

کلید واژه ها:
نقشه شماتیک ; شبکه مترو ؛ قرار دادن برچسب ؛ برچسب زدن خودکار ؛ شبکه های عصبی مصنوعی
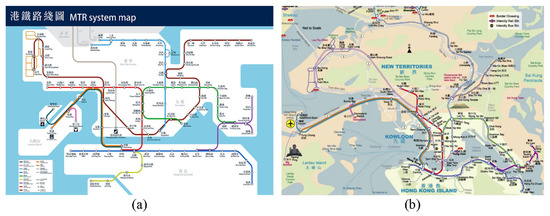
1. مقدمه
2. برچسب زدن خودکار نقشه ها: تجزیه و تحلیل روش های موجود و یک استراتژی
2.1. تجزیه و تحلیل روشهای برچسبگذاری خودکار موجود برای نقشهها
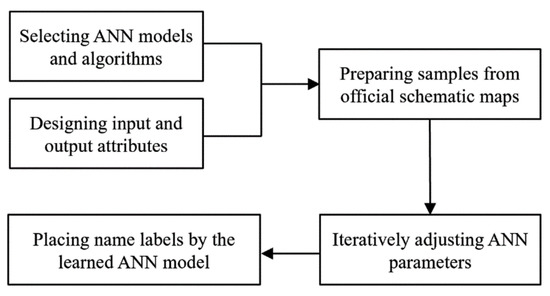
2.2. استراتژی مبتنی بر شبکه های عصبی مصنوعی
-
نمونههای قرارگیری برچسب نام از نقشههای شماتیک موجود استخراج میشوند.
-
نمونههای بهدستآمده برای آموزش و آزمایش شبکههای عصبی مصنوعی برای برچسبگذاری خودکار استفاده میشوند.
3. مدلها، ورودی و خروجی شبکههای عصبی مصنوعی برای برچسبگذاری خودکار
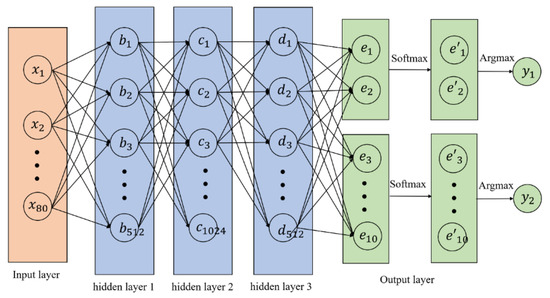
3.1. مدل های اساسی و پارامترهای شبکه های عصبی مصنوعی
3.2. ویژگی های ورودی برای شبکه های عصبی مصنوعی
-
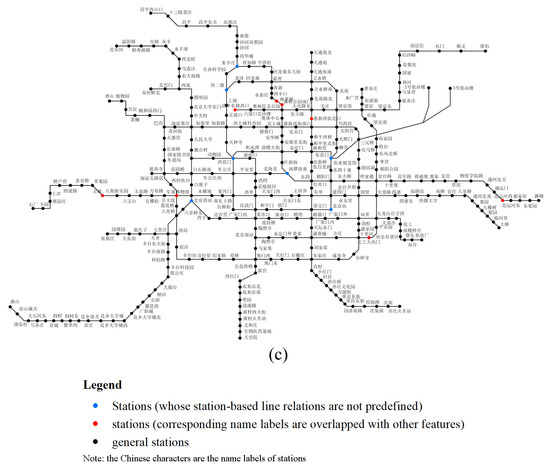
روابط خط مبتنی بر ایستگاه
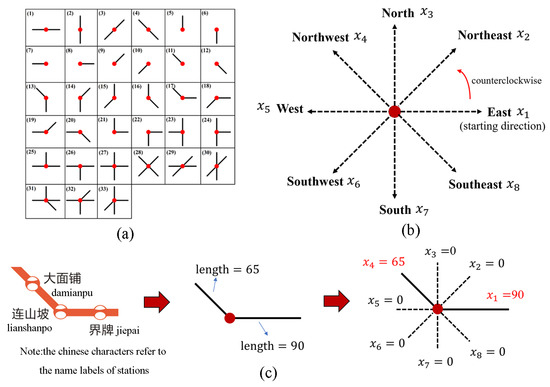
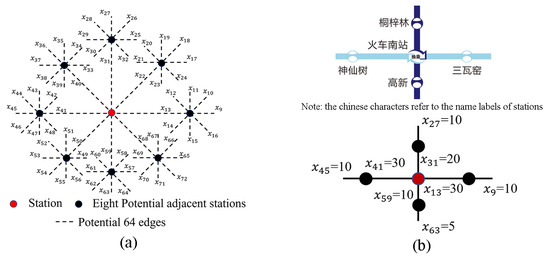
در نقشه های شماتیک مترو، هر برچسب نام با یک ایستگاه مستقل مرتبط است. متمایزترین ویژگی قرار دادن چنین برچسبهایی، روابط خط مبتنی بر ایستگاه بین ایستگاهها و خطوط اتصال (یا لبهها) است. تحت طراحی اکتی خطی خطوط، لبه ها را می توان در هشت جهت (یعنی دو جهت افقی، دو جهت عمودی و چهار جهت مورب) جهت داد. با توجه به ترکیبات موجود در ریاضیات، در مجموع 255 نوع روابط خط مبتنی بر ایستگاه تحت طراحی اکتی خطی وجود دارد:
-
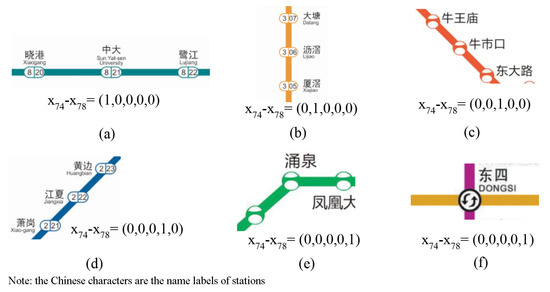
روابط اتصال بین ایستگاه های مجاور و لبه ها
-
طول برچسب نام
برچسب های نام از کاراکترهای زبان تشکیل شده اند. به طور کلی، در نقشه مترو شماتیک، اندازه کاراکترهای زبان یکسان است. یک متغیر اعشاری غیر منفی (یعنی ) برای ذخیره طول برچسب های نام داده می شود. در این مطالعه طول یک برچسب نام به صورت زیر محاسبه می شود:
جایی که به تعداد کاراکترهای زبان اشاره دارد و به طول کاراکتر زبان اشاره دارد. چند نمونه از برچسب های نام با طول های مختلف در شکل 6 آورده شده است.
-
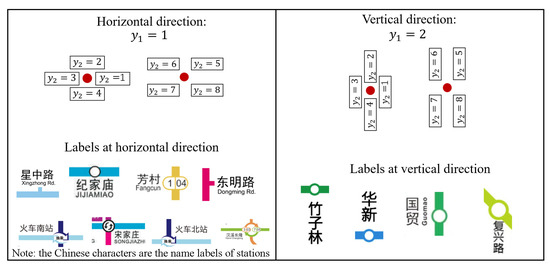
جهت خطوط عملیاتی
-
مختصات نقاط
3.3. ویژگی های خروجی برای شبکه های عصبی مصنوعی
4. آموزش و آزمایش مدل های ANN برای برچسب گذاری خودکار
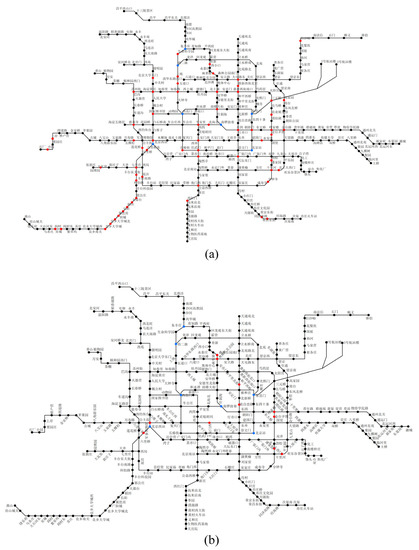
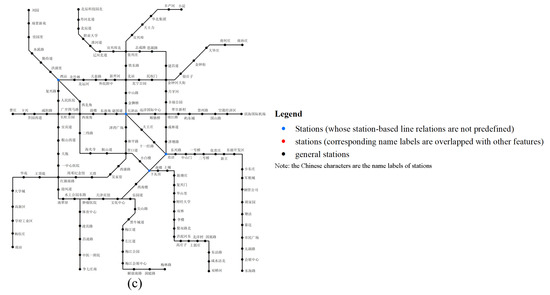
