

جایی که خیابان ها نامی ندارند احتمالاً مکان ترجیحی برای OpenStreetMapper داوطلب است. پروژه نقشه خیابان باز که در سال 2004 راه اندازی شد، با هدف به اشتراک گذاری داده های جغرافیایی بر اساس نقشه برداری داوطلبانه انجام شد و منجر به جمع آوری داده های جغرافیایی تقریباً از همه کشورهای جهان در عرض پانزده سال شد. افزایش انتشار داده های نقشه برداری از طریق اینترنت در زندگی واقعی و اجتماعی مفید بوده و منجر به افزایش سریع تعداد اسناد منتشر شده شده است. برای ارزیابی تأثیر نقشهبرداری داوطلبانه بر تحقیقات علمی، یک رویکرد نقشهبرداری علمی بر روی متون منتشر شده در پروژه نقشه خیابان باز بر اساس تحلیلهای همروندی و استنادی استفاده شد که نشان داد مضامین اصلی (شبکه مفهومی) از نظر فنی مرتبط بودند، همکاری بین محققان و مؤسسات (شبکه اجتماعی) قوی نبود و دانش و ایده ها در یک شبکه محدود پخش می شد. در این مطالعه، اسناد منتشر شده توسط OpenStreetMappers برای اولین بار مورد تجزیه و تحلیل قرار گرفت. بنابراین، میتوان شکافهای موجود در نقشهبرداری داوطلبانه را برجسته کرد و در مورد پیشرفتهای بیشتر در پروژه نقشه خیابان باز بحث کرد.
کلید واژه ها:
باز کردن نقشه خیابان ؛ کتاب سنجی ; ساختار اجتماعی ؛ کارتوگرافی کاربردی ; تاثیر علمی
1. مقدمه
هنگامی که پروژه OpenStreetMap در سال 2004 آغاز شد، احتمالاً غیرمنتظره بود که چنین حمایت سریع و وفادار توسط نقشهنگاران داوطلب برای پوشش دادههای جغرافیایی در سراسر جهان انجام شود.
OpenStreetMap (از این پس OSM) پروژه ای است که در سال 2004 با هدف به اشتراک گذاری داده های جغرافیایی از طریق نقشه برداری داوطلبانه به منظور تولید محصولات نقشه برداری شامل نقشه ها [ 1 ] تاسیس شد.
در سال 2009، پنج سال پس از آغاز پروژه، جمعآوری دادهها احتمالاً از دو مرکز انتشار نقشهبرداران داوطلب از اروپا و آمریکای شمالی شروع به گسترش کرد ( شکل S1 را ببینید )، اما تعهد به پروژه قبلاً در سراسر جهان گسترش یافته بود. پس از ده سال، تقریباً تمام قاره ها و جزایر جهان در پایگاه داده OSM با شکاف های قابل توجه و قابل درک در گرینلند و مناطق نزدیک به قطب شمال (به عنوان مثال، شمال کانادا و سیبری)، صحرای صحرا و هسته اصلی نقشه برداری شدند. آمازوناس پس از بیش از پانزده سال، حجم عظیمی از داده ها به طور داوطلبانه کارتوگرافی شدند ( شکل S2 را ببینید )، حتی اگر شکاف های اصلی در عرض های جغرافیایی شمالی همچنان باقی بماند. مجموع تجمعی اطلاعات جغرافیایی داوطلبانه [ 2] عمدتاً بر اروپا متمرکز بود، با چندین نقطه داغ در نپال، اندونزی، ژاپن، جمهوری کنگو آفریقای مرکزی، کالیفرنیا و ساحل غربی ایالات متحده. این نقاط داغ، به غیر از اروپا و ایالات متحده، نقاطی هستند که تحت تأثیر شرایط اضطراری زیست محیطی یا بهداشتی قرار دارند، به عنوان مثال، زلزله در نپال و ژاپن و ابولا در آفریقا، که به لطف استفاده از داده های OSM برای مقابله با مسائل بشردوستانه توسط سازمان بشردوستانه نقشه برداری شده است. ابتکار تیم OpenStreetMap (HOT؛ https://www.hotosm.org/ ).
کارتوگرافی داوطلبانه در OSM مکان ایده آلی پیدا کرد، زیرا بر اساس مشارکت تعداد فزاینده ای از نقشه کشان حرفه ای و همچنین مبتدی است که داده های جغرافیایی را جمع آوری کرده و تحت فلسفه منبع باز در دسترس قرار می دهند. واقعیت زمین با تفسیر بصری تصاویر ماهوارهای با دسترسی آزاد، بررسیهای میدانی و واردات انبوه به نقشهها تبدیل میشود. بنابراین، دقت و قابلیت اطمینان به وضوح تصویر و زمان به دست آوردن آن، و همچنین مهارت نقشهبردار بستگی دارد (نگاه کنید به [ 3 ]] برای بررسی). سپس، سازگاری دادههای معرفیشده میتواند توسط نقشهنگاران داوطلب دیگر یا با تأیید مستقیم روی زمین توسط کسانی که اولین بار آن را معرفی کردهاند، تأیید شود. در اولین سالهایی که OSM دادههای جغرافیایی را از تقریباً تمام سرزمینهای سراسر جهان جمعآوری میکرد، تمرکز بیشتری در کشورهای بسیار صنعتی وجود داشت، شاید به دلیل ارتباط یا همکاری بهتر بین محققان یا هر دو.
