1. معرفی
تقسیم بندی معنایی شامل تخصیص یک برچسب معنایی به هر پیکسل از یک تصویر حاوی یک شی است که می تواند اطلاعات ساختار سطح بالا را ارائه دهد [ 1 ]. تقسیمبندی معنایی یک کار حیاتی در برنامههای هوشمند مانند روباتهای متحرک و وسایل نقلیه رانندگی خودکار است، زیرا میتواند درک دقیقی از یک صحنه ارائه دهد [ 2 ]. اخیراً، پیشرفتهای قابل توجهی در تکنیکهای تقسیمبندی معنایی صحنههای RGB طبیعی به دلیل توسعه شبکههای عصبی پیچیده عمیق (CNN) حاصل شده است. مدلهای یادگیری عمیق میتوانند ویژگیهای انتزاعی سطح بالا را از تصاویر خام با عملکرد عالی بیاموزند. با این حال، این رویکردها بر نمونه های آموزشی بزرگ تکیه دارند [ 3]. برای برآورده کردن این نیاز، مجموعه دادههای عمومی مختلفی برای برچسبگذاری صحنه پیشنهاد شدهاند. به عنوان مثال، PASCAL VOC [ 4 ] یک مجموعه داده در مقیاس بزرگ است که برای تشخیص کلاس شیء استفاده می شود و شامل 2913 تصویر با برچسب گذاری در سطح پیکسل با 20 کلاس، مانند وسایل نقلیه و حیوانات است. ImageNet اگرچه مشابه PASCAL است، حاوی بیش از 20000 کلاس و 14 میلیون تصویر است [ 5 ]. مجموعه داده COCO بیش از 328000 تصویر را با 80 کلاس ارائه می دهد و تصاویر به مجموعه داده های آموزشی / اعتبار سنجی / آزمایشی مختلف تقسیم می شوند [ 6 ]. اخیراً، مجموعه داده Cityscape یک درک معنایی از صحنه های خیابان شهری ارائه کرده است [ 7]. این شامل 5000 تصویر با برچسب گذاری متراکم در سطح پیکسل از بیش از 30 کلاس صحنه است که معمولاً در حین رانندگی با آنها مواجه می شوند، مانند وسایل نقلیه، جاده ها و نرده ها.
تقسیمبندی معنایی را میتوان به طبقهبندی تصویر در حوزه سنجش از دور (RS) اشاره کرد و در کاربردهای مختلفی مانند طبقهبندی پوشش زمین، بررسیهای زمینشناسی و محیط زیست و برنامهریزی شهری مورد استفاده قرار گرفته است. [ 8 ، 9 ، 10 ]. روشهای یادگیری عمیق با موفقیت برای حل مشکل تقسیمبندی تصاویر ماهوارهای و هوایی به کار گرفته شدهاند و آنها از طبقهبندیکنندههای تصویر اصلی بهتر عمل میکنند [ 11 ]. شبکههای یادگیری عمیق مختلفی برای تقسیمبندی معنایی ایجاد شدهاند و برخی روشها عملکرد خوبی برای تصاویر RS به دست آوردهاند [ 12 ]. شبکه های کاملاً پیچیده (FCNs)، که توسط لانگ و همکاران پیشنهاد شده است. [ 13]، برای تقسیم بندی معنایی تصاویر هوایی با وضوح بسیار بالا [ 14 ، 15 ] استفاده شده است. در این رویکرد، لایه کاملاً متصل با یک لایه کانولوشن جایگزین میشود که به مجموعه دادههای ورودی با اندازه دلخواه اجازه میدهد. بر اساس مفهوم FCN، U-net توسط Ronneberger و همکاران ارائه شد. [ 16 ]؛ از معماری رمزگذار و رمزگشا استفاده می کند. U-net در اصل برای بخشبندی تصاویر پزشکی طراحی شده بود، اگرچه مطالعات قبلی نشان دادهاند که U-net میتواند با موفقیت برای تقسیمبندی تصاویر RS استفاده شود [ 17 ]. مشابه U-net، SegNet از معماری رمزگذار و رمزگشا استفاده می کند. فرم رمزگذار مبتنی بر لایه های کانولوشن VGG-16 است و رمزگشا هم نمونه برداری و هم طبقه بندی را انجام می دهد [ 18]]. Audevert و همکاران [ 18 ] اثربخشی استفاده از SegNet چند مقیاسی را برای تقسیم بندی مجموعه داده های انجمن بین المللی فتوگرامتری و سنجش از دور (ISPRS) نشان داد. علاوه بر این، DeepLab-V3+ از معماری رمزگذار و رمزگشا با کانولوشن شدید و زمینههای تصادفی شرطی کاملاً متصل برای تقسیمبندی معنایی استفاده میکند. سیستم DeepLab با موفقیت بر روی تصاویر RS اعمال شد و میتوانست به طور مناسب با اشیاء چند مقیاسی در تصاویر ماهوارهای با وضوح بالا اداره کند [ 19 ].
