

چکیده
از طریق قدرت فناوری های حسگر جدید، ما به طور فزاینده ای دنیای واقعی را دیجیتالی می کنیم. با این حال، ابزارها دادههای بدون ساختار را تولید میکنند، عمدتاً به شکل ابرهای نقطهای برای دادههای سه بعدی و تصاویر برای دادههای دو بعدی. با این وجود، بسیاری از برنامه ها (مانند ناوبری، بررسی، تجزیه و تحلیل زیرساخت) به داده های ساختاری حاوی اشیاء و هندسه آنها نیاز دارند. بنابراین، رویکردهای بینایی کامپیوتری مختلفی برای ساختار دادهها و شناسایی اشیاء موجود در آن ایجاد شدهاند. آنها را می توان به رویکردهای مدل محور، داده محور و مبتنی بر دانش تقسیم کرد. رویکردهای مدل محور عمدتاً از اطلاعات مربوط به اشیاء موجود در داده ها استفاده می کنند و بنابراین به اشیا و زمینه محدود می شوند. در میان رویکردهای داده محور، ما به طور فزاینده ای استراتژی های یادگیری عمیق را به دلیل استقلال آنها در تشخیص اشیا پیدا می کنیم. آنها الگوهای قابل اعتماد را در داده ها شناسایی می کنند و آنها را به موضوع مورد علاقه متصل می کنند. رویکردهای یادگیری عمیق باید این الگوها را در مرحله آموزش بیاموزند. رویکردهای مبتنی بر دانش از دانش مشخصه از حوزه های مختلف استفاده می کنند که امکان تشخیص و طبقه بندی اشیاء را فراهم می کند. دانش باید رسمی شود و آموزش را جایگزین یادگیری عمیق کند. فن آوری های وب معنایی امکان مدیریت چنین دانش انسانی را فراهم می کند. یادگیری عمیق و رویکردهای مبتنی بر دانش قبلاً نتایج خوبی را برای بخشبندی معنایی در مثالهای مختلف نشان دادهاند. هدف مشترک اما استراتژیهای متفاوت این دو رویکرد ما را درگیر انجام مقایسه برای دریافت ایدهای از نقاط قوت و ضعف آنها کرد. برای پر کردن این شکاف دانش، ما دو پیادهسازی از چنین رویکردهایی را در یک ابر نقطه نقشهبرداری موبایل اعمال کردیم. دسته بندی اشیاء شناسایی شده خودرو، بوته، درخت، زمین، چراغ خیابان و ساختمان است. رویکرد یادگیری عمیق از یک شبکه عصبی کانولوشنال استفاده میکند، در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. زمین، چراغ خیابان و ساختمان. رویکرد یادگیری عمیق از یک شبکه عصبی کانولوشنال استفاده میکند، در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. زمین، چراغ خیابان و ساختمان. رویکرد یادگیری عمیق از یک شبکه عصبی کانولوشنال استفاده میکند، در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. رویکرد یادگیری عمیق از یک شبکه عصبی کانولوشنال استفاده میکند، در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. رویکرد یادگیری عمیق از یک شبکه عصبی کانولوشنال استفاده میکند، در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. در حالی که رویکرد مبتنی بر دانش از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت پردازش دادهها و طبقهبندی بعدی استفاده میکند. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم. ابر نقطه LiDAR مورد استفاده توسط یک سیستم نقشه برداری سیار در یک محیط شهری به دست آمد و صحنه های پیچیده مختلفی را ارائه می دهد که به ما امکان می دهد مزایا و معایب این دو نوع رویکرد را نشان دهیم. رویکردهای یادگیری عمیق و مبتنی بر دانش یک تقسیم بندی معنایی با میانگین امتیاز F1 به ترتیب 0.66 و 0.78 ایجاد می کنند. جزئیات بیشتر با تجزیه و تحلیل دستههای شی منفرد ارائه میشود که به ما امکان میدهد ویژگیهای خاص هر دو نوع رویکرد را مشخص کنیم.
کلید واژه ها:
ابر نقطه ; یادگیری عمیق ؛ دانش محور ؛ SPARQL ; تقسیم بندی سه بعدی ؛ تقسیم بندی معنایی ; طبقه بندی
1. مقدمه
درک داده های بدون ساختار یک کار پیچیده برای رویکردهای مبتنی بر کامپیوتر است. این نیاز به اتصال ویژگی های داده ها با ماهیت و درک اشیاء مورد علاقه دارد. با این حال، نمایش یک شی در یک مجموعه داده به شدت متفاوت است و یک فرآیند خودکار در حالت ایده آل باید بتواند این تنوع را مدیریت کند.
برای مثال، ویژگی های داده ها به فرآیند اکتساب (به عنوان مثال، فناوری و روش مورد استفاده) که آنها را تولید می کند، بستگی دارد. ویژگی های اشیای دیجیتالی شده (مانند مواد، بازتاب، زبری، اندازه)، زمینه صحنه (به عنوان مثال، فضای باز شهری، ساختمان داخلی، حفاری خرابه)، و عوامل مختلف دیگر خارج از فرآیند اکتساب (به عنوان مثال، نور محیط ، شدت نور، شرایط آب و هوایی، حرکت ابزار اندازه گیری یا اشیاء دیجیتالی شده) بر فرآیند اکتساب تأثیر می گذارد. این تغییرات در ویژگیها تنوعی از نمایشهای شی در مجموعه دادههای مختلف ایجاد میکند که میتواند با انتظارات ما از واقعیت متفاوت باشد. تنوع نمایش شی یک چالش واقعی برای رویکردهای تقسیم بندی معنایی است. رویکردهای تقسیمبندی معنایی مختلف را میتوان در سه دسته جمعآوری کرد: رویکردهای مدل محور، داده محور و مبتنی بر دانش. در میان این سه دسته، رویکردهای داده محور با استفاده از رویکردهای یادگیری عمیق (DL) و مبتنی بر دانش (KB) نتایج بسیار خوبی را نشان داده اند. بنابراین، این تحقیق بر روی این دو تمرکز دارد.
از یک طرف، رویکردهای مبتنی بر DL (مانند یادگیری عمیق) فقدان درک عوامل فرآیند اکتساب را برای شناسایی الگوهای قابل اعتماد جایگزین میکنند. این الگوها را باید در مرحله آموزش آموخت. برای رویارویی با چالش تنوع نمایش اشیا، DL به حجم وسیعی از داده ها نیاز دارد تا تنوع کافی از نمایش شی و شناسایی الگوهای قابل اعتماد را فراهم کند. استفاده از حجم وسیعی از داده ها به DL اجازه می دهد تا نسبت به بازنمایی اشیاء مختلف قوی باشد. رویکردهای DL به مجموعه داده های مورد استفاده برای مرحله آموزش بستگی دارد. این وابستگی نقاط قوت و ضعف این رویکردها را مشخص می کند. در واقع، رویکردهای DL تا زمانی کار میکنند که دادههای در نظر گرفته شده محتوای قابل درک را نشان دهند. تنوع بیشتر در شی یا ظاهر رخ می دهد، داده های بیشتری برای آموزش مورد نیاز است. رویکردهای DL در تشخیص شی یا هندسه ای که برای آن آموزش ندیده اند مشکل دارند. این مورد برای اشیاء یا مجموعه دادههای منحصربهفرد موجود در زمینههایی مانند میراث فرهنگی است. به همین ترتیب، که رویکردهای DL به مجموعه داده های آموزشی بستگی دارد، رویکردهای KB به تعریف دانش بستگی دارد. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند. رویکردهای DL در تشخیص شی یا هندسه ای که برای آن آموزش ندیده اند مشکل دارند. این مورد برای اشیاء یا مجموعه دادههای منحصربهفرد موجود در زمینههایی مانند میراث فرهنگی است. به همین ترتیب، که رویکردهای DL به مجموعه داده های آموزشی بستگی دارد، رویکردهای KB به تعریف دانش بستگی دارد. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند. رویکردهای DL در تشخیص شی یا هندسه ای که برای آن آموزش ندیده اند مشکل دارند. این مورد برای اشیاء یا مجموعه دادههای منحصربهفرد موجود در زمینههایی مانند میراث فرهنگی است. به همین ترتیب، که رویکردهای DL به مجموعه داده های آموزشی بستگی دارد، رویکردهای KB به تعریف دانش بستگی دارد. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند. این مورد برای اشیاء یا مجموعه دادههای منحصربهفرد موجود در زمینههایی مانند میراث فرهنگی است. به همین ترتیب، که رویکردهای DL به مجموعه داده های آموزشی بستگی دارد، رویکردهای KB به تعریف دانش بستگی دارد. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند. این مورد برای اشیاء یا مجموعه دادههای منحصربهفرد موجود در زمینههایی مانند میراث فرهنگی است. به همین ترتیب، که رویکردهای DL به مجموعه داده های آموزشی بستگی دارد، رویکردهای KB به تعریف دانش بستگی دارد. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند. رویکردهای KB مبتنی بر فنآوریهای معنایی، دانش انسان از شی یا فرآیند سنجش را برای هدایت فرآیند تقسیمبندی معنایی یکپارچه میکند. این دانش امکان انطباق تعریف شی و فرآیند تقسیم بندی معنایی را با توجه به فرآیند سنجش که از بافت صحنه یا فرآیند اکتساب به دست آمده تشکیل شده است را می دهد. آنها این مزیت را دارند که در زمینه های مختلف قابل اجرا هستند.
هر دو رویکرد دارای یک هدف مشترک هستند اما استراتژی های متفاوتی را اعمال می کنند. بنابراین مقایسه آنها برای برجسته کردن نقاط قوت و ضعف آنها جالب است. به همین دلیل، این تحقیق دو پیاده سازی از این رویکردها را برای هر یک با هم مقایسه می کند. این مقایسه بر روی یک رویکرد DL نظارت شده توسعه یافته در موسسه Fraunhofer برای تکنیکهای اندازهگیری فیزیکی IPM و یک رویکرد کاملا مبتنی بر دانش توسعهیافته در موسسه اطلاعات مکانی و فناوری نقشهبرداری در دانشگاه علوم کاربردی ماینتس (i3mainz) متمرکز است. رویکرد DL از یک رمزگذار VGG6 با معماری FCN8 استفاده می کند [ 1 ]. رویکرد کاملاً KB از فناوریهای وب معنایی استاندارد SPARQL [ 2 ] و OWL2 [ 3 ] استفاده میکند.] برای هدایت انتخاب الگوریتم ها و فرآیند طبقه بندی بر اساس اشیا یا ویژگی های داده.
