1. مقدمه
با تبدیل شدن ماهواره ها به زیرساخت های ضروری برای توسعه اقتصاد ملی، دستیابی به
تصاویر سنجش از دور (RSIs) آسان تر شده است. RSI ها به طور گسترده در زمینه های مختلفی مانند زیرساخت ها، کشاورزی، جنگلداری، زمین شناسی، هیدرولوژی، حمل و نقل، پیش بینی بلایا و غیره استفاده شده اند. با این حال، 66.7 درصد از سطح زمین توسط ابرها پوشیده شده است [ 1 ].]، که عامل اصلی محدود کننده استفاده از RSI های نوری است. علاوه بر این، به دلیل ویژگیهای مشابه (به عنوان مثال، نرخ بازتاب بالا) ابر و برف در باندهای نوری، برخی از روشهای سنتی مانند روشهای مبتنی بر آستانه نمیتوانند آنها را تشخیص دهند و اغلب منجر به قضاوت نادرست میشوند. این امر تا حد زیادی مانع پردازش خودکار RSI ها می شود. علاوه بر این، نیاز عمیقتری برای شناسایی ابر و برف مانند ساخت پایگاهداده بازتاب اتمسفر وجود دارد که میتواند برای بازیابی ذرات معلق در جو استفاده شود [ 2 ]. بنابراین، تقسیم بندی سریع، دقیق و خودکار ابر و برف از اهمیت بالایی برخوردار است.
تعدادی از روشهای تقسیمبندی تصویر از دهه 1970 ارائه شدهاند، که در میان آنها کلاسیکترین آنها Otsu است [ 3 ].] توسط Nobuyuki Otsu در سال 1979 پیشنهاد شد. این روش از روش جامع برای تعیین آستانه ای استفاده می کند که منجر به حداکثر واریانس بین اشیاء در تصاویر می شود، بنابراین تصاویر را به تصاویر پیش زمینه و پس زمینه تقسیم می کند. با توجه به انعکاس بالای ابرها در باندهای نوری، می توانیم از روش Otsu برای جداسازی ابر و پس زمینه از تصاویر قابل مشاهده استفاده کنیم. با این حال، ابر و برف اغلب ویژگیهای مشابهی در باندهای نوری دارند که تشخیص آنها از یکدیگر را دشوار میسازد و تقریباً غیرممکن است که ابر را از اجسام دیگر با استفاده از Otsu به یکباره تقسیم کنیم. اگرچه روش های زیادی برای بهبود Otsu پیشنهاد شده است (مانند چند Otsu)، اما آنها از محدودیت هایی مانند حجم زیاد محاسبات، استحکام کم و غیره رنج می برند. شکل 1نتیجه تقسیم بندی ابر Otsu را نشان می دهد، جایی که نتایج کاملاً متفاوتی را در تصاویر مشابه ایجاد می کند.
روش تقسیمبندی ابر و برف بر اساس کمک ارتفاع [ 4 ] تفاوت ارتفاع را بین ابر، برف و سایر اشیاء ثبت میکند. ویژگیهای هندسی سهبعدی ابر از طریق تطبیق متراکم تصاویر متعدد به دست میآیند، پس از آن تفاوتهای بین ابرها و اشیاء پسزمینه با مقایسه اطلاعات ارتفاعی موجود مورد بهرهبرداری قرار میگیرد. اگرچه این نوع روش ها دارای دقت بالایی هستند، اما شامل بسیاری از عملیات مشروط و وقت گیر مانند تطبیق متراکم و ثبت مدل ارتفاعی دیجیتال می شوند.
در دهههای اخیر، با توسعه فناوریهای تشخیص الگو و یادگیری ماشین، محققان روشهای هوشمندی را برای تقسیمبندی ابری مطالعه کردهاند و به نتایج خوبی دست یافتهاند. آماتو و همکاران [ 5 ] تجزیه و تحلیل مؤلفه اصلی (PCA) را برای تشخیص ابر تصویر بر اساس تئوری آماری اعمال کرد. بازرگان و همکاران [ 6 ] یک الگوریتم تشخیص ابر را بر اساس نظریه بیز با احتمال کامل پیشنهاد کرد. ژائو شیائو [ 7] از خوشهبندی فازی C-Means برای تکمیل خوشهبندی تکرار نمونه با کمینهسازی تابع هدف استفاده کرد و از ماشین بردار پشتیبان (SVM) برای انجام طبقهبندی استفاده کرد، که مزیت تقسیمبندی بهتر نتایج را در شرایط دانش تجربی دارد، در حالی که مداخله انسان تا حد زیادی مانع میشود. راندمان تقسیم بندی علاوه بر این، طبقه بندی کننده های ادراکی پراکنده، کدک خودکار و روش های دیگر وجود دارد. به طور کلی، هزینه زمانی الگوریتمهای مبتنی بر یادگیری ماشین به صورت خطی با تعداد پیکسلهای تصویر افزایش مییابد. بنابراین، برای RSI های مقیاس بزرگ، زمان عملکرد چنین الگوریتمی اغلب بسیار طولانی است و برآوردن نیازها در برنامه های کاربردی دنیای واقعی دشوار است.
