1. معرفی
در طول دو دهه گذشته، نقشه برداری مشارکتی عمومی (PP) به سرعت از نقشه کاغذی به نقشه دیجیتالی تبدیل شده است [ 1 ، 2 ، 3 ]]. پلتفرمهای رسانههای اجتماعی (SM) که حجم عظیمی از دادههای جمعسپاری را برای نقشهبرداری دیجیتال فراهم میکنند، به عنوان یک منبع نقشهبرداری مشارکتی مناسب در نظر گرفته نمیشوند، حتی اگر SM میتواند بهعنوان یک پلتفرم پیشگام استفاده شود که نرخ مشارکت فردی را برای نقشهبرداری PP با ویژگیهای دادههای بزرگ افزایش میدهد. ظرفیت تولید و پلتفرم های جمع آوری بی وقفه داده ها. آنتنهای سیستمهای ماهوارهای ناوبری جهانی (GNSS) در دستگاههای هوشمند و استفاده عمومی از این دستگاهها، برنامههای crowdsourced مبتنی بر مکان را فعال و تقویت میکنند. داده ها توسط کاربران این برنامه ها تولید می شود و به عنوان اطلاعات جغرافیایی داوطلبانه (VGI) نامیده می شود [ 4 ، 5 ]]. کاربران را می توان به عنوان داوطلبان ناخودآگاه برای رسانه های اجتماعی (SM) VGI، به عنوان داوطلبان عمدی برای VGI تولید همتا و به عنوان مشارکت کنندگان عمومی در VGI مبتنی بر علم شهروندی [ 6 ، 7 ، 8 ] در نظر گرفت. روش تولید این اشکال VGI به عنوان نئوجغرافی نامیده می شود زیرا از نئوجغرافیدانان (به عنوان مثال، داوطلبان) استفاده می کند که بدون متخصص بودن در فعالیت های نقشه برداری مشارکت دارند [ 9 ]. این بی تجربگی در رابطه با تولید داده ها در زمینه کیفیت داده [ 10 ، 11 ، 12 ]، سوگیری جمعیت شناختی (مانند جنس، جنبه های اجتماعی-اقتصادی و آموزشی) مورد سوال قرار می گیرد [ 13 ، 14 ]] سوگیری نمونه گیری (اشاره به نمونه گیری داوطلبانه) و تأثیر آن بر داده های تولید شده [ 15 ، 16 ].
در اولین شکل خود، پروژه های دانش شهروندی در اولین اشکال با استفاده از نقشه های کاغذی انجام شد [ 1 ]. با این حال، با پیشرفت های تکنولوژیکی در علوم کامپیوتر و وب، امروزه آنها بیشتر با کمک طیف وسیعی از پلتفرم های آنلاین [ 17 ، 18 ، 19 ] طراحی شده برای جمع آوری داده ها برای اهداف علم شهروندی انجام می شوند. این پلتفرمها برای جمعآوری دادهها در بازه زمانی محدود برای اهداف مشخص طراحی شدهاند. از سوی دیگر، صفحات وب اختصاصی نیز برای پروژه های علمی شهروندی محلی مانند DYFI (آیا آن را احساس کردید) [ 20 ] وجود دارد.]. DYFI که توسط USGS ارائه می شود، داده هایی را از داوطلبان در مورد شدت احساس زلزله جمع آوری می کند تا میزان آسیب و شدت لرزش را بر روی نقشه نشان دهد. اگرچه این پروژه برای جمعآوری و پردازش دادهها طراحی و ساخته شده است، اما تعداد پاسخهای داوطلبان به زلزلههای منفرد (نرخ مشارکت) برای هر زلزله بسیار کم است [ 21 ]. اگرچه این پروژه برای کشورهای مختلف مانند نیوزلند، ایتالیا و ترکیه [ 20 ، 22 ] تکرار شده است، هنوز هیچ رویکرد سازمان یافته ای توسط مقامات مربوطه وجود ندارد [ 23 ].
پلتفرمهای SM، اگرچه بهعنوان راه مناسبی برای سازماندهی پروژههای مبتنی بر شهروند دیده نمیشوند، اما همچنان دارای ظرفیت سرویس دهی بالا و مستمر در سراسر جهان هستند که شامل 3 میلیارد کاربر است [ 24 ].]. در واقع SM با ظرفیت جمعآوری و سرویس دهی گسترده، مستمر و فعال خود میتواند به عنوان یک پلتفرم پیشگام برای انجام پروژههای مبتنی بر شهروندی به ویژه برای نظارت بر رویدادهای غیرعادی مانند شرایط چند اضطراری در شهرهای بزرگ استفاده شود. با این حال، سوگیری در دادههای SM میتواند مانعی برای چنین پروژههایی باشد. به منظور استفاده از داده های SM به عنوان یک سیستم نظارتی مبتنی بر شهروند، داده های جغرافیایی ارجاع شده در یک منطقه خاص (مانند یک شهر، منطقه یا کشور) باید از قبل ارزیابی شوند. به این ترتیب، راههایی برای استفاده و تفسیر دادههای SM به عنوان ابزاری با توجه به نظارت بر شهر قابل استنباط است.
1.1. مطالعات SMD در مورد نقشه برداری اضطراری
SMD بیش از یک دهه است که برای مدیریت بلایا استفاده می شود. هیوستون و همکاران [ 25 ] یک ادبیات جامع در مورد عملکرد SM از نظر مراحل مدیریت بلایا ارائه می کند. اولین نمونه از تشخیص رویداد با SMD توسط ساکاکی و همکاران انجام شد. [ 26 ]. رسانههای اجتماعی همچنین برای تلاشهای امدادرسانی در بلایای طبیعی توسط گائو و همکاران در نظر گرفته شدند. [ 27 ] و Muralidharan و همکاران. [ 28 ]، برای ارتباط بحران توسط آکار و موراکی [ 29 ] و مک کلندون و رابینسون [ 30 ] و برای هستی شناسی تخلیه توسط ایشینو و همکاران. [ 31 ] و ایواناگا و همکاران. [ 32 ].
بسیاری از مطالعات قبلی و اخیر فیلترینگ مبتنی بر متن را در ابتدا برای تشخیص یک رویداد متمرکز کردهاند [ 33 ، 34 ، 35 ، 36 ]. تکنیکهای فیلتر کردن بیشتر برای تعداد محدودی از کلمات کلیدی مرتبط با یک حوزه فاجعه (مانند؛ طوفان، سیل و طوفان برای بلایای هواشناسی) استفاده میشوند [ 36 ]. با توجه به آن، این نوع مطالعات به دلیل کلمات کلیدی تعیین شده دارای سوگیری انتخاب هستند [ 37]. با این حال، این ممکن است برای تجزیه و تحلیل های فضایی درشت دانه مشکلی به دلیل داده های فراوان نباشد. این ممکن است منجر به مشکلات شناسایی برای رویدادهای محلی شود. با این حال، مطالعات بیشتر بر اساس یک نوع رویداد است به جای اینکه یک سیستم نظارتی جامع برای تشخیص هر گونه ناهنجاری رویداد فاجعهبار باشد. علاوه بر آن، دانه فضایی تحلیلهای تشخیص عمدتاً در سطح شهرستان یا شهر درشت هستند [ 35 ، 36 ]، حتی مطالعات در ابتدا بر ملاحظات فضایی متمرکز هستند [ 37 ].
اکتشاف داده های تاریخی نقش مهمی در نظارت همه جانبه رویدادهای غیرمعمول در سطح فضایی دانه ریز در یک شهر دارد [ 37 ، 38 ]. به همین دلیل است که SMD باید از نظر ناهنجاری، روند و سوگیری ارزیابی شود. به این ترتیب، رد پای شهروندان در رسانههای اجتماعی میتواند به روشهای مختلفی به عنوان نقشههای پایه برای بررسیهای بیشتر تشخیص رویدادهای محلی تفسیر شود. عملیاتی ترین استفاده از روش پیشنهادی می تواند در نقشه برداری اضطراری به دلیل جانشینی سریع و توانایی مقایسه تفاوت با روندهای زندگی روزمره باشد. از آنجایی که مراحل مدیریت اضطراری به داده های بلادرنگ سریع در منطقه مورد نظر برای مقایسه وضعیت جاری با برنامه های آمادگی نیاز دارد.
1.2. هدف و منطقه مطالعه
در این مطالعه، هدف، ارائه روشی برای بررسی سوگیری به منظور آشکارسازی ردپای شهروندان در یک شهر و تهیه نقشههای مرجع (به احتمال زیاد نقشههای ناهنجاری منطقهای، نقشههای نمایش، نقشههای سوگیری مکانی و زمانی و غیره) است. شهر استانبول به عنوان منطقه مورد مطالعه انتخاب شد زیرا یکی از بزرگترین شهرهای جهان با 18 میلیون نفر جمعیت است و یکی از شهرهایی است که انتظار یک زلزله بزرگ را دارد که احتمالاً می تواند تأثیر فاجعه باری بر شهر داشته باشد [ 39 ، 40 ]. پلت فرم توییتر به عنوان منبع داده استفاده می شود، زیرا یکی از رایج ترین شبکه های رسانه اجتماعی مورد استفاده برای انتشار اطلاعات در سراسر جهان است [ 24 ، 41 ]]. در این مقاله از چنین داده هایی به عنوان داده های رسانه های اجتماعی (SMD) یاد می شود. با توجه به بررسی SMD، روش شامل مراحل زیر است: جمع آوری داده ها و مرتب سازی داده ها، تعیین نمایش و سوگیری زمانی در داده ها، عادی سازی داده ها برای حذف سوگیری نمایش کاربر، تشخیص ناهنجاری ها در غیر مکانی و مکانی داده ها، گسسته سازی ناهنجاری ها و تولید نقشه روند و بررسی سوگیری مکانی-زمانی. نتایج بررسی داده ها در این مطالعه از منظر نقشه برداری رویداد مبتنی بر شهروند با استفاده از داده های SM مورد بحث قرار می گیرد. به این ترتیب، تکنیک های ارزیابی با توجه به داده های SM در این مطالعه به نفع ظرفیت سازی نقشه برداری جغرافیایی مبتنی بر شهروند ارائه شده است.