این مقایسه از یک ابر نقطه بیرونی به دست آمده توسط دوربین ها و یک اسکنر لیزری در یک سیستم نقشه برداری موبایل استفاده می کند. به همین دلیل، اشیاء فقط از وسط جاده ای که خودرو در آن حرکت می کرد مشاهده می شود. این بر نمایش اشیاء در مجموعه داده تأثیر می گذارد. عوامل دیگر (تغییر در روشنایی، ارتعاش ابزار اندازهگیری، شرایط هواشناسی) نیز بر فرآیند اکتساب تأثیر میگذارند. این تنوع زیادی از بازنمایی اشیا را در داده ها ایجاد می کند (به عنوان مثال، ماشین کامل در مقابل ماشین نیمه به دست آمده، انواع مختلف ماشین ها، و غیره). این مقایسه بر اساس تشخیص مجموعهای از اجسام «منظم» (از نظر جنبه هندسی) است که شامل اتومبیلها، ساختمانها، زمین و چراغهای خیابان و مجموعهای از «اشیاء نامنظم» (اشکال نامتجانس) است که شامل بوته ها و درختان این مورد کاربردی دارای مزیت ارائه انواع اشیاء و نمایش آنها در داده ها برای مقایسه عملکرد این دو رویکرد است. عملکرد آنها بر اساس این معیارها ارزیابی و مقایسه می شود. ابتدا این تحقیق آثار مرتبط با تقسیم بندی معنایی را ارائه می کند. در مرحله دوم، گردش کار رویکرد DL ارائه شده است، به دنبال آن توضیحی در مورد گردش کار رویکرد کاملا مبتنی بر دانش ارائه شده است. این تحقیق سپس نتایج به دست آمده از هر رویکرد را ارائه و آنها را با هم مقایسه می کند. در نهایت، پژوهش نتایج به دست آمده را بر اساس تفاوت ها یا شباهت های مشاهده شده و ویژگی های متناظر هر دو رویکرد ارائه می کند. عملکرد آنها بر اساس این معیارها ارزیابی و مقایسه می شود. ابتدا این تحقیق آثار مرتبط با تقسیم بندی معنایی را ارائه می کند. در مرحله دوم، گردش کار رویکرد DL ارائه شده است، به دنبال آن توضیحی در مورد گردش کار رویکرد کاملا مبتنی بر دانش ارائه شده است. این تحقیق سپس نتایج به دست آمده از هر رویکرد را ارائه و آنها را با هم مقایسه می کند. در نهایت، پژوهش نتایج به دست آمده را بر اساس تفاوت ها یا شباهت های مشاهده شده و ویژگی های متناظر هر دو رویکرد ارائه می کند. عملکرد آنها بر اساس این معیارها ارزیابی و مقایسه می شود. ابتدا این تحقیق آثار مرتبط با تقسیم بندی معنایی را ارائه می کند. در مرحله دوم، گردش کار رویکرد DL ارائه شده است، به دنبال آن توضیحی در مورد گردش کار رویکرد کاملا مبتنی بر دانش ارائه شده است. این تحقیق سپس نتایج به دست آمده از هر رویکرد را ارائه و آنها را با هم مقایسه می کند. در نهایت، پژوهش نتایج به دست آمده را بر اساس تفاوت ها یا شباهت های مشاهده شده و ویژگی های متناظر هر دو رویکرد ارائه می کند. این تحقیق سپس نتایج به دست آمده از هر رویکرد را ارائه و آنها را با هم مقایسه می کند. در نهایت، پژوهش نتایج به دست آمده را بر اساس تفاوت ها یا شباهت های مشاهده شده و ویژگی های متناظر هر دو رویکرد ارائه می کند. این تحقیق سپس نتایج به دست آمده از هر رویکرد را ارائه و آنها را با هم مقایسه می کند. در نهایت، پژوهش نتایج به دست آمده را بر اساس تفاوت ها یا شباهت های مشاهده شده و ویژگی های متناظر هر دو رویکرد ارائه می کند.
2. کارهای مرتبط
تقسیم بندی اشیاء و هندسه ها از یک طرف به ویژگی های آنها (به عنوان مثال اندازه، شکل) و از طرف دیگر به ویژگی های داده ها (به عنوان مثال، چگالی، نویز، انسداد، ناهمواری) بستگی دارد.
رویکردهای مدل محور کاملاً بر اساس ویژگی های اشیاء هستند. رویکردهای ذکر شده در [ 4 ، 5 ، 6 ] تشخیص اجسام ساده را بر اساس مدل ریاضی شکل آنها پیشنهاد می کند. با این حال، آنها فقط قادر به تشخیص اجسام هندسی ساده (مانند دیوارها یا ستون ها) هستند. رویکردهای [ 7 ، 8 ] توصیف اشیا با توصیفگرهای مختلف را پیشنهاد میکنند. این رویکردها تنها در صورتی امکان تشخیص اشیاء را میدهند که ویژگیهای متفاوتی داشته باشند و دادهها متراکم و یکنواخت باشند.
رویکردهای مدرن مبتنی بر دادهها، که عمدتاً تحت تسلط تکنیکهای DL مبتنی بر شبکههای عصبی کانولوشن هستند، برای مدتی وجود داشتهاند [ 9 ]. اخیراً، تشخیص اشیا در دادههای ابری نقطهای سه بعدی با استفاده از یادگیری عمیق نه تنها به دلیل در دسترس بودن قدرت پردازش خام بیشتر در سالهای اخیر، بلکه به دلیل مشکلات با پراکندگی بسیاری از ابرهای نقطه، و مجموعه دادههای عظیم با تعداد زیادی مورد توجه قرار گرفته است. طبقات مختلف (به عنوان مثال، کل شهر)، که در آن توصیف پیشینی ویژگی های دانش معمولاً غیرممکن است [ 1 ، 10 ]]. رویکردهای DL می توانند اشیاء را پس از اولین آموزش کامل بدون دانش قبلی شناسایی کنند. این رویکردهای «پایین به بالا» انعطافپذیرتر هستند و معمولاً بهتر از رویکردهای مبتنی بر مدل تعمیم مییابند. وظایف بخشبندی معنایی در ابرهای نقطه سهبعدی را میتوان به طور کلی به دو رویکرد تقسیم کرد: مستقیم، از طریق روشهای مبتنی بر نقطه، و غیرمستقیم، از طریق شبکههای مبتنی بر طرح ریزی [ 11 ].
یکی از این رویکردهای مستقیم «PointNet [ 12 ]» است که چارچوب یادگیری عمیقی را ارائه میکند که ویژگیهای نقطهای را با چندین لایه DLP (پرسپترون چندلایه) یاد میگیرد و ویژگیهای شکل کلی را با یک لایه ادغام حداکثر استخراج میکند تا امکان تشخیص اشیا را فراهم کند. ابر نقطه بدون ساده کردن این مجموعه داده بزرگ و مرتب نشده است. با استفاده از یک ساختار شبکه عصبی سلسله مراتبی، همانطور که در PointNet++ [ 13 ] توضیح داده شد، رویکرد اصلی “PointNet” به طور قابل توجهی بهبود یافت، به ویژه در مورد اطلاعات ساختاری محلی. علاوه بر این پیادهسازی نقطهای DLP، رویکردهای مختلفی با استفاده از روشهای پیچش نقطه (DPC [ 14 ])، روشهای مبتنی بر RNN (DARNet [ 15 ])، روشهای مبتنی بر نمودار (DPAM [ 16 ]) وجود دارد.])، و روشهای نمایش شبکه (LatticeNet [ 17 ]). روش غیر مستقیم، با این حال، از تشخیص مبتنی بر تصویر استفاده میکند و این نتایج را در ابر نقطه نمایش میدهد.
این روش های مبتنی بر طرح ریزی را می توان بیشتر به پنج دسته تقسیم کرد [ 11 ]: چند نمای (TangentConv [ 18 ])، کروی (RangeNet++ [ 19 ])، حجمی (FCPN [ 20 ])، شبکه پرموتهدرال (LatticeNet [ 17 ]). و نمایش ترکیبی (MVPNet [ 21 ]). در [ 9 ] یک ابر نقطه سه بعدی از چندین نما دوربین مجازی بر روی صفحات دوبعدی نمایش داده می شود. با استفاده از یک شبکه کاملاً کانولوشنال (FCN) برای پیشبینی امتیازات پیکسلی در این تصاویر مصنوعی و ادغام نمرات پیشبینیشده مجدد، میتوان بدون کار مستقیم روی ابر نقطه به یک بخشبندی معنایی دست یافت. در [ 18] پیچیدگی های مماس برای تقسیم بندی ابر نقطه متراکم، بر اساس این فرض که ابرهای نقطه ای از سطوح محلی اقلیدسی نمونه برداری شده اند، معرفی شده اند. هندسه سطح محلی بر روی یک صفحه مماس مجازی پیش بینی می شود تا توسط پیچش های مماس پردازش شود.
اگرچه این روشهای غیرمستقیم به طور کامل از هندسه و اطلاعات ساختاری زیربنایی بهرهبرداری نمیکنند، اما برای مجموعههای داده بزرگ به خوبی عمل میکنند و مقیاس میشوند [ 11 ]. بر خلاف رویکردهای داده محور، رویکردهای KB از دانش در یک استراتژی “بالا به پایین” برای شناسایی اشیا استفاده می کنند.
علاقه به استفاده از هستی شناسی برای طبقه بندی اشیا در زمینه پردازش تصویر وجود دارد. کار [ 22 ] از یک طبقهبندی مبتنی بر هستیشناسی برای شناسایی انواع مختلف ساختمانها در دادههای اسکنر لیزری هوابرد استفاده میکند. هستی شناسی، مشخص شده در OWL2، هر نوع ساختمان را با استفاده از ویژگی های مناسب برای توصیف یک مفهوم کیفی شناسایی شده از طریق طبقه بندی جنگل تصادفی [ 23 ] رسمی می کند. این رویکرد شامل ابتدا ترسیم ردپای ساختمانها، سپس استخراج ویژگیهای آنها و افزودن آنها به هستیشناسی است. در نهایت، استدلال با استفاده از استدلال Fact++ [ 24] ساختمان های مختلف را با تعیین نوع آنها بر اساس مشخصات OWL2 طبقه بندی می کند. این رویکرد در طبقهبندی «ساختمانهای مسکونی/کوچک» به خوبی عمل کرده است (F-measure = 97.7%)، اما نویسندگان نیاز به اطلاعات اضافی را برای جلوگیری از همپوشانی بین دو کلاس دیگر – «ساختمانهای آپارتمانی» و «ساختمانهای صنعتی و کارخانهای» برجسته میکنند. “- که به ترتیب F-اندازه های 60% و 51% را بدست می آورند. کار [ 25] با هدف شناسایی اشیاء در مناطق شهری و حومه شهری در تصاویر سنجش از دور. این رویکرد تحلیل تصویر شی گرا شامل تقسیم بندی، استخراج ویژگی ها و شناسایی با استفاده از هستی شناسی دامنه است. هستی شناسی دامنه شامل توصیف اشیا بر اساس سه نوع صفت است: طیفی، فضایی و زمینه ای. تشخیص شی مبتنی بر هستی شناسی به هر منطقه یک امتیاز تطبیق مبتنی بر ویژگی برای هر مفهوم هستی شناسی اختصاص می دهد. در مرحله بعد، مفهومی را که بالاترین امتیاز تطابق را کسب کرده است، به عنوان مفهومی که منطقه را نشان می دهد، تعریف می کند. این رویکرد میانگین F-اندازه 87٪ را در تشخیص خانه نارنجی، پوشش گیاهی، جاده و آب به دست می آورد. رویکرد پایان نامه دکتری در [ 26] با هدف امکان نمایه سازی و بازیابی تصویر معنایی است. Maillot از تکنیک های هستی شناسی مفهومی بصری و استدلال برای استخراج و طبقه بندی اشیا از تصاویر تقسیم شده استفاده می کند. مفاهیم بصری هستی شناسی با ویژگی ها و الگوریتم های سطح پایین همراه است. این هستی شناسی رابطی بین دانش خبره و سطح پردازش تصویر فراهم می کند. از طریق این بررسی فشرده مرتبطترین روشهای پیشرفته برای تشخیص اجسام در ابرهای نقطهای، دو نوع از کارآمدترین رویکردها برجسته میشوند. رویکردهای یادگیری عمیق با استفاده از استراتژی «پایین به بالا» و رویکردهای KB با استفاده از طرح «بالا به پایین».
