1. معرفی
املاک و مستغلات یکی از نیازهای اصلی انسان است. علاوه بر این، این روزها ثروت و موقعیت یک فرد را نشان می دهد. پس انداز در اموال معمولاً سودآور است زیرا ارزش آن بلافاصله کاهش نمی یابد. بی ثباتی در قیمت ملک می تواند بر چندین سهامدار خانوار، سرمایه گذاران و سیاست گذاران تأثیر بگذارد. علاوه بر این، اکثر سرمایه گذاران ترجیح می دهند در بخش واقعی سرمایه گذاری کنند. بنابراین، پیشبینی بهای تمام شده املاک و مستغلات یک شاخص اقتصادی ضروری است. برای پیشبینی قیمت خانه، به یک مجموعه داده سازمانیافته خوب از املاک و مستغلات نیاز داریم. در این کار، ما از یک مجموعه داده در دسترس عموم از Kaggle Inc. [ 1]. این شامل 3000 مثال آموزشی با 80 ویژگی است که بر قیمت املاک تأثیر می گذارد. با این حال، تکنیکهای پیشپردازش دادهها مانند رمزگذاری یکطرفه، همبستگی ویژگیها و مدیریت دادههای از دست رفته باید برای به دست آوردن یک نتیجه خوب اعمال شوند.
رمزگذاری تک داغ پرکاربردترین روش رمزگذاری باینری برای تبدیل داده های متنی به داده های عددی است [ 2 ]. انتخاب ویژگیها ابعاد فضای ویژگی را کاهش میدهد و دادههای غیرضروری، نامرتبط یا نویزدار را حذف میکند. این تأثیر فوری بر روی یک پیشبینی دارد: بهبود کیفیت دادهها، شتاب فرآیند یادگیری ماشین (ML) و افزایش درک پیشبینی [ 3 ، 4 ]]. علاوه بر مشکلات پیش پردازش ذکر شده در بالا، داده های از دست رفته یک مشکل هستند، زیرا تقریباً تمام رویکردهای آماری معمولی اطلاعات کاملی را برای همه ویژگی های مربوط به بررسی فرض می کنند. مشاهدات مبهم نسبتاً کمی روی برخی متغیرها می تواند حجم نمونه را به میزان قابل توجهی کاهش دهد. بر این اساس، دقت اطمینان آسیب می بیند، قدرت آماری کمرنگ می شود و ارزیابی پارامترها ممکن است تحت تأثیر قرار گیرد [ 5 ].
در رویکرد خود، ما از الگوریتم همبسته ترین ویژگی های مبتنی بر KNN (KNN-MCF) برای مقابله با داده های از دست رفته استفاده کردیم. ایده اصلی این بود که فقط از معنیدارترین متغیرهای یافت شده با استفاده از شبیهسازی برای مدیریت دادههای موجود با الگوریتم KNN استفاده شود. در این روش پیشرفته، دقت پیشبینی قیمت مسکن به طور مشخص بهتر از روشهای سنتی مدیریت دادههای گمشده، مانند میانگین، میانه و حالت است. ما روش خود را با روشهای میانگین سنتی و KNN با پیادهسازی آنها بر روی چندین الگوریتم یادگیری ماشین مقایسه کردیم.
سازماندهی بقیه این مقاله به شرح زیر است: کارهای مرتبط در بخش 2 مورد بحث قرار گرفته است. بخش 3 شامل مجموعه داده ها و روش های مورد استفاده در این کار است. بخش 4 نتایج را نشان می دهد و بخش 5 این مقاله را با نتیجه گیری و بحث مختصری در مورد مسیرهای کاری آینده به پایان می رساند.
