

استفاده از حسگرهای مکان محور به طور تصاعدی افزایش یافته است. ردیابی اجسام متحرک به طور فزاینده ای رایج شده است و زمینه جدیدی از تحقیقات را که بر مدیریت داده های مسیر تمرکز دارد، تثبیت می کند. چنین مسیرهایی ممکن است با استفاده از حسگرها و رسانه های اجتماعی از نظر معنایی غنی شوند. این امکان تجزیه و تحلیل دقیق الگوهای رفتار مسیر را فراهم می کند. یکی از مشکلاتی که در این زمینه وجود دارد، جستجوی یک پایگاه داده مسیر معنایی است که منعطف و سازگار باشد. انعطافپذیری به معنای بازیابی مسیرهایی که به درخواست کاربر نزدیکترین هستند و فقط بر اساس تطابق دقیق نیستند. سازگاری به تعدیل با انواع مختلف مسیرهای معنایی اشاره دارد. این مقاله یک رویکرد جدید برای نمایش و پرس و جو مسیرهای معنایی بر اساس تکنیک های پردازش متن پیشنهاد می کند. علاوه بر این، ما یک چارچوب را توصیف می کنیم، SETHE (Semantic Trajectory HuntEr) نامیده می شود که پرس و جوهای شباهت را بر روی پایگاه داده های مسیر غنی شده از لحاظ معنایی انجام می دهد. SETHE را می توان با توجه به انواع جنبه های مطرح شده در پرس و جوهای کاربر تطبیق داد. ما همچنین ارزیابی چارچوب پیشنهادی را با استفاده از یک مجموعه داده واقعی ارائه کردیم و نتایج خود را با رویکردهای پیشرفته مقایسه کردیم.
کلید واژه ها:
مسیرهای معنایی ; جستجوی متنی ; اندازه گیری شباهت
1. مقدمه
گسترش تلفن های هوشمند، حسگرهای ارزان قیمت و دستگاه های ارتباطی بی سیم، امکان نظارت بر فضاهای جغرافیایی موجودات متحرک مانند افراد، حیوانات، اتومبیل ها، کشتی ها و پدیده های طبیعی را فراهم کرده است. در حال حاضر راه های مختلفی برای به دست آوردن مکان حرکت وجود دارد. اشیاء، با سیستم موقعیت یاب جهانی (GPS) ساده ترین و رایج ترین راه برای ساخت مسیرهای خام [ 1 ] است. GPS متشکل از دنباله ای از نقاط جغرافیایی (مختصات طول و عرض جغرافیایی، طول و ارتفاع) است که توسط مهرهای زمانی مرتب شده اند [ 2 ، 3 ، 4 ]]. داده های مسیر برای تجزیه و تحلیل و درک رفتار اجسام متحرک مهم هستند. به عنوان مثال، تجزیه و تحلیل مسیر ممکن است ترافیک، الگوهای رفتاری افراد، مسیرهای ناوبری، مناطق ماهیگیری، مهاجرت حیوانات و مسیرهای طوفان را شناسایی کند [ 5 ].
بسیاری از مطالعات داده های مسیر را با گنجاندن اطلاعات مبتنی بر زمینه غنی کرده اند. Emmanouilidis و همکاران. [ 6 ] زمینه را به عنوان مترادف طیف اطلاعاتی که ممکن است بر انطباق خدمات تأثیر بگذارد، تعریف کرد. چنین اطلاعاتی ممکن است از محیط، کاربر یا سایر سیستم ها ناشی شود. اطلاعات مبتنی بر زمینه، غنیسازی تحلیل مسیر را ممکن میسازد و درک رفتار شی متحرک را بهبود میبخشد [ 7 ]. استفاده از اطلاعات زمینه میتواند بینشهایی را در مورد جنبههای رفتاری اشیاء متحرک ارائه دهد که تنها با استفاده از مسیرهای خام امکانپذیر نخواهد بود، مانند اینکه کدام نقطه مورد علاقه (POI) بازدید شده است، نوع فعالیتهای انجامشده، و هدف مسیر.
محاسبات همه جا حاضر و اینترنت اشیا به دستیابی به اطلاعات مبتنی بر زمینه کمک می کند [ 8 ]. دستگاههای مختلفی مانند ساعتهای هوشمند، حسگرهای پزشکی، دستگاههای شناسایی فرکانس رادیویی (RFID) و حسگرهای محیطی میتوانند اطلاعات مبتنی بر زمینه را ضبط کنند. روش دیگر برای به دست آوردن ضمنی دادههای مسیر و اطلاعات زمینه، اطلاعات جغرافیایی داوطلبانه (VGI) است [ 9 ]، که شامل دادههای جغرافیایی ارائه شده توسط شهروندان از طریق شبکههای اجتماعی مبتنی بر مکان، مانند LinkedGeoData ( https://linkedgeodata.org/ ، قابل دسترسی در 22 مه 2022) و OpenStreetMap ( https://www.openstreetmap.org/ ، مشاهده شده در 22 مه 2022). علاوه بر این، برخی از سیستم عامل های رسانه های اجتماعی، مانند فلیکر ( https://www.flickr.com/، در 22 مه 2022، توییتر ( https://twitter.com/ ، دسترسی در 22 مه 2022)، فیس بوک ( https://www.facebook.com/ ، دسترسی در 22 مه 2022)، و Foursquare ( https ) ://foursquare.com/ ، در 22 مه 2022 قابل دسترسی است)، موقعیت جغرافیایی را از پست های خود ارائه می دهد. سایر اطلاعات رفتاری ممکن است از رسانه های اجتماعی استخراج شوند، مانند فعالیت کاربر و ارزیابی POI.
افزودن اطلاعات زمینه به داده های مسیر، یک مسیر غنی شده معنایی یا به سادگی یک مسیر معنایی ایجاد می کند [ 10 ، 11 ]. در یک مجموعه داده مسیر معنایی، مسیرها حاوی حاشیه نویسی هستند. نقاط بین راه با اطلاعاتی در مورد زمینه محیطی یا محیط شیء موبایل، مانند نام POI یا ضربان قلب کاربر، غنی شده است. یک جنبه، هر نوع اطلاعاتی است که می تواند به POI های مسیر مشروح شود. نمونه هایی از جنبه های POI شامل نام، دسته، آب و هوا، وسیله حمل و نقل و رتبه بندی آنها است [ 12 ]. از این رو، مسیر به یک شی پیچیده با چندین بعد داده متنی مرتبط با حرکت آن تبدیل می شود [ 13 ].
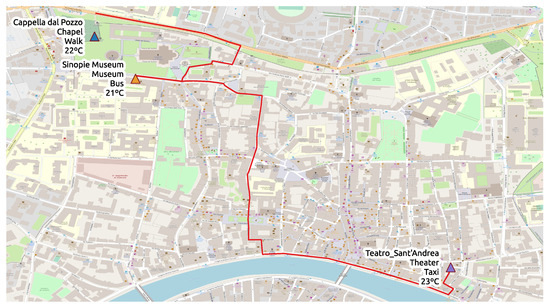
برای درک بهتر مسیرهای معنایی، به مثال نشان داده شده در شکل 1 توجه کنید که مسیر کوتاه یک گردشگر را در شهر پیزا در ایتالیا نشان می دهد. هر ایستگاه از نظر معنایی با چهار جنبه غنی شده است: نام POI، دسته بندی، وسیله حمل و نقل مورد استفاده برای رسیدن به POI، و دمای محیط. مسیر از POI Cappella dal Pozzo که متعلق به دسته Chapel است شروع می شود. گردشگر در حال پیاده روی است و دمای محلی 22 درجه است درجهC. سپس، گردشگر با اتوبوس به سمت موزه دل سینوپی حرکت می کند، جایی که دمای هوا 21 است. درجهج- در نهایت مسیر به تئاتر سنت آندریا ختم می شود، جایی که توریست با تاکسی به آنجا می رسد و دمای هوا 23 است. درجهسی.
وقتی با مسیرهای معنایی سروکار داریم، باید تصمیم بگیریم که چگونه اطلاعات زمینه را نمایش دهیم. برای مثال، نوئل و همکاران. [ 14 ] مسیرها را به شیوه ای چند بعدی نشان می داد، که در آن هر بعد بر یک جنبه متمرکز بود و هر جنبه توسط یک مسیر نشان داده می شد. جدول 1 نمایشی از مسیر را در شکل 1 نشان می دهد. در جدول 1 ، رویداد انتقال، جابجایی بین نقاط توقف است. خط اول مسیر نام POI است که از Cappella dal Pozzo شروع می شود و در Teatro Sant’Andrea به پایان می رسد.سپس ما مسیر دسته بندی را داریم که همان جهت را دنبال می کند، از یک کلیسای کوچک شروع می شود و به یک تئاتر ختم می شود. در نهایت، ما ابزار انتقال و مدارهای دما را بدست می آوریم. از این رو، می توان مسیرها را از دیدگاه های مختلف تجزیه و تحلیل کرد و سؤالات مربوط به جنبه های خاص را حل کرد. به عنوان مثال، می توان مسیرهایی را جستجو کرد که در آن شخص فقط با استفاده از اتوبوس به عنوان وسیله حمل و نقل سفر می کند یا مسیرهایی که از یک مرکز خرید شروع می شود و به یک تئاتر ختم می شود.