برای مطالعه دقیقتر اثربخشی این دو نوع رویکرد بر روی ابرهای نقطهای حاصل از فناوریهای نقشهبرداری موبایل، یک رویکرد DL توسعهیافته توسط IPM [ 9 ] ارائهشده در بخش 3 را با یک رویکرد KB توسعهیافته توسط i3mainz [ 27 ] ارائهشده در بخش مقایسه میکنیم. 4 . ما فرض میکنیم که رویکردهای توسعهیافته توسط IPM و i3mainz به ترتیب پیادهسازی کارآمد رویکردهای DL و KB هستند.
3. مواد و روش
3.1. جمع آوری داده ها
سیستم های نقشه برداری متحرک به طور فزاینده ای برای مستندسازی عناصر زیرساخت (به عنوان مثال، فضای شهری، سطح جاده و غیره) استفاده می شوند [ 28 ]. مزیت بزرگ این سیستم ها جمع آوری کارآمد داده ها در سرعت های رانندگی بالا و در ترافیک روان است. کیفیت داده ها به فناوری سنسور اندازه گیری مربوطه و محیط بستگی دارد (به عنوان مثال، ویژگی های سطح).
به طور معمول، یک سیستم نقشه برداری متحرک شامل یک سیستم موقعیت یابی (سیستم اولیه)، ترکیبی از یک سیستم ژیروسکوپ، یک سیستم موقعیت یابی جهانی (به عنوان مثال، سیستم ماهواره ای ناوبری جهانی، GNSS) و یک کیلومتر شمار است. یک فیلتر کالمن یک راه حل پیوسته رو به جلو را در زمان واقعی محاسبه می کند. تمام سنسورهای دیگر سنسورهای ثانویه هستند و با سیستم موقعیت یاب از نظر مسافت یا زمان هماهنگ می شوند. این حسگرها می توانند دوربین یا اسکنر لیزری باشند. نتایج یک اندازه گیری با چنین وسیله نقلیه ای، تصاویر جغرافیایی و مهر زمانی است و آنچه به عنوان ابر نقطه شناخته می شود.
یک ابر نقطه یک صحنه را به عنوان مجموعه ای از نقاط در ابتدا مرتب نشده در مختصات سه بعدی (ابر نقطه سه بعدی) نشان می دهد. علاوه بر اطلاعات سه بعدی، مقدار شدت لیزر پراکنده برگشتی دریافتی نیز موجود است (ابر نقطه 4 بعدی). سیستم های پیشرفته با اندازه گیری تا دو میلیون نقطه در ثانیه، ابرهای نقطه سه بعدی را با دقت مطلق در محدوده چند سانتی متر تولید می کنند.
سیگنال زمان مبنایی برای ادغام جریان های داده های مختلف از سیستم های حسگر ذکر شده (سیستم موقعیت یابی، اسکنر لیزری و دوربین ها) است. یک کالیبراسیون جداگانه جهت گیری فضایی سنسورها را به یکدیگر توصیف می کند به طوری که سه پارامتر چرخش و سه پارامتر ترجمه برای هر سنسور در دسترس است.
سیستم نقشهبرداری سیار که برای جمعآوری دادهها برای آزمایشهای ما استفاده شد، نقشهبرداری شهری موبایل (MUM) بود که توسط IPM [ 29 ] توسعه یافت. MUM شامل اسکنر لیزری پیشرفته Fraunhofer IPM CPS [ 30 ] با دو میلیون اندازه گیری در ثانیه است. فرکانس اسکن 200 هرتز بود، در حالی که هنوز دقت فاصله حدود 3 میلی متر (1 سیگما) را ارائه می دهد. چهار دوربین تمام محیط خودرو را ضبط کرده و در هر 5 متر تصاویری با وضوح 5 مگاپیکسل ثبت می کنند. MUM با Applanix LV420 ( https://www.applanix.com/products/poslv.htm در 9 آوریل 2020) در موقعیت و جهت قرار گرفت.
هر فناوری اندازه گیری و زمینه بر ویژگی های (به عنوان مثال، نویز، چگالی، نظم) ابر نقطه تولید شده تأثیر می گذارد. این ویژگی ها بر فرآیند تقسیم بندی معنایی و کارایی آن تأثیر دارند.
به دست آوردن یک صحنه در یک بافت فضای باز شهری که توسط یک سیستم نقشه برداری سیار به دست آمده است، با اسکن متوالی صحنه با استفاده از یک دستگاه لیزری نصب شده بر روی یک ماشین در حال حرکت در امتداد جاده به دست آمد. چنین روش اکتساب اسکن متوالی، از یک سو، اکتساب داده را در قالب «گامها» تولید میکند و از سوی دیگر، مناطق انسداد (بدون اطلاعات) را ایجاد میکند. علاوه بر این، مواد مختلف (به عنوان مثال، فلز، شیشه، و سنگ) و فاصله بین اشیاء و تکنولوژی اکتساب در زمان اکتساب تا حد زیادی بر فرآیند تاثیر می گذارد. بنابراین، بخشهایی از دادهها میتوانند متراکم و پیوسته باشند و برخی دیگر میتوانند با چگالی کم ناپیوسته باشند.
علاوه بر این، پیچیدگی عوامل مختلف مؤثر بر فرآیند اکتساب منجر به موقعیتها و مشکلات غیرقابل پیشبینی میشود که در آن ویژگیهای دادههای بهدستآمده به طور قابلتوجهی با ویژگیهای مورد انتظار متفاوت است.
در واقع، درختان و بوتهها شکلهای نامنظمی دارند که در نتیجه نمایشی کاملاً خشن، کم تراکم، خمیدگی زیاد و پر سر و صدا ایجاد میکند. علاوه بر این، خودروها عمدتاً ناپیوسته هستند و برخی از نمایشهای غیرقابل پیشبینی را نشان میدهند. ساختمانها و محوطهها به دلیل موقعیت مکانی خود دارای تغییرات چگالی بسیار زیادی هستند که بسیار دور از سیستم نقشهبرداری متحرک بوده و باعث انسداد ساختمان و زمین میشود. علاوه بر این، شکل زمین به طور مداوم افقی و مسطح نیست. در نهایت چراغ های خیابانی هستند که در مقایسه با بقیه اشیا کوچک و نازکی هستند و تراکم کمی دارند.
3.2. گردش کار یادگیری عمیق
گردش کار یادگیری عمیق این مطالعه بر اساس یک رویکرد چند دیدگاهی است که در ابتدا برای طبقهبندی بافتهای سطح شهری توسعه یافته بود [ 31]. مؤلفه کلیدی آن یک شبکه عصبی کانولوشنال (CNN) برای تقسیمبندی تصویر بود که به شیوهای تحت نظارت بر روی مجموعه بزرگی از تصاویر نقشهبرداری تلفن همراه آموزش دیده بود. انتخاب یک رویکرد چند نمای مبتنی بر تصاویر قرمز-سبز-آبی (RGB) برای این مشکل با انگیزه (الف) حساسیت آن به رنگ به عنوان یک ویژگی (که برای تشخیص بافت های مختلف سطح بسیار مهم است) و (ب) نیاز به کارایی در کاربرد پردازش ابرهای نقطهای متراکم تولید شده برای نقشهبرداری موبایل شهری نیازمند زمان و منابع زیادی بود، بنابراین انتقال تشخیص معنایی به تصاویر دوبعدی گرفتهشده در فواصل زمانی معین، روند تشخیص، آموزش CNN و بهینهسازی گردش کار را در مقایسه با یکدیگر سرعت میبخشد. به یک تقسیم بندی معنایی مبتنی بر یادگیری عمیق از داده های سه بعدی. پیادهسازی اولیه، ابرهای نقطهای را به بیش از 30 کلاس شی مختلف تقسیم میکند، برخی از آنها به ریزدانههایی مانند Gravel، Paving، Curbstone و Manhole Covers. برای این مطالعه، تعداد کلاسهای خروجی با فهرست موجود تطبیق داده شدبخش 4 (ماشین، بوته، درخت، زمین، چراغ خیابان و ساختمان) با ادغام تمام اشیاء سطحی در کلاس Ground. جزء عصبی یک FCN استاندارد [ 1 ] با رمزگذار VGG16 بود. یک پیاده سازی مبتنی بر چارچوب Caffe [ 32 ] برای آموزش شبکه استفاده شد. آموزش چند هفته بر روی مجموعه داده ای از 90000 تصویر تقسیم شده دستی از صحنه های شهری با افزایش داده ها (تغییر رنگ و روشنایی) طول کشید. داده ها طی سه کمپین نقشه برداری در سراسر آلمان در طول یک سال جمع آوری شده است. بهینه ساز Adam با پارامترهای زیر استفاده شد: نرخ یادگیری = 0.001، beta1 = 0.9، beta2 = 0.999، epsilon = 10-08.
شکل 1 اجزای خط لوله پردازش داده را نشان می دهد. FCN تمام تصاویر ورودی RGB را بر اساس پیکسل طبقهبندی کرد، که منجر به تقسیمبندی معنایی دوبعدی نماهای مختلف ابر نقطه سهبعدی از موقعیتهای دوربینها بر روی وسیلهای نقشهبرداری متحرک شد. سپس پارامترهای درونی و بیرونی دوربین برای نمایش طبقهبندیهای دوبعدی در ابر نقطه جغرافیایی استفاده شد.
در حالی که تقسیم بندی معنایی تصاویر ساده بود و به طور کامل توسط شبکه عصبی مدیریت می شد، پیچیدگی ها و ابهاماتی در این مرحله به دلایل مختلفی ایجاد شد.