2. آثار مرتبط
ما برخی از کارهای مرتبط را که سعی در پیشبینی قیمت مسکن با تکنیکهای پیشپردازش دادهها در این بخش داشتند، مرور کردیم. بررسی کردیم که چه کارهایی انجام شده است و چه چیزی از این تلاش ها می توان آموخت. یک بحث کاملتر در مورد روشهای داده از دست رفته را می توان در [ 6 ، 7 ] یافت. داده های از دست رفته یا ناقص یک اشکال رایج برای بسیاری از موارد دنیای واقعی در طبقه بندی الگو است [ 8 ، 9 ، 10 ]. در [ 11 ]، نویسنده بیشترین پارامترهای کلان اقتصادی را برشمرده است که بر نوسانات قیمت مسکن تأثیر می گذارد. در [ 12]، محققان سعی کردند با استفاده از چندین تکنیک یادگیری ماشینی، قیمت فروش خانه ها را پیش بینی کنند. داده های کار ما و کار آنها یکی است. با این حال، نویسندگان از یک راه ساده برای جلوگیری از داده های از دست رفته استفاده کردند. آنها فقط مشاهداتی را که ارزش گمشده داشتند حذف کردند. این روش منجر به کاهش اندازه مجموعه داده شد.
حذف مشاهدات می تواند باعث ارزیابی هایی با میانگین خطاهای نسبتاً بزرگ به دلیل کاهش حجم نمونه شود [ 13 ]. حذف ردیفهایی در مجموعه دادهای که دادههای گمشده دارند، پیامدهای تعصبآمیز یا نارضایتی به همراه دارد، حتی اگر چنین تکنیکهایی هنوز معمولاً در تولید نرمافزار استفاده میشوند [ 14 ]. ما این روش را به عنوان “تحلیل کامل موردی” می شناسیم. این استراتژی برخی از متغیرهایی را که برای برآورده کردن پیشبینیهای ضروری برای شفافسازی رضایتبخش مورد نیاز است، حذف میکند [ 13 ]. در تعدادی از مطالعات، انتساب مقادیر از دست رفته داده های عددی به طور منظم با استفاده از جایگزینی میانگین [ 14 ] بررسی شده است.]. نکته منفی اولیه این است که این استراتژی می تواند توزیع را برای صفتی که برای انتساب استفاده می شود با قضاوت نادرست انحراف استاندارد تغییر دهد [ 15 ]. علاوه بر این، انتساب متوسط برای افزایش دوام اجرا می شود، زیرا نقاط پرت مجموعه داده ممکن است بر مقدار میانگین تأثیر بگذارد. انتساب حالت عموماً برای ویژگیهای طبقهبندی بهجای انتساب میانگین و انتساب میانه استفاده میشود [ 16 ].
نقطه ضعف این روش این است که نمی تواند وابستگی های بین مقادیر ویژگی را کنترل کند [ 7 ]. علاوه بر این، مقاله [ 17 ] مجموعه داده آزمایشی را با برخی از داده های گمشده مورد بحث قرار داد و مقادیر درصد گمشده متنوعی را در کار خود انتخاب کرد. میانگین، میانه و انحراف معیار برای هر مقدار اختصاص داده شد. آنها برای هر مورد نتایج متفاوتی به همراه داشتند. در [ 5 ]، مکانیسم های داده های گمشده و الگوهای داده های از دست رفته به خوبی توضیح داده شده است. نویسندگان این مقاله برخی از تکنیکهای پیشرفته را برای مدیریت دادههای از دست رفته، مانند حداکثر احتمال و همچنین انتساب چندگانه در نظر گرفتند. طبق [ 18]، میتوانیم دو ویژگی مهم روش KNN را فهرست کنیم: تابع impute KNN میتواند بدون زحمت با ویژگیهای کمی و کیفی مقابله کرده و آنها را پیشبینی کند، و این روش میتواند مستقیماً تعدادی از مقادیر از دست رفته را کنترل کند. حتی اگر ورودی KNN به طور گسترده برای مقابله با داده های از دست رفته مورد استفاده قرار گرفته است ، هنگامی که بر روی یک مجموعه داده بزرگ اجرا می شود ، نکات منفی [ 19 ، 20 ، 21 ] وجود دارد .