با توجه به گسترش موفقیت آمیز ابتکار OSM، می توان انتظار داشت که با انتشارات منظم در مجلات علمی مرتبط باشد. بنابراین، هدف مقاله حاضر ارزیابی مسیر علمی، از نظر مقالات منتشر شده، کارتوگرافی داوطلبانه در OSM برای تعیین اینکه آیا نتیجه فعالیتهای OSM عمدتاً به کار ذخیرهسازی دادههای جغرافیایی محدود میشود (پس، اسناد عمومی کمی مورد انتظار است). ) یا اگر با فعالیت انتشار اسناد منسجم همراه باشد. سؤالات اصلی عبارتند از: بر اساس داده های کتاب سنجی: (1) چه تعداد و چه نوع مقاله منتشر شده است؟ (ii) آیا موضوعات ترجیحی در نشریات وجود دارد؟ (iii) آیا می توان شبکه ای از محققان را پیدا کرد که روی داده های OSM همکاری می کنند؟
2. مواد و روشها
پیروی از این فرضیه که ابتکار OSM با انتشار منظم در مجلات علمی مرتبط است به این معنی است که اسناد منتشر شده منعکس کننده تأثیر داده های جغرافیایی ثبت شده توسط OSM بر جامعه علمی است. بنابراین، تجزیه و تحلیل کتاب سنجی ابزار مفیدی برای ارزیابی مسیر علمی نقشه برداری داوطلبانه در ابتکار OSM است، زیرا بر اساس سوابق کتابشناختی است. یک رکورد کتابشناختی برای هر سند منتشر شده به عنوان مجموعه ای از اطلاعات ذخیره شده در چندین زمینه برای توصیف یک سند با جزئیات کافی تولید می شود [ 4 ، 5 ]. پس از چهار زمینه اجباری بیان شده توسط Panizzi [ 6]، ساختار یک رکورد کتابشناختی، به عنوان مثال، به فیلد 31 گانه اسکوپوس رسید، که در آن بیشترین معنا برای تحلیل حاضر، به جز عنوان، چکیده و کلمات کلیدی، فیلدهای نویسنده، وابستگی و ملیت هستند. همین فیلدها را می توان از پایگاه داده Clarivate Web of Science (WoS) استخراج کرد.
از Scopus و WoS برای تحقیق حاضر استفاده شد، زیرا آنها دو پایگاه داده هستند که کاملاً همپوشانی ندارند و با قدرت نسبی آنها از نظر اطلاعات ارائه شده توسط رکوردهای کتابشناختی و پوشش موضوعی گسترده اسناد منتشر شده مشخص می شود. سرویس بازیابی رایگان Google Scholar در حال رشد برای متون علمی احتمالاً اسناد نمایه شده بیشتری را ارائه می دهد، اما آنها با سوابق کتابشناختی حاوی اطلاعات محدودی همراه هستند که برای تحقیق حاضر مناسب نیستند ( برای بررسی انتقادی به [ 7 ] مراجعه کنید).
تجزیه و تحلیل کتابسنجی مجموعهای از پیشینههای کتابشناختی به برجسته کردن ویژگیهای موضوعی مشخصکننده ادبیات منتشر شده بر اساس کلماتی که در اسناد وجود دارند و همچنین حضور یک شبکه اجتماعی از محققان متمرکز بر اطلاعات جغرافیایی داوطلبانه از طریق نویسندگی اسناد کمک میکند. [ 7 ] (همچنین به [ 8 ، 9 ] مراجعه کنید).
مجموعه داده کتابشناختی تحلیل شده در پژوهش حاضر با سوابق کتابشناختی پایگاههای اطلاعاتی Scopus ( www.scopus.com ) و WoS ( www.webofscience.com ) با استخراج رکوردها بر اساس عبارت بولی «OpenStreetMap OR Open Street» ساخته شده است. نقشه» موجود در فیلدهای «عنوان یا چکیده یا کلمات کلیدی» که تا دسامبر 2021 منتشر شده است.
مجموعه داده کتابشناختی توسط کتابخانه R “bibliometrix” [ 7 ، 10 ] تجزیه و تحلیل شد. برای هر سند، رکورد کامل کتابشناختی دانلود شد. سپس، یک بررسی مضاعف برای موارد تکراری، ابتدا به طور خودکار توسط تابع convert2df انجام شد. سپس، مجموعه داده به صورت دستی با مقایسه DOI اسناد برای یافتن موارد تکراری بیشتر تنظیم شد.
چکیده یک سند یک نسخه مستقل، مختصر و ضروری از مقاله است [ 8 ، 11 ]. این شامل کلماتی در مورد موضوع اصلی و همچنین مضامین کلی تر مربوط به تحقیق منتشر شده است. با توجه به اینکه چکیده نوعی مینی مقاله است، از همروی کلمات سازنده چکیده برای توصیف مضامین اصلی اسناد منتشر شده بر اساس دادههای OpenStreetMap و برای تجزیه و تحلیل شبکهای از همواژههای تشکیلدهنده چکیده استفاده شد. ساختار مفهومی مجموعه داده [ 7 ]. به ویژه، توجه به قابلیت bibliometrix برای استخراج و تجزیه و تحلیل بیگرام ها، به عنوان مثال، یک نوع عبارت دو کلمه ای [ 12 ، 13 ، 14 ] معطوف شد.]، که به شناسایی بیشتر موضوعات تحت پوشش و فرضیه سازی زمینه معنایی مضامین درگیر کمک می کند.
تأثیر OpenStreetMap در محیط انتشارات دانشگاهی بر اساس ساختار اجتماعی ذاتی در مجموعه دادههای اسناد مورد مطالعه قرار گرفت، یعنی با تجزیه و تحلیل سه شبکه مختلف ارائه شده توسط همزمان در هر سند، موسسات، نویسندگان، یا کشورها [ 7 ، 15 ].
گره های منفرد در یک شبکه را می توان به طور کامل ایزوله یا متصل کرد، و “موقعیت” آنها در بین آنها پیچیدگی کم/بالا را به شبکه می دهد. این ویژگی بر اساس مقدار متوسط [ 16 ] ارزیابی شد: (i) چگالی، متناسب با تعداد اتصالات (از 0 تا 1). (2) گذر، که احتمال تولید یک خوشه با گره های همسایه را به یک گره می دهد. (iii) درجه تمرکز، که برابر با 1 (متمرکز) هنگامی که شبکه به شکل یک ستاره است، در حالی که در مورد یک شبکه کاملاً غیر متمرکز 0 است. (iv) مسیر میانگین، یعنی میانگین کوتاهترین تعداد مراحل بین دو گره.