به طور کلی، برای جبران کمبود فعلی مجموعه دادههای بزرگ، تقسیمبندی معنایی تصاویر RS با استفاده از روشهای یادگیری عمیق با شبکههای از پیش آموزشدیده، برای مجموعه دادههای تصویر RGB طبیعی مانند ImageNet و PASCAL VOC [20، 21] اعمال شده است . با این حال، بر خلاف تصاویر RGB طبیعی، تصاویر RS حاوی چندین نوع اشیاء با وضوح پایین هستند که شکل نامنظمی دارند، که بر طبقه بندی اشیاء بعدی تأثیر می گذارد [ 12 ]. علاوه بر این، همانطور که تصاویر RS از منظر چشم پرنده به دست میآیند، اشیاء در یک صفحه دو بعدی (2D) مسطح قرار میگیرند که در آن فقط بالای اجسام مشاهده میشود [22] .]. علاوه بر این، ساخت یک مجموعه داده تصویر RS در مقیاس بزرگ دشوارتر از استفاده از تصاویر RGB طبیعی است و ایجاد برچسب های داده برای تصاویر RS به دست آمده از حسگرهای مختلف زمان بر است. در واقع، خطاهای مختلفی را می توان به دلیل عواملی مانند جابجایی برجسته ناشی از تفاوت در ارتفاع و سایه در تصاویر RS معرفی کرد. علاوه بر این، تعریف کلاس های معنادار در یک صحنه در مورد مواد سطحی متعدد می تواند دشوار باشد. با این حال، با وجود این مشکلات، مجموعه داده های عمومی RS در مقیاس بزرگ اخیراً منتشر شده است. برای مثال، ISPRS مجموعه دادههای معیار Vaihingen/Germany و Potsdam/Germany را شامل 33 تصویر با سه باند مادون قرمز، قرمز و سبز (IRRG) و 38 تصویر با چهار باند فروسرخ، قرمز، سبز و آبی (IRRGB) ارائه کرد. به ترتیب،23 ]. علاوه بر این، چالشهای زوریخ [ 24 ] و کاگل [ 25 ] تصاویر ماهوارهای با وضوح بسیار بالا، یعنی Quickbird و Worldview-3، به ترتیب، که حاوی نقشههای برچسبگذاری با کلاسهای 8-10 هستند، به دست آوردند.
با افزایش مجموعه داده های بزرگی که توسط حسگرهای مختلف به دست می آید، نیاز به تحقیقی که قادر به یادگیری تصاویر با ویژگی های مختلف باشد، به یکباره افزایش می یابد. با این حال، هنگام استفاده از مجموعه داده های ناهمگن، توضیح تفاوت در ویژگی های تصاویر ورودی و انواع کلاس ها دشوار است. به عنوان مثال، ملتیس و همکاران. [ 26 ] از مجموعه دادههای معیار تشخیص علائم ترافیکی آلمان و منظر شهری ناهمگن استفاده کرد [ 27 ] برای تقسیمبندی معنایی صحنههای خیابان استفاده کرد. مجموعه داده های در نظر گرفته شده متفاوت بودند. با این حال، آنها حاوی کلاس های مرتبط معنایی بودند. این نویسندگان سلسله مراتبی از طبقهبندیکنندهها را با استفاده از آموزش سلسله مراتبی و قوانین استنتاج با استفاده از روابط معنایی بین برچسبهای هر مجموعه داده ایجاد کردند. قاسمی و همکاران [28] یک شبکه رمزگذار و رمزگشا برای تقسیم بندی تصاویر ماهواره ای مجموعه داده های ناهمگن طراحی کرد. آنها از یادگیری فعال استفاده کردند، که در آن یک شبکه آموزش دیده با استفاده از چند تصویر نمونه در مجموعه داده های آموزشی و آزمایشی ناهمگن اصلاح شد و روش آنها عملکرد شبکه را با کمترین مداخله انسانی بهبود بخشید. چندین مطالعه با استفاده از مجموعه داده های ناهمگن با انواع مشابه تصاویر و برچسب ها انجام شده است. با این حال، مطالعات بسیار کمی از مجموعه دادههای تصویر RGB و RS طبیعی استفاده کردهاند. برای تقسیمبندی تصاویر RS، مواردی وجود داشت که در آن شبکههای تقسیمبندی از پیش آموزشدیدهشده از مجموعه دادههای تصویر طبیعی، مانند ImageNet، بهعنوان مقادیر اولیه شبکه تقسیمبندی برای تصاویر RS استفاده شد، اما تحقیق در مورد یادگیری مستقیم RS و تصاویر RGB طبیعی با هم کافی نیستند [ 3، 29 ].
برای پرداختن به این کمبود تحقیق، امکان به اشتراک گذاری شبکه های مجموعه داده های ناهمگن را تجزیه و تحلیل می کنیم و تأثیر یادگیری را با استفاده از تابع کاهش وزن ترکیبی بین دو شبکه آموزش دیده در مجموعه داده های مختلف برای غلبه بر محدودیت های تحمیل شده توسط فقدان مجموعه داده های آموزشی شناسایی می کنیم. در این مطالعه از مجموعه داده های تصویری هوایی و جاده ای برای ارزیابی روش پیشنهادی استفاده شد. در نهایت، انتظار میرود که روش پیشنهادی نه تنها برای وظایف تقسیمبندی تصاویر هوایی، بلکه برای تقسیمبندی یا تشخیص شی تصویر نمای خیابان در وبسایتها و پلانهای کف اسکن شده نیز اعمال شود. ادامه این مقاله به شرح زیر سازماندهی شده است. معماری روش پیشنهادی در بخش 2 ارائه شده است، و مجموعه داده ها و شرایط محیطی برای آزمایش ها در بخش 3 و بخش 4 توضیح داده شده است . نتایج و بحث به ترتیب در بخش 5 و بخش 6 ارائه شده است و نتیجه گیری در بخش 7 ارائه شده است .
2. روش ها
هدف این مطالعه توسعه یک شبکه یادگیری عمیق است که می تواند دقت تقسیم بندی معنایی تصاویر RS را با استفاده از مجموعه داده های تصویر طبیعی در مقیاس بزرگ با ویژگی های مختلف بهبود بخشد. برای این منظور، با فرض اینکه تعداد تصاویر RS کافی نیست، آزمایشهایی انجام میشود تا مشخص شود که آیا مشکل دادههای آموزشی ناکافی را میتوان در زمانی که آموزش با استفاده از مجموعه دادههای تصویر RS و تصویر طبیعی انجام میشود حل کرد.