به منظور مقایسه روش خود با تکنیکهای فعلی، ابتدا از یک روش ساده، میانگین همه مشاهدات غیرمفقود، برای رسیدگی به دادههای گمشده استفاده کردیم. عیب اصلی این روش این است که تمام داده های از دست رفته با مقدار میانگین یکسان پر شدند [ 22 ]. بنابراین در حال حاضر از این روش در حوزه علم داده استفاده زیادی نمی شود. روش دومی که برای محاسبه داده های از دست رفته استفاده کردیم، الگوریتم KNN بود. در این روش، ما تابع الگوریتم KNN را بررسی کردیم تا مقادیر گمشده را به نام KNN impute [ 18 ] درج کنیم.]. اگر یک ویژگی جزئی وجود داشته باشد، این تکنیک نزدیکترین K نمونههای خود را از نمونههای آموزشی با مقادیر شناختهشده در ویژگیهایی که باید نسبت داده شوند، انتخاب میکند، به طوری که فاصله را کاهش میدهند. پس از به دست آوردن K نزدیکترین همسایگان، یک مقدار جایگزین باید برای بازیابی مقدار مشخصه گمشده ارزیابی شود. نوع ارزش جایگزینی به نوع داده های مورد استفاده بستگی دارد – میانگین می تواند برای داده های پیوسته و حالت برای داده های کیفی استفاده شود.
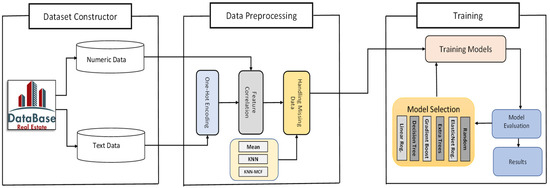
بر اساس مطالعات ذکر شده در بالا، متوجه شدیم که میتوانیم با انتخاب مهمترین ویژگیهایی که تأثیر زیادی در پیشبینی قیمت مسکن دارند، روششناسی برای منتسب کردن دادههای گمشده را با الگوریتم KNN بهبود دهیم. معماری سیستم به دست آمده با استفاده از روش پیشنهادی در زیر نشان داده شده است.
3. مواد و روشها
3.1. مجموعه داده
مجموعه داده اولیه ما از مجموعه داده Kaggle [ 23 ] به دست آمده است، که داده های زیادی را در اختیار دانشمندان داده برای آموزش مدل های یادگیری ماشینی خود قرار می دهد. توسط بارت دی کاک در سال 2011 جمع آوری شد و به طور قابل توجهی بزرگتر از مجموعه داده معروف مسکن بوستون است [ 24 ]]. این شامل 79 متغیر بیانی است که تقریباً هر ویژگی خانههای مسکونی در ایمز، آیووا، ایالات متحده را در دوره 2006 تا 2010 نشان میدهد. مجموعه داده شامل دادههای عددی و متنی است. داده های عددی شامل اطلاعاتی در مورد تعداد اتاق ها، اندازه اتاق ها و کیفیت کلی ملک است. برخلاف داده های عددی، داده های متنی به صورت کلمات ارائه می شوند. مکان خانه، نوع مصالح استفاده شده برای ساخت خانه، و سبک سقف، گاراژ و حصار نمونه هایی از داده های متنی هستند. جدول 1 شرح مجموعه داده را نشان می دهد.
دلیل اصلی تقسیم مجموعه داده ها به انواع مختلف داده این بود که داده های متنی باید قبل از آموزش با تکنیک رمزگذاری یک داغ به داده های عددی تبدیل می شد. ما این روش رمزگذاری را در بخش پیش پردازش داده های متدولوژی خود شرح خواهیم داد. در مجموع 19 ویژگی از مجموع 80 ویژگی دارای مقادیر گمشده هستند. درصد مقادیر از دست رفته 16٪ است.
