

چکیده
این کار مدلهای پیشبینی جدیدی را بر اساس پیشرفتهای اخیر در روشهای یادگیری ماشین، مانند Random Forest (RF) و AdaBoost ارائه میکند و آنها را با رویکردهای کلاسیکتر، به عنوان مثال، ماشینهای بردار پشتیبان (SVMs) و شبکههای عصبی (NN) مقایسه میکند. مدلها گونههای Pseudo-nitzschia را پیشبینی میکنند . در Rias Baixas گالیسی شکوفا می شود. این کار بر اساس مطالعه قبلی نویسندگان (doi.org/10.1016/j.pocean.2014.03.003) است اما از یک پایگاه داده توسعه یافته (از سال 2002 تا 2012) و الگوریتم های جدید استفاده می کند. نتایج ما نشان میدهد که RF و AdaBoost نتایج پیشبینی بهتری را در مقایسه با SVM و NN ارائه میکنند، زیرا معیارهای عملکرد بهبود یافته و تعادل بهتری بین حساسیت و ویژگی را نشان میدهند. روشهای یادگیری ماشین کلاسیک حساسیتهای بالاتری را نشان میدهند، اما به قیمت ویژگی کمتر و درصد بالاتر هشدارهای کاذب (دقت کمتر). به نظر می رسد این نتایج نشان دهنده سازگاری بیشتر الگوریتم های جدید (RF و AdaBoost) با مجموعه داده های نامتعادل است. مدل های ما می توانند به صورت عملیاتی برای ایجاد یک سیستم پیش بینی کوتاه مدت پیاده سازی شوند.
کلید واژه ها:
شکوفه های جلبکی مضر (HABs) ؛ گونه های شبه نیتسشیا ; Rias Baixas گالیسیایی ; فروافتادگی ساحلی ; ماشین های بردار پشتیبانی (SVMs) ; شبکه های عصبی (NN) ؛ جنگل تصادفی (RF) ; AdaBoost
1. مقدمه
شکوفایی جلبک های مضر (HABs) یک رویداد فزاینده مکرر و شدید در مناطق ساحلی در سراسر جهان است [ 1 ، 2 ]. HAB ها بر اکوسیستم و سلامت انسان تأثیر می گذارند و بر فعالیت های ماهی و آبزی پروری و اقتصادهای منطقه تأثیر می گذارند [ 3 ].
تشخیص و نظارت بر HAB ها به طور سنتی بر اساس نمونه برداری های میدانی است [ 3 ، 4 ]. اخیراً توجه فزایندهای به توسعه مدلهای پیشبینی شده است که میتواند به هشدار اولیه شکوفهها و بهبود اثربخشی برنامههای مدیریتی کمک کند. پیشبینی شکوفههای فیتوپلانکتون شامل استفاده از چندین روش است که میتواند در رویکرد مدلسازی و پیچیدگی متفاوت باشد [ 5 ].
به طور متعارف، پیشبینی رویدادهای مضر جلبکی بر اساس مدلهای عددی آماری، مانند رگرسیون لجستیک، درختان رگرسیون یا مدلهای بیزی است [ 6 ، 7 ، 8 ، 9 ، 10 ]. با این حال، بیشتر این رویکردها به سیستم های خطی محدود می شوند، در حالی که HAB ها معمولا در محیط های ساحلی پیچیده و بسیار پویا رخ می دهند [ 11 ، 12 ].
مدلهای یادگیری ماشین به دلیل توانایی آنها برای مقابله با مجموعه دادههای پیچیده، اغلب غیرخطی و پر سر و صدا و تولید مدلهای پیشبینی با دقت نسبتاً بالا مورد استفاده قرار گرفتهاند [ 13 ، 14 ، 15 ، 16 ].
ماشینهای بردار پشتیبان (SVM) برای اولین بار در سال 1992 [ 17 ] توصیف شدند و بعداً برای طبقهبندی و رگرسیون توسعه یافتند [ 18 ، 19 ]. به طور خلاصه، SVM ها یک طبقه بندی خطی هستند که در یک فضای ویژگی ابعاد بالاتر با استفاده از توابع هسته عمل می کنند. SVMها با به حداکثر رساندن حاشیه با استفاده از روش لاگرانژ برای حل یک مسئله بهینهسازی درجه دوم که توسط محدودیتهای خطی محدود شده است، ابر صفحه بهینه را جستجو میکنند [ 20 ]. SVMها در کاربردهای مختلف مربوط به تشخیص شکوفه انواع مختلف جلبک در هر دو آب شیرین به نتایج خوبی دست یافته اند [ 15 , 21 , 22 , 23 , 24 , 25] و محیط های ساحلی [16 , 20 , 26 , 27 , 28 , 29 ] محیط.
شبکه های عصبی (NN) به دلیل توانایی آنها در مدل سازی داده های چند متغیره، پیچیده و غیر خطی به طور گسترده در کاربردهای محیطی استفاده می شوند [ 30 ]. مبانی نظری NN ها توسط مک کالوچ و پیتس در دهه 1940 معرفی شد. 31 ].]. یک پرسپترون چندلایه (MLP) NN توسط مجموعهای از عناصر محاسباتی غیرخطی (نرونها یا گرهها) تشکیل شده است که در چندین لایه مرتب شدهاند که به روشی پیشخور به هم متصل شدهاند و هر اتصال با یک مقدار وزنی تعریف میشود. معمولاً شامل یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی است. در حالی که لایه ورودی سیگنال های ورودی را در شبکه توزیع می کند، نورون ها در لایه های مخفی و خروجی سیگنال های ورودی خود را با استفاده از یک تابع فعال سازی پردازش می کنند. MLP ها توسط یک روش یادگیری پس انتشار آموزش داده می شوند که به طور مکرر مقادیر وزن را به منظور به حداقل رساندن یک تابع خطا تنظیم می کند [ 30 ]. NN ها به طور گسترده برای پیش بینی HAB ها، به ویژه در سیستم های آب شیرین استفاده شده اند [ 15 ، 23 ، 32 ،33، 34 ]. در آبهای ساحلی، مدلهای NN برای پیشبینی شکوفههای گونههای خاص HAB [ 16 ، 28 ، 29 ، 35 ، 36 ، 37 ، 38 ] یا تخمین از قبل غلظت کلروفیل-a، که اغلب به عنوان نماینده ای برای فیتوپلانک استفاده میشود، توسعه یافته است. فراوانی [ 39 ، 40 ].
جنگل تصادفی (RF) در ابتدا توسط تین کام هو با استفاده از درخت های تصمیم گیری تصادفی ایجاد شد. بریمن و کاتلر این درختان تصمیم گیری تصادفی را با معرفی تکنیک بوت استرپ انباشتگی (یا بسته بندی) گسترش دادند [ 41 ]. RF یک الگوریتم یادگیری ماشین مجموعه ای است که از چندین درخت تصمیم تشکیل شده است که به طور موازی کار می کنند، به طوری که خروجی نهایی با استفاده از یک سیستم “رای گیری” تعریف می شود. در صورت طبقهبندی باینری ( شکوفه/بدون شکوفه )، نتیجه نهایی «محبوبترین» کلاس است، یعنی خروجی اکثر درختان [ 41 ]. RF به طور گسترده در مدل سازی اکولوژیکی استفاده شده است [ 42 ، 43 ، 44 ]، و در طول سال های گذشته، با موفقیت برای پیش بینی HAB استفاده شده است [42، 43، 44].RF به مدلسازی استفاده شده [45 ، 46 ، 47 ، 48 ].
تقویت یک تکنیک یادگیری ماشینی است که مبتنی بر ترکیب مجموعه ای از طبقه بندی کننده های ضعیف برای ایجاد یک قانون پیش بینی با عملکرد بالا است. AdaBoost ( تقویت تطبیقی )، معرفی شده توسط [ 49 ]، یکی از پرکاربردترین الگوریتم های تقویت است. AdaBoost درخت های تصمیم گیری تک گره به نام کنده را به صورت سری ترکیب می کند: هنگامی که یک درخت آموزش داده می شود، درخت بعدی سعی می کند با تطبیق وزن های مرتبط با هر درخت، اشتباهات قبلی را تصحیح کند تا تصمیم نهایی را بگیرد. AdaBoost اخیراً برای کاربردهای مختلف اکولوژیکی استفاده شده است [ 50 ، 51 ]، در حالی که آثار کمی نیز روی ریزجلبک ها متمرکز شده اند [ 16 ، 26 ، 52 ]].
تمام رویکردهای فوق بدون توجه به تکنیک مدلسازی از مجموعهای از پارامترها به عنوان داده ورودی استفاده میکنند. پیشبینیکنندههای معمول محیطی شامل دما و شوری آب، غلظت کلروفیل-a، مواد مغذی یا پارامترهای هواشناسی، مانند باد یا بارندگی است (به بررسی در [ 14 ، 15 ] مراجعه کنید). برخی از نویسندگان همچنین فراوانی گونهها را در هفتههای گذشته در نظر میگیرند [ 20 ، 37 ]، یا تصاویر ماهوارهای را در پیشبینی شکوفه ادغام میکنند [ 28 ، 53 ]. رویکردهای پیشبینی نیز خروجیهای مختلفی مانند فراوانی فیتوپلانکتون را تعریف میکنند [ 16 ، 21 ، 23 ، 24 ، 32،33 ، 34 ، 35 ، 36 ، 37 ، 38 ]، غلظت سم [ 22 ، 46 ]، و غلظت کلروفیل-a به عنوان شاخص زیست توده فیتوپلانکتون [ 25 ، 32 ، 39 ، 40 ] یا خروجی های ie, noombloom ، [ 20 ، 27 ، 28 ] یا غیبت/حضور [ 28 ، 47 ].
برخی از رویکردها مدل های یادگیری ماشین را با تکنیک های دیگر ترکیب می کنند. به عنوان مثال، SVM ها با بهینه سازی ازدحام ذرات [ 22 ، 24 ] ادغام شدند یا MLP ها با استفاده از یک الگوریتم ژنتیک برای جستجوی پارامترهای اولیه بهینه [ 29 ] بهبود یافتند. بورل و همکاران [ 26 ] روشهای اجماع متفاوتی را با ترکیب نتایج از طبقهبندیکنندههای باینری یادگیری ماشین مختلف (از جمله تقویت ، SVM و RF) برای پیشبینی حضور/غیاب گونههای مختلف فیتوپلانکتون پیشنهاد میکند.
برخی از مطالعات نتایج مقایسه ای را با استفاده از تکنیک های مختلف ماشین نشان می دهند. به عنوان مثال، یو و همکاران. [ 16 ] دریافتند که درخت نزولی تقویتشده با گرادیان عملکرد بهتری در مقایسه با روشهای دیگر مانند SVM، NN یا AdaBoost دارد. Ribeiro و Torgo [ 23 ] گزارش دادند که SVM دقت بهتری نسبت به درختان رگرسیون یا NN در پیشبینی شکوفههای جلبک در رودخانه دورو (پرتغال) ارائه میکند. روش اجماع بهترین دقت را برای اکثر مجموعه داده های فیتوپلانکتون تجزیه و تحلیل شده توسط [ 26 ] نشان داد. دومی نیز با استفاده از تقویت ، SVM و به ویژه RF نتایج خوبی به دست آورد . در رویکرد مبتنی بر داده های سنجش از دور که توسط [ 28]، حافظه کوتاه مدت عود کننده NN نتایج بهتری نسبت به MLP، RF یا SVM نشان داد. نتایج [ 29 ] در بندر طلوع (هنگ کنگ) نشان داد که MLP از SVM یا شبکه های عصبی رگرسیون تعمیم یافته بهتر عمل می کند.
با توجه به این نتایج، یک روش “بهترین” بدون تردید یادگیری ماشین برای پیشبینی HABs وجود ندارد و توسعه یک رویکرد کافی به گونههای هدف، منطقه و ویژگیهای مجموعه داده موجود بستگی دارد.
این مطالعه بر روی HAB های ناشی از گونه های Pseudo-nitzschia تمرکز دارد. در منطقه Rias Baixas در گالیسیا (NW اسپانیا). چندین گونه از جنس Pseudo-nitzschia مانند Pseudo-nitzschia multiseries و Pseudo-nitzschia australis با تولید سم عصبی دوموئیک اسید (DA)، که باعث مسمومیت آمنسیک صدف (ASP) می شود، مرتبط شده اند [ 54 ، 55 ] . این جنس به طور کلی در سیستم های بالارونده رایج است، به عنوان مثال، در سیستم جاری کالیفرنیا [ 56 ]، در سیستم ایبری [ 20 ، 57 ، 58 ] و منطقه بنگوئلا [ 59 ]].
تعداد کمی از آثار به پیشبینی گونههای Pseudo-nitzschia پرداختهاند . در مناطق ساحلی شکوفا می شود. بلوم و همکاران [ 60 ] مدلهای رگرسیون خطی چندگانه را برای پیشبینی سطح DA با استفاده از دادههای کشت و شکوفههای طبیعی در خلیج کاردیگان (کانادا) توسعه دادند. مدل های رگرسیون خطی و لجستیک گام به گام برای پیش بینی گونه های DA و Pseudo-nitzschia توسعه داده شدند . فراوانی در کانال سانتا باربارا [ 61 ]، خلیج مونتری [ 8 ] و خلیج چساپیک [ 6 ]. یک مدل مکانیکی توسط [ 62 ] برای شبیه سازی تولید DA پیشنهاد شد. رویکردهای تجربی مبتنی بر پیشبینی شرایط مساعد برای رشد شکوفههای شبه نیتسشیاspp برای خلیج لیسبون [ 58 ] یا سواحل گالیسی [ 63 ] کاوش شدند. کیوزاک و همکاران [ 64 ] شروع، فراوانی و مدت شکوفههای شبه نیتسشیا در آبهای ساحلی جنوب غربی ایرلند را با استفاده از یک مدل دوجملهای منفی با تورم صفر پیشبینی کرد. استفاده از مدلهای ردیابی ذرات برای شبیهسازی پویایی کوتاهمدت Pseudo-nitzschia spp. رویدادهایی برای جنوب غربی ایرلند [ 65 ] و شمال غربی اقیانوس آرام [ 66 ] پیشنهاد شده است. تاون هیل و همکاران [ 67 ] توزیع آتی شبه نیتسشیا را پیش بینی کرده اندspp و گونه های دیگر در قفسه شمال غربی اروپا با استفاده از مدل MaxEnt حداکثر آنتروپی. مدلهای پیشبینی کوتاهمدت غیبت/حضور و فراوانی مبتنی بر NN و با استفاده از سریهای زمانی طولانی بیولوژیکی و زیستمحیطی 20 ساله از خلیج آلفاکس (دریای شمال غربی مدیترانه) توسط [ 36 ] توسعه داده شد.