2.1. مدل ترکیبی U-Net پیشنهادی
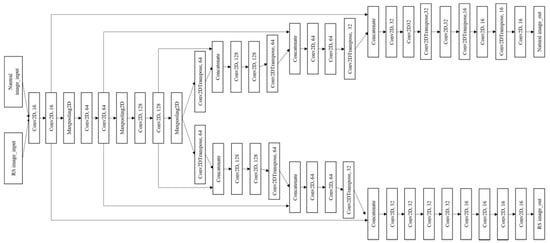
روش پیشنهادی تقسیم بندی معنایی را با استفاده از تکنیکی مبتنی بر نسخه ساده شده U-net انجام می دهد. U-net یک مدل یادگیری عمیق است که برای تقسیمبندی تصاویر RS استفاده میشود. برای کاهش بار آموزشی بر روی مدل پیشنهادی، U-net ساده شده در اینجا استفاده شده است. شکل 1 معماری مدل ترکیبی U-net را نشان می دهد.
مدل ترکیبی U-Net بر اساس معماری U-Net است. دو جزء اصلی معماری U-net رمزگذار و رمزگشا هستند. برای رمزگذاری، رمزگذار U-net ترکیبی از سه بلوک اصلی تشکیل شده است که در طول مرحله آموزش بین دو مجموعه داده مشترک است. مدل ورودی را از دو منبع داده مختلف دریافت می کند (یعنی مجموعه داده های تصویر RS و تصویر طبیعی)، که عرض و ارتفاع ورودی آن ها هستند. n×n. سه بلوک رمزگذاری داده ها را از دو منبع دریافت می کنند و وزن پارامترهای آموزشی را بین آنها به اشتراک می گذارند. هر بلوک در بلوک های قابل اشتراک گذاری عمدتاً از دو لایه کانولوشنال دوبعدی تشکیل شده است که به دنبال آن یک لایه حداکثر نظرسنجی برای کاهش مقیاس است. بنابراین، در پایان مرحله رمزگذاری، نقشه ویژگی دارای اندازه ای از n8×n8. لایه های کانولوشنال مشترک می توانند اطلاعات مشترکی را بیاموزند که برای همه مجموعه داده ها در همه دامنه ها اعمال می شود [ 3 ]. لی و همکاران [ 3 ] تأیید کرد که لایههای مشترک در سراسر یک دامنه میتوانند در بهینهسازی CNN به جای استفاده از تنها یک مجموعه داده مؤثرتر باشند، زیرا رویکرد لایه اشتراکگذاری به طور قابلتوجهی دقت طبقهبندی را در مقایسه با مورد آموزشدیده بهصورت جداگانه بهبود میبخشد. با این حال، در مطالعه لی و همکاران. [ 3]، فقط وسط شبکه به اشتراک گذاشته شد و تنها از سه تصویر RS برای آموزش شبکه ترکیبی استفاده شد. در مطالعه حاضر، سه بلوک رمزگذار اولیه در طول فرآیند یادگیری به اشتراک گذاشته میشوند و بلوکهای بعدی وظایف بخشبندی خاص مجموعه داده را انجام میدهند. پس از اتمام مرحله رمزگذاری، نقشه های ویژگی به طور جداگانه رمزگشایی می شوند، به این معنی که هر مجموعه داده یک مسیر رمزگشایی جداگانه را دنبال می کند و وزن های آموزشی جداگانه دارد.
دو مسیر رمزگشایی مختلف وجود دارد. اولین مسیر برای داده های تصویر RS از سه بلوک تشکیل شده است. دو بلوک اولیه در درجه اول از یک لایه کانولوشنال جابجا شده تشکیل شده است تا نقشه ویژگی را به دو تا ارتقاء دهد و به دنبال آن دو لایه کانولوشنال قرار دارد. علاوه بر این، آخرین بلوک شامل هشت لایه کانولوشن است. مسیر دوم برای داده های تصویر طبیعی از شش بلوک تشکیل شده است. هر بلوک عمدتاً از یک لایه کانولوشنال جابجا شده برای ارتقاء نقشههای ویژگی و به دنبال آن دو لایه کانولوشن تشکیل شده است. بلوک های رمزگشایی با یک نقشه ویژگی از اندازه خاتمه می یابند n×n×16 که با استفاده از عدد 1 اسکن می شود ×1 فیلتر کانولوشنال دوبعدی (3، 3) برای تولید خروجی با اندازه n×n×ج، که با شکل برچسب های داده مطابقت دارد. جتعداد کلاس های برچسب است.
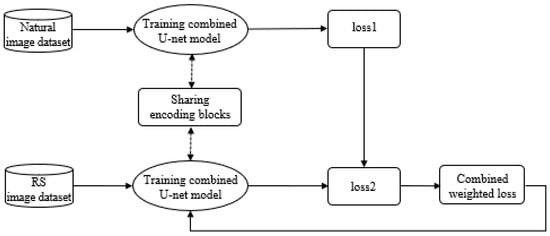
در این مقاله از مجموعه داده های تصویر طبیعی و تصویر RS استفاده می کنیم. در طول آموزش، U-net ترکیبی دو ورودی را به صورت موازی با به اشتراک گذاشتن سه بلوک رمزگذار کنترل می کند. علاوه بر این، شبکه با کاهش وزن ترکیبی آموزش داده می شود، Lج، که به عنوان مجموع وزنی تلفات دو مسیر تعریف می شود. سپس مدل ترکیبی با استفاده از تلفات وزنی ترکیبی به روز می شود ( شکل 2 ). تلفات مسیر اول و دوم با نشان داده می شود Ln1و Ln2به ترتیب، و تلفات آنتروپی متقاطع مکانی را می توان همانطور که در رابطه (1) نشان داده شده است، تعریف کرد.