1.3. تعصب در SM-VGI
نزدیک به نیمی از جمعیت جهان به دلیل سانسور اینترنت یا عدم دسترسی به آنها در SM حضور ندارند [ 42 ]. در نتیجه، این مطالعه سوگیری در داده های رسانه های اجتماعی (SMD) با در نظر گرفتن ناکافی بودن زیرساخت های فنی و سیاسی آغاز می شود. علاوه بر این، میزان استفاده از دستگاههای هوشمند و رایانهها بر میزان نمایندگی جوامع و افراد تأثیر میگذارد. علاوه بر این، نمایندگی جوامع ممکن است برابر نباشد که بیشتر برحسب تفاوت های جمعیتی (سن، تحصیلات، موقعیت اجتماعی) توضیح داده می شود. به دلایل متعدد، برخی از بخشهای یک جامعه ممکن است بیش از حد نشان داده شوند، در حالی که بخشهای دیگر ممکن است کمتر یا اصلاً نمایندگی نداشته باشند [ 15 ، 43 ]]. با این حال، تعیین سوگیری جمعیت شناختی عمدتاً به دلیل در دسترس نبودن داده های شخصی داوطلبان در VGI امکان پذیر نیست [ 16 ، 44 ]. علاوه بر این، داوطلبان پلتفرم ممکن است حتی یک شخص نباشند، زیرا می توانند یک ربات، یک عضو تیم کارکنان (که تجسم و تبلیغ یک شرکت است) و/یا یک ترول (یک حساب کاربری جعلی) باشند.
بصیری و همکاران. [ 44 ] نشان می دهد که بیش از 300 نوع سوگیری وجود دارد و داده های جمع سپاری ممکن است برخی از آنها را داشته باشند. از آنجایی که داوطلبان مستقیماً بدون درخواست مشارکت مشارکت می کنند، SMD شامل «سوگیری انتخاب» نمی شود. با این حال، داوطلبان به دلیل میزان فعالیت زیادشان، «سوگیری نمایندگی» را به طور متفاوتی نشان میدهند . همچنین، تراکم جمعیت احتمالاً “سوگیری سیستماتیک” را در فضا ایجاد می کند. با توجه به شهرت مکانها، داوطلبان تمایل دارند مکانهای محبوب را بیشتر به اشتراک بگذارند، خودنمایی کنند و در همان صفحه با دیگران قابل مشاهده باشند. این به عنوان “سوگیری باند واگن” نامیده می شود و بر توزیع فضایی VGI تأثیر می گذارد. ” سوگیری وضعیت موجود”همچنین بازتابی از پسزمینه جمعیتشناختی داوطلبان در فضا است و بهعنوان انواع خاصی که در یک نقطه مورد علاقه مشترک هستند دیده میشود [ 44 ]. در حالی که سوگیریهای Bandwagon و Status-Qo به تعصب فضایی اشاره میکنند، بعد زمانی الگوهای متفاوتی با توجه به تغییر فعالیتها یا نرخ مشارکت مربوط به زمان روز، روز هفته و فصل سال ایجاد میکند. این روند در حال تغییر به عنوان ” سوگیری فضایی -زمانی” نامیده می شود و در مورد مقایسه برش های زمانی نامناسب منجر به تفسیر نادرست می شود.
تلاشهای زیادی برای شناسایی الگوهای فضایی، روندها و سوگیریها با توجه به SMD صورت گرفته است. لی و همکاران [ 45 ] تحقیقی را بر روی دادههای توییتر و فلیکر در سطح شهرستان انجام داد تا رفتار کاربران را در نتیجه ویژگیهای جمعیت شناختی درک کند. این مطالعه همچنین برخی نمودارهای اکتشافی را در مورد تعداد توییتها در طول زمان ارائه میکند و نقشههای تراکم توییتها را ارائه میکند که با تراکم جمعیت در سطح شهرستان نرمال میشوند. مطالعه دیگری در مورد درک ویژگی های جمعیت شناختی کاربرانی است که خدمات مکان یابی را در توییتر فعال می کنند [ 41 ]. این مطالعه شواهد قوی بر اساس اثرات جمعیت شناختی بر تمایل به فعال کردن خدمات جغرافیایی و برچسب گذاری جغرافیایی ارائه می دهد. لنسلی و لانگلی [ 46] پویایی شهر لندن را با استفاده از مدلسازی موضوع جستجو کرد و مطابقت موضوعات را با ویژگیها و مکان کاربران اندازهگیری کرد. آرتور و ویلیامز [ 47 ] تحقیقی را برای شناسایی هویت منطقه ای و ارتباطات بین شهرها انجام دادند. محققان دریافتند هویت منطقهای که با شباهت متن و تحلیل احساسات توییتهای ارسالشده بر حسب چندین شهر بریتانیا اندازهگیری میشود. مالک و همکاران [ 48] تحقیقاتی را برای یافتن رابطه بین جمعیت سرشماری و تعداد توییتهای دارای برچسب جغرافیایی با استفاده از آزمونهای آماری انجام داد. آنها دریافتند که تأثیر جمعیت بر تراکم توییت ها وجود ندارد. با این حال، آنها چندین اثر دیگر مانند سطح درآمد جمعیت، بودن در مرکز شهر و سن جمعیت را شناسایی کردند. مطالعه دیگری با توجه به تعصب کاربر از نظر فراوانی توییت کاربران، حذف 5 درصد از کاربران فعال برتر از دادهها را برای جلوگیری از چنین سوگیریهایی پیشنهاد کرد [ 49 ].
از این نظر، مطالعات انجام شده بیشتر بر پیشینه جمعیت شناختی کاربران، رابطه بین جمعیت و تراکم توییت ها، سوگیری نمایش یا واریانس موضوع در فضای درشت دانه متمرکز بود. با این حال، آنها به دنبال الگوی دادههای مکانی دقیق مبتنی بر یک سال و سوگیریهایی نبودند که میتواند امکان نظارت بر یک شهر را با تفسیر بهتر دادههای مکانی-زمانی فراهم کند. با این حال، این مطالعه برای ارائه واریانسهای مکانی-زمانی با توجه به تنوع نمایش و ناهنجاریها و روندها در دادهها، بدون مسدود کردن یا حذف دادههای کاربران طراحی شده است که روش رایج مطالعات قبلی برای پاکسازی دادهها است.
2. مواد و روشها
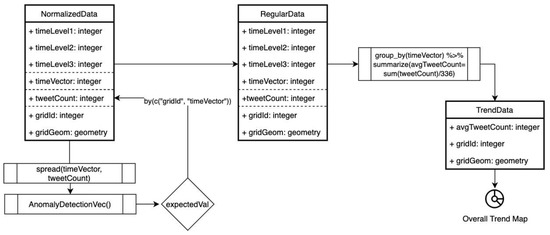
روش شناسی این مطالعه در پنج بخش فرعی ارائه شده است و جریان مفهومی روش شناسی را می توان از شکل 1 دنبال کرد. در بخش اول 2.1 ، جزئیات تکنیک های جمع آوری داده ها و مراحل مرتب سازی داده ها توضیح داده شده است. در بخش دوم 2.2 ، روش بررسی داده ها از نظر سطوح فعالیت کاربران و سطوح زمانی معرفی شده است. علاوه بر این، استفاده از تکنیکهای نرمالسازی وزن کاربر برای بررسی تأثیر سطوح فعالیت کاربران بر تغییرات دادههای زمانی معرفی شدهاست. در بخش سوم 2.3جزئیات بررسی ناهنجاریهای دادهها در دو مرحله تشخیص ناهنجاری نسبت به دادههای غیرمکانی و تشخیص ناهنجاری بر روی دادههای نمایهسازی شده فضایی ارائه شده است. در بخش چهارم 2.4 ، روش درگیر در به دست آوردن دادههای منظم به منظور تولید دادههای روند کلی شاخصشده مکانی و یک نقشه توضیح داده شده است. در بخش پنجم 2.5 ، جزئیات ارزیابی سوگیری در جریان روش شناسی گنجانده شده است. بررسی سوگیری از نظر سطوح زمانی گام به گام در این بخش آخر توضیح داده شده است.
