

کلید واژه ها:
کریجینگ معمولی (OK) ; جنگل تصادفی (RF) ; الگوریتم های یادگیری ماشین (MLA) ; زمین آمار ; تخمین فضایی ; SHAP ; یادگیری ماشینی قابل تفسیر
1. مقدمه
2. بررسی ادبیات
3. مواد و روشها
3.1. رگرسیون خطی چندگانه (MLR)
MLR [ 47 ، 91 ، 92 ] یک تکنیک شناخته شده است که پارامترهای p + 1 را تخمین می زند.β0،β1،β2…βپ�0،�1،�2…�پتعریف یک رابطه خطی بین ویژگی/های ورودی ( ایکسمن 1، ایکسمن 2…ایکسمن ص) ایکسمن1، ایکسمن2…ایکسمنپ) و ویژگی خروجی (yمن)(�من)برای n نمونه داده شدهi = 1 ، 2 ، … n .من=1،2،…�.
مدل با فرضیات معتبر است که ویژگی های ورودی مستقل هستند (همبستگی بالایی ندارند)، خطا همن=yمنˆ–yمن��=��^−��باید ثابت (همسانی)، مستقل و به طور معمول توزیع شود. عبارت ε�را می توان به عنوان نویز نامرتبط نادیده گرفت، در حالی که سایر پارامترها به صورت زیر تعیین می شوند:
جایی که X است ( n × p + 1 )�×�+1ماتریسی با ستونی از وحدت و Y نشان دهنده ( 1 × p + 1 )1×�+1بردار ستون خروجی با پارامتر intercept β0�0در انتهای ستون تعداد بیشتری از ویژگیها به یادگیری روابط غیرخطی کمک میکند و MLR را قادر میسازد تا مسائل پیچیده را با تنوع بالا درک کند [ 47 ، 48 ، 49 ]. یک مدل خودرگرسیون فضایی خطی در معادله (3) در زیر شامل چهار عبارت به عنوان مدل های خودرگرسیون فضایی با عبارت خطای خودرگرسیون فضایی (SAR-SAR) است [ 93 ]. اصطلاحات شامل (1) متغیرهای وابسته وزنی در یک منطقه با مقادیر همسایه مرتبط، و به دنبال آن دو عبارت رگرسیون، یعنی (2) متغیر با تاخیر مکانی متغیر وابسته، (3) متغیرهای دارای تاخیر مکانی برخی یا همه متغیرهای برون زا هستند. و (4) دو عبارت آخر نشان دهنده مدل فضایی برای اختلالات تصادفی [ 93 ] است.
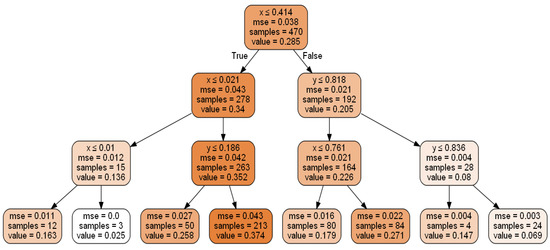
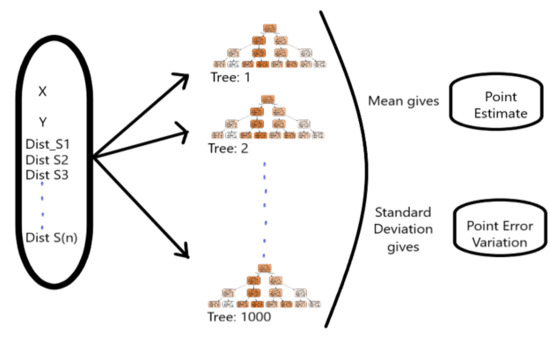
3.2. الگوریتم جنگل تصادفی
-
-row1: بهترین ویژگی ورودی انتخاب شده و مقادیر قطع آن در آن زیر مجموعه
-
-row2: میانگین مربعات خطا برای آن زیر مجموعه
-
-row3: تعداد نمونه ها در آن زیر مجموعه
-
-row4: V (خروجی به عنوان مثال، غلظت شیمیایی) در آن زیر مجموعه (مقادیر بین 0-1 نرمال می شوند، که برای درخت تصمیم ضروری نیست).
3.3. تعمیم مدل و تنظیم فراپارامتر
3.4. سنجش عملکرد
همه مدلهای رگرسیون رابطه ورودی به خروجی را با به حداقل رساندن یک متریک خطا (یعنی عدم تشابه بین خروجی مدل و خروجی واقعی) مانند «میانگین مربعات خطا (MSE)» یا «میانگین مطلق خطا (MAE)» بیان میکنند [ 47 ، 48 ، 49 ]. MSE و خطای میانگین مربعات ریشه “RMSE” قابل تمایز هستند، در حالی که MSE بیشتر از RMSE و MAE مستعد ابتلا به موارد پرت است [ 104 ]. مقدار R-squared مکمل نسبت واریانس خطا = است ∑(yˆ– y)2∑�^-�2به واریانس توضیح داده شده ∑( y–y¯)2∑�-�¯2داده شده به صورت:
با این حال، به جای استفاده از یک معیار عملکرد واحد، مانند ضریب همبستگی یا مقدار R-squared، محققان پیشنهاد می کنند از یک “مقدار مهارت” برای ترکیب مهم ترین معیار عملکرد به عنوان یک آمار خلاصه استفاده شود [ 24 ، 25 ، 105 ]. این اصطلاح چندین معیار عملکرد مهم مانند “R_squared”، “میانگین مطلق خطا (AME)”، “میانگین مطلق خطا (MAE)” و “ریشه میانگین مربعات خطا (RMSE)” را ترکیب می کند [ 25 ]. ارزش مهارت را می توان به صورت زیر ارائه کرد:
3.5. الگوریتم بهینه سازی بیزی (BOA)
منظم سازی برای یافتن بهترین تناسب بین واریانس کم، به عنوان مثال، زیر برازش، و واریانس بالا (یعنی اضافه برازش) اعمال می شود. بهترین مقادیر Hyperparameter با استفاده از یک استراتژی اعتبار سنجی متقابل Grid یا Bayesian [ 47 ، 48 ، 49 ] جستجو می شود. BOA [ 40 , 106 , 107 , 108 ] یک روش کارآمد برای یافتن فراپارامترها با استفاده از قضیه بیز است. بر اساس قضیه بیز، احتمال شرطی یک رویداد عبارت است از:
اصطلاح P(B) برای عادی سازی استفاده می شود که در مورد بهینه سازی مورد نیاز نیست. بنابراین، پس از حذف P(B)، احتمال خلفی P(A|B) ضربی از احتمال P(B|A) و P(A) قبلی است. نمونه های فراپارامتر احتمالی ( ایکس1، ایکس2، ایکس3…ایکسnایکس1، ایکس2، ایکس3…ایکس�) و هزینه ارزیابی شده آنها از تابع هدف f(ایکس1) ، f (ایکس2) ، f (ایکس3) … f(ایکسn)�ایکس1، �(ایکس2)، �(ایکس3)…�(ایکس�)داده D را تشکیل می دهد و برای محاسبه پیشین استفاده می شود. تابع احتمال P(D|f) با جمع آوری داده های بیشتر تغییر می کند، به عنوان مثال، (ایکسn + 1، اف (ایکسn + 1) )ایکس�+1، �ایکس�+1. احتمال پسین که تابع هدف جایگزین P(f|D) نیز نامیده میشود، دانش/تقریبی تابع هدف را نشان میدهد و برای ارزیابی هزینه نمونههای کاندید مختلف با استفاده از رابطه (7) زیر استفاده خواهد شد.