موتورهای جستجوی فعلی در مجموعه داده های مسیر معنایی تنها مجموعه مسیرهایی را بازیابی می کنند که دقیقاً با هر محدودیت تعریف شده در پرس و جو کاربر مطابقت دارد. برای مثال، فرض کنید شخصی به دنبال مسیر حرکت شخصی است که با اتوبوس به کلیسای معینی می رسد. در این حالت، نتیجه پرس و جو فقط شامل مسیرهایی با ویژگی دسته برابر با کلیسا و مشخصه میانگین حمل و نقل برابر با اتوبوس خواهد بود. گاهی اوقات، یافتن مسیرهایی که کاملاً با تمام محدودیت های پرس و جو مطابقت دارند، چالش برانگیز می شود. هر چه یک پرس و جو محدودیت های بیشتری داشته باشد، یافتن مسیرهای سازگار دشوارتر می شود. برای مثال، جستجوی مسیرهای افرادی که با تاکسی به کلیسای کوچک، سپس با اتوبوس به موزه رفته اند و پیاده به تئاتر رفته اند، مسیر نشان داده شده در را باز نمی گرداند.شکل 1 . در میان تمام محدودیت های تعریف شده در پرس و جو، تنها جنبه میانگین انتقال اولین و آخرین مکان ها توسط آن خط سیر برآورده نمی شود. از این رو، حتی زمانی که تقریباً تمام محدودیتهای پرس و جو را برآورده میکند، مسیر نشاندادهشده در شکل 1 در نتیجه قابل بازیابی نیست.
یک پرس و جو در پایگاه داده مسیر معنایی وضعیت نقاط توقف در طول مسیر را بیان می کند [ 15 ]. مثالها عبارتند از جستجوی مسیرهایی که از برج کج پیزا شروع میشوند ، مسیرهایی که به موزه ختم میشوند، یا مسیرهایی که از یک کلیسا و سپس یک تئاتر بازدید میکنند.
با هدف حل محدودیتهای فوق، این مطالعه یک چارچوب مسیر معنایی را پیشنهاد میکند که مسیرهای چندوجهی را نشان میدهد و میتواند مشابهترین مسیرها را با توجه به مقادیر جنبه موجود در پرس و جو از طریق یک رویکرد رتبهبندی جستجو کند. چارچوب یک پایگاه داده مسیر معنایی را با استفاده از تکنیک های پردازش متن جستجو می کند. از این رو، مسیر به عنوان یک بردار رشته نمایش داده می شود. هر رشته ممکن است نشان دهنده نام، دسته یا سایر جنبه های POI باشد. یک پرس و جو نیز توسط بردارها نشان داده می شود. فاصله بین بردارهای پرس و جو و مسیر، تطابق و رتبه بندی مجموعه نتایج را تعیین می کند. به عنوان پایه، ما از چارچوب جستجوی مسیر معنایی که توسط Izquierdo و همکاران توسعه یافته است استفاده کردیم. [ 15]، که چارچوبی رسمی برای مسیرهای معنایی با استفاده از منطق توصیف (DL) و SPARQL توصیف می کند.
بنابراین، عمدهترین مطالب این مقاله به شرح زیر است:
-
پیشنهاد یک رویکرد جدید برای نمایش داده های مسیر بر اساس متن.
-
توسعه یک موتور جستجو برای جستجوی مسیرهای معنایی با در نظر گرفتن نه تنها نام و دسته بندی POI، بلکه جنبه های مسیر معنایی.
-
مشخصات یک الگوریتم رتبه بندی جدید که جستجو برای شباهت مسیر را امکان پذیر می کند.
-
اجرای یک رویکرد ساده و کارآمد – زمان اجرا و الزامات ذخیره سازی – برای انجام پرس و جوها در مسیرهای معنایی، در مقایسه با رویکرد مبتنی بر SPARQL.
برای اعتبارسنجی رویکرد خود، ما یک مطالعه موردی را با استفاده از TripBuilder [ 16 ]، یک مجموعه داده مسیری که از دادههای فلیکر، ترکیب شده با دادههای ویکیپدیا ساخته شده است، اجرا کردیم.
ساختار باقی مانده مقاله به شرح زیر است. بخش 2 کارهای مرتبط را مورد بحث قرار می دهد. بخش 3 مفاهیم اساسی و تعریف رسمی چارچوب پرس و جو مسیر معنایی را ارائه می کند. بخش 4 یک مثال در حال اجرا برای نمونه سازی چارچوب SETHE ارائه می کند. بخش 5 آزمایش های انجام شده را شرح می دهد. در نهایت، بخش 6 مقاله را به پایان میرساند و کارهای بیشتری را که باید انجام شود مورد بحث قرار میدهد.
2. کارهای مرتبط
معمولاً دادههای خط سیر خام در یک پایگاه داده فضایی به نام پایگاه داده شی متحرک (MOD) گرفته و ذخیره میشوند [ 17 ]. با این حال، هنگامی که این دادهها جمعآوری و تجزیه و تحلیل شدند، لازم است آنها را با اطلاعات مبتنی بر زمینه غنی کنیم تا پردازش تحلیلی افزایش یابد و کاربران بتوانند کارهایی مانند شناسایی ترافیک، یافتن الگوهای رفتاری افراد، مشاهده مسیرهای ناوبری، شناسایی مناطق ماهیگیری را انجام دهند. ، مطالعه مهاجرت حیوانات، درک مسیرهای طوفان و غیره [ 5 ]. SeMiTri [ 18 ] یک سیستم غنی سازی مسیر است که از حاشیه نویسی معنایی برای شناسایی توقف ها و حرکت های مسیر استفاده می کند [ 19 ]]. SeMiTri مسیرها را با اطلاعاتی در مورد POI، وسایل حمل و نقل و نوع منطقه جغرافیایی (مسکونی، تجاری، بازار و غیره) به صورت معنایی توصیف می کند.
CONSTAnT یک مدل داده مفهومی است که جنبه های اصلی یک مسیر معنایی را نشان می دهد [ 20 ]. مدل به دو بخش تقسیم می شود. بخش اول موجودیت های ساده را توصیف می کند که اطلاعاتی در مورد شی متحرک، مسیر، مسیر فرعی، نقاط معنایی، محیط، مکان ها و رویدادها ارائه می دهد. بخش دوم موجودیت های پیچیده ای را توصیف می کند که در آنها از تکنیک های داده کاوی برای شناسایی اطلاعاتی مانند هدف حرکت، وسایل حمل و نقل مورد استفاده و رفتار شی متحرک استفاده می شود.
نول و همکاران [ 14 ] یک مدل مسیر معنایی متشکل از چندین جنبه را پیشنهاد کرد که در آن هر جنبه دارای گروهی از ویژگی های مرتبط است. نویسندگان استدلال می کنند که یک مسیر معنایی را می توان از دیدگاه های مختلف، مانند مسکونی و حرفه ای، تحلیل کرد. نام شهری که کاربر در آن اقامت داشته است، نوع مکان (خانه یا آپارتمان)، و ارزش اجاره به هنگام نگاه کردن به مسیر از نقطه نظر مسکونی ویژگیهایی هستند. هنگام بررسی مسیرها از منظر حرفه ای، کار، شغل و حقوق ویژگی های معنایی هستند.
نمودارها و هستی شناسی های RDF نیز به عنوان راه حل هایی برای غنی سازی مسیرهای معنایی ظاهر شده اند [ 13 ، 21 ]. نمایش داده های مسیر معنایی در RDF استنتاج دانش جدید و انتشار داده ها به عنوان داده های باز پیوندی (LoD) را امکان پذیر می کند. سیستم CRISIS نمونهای از برنامهای است که با جریانهای داده مسیر سر و کار دارد و از یک نمودار RDF استفاده میکند که به صورت معنایی دادههای دریایی دریافتشده از چندین حسگر را نشان میدهد [ 22 ]. باقارا 2نمونه دیگری از یک چارچوب مفهومی است که با استفاده از یک فرآیند قابل تنظیم، مسیرها را تحلیل و از نظر معنایی غنی می کند [ 7 ]. پروژه MASTER مسیر و زمینه آن را با استفاده از RDF مدل می کند و از پایگاه داده قرار ملاقات برای ذخیره داده های RDF استفاده می کند [ 13 ].
آلوارس و همکاران [ 23 ] مدلی را پیشنهاد کرد که بخشهای اساسی یک مسیر (توقف، حرکت و معناشناسی) را نشان میدهد و از زبان SQL برای انجام پرسوجوها در مکانهای بازدید شده، انواع مکانها و سایر تحلیلها استفاده میکند. ایزکویردو و همکاران [ 15 ] با استفاده از نمایش توقف و حرکت به مشکل پرس و جو در مسیرهای معنایی پرداخت. نویسندگان یک چارچوب رسمی با استفاده از DL برای معرفی رسمی نحو و معنایی مسیرها و مکانیسم های مورد نیاز برای بیان پرس و جوها در پایگاه داده خود توصیف کردند. به عنوان اثبات مفهوم، نویسندگان از TripBuilder استفاده کردند [ 16] مجموعه داده با عکس های جغرافیایی مرجع گرفته شده توسط کاربران فلیکر. نقاط توقف با نام POI، دسته بندی و حرکات با وسایل حمل و نقل غنی شد. مفاهیم توصیف شده در DL در RDF پیاده سازی شدند و پرس و جوها با استفاده از SPARQL بیان شدند.
مطالعات فوق از مدل های داده پیچیده برای نمایش مسیرهای معنایی استفاده کردند. این مدل ها شامل موجودیت ها و روابط بسیاری هستند که درک کل سناریو را چالش برانگیز می کند. اینها با اضافه شدن جنبه های جدید به مدل داده پیچیده تر می شوند. در نتیجه، بیان پرسشها دشوارتر میشود و بر اساس تطبیق دقیق بدون رتبهبندی است. این مطالعه یک نمایش متنی از مسیرهای معنایی را پیشنهاد میکند که منجر به یک مدل داده سادهتر میشود که الزامات اندازه حافظه و عملکرد پرس و جو را بهینه میکند. در نتیجه، پرس و جوی شباهت نتایج بیشتری را برمی گرداند و ناامیدی کاربر را به دلیل پاسخ های خالی کاهش می دهد.