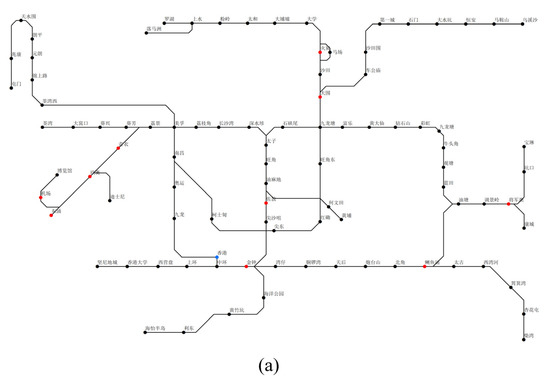
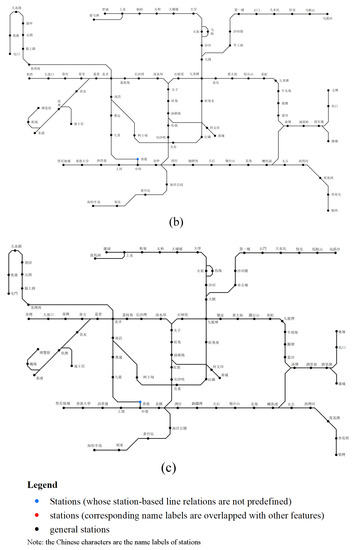
4.1. مجموعه داده های آموزش و تست
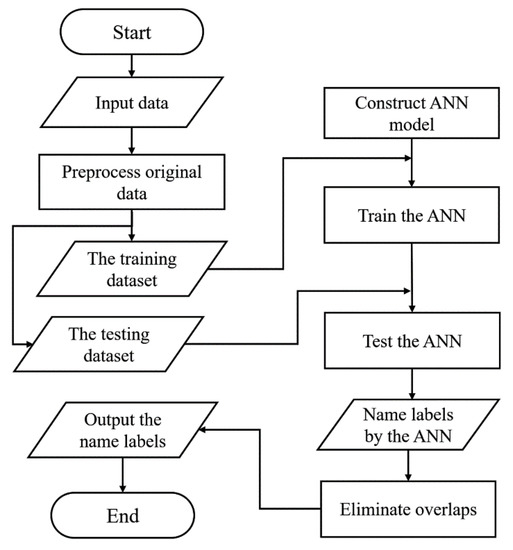
4.2. پیاده سازی روش مبتنی بر شبکه عصبی مصنوعی برای برچسب گذاری خودکار
-
پیش پردازش داده های اصلی
-
ساخت مدل ANN با استفاده از Python و PyTorch
-
آموزش و تست مدل شبکه های عصبی مصنوعی
-
همپوشانی ها را حذف کنید
5. ارزیابی تجربی
5.1. طراحی تجربی
-
داده های تجربی و معیار
-
معیارهای
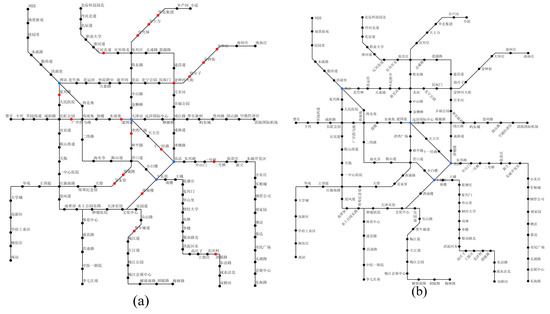
5.2. نتایج تجربی
6. نتیجه گیری
منابع
- Avelar، S. نقشه های شماتیک بر اساس تقاضا: طراحی، مدل سازی و تجسم. Ph.D. Thesis, ETH Zürich, Zürich, Switzerland, 2002. [ Google Scholar ]
- فارست، دی. علل و پیامدهای تغییر مقیاس در نقشه های شماتیک: آیا کاربران آگاه هستند و به آنها اهمیت می دهند؟ در مجموعه مقالات اولین کارگاه نقشه برداری شماتیک، اسکس، بریتانیا، 2 تا 3 آوریل 2014. [ Google Scholar ]
- Hong, S.-H.; مریک، دی. Nascimento، HA تجسم خودکار نقشه های مترو. J. Vis. لنگ محاسبه کنید. 2006 ، 17 ، 203-224. [ Google Scholar ] [ CrossRef ]
- آناند، اس. آولار، اس. Ware, JM; جکسون، ام. تولید نقشه شماتیک خودکار با استفاده از روش های بازپخت شبیه سازی شده و نزول گرادیان. در مجموعه مقالات پانزدهمین کنفرانس سالانه تحقیقات علم اطلاعات جغرافیایی انگلستان، Maynooth، UK، 11-13 آوریل 2007; صص 414-420. [ Google Scholar ]
- دونگ، WH; Guo، QS; لیو، JP نقشه شماتیک شبکه جاده تعمیم مترقی بر اساس محدودیت های متعدد. ژئو اسپات. Inf. علمی 2008 ، 11 ، 215-220. [ Google Scholar ] [ CrossRef ]
- دونگ، WH; Li، ZL; Guo، مدل خودکار QS تعمیم نقشه های شبکه شماتیک بر اساس تقسیم بندی پویا. Geomat. Inf. علمی دانشگاه ووهان 2010 ، 35 ، 892-895. [ Google Scholar ]
- ور، م. ریچاردز، ن. الگوریتم سیستم کلونی مورچه ها برای طرح بندی خودکار مجموعه داده های شبکه حمل و نقل. در مجموعه مقالات کنگره IEEE در محاسبات تکاملی، کانکون، مکزیک، 20-23 ژوئن 2013. صفحات 1892-1900. [ Google Scholar ]
- نکته.؛ لی، ز. Xu, Z. تولید خودکار نقشه های شبکه شماتیک که با اندازه نمایش تطبیق داده می شوند. کارتوگر. J. 2015 ، 52 ، 168-176. [ Google Scholar ] [ CrossRef ]