3. نتایج
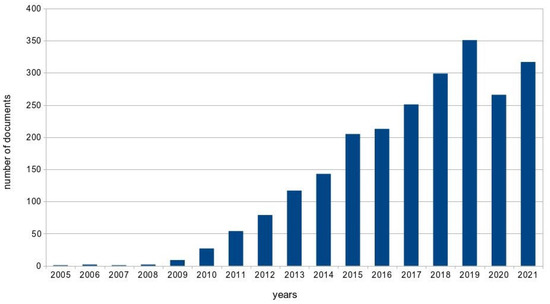
پرس و جو از پایگاههای اطلاعاتی آنلاین (به روشها مراجعه کنید) منجر به گردآوری مجموعه دادههای کتابشناختی OpenStreetMap (OSM) شد که از ابردادههای کتابشناختی 2337 سند، بهعنوان محصول جامعه علمی درگیر در نقشهنگاری داوطلبانه که از طرح OSM حمایت میکند، انجام شد. اولین سند مربوط به سواحل [ 1 ] بود، جایی که او شروع طرح نقشه خیابان باز را در سال 2004 اعلام کرد. در پنج سال بعد، پانزده سند منتشر شد (نگاه کنید به شکل 1 ). پس از آن، تولید تقریباً به صورت خطی تا 334 سند منتشر شده در سال 2019 افزایش یافت و به تعداد تجمعی 1757 سند در عرض پانزده سال رسید. روند مشابهی پس از سال 2019 تأیید نشد.
اکثر اسناد (51%) در مجلات علمی منتشر شده است ( جدول 1 )، در حالی که کمتر از نیمی (46%) از اسناد به صورت مقالات کنفرانس یا مجموعه مقالات و 3% به عنوان فصل کتاب یا مشابه منتشر شده است.
بیش از پنج هزار نویسنده (5419، جدول 2 را ببینید ) در انتشار مجموعه داده OSM مشارکت داشتند. 187 نفر (3.5٪) 221 سند تک نویسنده (9.6٪ از مجموعه داده) را تولید کردند. نود درصد مجموعه داده از مقالاتی با میانگین 3.6 نویسنده مشترک در هر سند و با شاخص همکاری 2.51 (یعنی نویسندگان اسناد مجموعه داده تقسیم بر تعداد مقالات چند نویسنده) تشکیل شده است.
ساختار مفهومی مجموعه داده OSM با مجموع 69460 بیگرم مشخص شد که 20 عدد از آن ها بسیار مکرر ظاهر می شوند (یعنی بیش از صد بار در مجموعه داده)، و به دنبال آن 725 بیگرم از 10 تا 100 بار ظاهر می شوند (به مواد تکمیلی مراجعه کنید). جدول S1 ). فقط تعداد کمی از آنها را می توان به بافت معنایی گسترده جغرافیا (یعنی مکان ها یا اشیاء واقعی در جهان) یا محیط طبیعی مرتبط کرد، در حالی که کلیت تقریباً آنها را می توان به عنوان تکنیک های انفورماتیک یا کارتوگرافی نام برد.
با توجه به تعداد بسیار زیاد بیگرام ها با فرکانس پایین، فقط آنهایی که حداقل ده بار ظاهر می شوند مورد تجزیه و تحلیل قرار گرفتند. شبکه تولید شده توسط همزمانی بیگرام ها ( شکل 2 ) اندازه 745 گره ( جدول 3 ) را نشان می دهد، و حتی اگر چگالی لبه کم باشد (0.12)، گره ها به خوبی با تمرکز درجه 0.71 و مسیر متوسط بین یک جفت گره کمتر از دو مرحله (1.89).
شبکه همزمانی بیگرام ها ساختار ناهمگنی را نشان می دهد که در پنج زیرشبکه از بیگرام ها سازماندهی شده است که در شکل 2 با رنگ های مختلف مشخص شده است. همه گروهها با مجموعهای از بیگرامها که عمدتاً به دادهها، نقشهبرداری و ویژگیهای جغرافیایی مرتبط بودند، مشخص شدند، در حالی که بیگرامهای مربوط به واقعیت واقعی یا اکوسیستمها بسیار نادر بودند ( جدول تکمیلی S2 را ببینید ).
اسناد مجموعه داده های OSM توسط 1779 موسسه منتشر شد، اما تنها دو مورد در بیش از صد سند مشارکت داشتند، به عنوان مثال، دانشگاه هایدلبرگ (183 سند) و دانشگاه ووهان (127)، در حالی که 68 مورد در میان بقیه در بیش از ده سند مشارکت داشتند. و بیش از صد موسسه بین پنج تا نه سند. کمتر از نیمی از مؤسسات فقط به یک سند کمک کردند.
ذاتی در مجموعه داده OSM، شبکه ای از روابط ارائه شده توسط همکاری بین مؤسسات مختلف، به عنوان مثال، یک شبکه همکاری وجود دارد ( شکل 3 ). بر اساس یک دیدگاه کلی، شبکه همکاری، در میان مؤسسههایی که حداقل پنج سند (190) را منتشر کردند، کمترین مقدار چگالی (0.01) را نشان داد ( جدول 4 )، اما میانگین طول و قطر مسیر وسیعترین در ساختار اجتماعی مجموعه داده OSM (به ترتیب 3.77 و 9). گرهها احتمال کمی برای ایجاد خوشهها، نه چندان دور از 20% (گذر 0.17) نشان دادند.
شبکه ای متشکل از 190 مؤسسه مولد به سیزده خوشه شامل 118 مؤسسه غیر ایزوله، با یک خوشه از بیش از بیست مؤسسه تشکیل شده بود ( جدول تکمیلی S3 را ببینید ).
بیش از پنج هزار نویسنده ( جدول 2 ) در اسناد موجود در مجموعه داده OSM مشارکت داشتند، و 201 نفر از آنها در پنج یا بیشتر سند مشارکت داشتند، در حالی که نزدیک به چهار هزار نویسنده در یک سند مشارکت داشتند.
