

چکیده
توسعه مستمر روشهای یادگیری ماشین و توسعه روشهای جدید نقشهبرداری بر اساس ادغام دادههای مکانی از منابع ناهمگن منجر به اتوماسیون بسیاری از فرآیندهای مرتبط با تولید کارتوگرافی مانند ارزیابی دقت موقعیتی (PAA) شده است. اتوماسیون PAA دادههای مکانی مبتنی بر رویههای تطبیق خودکار بین اشیاء فضایی متناظر (معمولاً چند ضلعیهای ساختمانی) از دو پایگاه داده مکانی (GDB) است که به نوبه خود به کمیت شباهت بین این اشیا مربوط میشود. بنابراین، ارزیابی قابلیتهای این روشهای تطبیق خودکار برای تبدیل اتوماسیون به یک راهحل کاملاً عملیاتی در فرآیندهای PAA، کلیدی است. مطالعه حاضر در پاسخ به نیاز به بررسی دامنه این قابلیت ها با استفاده از مقایسه با قابلیت های انسانی توسعه یافته است. بنابراین، با استفاده از یک الگوریتم ژنتیک (GA) و گروهی از متخصصان انسانی، دو آزمایش انجام شده است: (1) برای مقایسه مقادیر شباهت بین چند ضلعی های ساختمانی اختصاص داده شده توسط هر دو و (ii) برای مقایسه روش تطبیق توسعه یافته در هر دو مورد. . نتایج بهدستآمده نشان داد که توافق GA – کارشناسان بسیار بالا بود، با میانگین درصد توافق 93.3٪ (برای آزمایش 1) و 98.8٪ (برای آزمایش 2). این نتایج قابلیت رویههای مبتنی بر ماشین و بهویژه GAها را برای انجام وظایف تطبیق تأیید میکند. دو آزمایش انجام شده است: (1) برای مقایسه مقادیر شباهت بین چند ضلعی های ساختمانی اختصاص داده شده توسط هر دو و (2) برای مقایسه روش تطبیق توسعه یافته در هر دو مورد. نتایج بهدستآمده نشان داد که توافق GA – کارشناسان بسیار بالا بود، با میانگین درصد توافق 93.3٪ (برای آزمایش 1) و 98.8٪ (برای آزمایش 2). این نتایج قابلیت رویههای مبتنی بر ماشین و بهویژه GAها را برای انجام وظایف تطبیق تأیید میکند. دو آزمایش انجام شده است: (1) برای مقایسه مقادیر شباهت بین چند ضلعی های ساختمانی اختصاص داده شده توسط هر دو و (2) برای مقایسه روش تطبیق توسعه یافته در هر دو مورد. نتایج بهدستآمده نشان داد که توافق GA – کارشناسان بسیار بالا بود، با میانگین درصد توافق 93.3٪ (برای آزمایش 1) و 98.8٪ (برای آزمایش 2). این نتایج قابلیت رویههای مبتنی بر ماشین و بهویژه GAها را برای انجام وظایف تطبیق تأیید میکند.
کلید واژه ها:
یادگیری ماشینی ؛ دانش تخصصی ؛ تطبیق خودکار ؛ دقت داده های مکانی ; ارزیابی خودکار
1. مقدمه
با افزایش عملکرد ماشینها به سطح انسانی در بسیاری از وظایف تشخیص پیچیده – عمدتاً به دلیل توسعه هوش مصنوعی (AI) – تعداد زیادی از مطالعات با تمرکز بر مقایسه پردازش اطلاعات در انسان و ماشینها پدید آمده است [ 1 ، 2 ، 3 ، 4 ]، در نتیجه یک بحث دیرینه و رقابت بین شایستگی های هر دو را احیا می کند [ 5 ]]. هدف اصلی این مطالعات ایجاد درک عمیق تر از مکانیسم های ادراک انسان و بهبود روش های یادگیری ماشین است. این رویهها قادر به رسیدگی به انواع خاصی از وظایف هستند که به دلیل پیچیدگی یا حجمشان، حل آنها توسط انسان دشوار و پرهزینه است و به سطوح دقت مشابهی میرسد. در میان این کارها، ما تشخیص شی [ 6 ، 7 ]، تخمین عمق [ 8 ] و مهمترین آنها برای مطالعه خود را برجسته می کنیم: تطبیق اشیا [ 1 ، 9 ، 10 ].
تکنیکهای تطبیق ابزارهای اساسی برای برخورد با اطلاعات گرافیکی [ 11 ، 12 ] و بهویژه اطلاعات جغرافیایی (GI) هستند که ویژگی اصلی تعیینکننده آن موقعیت مکانی است. امروزه GI به دلیل استفاده از آن در بسیاری از مناطق مورد علاقه (مانند تجارت، گردشگری، مدیریت ناوگان، توسعه نظامی، مدیریت زمین و غیره) و اهمیت اقتصادی آن بسیار مورد تقاضا است [ 13 ]. به همین دلیل است که محصولات جدید کارتوگرافی به طور مداوم در پاسخ به تقاضاهای یک بازار رو به گسترش در حال ظهور هستند. این محصولات کارتوگرافی معمولاً از روشهای جدید نقشهبرداری مبتنی بر ادغام دادههای مکانی از منابع ناهمگن و با درجات مختلف جزئیات بدست میآیند [ 14 ، 15 ،16 ]، بنابراین سطوح کیفی نهایی آنها – که اغلب ناشناخته هستند – به سطوح کیفی منابع اولیه بستگی دارد. به طور خلاصه، میتوان گفت که این روشهای جدید نقشهبرداری به روشهای جدید و کارآمدتری برای ارزیابی دقت موقعیتی محصولات بهدستآمده نیاز دارند که معیارهای سنتی کیفیت دادهها برای آنها قابل اجرا نیستند، که به نوبه خود نیازمند خودکارسازی فرآیندهای مرتبط است.
با توجه به ادبیات موجود [ 17 ، 18 ، 19 ]، اتوماسیون فرآیندهای مرتبط با PAA داده های مکانی مبتنی بر مقایسه بین مکان های اشیاء فضایی متناظر از دو GDB (به نام GDB مرجع و GDB آزمایش شده) با متفاوت است. سطوح دقت و جزئیات در این راستا، باید توجه داشت که این رویکرد روششناختی بر این فرض استوار است که دقت یکی از GDB به اندازهای بالاست که تفاوت اندازهگیری نشده بین آن و واقعی را نادیده بگیرد [ 20 ]. برای مقایسه خودکار مکانهای این اشیاء متناظر، پیوندهای بین آنها لازم است [ 17]. در این زمینه، یک روش PAA خودکار اساساً به یک مشکل تطبیق الگو کاهش مییابد که در آن یک مسئله کلیدی وجود دارد: نحوه اندازهگیری شباهت بین اشیاء فضایی متناظر از دو مجموعه داده ناهمگن (در مورد ما، GDB) به منظور طبقهبندی و تطبیق آنها. به صورت خودکار
1.1. تطبیق خودکار به عنوان راه حلی برای رویه های PAA
تطبیق اشیاء فضایی از دو مجموعه داده ناهمگن یک فرآیند تصمیم گیری پیچیده است [ 9 ]. به گفته این نویسندگان، دو جنبه اصلی در این فرآیند وجود دارد: اول، مناسبترین شی فضایی برای تعیین تطابق چیست؟ دوم، اقدامات مشابه برای به کارگیری چیست؟ در پاسخ، و در بیشتر موارد، الگوریتم های تطبیق از چند ضلعی های ساختمانی به عنوان اشیاء فضایی برای تطبیق و از توصیفگرهای هندسی به عنوان معیارهای تشابه برای انجام فرآیند تطبیق استفاده می کنند. با توجه به معیارهای اعمال شده برای تعیین تطابق، این الگوریتمها بر اساس درصد سطح همپوشانی [ 10 ، 21 ، 22 ]، زمینه با استفاده از هر دو مثلث دلونی [ 23 ] است.] و نمودار ورونوی [ 24 ]، فاصله بین توابع چرخشی [ 25 ]، نظریه باور در موقعیت و جهت گیری [ 26 ] و طبقه بندی کننده های احتمال بر روی مجموعه ای از شواهد، هم هندسی و هم مبتنی بر ویژگی [ 27 ]. نتایج ارائه شده توسط اکثر مطالعات ذکر شده در بالا، نسبت موفقیت تطابق بالایی را بین اشیاء متعلق به منابع ناهمگن نشان می دهد. با این حال، با وجود این کارایی، بسیاری از جنبهها هنوز نیاز به بهبود دارند. این جنبهها با ایجاد جفتهای تطبیق کاذب در موارد تناظرهای 1:n یا n:m پیوند نزدیکی دارند – موارد تطبیق متعدد اغلب با فرآیندهای تعمیم مرتبط با ساخت چند ضلعی با خطوط نسبتاً پیچیده مرتبط هستند ( شکل 1).)—و به انتخاب دستی نشانه ها از داخل دو مجموعه داده. در هر دو مورد، افزایش سطح اتوماسیون به بهبود فرآیندهای تطبیق کمک میکند، و از پذیرش اشیاء تطبیق اشتباه جلوگیری میکند.