3.2. پیش پردازش داده ها
در این فرآیند، داده های خام و پیچیده را به داده های سازمان یافته تبدیل کردیم. این شامل چندین روش از رمزگذاری یکباره تا یافتن داده های گم شده و غیر ضروری در مجموعه داده بود. چندین تکنیک یادگیری ماشینی می توانند بلافاصله با داده های طبقه بندی شده کار کنند. به عنوان مثال، یک الگوریتم درخت تصمیم میتواند با دادههای طبقهبندی شده بدون نیاز به تبدیل داده عمل کند. با این حال، بسیاری از سیستمهای یادگیری ماشینی نمیتوانند با دادههای برچسبگذاری شده کار کنند. آنها نیاز دارند که همه متغیرها (ورودی و خروجی) عددی باشند. این را میتوان بهعنوان محدودیت بزرگ الگوریتمهای یادگیری ماشین بهجای محدودیتهای سخت در خود الگوریتمها در نظر گرفت. بنابراین، اگر دادههای دستهبندی داریم، باید آنها را به دادههای عددی تبدیل کنیم. دو روش متداول برای ایجاد داده های عددی از داده های طبقه بندی وجود دارد:
-
رمزگذاری تک داغ
-
رمزگذاری عدد صحیح
در مورد مکان خانه، خانه های موجود در مجموعه داده ممکن است در سه شهر مختلف واقع شوند: نیویورک، واشنگتن و تگزاس. نام شهرها باید به داده های عددی تبدیل شوند. در مرحله اول، به هر مقدار ویژگی منحصر به فرد یک مقدار صحیح داده می شود. به عنوان مثال، 1 برای “نیویورک”، 2 برای “واشنگتن”، و 3 برای “کالیفرنیا” است. برای چندین ویژگی، این ممکن است کافی باشد. این به این دلیل است که اعداد صحیح یک ارتباط منظم با یکدیگر دارند که تکنیکهای یادگیری ماشین را قادر میسازد تا این ارتباط را درک کرده و از آن استفاده کنند. در مقابل، متغیرهای طبقهای هیچ رابطه ترتیبی ندارند. بنابراین، رمزگذاری عدد صحیح قادر به حل مشکل نیست. استفاده از چنین رمزگذاری و اجازه دادن به مدل برای بدست آوردن نظم طبیعی بین دستهها ممکن است کاربرد ضعیف یا نتایج پیشبینی نشده داشته باشد.جدول 2 و رمزگذاری عدد صحیح آن در جدول 3 . می توان متوجه شد که ترتیب بین دسته ها منجر به پیش بینی دقیق تر قیمت خانه می شود.
برای حل مشکل، میتوانیم از رمزگذاری تک داغ استفاده کنیم. اینجاست که متغیر عدد صحیح تعیین شده حذف می شود و یک متغیر باینری جدید برای هر عدد صحیح منفرد اضافه می شود [ 2 ]]. همانطور که اشاره کردیم، بر اساس دادههایمان، ممکن است با این تصور که یک ستون دادهها را با نظم یا سلسله مراتب خاصی دارد، با وضعیتی مواجه شویم که مدل ما دچار سردرگمی شود. با این حال، میتوان با «رمزگذاری یکطرفه» که در آن دادههای طبقهبندی کدگذاریشده برچسب به ستونهای متعدد تقسیم میشوند، از آن اجتناب کرد. بر اساس مقادیر ستون ها، اعداد با 1 و 0 جایگزین می شوند. در مورد ما، ما سه ستون جدید، یعنی نیویورک، واشنگتن، و کالیفرنیا دریافت کردیم. برای سطرهایی که مقدار ستون اول آنها نیویورک است، “1” به ستون “نیویورک” اختصاص داده می شود و دو ستون دیگر “0” دریافت می کنند. به همین ترتیب، برای سطرهایی که مقدار ستون اول آنها واشنگتن است، “1” به “واشنگتن” اختصاص داده می شود، و دو ستون دیگر “0” و غیره خواهند داشت ( جدول 4 را ببینید.). ما از این نوع رمزگذاری در قسمت پیش پردازش داده ها استفاده کردیم.
در صورت وجود مقادیر از دست رفته، رمزگذاری یک گرم، مقادیر از دست رفته را به صفر تبدیل می کند. در اینجا مثال نشان داده شده در جدول 5 آمده است :
در جدول فوق، مقدار سوم وجود ندارد. هنگام تبدیل این مقادیر مقولهای به عددی، همه مقادیری که از دست نمیروند دارای یک (ها) در ردیفهای ID مربوطه خود هستند. با این حال، مقادیر از دست رفته، در ردیف های شناسه مربوطه صفر دریافت کنید. اکنون ما نتیجه را خواهیم دید که چگونه رمزگذاری یک داغ با این مقدار برخورد می کند.
بنابراین، مثال سوم همان طور که در جدول 6 می بینیم، فقط صفر می گیرد. قبل از انتخاب بیشتر ویژگیهای همبسته و پرداختن به مقادیر گمشده، این صفرها را دوباره به مقادیر گمشده تبدیل میکنیم.