3. SETHE: یک رویکرد بازیابی مسیر معنایی
در این بخش چارچوب SETHE (Semantic Trajectory HuntEr) را ارائه می کنیم، رویکردی جدید برای نمایش مسیرهای معنایی و جنبه های آنها با استفاده از پردازش متن. در SETHE، نامهای POI، دستهها و سایر جنبهها به صورت دنبالهای از اصطلاحات نشان داده میشوند. سپس پرس و جوها را با استفاده از پردازش متن انجام می دهیم و مجموعه نتایج را با توجه به نزدیک بودن مجموعه نتایج مسیر به پرس و جو رتبه بندی می کنیم. SETHE مسیرهایی را جستجو می کند که حاوی حداقل یک زیر دنباله مربوط به پرس و جو باشد و مقادیر معنایی آن به جنبه های مشخص شده در یک پرس و جو کاربر نزدیک ترین باشد. در این بخش، مدل مسیر زیربنایی SETHE را رسمیت می دهیم.
3.1. مفاهیم اساسی
چندین تعریف مشابه از مسیرها وجود دارد [ 18 ، 20 ، 23 ]. با این حال، ما یک رویکرد جدید برای نمایش و برخورد با داده های مسیر ارائه می دهیم که در آن یک مسیر معنایی به عنوان یک بردار متن نمایش داده می شود. از این رو، یک پرس و جو ممکن است با استفاده از عبارات منظم بیان شود، و یک رویکرد رتبه بندی برای بازگشت نه تنها مطابقت های دقیق، بلکه نتایج مشابه نیز استفاده می شود. با توجه به اینکه یک POI مکان خاصی است که ممکن است شخصی در آن علاقه مند باشد [ 24 ]، ما یک تعریف مسیر معنایی مبتنی بر جنبه ارائه می کنیم.
تعریف 1.
یک مسیر معنایی مبتنی بر جنبه، دنباله ای از POI است تی= ⟨پ1، پ2, … ,پn⟩به ترتیب زمانی و با مجموعه ای از تاپل ها نشان داده شده است استی= { ⟨ n a m e s _تی1⟩ ، ⟨ c a t e gیا آری _، ستی2〉، 〈 a s p e c t Nیک متره3، ستی3〉,…, ⟨ a s p e c t Nیک مترهآ، ستیآ⟩}، جایی که a ≥ 2. هر ستیمندنباله ای از n مقدار متن است که برای هر نقطه یکی است پمن∈ تی. یک POI از استیمی تواند ساده با نام و دسته باشد، بنابراین استی= { ⟨ n a m e , sتی1⟩، ⟨ c a t e gیا آری _، ستی2⟩ }، یا پیچیده تر، با جنبه های معنایی غیر از نام و دسته POI. بنابراین، نامها و دستهها اجباری هستند و سایر جنبهها اختیاری هستند .
با اعمال تعریف 1، می توانیم مسیر شکل 1 را به صورت زیر نمایش دهیم :
استیf1= { ⟨ n a m e , ⟨ Ca p p e l l aدیک لپo zzo ، Sمن n o p i eمتو هستی تو ، تی _ _e a t r oاسa nتی“A n dr e ⟩ ⟩ ، _⟨ c a t e gیا آری _، ⟨ سیh a p e l ، Mتو هستی تو ، تی _ _h e a t e r ⟩ ⟩ ,⟨ t r a n s p o r tm e a n ، ⟨ Wa l k ، B us ، T _a x i ⟩ ⟩⟨ t e m p e r a t u r e , ⟨ 22 , 21 , 23 ⟩ ⟩ }
یک زیر دنباله مفهوم مهم دیگری برای درک پردازش پرس و جو مسیر معنایی است. طبق گفته گاسفیلد [ 25 ]، در حالی که یک مسیر فرعی نشان دهنده نقاط متوالی یک مسیر T است، POI ها نیازی به متوالی بودن در یک زیر دنباله از T ندارند. دنباله های فرعی در طول پردازش پرس و جو برای بازیابی دنباله های POI از T استفاده می شوند که با پرس و جو کاربر مطابقت دارند.
تعریف 2.
یک مسیر زیر دنباله معنایی مبتنی بر جنبه اساستی= { ⟨ n a m e , s sتی1⟩, 〈رده , s sتی2⟩، ⟨ a s p e c t Nیک متره3، s sتی3⟩ ، … ، ⟨ a s p e c t Nیک مترهآ، اس استیآ⟩ }نشان دهنده یک زیر دنباله از POI های T است، که در آن a ≥ 2.
طبق تعریف 2، دنباله فرعی اساستیf1نشان دهنده یک زیر دنباله از استیf1. ما می توانیم ببینیم که اساستیf1POI نقاط متوالی هستند استیf1، اما لزوماً متوالی نیستند.
اساستیf1= { ⟨ n a m e , ⟨ Ca p p e l l aدیک لپo zzo ,تیe a t r oاسa nتی“A n dr e ⟩ ⟩ ، _⟨ c a t e gیا آری _، ⟨ سیh a p e l ، Th e a t e r ⟩ ⟩ ,⟨ t r a n s p o r tm e a n ، ⟨ Wa l k ، Ta x i ⟩ ⟩⟨ t e m p e r a t u r e , ⟨ 22 , 23 ⟩ ⟩ }
3.2. پردازش پرس و جو
برای انجام جستجو در یک مجموعه داده مسیر معنایی، کاربران باید برخی اطلاعات مانند نام POI، دستهها و/یا جنبههای دیگر را ارائه دهند. توقف ها را می توان بر اساس نام یا دسته بندی POI شناسایی کرد. شکل 2 یک مثال گرافیکی از یک پرس و جو را نشان می دهد که در آن کاربر در حال جستجوی مسیرهایی است که از یک موزه می گذرد و به برج کج پیزا ختم می شود.
علاوه بر تعیین توقف ها، کاربر همچنین می تواند مشخص کند که چه جنبه هایی با هر نقطه خاص مرتبط است. در شکل 2 ، کاربر می خواهد مسیر افرادی را که از تاکسی برای رفتن به موزه با امتیاز چهار و هوای بارانی استفاده می کنند، جستجو کند. در نهایت، شخص با یک اتوبوس به برج پیزا سفر کرد ، با امتیاز پنج، و هوا صاف بود.
استفاده از تطابق دقیق برای پرس و جو نشان داده شده در شکل 2 ممکن است به نتایج کمی یا بدون نتیجه منجر شود. برای حل این محدودیت، SETHE با استفاده از یک الگوریتم رتبهبندی، مسیرهایی را جستجو میکند که بیشترین تطابق را با پرس و جو دارند. برای این کار، کاربر باید تابع فاصله و وزن را برای هر نوع جنبه ارائه دهد. تابع فاصله، فاصله جنبه پرس و جو را از یک مسیر معین محاسبه می کند. علاوه بر تابع فاصله، وزن نشان دهنده درجه اهمیت هر یک از جنبه های درخواست کاربر است. فاصله و وزن بر رتبه نتیجه نهایی تأثیر می گذارد. جدول 2 نمونه هایی از این توابع را فهرست می کند که در آن مقادیر تصادفی با مقادیر جنبه نشان داده شده در شکل 2 مقایسه می شوند. در این مثال از a استفاده کردیم روزی _ _ _2 v e cتابع برای وسایل حمل و نقل، تابع برابر برای جنبه آب و هوا، و تابع اقلیدسی برای جنبه رتبه بندی. این روزی _ _ _2 v e cتابع فاصله معنایی بین عبارت ها را محاسبه می کند. تابع برابر تنها یکی از این دو مقدار را برمیگرداند: 0 (صفر) زمانی که عبارتها متفاوت هستند و 1 (یک) زمانی که عبارتها برابر هستند. تابع اقلیدسی به صورت محاسبه می شود Eu c l i de a n ( a , b ) = | ( a − b ) |.
بخشهای فرعی زیر جزئیات فرآیند جستجوی SETHE را شرح میدهند. این فرآیند در چندین مرحله انجام می شود: ساختن یک پرس و جو برای تفسیر توسط چارچوب، ساختن یک نمایش برداری برای پرس و جو، بازیابی دنباله فرعی با همان نقاط توقف مشخص شده در پرس و جو، ساختن یک نمایش برداری برای هر زیر بازیابی شده. دنباله و جنبه های آن و محاسبه شباهت بین بردارهای پرس و جو و زیر دنباله.
3.2.1. ساختمان پرس و جو
پرس و جو دنباله ای از عبارات است که ممکن است حاوی نام POI، دسته ها و جنبه های دیگر باشد که مسیر معنایی مورد علاقه کاربر را نشان می دهد. به عنوان مثال، با استفاده از دنباله دسته بندی ( m u s e u m; تو او آر _ _) و توالی جنبه های میانگین حمل و نقل ( بی تو _; تیa x iSETHE به دنبال مسیرهایی می گردد که از اتوبوس برای رسیدن به موزه و تاکسی برای رسیدن به برج استفاده می کنند.
در طول فرآیند جستجو، SETHE نام یا دسته بندی POI ها را در هر موقعیتی در مسیر در نظر می گیرد. با این حال، می توان از ویژگی های عبارات منظم برای اطلاع از موقعیت POI در مسیر متنی استفاده کرد. به عنوان مثال، هنگام استفاده از نماد ⌃، نشان می دهیم که POI باید در ابتدای یک مسیر باشد و با نماد $ می گوییم که POI باید در انتهای یک مسیر باشد. بنابراین، هنگام انجام یک پرس و جو با استفاده از دنباله (⌃ m u s e u m; تو او آر _ _$ )، SETHE به دنبال مسیرهایی است که از یک موزه شروع می شود و به یک برج ختم می شود.
جدول 3 پنج نماد عبارت منظم مورد استفاده در فرآیند پرس و جو و دو نماد جدید ((?-) و ~) را نشان می دهد که به ساخت عبارات پرس و جو کمک می کنند.
با الهام از [ 12 ]، پرس و جو را به صورت زیر تعریف می کنیم.
