

خلاصه
فناوریها در سرتاسر جهان دادههای مکانی را فوراً تولید میکنند و با آنها تعامل دارند، از برنامههای کاربردی وب تلفن همراه گرفته تا تصاویر ماهوارهای که روزانه در سراسر جهان جمعآوری و پردازش میشوند. دادههای شطرنجی بزرگ به محققان اجازه میدهد تا دانش جدید در مورد الگوها و فرآیندهای جغرافیایی را ادغام و کشف کنند. با این حال، ما در یک لحظه حساس هستیم، زیرا تعداد پلتفرمهای کلان داده در حال افزایشی داریم که برای پشتیبانی از تحلیل فضایی انتخاب میشوند. یک شکاف در ادبیات فقدان یک ارزیابی قوی برای مقایسه کارایی تجزیه و تحلیل دادههای شطرنجی بر روی پلتفرمهای کلان داده است. این تحقیق پرداختن به این موضوع را با ایجاد یک معیار داده شطرنجی آغاز میکند که از مجموعه دادههای قابل دسترسی آزاد استفاده میکند تا یک ارزیابی عملکرد جامع و مقایسه عملیات شطرنجی بر روی پلتفرمهای کلان داده ارائه دهد. این معیار برای ارزیابی عملکرد عملیات فضایی بر روی پلتفرم های کلان داده حیاتی است. مجموعه داده ها و عملیات محک زدن در سه پلتفرم کلان داده اعمال می شود. ما زمانهای محاسباتی و تنگناهای عملکرد را گزارش میکنیم تا دانشمندان GIS بتوانند انتخابهای آگاهانهای در مورد عملکرد هر پلتفرم داشته باشند. هر پلتفرم برای پنج عملیات شطرنجی ارزیابی میشود: تعداد پیکسل، طبقهبندی مجدد، افزودن شطرنجی، میانگینگیری کانونی و آمار منطقهای با استفاده از سه مجموعه داده شطرنجی مختلف.
کلید واژه ها:
جغرافیایی ; محاسبه ; معیار فضایی ; سایبرگیس
1. معرفی
ما در عصر داده های شطرنجی بزرگ هستیم. Planet که قبلاً Planet Labs نام داشت دارای مجموعه ای متشکل از 200 ماهواره است که روزانه 1.4 میلیون تصویر را جمع آوری می کند [ 1 ]. تصاویر ماهوارهای یا دادههای رصد زمین سالانه پتابایت داده تولید میکنند، و سازمانهایی مانند پانل بیندولتی تغییرات آب و هوا (IPCC) مجموعههای داده شطرنجی شبیهسازیشدهای را تولید میکنند که چندین پتابایت هستند [2 ] .
حجم دادههای موجود برای محققان زمینفضایی در حال رشد است، با این حال ما مجموعهای استاندارد از ابزارها و بهترین شیوهها برای دسترسی، دستکاری، و انجام تحلیلها بر روی دادههای بزرگ جغرافیایی نداریم. در حال حاضر، محققان در حال توسعه راههای جدیدی برای دانلود دادهها در ایستگاههای کاری خود برای انجام تحلیلهای خود هستند. اتکا به این گردش کار، توانایی مقیاسسازی تحلیلهای مکانی در مجموعه دادههای بزرگ را کاهش میدهد. با این حال، لازم است زیرا داده های مکانی متفاوت است. مقادیر داده های مکانی به صورت مجزا رخ نمی دهند و این مقادیر باید در زمینه مقادیر همسایه خود در نظر گرفته شوند. تحقیق ما بررسی میکند که آیا پلتفرمهای کلان داده که از دادههای مکانی پشتیبانی میکنند، هزینههای عملکرد محاسباتی متفاوتی را برای حفظ آن روابط متحمل میشوند یا خیر.
1.1. داده های بزرگ جغرافیایی
GIScience فناوری جدیدی را برای پشتیبانی از حل مسائل جغرافیایی انتخاب کرده است. به طور خاص، ظهور پلت فرم های توزیع شده، محاسبات فضایی موازی را تسهیل کرده است. به طور کلی، در حال حاضر سه نوع معماری دادههای بزرگ وجود دارد که از دادههای مکانی بزرگ پشتیبانی میکنند: پایگاههای داده موازی، پایگاههای داده No-SQL، و خانواده پلتفرمهای مبتنی بر Hadoop که کاهش نقشه را در حافظه (Spark) یا روی دیسک (Hadoop) پیادهسازی میکنند. . هاینز [ 3 ] شرح کاملی از معماری های پلتفرم ارائه می دهد که از داده های شطرنجی از جمله PostgreSQL، SciDB، RasDaMan، Hadoop-GIS، SparkArray و GeoTrellis پشتیبانی می کنند.
در حالی که تعدادی پلتفرم وجود دارند که از داده های شطرنجی پشتیبانی می کنند، شواهد کمی برای توصیف قابلیت ها و عملکرد اپراتورهای تجزیه و تحلیل فضایی بر روی پلت فرم های کلان داده وجود دارد. این مشکل ساز است زیرا نیاز است که جامعه GIScience بتواند از این پلتفرم ها برای پردازش داده های شطرنجی بزرگ استفاده کند. از نظر تئوری، مجموعه داده هایی که در حافظه قرار می گیرند باید با پلتفرم های درون حافظه مانند Apache Spark عملکرد خوبی داشته باشند. با این حال، مقالات اخیر نشان دادهاند که عملیات فضایی و مکانی به عملکرد بهینه بر روی پلتفرمهای مختلف میرسند [ 4 ، 5]]. عملکرد عملیات شطرنجی به اندازه کافی در جامعه کلان داده پرداخته نشده است. در عوض، ادبیات پیرامون پلتفرمهای داده شطرنجی بزرگ دارای سه موضوع است: (1) پیادهسازی جدید، (2) پیادهسازی علم حوزه، و (3) بررسیهای فراخوان.
1.2. پیاده سازی های رمان
مشخصههای پیادهسازی جدید، گسترش یک پلتفرم جدید برای پشتیبانی از دادهها و روشهای مکانی است. نمونه هایی از این پالاموتام [ 6 ] و وانگ [ 7 ] هستند که کتابخانه های آرایه ای چند بعدی را برای آپاچی اسپارک توسعه دادند. لی و همکاران [ 8 ]، FASTDB، یک پایگاه داده آرایه توزیع شده را توسعه دادند. سایر گروه های تحقیقاتی SciDB را برای حمایت از تحلیل فضایی گسترش داده اند [ 9 ، 10 ، 11 ]. این مقالات بر مشکلات خاص تمرکز دارند، موارد استفاده کوچکی دارند و بر روی مجموعه دادههای خاص پیادهسازی میشوند. در مقایسه با یک معیار، پیاده سازی آنها بسیار خاص است و نمی تواند توسط جامعه گسترده تر ترجمه یا اتخاذ شود.
1.3. پیاده سازی علوم دامنه
پیاده سازی های علم دامنه بر توسعه یک گردش کاری فضایی در یک پلت فرم داده های بزرگ تمرکز دارند. این کار یک نیاز حیاتی در ادبیات را برآورده میکند زیرا کاربرد کلی پلتفرم را نشان میدهد [ 12 ، 13 ، 14 ، 15 ]. در حالی که این مقالات به طور گسترده برای درک توانایی یک پلتفرم خاص مفید هستند، در مقایسه با یک معیار، توانایی آنها برای مقایسه گردش کار در بین پلتفرم ها محدود است.
1.4. بررسی های متا
بررسیهای متا پلتفرمها و قابلیتهای آنها را مورد بحث قرار میدهند [ 16 ، 17 ، 18 ، 19 ، 20 ]. این مقالات به سمت گستردهترین جوامع متمرکز شدهاند و بر قابلیتهای پلتفرم تمرکز دارند نه عملکرد پلت فرم. آنها جهت ها و روندهایی را که در افق هستند توصیف می کنند و نشان می دهند که چگونه اتخاذ آنها می تواند اهداف بزرگتری را در جامعه گسترده تر برآورده کند. با این حال، این موارد نیز در مقایسه با یک معیار محدود هستند زیرا هیچ نتیجه ای برای مقایسه سیستم های مختلف ارائه نمی دهند.
1.5. نیاز به یک معیار جغرافیایی
یک شکاف در جامعه محاسباتی با عملکرد بالا، فقدان یک معیار شطرنجی است که امکان ارزیابی عملگرهای فضایی را در سراسر پلتفرمها فراهم میکند. Ray و همکاران [ 21 ] یک معیار “Jackpine” برای داده های برداری ایجاد کردند. Jackpine نه عملیات تحلیل فضایی و پنج رابطه توپولوژیکی را روی سه نوع داده برداری اجرا کرد: نقطه، خطوط و چند ضلعی. رابل و همکارانش [ 22 ] محک زدن را برای پایگاه داده های آرایه ای پیاده سازی کردند اما فقط بارگذاری داده ها و عملگرهای زیرمجموعه آرایه را آزمایش کردند. بنابراین، یک معیار فضایی برای آزمایش عملگرهای شطرنجی مورد نیاز است. این معیار با ارائه مجموعه دادههای مرجع و روشهایی که محققان میتوانند برای مقایسه استفاده کنند، به جامعه مکانی کمک میکند.
این تحقیق در جهت ایجاد یک معیار شطرنجی کار خواهد کرد که ابزاری برای مقایسه دقیق عملکرد تحلیل فضایی شطرنجی بر روی داده های بزرگ فراهم می کند. معیار ما عملکرد عملیات محلی، کانونی و منطقه ای را در هر پلت فرم بررسی می کند. در حالی که آزمایش هر عملیات بالقوه غیرممکن است، معیار ما پنج اپراتور را بررسی می کند که موارد استفاده گسترده ای دارند. علاوه بر این، معیار عملکرد سیستم را با ویژگی های حجم و تنوع ارزیابی می کند.