شبکه نویسندگان ( جدول 4 ) کمترین درجه تمرکز را نشان داد (02/0). احتمال ایجاد خوشه ها زیر 50 درصد بود (گذرا: 0.31). شبکه 200 نویسنده برتر ( شکل 4 ، جدول مواد تکمیلی S4 ) خود را در 21 خوشه عمدتاً کوچک با 185 نویسنده، با پنج گروه از بیش از ده نویسنده، و یازده گروه با حداکثر دو نویسنده تشکیل شده است. .
شبکه کشورها از تعداد کمی گره (یعنی 89)، با بالاترین شاخصهای تراکم، گذر و درجه تمرکز (به ترتیب 0.05، 0.4 و 0.34) در ساختار اجتماعی مجموعه داده OSM و کوتاهترین مسیر میانگین تشکیل شده است. این به سه خوشه اصلی که 28 کشور را گروه بندی می کند، که 61 گره جدا شده باقی مانده هستند، ساختار یافته است ( شکل 5 ، جدول مواد تکمیلی S5 ).
4. بحث
ابتکار نقشه خیابان باز (OSM) به عنوان یکی از فرصت های متعدد ارائه شده توسط فضای مجازی شبکه جهانی وب آغاز شد و احتمالاً در ابتدا صرفاً به عنوان یک تازگی آغازین در علوم رایانه تلقی می شد. این احتمال وجود دارد که جامعه علمی به پتانسیل آن توجه نکرده یا آن را دست کم نگرفته باشد، زیرا حوزه اطلاعات جغرافیایی داوطلبانه در آن زمان آنچنان که گودچایلد [ 2 ] بیان کرد، ادغام نشده بود، به دلیل این واقعیت که فناوریهای توانمند و محبوبیت OSM هر دو بودند. هنوز در حال ظهور است. این امر کند تولید اسناد علمی را در سالهای اولیه OSM توضیح می دهد ( شکل 1) زمانی که به طور متوسط سه سند در سال از سال 2004 تا 2009 منتشر شد. سپس اسناد با افزایش کم و بیش ثابتی منتشر شد، احتمالاً به موازات توزیع مناطق گرفته شده توسط داده های OSM (همچنین به مواد تکمیلی شکل S2 مراجعه کنید ) . .
این امر پاسخی به نقطه شروع تحقیق حاضر می دهد، یعنی تولید رو به رشد اسناد در طول زمان نشان می دهد که OSM خودخواه نبوده و وقف دستیابی به داده های جغرافیایی خالص نبوده است، در حالی که با انتشار اسناد منسجم در طول زمان همراه بوده است. .
نوع اسناد تولید شده توسط کارتوگرافی داوطلبانه در فعالیت OSM نشان می دهد که فوری بودن انتقال دستاوردهای جدید یکی از مسائل اصلی است، زیرا مشخص شد که اسناد کنفرانس تقریباً نیمی از کل اسناد است و احتمالاً برای سرعت بخشیدن به انتشار نتایج است. OSM را بهدلیل شیوهی ارتباط سریع نتیجهای در محیطهای کنفرانس به کار گرفت. در عین حال، شاخص همکاری (یعنی نویسندگان همه اسناد تقسیم بر تعداد اسناد چند نویسنده) نشان می دهد که چنین نیازی برای انتشار انگیزه ای برای همکاری نبوده است، زیرا کل مجموعه نویسندگان این کار را انجام نداده اند. با توجه به اینکه شاخص همکاری کمتر از میانگین تعداد نویسندگان مشترک در هر سند بود، به طور مساوی در تولید اسناد جهانی کمک می کند. نسبتا،
ساختار مفهومی مجموعه داده OSM بر شرایطی با ماهیت عمدتاً فنی متمرکز شده است، که می تواند در یک زمینه معنایی با ماهیت کلی ادغام شود و اساساً بر یک یا چند موضوع خاص متمرکز نباشد. بحث مشابهی توسط تحلیل یان و همکاران پشتیبانی می شود. [ 17 ] (در رابطه با زمینه وسیعتر اطلاعات جغرافیایی داوطلبانه)، جایی که آنها نشان دادند که اهمیت زیادی به موضوعات مرتبط با کیفیت و اعتبار داده ها و به کارگیری و یکپارچه سازی اطلاعات داده شده است.
ماهیت فنی عبارات با فهرستی از پرتکرارترین بیگرام ها نشان داده شد، که به موجب آن متداول ترین عبارت اطلاعات جغرافیایی بود که به بافت معنایی جغرافیا مربوط می شد و به دنبال آن عباراتی که هیچ ارتباط نزدیکی با زندگی واقعی نداشتند (به عنوان مثال، OSM) داده ها، داده های مکانی و جغرافیای داوطلبانه؛ به جدول مواد تکمیلی S1 مراجعه کنید ، حتی اگر اغلب اوقات، برخی از اصطلاحات مرتبط با چشم انداز واقعی ظاهر می شوند (به عنوان مثال، شبکه جاده، پوشش زمین و زمین شهری). با این حال، به نظر می رسد این بیشتر استثنا بود تا قاعده. برای به دست آوردن اولین عبارت مرتبط با مسائل زیست محیطی، باید به جایگاه 124 برسیم، جایی که 31 بار از “فضای سبز” بزرگ استفاده شده است. این اولین ظهور اصطلاحی بود که در طبقه بندی پوشش زمین Corine نیز استفاده شد (نگاه کنید بهhttps://land.copernicus.eu )، در حالی که اصطلاح «جنگل»، یکی از سالمترین واژهها از نظر زیستمحیطی است، در فهرست بیگرام OSM در رتبه 664 قرار دارد (به جدول مواد تکمیلی S1 مراجعه کنید ). فهرست مشابه بر اساس عبارات نوشته شده در عناوین اسناد نتایج یکسانی را به همراه داشت (گزارش نشده). حتی اگر [ 17 ] متوجه شود که کارتوگرافی داوطلبانه یک زمینه چند دیدگاهی است که منجر به جهات تحقیقاتی متنوعی می شود (به عنوان مثال، علوم اجتماعی و طبقه بندی محیطی)، در مورد خاص OSM، چنین دیدگاه چند منظری بیشتر به جنبه های فنی جمع آوری داده ها این پاسخ به سوال در مورد موضوعات ترجیحی در نشریات تولید شده توسط ابتکار OSM می دهد.