-
به دلیل حرکت وسیله نقلیه، تصاویر و دیدگاهها با هم تداخل دارند و نقاط میتوانند چندین طبقهبندی مختلف را از یک پیکسل مربوطه دریافت کنند. هرچه از دوربین دورتر باشد، نتیجه طبقه بندی در اینجا بدتر است. از آنجایی که خطاهای کوچک در کالیبراسیون با نرخ نمایی در رابطه با فاصله دوربین تا نقطه/پیکسل خلاصه میشوند، ما یک طرح انتخاب را اجرا کردیم که در آن اطلاعات از تصویری که در نزدیکی خودرو به دست آمده بود وزن بیشتری دریافت میکرد. برای تعیین کلاس نهایی یک نقطه پس از اتمام طرح ریزی.
-
ابر نقطهای بهدستآمده به دلیل پخش شدن از طریق اشیایی مانند شیشههای پنجره (که اسکنر آنها را ضبط نمیکند)، اشیاء تا حدی ضبط شده به دلیل زاویه اسکنر و وضوح کمتر ابر نقطهای در مقایسه با تصویر، بسیار نویز داشت.
-
نتایج طبقه بندی به میدان دید دوربین ها محدود شد. مناطقی که در هیچ تصویر RGB قابل مشاهده نبودند، نمیتوانستند برچسبی را در حین نمایش دریافت کنند، و در نتیجه مناطقی طبقهبندی نشده در ابر نقطه ایجاد میشوند.
-
در نهایت، خطاهای کالیبراسیون با نرخ نمایی در رابطه با فاصله دوربین تا نقطه/پیکسل خلاصه میشوند.
بنابراین رویکرد DL چندین استراتژی فیلتر را در پس پردازش برای کاهش نویز اعمال کرد.
-
فیلتر هواپیمای خیابان: تمام نقاطی که برچسب زمین دریافت کرده و با هواپیمای RANSAC [ 33 ] مطابقت دارند، در صفحه خیابان دستهبندی شدند. در مرحله بعد، تمام برچسب ها به غیر از Ground on و 0.5 متر بالاتر از صفحه خیابان حذف شدند.
-
فیلتر عمق: برای جلوگیری از عبور برچسبها از میان اجسام به دلیل وضوح کمتر در ابر نقطه و خطاهای کوچک کالیبراسیون، پنجرهای با مقادیر عمق 20 پیکسل × 20 پیکسل در اطراف پیکسل پیشبینیشده فعلی برای اجسام بزرگ، یعنی Tree در نظر گرفته شد. و ساختمان یک برچسب تنها در صورتی نمایش داده میشود که در سطح اکثریت عمق (با حاشیه خطا 10 سانتیمتر) باشد.
3.3. گردش کار مبتنی بر دانش
3.3.1. مدل سازی دانش
رویکردهای KB از بازنمایی صریح دانش که از طریق هستی شناسی تعریف شده است استفاده می کنند. این رویکردها دانش در مورد دادهها، اشیا و الگوریتمها را برای هدایت فرآیند تقسیمبندی معنایی بر اساس دادهها و اشیاء یکپارچه میکنند [ 34 ، 35 ، 36 ]. در [ 27 ]، این رویکرد مدلی از الگوریتمها، دادهها و اشیاء را در OWL2 ارائه میکند. شکل 2 ساختار مدل سازی این مفاهیم را نشان می دهد.
مفهوم “داده” که داده ها را نشان می دهد به عنوان حاوی اشیاء و هندسه توصیف می شود. توصیف می شود که می تواند از یک فرآیند اکتساب یا یک الگوریتم تولید شود. این مفهوم همچنین به عنوان توانایی نمایش یک صحنه تعریف می شود. فرآیند اکتساب از طریق عوامل خارجی و صحنه ای که نشان می دهد بر داده ها تأثیر می گذارد. چنین دانشی از فرآیند اکتساب امکان توصیف داده ها و تطبیق آنها با ویژگی های آن را فراهم می کند [ 37 ].
یک شی متعلق به یک صحنه است، از هندسه تشکیل شده است و با اشیاء دیگر رابطه توپولوژیکی دارد. یک الگوریتم برای هندسه های خاص مناسب است و اشیا را تشخیص می دهد. مطابق با هندسههایی که اشیا را تشکیل میدهند، الگوریتمهایی انتخاب میشوند تا فرآیند را با ویژگیهای اشیاء تطبیق دهند [ 38 ].
الگوریتمها وابستگیهای متقابلی بین خود دارند، به این معنی که اجرای یک الگوریتم میتواند به اجرای الگوریتم دیگری نیاز داشته باشد. بنابراین، فرآیند تقسیمبندی معنایی از اطلاعات مربوط به الگوریتمها، وابستگی متقابل آنها، اشیاء و ویژگیهای داده برای انتخاب و اعمال الگوریتمهای مناسب استفاده میکند.
این اطلاعات با استفاده از منطق توصیف توضیح داده شده است. منطق های توصیف خانواده ای از زبان های رسمی برای نمایش دانش هستند. آنها عمدتاً در هوش مصنوعی برای توصیف و استدلال در مورد ارتباط مفاهیم در یک حوزه کاربردی استفاده می شوند. به عنوان مثال، منطق توصیف یک چراغ خیابان در نحو منچستر که برای مقایسه در بخش 5 استفاده می شود، در فهرست 1 نشان داده شده است.
| فهرست 1. شرح Streetlight در نحو منچستر. |
|
3.3.2. گردش کار مبتنی بر دانش
گردش کار رویکرد KB شامل تقسیم پیچیدگی ابر نقطه با گروهبندی مجدد نقاط در بخشهای همگن (بخشبندی)، سپس استخراج برخی از ویژگیهای مرتبط از این بخشها (استخراج ویژگی) بود تا در نهایت بخشها را بهعنوان اشیا یا قسمتهایی از اشیا شناسایی کرد. طبقه بندی) [ 39 ]. شکل 3 گردش کار رویکرد KB را نشان می دهد.
3.3.3. فرآیند تقسیم بندی
ترکیبی از الگوریتمها (مانند «تقسیمبندی منطقه در حال رشد مبتنی بر رنگ»، «برآورد نرمالهای سطح»، «فیلتر VoxelGrid»، «خوشهبندی سوپروکسل»، «تقسیمبندی در حال رشد منطقه») از کتابخانههایی مانند PCL 1.11.1 ( https:/ /github.com/PointCloudLibrary/pcl در 9 آوریل 2020 قابل دسترسی است) و OpenCV 4.5.2 ( https://opencv.org/ در 9 آوریل 2020 مشاهده شد) مراحل تقسیم بندی و استخراج ویژگی را انجام دادند. چنین رویکردی امکان تکرار تقسیم بندی و طبقه بندی را بر اساس اشیاء مختلف مورد نظر، مانند توضیح داده شده در [ 40]. چنین استراتژی را می توان یک فرآیند تقسیم بندی تصفیه شده در نظر گرفت. همانطور که در [ 41 ] توضیح داده شد، انتخابها و پیکربندیهای الگوریتمها بهطور خودکار مطابق با اشیاء و توصیف دادهها طراحی شدند . به طور دقیق تر، توصیف ویژگی های شی با هدف هدایت استراتژی تقسیم بندی معنایی. هر چه شکل شی ساده تر باشد، استراتژی تقسیم بندی معنایی آن می تواند ساده تر باشد. در مقابل، اشیاء با اشکال پیچیده به استراتژیهای تقسیمبندی معنایی دقیقتری نیاز داشتند.
سه بخش اصلی توصیف معنایی اشیا را تشکیل میدادند: ویژگیهای شی، هندسه آن و صحنهای که به آن تعلق داشت. هدف این بخش ها تسهیل انطباق استراتژی های تقسیم بندی معنایی است. مرحله استخراج ویژگی ویژگیهای هندسی ضروری مانند مرکز، جهت و ابعاد (ارتفاع، طول، عرض) آنها را توصیف میکند. سپس این ویژگی ها در هستی شناسی ادغام شدند.
4. مجموعه داده های تست
این دو رویکرد برای مجموعه دادههای نشاندادهشده در شکل 4 اعمال شد و نتایج بهدستآمده برای هر رویکرد بر اساس مرتبطترین معیارهای ادبیات مقایسه شد. مجموعه داده های مورد استفاده برای مقایسه، یک ابر نقطه در فضای باز شهری بود که توسط یک سیستم نقشه برداری سیار به دست آمد و از 7.5 میلیون نقطه تشکیل شده بود. شکل 5 ابر نقطه را نشان می دهد.
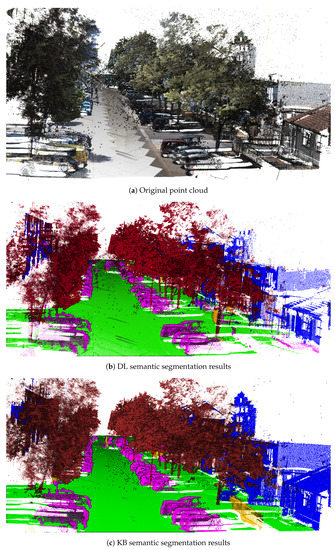
ما انتخاب کردیم تا تقسیمبندی معنایی گستردهترین دستهبندیهای اشیاء در محیطهای شهری، مربوط به شش دسته زیر را مطالعه کنیم: ماشین، بوته، درخت، زمین، چراغ خیابان و ساختمان.
دسته خودرو در اینجا نشان دهنده هر خودروی قابل مشاهده است، بدون هیچ وسیله نقلیه بزرگتر دیگری، مانند کامیون. یک بوته ساختار مزدوج قابل مشاهده بود، برای طبقه درخت یکسان است، در حالی که تاج و تنه در طول طبقه بندی با هم ترکیب می شوند. در برخی مناطق، درختان در بوته های بزرگ رشد می کنند. در اینجا دو رویکرد فقط بخشهای قابل مشاهده و قابل تشخیص درخت را طبقهبندی میکنند. بخش باقی مانده به عنوان بوته طبقه بندی شد. کلاس زمین شامل همه چیز در سطح زمین بدون در نظر گرفتن ویژگی سطح می شود. چراغهای خیابان زمانی که برای چشم انسان قابل تشخیص بودند، به این صورت طبقهبندی شدند. برای کلاس ساختمان، هر قسمت از خانه و اضافات آن، مانند ناودان، گنجانده شده بود.
ابتدا، زبری (از طریق رویکرد [ 42 ])، چگالی (از طریق رویکرد [ 43 ]) و انحنا (از طریق رویکرد [ 44 ]) مجموعه دادهها برای برجسته کردن چالشها برآورد شد. شکل 5 تخمین این سه ویژگی مجموعه داده را نشان می دهد.
یکی دیگر از ویژگی های ضروری مجموعه داده ها نویز بود. شکل 6 نویز تخمینی مجموعه داده را نشان می دهد.