جایی که اچ ×دبلیوبه ترتیب ارتفاع و عرض ورودی x به شبکه را نشان می دهد، c تعداد کلاس ها و yمن،کو y^من،کمقادیر واقعی و پیش بینی شده برای پیکسل i هستندایکسمنو کلاس k به ترتیب در بین C کلاس های ممکن مختلف [ 30 ]. کاهش وزن ترکیبی، Lج، به صورت زیر تعریف می شود:
جایی که w1و w2وزن دو شبکه است. این مقادیر به صورت تجربی تعیین می شوند. از آنجا که هدف نهایی این شبکه بهبود دقت تقسیم بندی معنایی تصاویر RS است، وزن شبکه که داده های تصویر RS را مدیریت می کند بیشتر از داده های تصویر طبیعی تنظیم می شود.
2.2. سنجش عملکرد
روش های مختلفی برای ارزیابی دقت تقسیم بندی معنایی وجود دارد. در این مقاله از دقت کلی (OA)، دقت، فراخوانی و امتیاز F1 استفاده شده است. OA نشان دهنده نسبت مشاهدات طبقه بندی شده به درستی نسبت به مقادیر حقیقت پایه است و می توان آن را بر حسب مثبت واقعی (TP)، منفی واقعی (TN)، منفی کاذب (FN) و مثبت کاذب (FP) به صورت توصیف کرد.
OA یک روش ساده و آسان برای ارزیابی دقت طبقه بندی است. با این حال، زمانی که توزیعهای کلاس متفاوت هستند، OA نمیتواند به طور مناسب برای نشان دادن اثربخشی نتایج استفاده شود. درعوض، امتیاز F1 روش بهتری برای ارزیابی نتایج در زمانی که کلاسهای نامتعادل وجود دارد، مشابه مورد ما است. امتیاز F1 (معادله (4)) میانگین هارمونیک دقت و یادآوری است، که به نوبه خود موارد مثبت شناسایی شده به درستی را از همه موارد مثبت پیش بینی شده و واقعی، به ترتیب، همانطور که در معادلات (5) و (6) آورده شده است، اندازه گیری می کند:
3. مجموعه داده ها
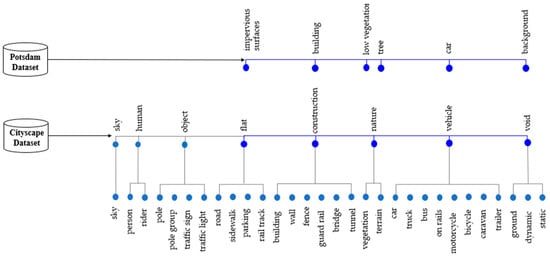
در اینجا، از دو مجموعه داده ناهمگن مختلف برای نشان دادن اثربخشی روش پیشنهادی استفاده میشود. مجموعه داده های ISPRS Potsdam و Cityscape به ترتیب به عنوان مجموعه داده های RS و تصویر طبیعی استفاده می شوند. با توجه به اینکه هدف این مقاله انجام بخشبندی معنایی مؤثر تصاویر RS با استفاده از مجموعه دادههای تصویر طبیعی در مقیاس بزرگ است، دو مجموعه داده با شباهت زیاد بین انواع برچسب دادهها انتخاب شدند، حتی اگر ویژگیهای تصاویر متفاوت باشد. . هر دو مجموعه داده Cityscape و ISPRS Potsdam عمدتاً از تصاویر مناطق شهری تشکیل شدهاند و دارای چندین ویژگی سطح معنایی یکسان مانند جادهها، اتومبیلها و ساختمانها هستند.
3.1. مجموعه داده ISPRS پوتسدام/آلمان
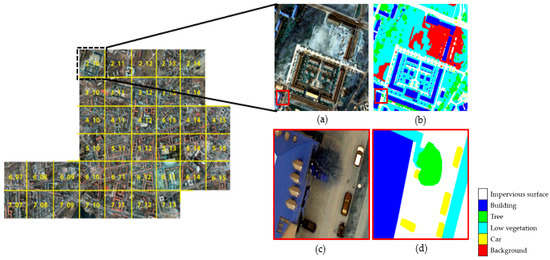
مجموعه دادههای برچسب معنایی ISPRS 2D Potsdam/Germany یک مجموعه داده معیار باز است که به صورت آنلاین ارائه شده است [ 31 ] که حاوی تصاویر هوایی با وضوح بالا با وضوح فضایی 5 سانتیمتر و متشکل از مادون قرمز نزدیک (NIR)، قرمز، آبی و سبز است. تصاویر با مدل های سطح دیجیتال مربوطه. علاوه بر این، حاوی تصاویر حقیقت زمینی است که شامل سطوح غیرقابل نفوذ، ساختمانها، درختان، پوشش گیاهی کم، اتومبیلها و اشیاء ناشناخته است ( شکل 3 ).
مجموعه داده 2 بعدی پوتسدام شامل 38 وصله است. تنها 24 تصویر با تصاویر برچسب گذاری مربوطه برای آموزش و اعتبار سنجی استفاده شد. جدول 1 شماره پچ داده های برچسب گذاری شده را نشان می دهد. بیست و چهار تصویر بزرگ چندطیفی با اندازه 6000×6000×4پیکسل ها با فرمت tiff به عنوان ورودی استفاده شدند. از آنجایی که اندازه تصاویر ISPRS بسیار بزرگ است، برش هایی از 256×256×4پیکسل های دارای برچسب استخراج شدند، به دسته ها جدا شدند و سپس ذخیره شدند. ما شبکه را تنها با استفاده از زیرمجموعه ای از تصاویر فرعی آموزش دادیم تا مواردی را در نظر بگیریم که داده های تصویر RS محدود است.