به منظور حل، تا آنجا که ممکن است، جنبه های مورد بحث در بالا، در [ 1 ] ما یک روش تطبیق خودکار ابتکاری برای GDB های شهری توسعه دادیم. این GDB ها به عنوان مجموعه ای از پوشش های برداری جغرافیایی ارجاع داده شده توسط لایه هایی از جمله لایه برداری از ساختمان ها (بلوک های شهری) ارائه می شوند. این روش – که در ابتدا به عنوان راه حلی برای رویه های PAA پیشنهاد شد – شباهت بین دو شکل چند ضلعی ساختمان را کمیت می کند و آنها را با استفاده از یک روش طبقه بندی مبتنی بر وزن با استفاده از توصیفگرهای ویژگی سطح پایین چند ضلعی و ابزارهای هوش مصنوعی مطابقت می دهد. به طور خاص، وزنهای تخصیصیافته از یک فرآیند تمرینی نظارت شده با استفاده از GA محاسبه شد [ 28 ، 29]. استفاده از یک GA به ما این امکان را میدهد که کیفیت تطبیق را از روی کمی تشابه با استفاده از مقدار دقت تطابق (MAV) از صفر تا یک طبقهبندی کنیم (به [ 1 ، 18 ، 19 مراجعه کنید.]). بنابراین، اگر MAV به دست آمده برابر با یک باشد، دو چند ضلعی ساختمانی منطبق دقیقاً برابر خواهند بود. این شاخص برای کار ما بسیار مرتبط بود زیرا به ما اجازه میدهد: (1) فقط جفتهای چند ضلعی ساختمان متناظر 1:1 را از بین تمام مطابقتهای ممکن انتخاب کنیم (با استفاده از مقدار آستانهای MAV)، بنابراین از پذیرش هر دو چند ضلعی که به اشتباه تطبیق داده شدهاند اجتناب میکنیم. و چند ضلعی های جفت نشده؛ و (ii) سطوح شباهت متفاوتی را بین جفتهای چند ضلعی ساختمان متناظر 1:1 تنظیم کنید. با توجه به نتایج بهدستآمده، GA ثابت کرد که یک ابزار مناسب و کارآمد در رویههای تطبیق خودکار با استفاده از توصیفگرهای سطح پایین برای طبقهبندی ویژگیهای داده به عنوان مشابه یا غیرمشابه با ویژگیهای مدل و تخصیص احتمالات به آن کلاسها است. این کارایی نه تنها از منظر رویه ای بلکه از نظر زمان و هزینه نیز به دست آمد. هر دو جنبه در [18 ، 19 ]. در مورد خاص زمان اجرا، آزمایشهای تطبیق ما نشان داد که برای GDBهایی که از 2000 تا 2500 چند ضلعی تشکیل شدهاند، میانگین زمان اجرا بهدستآمده 150 ثانیه بود. در مورد روش تطبیق دستی، این زمان اجرا باید در 110 ضرب شود.
1.2. رویکرد تحقیق
علیرغم نتایج مثبت و دلگرم کننده ای که در بالا ذکر شد، یک موضوع کلیدی وجود دارد که هنوز نیاز به تجزیه و تحلیل دارد تا اتوماسیون به یک راه حل کاملاً عملیاتی در تکنیک های تطبیق تبدیل شود: کشف قابلیت های آن در مقایسه با توانایی های انسانی.
مطالعات زیادی وجود دارد که نحوه درک اشکال چند ضلعی بسته توسط سیستم ادراکی انسان را تجزیه و تحلیل می کند و برای درک تفاوت در فرآیندهای استنتاجی هنگام مقایسه انسان و ماشین بسیار مهم است [ 2 ، 4 ، 30 ، 31 ، 32 ، 33 ، 34 ، 35 ، 36 ]. به گفته برخی از این نویسندگان، به نظر می رسد چالش اساسی در مطالعات مقایسه بین انسان و ماشین، تعصب قوی تفسیر درونی انسان است [ 4 ]]. از این نظر، ابزارهای تجزیه و تحلیل مناسب مانند ابزارهای هوش مصنوعی و روش های آموزشی آنها به منطقی کردن تفسیر یافته ها کمک می کند و این سوگیری داخلی را در چشم انداز قرار می دهد. در مجموع، باید مراقب بود که هنگام مقایسه ادراک انسان و ماشین، تعصب سیستماتیک انسانی خود را تحمیل نکنیم [ 4 ].
مطالعه حاضر در پاسخ به نیاز به کشف قابلیتهای واقعی رویکرد تطبیق مبتنی بر ماشین برای تعیین کمیت شباهت بین دو ویژگی چند ضلعی ارجاعشده جغرافیایی (ساختن چند ضلعی) و سپس تطبیق آنها توسعه یافته است. بنابراین، اگرچه ابزار خودکار ما می تواند اپراتورهای انسانی را تقلید کند، لازم است عملکرد آن را در مقایسه با آنها در یک برنامه خاص و با استفاده از داده های مشخص تجزیه و تحلیل کنیم. به طور خاص، با استفاده از یک GA، گروهی از متخصصان انسانی و دو پایگاه داده رسمی نقشهکشی، مقایسه بین یک روش تطبیق دستی و خودکار انجام شده است. برای این منظور، دو آزمایش مختلف توسعه داده شده است: (1) برای مقایسه مقادیر شباهت بین چند ضلعی های ساختمانی اختصاص داده شده توسط متخصصین GA و انسانی.
2. مواد و روشها
به منظور بهبود استحکام نتایج رویکرد مقایسه ای به کار رفته در این مطالعه، ما از همان گونه شناسی داده های به کار رفته در روش تطبیق خودکار توسعه یافته در [ 1 ] استفاده کرده ایم، یعنی مکان های چند ضلعی های ساختمان استخراج شده از دو پایگاه داده رسمی نقشه کشی در اندلس (جنوب اسپانیا) ( شکل 2 الف) با سطوح مختلف دقت و منطقه مشابه: (1) BCN25 (“Base Cartográfica Numérica E25k”)، مجموعه داده آزمایش شده، و (ii) MTA10 (“Mapa Topográfico de Andalucía E10k”)، مجموعه داده مرجع ( شکل 2 ب).
MTA10 توسط موسسه آمار و کارتوگرافی اندلس (اسپانیا) تولید شده و به مبدأ ED50 ارجاع داده شده است. این یک پایگاه داده برداری توپوگرافی با پوشش کامل قلمرو اندلس است که با بازیابی دستی فتوگرامتری به دست می آید. همانطور که در بالا ذکر شد، MTA10 شامل یک لایه برداری از ساختمان ها (بلوک های شهری) است که حاوی مقدار کافی اطلاعات هندسی است تا بتواند هم شکل و هم معیارهای هندسی مورد استفاده برای ارزیابی شکل هندسی چند ضلعی ها را محاسبه کند. از سوی دیگر، BCN25 توسط موسسه ملی جغرافیای اسپانیا تولید شده و به سیستم مرجع زمینی اروپا در سال 1989 ETRS89 ارجاع داده شده است. این مجموعه داده کل قلمرو ملی اسپانیا را در بر می گیرد – که منطقاً شامل قلمرو اندلس است. همانطور که در مورد قبلی،
در نهایت، هر دو پایگاه داده باید قابلیت همکاری داشته باشند، به این معنی که آنها باید هم از نظر سیستم مرجع و هم از نظر نقشه کشی قابل مقایسه باشند. علاوه بر این، آنها باید به طور مستقل تولید شوند و هیچ یک از آنها به نوبه خود نمی توانند از محصول نقشه برداری دیگری در مقیاس بزرگتر از طریق هر فرآیندی استخراج شوند [ 37 ].
پس از توصیف GDB های شهری و الزامات آنها، باید به طور رسمی داده های خاص مورد استفاده در مطالعه حاضر را تعریف کنیم. این دادهها از جفت چند ضلعی ساختمانی (بلوکهای شهری) تشکیل شدهاند که بر اساس معیارهای دقت توضیح داده شده در بخش بعدی مطابقت داده شدهاند و از 9 منطقه شهری موجود در سه صفحه MTN50k (نقشه توپوگرافی ملی اسپانیا در مقیاس 1:50000) به دست آمدهاند. ( شکل 2 الف) تا آنجا که ممکن است با تمام الزامات تغییرپذیری با توجه به گونهشناسی ساختمانها، یعنی پراکندگی جغرافیایی وسیع و تنوع زیاد در گونهشناسی آنها، رعایت شود. علاوه بر این، باید توجه داشته باشیم که این دادهها با دادههایی که برای اجرای رویه آموزشی تحت نظارت GA استفاده شده بودند، متفاوت بودند.
2.1. فرآیند تطبیق خودکار با استفاده از یک GA
همانطور که در بخش مقدمه ذکر شد، روش تطبیق خودکار ما شباهت بین دو شکل چند ضلعی ساختمان را کمیت کرد و آنها را با استفاده از روش طبقهبندی مبتنی بر وزن با استفاده از توصیفگرهای ویژگی سطح پایین چندضلعی و یک GA مطابقت داد. شکل 3 گردش کار فرآیند را نشان می دهد.