3.3. همبستگی ویژگی
انتخاب ویژگی یک حوزه قوی در علوم کامپیوتر است. از دهه 1970، این یک حوزه تحقیقاتی سازنده در تعدادی از زمینهها، مانند تشخیص الگوی آماری، یادگیری ماشین، و دادهکاوی بوده است [ 25 ، 26 ، 27 ، 28 ، 29 ، 30 ، 31 ، 32 .]. پیشنهاد اصلی در این کار این است که قبل از پرداختن به داده های گمشده با استفاده از الگوریتم KNN، همبستگی ویژگی را به مجموعه داده اعمال کنیم. با انجام این کار، میتوانیم یک الگوریتم K-نزدیکترین همسایه بهینهسازی شده را بر اساس همبستگیترین ویژگیها برای انتساب دادههای گمشده، یعنی KNN–MCF نشان دهیم. ابتدا، همانطور که در بخش فرعی قبلی توضیح داده شد، داده های طبقه بندی را در داده های عددی رمزگذاری کردیم. مرحله بعدی و اصلی انتخاب مهم ترین ویژگی های مربوط به قیمت خانه در مجموعه داده بود. معماری کلی مدل در شکل 1 نشان داده شده است .
سپس، ما سه روش مدیریت داده های از دست رفته را پیاده سازی کردیم:
دقت هر مدل اجرا شده در بخش آموزشی پس از اعمال روش بهبود یافت. اکنون انتخاب مهم ترین ویژگی ها را توضیح می دهیم. روش های مختلفی برای همبستگی ویژگی ها وجود دارد. در این کار از روش ضریب همبستگی برای انتخاب مهمترین ویژگی ها استفاده شده است. فرض کنید دو ویژگی داریم: a و b. ضریب همبستگی بین این دو متغیر را می توان به صورت زیر تعریف کرد:
ضریب همبستگی:
که در آن Cov(a,b) کوواریانس a و b و Var(.) واریانس یک ویژگی است. کوواریانس بین دو ویژگی با استفاده از فرمول زیر محاسبه می شود:
در این فرمول:
پس از پیاده سازی فرمول بالا در مجموعه داده، نتیجه نشان داده شده در شکل 2 را به دست آوردیم .
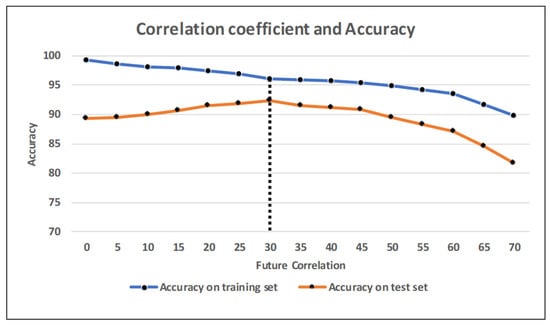
بدیهی است که صفات بر اساس ضریب همبستگی مرتب شده اند. کیفیت کلی خانه و کل مساحت زمین مهم ترین ویژگی مجموعه داده برای پیش بینی قیمت خانه بود. ما یک الگوریتم جنگل تصادفی با مقادیر مختلف ضریب همبستگی آموزش دادیم. دقت در مجموعه آموزشی با تعداد زیادی ویژگی بالا بود، در حالی که عملکرد در مجموعه آزمایشی به دلیل مشکل بیش از حد برازش بسیار پایینتر بود. به منظور دستیابی به مقدار کامل ضریب همبستگی، مجموعه داده را با جزئیات بیشتر و با دقت بیشتری شبیه سازی کردیم. شکل 3رابطه معنادار بین ضریب همبستگی و دقت مدل را در هر دو زیر مجموعه آموزش و آزمون نشان می دهد. محور عمودی درصد دقت آموزش و زیر مجموعه های آزمون را نشان می دهد. محور افقی نشان دهنده ضریب همبستگی بیش از مقدار داده شده است.
برای روشنتر شدن آن، مقدار اول، 0% را به عنوان مثال در نظر بگیرید. این نشان می دهد که ما از تمام 256 ویژگی در هنگام آموزش و آزمایش مدل استفاده کردیم. خط دقت مقادیر حدود 99% و 89% را به ترتیب برای مجموعه های آموزشی و تست نشان می دهد. مقدار دوم، 5٪، نشان می دهد که ما ویژگی ها را با ضریب همبستگی بیش از 5٪ در نظر گرفتیم. در این شرایط، تعداد ویژگی ها در فرآیند آموزش به 180 کاهش یافت. عملاً هر چه ویژگی های مجموعه آموزشی کمتر باشد، دقت ثبت شده کمتر می شود. پس از آموزش مدل ما با تعداد ویژگی های داده شده، دقت برای آموزش کاهش یافت، در حالی که دقت مجموعه تست به تدریج افزایش یافت زیرا سعی کردیم از بیش از حد برازش مدل خود جلوگیری کنیم.