این مطالعه بر اساس کار قبلی توسعه یافته توسط [ 20 ]، که در آن عدم وجود/حضور و عدم شکوفایی/شکوفایی Pseudo-nitzschia spp. مدلهای SVM برای Rias Baixas گالیسی با استفاده از یک مجموعه داده بلندمدت (1992-2001) از پارامترهای محیطی توسعه داده شد. برای مدلهای بدون شکوفه/شکوفه ، یکی از مسائل اصلی عدم تعادل مجموعه داده است، به طوری که تنها حدود 15 درصد از نمونهها بهعنوان بلوم شناسایی میشوند . در نتیجه، مدلهایی که حساسیت خوبی دارند، نرخ بالاتری از آلارمهای کاذب را نشان میدهند. بنابراین، هدف اصلی بررسی پتانسیل روشهای مختلف یادگیری ماشین برای یافتن تعادل بهتر بین حساسیت و دقت و بهبود نتایج یافتشده توسط [ 20 ] است.]. علاوه بر توسعهیافتهترین فناوریهای یادگیری ماشین برای پیشبینی HABs (SVM و NN)، روشهای یادگیری گروهی اخیر (RF و AdaBoost) را معرفی میکنیم، که انتظار میرود با ترکیب چند یادگیرنده ضعیف، توانایی تعمیم بهتری را نشان دهند [ 16 ].
به طور خلاصه، ما مقایسه ای از رویکردهای مختلف یادگیری ماشین، به عنوان مثال، MLP، SVM، RF و AdaBoost را برای پیشبینی شکوفایی گونههای Pseudo-nitzschia ارائه میکنیم . در ریاس بایکساس . مدلها با استفاده از مجموعه دادههای هفتگی بلندمدت (2002-2012) از پارامترهای محیطی با استفاده از همان رویکرد و ساختار مجموعه دادهها (ترکیب متغیرها) پیشنهاد شده توسط [ 20 ] توسعه و تأیید شدند.
2. مواد و روشها
2.1. منطقه مطالعه
ریا ( ریاس در جمع ) نامی اسپانیایی برای فروافتادگیهای ساحلی V شکل واقع در سواحل غربی گالیسیا (شمال غربی اسپانیا) است که در اثر غرق شدن جزئی درههای رودخانهای باستانی به وجود آمدهاند. Rias Baixas چهار ریا جنوبی هستند ، از جنوب به شمال: Vigo، Pontevedra، Arousa و Muros (نگاه کنید به شکل 1 ). آنها در امتداد مرز شمالی سیستم بالا آمدن شمال غربی آفریقا قرار دارند [ 68]. در این منطقه، فصلی بودن دینامیک اقیانوس توسط قدرتهای نسبی و تغییرات عرضی سیستمهای فشار بالا آزور و سیستمهای فشار پایین ایسلند کنترل میشود. فرآیندهای ناشی از باد در این منطقه باعث بالا آمدن قوی آب های سرد غنی از مواد مغذی در دوره از ماه مه تا سپتامبر می شود (این آب ها تا منطقه فوتیک بالا می روند و در بالا آمدن شدیدتر به سطح می رسند) [ 69 ، 70 ]، که منجر به قابل توجهی می شود. افزایش تولید اولیه (تا 7.4 گرم در مترمربع در روز 1 ) در طول رویدادهای بالا آمدن [ 71 ].
این منطقه با استفاده از قایقهای شناور از کشت نرم تنان فشرده (عمدتا صدفها) پشتیبانی میکند. گالیسیا منطقه ای با بالاترین تولید صدف های آبزی پروری در اروپا و یکی از پیشتازان جهان است. تولید صدف در این منطقه تقریباً به 250000 تن در سال می رسد که معادل 41 درصد تولید اروپا و 15 درصد تولید جهانی است [ 72 ].
این فعالیتها بهطور جدی توسط شکوفههای مضر جلبک (HABs)، که باعث تأثیرات مهم زیستمحیطی، اجتماعی و اقتصادی میشوند، مانع میشوند، زیرا حتی میتوانند مناطق تولید را تعطیل کنند [ 73 ، 74 ]. HAB ها یک پدیده مکرر و مستند در گالیسیا هستند و تعداد زیادی از مطالعات را می توان از دهه 1950 در ادبیات یافت [ 75 ، 76 ، 77 ، 78 ]. یکی از گروه های طبقه بندی اصلی تشکیل دهنده HAB، گونه های Pseudo-nitzschia است که از سال 1994 به عنوان عامل ایجاد حوادث سمی ASP به دلیل تولید اسید دوموئیک (DA) شناسایی شده است [ 79 ، 80 ، 81 ].].
با توجه به اهمیت اقتصادی آبزی پروری، برنامه پایش گونه های HAB در آب های گالیسیا راه اندازی شد. مؤسسه فناوری برای کنترل محیط زیست دریایی گالیسیا (INTECMAR) یک نمونه گیری معمول هفتگی را انجام می دهد و فراوانی گونه های Pseudo-nitzschia را اندازه گیری می کند . (و سایر گونه های بالقوه سمی)، پارامترهای کیفیت آب و سطوح بیوتوکسین در صدف ها و سایر نرم تنان [ 20 ].
پیشبینی HABها برای تولیدکنندگان نرم تن از نظر سازماندهی و لجستیک و همچنین برای سیاستهای اجتماعی مرتبط با یکی از نیروهای محرک اقتصادی اصلی در منطقه بسیار مهم است [ 20 ، 80 ، 81 ].
2.2. مجموعه داده
مجموعه داده مورد استفاده در این مطالعه شامل رکوردهای هفتگی پارامترهای آب (به عنوان مثال، دما، شوری و فراوانی گونههای شبه نیتزشیا ) و شاخصهای بالارفتن بین ژانویه 2002 و دسامبر 2012 است. ما از همان ساختار مجموعه داده و متغیرهای ارائه شده در [ 20 ] استفاده کردیم.
پارامترهای آب (به عنوان مثال، دما، شوری، فراوانی گونههای شبه نیتسچیا ) توسط INTECMAR به عنوان بخشی از برنامه نظارتی آن شامل یک نمونهبرداری هفتگی در 38 ایستگاه نمونهبرداری که در چهار Rias Baixas توزیع شده بود اندازهگیری شد . ما فقط دادههای ایستگاههای بیرونی واقع در دهانه هر ریا را در نظر گرفتیم ( شکل 1 ؛ V5 در ریا ویگو، P4 در ریا از پونتودرا، A0 در ریا از آروسا و M5 در ریا از موروس). این ایستگاهها تحت تأثیر فرآیندهای محلی (مثلاً تخلیه رودخانه) قرار نمیگیرند و بهعنوان معرف شرایط اقیانوس باز در نظر گرفته میشوند.
اندازهگیریهای دما و شوری در محل از سطح تا عمق 5 متری، تقریباً هر 10 سانتیمتر، با استفاده از Seabird مدل 25 CTD جمعآوری شد. به طور خاص، دما با استفاده از یک ترمیستور Seabird SB3 (محدوده: -5 درجه تا +35 درجه سانتیگراد؛ دقت: 0.02 درجه سانتیگراد؛ وضوح: 0.0003 درجه سانتیگراد) اندازه گیری شد و شوری بر اساس یک سلول رسانایی Sea Bird SBE4 (محدوده: 0-0) است. 7 S/m؛ دقت: 0.0003 S/m؛ وضوح: 0.00004 S/m). سپس مقادیر دما و شوری برای هر هفته و ایستگاه با ادغام تمام اندازهگیریهای معتبر موجود با استفاده از قانون ذوزنقهای محاسبه شد.
در مورد فیتوپلانکتون، نمونهها با استفاده از شبکههای بکسل (مش 10 میکرومتر) از سطح تا عمق 15 متر جمعآوری و با فرمالدئید 4 درصد تثبیت و در شرایط تاریک و خنک نگهداری شدند. فراوانی کل (در سلول های L -1 ) گونه های Pseudo-nitzschia . و سایر گروه های تاکسونومیک سمی بالقوه با استفاده از میکروسکوپ نوری معکوس در بزرگنمایی 250× و 400× شمارش شدند [ 82 ].
همانطور که توسط [ 20 ] پیشنهاد شد، پنج شاخص صعودی (Iw)، یکی برای روز نمونهبرداری و چهار شاخص برای هر یک از چهار روز قبل، از دادههای باد اندازهگیری شده در شناور اقیانوسشناسی کیپ سیلیرو (42.12 درجه شمالی، 9.43 درجه غربی، شکل 1 را ببینید ). این شناور که در عمق 323 متری لنگر انداخته است، یک شناور SeaWatch در Puertos del Estado است ( https://www.puertos.es ، در 20 ژانویه 2021 مشاهده شد) مجهز به ابزارهای هواشناسی برای اندازه گیری سرعت باد (محدوده: 0-60) متر بر ثانیه؛ دقت: ± 0.3 متر بر ثانیه) و جهت (محدوده: 0 تا 360 درجه؛ دقت: 3± درجه) در 10 متر بالاتر از سطح دریا هر ده دقیقه. بادهای این مکان نماینده شرایط باد در منطقه گالیسی [ 83 ] در نظر گرفته میشوند.
شاخص های افزایش با استفاده از روش باکون [ 84 ] محاسبه شد:
Iw = (−τ y )/(ρ w ·f) = (−1000·ρ a ·C D ·W·W y )/(ρ w ·f) m 3 /(s · کیلومتر)
در معادله بالا، τy مولفه نصف النهار نیروی باد است (N m -2 )، ρw چگالی آب دریا (1025 کیلوگرم متر -3 )، f ضریب کوریولیس است (9.9 × 10-5 ثانیه). −1 در 42 درجه عرض جغرافیایی)، ρa چگالی هوا است (1.2 کیلوگرم مترمکعب در 15 درجه سانتیگراد)، CD یک ضریب کشش تجربی بعدی (1.4 × 10−3 ) و W و W y است. به ترتیب میانگین روزانه سرعت باد و مولفه نصف النهاری آن هستند. شاخص های مثبت بالا آمدن شرایط بالا آمدن را نشان می دهد (بادهای شمالی غالب، W y منفیمقادیر) در حالی که شاخص های منفی مربوط به موقعیت های نزولی است (بادهای غالب جنوبی، مقادیر W y مثبت ).
ما دو دسته را بر اساس گونه های Pseudo-nitzschia ایجاد کردیم . فراوانی برای تعریف خروجی مدلها: بدون شکوفه (< 105 سلول L -1 ) و شکوفه (≥105 سلول L -1 ) [ 20 ]. ما همچنین به عنوان متغیرهای ورودی کد ria (1: Arousa؛ 2: Muros؛ 3: Pontevedra؛ 4: Vigo)، روز سال (بین 1 و 366) و وقوع یک شکوفه در هفته قبل را تعریف کردیم. bloom-1w ) یا دو هفته قبل ( bloom-2w ) با استفاده از مقداری بین 0 تا 15 که نشان می دهد در کدام ریاس شکوفه شناسایی شده است (0: بدون شکوفه؛ 1-4: شکوفه در یک ریا; 5-10; شکوفه در دو ریا ; 11-14: شکوفه در سه ریه . 15: تمام ریاس ) [ 20 ].
متغیرها در جدول 1 خلاصه شده اند. توجه داشته باشید که پارامترهای آب (دما، شوری، فراوانی گونههای Pseudo-nitzschia ) هر هفته به دو دلیل در دسترس نبود: (1) به دلیل آبوهوای بد یا خرابی کشتی، هیچ کمپین نمونهبرداری صحرایی وجود نداشت. (2) مشکلات نمونه برداری، مانند خوانش اشتباه، خرابی ابزار یا ریزش بیش از حد. تعداد رکوردهای معتبر برای این متغیرها نیز در جدول 1 نشان داده شده است.
مدلها با استفاده از ترکیبی مشابه از متغیرهای پیشنهاد شده توسط [ 20 ] و با استفاده از حروف A تا D برچسبگذاری شدهاند: A شامل تمام متغیرهای موجود است. B اثرات مکانی و زمانی ( کد ria و روز سال) را مستثنی می کند. C همچنین اطلاعات مربوط به وقوع شکوفه در هفتههای قبل را دور میاندازد ( bloom-1w، bloom-2w ) و D فقط بر اساس شاخصهای بالا آمدن است. یک مجموعه داده برای هر ترکیب با مرتبط کردن متغیرهای ورودی با خروجی مربوطه ( شکوفایی یا بدون شکوفایی ) برای هر روز و ria ساخته شد.، حذف رکوردهایی با مقادیر نامعتبر یا گمشده برای هر یک از متغیرهای ورودی یا خروجی. متغیرها و تعداد رکوردهای موجود برای هر ترکیب در جدول 2 نشان داده شده است.
پس از حذف مقادیر نامعتبر و گمشده، مجموعه داده های نهایی شامل 79.66٪ (ترکیب A یا B) و 83.62٪ (ترکیب B) از 2296 رکورد بالقوه (یعنی 574 هفته × 4 ایستگاه) است.