اخیراً یادگیری عمیق در طبقه بندی تصاویر، تقسیم بندی تصویر، تشخیص اشیا و سایر وظایف بینایی پیشرفت زیادی داشته است. در سال 2015، لانگ و همکاران. [ 8 ] شبکه عصبی کاملاً پیچیدگی (FCN) را پیشنهاد کرد و آن را برای تقسیم بندی معنایی تصویر به کار برد. برخلاف CNN کلاسیک که از لایه کاملاً متصل بعد از لایه پیچشی برای بدست آوردن بردار ویژگی طول ثابت برای طبقهبندی استفاده میکند، FCN روی تصاویر با اندازه انعطافپذیر عمل میکند و تقسیمبندی در سطح پیکسل را انجام میدهد. برای مثال، شائو و همکاران. [ 9] روشی را بر اساس مدل ویژگی چند مقیاسی MF-CNN پیشنهاد کرد که می تواند ابرهای نازک و ابرهای ضخیم را در RSI ها تشخیص دهد که منجر به دقت تشخیص خوب در داده های Landsat 8 می شود. به طور خلاصه، روشهای مبتنی بر یادگیری عمیق در تقسیمبندی ابری و برفی در RSI ظاهر میشوند.
ResNet [ 10 ] یک ستون فقرات استخراج ویژگی است که توسط He و همکارانش پیشنهاد شده است، که بر اساس ایده یادگیری باقیمانده برای حل مشکل ناپدید شدن/انفجار گرادیان و تخریب شبکه در CNN سنتی (زمانی که تعداد شبکه ها افزایش می یابد) ساخته شده است. ماژول ResNet اطلاعات ورودی را از طریق یک کانال اتصال اضافی به خروجی دور میکند تا از یکپارچگی ورودی محافظت کند. کل شبکه فقط باید بخشی از تفاوت بین ورودی و خروجی را بیاموزد، که مشکل یادگیری را زمانی که شبکه عمیق تر می شود ساده می کند و به حفظ اطلاعات معنایی اصلی کمک می کند.
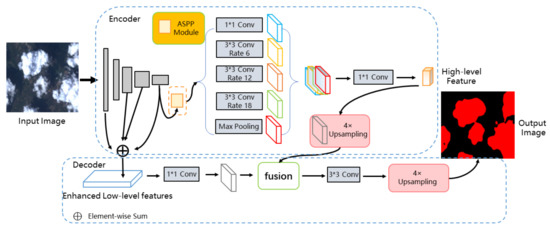
DeepLab [ 11 ، 12 ، 13 ] مدلهای تقسیمبندی معنایی یادگیری عمیق ارائه شده توسط Google هستند که شامل ساختار FCN رمزگذار-رمزگشا و ماژول ASPP برای ترکیب ویژگیهای چند مقیاسی و استفاده بهتر از ویژگیهای تصویر (در مقایسه با FCN ساده) هستند. ساختار رمزگذار-رمزگشا مجدداً در DeepLabV3 معرفی شده است. ترکیب ستون فقرات Xception [ 14] و ماژول ASPP به عنوان رمزگذار، که از نرخ انبساط متفاوت پیچیدگی سوراخ شده برای استخراج ویژگی ها استفاده می کند. پس از ادغام ویژگی و نمونهبرداری 4×، با ویژگیهای سطح پایین استخراجشده توسط Xception در رمزگشا ترکیب میشود و از نمونهبرداری 4× برای دریافت نتایج تقسیمبندی استفاده میشود. با توجه به استفاده از ASPP در DeepLabV3+، توانایی دسترسی چند مقیاسی به اطلاعات معنایی را بهبود می بخشد و به دقت پیشرفته در مجموعه داده های متعدد دست می یابد.
TH-1 [ 15] که اولین نسل از ماهواره انتقال استریو نقشه برداری در چین است، سه نوع از پنج بار دوربین شامل یک دوربین CCD آرایه خطی سه، دوربین پانکروماتیک با وضوح دو متر و
دوربین RGB ده متری را حمل می کند. داده های تحقیق ما شامل 470 کاشی RSI با باندهای RGB است که توسط ماهواره TH-1 از سال 2018 تا 2019 گرفته شده است. در مجموع 200 کاشی در 20 سپتامبر 2018 جمع آوری شد، در حالی که بقیه در 5 آوریل 2019 جمع آوری شدند. از قابلیت تعمیم شبکه اطمینان حاصل می کند، تصاویر انتخاب شده سطوح مختلف زیرین، فصول اکتساب و مراحل زمانی را با در نظر گرفتن موقعیت های جغرافیایی مختلف، شرایط آب و هوایی و ویژگی های ابر پوشش می دهند. طول جغرافیایی و محدوده عرض جغرافیایی به ترتیب 28°35′ E-120°05′ شرقی، 5°25′ شمالی تا 60°05′ شمالی است که سطوح مختلف زمین مانند بیابان ها را پوشش می دهد. مراتع، شهرها و کوه ها. علاوه بر این، به منظور تقسیم ابرها و برف به طور همزمان، 175 تصویر صحنه با برف انتخاب شده است.
روش های مبتنی بر آستانه هنوز در تولید واقعی استفاده می شود. برای حل مشکلات فوق، ما یک روش تقسیمبندی ابری و برفی مبتنی بر DCNN با ساختار رمزگذار – رمزگشا پیشنهاد میکنیم. در مقایسه با روشهای سنتی، بر دانش قبلی در انتخاب و استخراج ویژگی متکی نیست. ما مزایای ResNet50 [ 10 ] و ساختار رمزگذار-رمزگشا را ترکیب میکنیم و رمزگشا را برای درک تقسیمبندی همزمان ابر و برف در RSIs بهبود میدهیم. با بهبود ساختار شبکه، با استفاده از تابع فعال سازی نمایی (ELU) [ 16 ] و تابع از دست دادن کانونی [ 17 ]]، هدف ما بهینهسازی بخشبندی لبه ابری و افزایش قابلیت تعمیم شبکه است. از سوی دیگر، با تبدیل شدن DCNN به جریان اصلی تقسیمبندی معنایی تصویر، تولید یک برچسب سطح پیکسل با کیفیت بالا برای تقسیمبندی معنایی توجه بیشتری را به خود جلب کرده است. با این حال، حاشیه نویسی دقیق تصویر به نیروی انسانی زیادی نیاز دارد و مجموعه داده های موجود همه دارای برچسب دقیق نیستند. در حال حاضر، شبکههای DCNN بیشتر و بیشتر میشوند و دقت تقسیمبندی معنایی تصویر بالاتر و بالاتر است، که با این حال، بر اساس مجموعه دادههای منبع باز مانند Microsoft COCO [ 18 ] و PASCAL-VOC-2012 [ 19 ]]، عمدتاً برای نوآوری در ساختار شبکه و بهبود دقت تقسیم بندی بدون تجزیه و تحلیل بر روی تأثیر کیفیت و کمیت برچسب بر نتایج مطالعه شده است. بنابراین، جهت دیگر این مقاله بررسی تأثیر کیفیت و کمیت داده های مختلف بر عملکرد تقسیم بندی ابر و برف در RSI است. مشارکت های عمده تحقیقاتی ما به شرح زیر خلاصه می شود:
ابتدا، ما یک چارچوب DCNN سرتاسر با معماری رمزگذار-رمزگشا، ED-CNN، پیشنهاد میکنیم که رمزگشا را با ادغام ویژگیهای مراحل مختلف رمزگذاری بهبود میبخشد. خروجیهای ASPP، که پس از نمونهبرداری 1×1 و 4××، با ویژگیهای سطح پایین ارتقا یافته از رمزگشای پیشرفته الحاق میشوند. سپس، نقشههای ویژگی الحاقی به Conv 3 × 3 و 4 × upsampling فرستاده میشوند تا اندازه اصلی خود را بازیابی کنند تا پیکسلهای تصویر بخشبندی شوند. دوم، ما یک مجموعه داده ماهوارهای TH-1 را ارائه میکنیم که حاوی 23520 تصویر با برچسب درشت همراه با حاشیهنویسی است. علاوه بر این، یک مجموعه داده با برچسب دقیق از 300 تصویر برای پشتیبانی از آزمایشهای ما اضافه شده است. سوم، آزمایشها بر اساس مجموعه دادههای مختلف، از جمله تصاویر TH-1 از یک فاز زمانی متفاوت و تصاویر Google Earth، انجام شده است. که نشان می دهد که شبکه پیشنهادی نسبت به DeepLabV3+ با Xception و ResNet50 برتری دارد و می تواند برای RSI های چند منبعی اعمال شود. در نهایت، ما اثرات کیفیت و کمیت برچسبگذاری در مجموعه داده را از طریق آزمایشهای گسترده با شبکه پیشنهادی مورد بحث قرار میدهیم. نشان داده شده است که عملکرد تقسیمبندی ابر و برف به طور مثبت عمدتاً با کمیت برچسبگذاری مرتبط است. یعنی مجموعه داده با برچسب ناهموار کوچکتر به اضافه تعدادی عکس با برچسب ریز که 10٪ از کل تصاویر را تشکیل می دهد، برابر است با مجموعه داده با برچسب ناهموار بزرگتر با همان مقدار کل تصویر. علاوه بر این، در مصرف برچسبگذاری یکسان، مجموعه دادههای برچسبدار ناهموار بزرگتر از مجموعه دادههای برچسبدار ناهموار کوچکتر بهعلاوه چند تصویر با برچسب ریز بیشتر است. در نهایت، ما اثرات کیفیت و کمیت برچسبگذاری در مجموعه داده را از طریق آزمایشهای گسترده با شبکه پیشنهادی مورد بحث قرار میدهیم. نشان داده شده است که عملکرد تقسیمبندی ابر و برف به طور مثبت عمدتاً با کمیت برچسبگذاری مرتبط است. یعنی مجموعه داده با برچسب ناهموار کوچکتر به اضافه تعدادی عکس با برچسب ریز که 10٪ از کل تصاویر را تشکیل می دهد، برابر است با مجموعه داده با برچسب ناهموار بزرگتر با همان مقدار کل تصویر. علاوه بر این، در مصرف برچسبگذاری یکسان، مجموعه دادههای برچسبدار ناهموار بزرگتر از مجموعه دادههای برچسبدار ناهموار کوچکتر بهعلاوه چند تصویر با برچسب ریز بیشتر است. در نهایت، ما اثرات کیفیت و کمیت برچسبگذاری در مجموعه داده را از طریق آزمایشهای گسترده با شبکه پیشنهادی مورد بحث قرار میدهیم. نشان داده شده است که عملکرد تقسیمبندی ابر و برف به طور مثبت عمدتاً با کمیت برچسبگذاری مرتبط است. یعنی مجموعه داده با برچسب ناهموار کوچکتر به اضافه تعدادی عکس با برچسب ریز که 10٪ از کل تصاویر را تشکیل می دهد، برابر است با مجموعه داده با برچسب ناهموار بزرگتر با همان مقدار کل تصویر. علاوه بر این، در مصرف برچسبگذاری یکسان، مجموعه دادههای برچسبدار ناهموار بزرگتر از مجموعه دادههای برچسبدار ناهموار کوچکتر بهعلاوه چند تصویر با برچسب ریز بیشتر است. نشان داده شده است که عملکرد تقسیمبندی ابر و برف به طور مثبت عمدتاً با کمیت برچسبگذاری مرتبط است. یعنی مجموعه داده با برچسب ناهموار کوچکتر به اضافه تعدادی عکس با برچسب ریز که 10٪ از کل تصاویر را تشکیل می دهد، برابر است با مجموعه داده با برچسب ناهموار بزرگتر با همان مقدار کل تصویر. علاوه بر این، در مصرف برچسبگذاری یکسان، مجموعه دادههای برچسبدار ناهموار بزرگتر از مجموعه دادههای برچسبدار ناهموار کوچکتر بهعلاوه چند تصویر با برچسب ریز بیشتر است. نشان داده شده است که عملکرد تقسیمبندی ابر و برف به طور مثبت عمدتاً با کمیت برچسبگذاری مرتبط است. یعنی مجموعه داده با برچسب ناهموار کوچکتر به اضافه تعدادی عکس با برچسب ریز که 10٪ از کل تصاویر را تشکیل می دهد، برابر است با مجموعه داده با برچسب ناهموار بزرگتر با همان مقدار کل تصویر. علاوه بر این، در مصرف برچسبگذاری یکسان، مجموعه دادههای برچسبدار ناهموار بزرگتر از مجموعه دادههای برچسبدار ناهموار کوچکتر بهعلاوه چند تصویر با برچسب ریز بیشتر است.

2. روش شناسی
2.1. ایجاد مجموعه داده
ابتدا یک تصویر BMP تولید کردیم. فایل داده TH-1 RSI از فرمت TIF با چهار کانال در تصویر BMP با وضوح 6000 پیکسل × 6000 پیکسل ذخیره شد. دوم، مجموعه داده تقسیم شد و تصاویر برش داده شدند. 470 کاشی از تصاویر بر اساس نسبت عددی 3:1:1 به مجموعه آموزشی، مجموعه اعتبار سنجی و مجموعه تست تقسیم شدند. از آنجایی که تصویر اصلی اندازه بزرگی داشت و حافظه زیادی را اشغال میکرد، نمیتوان آن را مستقیماً در شبکه آموزش داد. بنابراین، تصاویر را به تکه هایی با ابعاد 480 × 360 پیکسل برش می دهیم. در مجموع 23520 تصویر شامل 13924 تصویر آموزشی، 4798 تصویر اعتبارسنجی و 4798 تصویر آزمایشی تولید شد. سوم، تصاویر دارای برچسب خشن بودند. لیبلمی [ 20] برای علامتگذاری تقریباً ناحیه ابری هر تصویر، تولید فایلهای JSON و تبدیل فایلهای JSON به تصاویر علامتگذاریشده با برچسب با همان اندازه برچسب به صورت دستهای استفاده شد. تصویر با برچسب ناهموار و ماسک آن در شکل 1 نشان داده شده است ، جایی که رنگ قرمز نشان دهنده ابر، سبز نشان دهنده برف و سیاه نشان دهنده پس زمینه است. چهارم، برخی از تصاویر دارای برچسب دقیق بودند. به منظور تأیید تأثیر تصویر حاشیه نویسی ظریف و تصویر حاشیه نویسی ناهموار بر نتایج آموزشی (توضیحات مفصل در بخش 2.3.2 آمده است.) 310 تصویر اضافی به طور تصادفی انتخاب شدند و سپس با دقت برچسب گذاری شدند تا فایل های JSON با زمان 6 برابر هزینه برچسب گذاری خشن برای هر تصویر تولید شوند، که سپس به تصاویر برچسب گذاری شده در مرحله 3 تبدیل شدند. تصاویر با برچسب ریز لبه دقیق تری داشتند. علامت گذاری (خطاهای کمتر از 5 پیکسل). تصویر با برچسب ریز و ماسک آن در شکل 2 نشان داده شده است ، که در آن برچسب 1 نشان دهنده ابر، برچسب 2 نشان دهنده برف و برچسب 0 نشان دهنده پس زمینه واقع در گوشه سمت راست پایین تصویر است. پنجم، پیش پردازش تصویر انجام شد. در مرجع [ 21] ثابت شده است که عملکرد شبکه را می توان به طور موثر با افزایش داده ها بهبود بخشید. به منظور افزایش توانایی تعمیم شبکه و جلوگیری از برازش بیش از حد، مجموعه داده ها افزوده شد. عملیات تقویت شامل تلنگر عمودی، چرخش افقی، تغییر کنتراست و غیره است. تصاویر اصلی و افزوده شده در شکل 3 و شکل 4 نشان داده شده است.
2.2. مواد و روش ها
2.2.1. ستون فقرات شبکه
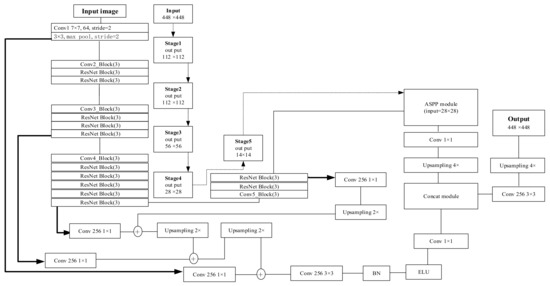
نحوه استخراج ویژگیها از انواع مختلف RSI به درستی و به طور موثر یک مشکل کلیدی است. ابر و برف در RSI ها بیشتر یک ساختار مسطح را نشان می دهند. اطلاعات معنایی آنها ساده است، در حالی که اطلاعات دقیق آنها غنی است، که تقاضای بالایی برای توانایی استخراج جزئیات ایجاد می کند. به عنوان مثال، با مقدار پارامتر 22.8 M [ 14 ]، Xception دارای تعداد زیادی پارامتر مناسب برای کارهای تقسیم بندی با انواع مختلفی از اشیاء است، در عین حال، به منابع محاسباتی عظیمی نیاز دارد و آموزش آن دشوار است، بنابراین واضح است که به طور کامل نیست. مناسب برای وظیفه تقسیم ابر و برف. در این مقاله، ستون فقرات Resnet50 به عنوان رمزگذار برای استخراج ویژگی های ابر و برف انتخاب شد (همانطور که در شکل 5 نشان داده شده است.). اندازه پارامتر ResNet50 تنها 0.85 M [ 10 ] بود و اتصالات مستقیم بیشتری در شبکه اضافه شد. با توجه به مزایایی مانند پارامترهای کمتر، آموزش آسان و همگرایی سریع، در مقایسه با Xception برای تقسیم بندی ابر و برف مناسب تر است.
2.2.2. رمزگشای پیشرفته
در معماریهای رمزگذار-رمزگشا مانند DeepLabV3+، زیرشبکه رمزگشا به تدریج اطلاعات مکانی را بازیابی میکند که معمولاً به اندازه رمزگذار قدرتمند نیست. در این راستا، علاوه بر جایگزینی ستون فقرات به ResNet50، اتصالات پرش را در رمزگشا اضافه کردیم. برای مشخص بودن، ویژگیهایی را در مراحل 1، مرحله 3، مرحله 4 و مرحله 5 از ResNet50 انتخاب کردیم تا یک هرم نقشه ویژگی اتصال از بالا به پایین ایجاد کنیم، که نمایش معنایی ویژگیهای سطح پایین را برای استفاده بهتر از فضای مکانی غنی کرد. اطلاعاتی که در شکل 5 نشان داده شده است. نقشههای ویژگی سطح پایین با وضوح بالا و نقشههای ویژگی سطح بالا با اطلاعات معنایی غنی ترکیب شدند، که میتواند به سرعت رمزگشا را با اطلاعات معنایی بهتر از ۴ مرحله بهجای یک مرحله بدون افزایش هزینه آشکار بسازد.
همانطور که شکل 6 نشان می دهد، ابتدا نقشه ویژگی از مرحله 5 بعد از انحراف 1 × 2 × نمونه برداری شد، که با خروجی مرحله 4، پس از انحراف 1×1 نیز اضافه شد. اعداد ابعاد این مراحل همگی روی 256 تنظیم شده بود تا اطمینان حاصل شود که این نقشه های ویژگی می توانند اضافه شوند. دوم، نقشه ویژگی اضافه شده برای بار دوم 2 × نمونه برداری شد تا به همان اندازه خروجی از مرحله 3 باشد، سپس این فرآیند برای به دست آوردن نقشه ویژگی ترکیب شده با خروجی از مرحله 1 تکرار شد. سوم، نقشه ویژگی ارتقا یافته رمزگشا با نقشه ویژگی تولید شده از ماژول ASPP پس از پیچیدگی 3 × 3، نرمال سازی دسته ای و عملیات ELU الحاق شد. در نهایت، نقشه تقسیم بندی با کانولوشن 3×3 و نمونه برداری 4× به دست آمد.
2.2.3. عملکرد از دست دادن
در عمل، انواع مختلفی از ابرها با اشکال مختلف وجود دارد. به طور کلی نسبت ابرهای نازک و ابرهای سیروس کمتر از ابرهای ضخیم است. مجموعه داده آموزشی در این مقاله همچنین ویژگی های داده های کمتر ابرهای نازک، ابرهای سیروس و برف را منعکس می کند. از دست دادن آنتروپی متقاطع (CE) نمی تواند یادگیری نمونه های کمتر را متعادل کند. فرمول آن به شرح زیر است
از طریق ترکیب پارامترهای مختلف، از دست دادن کانونی [ 17 ] می تواند مشکل عدم تعادل نمونه را در کار تقسیم بندی معنایی حل کند، که نسخه بهبود یافته ای از اتلاف CE با اضافه کردن وزن است. فرمول آن به شرح زیر است:
جایی که λو γدو ابرپارامتر هستند و پتی احتمال پیش بینی برچسب است. (λ-پتی)را می توان به عنوان وزن معادله (1) در نظر گرفت. کاغذ [ 17 ] مجموعه γ= 2 و λ= 1، زمانی که پیشبینی یک دسته خاص دقیق باشد، یعنی نزدیک به 1، مقدار آن نزدیک به 0 است. برای نمونه هایی که به راحتی قابل تشخیص هستند، وزن مربوط به افت کم خواهد بود، در حالی که برای اجسامی که تشخیص آنها دشوار است، وزن متناظر آنها بزرگتر خواهد بود تا ارزش از دست دادن نمونه های دشوار حفظ شود و ارزش تلفات کاهش یابد. نمونه های ساده تنظیم کردیم γ= 2 و λ= 1.
2.2.4. تابع فعال سازی
واحد خطی نمایی (ELU) در مقاله [ 16 ] پیشنهاد شد، که می تواند مقدار میانگین خروجی را نزدیک به 0 کند، بنابراین همگرایی شبکه را تسریع می کند و به طور موثر بر مشکلاتی مانند ناپدید شدن گرادیان غلبه می کند. اگر خروجی یک گره X باشد، خروجی پس از عبور از لایه ELU در رابطه (3) نشان داده شده است. ما فعال سازی ELU را پس از لایه های کانولوشن پذیرفتیم.
2.2.5. معیارهای ارزیابی
در اینجا ما از دقت پیکسل (PA) و تقاطع میانگین روی اتحاد (MIOU) به عنوان معیارهای ارزیابی استفاده کردیم.
-
PA: سادهترین و مستقیمترین نشانگر که فقط نسبت تعداد پیکسلهای طبقهبندی شده صحیح به تعداد تمام پیکسلها را محاسبه میکند. محاسبه در رابطه (4) نشان داده شده است.
-
MIOU: نسبت تصادفی بین تقاطع و اتحاد دو مجموعه را محاسبه می کند، یعنی نسبت اتحاد تقاطع بین تقسیم بندی واقعی و تقسیم بندی الگوریتم. این نسبت را می توان به صورت تعداد موارد مثبت واقعی (تقاطع) تقسیم بر تعداد کل (شامل موارد مثبت واقعی، موارد منفی کاذب و موارد مثبت کاذب (Union)) دوباره تعریف کرد. MIOU بر اساس کلاس محاسبه می شود و سپس میانگین می شود. محاسبه در رابطه (5) نشان داده شده است.