احتمال پسین صرفاً حاصل ضرب احتمال و شرایط قبلی است. عبارت ‘f’ نشان دهنده تابع هدف است که باید حداکثر شود. D داده های متشکل از نمونه ها را نشان می دهد (مقادیر فراپارامترهای مختلف ایکس1، ایکس2، ایکس3…ایکسnایکس1، ایکس2، ایکس3…ایکس�)، ارزیابی/دیده شده تا کنون) و هزینه های مرتبط با آنها f(ایکس1) ، f (ایکس2) ، f (ایکس3) … f(ایکسn)�ایکس1، �(ایکس2)، �(ایکس3)…�(ایکس�). پس از برازش تابع P(f|D) توسط یک تکنیک مدلسازی پیشبینیکننده مانند RF یا فرآیند گاوسی، تابع جانشین برای آزمایش نمونههای کاندید مختلف استفاده میشود. مجموعه جدیدی از مقادیر فراپارامتر از مدل با استفاده از احتمال بهبود (PI) ارائه شده در معادله (8) نمونه برداری شده است. اگر PI قابل توجه باشد، ابرپارامترها برای تعیین مقدار تابع هدف دقیق آنها با استفاده از اعتبارسنجی متقاطع 10 برابری استفاده میشوند و دادهها برای بازسازی تابع با استفاده از معادله (7) به روز میشوند.
که در آن cdf() = تابع توزیع تجمعی نرمال، mu = میانگین تابع جایگزین (P(f|D)) برای یک نمونه معین x، stdev = انحراف استاندارد تابع جایگزین برای یک نمونه معین x، و best_mu = میانگین تابع جانشین برای بهترین مجموعه فراپارامترهای یافت شده تاکنون.
- 1.
-
تابع هدف (مقدار R-square) را با استفاده از رابطه (7) مدل کنید (P(f|D t−1 ).
- 2.
-
best_mu را پیدا کنید یعنی میانگین بهترین مقادیر از مدل (P(f|D t−1 ))
- 3.
-
مجموعه جدیدی از بهترین نامزدها را پیدا کنید ایکسn + 1…ایکس�+1…(مقادیر فراپارامتر) از طریق PI
- 4.
-
تابع/های هدف واقعی را محاسبه کنید f(ایکسn + 1) …�ایکس�+1…توسط الگوریتم RF/MLR، یعنی مقدار R-square بر اساس اعتبارسنجی متقاطع 10 برابری.
- 5.
-
به روز رسانی داده ها به عنوان Dتی�تی، یعنی ایکس1، ایکس2، ایکس3…ایکسn + 1، …ایکس1، ایکس2، ایکس3…ایکس�+1،…و مقادیر تابع هدف مرتبط f(ایکس1) ،f (ایکس2) ، f (ایکس3) … f(ایکسn + 1) ، �ایکس1، �(ایکس2)، �(ایکس3)…�(ایکس�+1)، … و به مرحله 1 بروید
- 6.
-
اگر PI ناچیز است یا به N تکرار رسیده است، توقف کنید و بهترین پارامترها را گزارش کنید.
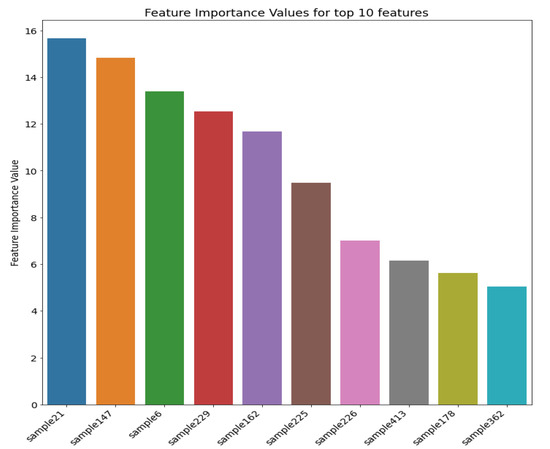
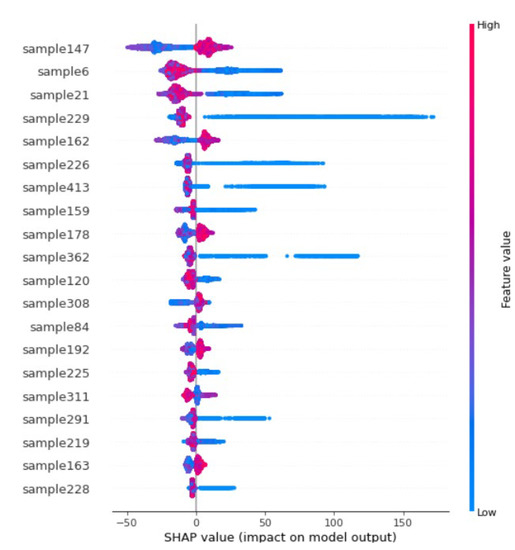
3.6. توضیحات افزودنی SHapley (SHAP)
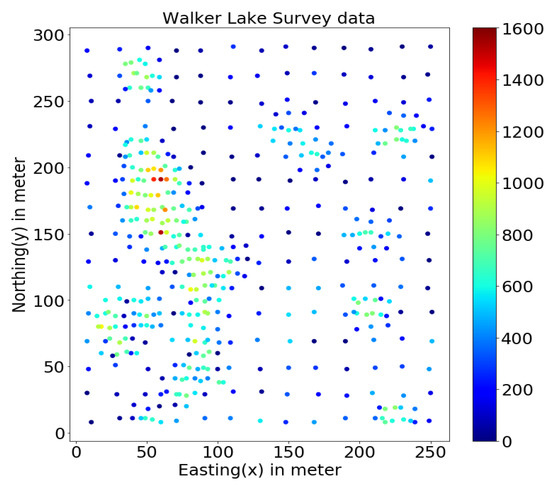
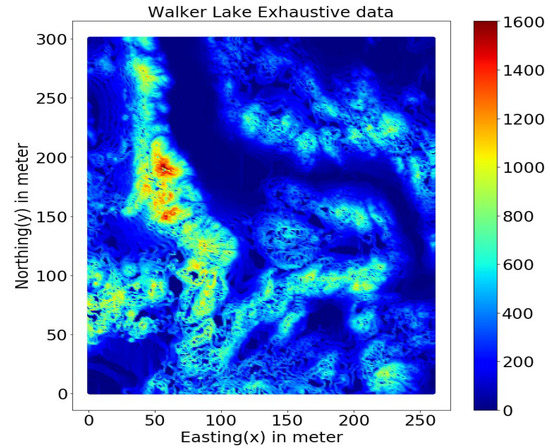
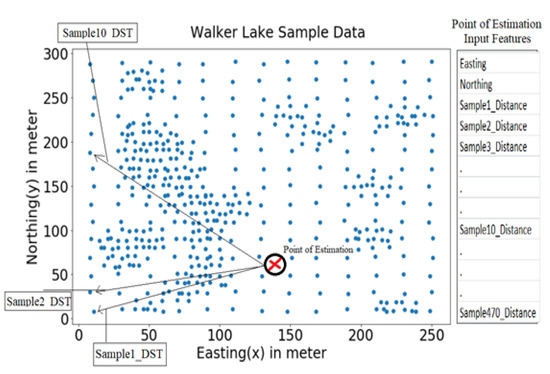
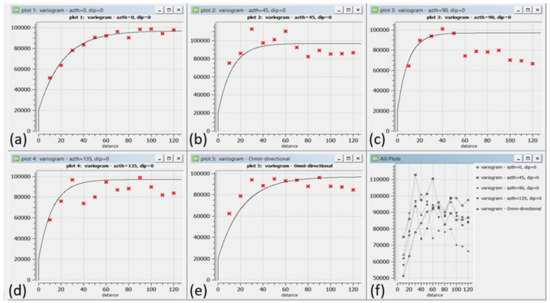
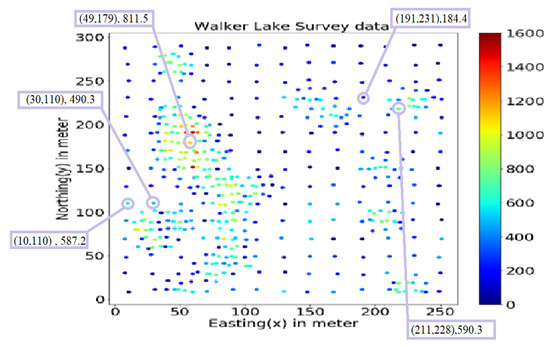
3.7. مجموعه داده دریاچه واکر
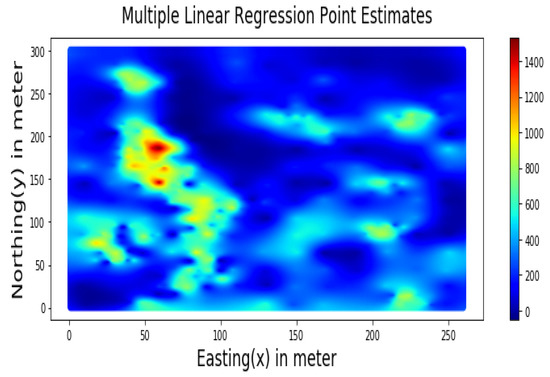
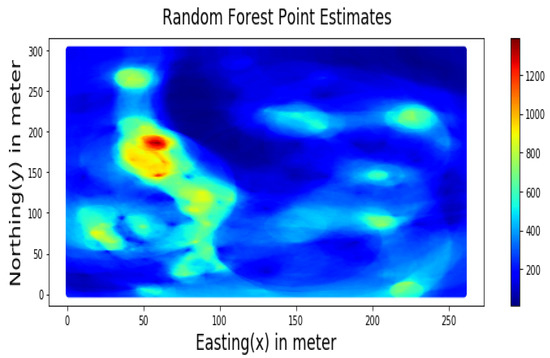
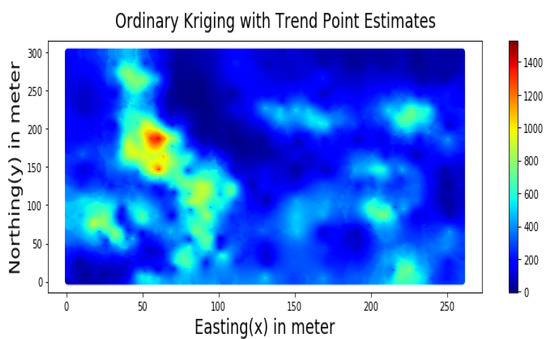
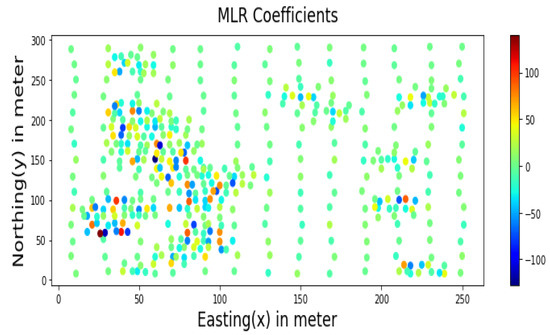
4. کاربرد MLR و RF برای تخمین فضایی
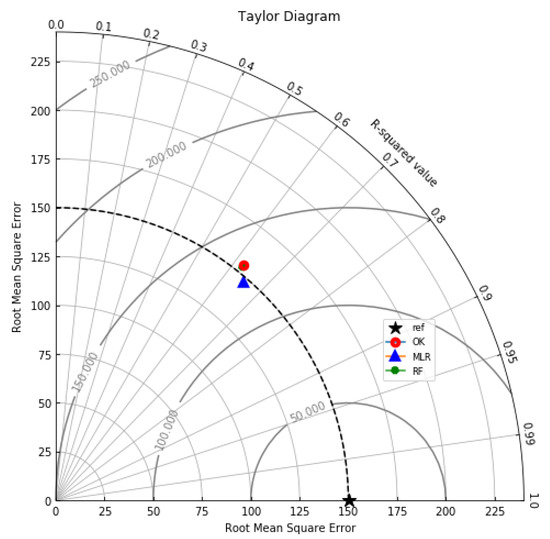
5. نتایج
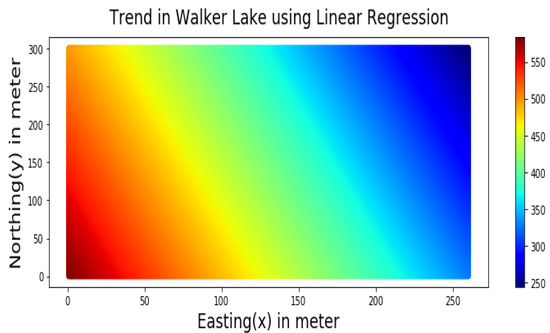
مؤلفه روند، همانطور که در شکل 6 نشان داده شده است ، با استفاده از معادله رگرسیون خطی زیر (9) با استفاده از مختصات دکارتی Easting (X) و Northing (Y) مدل شده است:
6. بحث
7. نتیجه گیری
منابع
- روسی، من؛ Deutsch, CV برآورد منابع معدنی ; Springer: Dordrecht، هلند، 2014; ISBN 9781402057175. [ Google Scholar ]
- Pyrcz، MJ; Deutsch, C. Geostatistical Reservoir Modeling , 2nd ed.; انتشارات دانشگاه آکسفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 2002; شابک 0-19-513806-6. [ Google Scholar ]
- مونستیز، پ. آلارد، دی. Froidevaux, R. geoENV III-Geostatistics for Environmental Applications. مجموعه مقالات سومین کنفرانس اروپایی زمین آمار برای کاربردهای زیست محیطی که در آوینیون، فرانسه، 22 تا 24 نوامبر برگزار شد . Springer: Dordrecht، هلند، 2000; شابک 978-0-7923-7107-6. [ Google Scholar ]
- الیور، کارشناسی ارشد برنامه های زمین آماری برای کشاورزی دقیق . Springer: New York, NY, USA, 2010; شابک 978-90-481-9132-1. [ Google Scholar ]