تعریف 3.
Query Q یک تاپل است Q = ( E,A,W,D,L)، جایی که:
-
E نشان دهنده دنباله POI یک مجموعه غیر خالی از تاپل ها است E={⟨name,e1⟩، ⟨category، e2⟩}. هر یک eiدنباله ای از m عبارات منظم است که برای هر POI یکی است.
-
A نمایش دیگری از دنباله POI است که با مجموعه ای از تاپل ها نمایش داده می شود A={⟨ aspectName1، ب α1〉,…, ⟨aspectNameb,αb⟩}، جایی که b≥0تعداد جنبه های اختیاری است. هر یک αمندنباله ای از m عبارات منظم است که برای هر POI یکی است.
-
W={w1,w2,…,wb}مجموعه ای از وزن ها است که در آن هر وزن با یک جنبه اختیاری همراه است و ∑bi=1wi=1. اگر A={⌀}، سپس W={⌀}.
-
D={d1,d2,…,db}مجموعه ای از توابع فاصله را نشان می دهد. یک تابع فاصله برای هر جنبه اختیاری وجود دارد. اگر A={⌀}، سپس D={⌀}.
-
L={thr1,thr2,…,thrb}مجموعه آستانه ای است که هر تابع فاصله ممکن است به آن برسد. برای هر تابع یک آستانه وجود دارد و اگر A={⌀}، L = { ⌀ }.
برای تسهیل مقایسه پرس و جو، ما فقط از تابع فاصله در جنبه های اختیاری استفاده می کنیم. طبق تعریف 3 می توانیم از تاپل استفاده کنیم سf3= (Ef3،آf3،دبلیوf3،دیf3،Lf3)برای بیان پرس و جو در شکل 2 . این کوئری دو نقطه را مشخص می کند. اولی یک دسته است ( m u s e u m، و دومی یک نام POI است ( تیo r e _پe n de n t eدمنپمن یک _). بنابراین، دنباله E باید شامل دو تاپل ( n a m eو c a t e gیا آری _) و توالی همنباید دو نقطه، که در آن
Ef3= { ⟨ n a m e , ⟨ . * _ تیo w e rپe n de n t eدمنپمن یک ⟩ ⟩ ، ⟨ c a t e g هستمیا آری _, ⟨ m u s e u m ; . * ⟩ ⟩ }
بیان منظم . *زمانی استفاده می شود که نام و دسته بندی POI ناشناخته باشد. جنبه های اختیاری در شکل 2 عبارتند از وسایل حمل و نقل، آب و هوا و درجه بندی. وزن هر جنبه به انتخاب کاربر بستگی دارد. در این مثال ما بیشترین اولویت را برای وسیله حمل و نقل و جنبه آب و هوا را به عنوان کمترین اولویت قرار داده ایم. بنابراین، ما ترتیب وزن زیر را اختصاص دادیم: دبلیوf3= { 0.5 ، 0.2 ، 0.3 }. برای محاسبه فاصله بین دو مقدار جنبه، از عدد استفاده می کنیم روزی _ _ _2 v e cعملکرد برای وسایل حمل و نقل، e qتو یک س _عملکرد برای جنبه آب و هوا، و Eu c l i de a nعملکرد برای جنبه رتبه بندی. از این رو، دیf3= { w o r d2 v e c ، e qu a l s ، Eu c l i de a n }. ما ارزش ها را پذیرفتیم Lf3={1,1,5}برای دنباله آستانه مقدار 1 (یک) بالاترین مقدار ممکن برای روزی _ _ _2 v e cعملکرد. حداکثر e qتو یک س _مقدار تابع 1 است و 5 حداکثر مقدار برای Eu c l i de a nتابع جنبه رتبه بندی، که بین 1 و 5 متغیر است. بنابراین، پرس و جو کنید سf3به صورت بیان می شود
سf3= ( { ⟨ n a m e , ⟨ . * ؛ To r e _پe n de n t eدمنپمن یک ⟩ ⟩ هستم ،⟨ c a t e gیا آری _،⟨ m u s e u m ;. * ⟩ ⟩ } ،{ ⟨ t r a n s p o r tمن یک نفر ، _⟨ با تو ، _تیa x i ⟩ ⟩ ،⟨ ما با هم ، _ _ _ _⟨ من نیستم ، _ _c l e a r ⟩ ⟩ ,⟨ r a t i n g،⟨ 4 ، 5 ⟩ ⟩ } ،{ 0.5 ،0.2 ،0.3 } ،{ w o r d2 v e c _e qتو هستی ، _ _Eu c l i de a n } ،{ 1 ،1 ،5 } )
SETHE یک پرس و جو را به متن تبدیل می کند تا آن را با پایگاه داده مسیر متنی مقایسه کند. این فرآیند به چهار مرحله اصلی تقسیم می شود.
-
استفاده از تابع regex برای به دست آوردن مسیرهایی که از POI ها با نام و دسته عبارات عبور می کنند.
-
استخراج زیر دنبالههای مسیر T، که در آن نام و دسته POI با عبارات منظم E مطابقت دارند.
-
استفاده از توابع فاصله و وزن جنبه برای محاسبه شباهت ضریب پرس و جو با دنباله های فرعی.
-
رتبه بندی نتیجه بر اساس ضریب به ترتیب نزولی.
کارکرد regex(text,pattern)برای تعیین مسیرها استفاده شد. این textپارامتر می تواند یکی از دو جمله را داشته باشد: یا دنباله نام POI st1یا دنباله دسته POI st2. این p a t t e r nپارامتر یک عبارت منظم است که از الحاق همنعناصر. بیان منظم ( . * )برای ادغام استفاده شد همناصطلاحات. این r e ge xتابع اطلاع می دهد که اگر ستیمنبالاخره یک زیر دنباله دارد که با آن مطابقت دارد p a t t e r n. با استفاده از سf3به عنوان مثال، p a t t e r nارزش است ( . * ) ( . * ) ( تیo r e _پe n de n t eدمنپمن یک ) _برای t e x tمساوی با ستی1و ( m u s e u m ) ( . * ) ( . * )برای t e x tمساوی با ستی2.
در نهایت، SETHE از دو استفاده می کند r e ge xبر روی پایگاه داده کار می کند تا مسیرهای معنایی را که از موزه و موزه عبور کرده است جستجو کند L e a n i n gتیo w e ro fپمن یک _. بیان نهایی به شرح زیر است:
r e ge x ( sتی1،( . * ) ( . * ) ( تی _o r e _پe n de n t eدمنپمن یک هستم ) ” )a n dr e ge x ( sتی2،” ( m u s e u m ) ( . * ) ( . * ) ” )
قبل از ادامه، لازم است یک پرس و جو را به یک نمایش برداری تبدیل کنید. یک پرس و جو Q با جمله نشان داده می شود δqو بردار vq→. جمله δq= (y11،y21، ⋯ ،yب1،y12،y22، ⋯ ، yب2،y1متر،y2متر، ⋯ ،yبمتر)الحاق به هم پیوسته برای هر POI از عبارات منظم است αمناز جنبه های اختیاری مختصات بردار vq→= (v1،v2،v3، ⋯ ،vz)وزنهای در همپیچیده مرتبط با هر جنبه POI هستند، که در آن معادله ( 1 ) وزن جنبه را در W مشخص میکند.
vمن= (wک|1 ≤ i ≤ z) ،wh e r e _k = ( ( i − 1 ) m o dب ) + 1
با استفاده از مثال سf3و با استفاده از معادله ( 1 ) به δq= ( t a x ir a i n4ب تو _c l e a r5 )، بردار را بدست می آوریم vq→= ( 0.5 ،0.2 ،0.3 ،0.5 ،0.2 ،0.3 ).
3.2.2. کشف زیر دنباله ها
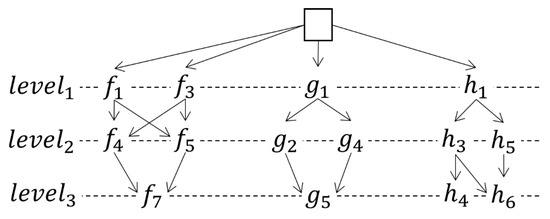
پس از بازیابی مسیرهای معنایی با استفاده از پرس و جوی regex، SETHE یک نمایش برداری برای هر یک محاسبه می کند. استیزیر دنباله ای که با تمام عبارات منظم تعریف شده در مطابقت دارد ه1و ه2. ما این فرآیند را با چهار الگوریتم توصیف می کنیم. الگوریتم 1 (عملکرد اصلی) وظیفه فراخوانی توابع شرح داده شده در سایر الگوریتم ها را بر عهده دارد. الگوریتم 1 نحوه استخراج زیر دنباله ها از یک مسیر معنایی مبتنی بر جنبه را نشان می دهد. این c a l c Su b s e qu e n c e sتابع پارامترها را دریافت می کند ستی1، ستی2، ه1، و ه2. ما از یک درخت به عنوان ساختار داده استفاده کردیم که به تعیین زیر دنباله های مسیر کمک می کند. درخت با یک فرزند خالی شروع می شود که ریشه درخت خواهد بود و فرزندان آن زیر دنباله شروع POI خواهند بود. طبق تعریف 3، عبارات منظم ه1و ه2باید یک اندازه داشته باشد الگوریتم 1 در ابتدا تأیید می کند که آیا ه1برابر “.*” است، سپس طول می کشد ه2. تابع regex تمام موارد مطابق در متن را برای هر کدام جستجو می کند همنعبارت منظم. هر مورد در متغیر مطابقت دارای یک متن POI (نام یا دسته) و موقعیت POI در مسیر است. برای هر مسابقه یک گره ایجاد می شود و به درخت اضافه می شود. گره جدید مقدار متن مطابقت، موقعیت متن را دریافت می کند ستیمنو شاخص عبارت منظم در همن. اگر اولین عبارت منظم باشد، گره به عنوان فرزند ریشه درخت اضافه می شود. در غیر این صورت، تابع بازگشتی a dدنe w No dهموقعیت صحیح گره را در درخت جستجو می کند. این fمن x Tr e eتابع تمام شاخه های درختی را که ارتفاع آنها کمتر از اندازه است حذف می کند همن. بنابراین، تنها استیدنباله های فرعی که مطابقت دارند ه1و ه2در درخت بماند این e x t r a c t Su b s e qu e n c eتابع وظیفه پیمایش گره های درخت برای استخراج زیر دنباله های مسیر و ذخیره آنها در من اس هستم _ _u b sمتغیر. در فینال از c a l c Su b s e qu e n c e sتابع، من اس هستم _ _u b sمتغیر دارای تمام دنباله های فرعی است استی.