2.1. جمع آوری داده ها و مرتب سازی داده ها
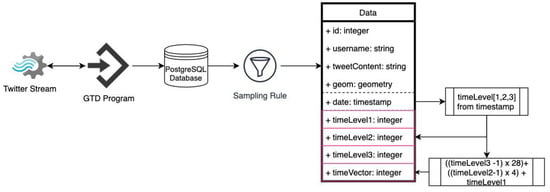
جریان داده این بخش از مراحل زیر تشکیل شده است – دانلود داده، ذخیره سازی، نمونه برداری و مرتب کردن ( شکل 2 ). Geo Tweets Downloader (GTD) [ 50] به عنوان نرم افزار بارگیری انتخاب شده است، زیرا هدف این مطالعه نظارت بر الگوی توییت در یک جعبه محدود فضایی است. GTD نرم افزاری است که از API های توییتر برای دانلود توییت های جغرافیایی مرجع استفاده می کند و این داده ها را در زمان واقعی در PostgreSQL وارد می کند. GTD داده ها را در طول سال 2018 در جعبه مرزی شهر استانبول به دست آورده است. در طول این فرآیند جمعآوری دادهها که یک سال به طول انجامید، چندین وقفه مانند قطع برق و اینترنت در سرور بارگیری رخ داد. بنابراین، داده های به دست آمده در هفته نمونه برداری شده است. تداوم دادهها از دوشنبه تا یکشنبه بهعنوان تنها قانون نمونهگیری تعیین شد و از هفته اول هر ماه، هر ساعت بررسی میشد که آیا دادهای از دست رفته است یا نه. بر این اساس،
داده ها با افزودن سه ستون سطح زمانی برای بررسی بیشتر در بخش های زیر مرتب شدند. سطح اول (timeLevel1) چهار بازه زمانی مختلف از روز را نشان می دهد. شب (00:00-06:00)، قبل از ظهر (6:00-12:00)، بعد از ظهر (12:00-18:00) و عصر (18:00-00:00). سطح دوم (timeLevel2) روز هفته را از دوشنبه تا یکشنبه نشان می دهد. سطح سوم (timeLevel3) ماه سال را از ژانویه تا دسامبر شامل می شود. در پایگاه داده مقادیر سطح زمان با یک مقدار صحیح نشان داده می شوند. بر این اساس، timeLevels 1، 2 و 3 به ترتیب دارای 4، 7 و 12 مقادیر صحیح هستند. علاوه بر این ستون های سطح زمانی، یک ستون بردار زمان با فرمول ارائه شده در شکل 2 محاسبه شد. بر اساس این محاسبه، timeVector دارای مقادیری از 1 (شب، دوشنبه، ژانویه) تا 336 (عصر، یکشنبه، دسامبر) است.
2.2. بررسی اجمالی داده ها
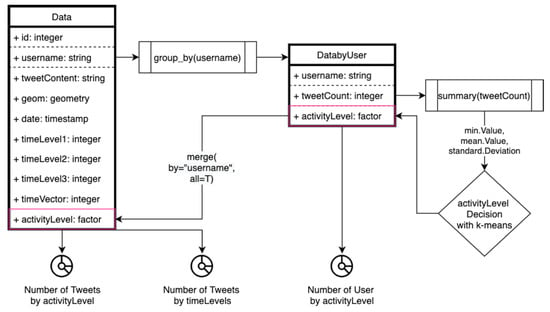
بررسی دادهها از جستجوی سطح نمایش کاربر، تنوع تعداد توییتها بر حسب سطح زمانی و تعداد توییتهای عادی از نظر سطح زمانی تشکیل شده بود. تحقیقات با سطوح نمایش تولید کننده داده آغاز شد که ممکن است باعث ایجاد وزن های نویز بر روی داده ها شود. سطح فعالیت هر کاربر با استفاده از یکی از متداولترین تکنیکهای خوشهبندی k-means بر روی فعالیتهای کلی کاربران تعیین شد. از نظر تصمیم گیری سطح فعالیت، 1. داده ها بر اساس نام کاربری گروه بندی شدند، 2. تعداد توییت برای هر کاربر محاسبه شد، 3. حداقل، میانگین، مقادیر انحراف استاندارد تعداد توییت ها محاسبه شد ( شکل 3 ). هیستوگرام تعداد توییتها به خوبی نمایش داده نمیشد، زیرا بسیار راست بود. با این حال، خلاصه ای از تعداد توییت ها به شرح زیر است:
| حداقل |
1 ق. |
میانه |
منظور داشتن |
3 ق. |
حداکثر |
Std. |
| 1.00 |
1.00 |
4.00 |
53.91 |
ساعت 17.00 |
4378.00 |
185.474 |
4. از آنجایی که توییت شماره 1 با بسیاری از کاربران در مجموعه داده کلی مرتبط است، به عنوان اولین خوشه از هم جدا شده است. از آنجایی که داده ها به طور معمول توزیع نمی شوند، خوشه بندی k-means بر روی مجموعه داده باقی مانده با جداسازی آن به 3 خوشه اعمال می شود. در پیادهسازی خوشهبندی k-means، ما از رویکرد سنتی که در زیر فهرست شده است پیروی کردیم.
-
4 به عنوان شماره خوشه انتخاب می شود
-
مرکزهای c 1 , c 2 , c 3 و c 4 را به صورت تصادفی قرار دهید
-
مراحل 4 و 5 را تا زمان همگرایی یا تا پایان تعداد ثابتی از تکرارها تکرار کنید
-
برای شماره توییت هر کاربر – نزدیکترین مرکز (c 1 , c 2 , c 3 و c 4 ) را پیدا کنید – کاربر را به آن خوشه اختصاص دهید
-
برای هر خوشه j = 1..4 – مرکز جدید = میانگین تمام نقاط اختصاص داده شده به آن خوشه
-
پایان
هر نمایش خوشه ای را می توان در جدول 1 مشاهده کرد.
بر این اساس، مقدار حداقل 1 به عنوان کلاس نمایش واحد سطح فعالیت مشخص شد، حداکثر مقدار خوشه 2 (261) قسمت بالایی کلاس فعالیت دوم را محدود می کند، حداکثر مقدار خوشه 3 (944) است. محدود کردن قسمت بالای کلاس فعالیت سوم و در نهایت، حداکثر مقدار حداکثر خوشه 4 (4378) قسمت بالای کلاس فعالیت چهارم را محدود می کند. با افزودن سطوح فعالیت کاربر به مجموعههای داده همانطور که در شکل 3 نشان داده شده است ، تعداد کاربران و توییتها از نظر سطح فعالیت بر اساس نمودارهای بخش «نتایج» مورد بررسی قرار گرفت.
تعداد توییتها از نظر سطوح زمانی نیز از نظر نمودارهای نوار دایرهای در بخش «نتایج» مورد بررسی قرار گرفت تا استنتاج کلی با توجه به هرگونه سوگیری زمانی انجام شود. تغییرات در تعداد توییتها ابتدا بر روی تعداد دادههای خام بدون وزندهی ترسیم شد. علاوه بر این، تعداد توییت ها با تکنیک توضیح داده شده در زیر عادی می شود. تعداد عادی توییتها از نظر سطح زمانی به منظور بحث در مورد تأثیرات سطح نمایش بر تغییرات دادههای زمانی مورد بررسی قرار میگیرد.
با توجه به ماهیت دادههای SMD، تفاوت قابلتوجهی در تعداد توییتها و رفتارهای کاربر وجود دارد که باعث میشود برخی از دادهها «فرتتر» باشند، اصطلاحی که برای توصیف هرگونه رفتار غیرعادی استفاده میشود. با این حال، اغلب نمی توان تعیین کرد که آیا آن داده های پرت نامعتبر هستند یا اینکه آیا داده ها اطلاعات معتبری را برای مجموعه داده کلی یا کار برای دستیابی به آن نشان می دهند. بنابراین، در این مقاله، آن دسته از شمارههای توییت/رفتارهای کاربران، که بهطور محسوسی از دادههای کلی منحرف میشوند، عمدا حذف نمیشوند، بلکه به همه کاربران بر اساس سطوح فعالیت آنها وزن اختصاص داده میشود. از طریق استفاده از این وزن های اختصاص داده شده، هر کاربر در سطوح مختلف در داده های استفاده شده نشان داده می شود. بدین ترتیب،
از نظر درون عادی سازی، وزن هر کاربر بر اساس اعداد توییت آنها در مقایسه با مجموعه داده کلی توییت تعیین می شود. در این مقاله، ما از این قیاس پیروی می کنیم که اگر کاربر A تمایل به ارسال تعداد زیادی توییت (به عنوان مثال، ~ 100) در یک روز عادی داشته باشد، این تعداد توییت افزایش می یابد – بر این اساس در صورت وقوع فاجعه. از طرف دیگر، کاربر B که تمایل دارد تعداد کمتری توییت (مثلاً 1 یا 0) را در یک روز عادی ارسال کند، تعداد توییتها را به موازات این تعداد توییت روزانه عادی افزایش میدهد. بنابراین، به کاربر A وزن کمتری نسبت به کاربر B برای هر توییت اختصاص داده می شود. این رویکرد می تواند به ما اجازه دهد تا با هر گونه اختلاف در رفتار توییت کردن بین کاربران مقابله کنیم. جمترآایکس) تعداد توییت ها.
وزن دهی کاربر به صورت زیر پیاده سازی می شود:
جایی که wمنوزن تعیین شده کاربر اول است ،تومنتعداد کل توییت ها و جمترآایکسحداکثر تعداد توییت هایی است که به ترتیب ارسال شده است.