به طور خاص، هر شکل چند ضلعی ساختمان با استفاده از حداقل مستطیل مرزی آن (MBR) مشخص میشود که با مقادیر مختصات گوشههای آن، تعداد زاویهها (مقعر و محدب)، محیط، مساحت، ممان اینرسی و مساحت منطقه مشخص میشود. زیر تابع چرخش آن (به [ 1 ] مراجعه کنید). با توجه به GA، ما از یک GA مبتنی بر نمایش اعداد واقعی (به نام GA با کد واقعی (RCGA)) استفاده کردیم. یک بار دیگر، باید توجه داشته باشیم که تمام این جنبه ها به طور مفصل در [ 1]، بنابراین در اینجا مورد بحث قرار نخواهند گرفت. با این حال یک موضوع مهم برای توسعه مطالعه حاضر وجود دارد: نحوه انجام گسسته سازی مقادیر MAV به دست آمده. همانطور که قبلاً گفته شد، برای طبقهبندی کیفیت تطبیق، استفاده از RCGA به ما این امکان را میدهد که شباهت را با استفاده از یک MAV در محدوده صفر تا یک، کمی کنیم. با این حال، لازم است این نتایج را گسسته کنیم، محدوده هایی را تعریف کنیم – که با قابلیت تشخیص انسان مبتنی بر محدودیت ادراک بصری سازگار شده است – که به اپراتور انسانی اجازه می دهد تا ارزیابی خارجی چنین نتایجی را توسعه دهد. از این نظر، جفتهای چند ضلعی ساختمانی که مطابقت داشتند به سه سطح مختلف از شباهت طبقهبندی شدند: سطح پایین (MAV <0.5) (نتایج تطبیق بد)، سطح متوسط (0.5 ≤ MAV <0.8) (نتایج تطبیق متوسط) و سطح بالا ( MAV ≥ 0.8) (نتایج تطبیق خوب). این آستانه بین سطوح با اختصاص یک ماتریس سردرگمی به GDB مورد استفاده برای آموزش GA محاسبه شد. همه آنها نشان دهنده اندازه تشابه شکل بین دو چند ضلعی منطبق – مطابقتهای 1:1 – صرف نظر از موفقیت تطبیق هستند. با این حال، ماتریس سردرگمی نشان داد که (i) یک MAV بزرگتر یا مساوی 0.8 اجازه می دهد تا از پذیرش چند ضلعی های منطبق اشتباه جلوگیری کند (خطای کار)، (2) عدم وجود این نوع خطا برای مقادیر MAV تضمین نشده است. بین 0.8 و 0.5، اگرچه وقوع آن بعید بود، و (iii) یک MAV کمتر از 0.5 پذیرش چند ضلعی های منطبق اشتباه با درجه بالایی از قابلیت اطمینان را تضمین نمی کرد [ همه آنها نشان دهنده اندازه تشابه شکل بین دو چند ضلعی منطبق – مطابقتهای 1:1 – صرف نظر از موفقیت تطبیق هستند. با این حال، ماتریس سردرگمی نشان داد که (i) یک MAV بزرگتر یا مساوی 0.8 اجازه می دهد تا از پذیرش چند ضلعی های منطبق اشتباه جلوگیری کند (خطای کار)، (2) عدم وجود این نوع خطا برای مقادیر MAV تضمین نشده است. بین 0.8 و 0.5، اگرچه وقوع آن بعید بود، و (iii) یک MAV کمتر از 0.5 پذیرش چند ضلعی های منطبق اشتباه با درجه بالایی از قابلیت اطمینان را تضمین نمی کرد [ همه آنها نشان دهنده اندازه تشابه شکل بین دو چند ضلعی منطبق – مطابقتهای 1:1 – صرف نظر از موفقیت تطبیق هستند. با این حال، ماتریس سردرگمی نشان داد که (i) یک MAV بزرگتر یا مساوی 0.8 اجازه می دهد تا از پذیرش چند ضلعی های منطبق اشتباه جلوگیری کند (خطای کار)، (2) عدم وجود این نوع خطا برای مقادیر MAV تضمین نشده است. بین 0.8 و 0.5، اگرچه وقوع آن بعید بود، و (iii) یک MAV کمتر از 0.5 پذیرش چند ضلعی های منطبق اشتباه با درجه بالایی از قابلیت اطمینان را تضمین نمی کرد [1 ]. در نهایت، و با توجه به چند ضلعی های بی همتا (مطابقات 1:0)، این نوع از کاردینالیته در فرآیند تطبیق به عنوان جفت نشده یا بی همتا طبقه بندی شدند.
2.2. تطبیق دستی توسط یک گروه متخصص انجام شده است
رویکرد مقایسهای ما مستلزم انجام یک روش تطبیق دستی است – تطبیق توسط متخصص. برای این منظور، ابتدا تجزیه و تحلیل روشی که انسان و ماشین روابط بین اشکال بصری را یاد می گیرند، بسیار مهم است. در این راستا، یک آزمایش کنترل شده به نام آزمون استدلال مصنوعی (SVRT) در [ 2 ] توسعه یافت.]. این SVRT توسط 23 مسئله طبقه بندی بر اساس استدلال انتزاعی تشکیل شده و توسط 20 متخصص انسانی و یک تکنیک یادگیری ماشینی ارزیابی شده است. با این روش، این نویسندگان با اشکال تصادفی مسطح کار کردند و طبقهبندی در سطح روابطی مانند «درون»، «بین»، «همان» و غیره انجام شد. بهویژه یکی از مسائل مربوط به دسته 1 است. SVRT آنها در مورد چگونگی حل این سوال بود: آیا دو شکل یکسان در تصویر وجود دارد؟ ( شکل 4 ). این مشکل ارتباط نزدیکی با رویههای تطبیق دارد و همانطور که در زیر مشاهده خواهد شد، هدف اصلی یکی از آزمایشهای ما است.
با توجه به نتایج، این نویسندگان دو نتیجه مهم برای کار ما به دست آوردند: (من) انسان ها برای یادگیری روابط بین اشکال و حل درصد بسیار بالایی از مسائل تنها به چند مثال نیاز داشتند، در حالی که الگوریتم یادگیری ماشینی برای رسیدن به موارد بسیار بیشتری نیاز داشت. درصد کمتر؛ (2) معیارهای شباهت در اشکال پیچیده آسان تر از اشکال ساده است. نتیجهگیری اول نشان میدهد که انسانها و دانش تخصصی آنها ممکن است بهطور پیشینی، ابزار ارزشمندی برای ارزیابی یک روش تطبیق خودکار باشد که – همانطور که در بخش بعدی ذکر شد – یکی از اهداف فرآیند مقایسه ما و فرضیه اصلی فعلی است. کار کردن با توجه به نتیجه دوم، یک فرضیه موازی را به ما پیشنهاد می کند که باید در مطالعه ما نیز به آن پرداخته شود:
پس از تجزیه و تحلیل فرآیندهای یادگیری در انسان و ماشین، سه جنبه کلیدی برای تعریف روش های تطبیق دستی وجود دارد: (1) انتخاب نمونه ای نماینده از عناصر برای ارزیابی آنها (در مورد ما، ساختن چند ضلعی ها، بلوک های شهر، که قبلا انجام شده است. قبلاً به طور خودکار توسط GA مطابقت داده شده است، (2) انتخاب گروهی از کارشناسان که این روش را انجام خواهند داد، و (iii) تعریف آنچه که اقدامات توافقی نامیده می شود. این معیارها مقادیر عددی را نشان می دهند که می توانند برای تجزیه و تحلیل کارایی نتایج به دست آمده از روش پیشنهادی استفاده شوند. با توجه به این جنبه آخر، اقدامات را می توان به دو دسته زیر طبقه بندی کرد:
-
سطح توافق به عنوان درجه تشابه بین احکام صادر شده به طور مستقل توسط کارشناسان مختلف تعریف شده است.
-
ثبات. به عنوان درجه تشابه بین قضاوت های صادر شده توسط کارشناسان و نتایج ارائه شده توسط فرآیند تطبیق خودکار (GA) تعریف می شود.
2.2.1. اهداف فرآیند مقایسه
در گام اول لازم بود اهداف اصلی که با انجام آزمایشات با گروه متخصصان دنبال می شود، تدوین شود که عبارتند از:
-
ارائه یک MAV جایگزین (مقدار تخصصی) برای MAV ارائه شده توسط GA برای ارزیابی شباهت بین چند ضلعی های ساختمان.
-
ارائه یک عنصر جایگزین مطابق با عناصر ارائه شده توسط GA برای ارزیابی سطح اثربخشی فرآیند تطبیق خودکار.
2.2.2. انتخاب گروه کارشناسان
دانش خبره نقش مهمی در بسیاری از زمینه های علم ایفا می کند. بنابراین، در جایی که داده های تجربی کمیاب یا در دسترس نیستند، دانش تخصصی اغلب به عنوان بهترین یا تنها منبع اطلاعات در نظر گرفته می شود [ 38 ]. علاوه بر این، با ظهور روشهای یادگیری ماشینی، نقش دانش متخصص بیش از پیش مهم شده است. درک عمیقتر مکانیسمهای ادراک انسان به منظور بهبود روشهای یادگیری ماشین، مستلزم بررسی مناسب نظرات متخصص است. بنابراین، انتخاب کارشناسان و استنباط نظرات آنها باید با دقت انجام شود و با شناخت کامل عدم قطعیت های ذاتی آن نظرات [ 39 ].
همانند سایر علوم، دانش تخصصی برای GIScience بسیار مهم است. با این حال، اگرچه دانش تخصصی مدتهاست که یک ورودی ارزشی در تحقیقات جغرافیایی بوده است، در زمینه رویههای PAA خودکار به تفصیل مورد بررسی قرار نگرفته است. رویکردهای سنتی به PAA GI تحت سلطه یک پارادایم وام گرفته شده از معماری داده های تراکنش است که در آن معیارهای اختلاف را می توان به راحتی فرموله کرد [ 40 ]. متأسفانه، این رویکرد برای رویههای خودکار PAA کاربرد محدودی دارد، جایی که این معیارها به شدت به تکنیکهای تطبیق استفاده شده قبلی وابسته هستند. به همین دلیل است که این تکنیک ها باید تحت فرآیندهای ارزیابی خارجی قرار گیرند.
روش های زیادی برای انتخاب گروهی از متخصصان وجود دارد که روش های انتخاب کمی را برجسته می کند. آنها بر اساس محاسبه ضرایب شایستگی هستند. در مورد ما، کارشناسان با استفاده از این روش و بر اساس صلاحیت حرفه ای، تجربه و اعتبار انتخاب شدند. با توجه به اندازه، استفاده از یک گروه تا حد امکان به ما امکان داد تا ثبات نتایج و همچنین ارزیابی سازگاری انسانی را بهبود بخشیم. بنابراین، ما روی مشارکت فعال 24 کارشناس از کشورها و مؤسسات زیر حساب میکنیم: برزیل (Universidade de Sao Paulo)، فنلاند (نشنال زمینشناسی فنلاند)، فرانسه (Institut Géographique National)، آلمان (Institut für Kartographie)، اسکاتلند. (دانشگاه ادینبورگ)، اسپانیا (از چندین موسسه)، سوئیس (Iniversität Zurich)،
2.2.3. چارچوب کاری و مستندات ارائه شده است
چارچوب کاری به کار گرفته شده به شدت با گسترش جغرافیایی شرکت کنندگان مشروط بود. این شرایط به ما اجازه نمی داد که روش های ارزیابی را به صورت چهره به چهره انجام دهیم، لازم است روش های ارزیابی از راه دور را اجرا کنیم. دو راه اساسی برای اعمال این نوع روش وجود دارد [ 38 ]: با پشتیبانی آنالوگ (روش سنتی) یا با پشتیبانی دیجیتال. در مورد ما، این آخرین گزینه اعمال شد.