معیار جغرافیایی بینش هایی را در مورد پیچیدگی انجام تجزیه و تحلیل فضایی داده های بزرگ ارائه می دهد. این معیار برای (1) شناسایی مسائل مربوط به عملکرد اپراتور، (2) تعیین اینکه آیا دلایل زمینهای مربوط به معماری یا پیادهسازی است یا خیر، و (3) شناسایی مناطقی که در آن تحقیقات مورد نیاز است، مورد نیاز است.
2. Raster Big Data Benchmark
معیارها به عنوان مجموعه داده، پلت فرم(ها) و مجموعه ای از عملیات تعریف می شوند. تعریف معیار شطرنجی مشابه است. ابتدا مجموعه داده را با یک وسعت فضایی ثابت تعریف می کنیم. از آنجایی که هیچ مقاله منتشر شده قبلی در مورد معیارهای شطرنجی وجود ندارد، ما از مجموعه داده های متعدد با وضوح فضایی افزایش یافته برای تعیین عملکرد هر پلت فرم استفاده کردیم. ما از سه پلتفرم مختلف در این تحلیل استفاده کردیم و سه مورد از عملیات فضایی اصلی مورد استفاده در تحلیلهای شطرنجی را به کار بردیم. ما سه پلتفرم کلان داده را انتخاب کردیم که در ادبیات مستند شده اند و از معماری های مختلف استفاده می کنند. سه پلتفرم انتخاب شده PostGIS در PostgreSQL، SciDB و GeoTrellis در Apache Spark هستند.
2.1. داده ها
ما از سه مجموعه داده مختلف در تجزیه و تحلیل خود استفاده کردیم ( جدول 1 ). هر یک از این مجموعه دادههای در دسترس عموم به گستره فضایی قاره ایالات متحده بریده شد. هر مجموعه داده مورد استفاده در این تجزیه و تحلیل از طبقهبندیهای کاربری زمین/پوشش زمین از قبل تعریف شده استفاده میکند. آنها به دلیل در دسترس بودن و استفاده گسترده آنها در برنامه های کاربردی جغرافیایی انتخاب شدند. ما سه مجموعه داده مختلف را انتخاب کردیم که نشان دهنده افزایش سطح دانه بندی فضایی است. جدول 1 تعداد پیکسل های موجود در هر مجموعه داده را گزارش می کند. جدول 1 باید توسط محققان زمین فضایی به عنوان راهنمایی برای مقایسه پروژه خود و تعیین سطوح عملکردی که باید بر اساس پلت فرمی که انتخاب کرده اند، مورد استفاده قرار گیرد.
برای محک زدن عملیات منطقه ای، ما همچنین سه مجموعه داده برداری از قاره ایالات متحده را گنجانده ایم. ما از مرزهای نقشه برداری ایالت، شهرستان و سرشماری از ایالات متحده استفاده کردیم ( جدول 2 ). همه مجموعههای داده دارای وسعت مکانی یکسان هستند و تنها تفاوت آنها در تعداد ویژگیهای موجود در مجموعه داده است. GeoTrellis فایلهای شکل را نمیخواند، بنابراین مجموعه دادهها به نمادگذاری شی جاوا اسکریپ جغرافیایی (GeoJSON) تبدیل شدند.
2.2. پارتیشن بندی فضایی
مانند تمام پلتفرم های کلان داده، پارتیشن بندی داده ها یک مرحله مهم و ضروری است. پارتیشن بندی داده ها، به ویژه، برای پلتفرم های کلان داده بسیار مهم است، زیرا یکی از راه های تنظیم پلت فرم با سخت افزار و داده است. در این تحقیق، ما پلتفرم ها را با استفاده از مجموعه ای تعریف شده از اندازه های پارتیشن داده تنظیم کردیم. اصطلاح اندازه کاشی برای تعیین طرح پارتیشن بندی شطرنجی استفاده می شود. اندازه کاشی 50 به این معنی است که 2500 پیکسل (50 × 50) در یک پارتیشن از داده ها وجود دارد. اندازههای کاشی در سراسر پلتفرمها برای مقایسه عملکرد استاندارد شدند. هر پلت فرم در یک سری از اندازههای کاشی که بهینه یا کمتر از حد مطلوب بود، ارزیابی شد. همه پلتفرمها با تمام اندازههای کاشی مقایسه نشدند، به دلیل مشکلات بارگذاری دادهها.
2.3. عملیات فضایی
تجزیه و تحلیل ما بر سه دسته از عملیات شطرنجی متمرکز است: محلی، کانونی و ناحیه ای. جدول 3 شرحی از نحوه ترجمه و اجرای هر پلت فرم و عملگرهای فضایی آن بر روی مجموعه داده داده شده ارائه می دهد. دو نوع ارزیابی وجود دارد: تنبل و مشتاق. ارزیابی مشتاق، که از لحاظ تاریخی رایجتر بوده است، اپراتوری است که تجزیه و تحلیل را بر روی مجموعه داده انجام میدهد. پلتفرمهای جدیدتر از ارزیابی تنبلی استفاده میکنند که تنها زمانی روی دادهها عمل میکند که نتیجه آن عملیات مورد نیاز باشد. با این حال، این باعث می شود مقایسه بین پلتفرم هایی با ارزیابی های مختلف پیچیده شود. بنابراین، هنگامی که یک پلتفرم تنبل ارزیابی میشود، یک مرحله اضافی، تعداد پیکسلها را اضافه میکنیم که ارزیابی را مجبور به تکمیل میکند. روش مشتاق برای اطمینان از سازگاری در بین پلتفرم های داده استفاده شد.
2.4. عملیات محلی
عملیات شطرنجی محلی بدون اشاره به سلول های اطراف آنالیز را بر روی هر سلول به صورت جداگانه انجام می دهد. این نوع عملیات خود را به موازی سازی می رساند زیرا مجموعه داده پس از تقسیم بندی می تواند به طور مستقل بر روی آن کار کند. در معیار خود، از تعداد پیکسل، طبقهبندی مجدد و افزودن شطرنجی استفاده کردیم. در حالی که عملیات محلی بر روی یک سلول به صورت جداگانه عمل می کنند، آنها بر روی کل مجموعه داده عمل می کنند.
2.4.1. تعداد پیکسل
عملیات شمارش پیکسل، تعداد وقوع یک مقدار پیکسل معین را در یک شطرنجی برمی گرداند. این تابع مبنایی برای هر تابع هیستوگرام مانند است که در آن مجموعه داده باید طی شود و اطلاعات مربوط به مقادیر سلولی که تعریف شده اند جمع آوری شود. شناسایی پیکسل ها بر اساس ارزش برای تجزیه و تحلیل تغییر پوشش زمین از اهمیت ویژه ای برخوردار است. علاوه بر این، ما از این روش استفاده کردیم زیرا به ما اجازه میدهد یک روش استاندارد شده برای وادار کردن عملیاتهای ارزیابیشده تنبلی برای مشتاق شدن در سراسر پلتفرمها به ما امکان دهد.
در این برنامه، هر مقدار پیکسل یک نوع پوشش زمین را نشان می دهد و این عملیات تعداد دفعاتی که این مقدار رخ می دهد را برمی گرداند. از آنجایی که تابع باید کل مجموعه داده را طی کند، زمانی که یک مقدار پیکسل در مجموعه داده مکرر یا نادر باشد، هیچ افزایش یا ضرر عملکردی وجود ندارد.
2.4.2. طبقه بندی مجدد
طبقهبندی مجدد پیکسلهای یک مقدار معین را شناسایی میکند و آنها را به مقدار جدیدی که توسط کاربر مشخص شده تغییر میدهد. طبقه بندی مجدد یک مورد خاص از جبر نقشه است که در آن یک مقدار پیکسل ارزیابی می شود و سپس با یک مقدار جدید جایگزین می شود. دو امکان برای عملگرهای طبقه بندی مجدد در PostGIS (1) عملگر جبر نقشه و (2) عملگر طبقه بندی مجدد وجود دارد. ما به طور تجربی عملگرهای ST_Reclassify و ST_MapAlgebra را مقایسه کردیم و مشخص کردیم که ST_Reclassify عملگر سریعتر است. هر دو GeoTrellis و SciDB در مورد تفاوت بین طبقهبندی مجدد و جبر نقشه نادیدهانگیز هستند. اجرای مجدد طبقهبندی ما در GeoTrellis از تابع محلی if استفاده میکند. پیادهسازی طبقهبندی مجدد SciDB یک عبارت «اگر-پس-دیگر» است. عملگر شمارش پیکسل پس از طبقه بندی مجدد برای SciDB و GeoTrellis نامیده شد.
2.4.3. افزودن شطرنجی
افزودن رستر یک عملیات جبر نقشه است. دو رستر را به عنوان ورودی می گیرد و مقادیر هر سلول را اضافه می کند و سپس یک رستر جدید برمی گرداند. در مطالعه ما، مجموعه دادهها شطرنجی تک باندی بودند و ما از همان مجموعه دادههای شطرنجی اول و دوم استفاده کردیم. افزودن شطرنجی در GeoTrellis و SciDB با تنبلی ارزیابی میشود، بنابراین تابع شمارش پیکسل برای ارزیابی اجباری فراخوانی شد. تابع افزودن شطرنجی توانایی هر پلتفرم را برای پیوستن به این مجموعه داده های بزرگ و برگرداندن یک مقدار آزمایش می کند.