با توجه به فراوانی اصطلاحات، اسناد موجود در مجموعه داده OSM یک شبکه همزمان از اصطلاحات (شبکه مفهومی) را تشکیل میدهند که در آن ارتباطات عمدتاً با موضوعاتی که ارتباط نزدیکی با جغرافیای واقعی، بومشناسی و اقتصاد ندارند برقرار میشود. این شبکه مفهومی ثابت شد، زیرا تنوع 746 عبارت در یک پیچیدگی شبکه با درجه تمرکز بالا (=0.71) سازماندهی شد، که در آن چگالی لبه پایین را می توان به عنوان فقدان افزونگی تفسیر کرد. بنابراین، اگرچه اطلاعات از طریق شبکهای جریان مییابد که خیلی منشعب نبود، اما میتوانست از کوتاهترین مسیر میانگین (1.89) بین دو کلمه استفاده کند.
این بدان معنی است که حداقل اصطلاحات اصلی مجموعه داده OSM به راحتی به هم مرتبط بودند، به عنوان مثال، اکثر اسناد با موضوعاتی سروکار داشتند که از نظر معنایی به هم مرتبط بودند. این را می توان به عنوان یک گام اولیه در مرحله توسعه شبکه مفهومی تفسیر کرد، جایی که ممکن است در آینده رئوس مطالب زیرشبکه های موضوعی جدید مورد انتظار باشد. برخی از نویسندگان [ 17 ، 18] پیشنهاد کرد که یکی از نیازهای OSM ابزاری بهتر و استاندارد شده برای ورودی داده برای پشتیبانی از کیفیت داده است. در حالی که، اگر درست باشد، کیفیت دادهها قابلیت اطمینان دادههای OSM را تضمین میکند، این احتمال وجود دارد که توسعه زیرشبکههای موضوعی بیشتر، اطلاعات ناشی از ساختار معنایی دادههای OSM را افزایش دهد، جایی که میتوان با توجه بیشتر به آن به این امر دست یافت. مسائل مربوط به زندگی واقعی، حفظ سطح بالایی از کیفیت داده ها.
آیا چنین شبکه مفهومی حاصل همکاری بین بازیگران (یعنی مؤسسات، نویسندگان و کشورهای) است که OSM را حفظ می کنند؟ مشخص شد که سهم مؤسسات به طور نابرابر توزیع شده است و تنها چند مؤسسه اسناد زیادی را ارائه می دهند و تولید اسناد در چند مرکز، عمدتاً دانشگاه ها متمرکز شده است.
این مؤسسات یک شبکه همکاری نازک با گرههای مجزا ایجاد کردند، که در آن خوشههای مؤسسهها وضعیت کلی اتصال کم را ارائه میکردند (همانطور که در شکل 4 و جدول 4 نشان داده شده است.)، با مسیرهای طولانی برای اطلاعات برای عبور از شبکه همکاری. این واقعیت که گروههای داخل شبکه از مؤسسههایی از ملیتهای مختلف تشکیل شده بودند، نشان میدهد که همکاری در داخل گروههای مؤسسهها و فراملی بوده است، در حالی که بین گروهها، همکاری به میزان کمتری فعال بوده است. آنها بدون توجه به اندازه آنها از یکدیگر جدا می شوند. مشخص شد که ترتیب رتبه موسسات بر اساس شاخص مرکزیت در تعداد اسناد منتشر شده توسط موسسات منعکس نشده است. بنابراین، مولدترین مؤسسات لزوماً بیشترین همکاری را نداشتند.
همین امر در مورد شبکه نویسندگان نیز صدق می کند، جایی که اکثر آنها در 21 گروه دسته بندی شده بودند و بسیاری از آنها مانند “ماهواره ها” از چند نویسنده رفتار می کردند. این شبکه یک محیط همکاری را نشان داد که عمدتاً به گروههای کوچکی که به یکدیگر متصل نبودند تقسیم شده بود، جدای از مجموعه کوچکی از پنج گروه متصل، که شبکه واقعی نویسندگان را میسازد.
با در نظر گرفتن کشور نویسندگان به عنوان گره شبکه، به نظر می رسد همان ساختار مؤسسات توسط 28 کشور متصل منعکس شده است، جایی که مقادیر بالای تمرکز احتمالاً به دلیل اندازه کوچک شبکه است. این را می توان به گونه ای تفسیر کرد که گویی اطلاعات بین تعداد محدودی از کشورها بدون همکاری با بسیاری از کشورهای دیگر در جریان است. کشورهای اصلی که در شبکه همکاری مشارکت داشتند آلمان، ایالات متحده آمریکا، چین و بریتانیا بودند که نوعی چولگی شبکه اروپایی را نشان میدهند ( شکل 5 را ببینید ). ساختار شبکه مشابهی در [ 19 ] در زمینه وسیعتر اطلاعات جغرافیایی داوطلبانه پیشنهاد شد.
از دیدگاه کلی، مضامین تحقیقاتی که توسط نقشهنگاری داوطلبانه در OSM ایجاد شد، نشان داد که جنبه کاربردی OSM عمدتاً عمومی است و تا حدی به زمینههای خاص تقسیم میشود، زیرا از یک ساختار نهایی به زیرشبکههایی که در واقع تا حدی هستند ظهور میکند. شناسایی شده. نتایج ممکن است نشان دهد که توجه زیادی به روشها، تکنیکهای نمونهگیری و ورود دادهها شده است، در حالی که برنامههای کاربردی برای موارد دنیای واقعی یا برای تأیید قابلیت اطمینان دادههای OSM اعمال شده در موارد دنیای واقعی کمتر مستند شده یا تا حدودی نادیده گرفته شدهاند، حداقل. تا جایی که به اسناد منتشر شده مربوط می شود. واضح است که هنگام مطالعه نتایج تحقیق حاضر باید در نظر داشت که آنها از یک تحلیل آماری ساده فراداده های کتابشناختی به دست آمده اند، یعنی:
ویژگیهای اصلی ساختار مفهومی نشان میدهد که اسناد منتشر شده به طور جزئی به واقعیت جغرافیایی نمیپردازند. این احتمالاً نشانه ای از نیاز به انتقال داده ها و فعالیت های انجام شده توسط OSM به یک محیط علمی تجربی تر است، جایی که ممکن است مهم باشد، برای مثال، ارزیابی اثربخشی تعامل OSM با OSM بشردوستانه همانطور که توسط [ 20 ] تاکید شده است. .