- آزودو، ال. Soares, A. Methods Geostatistical Methods for Reservoir Geophysics ; Springer: Cham, Switzerland, 2017; شابک 978-3-319-53200-4. [ Google Scholar ]
- Leuangthong، O. خان، ک.د. Deutsch, CV مسائل حل شده در زمین آمار ; وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2008; شابک 978-0-470-17792-1. [ Google Scholar ]
- Sarma, D. زمین آمار با کاربرد در علوم زمین ; Springer: Dordrecht، هلند، 2006; شابک 978-1-4020-9379-1. [ Google Scholar ]
- تخمین درجه فام، TD با استفاده از الگوریتمهای مجموعه فازی. ریاضی. جئول 1997 ، 29 ، 291-305. [ Google Scholar ] [ CrossRef ]
- Matheron، G. اصول زمین آمار. اقتصاد جئول 1962 ، 58 ، 1246-1266. [ Google Scholar ] [ CrossRef ]
- کوون، اچ. یی، اس. Choi, S. بررسی عددی برای رفتار نامنظم مدل جایگزین کریجینگ. جی. مکانیک. علمی تکنولوژی 2014 ، 28 ، 3697-3707. [ Google Scholar ] [ CrossRef ]
- ایزاکس، EH; Srivastava, RM Applied Geostatistics , 1st ed.; انتشارات دانشگاه آکسفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 1989; ISBN 978-0- 19-605013-4. [ Google Scholar ]
- عابدی، م. علی ترابی، س. نوروزی، غلامرضا; حمزه، م. Elyasi، GR PROMETHEE II: یک روش دانش محور برای اکتشاف مس. محاسبه کنید. Geosci. 2012 ، 46 ، 255-263. [ Google Scholar ] [ CrossRef ]
- دوتاوت، آر. مارکوت، دی. یک رویکرد نیمه حریصانه جدید برای افزایش برنامه ریزی حفاری. نات منبع. Res. 2020 ، 29 ، 3599–3612. [ Google Scholar ] [ CrossRef ]
- فاتحی، م. اسدی، ح. حسین مرشدی، ع. طراحی سه بعدی گمانه های مکمل بهینه با تحلیل تلفیقی داده های اکتشافی مختلف با استفاده از رویکرد MADM ترتیبی. نات منبع. Res. 2020 ، 29 ، 1041-1061. [ Google Scholar ] [ CrossRef ]
- کومرال، م. اوزر، کامپیوتر و علوم زمین برنامه ریزی کمپین حفاری اضافی با استفاده از الگوریتم ژنتیک دو فضایی: یک رویکرد نظری بازی. محاسبه کنید. Geosci. 2013 ، 52 ، 117-125. [ Google Scholar ] [ CrossRef ]
- بندورف، جی. حرکت به سمت مدیریت زمان واقعی ذخایر معدنی – یک چارچوب حلقه بسته زمین آماری و بهینه سازی معدن. در برنامه ریزی معدن و انتخاب تجهیزات. ; Drebenstedt, C., Singhal, R., Eds. انتشارات بین المللی Springer: چم، سوئیس، 2014; صفحات 989-999. شابک 978-3-319-02678-7. [ Google Scholar ]
- باکستون، ام. Benndorf, J. استفاده از داده های مشتق شده حسگر در بهینه سازی در امتداد زنجیره ارزش معدن. در مجموعه مقالات پانزدهمین کنگره بین المللی ISM، آخن، آلمان، 16 تا 20 سپتامبر 2013. صص 324-336. [ Google Scholar ]
- محمد، ک. تغییرپذیری و عدم قطعیت در مقیاس کوتاه مدل سازی شیشه، HJ در حین تخمین منابع معدنی با استفاده از تکنیک تخمین فازی جدید. ژئواستند. نتایج جغرافیایی تحلیلی 2011 ، 35 ، 369-385. [ Google Scholar ] [ CrossRef ]
- توتمز، بی. Tercan، AE; کیماک، یو. اپلهانس، تی. موانگومو، ای. هاردی، DR; کنف، A.; ناوس، تی. توتمز، بی. Tercan، AE; و همکاران مدلسازی فازی برای تخمین ذخیره بر اساس تغییرپذیری فضایی. ریاضی. جئول 2007 ، 39 ، 87-111. [ Google Scholar ] [ CrossRef ]
- اپلهانس، تی. موانگومو، ای. هاردی، DR; کنف، A.; Nauss, T. ارزیابی رویکردهای یادگیری ماشین برای درونیابی دمای ماهانه هوا در کوه کلیمانجارو، تانزانیا. تف کردن آمار 2015 ، 14 ، 91-113. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاپاپریدیس، IK; دنبی، ب. مدلسازی شبکه عصبی تنوع فضایی درجه سنگ معدن. In Perspectives in Neural Computing، مجموعه مقالات ICANN، Skovde، سوئد، 2-4 سپتامبر 1998 . Niklasson, L., Bodén, M., Ziemke, T., Eds. Springer: لندن، انگلستان، 1998; ص 209-214. [ Google Scholar ]
- Dean, S. Journal of Natural Gas Science and Engineering Reservoir شبیه سازی و مدل سازی بر اساس داده ها و هوش مصنوعی. جی. نات. علوم گاز مهندس 2011 ، 3 ، 697-705. [ Google Scholar ] [ CrossRef ]