2.5. عملیات کانونی
توابع کانونی با توابع محلی تفاوت دارند زیرا مقادیر خروجی تحت تأثیر سلول های اطراف قرار می گیرند. یک هسته یا پنجره برای تعیین اندازه تجزیه و تحلیل یا تعداد پیکسل های مجاور مورد نیاز برای تعیین مقدار خروجی استفاده می شود. عملیات کانونی عمدتاً در محاسباتی که شامل هموارسازی یا درون یابی هستند استفاده می شود. به عنوان مثال، حذف پیکسل های گیاهی از یک مدل ارتفاعی دیجیتالی زمین برهنه [ 23 ]. علاوه بر این، عملگرهای کانونی پیچیده هستند زیرا اگر مجموعه داده توزیع شود، اپراتور باید کاشیها و پیکسلهای مجاور را پیدا کند.
2.6. عملیات منطقه ای
توابع منطقهای، بهویژه خلاصههای چند ضلعی، تجزیه و تحلیل پیچیدهای هستند زیرا شامل مجموعه دادههای شطرنجی و برداری هستند. مناطق نامنظم فضایی (یعنی جزایر هاوایی) منجر به افزایش پیچیدگی می شود. بنابراین، هنگامی که یک محاسبه برای یک منطقه خاص اعمال می شود، تنها یک زیر مجموعه از مجموعه داده باید پردازش شود. دینگ و دشام [ 24 ] این مشکل را به صورت سست-همگام تعریف می کنند. برای معیار، مفهوم خلاصه های چند ضلعی مجموعه داده های شطرنجی را آزمایش کردیم. هر مجموعه داده برداری شامل چند ضلعی و چند ضلعی در مقیاس های کاهشی (مثلاً ایالت ها، شهرستان ها و بخش ها) بود. اپراتورها مقدار حداقل، حداکثر و میانگین را در هر منطقه محاسبه کردند.
3. مقایسه پلت فرم داده های بزرگ
3.1. توضیحات پلت فرم
بسیاری از ادبیاتی که بهبودهایی را در پلتفرمهای کلان داده ایجاد میکنند، از سفارشیسازی استفاده میکنند، مانند توسعه روشهای اضافی یا تنظیم نرمافزار برای پشتیبانی از سختافزار خاص. رویکرد ما از این جهت متفاوت است که بر توسعه یک معیار جغرافیایی برای تحلیل فضایی تمرکز میکنیم. سپس معیار را بر روی پلتفرم ها اعمال می کنیم و توانایی آنها را برای انجام تحلیل های فضایی ارزیابی می کنیم.
3.1.1. PostGIS 2.4 (PostgreSQL 9.6)
PostgreSQL یک پایگاه داده رابطه ای است که از زمان انتشار اولیه PostGIS در سال 2001 از انواع داده های مکانی پشتیبانی می کند. نوع داده شطرنجی به عنوان یک نوع داده رسمی PostGIS در سال 2012 اضافه شد. یک مجموعه داده شطرنجی، پس از بارگذاری در PostgreSQL، یک نمایش جدول متشکل از دو را فرض می کند. ستون ها: RID و Raster. ستون RID یک کلید اولیه است و ستون شطرنجی حاوی دادههای مقدار پیکسل باینری است که در شی بزرگ باینری (BLOB) ذخیره میشود و فقط با استفاده از توابع شطرنجی PostGIS قابل دسترسی است.
3.1.2. SciDB 16.9
SciDB یک پایگاه داده آرایه چند بعدی منبع باز است که توسط دکتر مایکل استون بریکر طراحی شده است [ 12 ، 25 ]. توسعه آن توسط این مفهوم تحریک شد که بسیاری از مجموعه داده های علمی دارای ساختارهای آرایه مانند هستند، و هزینه هایی برای بازسازی مجموعه داده ها وجود دارد تا به عنوان آرایه در یک پایگاه داده رابطه ای باقی بمانند. پلتفرم SciDB از آرایهها به عنوان ساختار داده اولیه استفاده میکند و توسط جامعه جغرافیایی انتخاب شده است [ 11 ، 19 ، 26 ، 27 ]. معماری پردازش موازی انبوه SciDB (پایگاه داده موازی مشترک هیچ چیز) به آن اجازه می دهد تا آرایه های چند بعدی یا تصاویر مکانی را که چندین پتابایت هستند پردازش کند [ 12 ، 25].
SciDB تنها پلتفرم پایگاه داده آرایه ای نیست. RasDaMan، توسعه یافته توسط دکتر پیتر باومن، به طور خاص برای کار با مجموعه داده های شطرنجی طراحی شده است [ 28 ]. ما SciDB را انتخاب کردیم زیرا نسخه جامعه SciDB را می توان به چندین نمونه یا گره گسترش داد، در حالی که فقط نسخه سازمانی RasDaMan از این پشتیبانی می کند. در حال حاضر، SciDB قابلیت های داخلی برای خواندن تصاویر ارجاع شده جغرافیایی ندارد. تلاشهای جامعه برای افزودن قابلیتهای مکانی به SciDB رخ داده است، اما هیچ چیزی به طور رسمی تصویب نشده است [ 9 ، 29 ].
3.1.3. GeoTrellis 1.2 (Apache Spark 2.1)
Apache Spark یک محیط محاسباتی توزیع شده با کارایی بالا منبع باز است که در سال 2009 در آزمایشگاه RDAD UC Berkeley آغاز شد. اسپارک آپاچی جزئی از اکوسیستم هدوپ است و در برخی عملیات نشان داده شده است که 20× سریعتر از هادوپ است [ 30 ]. این عملکرد بهبود یافته به این دلیل است که Apache Spark داده ها را در حافظه نگه می دارد و به جای نوشتن روی دیسک مانند Hadoop، عملیات را در حافظه انجام می دهد.
ادبیات رو به رشدی وجود دارد که آرایه های چند بعدی را در آپاچی اسپارک بررسی می کند. وانگ و همکارانش [ 7 ] یک نوع داده آرایه جدید، SparkArray، برای بارگذاری و پردازش داده های شطرنجی پیاده سازی کردند. Doan و همکاران [ 17 ] عملکرد بارگذاری و عملیات زیرمجموعه را بین SciDB و Apache Spark مقایسه کردند. کتابخانه GeoTrellis یکی از اولین کتابخانه هایی است که فراتر از انواع داده های آرایه ساده است، زیرا برای پردازش، تجسم و تجزیه و تحلیل داده های مکانی توسعه یافته است.
GeoTrellis به عنوان یک پروژه تحقیقاتی Azavea در سال 2006 آغاز شد. با این حال، در سال 2013، پروژه GeoTrellis به عضویت بنیاد اکلیپس درآمد و در اسکالا و با استفاده از اسپارک آپاچی به عنوان موتور توزیع و پردازش آن، دوباره توسعه یافت. کتابخانه GeoTrellis مجموعه دادههای توزیعشده انعطافپذیر جفتی (RDD) را برای مجموعه دادههای فضایی پیادهسازی میکند، که در آن هر RDD جفت شده بهعنوان یک جفت کلید و ارزش نشان داده میشود. کلید به موقعیت جغرافیایی خاصی از کاشی شطرنجی اشاره دارد و مقدار آن یک ماتریس چند بعدی است.
3.2. سخت افزار
ما از زیرساخت سایبری Extreme Science and Engineering Discovery Environment (XSEDE) برای ارائه منابع محاسباتی برای محیط محاسباتی خود استفاده می کنیم [ 31 ]. XSEDE یک سرمایه گذاری بنیاد ملی علوم است که به درخواست تخصیص محاسباتی با کارایی بالا اجازه می دهد. ابررایانه Wrangler درخواست ما را در دانشگاه ایندیانا انجام داد، که سه گره محاسباتی را اختصاص داد و نرم افزار ما (TG-SES160012) را نصب کرد.
هر نود یک Dell PowerEdge R630 بود، مجهز به دو پردازنده Intel(R) Xeon(R) E5-2680 v3 @ 2.50 GHz، با 12 هسته برای هر Xeon. علاوه بر این، هر گره دارای 128 گیگابایت رم DDR4 با فرکانس 2133 مگاهرتز است. در حالی که هر گره دارای 24 هسته بود، همه زمان های عملکرد از 12 هسته برای SciDB و Apache Spark استفاده می کردند. PostgreSQL در این زمان یک رابطه یک به یک بین پرس و جوها و هسته ها دارد. همه پلتفرم ها از یک باطن Luster برای ذخیره سازی داده های بزرگ استفاده می کنند. نسخه Luster Luster 2.5.5 و Luster Client 2.10.3 بود. یک اختلاف کوچک در سیستم عامل ها وجود داشت، زیرا SciDB 16.9 در آن زمان به درستی برای اجرای CentOS 7 پیکربندی نشده بود. بنابراین، SciDB بر روی سیستم عامل CentOS 6 ساخته شد، در حالی که هر دو Apache Spark و PostgreSQL برای اجرا در یک محیط CentOS7 پیکربندی شده بودند. .
4. نتایج
نتایج مجموعهای از تحلیلهایی است که ما برای نشان دادن معیار خود انجام دادیم. نتایج توصیفهای گستردهای را نشان میدهند که کاربران باید در هنگام انجام عملیات فضایی روی پلتفرمها انتظار داشته باشند.