در مقایسه با روشهای سنتی، روشهای ارزیابی مبتنی بر پشتیبانی دیجیتال در سالهای اخیر از طریق توسعه فناوریهای اطلاعات و ارتباطات (ICT) و فناوریهای مبتنی بر خدمات وب (WST) رشد استثنایی را تجربه کردهاند. بنابراین، ظرفیت تعامل در سراسر شبکه ارائه شده توسط این فناوری ها به ما امکان می دهد منابعی مانند داده ها، ماژول های پردازش و برنامه ها را به سرعت و کارآمد به اشتراک بگذاریم. WST ها به طور گسترده در حوزه جغرافیایی استفاده می شوند و تمرکز سنتی بر کشف و دسترسی به داده های مکانی را گسترش می دهند. WST های جغرافیایی برای ادغام، ویرایش و ذخیره حجم زیادی از اطلاعات مکانی و ابرداده های مربوطه آنها طراحی شده اند، که کار مشترک را ارتقا می دهد و درخواست های کاربران را برآورده می کند [ 41 ]]. با این حال، چارچوب کاری ما شامل حجمی از اطلاعات به اندازه کافی برای پیاده سازی یک سرویس وب نیست که معماری آن برای پشتیبانی از زیرساخت های داده پیچیده تعریف شده است. با در نظر گرفتن این موضوع، ما تصمیم گرفتیم یک برنامه کاربردی توسعه دهیم که استفاده از آن آسان باشد تا کار کارشناسان را آسان تر کنیم و بیشترین تعداد ارزیابی ممکن را به دست آوریم. برنامه ما در Visual-Basic.NET پیاده سازی شد و در یک ماشین مجازی میزبانی شد. در نهایت، دسترسی به ماشین مجازی – و در نتیجه به برنامه ما – با استفاده از یک اتصال دسکتاپ از راه دور انجام شد. این شیوه کار به ما اجازه داد تا از مزایای WST لذت ببریم و از معایب مرتبط با معماری آن اجتناب کنیم. برخی از این مزایا عبارتند از:
-
دسترسی چندگانه همزمان به طوری که همه کارشناسان می توانند در هر زمان وارد برنامه شوند.
-
محدودیت دسترسی. این محدودیت در دو سطح مختلف ایجاد شد: (1) محدودیت دسترسی به هر نوع اطلاعات یا نرم افزار دیگری که در رایانه میزبان ذخیره شده است – با هر روش کار دیگری، این اطلاعات کاملاً در معرض دید قرار می گیرد. و (ii) محدودیت دسترسی به حساب های کاربری سایر کارشناسان.
در نهایت و همراه با کاربرد فوق الذکر، راهنمای تطبیقی متشکل از یک سند واحد به گروه کارشناسان ارائه شد که در آن دستورالعمل هایی که باید برای تکمیل آزمایش های پیشنهادی رعایت شود به اختصار ارائه شد. بخش مهمی از این راهنما با مثالهای گرافیکی از جفتهای چندضلعی با درجات شباهت مختلف تشکیل شده است ( شکل 5 ).
با این سند قصد داشتیم کارشناسان را در انجام وظایف مختلف راهنمایی کنیم. از آنجایی که موفقیت نهایی ارزیابی به درک کامل آن بستگی دارد، نوشته آن باید واضح و مختصر باشد. این سند همراه با برنامه در ماشین مجازی میزبانی شده است که از طریق اتصال دسکتاپ از راه دور قابل بازیابی است.
2.2.4. طراحی آزمایش ها
به منظور دستیابی به اهداف پیشنهادی در بخش 2.2.1، روش ارزیابی از دو آزمایش مختلف تشکیل شده بود. جنبه مهمی که برای طراحی آنها باید در نظر گرفته شود، زمان لازم برای تکمیل آنها بود. در این رابطه، دو الزام وجود دارد که باید رعایت شود: (1) زمان مورد نیاز باید تا حد امکان کوتاه باشد، بدون اینکه روی دستیابی به اهداف تأثیر بگذارد، و (2) تعداد کل مواردی که باید توسط هر متخصص ارزیابی شود. تا حد امکان کوچک باشد بدون اینکه بر اهمیت نتایج تأثیر بگذارد. با توجه به این الزامات، تخمین زده شد که زمان مورد نیاز در هر صورت نباید بیش از 20 دقیقه باشد. این حداکثر فاصله زمانی توصیه شده است زیرا توجه کاربر و بنابراین کیفیت پاسخ پس از 20 دقیقه کاهش می یابد [ 42 ]]. علاوه بر این و به گفته این آخرین نویسندگان، بسیار دشوار است که کاربر با پر کردن یک پرسشنامه بیش از 20 دقیقه آنلاین بماند. به طور منطقی، این زمان پاسخ، تعداد نهایی چند ضلعی های مورد استفاده را مشروط کرد که در هر صورت برای رسیدن به نتایج آماری معنی دار کافی بود.
آزمایش MAV
این آزمایش اول بر روی نمونه ای از 18 جفت چند ضلعی ساختمانی همولوگ اعمال شد. در این مورد، هر متخصص باید یک MAV جایگزین برای MAV ارائه شده توسط GA در هنگام ارزیابی شباهت بین چند ضلعی های ساختمانی در طول فرآیند تطبیق خودکار ارائه دهد. برای این منظور، از دو پنجره گرافیکی استفاده شد تا هر یک از دو چند ضلعی ساختمان در یک پنجره گرافیکی متفاوت نشان داده شود ( شکل 6).آ). پس از بررسی بصری، MAV ارائه شده توسط هر متخصص می تواند در سه سطح گسسته گنجانده شود: سطح پایین، متوسط و بالا – بسته به درجه شباهت بین چند ضلعی های منطبق. جفتهای چند ضلعی ساختمانی مورد استفاده بهگونهای انتخاب شدند که تمام مقادیر ممکن MAV نشان داده شود و تا آنجا که ممکن است، با تمام الزامات تغییرپذیری با توجه به گونهشناسی چند ضلعیها با در نظر گرفتن تغییرپذیری با توجه به تعداد راسها، مطابقت داشته باشد. استفاده از این پارامتر به ما این امکان را می دهد که نتایج را به طور شهودی مشخص کنیم و تعیین کنیم که آیا نوعی هندسه وجود دارد که به ویژه هنگام ارزیابی درجه تشابه بین چند ضلعی ها مشکل ساز باشد.
به منظور اطمینان از استحکام نتایج مربوط به این آزمایش اول، لازم بود برخی از نتایج ارائه شده توسط GA به کارشناسان انتقال داده شود و به آنها توضیح داده شود که همه توصیفگرهای مورد استفاده در طبقه بندی بر اساس وزن اهمیت یکسانی ندارند. متدولوژی توسعه یافته توسط GA. اطلاعات مربوط به این مجموعه معیارهای وزن دهی از طریق مثال های مختلف در اختیار کارشناسان قرار گرفت و اطمینان حاصل شد که همه آنها به هر یک از توصیفگرها اهمیت یکسانی می دهند و از این طریق امکان یکسان سازی پاسخ ها فراهم می شود.
آزمایش تطبیق
این آزمایش دوم نیز بر روی یک نمونه از 18 جفت چند ضلعی همولوگ اعمال شد. این چند ضلعی ها باید با آنهایی که به آزمایش MAV تعلق دارند متفاوت باشند. هدف این آزمایش دوم ارزیابی کارایی به دست آمده توسط GA مربوط به وظایف شناسایی و تطبیق چند ضلعی های ساختمانی همولوگ بود. همانند آزمایش قبلی، از دو پنجره گرافیکی استفاده شد ( شکل 6ب). در این مورد، پنجره سمت چپ چند ضلعی را نشان می دهد که همولوگ آن باید توسط متخصص در پنجره سمت راست پیدا شود، بنابراین یک عنصر جایگزین مطابق با عناصر ارائه شده توسط GA برای ارزیابی سطح اثربخشی فرآیند تطبیق خودکار فراهم می کند. کار کارشناسان در این مورد بسیار ساده بود. بنابراین، نیازی به ارائه هیچ نوع اطلاعات اضافی دیگری به آنها نبود. با این حال، در این مورد، ارزیابی بصری نقش بسیار مهمی دارد. به همین دلیل چندین گزینه ویرایش مانند ابزارهای زوم، سیستم شبکه، دکمه های همپوشانی چند ضلعی ها با توجه به مختصات آنها و غیره پیاده سازی شد.
طراحی تجربی
با توجه به طرح آزمایشی، نمونه چند ضلعی های ساختمانی در مجموع شامل 54 جفت چند ضلعی برای هر یک از دو نوع آزمایش (MAV و تطبیق) بود که با آن چهار تست مختلف انجام شد. برای سه آزمون اول (اعداد 1، 2 و 3)، از 18 جفت چند ضلعی مختلف (18+18+18=54) استفاده شد. این آزمونها با انتخاب تصادفی 15 نفر از متخصصان گروه اولیه مورد ارزیابی قرار گرفتند. آزمون شماره 4 با 18 جفت چند ضلعی انتخاب شده از آنهایی که در سه آزمون اول به کار گرفته شده بودند انجام شد که هر کدام از آنها شش جفت چند ضلعی داشتند. این آخرین آزمون توسط تعداد کل متخصصان شامل گروه فوق مورد ارزیابی قرار گرفت. در نهایت، باید توجه داشته باشیم که هدف از این نوع توزیع، افزایش فشار ارزیابی بر روی موارد خاص بوده است.