- دوو، جی. یونس، AP; تین بوی، دی. مرغدی، ع. ساهانا، م. زو، ز. چن، CW; خسروی، ک. یانگ، ی. Pham، BT ارزیابی الگوریتمهای جنگل تصادفی پیشرفته و درخت تصمیم برای مدلسازی حساسیت زمین لغزش ناشی از بارندگی در جزیره آتشفشانی ایزو-اوشیما، ژاپن. علمی کل محیط. 2019 ، 662 ، 332-346. [ Google Scholar ] [ CrossRef ]
- دوتا، اس. عملکرد پیشبینی الگوریتمهای یادگیری ماشین برای تخمین ذخایر معدنی در دادههای پراکنده و غیردقیق. Ph.D. پایان نامه، دانشگاه آلاسکا فیربنکس، فیربنکس، AK، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- دوتا، اس. باندوپادیای، س. گنگولی، ر. Misra, D. الگوریتم های یادگیری ماشین و کاربرد آنها در تخمین ذخایر معدنی داده های پراکنده و غیر دقیق. جی. اینتل. فرا گرفتن. سیستم Appl. 2010 ، 2 ، 86-96. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گیلاردی، ن. Bengio، S. مقایسه چهار الگوریتم یادگیری ماشین برای تجزیه و تحلیل داده های مکانی. در نقشه برداری رادیواکتیویته در محیط – مقایسه درونیابی فضایی 1997 ; Dubois, G., Malczewski, J., DeCort, M., Eds. دفتر انتشارات رسمی جوامع اروپایی: لوکزامبورگ، 2003; ص 222-237. [ Google Scholar ]
- Gonçalves، Í.G. کومیرا، اس. Guadagnin، F. کامپیوترها و علوم زمین یک رویکرد یادگیری ماشینی به روش میدان بالقوه برای مدلسازی ضمنی ساختارهای زمینشناسی. محاسبه کنید. Geosci. 2017 ، 103 ، 173-182. [ Google Scholar ] [ CrossRef ]
- گوموس، ک. Sen, A. مقایسه روشهای درونیابی فضایی و شبکههای عصبی چند لایه برای توزیعهای نقطهای مختلف در یک مدل ارتفاعی دیجیتال. Geod. وستن 2013 ، 57 ، 523-543. [ Google Scholar ] [ CrossRef ]
- کویکه، ک. ماتسودا، اس. سوزوکی، تی. Ohmi، M. برآورد مبتنی بر شبکه عصبی محتویات فلزی اصلی در منطقه هوکوروکو، شمال ژاپن، برای کاوش ذخایر نوع Kuroko. نات منبع. Res. 2002 ، 11 ، 135-156. [ Google Scholar ] [ CrossRef ]
- لئونه، اس. روتیل، اس. محدود، سی. لئون، اس. یکپارچه سازی شبکه های عصبی مصنوعی و زمین آمار برای مدل سازی بلوک های زمین شناسی سه بعدی بهینه در تخمین ذخایر معدنی – مطالعه موردی. بین المللی J. Min. علمی تکنولوژی 2015 ، 26 ، 581-585. [ Google Scholar ]
- لی، جی. هیپ، AD; پاتر، ا. دانیل، جی جی استفاده از روش های یادگیری ماشین برای درونیابی فضایی متغیرهای محیطی. محیط زیست مدل. نرم افزار 2011 ، 26 ، 1647-1659. [ Google Scholar ] [ CrossRef ]
- مروین، دی. کراملی، آر جی. شبکههای عصبی مصنوعی Civco، DL به عنوان روشی برای درونیابی فضایی برای مدلهای ارتفاعی دیجیتال. کارتوگر. Geogr. Inf. علمی 2002 ، 29 ، 99-110. [ Google Scholar ] [ CrossRef ]
- ریگل، جی پی. جارویس، CH; استوارت، N. شبکه های عصبی مصنوعی به عنوان ابزاری برای درونیابی فضایی. بین المللی جی. جئوگر. Inf. علمی 2001 ، 15 ، 323-343. [ Google Scholar ] [ CrossRef ]
- یداو، ع. Satyannarayana، P. بهینه سازی الگوریتم ژنتیک چندهدفه شبکه عصبی مصنوعی برای تخمین میزان رسوب معلق در حوضه رودخانه ماهانادی، هند. بین المللی J. رودخانه Manag حوضه. 2020 ، 18 ، 207-215. [ Google Scholar ] [ CrossRef ]
- Carranza، EJM; Laborte، AG مدلسازی پیشبینی جنگل تصادفی چشمانداز معدنی با مقادیر گمشده در آبرا (فیلیپین). محاسبه کنید. Geosci. 2015 ، 74 ، 60-70. [ Google Scholar ] [ CrossRef ]
- ورونزی، اف. Schillaci، C. مقایسه بین مدلهای زمینآماری و یادگیری ماشینی به عنوان پیشبینیکننده کربن آلی خاک سطحی با تمرکز بر تخمین عدم قطعیت محلی. Ecol. اندیک. 2019 ، 101 ، 1032-1044. [ Google Scholar ] [ CrossRef ]
