1. مقدمه
با توسعه و محبوبیت سریع فناوریهای اینترنتی و دستگاههای تلفن همراه، شبکههای اجتماعی مبتنی بر مکان (LBSNs)، مانند Foursquare و Yelp، به طور فزایندهای محبوب شدهاند. با کمک دستگاه های تلفن همراه، کاربران می توانند به راحتی مکان های جغرافیایی خود را در LBSN ها از طریق رفتارهای “چک کردن” به اشتراک بگذارند. محبوبیت LBSN ها آنها را قادر می سازد انواع مختلفی از اطلاعات را در مورد کاربران از جمله تحرک کاربران، بازخورد و زمینه جمع آوری کنند. سرویس توصیه نقطه مورد علاقه (POI) شخصی شده برای بهبود تجربه خدمات LBSN با استخراج تنظیمات برگزیده کاربر از طریق داده های ورود طراحی شده است [ 1 ].
کلید توصیه موثر POI این است که چگونه اطلاعات بافت غنی را دقیقاً مدلسازی کنیم. در واقع، عوامل زیادی وجود دارند که بر مکان بعدی که کاربر بازدید می کند تأثیر می گذارد. به عنوان مثال، کاربران ممکن است رفتارهای زمانی خاص داشته باشند، که عامل زمانی را نشان می دهد [ 1 ]. علاوه بر این، یک کاربر ممکن است ترجیح دهد در روزهای بارانی از کتابخانه بازدید کند و دوست داشته باشد در روزهای آفتابی به زمین فوتبال برود، که بر عامل شرایط آب و هوایی دلالت دارد [ 2 ]. در نهایت، بسیاری از کارهای قبلی [ 3 ، 4 ] نشان داده اند که تحرک کاربر نیز به طور قابل توجهی تحت تأثیر فاصله جغرافیایی قرار می گیرد، به این معنی که افراد تمایل بیشتری به بازدید از مکان های نزدیک تر دارند. در واقع، کارهای توصیه های عمومی POI به طور گسترده در [ 5 ، ] بررسی شده است.6 ]، که عملکرد توصیه عمومی POI را با استفاده از اطلاعات زمینه بهبود می بخشد.
متأسفانه، توصیه POIهای مختص به زمینه با چالش جدی پراکندگی داده ها نسبت به آن بدون در نظر گرفتن زمینه ها مواجه است [ 7 ]]. در واقع، تعداد POI های بازدید شده توسط یک کاربر معمولاً تنها بخش کوچکی از همه POI ها را تشکیل می دهد، که منجر به یک ماتریس ورود کاربر-POI پراکنده می شود. بدیهی است که این مشکل زمانی بدتر میشود که ماتریس ورود کاربر-POI با توجه به زمینههای مختلف جدا شده و بهعنوان یک تانسور سه مرتبهای R برای توصیه POI مربوط به زمینه نمایش داده شود. از سوی دیگر، LBSN اغلب فاقد بازخورد منفی است، زیرا POI هایی که کاربر بررسی کرده است معمولاً به عنوان نمونه های مثبت در نظر گرفته می شوند. در واقع، POI هایی که کاربر هنوز از آنها بازدید نکرده است، صرفاً به این معنا نیست که آنها علاقه مند نیستند (مثلاً ممکن است نتوانند این مکان را پیدا کنند). علاوه بر این، محبوبیت POI همچنین می تواند به ترجیحات کاربر اشاره کند. اگر کاربر در یک مکان نزدیک چک نکرد، معمولاً تصور می شود که او به آن علاقه ای ندارد. با این حال، توصیههای POI مربوط به زمینه موجود نتوانسته چنین مشکلاتی را مدیریت کند، بنابراین منجر به نتایج رضایتبخش نمیشود.
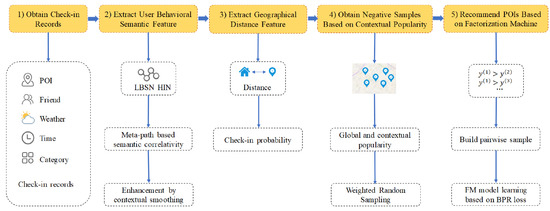
برای مقابله با این چالشها، در این مقاله، یک مدل پیشنهادی POI با زمینه خاص به نام ContextSWRank پیشنهاد شدهاست که میتواند به طور موثر اولویت کاربر را برای POI در یک زمینه خاص پیشبینی کند. در مقایسه با کار مرتبط، هسته و سهم این کار را می توان به صورت زیر خلاصه کرد: (1) یک متریک همبستگی تأثیر دو طرفه بین کاربران و POI ها برای اندازه گیری ویژگی معنایی رفتاری کاربر و درک بهتر ترجیح کاربر برای POI در LBSN. (2) با توجه به این که رفتارهای ورود کاربر در زمینههای نزدیکتر شبیهتر است، یک روش هموارسازی زمینهای برای کاهش موثر پراکندگی دادهها معرفی شده است. (3) از آنجایی که کاربران ترجیح می دهند از POI های نزدیک بازدید کنند، احتمال ورود بر اساس فاصله جغرافیایی بین خانه کاربر و POI محاسبه می شود. (4) برای رسیدگی به مشکل عدم بازخورد منفی در LBSN، یک روش نمونهگیری تصادفی وزنی بر اساس محبوبیت زمینهای پیشنهاد شده است. (5) نتایج توصیه برای کاربران با ترکیب چندین ویژگی در ماشین فاکتورسازی با از دست دادن رتبهبندی شخصی بیزی (BPR) به دست میآید. آزمایشها عملکرد توصیهای بهتر روش پیشنهادی را نسبت به سایر روشها در زمینههای خاص نشان میدهند. تا آنجا که نویسندگان دانش دارند، آثار کمی اطلاعات زمینه ای زمان و آب و هوا و تأثیر فاصله جغرافیایی را برای توصیه POI در نظر می گیرند. (5) نتایج توصیه برای کاربران با ترکیب چندین ویژگی در ماشین فاکتورسازی با از دست دادن رتبهبندی شخصی بیزی (BPR) به دست میآید. آزمایشها عملکرد توصیهای بهتر روش پیشنهادی را نسبت به سایر روشها در زمینههای خاص نشان میدهند. تا آنجا که نویسندگان دانش دارند، آثار کمی اطلاعات زمینه ای زمان و آب و هوا و تأثیر فاصله جغرافیایی را برای توصیه POI در نظر می گیرند. (5) نتایج توصیه برای کاربران با ترکیب چندین ویژگی در ماشین فاکتورسازی با از دست دادن رتبهبندی شخصی بیزی (BPR) به دست میآید. آزمایشها عملکرد توصیهای بهتر روش پیشنهادی را نسبت به سایر روشها در زمینههای خاص نشان میدهند. تا آنجا که نویسندگان دانش دارند، آثار کمی اطلاعات زمینه ای زمان و آب و هوا و تأثیر فاصله جغرافیایی را برای توصیه POI در نظر می گیرند.