| الگوریتم 1 دنباله فرعی را از ST استخراج کنید |
|
الگوریتم 2 شرح می دهد a dدنe w No dهتابع بازگشتی این تابع دو پارامتر دریافت می کند: گره پدر و فرزند ایجاد شده توسط الگوریتم 1. برای اضافه کردن گره جدید به عنوان فرزند گره پدر، دو محدودیت وجود دارد: اول، موقعیت گره باید بزرگتر از موقعیت گره پدر باشد. دوم، شاخص گره جدید باید یک واحد بالاتر از شاخص گره والد باشد.
| الگوریتم 2 درج یک گره در درخت |
|
الگوریتم 3 تابع بازگشتی را توصیف می کند fixTree. این تابع سه پارامتر را دریافت می کند: درخت، گره ای که باید بررسی شود و ارتفاع گره برگ. هر گره درخت تا رسیدن به گره های برگ به صورت بازگشتی بازدید می شود. اگر شاخص گره برگ با ارتفاع متفاوت باشد ( eiاندازه)، گره از درخت حذف می شود. این فرآیند تا انتها تکرار می شود تا تمام گره ها بدون فرزند و شاخص کمتر از ارتفاع حذف شوند.
| الگوریتم 3 زیر دنباله ناقص را از درخت حذف کنید |
|
الگوریتم 4 تابع را توصیف می کند extractSubsequenceرفتار – اخلاق. این تابع بازگشتی سه پارامتر دریافت می کند: گره درخت، زیر دنباله ای که در حال حاضر پردازش می شود، و لیست زیر دنباله، که متغیری است که نتیجه نهایی را ذخیره می کند. الگوریتم در تمام گره های فرزند تکرار می شود و مقدار را به آن اضافه می کند subsequenceمتغیر. اگر یک گره بیش از یک فرزند داشته باشد، به این معنی است که زیر دنباله های بیشتری حاوی آن گره هستند. بنابراین، s u b s e qu e n c eکلون شده است، و extractSubsequenceتابع دوباره با پارامترهای زیر فراخوانی می شود: گره فرزند، کلون و لیست زیر دنباله ها listSub. وقتی پارامتر گره خالی است، هیچ فرزند دیگری برای پردازش وجود ندارد. از این رو subsequenceارزش یک خواهد بود STدنباله فرعی سپس، ارزش subsequenceمتغیر به آن اضافه می شود listSub. در انتهای تابع، متغیر listSubلیستی از همه خواهد داشت STدنباله های فرعی که هر دو را برآورده می کند e1و e2.
یک مسیر را فرض کنید STدارای پنج POI است، و برای سادگی، ما فقط مسیر را برجسته کردیم st2. به دنبال الگوریتم 1، دو زیر دنباله از آن استخراج می شود st2، که ما به آن می گوییم SST1و SST2، حاوی زیر دنباله های دسته بندی است (c2c5)و (c4c5).
| c1 | c2 | c3 | c4 | c5 | ||||||
| st2=( | فروشگاه | موزه | کلیسا | موزه | برج | ) |
| الگوریتم 4 دنباله فرعی را از الگوریتم درخت استخراج کنید |
|
3.2.3. تبدیل یک زیر دنباله به بردار
پس از شناسایی SST1و SST2در زیر دنباله ها، SETHE یک جمله ایجاد می کند δبرای هر یک از آنها، مشابه آنچه برای پرس و جو انجام شد سf3. یه جمله جدید δسستیو یک بردار v→سستیبرای هر زیر دنباله، که در آن ایجاد می شود δسستی=(r11،r12،⋯،r1ب،r21،r22،⋯،r2ب،rn1،rn2،⋯،rnب)و v→سستی=( ν11، ν12,…, ν1ب، ν21، ν22,…, ν2ب،νn1،νn2،⋯،νnب)، به طوری که r مطابق با اساستیجنبه های اختیاری و νمنj=سجorه(yمنj،rمنj).
امتیاز برای هر ترم محاسبه می شود δسستیو مقدار آن برداری است v→سستی. تابع امتیاز از تابع فاصله برای محاسبه نزدیکی یک عبارت استفاده می کند δسستیبه همان مدت شاخص از δq.
هر چه فاصله کمتر باشد، امتیاز ترم بالاتر است δسستی. اگر دو عبارت وجود داشته باشد، یکی متعلق به Query Q و دیگری متعلق به زیر دنباله ای از استی، به طوری که yمنj ϵ δqو rمنj ϵ δسستی، معادله محاسبه امتیاز بین دو عبارت است
سجorه(yمنj،rمنj)={0،منfدj(yمنj،rمنj)>تیساعتrj،wj،منfyمنj=(.*)،||(wj*دj(yمنj،rمنj))تیساعتrj|–wj|،oتیساعتهrwمنسه}
جایی که wj∈دبلیو، دj∈دیو تیساعتrj∈L
ضریب مسیر استیشامل بیشترین مقدار شباهت بین بردار پرس و جو Q و بردارهای است استی. تابع شباهت باید مقداری بین صفر و یک برگرداند. نمونه هایی از این توابع شباهت عبارتند از توابع ژاکارد و کسینوس. اجازه دهید Vتیسمجموعه ای از تمام بردارهای ایجاد شده توسط استیدنباله های فرعی ضریب به صورت محاسبه می شود
جoهf(استی)=مترآایکس(سمنمترمنلآrمنتیy(v→q،ایکس→))|v→q∈Vq،ایکس→منnVتیس
جایی که، 0≪سمنمترمنلآrمنتیy(.،.)≪1
یک پرس و جو ترکیبی سیس=(س1،س2،⋯،سn)شامل چندین پرس و جو است که در یک پرس و جو جمع شده اند، که در آن SETHE هر پرس و جو را به طور جداگانه اجرا می کند و نتایج هر پرس و جو را در یک مجموعه نتیجه ادغام می کند.
4. مثال در حال اجرا
این بخش نمونه ای از نحوه کار SETHE با استفاده از یک پرس و جو و یک پایگاه داده متشکل از سه مسیر را ارائه می دهد. اجازه دهید یک پرسش Q را در نظر بگیریم که به دنبال مسیرهایی میگردد که در آن یک شی متحرک ابتدا به برج پیزا میرود، سپس از کلیسای کوچک یا کلیسا بازدید میکند و بعداً در یک موزه توقف میکند.
اجازه پرس و جو س=(E،آ،دبلیو،دی،L)، جایی که
-
E={〈nآمتره،〈Lهآnمنng_تیowهr_of_پمنسآ;.*; .*〉〉، 〈جآتیهgory،〈.*;(جساعتتوrجساعت|جساعتآپهل);مترتوسهتومتر 〉〉}. همانطور که اولین نقطه را به عنوان برج کج پیزا تعریف می کنیم، نیازی به تعیین دسته بندی نقطه اول نداریم.
-
آ={〈تیrآnسپorتیمترهآn،〈تیآایکسمن،بتوس،wآلک〉〉،〈rآتیمنng،〈5،5،4〉〉}.
-
دبلیو={0.7،0.3}.
-
دی={هqتوآلس،Eتوجلمندهآn}.
-
L={1،5}.
در این مثال می بینیم که میانگین حمل و نقل دارای وزن بالاتری نسبت به رتبه است. تبدیل پرس و جو به جمله δqو با استفاده از رابطه ( 1 )، بردار پرس و جو را بدست می آوریم
v→q=(0.7،0.3،0.7،0.3،0.7،0.3)
فرض کنید یک پایگاه داده مسیر معنایی داریم استیهمانطور که در بخش 3.2.1 توضیح داده شد . SETHE یک جستجو را با استفاده از rهgهایکستابع، که مسیر متنی و عبارت منظم تشکیل شده توسط عناصر را به عنوان پارامتر دریافت می کند ه1و ه2. در این مورد، دو rهgهایکستوابع استفاده شد: یکی برای ستی1و دیگری برای ستی2.