3.2. مجموعه داده Cityscape
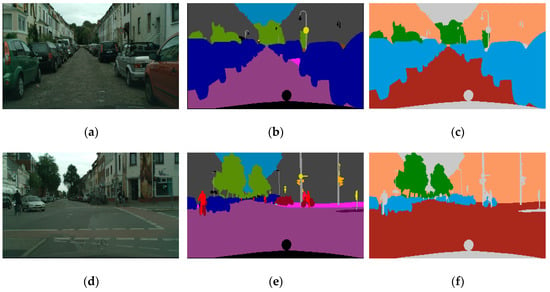
Cityscape مجموعه بزرگ و متنوعی از توالیهای ویدئویی استریو را ارائه میکند که از خیابانهای 50 شهر مختلف با تصاویر واقعی در سطح پیکسل کدگذاری شدهاند [ 7 ]. این مجموعه داده بزرگ صحنه جاده است که می تواند درک معنایی صحنه های خیابان شهری را ارائه دهد. Cityscape 19 برچسب معنایی حاوی کلاس “void” برای مناطق “do-not-care” تعریف می کند. شکل 4 a,d چند نمونه از تصاویر Cityscape را نشان می دهد و شکل 4 b,e تصاویر برچسب مربوطه آنها را نشان می دهد. جدول 2 برچسب های معنایی مجموعه داده Cityscape را نشان می دهد.
برای بهبود کارایی عملکرد روش پیشنهادی با به حداقل رساندن تفاوت بین دو مجموعه داده، چندین مرحله پیش پردازش به کار گرفته شد. به عنوان مثال، در مورد مجموعه داده Cityscape، که جزئیات سطح معنایی عمیقتری نسبت به مجموعه داده ISPRS Potsdam دارد، کلاسهای نهایی برای مطابقت با مجموعه دادههای پوتسدام تنظیم شدند (شکل 5 ) . بنابراین، کلاسهای نهایی مجموعه داده Cityscape شامل مناطق مسطح، ساختوساز، طبیعت، وسایل نقلیه و فضاهای خالی بود. علاوه بر این، تمام مواردی که در کلاس های نهایی فوق گنجانده نشده بودند، مجدداً به عنوان باطل طبقه بندی شدند. جدول 3 رابطه بین کلاس های اصلی و نهایی در مجموعه داده Cityscape را نشان می دهد و شکل 4 c,f نقشه های برچسب کلاس های نهایی را نشان می دهد که به ترتیب نشان داده شده است.شکل 4 a,d. علاوه بر این، برای به اشتراک گذاشتن بلوکهای کدگذاریشده مدل ترکیبی U-net، تنها باندهای قابل مشاهده مجموعه داده ISPRS Potsdam استفاده شد زیرا Cityscape فقط از این باندها تشکیل شده است.
4. شرایط آزمایشی
برای نشان دادن اثربخشی روش پیشنهادی، چندین آزمایش برای مقایسه نتایج تقسیمبندی تصاویر پوتسدام انجام شد. SegNet، DeepLab-V3+، و U-net ساده شده، که مسیر تصویر RS را در مدل U-net ترکیبی دنبال میکردند، برای تقسیمبندی مجموعه داده پوتسدام با چهار باند اصلی آن استفاده شد. علاوه بر این، مجموعه داده پوتسدام تنها با باندهای RGB با استفاده از مدل U-net ساده شده برای مقایسه با مدل U-net ترکیبی، که فقط با باندهای RGB در تصاویر پوتسدام برای به اشتراک گذاشتن لایههای کانولوشنال سروکار دارد، آموزش داده شد. ما به طور تصادفی زیر مجموعه ای از تصاویر را از مجموعه داده پوتسدام برای آموزش شبکه ها انتخاب کردیم. به طور خاص، 1600 تصویر به عنوان داده آموزشی و 400 و 150 تصویر به ترتیب به عنوان داده های اعتبار سنجی و آزمون استفاده شد. سرانجام، مدل ترکیبی U-net مجموعه داده پوتسدام را با دو شرایط مختلف آموزش داد. در مورد 1، از همان تعداد مجموعه داده آموزشی از مجموعه داده Cityscape استفاده شد. علاوه بر این، ما تعداد تصاویر Cityscape را برای تأیید تأثیر اندازه مجموعه داده Cityscape هنگام آموزش با استفاده از مدل ترکیبی U-net تغییر دادیم. در مورد 2، 3000، 550 و 300 تصویر از مجموعه داده Cityscape به ترتیب به عنوان داده های آموزشی، اعتبار سنجی و آزمون استفاده شد. علاوه بر این، برای ارائه وزن های بزرگتر به مجموعه داده پوتسدام، اعتبارسنجی و داده های آزمایشی به ترتیب. علاوه بر این، برای ارائه وزن های بزرگتر به مجموعه داده پوتسدام، اعتبارسنجی و داده های آزمایشی به ترتیب. علاوه بر این، برای ارائه وزن های بزرگتر به مجموعه داده پوتسدام، w1(وزن از دست دادن در مسیر تصویر RS) و w2(وزن کاهش در مسیر تصویر طبیعی) به ترتیب 0.8 و 0.2 تعیین شد.
مدل ترکیبی U-net بر روی پلت فرم رایگان Google Colaboratory (Colab) آموزش داده شد [ 32 ]. دوره آخر با نرخ یادگیری 1000 سال آدم تعیین شد 10-3. با توجه به حافظه موجود در Colab، اندازه دسته روی 4 تنظیم شد. اندازه دو ورودی یکسان بود (256 ×256 ×3)؛ بنابراین، میتوانیم وزنها را در لایههای اولیه به اشتراک بگذاریم. علاوه بر این، 256 ×256 ×3 در هنگام استفاده از منابع آموزشی محدود مانند RAM و GPU اندازه مناسبی است. بنابراین اصل 6000 ×6000 ×4 تصویر پوتسدام به نمونه های کوچکتر 256 تقسیم شدند ×256 ×3، و تصاویر Cityscape به 256 تغییر مقیاس داده شدند ×256 ×3. به طور خاص، در مسیر دوم U-Net ترکیبی، به عنوان شش بلوک رمزگشایی پایان یک نقشه ویژگی به اندازه 1024 خروجی می شود. ×2048 ×16، این نقشه ویژگی با استفاده از 1 اسکن شد ×1 فیلتر کانولوشن دو بعدی برای تولید نقشه های خروجی با اندازه 1024 ×2048 ×5 برای مطابقت با شکل برچسب ها. ما تصاویر برچسب را تغییر مقیاس ندادیم تا اندازه تصاویر ورودی را به دست آوریم زیرا تغییر مقیاس منجر به از دست رفتن اطلاعات کلاس می شود که به نوبه خود خروجی تحریف شده ای را به همراه خواهد داشت. بنابراین، ما تصمیم گرفتیم خروجی مسیر Cityscape را با اندازه اندازه برچسب اصلی (یعنی 1024) مطابقت دهیم. ×2048) برای دست نخورده نگه داشتن اطلاعات کلاس.