شکل 3 نشان می دهد که بهترین مقدار 30 درصد بوده است. مجموعه داده شامل 45 ویژگی است که با این نیاز مطابقت دارد.
بنابراین، ما دقت مدل را بهبود بخشیم، زیرا استفاده از چند ویژگی مناسب برای آموزش مدل بهتر از حجم عظیمی از دادههای نامربوط و غیر ضروری است. علاوه بر این، میتوانیم از اضافهبرازش جلوگیری کنیم، زیرا با افزایش تعداد ویژگیهای نامرتبط، احتمال بیشبرازش افزایش مییابد.
3.4. رسیدگی به داده های از دست رفته
چندین مفهوم برای تعریف فاصله برای KNN تا کنون شرح داده شده است [ 6 ، 9 ، 10 ، 33 ، 34 ]. اندازه گیری فاصله را می توان با استفاده از فاصله اقلیدسی محاسبه کرد. فرض کنید که jامین ویژگی ورودی x در جدول 7 وجود ندارد . همانطور که در رابطه (3) نشان داده شده است، پس از محاسبه فاصله x تا تمام مثال های آموزشی، K نزدیکترین همسایه آن را از زیر مجموعه آموزشی انتخاب کردیم.
مجموعه در معادله (3) K نزدیکترین همسایه x را نشان می دهد که به ترتیب صعودی دور بودن آنها قرار گرفته اند. بنابراین، v 1 نزدیکترین همسایه x بود. K نزدیکترین موارد با بررسی فاصله با ورودیهای گم نشده در ویژگی ناقص برای منتسب انتخاب شدند. پس از انتخاب نزدیکترین همسایههای K آن، مقدار مجهول با تخمینی از مقادیر ویژگی j ام Ax نسبت داده شد . مقدار نسبت داده شده ایکسj˜در صورتی که ویژگی j یک متغیر عددی باشد، با استفاده از مقدار میانگین K نزدیکترین همسایگان آن به دست می آید. یکی از تغییرات مهم وزن کردن تأثیر هر مشاهده بر اساس فاصله آن تا x بود که وزن بیشتری را برای همسایگان نزدیکتر فراهم کرد (به معادله (4) مراجعه کنید).
کاستی اصلی این روش این است که وقتی impute KNN مشابه ترین نمونه ها را مطالعه می کند، الگوریتم از کل مجموعه داده استفاده می کند. این محدودیت می تواند برای پایگاه های داده بزرگ بسیار جدی باشد [ 35]. تکنیک پیشنهادی روش KNN-MCF را برای یافتن مقادیر گمشده در مجموعه دادههای بزرگ پیادهسازی میکند. نقطه ضعف کلیدی استفاده از انتساب KNN این است که می توان آن را با داده های با ابعاد بالا به شدت تخریب کرد زیرا تفاوت کمی بین نزدیک ترین و دورترین همسایه وجود دارد. در این تحقیق به جای استفاده از تمام صفات، تنها از مهمترین ویژگی های انتخاب شده با استفاده از معادلات (1) و (2) استفاده کردیم. تکنیک انتخاب ویژگی معمولاً برای چندین هدف در یادگیری ماشین استفاده می شود. اول، دقت مدل را می توان بهبود بخشید، زیرا استفاده از تعدادی ویژگی مناسب برای آموزش مدل بهتر از استفاده از تعداد زیادی داده غیرمرتبط و اضافی است. دومین و مهم ترین دلیل برخورد با مشکل بیش از حد برازش است. از آنجایی که با افزایش تعداد ویژگی های نامربوط، امکان بیش از حد برازش زیاد است. ما فقط از 45 مورد از مهمترین ویژگی ها برای مدیریت داده های از دست رفته با مدل خود استفاده کردیم. با انجام این کار، به هدف اجتناب از اشکالات الگوریتم impute KNN دست یافتیم. برای راستیآزمایی مدل پیشنهادی، ما سه روش فوقالذکر برای مدیریت دادههای گمشده، یعنی میانگین، KNN و KNN-MCF را برای چندین الگوریتم پیشبینی مبتنی بر یادگیری ماشین اعمال کردیم.