بقیه مقاله به شرح زیر سازماندهی شده است. پس از ارائه کار مرتبط در بخش 2 ، بخش 3 ویژگی های رفتاری کاربران را بر اساس زمینه های ورود مورد بحث قرار می دهد. پس از آن، بخش 4 نشان می دهد که چگونه فاصله جغرافیایی بر احتمال ورود کاربران تأثیر می گذارد. مدل توصیه در بخش 5 و به دنبال آن ارزیابی تجربی آن در بخش 6 ارائه شده است. در نهایت، پس از بحث در مورد محدودیت آن در بخش 7 ، بخش 8 این مقاله را به پایان میرساند و کارهای آینده را تشریح میکند.
2. کارهای مرتبط
توصیه POI به موضوع مهم تحقیق در سیستم های توصیه گر تبدیل شده است. رویکردهای زیادی برای توصیه POI وجود داشته است، مانند مبتنی بر مدل و مبتنی بر فیلتر مشارکتی. به عنوان مثال، Ye et al. [ 8 ] پیشنهاد کرد که از رکورد ورود دوستان کاربر استفاده شود و امتیاز کاربر از POI هایی که بازدید نکرده است بر اساس فیلتر مشترک مبتنی بر کاربر تخمین بزند. لی و همکاران [ 9 ] پیشنهاد کرد که مکانهای بالقوه را از سه نوع دوست یاد بگیرند و مکانهای بالقوه را در مدل فاکتورسازی ماتریسی ادغام کنند تا بر مشکل شروع سرد غلبه کنند. با این حال، تنها حدود 4٪ از دوستان در بیش از 10٪ از مکان های مشابه در یک موقعیت واقعی چک کرده بودند [ 8 ]]. به عبارت دیگر، روابط اجتماعی نباید نقش مهمی برای توصیه POI ایفا کند. لیان و همکاران [ 4 ] ویژگی های خوشه بندی فضایی را در فاکتورسازی ماتریس برای توصیه POI گنجانده است. می توان آن را به عنوان یادگیری یک تابع نگاشت از ترکیب کاربر-POI تا رتبه بندی مشاهده کرد. با این حال، این کار نادیده می گیرد که علاوه بر روابط فضایی، اطلاعات زمینه مانند زمان و دما نیز می تواند بر رفتار کاربر تأثیر بگذارد. کای و همکاران [ 10] یک الگوریتم پیشنهادی POI دو مرحلهای درشت به ریز را بر اساس فاکتورسازی تانسور، با پیشبینی اولویت کاربر از نظر دانهبندیهای مختلف، پیشنهاد کرد. با این وجود، آنها عمدتاً اولویت مکان دسته کاربر، زمان ورود و فاصله زمانی را در نظر گرفتند. در واقع، ترجیحات کاربران ممکن است با زمینه هایی مانند وضعیت آب و هوا حتی در یک زمان و بازه زمانی مشابه متفاوت باشد. علیان نژادی و همکاران [ 11] یک الگوریتم رتبهبندی مشارکتی دو فازی را پیشنهاد کرد که یک تنظیمکننده حساس به زمان را در خود جای داده است. تنظیمکننده، کاربران و POIهایی را که در گذشته به زمان حساستر بودهاند جریمه میکند، بنابراین به مدل کمک میکند تا الگوهای رفتاری بلندمدت آنها را در حین یادگیری از تعاملات کاربر-POI توضیح دهد. با این حال، تنها از عامل زمان به عنوان تنظیم کننده به جای یک عامل تأثیرگذار اصلی استفاده می کند. در واقع، رفتارهای کاربر در فواصل زمانی مجاور می تواند بسیار مشابه باشد.
برای وظایف پیشنهادی POI خاص زمینه، کاربر، POI و زمینه به رتبه بندی ها نگاشت می شوند. در [ 12 ]، یوان و همکاران. یک مدل توصیه مشترک ارائه کرد که CF مبتنی بر کاربر را گسترش میدهد تا هم تأثیر زمانی و هم تأثیر فضایی را برای توصیههای POI خاص زمان گنجانده شود. علاوه بر این، یوان و همکاران. همچنین یک الگوریتم انتشار ترجیحی به نام انتشار اولویت اول (BPP) بر اساس تأثیرات جغرافیایی-زمانی Aware Graph (GTAG) ارائه کرد [ 13]. اگرچه دو مدل ذکر شده در بالا عناصر زمانی و مکانی را با هم ترکیب میکنند، اما به دلیل ماهیت فیلتر مشترک، مدیریت مجموعه دادههای پراکنده دشوار بود. برای افزایش دقت توصیهگر، تراتنر و همکاران. یک الگوریتم مبتنی بر مدل را با ویژگی های اضافی مرتبط با آب و هوا گسترش داد [ 2 ]. با این حال، تنها با تقسیم کردن سوابق ورود بر اساس این ویژگی ها، داده ها را پراکنده تر کرد. در [ 14 ]، سی و همکاران. یک رویکرد پیشنهادی POI تطبیقی ارائه کرد که فعالیت سه بعدی کاربر، محبوبیت POI مبتنی بر زمان، و ویژگیهای فاصله را با استفاده از یک روش تحلیل آماری احتمالی از مجموعه دادههای بررسی تاریخی در LBSNها استخراج میکند. متأسفانه، این واقعیت را نادیده می گیرد که محبوبیت POI تنها به زمان مربوط نمی شود.
در سالهای اخیر، برخی از محققان تلاش کردهاند شبکه اطلاعات ناهمگن (HIN) را برای وظایف توصیهای به کار ببرند تا اطلاعات بیشتری را یکپارچه کنند و معنایی رفتار کاربر را نشان دهند. به عنوان مثال، ژائو و همکاران. [ 15 ] یک روش توصیه مبتنی بر HIN را پیشنهاد کرد که از فاکتورسازی ماتریس و ماشین فاکتورسازی برای حل مسئله ترکیب اطلاعات استفاده میکند. وانگ و همکاران [ 16 ] از رویکرد مبتنی بر فرامسیر برای استخراج روابط ضمنی بین یک کاربر و یک POI استفاده کرد و از رگرسیون لجستیک برای ایجاد یک مدل پیشبینی برای توصیه استفاده کرد. با این حال، آنها به سادگی مکانی را که کاربر از آن بازدید نکرده است به عنوان یک نمونه منفی در نظر گرفتند، بدون در نظر گرفتن ویژگی بازخورد ضمنی LBSN.