5. نتایج
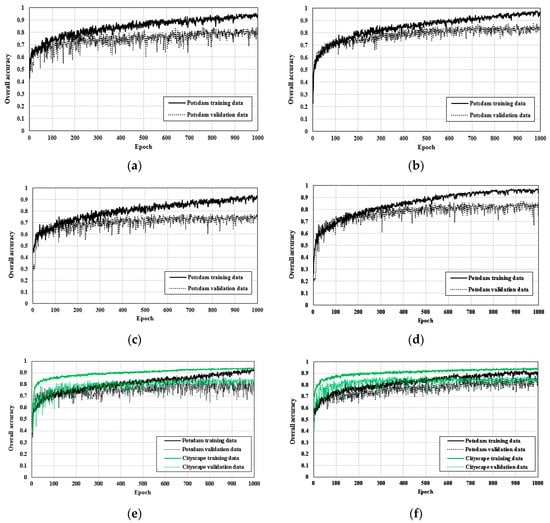
شکل 6 نمودارهای یادگیری OA مجموعه های آموزشی و اعتبار سنجی را برای شش مورد فوق الذکر نشان می دهد. از آنجایی که تعداد محدودی از تصاویر برای آموزش استفاده شد، تفاوتی در OA بین مجموعه آموزشی و اعتبارسنجی وجود داشت. هنگامی که یک مدل دارای آموزش بالا و دقت اعتبار پایین است، این مورد احتمالا به عنوان overfitting شناخته می شود. از آنجایی که تنها بخشی از مجموعه داده پوتسدام برای آموزش استفاده شد، داده های آموزشی ناکافی گاهی اوقات می تواند منجر به مشکلات بیش از حد برازش شود [ 33 ]. DeepLab-V3+ OA بالاتری را برای مجموعه اعتبار سنجی در مقایسه با SegNet و مدل های U-net ساده شده نشان داد ( شکل 6ب). همچنین، تفاوت در OA بین مجموعه های اعتبار سنجی و آموزشی کمتر از زمانی بود که از مدل SegNet استفاده می شد. در مورد مدل U-net ساده شده، زمانی که آموزش فقط با استفاده از باندهای RGB تصاویر پوتسدام انجام میشد، OA مجموعه اعتبارسنجی کمتر از زمانی بود که از چهار باند اصلی استفاده میشد (شکل 6 c,d ) . همچنین نمودار یادگیری مدل U-net ساده شده تصاویر پوتسدام آموزشی با چهار باند آن نشان داد که OA مجموعه آموزشی بالاتر از دو حالت دیگر با مدل های ترکیبی U-net است. با این حال، OA مجموعه اعتبار سنجی نسبتا کمتر از مجموعه آموزشی بود.
هنگام مقایسه بین آموزش مدل U-net ساده شده با چهار باند اصلی و Case 1 در مدل ترکیبی، می توان دریافت که OA مجموعه های اعتبار سنجی هر دو مشابه است، اما OA های مجموعه آموزشی در مورد 1 کمتر بود. نسبت به مدل های ساده شده U-net ( شکل 6 d,e). اگرچه مدل ترکیبی U-net مورد استفاده برای Case 1 مجموعه داده های Potsdam و Cityscape را با هم آموزش داد، اما فقط از تصاویر RGB از داده های Potsdam استفاده کرد. در مقابل، مدل U-net ساده شده همچنین از باند NIR دادههای پوتسدام به جای استفاده از باندهای RGB استفاده کرد، که به طبقهبندی معنادار اشیایی مانند درختان و پوشش گیاهی کم که بهویژه در طول موجهای NIR برجسته هستند، کمک کرد.
در مورد 2 از مدل ترکیبی U-net، که در آن اندازه مجموعه داده Cityscape نسبت به مورد 1 افزایش یافته بود، OAs مجموعه های آموزشی و اعتبار سنجی نسبت به مورد 1 بیشتر بهبود یافته است. اگرچه OA داده های آموزشی در Case 2 کمتر از DeepLab-V3+ و U-net ساده شده بود، شکاف در آموزش و دقت اعتبار سنجی کاهش یافت. با افزایش مقدار داده در مجموعه داده Cityscape، مشکل بیش از حد برازش به طور موثر کاهش یافت. برای OAهای مجموعه داده Cityscape در مورد 1 و مورد 2، آنها تمایل مشابهی را نشان دادند. علاوه بر این، با افزایش مقدار داده ها، دقت اعتبار مجموعه داده Cityscape بهبود یافت.
جدول 3 میانگین نمرات F1 پنج کلاس و OA مجموعه آزمون را برای شش مدل نشان می دهد. OAهای SegNet، DeepLab-V3+، مدلهای U-net ساده شده با دو مورد، و مدلهای U-net ترکیبی با دو مورد، به ترتیب 0.8346، 0.8605، 0.8477، 0.7841، 0.8268 و 0.8721 هستند. در میان مدلهای تک، OA DeepLab-V3+ بالاترین بود و مورد 2 از مدل ترکیبی U-net پیشنهادی OA بالاتری نسبت به DeepLab-V3+ داشت. مدل U-net ساده شده آموزش داده شده تنها با استفاده از باندهای RGB تصاویر پوتسدام دارای کمترین OA بود.