4. نتایج
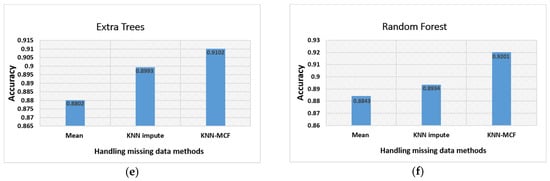
ما عملکرد الگوریتم KNN-MCF خود را با استفاده از شش الگوریتم مختلف پیشبینی مبتنی بر یادگیری ماشین ارزیابی کردیم و آنها را با دقت میانگین سنتی و روشهای ورودی KNN برای رسیدگی به دادههای از دست رفته مقایسه کردیم. مقادیر گمشده در مجموعه داده بر این اساس با روشهای میانگین استاندارد، ورودی KNN و KNN-MCF قبل از مرحله آموزش پر شدند. شکل 4 عملکرد الگوریتم های یادگیری ماشین را نشان می دهد.
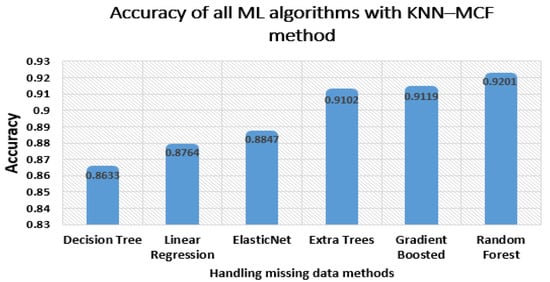
الگوریتم درخت تصمیم کمترین دقت را نشان داد که کمتر از 80 درصد برای روش قبلی و 0.8633 درصد برای روش پیشنهادی بود. الگوریتمهای تقویتشده گرادیان، درختهای اضافی، و الگوریتمهای جنگل تصادفی نسبت به الگوریتمهای رگرسیون خطی و ElasticNet صحت نسبتاً بالاتری با دقت بیش از ۹۰ درصد داشتند. بهترین عملکرد الگوریتم جنگل تصادفی با نرخ دقت 88.43، 89.34 درصد و 92.01 درصد برای روشهای میانگین، ورودی KNN و KNN-MCF بود.
پس از تغییر روش میانگین سنتی به الگوریتم impute KNN، مشاهده کردیم که دقت در هر الگوریتم یادگیری ماشین برای پیشبینی اندکی افزایش یافت. یکی از ملاحظات عمده در شکل های فوق الذکر این است که عملکرد هر الگوریتم ML به طور متفاوتی تحت تأثیر تغییرات در روش مدیریت داده های از دست رفته قرار گرفته است. افزایش دقت در برخی نمونه ها کم بود، در حالی که در برخی دیگر بالا بود. اکنون، ما اجرای تمام الگوریتمهای یادگیری ماشین را با توجه به روش KNN–MCF مقایسه میکنیم. از شکل 5 مشهود است که حداکثر دقت برای الگوریتم جنگل تصادفی ثبت شده است.
علاوه بر این، روش KNN در مقایسه با KNN-MCF از نظر محاسباتی گرانتر است. دلیل اصلی این تفاوت این است که KNN کل مجموعه داده را بررسی میکند در حالی که KNN–MCF تنها ویژگیهای انتخاب شده را در هنگام برخورد با دادههای از دست رفته تجزیه و تحلیل میکند. ما می توانیم جدول 8 را برای نشان دادن تفاوت هزینه محاسباتی بین این دو روش ارائه کنیم.