2.3. انتخاب مدل
ما مجموعه داده کامل را برای هر ترکیبی از ویژگیها (A، B، C یا D) به دو مجموعه داده مستقل، آموزش (2/3 کل رکوردها) و مجموعههای اعتبارسنجی (1/3 از رکوردها) تقسیم کردیم. هر دو زیر مجموعه شامل درصد مشابهی از هر دو کلاس ( شکوفه و بدون شکوفه ) ساخته شدند. مدلها با استفاده از مجموعه آموزشی توسعه داده شدند (یعنی آموزش دیدند)، در حالی که مجموعه اعتبارسنجی برای به دست آوردن مجموعهای مستقل از اندازهگیریهای عملکرد برای انتخاب مدل بهینه مفید بود. جدول 3 تعداد رکوردهای موجود در هر مجموعه داده را برای هر دو کلاس خلاصه می کند.
در مورد SVM و NN، دادههای ورودی قبل از آموزش بهمنظور جلوگیری از تأثیر بیشتر متغیرها با دامنههای عددی بزرگتر، بهصورت خطی در محدودهای بین ۱- و ۱+ مقیاسبندی شدند [ 85 ]. ویژگی های طبقه بندی ( وقوع شکوفه در هفته های گذشته و کد ریا ) ابتدا به داده های عددی تبدیل شدند. جدول 1 حداقل و حداکثر مقادیر مورد استفاده برای مقیاس این متغیرها را نشان می دهد.
پیکربندی پارامتری بهینه برای هر ترکیبی از ویژگیها و روش با بهینهسازی فراپارامتر انتخاب شد. این بر اساس یک رویکرد جستجوی شبکه ای بود، به عنوان مثال، مدل هایی با استفاده از پارامترهای مختلف کنترل کننده فرآیند یادگیری، آموزش و ارزیابی می شوند و بهترین مدل ها با توجه به دو معیار (امتیاز F1 و فاصله تا نقطه (0،1) در گیرنده عامل انتخاب می شوند. منحنی مشخصات (ROC)، به بخش 2.3 مراجعه کنید . معیارها با استفاده از مجموعه اعتبارسنجی محاسبه شدند. فراپارامترهای انتخاب شده و مقادیر جابجایی در بخش 2.4 نشان داده شده است. تمام آزمایش ها با استفاده از کتابخانه های موجود در MATLAB به استثنای NN ها که در Matlab نیز برنامه ریزی شده بودند اما با استفاده از یک کد سفارشی انجام شد. کد در مخزن GitHub موجود است:https://github.com/currobellas/NeuralNetwork (در 20 ژانویه 2021 قابل دسترسی است).
2.4. اندازه گیری عملکرد
عملکرد مدل ها با مقایسه نتایج با خروجی واقعی از طریق یک ماتریس سردرگمی [ 86 ]، یک جدول 2 × 2 که تعداد نمونه ها را به درستی برای هر دو کلاس طبقه بندی شده ( بدون شکوفه و شکوفه ) و همچنین تعداد نمونه ها نشان می دهد، ارزیابی شد. مثبت کاذب و منفی کاذب.
معیارهای مختلف استخراج شده از ماتریس سردرگمی در ادبیات ارائه شده است. در این کار، حساسیت و ویژگی را در نظر گرفتیم، یعنی به ترتیب درصد شکوفایی و عدم شکوفایی را به درستی طبقهبندی کردیم. و دقت، کسری از مثبت های واقعی با توجه به تعداد کل رکوردهای طبقه بندی شده به عنوان شکوفه . با توجه به معیارهای جهانی، دقت جهانی (درصد رکوردهایی که به درستی طبقه بندی شده اند) می تواند اطلاعات گمراه کننده ای را به دلیل توزیع نابرابر طبقات ارائه دهد (حدود 16٪ از شکوفایی ، 84٪ از عدم شکوفایی ). از این رو، ما از امتیاز F1 استفاده کردیم که به عنوان میانگین هارمونیک دقت و حساسیت تعریف شده است که به طور گسترده با مجموعه داده های نامتعادل استفاده می شود [87 ].
به منظور مقایسه مدلها به صورت گرافیکی، منحنیهای ویژگیهای گیرنده عامل (ROC) را ایجاد کردیم که حساسیت را در برابر نرخ مثبت کاذب (1-ویژگی) رسم میکردیم و فاصله تا نقطه بهینه (0،1) را محاسبه کردیم (یعنی تمام رکوردهای شکوفایی در این مرحله به درستی طبقه بندی می شوند) به عنوان یک متریک ترکیبی از حساسیت و ویژگی [ 88 ، 89 ].
اگرچه ماتریس های سردرگمی از زیر مجموعه های آموزشی و اعتبار سنجی ساخته شده اند، انتظار می رود نتایج حاصل از مجموعه اعتبار سنجی قابل اعتمادتر باشد زیرا این زیر مجموعه در فرآیند آموزش گنجانده نشده است. بنابراین، مدلهای بهینه بر اساس دو معیار بر اساس معیارهای محاسبهشده از مجموعه اعتبارسنجی انتخاب شدند: حداکثر امتیاز F1 و حداقل فاصله تا نقطه بهینه (0،1) در منحنی ROC. تمام معیارهای نشان داده شده در این کار بر اساس نتایج اعتبارسنجی است.
2.5. روش های یادگیری ماشینی
2.5.1. ماشینهای بردار پشتیبانی (SVM)
در این کار، علاوه بر هسته پایه شعاعی گاوسی (RBF) انتخاب شده توسط [ 20 ]، ما هسته های چند جمله ای درجات مختلف (تا 50) را برای هر ترکیبی از ویژگی ها (A، B، C یا D) آزمایش کردیم.
2.5.2. پرسپترون چند لایه (MLP)
برای هر ترکیبی از ویژگی ها (A، B، C و D)، ما 660 تست را انجام دادیم که تنظیمات زیر را تغییر می داد:
-
تعداد لایه های پنهان در شبکه عصبی: از 1 تا 10.
-
تعداد تکرارها در الگوریتم پس انتشار: 50، 100، 500، 1000، 1500 و 2000.
-
ضریب تنظیم لامبدا: 0.00001، 0.00005، 0.0001، 0.0005، 0.001، 0.005، 0.01، 0.05، 0.1، 0.5، و 1.
2.5.3. جنگل تصادفی (RF)
ما از پارامترهای زیر برای کشف پیکربندی پارامتریک بهینه برای هر ترکیبی از متغیرها (A، B، C یا D) استفاده کردیم:
-
تعداد کیسه برای بوت استرپ: 30، 40، 50، 60، 70، 80، 100، 200، 300، 400، 500 و 1000.
-
تعداد پیش بینی کننده های ضعیف انتخاب شده به عنوان زیر مجموعه برای هر درخت: بین 2 تا 4.
توجه داشته باشید که یک پیش بینی ضعیف به عنوان یک متغیر برای تصمیم گیری در نظر گرفته می شود و از این رو تعداد پیش بینی کننده های ضعیف باید کمتر از تعداد کل متغیرهای ورودی باشد.
2.5.4. AdaBoost
ما دو پارامتر را برای جستجوی مدل بهینه برای هر ترکیبی از ویژگی ها (A، B، C یا D) ترکیب کرده ایم:
-
نوع تقویت کننده: GentleBoost، AdaBoostM1 و RUSBoost.
-
تعداد چرخه ها (پارامتر به طور مستقیم با تعداد طبقه بندی کننده های ضعیف مرتبط است): 10، 50، 100، 150، 200، 500، 1000 و 2000.
2.6. منحنی های یادگیری
منحنی های یادگیری با ترسیم خطاهای آموزش و اعتبارسنجی در برابر تعداد نمونه های مورد استفاده در فرآیند آموزش به دست آمد [ 90 ]. زمانی که تعداد نمونه ها کم باشد، انتظار می رود خطای آموزشی کم باشد، اما با گنجاندن نمونه های جدید در فرآیند آموزش، این خطا افزایش می یابد. انتظار می رود خطای اعتبارسنجی با افزایش تعداد نمونه های آموزشی کاهش یابد. این منحنی ها برای تجزیه و تحلیل مبادله بین خطاهای بایاس و واریانس مفید هستند.
اگر مدلی تناسب خوبی با مجموعه آموزشی نشان دهد اما با مجموعه اعتبارسنجی مطابقت نداشته باشد، مشکل واریانس یا اضافه برازش وجود دارد. در منحنی یادگیری، با افزایش تعداد نمونه ها، خطای آموزش کم می ماند، اما خطای اعتبارسنجی زیاد است. در این حالت می توان با افزایش تعداد نمونه های آموزشی مدل را بهبود بخشید.
با این حال، اگر هر دو خطای آموزش و اعتبارسنجی مشابه اما با مقادیر بالا باشند، مشکل سوگیری یا عدم تناسب وجود دارد. در منحنی های یادگیری، با افزایش تعداد نمونه ها، هر دو منحنی خطا تمایل دارند خودشان را لمس کنند. در این صورت افزایش تعداد نمونه ها باعث کاهش خطا نمی شود و می توان با افزودن متغیرهای جدید مدل را بهبود بخشید.
3. نتایج
3.1. مشاهدات
3.1.1. Pseudo-nitzschia Spp. توزیع
گونه های شبه نیتسشیا تقریباً در 63 درصد نمونهها (بالاتر از حد تشخیص) شناسایی شد، اگرچه فقط 15 درصد به عنوان شکوفه (فراوانی بیش از 105 سلول در لیتر) شناسایی شد. یازده رکورد فراوانی بیش از 106 سلول در لیتر، با پیک 3.19 × 106 سلول در لیتر و مقدار متوسط حدود 62000 سلول در لیتر را نشان دادند.
جدول 4 تلاش نمونه برداری را نشان می دهد، به عنوان مثال، تعداد کل هفته های نمونه برداری شده، و بروز شکوفه ، که به عنوان درصد هفته های تحت تاثیر یک گونه Pseudo-nitzschia تعریف شده است. شکوفه ، برای هر ریا و سال. توجه داشته باشید که Muros تلاش نمونه برداری کمتری را نشان می دهد زیرا این ria توسط جزایر واقع در دهانه محافظت نمی شود ( شکل 1 ) و از این رو ایستگاه M5 بیشتر تحت تأثیر شرایط آب و هوایی شدید قرار می گیرد.
ویگو با 94 شکوفه (نزدیک به 30 درصد از تعداد کل شکوفه ها ) بیشترین آسیب را به خود اختصاص داد و پس از آن Pontevedra (84)، آروسا (76) و Muros (72) قرار گرفتند. بروز شکوفهها از 16.85% در ویگو تا 13.74% در آروسا، با مقادیر حدود 15% در Pontevedra و Muros متفاوت بود ( جدول 4 ). این نتایج با نتایج مشاهده شده در [ 20 ] برای دهه قبل (1992-2000) متفاوت است، که Pontevedra را به عنوان بیشترین آسیب دیده گزارش می دهد.در واقع، بروز شکوفه در پونتودرا (از 24.28٪ به 15.11٪) و Muros (از 21.39٪ به 14.81٪) بسیار کمتر بود، اما مقادیر مشابهی را در Vigo (از 17.13٪ به 16.85٪) و Arousa (از 5.7٪ به 13) نشان داد. ٪. تحقیقات بیشتری برای آزمایش اینکه آیا تغییر واقعی در گونههای Pseudo-nitzschia وجود دارد یا خیر، مورد نیاز است. الگوی توزیع فضایی یا این تغییرات به سادگی در تنوع مورد انتظار قرار می گیرند.
تغییرات قابل توجهی در توزیع شکوفه در طول سالهای تحت پوشش مجموعه داده وجود داشت ( جدول 4 ). تعداد هفتههایی که حداقل یک ریا تحت تأثیر گونههای شبه نیتسشیا قرار گرفته است. شکوفه از 18 در سال 2005 و 2009 تا کمتر از 10 در سال های 2006 و 2012 متغیر بود. علاوه بر این، الگوهای فضایی نیز بسیار متغیر بودند: اگرچه ویگو به طور کلی بیشترین تأثیر را داشت (2003، 2007، 2009، 2011 و 2012، آرونته ، پوندراوس)، Muros بیشترین میزان بروز را به ترتیب در سال های 2005، 2002 و 2010 نشان داد. در مقایسه با مجموعه داده مورد استفاده در [ 20 ]، قابل توجه است که هیچ یک از سال ها بیش از 20 شکوفه نشان ندادند.هفته هایی که در سال 1992 و 1993 مشاهده شد.
شکل 2 توزیع ماهانه گونه های Pseudo-nitzschia را نشان می دهد . در منطقه برای دوره کامل (2002-2012). بیشتر شکوفه ها (74/83 درصد) بین ماه های می و سپتامبر شناسایی شدند، در حالی که تعداد آنها بین اکتبر و آوریل بسیار کم و در دسامبر و ژانویه حتی صفر بود. نتایج، یافتههای مطالعات قبلی را تأیید میکند که نشان میدهد Pseudo-nitzschia spp. در بهار و اواخر تابستان به عنوان یک نتیجه از بالا آمدن شرایط مطلوب رایج است [ 20 ، 58 ]. میزان بروز شکوفه بین ماه های می و سپتامبر به غیر از کاهش شدید در ژوئن، در مقادیر حدود 30 درصد باقی می ماند. این الگو با الگوی مشاهده شده در دوره 1992-2002 متفاوت است [ 20]: در ماه مه و سپتامبر تقریباً دو برابر می شود (از 15% به 30%) اما در ژوئن (از 29.27% به 21.98%) و جولای (از 42.47% به 31.61%) کاهش می یابد. تغییرات می تواند به تغییرات در الگوهای بالا آمدن مربوط باشد که نیاز به تحقیق بیشتر دارد.
3.1.2. متغیرهای ورودی
در این مطالعه، ما با همان متغیرهای ورودی انتخاب شده در [ 20 ] کار کردیم که قبلاً گزارش شده بود که مربوط به وقوع Pseudo-nitzschia spp بودند. در منطقه مورد مطالعه شکوفا می شود. این روابط با تجزیه و تحلیل اکتشافی مجموعه داده تایید شد.