پس از تعیین وزن هر کاربر، تعداد کلی توییت ( nمن) هر کاربر در استخر عمومی به سادگی با ضرب وزن کاربر در تعداد کلی توییت کاربران محاسبه می شود. در نتیجه، بین عادی سازی با اجازه دادن به هر توییت کاربر برای کمک به “به شیوه ای سازشکارانه” به مجموعه عمومی تکمیل می شود. علاوه بر این، با پیروی از این رویه، سهم هر کاربر بدون نادیده گرفتن یا حذف از مجموعه داده مورد استفاده قرار می گیرد. پس از جمع آوری اعداد وزنی توییت ( nمن) از هر کاربر، در داخل عادی سازی، اعداد توییت های مبتنی بر زمان جمع می شوند و تبدیل ریشه مکعبی که معمولاً استفاده می شود برای هر عدد توییت مبتنی بر زمان (2) پیاده سازی می شود و نرمال سازی min-max روی این جمع آوری شده اعمال می شود. ( جتی) مجموعه داده اعداد توییت
جایی که جتیعدد توییت تبدیل شده در زمان t است. N اعداد کاربر وزنی است که در زمان t و توییت می شوندnمناعداد وزنی توییت از نرمال سازی درونی است. در نتیجه، استفاده از رویههای درون و بین نرمالسازی، نمایش هر کاربر و هر توییت را در مجموعه داده نرمالشده نهایی ممکن میسازد.
2.3. ناهنجاری در داده ها
بررسی ناهنجاری در دو مرحله انجام شد که هم برای دادههای غیرمکانی و هم برای دادههای مکانی اعمال شد. بسته AnomalyDetection R [ 51 ، 52] برای برنامه های کاربردی به تصویب رسید. این بسته توسط توییتر برای تشخیص ناهنجاری و برای تجسم ایجاد شده است که در آن داده های ورودی توییتر بسیار فصلی است و همچنین شامل یک روند است. این بسته از آزمون انحراف دانشجویی افراطی ترکیبی فصلی (SH-ESD) استفاده می کند که از تجزیه سری های زمانی و معیارهای آماری قوی همراه با آزمون انحراف شدید دانشجویی معمولی (ESD) استفاده می کند. SH-ESD خروجی ناهنجاری حساسی را ارائه میکند که متخصص در دادههای توییتر است، با توانایی تشخیص ناهنجاریهای جهانی و همچنین ناهنجاریهایی که اندازه کمی دارند و فقط به صورت محلی قابل مشاهده هستند. برای محاسبه آزمون SH-ESD، بسته تشخیص ناهنجاری از روش سری زمانی و روش بردار مقادیر عددی پشتیبانی می کند که در آن روش سری زمانی مقادیر مهر زمانی را به عنوان ورودی دریافت می کند در حالی که روش برداری به یک متغیر ورودی اضافی “دوره” برای سریال سازی نیاز دارد. هر دو روش به حداکثر درصد ناهنجاری نیاز دارند، “max_anoms” (کران بالای ESD) و “جهت” ناهنجاری (منفی، مثبت یا هر دو) [51 ، 52 ].
در این تحقیق از روش برداری بسته AnomalyDetection استفاده شده است. متغیر دوره به عنوان 28 تنظیم شده است، زیرا 7 روز داده استفاده می شود و هر روز با توجه به ساعت توییت های داده شده به 4 دوره تقسیم می شود. هوچنباوم و همکاران [ 53 ] با 0.05 و 0.001 به عنوان حداکثر درصد ناهنجاری در آزمایشات خود آزمایش کردند. آنها به دقت، یادآوری و مقادیر F-measure بهتری با 0.001 دست یافتند، هرچند با تفاوت های بسیار کمی بین یکدیگر. با در نظر گرفتن تنظیمات آزمایشی هوچنبام، والیس و کجاریوال [ 53 ]، حداکثر درصد ناهنجاری 0.02 به عنوان مقدار بهینه انتخاب شده است.
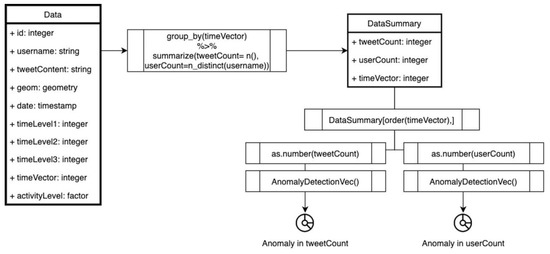
برای اولین مرحله اعمال ناهنجاری همانطور که در شکل 4 ارائه شده است ، 1. داده ها بر اساس timeVector گروه بندی می شوند و به صورت tweetCount، userCount و normalizedTweetCount خلاصه می شوند، 2. شمارش ها بر اساس timeVector مرتب می شوند، 3. تشخیص ناهنجاری برای تعداد بردار اعمال می شود.
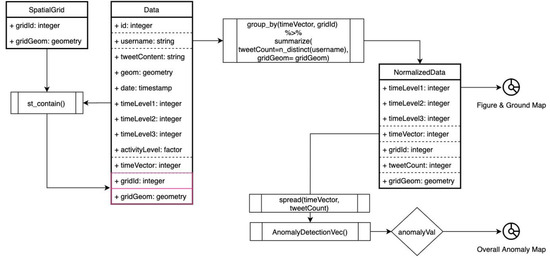
برای مرحله دوم، ناهنجاری فضایی-زمانی همانطور که در شکل 5 ارائه شده است ارزیابی می شود . مراحل عبارتند از 1. شبکههای فضایی (1×1 کیلومتر) در کادر محدود استانبول، که به صورت مکانی با دادهها پیوند میخورد، 2. دادهها بر اساس timeVector و gridId گروهبندی میشوند و به صورت tweetCount (به عنوان تعداد متمایز نامهای کاربری) خلاصه میشوند. هندسه شبکه، 3. یک شکل و نقشه زمین برای نمایش شبکههای فضایی نشان داده نشده تجسم میشود، 4. تشخیص ناهنجاری برای تعداد توییت نرمالشده فضایی برای هر شبکه اعمال میشود، 5. ارزیابی ناهنجاری با نرخ ناهنجاری نرمال شده بر حسب فواصل زمانی انجام میشود. 6. یک نقشه ناهنجاری تجسم می شود و الگوی فضایی با Moran I آزمایش می شود.
در مرحله دوم، توییتهای یک کاربر در یک بازه زمانی یکسان و یک شبکه 1×1 کیلومتری به عنوان 1 توییت محاسبه میشود. این کار برای جلوگیری از نمایش بیش از حد یک کاربر انجام می شود. در مرحله پنجم، نرخ ناهنجاری نرمال شده (3) برای ارزیابی ناهنجاری فرموله شده است. مقادیر ناهنجاری و مورد انتظاری که توسط قسمت AnomalyDetectionVec ارائه می شود، با شاخص های timeVector (i) در این فرمول استفاده می شود و نرخ ناهنجاری نرمال شده برای هر جفت شبکه و timeVector محاسبه می شود. نقشه کلی ناهنجاری با مجموع نرخ ناهنجاری نرمال شده برای هر شبکه تولید می شود. با این مقادیر نرخ ناهنجاری نرمالشده، غیرعادیترین شبکههای فضایی ترسیم شدند و با الگوریتم موران I آزمایش شدند.
من موران معیار خودهمبستگی فضایی جهانی و محلی است. موران I جهانی و محلی برای این بخش و برای بخشهای بعدی مطالعه به منظور تعیین ناهنجاریهای مشاهدهشده، روندها و تفاوتهای زمانی، اعم از خوشهای، پراکنده یا تصادفی در فضا، استفاده میشود. بسته R “spdep” [ 54 ] برای محاسبه Moran’s I جهانی و محلی استفاده شد که (4)، (5) بر اساس مکان ویژگی و مقادیر ویژگی ها [ 55 ] فرموله شده است.
متغیرها n = تعداد ویژگی های نمایه شده با i و j ، x = مقادیر ویژگی فضایی، ایکس¯= میانگین x ، w ij = ماتریس وزن ارزش ویژگی. مقادیر Moran’s I از -1 (خودهمبستگی فضایی منفی) تا 1 (خودهمبستگی فضایی مثبت) متغیر است و مقدار 0 را برای توزیع تصادفی برمی گرداند. بسته Spdep توابع moran.test() و localmoran() را ارائه می دهد. در این مطالعه، هم برای محاسبات خودهمبستگی فضایی سراسری و هم محلی، از توابع moran.test() و localmoran () با آرگومان های زیر استفاده شد:(بردار عددی ویژگیهای ویژگی)، listw (وزنهای فضایی برای لیستهای همسایه که توسط تابع nb2listw در بسته spdep محاسبه میشود)، zero.policy (برای تخصیص مقدار صفر برای ویژگیهای بدون همسایه به عنوان TRUE مشخص شده است). مقادیر برگشتی توابع شامل آمار موران (I, I i ) و p -value آمار ( p value, Pr()) می باشد. مقدار کمتر از 0.05 برای p-value به این معنی است که این فرضیه پذیرفته شده است و از نظر مکانی برای موران I همبستگی دارد [ 54 ، 55 ]. همچنین برای تفسیر نتایج تمامی آزمونهای موران I در این مطالعه مورد توجه قرار گرفته است.
2.4. گسسته سازی داده ها و روندها
در این بخش از مطالعه، مجموعه داده روند همانطور که در شکل 6 ارائه شده است، دستکاری می شود . مراحل به شرح زیر است: 1. ناهنجاری های شناسایی شده در داده ها گسسته شدند، 2. ناهنجاری های گسسته با مقادیر مورد انتظار از نظر gridId و timeVector جایگزین شدند و به عنوان داده های معمولی اختصاص داده شدند، 3. داده ها بر اساس gridId با خلاصه tweetCount گروه بندی شدند. مقدار میانگین برای دادههای روند کلی، 4. یک نقشه روند کلی تولید و با Moran I برای تعیین الگوی فضایی مقادیر روند آزمایش شد. نقشه روند تولید شده، پویایی عمومی شهر را نشان می دهد و همچنین به عنوان مرجع به منظور کمی سازی سوگیری مکانی-زمانی در بخش بعدی استفاده می شود.