به منظور ارزیابی موثر اثر تنظیم در نتایج، هر اپراتور روی کل مجموعه داده با اندازههای کاشی مختلف انجام داد. با تغییر اندازه کاشی در فواصل زمانی مشخص، می توانیم تعیین کنیم که عملکرد بهینه یک پلت فرم خاص در یک مجموعه داده خاص چه زمانی رخ می دهد. طیف کامل اندازههای کاشی در هر پلتفرم به دلیل تغییرات حاشیهای در عملکرد و مشکلات بارگذاری داده اعمال نشد. با این حال، ما مجموعهای از اندازههای کاشی را شناسایی کردیم که امکان مقایسه منصفانه را در بین پلتفرمها فراهم میکند و عملکرد بهینه تحلیلهای شطرنجی را در پلتفرمهای کلان داده مشخص میکند.
ما میانگین زمان را که از سه آزمایش متوالی تعیین شد، گزارش میکنیم. از PostGIS به عنوان خط مبنا برای مقایسه استفاده شد. بنابراین، افزایش سرعت با گرفتن بهترین زمان عملکرد برای PostGIS و مقایسه آن با بهترین زمان عملکرد برای SciDB و GeoTrellis تعیین شد. بهترین زمان عملکرد استفاده شد زیرا این نشان دهنده عملکرد تنظیم شده بهینه برای هر پلتفرم برای هر مجموعه داده است. از آنجایی که تمام پرس و جوهای PostGIS تک هسته ای هستند، افزایش سرعت به ازای هر هسته با تقسیم سرعت بر تعداد پردازنده ها یا نمونه های استفاده شده تعیین شد. برای همه تجزیه و تحلیل ها، این مقدار 12 بود.
4.1. عملیات محلی
4.1.1. تعداد پیکسل
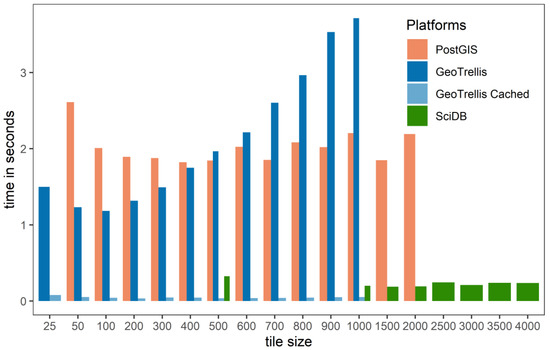
شکل 1 یک مشکل رایج را هنگام تجزیه و تحلیل داده های شطرنجی بر روی پلتفرم های مختلف بدون تست حساسیت گزارش می کند. تنظیم کاشی شطرنجی مخصوص پلتفرم است. شکل 1 نشان می دهد که اندازه کاشی که به خوبی روی یک پلت فرم کار می کند، نباید روی پلت فرم دیگر اعمال شود، زیرا منجر به عملکرد کمتر از حد مطلوب می شود. به عنوان مثال، در شکل 1 ، اندازه کاشی 1000 (1،000،000 پیکسل در هر کاشی) برخی از بدترین زمان های عملکرد را برای PostGIS و GeoTrellis نشان می دهد، در حالی که برای SciDB، عملکرد بسیار خوب است. با کاهش اندازه کاشی، هر دو عملکرد PostGIS و GeoTrellis بهبود می یابند، در حالی که عملکرد SciDB کاهش می یابد.
نتایج عملگر شمارش پیکسل بیشتر در جدول 4 نشان داده شده است . جدول 4 نتایج حاصل از کوچکترین و بزرگترین مجموعه داده ها (یعنی GLC و NLCD) را نشان می دهد – نتایج کامل در جدول S1 مواد تکمیلی گزارش شده است . نتایج جدول 4 نشان می دهد که مجموعه داده GLC (18 میلیون پیکسل) کلان داده نیست. برای پلتفرمهای کلان داده مانند GeoTrellis یا SciDB، این مجموعه داده کوچکی است و حداقل دستاوردهای عملکردی دارد. با این حال، با افزایش حجم داده ها، عملکرد قابل توجهی در پلتفرم های کلان داده وجود داشت ( جدول 4 ). جدول 5گزارش می دهد که افزایش سرعت در هر هسته (2.49) برای اولین بار توسط SciDB در مجموعه داده مریس (186 میلیون پیکسل) به دست آمد. بهبود SciDB در هر هسته تا 5.7 برابر در هر هسته افزایش یافته است. بهترین عملکردهای GeoTrellis با خواندن های Cached رخ می دهد که در آن داده ها یک بار خوانده شده و در حافظه کش ذخیره می شوند.
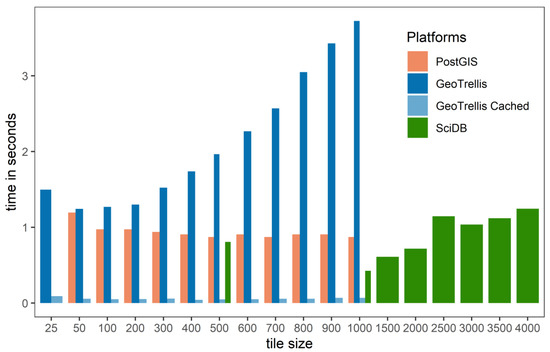
4.1.2. طبقه بندی مجدد
نتایج عملگر طبقه بندی مجدد به شدت با عملگر شمارش پیکسل متفاوت است. تابع طبقه بندی مجدد PostGIS بسیار کارآمد عمل کرد و به آن اجازه داد تا از پلتفرم های کلان داده بهتر عمل کند ( شکل 2 ). PostGIS زمانهای عملکرد سریعتری را نسبت به GeoTrellis و SciDB در مجموعه داده GLC گزارش کرد. جدول 6 نشان می دهد که در هنگام استفاده از پلتفرم های کلان داده، تنها حداقل افزایش سرعت عملکرد هر هسته رخ داده است. هنگام بررسی دو مجموعه داده کوچکتر (GLC و MERIS)، زمان محاسبه GeoTrellis کندتر از PostGIS بود، به این معنی که پلت فرم برای استفاده از داده های کوچک جریمه شد ( جدول 6) .). افزایش سرعت با پلتفرم های کلان داده با بزرگترین داده NLCD اتفاق افتاد. با این حال، ما هیچ بهبودی در افزایش سرعت هر هسته برای اپراتور طبقهبندی مجدد گزارش نمیکنیم.
4.1.3. افزودن شطرنجی
جدول 7 عملکرد عملکرد افزودن شطرنجی را در هر سه پلت فرم توضیح می دهد. نتایج تابع افزودن شطرنجی مشابه نتایج در تعداد پیکسل است. پلتفرم های کلان داده دارای مزیت عملکرد فوق العاده ای نسبت به PostGIS بودند. جدول 7 نشان می دهد که بهترین عملکرد PostgreSQL زمانی رخ می دهد که اندازه کاشی ها بزرگ ترین بودند. با افزایش اندازه کاشی، عملکرد افزایش یافت، اما PostGIS نتوانست با موفقیت به مجموعه داده NLCD در هر اندازه کاشی بپیوندد. این عملیات بیش از 24 ساعت بدون پایان انجام شد. هم SciDB و هم GeoTrellis توانستند به تمام مجموعه داده های شطرنجی بپیوندند، و ما تفاوت هایی را در عملکرد اتصال بین پلتفرم ها پیدا کردیم.
4.2. تحلیل های کانونی
PostGIS در مجموعه داده های کوچک و متوسط (GLC و MERIS) عملکرد خوبی داشت. با این حال، نتوانست محاسبات را بر روی مجموعه داده NLCD (1.69 میلیارد) پیکسل برای هر اندازه کاشی به پایان برساند ( جدول 8 ). برای عملیات کانونی، بهترین عملکرد زمانی رخ میدهد که اندازه کاشی در 50 کوچکترین باشد، با افزایش اندازه کاشی، زمان تکمیل پرس و جو افزایش یافت.
عملکرد SciDB در عملیات کانونی چالش برانگیز بود، و ما مقادیر عملکرد کامل را ارائه می دهیم ( جدول مواد تکمیلی S2 ). زمانهای عملکرد نامنظم در مجموعه دادههای متراکم بزرگ با اندازههای کاشی بیشتر از ۱۵۰۰ × ۱۵۰۰ پیکسل رخ داده است. زمان عملکرد آرایه همپوشانی با استفاده از عملگر کانونی دو برابر سریعتر از آرایه استاندارد بود. این کاهش در عملکرد به دلیل شناسایی برنامهریز پرس و جو SciDB است که آرایه برای پیادهسازی موازی ساختاری ندارد و یک مرحله تغییر اندازه را آغاز میکند که از نظر محاسباتی گران است.
عملکرد GeoTrellis برای عملیات کانونی برتر از SciDB و PostgreSQL است. بهبود عملکرد با مجموعه داده های کوچک و بزرگ مشهود بود. به عنوان مثال، GeoTrellis به یک سرعت 7× در هر هسته در کوچکترین مجموعه داده GLC دست یافت. عملکرد GeoTrellis همچنان به بهبود خود ادامه داد زیرا به 9× سرعت در هر هسته در Meris رسید و NLCD را به پایان رساند. در حالی که عملکرد GeoTrellis نسبت به SciDB چندان زیاد نیست، سهولت و عملکرد کلی GeoTrellis را به پلتفرم برتر تبدیل کرده است.