- گالوائو، ام. راموس، اف. لامار، م. Taco, P. تجسم دینامیک اطلاعات ترانزیت با استفاده از الگوریتم های ژنتیک برای طرحواره سازی مسیر. در مجموعه مقالات GIS Ostrava، Ostrava، جمهوری چک، 22-24 مارس 2017. صص 99-113. [ Google Scholar ]
- لی، جی تی. جیا، CL; ژانگ، ال. لی، XK؛ Li، YY; Luo، FL ایجاد نقشه های شبکه شماتیک با ساده سازی و پارتیشن. Geomat. Inf. علمی دانشگاه ووهان 2017 ، 42 ، 721-725. [ Google Scholar ]
- لان، تی. Li، ZL; Ti، P. ادغام اصول کلی در برنامه نویسی عدد صحیح مختلط برای بهینه سازی نقشه های شبکه شماتیک. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 2305-2333. [ Google Scholar ] [ CrossRef ]
- لان، تی. Li، ZL; پنگ، کیو. گونگ، XY برچسب زدن خودکار نقشه های شماتیک با بهینه سازی با دانش به دست آمده از نقشه های موجود. ترانس. GIS 2020 ، 24 ، 1722-1739. [ Google Scholar ] [ CrossRef ]
- گوان، کیو. وانگ، ال. کلارک، KC یک مدل CA محدود مبتنی بر شبکه عصبی مصنوعی برای شبیه سازی رشد شهری. کارتوگر. Geogr. Inf. علمی 2005 ، 32 ، 369-380. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آلمیدا، سی ام. گلریانی، ج.م. کاستیون، EF; Soares, B. استفاده از شبکههای عصبی و اتوماتای سلولی برای مدلسازی دینامیک کاربری زمین درون شهری. بین المللی جی. جئوگر. Inf. 2008 ، 22 ، 943-963. [ Google Scholar ]
- وانگ، جی. Mountrakis، G. توسعه یک مدل شهرنشینی چند شبکه ای: مطالعه موردی رشد شهری در دنور، کلرادو. بین المللی جی. جئوگر. Inf. علمی 2011 ، 25 ، 229-253. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژای، ی. یائو، ی. گوان، کیو. لیانگ، ایکس. لی، ایکس. پان، ی. یو، اچ. یوان، ز. ژو، جی. شبیه سازی تغییر کاربری زمین شهری با ادغام یک شبکه عصبی کانولوشنال با اتوماتای سلولی مبتنی بر برداری. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 1475-1499. [ Google Scholar ] [ CrossRef ]
- ژو، Q. Li، Z. استفاده از شبکه های عصبی مصنوعی برای حذف انتخابی در به روز رسانی شبکه های جاده ای. کارتوگر. J. 2014 ، 51 ، 38-51. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. چن، دی. ژائو، ز. رن، اف. Du, Q. یک رویکرد مبتنی بر شبکه عصبی پس انتشار برای تطبیق ویژگی های چندگانه در انتشار به روز رسانی. ترانس. Gis Tg 2015 ، 19 ، 964-993. [ Google Scholar ] [ CrossRef ]