توصیه POI شخصی شده کاربران هنوز با دو چالش روبرو است: نحوه استخراج ویژگی های مؤثرتر با استفاده از اطلاعات محدود کاربر و مکان به منظور کاهش پراکندگی داده ها در توصیه POI، و نحوه استخراج و ادغام عوامل مرتبط که می توانند ترجیحات کاربر را متمایز کنند. برای پرداختن به این مسائل، بسیاری از مدل های توصیه مبتنی بر یادگیری عمیق ارائه شده است. به عنوان مثال، در [ 17 ]، موشه آنگر و همکاران. از تکنیکهای یادگیری عمیق بدون نظارت و تجزیه و تحلیل مؤلفه اصلی (PCA) برای یادگیری خودکار زمینههای پنهان برای هر کاربر در دادههای جمعآوریشده از تلفنهای همراه کاربران استفاده کرد. با این حال، همه کاربران مایل به اعطای مجوزهای خود نیستند، که این امر دشواری دریافت اطلاعات زمینه را افزایش می دهد. در [ 18]، چانگ و همکاران. یک مدل پیشنهادی POI مبتنی بر شبکه عصبی Graph (GPR) پیشنهاد کرد که از نمایشهای نهفته جغرافیایی آموزشدیده تأثیرات ورودی و خروجی برای تخمین ترجیحات کاربر استفاده میکند. با استفاده از شبکه های عصبی بلند مدت حافظه کوتاه مدت (LSTM) و تخمین چگالی هسته (KDE)، Ma et al. [ 19 ] تأثیر مکان و دسته POI را بر رفتار ورود کاربران بر اساس داده های ترتیب ورود یکپارچه کرد. در [ 20]، یو و همکاران. یک مدل عمیق آگاه از مقوله ارائه کرد که دارای دسته بندی POI و تأثیر جغرافیایی برای کاهش فضای جستجو برای غلبه بر پراکندگی داده ها است. آنها دو رمزگذار عمیق بر اساس LSTM برای مدل سازی داده های سری زمانی طراحی کردند. رمزگذار اول تنظیمات برگزیده کاربر را در دسته های POI ثبت می کند، در حالی که دومی از تنظیمات برگزیده کاربر در POI بهره برداری می کند. با این حال، برخی از محققان استدلال کردهاند که رویکردهای عصبی به پارامترهای بیشتری برای ثبت انتقالهای مرتبه بالا نیاز دارند (یعنی گویا هستند اما به راحتی بیش از حد مناسب هستند)، در حالی که مدلهای با دقت طراحی شده اما سادهتر در تنظیمات با پراکندگی بالا مؤثرتر هستند [ 21 ].
3. ویژگی معنایی رفتاری کاربر بر اساس زمینه های ورود
این بخش نحوه استخراج ویژگیهای ورود کاربران را با در نظر گرفتن اطلاعات متنی بر اساس متا مسیر در شبکه اطلاعات ناهمگن LBSN (HIN) توضیح میدهد.
3.1. همبستگی معنایی بر اساس فرامسیر
به عنوان یک نمایش انتزاعی از دنیای واقعی، شبکه اطلاعات بر ارتباط بین انواع مختلف اشیاء تمرکز می کند. هنگامی که بیش از یک نوع شی یا یک نوع روابط بین اشیا وجود داشته باشد، شبکه یک شبکه اطلاعات ناهمگن [ 22 ] یا HIN نامیده می شود. بنابراین، روابط پیچیده در LBSN را می توان از طریق HIN همانطور که در شکل 1 نشان داده شده است نشان داد.
به منظور استخراج ویژگیهای معنایی رفتاری کاربر بهدستآمده، مدل فرامسیری، پیشنهاد شده در [ 23 ]، اعمال میشود. به عنوان مثال، یک کاربر به طور غیرمستقیم با یک POI از طریق یک مسیر متصل می شود [ خطای پردازش ریاضی ]�⟶��منه�د�منتیساعت�⟶جساعتهجک-من�پ، مخفف شده است [ خطای پردازش ریاضی ]��پ، به این معنی که کاربر مکانی را که توسط دوست سوم بررسی شده است ترجیح می دهد. علاوه بر این، مسیر [ خطای پردازش ریاضی ]�⟶جساعتهجک-من�پ⟶جساعتهجک-من�ب��⟶جساعتهجک-من�پنشان میدهد که کاربران مکانهایی را ترجیح میدهند که افرادی با سوابق اعلام حضور مشترک در آنجا اعلام حضور کردهاند، که یک توصیه مشترک مبتنی بر کاربر است. به این ترتیب، توصیه را می توان با طراحی چنین متا مسیرهای معقولی برای نشان دادن معنایی رفتار کاربر مختلف توضیح داد. جدول 1 متا مسیرها و معنای متناظر آنها را فهرست می کند، جایی که G نشان دهنده دسته POI است.
با توجه به تعریف فوق از متا مسیر، می توان همبستگی بین کاربران و POI ها را محاسبه کرد. تعداد نمونه های مسیر بین کاربر [ خطای پردازش ریاضی ]تو∈�و [ خطای پردازش ریاضی ]پ�منپ∈پاز طریق متا مسیر M به صورت تعریف شده است [ خطای پردازش ریاضی ]پسیم(تو،پ)، که قدرت رابطه را مستقیماً منعکس می کند. سپس، همبستگی معنایی بین u و p را می توان به صورت زیر تعریف کرد:
جایی که [ خطای پردازش ریاضی ]پسیم(تو،·)تعداد کل نمونه های مسیر را نشان می دهد که از u تا M شروع می شود. ترجیح کاربر را می توان از اشیاء مکان در امتداد متا مسیر استنباط کرد. از سوی دیگر، اشیاء مکان بر ترجیح رفتار کاربر تأثیر منفی میگذارند. به عبارت دیگر، هم متا مسیر و هم مسیر معکوس آن اطلاعات معنایی غیر قابل اغماض را ارائه می دهند. از این رو، همبستگی معنایی دو طرفه به عنوان معادله ( 2 ) تعریف می شود. اینجا، [ خطای پردازش ریاضی ]م-1متا مسیر معکوس M را نشان می دهد :
اجازه دهید [ خطای پردازش ریاضی ]�تو،پ،ج∈آرتعداد دفعاتی را که کاربر نشان می دهد [ خطای پردازش ریاضی ]تو∈�محل را بررسی می کند [ خطای پردازش ریاضی ]پ∈پدر شکاف زمینه [ خطای پردازش ریاضی ]ج∈سی، مانند [ خطای پردازش ریاضی ]�تو،پ،ج=آر(ب�ب،سیآ�ه،آ�تیه�����). همبستگی معنایی دو طرفه برای هر عنصر [ خطای پردازش ریاضی ]�تو،پ،ج∈آررا می توان به عنوان معادله ( 3 ) برای به دست آوردن یک تانسور معنایی جدید محاسبه کرد[ خطای پردازش ریاضی ]آرم.