4.3. تجزیه و تحلیل منطقه ای
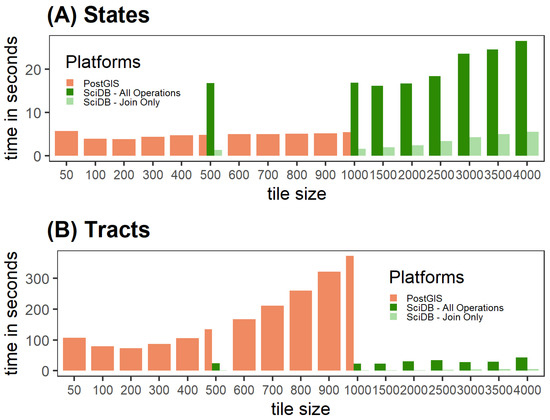
برخلاف سایر عملیات، PostGIS بهترین عملکرد کلی را در عملیات منطقه ای در میان مجموعه داده ها ارائه کرد ( جدول 9 ). نتایج کامل عملیات منطقه ای گزارش شده است ( جدول مواد تکمیلی S3 ). عملکرد برتر PostGIS متکی به عملیات داخلی است که از انواع داده های برداری و شطرنجی پشتیبانی می کند. فرآیند شطرنجی سازی PostGIS سریالی است اما بسیار کارآمد است. علاوه بر این، تابعی که برای انجام آمار ناحیه ای با PostGIS، ST_SummaryStatsAgg استفاده می شود، یک تابع جمع است، به این معنی که بر روی هر ویژگی جغرافیایی و کاشی شطرنجی به طور مستقل عمل می کند. یک مورد اصلی نگرانی منحنی عملکرد شکل “U” است که PostGIS ایجاد می کند [ 19]. ما متوجه شدیم که این روندها در تمام مجموعه دادهها سازگار هستند. اندازه کاشی عملکرد بهینه با افزایش تعداد ویژگیها و کاهش گستره جغرافیایی ویژگیها متفاوت بود.
نتایج عملکرد برای SciDB مختلط است. شکل 3 شواهدی را نشان می دهد که SciDB به طور بالقوه یک پلت فرم خوب برای انجام آمار منطقه ای است. شکل 3 A عملکرد بین SciDB و PostgreSQL را در مجموعه داده وضعیت نشان می دهد، که در آن PostgreSQL به راحتی از SciDB-All Operations بهتر عمل کرد. با این حال، شکل 3 B نشان می دهد که با افزایش تعداد ویژگی ها، SciDB به پلت فرم برتر تبدیل شد. برخلاف PostGIS یا GeoTrellis، با SciDB، با افزایش اندازه قطعه، تغییر نسبتا کمی در عملکرد وجود داشت.
شکل 3 نتایج را برای SciDB گزارش میکند که هر دو «فقط پیوستن» و «همه عملیات» هستند. زمانهای عملکرد فقط پیوستن فرض میکند که فرآیند پوشاندن قبلاً انجام شده است. این یک فرض بعید است و نتایج تمام وقت در جدول مواد تکمیلی S4 آمده است .
نتایج GeoTrellis شگفت آور است ( جدول 10 ). GeoTrellis 1.2 اپراتور ندارد که به آن اجازه دهد مجموعه ای از هندسه ها را بگیرد و تجزیه و تحلیل را در همه ویژگی ها انجام دهد. بنابراین، عملیات سریال بود که منجر به عملکرد ضعیف شد. جدول 10 نشان می دهد که عملکرد بهتر با کاشی های بزرگتر رخ داده است.
5. بحث
5.1. اپراتورهای محلی
به طور کلی، پلتفرم های کلان داده هنگام انجام عملیات محلی برتر هستند. پلتفرم های کلان داده در پارتیشن بندی مجموعه داده های بزرگ و تجزیه و تحلیل موازی آنها تخصص دارند. ساختارهای داده و معماری های به کار گرفته شده توسط هر دو پلتفرم احتمالاً روی داده های شطرنجی بزرگ عملکرد خوبی دارند. معماری آرایهای SciDB در بسیاری از موارد در واکشی و پردازش سریع دادهها بهتر از GeoTrellis و PostGIS بود. به طور خاص، نتایج عملیات شمارش پیکسل، مزایای محاسباتی استفاده از یک پلتفرم کلان داده را به تصویر میکشد. با این حال، ما همچنین گزارش می دهیم که توابع بهینه شده به جای توابع تعمیم یافته می توانند عملکرد را بهبود بخشند.
نتایج معیار برای عملیات افزودن شطرنجی قابل توجه بود. در مقایسه با سایر عملیات محلی، عملیات افزودن شطرنجی بیشترین دستاوردهای عملکردی را هنگام استفاده از یک پلتفرم کلان داده مانند SciDB یا GeoTrellis نشان میدهد. PostGIS نمی تواند اتصال بین این دو مجموعه داده بزرگ شطرنجی (یعنی NLCD) را پردازش کند. جدول 7نتایج جالبی را هنگام مقایسه عملکرد بین SciDB و GeoTrellis گزارش می دهد. در ابتدا، SciDB بهترین عملکرد را در مجموعه داده های GLC و Meris با 18 میلیون و 186 میلیون پیکسل داشت. بهترین عملکرد SciDB برای هر مجموعه داده تقریباً دو برابر سریعتر از GeoTrellis بود. با این حال، عملکرد GeoTrellis در مجموعه داده NLCD با 1.69 میلیارد پیکسل برتر بود. بهترین عملکرد GeoTrellis با 171 ثانیه دو برابر سریعتر از SciDB در 359 ثانیه بود.
دلیل اینکه ما تغییرات در عملکرد این پلتفرم ها را مشاهده می کنیم در معماری سکوها نهفته است. تفاوت های مشاهده شده مربوط به تعادل بار است که به عنوان نسبت نمونه های SciDB به پارتیشن های داده موجود تعریف می شود. برای مثال، اگر 12 نمونه SciDB و 24 قطعه داشته باشیم و عملیات برای یک قطعه 10 ثانیه طول بکشد، SciDB 20 ثانیه طول می کشد تا این عملیات با 24 قطعه و 12 نمونه تمام شود. اگر همان مجموعه داده را به 26 قطعه تقسیم کنیم، SciDB 30 ثانیه طول می کشد.
رویکرد استفاده شده برای فریم ورک آپاچی اسپارک متفاوت است زیرا پلتفرم نسبت هسته ها به تعداد پارتیشن های داده را آگنوستیک می کند زیرا داده ها همه در حافظه هستند. برنامه Apache Spark تعداد هسته های موجود را تعریف می کند و داده ها را به هسته های موجود اختصاص می دهد. نتایج ما نشان میدهد که در حالی که SciDB از تعادل بار ناقص در همه مجموعههای داده رنج میبرد، توانایی آن برای واکشی دادهها برتر بود و به آن اجازه میداد در مجموعه دادههای کوچکتر از GeoTrellis بهتر عمل کند. با این حال، زمانی که عدم تعادل بار وجود داشت، چارچوب آپاچی اسپارک بهتر عمل می کرد زیرا می توانست از مشکلات تعادل بار جلوگیری کند.
5.2. اپراتورهای کانونی
ایجاد روشهای قابل مقایسه برای تحلیلهای کانونی پیچیده بود، اما نتایج ما نشان میدهد که تفاوتهای ظاهری در پلتفرمها وجود دارد.
هنگام استفاده از PostGIS باید از عملیات کانونی اجتناب شود زیرا نتایج رضایت بخشی ارائه می دهد – به دلیل اینکه مجموعه داده حاصل از PostGIS معادل مجموعه داده حاصل از SciDB یا GeoTrellis نیست. اپراتور کانونی PostGIS یک مجموعه نیست. در عوض، روی هر کاشی به طور مستقل عمل می کند. هر عملیات کانونی باید با تابع MapAlgebra PostGIS ترکیب شود. بنابراین، پیکسل هایی که در لبه کاشی قرار دارند، ارزش کانونی خود را توسط سلول های مجاور آن در کاشی بعدی تعیین نمی کنند. این پیامدهای بالقوه جدی برای مجموعه دادههای بزرگ مانند NLCD زمانی که کاشیهای کوچک زیادی دارد، دارد. جایگزین استفاده از عملگر ST_Union برای ادغام تمام کاشی ها و سپس اجرای عملگر کانونی است. بعید است که ادغام کاشی ها ناموفق باشد زیرا اندازه مجموعه داده های شطرنجی می تواند از محدودیت حافظه ردیف PostgreSQL تجاوز کند. هاینز نشان می دهد که عملگر ST_Union از نظر محاسباتی فشرده است و عملکرد پرس و جو را کاهش می دهد [19 ].
SciDB همچنین چالشهای غیرمنتظرهای را ارائه کرد. آرایه های همپوشانی یک کلاس منحصر به فرد از آرایه ها نیستند. آنها یک مشخصات اضافی از طرح آرایه هستند. یک آرایه SciDB را می توان با همپوشانی در هر بعد تعریف کرد [ 25 ]. همپوشانی به هر آرایه SciDB اجازه می دهد تا داده هایی از کاشی های مجاور داشته باشد. آرایه ای با مقدار همپوشانی تعریف شده اکنون می تواند یک عملیات کانونی را به صورت موازی انجام دهد.
هنگام استفاده از اپراتور کانونی، عملکردهای گسترده ای مشاهده می شد که مسائل معماری را با استفاده از اندازه های کاشی بزرگ (یعنی بیشتر از 1500 × 1500 پیکسل) در آرایه های بزرگ برجسته می کرد. عملگر پنجره، برای SciDB، روی کاشی ها به صورت متوالی کار می کند و آنها را در حافظه ذخیره می کند. این فرآیند حافظه 128 گیگابایتی را در گره تمام کرد. جستارهایی که از کاشیهایی با اندازههای 2000 یا بیشتر استفاده میکردند، حتی در صورت تکمیل شدن، پرسوجو قطع میشد و گاهی اوقات منجر به نیاز به راهاندازی مجدد SciDB میشد.