علاوه بر این، در U-net ساده شده آموزش داده شده با استفاده از چهار باند اصلی، امتیاز F1 کلاس های سطح نفوذناپذیر، ساختمان، پوشش گیاهی کم، درخت و خودرو به ترتیب 0.8623، 0.8535، 0.8205، 0.8457 و 0.8123 است. اگرچه مورد 1 در مدل ترکیبی U-net نمرات F1 بالاتری را برای کلاسهای سطح غیرقابل نفوذ و ساختمان نشان داد، اما امتیازات F1 پایینتری را برای کلاسهای پوشش گیاهی و درخت نشان داد. به طور خاص، Case 2 در مدل ترکیبی U-net نمرات F1 بالاتری را برای سطوح غیرقابل نفوذ، ساختمان و کلاس خودرو به نمایش گذاشت. مرزهای جاده و شکل خودرو در مورد 2 به خوبی پیشبینی شده بود. به منظور تجزیه و تحلیل بصری نتایج تقسیمبندی هنگام استفاده از مدل ترکیبی U-net به جای استفاده از مدل U-net ساده شده، سایتهایی را انتخاب کردیم که میتوانند ویژگیهای سه مورد را نشان دهند. موارد به عنوان مثال،شکل 7 . در مدل ساده شده U-net آموزش داده شده با چهار باند اصلی، خطاهایی در طبقه بندی جاده ها و ساختمان ها وجود داشت. با این حال، در مقایسه با موارد 1 و 2، طبقات کم پوشش گیاهی و درختان به طور موثری متمایز شدند ( شکل 7 a-j). در مورد 1، مواد روی سقف به اشتباه به عنوان خودرو طبقه بندی شدند زیرا شکل و رنگ آنها مشابه بود ( شکل 7 k-o). مورد 2 بیشترین کارایی را در طبقه بندی ساختمان ها و جاده ها نشان داد. با این حال، نمی تواند به وضوح بین درختان و پوشش گیاهی کم تمایز قائل شود ( شکل 7 k-u).
6. بحث
6.1. مقایسه با سایر الگوریتم ها
در بین مدلهای تک، مدل DeepLab-V3+ دارای OAهای تقسیمبندی بالاتری برای تصاویر پوتسدام نسبت به SegNet و مدلهای U-net سادهشده بود. به طور خاص، مدل U-net ساده شده کمترین OA را در بین سایر شبکه ها در مقایسه با زمانی که فقط با تصاویر RGB آموزش می دید، داشت. این به این دلیل است که دقت تقسیم بندی درخت و طبقات کم پوشش گیاهی هنگام تمرین بدون باند NIR کاهش می یابد. در این زمینه، اگرچه مجموعه داده پوتسدام با استفاده از مجموعه دادههای Cityscape با اندازه یکسان در مورد 1 آموزش داده شد، امتیازات OA و F1 کلاسهای پوشش گیاهی، درختان و خودروها در مقایسه با DeepLab-V3+ و U-net ساده شده، هیچ پیشرفتی نشان ندادند. نتایج نشان میدهد که آموزش با استفاده از دادههای پوتسدام در چهار باند اصلی آن در طبقهبندی کلاسهای گیاهی مؤثرتر از استفاده از باندهای RGB است. این به این دلیل است که نوار NIR یک نوار کلیدی برای طبقه بندی درختان و پوشش گیاهی کم است. علاوه بر این، چندین درخت و پوشش گیاهی کم با بازتاب کم رنگهای مشابهی با سطوح زمینی و غیرقابل نفوذ در تصاویر RGB داشتند. با این حال، دقت تقسیم بندی معنایی با افزایش اندازه مجموعه داده Cityscape هنگام آموزش با استفاده از مدل ترکیبی U-net بهبود یافت. به ویژه، امتیازات F1 سطوح غیرقابل نفوذ، ساختمان ها و اتومبیل ها در مورد 2 نسبت به شبکه های دیگر بهبود یافت. علاوه بر این، هنگام آموزش پوتسدام با استفاده از مجموعه داده Cityscape، مشکل اضافه برازش کاهش یافت. این به این دلیل است که اگرچه جادهها، ماشینها و ساختمانهای مختلفی در مجموعه دادههای Cityscape وجود دارد و زاویه عکسبرداری و شکلها نسبت به چنین اشیایی در تصاویر پوتسدام متفاوت است.
6.2. تأثیر مجموعه داده های شهری
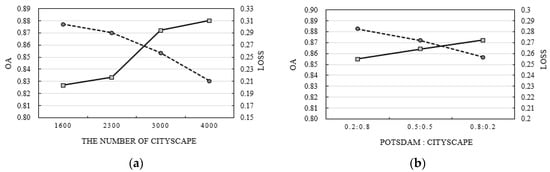
با مقایسه نتایج مورد 1 و مورد 2، تأیید شد که مدل ترکیبی U-net تحت تأثیر تعداد مناظر شهری قرار گرفته است. ما تعداد داده های آموزشی Cityscape را تغییر دادیم و مقادیر وزن مجموعه داده های Potsdam و Cityscape را تغییر دادیم ( w1و w2) ( شکل 8 ). هنگامی که همان تعداد مجموعه داده پوتسدام استفاده شد. به عنوان مثال، 1600 تصویر به عنوان داده آموزشی و 400 و 150 تصویر به ترتیب به عنوان داده های اعتبار سنجی و آزمون استفاده شد، که دقت داده های آزمون پوتسدام با افزایش داده های آموزشی Cityscape بهبود یافت. به طور خاص، زمانی که تعداد تصاویر Cityscape حدود 2500-2900 بود، OA مدل ترکیبی U-net شبیه به مدل های منفرد مانند SegNet، U-net ساده شده، و DeepLab-V3+ شد و تعداد تصاویر منظره شهری 3000 بود که تقریباً دو برابر مجموعه داده پوتسدام است، بنابراین OA به طور چشمگیری افزایش یافت ( شکل 8 a).