جایی که [ خطای پردازش ریاضی ]باسسیم(ج)(تو،پ)همبستگی معنایی دو طرفه در شکاف زمینه c است.
پس از طراحی متا مسیرهای L ، همبستگی معنایی دو طرفه برای تانسور R در هر متا مسیر را می توان محاسبه کرد و تانسورهای معنایی L[ خطای پردازش ریاضی ]آرم1،آرم2،…،آرم�در نهایت به دست می آیند.
3.2. افزایش با هموارسازی متنی
تانسور R که اطلاعات زمینه را در بر می گیرد، آشکارا پراکنده تر از ماتریس ورود کاربر-POI است. با اينكه [ خطای پردازش ریاضی ]آرم، محاسبه شده برای همبستگی معنایی پیشنهادی، حاوی عناصر غیر صفر بیشتری نسبت به تانسور اصلی R است، مشکل پراکنده هنوز وجود دارد. برای حل این مشکل، تأثیر متقابل بین اسلاتهای زمینه برای کاهش بیشتر پراکندگی دادهها با هموارسازی زمینه در نظر گرفته میشود.
اعتقاد بر این است که در LBSN، رفتارهای کاربر در اسلات های زمینه های مختلف همبستگی خاصی دارند. با در نظر گرفتن زمینه زمانی به عنوان مثال، با فرض اینکه کاربر بین ساعت 9 صبح تا 10 صبح از مکان p بازدید کرده است، به احتمال زیاد کاربر مکان p را بین ساعت 10 صبح تا 11 صبح نیز بررسی خواهد کرد، زیرا این دو بازه زمانی هستند. در تمام ساعات کاری، رفتار ورود کاربر در این دو بازه زمانی مشابه خواهد بود.
یک تانسور رفتار کاربر جدید B به عنوان معادله ( 4 )، که در آن ساخته شده است[ خطای پردازش ریاضی ]بتو،پ،ج∈بنشان می دهد که آیا کاربر u در POI p در زمینه c بررسی کرده است یا خیر :
فرض کنید [ خطای پردازش ریاضی ]بتو،ج={بتو،1،ج،بتو،2،ج،…،بتو،پ،ج}به عنوان بردار ورود کاربر u در زمینه c . برای هر دو اسلات زمینه [ خطای پردازش ریاضی ]جمنو [ خطای پردازش ریاضی ]ج�، شباهت کسینوس بردار ورود کاربر u در شکاف زمینه مربوطه در معادله ( 5 ) نشان داده شده است:
شباهت بین شکاف های زمینه [ خطای پردازش ریاضی ]جمنو [ خطای پردازش ریاضی ]ج�میانگین شباهتهای همه کاربران، همانطور که در رابطه ( 6 ) نشان داده شده است:
همانطور که در شکل 2 نشان داده شده است ، 24 ساعت از روز و محدوده دما (آب و هوا) به 8 شکاف تقسیم شده است، و شباهت سه شکاف زمینه با سایر شکاف ها تحلیل شده است، که در آن شباهت بین شکاف زمینه های مشابه 1 است. از شکل مشاهده می شود، شباهت بین شکاف های زمینه نزدیک تر بیشتر است. بنابراین، تانسور معنایی [ خطای پردازش ریاضی ]آرمرا می توان بر اساس شباهت رفتار کاربر بین اسلات های زمینه مختلف با دادن وزن های بالاتر بر روی اسلات های همسایه آن هموار کرد:
بنابراین، با هموارسازی زمینه، مشکل پراکندگی تانسور اصلی R را می توان به طور قابل توجهی کاهش داد.
4. فاصله ها و احتمالات ورود
این بخش عمدتاً تأثیر فاصله بین مکان منزل کاربر و POI را بررسی می کند. از آنجایی که کاربر به طور کلی مکان خانه خود را نشان نمی دهد، طول و عرض جغرافیایی زمین ابتدا به تعداد معینی 4.9 کیلومتر تقسیم می شود. × سلول های 4.9 کیلومتر بر اساس GeoHash [ 24 ]، و سپس میانگین طول و عرض جغرافیایی سلولی که بیشترین رکورد ورود کاربر را دارد، تقریباً به عنوان خانه کاربر تنظیم می شود. به طور کلی توافق شده است که با افزایش فاصله تا POI، احتمال ورود به طور قابل توجهی کاهش می یابد و تقریباً از توزیع قانون قدرت پیروی می کند [ 9 ]. اولویت جغرافیایی کاربر با احتمال ورود کاربر از خانه خود نشان داده می شود (مشخص شده به عنوان [ خطای پردازش ریاضی ]ساعتتو) به [ خطای پردازش ریاضی ]ایکس(کمتر)مکان دور p ، همانطور که در معادله ( 8 ) نشان داده شده است:
اجازه دهید [ خطای پردازش ریاضی ]آ=2�0و [ خطای پردازش ریاضی ]ب=�1و سپس معادله ( 8 ) با گرفتن لگاریتم به معادله ( 9 ) تبدیل می شود:
اجازه دهید [ خطای پردازش ریاضی ]�”=ورود به سیستم�و [ خطای پردازش ریاضی ]ایکس”=ورود به سیستمایکساز روش رگرسیون خطی برای بهینه سازی تابع زیان زیر برای به دست آوردن ضریب رگرسیون استفاده می شود:
جایی که [ خطای پردازش ریاضی ]�0و [ خطای پردازش ریاضی ]�1ضرایب رگرسیون هستند که با نشان داده می شوند [ خطای پردازش ریاضی ]�، [ خطای پردازش ریاضی ]پ�احتمال ورود واقعی به است [ خطای پردازش ریاضی ]ایکس”و پارامتر منظم سازی [ خطای پردازش ریاضی ]�برای جلوگیری از برازش بیش از حد مدل استفاده می شود. سپس احتمال ورود با معادله ( 11 ) نرمال می شود:
که در آن مخرج نشان دهنده حداکثر احتمال ورود در میان سوابق ورود کاربر u است.
5. مدل توصیه
ماشین فاکتورسازی (FM) [ 25 ] برای حل مشکل ترکیب ویژگی ها تحت داده های پراکنده در مقیاس بزرگ پیشنهاد شد. برای سناریوی پیشنهادی خاص زمینه، دادههای ورود کاربر بر اساس اطلاعات زمینه تقسیمبندی میشوند تا دادهها پراکندهتر باشند. علاوه بر این، ویژگیهای رفتاری کاربر ممکن است بر یکدیگر تأثیر بگذارند، بنابراین ماشین فاکتورسازی برای سناریوی هدف این مقاله بسیار مناسب است. برای سناریوی بازخورد ضمنی LBSN، یک استراتژی نمونهگیری تصادفی وزندار بر اساس محبوبیت POIs پیشنهاد شده است، و رتبهبندی شخصی بیزی [ 26 ] برای آموزش مدل ماشین عاملسازی به کار گرفته میشود. روند مدل پیشنهادی ارائه شده در این مقاله در شکل 3 نشان داده شده است .