همه متغیرهای عددی به طور معنیداری با گونههای شبه نیتسشیا همبستگی مثبت دارند (01/ 0p <) . فراوانی ( جدول 5 ). علاوه بر این، علیرغم اینکه درجاتی از همپوشانی بین کلاسهای بدون شکوفه و شکوفه وجود دارد (مقادیر حداقل و حداکثر را در جدول 5 بررسی کنید )، تفاوتهای معنیداری ( 01/ 0p <) برای هر متغیر بین هر دو کلاس با استفاده از آزمونهای من ویتنی یافت شد. .
میانگین دمای بالاتر نمونههای شکوفه با الگوی فصلی معمول گونههای Pseudo-nitzschia توضیح داده میشود که در بهار و تابستان فراوانتر است ( شکل 2 ). همانطور که در [ 20 ] نشان داده شده است، اگرچه گونه های Pseudo-nitzschia شکوفا می شوند. اغلب با کاهش دما در ارتباط با رویدادهای بالا آمدن در بهار و تابستان همزمان است، دما در پاییز و زمستان حتی کمتر است.
با توجه به شوری، افزایش بارندگی و/یا ورودی رودخانه منجر به دورههای شوری کم میشود که در پاییز و زمستان بیشتر است [ 20 ]. از این رو، میانگین شوری کمتر نمونه های بدون شکوفه نیز می تواند با الگوی فصلی مرتبط باشد.
رویدادهای بالا آمدن بالا (شاخص های بالا آمدن مثبت) معمولاً در بهار-تابستان بیشتر است در حالی که رویدادهای رو به بالا (شاخص های بالا آمدن منفی) در پاییز-زمستان رایج است [ 20 ]. علاوه بر این، گونه های Pseudo-nitzschia شکوفا می شوند. معمولاً در طول هر دو رویداد بالا آمدن و دوره آرامش خلفی شناسایی می شوند [ 20 ]. در نتیجه، همه شاخصهای صعودی مقادیر مثبت متوسط را برای کلاس شکوفه در مقابل مقادیر میانگین منفی یا نزدیک به صفر نمونههای بدون شکوفه نشان دادند ( جدول 5 ). توجه داشته باشید که حداکثر همبستگی و تفاوت بین هر دو کلاس با استفاده از شاخص صعودی که سه روز قبل از تاریخ نمونهگیری اندازهگیری شده است، به دست میآید ( جدول 5).).
وقوع شکوفه های Pseudo-nitzschia spp. در هفتههای گذشته به موارد مشاهدهشده اضافه شد زیرا به نظر میرسد که شکوفههای فیتوپلانکتون (شامل گونههای Pseudo-nitzschia ) در امتداد سواحل گالیسیا مطابق با بادها و جریانهای غالب پیشرفت میکنند [ 20 ، 74 ]. با استفاده از آزمونهای من ویتنی، تفاوتهای قابلتوجهی برای هر دو bloom-1w و bloom-2w بین بدون شکوفه و شکوفه یافت شد. حدود 89 درصد از نمونههای بدون شکوفه مربوط به شکوفههای هفتههای قبل نبودند ( شکوفه-1w = 0 و bloom-1w = 0) در حالی که 47.62 درصد و 39.12 درصد شکوفهنمونه ها به ترتیب در هفته قبل ( شکوفه-1w ≥ 1 ) و دو هفته قبل (یعنی شکوفه-2w ≥ 1 ) شکوفه داشتند.
کد ریا و روز سال مربوط به توزیع مکانی و زمانی Pseudo-nitzschia spp است. فراوانی (به بخش 3.1.1 مراجعه کنید ). برای این متغیرها، بر اساس نتایج آزمون من ویتنی، به دلیل همپوشانی بالاتر، تفاوت معنیداری بین هر دو کلاس وجود ندارد.
مقایسه مجموعه داده در [ 20 ] (1992-2002) با مورد استفاده شده در این کار (2002-2012)، افزایش جزئی در میانگین دما (از 14.75 درجه به 15.02 درجه) و شاخص بالا آمدن (از 39.68 به 170.43، نشان دهنده شیوع بالاتر شرایط بالا آمدن) قابل توجه است. تحقیقات بیشتری برای بررسی اینکه آیا این تغییرات با تغییرپذیری آب و هوا مرتبط هستند مورد نیاز است.
3.2. ماشینهای بردار پشتیبانی (SVM)
شکل 3 امتیاز F1 محاسبه شده در مجموعه اعتبارسنجی را با استفاده از SVM با RBF و هسته های چند جمله ای (درجات 2 تا 9) برای هر ترکیبی از ویژگی ها نشان می دهد. به طور کلی، هسته های چند جمله ای نتایج حاصل از هسته RBF را با افزایش حساسیت و ویژگی، اما به قیمت افزایش تعداد مثبت کاذب (دقت کمتر) با افزایش درجه چند جمله ای، بهبود می بخشند.
بهترین نتایج جهانی با مدل B، به ویژه با استفاده از یک هسته چند جمله ای درجه 5 (F1-score = 0.46) به دست می آید. بهترین SVM با ترکیب A با درجه 4 به دست می آید، در حالی که ترکیبات C و D به درجه بالاتر 9 نیاز دارند.
3.3. شبکه های عصبی (NN)
بهترین نتایج NN با استفاده از ترکیب A به دست می آید، اگرچه مدل های B و C نتایج مشابهی را نشان می دهند ( جدول 6 ). توجه داشته باشید که مدل C به بار محاسباتی بیشتری (بهینه با 10 لایه پنهان به دست می آید) نسبت به A (شش لایه پنهان) یا B (چهار لایه پنهان) نیاز دارد. نتایج با استفاده از ترکیب D از نظر امتیاز F1 و فاصله تا نقطه (0،1) در منحنی ROC ضعیفتر هستند، که نشان میدهد شاخصهای بالارفتگی برای به دست آوردن پیشبینیهای قابل اعتماد با استفاده از NN کافی نیستند.
بهترین MLP NN جهانی، با حداکثر امتیاز F1 0.53 و بر اساس ترکیب A، با شش لایه پنهان، 500 تکرار و ضریب تنظیم 0.05 به دست آمد. MLP با حداقل فاصله تا نقطه (0،1) در ROC، که همچنین بر اساس A است، حساسیت بالاتری را نشان میدهد اما به قیمت ویژگی و دقت پایینتر (مثبتهای غلط بیشتر) ( جدول 6 ).
3.4. جنگل تصادفی (RF)
به طور کلی، RF نتایج خوبی را با تعادل خوبی بین حساسیت، ویژگی و دقت، بدون توجه به پارامترهای آموزشی نشان میدهد. متأسفانه، تمایل زیادی برای اضافه کردن نیز وجود دارد، با معیارهای نزدیک به 1 در نتایج محاسبه شده در مجموعه آموزشی، به ویژه در مدل های A، B و C ( جدول 7 ).
با این حال، RF تمایل به بهبود با استفاده از متغیرهای کمتر دارد، که نشان میدهد این الگوریتمها را میتوان با گنجاندن دادههای بیشتر به جای متغیرهای بیشتر بهبود بخشید. در واقع، پیش بینی بهینه (40 کیسه و چهار متغیر انتخاب شده به عنوان پیش بینی کننده ضعیف) بر اساس ترکیب D (فقط با پنج متغیر)، با حداکثر امتیاز F1 0.60 و حداقل فاصله تا نقطه (0،1) در منحنی ROC 0.45. همچنین در مقایسه با سایر مدلهای بهینه، اضافه برازش کمتری را نشان میدهد ( جدول 7 ).
3.5. AdaBoost
برخلاف سایر روشهای یادگیری ماشینی نشاندادهشده در این کار، مدلهای AdaBoost با توجه به حداکثر امتیاز F1 و حداقل فاصله تا نقطه (0،1) در منحنی ROC انتخاب شدند که برای همه ترکیبهای متغیرها متفاوت است ( جدول 8 ). به طور کلی، مدلهایی با حداقل فاصله، حساسیت بالاتری را نشان میدهند، اما به قیمت ویژگی و دقت کمتر، نتایج مثبت کاذب بیشتری تولید میکنند. با این حال، در حالی که مدلهای مبتنی بر A و B تعادل بهتری را در بین معیارهای مختلف و نتایج مشابه در هر دو پیشبینیکننده ارائه میدهند، تفاوتهای مشخصتری بین هر دو مدل بهینه برای ترکیبهای C و D وجود دارد. به طور کلی، مدلهای بهتری با استفاده از نوع RUSBoost به دست آمد به استثنای مدل D مبتنی بر GentleBoost که حداکثر امتیاز F1 را دارد.
بهترین مدل های جهانی بر اساس ترکیب B، شامل همه متغیرها به جز روز سال و ریا هستند. مدل به حداکثر رساندن امتیاز F1 که با 200 چرخه آموزش داده شده است، امتیاز F1 0.61 و تعادل خوبی بین حساسیت و ویژگی را نشان می دهد. نتایج پیش بینی کننده به حداقل رساندن فاصله تا نقطه (0،1) در منحنی ROC (بر اساس 10 چرخه) بسیار مشابه است، با حساسیت کمی بالاتر اما ویژگی کمتر. نتایج مدل D به حداکثر رساندن امتیاز F1 (F1-score = 0.59) نیز قابل توجه است، زیرا این مدل تنها از شاخص های صعودی استفاده می کند ( جدول 8 ).
4. بحث
4.1. عملکرد مدل ها
به طور کلی، انتظار می رود که یک طبقه بندی کننده باینری خوب تعادل خوبی بین حساسیت و ویژگی نشان دهد، به عنوان مثال، دقت فردی خوب برای هر دو کلاس ( بدون شکوفه و شکوفایی ). از این رو، حداقل فاصله تا نقطه بهینه (0،1) در منحنی ROC به عنوان یکی از معیارها برای جستجوی مدلهای بهینه استفاده شد. با این حال، به دلیل توزیع نابرابر هر دو کلاس (~ 15٪ از شکوفه، جدول 3 را ببینید )، مدل های انتخاب شده بر اساس این معیار درصد بالایی از مثبت کاذب (دقت کم) را نشان می دهند. بنابراین، امتیاز F1 نیز برای انتخاب الگوریتمهای بهینه استفاده شد، زیرا این معیار برای مجموعه دادههای نامتعادل متعادلتر در نظر گرفته میشود [ 91 ، 92 ].
در برخی موارد، مدلهایی با حداکثر امتیاز F1، حداقل فاصله را تا نقطه بهینه (0،1) در منحنی ROC نشان میدهند. در مواردی که اختلاف وجود دارد، الگوریتمهایی با حداکثر امتیاز F1 معمولاً حساسیت کمتری نسبت به نمونههای معادل انتخاب شده با حداقل فاصله نشان میدهند، اما تعادل بهتری بین حساسیت، ویژگی و دقت نشان میدهند.
جدول 9 معیارهای محاسبه شده از مجموعه اعتبار سنجی را با استفاده از بهترین مدل ها برای هر روش با توجه به هر دو معیار، همچنین شامل نتایج [ 20 ] مقایسه می کند. به طور کلی، الگوریتمهای جدید (RF و AdaBoost) نتایج مناسبتری نسبت به الگوریتمهای کلاسیک (SVM و NN) ارائه میکنند، که مقادیر بهتری را برای معیارهای جهانی (امتیاز F1 و فاصله) و تعادل بهتری بین حساسیت و ویژگی نشان میدهند. الگوریتمهای کلاسیک حساسیت بالاتری را نشان میدهند، اما به قیمت ویژگی و دقت پایینتر و درصد بالای هشدارهای غلط.
شکل 4 منحنیهای ROC را برای چهار روش نشان میدهد و مدلهایی را با تعادل بهتر بین حساسیت و ویژگی نشان میدهد (یعنی با فاصله کوتاهتر تا نقطه بهینه (0،1)). برای NN ها و SVM ها، مدل های بهتر بر اساس همه متغیرها هستند (ترکیب A). برای RF، مدلهایی که از متغیرها در ترکیب D استفاده میکنند، فواصل کوتاهتری را نشان میدهند، که نشان میدهد شاخصهای صعودی برای تولید نتایج پیشبینی قابل اعتماد کافی هستند. در مورد AdaBoost، مدل های B بهترین نتایج جهانی را نشان می دهند. در واقع، الگوریتمهای RUSBoost مبتنی بر ترکیب B نه تنها فاصله کوتاهی تا نقطه بهینه (0،1) در منحنی ROC، بلکه مقادیر بالای امتیاز F1 را نیز نشان میدهند ( جدول 8 ).
نتایج بهتر به دست آمده توسط الگوریتم های جدید (RF و AdaBoost) را می توان با چندین دلیل توضیح داد. اولاً، الگوریتمهای کلاسیک به مقیاسبندی دادهها نیاز دارند، زیرا برای کارکرد صحیح به محدودههای ویژگیهای همگن متکی هستند. با این حال، مقیاس بندی هیچ تاثیری بر عملکرد RF و AdaBoost ندارد [ 85 ، 86 ، 90 ]. ثانیاً، ترکیب یادگیرندگان روشهای مجموعه منجر به مبادله سوگیری/واریانس بهتر و بهبود توانایی تعمیم در مقایسه با الگوریتمهای تکیه بر فرضیه واحد میشود [ 16 ، 86 ]]. توجه داشته باشید که نتایج از یک زیرمجموعه اعتبار سنجی که در روش آموزشی استفاده نشده است، محاسبه شده است. در نهایت، به نظر می رسد نتایج همچنین نشان دهنده انطباق بهتر الگوریتم های مجموعه (RF و AdaBoost) با مجموعه داده های نامتعادل است [ 93 ، 94 ].