- چو، TY; هوانگ، تلویزیون؛ نیش، YM; نگوین، کیو. Bui، بهینهساز مبتنی بر ازدحام QT برای شبکه عصبی کانولوشن: برنامهای برای نقشهبرداری حساسیت سیل. ترانس. GIS 2020 ، 25 ، 1009-1026. [ Google Scholar ] [ CrossRef ]
- سعیدی مقدم، م. Stepinski، TF استخراج خودکار نقاط تقاطع جاده از سری نقشه های تاریخی USGS با استفاده از شبکه های عصبی کانولوشن عمیق. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 947-968. [ Google Scholar ] [ CrossRef ]
- شنورر، آر. سیبر، آر. اشمید لنتر، جی. Öztireli، AC; Hurni، L. تشخیص اشیاء نقشه تصویری با شبکه های عصبی کانولوشن. کارتوگر. J. 2020 ، 58 ، 50-68. [ Google Scholar ] [ CrossRef ]
- Chirie, F. قرار دادن خودکار نام با کیفیت بالای نقشه برداری: نقشه های خیابان شهر. کارتوگر. Geogr. Inf. علمی 2000 ، 27 ، 101-110. [ Google Scholar ] [ CrossRef ]
- Yoeli, P. منطق حروف خودکار نقشه. کارتوگر. J. 1972 , 9 , 99-108. [ Google Scholar ] [ CrossRef ]
- کریستنسن، جی. مارکس، جی. Shieber, S. یک مطالعه تجربی از الگوریتمها برای قرار دادن برچسب نقطه ویژگی. ACM Trans. نمودار. (TOG) 1995 ، 14 ، 203-232. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Raidl, G. الگوریتم ژنتیک برای برچسب زدن ویژگی های نقطه. در مجموعه مقالات کنفرانس بین المللی علوم، سیستم ها و فناوری تصویربرداری، لاس وگاس، NV، ایالات متحده، 6-9 ژوئیه 1998. ص 189-196. [ Google Scholar ]
- یاماموتو، ام. کامارا، جی. Lorena، LAN Tabu جستجوی اکتشافی برای قرار دادن برچسب نقشهبرداری نقطهای. GeoInformatica 2002 ، 6 ، 77-90. [ Google Scholar ] [ CrossRef ]
- کلاو، GW; Mutzel, P. برچسبگذاری بهینه ویژگیهای نقطهای در مدلهای برچسبگذاری مستطیلی. ریاضی. برنامه. 2003 ، 94 ، 435-458. [ Google Scholar ] [ CrossRef ]
- کراوو، جی ال. ریبیرو، جنرال موتورز; Lorena، LAN یک روش جستجوی تصادفی تطبیقی حریصانه برای قرار دادن برچسب کارتوگرافی با ویژگی نقطهای. محاسبه کنید. Geosci. 2008 ، 34 ، 373-386. [ Google Scholar ] [ CrossRef ]
- Do Nascimento، HA; Eades، P. نکات کاربر برای برچسب زدن نقشه. J. Vis. لنگ محاسبه کنید. 2008 ، 19 ، 39-74. [ Google Scholar ] [ CrossRef ]