5.1. نمونهگیری تصادفی وزنی بر اساس محبوبیت زمینهای
برای توصیه زمینه خاص، لازم است ابتدا اولویت کاربر برای POIها در یک زمینه خاص تخمین زده شود و سپس POIهای بازدید نشده Top-K بر اساس اولویت به کاربر توصیه شود. نمونه های آموزشی ماشین فاکتورسازی شامل تعداد زیادی از [ خطای پردازش ریاضی ]<تو،پ،ج>سه برابر می شود و هر کدام به ویژگی هایی برای آموزش مدل نیاز دارند. برای انجام این کار، ابتدا کدگذاری One-Hot [ 27 ] روی کاربران، POI ها و زمینه ها برای شناسایی نمونه خاص انجام می شود. ثانیا، با فرض وجود L متا مسیرها، تانسورهای معنایی رفتار کاربر L را می توان به دست آورد که به صورت نشان داده می شوند.[ خطای پردازش ریاضی ]{آر˜م1،آر˜م2،…،آر˜م�}. بنابراین، هر نمونه آموزشی ویژگی های معنایی L را تولید می کند که به عنوان نشان داده می شود[ خطای پردازش ریاضی ]{�˜تو،پ،ج1،�˜تو،پ،ج2،…،�˜تو،پ،ج�}. در نهایت، ویژگی فاصله جغرافیایی ساخته شده در بخش 4 برای تکمیل ساخت ویژگی برای هر نمونه اضافه می شود.
سابقه ای که کاربر واقعاً دارای رفتار ورود است را می توان به عنوان یک نمونه مثبت در نظر گرفت. با این حال، کاربر مکانی را که دوست ندارد نشان نمی دهد، به این معنی که هیچ نمونه منفی وجود ندارد. بنابراین، یک روش نمونهگیری تصادفی وزنی پیشنهاد شده است که محبوبیت زمینه را برای تولید نمونههای منفی مورد نیاز برای آموزش مدل در نظر میگیرد. اگر کاربر بدون بازدید از مکانهای اطراف p ، POI p را بررسی کرد ، نشان میدهد که کاربر ترجیح بیشتری برای p دارد .به جای مکان های اطراف آن. علاوه بر این، هر چه تعداد دفعات بررسی یک POI در یک منطقه بیشتر باشد، محبوبیت بیشتری داشته و احتمال شناخته شدن آن توسط کاربران بیشتر میشود. از سوی دیگر، اگر کاربر هرگز یک POI بسیار محبوب را در اطراف POI که بررسی کرده است بررسی نکرده باشد، می توان نتیجه گرفت که احتمال زیادی وجود دارد که او دوست ندارد از POI محبوب سابق بازدید کند. برای یک POI p معین ، محبوبیت آن در شکاف زمینه c به صورت زیر تعریف می شود.
جایی که [ خطای پردازش ریاضی ]|سیکپ|نشان دهنده تعداد ورود در p توسط همه کاربران و [ خطای پردازش ریاضی ]|سیکپ،ج|تعداد ورودها را در p در شکاف زمینه c نشان می دهد. به عبارت دیگر، محبوبیت POI p در شکاف زمینه c با محبوبیت جهانی و محبوبیت زمینه ای آن تعیین می شود. اینجا، [ خطای پردازش ریاضی ]�پارامتر تنظیمی است.
برای نمونه [ خطای پردازش ریاضی ]<تو،پ،ج>، مجموعه ای از POI در محدوده k کیلومتر در اطراف p به دست می آید و محبوبیت [ خطای پردازش ریاضی ]پ�پج(پمن)به عنوان وزن نمونه برای هر یک محاسبه می شود [ خطای پردازش ریاضی ]پمن، برای تولید یک مجموعه POI وزن دار [ خطای پردازش ریاضی ]�={پ1،پ2،…،پمن}. در اینجا، یک روش نمونهگیری منفی [ 28 ] معرفی میشود که شامل دو مرحله زیر است: (1) برای هر POI [ خطای پردازش ریاضی ]پمن∈�، یک عدد تصادفی توزیع شده یکنواخت را انتخاب کنید [ خطای پردازش ریاضی ]توپمن=�آ�د(0،1)، و امتیاز نمونه گیری را محاسبه کنید [ خطای پردازش ریاضی ]سپمن=توپمن(1/پ�پج(پمن))و (2) m POI را با بیشترین امتیاز نمونه انتخاب کنید[ خطای پردازش ریاضی ]سپمنبه عنوان نمونه های نتیجه
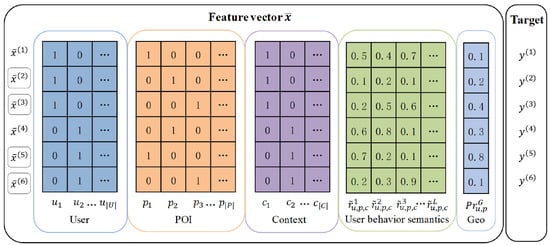
شکل 4 نمونه ای از نمونه ها و ویژگی های استخراج شده را نشان می دهد که در آن هر ردیف یک نمونه را نشان می دهد. بردار ویژگی نمونه [ خطای پردازش ریاضی ]ایکس¯(من)=(ایکس1،ایکس2،…،ایکس|�|+|پ|+|سی|+�+1)از پنج بخش تشکیل شده است. قسمت اول بردار باینری رمزگذاری شده One-Hot کاربر است که طول آن تعداد کل کاربران است. [ خطای پردازش ریاضی ](|�|). مشابه قسمت اول، قسمت دوم و سوم بردارهای باینری هستند که طول آنها تعداد کل POI است. [ خطای پردازش ریاضی ](|پ|)و تعداد کل اسلات های زمینه [ خطای پردازش ریاضی ](|سی|)به ترتیب. بخش چهارم، ویژگیهای معنایی رفتاری کاربر با طول L است، که در آن هر بعد نشاندهنده مقدار ویژگی در تانسور معنایی رفتاری کاربر است که توسط یک فرامسیر خاص استخراج شده است. قسمت پنجم احتمال ورود بر اساس فاصله است که در بخش 4 معرفی شده است. هدف [ خطای پردازش ریاضی ]�(من)=�^(ایکس¯(من))مقدار پیش بینی شده بردار ویژگی را نشان می دهد [ خطای پردازش ریاضی ]ایکس¯(من)، به عنوان مثال، ترجیح پیش بینی شده یک کاربر خاص در یک POI خاص، در ماشین Factorization. به عنوان یک مثال گویا، شکل 4 دو نمونه مثبت را نشان می دهد، به عنوان مثال، [ خطای پردازش ریاضی ]<تو1،پ1،ج1>و [ خطای پردازش ریاضی ]<تو2،پ2،ج2>با بردارهای ویژگی مربوطه خود [ خطای پردازش ریاضی ]ایکس¯(1)و [ خطای پردازش ریاضی ]ایکس¯(4). برای [ خطای پردازش ریاضی ]<تو1،پ1،ج1>، دارای دو نمونه منفی است، [ خطای پردازش ریاضی ]<تو1،پ2،ج1>و [ خطای پردازش ریاضی ]<تو1،پ3،ج1>با بردارهای ویژگی آنها [ خطای پردازش ریاضی ]ایکس¯(2)و [ خطای پردازش ریاضی ]ایکس¯(3)که در شکل 4 قاب شده اند . به همین ترتیب، [ خطای پردازش ریاضی ]<تو2،پ2،ج2>دارای دو نمونه منفی، [ خطای پردازش ریاضی ]<تو2،پ1،ج2>و [ خطای پردازش ریاضی ]<تو2،پ3،ج2>با بردارهای ویژگی آنها [ خطای پردازش ریاضی ]ایکس¯(5)و [ خطای پردازش ریاضی ]ایکس¯(6).