با مقایسه الگوریتمهای کلاسیک، MLP SVMها را بهبود بخشید، علیرغم اینکه انتظار میرود SVMها تکنیک قویتری برای مسائل طبقهبندی دو کلاسه باشند. با این حال، به نظر می رسد نتایج SVM بیشتر تحت تأثیر عدم تعادل بین هر دو کلاس باشد. منحنی یادگیری ( شکل 5 ) مقداری بیش از حد برازش را نشان می دهد، به طوری که مدل تمایل دارد تا بیشترین کلاس ( بدون شکوفه ) را بهتر پیش بینی کند که منجر به ویژگی بالاتر اما به قیمت حساسیت کمتر می شود. SVM وزنی، به عنوان مثال، استفاده از وزن متفاوت برای هر کلاس برای اصلاح اثر عدم تعادل [ 20 ]، می تواند نتایج را بهبود بخشد. از سوی دیگر، منحنی یادگیری برای MLP ( شکل 5) وضعیتی را نشان می دهد که مناسب نیست و از این رو انتظار می رود مدل با افزودن متغیرهای جدید بهبود یابد.
بین RF و AdaBoost، AdaBoost کمی بهتر کار می کند. اگرچه بهترین مدل RF بهترین مقادیر دقت، ویژگی و دقت کلی را نشان میدهد، اما در مقایسه با مدلهای AdaBoost که بالاترین حساسیتها را برای دهه 2001-2012 نشان میدهند و بهترین تعادل بین معیارها را نشان میدهند، از نظر حساسیت شکست میخورد و منجر به حداکثر F1 میشود. -امتیاز و حداقل فاصله تا نقطه (0,1) در منحنی ROC.
مانند SVM، منحنی یادگیری بهترین الگوریتم RF (مدل D، شکل 5 ) نشان دهنده مقداری بیش از حد برازش است که منجر به دقت بالاتر کلاس اکثریت ( بدون شکوفایی ) و حساسیت کمتر در مقایسه با AdaBoost می شود. به طور کلی، انتظار می رود مدل های دارای اضافه برازش با افزایش تعداد نمونه ها بهبود یابند. در مورد RF، خطای واریانس را نیز می توان با کاهش پیچیدگی مدل (یعنی تعداد درختان تصمیم فردی) با انتخاب متغیرهای ورودی کمتر کاهش داد. در واقع، همانطور که در بخش 3.3 توضیح داده شد، اضافه برازش با RF بر اساس A، B و C واضح است، با یک تناسب تقریبا کامل در مجموعه تمرین مشاهده می شود، در حالی که مدل D نتایج بهتری را نشان می دهد. توجه داشته باشید که این مدل علیرغم اینکه با متغیرهای کمتری کار می کند، به دلیل در دسترس بودن رکوردهای معتبرتر، از نمونه های ورودی بیشتری استفاده می کند ( جدول 2 و جدول 3 را ببینید).
در مورد AdaBoost، منحنی یادگیری ( شکل 5 ) بهترین مدل، مقداری عدم تناسب را نشان میدهد، و از این رو، مدل را میتوان با انتخاب دیگری از متغیرهای ورودی بهبود بخشید. به نظر نمی رسد تعداد نمونه ها حیاتی باشد، زیرا خطای آموزش در بیش از 1000 نمونه آموزشی کم و بیش ثابت می ماند.
یکی از محدودیتهای اصلی مدلسازی شکوفههای Pseudo-nitzschia spp. در گالیسیا عدم تعادل در مجموعه داده است. نتایج را می توان با ایجاد یک مجموعه داده متعادل از طریق انتخاب تعدادی از نمونه های بدون شکوفه تقریباً برابر با تعداد رکوردهای شکوفایی بهبود بخشید. با این حال، این فرآیند می تواند منجر به از دست دادن اطلاعات مهم برای تبعیض هر دو طبقه شود.
کار آینده میتواند شامل توسعه مدلهای خاص برای یک دوره ria و/یا زمانی برای کار با مجموعه دادههای متعادلتر باشد. به عنوان مثال، برای دوره از ماه می تا سپتامبر، که بیش از 80٪ از کل گونه های Pseudo-nitzschia را تشکیل می دهد. رویدادها (به بخش 3.1.1 مراجعه کنید )، مجموعه داده نزدیک به 30 درصد از نمونه های شکوفه (70 درصد بدون شکوفه ) را شامل می شود. با این حال، علاوه بر کاربرد زمانی و/یا مکانی محدود آنها، تعداد کمتر رکوردها یا از دست دادن اطلاعات کلیدی ممکن است بر نتایج تأثیر بگذارد.
در این مطالعه، مدل ها را با استفاده از 2/3 کل رکوردها، با استفاده از رکوردهای باقی مانده (1/3) به عنوان مجموعه ای مستقل برای اعتبار سنجی آموزش دادیم. مقایسه مدلهایی که با استفاده از تعداد فزایندهای از نمونههای آموزشی (به عنوان مثال، 2/3، 3/4 و 4/5)، و در نتیجه رکوردهای کمتری برای اعتبارسنجی ایجاد شده است (به عنوان مثال، 1/3، 1/4 و 1/5) ، یک رویکرد جالب برای به دست آوردن بینشی در مورد قابلیت تعمیم تکنیک های مختلف یادگیری ماشین یا ترکیب ویژگی ها خواهد بود.
این کار عمدتاً بر مقایسه تکنیکهای مختلف یادگیری ماشین متمرکز بود، به طوری که مدلها با استفاده از گزینههای پیشفرض و یک رویکرد جستجوی شبکهای ساده برای انتخاب مقادیر بهینه پارامترهای اصلی آنها توسعه یافتند. بنابراین، تمام نتایج را می توان با تنظیم دقیق تر یا استفاده از رویکردهای پیشرفته در مراحل پیش پردازش، به عنوان مقیاس بندی (برای SVM و MLP) یا انتخاب ویژگی، بهبود بخشید.
4.2. مشارکت متغیر
علیرغم همبستگیهای موجود بین متغیرهای ورودی و گونههای شبه نیتسچیا . فراوانی ( جدول 5 )، تمایز بین کلاس های شکوفه و بدون شکوفه یک مسئله پیچیده و غیر خطی است. به دلیل همپوشانی بین هر دو کلاس، هیچ یک از متغیرها برای شناسایی شرایط شکوفه کافی نیستند.
به طور کلی، مدل های B بهتر از مدل های C و مشابه یا بهتر از مدل های A (به عنوان مثال، AdaBoost، به جدول 8 مراجعه کنید )، عملکرد بهتری دارند، که نشان دهنده اهمیت وقوع شکوفه ها در هفته قبل برای پیش بینی ها است. در مقابل، چندین مدل بدون اطلاعات زمانی (روز سال) یا مکانی ( ریا ) به درستی کار می کنند. توجه داشته باشید که تفاوت معنیداری بین هر دو کلاس برای این دو متغیر با استفاده از آزمونهای من ویتنی یافت نشد (به بخش 3.1.2 مراجعه کنید )، در حالی که سایر متغیرها مستقیماً با زمانی (به عنوان مثال، دما، شوری، شاخصهای بالا آمدن) و مکانی (شکوفه) مرتبط هستند. وقوع در هفته های گذشته) الگوهای توزیع گونه های Pseudo-nitzschia .
به نظر میرسد که شاخصهای صعودی یک متغیر حیاتی و ضروری برای پیشبینی هستند، زیرا حتی مدلهایی که فقط با شاخصهای افزایشی (مدل D) اجرا میشوند به نتایج معقولی دست مییابند (به عنوان مثال، RF، جدول 7 را ببینید ). شاخص های صعودی شامل چندین قله مثبت و منفی هستند، به طوری که نتایج خوب به دست آمده توسط RF/D را می توان با استحکام آن نسبت به الگوریتم های پرت توضیح داد [ 41 ].
گنجاندن متغیرهای جدید میتواند نتایج را بهبود بخشد، بهویژه برای مدلهایی که عدم تناسب را در منحنیهای یادگیری نشان میدهند (MLP و AdaBoost). بدون استفاده از مجموعه داده های جدید، تغییرات دما یا شوری از هفته قبل تا کنون می تواند اطلاعات مهمی در مورد تکامل گونه های Pseudo-nitzschia ارائه دهد. شکوفه می دهد.
غلظت کلوفیل یک نماینده خوب برای فراوانی فیتوپلانکتون است. اسپیراکوس و همکاران [ 74 ] پتانسیل الگوریتمهای کلروفیل-a منطقهای ماهوارهای را برای شناسایی «لکههای» فراوانی شبه نیتسشیا در ریاس نشان داد . چندین نویسنده استفاده از داده های ماهواره ای (غلظت کلروفیل، دمای سطح دریا) را به عنوان ورودی گونه های Pseudo-nitzschia پیشنهاد کرده اند. مدل های پیش بینی [ 61 ، 63 ، 65 ].
رابطه بین فراوانی گونه های شبه نیتسشیا . و غلظت مواد مغذی مختلف (عمدتا نیترات، نیتریت، فسفات و سیلیکات) به طور گسترده در مطالعات مشاهده ای مورد تجزیه و تحلیل قرار گرفته است [ 95 ، 96 ]. تعریف نقش مواد مغذی یک کار چالش برانگیز است زیرا غلظت ها در طول رشد شکوفه متفاوت است و از این رو روابط می تواند بسته به لحظه ای که در آن فراوانی اندازه گیری می شود متفاوت باشد. با این حال، غلظت مواد مغذی با موفقیت به عنوان یک محرک اجباری در گونه های Pseudo-nitzschia گنجانده شده است. مدل های پیش بینی [ 6 ، 8 ، 41 ].
متغیرهای جالب دیگر می تواند ورودی رودخانه یا بارش باشد، به عنوان شاخص های غیرمستقیم ورودی مواد مغذی از طریق تخلیه آب شیرین. توجه داشته باشید که این اثر تا حدودی در مقادیر شوری گنجانده شده است. علاوه بر این، برخی از نویسندگان ([ 97 ] و منابع موجود در آن) نشان داده اند که بالا آمدن منبع اصلی مواد مغذی در منطقه Rias Baixas است، در حالی که تخلیه آب شیرین نقش کمتری دارد.
4.3. مقایسه با سایر آثار
الگوریتمهای SVM با دادههای سالهای 1992 تا 2002 [ 20 ]، حساسیت خوبی را نشان میدهند، اما به قیمت تعداد زیادی از مثبتهای کاذب، ویژگی و دقت ضعیفتری را در مقایسه با RF یا AdaBoost نشان میدهند ( جدول 9 ). با این حال، بهترین SVM را برای دهه 2002-2012 با در نظر گرفتن امتیاز F1 و فاصله تا نقطه (0،1) در منحنی ROC بهبود میبخشد. این عملکرد بهتر را میتوان توضیح داد زیرا SVMهای توسعهیافته توسط [ 20 ] شامل تنظیم دقیقتری از مدلها، با استفاده از وزن متفاوت برای هر کلاس برای اصلاح اثر عدم تعادل است.
بهترین مدل خطی مناسب برای گونه های Pseudo-nitzschia . فراوانی توسعه یافته توسط [ 61 ] برای کانال سانتا باربارا توانست حدود 75 درصد از مشاهدات شکوفه و 93 درصد از مشاهدات بدون شکوفه را به درستی طبقه بندی کند ، که منجر به امتیاز F1 عالی 0.82 شد. نتایج به طور مستقیم قابل مقایسه نیستند، زیرا آنها با یک مجموعه داده کوچک ( 77 = n ) و متعادل با توزیع نرمال ورود به سیستم از گونههای Pseudo-nitzschia کار میکردند . فراوانی، از یک آستانه متفاوت برای تمایز بین کلاسهای بدون شکوفه و شکوفه استفاده کرد و ویژگیهای ورودی شامل دادههای تصاویر ماهوارهای و غلظت مواد مغذی بود.
نتایج خوبی نیز با استفاده از [ 8 ] با استفاده از رگرسیون لجستیک برای پیشبینی سالانه و فصلی شکوفههای سمزا Pseudo-nitzschia spp یافت شد. در خلیج مونتری (کالیفرنیا)، با استفاده از دما، شوری، شاخص های بالا آمدن، غلظت مواد مغذی و جریان رودخانه به عنوان ویژگی های ورودی. آنها با کار با مجموعه داده های متعادل تر (حدود 40٪ از شکوفه ها، بین 207 تا 222 نمونه)، مقادیر امتیاز F1 را بین 0.70 و 0.76 در بهترین مدل های خود گزارش کردند.
با استفاده از ویژگی های ورودی مشابه به عنوان [ 8 ] و یک مجموعه داده بلند مدت 22 ساله، یک رویکرد مدل خطی تعمیم یافته لجستیک (GLM) برای پیش بینی شکوفه های بالقوه سمی شبه نیتسشیا در خلیج Chesapeake [ 6 ] ایجاد شد، و مقادیر بهینه حساسیت را گزارش کرد. و دقت 0.75 و 0.48 به ترتیب. آنها با مجموعه دادههای نامتعادل (حدود 10 درصد شکوفهها با آستانه 100 سلول در لیتر) کار کردند، اما آستانههای پایینتری (10، 100 و 1000 سلول در لیتر) نسبت به کار ما برای تفکیک کلاسهای بدون شکوفه و شکوفایی اعمال کردند.
5. نتیجه گیری ها
در این کار، ما مجموعهای از مدلها را برای پیشبینی ظاهر گونههای Pseudo-nitzschia توسعه دادهایم . در منطقه Rias Baixas در یک تاریخ خاص و ریا شکوفا می شود. مدلها بر اساس متغیرهایی هستند که میتوانند در کوتاهمدت به صورت عملیاتی نظارت و/یا پیشبینی شوند، و از این رو میتوانند به راحتی برای ایجاد یک سیستم هشدار اولیه پیادهسازی شوند. این سیستم می تواند اطلاعات مفیدی را در اختیار تولیدکنندگان محلی صدف قرار دهد تا برنامه پایش را تکمیل کند و به کاهش تأثیر بالقوه شکوفه ها بر تولید صدف و سلامت عمومی کمک کند.