rهgهایکس(ستی1،“Lهآnمنng_تیowهr_of_پمنسآ“)آnدrهgهایکس(ستی2،“(جساعتتوrجساعت|جساعتآپهل)(.*)(مترتوسهتومتر)”)
پس از جستجوی مجموعه مسیرهای معنایی با استفاده از regex، SETHE سه مسیر را بازیابی می کند: استیاف={< nآمتره،ستیاف1 >،< جآتیهgory،ستیاف2 >،< تیrآسپorتیمترهآnس،ستیاف3 >،< rآتیمنng، ستیاف4 >}، استیجی={< nآمتره،ستیجی1 >،< جآتیهgory،ستیجی2 >،< تیrآسپorتیمترهآnس،ستیجی3 >،< rآتیمنng،ستیجی4 >}، و استیاچ={< nآمتره،ستیاچ1 >،< جآتیهgory،ستیاچ2 >،< تیrآسپorتیمترهآnس،ستیاچ3 >،< rآتیمنng،ستیاچ4 >}. برای سادگی، ما فقط دسته و جنبه های مسیر را که در زیر نشان داده شده است، برجسته کردیم. علاوه بر این، برای سهولت توضیح، ما یک شاخص برای هر عبارت در مسیر قرار دادیم:
f1f2f3f4f5f6f7
ستیاف2=〈تیowهr،gآتیه،تیowهr،جساعتآپهل،جساعتتوrجساعت،جآمترپآnمنله،مترتوسهتومتر〉
g1g2g3g4g5
ستیجی2=〈تیowهr،جساعتآپهل،جآمترپآnمنله،جساعتآپهل،مترتوسهتومتر〉
ساعت1ساعت2ساعت3ساعت4ساعت5ساعت6
ستیاچ2=〈تیowهr،پمنآzzآ،جساعتآپهل،مترتوسهتومتر،جساعتآپهل،مترتوسهتومتر〉
مسیرهای وسایل حمل و نقل و جنبه های رتبه بندی مربوط به استیاف، استیجی، و استیاچمسیرها به ترتیب عبارتند از
ستیاف3=〈استوبwآy،استوبwآy،بتوس،دبلیوآلک،استوبwآy،استوبwآy،دبلیوآلک〉
ستیاف4=〈4،4،4،5،4،3،3〉
ستیجی3=〈دبلیوآلک،دبلیوآلک،استوبwآy،بتوس،استوبwآy〉
ستیجی4=〈5،3،4،3،3〉
ستیاچ3=〈تیآایکسمن،تیآایکسمن،بتوس،استوبwآy،بتوس،دبلیوآلک〉
ستیاچ4=〈5،2،3،4،3،3〉
مرحله دوم شناسایی زیر توالی هایی است که رضایت شما را برآورده می کند ه1و ه2اصطلاحات. طبق الگوریتم 1، درختی از مسیرها ساخته شده است، همانطور که در شکل 3 نشان داده شده است. هر سطح از درخت، به جز ریشه، بیانگر یک عبارت در هر یک است ه1یا ه2. هر POI از استیکه راضی می کند rهgهایکس(ستی1،ه1)یاrهgهایکس(ستی2،ه2)به عنوان فرزند عبارات شاخص پایین تر به درخت اضافه می شود. به عنوان مثال، با استفاده از تابع rهgهایکس(f4، “(جساعتتوrجساعت|جساعتآپهل)”)، مقوله f4با عبارت منظم مطابقت دارد (جساعتتوrجساعت|جساعتآپهل)، بنابراین الگوریتم اضافه می کند f4به عنوان یک f1و f3کودک در درخت دسته بندی ساعت4برای مثال، فقط به عنوان فرزند اضافه می شود ساعت3و نه از ساعت5، مانند ساعت4قبل رخ می دهد ساعت5در مسیر حرکت
زیر دنباله های استخراج شده از درخت POI عبارتند از:
| σافآ=〈f1،f4،f7〉 σافب=〈f1،f5،f7〉 σافج=〈f3،f4،f7〉 σافد=〈f3،f5،f7〉 |
σجیآ=〈g1،g2،g5〉 σجیب=〈g1،g4،g5〉 |
σاچآ=〈ساعت1،ساعت3،ساعت4〉 σاچب=〈ساعت1،ساعت3،ساعت6〉 σاچج=〈ساعت1،ساعت5،ساعت6〉 |
پس از شناسایی زیر دنباله های مسیر، گام بعدی محاسبه امتیاز هر جنبه اختیاری برای ایجاد بردار است که به عنوان مقایسه شباهت با v→qبردار
جدول 4 ، جدول 5 ، جدول 6 و جدول 7 جملات هر یک را ارائه می کنند استیافدنباله فرعی که با در هم آمیختن جنبه های اختیاری ایجاد شد. هر عبارت مربوط به یک جنبه اختیاری زیر توالی است که با میانگین انتقال و جنبه های رتبه بندی مربوط به هر زیر دنباله POI شروع می شود. همانطور که در پرس و جو Q مشخص شده است هqتوآلستابع برای محاسبه شباهت بین دو جنبه از نوع میانگین حمل و نقل استفاده می شود. بنابراین، تنها دو مقدار ممکن وجود دارد: 1 (یک)، اگر مقادیر یکسان باشند، و 0 (صفر)، اگر متفاوت باشند. برای جنبه رتبه بندی، از تابع فاصله اقلیدسی استفاده می کنیم. با اعمال معادله ( 2 ) برای هر کلمه، امتیاز هر جنبه را پیدا می کنیم. به عنوان مثال، امتیاز رتبه بندی ارزش 4 (چهار) به صورت زیر محاسبه می شود:
سجorهrآتیمنng(5،4)=0.3(4–5)5–0.3=0.24
جدول 8 و جدول 9 امتیاز را برای استیجی، و جدول 10 ، جدول 11 و جدول 12 شامل امتیازات برای استیاچدنباله های فرعی
مختصات هر بردار مسیر شامل امتیاز محاسبه شده برای هر زیر دنباله است. بنابراین، ما بردارهای زیر را برای the داریم استیافدنباله های فرعی:
v→افآ(0،0.24،0،0.3،0.7،0.24)،v→افب(0،0.24،0،0.24،0.7،0.24)،
v→افج(0،0.24،0،0.3،0.7،0.24)،v→افد(0،0.24،0،0.24،0.7،0.24)
در این مثال، ما از شاخص جاکارد برای محاسبه شباهت بین بردارهای مسیرها و بردار پرس و جو استفاده می کنیم. v→q. معادله ( 4 ) شاخص جاکارد را محاسبه می کند:
جی(v→من،v→q)=∑کمترمنn(v→من[ک]،v→q[ک])∑کمترآایکس(v→من[ک]،v→q[ک])
استفاده از معادله ( 4 ) برای استیافو v→qبردارها، مقادیر زیر را داریم:
جی(σ→افآ،v→q)=0.493،جی(σ→افب،v→q)=0.473
جی(σ→افج،v→q)=0.493،جی(σ→افد،v→q)=0.473
با استفاده از معادله ( 3 )، ضریب برای استیافمسیر 0.493 است. پس از انجام همین فرآیند برای استیجیو استیاچمسیرها، نتیجه نهایی را داریم:
جoهf(استیاچ)=0.94،جoهf(استیاف)=0.493،جoهf(استیجی)=0.47
بنابراین، استیاچخط سیر بالاترین ضریب را دارد که نزدیکترین ضریب به درخواست کاربر است. دوم این است استیافمسیر، و استیجیمسیری است که کمترین شباهت را به کوئری Q دارد.
5. آزمایش ها و نتایج
ما از مجموعه داده TripBuilder [ 16 ] برای ارزیابی عملکرد راه حل خود استفاده کردیم. ما عملکرد SETHE را بر اساس چارچوب توصیف شده در [ 15 ] ارزیابی کردیم که مجموعه ای از 10 پرسش را برای شهر پیزا، ایتالیا ارائه می دهد.
5.1. مجموعه داده
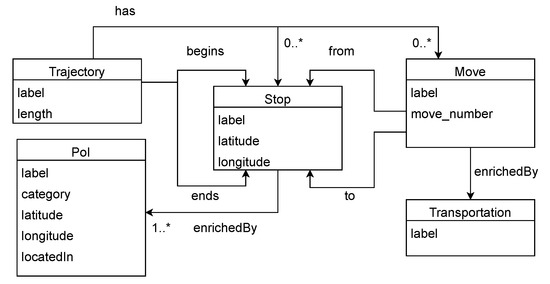
مجموعه داده TripBuilder RDF شامل 1,617,582 سه گانه و 55,474 مسیر است که در کلاس های Trajectory ، Stop ، Move ، Transportation و POI مدل شده است. شکل 4 نمایش UML TripBuilder را نشان می دهد . یک مسیر می تواند چندین توقف و حرکت داشته باشد که با نماد * در رابطه نشان داده می شود. هر مسیر دارای نقاط شروع و پایان است و هر نقطه نشان دهنده یک نقطه نقطه است. کلاس Move انتقال بین دو ایستگاه را نشان می دهد و از نظر معنایی توسط کلاس Transport غنی شده است.
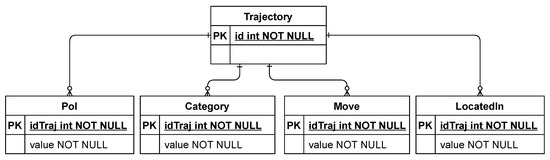
برای انجام آزمایشها با SETHE، مجموعه داده RDF TripBuilder را به یک مجموعه داده متنی تبدیل کردیم. ما یک پایگاه داده را برای ذخیره مسیرهای متنی، همانطور که در شکل 5 نشان داده شده است، مدل کردیم . موجودیت Trajectory یک رابطه یک به چند برای هر موجودیت دارد که نشان دهنده نوع مسیر متفاوتی است. موجودیت POI نشان دهنده مسیر متنی است که در آن هر نقطه حاوی نام مکانی است که شی متحرک در آن متوقف شده است. موجودیت Category شامل مسیرهای متنی دسته است. موجودیت Move شامل مسیرهای متنی میانگین حمل و نقل است که برای رسیدن به هر ایستگاه استفاده می شود . The LocatedInموجودیت شامل مسیرهای نواحی است که جسم متحرک در آنجا متوقف شده است.
جدول 13 نمونه ای از داده های مسیر نام POI ذخیره شده در را نشان می دهد Vآلتوهستون جدول 14 مسیرهای دسته بندی را نشان می دهد. جدول 15 نمونه هایی از مسیرهای میانگین حمل و نقل را ارائه می دهد. حرکت اول یک وسیله حمل و نقل مرتبط ندارد. بنابراین، مقدار N/A را دریافت می کند. در واقع، SETHE مسیرهای با اطلاعات از دست رفته را برای یک جنبه خاص فعال می کند. وقتی این اتفاق می افتد، یعنی یک POI داده شده بدون جنبه، از مقدار ویژه N/A استفاده می کنیم. به عنوان مثال، مسیری را در نظر بگیرید که در آن POI اول و سوم جنبه خاصی ندارند، مثلا حمل و نقل. سپس جنبه حمل و نقل برای آن مسیر به شکل زیر نشان داده می شود: 〈ن/آ،استوبwآy،ن/آ،تیآایکسمن،بتوس،استوبwآy〉.