5.2. مدل یادگیری بر اساس رتبه بندی شخصی بیزی
بیان ماشین فاکتورسازی مورد استفاده در این مقاله به صورت معادله ( 13 ) نشان داده شده است.
که در آن n تعداد ویژگی ها را نشان می دهد، [ خطای پردازش ریاضی ]�0تعصب جهانی است و [ خطای پردازش ریاضی ]�منقدرت ویژگی مربوطه را مدل می کند، [ خطای پردازش ریاضی ]�¯من=(�من،1،�من،2،…،�من،�)بردار ضریب پنهان f بعدی ویژگی i است و [ خطای پردازش ریاضی ]<�من،��>محصول داخلی دو بردار عامل نهفته را نشان می دهد. علاوه بر این، عبارت درجه دوم در معادله ( 13 ) به طور شهودی ترکیبی از ویژگیها را در مدل معرفی میکند، که این ایده را منعکس میکند که ویژگیهای رفتار کاربر با یکدیگر تعامل دارند، و منجر به بهبود عملکرد توصیه میشود.
LBSN اغلب فاقد بازخورد منفی است. در واقع، POI هایی که کاربر هنوز از آنها بازدید نکرده است به این معنی نیست که آنها علاقه ای ندارند (ممکن است نتوانند این مکان را پیدا کنند). اگرچه نمونهگیری منفی مانند بخش 5.1 انجام میشود، اما غیرمنطقی است که مستقیماً POIهایی را که کاربر از آنها بازدید نکرده است به عنوان نمونههای منفی برای آموزش مدل طبقهبندی باینری در نظر بگیریم. بنابراین، یک مدل توصیه مستقیم و مؤثر باید بتواند جفتهای نمونه را برای کاربران رتبهبندی بهتری داشته باشد، که نشان میدهد ترجیح کاربر برای POIهایی که کاربر در آنها بررسی کرده است بیشتر از POIهایی است که کاربر بررسی نکرده است. در اینجا، ایده یادگیری زوجی پذیرفته شده است. گرفتن نمونه های مربوط به [ خطای پردازش ریاضی ]تو1به عنوان مثال در شکل 4 ، به جفت نمونه در قالب تبدیل شده است [ خطای پردازش ریاضی ]�(1)>�(2)و [ خطای پردازش ریاضی ]�(1)>�(3)، که نشان می دهد کاربر [ خطای پردازش ریاضی ]تو1مکان را ترجیح می دهد [ خطای پردازش ریاضی ]پ1بجای [ خطای پردازش ریاضی ]پ2و [ خطای پردازش ریاضی ]پ3. در نتیجه، مقدار پیش بینی شده [ خطای پردازش ریاضی ]�(1)=�^(ایکس¯(1))به دست آمده برای [ خطای پردازش ریاضی ]پ1بالاتر است.
بر اساس روش ارائه شده در [ 26 ]، از معادله ( 14 ) برای بیان این احتمال استفاده می شود که [ خطای پردازش ریاضی ]�^(ایکس¯(من))بزرگتر از [ خطای پردازش ریاضی ]�^(ایکس¯(�)):
جایی که [ خطای پردازش ریاضی ]�پارامترهای مورد استفاده در مدل را نشان می دهد و [ خطای پردازش ریاضی ]>تورابطه ترتیب دو نمونه را نشان می دهد.
با توجه به فرمول بیزی، اگر همه نمونه ها به درستی مرتب شوند، لازم است که احتمال بعدی زیر را به حداکثر برسانیم:
با فرض اینکه اولویت رتبهبندی کاربر برای جفتهای نمونه مستقل است، تابع احتمال را میتوان به صورت زیر تعریف کرد:
که در آن S مجموعه ای از روابط ترتیبی جفت های نمونه را نشان می دهد.
فرض می شود که [ خطای پردازش ریاضی ]پ(�)یک توزیع گاوسی [ 29 ] با میانگین صفر و ماتریس واریانس کوواریانس است. [ خطای پردازش ریاضی ]∑�=��من. بنابراین، تابع هدف بهینه سازی رتبه بندی را می توان به صورت زیر فرموله کرد:
جایی که [ خطای پردازش ریاضی ]��یک پارامتر منظم سازی است. در نهایت، نزول گرادیان تصادفی (SGD) [ 30 ] برای بهینهسازی تابع هدف بالا استفاده میشود:
گرادیان هر پارامتر به شکل معادله ( 19 ) بیان می شود:
پس از آن، [ خطای پردازش ریاضی ]�در امتداد جهت گرادیان منفی به روز می شود، که در تعداد معینی بار تکرار می شود تا زمانی که نتایج همگرا شوند یا تکرار به پایان برسد. پس از تکمیل آموزش مدل، مقدار پیش بینی شده کاربر u برای همه POI ها در زمینه c را می توان با معادله ( 13 ) محاسبه کرد. در نهایت، K POI های برتری که کاربر از آنها بازدید نکرده است با بالاترین مقدار پیش بینی شده به کاربر توصیه می شود.