- دادی، س. Marathe، MV; میرزائیان، ع. مورت، بی.ام. ژو، بی. برچسب گذاری نقشه و تعمیم های آن. در مجموعه مقالات انجمن سالانه ماشین های محاسباتی (ACM) – انجمن ریاضیات صنعتی و کاربردی (SIAM) سمپوزیوم در مورد الگوریتم های گسسته، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 5-7 ژانویه 1997. صص 148-157. [ Google Scholar ]
- ون کرولد، ام. استریجک، تی. Wolff, A. برچسب گذاری نقطه ای با برچسب های کشویی. محاسبه کنید. Geom. 1999 ، 13 ، 21-47. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کامدا، تی. Imai، K. قرار دادن برچسب نقشه برای نقاط و منحنی ها. IEICE Trans. فاندم الکترون. اشتراک. محاسبه کنید. علمی 2003 ، 86 ، 835-840. [ Google Scholar ]
- ابنر، دی. کلاو، GW; Weiskircher, R. Label Number Maximization در مدل Slider. در مجموعه مقالات سمپوزیوم بین المللی ترسیم نمودار، نیویورک، نیویورک، ایالات متحده آمریکا، 29 سپتامبر تا 2 اکتبر 2004. صص 144-154. [ Google Scholar ]
- Poon, S.-H.; Shin, C.-S.; استریجک، تی. یونو، تی. Wolff, A. برچسب زدن به نقاط با وزنه. الگوریتمیکا 2004 ، 38 ، 341-362. [ Google Scholar ] [ CrossRef ]
- شوارتگز، ن. هاونرت، جی.-اچ. ولف، ا. Zwiebler, D. برچسبگذاری نقطهای با برچسبهای کشویی در نقشههای تعاملی. در اتصال اروپای دیجیتال از طریق مکان و مکان ؛ Springer: برلین/هایدلبرگ، آلمان، 2014; صص 295-310. [ Google Scholar ]
- شوارتگز، ن. ولف، ا. هاونرت، جی.-اچ. برچسبگذاری خیابانها در نقشههای تعاملی با استفاده از برچسبهای تعبیهشده. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM Sigspatial در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، 4-7 نوامبر 2014. صص 517–520. [ Google Scholar ]
- نولنبورگ، ام. Wolff, A. ترسیم و برچسب گذاری نقشه های مترو با کیفیت بالا با برنامه نویسی عدد صحیح مختلط. IEEE Trans. Vis. محاسبه کنید. نمودار. 2011 ، 17 ، 626-641. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- وو، هی؛ تاکاهاشی، س. هیرونو، دی. آریکاوا، م. Lin، CC; ین، HC طراحی کارآمد فضایی نقشه های مشروح مترو. در مجموعه مقالات انجمن گرافیک کامپیوتری، پورتلند، OR، ایالات متحده آمریکا، 22-25 آوریل 2013. ص 261-270. [ Google Scholar ]