3. نتایج
3.1. نتایج حاصل از آزمایش MAV
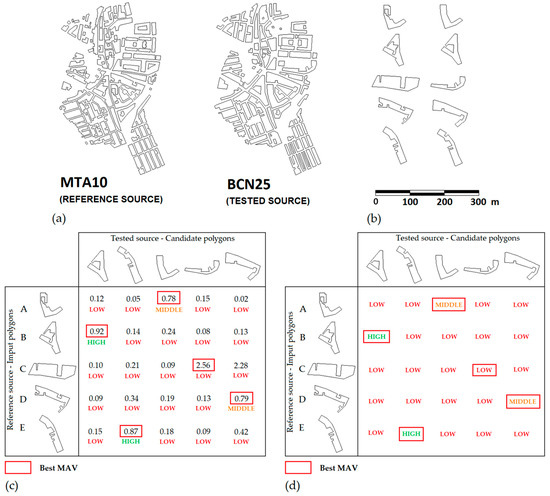
جدول A1 ( پیوست A ) تمام نتایج به دست آمده از طریق GA را برای هر یک از آزمون هایی که انجام شده است (1، 2، 3، و 4) ارائه می دهد. این جدول هم MAV محاسبهشده – از صفر تا یک – و هم مقادیر گسستهشده مربوط به این MAV را نشان میدهد (بالا → 2، متوسط → 1، کم → 0). این نتایج در شکل 7 خلاصه شده است . به طور خاص، شکل 7 a توزیع درصد چند ضلعی های منطبق را برای هر سطح از MAV نشان می دهد – همانطور که در بالا ذکر شد، این توزیع همگن بود – در حالی که شکل 7 b نتایج توزیع درصد چند ضلعی های منطبق را برای هر بازه MAV گروه بندی شده بر اساس عدد نشان می دهد. از رأس ها
با توجه به نتایج توافق حاصل از گروه خبرگان، و بر اساس طرح آزمایشی، 612 ارزیابی انجام شد (270 ارزیابی از آزمایشهای 1، 2 و 3؛ و 342 ارزیابی جدید از آزمایش 4). جدول A2 و جدول A3 ( ضمیمه A ) MAV گسسته ارائه شده توسط کارشناسان را ارائه می دهد که در شکل 8 نیز خلاصه شده است . برای پردازش آن از مدل جدول ورودی دوتایی استفاده شد. این نوع جدول تمام گزینه های ( Cij ) انتخاب شده توسط n متخصص در نظر گرفته شده را نشان می دهد و برای mجفت چند ضلعی در نهایت ارزیابی شد. علاوه بر این، MAV ارائه شده توسط GA نیز نشان داده شده است، بنابراین از چندین مقدار Cij سطوح توافق و سازگاری به دست آمده در ارزیابی محاسبه و به عنوان درصد توافق بیان شد. به منظور تسهیل تفسیر نتایج، شکل 9 نمونه ای از MAV محاسبه شده توسط GA ( شکل 9 ج) و مقادیر گسسته اختصاص داده شده توسط یک متخصص ( شکل 9 د) برای پنج چند ضلعی ( شکل 9 ب) متعلق به نمونه مورد استفاده در پژوهش حاضر.
3.2. نتایج حاصل از آزمایش تطبیق
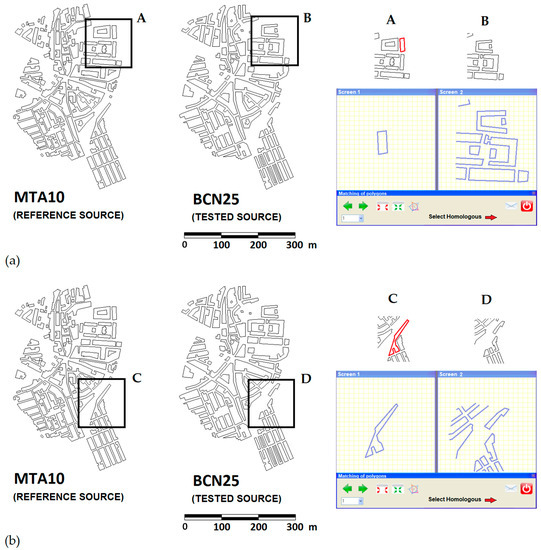
جدول A4 ( پیوست A ) چند ضلعی را نشان می دهد که در فرآیند تطبیق توسعه یافته توسط GA به عنوان همولوگ اختصاص داده شده است. با توجه به نتایج به دست آمده از گروه خبرگان، جداول نتایج ساختاری مشابه با موارد بخش قبل دارند که به مدل دو ورودی در پردازش دادههایی که در بالا توضیح داده شد، پاسخ میدهند. بنابراین، در جدول A5 و جدول A6 ( پیوست A ) هر ورودی نشان دهنده چند ضلعی ساختمان (از طریق شناسه آن) است که توسط متخصص به عنوان همولوگ با دیگری متعلق به نمونه انتخاب شده انتخاب شده است. همانطور که در آزمایش MAV، در این آزمایش نیز 612 تکلیف انجام شد. با توجه به جدول A4لازم به ذکر است که برای چند ضلعی اعداد 7، 9، 13، 16، 24، 29 و 32، GA قادر به یافتن همولوگ هایی برای مطابقت با این چند ضلعی ها نبود، بنابراین به عنوان چند ضلعی های بی همتا برچسب گذاری شده اند. به همین ترتیب، هیچ یک از کارشناسان نتوانستند آنها را مطابقت دهند ( جدول A5 و جدول A6 ).
چند ضلعی های بی همتا عمدتاً با یک نوع کاردینالیته، 1:0 مرتبط هستند. به این معنا که چند ضلعی ها تنها در یکی از منابع داده نشان داده شده اند ( شکل 10 a). به طور خاص، این مورد مربوط به چند ضلعی شماره 7 متعلق به جدول A4 و جدول A5 است. از سوی دیگر، چند ضلعی های بی همتا را می توان با مکاتبات m:n بین چند ضلعی ها با خطوط نسبتاً پیچیده که تحت فرآیندهای تعمیم کارتوگرافی قرار گرفته اند، مرتبط کرد ( شکل 10 ب).
4. بحث
4.1. آزمایش MAV
نمودارهای میله ای از شکل 7 ب و شکل 8b می تواند به تفسیر بهتر نتایج حاصل از آزمایش MAV کمک کند زمانی که چند ضلعی ها با تعداد رئوس خود مشخص می شوند. هر دو نمودار میله ای رفتار مشابهی را هم در مورد ارزیابی شباهت ایجاد شده توسط GA و هم در مورد ارزیابی شباهت ایجاد شده توسط گروه کارشناسان نشان می دهند. در هر دو مورد، نسبت MAV پایین، متوسط و بالا با افزایش تعداد راسها معکوس میشود. به طور خاص، درصد جفت چند ضلعی های ارزیابی شده توسط GA به عنوان دارای سطح تشابه پایین 25٪ در مورد چند ضلعی با تعداد رئوس کمتر از 5 است. با این حال، این درصد عملاً برای چند ضلعی هایی با تعداد رئوس بالاتر از بیست صفر است. این روند حتی در ارزیابی انجام شده توسط گروه کارشناسان بسیار شدیدتر است. در این مورد آخر، هیچ جفت چندضلعی با تعداد رئوس بالاتر از بیست وجود ندارد که به عنوان سطح تشابه پایین ارزیابی شده باشد. با توجه به موارد فوق، می توان نتیجه گرفت که هم برای GA و هم برای متخصصان انسانی، ارزیابی شباهت بین دو چند ضلعی منطبق زمانی که تعداد راس بالایی دارند آسان تر است. این یکی از نتایج بدست آمده در [2 ] و یکی از فرضیه های در نظر گرفته شده در مطالعه ما را تأیید می کند، ارزیابی تشابه در اشکال پیچیده آسان تر از اشکال ساده است. در مورد خاص انسان، به دلیل روند شهودی تجزیه جفت اشیاء پیچیده به اجزای تشکیلدهندهشان – که به صورت جداگانه قابل تشخیص هستند – به منظور تسهیل شناسایی اشکال مشترک بین این اشیاء و سپس تطبیق آنها است [ 43 ].
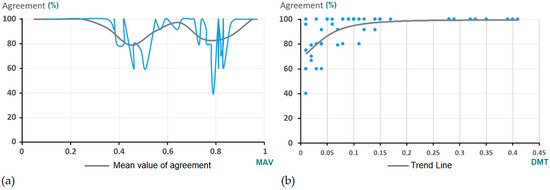
در مورد معیارهای توافق، می توان گفت که سازگاری به دست آمده برای این آزمایش اول (در تمام آزمایش های انجام شده) بسیار بالا بود، با میانگین درصد توافق GA – کارشناسان – محاسبه شده بر تعداد کل ارزیابی ها 612 – 93.3٪. در حالی که برای 75.9 درصد از جفت های چند ضلعی ساختمان، درصد توافق 100 درصدی بین نتایج شباهت ارائه شده توسط کارشناسان و نتایج به دست آمده از طریق AG به دست آمد. همراه با این درصد سازگاری بالا، سطح توافق بین کارشناسان جنبه مهمی از مطالعه را نشان می دهد. سردرگمی (اختلاف GA-کارشناس و متخصص-کارشناس) هنگام ارزیابی شباهت بین جفت چند ضلعی که MAV آنها – محاسبه شده توسط GA – نزدیک به مقادیر آستانه 0.5 و 0.8 است.44 ]. این نویسندگان تأثیر خطاهای تخمینی را بر دادههای مرجع جمعآوریشده برای اعتبارسنجی نقشههای پوشش زمین تجزیه و تحلیل کردند و به این نتیجه رسیدند که این خطاها زمانی که نسبتهای کلاس نزدیک به آستانه تعریف کلاس باشد، شایعتر هستند. با در نظر گرفتن ویژگیهای آزمایشهای ما – که عمدتاً مربوط به عدم قطعیتهای ذاتی در نظرات کارشناسان است – و با احتیاط کامل، میتوان استدلال کرد که مورد ما مشابه موردی است که در [ 44 ] به آن پرداخته شد. بنابراین، شکل 11 a نشان می دهد که کمترین مقادیر توافق مربوط به جفت چند ضلعی است که MAV آنها نزدیک به مقادیر آستانه 0.5 و 0.8 است. به طور خاص، خط خاکستری نشان دهنده مقدار میانگین توافق برای هر بازه 0.1 واحد MAV است. از سوی دیگر، شکل 11b نشان دهنده توافق حاصل شده در رابطه با فاصله تا آستانه MAV (DMT) است. در این مورد آخر، هر نقطه آبی نشان دهنده یک جفت چند ضلعی منطبق است که شباهت آنها با سطح معینی از توافق بین GA و کارشناسان و فاصله آن تا نزدیکترین مقدار آستانه – 0.5 یا 0.8 ارزیابی شد. در اینجا خط خاکستری نشان دهنده خط روند به دنبال داده ها است.