6. آزمایشات
مجموعه داده های تجربی آزمایشها بر اساس مجموعه دادههای Foursquare ( https://dropbox.com/s/pa1mni3h8qdkdby/Foursquare.zip?dl=0 ، مشاهده شده در 7 آوریل 2019) توسط نویسنده ادبیات [ 9 ]، از جمله بررسی دنیای واقعی، انجام شد. -in داده ها از سال 2010 تا 2011. هر رکورد ورود شامل شناسه کاربری، شناسه موقعیت مکانی و مهر زمانی است که در آن هر مکان دارای اطلاعات طول و عرض جغرافیایی، طول جغرافیایی و دسته بندی است و هر کاربر اطلاعات دوستان خود را دارد. علاوه بر این، APIهای darksky.net ( https://darksky.net/dev ، دسترسی به 24 آوریل 2019) برای جمعآوری دما برای هر کدام استفاده شد. [ خطای پردازش ریاضی ]<لآتیمنتیتوده،ل���منتیتوده،تیمنمترهستیآمترپ>. آن مکانهایی که کمتر از 10 کاربر بازدید کردهاند، و آن دسته از کاربرانی که کمتر از 5 مکان را بازدید کردهاند یا کمتر از 10 اعلام حضور داشتهاند، حذف شدند. آمار به دست آمده پس از فیلتر کردن داده ها در جدول 2 نشان داده شده است.
به منظور سازگاری بیشتر آزمایش ها با وضعیت واقعی، داده های آموزشی [ خطای پردازش ریاضی ]�تی�آمن�و داده های تست [ خطای پردازش ریاضی ]�تیهستیبه شرح زیر تقسیم می شوند: برای هر کاربر مجزا، (1) جمع آوری اعلام حضور کاربر برای هر مکان. (2) مرتب سازی مکان بر اساس اولین باری که کاربر وارد شده است. و (3) انتخاب 80% اولیه برای آموزش مدل ( [ خطای پردازش ریاضی ]�تی�آمن�) و استفاده از 20% باقیمانده برای آزمایش مدل ( [ خطای پردازش ریاضی ]�تیهستی).
تنظیمات پارامترها متا مسیرهای فهرست شده در جدول 1 برای استخراج ویژگی های معنایی رفتاری کاربر استفاده می شود. دادهها بر اساس تعداد اسلاتهای زمینه تقسیم شدند. برای شرایط آب و هوایی، دمای محدوده از حداقل 4 درجه سانتیگراد تا حداکثر 43 درجه سانتیگراد در مجموعه داده به 3، 6، 8 و 12 اسلات تقسیم شد. برای زمینه زمانی، 24 هکتار روز نیز به 3، 6، 8 و 12 شکاف تقسیم شد. پارامترهای احتمال ورود از طریق یادگیری به دست می آیند، در حالی که بقیه در جدول 3 خلاصه شده اند. نرمافزار، کتابخانهها، بستههای مورد استفاده برای کدنویسی مدل عبارتند از python 2.7، numpy 1.16.5، py-geohash-any 1.1، scipy 1.2.1، sklearn 0.20.3، pandas 0.24.2 و fastFM 0.2.11.
معیارهای ارزیابی دو معیار پرکاربرد برای ارزیابی عملکرد روشهای پیشنهادی مختلف، یعنی دقت و یادآوری استفاده میشوند که با Pre@K و Rec@K نشان داده میشوند ، که در آن K تعداد POI توصیهشده است. با توجه به کاربر u و زمینه c ، [ خطای پردازش ریاضی ]تیپتو،جتعداد POI های موجود در هر دو نتایج واقعی و Top-K است، [ خطای پردازش ریاضی ]�پتو،جتعداد POI در نتایج Top-K است اما در حقیقت پایه نیست، و [ خطای پردازش ریاضی ]تی�تو،جتعداد POI های موجود در حقیقت زمین است اما در نتایج Top-K وجود ندارد. Pre@K ( c ) و Rec@K ( c ) برای شکاف زمینه c به صورت زیر محاسبه می شوند [ 12 ]:
دقت کلی و فراخوانی با میانگین گیری دقت و فراخوان در تمام شکاف های زمینه محاسبه می شود.
روش های مقایسه از روش های زیر به عنوان روش مقایسه استفاده می شود:
-
UTE [ 12 ]: یک مدل توصیه مشترک که تأثیر زمانی را برای توصیه POI خاص زمان در بر می گیرد.
-
UTE+SE [ 12 ]: یک مدل توصیه مشترک که هم تأثیر زمانی و هم جغرافیایی را برای توصیههای POI ویژه زمان در بر میگیرد.
-
ContextWRank: مدل پیشنهادی در این مقاله، اما از روش هموارسازی زمینه ای ارائه شده در بخش 3.2 استفاده نمی کند .
-
ContextSWRank: مدل پیشنهادی در این مقاله که از روش هموارسازی زمینه ای در بخش 3.2 استفاده می کند.
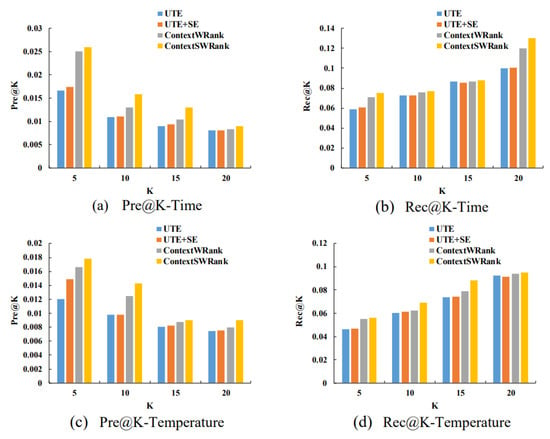
مقایسه عملکرد. همانطور که در شکل 5 نشان داده شده است ، دقت و یادآوری روش های مختلف با در نظر گرفتن شرایط زمانی و آب و هوا (دما) زمانی که شکاف زمینه روی 8 تنظیم شده است، مقایسه شده است. که اثربخشی در نظر گرفتن نفوذ جغرافیایی را نشان می دهد. در همین حال، ContextWRank از UTE و UTE+SE، از نظر Pre@5 در مقایسه زمانی، به ترتیب 50.3٪ و 44٪ بهتر عمل می کند. علاوه بر این، با افزایش هموارسازی متنی، ContextSWRank بهترین عملکرد را در همه موارد نشان می دهد.