- هنگل، تی. نوسبام، م. رایت، MN; Heuvelink، GBM؛ Gräler، B. جنگل تصادفی به عنوان یک چارچوب عمومی برای مدل سازی پیش بینی متغیرهای مکانی و مکانی-زمانی. PeerJ 2018 , 2018 , e5518. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Baez-Villanueva، OM; زامبرانو-بیگیارینی، م. بک، او؛ مک نامارا، آی. ریب، ال. ناودیت، ا. بیرکل، سی. وربیست، ک. Giraldo-Osorio، JD; Xuan Thinh، N. RF-MEP: یک روش جدید جنگل تصادفی برای ادغام محصولات بارش شبکه ای و اندازه گیری های زمینی. سنسور از راه دور محیط. 2020 , 239 , 111606. [ Google Scholar ] [ CrossRef ]
- فیورنتینی، ن. معبودی، م. لوسا، م. گرک، ام. ارزیابی انعطافپذیری زیرساختها در برابر رویدادهای برونزا با استفاده از تخمینهای حرکت سطحی مبتنی بر ps-insar و تکنیکهای رگرسیون یادگیری ماشین. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2020 ، 5 ، 19-26. [ Google Scholar ] [ CrossRef ]
- فیورنتینی، ن. معبودی، م. لندری، پ. لوسا، م. Gerke، M. پیشبینی حرکت سطحی و نقشهبرداری برای مدیریت زیرساختهای جادهای با اندازهگیریهای PS-InSAR و الگوریتمهای یادگیری ماشین. Remote Sens. 2020 , 12 , 3976. [ Google Scholar ] [ CrossRef ]
- زی، ز. چن، جی. منگ، ایکس. ژانگ، ی. کیائو، ال. Tan, L. مطالعه تطبیقی نقشهبرداری حساسیت زمین لغزش با استفاده از وزن شواهد، رگرسیون لجستیک و ماشین بردار پشتیبان و ارزیابی شده توسط نظارت SBAS-InSAR: بخش Zhouqu به Wudu در حوضه رودخانه Bailong، چین. محیط زیست علوم زمین 2017 ، 76 ، 313. [ Google Scholar ] [ CrossRef ]
- لسنیاک، ا. Porzycka، S. محاسبات زمین آماری در تجزیه و تحلیل داده های psinsar. در علوم محاسباتی-ICCS 2009 ; Allen, G., Nabrzyski, J., Seidel, E., van Albada, GD, Dongarra, J., Sloot, PMA, Eds. یادداشت های سخنرانی در علوم کامپیوتر; Springer: برلین/هایدلبرگ، آلمان، 2009; جلد 5544. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، دبلیو. دو، پ. Wang, D. Ensemble Learning برای درونیابی فضایی محتوای پتاسیم خاک بر اساس اطلاعات محیطی. PLoS ONE 2015 ، 10 ، e0124383. [ Google Scholar ] [ CrossRef ]
- لیو، اس. ژانگ، ی. ما، پ. لو، بی. Su, H. یک روش جدید درون یابی فضایی بر اساس شبکه عصبی RBF یکپارچه. Procedia Environ. علمی 2011 ، 10 ، 568-575. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کرکوود، سی. غار، م. بیمیش، دی. گربی، اس. فریرا، A. رویکرد یادگیری ماشین برای نقشه برداری ژئوشیمیایی. جی. ژئوشیم. کاوش کنید. 2016 ، 167 ، 49-61. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دای، اف. ژو، Q. Lv، Z. وانگ، ایکس. لیو، جی. پیشبینی فضایی محتوای ماده آلی خاک با ادغام شبکه عصبی مصنوعی و کریجینگ معمولی در فلات تبت. Ecol. اندیک. 2014 ، 45 ، 184-194. [ Google Scholar ] [ CrossRef ]
- هستی، تی. طبشیرانی، ر. Friedman, J. The Elements of Statistical Learning Data Mining, Inference, and Prediction , 2nd ed.; سری در آمار; Springer: New York, NY, USA, 2009; شابک 978-0-387-84857-0. [ Google Scholar ]
- Bishop، CM Pattern Recognition and Machine Learning ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2006; جلد 2، ISBN 9780387310732. [ Google Scholar ]
- راسل، اس جی. Norvig, P. Artificial Intelligence A Modern Approach 4th Edition , 3rd ed.; پرنتیس هال: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2003; ISBN 9780136042594. [ Google Scholar ]
- Anees، MT; عبدالله، ک. نواوی، MNM; آب رحمان، NNN; Piah, AR, Mt. سیاکیر، MI; علی خان، م.م. Abdul, AK برآورد فضایی میانگین بارش روزانه با استفاده از رگرسیون خطی چندگانه با استفاده از متغیرهای توپوگرافی و سرعت باد در اقلیم گرمسیری. جی. محیط زیست. مهندس Landsc. مدیریت 2018 ، 26 ، 299-316. [ Google Scholar ] [ CrossRef ]
- Baltensperger، AP; کفال، TC; اشمید، ام اس; Humphries، GRW; کوور، ال. Huettmann، F. مشاهدات فصلی و پیشبینیهای مدل فضایی مبتنی بر یادگیری ماشینی برای کلاغ معمولی (Corvus corax) در محیط شهری، زیر قطب شمال فیربنکس، آلاسکا. قطبی بیول. 2013 ، 36 ، 1587-1599. [ Google Scholar ] [ CrossRef ]