درختان و بوتهها صدای زیاد، تراکم کم و زبری سطح بالایی داشتند. این ویژگی ها پیش بینی شکل آنها را بسیار دشوار می کرد. بنابراین، تقسیم بندی معنایی آنها یک چالش بود. تقسیم بندی معنایی خودروها نیز به دلیل اشکال مختلف چالش برانگیز بود. به همین ترتیب، بخشبندی معنایی ساختمان و زمین به دلیل تنوع چگالی و ناقص بودن ناشی از انسداد چالشبرانگیز بود. در نهایت، چالش اصلی تقسیمبندی معنایی چراغ خیابان در چگالی کم و نازکی تصویر آنها باقی ماند.
5. نتایج
شناسایی شی شامل تخصیص یک برچسب (که با یک رنگ نشان داده می شود) به هر دسته و اعمال این برچسب به هر نقطه از ابر نقطه ای که به یکی از این دسته ها تعلق دارد (خودرو: دارای برچسب سرخابی، بوته: با برچسب زرد، درختی) است. : با برچسب قهوه ای؛ زمین: با برچسب سبز؛ چراغ خیابان: با برچسب قرمز؛ ساختمان: با برچسب آبی).
در میان معیارهای کمی متفاوت موجود در ادبیات برای ارزیابی تقسیمبندی معنایی شی در مجموعههای گسسته، متریکهایی که اغلب مورد استفاده قرار میگیرند عبارتند از: دقت، یادآوری، امتیاز F1 و IoU. دقت توانایی طبقهبندی صحیح یک بخش را اندازهگیری میکرد، در حالی که یادآوری توانایی عدم از دست دادن بخشها را برای یک کلاس اندازهگیری میکرد. امتیاز F1 که میانگین هارمونیک یادآوری و دقت است، امکان اندازه گیری میانگین عملکرد طبقه بندی کننده را فراهم می کند. در مقابل، امتیاز IoU بدترین عملکرد طبقهبندیکننده را اندازهگیری کرد.
5.1. نتایج جهانی
نتایج با استفاده از دو رویکرد KB و DL به مجموعه دادههای آزمون به دست آمد. هیچ یک از این رویکردها برای این مجموعه داده بهینه نشده است. معیارهای امتیاز با مقایسه نتایج هر یک از دو رویکرد با یک حقیقت پایه که به طور کامل توسط حاشیه نویسی دستی ایجاد شده بود، محاسبه شد.
شکل 7نمای کلی نتایج از تقسیم بندی معنایی انجام شده توسط رویکرد DL و رویکرد KB در این مجموعه داده را نشان می دهد. دو رویکرد میانگین امتیاز F1 بالاتر از 78٪ (KB) و 66٪ (DL) و یک امتیاز IoU (که نشان دهنده “بدترین حالت” است) بالاتر از 65٪ (KB) و 51٪ (DL) به دست آوردند. . هر دو رویکرد برای تقسیم بندی معنایی زمین و درخت به امتیاز بالایی می رسند. هر دوی آنها دقت پایینی داشتند اما یادآوری خوبی برای تقسیم معنایی چراغ های خیابان داشتند. این بدان معنی است که بیشتر چراغ های خیابان به درستی شناسایی شده اند اما عناصر دیگری را در خود جای داده اند. بوته ها، اتومبیل ها و ساختمان ها در مجموع به خوبی تقسیم شدند و به امتیاز F1 بین 56 تا 76.7 رسیدند. نتایج آماری نشان داد که رویکرد KB در تشخیص همه کلاسها به جز کلاس بوش کارآمدتر است. که رویکرد ارائه شده توسط IPM کارآمدتر بود. در میان نتایج مختلف، مشاهده کردیم که رویکرد DL دقت بهتری برای تقسیمبندی معنایی ساختمانها و بوتهها و یادآوری بهتر برای بوتهها نسبت به رویکرد KB دارد. در بخش بعدی، نتایج بهدستآمده از طریق مثالهای توضیحی بیشتر توضیح داده میشود.
مقایسه بین رویکرد KB و رویکرد DL در جدول 1 و جدول 2 برای طبقه بندی شش کلاس اصلی در داده ها ارائه شده است.
5.2. نتایج تفصیلی
بوته ها با توجه به هندسه و رابطه آنها با عناصر دیگر در رویکرد KB مورد مطالعه به صورت معنایی توصیف شدند. با این حال، بوته ها هندسه ثابت یا پیوند رابطه ای بازگشتی با عناصر دیگر نداشتند. از این رو، شناسایی آنها برای رویکرد KB پیچیده تر بود.
شکل 8 نمونه ای از تقسیم بندی معنایی نادرست بوش را با رویکرد KB در مقایسه با رویکرد DL نشان می دهد.
شکل 8 نشان می دهد که رویکرد DL بوش (به رنگ زرد) را به درستی تشخیص داده است. در مقابل، رویکرد دانش محور موانع را از بوته ها جدا نکرد و آنها را به عنوان بوته ها شناسایی کرد. این عدم تقسیمبندی عمدتاً ناشی از توصیف منطقی بوتهها بود، که به اندازه کافی مشخص نبود تا عناصر دیگر را حذف کند.
مقولههایی که میتوانستند به طور رسمی به صورت هندسی یا با پیوندهای رابطهای مانند اتومبیلها، درختان، زمین، ساختمانها و چراغهای خیابان توصیف شوند، با رویکرد KB بهتر شناسایی شدند.
شکل 9 نشان می دهد که رویکرد DL بخش های ساختمان و شفت را از دست داده است. علاوه بر این، بخش هایی از زمین به عنوان خودرو طبقه بندی می شد. علاوه بر این، برخی از بخشهای ساختمانها به عنوان درخت طبقهبندی شدند. این – تا حد زیادی – ناشی از خطاهای طرح ریزی و طبقه بندی اشتباه تصاویر بود.
هر سنسور وسیله نقلیه اکتسابی باید کالیبره شده و در ارتباط با وسیله نقلیه قرار می گرفت: هر دوربین و لنز باید تصحیح و کالیبره می شد. هر حسگر باید به شکلی وابسته به وسیله نقلیه قرار می گرفت، و در نهایت، خود وسیله نقلیه باید در یک سیستم مختصات جهانی قرار می گرفت. این یک فرآیند بسیار شکننده بود، که در آن یک خطای کوچک در مقدار زیادی منتشر شد و نقاط طبقهبندی نادرست ایجاد کرد.
همانطور که در شکل 10 مشاهده میشود ، نتیجه طبقهبندی خالص تصاویر RGB بهدستآمده – در مقابل – درست و بسیار دقیقتر از ابر نقطهای به دست آمده بود. برای خط لوله پردازش کامل، بسته به منطقه تصویر، با افزایش اعوجاج در مرزهای تصویر، افست تا 100 پیکسل اندازهگیری شد.
در مقابل، رویکرد مبتنی بر معنایی، درختان و ساختمانهای بیشتری را با استفاده از روابط توپولوژیکی که عناصر بین آنها داشتند، شناسایی کرد و امکان طبقهبندی بخشها را بر اساس نزدیکی آنها به یکدیگر فراهم کرد. این امر باعث شد که بخشهای طبقهبندینشده به بخشهای طبقهبندیشده قبلی مرتبط شوند و بنابراین از طبقهبندی اشتباه جلوگیری شود. علاوه بر این، هندسه های توصیفی درختان، ساختمان ها و اتومبیل ها با یکدیگر متفاوت بودند. رویکرد معنایی به درستی این طبقات را تفکیک کرد.
تفاوت در دقت بین رویکرد KB و رویکرد DL برای بخشبندی معنایی نور خیابان حداکثر بود. از یک طرف، این را می توان با خطاهای طرح ریزی در رویکرد DL توضیح داد، که در آن نازک ترین عناصر دشوارترین برای نمایش خوب بودند. از سوی دیگر، فاصله ثابت بین دو چراغ خیابان، یک پیوند رابطهای قوی را برای رویکردهای مبتنی بر معنایی تضمین میکند، و به رویکرد KB اجازه میدهد موقعیت نور خیابان را نسبت به یک چراغ خیابان شناساییشده دیگر استنتاج کند. شکل 11 یک نمای مجزا از تقسیم بندی معنایی چراغ خیابان برای هر دو رویکرد مورد مطالعه را نشان می دهد.
رویکرد DL در مورد تقسیم بندی معنایی کلاس ساختمان دقیق تر بود. ساختمانها عمدتاً با استفاده از معیارهای هندسه آنها در رویکرد KB شناسایی شدند. هندسه ساختمان ها به اندازه کافی در رویکرد KB از نظر معنایی تعریف نشده است. این دلیل اصلی عدم شناسایی ساختمانها توسط رویکرد مبتنی بر معنایی است. بنابراین، گروههایی از نقاط متشکل از بوته و درخت، معیارهای هندسی یکسانی را ارائه کردند و با رویکرد KB به اشتباه شناسایی شدند، همانطور که در شکل 12 نشان داده شده است. اگر بتوان قواعد معنایی کافی را بیان کرد، آنگاه رویکرد KB میتواند سازههای ساختمانی پیچیده را شناسایی کرده و آنها را از سایر عناصر متمایز کند.
با این حال، استفاده از ویژگیهای هندسی ساختمان به رویکرد KB مورد مطالعه اجازه داد تا مجموعه بزرگتری از ساختمانها (یادآوری بهتر) را نسبت به رویکرد DL شناسایی کند، همانطور که در شکل 13 نشان داده شده است.
علاوه بر خطاهای طرح ریزی، طبقه بندی رویکرد DL توسط میدان دید دوربین ها محدود شد. بهویژه ساختمانهای بلند و/یا باریک، که کاملاً توسط دوربینهای RGB ثبت نشدهاند، قابل پردازش نیستند و بنابراین به درستی شناسایی نمیشوند. همانطور که در شکل 13 مشاهده می شود (نقاط طبقه بندی نشده به رنگ آبی)، کمتر از نیمی از نما به درستی طبقه بندی شده است. در تصویر اصلی در شکل 14 ، در سمت راست پایین، میدان دید دوربین فعلی قابل مشاهده است. این به نتیجه طبقه بندی در سمت چپ پایین ترجمه می شود.
6. بحث
رویکردهای DL و KB استراتژیهای متضادی را برای تقسیمبندی معنایی ابرهای نقطه ارائه میکنند. رویکردهای DL از یک استراتژی از پایین به بالا (از نمایش داده تا نمایش شی) استفاده می کنند، در حالی که رویکردهای KB از یک استراتژی از بالا به پایین (از نمایش شی هستی شناختی تا داده ها) استفاده می کنند. با توجه به فرآیند اکتساب، عناصر موجود در داده ها تا حدی اکتسابی (یک طرف)، ناپیوسته (انسداد) و نویزدار هستند. این ویژگی ها چالش های رایج در تقسیم بندی معنایی عناصر را نشان می دهد و منجر به پیچیدگی پردازش بالا می شود. چنین پیچیدگی امکان مطالعه استحکام هر دو رویکرد DL و KB را فراهم می کند. بنابراین، مناسب است که کارایی این دو رویکرد را با مطالعه نتایج بهدستآمده از پیادهسازی هر یک از آنها بر روی یک ابر نقطهای بهدستآمده توسط فناوری نقشهبرداری موبایل، مقایسه کنیم.