به عنوان راه حلی برای به حداقل رساندن این نوع خطا، نویسندگان پیشنهاد می کنند که سیستم طبقه بندی با مقادیر آستانه تا حد امکان از حالت های توزیع نسبت های پوشش زمین به دقت انتخاب شود [ 44 ]. با این حال، در مورد ما این راه برای ادامه معنی ندارد. باید به یاد بیاوریم که مکان مقادیر آستانه قبلاً توسط یک ماتریس سردرگمی بهینه شده است که هدف آن جلوگیری از پذیرش چند ضلعی های منطبق اشتباه است (خطا در کمیسیون).
با توجه به موارد خاص، چند ضلعی های با بیشترین میزان اختلاف در شکل 11 با اعداد 1، 2، 9، 20، 21، 28، 31، 48 و 49 مطابقت دارند ( جدول A2 و جدول A3 ). به طور خاص، موارد چند ضلعی شماره 9 و 49 بسیار قابل توجه است. در مورد چند ضلعی شماره 9، MAV اختصاص داده شده توسط GA 0.79 است – درست زیر آستانه 0.8. این مورد مربوط به چند ضلعی است که به عنوان D در شکل 9 ج نشان داده شده است. حالت چند ضلعی شماره 49 بسیار شبیه است. در این مورد، که با چند ضلعی برچسبگذاری شده با A در شکل 9c مطابقت دارد ، MAV اختصاص داده شده توسط GA 0.78 است – همچنین نزدیک به آستانه 0.8 است.
از سوی دیگر و با توجه به متغیر بودن ارزیابی های ارائه شده – که نشان دهنده میزان توافق بین قضاوت های صادر شده به طور مستقل توسط کارشناسان است – باید توجه داشت که در هیچ یک از زوج های چند ضلعی سه نوع مقدار ( 0، 1 یا 2) – متعلق به ارزیابی MAV – به طور همزمان توسط کارشناسان اختصاص داده شده است.
در نهایت، نتایج بهدستآمده با افزایش فشار ارزیابی روی موارد خاص (آزمون 4) تنوع مشخصی را در درصد توافق حاصل در چند ضلعیهای زیر نشان داد:
-
چند ضلعی شماره 1. این چند ضلعی در تست شماره 1 به توافق 100% رسید در حالی که در عدد 4 به 80% (79.1%) نرسید.
-
چند ضلعی شماره 4. در این مورد، سطح توافق حاصل از 100٪ (آزمون 1) به 91.6٪ (آزمون 4) کاهش یافت.
-
چیزی مشابه با چند ضلعی های شماره 48 و 49 اتفاق افتاد. هر دو در تست شماره 3 به توافق 100% رسیدند، در حالی که در تست شماره 4 به کمتر از 80% کاهش یافتند.
همانطور که در بالا ذکر شد، این موارد آخر مربوط به ساخت چند ضلعی است که درجه تشابه آنها نزدیک به دو مقدار آستانه است، که سه سطح مختلف را که پس از فرآیند گسسته سازی MAV ایجاد شده است، تعریف می کند.
4.2. آزمایش تطبیق
سازگاری بهدستآمده برای این آزمایش دوم حتی بیشتر از مورد آزمایش اول بود، با میانگین درصد توافق GA – متخصص 98.8٪ – محاسبهشده بر روی تعداد کل تکالیف، 612. در این مورد، نتایج بسیار قوی بود. با درصد توافق 100% در اکثر موارد. حتی چند ضلعی هایی که AG قادر به تطبیق آنها نبود توسط کارشناسان به عنوان بی همتا شناخته شدند. با این حال، استثناهای قابل توجهی وجود دارد. چنین موردی برای شماره خبره 21 – در مورد خاص چند ضلعی شماره 9 – و به ویژه مورد شماره خبره 11 است. طبق جدول A6، این آخرین متخصص نتوانست یک عنصر همولوگ را به چند ضلعی های زیر اختصاص دهد: 10، 26، 28، 31، 50 و 52. همه این چند ضلعی ها چند ضلعی با شکل مربع یا مستطیل هستند که استفاده از ابزارهای ویرایش برای آنها مفید است. مانند سیستم شبکه یا دکمه ای برای همپوشانی چند ضلعی ها بر اساس MBR های آنها – به منظور تسهیل روند تخصیص. بنابراین، این واقعیت که قادر به انجام هیچ تکلیفی نیستیم ممکن است به دلیل تفسیر نادرست راهنمای تطبیق یا عدم استفاده از آن باشد.
شکل 12 نمونه ای را نشان می دهد که این وضعیت را نشان می دهد: یک منطقه شهری که در آن یک گونه شناسی سازنده غالب است که با بلوک های شهری مستطیلی مشخص می شود. به طور خاص، با حالت چند ضلعی شماره 10 مطابقت دارد. ابتدا، شکل 12 a رابط کاربری گرافیکی مورد استفاده برای اختصاص چند ضلعی همولوگ (از صفحه 2) مربوط به چند ضلعی نشان داده شده در صفحه 1 را نشان می دهد. در این مورد، اگر از ابزارهای ویرایش استفاده نشود، روند انتساب می تواند بسیار دشوار باشد. شکل 12 ب مفید بودن این ابزارها را نشان می دهد. به طور خاص، ما از دکمه همپوشانی استفاده کرده ایم. به این ترتیب، عدم اطمینان در انتساب به طور قابل توجهی کاهش می یابد. بر این اساس، و همانطور که در بخش 4.1 بحث شدمی توان نتیجه گرفت که ارزیابی شباهت بین دو چند ضلعی منطبق زمانی که تعداد راس بالایی دارند نه تنها آسان تر است، بلکه تطبیق آنها نیز آسان تر است. این نتیجه گیری های بدست آمده در [ 2 ] را مجدداً تأیید می کند و فرضیه در نظر گرفته شده در مطالعه ما را تأیید می کند.
در نهایت، نتایج بهدستآمده با افزایش فشار ارزیابی روی موارد خاص (آزمون 4) تنوع مشخصی را در درصد توافق حاصل در چند ضلعیهای زیر نشان داد:
-
چند ضلعی شماره 31. این چند ضلعی در تست شماره 2 به توافق 100% رسید در حالی که در تست شماره 4 به 87.5% نرسید.
-
چند ضلعی شماره 52 که سطح تطابق آن در تست های 3 و 4 ثابت مانده است. علاوه بر این، این مورد در آزمون شماره 4 به کمترین سطح توافق (79.1٪) رسیده است. چند ضلعی هایی با شکل مربع یا مستطیل که برای آنها استفاده از ابزارهای ویرایش توصیه می شود. همانطور که گفته شد، این واقعیت که کارشناسان 2، 5، 7، 9 و 11 نتوانستند با آن مطابقت داشته باشند، ممکن است به دلیل عدم رعایت دستورالعمل های تعیین شده توسط راهنمای تطبیق باشد.
5. نتیجه گیری ها
مطالعه حاضر قابلیتهای واقعی یک رویکرد تطبیق مبتنی بر ماشین را برای ارزیابی شباهت بین دو ویژگی چند ضلعی ارجاعشده جغرافیایی (ساختن چند ضلعی) و سپس تطبیق آنها بررسی میکند. برای این منظور، ما گروهی از کارشناسان را انتخاب کردیم – متشکل از متخصصان معتبر و با سابقه حرفه ای طولانی در زمینه کارتوگرافی – که هدف اصلی آنها ارائه ارزیابی های جایگزین (از شباهت و تطابق) با ارزیابی های ارائه شده توسط مکانیسم تطبیق خودکار ما بود. (GA). در هر دو مورد، نتایج ما سطوح بالایی از سازگاری را نشان میدهد، یعنی درجه بالایی از توافق بین قضاوتهای صادر شده توسط کارشناسان و نتایج ارائه شده توسط GA. به طور خاص، 93.3٪ در مورد آزمایش MAV (ارزیابی شباهت) و 98. 8٪ در مورد آزمایش تطبیق (تخصیص چند ضلعی همولوگ). علاوه بر این، توصیف جفت چند ضلعی ها بر اساس تعداد رئوس به ما اجازه داد تا این فرضیه را تأیید کنیم که به طور کلی، ارزیابی تشابه در اشکال پیچیده آسان تر از اشکال ساده است. ممکن است با این واقعیت مرتبط باشد که در اشکال پیچیده تشخیص آنچه به عنوان اصول سازماندهی ادراکی شناخته می شود آسان تر است.2 ]، مانند مجاورت، تشابه، تقارن، شمول، هم خطی و غیره.
با این حال، و با وجود سطوح بالای سازگاری ذکر شده، دو جنبه وجود دارد که باید برجسته شود: (1) موارد اختلاف بین GA و متخصص و متخصص و متخصص به شدت به جفتهایی از چند ضلعیها مرتبط است که MAV آنها نزدیک به آستانه تعیینشده است. ارزش های؛ و (ب) آزمایش تطبیق نشان داده است که اپراتورهای انسانی در تطبیق چند ضلعی ها با اشکال مربع یا مستطیل زمانی که موقعیت جغرافیایی این چند ضلعی ها در نظر گرفته نمی شود با مشکلاتی مواجه می شوند. هر دو جنبه بر وابستگی نتایج به هر دو نوع شناسی سازنده غالب در یک GDB شهری خاص و خود طراحی آزمایشی تأکید می کنند. از این نظر، تلاشها باید با افزایش قابلتوجه در تعداد چند ضلعیهای مورد استفاده در مطالعه به سمت بهبود آزمایشها منتهی شود.