شکوفه ها بر حسب فراوانی کلی (105 سلول در لیتر) تعریف می شوند. بنابراین، یک محدودیت مهم این است که شکوفه های سمی تبعیض نمی شوند، با توجه به اینکه تولید DA به گونه بستگی دارد و همه شکوفه ها سمی نیستند [ 14 ]. اگرچه دادههای مربوط به گونههای خاص در دسترس نیست، اطلاعات محدودی در مورد بسته شدن پارکهای پرورش شناور صدف ناشی از غلظت ASP و DA روی نرم تنان وجود دارد (فقط از سال 2016)، که میتواند برای تشخیص شکوفههای سمی و بهبود مدلها در آینده مفید باشد. متغیرهای جدید، به عنوان مثال، غلظت مواد مغذی یا توزیع عمودی، نیز میتوانند برای بهبود الگوریتمها معرفی شوند.
مدلهایی که امتیاز F1 را به حداکثر میرسانند، بهعنوان مدلهای بهینه برای ایجاد یک سیستم پیشبینی HAB انتخاب شدند، زیرا انتظار میرود حساسیت بالایی (اگر شکوفهای در منطقه مورد مطالعه رخ دهد، سیستم باید آن را پیشبینی کند) و دقت (اگر شکوفایی وجود دارد) را نشان دهند. پیش بینی شده، باید وجود داشته باشد) [ 60 ]. با این حال، اگر کاربران علاقه بیشتری به پیشبینی شکوفههای بیشتر به قیمت آلارمهای کاذب بیشتر دارند، مدلهایی که فاصله تا نقطه بهینه (۰،۱) در منحنی ROC را به حداقل میرسانند میتوانند گزینه بهتری باشند.
اگر سیستم های پیش بینی HAB شامل داده های نظارتی با فرکانس زمانی و پوشش مکانی بالاتر باشد، دقیق تر خواهند بود. به عنوان مثال، تجزیه و تحلیل محصولات نقشه به دست آمده از تصاویر ماهواره ای نوری، از جمله کلروفیل-یک غلظت یا شاخص های گونه، می تواند مکمل برنامه نظارت موجود بر اساس مشاهدات مستقیم باشد [ 98 ]. علاوه بر این، توسعه سیستمهای حسگر خودکار با فرکانس اندازهگیری بالا در ایستگاهها و اعماق مختلف، یا استفاده از پهپادها امکان دستیابی به موفقیت در تشخیص رویدادهای توسعه جلبکهای سمی در سیستمهای ساحلی را فراهم میکند.
در نهایت، روشهای یادگیری ماشین همچنین میتوانند برای مطالعه تغییرات بالقوه در الگوهای توزیع گونههای تشکیلدهنده HAB مرتبط با تنوع آب و هوا مفید باشند.
منابع
- Gobler، CJ; Doherty، OM; Hattenrath-Lehmann، TK; گریفیث، AW; کانگ، ی. Litaker، RW گرم شدن اقیانوس از سال 1982، شکوفه های جلبکی سمی را در اقیانوس اطلس شمالی و اقیانوس آرام شمالی گسترش داده است. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2017 ، 114 ، 4975–4980. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- گریفیث، AW; Gobler, CJ شکوفه های جلبکی مضر: یک عامل استرس زا در تغییرات آب و هوا در اکوسیستم های دریایی و آب شیرین. جلبک مضر 2020 ، 91 ، 101590. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- اندرسون، دی. Cembella، A. هالگراف، جی. پیشرفت در درک شکوفه های جلبکی مضر: تغییرات پارادایم و فناوری های جدید برای تحقیق، نظارت و مدیریت. ان Rev. Mar. Sci. 2012 ، 4 ، 143-176. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رویکردهای اندرسون، DM برای نظارت، کنترل و مدیریت شکوفه های جلبکی مضر (HABs). ساحل اقیانوس مناگ. 2009 ، 52 ، 342. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- اندرسون، CR; مور، اسکی. تاملینسون، ام سی؛ سیلک، جی. Cusack، CK زندگی با شکوفه های جلبکی مضر در جهان در حال تغییر: استراتژی هایی برای مدل سازی و کاهش اثرات آنها در اکوسیستم های دریایی ساحلی. در خطرات، خطرات و بلایای ساحلی و دریایی ؛ Shroeder، JF، Ellis، JT، Sherman، DJ، Eds. الزویر: آمستردام، هلند، 2015; ص 495-561. [ Google Scholar ]
- اندرسون، CR; متیو ساپیانو، آرپی؛ کریشنا پراساد، MB; لانگ، دبلیو. تانگو، پی جی؛ براون، CW; Murtugudde, R. پیشبینی شکوفههای شبه نیتزشیای سمی بالقوه در خلیج Chesapeake. جی مارس سیست. 2010 ، 83 ، 127-140. [ Google Scholar ] [ CrossRef ]
- منینگ، NF; وانگ، Y.-C. طولانی، CM؛ برتانی، IM; سیرز، جی. Bosse، KR; شوچمن، RA; Scavia, D. گسترش مدل پیشبینی: پیشبینی شکوفههای جلبکی مضر دریاچه ایری غربی در مقیاسهای فضایی متعدد. J. Great Lakes Res. 2019 ، 45 ، 587-595. [ Google Scholar ] [ CrossRef ]
- لین، جی. Raimondi، PT; Kudela، RM توسعه یک مدل رگرسیون لجستیک برای پیشبینی شکوفههای سمی شبه نیتسشیا در خلیج مونتری، کالیفرنیا. مارس اکل. Prog. سر. 2009 ، 383 ، 37-51. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- راین، آر. مک درموت، جی. سیلک، جی. لیون، ک. نولان، جی. Cusack، C. یک مدل برد کوتاه ساده برای پیشبینی رویدادهای مضر جلبکی در خلیجهای جنوب غربی ایرلند. جی مارس سیست. 2010 ، 83 ، 150-157. [ Google Scholar ] [ CrossRef ]
- ولف، جی. آتاناسوا، ن. کمپاره، بی. پرکالی، ر. Ožanić، N. مدل های توصیفی و پیش بینی فیتوپلانکتون در شمال آدریاتیک. Ecol. مدل. 2011 ، 222 ، 2502-2511. [ Google Scholar ] [ CrossRef ]
- مک گوان، جی. دیل، ای آر. بله، اچ. کارتر، ام ال. پرتی، سی تی. Seger، KD; دو ورنیل، ا. Sugihara, G. پیش بینی شکوفه های جلبک ساحلی در جنوب کالیفرنیا. اکولوژی 2017 ، 98 ، 1419-1433. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دروت، جی. یاجیما، اچ. Jacquet, S. پیشرفت در پیشبینی شکوفههای مضر جلبکی با استفاده از مدلهای یادگیری ماشین: مطالعه موردی با Planktothrix rubescens در دریاچه ژنو. جلبک مضر 2020 ، 99 ، 101906. [ Google Scholar ] [ CrossRef ]
- Huettmann، F. کریگ، ای اچ. هریک، کالیفرنیا؛ Baltensperger، AP; Humphries، GRW; لیسک، دی جی؛ میلر، ک. کفال، TC; اوپل، اس. رزندیز، سی. و همکاران استفاده از یادگیری ماشین (ML) برای پیشبینی و تجزیه و تحلیل دادههای اکولوژیکی و «فقط حضور»: مروری بر برنامهها و چشمانداز خوب. در یادگیری ماشینی برای اکولوژی و مدیریت منابع طبیعی پایدار ؛ هامفریز، جی.، مگنس، DR، Huettmann، F.، ویرایش. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2018; صص 27-61. [ Google Scholar ]
- رالستون، آر. مور، SK مدلسازی شکوفههای جلبکی مضر در آب و هوای متغیر. جلبک مضر 2020 ، 91 ، 101729. [ Google Scholar ] [ CrossRef ]
- روسو، BZ; برتون، ای. استوارت، آر. همیلتون، DP مروری بر ادبیات سیستماتیک مدلهای پیشبینی و پیشبینی شکوفههای سیانوباکتری در دریاچههای آب شیرین. Water Res. 2020 , 182 , 115959. [ Google Scholar ] [ CrossRef ]
- آره.؛ گائو، آر. ژانگ، دی. لیو، Z.-P. پیشبینی شکوفههای جلبک ساحلی با عوامل محیطی با روشهای یادگیری ماشینی Ecol. اندیک. 2021 ، 123 ، 107334. [ Google Scholar ] [ CrossRef ]
- Boser، BE; Guyon، IM; Vapnik، VN یک الگوریتم آموزشی برای طبقهبندیکننده حاشیه بهینه. در مجموعه مقالات پنجمین کارگاه سالانه تئوری یادگیری محاسباتی، پیتسبورگ، PA، ایالات متحده آمریکا، 27-29 ژوئیه 1992; انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 1992. [ Google Scholar ]
- Vapnik، V. روش بردار پشتیبان تخمین تابع. در مدلسازی غیرخطی ; Suykens, JAK, Vandewalle, J., Eds. Springer: Boston, MA, USA, 1998; صص 55-85. [ Google Scholar ]
- Vapnik، VN ماهیت نظریه یادگیری آماری . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- گونزالس ویلاس، ال. اسپیراکوس، ای. تورس پالنزوئلا، جی.ام. Pazos, Y. روش مبتنی بر ماشین بردار پشتیبان برای پیشبینی گونههای Pseudo-nitzschia . در آب های ساحلی (ریاس گالیسی، شمال غربی اسپانیا) شکوفا می شود. Prog. اقیانوسگر. 2014 ، 124 ، 66-77. [ Google Scholar ] [ CrossRef ]
- چن، اس. زی، ز. لو، آی. Ung، WK; Mok، KM پیشبینی شکوفه جلبکی آب شیرین توسط ماشین بردار پشتیبان در مخازن ذخیرهسازی ماکائو. ریاضی. مشکل مهندس 2012 ، 2012 ، 397473. [ Google Scholar ]
- گارسیا نیتو، پی جی; آلونسو فرناندز، جی آر. گونزالس سوارز، VM; دیاز مونیز، سی. گارسیا-گونزالو، ای. مایو بایون، R. یک روش مبتنی بر SVM بهینه سازی شده PSO ترکیبی برای پیش بینی محتوای سیانوتوکسین از غلظت سیانوباکتری های تجربی در مخزن تراسونا: مطالعه موردی در شمال اسپانیا. Appl. ریاضی. محاسبه کنید. 2015 ، 260 ، 170-187. [ Google Scholar ]
- ریبیرو، آر. Torgo، L. یک مطالعه مقایسه ای در مورد پیش بینی شکوفه جلبک در رودخانه Douro، پرتغال. Ecol. مدل. 2008 ، 212 ، 86-91. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لو، آی. زی، ز. Ung، WK; Mok، KM ادغام رگرسیون بردار پشتیبانی با بهینهسازی ازدحام ذرات برای مدلسازی عددی برای شکوفههای جلبکی آب شیرین. Appl. ریاضی. مدل. 2015 ، 39 ، 5907-5916. [ Google Scholar ] [ CrossRef ]
- شن، جی. Qin، Q. وانگ، ی. سیسون، ام. یک رویکرد مدلسازی مبتنی بر داده برای شبیهسازی شکوفههای جلبکی در آب شیرین جزر و مدی رودخانه جیمز در پاسخ به بارگذاری مواد مغذی رودخانه. Ecol. مدل. 2019 ، 398 ، 44-54. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بورل، ام. کریشی، سی. مارتینز، A. روشهای اجماع مبتنی بر تکنیکهای یادگیری ماشین برای پیشبینی حضور-غیاب فیتوپلانکتونهای دریایی. Ecol. Inf. 2017 ، 42 ، 46-54. [ Google Scholar ] [ CrossRef ]
- گوکاراجو، بی. دوربه، اس اس. پادشاه، RL; Younan، NH رویکرد داده کاوی مکانی-زمانی مبتنی بر یادگیری ماشین برای تشخیص شکوفه های جلبکی مضر در خلیج مکزیک. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2011 , 4 , 710–720. [ Google Scholar ] [ CrossRef ]
- هیل، روابط عمومی؛ کومار، ا. تمیمی، م. Bull, DR HABNet: یادگیری ماشینی، تشخیص شکوفه های جلبکی مضر بر اساس سنجش از راه دور. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2020 , 13 , 3229–3239. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. یو، جی. جیا، ز. آهنگ، جی. پیشبینی شکوفههای جلبکی مضر با مدلهای یادگیری ماشینی در بندر طلوع. در مجموعه مقالات کنفرانس بین المللی محاسبات هوشمند، هنگ کنگ، چین، 3 تا 5 نوامبر 2014. انجمن کامپیوتر IEEE: واشنگتن، دی سی، ایالات متحده آمریکا، 2015; ص 245-250. [ Google Scholar ]