شبکه اجتماعی ضعیف و کند بود، و این را می توان نه به عنوان یک نوع نگرش حمایت گرایانه در بین موسسات یا محققان، بلکه احتمالاً به عنوان پیامد «فنی بودن» مشخص کننده OSM تفسیر کرد، به این دلیل که اسناد عمدتاً به مسائل فنی می پردازند. جنبه های مدیریت داده ها به نظر می رسد که تلاش عمده محققان بر روی بهترین راه برای به دست آوردن، برچسب گذاری و ارائه داده ها متمرکز شده است. به این ترتیب، دانش به دست آمده در این زمینه برای گردش و استفاده برای حل مشکلات واقعی دشوار است. اگر بسیاری از اسناد به موارد مطالعاتی غیرفنی می پرداختند، شاید برعکس باشد.
منطقی است که بگوییم به اشتراک گذاری داده های OSM را می توان با توجه بیشتر از آنچه که در واقع به انتشار مقالات در مورد موارد واقعی داده می شود بهبود بخشید، به طوری که اسناد منتشر شده در ابتکار OSM، یا به عنوان خروجی، می توانند کمک کنند. به تولید ساختار مفهومی ناهمگون تر، همکاری بهتر بین دانشمندان و موسسات، و ساختار فکری پویا که در آن مفاهیم بین همه بازیگران مختلف در سیستم انتشار جریان دارد. این احتمالاً به استانداردسازی بهتر پروتکلها برای کاربرد OSM برای حل مسئله (به جای مستندسازی) موارد واقعی، مانند مواردی که با فرکانس یا شدت خاصی مانند سیل، زلزله و خشکسالی رخ میدهند، کمک میکند. بحث مشابهی در [ 17 ] ایجاد شد] که پتانسیل اطلاعات جغرافیایی داوطلبانه را در بازیابی پس از فاجعه و بحران ترسیم کرد.
5. نتیجه گیری ها
یک رویکرد جدید برای مطالعه تأثیر نقشه برداری داوطلبانه OSM بر اساس تجزیه و تحلیل کتاب سنجی اسناد منتشر شده در ابتکار OSM پیشنهاد شد. مشخص شد که نقشهبرداری داوطلبانه OSM باید بیشتر به انتشار مقالات علمی مرتبط شود که در آن جغرافیای واقعی به موازات کیفیت دادهها مورد تجزیه و تحلیل و بحث قرار میگیرد. ممکن است دسترسی به دومی در عصر هوش مصنوعی بسیار آسان باشد، اما مطالعات موردی در مورد زندگی واقعی باید در نظر گرفته شود که آنها باید توسط جغرافیدانان داوطلب انسانی هدایت شوند.
پروژه OSM، یکی از پدیده های اصلی نقشه برداری داوطلبانه، دانشمندانی را گرد هم آورده است که در انتشار چندین سند مربوط به داده های جغرافیایی برای به روز رسانی پایگاه داده OSM همکاری کرده اند.
گروههای پژوهشی که شبکه مفهومی را ایجاد کردند، پیشینه فرهنگی مشترکی را نشان دادند که عمدتاً مربوط به جنبههای فنی مدیریت دادههای نقشهبرداری بود.
گروههای تحقیقاتی به خوبی در شبکه اجتماعی شبکهای نبودند، به این معنی که تولید علمی تولید شده توسط کارتوگرافی داوطلبانه تأثیر کمی بر تبادل اطلاعات در شبکه فکری دارد. این نشان می دهد که احتمالاً محیط انتشارات آکادمیک آنطور که انتظار می رود (و همانطور که توسط برخی نویسندگان [ 21 ، 22 ، 23 ] مورد بحث قرار گرفته است) مشارکتی نیست.
پایگاه داده OSM در حال حاضر عمدتاً بر اروپا و بخشهایی از ایالات متحده متمرکز است (به https://osm-analytics.org مراجعه کنید ) و نشان میدهد که میتواند تمایل به تمرکز دانش، مهارت و فناوری در چند گروه تحقیقاتی وجود داشته باشد با این خطر که برخی بخشی از ارزش افزوده ارائه شده توسط OSM می تواند به نوعی در انحصار باشد. بنابراین، باید انتظار داشت که OSM با اجرای پوشش منطقهای جهانی دادههای جغرافیایی داوطلبانه، به ابزار رایجتری در جامعه علمی مبتنی بر دادههای جغرافیایی (مثلاً نقشهبرداران، بومشناسان و جامعهشناسان) تبدیل شود. این می تواند کمک بزرگی برای اعمال داده های OSM در تعداد بیشتری از موارد واقعی باشد (به عنوان مثال، تیم بشردوستانه OpenStreetMap در https://tasks.hotosm.org/) که در آن هدف حل مشکلاتی مانند شرایط اضطراری بهداشتی یا اقلیمی یا برجسته کردن اکوسیستمهای بحرانی/در معرض خطر از دست رفتن تنوع زیستی خواهد بود.
منابع
- Coast, S. OpenStreetMap. Soc. کارتوگر. گاو نر 2005 ، 39 ، 6. [ Google Scholar ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مونی، پی. مینگینی، ام. لااکسو، ام. آنتونیو، وی. اولتئانو-ریموند، A.-M. Skopeliti، A. Towards a Protocol for Collection of VGI Vector Data. بین المللی J. Geo-Inf. 2016 ، 5 ، 217. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پرسکات، الف. سوابق کتابشناختی به عنوان کلان داده های علوم انسانی. در مجموعه مقالات کنفرانس بین المللی IEEE 2013 در مورد داده های بزرگ، سیلیکون ولی، کالیفرنیا، ایالات متحده، 6 تا 9 اکتبر 2013. صص 55-58. [ Google Scholar ]
- ریتز، دیکشنری آنلاین JM برای کتابداری و علم اطلاعات. 2022. در دسترس آنلاین: https://products.abc-clio.com/ODLIS/odlis_b#bibrecord (در 24 ژوئن 2022 قابل دسترسی است).