5.2. نتایج و بحث
آزمایشها روی رایانهای با پردازنده Core i7-7700 3.60 گیگاهرتز، 32 گیگابایت رم و 500 گیگابایت HD، با سیستمعامل GNU/Linux Ubuntu 18.04 انجام شد. ما مجموعه داده RDF را در پایگاه داده تاپل (TDB) سرور Apache Jena Fuseki 4.3.2 در حال اجرا بر روی پلتفرم جاوا jdk-16.0.2 نصب کردیم. ما از PostgreSQL 13.2 برای ذخیره پایگاه داده مسیر متنی استفاده کردیم. ما سهگانههای RDF را به صفحات گسترده CSV تبدیل کردیم، لهجهها و کاراکترهای خاص را حذف کردیم و سپس دادهها را در پایگاه داده متن بارگذاری کردیم. ایزکویردو و همکاران [ 15 ] یک چارچوب جستجوی مسیر معنایی را توصیف کرد و ده پرس و جو را برای شهر پیزا برای ارزیابی عملکرد چارچوب آنها مشخص کرد. از همین پرسش ها برای ارزیابی چارچوب SETHE استفاده شد. پرس و جوها در جدول 16 فهرست شده اند .
جدول 17 نحوه استفاده از چارچوب SETHE برای پاسخگویی به پرس و جوهای فوق الذکر را نشان می دهد. برخی از پرس و جوها نیاز به بازدید متوالی POI دارند. بنابراین، نزدیکی بین نقاط توقف نیز به عنوان یک جنبه مسیر استفاده شد. در این مورد، نزدیکی به تعداد توقف بین دو نقطه نقطه اشاره دارد. در SETHE، هنگامی که یک ویژگی مجاورتی روی یک نماد tilde (~) تنظیم میشود، هر چه دو POI نزدیکتر باشند، امتیاز آنها بالاتر است. ایزکویردو و همکاران [ 15 ] استفاده کنید هqتوآلساپراتور برای مقایسه وسایل حمل و نقل؛ بنابراین از تابع فاصله استفاده کردیم هqتوآلسبرای جنبه میانگین حمل و نقل در جستارهایی که از هر دو جنبه استفاده می کنند (مثلاً میانگین انتقال و مجاورت)، وزن دقیق 0.5 را در این مثال ها اتخاذ کردیم.
همانطور که در جدول 17 نشان داده شده است ، زمانی که پرس و جو دارای مقدار نیست ه1، فرض می شود که این مقدار خالی است. همه پرس و جوها ساده هستند، به جز پرس و جو Q4 که یک پرس و جو ترکیبی است.
ما عملکرد پرس و جوهای SETHE PostgreSQL را با پرس و جوهای SPARQL مقایسه کردیم. عبارات با قاعده با ~ و گسترش یافتند (?–)اپراتورها هر کوئری ده بار برای SPARQL و SETHE اجرا شد. شکل 6 میانگین زمان اجرای هر پرس و جو را در مقیاس لگاریتمی نشان می دهد. ما مشاهده کردیم که SETHE در اکثر موارد نسبت به SPARQL زمان پاسخ بهتری دارد [ 15 ]. این س10پرس و جو SPARQL نمودار نشد زیرا اجرای آن تقریباً یک ساعت طول کشید.
با توجه به الگوریتم رتبه بندی، که به یادآوری بهتر دلالت دارد، همانطور که در شکل 7 نشان داده شده است. اولین نتایج پرس و جوی SETHE مانند پرس و جو SPARQL است. آنها کاملاً با درخواست کاربر مطابقت دارند. نوارهای آبی در نمودار در شکل 7 مجموعه نتایجی را نشان می دهد که توسط SETHE برگردانده شده است که توسط SPARQL بازیابی نشده است. مسیرهای موجود در ناحیه آبی مشابه مشخصات پرس و جو کاربر است اما کاملاً با پرس و جوهای SPARQL مطابقت ندارد.
موضوع مهم دیگری که باید تحلیل شود، فضای ذخیره سازی هر رویکرد بررسی شده است. سرور Apache Jena از TDB برای ذخیره گراف RDF استفاده می کند. شکل 8 فضای ذخیره سازی بین TDB و PostgreSQL را نشان می دهد. مشاهده شد که TDB بیش از پنج برابر اندازه حافظه مورد نیاز رویکرد متنی ما را می طلبد.
پایگاه داده TripBuilder از مخزن https://figshare.com/articles/online_resource/Trajectories_RDF_Dataset_From_TripBuilder/11559090 (در 22 مه 2022) به دست آمده است. کد منبع پروژه ما را می توان از https://github.com/DamiaoRA/SETHE (در 22 مه 2022) دانلود کرد.
6. نتیجه گیری
درج اطلاعات مبتنی بر زمینه در داده های مسیر منجر به مسیرهای غنی شده معنایی می شود. بنابراین، مسیرها ممکن است از منظرهای مختلفی تحلیل شوند، که به عنوان جنبهها نیز شناخته میشوند. هر دیدگاه، تجزیه و تحلیل اطلاعات مبتنی بر زمینه مکانی-زمانی را امکان پذیر می کند. در این پژوهش، این مسیرها را مسیرهای معنایی مبتنی بر جنبه نامیدند. بسته به کاربرد، جنبه های مسیر ممکن است به طور قابل توجهی از نظر کمیت و نوع متفاوت باشد. برخی از رویکردهای مرتبط، مسیرهای معنایی را با استفاده از نمودارهای RDF، هستیشناسی یا مدلهای مفهومی نشان میدهند که در آن فرآیند جستجو فقط بر اساس یک تطابق دقیق است. بسته به پیچیدگی پرس و جو، تطابق دقیق ممکن است نتایج کمی داشته باشد یا هیچ نتیجه ای نداشته باشد.
این مقاله چارچوب SETHE را پیشنهاد میکند، یک موتور جستجو برای جستوجوی مجموعه دادههای مسیر معنایی مبتنی بر جنبه با استفاده از پردازش متن. SETHE تطبیق جزئی را با استفاده از ضریب شباهت بین مسیر معنایی مبتنی بر جنبه و جستجوی کاربر برای رتبهبندی مجموعه نتایج پیادهسازی میکند. در ابزارهای جستجوی مسیر معنایی سنتی، وزن مربوط به یک جنبه مشخص وجود ندارد. از این رو، همه جنبه ها دارای اولویت یکسان با کاربر هستند. رویکرد ما از یک تابع فاصله و وزن اختصاص داده شده به هر جنبه استفاده می کند که بر الگوریتم رتبه بندی تأثیر می گذارد. مجموعه نتیجه شامل مسیرهایی است که با ضرایب آنها محاسبه شده از توابع فاصله و وزن ها رتبه بندی شده اند. با استفاده از رویکرد رتبهبندی، نزدیکترین مسیرها به درخواست کاربر ممکن است برگردانده شوند.
ما همچنین یک رویکرد جدید برای نمایش دادههای مسیر معنایی مبتنی بر جنبه ارائه میکنیم، که در آن هر مسیر تنها با متن نشان داده میشود. آزمایشها با استفاده از این رویکرد نشان دادند که مصرف حافظه برای ذخیره مسیرها و جنبههای آنها کمتر از یک رویکرد با استفاده از نمودار RDF، یکی از اصلیترین نمایشهای مسیر معنایی مورد استفاده است.
برای ارزیابی ارتباط کارمان، نتایج را با نتایج یکی از جدیدترین مطالعات در زمینه جستجوی مسیر معنایی مقایسه کردیم. نتایج نشان داد که SETHE میانگین زمان پاسخگویی بهتری دارد. علاوه بر این، یک پرس و جو SETHE معمولاً نتایج بیشتری را با استفاده از رویکرد رتبهبندی شده با تطابق جزئی نشان میدهد. در کار آینده، ما قصد داریم از سود تجمعی تنزیل شده نرمال شده (NDCG) برای اندازه گیری کیفیت رتبه بندی استفاده کنیم. ما قصد داریم چارچوب SETHE خود را به گونهای گسترش دهیم که مدلسازی چند بعدی را در بر بگیرد تا کاربران بتوانند اپراتورها را جمعآوری کرده و بر روی جنبههای مسیر حرکت کنند. در نهایت، ما روی پیادهسازی یک رابط کاربری گرافیکی (GUI) کار خواهیم کرد و ارزیابی کاربر را با استفاده از استاندارد ISO 9241 – بخشهای 14، 16 و 17 انجام خواهیم داد.