- لک، س. دلاکوست، ام. باران، پ. لاوگا، جی. Aulagnier, S. کاربرد شبکه عصبی برای مدلسازی غیرخطی در اکولوژی. Ecol. مدل. 1996 ، 90 ، 39-52. [ Google Scholar ] [ CrossRef ]
- McCulloch، WS; پیتس، دبلیو. حساب منطقی ایدههای ماندگار در فعالیت عصبی. گاو نر ریاضی. Biol. 1990 ، 52 ، 99-115. [ Google Scholar ] [ CrossRef ]
- رکنگل، اف. بابین، جی. ویگهام، پی. ویلسون، اچ. کاربرد مقایسه ای شبکه های عصبی مصنوعی و الگوریتم های ژنتیک برای مدل سازی سری زمانی چند متغیره شکوفه های جلبکی در دریاچه های آب شیرین. J. Hydroinform. 2002 ، 4 ، 125-133. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وی، بی. سوگیورا، ن. Maekawa, T. استفاده از شبکه عصبی مصنوعی در پیشبینی شکوفههای جلبکی. Water Res. 2001 ، 35 ، 2022-2028. [ Google Scholar ] [ CrossRef ]
- شیائو، ایکس. او، جی. هوانگ، اچ. Miller, TR; کریستاکوس، جی. Reichwaldt، ES; قدوانی، ع. لین، اس. خو، X. شی، جی. یک رویکرد تک پارامتری جدید برای پیشبینی شکوفههای جلبکی. Water Res. 2017 ، 108 ، 222-231. [ Google Scholar ] [ CrossRef ]
- براون، CW; هود، RR; لانگ، دبلیو. جیکوبز، جی. رامرز، دی. وزنیاک، سی. ویگرت، جی. وود، آر. Xu, J. پیشبینی اکولوژیک در خلیج چساپیک: با استفاده از یک رویکرد مدلسازی مکانیکی-تجربی. جی مارس سیست. 2013 ، 125 ، 113-125. [ Google Scholar ] [ CrossRef ]
- گولار، سی. دلگادو، م. دیوگن، جی. Fernández-Tejedor، M. رویکرد شبکه عصبی مصنوعی به پویایی جمعیت شکوفههای جلبکی مضر در خلیج آلفاکس (در شمال غربی مدیترانه): مطالعات موردی Karlodinium و Pseudo-nitzschia . Ecol. مدل. 2016 ، 338 ، 37-50. [ Google Scholar ] [ CrossRef ]
- لی، JHW; هوانگ، ی. دیکمن، ام. Jayawardena، مدلسازی شبکه عصبی AW شکوفههای جلبکی ساحلی. Ecol. مدل. 2003 ، 159 ، 179-201. [ Google Scholar ] [ CrossRef ]
- ولو سوارز، ال. رویکردهای شبکه عصبی مصنوعی Gutierrez-Estrada، JC برای پیشبینی هفتگی یک مرحلهای شکوفههای Dinophysis acuminata در Huelva (غرب اندلس، اسپانیا). جلبک مضر 2007 ، 6 ، 361-371. [ Google Scholar ] [ CrossRef ]
- کود، پ. کاترز، بی. توپ، JE; Kadluczka، R. مدیریت فعال شکوفه های جلبکی دهانه رودخانه با استفاده از شناور نظارت خودکار همراه با یک شبکه عصبی مصنوعی. محیط زیست مدل. نرم افزار 2014 ، 61 ، 393-409. [ Google Scholar ] [ CrossRef ]
- تیان، دبلیو. لیائو، ز. Zhang, J. بهینه سازی مدل شبکه عصبی مصنوعی برای پیش بینی دینامیک کلروفیل. Ecol. مدل. 2017 ، 364 ، 42-52. [ Google Scholar ] [ CrossRef ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. Wu, H. مدل هشدار شکوفایی آب بر اساس جنگل تصادفی. در مجموعه مقالات کنفرانس بین المللی 2017 در زمینه انفورماتیک هوشمند و علوم زیست پزشکی (ICIIIBMS)، اوکیناوا، ژاپن، 24 تا 26 نوامبر 2017؛ موسسه مهندسین برق و الکترونیک (IEEE): نیویورک، نیویورک، ایالات متحده آمریکا، 2018؛ ص 45-48. [ Google Scholar ]
- ایوانز، جی اس. مورفی، MA; هولدن، ZA; Cushman، SA مدلسازی توزیع و تغییر گونه ها با استفاده از جنگل تصادفی. در مدل سازی گونه های پیش بینی و زیستگاه در بوم شناسی منظر ; Drew, C., Wiersma, Y., Huettmann, F., Eds.; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; صص 139-159. [ Google Scholar ]
- وی، CL; رو، GT؛ اسکوبار-بریونز، ای. بوتیوس، ا. سولت ودل، تی. کیلی، ام جی; سلیمان، ی. Huettmann، F. کو، اف. یو، ز. و همکاران الگوهای جهانی و پیش بینی زیست توده بستر دریا با استفاده از جنگل های تصادفی. PLoS ONE 2010 , 5 , 15323. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دروت، جی. یاجیما، اچ. اشمیت، جی. مزایای یادگیری ماشین و فرکانس نمونه برداری در پیش بینی شکوفایی فیتوپلانکتون در مناطق ساحلی. Ecol. Inf. 2020 , 60 , 101174. [ Google Scholar ] [ CrossRef ]
- هارلی، جی آر. Lanphier، K. کندی، ای. وایتهد، سی. Bidlack، JR طبقهبندی جنگل تصادفی برای تعیین محرکهای محیطی و پیشبینی سموم فلجکننده صدف در جنوب شرقی آلاسکا با وضوح زمانی بالا. جلبک مضر 2020 ، 99 ، 101918. [ Google Scholar ] [ CrossRef ]
- والبی، ای. ریچی، اف. کاپلاچی، اس. کازابیانکا، اس. اسکاردی، م. Penna، A. یک مدل پیش بینی PSP دینوفلاژلات سمی Alexandrium minutum در آب های ساحلی دریای آدریاتیک NW. علمی جمهوری 2019 ، 9 ، 4166. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ینیگز، AT; Ottong، ZJ با استفاده از یک مدل یادگیری ماشینی، کشتار ماهی و شکوفههای سمی را در یک سایت دریایی فشرده در فیلیپین پیشبینی میکند. علمی کل محیط. 2020 , 707 , 136173. [ Google Scholar ] [ CrossRef ]
- فروند، ی. Schapire، RE یک تعمیم تصمیم-نظری یادگیری آنلاین و یک کاربرد برای تقویت. جی. کامپیوتر. سیستم علمی 1997 ، 55 ، 119-139. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کدوی، روابط عمومی; لی، سی.- دبلیو. لی، اس. کاربرد مدلهای یادگیری ماشینی مبتنی بر مجموعه برای نقشهبرداری حساسیت زمین لغزش. Remote Sens. 2018 , 10 , 1252. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پنگ، ال. لیو، ک. کائو، جی. زو، ی. لی، اف. لیو، ال. ترکیب دادههای ماهوارهای GF-2 و RapidEye برای نقشهبرداری از گونههای حرا با استفاده از روشهای یادگیری ماشینی مجموعه. بین المللی J. Remote Sens. 2020 , 41 , 813-838. [ Google Scholar ] [ CrossRef ]
- تران، تی. Hoang, N. پیشبینی ظاهر جلبک روی سطح ملات با مجموعهای از مدلهای فازی عصبی تطبیقی: مطالعه مقایسهای استراتژیهای گروه. بین المللی جی. ماخ. فرا گرفتن. سایبر. 2019 ، 10 ، 1687-1704. [ Google Scholar ] [ CrossRef ]
- Stumpf، RP; تاملینسون، ام سی؛ کالکینز، جی. کرک پاتریک، بی. فیشر، ک. نیرنبرگ، ک. کریر، آر. ارزیابی مهارت Wynne، TT برای یک سیستم پیشبینی شکوفه جلبکی عملیاتی. جی مارس سیست. 2009 ، 76 ، 151-161. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- هالگراف، شکوفههای جلبکی مضر GM: مروری بر جهانی. در کتابچه راهنمای میکروجلبک های دریایی مضر . Hallegraeff, GM, Anderson, DM, Cembella, ED, Eds. یونسکو: پاریس، فرانسه، 2004; جلد 33، صص 25–80. [ Google Scholar ]
- بیتس، اس اس. پادگان، DL; هورنر، دینامیک RA بلوم و فیزیولوژی گونه های سودونیتزشیا تولید کننده اسید دوموئیک . در بوم شناسی فیزیولوژیکی شکوفه های مضر جلبک ; Anderson، DM، Cembella، ED، Hallegraeff، GM، Eds. Springer: برلین/هایدلبرگ، آلمان، 1998; ص 267-292. [ Google Scholar ]
- اندرسون، CR; برژینسکی، کارشناسی ارشد؛ واشبرن، ال. Kudela، R. گردش خون و شرایط محیطی در طول یک شکوفه سمی Pseudo-nitzschia australis در کانال سانتا باربارا، کالیفرنیا. مارس اکل. Prog. سر. 2006 ، 327 ، 119-133. [ Google Scholar ] [ CrossRef ]
- فراگا، اس. آلوارز، ام جی. میگز، آ. فرناندز، ام ال. کاستاس، ای. Lopez-Rodas، V. Pseudo-nitzschia گونه های جدا شده از آب های گالیسی: سمیت، محتوای DNA و سنجش اتصال لکتین. در جلبک های مضر ; Reguera, B., Blanco, B., Fernández, ML, Wyatt, T., Eds. Xunta de Galicia و کمیسیون بین دولتی یونسکو: سانتیاگو د کامپوستلا، اسپانیا، 1998; ص 270-273. [ Google Scholar ]
- پالما، اس. مورینو، اچ. سیلوا، ا. بارائو، م. Moita، MT آیا می توان شکوفه های شبه نیتسشیا را با بالا آمدن ساحلی در خلیج لیسبون مدل کرد؟ جلبک مضر 2010 ، 9 ، 294-303. [ Google Scholar ] [ CrossRef ]
- لوو، دی سی؛ Doucette، GJ; Lundholm، N. مورفولوژی و سمیت گونه های Pseudo-nitzschia در شمال سیستم بالا آمدن بنگوئلا. جلبک مضر 2018 ، 75 ، 118-128. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بلوم، آی. رائو، دی اس؛ یولیان، پی. سوامیناتان، اس. آدامز، NG; Subba Rao، DV توسعه مدلهای آماری برای پیشبینی سطوح اسید دوموئیک نوروتوکسین در دیاتومهای پنتی Pseudo-nitzschia pungens f. چند سری با استفاده از داده های فرهنگ ها و شکوفه های طبیعی. در فرهنگ های جلبکی، آنالوگ های شکوفه ها و کاربردها . سوبا رائو، دی وی، اد. Science Publishers: Enfield, CT, USA, 2006; جلد 2، ص 891–916. [ Google Scholar ]
- اندرسون، CR; سیگل، دی. کودلا، آر. برژینسکی، MA مدل های تجربی شکوفه های سمی شبه نیتسشیا : استفاده بالقوه به عنوان ابزار تشخیص از راه دور در کانال سانتا باربارا. جلبک مضر 2009 ، 8 ، 478-492. [ Google Scholar ] [ CrossRef ]
- ترسلیر، ن. گیپنس، ن. Lancelot, C. عوامل کنترل کننده تولید اسید دوموئیک توسط Pseudo-nitzschia (Bacillariophyceae) : یک مطالعه مدل. جلبک مضر 2013 ، 24 ، 45-53. [ Google Scholar ] [ CrossRef ]
- ساکائو کوادرادو، ام. Conde-Pardo، P. Otero-Tranchero، P. پیش بینی جزر و مد قرمز در سواحل گالیسیا. فضانورد Acta. 2003 ، 53 ، 439-443. [ Google Scholar ] [ CrossRef ]
- کیوزاک، سی. مورینو، اچ. مویتا، MT; Silke, J. مدلسازی رویدادهای شبه نیتسشیا در جنوب غربی ایرلند. J. Sea Res. 2015 ، 105 ، 30-41. [ Google Scholar ] [ CrossRef ]
- کیوزاک، سی. دابروفسکی، تی. لیون، ک. بری، ا. وستبروک، جی. سالاس، آر. دافی، سی. نولان، جی. Silke, J. سیستم پیشبینی شکوفه جلبکی مضر برای جنوب ایرلند. بخش دوم: آیا مدل های عملیاتی اقیانوس شناسی در سیستم هشدار HAB مفید هستند؟ جلبک مضر 2016 ، 53 ، 86-101. [ Google Scholar ] [ CrossRef ]
- Giddings، SN; مک کریدی، پی. هیکی، BM; بناس، NS; دیویس، کالیفرنیا؛ Siedlecki، SA; ترینر، VL; کودلا، آر.ام. پلند، NA; Connolly، TP از مسیرهای حمل و نقل مضر بالقوه شکوفه جلبکی در ساحل شمال غربی اقیانوس آرام. جی. ژئوفیس. Res. اقیانوس. 2014 ، 119 ، 2439-2461. [ Google Scholar ] [ CrossRef ]