در حالی که هر دو پلتفرم کلان داده جایگزین بهتری برای PostGIS هستند، GeoTrellis بهترین عملکرد را دارد. هنگامی که یک عملیات کانونی آغاز می شود، GeoTrellis از آرایش فضایی برای هر کاشی از مجموعه داده آگاه است. سپس تمام پیکسلهای لبهای را که برای هر کاشی لازم است جمعآوری میکند و آنها را به کاشیهای همسایه متصل میکند و عملیات کانونی را موازی میکند.
یکی دیگر از مزایای پیاده سازی GeoTrellis نسبت به SciDB این است که در حال حاضر در سطح کاشی ذخیره می شود. اولین باری که عملیات کانونی روی یک کاشی آغاز می شود، GeoTrellis اطلاعات بسیار کمی در مورد پیکسل های مجاور خود می داند. بنابراین باید اطلاعات مربوط به پیکسل های مجاور را جمع آوری کند. هنگامی که عملگر به یک پیکسل مجاور حرکت می کند، از قبل اطلاعاتی در مورد ⅓ از پیکسل های مجاور از پرس و جو قبلی دارد. پیادهسازی GeoTrellis به آن اجازه میدهد تا از طریق کش کردن، از دادههایی که قبلا خواندهاند، استفاده مجدد کند و سرعت عملیات را افزایش دهد. در حال حاضر، در SciDB، اپراتور کانونی کش نمی کند. محققان عملگرهای دیگری را برای SciDB نوشتهاند که عملکرد عملیات کانونی را با اجرای حافظه پنهان [ 10] بهبود میبخشد.]. آزمایش این کد فراتر از حد تحقیق ما بود.
5.3. اپراتورهای منطقه ای
ایجاد روش های قابل مقایسه برای تجزیه و تحلیل منطقه ای پیچیده ترین بود زیرا شامل دو مجموعه داده مختلف بردار و شطرنجی بود. هر دو PostGIS و GeoTrellis به طور بومی از انواع داده های برداری پشتیبانی می کنند. با این حال، SciDB این کار را نمی کند، که برای انجام عملیات منطقه ای مشکل ساز است.
اپراتورهای منطقه ای منطقه ای هستند که در آن هر دو پلتفرم کلان داده در مقایسه با PostGIS با مشکل مواجه هستند. خلاصه های چند ضلعی حوزه ای هستند که در آن برای پلتفرم های کلان داده به تحقیق نیاز است. یک دلیل بالقوه این است که آمار خلاصه چند ضلعی یا منطقه ای تمایل دارد به عنوان یک عملیات واحد در نظر گرفته شود، در حالی که در واقع یک سری مراحل وجود دارد.
-
شطرنجی کردن مجموعه داده برداری به همان وسعت جغرافیایی که مجموعه داده شطرنجی است.
-
به صورت فضایی به مجموعه دادههای شطرنجی ماسکدار و شطرنجی اصلی بپیوندید.
-
یک تجمیع (یعنی حداقل، حداکثر، مجموع، میانگین) بین دو مجموعه داده متصل انجام دهید.
در هر پلتفرم، خلاصه سازی چند ضلعی متفاوت عمل می کند. برای PostGIS، فرآیند خلاصه سازی چند ضلعی سریال است. هر چند ضلعی را می گیرد و آن را با کاشی های تراز فضایی قطع می کند. سپس دو مجموعه داده را به هم متصل می کند و آمار درخواستی را برمی گرداند.
مسئله اصلی برای SciDB عدم پشتیبانی از مجموعه داده برداری است که پس از آن نیاز به یک فرآیند خارجی برای ایجاد و بارگذاری یک مجموعه داده پوشانده دارد. Rasterization یک گلوگاه برای SciDB ایجاد می کند، زیرا مجموعه داده دومی را ایجاد می کند که باید در پلتفرم بارگذاری شود. اجرای عملیات scanline یا عملیات scanline موازی می تواند به SciDB گسترش یابد [ 32 ، 33 ].
GeoTrellis از شطرنجیسازی اجتناب میکند و از یک الگوریتم خط اسکن برای شناسایی پیکسلهای مورد علاقه استفاده میکند و سپس یک RDD جدید ایجاد و برمیگرداند. با این حال، حل مسئله خلاصه چند ضلعی برای GeoTrellis (Apache Spark) پیچیده است. Zonal Statistics از مجموعه داده های ناهمگن استفاده می کند که باعث ایجاد مشکلاتی برای Apache Spark می شود. روش معمول آن برای مدیریت این است که داده ها را به هم بزنند. با این حال، مقدار به هم زدن اجرا شده در طول تجزیه و تحلیل منطقه ای نگرانی زیادی دارد. مخلوط کردن ضروری است زیرا Apache Spark به مجموعه داده های ناهمگن نمی پیوندد یا ادغام نمی کند.
به عنوان مثال، یک مجموعه داده شطرنجی با کاشیهای زیاد بگیرید و آنها را در یک سری از گرهها پراکنده کنید و سپس همین کار را با یک مجموعه داده برداری با ویژگیهای زیاد انجام دهید. تجزیه و تحلیل حاصل جریمه های محاسباتی بیشتری را هنگام به هم زدن داده ها متحمل می شود. نتایج جدول 10 این را تایید می کند. عملکرد هنگام استفاده از مجموعه داده با ویژگیهای کمی مانند حالتها در مقایسه با مجموعه دادههایی با ویژگیهای زیادی مانند سرشماری افزایش مییابد. GeoTrellis بیشتر زمان خود را صرف به هم زدن داده ها می کند تا بتواند مجموعه داده های برداری و شطرنجی را با هم تطبیق دهد. عملکرد GeoTrellis زمانی بهبود مییابد که کاشیهای شطرنجی کمتر و ویژگیهای برداری کمتری وجود داشته باشد.
یانگ [ 34 ] یک راه حل بالقوه به نام Map-Reduce-Merge را مورد بحث قرار می دهد که برای مدیریت مجموعه داده های ناهمگن طراحی شده است. اجرای چنین ویژگی برای تجزیه و تحلیل جغرافیایی بدون چالش نیست زیرا Apache Spark با پارتیشن های کوچک بهترین کار را دارد. در حال حاضر، پارتیشن GeoTrellis در سطح چند ضلعی. این مشکل ساز است زیرا چند ضلعی ها می توانند چندین کاشی را پوشش دهند. برای اینکه داده ها یکدست تر شوند، یک پارتیشن خاص بردار باید پیاده سازی شود. پارتیشن بندی باید در دو سطح اجرا شود. اولین سطح پارتیشن بندی در چند ضلعی است و سطح دوم پارتیشن بندی به گونه ای است که چند ضلعی ها را به قطعاتی می شکند که با ساختار پارتیشن بندی شطرنجی هماهنگ هستند. عفراتی و اولمان [ 35] بر اساس این کار در مورد استراتژی مشابه، نقشه-کاهش-پیوستن بحث می کند. استراتژی نقشه-کاهش-پیوستن اجازه می دهد تا مجموعه داده های ناهمگن را بر اساس اتصال ستاره به هم بپیوندد. که در آن مجموعه داده کوچکتر (بردار) به تمام کاشی های تطبیق بالقوه تکرار می شود و سپس اتصالات انجام می شود. GeoSpark یک استراتژی پارتیشن بندی مشابه را هنگام پیوستن به مجموعه داده های برداری در Apache Spark [ 36 ] پیاده سازی می کند.
6. نتیجه گیری
این تحقیق اولین معیار شطرنجی را ایجاد کرد که می تواند برای مقایسه جامع تجزیه و تحلیل شطرنجی بر روی پلتفرم های کلان داده استفاده شود. این یک نمای کلی از یک گروه منتخب از پلتفرمهای کلان داده ارائه کرد و آنها را در سه کلاس از اپراتورهای فضایی اعمال کرد. توسعه معیار جغرافیایی برای عملیات شطرنجی ضروری است و به توسعه پلت فرم های داده شطرنجی بزرگ کمک می کند. معیار یک جزء حیاتی از زیرساخت های فضایی و جامعه فضایی بزرگ است و یک ابزار مرجع برای ارزیابی پلت فرم های شطرنجی بزرگ در اختیار جامعه مکانی قرار می دهد. کاربرد معیار در استفاده از معیار برای سه پلتفرم کلان داده موجود و کاربرد بالقوه آنها برای پردازش داده های بزرگ مکانی نشان داده شده است.