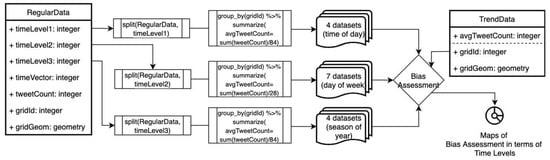
2.5. ارزیابی سوگیری مکانی-زمانی
سوگیری مکانی – زمانی بر حسب ساعت، روز و سطوح فصلی ارزیابی شد و جریان ارزیابی در شکل 7 نشان داده شد . مراحل ارزیابی به شرح زیر است: 1. داده ها از نظر سطوح زمانی به زیر مجموعه داده ها به عنوان 4 زیر مجموعه داده (شب، صبح، نیمه روز، عصر) برای timeLevel1، 7 مجموعه داده فرعی (از دوشنبه تا یکشنبه) برای timeLevel2 تقسیم شدند. 4 مجموعه داده (زمستان، بهار، تابستان، پاییز) برای timeLevel3، 2. این زیر مجموعههای داده بر اساس gridId گروهبندی شدند و به عنوان میانگین tweetCount خلاصه شدند. دادههای فرعی و دادههای روند، 4. نقشههای ارزیابی سوگیری مشاهده شد و با Moran I برای بررسی الگوی فضایی آزمایش شد.
در بخش ارزیابی سوگیری جریان، مقایسه با در نظر گرفتن میانگین تفاوت تعداد توییت ها در زیر مجموعه داده ها و داده های روند انجام شد. این تفاوت در ارزش در پنج کلاس ترسیم شد. دو کلاس (کم، کمتر) برای مقادیر منفی، یک کلاس روند برای مقادیر 0، دو کلاس (بیشتر، زیاد) برای مقادیر مثبت. این مقادیر با Moran I برای تعیین کمیت همبستگی فضایی مقادیر مورد آزمایش قرار گرفتند.
3. نتایج
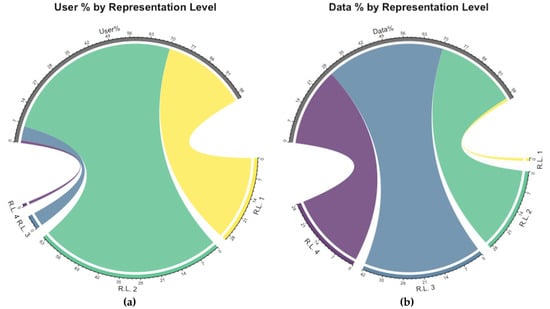
دادههای جمعآوریشده و نمونهبرداری شده برای این مطالعه بیش از 4 میلیون توییت ایجاد شده توسط نزدیک به 76 هزار داوطلب را پوشش میدهد. فعال ترین داوطلب دارای 4378 توییت است، در حالی که یک سوم از همه داوطلبان فقط یک توییت در کل داده ها دارند. میانگین تعداد توییت برای هر کاربر 54 با انحراف معیار 186 است. این نشان می دهد که فعالیت داوطلبان از هم گسیخته است و فعال ترین گروه به شدت بیش از حد حضور دارند. این شرایط مستلزم بررسی دقیق است تا بفهمیم آیا این گروه ها به دلیل موقعیت های غیرعادی فعال تر هستند یا به عنوان رفتار عمومی آنها. به عنوان گام اولیه برای کاوش داده ها، سطوح فعالیت کاربر بسته به روش خوشه بندی k-means به جای استفاده از مقادیر حداقل، میانگین و انحراف استاندارد اعداد توییت کاربر همانطور که در روش توضیح داده شده است، طبقه بندی می شود. با توجه به این، سطوح نمایندگی کاربران (RL ) به عنوان یک (1)، نمایش سطح دوم (2)، سطح سوم (3) و سطح چهارم (4) به عنوان بالاترین کلاس فعال طبقه بندی می شوند. درصد کاربران در هر سطح نمایش (الف) و درصد مقادیر توییت مربوط به سطوح نمایندگی کاربران (ب) در زیر نشان داده شده است.شکل 8 به عنوان نمودار وتر. نمودارهای موجود، تقریباً 90٪ از کاربران خود را یک بار یا کمتر از 262 بار نشان می دهند، درست برعکس کل نمایش آنها در داده ها برابر با کمتر از 30٪ است. این تحلیل اولیه واقعیت را در سطوح مختلف بازنمایی کاربران آشکار می کند و این تنوع به سوگیری بازنمایی اشاره می کند. بسیاری از مطالعات در ادبیات، دادههایی را که از گروههایی که بیش از حد نشان داده شدهاند، حذف میکنند تا نابرابری بازنمایی را کاهش دهند، اما همچنین باعث میشوند که بخش بزرگی از دادهها به این طریق پنهان شوند.
تعداد کل توییتهای متعلق به هر کاربر به ترسیم نمای کلی از نمایندگی کاربران کمک میکند. با این حال، این ممکن است بدون در نظر گرفتن تغییرات زمانی اشتباه تفسیر شود. بازنمایی بالای یک کاربر ممکن است نشاندهندهی نمایش بیش از حد بهطور منظم اضافهکاری یا وضعیت خاصی باشد که فقط برای یک دوره زمانی اهمیت بیشتری دارد. به عبارت دیگر، برخی از کاربران خود را بیش از حد نشان می دهند در حالی که این نمایش را در یک بازه زمانی محدود انجام می دهند، اما در بقیه زمان ها کمتر ارائه می شوند. با توجه به آن، بازنمایی در بین کاربران متفاوت است، به همین ترتیب، به دلیل شرایط مختلف فصلی (تابستان یا زمستان)، شرایط اضطراری (فاجعه طبیعی، حملات تروریستی)، سیاست (انتخابات، رفراندوم) به طور موقت برای کاربر متفاوت است.
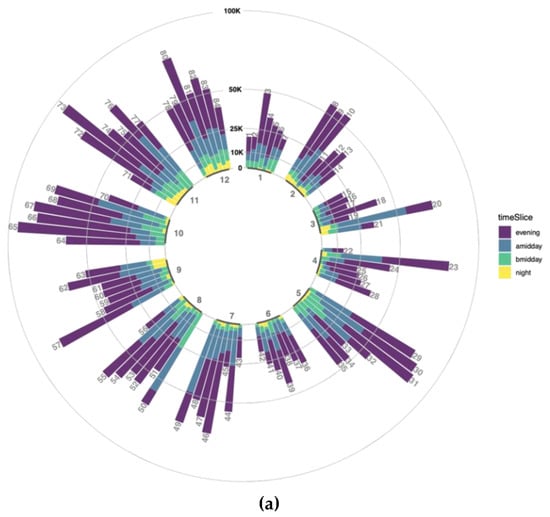
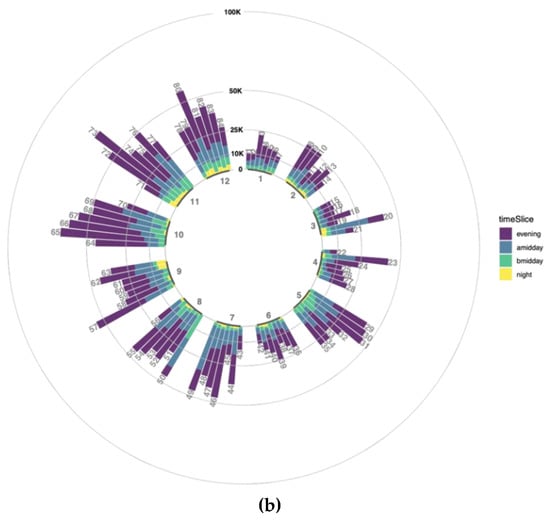
به منظور کاوش تعدادی توییت در هر سطح زمانی در یک دست، یک طرح نوار دایره ای ترکیب شده است. این یک نمای کلی تغییرات زمانی داده های مرتب با برخی توهمات ناشی از نابرابری در نمایش های کاربر/ربات را ارائه می دهد. هر نوار در نمودار اندازه داده های روزانه را با توجه به برش های زمانی انباشته شده در روز نشان می دهد همانطور که در بخش روش شناسی توضیح داده شده است. داده های بدون هیچ وزنی با در نظر گرفتن نمایش و نرمال سازی کاربر در شکل 9 نشان داده شده استآ. با توجه به آن، تولید داده در طول یک بازه زمانی شبانه بسیار کم است یا تقریباً برای برخی روزها وجود ندارد، نه به دلیل خرابی سیستم بلکه به دلایل زمانی. بیشترین تعداد توییت تقریباً هر روز در زمان عصر تولید می شود، اگرچه برای برخی از روزها مانند 20، 49، 50 به صراحت کمتر از بعد از ظهر است ( شکل 9 a).