5. بحث
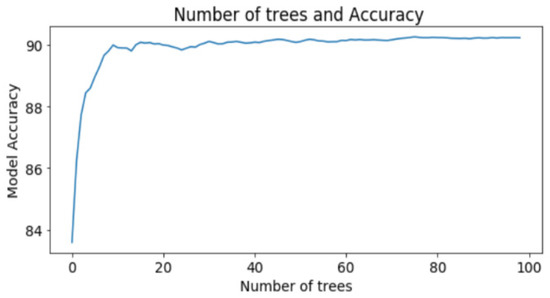
از آنجایی که حداکثر دقت با الگوریتم جنگل تصادفی به دست آمد، تصمیم گرفتیم دو پارامتر اصلی این الگوریتم را مورد بحث قرار دهیم. این تعداد درخت ها و تعداد گره های هر درخت است. هر دو قبل از اجرای جنگل تصادفی توسط برنامه نویس تعریف می شوند. این پارامترها بسته به نوع کار و مجموعه داده می توانند متفاوت باشند. اگر مقادیر کامل این دو پارامتر را از قبل شناسایی کنیم، نه تنها میتوانیم بالاترین دقت را بدست آوریم، بلکه در بیشتر موارد زمان کمتری را نیز صرف خواهیم کرد. شکل 6 به وضوح نشان می دهد که تعداد درختان برای دستیابی به دقت تست ایده آل 20 عدد بوده است. طبق نتایج، خط عملکرد برای بیش از 20 درخت بین 91% و 92% در نوسان بوده است.
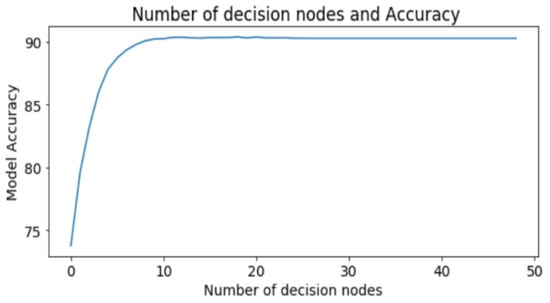
تعداد گرهها مشخص میکند که چند گره از گره ریشه تا برگ هر درخت در جنگل تصادفی داریم. شکل 7 نشان می دهد که بهترین مقدار برای این پارامتر در مورد ما 10 بود. بنابراین، ما یک جنگل تصادفی با 20 برآوردگر و 10 گره در هر برآوردگر پیاده سازی کردیم.
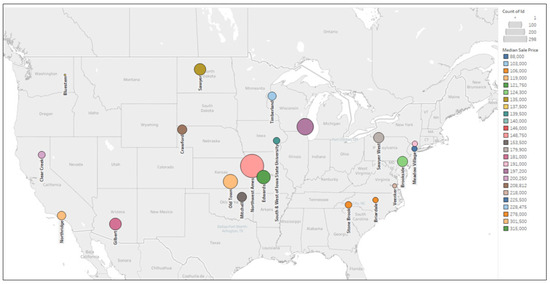
هنگام انتخاب یک خانه جدید، مردم همیشه به عوامل خاصی مانند پیادهروی، کیفیت مدرسه و ثروت منطقه توجه میکنند. از این منظر موقعیت خانه به طور مستقیم بر قیمت ملک تاثیر می گذارد. رابطه بین قیمت متوسط خانه در مکان معین و منطقه محله در شکل 8 نشان داده شده است . مقادیر میانه های مختلف با رنگ های مختلف داده می شود. این نمودار نشان می دهد که قیمت فروش خانه با توجه به موقعیت خانه بین 100000 تا 300000 دلار متغیر است.
6. نتیجه گیری
ما یک تکنیک موثر برای مقابله با داده های از دست رفته در این مقاله پیشنهاد کردیم. ایده اصلی در پس این روش، انتخاب مرتبط ترین ویژگی ها و استفاده از این ویژگی ها برای پیاده سازی الگوریتم KNN است. برای بررسی عملکرد یک مدل با استفاده از تکنیک خود، آن را با روشهای میانگین میانگین سنتی و مدلسازی KNN با تجزیه و تحلیل عملکرد این سه روش در چندین الگوریتم پیشبینی مبتنی بر یادگیری ماشین به طور همزمان مقایسه کردیم. نتایج رویکرد ما بالاتر از نتایج همه الگوریتمهای یادگیری ماشین بود. علیرغم دستیابی به دقت مناسب برای پیشبینی قیمت مسکن، ما معتقدیم که در آینده میتوان پیشرفتهای مختلفی کرد، مانند انتخاب مهمترین ویژگیها با استفاده از یادگیری عمیق.






بدون دیدگاه