دو پیادهسازی مورد مطالعه رویکردهای DL و KB به ترتیب میانگین امتیاز IoU 51.43% و 65.21% را در مجموعه دادههای مورد مطالعه به دست آوردند. سایر رویکردهای موجود در ادبیات [ 45 ] که در مجموعه دادههای مشابه استفاده میشوند، میانگین IoU بین 39% و 63% دارند. در مقایسه با این رویکردها، هر دو پیادهسازی DL و KB کیفیت خوبی با نتایج کمی بهتر برای رویکرد KB در مجموعه دادههای مورد مطالعه دارند.
پیاده سازی KB به ویژه در تشخیص عناصر با ویژگی های هندسی، توپولوژیکی یا رابطه ای مشخص مانند ساختمان ها، درختان، اتومبیل ها و چراغ های خیابان موثر بود. از سوی دیگر، اجرای DL برای شناسایی عناصری با ویژگی هایی که توصیف صریح آنها دشوارتر است، مانند بوش ها، مؤثرتر است. برای این نوع شی، اطلاعات رنگ به طور خاص به شناسایی اشیاء کمک می کند. همچنین ممکن است امتیاز بهتر برای DL را توضیح دهد، زیرا رویکرد KB فقط از هندسه ها استفاده می کند و اطلاعات رنگ را در نظر نمی گیرد. این واقعیت یک ویژگی کلی نیست; به دلیل وضعیت واقعی توسعه رویکرد KB، این یک روش عملی است.
تفاوت در کیفیت عمدتاً به این دلیل است که رویکرد DL دارای بسیاری از خطاهای طرح ریزی، تکه های “نامرئی” است، جایی که هیچ تصویر دو بعدی به دست نیامده است، و غیره. نمایش خطاهای طبقه بندی دوبعدی در ابر نقطه سه بعدی، کارایی رویکرد DL را کاهش می دهد، عمدتاً با کاهش امتیاز یادآوری. کیفیت بهتر برای ثبت بین تصاویر و نقطه ابری باید این اثر را کاهش دهد.
یک تفاوت کلی در هر دو رویکرد، روشی است که آنها مبنای تقسیم بندی را فرموله می کنند. DL از محتوای ضمنی ارائه شده در تصاویر و همراه با حاشیه نویسی آنها استفاده می کند. این پایه از طریق تصاویر موجود و فرآیند آموزشی ثابت شده است و فقط حاوی اطلاعاتی است که در آنجا نشان داده شده است. رویکرد KB، به نوبه خود، پایه را به روشی صریح فرموله می کند. از ویژگی هایی مانند جنبه های هندسی و توپولوژیکی و بسیاری از عناصر دیگر متعلق به اشیا، داده ها، محیط، فرآیند اکتساب و غیره با ارتباط منطقی آنها استفاده می کند. این امکان را برای افزودن و/یا اصلاح دانش در هر زمان فراهم میکند و در صورت نیاز، انعطافپذیری و فضای زیادی برای بهینهسازی فراهم میکند.
به همین دلیل، کیفیت نمایشهای منطقی نیز تأثیر زیادی بر نتایج رویکردهای KB دارد. با این حال، کاربران متخصص همیشه می توانند توضیحات منطقی را برای افزایش کیفیت بهبود بخشند. در مقابل، رویکردهای DL از الگوهای آموخته شده در مرحله آموزش برای نمایش عناصر شناسایی شده استفاده می کنند. بنابراین، این رویکردها به طور مستقیم به کیفیت یادگیری آنها در رابطه با داده های مورد پردازش بستگی دارد. انجام تغییرات یا اضافات برای رویکردهای DL پیچیده تر است.
با این حال، قدرت تشخیص الگوی مبتنی بر تصویر به رویکرد DL اجازه میدهد حتی اشیایی با ساختار ضعیف، مانند بوشها را به خوبی تشخیص دهد. ویژگی های هندسی در اینجا تعیین کننده نیستند. مطمئناً این برای رویکرد KB حیاتی است. هر چه ویژگی های مشابه اشیایی که باید جدا شوند بیشتر باشد، توصیف منحصر به فرد آنها دشوارتر است. رویکردهای KB نمیتوانند توصیفات شی را به گونهای فرموله کنند که همه موارد را در دادهها نشان دهد، و در تشخیص اشیایی که هیچ یا مشخصههای صریح کمی ندارند، با مشکل مواجه میشوند. بنابراین، هنگامی که عناصر به طور متمایز توصیف نمی شوند، رویکرد KB نتایج زیر سطح رویکرد DL ایجاد می کند.
با توجه به جنبه گسترش این دو رویکرد، هر دو نیازمند مداخله انسان هستند. به روز رسانی خط لوله DL با یک کلاس جدید معمولاً مستلزم بازآموزی کامل و حاشیه نویسی های جدید است، در حالی که به روز رسانی رویکردهای KB مستلزم افزودن دانش صریح از یک کلاس جدید است. بنابراین، هر دو رویکرد قابل توسعه هستند اما با تلاش ها و پیامدهای متفاوت. حاشیه نویسی های جدید برای رویکرد DL به ورودی انسانی و تلاش محاسباتی برای آموزش نیاز دارد، در حالی که رویکرد KB به متخصصان نیاز دارد تا دانش صریح را تعریف کنند. با این حال، این فرآیند غنیسازی این مزیت را دارد که میتوان آن را با رویکردهایی مانند خودآموزی مبتنی بر دانش خودکار کرد [ 41 ، 46 ].
برای نتیجه گیری، رویکرد DL با استفاده انحصاری از تصاویر RGB برای تقسیم بندی معنایی، بخش بندی خوبی را در تصاویر ارائه می دهد، اما در 3D با توجه به خطاهای طرح ریزی محدود است. همچنین این مزیت را دارد که طبقات “بدون ساختار” مانند بوته ها را تشخیص دهد زیرا نه تنها به هندسه بلکه بر الگوهای دیگر نیز متکی است. اشیایی با ویژگی های هندسی نامتعارف مانند حصار باغ منحنی یا یک ساختمان بسیار شیک باید شناسایی شوند. با این وجود، هنگامی که عناصری مانند درختان در جلوی ساختمان وجود دارند که باعث انسداد می شوند، رویکرد DL به دلیل میدان دید دوربین، در نمایش نقاط با مشکل مواجه می شود که باعث خطاهای طرح ریزی می شود. علاوه بر این، DL به مقدار کافی داده برای استخراج الگوهای قابل اعتماد نیاز دارد. این منجر به مشکلات خاصی برای اشیاء کوچکتر می شود،
در مقابل، رویکردهای KB مستقیماً هر نقطه را پردازش میکند و میتواند هر نوع کلاس را بخشبندی کند و با ادغام دانش فرآیند سنجش با انسداد مقابله کند [ 41 ]. این اجازه می دهد تا دانش در مورد موقعیت و زاویه دید سیستم اکتساب متحرک را به منظور شناسایی مناطق دارای انسداد، و همچنین دانش بازتاب عناصر و نوع سیستم اکتساب برای تعیین چگالی برخی از مناطق، ادغام کند. به عنوان مثال، اجسام با بازتاب بالا با چگالی بسیار کم توسط سیستم های مبتنی بر اسکنر لیزری به دست می آیند.
رویکرد KB در دقت تقسیمبندی معنایی اشیاء ساختاریافته که دارای ویژگیهای متمایز هستند، قدرت را نشان میدهد، در حالی که رویکرد DL با استفاده از تصاویر RGB برای تقسیمبندی، قدرت را در تشخیص اشیاء ساختاری کمتر با ویژگیهای هندسی پایین نشان میدهد.
به طور کلی، نتایج با داده های داده شده در یک مورد کاربردی معین مقایسه می شود. همانطور که تأثیر خطای ثبت بین ابر نقطه و تصاویر نشان داده است، تغییرات در پایگاه داده نتیجه را تغییر می دهد. علاوه بر این، پایگاه دانش با این مقایسه خاص سازگار نیست، بنابراین اصلاح آن به احتمال زیاد به طور قابل توجهی نتیجه را بهبود می بخشد. با این وجود، نتایج ارائه شده باید برای ماهیت های مختلف این دو رویکرد معمولی باشد.
7. نتیجه گیری
این تحقیق یک رویکرد یادگیری ماشین توسعه یافته توسط IPM و یک رویکرد مبتنی بر دانش به نام KnowDIP، توسعه یافته توسط i3mainz را مقایسه می کند. رویکرد DL یک راه حل یادگیری عمیق نظارت شده است که از رمزگذار VGG6 با معماری FCN8 بر روی تصاویر RGB خالص با نمایش نتایج بر روی ابر نقطه استفاده می کند. رویکرد KB از فناوریهای وب معنایی استاندارد مانند SPARQL و OWL2 برای هدایت انتخاب الگوریتمها از کتابخانه استاندارد (PCL) [ 47 ] و فرآیند طبقهبندی بر اساس اشیا یا ویژگیهای داده در یک فرآیند تکراری استفاده میکند.
مقایسه دو رویکرد در یک مجموعه داده، نقاط قوت و ضعف هر دو رویکرد را برجسته میکند. این مقایسه بر اساس تقسیم بندی معنایی طبقات خودرو، درخت، بوته، چراغ خیابان، زمین و ساختمان در یک ابر نقطه در فضای باز شهری است. یک سیستم نقشه برداری سیار این ابر نقطه را به دست آورده است. ویژگی های این ابر نقطه ای با رنگ، زبری، چگالی، انحنا و نویز آن تخمین زده می شود. این ویژگیها به ما اجازه میدهد تا چالشها را در بخشبندی معنایی برجسته کنیم.
این کیس کاربردی به دلیل اشکال نامنظم، اشیاء جزئی به دست آمده، مشکلات هندسی، رنگ های اشتباه و نویز زیاد چالش های متعددی را ارائه می دهد. با این حال، هر دو رویکرد نتایج نزدیک به رویکردهای پیشرفته را ارائه می دهند [ 45 ]. نتایج با استفاده از معیارهای کمی ارزیابی شده است: نمرات یادآوری، دقت، F1 و IoU.
در سطح جهانی، در دسته بندی های مختلف اشیاء برای تقسیم معنایی، رویکرد KB در تقسیم بندی معنایی اشیاء با ویژگی های متمایز، مانند چراغ های خیابان، قدرت نشان داده است. در مقابل، رویکرد DL اشیاء ساختار کمتری مانند بوته ها را بهتر تشخیص می دهد. کارایی رویکرد DL با خطاهای طرح ریزی کاهش می یابد، که بر امتیاز یادآوری تأثیر می گذارد. رویکرد KB دقت بالاتری را برای چهار دسته از شش دسته نشان می دهد. در صورت تمدید یا انطباق مطلوب با سناریوی دیگر، تلاش باید در هر دو رویکرد سرمایه گذاری شود. در سمت DL، این آموزش عمدتاً جدید یا توسعه یافته است، در حالی که برای KB توسعه مدل دانش است. با این حال، رویکرد KB دارای آزادی عمل بیشتری برای بهبود نتایج خود با بهبود و اصلاح توضیحات شی در مقایسه با DL و تلاشهای آموزشی عظیم آن است.