جدول 11گزارش یک ارزیابی کلی از عملکرد پلت فرم در عملیات فضایی بزرگ. هر دو پلتفرم کلان داده، SciDB و GeoTrellis، روش های عملکردی برتر را در عملیات محلی به نمایش گذاشتند. به طور خاص، عملیات جبر نقشه منطقهای است که این پلتفرمها عملکرد برتر خود را نشان میدهند، زیرا PostGIS قادر به اتمام محاسبات برای عملگر افزودن شطرنجی با افزایش حجم دادهها نبود. GeoTrellis همچنین پلت فرم برتر هنگام انجام عملیات کانونی بود. GeoTrellis سطوح مختلفی از کش را پیاده سازی می کند که منجر به عملکرد خوب در مجموعه داده ها در هر اندازه می شود. علاوه بر این، هر دو پلتفرم کلان داده توانایی بازسازی داده ها را در قالبی موازی در صورت تقاضا دارند. در نهایت، پلتفرمهای کلان داده برای پشتیبانی از عملیات منطقهای به کار توسعه بیشتری نیاز دارند. هر دو SciDB و GeoTrellis عملکردهای پایین تر برای عملیات منطقه ای تولید کردند. از بین دو پلتفرم، عملکرد SciDB مشابه یا مشابه PostGIS در مجموعه داده های متوسط و کوچک بود. گلوگاه اصلی SciDB نیاز به شطرنجی کردن و بارگذاری مجموعه داده خارجی است که برای مجموعه داده های بزرگ مشکل ساز است. SciDB یک عملکرد متوسط برای تجزیه و تحلیل Zonal است، زیرا مراحل پیش پردازش معمولاً در عملیات داده های بزرگ استفاده می شود. در حالی که GeoTrellis روشهایی را برای جلوگیری از شطرنجیسازی پیادهسازی میکند، ناتوانی معماری کنونی در مطابقت با مجموعه دادههای ناهمگن بدون درهمآمیزی زیاد، استفاده از پلتفرم را در عملیات ناحیهای که حاوی تعداد زیادی ویژگی برداری هستند یا دارای اندازه کاشی کوچک هستند، محدود میکند. گلوگاه اصلی SciDB نیاز به شطرنجی کردن و بارگذاری مجموعه داده خارجی است که برای مجموعه داده های بزرگ مشکل ساز است. SciDB یک عملکرد متوسط برای تجزیه و تحلیل Zonal است، زیرا مراحل پیش پردازش معمولاً در عملیات داده های بزرگ استفاده می شود. در حالی که GeoTrellis روشهایی را برای جلوگیری از شطرنجیسازی پیادهسازی میکند، ناتوانی معماری کنونی در مطابقت با مجموعه دادههای ناهمگن بدون درهمآمیزی زیاد، استفاده از پلتفرم را در عملیات ناحیهای که حاوی تعداد زیادی ویژگی برداری هستند یا دارای اندازه کاشی کوچک هستند، محدود میکند. گلوگاه اصلی SciDB نیاز به شطرنجی کردن و بارگذاری مجموعه داده خارجی است که برای مجموعه داده های بزرگ مشکل ساز است. SciDB یک عملکرد متوسط برای تجزیه و تحلیل Zonal است، زیرا مراحل پیش پردازش معمولاً در عملیات داده های بزرگ استفاده می شود. در حالی که GeoTrellis روشهایی را برای جلوگیری از شطرنجیسازی پیادهسازی میکند، ناتوانی معماری کنونی در مطابقت با مجموعه دادههای ناهمگن بدون درهمآمیزی زیاد، استفاده از پلتفرم را در عملیات ناحیهای که حاوی تعداد زیادی ویژگی برداری هستند یا دارای اندازه کاشی کوچک هستند، محدود میکند.جدول 11 دومین مسئله مهم را نشان می دهد. هیچ یک از پلتفرم هایی که ما تحلیل کردیم در هر سه کلاس عملیات شطرنجی موفق نبودند. GeoTrellis در دو مورد از این سه دسته بهترین عملکرد را داشت و آن را به یک پلتفرم ایدهآل برای توسعه گردشهای کاری فضایی تبدیل کرد.
6.1. محدودیت ها
در حالی که در این مطالعه سعی کردیم در تحلیل خود بسیار دقیق و قوی عمل کنیم، این تحقیق دارای محدودیت هایی است. اولین محدودیت این است که ما هر پلتفرم کلان داده ای را که در حال حاضر داده های شطرنجی را تجزیه و تحلیل می کند، بررسی نکردیم. ما مجموعهای از پلتفرمهایی را که در ادبیات مستند شدهاند، بررسی کردیم و از معماریهای مختلف داده بزرگ استفاده کردیم: پایگاههای داده رابطهای، پایگاههای داده آرایهای No-SQL، و Apache Spark (هدوپ در حافظه). به دلیل مشکلات بارگذاری داده ها، همه سیستم ها در هر اندازه کاشی مقایسه نشدند. این توانایی مقایسه مستقیم را محدود می کند. با این حال، تمام پلت فرم ها در اندازه های 500 و 1000 کاشی مقایسه شدند. محدودیت دوم و مرتبط این است که نسخه های جدید نرم افزار عملکرد این پلتفرم ها را تغییر می دهد. درست است؛ با این حال، دوباره به محدودیت های معماری که شناسایی کردیم اشاره می کنیم.
6.2. کار آینده
این تحقیق از طریق توسعه یک معیار شطرنجی که میتواند برای ارزیابی تحلیل فضایی بر روی پلتفرمهای کلان داده استفاده شود، به شکاف قابلتوجهی در ادبیات میپردازد. تحقیق باید در چند جهت پیشرفت کند. ابتدا، ما پیشنهاد می کنیم یک معیار مکمل برای مجموعه داده های برداری ایجاد کنیم. بسیاری از پلتفرمها عملگرهای تحلیل فضایی را برای دادههای فضایی برداری ارائه میدهند، و این معیار باید به گونهای گسترش یابد که دو نوع داده مکانی اصلی را در بر گیرد. ثانیاً، کار مقایسه پلتفرمها باید در محیطهای محاسباتی مختلف گسترش یابد. کار ما یک محیط با عملکرد بالا تک گره حافظه بزرگ را مورد بررسی قرار داد، اما نتایج میتوانند در یک محیط محاسباتی توزیعشده بهطور قابل ملاحظهای متفاوت باشند. در نهایت، معیار ارزیابی باید با پلتفرمهای بیشتر، نسخههای جدید پلتفرمهای موجود بهروزرسانی شود، مجموعه دادههای چند طیفی بزرگتر و ادغام گردشهای کاری فضایی. توسعه چنین معیار جاهطلبی مکانی برای کل جامعه مکانی مفید خواهد بود، زیرا راهنماییهای روشنی را ارائه میدهد و گلوگاهها و موفقیتها را برای محاسبات مکانی با کارایی بالا شناسایی میکند.
منابع
- بوشویزن، سی. میسون، جی. کلوپار، پ. Spanhake, S. نتایج حاصل از آزمایشگاه های سیاره گله صورت فلکی. 2014. [ Google Scholar ]
- یانگ، سی. هوانگ، Q. لی، ز. لیو، ک. Hu, F. داده های بزرگ و رایانش ابری: فرصت ها و چالش های نوآوری. بین المللی جی دیجیت. زمین 2017 ، 10 ، 13-53. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Haynes, D. Array Databases. مجموعه دانش فناوری های علم اطلاعات جغرافیایی. 2019. در دسترس آنلاین: https://gistbok.ucgis.org/bok-topics/array-databases (در 19 نوامبر 2020 قابل دسترسی است).
- دینگ، ام. یانگ، م. چن، اس. ذخیره و جستجوی نمودارهای فضایی-زمانی در مقیاس بزرگ با درجهای لبه با توان عملیاتی بالا. arXiv 2019 ، arXiv:1904.09610. [ Google Scholar ]
- آرنولد، جی. گلاویچ، بی. Raicu، I. یک سیستم پایگاه داده رابطه ای توزیع شده با کارایی بالا برای پردازش OLAP مقیاس پذیر. در مجموعه مقالات سمپوزیوم بین المللی پردازش موازی و توزیع شده IEEE (IPDPS) 2019، ریودوژانیرو، برزیل، 20 تا 24 مه 2019؛ صص 738-748. [ Google Scholar ] [ CrossRef ]
- پالاموتام، آر. Mogrovejo، RM; متمن، سی. ویلسون، بی. وایت هال، ک. ورما، ر. مک گیبنی، ال. Ramirez, P. SciSpark: استفاده از محاسبات توزیع شده در حافظه برای تشخیص و ردیابی رویدادهای آب و هوایی. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2015 درباره داده های بزرگ (داده های بزرگ)، سانتا کلارا، کالیفرنیا، ایالات متحده آمریکا، 29 اکتبر تا 1 نوامبر 2015؛ صفحات 2020–2026. [ Google Scholar ] [ CrossRef ]
- وانگ، دبلیو. لیو، تی. تانگ، دی. لیو، اچ. لی، دبلیو. Lee, R. SparkArray: یک سیستم مدیریت داده علمی مبتنی بر آرایه که بر روی Apache Spark ساخته شده است. در مجموعه مقالات کنفرانس بین المللی IEEE 2016 در زمینه شبکه، معماری و ذخیره سازی (NAS)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 8 تا 10 اوت 2016؛ صص 1-10. [ Google Scholar ] [ CrossRef ]
- لی، اچ. کیو، ن. چن، ام. لی، اچ. دای، ز. زو، ام. Huang, M. FASTDB: یک سیستم پایگاه داده آرایه ای برای ذخیره سازی و تجزیه و تحلیل کارآمد داده های علمی. در مجموعه مقالات کنفرانس بین المللی الگوریتم ها و معماری برای پردازش موازی، Zhangjiajie، چین، 18-20 نوامبر 2015. Wang, G., Zomaya, A., Martinez, G., Li, K., Eds. انتشارات بین المللی Springer: چم، سوئیس، 2015; ص 606-616. [ Google Scholar ]
- اپل، م. لان، اف. پبسما، ای. Buytaert، W. Moulds, S. تجزیه و تحلیل مشاهدات زمین مقیاس پذیر برای دانشمندان زمین شناسی: پسوند فضا-زمان به پایگاه داده آرایه SciDB. در مجموعه مقالات کنفرانس مجمع عمومی EGU، وین، اتریش، 17-22 آوریل 2016. جلد 18، ص. 11780. [ Google Scholar ]