- تاون هیل، BL; تینکر، جی. جونز، ام. پیتویس، اس. کریچ، وی. سیمپسون، SD; رنگ، اس. خرس، ای. Pinnegar، JK شکوفه های جلبکی مضر و تغییرات آب و هوایی: بررسی تغییرات توزیع در آینده. Ices J. Mar. Sci. 2018 ، 75 ، 1882-1893. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Wooster، WS; باکون، ع. مکلین، DR چرخه افزایش فصلی در امتداد مرز شرقی اقیانوس اطلس شمالی. J. Mar. Res. 1976 ، 34 ، 131-141. [ Google Scholar ]
- فراگا، اف. در سواحل گالیسیا، شمال غربی اسپانیا. در بالا آمدن ساحل ; ریچاردسون، FA، اد. اتحادیه ژئوفیزیک آمریکا: واشنگتن، دی سی، ایالات متحده آمریکا، 1981; صص 176-182. [ Google Scholar ]
- بلانتون، جو. تنور، KR؛ کاستیلیخو، FF; اتکینسون، LP; شوینگ، FB; Lavín، A. رابطه بالا آمدن با تولید صدف در ریاس سواحل غربی اسپانیا. J. Mar. Res. 1987 ، 45 ، 497-511. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بود، ا. وارلا، م. بارکورو، اس. اوسوریو آلوارز، م. گونزالس، N. مطالعات مقدماتی در مورد صادرات مواد آلی در طول شکوفایی فیتوپلانکتون در لاکرونیا (شمال غربی اسپانیا). جی. مار. بیول. دانشیار انگلستان 1998 ، 78 ، 1-15. [ Google Scholar ] [ CrossRef ]
- لابارتا، یو. Fernández-Reiriz، MJ صنعت صدف گالیسی: نوآوری و تغییرات در چهل سال گذشته. ساحل اقیانوس. مدیریت 2019 ، 167 ، 208-218. [ Google Scholar ] [ CrossRef ]
- آودلاس، ال. Avdic-Mravlje، E. بورخس مارکز، AC; کانو، اس. کپل، جی جی؛ کاروالیو، ن. کوزولینو، ام. دنیس، جی. الیس، تی. فرناندز پولانکو، جی.ام. و همکاران کاهش آبزی پروری صدف در اتحادیه اروپا: علل، اثرات اقتصادی و فرصت ها کشیش آبزیان. 2021 ، 13 ، 91-118. [ Google Scholar ] [ CrossRef ]
- اسپیراکوس، ای. گونزالس ویلاس، ال. تورس پالنزوئلا، جی.ام. بارتون، ED کلروفیل سنجش از دور a از آبهای پیچیده نوری (ریاس بایکساس، شمال غربی اسپانیا): استفاده از یک کلروفیل خاص منطقهای، یک الگوریتم برای دادههای با وضوح کامل MERIS در طول یک چرخه بالا آمدن. سنسور از راه دور محیط. 2011 ، 115 ، 2471-2485. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Margalef، R. Estructura y dinámica de la “purga de mar” en Ría de Vigo. تحقیق کنید. Pesq. 1956 ، 5 ، 113-134. [ Google Scholar ]
- Tilstone، GH; Figueiras، FG; Fraga، F. توالی بالارونده-پایین در تولید جزر و مد قرمز در یک سیستم بالا آمدن ساحلی. مار اکل. برنامه سر. 1994 ، 112 ، 241-253. [ Google Scholar ] [ CrossRef ]
- Figueiras، FG; جونز، کی جی. مسجدی، ع.م. آلوارز-سالگادو، XA; ادواردز، آ. مکدوگال، N. تشکیل مجمع جزر و مد قرمز در یک اکوسیستم رو به رشد رودخانه-ریا-دی-ویگو. J. Plankton Res. 1994 ، 16 ، 857-878. [ Google Scholar ] [ CrossRef ]
- GEOHAB. اکولوژی جهانی و اقیانوس شناسی شکوفه های مضر جلبک. در پروژه تحقیقاتی هستهای GEOHAB: HABs در سیستمهای Upwelling . Pitcher, P., Moita, T., Trainer, VL, Kudela, R., Figueiras, P., Probyn, T., Eds. IOC: پاریس، فرانسه؛ امتیاز: بالتیمور، MD، ایالات متحده آمریکا، 2005; صص 11-82. [ Google Scholar ]
- Figueiras، FG; Pazos، Y. هیدروگرافی و فیتوپلانکتون Ría de Vigo قبل و در طول جزر و مد قرمز Gymnodinium catenatum Graham. J. Plankton Res. 1991 ، 13 ، 589-608. [ Google Scholar ] [ CrossRef ]
- آلوارز-سالگادو، XA; لابارتا، یو. فرناندز-ریریز، ام جی. Figueiras، FG; روسون، جی. پیدراکوبا، اس. فیلگوئیرا، آر. Cabanas، JM زمان تجدید و تأثیر شکوفه های جلبکی مضر بر فرهنگ گسترده قایق صدفی سیستم بالا آمدن ساحلی ایبری (SW اروپا). جلبک مضر 2008 ، 7 ، 849-855. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رودریگز، GR; ویلاسانته، اس. García-Negro, MC آیا جزر و مد قرمز از نظر اقتصادی بر تجاری سازی پرورش صدف گالیسی (NW اسپانیا) تأثیر می گذارد؟ سیاست مارس 2011 ، 35 ، 252-257. [ Google Scholar ] [ CrossRef ]
- Utermöhl، H. Zur vervollkommnung der quantitativen phytoplankton-methodik. میت بین المللی نسخه نظریه. Unde Amgewandte Limnol. 1958 ، 9 ، 1-38. [ Google Scholar ] [ CrossRef ]
- هررا، جی ال. پیدراکوبا، اس. وارلا، RA; Roson، G. تحلیل آماری میدان باد در سواحل غربی گالیسیا (NW اسپانیا) از اندازهگیریهای درجا. ادامه Shelf Res. 2005 ، 25 ، 1728-1748. [ Google Scholar ] [ CrossRef ]
- باکون، A. شاخصهای افزایش سواحل، ساحل غربی آمریکای شمالی، 1946-1971 . گزارش فنی NOAA NMFS SSRF-671; وزارت بازرگانی ایالات متحده: سیاتل، WA، ایالات متحده آمریکا، 1973; صص 1-103.
- سارل، شبکه های عصبی WS و مدل های آماری. در مجموعه مقالات نوزدهمین کنفرانس بین المللی سالانه گروه کاربران SAS، Cary، NC، ایالات متحده، 10-13 آوریل 1994. موسسه SAS: Cary, NC, USA, 1994; صص 1538-1550. [ Google Scholar ]
- کهوی، ر. Provost, F. واژه نامه اصطلاحات. یادگیری ماشین – موضوع ویژه در مورد کاربردهای یادگیری ماشین و فرآیند کشف دانش. ماخ فرا گرفتن. 1998 ، 30 ، 271-274. [ Google Scholar ]
- کاروانا، آر. Niculescu-Mizil، A. مقایسه تجربی الگوریتم های یادگیری تحت نظارت. در مجموعه مقالات بیست و سومین کنفرانس بین المللی یادگیری ماشین (ICML’06)، پیتسبورگ، PA، ایالات متحده آمریکا، 25-29 ژوئن 2006. کوهن، دبلیو دبلیو، مور، ا.، ویرایش. انجمن ماشین های محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2006; صص 161-168. [ Google Scholar ]
- هستی، تی. طبشیرانی، ر. فریدمن، جی . عناصر یادگیری آماری. داده کاوی، استنتاج و پیش بینی ، ویرایش دوم. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2017. [ Google Scholar ]
- جنی، لس آنجلس; Cohn، JF; De La Torre, F. مواجهه با داده های نامتعادل – توصیه هایی برای استفاده از معیارهای عملکرد. در مجموعه مقالات کنفرانس انجمن انسانی 2013 در مورد محاسبات مؤثر و تعامل هوشمند، ژنو، سوئیس، 2 تا 5 سپتامبر 2013. انجمن کامپیوتر IEEE: واشنگتن، دی سی، ایالات متحده آمریکا، 2013; ص 245-251. [ Google Scholar ]
- Kubat, M. Introduction to Machine Learning , 2nd ed.; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2018. [ Google Scholar ]
- داسکالکی، س. کوپناس، آی. آووریس، ن. ارزیابی طبقهبندیکنندهها برای مسئله توزیع کلاس ناهموار. Appl. آرتیف. هوشمند 2006 ، 20 ، 381-417. [ Google Scholar ] [ CrossRef ]
- Ghoneim، S. دقت، یادآوری، دقت، امتیاز F و ویژگی. کدام را بهینه کنیم؟ به سوی علم داده 2 آوریل 2019. در دسترس آنلاین: https://towardsdatascience.com/accuracy-recall-precision-f-score-specificity-which-to-optimize-on-867d3f11124 (در 18 ژانویه 2021 قابل دسترسی است).
- کائور، اچ. Pannu، HS; Malhi، AK مروری سیستماتیک در مورد چالش های داده های نامتعادل در یادگیری ماشین: کاربردها و راه حل ها. کامپیوتر ACM. Surv. 2019 ، 52 ، 79. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لوپز، وی. فرناندز، آ. گارسیا، اس. پالاد، وی. هررا، اف. بینشی در طبقه بندی با داده های نامتعادل: نتایج تجربی و روندهای فعلی در استفاده از ویژگی های ذاتی داده ها. Inf. علمی 2013 ، 250 ، 113-141. [ Google Scholar ] [ CrossRef ]
- تورل، ام. کلاکوین، پی. شاپیرا، م. لو ژاندر، آر. ریو، پی. گوکس، دی. لو روی، بی. رایمبو، وی. Deton-Cabanillas، AF; بازین، پ. و همکاران نسبتهای مواد مغذی بر تنوع در تنوع گونههای شبه نیتسشیا و تولید اسید دوموئیک ذرات در خلیج سن (فرانسه) تأثیر میگذارند. جلبک مضر 2017 ، 68 ، 192-205. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- تورس پالنزوئلا، جی.ام. گونزالس ویلاس، ال. بلاس، اف ام؛ گرت، ای. گونزالس-فرناندز، Á. اسپیراکوس، ای . Water 2019 ، 11 ، 1954. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Doval، MD; لوپز، آ. Madriñán، M. تغییرات زمانی و روند مواد مغذی معدنی در بالا آمدن ساحلی شمال غربی اسپانیا (Rías Galician Atlantic). J. Sea Res. 2016 ، 108 ، 19-29. [ Google Scholar ] [ CrossRef ]
- تورس پالنزوئلا، جی.ام. گونزالس ویلاس، ال. بلاس آلائز، FM; Pazos، Y. کاربرد بالقوه ماهواره های نگهبان جدید برای نظارت بر شکوفه های جلبکی مضر در آبزی پروری گالیسی. تالاساس 2020 ، 36 ، 85-93. [ Google Scholar ] [ CrossRef ]
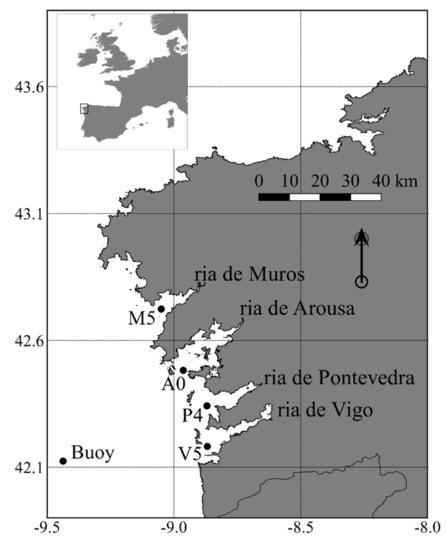
شکل 1. Rias Baixas (Muros، Arousa، Pontevedra و Vigo) در سواحل جنوب غربی گالیسیا (شمال غربی شبه جزیره ایبری) واقع شده است. مکان ایستگاه های مورد استفاده برای این مطالعه (M5، A0، P4، V5 و بویه Cabo Silleiro) نشان داده شده است.
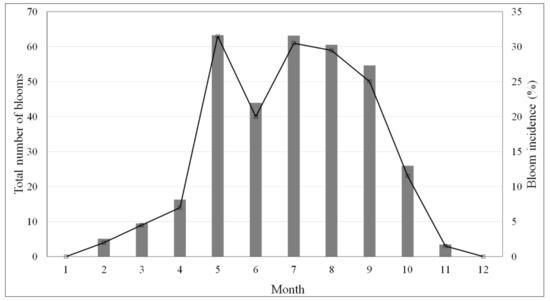
شکل 2. توزیع ماهانه تعداد کل شکوفه های Pseudo-nitzschia spp. (خط سیاه، محور چپ) و بروز شکوفه (نوار خاکستری، محور راست) برای Rias Baixas گالیسی از سال 2002 تا 2012.
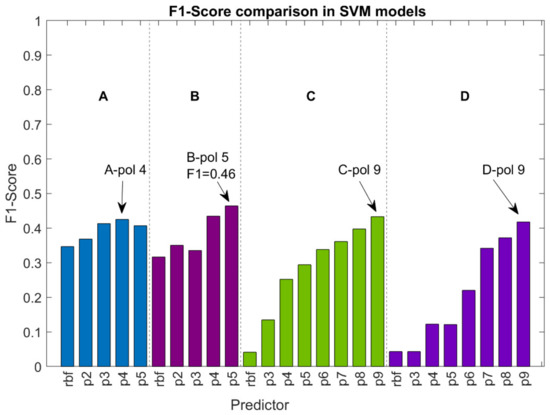
شکل 3. مقایسه مدل های ماشین های بردار پشتیبان (SVM) با استفاده از آماره امتیاز F1. الف، ب، ج، د: ترکیبی از ویژگی ها. rbf: هسته پایه شعاعی گاوسی. p2–p9: هسته چند جمله ای درجه از 2 تا 9.
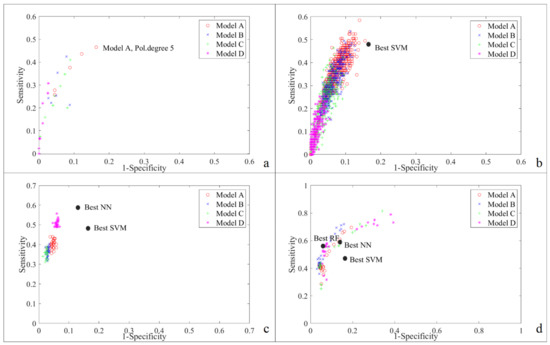
شکل 4. منحنیهای ROC که نتایج طبقهبندی را رسم میکنند، از مجموعه اعتبارسنجی برای مدلهای مبتنی بر پیکربندیهای پارامتری مختلف و ترکیبهای متغیر (A، B، C یا D) برای چهار روش یادگیری ماشینی مورد استفاده در این کار محاسبه میشوند: ( الف ) SVM. ( ب ) MLP NN; ( ج ) RF؛ و ( د ) AdaBoost.
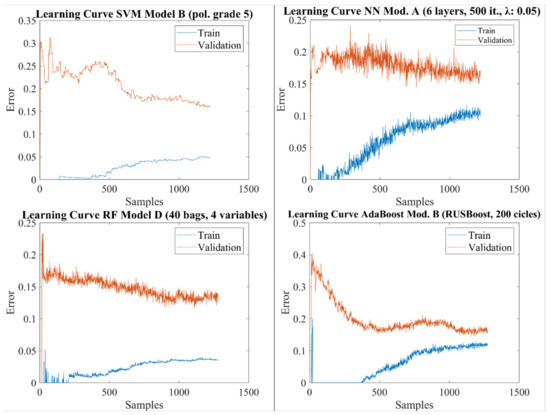
شکل 5. منحنی های یادگیری برای بهترین مدل ها (به حداکثر رساندن F1) برای هر روش یادگیری ماشین.


بدون دیدگاه