- بل، ال. آلارد، دی. لوران، جی.ام. چدادی، ر. بار-هن، A. الگوریتم سبد خرید برای داده های مکانی: کاربرد در داده های زیست محیطی و اکولوژیکی. محاسبه کنید. آمار داده آنال. 2009 ، 53 ، 3082-3093. [ Google Scholar ] [ CrossRef ]
- چاترجی، اس. باندوپادیای، س. Machuca، D. پیشبینی عیار سنگ معدن با استفاده از الگوریتم ژنتیک و خوشهبندی مبتنی بر مدل شبکه عصبی مجموعهای. ریاضی. Geosci. 2010 ، 42 ، 309-326. [ Google Scholar ] [ CrossRef ]
- چاترجی، اس. باتاچرجی، ا. Samanta، B. برآورد عیار سنگ معدن یک کانسار سنگ آهک در هند با استفاده از شبکه عددی مصنوعی. Appl. GIS 2006 ، 2 ، 1-20. [ Google Scholar ] [ CrossRef ]
- یوکو، سی. یونگگو، ی. Wangwen، W. پیشبینی ضخامت درز زغال سنگ بر اساس ماشینهای بردار پشتیبان حداقل مربعات و روش کریجینگ. الکترون. جی.ژئوتک. مهندس 2015 ، 20 ، 167-176. [ Google Scholar ]
- بادل، م. انگورانی، س. شریعت پناهی، م. کاربرد کریجینگ نشانگر میانه و شبکه عصبی در مدلسازی جمعیت مختلط در یک کانسار سنگ آهن. محاسبه کنید. Geosci. 2011 ، 37 ، 530-540. [ Google Scholar ] [ CrossRef ]
- کانفسکی، م. پوزدنوخوف، ا. Timonin، V. یادگیری ماشینی برای متغیرهای محیطی فضایی . انتشارات EPFL: لوزان، سوئیس، 2018؛ ISBN 9781783980284. [ Google Scholar ]
- Rigol-Sanchez، JP درونیابی فضایی سطوح تابش طبیعی با اطلاعات قبلی با استفاده از شبکههای عصبی مصنوعی پس انتشار. Appl. GIS 2005 ، 1 ، 1-15. [ Google Scholar ] [ CrossRef ]
- گوپتا، ا. کمبل، تی. Machiwal، D. مقایسه تکنیکهای کریجینگ معمولی و بیزی در به تصویر کشیدن تغییرپذیری بارندگی در مناطق خشک و نیمهخشک شمال غرب هند. محیط زیست علوم زمین 2017 ، 76 ، 512. [ Google Scholar ] [ CrossRef ]
- بارگاوی، ز.ک. Chebbi, A. مقایسه دو روش درونیابی کریجینگ بکار رفته در بارندگی مکانی-زمانی. جی هیدرول. 2009 ، 365 ، 56-73. [ Google Scholar ] [ CrossRef ]
- نادبی، ا. لدرو، ای. برنینگ، الف. نقشهبرداری پیشبینیکننده غنای گونههای ماهی صخره، تنوع و زیست توده در زنگبار با استفاده از تصویربرداری IKONOS و تکنیکهای یادگیری ماشینی. سنسور از راه دور محیط. 2010 ، 114 ، 1230-1241. [ Google Scholar ] [ CrossRef ]
- بنیتو، ام. بلاژک، آر. نتلر، ام. روت، اس. اولرو، اچ اس. Furlanello، C. پیش بینی تناسب زیستگاه با مدل های یادگیری ماشین: منطقه بالقوه Pinus sylvestris L. در شبه جزیره ایبری. Ecol. مدل 2006 ، 7 ، 383-393. [ Google Scholar ] [ CrossRef ]
- هونگ، اچ. پرادان، بی. Bui، DT; خو، سی. یوسف، ع.م. چن، دبلیو. مقایسه چهار تابع هسته مورد استفاده در ماشینهای بردار پشتیبان برای نقشهبرداری حساسیت زمین لغزش: مطالعه موردی در منطقه سوئیچوان (چین). Geomat. نات خطر خطرات 2017 ، 8 ، 544-569. [ Google Scholar ] [ CrossRef ]
- عربامری، ع. پرادان، بی. نقشهبرداری پهنهبندی فرسایش خندقی رضایی با استفاده از رگرسیون وزندار جغرافیایی یکپارچه با ضریب قطعیت و مدلهای جنگل تصادفی در GIS. جی. محیط زیست. مدیریت 2019 ، 232 ، 928–942. [ Google Scholar ] [ CrossRef ]
- نوری، ع.م. پرادان، بی. ارزیابی تناسب سایت سد QM Ajaj در رودخانه زاب بزرگ در شمال عراق با استفاده از داده های سنجش از دور و GIS. جی هیدرول. 2019 ، 574 ، 964–979. [ Google Scholar ] [ CrossRef ]
- صبا، ک. کاربرد الگوریتم های یادگیری ماشین در اکتشاف هیدروکربن و مشخصه سازی مخزن. پایان نامه دکتری، دانشگاه آریزونا، توسان، AZ، ایالات متحده آمریکا، 2018. [ Google Scholar ]
- سامانتا، بی. باندوپادیای، س. گانگولی، ر. ارزیابی مقایسه ای الگوریتم های یادگیری شبکه عصبی برای تخمین عیار سنگ معدن. ریاضی. جئول 2006 ، 38 ، 175-197. [ Google Scholar ] [ CrossRef ]