- پانیزی، الف. قوانینی برای گردآوری کاتالوگ ها در بخش کتاب های چاپی موزه بریتانیا . موزه بریتانیا لندن: لندن، بریتانیا، 1900; در دسترس آنلاین: https://ia800207.us.archive.org/21/items/rulesforcompilin00britrich/rulesforcompilin00britrich.pdf (دسترسی در 1 ژوئیه 2022).
- آریا، م. Cuccurullo، C. bibliometrix: یک ابزار R برای تجزیه و تحلیل نقشههای علمی جامع. J. Informetr. 2017 ، 11 ، 959-975. [ Google Scholar ] [ CrossRef ]
- Katz، MJ از تحقیق تا نسخه خطی . Springer: برلین/هایدلبرگ، آلمان، 2006. [ Google Scholar ]
- کیپر، LM; Furstenau، LB; هوپ، دی. فروزا، ر. تولید نقشه علمی Iepsen، S. Scopus در صنعت 4.0 (2011-2018): تجزیه و تحلیل کتاب سنجی. بین المللی J. Prod. Res. 2020 ، 58 ، 1605-1627. [ Google Scholar ] [ CrossRef ]
- تیم اصلی R. R: زبان و محیطی برای محاسبات آماری. 2022. در دسترس آنلاین: https://www.R-project.org/ (دسترسی در 1 ژوئن 2022).
- پیت، جی. الیوت، ای. باور، ال. Keena, V. Scientific Writing: Easy When You Know How ; کتابهای BMJ: لندن، بریتانیا، 2002. [ Google Scholar ]
- Pedersen, T. شناسایی بیگرام وابسته. در مجموعه مقالات دهمین کنفرانس 1998 در مورد کاربردهای نوآورانه هوش مصنوعی، مجموعه مقالات IAAI-98، مدیسون، WI، ایالات متحده آمریکا، 27-29 ژوئیه 1998. در دسترس آنلاین: https://www.aaai.org/Papers/AAAI/1998/AAAI98-193.pdf (در 1 ژوئیه 2022 قابل دسترسی است).
- تان، سی.-م. وانگ، Y.-F. لی، سی.-دی. استفاده از بیگرام برای افزایش دسته بندی متن. Inf. پردازش Manag. 2002 ، 38 ، 529-546. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسعدی، س. محمد، س. کیریچنکو، اس. پرنده بزرگ: مجموعه داده ای بزرگ، ریز دانه و ارتباط بیگرام برای بررسی ترکیب معنایی. در مجموعه مقالات کنفرانس بخش آمریکای شمالی انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، مینیاپولیس، MN، ایالات متحده آمریکا، 2 تا 7 ژوئن 2019؛ ص 505-516. در دسترس آنلاین: https://aclanthology.org/N19-1050 (در 1 ژوئیه 2022 قابل دسترسی است).
- دی پائولو، اف. پورتو، فناوریهای انرژی خورشیدی GS و نوآوری باز: مطالعهای بر اساس تحلیل کتابسنجی و شبکههای اجتماعی سیاست انرژی 2017 ، 108 ، 228-238. [ Google Scholar ] [ CrossRef ]
- آسنوف، ی. رامیرز، اف. شلهورن، اس.-ای. لنگاور، تی. آلبرشت، ام. محاسبه پارامترهای توپولوژیکی شبکه های بیولوژیکی. بیوانفورماتیک 2007 ، 24 ، 282-284. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- یان، ی. فنگ، سی.-سی. هوانگ، دبلیو. فن، اچ. وانگ، Y.-C. Zipf، A. داوطلبانه تحقیقات اطلاعات جغرافیایی در دهه اول: مروری بر مقالات مجلات منتخب در GIScience. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 1765-1791. [ Google Scholar ] [ CrossRef ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی – مورد OpenStreetMap. بین المللی J. Geo-Inf. 2012 ، 1 ، 146-165. [ Google Scholar ] [ CrossRef ]
- یان، ی. ما، دی. هوانگ، دبلیو. فنگ، سی.-سی. فن، اچ. دنگ، ی. Xu, J. داوطلبانه تحقیقات اطلاعات جغرافیایی در دهه اول: تجسم و تجزیه و تحلیل ارتباط نویسنده مقالات منتخب مجله در GIScience. جی. جوویس. تف کردن مقعدی 2020 ، 4 ، 24. [ Google Scholar ] [ CrossRef ]
- هرفورت، بی. لاتنباخ، اس. پورتو دو آلبوکرک، جی. اندرسون، جی. Zipf، A. تکامل نقشه برداری بشردوستانه در جامعه OpenStreetMap. علمی Rep. 2021 , 11 , 3037. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- پیکهاوس، دبلیو. محصور شدن و بیگانگی انتشارات آکادمیک: درس هایی برای اساتید. TripleC Commun. سرمایه، پایتخت. نقد. دسترسی باز J. A Glob. حفظ کنید. Inf. Soc. 2012 ، 10 ، 577-599. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پین، من؛ Ngo، LB; آپون، انتشارات آکادمیک AW به عنوان یک پارادایم رسانه اجتماعی. در مجموعه مقالات کنفرانس بین المللی IEEE 2013 در مورد داده های بزرگ، سیلیکون ولی، کالیفرنیا، ایالات متحده، 6 تا 9 اکتبر 2013. ص 9-12. [ Google Scholar ]
- پادملوچانان، ص. دانشگاهیان و حوزه انتشارات دانشگاهی: چالش ها و رویکردها. انتشار Res. Q. 2019 , 35 , 87-107. [ Google Scholar ] [ CrossRef ]
شکل 1. تعداد اسناد در سال.