با این حال، مقایسه نتایج با رویکردهای اضافی از این دو دسته برای مطالعه بیشتر مزایا و معایب هر دسته جالب خواهد بود. بنابراین، کار آینده شامل (1) گسترش مطالعه به داده ها و اشیاء بیشتر برای تأیید نتایج، (2) بهبود رویکرد DL با کاهش خطای طرح ریزی و بهبود رویکرد KB با افزودن ویژگی های داده بیشتر مانند رنگ، (3) کاوش در رویکردی که دانش و یادگیری عمیق را ترکیب می کند. ترکیب این دو رویکرد، تقسیمبندی معنایی ضعیف نور خیابان رویکرد DL و تقسیمبندی معنایی هفته بوش رویکرد KB را افزایش میدهد. به عنوان مثال، رویکرد KB می تواند رویکردهای DL را با استفاده از تصاویر RGB به عنوان خط لوله تقسیم بندی بهبود بخشد. برای مناطقی که FOV دوربین قادر به گرفتن همه چیز نیست،
علاوه بر این، DL میتواند ویژگیهای ضمنی را برای تقسیمبندی عناصر بدون ساختار مانند بوتهها فراهم کند، بنابراین جدایی از کلاسهای دیگر، مانند نردهها را افزایش میدهد. علاوه بر این، ادغام DL در خط لوله یک رویکرد KB میتواند به دانش اجازه دهد تا به جای الگوریتمها، بخشبندی یادگیری عمیق را هدایت کند تا محدودیت تقسیمبندی شی «بدون ساختار» را برآورده کند و بنابراین از هر دو رویکرد سود ببرد.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| DL | یادگیری عمیق |
| کیلوبایت | دانش محور |
منابع
- شلهامر، ای. لانگ، جی. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 640-651. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hommeaux، EP; Seaborne، A. SPARQL Query Language for RDF. توصیه W3C 2008. در دسترس آنلاین: https://www.w3.org/TR/rdf-sparql-query (در 9 آوریل 2020 قابل دسترسی است).
- Grau، BC; هوراکس، آی. موتیک، بی. پارسیا، بی. پاتل اشنایدر، پی. Sattler, U. OWL 2: مرحله بعدی برای OWL. وب سمنت 2008 . [ Google Scholar ] [ CrossRef ]
- دیاز-ویلارینو، ال. کوند، بی. لاگوئلا، اس. لورنزو، اچ. تشخیص خودکار و تقسیم بندی ستون ها در ساختمان های ساخته شده از ابرهای نقطه ای. Remote Sens. 2015 ، 7 ، 15651–15667. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آناگنوستوپولوس، آی. PǍtrǍucean، V.; بریلاکیس، آی. Vela، P. تشخیص دیوارها، کف ها و سقف ها در داده های ابر نقطه ای. کنگره تحقیقات ساخت و ساز 2016: فن آوری های ساخت و ساز قدیمی و جدید در سن خوان تاریخی همگرا می شوند. در مجموعه مقالات کنگره تحقیقات ساخت و ساز 2016، CRC 2016 ; انجمن مهندسین عمران آمریکا: Reston، VA، ایالات متحده آمریکا، 2016; صص 2302-2311. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، پی. دونگ، ز. یوان، پی. لیانگ، اف. یانگ، ب. بازسازی مدل های سه بعدی از ابرهای نقطه ای با نمایش ترکیبی. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی طاق ISPRS. 2018 ، 42 ، 449-454. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- درست، بی. اولریش، ام. نواب، ن. Ilic، S. مدل جهانی، مطابقت محلی: تشخیص اشیاء سه بعدی کارآمد و قوی. در مجموعه مقالات کنفرانس IEEE Computer Society در مورد دید کامپیوتری و تشخیص الگو . IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2010؛ ص 998-1005. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تومبری، ف. سالتی، س. دی استفانو، ال. توصیفگر ترکیبی شکل بافت برای تطبیق ویژگی های سه بعدی پیشرفته. در مجموعه مقالات 2011 هجدهمین کنفرانس بین المللی IEEE در مورد پردازش تصویر ; IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2011؛ ص 809-812. [ Google Scholar ] [ CrossRef ]
- لاوین، اف جی. دانلجان، م. توستبرگ، پی. بات، جی. خان، اف اس. فلسبرگ، ام. بخشبندی معنایی سه بعدی تصویری عمیق. در یادداشت های سخنرانی در علوم کامپیوتر (شامل یادداشت های سخنرانی های فرعی در هوش مصنوعی و یادداشت های سخنرانی در بیوانفورماتیک) ؛ انتشارات بین المللی Springer: Ystad، سوئد، 2017; جلد 10424 LNCS، صص 95-107. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- نگوین، ا. Le, B. تقسیم بندی ابر نقطه سه بعدی: یک بررسی. در مجموعه مقالات ششمین کنفرانس IEEE در سال 2013 در مورد رباتیک، اتوماسیون و مکاترونیک (RAM) ؛ IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2013؛ ص 225-230. [ Google Scholar ]
- گوا، ی. وانگ، اچ. هو، کیو. لیو، اچ. لیو، ال. بننامون، ام. یادگیری عمیق برای ابرهای نقطه سه بعدی: یک بررسی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2019 ، 1. [ Google Scholar ] [ CrossRef ]
- چارلز، آر کیو؛ سو، اچ. کایچون، م. Guibas، LJ PointNet: یادگیری عمیق در مجموعه های نقطه برای طبقه بندی و تقسیم بندی سه بعدی. در مجموعه مقالات کنفرانس IEEE 2017 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR) ؛ IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ جلد 2017-ژانوا، صص 77–85. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Qi، CR; یی، ال. سو، اچ. Guibas، LJ PointNet++: یادگیری ویژگی های سلسله مراتبی عمیق در مجموعه های نقطه در یک فضای متریک. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ دوره 2017-دسامبر، صص 5100–5109. در دسترس آنلاین: https://arxiv.org/pdf/1706.02413.pdf (دسترسی در 9 آوریل 2020).
- انگلمن، اف. کنتوگیانی، تی. Leibe, B. پیچش نقطه گشاد شده: در اندازه میدان پذیرنده پیچش نقطه در ابرهای نقطه سه بعدی. Proc. IEEE Int. Conf. ربات. خودکار 2020 ، 9463–9469. [ Google Scholar ] [ CrossRef ]
- استرایفر، سی. راگاوندرا، ر. بنسون، تی. Srivatsa، M. DarNet: یک راه حل یادگیری عمیق برای تشخیص رانندگی حواس پرت. در Proceedings of the Middleware 2017 — مجموعه مقالات کنفرانس بین المللی Middleware 2017 (مسیر صنعتی) ; Zhu, X., Roy, I., Eds. ACM Press: نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ ص 22-28. [ Google Scholar ] [ CrossRef ]
- لیو، جی. نی، بی. لی، سی. یانگ، جی. Tian، Q. تجمع پویا نقاط برای یادگیری مجموعه نقطه سلسله مراتبی. Proc. IEEE Int. Conf. محاسبه کنید. Vis. 2019 ، 2019 ، 7545–7554. [ Google Scholar ] [ CrossRef ]
- روزو، RA; شوت، پی. کوئنزل، جی. Behnke, S. LatticeNet: تقسیم بندی ابر نقطه ای سریع با استفاده از شبکه های پرموتوهدرال. 2019. در دسترس آنلاین: https://arxiv.org/pdf/1912.05905 (در 9 آوریل 2020 قابل دسترسی است).
- تاتارچنکو، م. پارک، جی. کلتون، وی. ژو، پیچیدگی های مماس QY برای پیش بینی متراکم در سه بعدی. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در مورد دید کامپیوتری و تشخیص الگو ؛ بنیاد بینایی کامپیوتر: سالت لیک سیتی، UT، ایالات متحده آمریکا، 2018؛ صص 3887–3896. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میلیوتو، ا. ویزو، آی. بهلی، جی. Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Semantic Segmentation. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد ربات ها و سیستم های هوشمند . IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2019؛ صص 4213–4220. [ Google Scholar ] [ CrossRef ]
- رتاژ، دی. والد، جی. استورم، جی. نواب، ن. Tombari, F. شبکه های نقطه ای کاملاً کانولوشن برای ابرهای نقطه ای در مقیاس بزرگ. 2018. در دسترس آنلاین: https://openaccess.thecvf.com/content_ECCV_2018/papers/Dario_Rethage_Fully-Convolutional_Point_Networks_ECCV_2018_paper.pdf (در 9 آوریل 2020 قابل دسترسی است).
- وانگ، جی. سان، بی. Lu, Y. MVPNet: شبکههای رگرسیون چند نما برای بازسازی شیء سه بعدی از یک تصویر واحد. 2019. در دسترس آنلاین: https://arxiv.org/pdf/1811.09410 (در 9 آوریل 2020 قابل دسترسی است).
- بلژیک، م. تاملینوویچ، آی. Lampoltshammer، TJ; بلاشکه، تی. Höfle, B. طبقهبندی مبتنی بر هستیشناسی انواع ساختمانهای شناسایی شده از دادههای اسکن لیزری هوابرد. Remote Sens. 2014 , 6 , 1347–1366. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پال، M. طبقه بندی جنگل تصادفی برای طبقه بندی سنجش از دور. بین المللی J. Remote Sens. 2005 ، 26 ، 217-222. [ Google Scholar ] [ CrossRef ]
- تسارکوف، دی. Horrocks, I. FaCT++ description logic reasoner: توضیحات سیستم. در یادداشت های سخنرانی در علوم کامپیوتر (شامل یادداشت های سخنرانی های فرعی در هوش مصنوعی و یادداشت های سخنرانی در بیوانفورماتیک) ؛ Springer: برلین/هایدلبرگ، آلمان، 2006; جلد 4130 LNAI، ص 292-297. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دوراند، ن. دریوو، اس. فارستیر، جی. ومرت، سی. گانچارسکی، پ. بوسعید، او. Puissant، A. تشخیص شی مبتنی بر هستی شناسی برای تفسیر تصویر سنجش از دور. در مجموعه مقالات – کنفرانس بین المللی ابزارهای با هوش مصنوعی، ICTAI ; IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2007; جلد 1، ص 472-479. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Maillot، N.; تونات، م. Hudelot، C. یادگیری و تشخیص شی مبتنی بر هستی شناسی: کاربرد برای بازیابی تصویر. در مجموعه مقالات کنفرانس بین المللی ابزارهای با هوش مصنوعی، ICTAI، بوکا راتون، فلوریدا، ایالات متحده آمریکا، 15-17 نوامبر 2004. صص 620-625. [ Google Scholar ] [ CrossRef ]
- پونچیانو، جی جی. بوچس، اف. Trémeau، A. تشخیص شی مبتنی بر دانش در ابرهای نقطه و مجموعه داده های تصویر. Gis Science-Die Zeitschrift für Geoinformatik 2017 ، 3 ، 97-104. [ Google Scholar ]
- فلورکووا، ز. دوریس، ال. وسلوفسکی، م. سدیو، اس. Kovalova, D. سیستم نقشه برداری سیار سه بعدی و استفاده از آن در مهندسی راه. MATEC Web Conf. 2018 ، 196 ، 4082. [ Google Scholar ] [ CrossRef ]
- ریترر، آ. Leidinger, M. Mobile Urban Mapping System: MUM. در دسترس آنلاین: https://www.ipm.fraunhofer.de/content/dam/ipm/en/PDFs/product-information/OF/MTS/mobile-urban-mapping-system-MUM.pdf (در 9 آوریل 2020 قابل دسترسی است ).