- سامانتا، بی. Bandopadhyay, S. ساخت یک شبکه تابع پایه شعاعی با استفاده از یک الگوریتم تکاملی برای تخمین عیار در یک کانسار طلای پلاسر. محاسبه کنید. Geosci. 2009 ، 35 ، 1592-1602. [ Google Scholar ] [ CrossRef ]
- Tutmez, B. روش شناسی فازی عدم قطعیت گرا برای تخمین درجه. محاسبه کنید. Geosci. 2007 ، 33 ، 280-288. [ Google Scholar ] [ CrossRef ]
- جعفرسته، ب. فتحیان پور، ن. الگوریتم کلونی زنبور مصنوعی اغتشاش همزمان ترکیبی و الگوریتم پس انتشار برای آموزش شبکه عصبی پایه شعاعی خطی محلی بر روی تخمین عیار سنگ معدن. محاسبات عصبی 2017 ، 235 ، 217-227 . [ Google Scholar ] [ CrossRef ]
- گوسوامی، ا. Mishra, MK; پاترا، دی. بررسی معماری شبکه عصبی رگرسیون عمومی برای تخمین عیار یک کانسار سنگ آهن هند. عرب جی. ژئوشی. 2017 ، 10 ، 80. [ Google Scholar ] [ CrossRef ]
- کویکه، ک. ماتسودا، اس. Gu, B. ارزیابی دقت درونیابی کریجینگ عصبی با کاربرد در تجزیه و تحلیل توزیع دما. ریاضی. جئول 2001 ، 33 ، 421-448. [ Google Scholar ] [ CrossRef ]
- Matías، JM; واموند، ا. تابودا، ج. گونزالس-مانتیگا، W. مقایسه کریجینگ و شبکه های عصبی با کاربرد در بهره برداری از یک معدن تخته سنگ. ریاضی. جئول 2004 ، 36 ، 463-486. [ Google Scholar ] [ CrossRef ]
- Raghuvanshi، N. فهرستی جامع از تکنیک های اثبات شده برای رسیدگی به کمبود داده در سفر هوش مصنوعی شما. در دسترس آنلاین: https://towardsdatascience.com/a-comprehensive-list-of-proven-techniques-to-address-data-scarcity-in-your-ai-journey-1643ee380f21 (در 12 مه 2022 قابل دسترسی است).
- چاترجی، اس. Bandopadhyay, S. Goodnews Bay تخمین منبع پلاتین با استفاده از حداقل مربعات پشتیبان رگرسیون برداری با انتخاب ابعاد فضای ورودی و فراپارامترها. نات منبع. Res. 2011 ، 20 ، 117-129. [ Google Scholar ] [ CrossRef ]
- پراسومفان، اس. Mase، S. ایجاد نقشه پیشبینی برای دادههای زمینآماری براساس یک شبکه عصبی تطبیقی با استفاده از نزدیکترین همسایهها. بین المللی جی. ماخ. فرا گرفتن. محاسبه کنید. 2013 ، 3 ، 98-102. [ Google Scholar ] [ CrossRef ]
- سکولیچ، آ. کلیبردا، م. Heuvelink، GBM؛ نیکولیچ، م. باجات، ب. درونیابی فضایی تصادفی جنگل. Remote Sens. 2020 , 12 , 1687. [ Google Scholar ] [ CrossRef ]
- زو، جی. پتروسیان، او. هوش مصنوعی قابل توضیح: استفاده از ارزش شیپلی برای توضیح سیستمهای مبتنی بر ML تشخیص ناهنجاری پیچیده. جلو. آرتیف. هوشمند Appl. 2020 ، 332 ، 152-164. [ Google Scholar ] [ CrossRef ]
- رودریگز-پرز، آر. بایورث، جی. تفسیر مدلهای یادگیری ماشین با استفاده از مقادیر شیپلی: کاربرد برای پیشبینیهای فعالیت چند هدفه و توان ترکیبی. جی. کامپیوتر. کمک کرد. مول. دس 2020 ، 34 ، 1013-1026. [ Google Scholar ] [ CrossRef ]
- کرسی، N. پیش بینی فضایی و کریجینگ معمولی. ریاضی. جئول 1988 ، 20 ، 405-421. [ Google Scholar ] [ CrossRef ]
- فاکس، EW; Ver Hoef، JM; اولسن، AR مقایسه رگرسیون فضایی با جنگل های تصادفی برای مجموعه داده های محیطی بزرگ. PLoS ONE 2020 , 15 , e0229509. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هنگل، تی. Heuvelink، GBM؛ Stein، A. چارچوبی عمومی برای پیشبینی فضایی متغیرهای خاک بر اساس رگرسیون-کریجینگ. ژئودرما 2004 ، 120 ، 75-93. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژورنل، ا. Huijbregts, C. زمین آمار معدن ; انتشارات آکادمیک: لندن، بریتانیا، 1978. [ Google Scholar ]
- شی، ی. لاو، AK; نگ، ای. هو، اچ. بلال، م. یک رویکرد رگرسیونی کاربری زمین در مقیاس چندگانه برای برآورد تغییرپذیری فضایی درون شهری غلظت PM 2.5 با یکپارچه سازی مجموعه داده های چند منبعی. بین المللی جی. محیط زیست. Res. بهداشت عمومی 2022 ، 19 ، 321. [ Google Scholar ] [ CrossRef ]
- واتسون، استنتاج قوی همبستگی فضایی MW در مدلهای رگرسیون خطی و تابلویی. در دسترس آنلاین: https://www.princeton.edu/~umueller/SHAR.pdf (در 20 ژانویه 2022 قابل دسترسی است).