ممکن است در حین ارزیابی تعداد توییتها در برشهای زمانی به دلیل سطوح مختلف نمایش کاربران، چندین تفسیر نادرست وجود داشته باشد. برای جلوگیری از این امر، تعداد توییتها تا سطح زمانی 1 با تخصیص وزن به هر کاربر عادی میشود. با توجه به این عادی سازی، تعداد توییت ها برای هر برش بار با در نظر گرفتن مجموع تعداد توییت های هر کاربر ضرب در وزن کاربر آن دوباره محاسبه می شود. داده های نرمال شده در شکل 9 ب مشابه شکل 9 الف نمایش داده شده است . بدیهی است که تعداد توییتها برای همه نوارها کاهش مییابد و کاهش بیشتر نسبت به اعداد قبلی به این معنی است که سطح نمایش بیش از حد بالاتر برای برشهای زمانی عادی شده است.
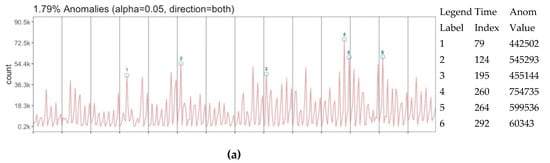
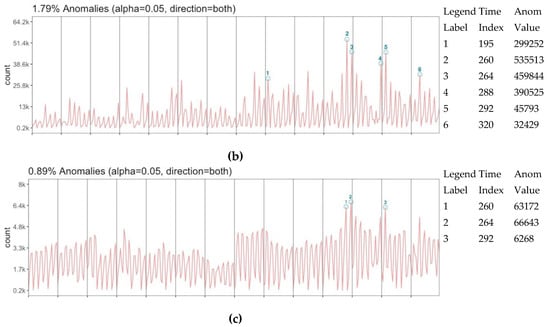
تنوع در سطح نمایش ممکن است عدم قطعیت در تعداد دادهها ایجاد کند و مستلزم این سؤال است که آیا دادهها روندی برای استنتاج بیشتر بسته به آن دارند یا خیر. در این دیدگاه کلی بدون هیچ بعد مبتنی بر مکان، داده ها با الگوریتم تشخیص ناهنجاری ارزیابی می شوند تا هر گونه فعالیت روند را استخراج کنند. سه ارزیابی ناهنجاری بر روی تعداد توییتها (a)، تعداد کاربران (b) و تعداد توییتهای عادی (c) انجام میشود ( شکل 10 ).) با توجه به بردار زمان. در حالی که تعداد توییت و تعداد کاربران دارای 6 برش ناهنجاری است که 4 مورد از آنها با یکدیگر مطابقت دارند، تعداد عادی دارای 3 برش ناهنجاری است که همگی با ناهنجاری های توییت و تعداد کاربران مشترک هستند. با توجه به این تطابق ها، تنوع در بازنمایی سه ناهنجاری بیشتر از بازنمایی نرمال شده ایجاد می کند. با این حال، برش های ناهنجاری تطبیق 195 بین توییت و تعداد کاربران نیز قابل توجه است، حتی اگر در ناهنجاری تعداد عادی نباشد. مقادیر ناهنجاری در داده های کلی به ترتیب 1.79٪، 1.79٪ و 0.89٪ تشخیص داده شده است. این می تواند تفسیر شود که داده ها دارای روندهای قوی برای ارزیابی 24 برش زمانی دوره ای هستند.
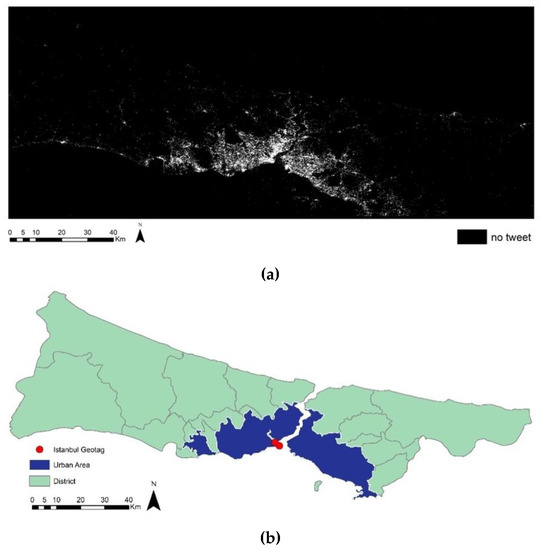
علاوه بر سطوح مختلف بازنمایی کاربران، بازنمایی فضایی جنبه دیگری برای درک داده ها است. جعبه مرزی استانبول به شبکه های 100 متر × 100 متر تقسیم می شود تا این نمایش به صورت نمایش داده شده و شبکه های “بازنمایی نشده” به عنوان داده های از دست رفته تجسم شود. شکل و نقشه زمین ( شکل 11 الف) داده های از دست رفته کاملاً با شکل شهر مطابقت دارد ( شکل 11 ب). این تطابق را می توان به عنوان توییتر یک ابزار بیونیک زنده برای استانبول دانست که کم و بیش نمایانگر منطقه زندگی شهر است.
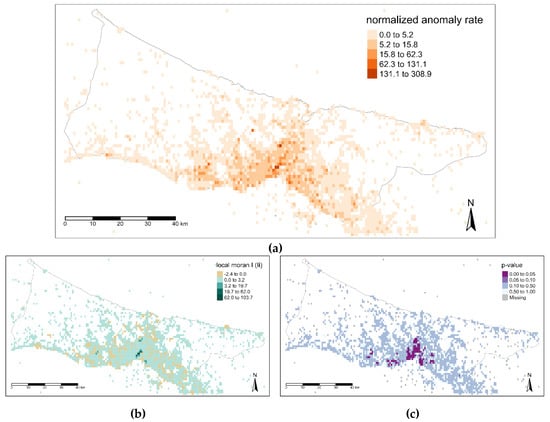
یک سیستم مانیتورینگ مبتنی بر شبکه به منظور درک ردپای فضایی کاربران طراحی شده است. اندازه شبکه 1 کیلومتر × 1 کیلومتر تعیین می شود زیرا برای تشخیص رویدادهای ریز دانه کافی است. تعداد توییتها مطابق با شبکهها از نظر مکانی-زمانی عادی شده است. به منظور کشف پویایی فضایی استانبول، تجزیه و تحلیل ناهنجاری برای هر شبکه بر روی مقادیر شمارش توییت نرمال شده فضایی به عنوان بردار زمان با 336 برش انجام میشود. هر مقدار ناهنجاری شناسایی شده برای یک شبکه با مقدار ناهنجاری کلی شناسایی شده در بازه زمانی آن نرمال می شود. به این ترتیب، اندازه ناهنجاری شناسایی شده برای یک شبکه با توجه به ناهنجاری کلی محاسبه می شود. نرخ ناهنجاری نرمال شده در هر شبکه با اضافه کردن تمام بزرگی های ناهنجاری برای یک شبکه محاسبه شد و در شکل 12 مشاهده شد.. این مکانهایی را نشان میدهد که به احتمال زیاد در آن ناهنجاری در شهر وجود دارد. علاوه بر این، این نقشه گرایش ناهنجاری با الگوریتم همبستگی فضایی موران I جهانی و محلی مورد آزمایش قرار گرفت. نمره جهانی I و مقدار p به ترتیب 0.24 و کمتر از 0.0001 بود، که به این معنی است که مقادیر کمی همبستگی مثبت داشتند و اهمیت آزمون بسیار بالا است. به منظور ارزیابی همبستگی فضایی مثبت و منفی، نقشه گرایش ناهنجاری نیز با موران I محلی مورد آزمایش قرار گرفت. از شکل 12 الف به نظر می رسد، نرخ ناهنجاری بالایی در بخش مرکزی استانبول وجود دارد، آزمون موران محلی تأیید می کند که وجود دارد. خود همبستگی فضایی مثبت با Ii مثبت بالا ( شکل 12 ب) و p پایین-value ( شکل 12 ج) در این ناحیه.
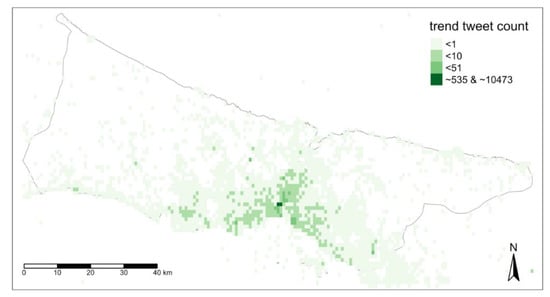
به منظور درک پویایی کلی شهر، داده ها از ناهنجاری های آن که قبلا شناسایی شده بودند، گسسته شدند. مقادیر غیرعادی با مقادیر مورد انتظار برای بخش مرتبط از داده ها جایگزین شدند. در شکل 13 ، مقدار متوسط این داده روند بازیابی شده در 4 کلاس نشان داده شده است. کلاس اول شامل دو شبکه فعال است که میانگین 535 و 10473 برای 6 ساعت دارند. این نقاط پرت هستند و نزدیکترین مقدار به نقاط پرت تقریباً 50 توییت میانگین در سطح زمانی تعریف شده است. دو دلیل اصلی در پشت این پرت ها وجود دارد. اول، برچسبهای جغرافیایی استانبول پلتفرمهای رسانههای اجتماعی ( شکل 11 ب) در این شبکهها قرار دارند. دوم، نقاط در منطقه مرکزی استانبول واقع شده است ( شکل 11ب) جایی که شهر قدیمی و جاذبه های گردشگری متراکم است. شبکه های طبقه دوم و سوم بر اساس فعالیت خود تقریباً 10 درصد دیگر شبکه ها را در اختیار دارند. منطقه تحت پوشش با طبقه دوم و سوم با منطقه شهری استانبول مطابقت دارد. این شبکههای سبز تیرهتر، سوگیری مکان مرکزی دادهها را برای عبارات کلی نشان میدهند، اما همچنین فرصت نظارت بر آنها را با ظرفیت بالاتر نمایش کاربران میدهند. آخرین کلاسی که نزدیک به 90 درصد شبکههای فضایی را پوشش میدهد، کمتر از 1 توییت میانگین در بازه زمانی 6 ساعته را شامل میشود. این پایینترین طبقه فعال عمدتاً مناطق مسکونی، بخشهای روستایی و کنار دریا را شامل میشود. در حالی که تصور میشود فعالیتهای کلی در مناطق تاریکتر به راحتی از محتوای توییت استنباط میشوند، پایینترین ناحیه فعال را میتوان به راحتی در صورت وقوع رویدادهای خارقالعاده مشاهده کرد.