- جیانگ، ال. کاواشیما، اچ. Tatebe، O. تجمیع پنجره سریع در پایگاه داده آرایه با محاسبات افزایشی بازگشتی. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE در سال 2016 در علوم الکترونیک (E-Science)، بالتیمور، MD، ایالات متحده آمریکا، 23 تا 27 اکتبر 2016؛ صص 101-110. [ Google Scholar ]
- لو، ام. اپل، م. Pebesma، آرایه های چند بعدی EJ برای تجزیه و تحلیل داده های علم زمین. ISPRS Int. J. Geo-Information 2018 ، 7 ، 313. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پلنتابر، جی. استون بریکر، م. Frew, J. EarthDB: تجزیه و تحلیل مقیاس پذیر داده های MODIS با استفاده از SciDB. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد تجزیه و تحلیل برای داده های جغرافیایی بزرگ، ردوندو بیچ، کالیفرنیا، ایالات متحده، 6-9 نوامبر 2012. صص 11-19. [ Google Scholar ]
- کارماس، ا. کارانتزالوس، ک. آتاناسیو، اس. تحلیل آنلاین داده های سنجش از دور برای کاربردهای کشاورزی. در مجموعه مقالات کنفرانس اروپایی OSGeo در مورد نرم افزار رایگان و متن باز برای Geospatial، برمن، آلمان، 15 ژوئیه 2014. [ Google Scholar ]
- پیکولی، MCA؛ کامارا، جی. Sanches، ID; Simões، REO; د کاروالیو، AXY; ماسیل، ا. کوتینیو، آ. اسکوردو، جی. Antunes، JFG; Begotti، RA; و همکاران تجزیه و تحلیل سری زمانی رصد زمین بزرگ برای نظارت بر کشاورزی برزیل ISPRS J. Photogramm. Remote Sens. 2018 , 145 , 328–339. [ Google Scholar ] [ CrossRef ]
- سیدو، ن. پبسما، ای. Câmara, G. استفاده از موتور Google Earth برای تشخیص تغییر پوشش زمین: سنگاپور به عنوان یک مورد استفاده. یورو جی. ریموت. Sens. 2018 , 51 , 486–500. [ Google Scholar ] [ CrossRef ]
- الدوی، ا. Mokbel, MF عصر داده های مکانی بزرگ. در مجموعه مقالات سی و یکمین کنفرانس بین المللی IEEE 2015 در کارگاه های مهندسی داده، پیتسبورگ، PA، ایالات متحده آمریکا، 15 تا 18 ژوئن 2015. ص 42-49. [ Google Scholar ]
- دوان، ک. Oloso، AO; کو، ک.-اس. Clune، TL; یو، اچ. نلسون، بی. Zhang, J. ارزیابی تأثیر قرار دادن داده ها بر جرقه و SciDB با یک مورد استفاده از علوم زمین. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2016 درباره داده های بزرگ (داده های بزرگ)، واشنگتن، دی سی، ایالات متحده آمریکا، 5 تا 8 دسامبر 2016؛ صص 341-346. [ Google Scholar ]
- اولاس، ا. تایلندی، BN; کریستوف، دی. یک ابتکار جدید برای کاشی کاری، دوخت و پردازش داده های بزرگ جغرافیایی در محیط های محاسباتی توزیع شده. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2016 ، 3 ، 111. [ Google Scholar ]
- هاینز، دی. منسون، اس ام. شوک، ای. منسون، معماری S. Terra Populus برای خدمات یکپارچه بزرگ جغرافیایی. ترانس. GIS 2017 ، 21 ، 546-559. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- وینر، پی. سیمکو، وی. نیمیس، جی. رام کردن تکامل داده های بزرگ و فن آوری های آن در BigGIS یک چارچوب مفهومی معماری برای تجزیه و تحلیل مکانی-زمانی در مقیاس. در مجموعه مقالات سومین کنفرانس بین المللی نظریه، کاربردها و مدیریت سیستم های اطلاعات جغرافیایی، پورتو، پرتغال، 27-28 آوریل 2017; ص 90-101. [ Google Scholar ]
- ری، اس. سیمیون، بی. براون، AD Jackpine: معیاری برای ارزیابی عملکرد پایگاه داده فضایی. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی مهندسی داده IEEE 2011، هانوفر، آلمان، 11-16 آوریل 2011. صص 1139–1150. [ Google Scholar ]
- بارو، سی. باندارکار، م. نامبیار، ر. پوس، م. رابل، تی. محک زدن داده های بزرگ. در مجموعه مقالات ششمین کارگاه بین المللی، WBDB 2015، تورنتو، ON، کانادا، 16-17 ژوئن 2015 و هفتمین کارگاه بین المللی، WBDB 2015، دهلی نو، هند، 14-15 دسامبر 2015. مقالات منتخب اصلاح شده اسپرینگر: برلین/هایدلبرگ، آلمان؛ جلد 10044. [ Google Scholar ] [ CrossRef ]
- شارما، م. پیج، گیگابایت؛ میلر، توسعه SN DEM از داده های LiDAR مبتنی بر زمین: روشی برای حذف اشیاء غیر سطحی. از راه دور. Sens. 2010 , 2 , 2629-2642. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دینگ، ی. دنشم، PJ استراتژیهای فضایی برای مدلسازی فضایی موازی. بین المللی جی. جئوگر. Inf. سیستم 1996 ، 10 ، 669-698. [ Google Scholar ] [ CrossRef ]
- استون بریکر، م. براون، پ. پولیاکوف، آ. رامان، اس. معماری SciDB. در مجموعه مقالات رمزنگاری کلید عمومی PKC 2018، ژانیرو، برزیل، 25 تا 29 مارس 2018؛ صص 1-16. [ Google Scholar ]
- کامارا، جی. Assis، LF; ریبیرو، جی. فریرا، KR; لاپا، ای. Vinhas، L. تجزیه و تحلیل داده های مشاهده زمین بزرگ: تطبیق الزامات با معماری سیستم. در مجموعه مقالات پنجمین کارگاه بین المللی ACM SIGSPATIAL در مورد تجزیه و تحلیل برای داده های جغرافیایی بزرگ—BigSpatial’16، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 31 اکتبر 2016. صص 1-6. [ Google Scholar ]
- لو، ام. پبسما، ای. سانچز، ق. Verbesselt، J. تشخیص تغییرات مکانی-زمانی از آرایههای چند بعدی: تشخیص جنگلزدایی از سریهای زمانی MODIS. ISPRS J. Photogramm. Remote Sens. 2016 , 117 , 227–236. [ Google Scholar ] [ CrossRef ]
- باومن، پی. مازتی، پی. اونگار، ج. باربرا، آر. باربونی، دی. بکتی، ا. بیگاگلی، ال. بولدرینی، ای. برونو، آر. کالاندوچی، آ. و همکاران تجزیه و تحلیل داده های بزرگ برای علوم زمین: رویکرد EarthServer. بین المللی جی دیجیت. زمین 2015 ، 9 ، 3-29. [ Google Scholar ] [ CrossRef ]
- موسسه ملی تحقیقات فضایی E-Sensing: تجزیه و تحلیل داده های مشاهده زمین Bg برای LUCC. 2014. در دسترس آنلاین: https://esensing.org/ (دسترسی در 1 ژوئن 2019).
- گو، ال. Li, H. Memory or Time: Performance Evaluation for Iterative Operation on Hadoop and Spark. در مجموعه مقالات دهمین کنفرانس بین المللی IEEE 2013 در مورد محاسبات و ارتباطات با عملکرد بالا و کنفرانس بین المللی IEEE 2013 در محاسبات جاسازی شده و همه جا حاضر (HPCC_EUC)، Zhangjiajie، چین، 13 تا 15 نوامبر 2013. صص 721-727. [ Google Scholar ]
- تاونز، جی. کوکریل، تی. دهان، م. فاستر، آی. گیتر، ک. گریمشاو، ا. هازلوود، وی. لاتروپ، اس. لیفکا، دی. پترسون، جی دی. و همکاران XSEDE: تسریع کشف علمی. محاسبه کنید. علمی مهندس 2014 ، 16 ، 62-74. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. چن، ز. چنگ، ال. لی، ام. وانگ، جی. الگوریتم پویش موازی برای شطرنجی سازی سریع داده های جغرافیایی برداری. محاسبه کنید. Geosci. 2013 ، 59 ، 31-40. [ Google Scholar ] [ CrossRef ]
- الدوی، ا. نیو، ال. هاینز، دی. Su, Z. تجزیه و تحلیل مقیاس بزرگ داده های فضایی بزرگ بردار+راستر. در مجموعه مقالات بیست و پنجمین کنفرانس بینالمللی ACM SIGSPATIAL در مورد پیشرفتها در سیستمهای اطلاعات جغرافیایی-SIGSPATIAL’17، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 7 تا 10 نوامبر 2017؛ صص 1-4. [ Google Scholar ] [ CrossRef ]
- یانگ، اچ.-سی. داسدان، ع. Hsiao، R.-L. پارکر، نقشه DS-کاهش-ادغام. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در سال 2007 در مورد مدیریت داده ها-SIGMOD’07، پکن، چین، 12 تا 14 ژوئن 2007. ص 1029–1040. [ Google Scholar ] [ CrossRef ]
- افراتی، FN; Ullman، JD Optimizing در یک محیط کاهش نقشه می پیوندد. در مجموعه مقالات سیزدهمین کنفرانس بین المللی گسترش فناوری پایگاه داده-EDBT’10، لوزان، سوئیس، 22 تا 26 مارس 2010. صص 99-110. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یو، جی. ژانگ، ز. Sarwat، M. مدیریت داده های فضایی در اسپارک آپاچی: دیدگاه GeoSpark و فراتر از آن. GeoInformatica 2019 ، 23 ، 37–78. [ Google Scholar ] [ CrossRef ]
شکل 1. عملکرد تعداد پیکسل در مجموعه داده GLC در همه سیستم عامل ها.
شکل 2. عملکرد طبقه بندی مجدد در مجموعه داده GLC در تمام پلت فرم ها.
شکل 3. زمان عملکرد اپراتور ناحیه ای SciDB و PostGIS در GLC با حالت های ( A ) و تراکت ها ( B ).


بدون دیدگاه