اثر تعداد شکاف های زمینه. شکل 6 دقت و یادآوری را با تعداد مختلف شکاف های زمینه از 3 تا 12 هنگام در نظر گرفتن شرایط زمان و آب و هوا (دما) مقایسه می کند. بدیهی است که هر چه تعداد اسلات ها کمتر باشد، کمتر به زمینه خاص اختصاص دارد. همانطور که شکل 6 نشان می دهد، زمانی که تعداد اسلات های زمینه روی 3 یا 6 تنظیم شود، Pre@5 بهترین و Rec@5 بدترین را برای همه روش ها به دست می آورد. وقتی تعداد اسلات های زمینه افزایش می یابد، Pre@5 کاهش می یابد در حالی که Rec@5 به طور کلی افزایش می یابد. در نهایت Pre@5 به بدترین و Rec@5 می رسددر 12 اسلات زمینه برای همه روش ها به بهترین حالت می رسد. دلیل ممکن است این باشد که هر چه تعداد اسلاتها بیشتر باشد، دادهها پراکندهتر خواهند بود، که منجر به سختتر شدن توصیه میشود. از طرف دیگر، افزایش تعداد اسلات ها باعث می شود که تعداد صحت زمینی POI برای هر شکاف کمتر شود و در نتیجه منجر به فراخوانی بهتر شود. مهمتر از همه، ContextWRank و ContextSWRank همیشه عملکرد بهتری نسبت به UTE و UTE+SE دارند بدون توجه به تعداد اسلات های زمینه که بیشتر کارایی روش پیشنهادی را ثابت می کند.
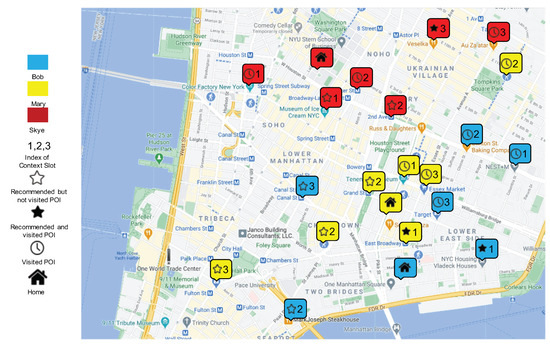
تجسم فضایی توصیه POI. شکل 7 POI های بازدید شده، توصیه شده و بازدید شده و توصیه شده اما بازدید نشده برای Bob، Mary و Skye را به عنوان مثال نشان می دهد. بدیهی است که می توان دریافت که POI های توصیه شده با در نظر گرفتن خانه ها و زمینه های آنها معقول هستند.
7. تهدید به اعتبار
مدل ارائهشده در این مقاله، توصیههای نقطهبهنفع زمینه خاص را بر اساس نمونهگیری تصادفی با وزن محبوبیت و ماشین فاکتورسازی ارائه میدهد. با این حال، اعتبار آن ممکن است هنوز محدود باشد. در ادامه به تهدیدات اعتبار داخلی و خارجی آن می پردازیم.
تهدیدهای اعتبار داخلی به عواملی مربوط می شود که می توانست بر نتایج تأثیر بگذارد. در مطالعه، این عمدتا به دلیل عوامل زمینه ای است که بر عملکرد مدل تأثیر می گذارد. ContextSWRank مهمترین عوامل را در نظر می گیرد: زمان، مسافت و دما. بررسی برخی عوامل دیگر مانند روابط اجتماعی ارزش دارد. با این حال، اکثر مجموعه داده ها فاقد چنین اطلاعاتی هستند. تهدید دیگر برای اعتبار داخلی، کاربرد آن است. در واقع، ContextSWRank نسبت به سایر خطوط پایه منابع محاسباتی و حافظه بیشتری مصرف می کند، زیرا شامل بسیاری از اطلاعات متنی است. با این حال، ContextSWRank توانایی رضایت بخش خود را هنگام برخورد با داده های تست نشان داده است.
تهدیدهای اعتبار خارجی مربوط به تعمیم نتایج است. در اینجا، یک نگرانی خاص از مجموعه داده برای ارزیابی ناشی می شود. می توان استدلال کرد که عملکرد می تواند با مجموعه داده های مختلف متفاوت باشد. با این حال، به دست آوردن چنین سوابق ورود واقعی که حاوی اطلاعات متنی غنی باشد، دشوار است. اگرچه مجموعه داده، سوابق ورود به چندین سال پیش را در خود نگهداری می کند، بسیاری از محققان اخیر مدل های خود را بر روی چنین مجموعه داده های سنتی دنیای واقعی ارزیابی کرده اند، همانطور که در [ 10 ، 31 نشان داده شده است.]. علاوه بر این، از آنجا که Foursquare یک LBSN بسیار محبوب است، مجموعه داده های عمومی در دسترس از Foursquare یک محیط محکم برای آزمایش موثر فراهم می کند. در آینده، مدل پیشنهادی میتواند در صورت امکان بر روی سایر مجموعههای داده ارزیابی شود.
8. نتیجه گیری و کار آینده
امروزه بسیاری از مردم دوست دارند مکان هایی را که بازدید می کنند در شبکه های اجتماعی مبتنی بر مکان (LBSN) به اشتراک بگذارند. توصیه نقطه مورد علاقه (POI)، به عنوان یکی از خدمات مبتنی بر مکان، به کاربران کمک می کند مکان های جدیدی را برای بازدید پیدا کنند. مطالعات قبلی با استفاده از نفوذ جغرافیایی و ترجیحات کاربر موفقیت زیادی در توصیه POI داشته است. با این حال، ما معتقدیم که تصمیم انسان در مورد مکان بازدید بسیار پیچیده است و شامل عوامل زمینه ای است. این مقاله یک مدل پیشنهادی POI مختص زمینه به نام ContextSWRank را پیشنهاد می کند. بهویژه، یک متریک همبستگی تأثیر دو طرفه بین کاربران و POI برای اندازهگیری ویژگی معنایی رفتاری کاربر پیشنهاد شد، و یک روش هموارسازی متنی برای کاهش مؤثر پراکندگی دادهها معرفی شد. علاوه بر این، احتمال ورود بر اساس فاصله جغرافیایی بین خانه کاربر و POI محاسبه شد. علاوه بر این، برای رسیدگی به مشکل عدم بازخورد منفی در LBSN، یک روش نمونهگیری تصادفی وزنی بر اساس محبوبیت زمینهای پیشنهاد شد. در نهایت، نتایج توصیهها با ترکیب چندین ویژگی در ماشین فاکتورسازی با از دست دادن رتبهبندی شخصی بیزی به دست آمد. نتایج تجربی بر روی یک مجموعه داده واقعی جمعآوریشده از Foursquare نشان داد که رویکرد پیشنهادی نسبت به روشهای دیگر به عملکرد توصیه بهتری دست یافت. در آینده، مسائل زیر باید بیشتر مورد مطالعه قرار گیرند: (الف) عمیقاً عوامل تأثیرگذار بر رفتار کاربر در LBSN را بررسی کنید. (ب) با تسریع فرآیند توصیه، تجربه کاربر را بهبود بخشد.







بدون دیدگاه