- استات، جی.ام. راجرز، پی. مارتینز-اواندو، جی سی. طرحبندی نقشه مترو واکر، SG خودکار با استفاده از بهینهسازی چند معیاره. IEEE Trans. Vis. محاسبه کنید. نمودار. 2011 ، 17 ، 101-114. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- وانگ، Y.-S. چی، M.-T. فوکوس + زمینه نقشه های مترو. IEEE Trans. Vis. محاسبه کنید. نمودار. 2011 ، 17 ، 2528-2535. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- وو، هی؛ تاکاهاشی، س. Lin، CC; ین، طرحبندی و حاشیهنویسی نقشه مترو محور سفر-مسیر HC. در مجموعه مقالات انجمن گرافیک کامپیوتری، آکسفورد، انگلستان، 5 تا 8 ژوئن 2012. ص 925-934. [ Google Scholar ]
- هوانگ، بی. ژائو، بی. Song، Y. نقشهبرداری کاربری زمین شهری با استفاده از یک شبکه عصبی پیچیده عمیق با تصاویر سنجش از دور چندطیفی با وضوح فضایی بالا. سنسور از راه دور محیط. 2018 ، 214 ، 73-86. [ Google Scholar ] [ CrossRef ]
- کمکر، آر. سالواجو، سی. کانان، سی. الگوریتمهای تقسیمبندی معنایی تصاویر سنجش از دور چندطیفی با استفاده از یادگیری عمیق. ISPRS J. Photogramm. Remote Sens. 2018 ، 145 ، 60-77. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، اس. کوان، دی. لیانگ، ایکس. نینگ، ام. گوا، ی. Jiao, L. چارچوب یادگیری عمیق برای ثبت تصویر سنجش از راه دور. ISPRS J. Photogramm. Remote Sens. 2018 , 145 , 148–164. [ Google Scholar ] [ CrossRef ]
- هیوز، LH؛ مارکوس، دی. لوبری، اس. تویا، دی. اشمیت، ام. چارچوب یادگیری عمیق برای تطبیق SAR و تصاویر نوری. ISPRS J. Photogramm. Remote Sens. 2020 , 169 , 166–179. [ Google Scholar ] [ CrossRef ]
- شائو، ز. Cai, J. ادغام تصویر سنجش از دور با شبکه عصبی کانولوشنال عمیق. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2018 ، 11 ، 1656–1669. [ Google Scholar ] [ CrossRef ]
- چن، ی. شی، ک. Ge, Y. تلفیق تصویر سنجش از دور فضایی-زمانی با استفاده از شبکه های عصبی کانولوشنال دو جریانی چند مقیاسی. IEEE Trans. Geosci. Remote Sens. 2021 ، 60 ، 1-12. [ Google Scholar ] [ CrossRef ]
- شلمپر، جی. کابالرو، جی. Hajnal, JV; قیمت، AN; روکرت، دی. یک آبشار عمیق از شبکه های عصبی کانولوشن برای بازسازی تصویر MR پویا. IEEE Trans. پزشکی تصویربرداری 2017 ، 37 ، 491-503. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، ز. چن، جی. Hoi, SC یادگیری عمیق برای وضوح تصویر فوق العاده: یک نظرسنجی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2020 ، 43 ، 10. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ریگل، جی پی. جارویس، CH; استوارت، N. شبکه های عصبی مصنوعی به عنوان ابزاری برای درونیابی فضایی. بین المللی جی. جئوگر. Inf. علمی 2001 ، 15 ، 323-343. [ Google Scholar ] [ CrossRef ]