منابع
- کنگ، ایکس. لی، ام. ما، ک. تیان، ک. وانگ، ام. نینگ، ز. Xia, F. داده های مسیر بزرگ: بررسی برنامه ها و خدمات. دسترسی IEEE 2018 ، 6 ، 58295–58306. [ Google Scholar ] [ CrossRef ]
- فیلتو، ر. رافائتا، ا. رونکاتو، ا. ساسنتی، ج.ا. می، سی. کلاین، دی. یک مدل معنایی برای انبارهای داده حرکت. در مجموعه مقالات هفدهمین کارگاه بین المللی در مورد ذخیره سازی داده ها و OLAP، شانگهای، چین، 3-7 نوامبر 2014. ص 47-56. [ Google Scholar ]
- ناردینی، اف.ام. اورلاندو، اس. پرگو، آر. رافائتا، ا. رنسو، سی. Silvestri، C. تجزیه و تحلیل مسیرهای کاربران تلفن همراه: از انبارهای داده تا سیستم های توصیه کننده. در یک راهنمای جامع از طریق تحقیقات پایگاه داده ایتالیا در 25 سال گذشته ؛ Springer: برلین/هایدلبرگ، آلمان، 2018; ص 407-421. [ Google Scholar ]
- واگنر، آر. Macedo، JAFd; رافائتا، ا. رنسو، سی. رونکاتو، ا. Trasarti، R. Mob-warehouse: یک رویکرد معنایی برای تجزیه و تحلیل تحرک با یک انبار داده مسیر. در مجموعه مقالات کنفرانس بین المللی مدل سازی مفهومی، هنگ کنگ، چین، 11-13 نوامبر 2013. Springer: برلین/هایدلبرگ، آلمان، 2013; صص 127-136. [ Google Scholar ]
- الصحفی، ت. المطیری، م. الماسری، ر. نظرسنجی در مورد انبار داده مسیر. تف کردن Inf. Res. 2020 ، 28 ، 53-66. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- امانوئیلیدیس، سی. کوتسیامانیس، RA; تاسیدو، ا. راهنمای موبایل: طبقه بندی معماری ها، آگاهی از زمینه، فناوری ها و کاربردها. J. Netw. محاسبه کنید. Appl. 2013 ، 36 ، 103-125. [ Google Scholar ] [ CrossRef ]
- فیلتو، ر. می، سی. رنسو، سی. پلکیس، ن. کلاین، دی. Theodoridis, Y. چارچوب مبتنی بر دانش Baquara2 برای غنی سازی معنایی و تجزیه و تحلیل داده های حرکت. دانستن داده ها مهندس 2015 ، 98 ، 104-122. [ Google Scholar ] [ CrossRef ]
- Qin، Y. شنگ، QZ; فالکنر، نیوجرسی؛ دوستدار، س. وانگ، اچ. Vasilakos، AV وقتی همه چیز مهم است: نظرسنجی در مورد اینترنت اشیا مبتنی بر داده. J. Netw. محاسبه کنید. Appl. 2016 ، 64 ، 137-153. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پدر و مادر، سی. اسپاکاپیترا، اس. رنسو، سی. آندرینکو، جی. آندرینکو، ن. بوگورنی، وی. دامیانی، ام.ال. گکولالاس-دیوانیس، ع. مکدو، جی. پلکیس، ن. و همکاران مدلسازی و تحلیل مسیرهای معنایی کامپیوتر ACM. Surv. CSUR 2013 ، 45 ، 42. [ Google Scholar ] [ CrossRef ]
- آلمیدا، DRd; باپتیستا، سی دی اس. Andrade، FGd; Soares, A. A Survey on Big Data for Trajectory Analytics. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 88. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پتری، LM; فررو، کالیفرنیا؛ آلوارس، لو. رنسو، سی. Bogorny, V. Towards towards semantic-aware-semantic-aware-semantic-aware-signity syney measuring. ترانس. GIS 2019 ، 23 ، 960–975. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Mello، RdS; بوگورنی، وی. آلوارس، لو. سانتانا، LHZ؛ فررو، کالیفرنیا؛ فروزا، AA; شراینر، GA; Renso، C. MASTER: یک نمای چند وجهی در مسیرها. ترانس. GIS 2019 ، 23 ، 805-822. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- نوئل، دی. ویلانوا-الیور، ام. جنسل، جی. Le Quéau, P. مدلسازی مسیرهای معنایی شامل دیدگاههای متعدد و عوامل توضیحی: کاربرد در مسیرهای زندگی. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در شهرهای هوشمند و تجزیه و تحلیل شهری، Bellevue، WA، ایالات متحده آمریکا، 3-6 نوامبر 2015. صص 107-113. [ Google Scholar ]
- Izquierdo، YT; مونته آگودو گارسیا، جی. کازانووا، MA; Paes Leme، LAP; ساردیانوس، سی. تسرپس، ک. وارلامیس، آی. Ruback Rodrigues، LC عبارات توالی توقف و حرکت در مسیرهای معنایی. بین المللی جی. جئوگر. Inf. علمی 2021 ، 35 ، 793-818. [ Google Scholar ] [ CrossRef ]
- بریلهانت، آی. Macedo، JA; ناردینی، اف.ام. پرگو، آر. Renso, C. Tripbuilder: ابزاری برای توصیه تورهای گشت و گذار. در مجموعه مقالات کنفرانس اروپایی در مورد بازیابی اطلاعات، آمستردام، هلند، 13-16 آوریل 2014. Springer: برلین/هایدلبرگ، آلمان، 2014; صص 771-774. [ Google Scholar ]
- گوتینگ، RH; Schneider, M. Moving Object Databases ; الزویر: آمستردام، هلند، 2005. [ Google Scholar ]
- یان، ز. چاکرابورتی، دی. پدر و مادر، سی. اسپاکاپیترا، اس. Aberer, K. SeMiTri: چارچوبی برای حاشیه نویسی معنایی مسیرهای ناهمگن. در مجموعه مقالات چهاردهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، اوپسالا، سوئد، 21 تا 24 مارس 2011. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; صص 259-270. [ Google Scholar ]
- اسپاکاپیترا، اس. پدر و مادر، سی. دامیانی، ام.ال. de Macedo، JA; پورتو، اف. وانگنوت، سی. دیدگاه مفهومی در مسیرها. دانستن داده ها مهندس 2008 ، 65 ، 126-146. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بوگورنی، وی. رنسو، سی. د آکینو، آر. د لوکا سیکیرا، اف. Alvares، LO Constant-یک مدل داده مفهومی برای مسیرهای معنایی اجسام متحرک. ترانس. GIS 2014 ، 18 ، 66-88. [ Google Scholar ] [ CrossRef ]
- نیکیتوپولوس، پی. ولاچو، ع. دولکریدیس، سی. Vouros، GA DiStRDF: پرس و جوهای RDF فضایی-زمانی توزیع شده در Spark. در مجموعه مقالات کارگاه های آموزشی EDBT/ICDT، وین، اتریش، 26 مارس 2018؛ صص 125-132. [ Google Scholar ]
- دیویدینو، آر. سوآرس، آ. ماتوین، اس. ایزنور، AW؛ وب، اس. Brousseau، M. ادغام معنایی جریانهای داده ناهمگن زمان واقعی برای تصمیمگیری مرتبط با اقیانوس. در مجموعه مقالات کلان داده و هوش مصنوعی برای تصمیم گیری نظامی، بوردو، فرانسه، 30 مه تا 1 ژوئن 2018. [ Google Scholar ] [ CrossRef ]
- آلوارس، لو. بوگورنی، وی. کویجپرز، بی. de Macedo، JAF; مولانز، بی. Vaisman, A. مدلی برای غنی سازی مسیرها با اطلاعات جغرافیایی معنایی. در مجموعه مقالات پانزدهمین سمپوزیوم بین المللی سالانه ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 7-9 نوامبر 2007. صص 1-8. [ Google Scholar ]
- چانگ، بی. پارک، ی. کیم، اس. Kang, J. DeepPIM: مدل انتساب نقطه عصبي عميق. Inf. علمی 2018 ، 465 ، 61-71. [ Google Scholar ] [ CrossRef ]
- گاسفیلد، دی. الگوریتمهای رشتهها، درختان و توالیها: علوم کامپیوتر و زیستشناسی محاسباتی . انتشارات دانشگاه کمبریج: نیویورک، نیویورک، ایالات متحده آمریکا، 1997. [ Google Scholar ]
شکل 1. نمونه ای از مسیر گردشگری در شهر پیزا.

شکل 2. نمونه ای از پرس و جوی مسیر با اطلاعات توقف ها و جنبه ها.
شکل 3. درخت POI.
شکل 4. نمایش مجموعه داده TripBuilder .
شکل 5. نمودار ER پایگاه داده مسیرهای متنی.
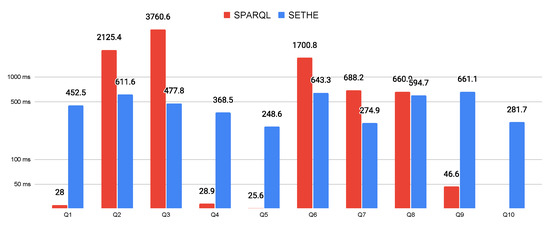
شکل 6. نمودار عملکرد.
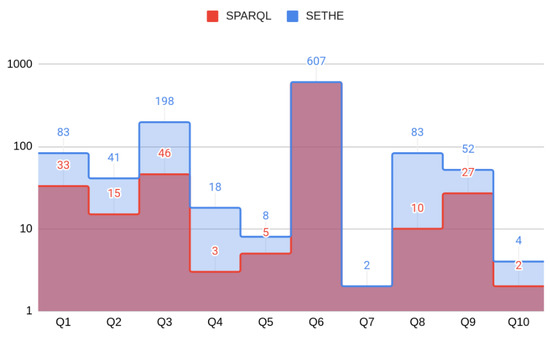
شکل 7. تعداد نتایج در هر پرس و جو.
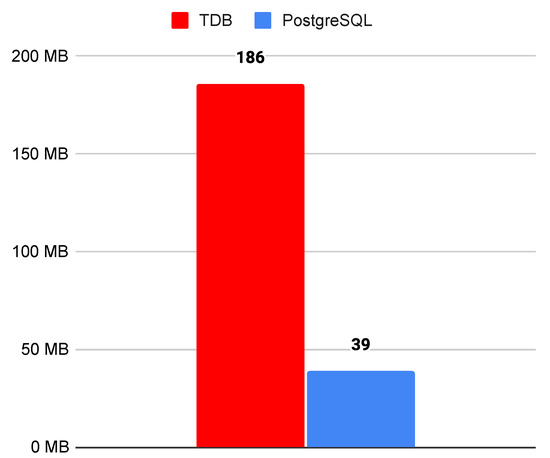
شکل 8. مصرف فضای حافظه.


8 نظرات