2.3. آزمایش
2.3.1. پلتفرم آزمایشی
سخت افزار آزمایشی ایستگاه کاری لنوو با فرکانس CPU 2.1 گیگاهرتز پردازنده Intel Xeon و GPU NVIDIA Titan XP است. ما از چارچوب Tensorflow + Keras برای ساخت مدل های یادگیری عمیق استفاده کردیم. آموزش شبکه بر اساس افزایش داده ها انجام شد. میزان یادگیری اولیه بر روی تنظیم شد 3ه-4و کاهش نرخ یادگیری به 0.1 تنظیم شد. با استفاده از تابع فعالسازی ELU و بهینهساز Adam [ 22 ]، اندازه دسته با توجه به قابلیت GPU روی 8 تنظیم شد.
2.3.2. تنظیمات آزمایش گروهی
ما آزمایش را در دو مرحله با شماره 0 تا 4 نشان دادیم که در جدول 1 نشان داده شده است. ابتدا، عملکرد یک شبکه متفاوت بر روی مجموعه داده 1، که شامل 23520 تصویر بود، ارزیابی شد. دوم، یک مجموعه داده کوچکتر 2 شامل 6660 تصویر با برچسب ناهموار و 310 تصویر با برچسب ریز از مجموعه داده 1 انتخاب شد تا تأثیر کمیت و کیفیت برچسب های تصویر را بر دقت تقسیم بندی ابر و برف بررسی کند.
3. نتایج و تجزیه و تحلیل
3.1. فرآیند آموزش و نتایج
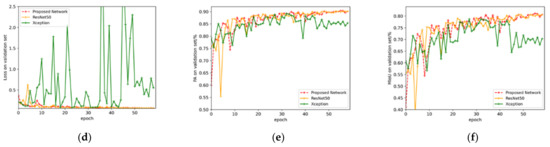
ابتدا از مجموعه داده 1 برای آموزش شبکه پیشنهادی ResNet50 و Xception به ترتیب برای 60 دوره استفاده کردیم. شکل 7 مقایسه از دست دادن و دقت بین سه شبکه در مجموعه آموزشی و مجموعه اعتبار سنجی را نشان می دهد. خط قرمز نشان دهنده روش پیشنهادی است، در حالی که خطوط زرد و سبز به ترتیب ResNet50 و Xception را نشان می دهند.
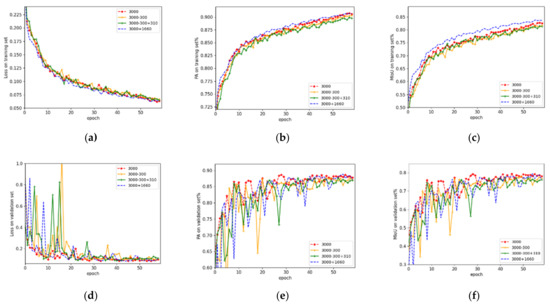
دوم، مجموعه داده 2 از 6660 تصویر به طور تصادفی از مجموعه 1 انتخاب شد و به 4660 برای مجموعه آموزشی، 1000 برای مجموعه اعتبار سنجی و 1000 برای مجموعه آزمایش تقسیم شد. 310 تصویر با برچسب دقیق دیگر به مجموعه آموزشی اضافه شد. چهار گروه آزمایش برای بررسی تأثیر استراتژی استفاده از داده بر شبکه پیشنهادی انجام شد. شکل 8 نتایج را نشان می دهد.
3.2. مقایسه و تحلیل
ابتدا، نتایج آزمایش سه روش روی مجموعه داده 1 در جدول 2 نشان داده شده است. در مجموعه آزمایشی از 4798 تصویر، PA تقسیمبندی ابر و برف بهدستآمده با روش پیشنهادی 90.3 درصد بود، در حالی که PA Xception، ResNet50 و DANet [ 23 ] به ترتیب 87.4، 89.2 درصد و 88.9 درصد بود. MIoU روش پیشنهادی 81.1 درصد بود که به ترتیب 4.2٪، 0.6٪ و 0.8٪ از Xception و ResNet50 بیشتر بود. هنگامی که رمزگشای پیشرفته پیشنهادی برای بهبود ویژگیهای سطح پایین استفاده شد، PA و MIoU شبکه به وضوح افزایش یافت.
دوم، چهار گروه آزمایش بر روی مجموعه داده 2 برای بررسی تأثیر کیفیت و کمیت داده های مختلف بر روی شبکه پیشنهادی انجام شد. نتایج در جدول 3 نشان داده شده است، که در آن گروه 1 و گروه 2 ثابت کردند که کاهش 10 درصدی در تعداد داده های آموزشی باعث کاهش عملکرد کلی می شود. در مقابل، گروه 2 و گروه 3 نشان میدهند که افزایش 10 درصدی دادههای با برچسب ریز که جایگزین کاهش شده است، تأثیر جانبی جزئی بر عملکرد داشته است. به نظر ما، افزودن ویژگی های مختلف داده در زمانی که مجموعه آموزشی به اندازه کافی بزرگ نیست منجر به مشکل فوق می شود. علاوه بر این، به طور متوسط، برچسب زدن یک تصویر با برچسب دقیق، شش برابر بیشتر از ساخت یک تصویر با برچسب ناهموار طول کشید. با این حال، گروه 4 نشان می دهد که 4660 تصویر با برچسب ناهموار در مقایسه با سه گروه دیگر نتایج بهتری به دست آوردند.