- مروین، دی. کراملی، آر جی. شبکه های عصبی مصنوعی Civco، DL به عنوان یک روش درون یابی فضایی برای مدل های ارتفاعی دیجیتال. صبح. کارتوگر. 2002 ، 29 ، 99-110. [ Google Scholar ] [ CrossRef ]
- مروین، دی. کراملی، آر. Civco، D. یک روش مبتنی بر شبکه عصبی برای حل مسائل درون یابی منطقه ای “سلسله مراتب تودرتو”. صبح. کارتوگر. 2009 ، 36 ، 347-365. [ Google Scholar ] [ CrossRef ]
- زو، دی. چنگ، ایکس. ژانگ، اف. یائو، ایکس. گائو، ی. لیو، ی. درونیابی فضایی با استفاده از شبکه های عصبی متخاصم مولد شرطی. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 735-758. [ Google Scholar ] [ CrossRef ]
- استایگر، ای. رسچ، بی. Zipf، A. کاوش خوشههای مکانی-زمانی و معنایی دادههای توییتر با استفاده از شبکههای عصبی بدون نظارت. بین المللی جی. جئوگر. Inf. علمی 2015 ، 30 ، 1694-1716. [ Google Scholar ] [ CrossRef ]
- هاگناور، جی. Helbich، M. SPAWNN: یک کیت ابزار برای تجزیه و تحلیل فضایی با شبکه های عصبی خودسازمانده. ترانس. Gis 2016 ، 20 ، 755-774. [ Google Scholar ] [ CrossRef ]
- لین، YP; چو، اچ جی; Wu، CF; Verburg، PH توانایی پیشبینی رگرسیون لجستیک، رگرسیون لجستیک خودکار و مدلهای شبکه عصبی در مدلسازی تجربی تغییر کاربری زمین – مطالعه موردی. بین المللی جی. جئوگر. Inf. سیستم 2010 ، 25 ، 65-87. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شی، دبلیو. لیو، ز. آن، ز. Chen, P. RegNet: یک مدل شبکه عصبی برای پیشبینی مطلوبیت منطقهای با دادههای VGI. بین المللی جی. جئوگر. Inf. علمی 2020 ، 25 ، 175-192. [ Google Scholar ] [ CrossRef ]
- وو، اس. وانگ، ز. دو، ز. هوانگ، بی. لیو، آر. رگرسیون وزنی شبکه عصبی از نظر جغرافیایی و زمانی برای مدلسازی روابط غیر ثابت فضایی و زمانی. بین المللی جی. جئوگر. Inf. علمی 2020 ، 35 ، 582-608. [ Google Scholar ] [ CrossRef ]