در هر صورت و با دقت در تفسیر نتایج می توان نتیجه گرفت که فرضیه اصلی کار حاضر تایید شده است. به عبارت دیگر، GAها در هنگام ارزیابی شباهت بین ویژگیهای چند ضلعی، و بنابراین در رویههای تطبیق خودکار با استفاده از توصیفگرهای ویژگی سطح پایین، ابزار کارآمدی هستند.
در نهایت، و با وجود تضمین های ارائه شده توسط دانش تخصصی به طور کلی و توسط گروه متخصصان ما به طور خاص، مطالعه ما یک آزمایش کامل با ابزارهای اتوماسیون را پوشش نمی دهد، بلکه خود را به استفاده از یک ابزار خاص (GAs) محدود می کند. علاوه بر این، بر روی یک مجموعه داده مکانی خاص اعمال شده است. از این نظر، مطالعات بیشتری با استفاده از ابزارهای دیگر هوش مصنوعی و سایر مطالعات موردی برای درک بیشتر مکانیسمهای ادراک انسان و بهبود روشهای یادگیری ماشین مورد نیاز است.
منابع
- رویز-لندینز، جی جی. Ureña-Cámara، MA; Ariza-López، FJ A Polygon and Point-based Approach to Matching Geospatial Features. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 399. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- فلورت، اف. لی، تی. دوبو، سی. Wampler، EK; Yantis، S. Geman, D. مقایسه ماشینها و انسانها در آزمون طبقهبندی بصری. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2011 ، 108 ، 17621–17625. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- حسابیس، د. کوماران، دی. سامرفیلد، سی. بوتوینیک، ام. هوش مصنوعی الهام گرفته از علوم اعصاب. Neuron 2017 ، 95 ، 245-258. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- بورووسکی، جی. فونکه، سی. استوسیو، ک. برندل، دبلیو. والیس، تی. بثگه، ام. دشواری بدنام مقایسه ادراک انسان و ماشین. در مجموعه مقالات کنفرانس علوم اعصاب محاسباتی شناختی، برلین، آلمان، 13 تا 16 سپتامبر 2019. [ Google Scholar ]
- نیاندوی، ای. کووا، م. کهلی، د. Bennett, R. مقایسه استخراج ویژگی های مرزی کاداستر انسان در مقابل ماشین محور. Remote Sens. 2019 ، 11 ، 1662. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Quackenbush، LJ مروری بر تکنیکهای استخراج ویژگیهای خطی از تصاویر. فتوگرام مهندس Remote Sens. 2004 ، 70 ، 1383-1392. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE ImageNet طبقه بندی با شبکه های عصبی کانولوشن عمیق. Adv. عصبی Inf. Proc. سیستم 2012 ، 25 ، 1097-1105. [ Google Scholar ] [ CrossRef ]
- ایگن، دی. فرگوس، آر. پیشبینی عمق، نرمالهای سطحی و برچسبهای معنایی با معماری کانولوشنال چند مقیاسی رایج. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، سانتیاگو، شیلی، 7 تا 13 دسامبر 2015. [ Google Scholar ]
- ژانگ، ایکس. ژائو، ایکس. مولنار، م. استوتر، جی. کراک، ام. Tinghua، A. رویکردهای طبقه بندی الگو برای تطبیق چند ضلعی های ساختمانی در مقیاس های چندگانه. در مجموعه مقالات ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences، جلد I-2، XXII کنگره ISPRS، ملبورن، استرالیا، 25 اوت تا 1 سپتامبر 2012. [ Google Scholar ]
- فن، اچ. Zipf، A.; فو، س. Neis, P. ارزیابی کیفیت برای ایجاد داده های ردپایی در OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 700-719. [ Google Scholar ] [ CrossRef ]
- تانگ، جی. جیانگ، بی. ژنگ، ا. Luo, B. تطبیق نمودار بر اساس جاسازی طیفی با مقدار گمشده. تشخیص الگو 2012 ، 45 ، 3768-3779. [ Google Scholar ] [ CrossRef ]
- فنگ، دبلیو. لیو، ز. وان، ال. Pun, C. جیانگ، جی. یک رویکرد متحمل به چندگانه طیفی برای تطبیق نمودار قوی. تشخیص الگو 2013 ، 46 ، 2819-2829. [ Google Scholar ] [ CrossRef ]
- دلد، جی. گروپمن، جی. علم اطلاعات جغرافیایی – فضایی آینده هوش مکانی. Geospat آینده. هوشمند 2017 ، 20 ، 5020–5151. [ Google Scholar ]
- دووگل، تی. ترویسان، جی. Raynal، L. ساخت یک پایگاه داده چند مقیاسی با روابط مقیاس – انتقال. در مجموعه مقالات هفتمین سمپوزیوم بین المللی در مورد مدیریت داده های فضایی، دلفت، هلند، 12-16 اوت 1996. تیلور و فرانسیس: آکسفورد، بریتانیا، 1996; صص 337-351. [ Google Scholar ]
- یوان، اس. تائو، سی. توسعه مولفه های ادغام. در مجموعه مقالات کنفرانس ژئوانفورماتیک 99، ان آربور، MI، ایالات متحده آمریکا، 19-21 ژوئن 1999; صص 1-13. [ Google Scholar ]
- آهنگ، دبلیو. کلر، جی. هیثکت، تی. دیویس، سی. تطبیق ویژگی نقطه مبتنی بر آرامش برای ترکیب نقشه برداری. ترانس. GIS 2011 ، 15 ، 43-60. [ Google Scholar ] [ CrossRef ]
- استوتر، جی. بورگاردت، دی. دوچن، سی. بائلا، بی. بیکر، ن. بلوک، سی. پلا، م. رگنولد، ن. تویا، جی. اشمید، اس. روش برای ارزیابی تعمیم خودکار نقشه در نرم افزارهای تجاری. محاسبه کنید. محیط زیست سیستم شهری 2009 ، 33 ، 311-324. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رویز-لندینز، جی جی. آریزا-لوپز، FJ; Ureña-Cámara, MA ارزیابی دقت موقعیتی خودکار پایگاههای اطلاعاتی مکانی با استفاده از روشهای مبتنی بر خط. Surv. Rev. 2013 , 45 , 332-342. [ Google Scholar ] [ CrossRef ]
- رویز-لندینز، جی جی. آریزا-لوپز، FJ; Ureña-Cámara, MA روشی مبتنی بر نقطه برای ارزیابی دقت موقعیتی خودکار پایگاههای دادههای مکانی. Surv. Rev. 2016 , 48 , 269-277. [ Google Scholar ] [ CrossRef ]
- گودچایلد، م. هانتر، جی. اندازه گیری دقت موقعیتی ساده برای ویژگی های خطی. بین المللی جی. جئوگر. Inf. علمی 1997 ، 11 ، 299-306. [ Google Scholar ] [ CrossRef ]
- هاستینگز، JT ترکیب خودکار داده های روزنامه دیجیتال. بین المللی جی. جئوگر. Inf. علمی 2008 ، 22 ، 1109-1127. [ Google Scholar ] [ CrossRef ]
- ها، ی. یو، ک. Heo, J. تشخیص جفت نقطه مزدوج برای تراز نقشه بین دو مجموعه داده چند ضلعی. محاسبه کنید. محیط زیست سیستم شهری 2011 ، 35 ، 250-262. [ Google Scholar ] [ CrossRef ]
- سمال، ع. ست، اس. Cueto، K. یک رویکرد مبتنی بر ویژگی برای ترکیب منبع جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 459-489. [ Google Scholar ] [ CrossRef ]
- کیم، جی. یو، ک. هیو، جی. لی، دبلیو. یک روش جدید برای تطبیق اشیاء در دو مجموعه داده جغرافیایی مختلف بر اساس زمینه جغرافیایی. محاسبه کنید. Geosci. 2010 ، 36 ، 1115-1122. [ Google Scholar ] [ CrossRef ]
- آرکین، ای. جویدن، ال. هاتنلوچر، دی. Kedem، K. میچل، جی. یک متریک قابل محاسبه کارآمد برای مقایسه اشکال چند ضلعی. IEEE Trans. الگوی مقعدی ماخ هوشمند 1991 ، 13 ، 209-216. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اولتئانو-ریموند، ا. موستیر، اس. رواس، الف. رسمیسازی دانش برای تطبیق دادههای برداری با استفاده از نظریه باور. جی. اسپات. Inf. علمی 2015 ، 10 ، 21-46. [ Google Scholar ] [ CrossRef ]