در نهایت، تجزیه و تحلیل کیفی تصاویر معمولی برای مقایسه نتایج روش پیشنهادی با Otsu و دو شبکه دیگر (Xception و ResNet50) انجام شد. شکل 9 نتایج مقایسه روش سنتی Otsu را در مقابل سه شبکه نشان می دهد و قسمت قرمز ابر و قسمت سبز برف است. می توان دریافت که زمانی که شرایط روشنایی تصویر ایده آل نبود و کنتراست سطح زیرین بالا نبود، Otsu یک هشدار کاذب در شکل 9 b ایجاد کرد و نمی توانست ابر و برف را همزمان تقسیم بندی کند (مانند شکل 9 d ). دلیل آن این است که الگوریتم Otsu اطلاعات همسایگی را در تقسیم بندی در نظر نمی گیرد و به نویز حساس است. در شکل 9a,c, Xception برخی از پیکسل ها را از دست داد و نتیجه اشتباه را در شکل 9 b دریافت کرد، در حالی که در شکل 9 d کاملاً اشتباه بود. عملکرد شبکه پیشنهادی در حفظ جزئیات فضایی کمی بهتر از ResNet50 بود.
علاوه بر این، تصاویر TH-1 از مراحل زمانی مختلف برای تأیید عملکرد تعمیم روش پیشنهادی انتخاب میشوند. نتایج در شکل 10 نشان داده شده است. نشان داده شده است که روش پیشنهادی میتواند ابر و برف را با دقت بخشبندی کند و توانایی تعمیم بهتری را نشان دهد.
https://gisland.org/
4. نتیجه گیری
4.1. روش پیشنهادی برای تقسیم بندی ابر و برف
در این مقاله، ما یک شبکه تقسیمبندی ابری و برفی انتها به انتها برای RSIs TH-1 پیشنهاد کردیم که مزایای معماری رمزگذار-رمزگشا و رمزگشای پیشرفته را ترکیب میکند. از یک طرف، از کاستیهای الگوریتمهای تشخیص ابر سنتی (مانند وابسته بودن به پارامتر، زمانبر بودن و دامنه کاربرد محدود) اجتناب کرد. در 4798 تصویر آزمایشی به mIo 81.1% دست یافت و زمان بخشبندی (در یک تصویر 480 × 360) را به 49.2 میلیثانیه کاهش داد که اساساً میتواند الزامات پیشپردازش تصویر را برآورده کند. از سوی دیگر، بهبود رمزگشا راهی مفید برای بهبود عملکرد بخشبندی از طریق بهرهبرداری از ویژگیها در مراحل مختلف رمزگذار است که شکاف بین سطوح مختلف ویژگیها را پر میکند.شکل 11 .
هنوز جا برای بهبود بیشتر در روش تقسیمبندی ابری و برفی پیشنهاد شده در این مقاله وجود دارد، مانند بهبود دقت آموزش و استفاده از RSIهای چند منبعی اضافی برای یادگیری انتقال. جهت تحقیق دیگر استفاده از اطلاعات چند طیفی برای حل مشکل تشخیص ابر، مه و برف در مناطق مختلط است.
4.2. تأثیر مجموعه داده های مختلف بر عملکرد بخش بندی
با توجه به یک شبکه خاص، متوجه شدیم که عملکرد بخشبندی آن عمدتاً به تعداد تصاویر و برچسبهای آموزشی مرتبط است. به طور خاص، زمانی که زمان تمرین کافی بود، تصاویر آموزشی بیشتر منجر به دقت بالاتر میشد، در حالی که افزایش 10 درصدی دادههای با برچسب ریز که جایگزین کاهش برچسبهای خشن اولیه میشد، یک اثر جانبی جزئی بر عملکرد داشت. با توجه به دستهبندیهای کمتر و پیچیدگی کمتر تقسیمبندی ابر و برف، نتیجهگیری ما این بود که وقتی همان زمان برچسبگذاری در نظر گرفته شد، تنها با برچسبگذاری تقریباً دادهها به نتایج بهتری دست یافتیم. به جای صرف منابع دستی بیشتر برای ساخت ماسک هایی با برچسب ریز، برچسب زدن تقریباً داده های بیشتر می تواند به همان دقت تقسیم بندی منجر شود.
حاشیه ای برای تحقیقات بیشتر در مورد اثرات کیفیت و کمیت برچسب، مانند روشن کردن خطای پیکسل برچسب های درشت علامت گذاری و بررسی تأثیر انواع و اندازه خطا بر نتایج تقسیم بندی ابر و برف وجود دارد.
















بدون دیدگاه