در آزمایشها، برای دادن وزنهای بزرگتر به مجموعه داده پوتسدام، w1و w2به ترتیب روی 0.8 و 0.2 ثابت شدند. ما اثر مقادیر وزن را از طریق یک آزمایش بررسی کردیم، که در آن w1روی 0.2 تنظیم شد و w2روی 0.8 تنظیم شد که در آن وزن دو مجموعه داده یکسان بود. در این مورد، تعداد مجموعه داده های Potsdam و Cityscape مانند مورد 2 مدل ترکیبی U-net بود. در نتیجه، با کاهش وزن مجموعه داده پوتسدام، OA مجموعه تست کاهش یافت. این به این دلیل است که ضرر ناشی از مجموعه داده پوتسدام در هنگام آموزش مدل ترکیبی U-net کمتر منعکس شد ( شکل 8 ب). به ویژه، زمانی که w1و w2به ترتیب روی 0.2 و 0.8 تنظیم شدند، OA کمتر از مدل DeepLab-V3 + بود.
6.3. محدودیت ها و کار آینده
اگرچه مدل ترکیبی U-net میتواند مجموعه دادههای ناهمگن را آموزش دهد، ساختار شبکه آن نسبتاً پیچیده است و در مقایسه با یادگیری شبکه با یک مجموعه داده واحد، انجام فرآیندهای یادگیری زمان زیادی طول میکشد. به عنوان مثال، هنگام آموزش مدل ترکیبی U-net در Google Colab، زمانی که اندازه دسته بیش از 4 (8 یا 16) تعیین شده بود، با مشکل حافظه مواجه شدیم. علاوه بر این، محدودیتی در این که عملکرد مدل ترکیبی U-net با توجه به تعداد مناظر شهری و مقادیر وزن تغییر میکرد، وجود داشت.
علاوه بر این، از آنجایی که تصاویر RS به طور کلی دارای بیش از چهار باند، از جمله باند NIR هستند، عدم استفاده از باندهای اضافی برای یادگیری با تصاویر RGB طبیعی می تواند دقت تقسیم بندی کلاس های مربوط به پوشش گیاهی را کاهش دهد. برای غلبه بر این محدودیتها، کار آینده برای توسعه روشی مورد نیاز است که میتواند بهطور مؤثر باند NIR تصاویر RS را در حین یادگیری با تصاویر RGB طبیعی در بر گیرد. علاوه بر این، برای بررسی تأثیر معماری مدل ترکیبی U-Net، ما قصد داریم ببینیم که چگونه OA مجموعه داده پوتسدام با تغییر فاز مشترک در بخش رمزگذار و رمزگشای مدل ترکیبی U-net تغییر میکند (مثلاً ، رمزگذار غیر اشتراکی و رمزگشای مشترک).
7. نتیجه گیری
در این مقاله، ما مدل ترکیبی U-net را پیشنهاد کردیم که میتواند تصاویر RS را با استفاده از مجموعه دادههای تصویر طبیعی آموزش دهد. شبکه متشکل از بلوکهای رمزگذار و رمزگشا، و بلوکهای رمزگذار با دو مجموعه داده مختلف (Potsdam و Cityscape) به اشتراک گذاشته شدند. شبکه با استفاده از تابع کاهش وزن ترکیبی به روز شد. نتایج بهدستآمده از آزمایشها نشان داد که هنگام آموزش با استفاده از دادههای پوتسدام با اندازه یکسان با باندهای RBG و دادههای Cityscape، OA در مقایسه با آموزش مدلهای منفرد با استفاده از دادههای اصلی پوتسدام کاهش مییابد. با این حال، دقت مجموعه داده پوتسدام با افزایش اندازه مجموعه داده Cityscape بهبود یافت. این نتایج نشان می دهد که استفاده از یک مجموعه داده تصویر طبیعی در مقیاس بزرگ می تواند دقت تقسیم بندی معنایی مجموعه داده تصویر RS را با استفاده از روش پیشنهادی بهبود بخشد. روش پیشنهادی میتواند مشکل مجموعه دادههای تصویر RS به اندازه کافی برای تقسیمبندی معنایی را حل کند. علاوه بر این، این مطالعه امکان یادگیری مجموعه دادههای ناهمگن را همزمان با به اشتراک گذاشتن فاز رمزگذار و وزنهای تولید شده از دو مجموعه داده در شبکههای یادگیری عمیق تأیید میکند. انتظار میرود که این رویکرد نه تنها برای وظایف تقسیمبندی تصاویر هوایی بلکه برای کارهایی با اهداف مختلف استفاده از مجموعه دادههای ناهمگن بزرگ نیز اعمال شود. به عنوان مثال، هنگام استفاده از تعداد نسبتاً محدودی از مجموعه دادهها مانند پلانهای طبقه جدید و تصاویر نمای خیابان در وبسایتها برای کارهای ویژه مانند طبقهبندی و تشخیص اشیا، مجموعه دادههای بزرگ،
با این حال، بار محاسباتی روش پیشنهادی نسبتاً زیاد است زیرا مدل ترکیبی U-net مجموعههای داده ناهمگن را در همان زمان آموزش میدهد. علاوه بر این، دقت تقسیم بندی را می توان با توجه به تعداد مجموعه داده های Cityscape و مقادیر وزن بین Potsdam و Cityscape تغییر داد. همچنین مشکلی وجود داشت که اطلاعات ارائه شده توسط باند NIR قابل استفاده نبود زیرا فقط از باندهای RGB استفاده می شد. برای کار آینده، هدف ما بهبود ساختار مدل ترکیبی U-net با انجام آزمایشهایی در رابطه با گنجاندن اطلاعات باند NIR مجموعه داده پوتسدام است.





بدون دیدگاه