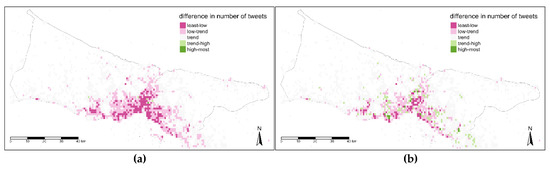
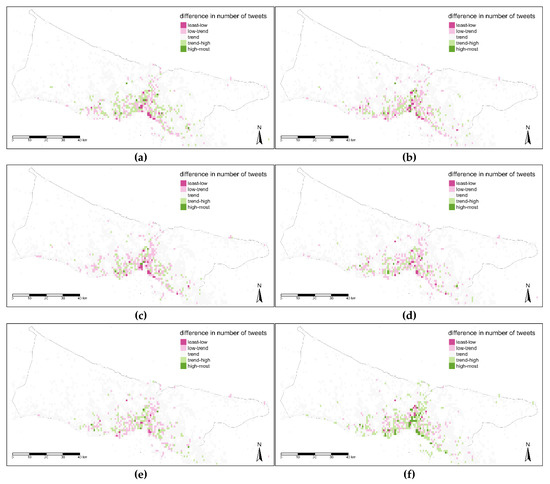
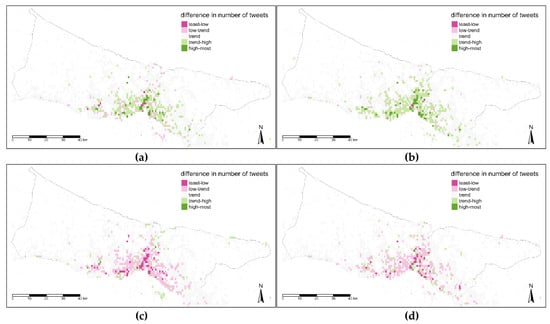
زمان جنبه دیگری برای بررسی جزئیات داده های مکانی است و ردپای شهروندان ممکن است از نظر سطوح زمانی مختلف متفاوت باشد. بنابراین، مقایسه بین نقشه روند و نقشه های متعلق به سطوح زمانی مختلف در سه سطح زمانی بررسی شد. مقادیر تفاوت با پنج کلاس تعریف شده است که زیر روند (کمترین-پایین، کم روند)، روند، بالاتر از روند (روند-بالا، بیشترین میزان) هستند. مقادیر اختلاف دارای اعداد مثبت و منفی هستند، علاوه بر این، به استثنای معدود مقادیر در این نقشه ها تفاوت چندانی ندارند. با توجه به این، مقادیر آستانه برای این کلاسها پس از بررسی دادهها با چندین تکنیک طبقهبندی خودکار (مانند چندک، مساوی، انحراف استاندارد، کیلومتر و غیره) به صورت دستی تعیین شد. در شکل 14، نقشه شب (a) دارای مقادیر کمتری نسبت به نقشه روند در قسمت های مرکزی است در حالی که بخش های حاشیه ای مناطق شهری دارای مقادیر نزدیک به روند هستند. تفاوت در نقشه دوم (ب) تنوع بیشتری دارد و در برخی مناطق پراکنده مقدار آن بیشتر از روند است. در نقشه سوم برای بعد از ظهر (c) و نقشه چهارم برای زمان عصر (d)، این تفاوت معکوس شد زیرا مقادیر تقریباً در تمام نقاط شهر بالاتر هستند اما در منطقه مرکزی استانبول متراکم هستند ( شکل 14 a) .
برای سطح زمانی دوم، روزهای هفته در نظر گرفته شد. به صراحت مشاهده می شود، نقشه های روزهای هفته (a, b, c, d, e) بسیار شبیه به یکدیگر هستند در حالی که روزهای آخر هفته (f, g) جدا از آنها با نقاطی که ارزش بیشتری در نزدیکی تنگه استانبول و در امتداد دریا دارند. شکل 15 ). بر اساس نقشه این روز هفته، هیچ ارزش خوشهای مستقیمی برای یک منطقه وجود ندارد و مناطق مرکزی ترکیبی از کلاسهای بالاتر و پایینتر از مقادیر روند هستند. بیشترین قسمت متعلق به طبقاتی است که کمتر از روند روزهای هفته هستند، در حالی که بیشتر و به طور خاص قسمت های مرکزی و ساحلی دارای ارزش بالاتری نسبت به روندهای آخر هفته هستند.
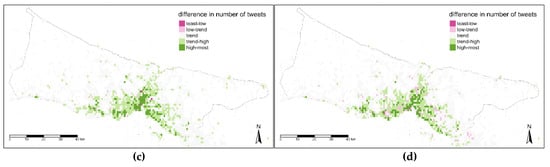
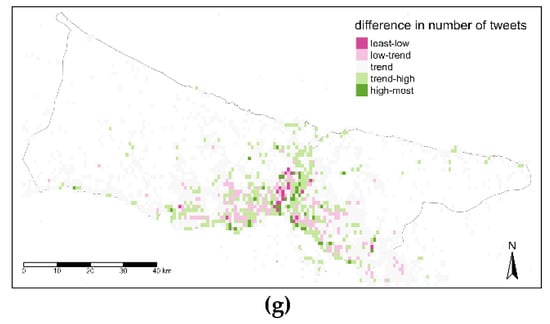
در ارزیابی سطح زمانی سوم، فصول سال نقشه برداری شد ( شکل 16 ). منطقه مرکزی در فصول زمستان و بهار دارای لکه های با ارزش بالایی است در حالی که این ناحیه در فصول تابستان و پاییز ارزش کمتری دارد ( شکل 16 ). این قطعات فصلی منعکس کننده یک طبقه برای تمام نقاط شهر هستند که در فصل زمستان و بهار بالاتر از روند و برای تابستان و پاییز پایین ترند.
Global Moran’s I برای آزمایش همبستگی فضایی مقادیر نقشه های مقایسه ای اتخاذ شد. اگرچه مقدار I بین 0.1- و 0.1 برای هر نقشه تغییر می کند و مقادیر p بالای 0.1 است، نمی توان گفت که واریانس زمانی از نظر مکانی همبستگی خودکار دارد. این بدان معناست که هیچ تفاوت معنیداری بین مقادیر اختلاف از نظر مکانی وجود ندارد، اگرچه تفاوت مشخصی بین نقشههای روند و سطح زمانی وجود دارد، همانطور که در شکل 14 ، شکل 15 و شکل 16 مشاهده میشود .
4. بحث
رسانههای اجتماعی منبع ارزشمندی از دادهها هستند که توسط حسگرهای انسانی به دلیل توانایی و تداوم حسی عظیم آن تولید میشوند [ 56 ، 57 ]. اگرچه دارای انواع مختلفی از حسابداران است [ 58 ]، محتوا و فعالیت فضایی هر یک از آنها نیز متفاوت است [ 59 ]. تحقیقاتی وجود دارد که اطلاعات پسزمینهای برای توضیح فعالیتهای کاربران در رسانههای اجتماعی و دستهبندی آنها ارائه میکند [ 41 ، 60 ]. و برخی تحقیقات در مورد اعتبار کاربران [ 61 ، 62 ] و برخی دیگر تلاش می کنند تا کاربران هماهنگی را که با هم رفتار می کنند و محتوای داده ها را دستکاری می کنند، تعیین کنند [ 63 ]]. و مطالعات ادعا میکنند که رسانههای اجتماعی مملو از شایعات هستند و اکثر صاحبان حسابها اطلاعات غلط را در مواقع اضطراری منتشر میکنند و حتی اگر بعداً مطلع شوند، محتوا را اصلاح نمیکنند [ 64 , 65 ]]. با توجه به این موضوع، دادههای رسانههای اجتماعی باید بدون حذف دادهها، اما با پذیرش همه این کاستیها و در نظر گرفتن آنها با ماهیت خود، ارزیابی شوند، زیرا کنترل اعتبار هر کاربر در زمان واقعی بدون دادههای تاریخی یا اطلاعات جمعیتی امکانپذیر نیست. . اگرچه داده ها شامل چندین موضوع مانند اعتبار، شایعات، نابرابری های بازنمایی از نظر کاربر است، اما دارای یک الگوی مرجع برای ارزیابی سیستم های نظارتی است. این مطالعه ردپای عمومی شهروندان، به احتمال زیاد نقشههای ناهنجاری منطقهای و سوگیریهای مکانی-زمانی در استانبول را ارزیابی و ارائه کرد. این استنباط ها به عنوان نقشه های مرجع، سهولت تفسیر را برای نظارت بر شهر فراهم می کنند.
