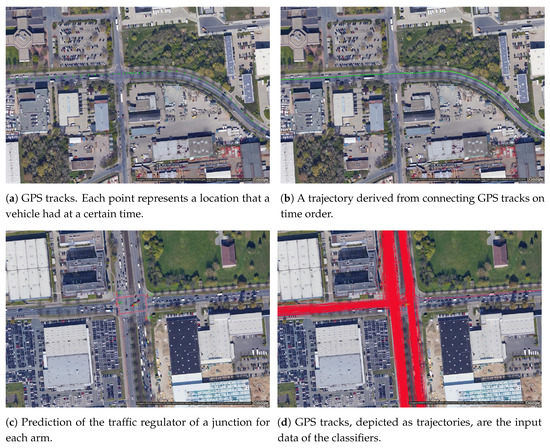
شکل 1. دادههای جغرافیایی جمعآوریشده از یک برنامه تلفن همراه، که بهعنوان مسیرهای ( a , b ) نشان داده شدهاند. نقشه غنیشده با تنظیمکنندههای ترافیک ( c ) از مسیرهای GPS وسایل نقلیه جمعسپاری ( d ).
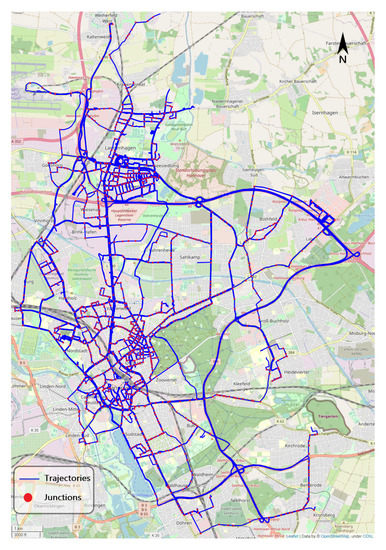
شکل 2. مجموعه داده هانوفر. مسیر وسایل نقلیه خطوط آبی و نقاط قرمز نماد اتصالات هستند. داده های © OpenStreetMap [ 7 ].

شکل 3. خط لوله مدل Conditional Variational Auto-Encoder (CVAE).

شکل 4. مسیرهای GPS استخراج شده از محل اتصال داده شده برای تنظیم کننده های ترافیک مانند علائم اولویت، چراغ های راهنمایی و کنترل نشده. ( الف ) تقاطع علامت اولویت (PS). ( ب ) تقاطع چراغ راهنمایی (TL). ( ج ) اتصال کنترل نشده (UC).

شکل 5. ماتریس های سردرگمی (در درصد) برای بهترین طبقه بندی تصادفی جنگل و مدل CVAE برای پیش بینی قاعده بازوی اتصال. ( الف ) ماتریس سردرگمی برای طبقه بندی جنگل تصادفی با نمونه برداری بیش از حد و AdaBoost. ( ب ) ماتریس سردرگمی برای مدل CVAE برای پیشبینی قاعده بازوی اتصال.


بدون دیدگاه