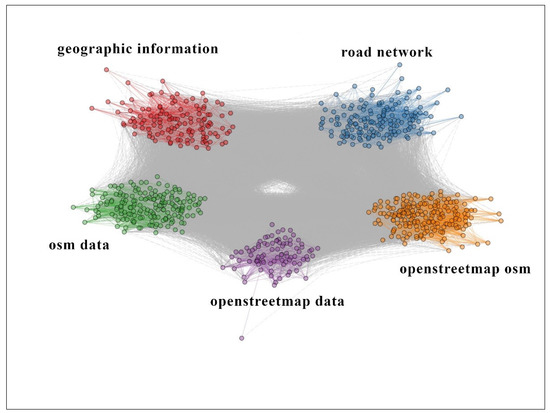
شکل 2. شبکه همزمانی بیگرام ها که حداقل ده بار ظاهر می شوند. این ساختار با پنج زیرشبکه مشخص میشود: چهار زیرشبکه با اندازه بزرگتر که توسط بیگرامهای “اطلاعات جغرافیایی”، “شبکه جاده” “osm data” و “openstreetmap osm” هدایت میشوند و یکی کوچکتر با رهبری بیگرام “دادههای openstreetmap”.
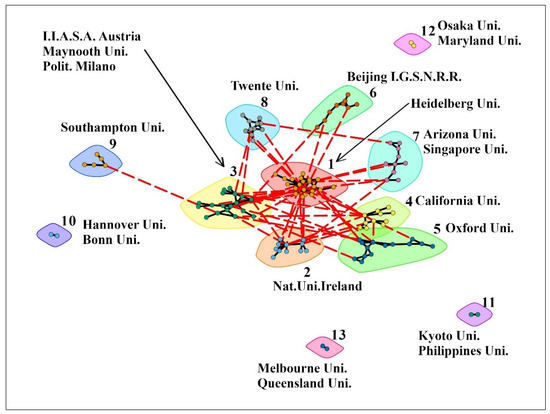
شکل 3.شبکه همکاری در میان 190 مؤسسه تولیدکننده، نشان می دهد که هشت زیرشبکه بزرگ تا متوسط و پنج شبکه کوچک وجود دارد. خوشه های موسسات با چند ضلعی های رنگی مختلف برجسته می شوند. عنوان خوشه ها توسط مؤسسه ای با درجه مرکزیت بالاتر (بیش از یک در صورت پیش فرض) ارائه می شود. در هر خوشه، هیچ تجانسی در ملیت مؤسسه وجود نداشت. (1) دانشگاه هایدلبرگ، آلمان؛ (2) دانشگاه ملی ایرلند؛ (3) موسسه بین المللی اتریش برای تجزیه و تحلیل سیستم های کاربردی. دانشگاه Maynooth، ایرلند؛ Politecnico di Milano، ایتالیا؛ (4) دانشگاه کالیفرنیا، ایالات متحده آمریکا؛ (5) دانشگاه آکسفورد، انگلستان؛ (6) موسسه تحقیقات علوم جغرافیایی و منابع طبیعی پکن، چین؛ (7) دانشگاه ایالتی آریزونا، ایالات متحده؛ دانشگاه ملی سنگاپور؛ (8) دانشگاه توئنته، هلند؛ (9) دانشگاه ساوتهمپتون، انگلستان؛ (10) دانشگاه هانوفر لایبنیتز، آلمان؛ دانشگاه بن آلمان؛ (11) دانشگاه کیوتو، ژاپن؛ دانشگاه فیلیپین؛ (12) دانشگاه اوزاکا، ژاپن؛ دانشگاه مریلند استرالیا؛ (13) دانشگاه ملبورن، استرالیا؛ دانشگاه کوئینزلند استرالیا دیدنجدول تکمیلی S3 برای لیست کامل موسسات.
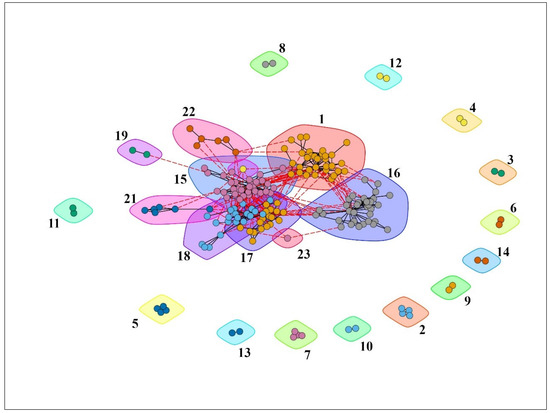
شکل 4. شبکه همکاری در بین 201 نویسنده پربار. نام نویسندگان حذف شد، زیرا تمرکز اصلی بر ساختار شبکه است، جایی که می توان مجموعه ای از خوشه ها و چندین خوشه کوچک “ماهواره” را مشاهده کرد. خوشه های نویسندگان با چند ضلعی های رنگی مختلف برجسته می شوند. برای اسامی نویسندگان به جدول مواد تکمیلی S4 مراجعه کنید .
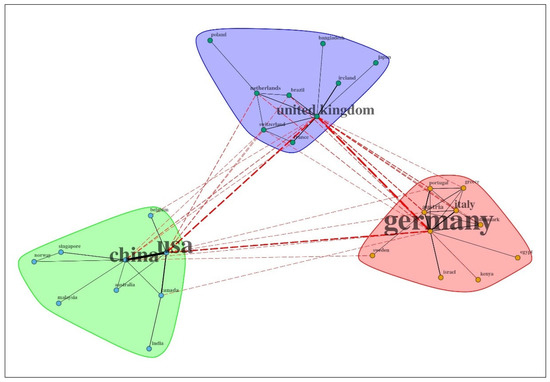
شکل 5. شبکه همکاری بین همه کشورهای غیر منزوی (88) درگیر در تولید اسناد مجموعه داده نقشه خیابان باز. کشورهای پیشرو برجسته می شوند. فهرست کامل در جدول S5 آورده شده است.


بدون دیدگاه