- هالین، ام. لو، ز. Tran، LT رگرسیون فضایی خطی محلی. ان آمار 2004 ، 32 ، 2469-2500. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اوکونلولا، OA؛ آلوبید، م. Olubusoye، OE; آینده، ک. لوکمان، اف. Szűcs، I. رگرسیون فضایی و گفتمان زمین آمار با کاربرد تجربی برای داده های بارش در نیجریه. علمی Rep. 2021 , 11 , 16848. [ Google Scholar ] [ CrossRef ]
- گریث، DA یک راه حل رگرسیون خطی برای مسئله خودهمبستگی فضایی. جی. جئوگر. سیستم 2000 ، 2 ، 141-156. [ Google Scholar ] [ CrossRef ]
- طهماسبی، پ. هزارخانی، ع. شبکه های عصبی ترکیبی – منطق فازی – الگوریتم ژنتیک برای تخمین درجه. محاسبه کنید. Geosci. 2012 ، 42 ، 18-27. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آن، اس. ریو، دی. لی، اس. یک رویکرد مبتنی بر یادگیری ماشین برای تخمین فضایی با استفاده از ویژگیهای فضایی اطلاعات مختصات. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 587. [ Google Scholar ] [ CrossRef ]
- بیل، سی ام. لنون، جی جی؛ Yearsley، JM; بروور، ام جی. Elston, DA تجزیه و تحلیل رگرسیون داده های مکانی. Ecol. Lett. 2010 ، 13 ، 246-264. [ Google Scholar ] [ CrossRef ]
- مدلهای رگرسیون خطی فضایی آربیا، جی. در یک آغازگر برای اقتصاد سنجی فضایی با کاربرد در R ; پالگریو مک میلان: لندن، بریتانیا، 2014; صص 51-98. شابک 978-0-230-36038-9. [ Google Scholar ]
- ساپوترو، DRS؛ محسنین، RY; ویدیانینگسیه، پ. سولیستیانینگسیه. خودرگرسیون فضایی با مدل خطای خودرگرسیون فضایی و برآورد پارامتر آن با روش حداقل مربع فضایی تعمیم یافته دو مرحله ای. J. Phys. Conf. سر. 2019 , 1217 , 012104. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Cheung، TKY; Cheung، KC مدل وابستگی فضایی با تفاوت ویژگی. J. پیش بینی. 2020 ، 39 ، 615-627. [ Google Scholar ] [ CrossRef ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هیز، تی. اوسامی، س. یاکوبوچی، آر. McArdle، JJ استفاده از درختان طبقه بندی و رگرسیون (CART) و جنگل های تصادفی برای تجزیه و تحلیل ساییدگی: نتایج از دو شبیه سازی. روانی پیری 2015 ، 30 ، 911-929. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شمرات، FMJM; رنجان، ر. حسیب، ک.م. یداو، ع. صدیق، ارزیابی عملکرد AH در میان الگوریتمهای درخت تصمیمگیری ID3، C4.5 و CART، الگوریتمهای درخت تصمیم CART. در مجموعه مقالات کنفرانس بین المللی محاسبات فراگیر و شبکه های اجتماعی [ICPCSN 2021]، سالم، تامیل نادو، هند، 19 تا 20 مارس 2021؛ پ. 15. [ Google Scholar ]
- یداو، س. Shukla، S. تجزیه و تحلیل k-Fold Cross-Validation بر روی Hold-Out Validation در مجموعه داده های عظیم برای طبقه بندی کیفیت. در مجموعه مقالات ششمین کنفرانس بین المللی محاسبات پیشرفته، IACC 2016، Bhimavaram، هند، 27-28 فوریه 2016. صص 78-83. [ Google Scholar ]
- Bui، DT; شهابی، ح. امیدوار، ای. شیرزادی، ع. گیرتسما، م. کلگ، جی جی. خسروی، ک. پرادان، بی. فام، بی تی؛ چاپی، ک. و همکاران پیش بینی زمین لغزش کم عمق با استفاده از یک الگوریتم جدید یادگیری ماشین عملکردی ترکیبی. Remote Sens. 2019 , 11 , 931. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پرادان، ب. مطالعه تطبیقی بر روی توانایی پیشبینی درخت تصمیم، ماشین بردار پشتیبان و مدلهای عصبی فازی در نقشهبرداری حساسیت زمین لغزش با استفاده از GIS. محاسبه کنید. Geosci. 2013 ، 51 ، 350-365. [ Google Scholar ] [ CrossRef ]
- خسروی، ک. شهابی، ح. فام، بی تی؛ آداموفسکی، جی. شیرزادی، ع. پرادان، بی. دوو، جی. Ly، HB; گروف، جی. هو، اچ ال. و همکاران ارزیابی مقایسهای مدلسازی حساسیت سیل با استفاده از روشهای تحلیل تصمیمگیری چند معیاره و یادگیری ماشینی. جی هیدرول. 2019 ، 573 ، 311-323. [ Google Scholar ] [ CrossRef ]
- مریانوویچ، م. کوواچویچ، م. باجات، بی. Voženílek، V. ارزیابی حساسیت زمین لغزش با استفاده از الگوریتم یادگیری ماشین SVM. مهندس جئول 2011 ، 123 ، 225-234. [ Google Scholar ] [ CrossRef ]
- تهرانی، ام اس; پرادان، بی. نقشهبرداری حساسیت به سیل جبور، MN با استفاده از یک مجموعه جدید وزنهای شواهد و مدلهای ماشین بردار پشتیبان در GIS. جی هیدرول. 2014 ، 512 ، 332-343. [ Google Scholar ] [ CrossRef ]
- باجاج، الف. معیارهای عملکرد در یادگیری ماشین [راهنمای کامل]. در دسترس آنلاین: https://neptune.ai/blog/performance-metrics-in-machine-learning-complete-guide (در 1 مه 2022 قابل دسترسی است).
- سینکلر، ای جی. Blackwell, GH Applied Mineral Inventory Estimation , 1st ed.; انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2002; ISBN 0511031459. [ Google Scholar ]
- وو، جی. چن، XY; ژانگ، اچ. Xiong، LD; لی، اچ. بهینه سازی فراپارامتر دنگ، SH برای مدل های یادگیری ماشین بر اساس بهینه سازی بیزی. جی. الکترون. علمی تکنولوژی 2019 ، 17 ، 26–40. [ Google Scholar ] [ CrossRef ]
- اسنوک، جی. لاروچل، اچ. آدامز، RP بهینه سازی عملی بیزی الگوریتم های یادگیری ماشین. در مجموعه مقالات NIPS’12: مجموعه مقالات بیست و پنجمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، دریاچه تاهو، NV، ایالات متحده آمریکا، 3-6 دسامبر 2012. صفحات 2951-2959. [ Google Scholar ]
- مارتین، پی. دیوید، EG; اریک، سی.-پی. BOA: الگوریتم بهینه سازی بیزی. در مجموعه مقالات اولین کنفرانس سالانه محاسبات ژنتیکی و تکاملی – جلد 1، اورلاندو، فلوریدا، ایالات متحده آمریکا، 13 تا 17 ژوئیه 1999. Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; صص 525-532. [ Google Scholar ]
- خان، AU; سلمان، س. محمد، ک. حبیب، م. مدلسازی قابلیت انفجار گرد و غبار زغال سنگ زغال سنگ خیبر پختونخوا با استفاده از الگوریتم جنگل تصادفی. Energies 2022 , 15 , 3169. [ Google Scholar ] [ CrossRef ]
- Shapely، LS یک ارزش برای بازی های n-Person. در کمک به نظریه بازی ها (AM-28)، جلد دوم. در سالنامه مطالعات ریاضی ; Kuhn, HWA, Tucker, AW, Eds. انتشارات دانشگاه پرینستون: پرینستون، نیوجرسی، ایالات متحده آمریکا، 1953; صص 307-317. [ Google Scholar ]
- Py با فهرست بسته Python بسته های پایتون را پیدا، نصب و منتشر کنید. در دسترس آنلاین: https://pypi.org/ (دسترسی در 22 دسامبر 2021).
- اوشیرو، TM; پرز، ص. Baranauskas، JA چند درخت در یک جنگل تصادفی؟ BT – یادگیری ماشین و داده کاوی در تشخیص الگو. در یادداشت های سخنرانی در علوم کامپیوتر، مجموعه مقالات یادگیری ماشین و داده کاوی در تشخیص الگو، MLDM 2012 ؛ پرنر، پی، اد. Springer: برلین/هایدلبرگ، آلمان، 2012; جلد 7376، صص 154–168. [ Google Scholar ]
- مری، ن. مارکوت، دی. کمی کردن منابع معدنی و عدم قطعیت آنها با استفاده از دو روش یادگیری ماشینی موجود. ریاضی. Geosci. 2022 ، 54 ، 363-387. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه