

از آنجایی که لندفرم های تشکیل دهنده سطح زمین از نظر خصوصیات و ظاهر متفاوت هستند، نقش برجسته های سایه دار آنها نیز برداشت بصری متفاوتی از زمین ارائه می دهند. در این کار، ما یک U-Net را تطبیق میدهیم تا بتواند منتخبی از فرمهای زمین را تشخیص دهد و بتواند زمین را قطعهبندی کند. ما کارایی 10 مدل مجزا را آزمایش میکنیم و یک رویکرد مجموعهای را اعمال میکنیم، که در آن همه مدلها ترکیب میشوند تا بالقوه بهتر از مدلهای منفرد عمل کنند. الگوریتم ما بهویژه برای کوههای بلوک، Prealps، درهها و تپهها خوب کار میکند و دقت متوسط و مقادیر f1 را بالای 60% ارائه میکند. بخشبندی فلاتها و کوههای چین خورده چالشبرانگیزتر است و مقادیر دقت آنها به دلیل مناطق کوچکتر در دسترس برای آموزش پراکنده است. کوههایی که در اثر فرآیندهای فرسایش تشکیل شدهاند، به دلیل شباهتهایشان با سایر فرمهای زمین، کمترین شکل زمین را در بین همگان شناسایی کردهاند. بالاترین دقت یکی از 10 مدل 65 درصد است در حالی که دقت مجموعه 61 درصد است. ما تکنیکهای سایهاندازی را به کار میگیریم که مشخص شد در مورد لندفرمهای خاص در مناطق تقسیمبندی شده مربوطه کارآمد هستند و آنها را با هم ترکیب میکنیم. در نهایت، ما مدل آموزش دیده را با بهترین دقت در سایر مناطق کوهستانی در سراسر جهان آزمایش می کنیم و ثابت می کند که در مناطق دیگر فراتر از منطقه آموزشی کار می کند.
کلید واژه ها:
تشخیص شکل زمین ؛ شبکه های عصبی کانولوشنال ; سایه زنی امدادی ; ژئومورفولوژی ; یادگیری ماشینی ؛ geoAI
1. مقدمه
تقسیمبندی زمین به ما اجازه میدهد تا شکلهای زمین را ترسیم کرده و آنها را برای اهداف متعدد به کار ببریم. در کارتوگرافی، از چنین تقسیم بندی می توان برای ایجاد برجستگی سایه دار مرکب با استفاده از یک تکنیک سایه زنی مناسب برای هر لندفرم شناسایی شده به طور جداگانه استفاده کرد. این مقاله توضیح میدهد که چگونه زمین را تقسیمبندی میکنیم تا تکنیک سایهاندازی تحلیلی واضحتر و معنادارتر را در منطقه تقسیمبندی شده اعمال کنیم. علاوه بر این، سایههای برجسته انتخاب لندفرمهایی را که در این مقاله روی آنها تمرکز میکنیم، تعریف و توضیح میدهد. ما شبکه را در قلمرو سوئیس آموزش دادیم زیرا دادههای حقیقت زمینی برای کل کشور داریم، و آن را بیشتر به مناطق آزمایشی مختلف در سراسر جهان گسترش دادیم تا عملکرد آن را در خارج از حوزه آموزش بررسی کنیم.
چندین روش خودکار موجود برای تقسیمبندی و طبقهبندی لندفرمها وجود دارد. یکی از رویکردهای اولیه از تحلیل چند مقیاسی شکل زمین [ 1 ] استفاده می کند که منجر به مدل های بهبود یافته مشتقات سطحی و طبقه بندی های شکل زمین جدید می شود. الگوریتم دیگری مبتنی بر منطق فازی توسط Drăguţ و Blaschke [ 2 ] پیشنهاد شده است که عناصر شکل زمین مانند قله ها و شیب ها را مشخص می کند و زمین را بیشتر به مناطق مرتفع، میانی و پست طبقه بندی می کند. رویکرد تجزیه و تحلیل تصویر مبتنی بر شی [ 3 ] امکان طبقه بندی لندفرم ها را به هشت کلاس توپوگرافی با استفاده از داده های SRTM می دهد.
تقاضای فزاینده برای روشهای تشخیص و طبقهبندی خودکار شکل زمین همراه با توسعه سریع شبکههای عصبی منجر به ایجاد چندین الگوریتم یادگیری ماشینی در چند سال اخیر شده است. تشخیص توپوگرافی خودکار توسط لیو و لی انجام شد [ 4] با استفاده از طیف شیب به عنوان عامل کمی همراه با یک شبکه عصبی پس انتشار اعمال شده به لندفرم های لس استان شانشی در چین. میانگین نرخ تشخیص 70% از 25% تا 75% برای لندفرمهای تپهای-خندقی لس و کوههای کم ارتفاع تا 100% برای دشتهای لس، تراسها، پشتههای لس و کوههای مرتفع متغیر است. دقت در هنگام استفاده از پارامترهای متعدد (طیف شیب، انحراف استاندارد طیف شیب و غیره) بالاترین میزان است که امیدوارکننده به نظر می رسد و نیاز به تحقیقات بیشتر دارد. در چندین مورد، شبکههای عصبی کانولوشنال نیز برای طبقهبندی و برچسبگذاری مناظر طبیعی مبتنی بر پیکسل [ 5 ، 6 ، 7 ، 8 ] و پوشش زمین [ 8 ] از تصاویر ماهوارهای استفاده شد.
تشخیص شکل زمین با استفاده از رویکرد یادگیری عمیق چندوجهی [ 9 ] به دلیل به کارگیری هر دو ویژگی فیزیکی (ارتفاع، شیب، و انحنا) و ویژگیهای بافت بصری (تسکین با سایه خاکستری) دادههای ژئومورفولوژیکی تقویت شد. منطقه مورد مطالعه شامل مجموعه دادههای لندفرم شش طبقه در چین مرکزی است که بر اساس نوع منشأ آنها طبقهبندی شدهاند، به عنوان مثال، لندفرمهای بادی، خشک، لس، کارست، اطراف یخبندان، و لندفرمهای رودخانهای. این الگوریتم در مقایسه با روشهای مرسوم با بالاترین مقدار دقت 89.47 درصد، عملکرد قابل توجهی بهتری را ممکن میسازد.
یکی دیگر از الگوریتم های اخیر بر استخراج ویژگی های لندفرم پیچیده و انتقالی از منابع داده یکپارچه، که شامل تصاویر همراه با مدل های ارتفاعی دیجیتال (DEM) و مشتقات زمین است، تمرکز دارد [ 10 ]. منطقه مورد مطالعه در فلات Loess، چین است و بالاترین دقت طبقهبندی شکل زمین از روش جنگل تصادفی [ 11 ] که با آن مقایسه شد، بیشتر بود.
علاوه بر این، رویکردهای مبتنی بر قاعده، به عنوان مثال، الگوریتم میانگین تو در تو بدون نظارت [ 12 ]، برای طبقهبندی زمین با استفاده از شیب شیب، تحدب محلی، و بافت سطح ساخته شد، جایی که شیب و بافت در تشخیص کوهها مهم به نظر میرسد و تحدب سطح مفید است. برای تمایز بین زمین های کم ارتفاع مانند دشت سیلابی، تراس رودخانه و مخروط افکنه. یکی از اولین شبکه های عصبی که روش یادگیری بدون نظارت را به کار می برد، از یک رمزگذار خودکار برای تعریف seamounts در داده های عمق سنجی استفاده کرد [ 13 ].
کاربردهای الگوریتم های ذکر شده ( جدول 1 ) متفرقه است، که نشان دهنده نیاز روزافزون به روش های موثر تشخیص شکل زمین و تقسیم بندی است. در بیشتر موارد، DEM، ویژگیهای بافت بصری و اطلاعات ژئومورفولوژیکی اضافی به عنوان دادههای ورودی عمل میکنند.
2. داده ها و روش
گردش کار پیشنهادی به شرح زیر است ( شکل 1 ): به عنوان داده ورودی، از چند ضلعی های شطرنجی (تصاویر دودویی) شکل های زمین استفاده می کنیم. پس از استخراج مناطق، کاشی های نقشه را جمع آوری می کنیم و شبکه عصبی کانولوشنال انتخابی U-Net را 10 بار آموزش می دهیم. در مرحله بعد، پیشبینیها را برای کل منطقه محاسبه میکنیم و مدل را با محاسبه معیارها (دقت، یادآوری و امتیاز f1) ارزیابی میکنیم. به عنوان آخرین مرحله، ما نقش برجسته های سایه دار مختلف را بر اساس “مناسب بودن” سایه های برجسته برای اشکال مختلف زمین ترکیب می کنیم. برای ارزیابی عملکرد الگوریتم در خارج از منطقه نمونه، مدل را اجرا کردیم تا پیشبینیهایی را در مناطق دیگر در سراسر جهان به دست آوریم.
2.1. حوزه و داده های مطالعه
با توجه به در دسترس بودن داده ها، ما ترجیح دادیم مدل خود را در قلمرو سوئیس آموزش دهیم. ما استخراج دادههای منبع از چندین نقشه مانند مناطق جغرافیایی زیستی، گونهشناسی منظر، ژئومورفولوژی، زمینشناسی، زمینشناسی، و نقشههای مناطق استقرار را در نظر گرفتیم. در نهایت، ما لندفرم ها را به عنوان واحدهای ژئومورفولوژیکی از نقشه گونه شناسی منظر [ 16 ] که توسط اطلس سوئیس به صورت آنلاین ارائه شده است استخراج کردیم ( شکل 2 ).
برای تطبیق دادهها با مجموعهای از شکلهای زمین که به آنها علاقه مندیم [ 18 ]، ما لندفرمها را به انواع فرعی از انواع منظره بالا اختصاص دادیم. در نتیجه، شکلهای زمین زیر را از این دادهها استخراج کردیم ( جدول 2 ):
-
بلوک کوه ها (مناظر کوهستانی آلپ سوئیس)
-
کوه های چین خورده (چشم انداز کوهستانی ژورای چین خورده)
-
پرآلپ (عمدتاً مناظر کوهستانی و تپه ای سنگ آهک آلپ سوئیس)
-
فلات ها (مناظر فلات و تپه های چین خورده و جدول جورا)
-
فرسایش (چشم انداز کوهستانی فلات سوئیس، از جمله منطقه Napf)
-
تپه ای (مناظر تپه ای فلات سوئیس، چین خورده و جدول ژورا)
-
دره ها
-
دشت ها
همانطور که از جدول مشاهده می شود، ما Prealps را شامل می شود، یعنی مناطقی که در حاشیه کوه های آلپ قرار دارند، عمدتاً در سمت شمالی آن، و عمدتاً از سنگ آهک ساخته شده اند، زیرا آنها منطقه نسبتاً بزرگی را تشکیل می دهند و یک طبقه موقت بین تپه ها و کوه ها را تشکیل می دهند. از نظر ارتفاع معمولاً از 2500 متر تجاوز نمی کند. در عین حال، شکلهای زمین در مقیاس بزرگ مانند یخچالهای طبیعی، مخروط افکنهها و دراملینها را از این فهرست حذف کردیم. شکل 3 تصویر حاصل از هشت لندفرم انتخاب شده برای آموزش را نشان می دهد.
برای ارائه مدل با برچسب، ما یک شبکه 10 کیلومتری از نقاط آموزشی به طور منظم توزیع کردیم. از آنجایی که این مدل تا نواحی بالشتک به نظر میرسد، باید مطمئن میشد که همه جعبههای مرزی 16 کیلومتری (10 کیلومتری و بالشتکی 3 کیلومتری از هر دو طرف) به طور کامل در مرز سوئیس قرار میگیرند، یعنی جایی که حقیقت زمین است. داده ها وجود دارد. به همین دلیل، ما به صورت دستی نقاط نزدیک به مرز را از مرز دور کردیم و آنهایی را که خارج از سوئیس بودند از مجموعه داده حذف کردیم. از 357 امتیاز، 80% (یعنی 286) از نقاطی که ما برای آموزش و اعتبار سنجی انتخاب می کنیم، در حالی که 20% دیگر آنها برای اهداف آزمایشی استفاده می شوند ( شکل 3 ). برش مورب منطقه، حضور بیشتر لندفرم ها را در هر دو مجموعه آموزشی و آزمایشی تضمین می کند.
2.2. معماری شبکه
ما انتخاب کردیم که از یک معماری شبکه عصبی تثبیت شده برای تقسیم بندی معنایی استفاده کنیم، U-Net [ 19]. U-Net، در اصل، از معماری رمزگذار – رمزگشای معمولی استفاده می کند. در طول مسیر رمزگذاری مدل، تصویر ورودی (در مورد داده شده، کاشی DEM) به تدریج به نقشههای ویژگی فشردهتر و فشردهتری تبدیل میشود که هر کدام تصویر ورودی را در سطح فزایندهای از انتزاع نشان میدهند. این با اعمال تکراری لایههای کانولوشن و لایههای max-pooling به دست میآید. از این رو، ابعاد فضایی DEM کاهش می یابد، در حالی که تعداد کانال ها افزایش می یابد. از آنجایی که هدف نهایی یک بخشبندی، ارائه طبقهبندی برای هر پیکسل از DEM است، این نمایش فشرده باید به گسترههای فضایی اولیه تبدیل شود. این با اعمال مکرر عملیات de-convolutional انجام می شود، تا زمانی که گستره فضایی اصلی به دست آید. معماری رمزگذار-رمزگشای مرسوم این هشدار را دارد که نتایج مبهم را به همراه دارد. معماری U-Net با افزودن اتصالات پرش بین لایههای مسیر رمزگذار با لایههایی از مسیرهای رمزگشا که ابعاد مشابهی دارند، این مشکل را دور میزند. در اصل، این اتصالات پرش، نقشههای ویژگی مربوطه را ادغام میکنند. به این ترتیب، آنها را می توان در پیوند با عملیات کانولوشن بعدی تجزیه و تحلیل کرد. در عمل، ابعاد ورودی U-Net (یعنی ناحیهای که شبکه میبیند) بزرگتر از ابعاد خروجی است (یعنی منطقهای که برای آن طبقهبندی پیکسلها باید تولید شود). دلیل این امر در این ایده نهفته است که اطلاعات زمینه کافی برای پیکسل های مرزی وجود ندارد تا بتوانند طبقه بندی های منطقی ایجاد کنند. از این رو، یک عملیات برش نهایی برای حذف پیکسل های حاشیه ای اعمال می شود که هیچ نتیجه معنی داری برای آنها انتظار نمی رود. در نهایت، لایههای drop out برای جلوگیری از برازش بیش از حد وارد میشوند، تکنیکی که برای کاربردهای مشابه مفید است.20 ]. لایه کانولوشن نهایی از یک تابع فعال سازی softmax استفاده می کند. همه فعالسازیهای دیگر روی ReLu تنظیم شدهاند.
ابعاد ورودی اصلی 192 × 192 پیکسل به 6 × 6 پیکسل کاهش می یابد. با این حال، تعداد کانال ها از 1 (یعنی ارتفاع نرمال شده) به 128 افزایش یافته است. برای خروجی، ما هشت کانال داریم، یکی برای هر لندفرم، در حالی که U-Net اصلی تنها دو کانال خروجی دارد.
بهینه ساز آدام که برای یادگیری و آنتروپی متقاطع طبقه ای استفاده می شود به عنوان یک تابع ضرر استفاده می شود. تعداد دوره ها 2000 و توقف زودهنگام با صبر 400 استفاده می شود.
معماری دارای تفاوت های زیر با معماری اصلی است و بنابراین بیشتر شبیه به آنچه در [ 20 ] توضیح داده شده است. همانند معماری U-Net [ 20 ]، ورودی را به جای چهار بار که در معماری اصلی انجام می شود، پنج بار (تعداد حداکثر لایه های ادغام) پایین می آورد. علاوه بر این، ریزش به هر لایه با احتمال ثابت 0.015 اضافه میشود (معماری اصلی U-Net تنها برای داخلیترین لایهها حذف شد). با این حال، بر خلاف معماری [ 20 ]، ابعاد ورودی از 256 × 256 به 192 × 192 تغییر یافته است. بنابراین، داخلی ترین نمایش دارای ابعاد 6 × 6 به جای 8 × 8 است که در [ 20 ] توضیح داده شد.]. تعداد کانال ها از 1 به 128 افزایش می یابد در حالی که [ 20 ] به 256 کانال در گلوگاه فشرده می شود. از آنجا که هشت لندفرم وجود دارد، لایه نهایی U-Net ما دارای هشت کانال است (به جای یکی از معماری [ 20 ] و دو کانال از U-Net اصلی). علاوه بر این، نویسندگان در [ 20 ] با یک مشکل رگرسیون سر و کار دارند، در حالی که وظیفه این مقاله یک مشکل طبقه بندی است. از این رو، ما از یک فعال سازی SoftMax به جای فعال سازی ReLU برای لایه نهایی استفاده می کنیم.
2.3. ترکیب سایه ها بر اساس تقسیم بندی ها
برای اطمینان از اینکه نقش برجسته های سایه دار را بدون تغییر قابل توجه بین آنها ترکیب می کنیم، از گردش کار زیر استفاده می شود. ابتدا، مرزهای هر کلاس لندفرم تقسیمبندی شده توسط مقدار تعریف شده توسط کاربر بافر میشوند. این منجر به همپوشانی مناطق در امتداد مرزهای این لندفرم ها می شود. سپس، تبدیل فاصله برای مناطق بافر محاسبه می شود، که نشان می دهد برای هر پیکسل چقدر از مرز بافر فاصله دارد. سپس این مقادیر فاصله بر دو برابر فاصله بافر تقسیم می شوند. بنابراین، پیکسلهای نزدیک به مرز بافر به صفر نزدیک میشوند در حالی که پیکسلهای درون چندضلعی اصلی که دو برابر فاصله بافر از مرز بافر فاصله دارند (1 فاصله بافر از مرز اصلی) مقدار 1 را نگه میدارند. مقادیر بزرگتر از یک. به 1 بست خواهد شد. این در نشان داده شده استشکل 4 .
در مواردی که بیش از دو سایه با هم همپوشانی دارند، عادی سازی آنها انجام می شود به طوری که تمام مقادیر آلفا برای هر پیکسل 1 جمع می شوند. هنگامی که این مورد به دست آمد، سایه های مختلف را می توان مطابق با رابطه (1) ترکیب کرد:
Unknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: fontUnknown node type: font
در اینجا C blend مقدار مقیاس خاکستری ترکیب شده است، α i مقدار آلفا برای یک لندفرم خاص با شاخص i در آن پیکسل است و c i مقدار سایه خاکستری شکل زمین i در آن پیکسل است، n تعداد لندفرم ها است.
3. نتایج
در این بخش، ما تنظیمات آموزشی و پیشبینی لندفرمها را به عنوان نتیجه آموزش ارائه میکنیم. علاوه بر این، عملکرد مدلها و رویکرد مجموعه را با استفاده از معیارهای طبقهبندی ارزیابی میکنیم. در نهایت، نشان میدهیم که چگونه میتوان نقش برجستههای سایهدار را با هم ترکیب کرد تا تصاویری صاف و عاری از ترکیب باستانی ارائه کند.
3.1. آموزش
تعداد دورهها از تمرینی به آموزشی دیگر متفاوت بود و برای 10 مدل در محدوده 525 تا 1128 دوره (به ترتیب 845، 744، 712، 979، 654، 640، 783، 826، 1128 و 525 دورههای اولیه) بود. متوقف کردن برای 845 دوره، آموزش تقریباً 22 ساعت طول کشید. این تنظیمات شامل کارت گرافیک NVIDIA GeForce RTX 2080 Ti، 32 گیگابایت رم و پردازنده Intel(R) Core(TM) i9-7940X @ 3.10 گیگاهرتز است. شبکه عصبی در Keras [ 21 ] پیاده سازی شده است.
پیشبینیهای تولید شده بر اساس هر یک از 10 مدل، پیشبینیهای میانگین آنها و دادههای حقیقت زمین که از نقشه گونهشناسی منظر برای مقایسه به دست آمدهاند در شکل 5 و شکل 6 نشان داده شدهاند . همه آنها ساختار لندفرم مشابهی را با تفاوت های قابل مشاهده در مرزهای تقسیم بندی مشخص شده با رنگ زرد نشان می دهند. داده های حقیقت زمین ( شکل 6ب) یکنواخت تر است و مرزهای واضحی را بین انواع منظر نشان می دهد، در حالی که همه کلاس های پیش بینی به طور کلی پراکنده تر به نظر می رسند با تفاوت های قابل مشاهده بیشتر در جدول و ژورای چین خورده و در بخش مرکزی کشور. بر خلاف کوه های بلوکی یا پرآلپ، مناطق شمال غربی سوئیس مملو از فلات ها و چین خوردگی ها بسیار چالش برانگیزتر است. فلات های Table Jura در امتداد شمال شرقی کوه های Jura توسط هر 10 مدل بهتر تشخیص داده می شوند، در حالی که فلات های Folded Jura به عنوان مخلوطی از تپه ها، فرسایش و کوه های بلوکی نشان داده می شوند. به نظر میرسد کوههای فرسایشی سوئیس مرکزی عمدتاً با تپهها و حتی برخی فلاتها مخلوط شدهاند که در دادههای حقیقت زمین وجود ندارند. همین موضوع به قلمروهای آپنزل در شمال شرقی سوئیس نیز مربوط می شود. بخش جنوبی تیچینو نسبت متفاوتی از دشت ها، تپه ها و فلات ها با پرآلپ های غالب در اطراف آنها را نشان می دهد. علاوه بر این، در دره رودخانه Rhône در کانتون Valais میتوان شاهد توزیع متفاوت درهها، دشتها و Prealps بود.
3.2. ارزیابی عملکرد
برای ارزیابی و کمی کردن کیفیت پیشبینیها، معیارهای طبقهبندی زیر را با استفاده از کتابخانه Scikit-learn [ 22 ] – دقت، یادآوری، و امتیاز f1 [ 23 ] محاسبه میکنیم:
-
دقت نسبت لندفرمهای درست پیشبینیشده را به کل همه موارد مثبت پیشبینیشده نشان میدهد و به ما کمک میکند تا یک لندفرم اشتباه را بهعنوان صحیح برچسب نزنیم.
-
Recall نسبت مثبت واقعی را با توجه به تعداد کل نتایج مثبت واقعی و منفی کاذب برمی گرداند، که اساساً امکان یافتن تمام شکل های زمینی صحیح را فراهم می کند.
-
امتیاز f1 یک میانگین هارمونیک از دقت و یادآوری است
ماتریس های سردرگمی در شکل 7 تعداد مثبت های درست، منفی های درست، مثبت های کاذب و منفی های کاذب را برای همه مدل ها نشان می دهد و جدول 3 نمای کلی از مقادیر معیارهای ارزیابی اصلی و متوسط هر مدل و مجموعه و همچنین ارائه می دهد. دقت آنها، که معیارهایی هستند که یک عدد واحد را برای مقایسه ارائه می کنند.
تعیین بهترین مدل آسان نیست، زیرا قدرت پیشبینی آنها در بین کلاسهای شکل زمین بسیار متفاوت است. بنابراین، پیشبینیهای همه مدلها را در جدول 3 بهطور میانگین محاسبه کردیم تا نتایج بالقوه بهتری نسبت به هر مدل جداگانه دریافت کنیم.
همانطور که می بینیم، مدل ها به ویژه برای کوه های بلوکی، پری آلپ، دره ها و تپه ها با امتیاز f1 در محدوده 60 تا 70 درصد عملکرد خوبی دارند ( جدول 3 ). این لندفرم ها همراه با دشت ها بالاترین دقت را در بین 10 مدل دارند، اما همچنین یادآوری نسبتاً بالایی دارند که تأثیر قابل توجهی بر دقت مدل دارد.
کمترین لندفرم های شناسایی شده کوه های فرسایشی هستند که میزان دقت آنها در هیچ مدلی از 10% تجاوز نمی کند. مدلها عمدتاً هنگام تقسیمبندی فلاتها و کوههای چین خورده، با پراکندهترین مقادیر دقت از 0٪ تا 51.9٪ برای فلات و از 31.23٪ تا 98.22٪ برای کوههای چین خورده، اشتباه میشوند. دلیل چنین انحراف شدید و نرخ های تشخیص پایین به طور کلی مناطق آموزشی بسیار کوچکتر در دسترس برای کوه های چین خورده، فلات ها، و کوه های فرسایشی در مقایسه با سایر اشکال زمین است ( جدول 4 ). برای بقیه لندفرمها، تفاوتها در مقادیر دقت کمتر بود، و انحراف استاندارد دقت در بین مدلها در محدوده 3.71-8.51 درصد است، در مقابل 17.35 درصد برای فلاتها و 19.98 درصد برای کوههای چینخورده.
در مقایسه با مقادیر میانگین دقت 10 مدل، رویکرد گروهی ( جدول 3 ) دقت قابل توجهی بهتری را برای درهها، دشتها و پرآلپها و مقادیر کمی بهتر برای کوههای بلوکی، کوههای چین خورده و تپهها ارائه میدهد. در رابطه با فلات ها و کوه های فرسایشی کمی بدتر عمل می کند و از نظر دقت از میانگین دقت مدل ها 61% در مقابل 57.40% بهتر عمل می کند. در همان زمانها، مدل 6 دقت حتی بالاتر از 65% را نشان داد که به ما امکان میدهد از آن برای آزمایش الگوریتم در سایر مناطق جغرافیایی استفاده کنیم.
3.3. ترکیب نقش برجسته های سایه دار
با توجه به نتایج نظرسنجی کاربران سایهدار [ 18 ]، جدول 5 شامل ترکیبی از تکنیکهای سایهزنی برجسته است که برای ترکیب کردن نقش برجستههای سایهدار که توسط نقشههای پیشبینی تقسیمبندی شدهاند، استفاده میشود.
همه هشت فرم زمین در بررسی حضور ندارند، بنابراین ما تصمیم گرفتیم که تپهها را به عنوان دراملین در نظر بگیریم تا دو تکنیک سایهاندازی مختلف را آزمایش کنیم. از آنجایی که نتایج بررسی های متفاوتی برای دره های V و U شکل وجود دارد، ما هر دو نوع را به عنوان دره های V شکل در نظر خواهیم گرفت، زیرا اعمال نور سفارشی برای هر دره U شکل در سوئیس غیرممکن است، در حالی که مدل آسمان صاف است. به هر حال رتبه دوم بهترین را برای دره های U شکل دارد. پیشآلپها و دشتها، که در بررسیها نیز وجود ندارند، با استفاده از بهترین تکنیک سایهزنی برجسته در سراسر شکلهای زمین، یعنی مدل آسمان صاف، ارائه خواهند شد. ما نقش برجسته سایه دار را با استفاده از مدل 6 ( شکل 8 ، شکل 9 و شکل 10) با هم ترکیب می کنیم.) از آنجایی که بالاترین دقت را در بین 10 مدل و مجموعه نشان داد. برای انتقال صاف بین قطعات تقسیم شده، ما 150 تکرار را اعمال کردیم، به عنوان مثال، یک منطقه ترکیبی به عرض 150 پیکسل.
3.4. مناطق تست
برای اینکه بفهمیم آیا مدلها و انتخاب شکلهای زمین ممکن است در سایر مناطق کوهستانی در سراسر جهان نیز اعمال شوند، ما این مدل را بر روی تعدادی از مناطق خارج از سوئیس آزمایش کردیم. پیششرطها برجستگی قابل مقایسه از نظر نوع و اندازه لندفرمها، دادهها در سیستم مختصات پیشبینیشده و وضوح مشابه با دادههای ورودی، یعنی 100 متر است. از آنجایی که مدل 6 بالاترین دقت را در بین همه مدل ها و مجموعه دارد، پیش بینی ها را بر اساس مدل 6 ایجاد کردیم. به دلیل عدم وجود داده های حقیقت زمین (مرزهای تقسیم بندی چشم انداز) برای این مناطق، ارزیابی بصری از پیش بینی های حاصل برای مناطق آزمایش، ما دادههای ماموریت توپوگرافی رادار شاتل (SRTM) را انتخاب کردیم که از طریق USGS EarthExplorer [ 24 ] در دسترس بود.]: کوه های زاگرس، کارپات ها، کوه های اواچیتا و قفقاز (همه کوه های چین خورده)، و همچنین سیرا نوادا (کوه های بلوکی).
رشته کوه های زاگرس که در ایران، شمال عراق و جنوب شرقی ترکیه واقع شده است، دارای شکل های زمینی متعددی است که ما به آنها علاقه مندیم. این رشته کوه طولانی به طول 1600 کیلومتر است و بلندترین نقطه آن کوه دنا (4409 متر) در همان محدوده قرار دارد. از کوه های آلپ کوه ها عمدتاً از سنگ آهک ساخته شده اند. بخشهای مرکزی و شمالی پیشبینیها، کوههای بلوکی را به تصویر میکشند (آنها نیز مرتفعترین نواحی رشته کوه هستند)، و مناطق بزرگ اطراف آنها به عنوان Prealps تعریف میشوند ( شکل 11 ). به دلیل دقت پایین تر برای فلات ها و کوه های چین خورده، بیشتر به صورت پراکنده در قسمت جنوبی به نظر می رسند، جایی که کوه ها فلات ایران را پوشانده اند، هرچند چین های کشیده زیادی وجود دارد که در امتداد کمربند چین خورده فلات کشیده شده اند [ 25 ].].
کارپات ها رشته کوهی به شکل کمان در اروپای مرکزی و شرقی هستند. در مقایسه با رشته کوه های آلپ پایین تر است و بلندترین قله آن 2655 متر در قسمت شمالی است [ 26 ]. پیشبینیهای آن ( شکل 12 ) به نظر میرسد که با ارتفاع زیاد تغییر میکند و بیشتر مناطق کوهستانی به دلیل ارتفاعات و شکل گرد مشابه، به ترتیب به عنوان کوههای فرسایشی تعریف میشوند. الگوهای مربعی روی دشتها به دلیل کاشیکاری ایجاد میشوند، و این مصنوعات رخ میدهند، زیرا مدل مناطق وسیعی از دشتها را در مجموعه داده ورودی «نمیدید».
کوه های اواچیتا در بخش مرکزی ایالات متحده تقریباً 360 کیلومتر از شرق به غرب و تقریباً 80 تا 95 کیلومتر از شمال به جنوب با بالاترین ارتفاع 839 متر گسترش یافته است. از آنجایی که درجه چین خوردگی بالایی دارد، کل محدوده به زیرشاخه هایی تقسیم می شود که پشته هایی با دره های نسبتاً وسیع از هم جدا شده اند [ 27 ]. شکل 13 نشان می دهد که مدل می تواند دره ها را بین چین ها تقسیم کند، اما خود چین ها را به عنوان کوه های بلوکی تشخیص می دهد و نه چین ها، احاطه شده توسط مناطق نسبتاً بزرگی که به عنوان Prealps تعریف شده اند.
شکل 14 پیش بینی رشته کوه سیرا نوادا در غرب ایالات متحده را نشان می دهد که بخشی از کوردیلرا آمریکا نیز می باشد. با بالاترین ارتفاع 4421 متری، عمدتاً از کوه های بلوکی تشکیل شده است که توسط پیش بینی ها نیز نشان داده شده است. مناطق مجاور به عنوان Prealps پیشبینی میشوند، در حالی که قسمتهای پایینتر تپههای همسایه فلاتهای متعدد را به تصویر میکشند. این به دلیل وجود کوههای جدولی در این منطقه است که توسط گدازهای که برخی از درهها را پر میکرد، تشکیل شده بود، که به نوبه خود فرسایش یافته و به جای آن کوههای جدولی باقی ماند [ 28 ].
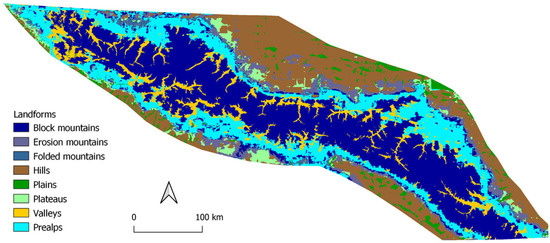
در نهایت، شکل 15 پیش بینی های مربوط به کوه های قفقاز را نشان می دهد. بلندترین قله آن کوه البروس در ارتفاع 5642 متری است [ 29 ]، و منطقه پیش بینی گسترده، کوه های بلوکی، دره های حک شده در کوه ها و نواحی پایین تر مربوط به پری آلپس را به تصویر می کشد. این مدل همچنین میتواند نواحی فلات را در دامنههای محدوده اصلی پیشبینی کند.
همانطور که می بینیم، پیش بینی های ایجاد شده برای مناطق آزمایشی تصویر و درک اساسی از آن سازه های کوهستانی را به ما می دهد. با توجه به دقت دریافتی، ما نمیتوانیم انتظار نتایج تقریباً واقعی را داشته باشیم، اما قطعاً پتانسیل افزایش کیفیت پیشبینیها با بهبود کل شبکه، آموزش مدلهای بیشتر، یا انتخاب بهترین مدل با عملکرد برای یک لندفرم خاص، به عنوان مثال، وجود دارد. 8 برای کوه های چین خورده یا مدل 9 برای دره ها.
4. بحث
آزمایشهای ارائهشده چالشهای متعددی را نشان میدهند که باید بر آنها غلبه کرد تا یک تشخیص لندفرم قابل اعتماد و تقسیمبندی زمین به منظور سایهاندازی امدادی به دست آید. ابتدا، باید تعریف روشنی از لندفرم ها ایجاد شود که به مدل های یادگیری ماشینی اجازه دهد شکل زمین صحیح را از مجموعه کوچکی از داده های ورودی، در حالت ایده آل، فقط DEM استنتاج کنند. این موضوع به ویژه با استفاده از یک تعریف ساده از یک دره و یک خط الراس آشکار می شود: اگر کسی یک دره را به عنوان “منطقه بین دو یال” و یک خط الراس را به عنوان “منطقه بین دو دره” تعریف کند، هر دو کلاس ویژگی تقریباً کاملاً همپوشانی دارند. چنین موردی در وهله اول تقسیم بندی را غیرممکن می کند. بنابراین مرز بین اشکال مختلف زمین را کجا می توان ترسیم کرد؟ همراه با این سوال این مفهوم مطرح می شود که آیا اشکال مختلف زمین می توانند واقعاً همپوشانی داشته باشند یا خیر. به عنوان مثال، آیا یک تپه منفرد در یک فلات هم به کلاس فلات و هم به کلاس تپه تعلق دارد. این ممکن است دوباره بر روی معماری شبکه عصبی مورد استفاده تأثیر بگذارد.
دوم، به دلیل محدودیتهای محاسباتی، شبکههای عصبی فقط یک «میدان دید» محدود دارند، یعنی منطقهای که میتوانند برای پیشبینی در نظر بگیرند. در نتیجه، استفاده از آنها برای طبقهبندی لندفرمهایی که گسترههای زیادی را پوشش میدهند، محدود میکند، زیرا احتمالاً نمیتوان آنها را به عنوان یک کل تجزیه و تحلیل کرد. این به طور مستقیم با تأثیر وضوح داده های ورودی، عمدتاً DEM مرتبط است. هرچه رزولوشن کمتر باشد، یک شبکه عصبی از نظر گستره جغرافیایی می تواند بیشتر را ببیند. بنابراین، برای لندفرمهای کوچک، وضوح بالاتر ممکن است مفید باشد، در حالی که وضوح پایینتر ممکن است برای انجام بخشبندی برای لندفرمهای بزرگتر سودمندتر باشد. این چالش احتمالاً با پیشرفت مداوم سخت افزار رایانه از بین خواهد رفت.
سوم، ما فقط یک معماری استاندارد U-Net را برای انجام بخشبندی شکل زمین بررسی کردیم. با این حال، بسیاری از طعمهای مختلف U-Net [ 30 ] یا معماریهای کاملاً متفاوت برای تقسیمبندی وجود دارد (به عنوان مثال، [ 31 ، 32 ، 33 ، 34 ]). مقایسه معماری های مختلف احتمالاً تلاش ارزشمندی است.
همچنین ذکر این نکته ضروری است که داده های ورودی، یعنی نقشه گونه شناسی منظر، به صورت دستی توسط انسان ساخته شده است و یک طبقه بندی بهبود یافته و دقیق تر نیز می تواند نتایج بهتری ارائه دهد و آنها را سازگارتر کند. یک داده ورودی بالقوه دقیق تر به غیر از نقشه های ساخته شده توسط انسان نیز می تواند اطلاعاتی در مورد ترکیبات خاک و سنگ بستر، تصاویر ماهواره ای، یا احتمالاً اطلاعات مربوط به ویژگی های سطحی مانند رودخانه ها، ساختمان ها و غیره باشد. نقشه برچسب گذاری شده در مورد ویژگی های ژئومورفولوژیکی
علاوه بر این، محدودیتهای خاصی در رابطه با نرخ شناسایی لندفرمها وجود دارد. اول، برخی از اشکال زمین مانند کوه های فرسایشی به دلیل شباهت بصری آنها با مناطق تپه ای، به خودی خود شناسایی یا طبقه بندی چالش برانگیزتر هستند. علاوه بر این، مکانهایی با ظاهر مشابه در تپهها، پرآلپها و مناطق فلات وجود دارد که همیشه نمیتوان آنها را با موفقیت از یکدیگر متمایز کرد. علاوه بر این، در این رویکرد ما از یک شبکه منظم از نقاط آموزشی استفاده کردیم و تعداد بسیار متفاوتی از نقاط در قالبهای مختلف زمین قرار گرفتند. در عین حال، برخی از لندفرم ها مناطق بسیار بزرگ تری را نسبت به بقیه پوشش می دهند. به عنوان مثال، منطقه تحت پوشش کوه های بلوکی بیش از 10 برابر بزرگتر از منطقه پوشیده شده توسط کوه های چین خورده است ( جدول 4). در نتیجه، آموزش نمیتواند برای همه لندفرمها به یک اندازه کارآمد باشد. در نهایت، یک غیرقابل پیش بینی در مورد موضوع آموزش وجود دارد: از یک مدل به مدل دیگر، ممکن است نتایج بسیار متفاوتی وجود داشته باشد، به عنوان مثال، یک مدل ممکن است فلات ها را تشخیص دهد، در حالی که مدل دیگر اصلاً نمی شناسد.
5. نتیجه گیری ها
در این کار، ما یک رویکرد جدید برای بخشبندی زمین با استفاده از معماری U-Net سازگار با هدف بهبود کیفیت سایههای برجسته اعمال شده در مناطق تقسیمبندی شده پیشنهاد کردیم. ارزیابی کمی بالاترین ارزش دقت 89.33% را برای درهها و 81.71% را برای Prealps نشان داد. برای کوهها و تپههای بلوکی، مقادیر دقت به ترتیب به 06/72 و 58/63 درصد رسید و برای کوهها و فلاتهای چینخورده، مقادیر پراکندهتر بوده و به دلیل وجود مناطق کوچکتر، از 23/31 تا 22/98 درصد و از 0 تا 90/51 درصد متغیر است. برای آزمایش. میانگین دقت در بین 10 مدل 57.40٪ است و یکی از مدل ها به دقت 65٪ رسیده است، در حالی که رویکرد مجموعه موفق به بهتر شدن از مدل های تکی نشده و دقت 61٪ را ارائه می دهد.
منابع
- اشمیت، جی. اندرو، آر. خصوصیات لندفرم چند مقیاسی. Area 2005 , 37 , 341-350. [ Google Scholar ] [ CrossRef ]
- دراگوت، ال. Blaschke, T. طبقه بندی خودکار عناصر شکل زمین با استفاده از تجزیه و تحلیل تصویر مبتنی بر شی. ژئومورفولوژی 2006 ، 81 ، 330-344. [ Google Scholar ] [ CrossRef ]
- دراگوت، ال. Eisank، C. طبقه بندی خودکار توپوگرافی مبتنی بر شی از داده های SRTM. ژئومورفولوژی 2012 ، 141 ، 21-33. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- لیو، اس. Li, F. روشی برای تشخیص خودکار توپوگرافی بر اساس طیف شیب. ژئومورفومتری Geosci. 2015 ، 129-132. در دسترس آنلاین: https://geomorphometry.org/wp-content/uploads/2021/07/Liu2015geomorphometry.pdf (دسترسی در 30 آوریل 2022).
- بوسکومب، دی. ریچی، طبقهبندی چشمانداز AC با شبکههای عصبی عمیق. Geosciences 2018 , 8 , 244. [ Google Scholar ] [ CrossRef ][ Green Version ]
- محمدی منش، ف. صالحی، ب. مهدیان پری، م. گیل، ای. مولینیر، ام. یک شبکه عصبی کاملاً پیچیده جدید برای تقسیم معنایی تصاویر SAR قطبی در اکوسیستم پوشش زمین پیچیده. ISPRS J. Photogramm. Remote Sens. 2019 , 151 , 223–236. [ Google Scholar ] [ CrossRef ]
- Bhuiyan، MAE; ویتارانا، سی. لیلجدال، AK; جونز، بی.ام. دانن، آر. اپستاین، HE; کنت، ک. گریفین، سی جی; اگنیو، الف. درک اثرات ترکیب بهینه باندهای طیفی بر پیشبینیهای مدل یادگیری عمیق: مطالعه موردی بر اساس نقشهبرداری شکل زمین دائمی تاندرا با استفاده از تصاویر ماهوارهای چندطیفی با وضوح بالا. J. Imaging 2020 ، 6 ، 97. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ساح، دی. تنسون، ک. پورتینگا، ا. نگوین، کیو. چشتی، ف. Aung، KS; مارکرت، KN; کلینتون، ن. اندرسون، ER; کاتر، پ. و همکاران اولیه به عنوان بلوک های ساختمانی برای ساختن نقشه های پوشش زمین. بین المللی J. Appl. زمین Obs. Geoinf. 2020 ، 85 ، 101979. [ Google Scholar ] [ CrossRef ]
- دو، ال. شما، X. لی، ک. منگ، ال. چنگ، جی. شیونگ، ال. وانگ، جی. یادگیری عمیق چندوجهی برای تشخیص شکل زمین. ISPRS J. Photogramm. Remote Sens. 2019 ، 158 ، 63–75. [ Google Scholar ] [ CrossRef ]
- لی، اس. شیونگ، ال. تانگ، جی. استروبل، جی. رویکرد مبتنی بر یادگیری عمیق برای طبقهبندی شکل زمین از منابع داده یکپارچه مدل ارتفاعی دیجیتال و تصاویر. ژئومورفولوژی 2020 ، 354 ، 107045. [ Google Scholar ] [ CrossRef ]
- ژائو، W.-F. Xiong، L.-Y. دینگ، اچ. تانگ، G.-A. شناسایی خودکار لندفرم های لس با استفاده از روش جنگل تصادفی. J. Mt. Sci. 2017 ، 14 ، 885-897. [ Google Scholar ] [ CrossRef ]
- ایواهاشی، جی. Pike، RJ طبقه بندی خودکار توپوگرافی از DEM ها توسط یک الگوریتم میانگین تو در تو بدون نظارت و یک امضای هندسی سه بخشی. ژئومورفولوژی 2007 ، 86 ، 409-440. [ Google Scholar ] [ CrossRef ]
- ولنتاین، AP; Kalnins، LM; Trampert، J. کشف و تجزیه و تحلیل ویژگی های توپوگرافی با استفاده از الگوریتم های یادگیری: مطالعه موردی seamount. ژئوفیز. Res. Lett. 2013 ، 40 ، 3048-3054. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- استفن، I. هوش مصنوعی برای تشخیص شکل زمین . گزارش سمینار ژئوماتیک; ETH زوریخ: زوریخ، سوئیس، 2020. [ Google Scholar ]
- Catani، F. تشخیص زمین لغزش با یادگیری عمیق تصاویر نوری غیر نادرال و جمعسپاری شده. رانش زمین 2021 ، 18 ، 1025-1044 . [ Google Scholar ] [ CrossRef ]
- Landschaftstypologie Schweiz. در دسترس آنلاین: https://www.are.admin.ch/are/de/home/laendliche-raeume-und-berggebiete/grundlagen-und-daten/landschaftstypologie-schweiz.html (دسترسی در 30 آوریل 2022).
- اطلس سوئیس-آنلاین. در دسترس آنلاین: https://www.atlasderschweiz.ch/swiss-landscape-typology/ (در 19 آوریل 2022 قابل دسترسی است).
- فارماکیس-سربریاکوا، م. Hurni, L. مقایسه تکنیک های سایه افکنی به کار رفته در لندفرم ها. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 253. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکههای کانولوشن برای تقسیمبندی تصویر پزشکی. در محاسبات تصویر پزشکی و مداخله به کمک کامپیوتر 2015 ; نواب، ن.، هورنگر، ج.، ولز، دبلیو ام، فرانگی، اف.اف.، ویرایش. Springer: Cham, Switzerland, 2015; صص 234-241. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جنی، بی. هایتسلر، ام. سینگ، دی. فارماکیس-سربریاکوا، م. لیو، جی سی. Hurni، L. سایه زنی برجستگی کارتوگرافی با شبکه های عصبی. IEEE Trans. Vis. محاسبه کنید. نمودار. 2020 ، 27 ، 1225-1235. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کراس. در دسترس آنلاین: https://keras.io/about/ (دسترسی در 30 آوریل 2022).
- پدرگوسا، اف. واروکو، جی. گرامفورت، آ. میشل، وی. تیریون، بی. گریزل، او. بلوندل، م. پرتنهوفر، پی. ویس، آر. دوشنی، ای. و همکاران Scikit-learn: یادگیری ماشینی در پایتون. جی. ماخ. فرا گرفتن. Res. 2011 ، 12 ، 2825-2830. [ Google Scholar ] [ CrossRef ]
- Scikit-Learn. یادگیری ماشینی در پایتون در دسترس آنلاین: https://scikit-learn.org/stable/index.html (دسترسی در 30 آوریل 2022).
- USGS Earth Explorer. در دسترس آنلاین: https://earthexplorer.usgs.gov/ (دسترسی در 30 آوریل 2022).
- رشته کوه های زاگرس. در دسترس آنلاین: https://en.wikipedia.org/wiki/Zagros_Mountains (دسترسی در 30 آوریل 2022).
- کوه های کارپات. در دسترس آنلاین: https://en.wikipedia.org/wiki/Carpathian_Mountains (دسترسی در 30 آوریل 2022).
- کوه های اواچیتا در دسترس آنلاین: https://en.wikipedia.org/wiki/Ouachita_Mountains (دسترسی در 30 آوریل 2022).
- سیرا نوادا. در دسترس آنلاین: https://en.wikipedia.org/wiki/Sierra_Nevada (دسترسی در 30 آوریل 2022).
- کوه های قفقاز. در دسترس آنلاین: https://en.wikipedia.org/wiki/Caucasus (دسترسی در 30 آوریل 2022).
- وو، اس. هایتسلر، ام. Hurni، L. استفاده از تخمین عدم قطعیت و ادغام هرم فضایی برای استخراج ویژگی های هیدرولوژیکی از نقشه های توپوگرافی تاریخی اسکن شده. GIScience Remote Sens. 2022 ، 59 ، 200-214. [ Google Scholar ] [ CrossRef ]
- یو، سی. وانگ، جی. پنگ، سی. گائو، سی. یو، جی. سانگ، N. BiSeNet: شبکه تقسیمبندی دوطرفه برای تقسیمبندی معنایی بلادرنگ. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018. [ Google Scholar ] [ CrossRef ]
- بدرینارایانان، وی. کندال، ا. Cipolla، R. SegNet: یک معماری رمزگذار-رمزگشا کانولوشنال عمیق برای تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 2481-2495. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- وو، اچ. ژانگ، جی. هوانگ، ک. لیانگ، ک. Yu, Y. FastFCN: بازاندیشی در پیچیدگی گشاد شده در ستون فقرات برای تقسیم بندی معنایی. arXiv 2019 ، arXiv:1903.11816. [ Google Scholar ] [ CrossRef ]
- تاکیکاوا، تی. آکونا، دی. جامپانی، وی. Fidler, S. Gated-SCNN: CNN های شکل دروازه ای برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF 2019 در بینایی رایانه (ICCV)، سئول، کره، 27 اکتبر تا 2 نوامبر 2019. [ Google Scholar ]
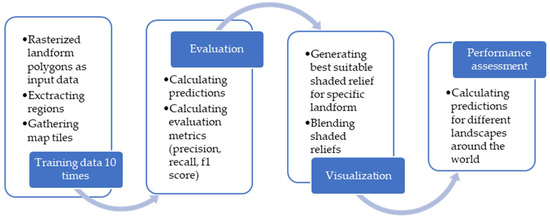
شکل 1. گردش کار.
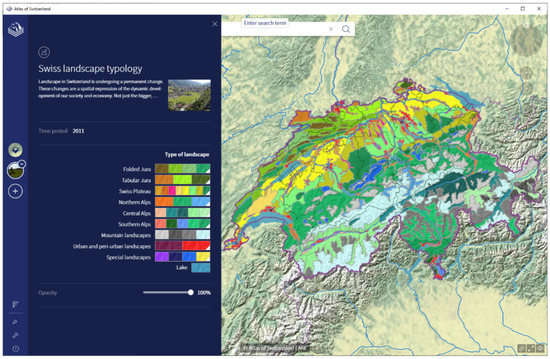
شکل 2. نقشه گونهشناسی منظر سوئیس از اطلس سوئیس – آنلاین [ 17 ] © 2022 Atlas of Switzerland.
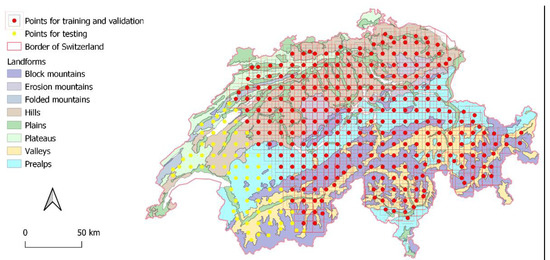
شکل 3. لندفرم های استخراج شده از نقشه گونه شناسی منظر با نقاط آموزشی برای آموزش و اعتبارسنجی، که در آن هر دو مرز لایه داخلی (خاکستری) و بیرونی (قرمز) در مرز سوئیس قرار دارند.
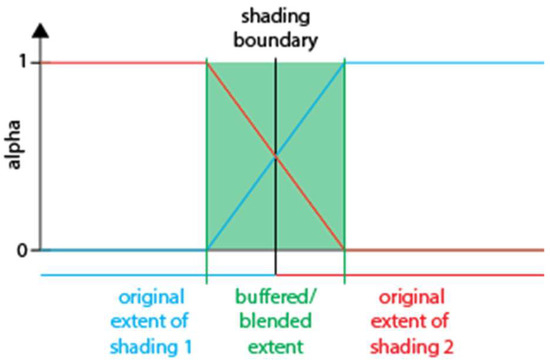
شکل 4. ساخت ناحیه انتقال هنگام ترکیب دو سایه.
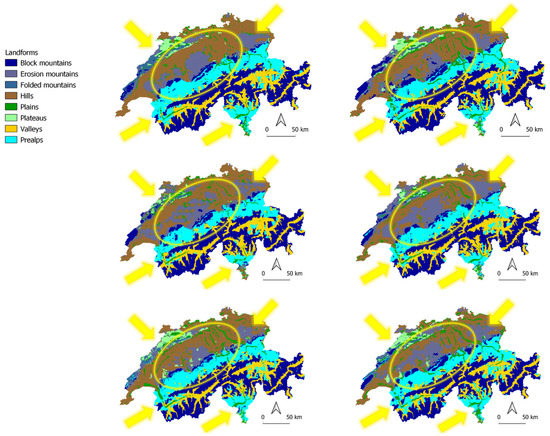
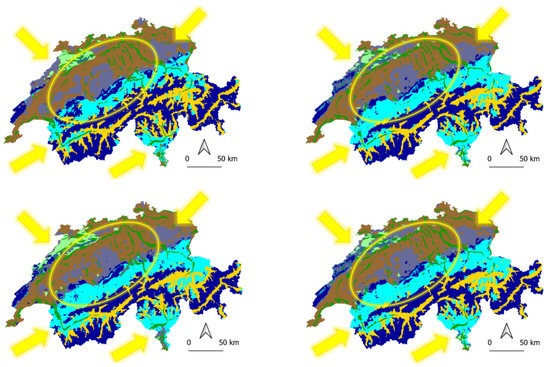
شکل 5. پیش بینی هر یک از 10 مدل آموزشی با تفاوت هایی که با رنگ زرد مشخص شده اند.
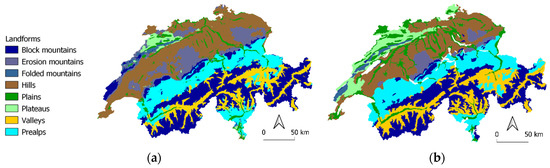
شکل 6. ( الف ) میانگین پیشبینیهای 10 مدل با هم، ( ب ) دادههای حقیقت پایه.
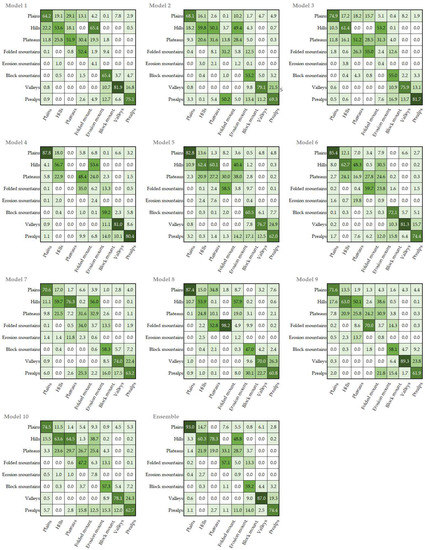
شکل 7. ماتریس های سردرگمی برای همه مدل ها و مجموعه (%). هرچه پسزمینه سلول تیرهتر باشد، مقدار آن بالاتر است.

شکل 8. نقش برجسته های سایه دار ترکیبی انتخاب اول.

شکل 9. نقش برجسته های سایه دار ترکیبی انتخاب دوم.

شکل 10. سایه زنی برجسته تحلیلی سنتی با استفاده از منبع روشنایی از یک جهت (315 درجه).
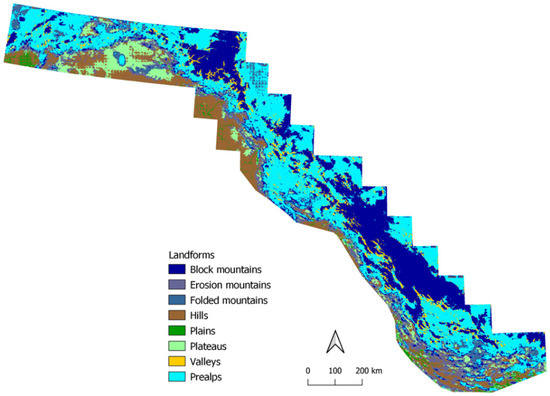
شکل 11. پیش بینی رشته کوه های زاگرس.
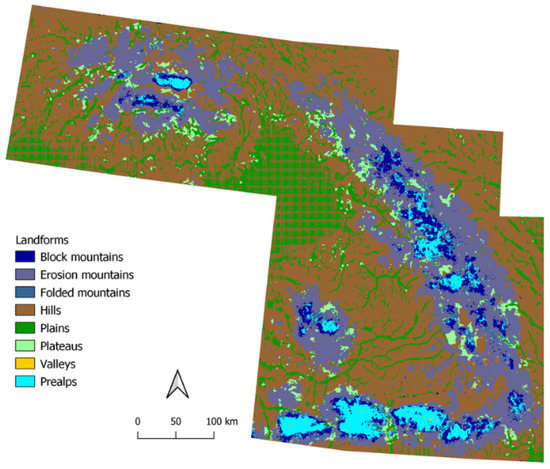
شکل 12. پیش بینی برای کوه های کارپات.
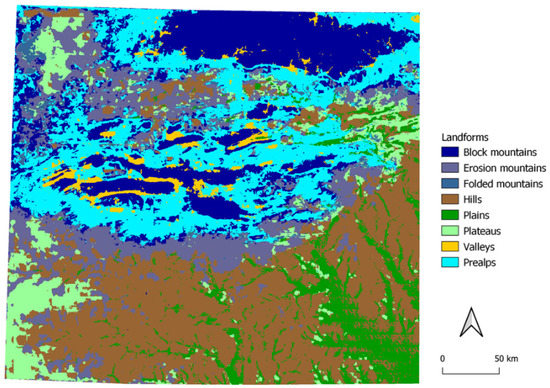
شکل 13. پیش بینی برای کوه های اواچیتا.
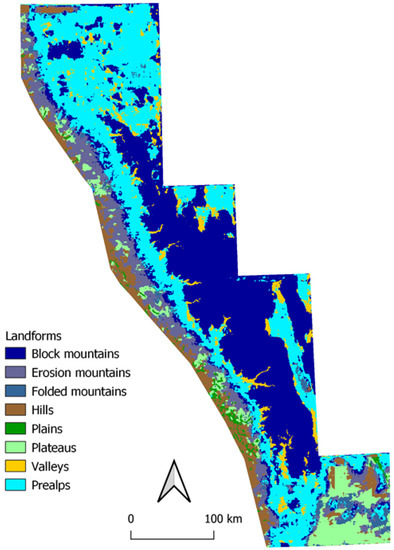
شکل 14. پیش بینی رشته کوه سیرا نوادا.
شکل 15. پیش بینی برای کوه های قفقاز.


بدون دیدگاه