این مطالعه SMD یک ساله را با روش ارائه شده در بخش 2.1 ارزیابی می کند. از دادههای نشاندادهشده در این مطالعه متوجه شدیم که برای بررسی تغییر مکانی-زمانی در SMD، تفاوت در سطوح نمایش کاربران باید نرمال شود. برای کاوش فضایی، از نمایش های متفرقه کاربران با تکنیک عادی سازی مکانی-زمانی اجتناب می شود. ناهنجاری هایی که ممکن است داده ها به دلیل یک رویداد غیرمعمول یا فعالیت هماهنگ شده کاربران داشته باشند، شناسایی شده و با مقدار مورد انتظار جایگزین می شوند. مکان هایی که تمایل به تعداد ناهنجاری بیشتری دارند به عنوان نقاط مغرضانه مکان تعیین می شوند. و هنجار داده بیشترین مکانها را توسط دارندگان حساب بیشتر نشان میدهد. علاوه بر این، هنجار داده به عنوان مرجع برای کشف سوگیری های مکانی-زمانی استفاده می شود. بدیهی است که داده ها دارای چندین نوع سوگیری هستند و داده های ارزیابی شده می توانند به عنوان مرجعی برای تشخیص هرگونه نابهنجاری مورد استفاده قرار گیرند.
نتایج این مطالعه را می توان با دانه بندی فضایی ریزتر برای نظارت مبتنی بر شبکه و دانه بندی زمان ریزتر به جای 6 ساعت در ساعت افزایش داد. همچنین میتوان با انجام چندین تحلیل متنی، مطالعات بیشتری را بر روی محتوای دادهها توسعه داد تا بیشترین کلمه را در شبکه پیدا کرد و از این طریق به نقشه مرجع کمک کرد.
استانبول پرجمعیت ترین شهر ترکیه با بیش از 15 میلیون شهروند [ 66 ] و 3 میلیون بازدید کننده است که این امر باعث می شود این شهر به دلیل استانداردهای زندگی و همچنین مدیریت پاسخگوی اضطراری نظارت شود. چندین پروژه شهر هوشمند جداگانه توسط مقامات محلی انجام شده است. با این حال، این پروژه ها با دیجیتالی کردن نقشه پایه یا برخی از فرآیندهای کاغذی شهرداری محدود می شوند. از آنجایی که شهروندان ترکیه دارای پتانسیل بالایی برای تولید داده های مکانی در توییتر در مقایسه با بسیاری از کشورها هستند، توییتر برای پروژه های مبتنی بر شهروندی در استانبول واجد شرایط است [ 41 ]. در مطالعات بیشتر، دادههای ارزیابی شده در این مطالعه، دانش معیار را برای ایجاد یک سیستم نظارت پویا برای استانبول فراهم میکند.
این مطالعه چهار پیامد را که در زیر ذکر شده است نشان داد. اولین نتیجه نشان میدهد که کاربران بسیار فعال اکثر دادهها را تولید میکنند و به عنوان یک رویکرد کلی، حذف این دادهها در یک فرآیند شبه پاکسازی، حجم زیادی از دادهها را پنهان میکند. مورد دوم تغییرات نتایج ناهنجاری ناشی از سطوح نمایندگی متنوع کاربران است. به همین دلیل است؛ نرمال سازی داده ها از نظر سطوح نمایش نقش مهمی در تشخیص ناهنجاری واقعی دارد. نتیجه سوم نشان می دهد که همانطور که در شکل 12 نشان داده شده استالف، داده های نرمال شده از نظر مکانی-زمانی نشان دهنده گرایش ناهنجاری فضایی قوی در مرکز شهری است. آخرین نتیجه نشان میدهد که دادههای روند در مرکز شهری متراکم است و ارزیابیهای سوگیری مکانی-زمانی نشان میدهد که چگالی دادهها برحسب زمان روز، روز هفته و فصل سال متفاوت است.
Twitter API در این مطالعه همانطور که معمولاً برای سایر مطالعات دانشگاهی استفاده می شود استفاده می شود. توییتر اعلام می کند که این API به صورت تصادفی 1٪ از توییت های عمومی را در زمان واقعی ارائه می دهد [ 67 ]. تحقیقات تجربی وجود دارد که این تصادفیسازی را با مقایسه این مقدار نمونهگیری شده با دادههای API Firehose که کل توییتهای عمومی را ارائه میکند، آزمایش میکند [ 68 , 69]. مطالعات نشان دادند که هیچ نشانه قابل توجهی وجود ندارد که نمونه برداری از API توییتر مغرضانه است، به استثنای یک استثنا، زیرا توییتر توییت ها را با اختصاص شناسه برای هر توییت با توجه به زمان میلی ثانیه ای تصادفی کرد. زیرا، این تصادفیسازی قابل قبول است، زیرا برخلاف رباتها، از توانایی افراد برای اشتراکگذاری توییتها با این سرعت فراتر میرود. دادههای مورد استفاده در این مطالعه هم بهصورت مکانی و هم غیرمکانی نرمالسازی میشوند تا از سوگیری نمایشی جلوگیری شود که میتواند نویز ناشی از حسابهای ربات را نیز حذف کند.
در این مطالعه از PostgreSQL با پسوند PostGIS برای مدیریت داده ها استفاده شده است. PostgreSQL یک سیستم مدیریت پایگاه داده رابطه ای منبع باز (RDBMS) است که می تواند در محیط های مختلف مانند دسکتاپ، ابر یا پایگاه داده محیط ترکیبی مستقر شود. ظرفیت ذخیره سازی و هزینه زمانی فرآیندها به مشخصات محیط بستگی دارد. این پایگاه داده رابطهای برای مدیریت حجم زیادی از دادهها برای عملیات اساسی (مانند درج، انتخاب و بهروزرسانی) مانند این مطالعه کافی است، اما نمیتواند بهترین گزینه برای معاملات مطالعات کلان داده باشد [ 70 ]]. پایگاه داده NoSQL مانند MongoDB عملکردی را در عملکرد پردازش داده های بزرگ به ویژه آنهایی که بر روی داده های بدون ساختار انجام می شود، افزایش داده است. SMD دارای محتوای بدون ساختار است و RDBMS در هنگام ساختاردهی حجم زیادی از داده ها دارای مشکلاتی است. به همین دلیل، NoSQL باید هنگام پردازش مقدار زیادی از متن بدون ساختار SMD ترجیح داده شود [ 70 ، 71 ]. این کار همچنین برنامه ریزی شده است تا با داده های شهرهای دیگر از جمله متن کاوی در زمینه فضا-زمان و تحلیل های زمانی دقیق تر گسترش یابد. بنابراین، در مطالعات بیشتر یک سیستم مدیریت پایگاه داده NoSQL برای مدیریت چنین داده هایی در نظر گرفته خواهد شد.
مطالعات متعددی وجود دارد که معیارهای کیفیت داده ها را در زمینه VGI مفهوم سازی می کند [ 72 ، 73 ]. مطالعات کیفیت داده در VGI عمدتاً به معیارهای کیفیت دادهها مانند: کامل بودن، دقت موقعیت و دانه بندی در نقشه خیابان باز [ 11 ، 73 ، 74 ]. به طور کلی رویکردهای کیفیت داده ها در دو دسته درونی و بیرونی ارزیابی می شوند. در ارزیابی درونی، برخلاف ارزیابی کیفیت داده های بیرونی، از نقشه مرجع خارجی استفاده نمی شود [ 75 ]]. SMD در چندین جنبه در این مطالعه به منظور درک سوگیری داده ها، ناهنجاری ها و روندها مورد ارزیابی قرار گرفت. از آنجایی که در این مطالعه استفاده از داده های خارجی برای این ارزیابی ها وجود ندارد، این مطالعه روشی را برای ارزیابی کیفیت داده های ذاتی SMD ارائه می دهد.
روش پیشنهادی در این مطالعه میتواند برای استخراج روالهای روزانه بیطرفانه دادههای رسانههای اجتماعی مناطق برای روزهای عادی استفاده شود و این میتواند برای موارد اضطراری یا رویدادهای غیرمنتظره برای تشخیص تغییر یا تأثیرات ارجاع شود. ارزیابی دادهها در این مطالعه بر اساس آشکار کردن ردپای شهروندان در SM است و برای کشف ناهنجاریها، روندها و سوگیری در دادهها طراحی شده است.
در مطالعات بیشتر، استنباط از این مطالعه برای عملکرد یک سیستم نظارت مبتنی بر شهروندی برای استانبول استفاده خواهد شد. طراحی سیستم از نظر مفهومی مراحل را دنبال خواهد کرد. توییتها در زمان واقعی جمعآوری میشوند، تعدادی توییت از کاربران مجزا برای هر شبکه فضایی محاسبه میشود، تعداد عادی توییتها با الگوریتم تشخیص ناهنجاری با خط رگرسیون روی دادههای روند ارزیابی میشوند، ناهنجاریهای شناساییشده با محتملترین منطقهای ارزیابی میشوند. نقشه های ناهنجاری و تصمیم گیری برای شرایط اضطراری گرفته می شود. علاوه بر این، روش پیشنهادی برای کار در شهرهای بزرگ دیگر برنامه ریزی شده است تا با ارائه نتایج (نقشه های مرجع) در یک صفحه وب طراحی شده برای پروژه های آینده ما به سایر محققان کمک کند.





بدون دیدگاه