- جونز، CB; Ware, JM; Miller, DR یک رویکرد احتمالی برای تشخیص تغییرات محیطی با داده های نقشه کلاس منطقه. در پایگاه داده های فضایی یکپارچه ; آگوریس، پ.، استفانیدیس، ا.، ویرایش. Springer: برلین/هایدلبرگ، آلمان، 1999; صص 122-136. [ Google Scholar ]
- هررا، اف. لوزانو، م. Verdegay، J. مقابله با الگوریتم های ژنتیک کدگذاری شده واقعی: اپراتورها و ابزارهایی برای تجزیه و تحلیل رفتار. آرتیف. هوشمند Rev. 1998 , 12 , 265-319. [ Google Scholar ] [ CrossRef ]
- هررا، اف. لوزانو، م. سانچز، الف. یک طبقهبندی برای اپراتور متقاطع برای الگوریتمهای ژنتیک با کدگذاری واقعی: یک مطالعه تجربی. بین المللی جی. اینتل. سیستم 2003 ، 18 ، 309-338. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- الدر، ج. Zucker, S. اثر بسته شدن کانتور بر تشخیص سریع اشکال دو بعدی. Vis. Res. 1993 ، 33 ، 981-991. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کوواچ، آی. Julesz, B. یک منحنی بسته بسیار بیشتر از یک منحنی ناقص است: اثر بسته شدن در تقسیم بندی شکل-زمین. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 1993 ، 90 ، 7495-7497. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Ringach، DL; Shapley, R. خصوصیات مکانی و زمانی خطوط توهم و تکمیل مرز آمودال. Vis. Res. 1996 ، 36 ، 3037-3050. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تورسکی، تی. Geisler، WS; Perry، JS Contour grouping: جلوه های بسته شدن با ادامه و مجاورت خوب توضیح داده می شود. Vis. Res. 2004 ، 44 ، 2769-2777. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- اولمان، اس. آصیف، ال. فتایا، ای. هراری، دی. اتم های تشخیص در بینایی انسان و کامپیوتر. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2016 ، 113 ، 2744–2749. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- ماجاج، نیوجرسی؛ Pelli، DG یادگیری ماشینی با استفاده از یادگیری عمیق برای مطالعه بینایی بیولوژیکی. J. Vis. 2018 ، 18 ، 22. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کار، ک. کوبیلیوس، جی. اشمیت، ک. عیسی، EB; DiCarlo، JJ شواهدی وجود دارد که مدارهای مکرر برای اجرای رفتار تشخیص جسم اصلی توسط جریان شکمی حیاتی هستند. نات. نوروسک. 2019 ، 22 ، 974. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- رویز-لندینز، جی جی. آریزا-لوپز، FJ; Ureña-Cámara، کارشناسی ارشد مطالعه تغییرپذیری NSSDA با استفاده از روشهای ارزیابی دقت موقعیت خودکار. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 552. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کوهنرت، نخست وزیر؛ مارتین، تی جی; گریفیث، SP راهنمای استخراج و استفاده از دانش تخصصی در مدلهای اکولوژیکی بیزی. Ecol. Lett. 2010 ، 7 ، 900-914. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ایوب، BM استخراج نظرات کارشناسان برای عدم قطعیت و خطرات ; CRC Press: Boca Ratón، FL، USA، 2001. [ Google Scholar ]
- رابرسون، سی. Feick, R. تعریف کارشناسان محلی: تخصص جغرافیایی به عنوان مبنایی برای کیفیت اطلاعات جغرافیایی. در مجموعه مقالات کارگاه ها و پوسترهای سیزدهمین کنفرانس بین المللی تئوری اطلاعات فضایی (COSIT 2017) ؛ Clementini, E., Fogliaroni, P., Ballatore, A., Eds.; Springer: L’Aquila، ایتالیا، 2017; ماده 22; ص 22:1-22:14. [ Google Scholar ]
- بروداریک، بی. فاکس، پی. مک گینس، نمایندگی دانش زمین علوم زمین در زیرساخت های سایبری. محاسبه کنید. Geosci. 2009 ، 35 ، 697-699. [ Google Scholar ] [ CrossRef ]
- کاساس، جی. رپولو، جی. Donado, J. La encuesta como técnica de research. Elaboración de cuestionarios y tratamiento estadístico de los datos (I). آتن. Primaria 2003 ، 31 ، 527-538. [ Google Scholar ] [ CrossRef ]
- فیشلر، ام. Elschlager, R. بازنمایی و تطبیق ساختارهای تصویری. IEEE Trans. محاسبه کنید. 1973 ، 22 ، 67-92. [ Google Scholar ] [ CrossRef ]
- رادوکس، جی. والدنر، اف. بوگارت، پی. چگونه طرحهای پاسخ و تناسب کلاسها بر صحت دادههای اعتبارسنجی تأثیر میگذارند. Remote Sens. 2020 , 12 , 257. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
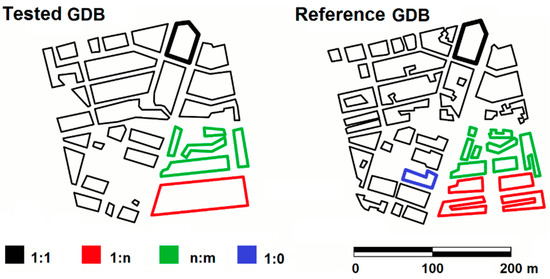
شکل 1. چند نمونه از تطابق بین چند ضلعی. مثالی از تناظر 1:1 (سیاه)، مثالی از مطابقت 1:n (قرمز)، نمونههایی از تناظر n:m (سبز) و مثالی از مطابقت 1:0 (آبی). منبع: [ 1 ].
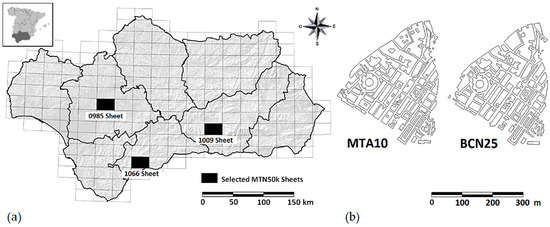
شکل 2. ( الف ) برگه های منتخب نقشه ملی توپوگرافی E50k منطقه اندلس (جنوب اسپانیا) و مرزهای اداری آن، و ( ب ) نمونه هایی از ویژگی های چند ضلعی متعلق به Mapa Topográfico de Andalucía E10K (MTA10) و Base Cartogréricáficaum E25k (BCN25). منبع: [ 1 ].
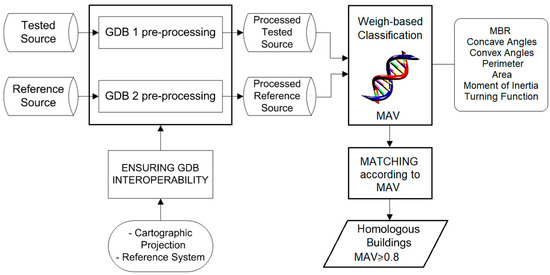
شکل 3. گردش کار رویه تطبیق خودکار.
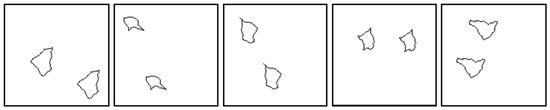
شکل 4. اشکال متعلق به دسته 1 SVRT. آیا دو شکل یکسان در تصویر وجود دارد؟ منبع: [ 2 ].
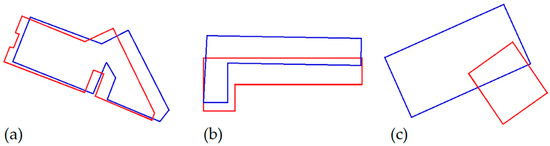
شکل 5. درجه شباهت بین هر جفت چند ضلعی که قبلا مطابقت داده شده اند. نمونه هایی متعلق به راهنمای تطبیق ما. چند ضلعی های BCN25 با خطوط آبی نشان داده می شوند، در حالی که چند ضلعی های MTA10 با خطوط قرمز نشان داده می شوند. ( الف ) سطح بالای شباهت؛ ( ب ) سطح میانی شباهت؛ و ( ج ) سطح پایین تشابه.
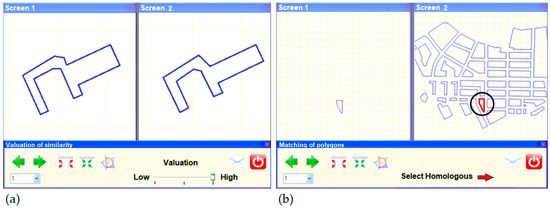
شکل 6. رابط کاربری گرافیکی. ( الف ) رابط متعلق به آزمایش MAV. ( ب ) رابط متعلق به آزمایش تطبیق.
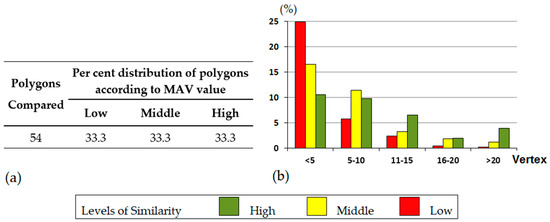
شکل 7. ( الف ) توزیع چند ضلعی ها بر اساس MAV محاسبه شده توسط GA، ( ب ) توزیع درصد چند ضلعی های منطبق برای هر سطح از MAV گروه بندی شده بر اساس تعداد رئوس.
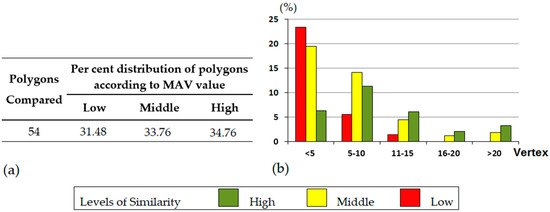
شکل 8. ( الف ) توزیع چند ضلعی ها بر اساس MAV محاسبه شده توسط گروه خبرگان، ( ب ) توزیع درصد چند ضلعی های منطبق برای هر سطح از MAV گروه بندی شده بر اساس تعداد رئوس.
شکل 9. ( الف ) یکی از 9 منطقه شهری مورد استفاده در این مطالعه. ( ب ) چند ضلعی های متعلق به این منطقه شهری و انتخاب شده برای آزمایش MAV. ( ج ) MAV محاسبه شده توسط GA. ( د ) MAV گسسته شده که توسط یک متخصص خاص تعیین شده است.
شکل 10. موارد چند ضلعی بی همتا. ( الف ) چند ضلعی های بی همتا مرتبط با تناظرهای 1:0. ( ب ) چند ضلعی های بی همتا مرتبط با مکاتبات m:n.
شکل 11. عدم قطعیت در اطراف مقادیر آستانه. ( الف ) سطح توافق بر اساس MAV. ( ب ) توافق با توجه به فاصله تا آستانه MAV.
شکل 12. رابط کاربری گرافیکی متعلق به آزمایش تطبیق. ( الف ) نمونه ای از تکلیف بدون کمک ابزار ویرایش؛ ( ب ) مثالی از انتساب با استفاده از ابزارهای ویرایش.


بدون دیدگاه