- فنگ، ی. تیمن، اف. سستر، ام. یادگیری تعمیم ساختمان نقشه برداری با شبکه های عصبی کانولوشنال عمیق. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 258. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تویا، جی. ژانگ، ایکس. Lokhat, I. آیا یادگیری عمیق عامل جدیدی برای تعمیم نقشه است؟ بین المللی جی. کارتوگر. 2019 ، 5 ، 142-157. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دادگاهی، ع. الایدی، ع. تویا، جی. ژانگ، ایکس. بررسی پتانسیل تقسیمبندی یادگیری عمیق برای تعمیم جادههای کوهستانی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 338. [ Google Scholar ] [ CrossRef ]
- هنری، سی جی; داستان، سی دی; پالانیاپان، م. الحسن، و. سوامی، م. آلشینلویه، دی. کرتیس، ای. کیم، دی. تولید نقشه خودکار LULC با استفاده از شبکه های عصبی عمیق. بین المللی J. Remote Sens. 2019 , 40 , 4416–4440. [ Google Scholar ] [ CrossRef ]
- کانگ، ی. گائو، اس. Roth، RE انتقال سبک های نقشه چند مقیاسی با استفاده از شبکه های متخاصم مولد. بین المللی جی. کارتوگر. 2019 ، 5 ، 115–141. [ Google Scholar ] [ CrossRef ]
- Abreu, S. طراحی معماری خودکار برای شبکه های عصبی عمیق. arXiv 2019 ، arXiv:1908.10714. [ Google Scholar ]
- سووزیل، دی. کواسنیکا، وی. Pospichal، J. مقدمه ای بر شبکه های عصبی پیشخور چند لایه. شیمی. هوشمند آزمایشگاه. سیستم 1997 ، 39 ، 43-62. [ Google Scholar ] [ CrossRef ]
- ژو، ز. یادگیری ماشینی . انتشارات دانشگاه Tsinghua: پکن، چین، 2016. [ Google Scholar ]
- هورنیک، ک. استینچکامب، ام. وایت، H. شبکه های پیشخور چندلایه تقریبگرهای جهانی هستند. شبکه عصبی 1989 ، 2 ، 359-366. [ Google Scholar ] [ CrossRef ]
- Hornik، K. برخی از نتایج جدید در تقریب شبکه عصبی. شبکه عصبی 1993 ، 6 ، 1069-1072. [ Google Scholar ] [ CrossRef ]
- Bishop, CM Neural Networks for Pattern Recognition ; انتشارات دانشگاه آکسفورد: آکسفورد، انگلستان، 1995. [ Google Scholar ]
- Luashchuk، A. 8 دلیل برای اینکه Python برای هوش مصنوعی و یادگیری ماشین خوب است. در دسترس آنلاین: https://djangostars.com/blog/why-python-is-good-for-artificial-intelligence-and-machine-learning/ (در 27 اوت 2021 قابل دسترسی است).
- Dijk, Sv; کرولد، ام وی؛ استریجک، تی. Wolff، A. به سوی ارزیابی کیفیت برای روش های قرار دادن نام ها. بین المللی جی. جئوگر. Inf. علمی 2002 ، 16 ، 641-661. [ Google Scholar ] [ CrossRef ]



بدون دیدگاه