- Fraunhofer-Institut für Physikalische Messtechnik. CPS اسکنر نمایه پاکسازی. در دسترس آنلاین: https://www.ipm.fraunhofer.de/content/dam/ipm/en/PDFs/product-information/OF/MTS/Clearance-Profile-Scanner-CPS.pdf (در 9 آوریل 2020 قابل دسترسی است).
- ریترر، آ. واشله، ک. استورک، دی. لیدکر، ا. گیتزن، ن. بخشبندی کاملاً خودکار دادههای نقشهبرداری موبایل دوبعدی و سهبعدی برای مدلسازی قابل اعتماد سازههای سطحی با استفاده از یادگیری عمیق. Remote Sens. 2020 , 12 , 2530. [ Google Scholar ] [ CrossRef ]
- جیا، ی. شلهامر، ای. دوناهو، جی. کارایف، اس. لانگ، جی. گیرشیک، آر. گواداراما، اس. Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. 2014. در دسترس آنلاین: https://arxiv.org/pdf/1408.5093v1 (در 9 آوریل 2020 قابل دسترسی است).
- خو، بی. جیانگ، دبلیو. شان، جی. ژانگ، جی. Li, L. بررسی رویکردهای وزنی RANSAC برای تقسیم بندی صفحه سقف ساختمان از ابرهای نقطه LiDAR. Remote Sens. 2016 ، 8 ، 5. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بن همیدا، اچ. کروز، سی. بوچس، اف. نیکول، سی. از ابرهای نقطه سه بعدی تا اشیاء معنایی: یک رویکرد تشخیص مبتنی بر هستی شناسی. در مجموعه مقالات KEOD 2011 — کنفرانس بین المللی مهندسی دانش و توسعه هستی شناسی، پاریس، فرانسه، 26-29 اکتبر 2011. صص 255-260. [ Google Scholar ]
- کارماچاریا، ا. بوچس، اف. Tietz، B. تشخیص و شناسایی شی هدایت شده با دانش در ابرهای نقطه سه بعدی. در مجموعه مقالات ویدئومتری، تصویربرداری محدوده، و برنامه های سیزدهم، مونیخ، آلمان، 22 تا 23 ژوئن 2015. [ Google Scholar ] [ CrossRef ]
- دیتنبک، تی. ترخانی، ف. عثمانی، ع. آتن، م. Favreau، JM چند لایه هستی شناسی برای تقسیم بندی شکل سه بعدی و حاشیه نویسی یکپارچه. در مطالعات هوش محاسباتی ; انتشارات بین المللی Springer: برلین/هایدلبرگ، آلمان، 2017; جلد 665، ص 181–206. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پونچیانو، جی جی. کارماچاریا، ا. وفرز، اس. آتورف، پی. Boochs, F. مفاهیم معنایی متصل به عنوان پایه ای برای ثبت بهینه و مدل سازی مبتنی بر رایانه از اشیاء میراث فرهنگی. در تحلیل ساختاری بناهای تاریخی ; آگیلار، آر.، تورئالوا، دی.، موریرا، اس.، پاندو، MA، راموس، LF، ویراستاران. انتشارات بین المللی Springer: چم، سوئیس، 2019; صص 297-304. [ Google Scholar ]
- پونچیانو، جی جی. بوچس، اف. Tremeau، A. شناسایی و طبقه بندی اشیاء در ابرهای نقطه سه بعدی بر اساس یک مفهوم معنایی. در Oldenburger 3D-Tage 2019 ؛ Wichmann: Oldenburger، آلمان، 2019؛ صص 98-106. [ Google Scholar ]
- پونچیانو، جی جی. بوچس، اف. Trémeau، A. شناسایی شی سه بعدی از طریق فرآیندی مبتنی بر معناشناسی و در نظر گرفتن زمینه. در Photogrammetrie، Laserscanning، Optische 3D-Messtechnik، Beiträge der Oldenburger 3D-Tage 2020 ؛ ویچمن: اولدنبورگ، آلمان، 2020؛ صص 1-12. [ Google Scholar ]
- Ponciano، JJ Object Detection در مجموعه داده های سه بعدی بدون ساختار با استفاده از معناشناسی آشکار. Ph.D. پایان نامه، دانشگاه لیون، لیون، فرانسه، 2019. [ Google Scholar ]
- پونچیانو، جی جی. ترمو، آ. Boochs, F. تشخیص خودکار اشیاء در ابرهای نقطه سه بعدی بر اساس فرآیندهای هدایت شده منحصراً معنایی. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 442. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تونیتتو، ال. گونزاگا، ال. ورونز، MR; Kazmierczak، CdS; آرنولد، DCM؛ da Costa، CA روش جدید برای ارزیابی پارامترهای زبری سطح به دست آمده توسط اسکن لیزری. علمی جمهوری 2019 ، 9 ، 1-16. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لاری، ز. حبیب، الف. روشهای جایگزین برای تخمین شاخص چگالی نقطه محلی: حرکت به سمت پردازش دادههای LiDAR تطبیقی. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2012 ، 39 ، B3. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ایکس. لی، اچ. Cheng, Z. تخمین انحنای سطوح ابر نقطه سه بعدی از طریق برازش انحناهای بخش معمولی. Proc. ASIAGRAPH 2008 ، 2008 ، 23–26. [ Google Scholar ]
- هاکل، تی. ساوینوف، ن. لدیکی، ال. Wegner، JD; شیندلر، ک. Pollefeys، M. Semantic3D.Net: معیار طبقه بندی ابر نقطه ای جدید در مقیاس بزرگ. ISPRS سالنامه فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی. گوتینگن 2017 ، 4 ، 91-98. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پوکس، اف. Ponciano، JJ هستی شناسی خودآموز برای مثال تقسیم بندی ابر نقطه داخلی سه بعدی. در ISPRS-بایگانی بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی ؛ Copernicus: Bethel Park, PA, USA, 2020. [ Google Scholar ] [ CrossRef ]
- Rusu، RB; Cousins, S. 3D اینجاست: Point Cloud Library (PCL). در مجموعه مقالات کنفرانس بین المللی IEEE در مورد رباتیک و اتوماسیون، شانگهای، چین، 9 تا 13 مه 2011. [ Google Scholar ] [ CrossRef ][ Green Version ]
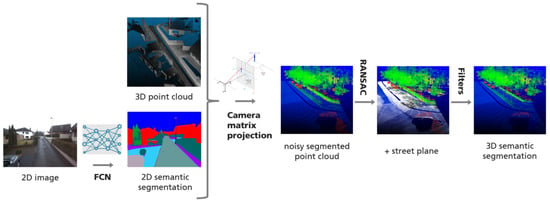
شکل 1. خط لوله و اجزای جریان کار یادگیری عمیق.
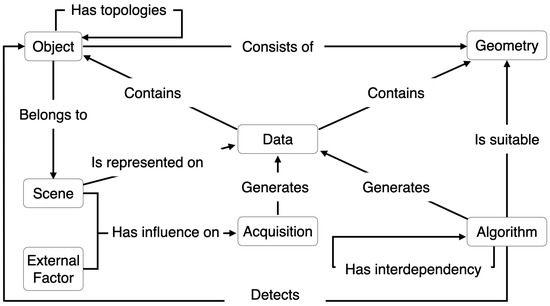
شکل 2. مروری بر مدل سازی دانش.

شکل 3. مروری بر مدل سازی دانش.

شکل 4. ابر نقطه ای: به دست آمده توسط سیستم نقشه برداری موبایل، برای مقایسه استفاده می شود.
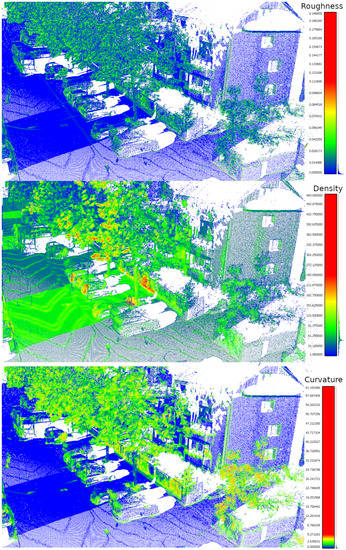
شکل 5. ابر نقطه ای مورد استفاده برای مقایسه معیارها: ( بالا ) تخمین زبری، ( مرکز ) تخمین چگالی، ( پایین ) تخمین انحنا.

شکل 6. تصویر نویز به رنگ قرمز بر روی ابر نقطه ای که توسط سیستم نقشه برداری موبایل به دست آمده است.
شکل 7. ابرهای نقطه ای مورد استفاده برای مقایسه.

شکل 8. نمونه ای از نتایج تقسیم بندی معنایی بوش و موانع.

شکل 9. نمونه نتایج تقسیم بندی معنایی.

شکل 10. تصویر اصلی RGB ( سمت چپ ). تقسیم بندی معنایی تولید شده با رویکرد DL ( سمت راست ).

شکل 11. نتایج تقسیم بندی معنایی Streetlight (قرمز).

شکل 12. نمونه تقسیم بندی معنایی یک ابر نقطه چالش برانگیز.

شکل 13. نمونه تقسیم بندی معنایی ابر نقطه ای که نمای ساختمان را نشان می دهد.
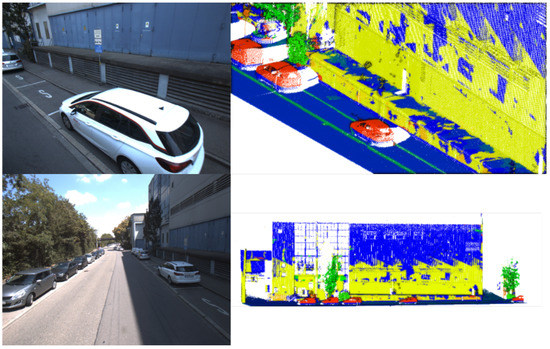
شکل 14. تصویر اصلی ( سمت چپ )، تقسیم بندی معنایی تولید شده با رویکرد DL ( راست ).


بدون دیدگاه