1. معرفی
به عنوان یک حامل مهم اطلاعات مکانی، تصاویر سنجش از دور با وضوح بالا (HRRS) به طور گسترده در اکتشافات نظامی [ 1 ]، نظارت بر منابع [ 2 ]، ارزیابی بلایا [ 3 ]، ناوبری با دقت بالا [ 4 ] و بسیاری دیگر استفاده شده است. زمینه های. اخیراً با استفاده گسترده از نرم افزارهای پردازش تصویر سنجش از دور و توسعه سریع فناوری به اشتراک گذاری اطلاعات، میزان استفاده از تصاویر HRRS به تدریج در حال افزایش است. در همین حال، خطر دستکاری بدخواهانه آن نیز بیش از همیشه است. اگر یکپارچگی محتوای تصاویر HRRS زیر سوال رود، ارزش استفاده از آنها بسیار کاهش می یابد [ 5]. بنابراین، چگونگی شناسایی یکپارچگی محتوای تصاویر HRRS یک موضوع مهم است.
یکپارچگی داده به این واقعیت اشاره دارد که محتوای داده ها در طول انتقال و کاربرد تغییر نمی کند [ 6 ]. بسیاری از محققان روشهای احراز هویت یکپارچگی تصاویر سنجش از دور را مطالعه کردهاند، و این روشها بیشتر بر اساس فناوری امضای دیجیتال [ 7 ]، فناوری واترمارک دیجیتال [ 8 ] و فناوری هش ادراکی [ 9 ] است. به طور کلی، امضای دیجیتال به این معنی است که فرستنده داده، داده های اصلی را به عنوان یک خلاصه رشته منحصر به فرد از طریق الگوریتم های MD5، SHA-1 و سایر الگوریتم ها توصیف می کند [ 10 ].]، و گیرنده داده احراز هویت یکپارچگی را از طریق تطبیق خلاصه اجرا می کند. این نوع روش نسبت به تغییرات سطح بیت بسیار حساس است (تغییر 1 بیتی در داده ها دستکاری در نظر گرفته می شود)، که فقط برای احراز هویت دقیق مانند اطلاعات متن مناسب است و برای عملیات حفظ محتوا قوی نیست. در اصل، فقط سازگاری داده ها را در نمایش باینری بدون در نظر گرفتن سازگاری محتوای داده آزمایش می کند.
واترمارکینگ دیجیتال معمولاً اطلاعات هویتی را در داده های اصلی جاسازی می کند و گیرنده داده اطلاعات شناسایی را از طریق الگوریتم های استخراج استخراج می کند. یکپارچگی این اطلاعات شناسایی نشان دهنده یکپارچگی داده ها است. این روشها معمولاً ویژگیهای محتوایی دادهها را در نظر میگیرند و برخی از آنها میتوانند به محلیسازی دستکاری دست یابند. لی [ 11 ] یک الگوریتم واترمارک شکننده سنجش از دور بر اساس فناوری بهبود یافته حداقل بیت مهم (LSB) پیشنهاد کرد که امنیت و کارایی محاسباتی الگوریتمهای احراز هویت شکننده سنتی واترمارک را بهبود بخشید. جوردی [ 12] یک طرح احراز هویت یکپارچگی واترمارک نیمه شکننده برای تصاویر سنجش از راه دور چند باندی پیشنهاد کرد. روش کوانتیزاسیون برداری ساختار درختی برای تولید اطلاعات شناسایی، که برای فشرده سازی JPEG، نویز گاوسی و غیره قوی است، استفاده شد . تصویر سنجش از راه دور ناحیه دستکاری شده تقریباً قابل بازیابی است. همچنین محققان دیگری در حال مطالعه روش احراز هویت یکپارچگی تصویر سنجش از دور بر اساس فناوری واترمارک دیجیتال هستند [ 14,15 , 16]. با این حال، الگوریتم احراز هویت یکپارچگی مبتنی بر واترمارک دیجیتال به طور کلی دارای کاستی های زیر است:
-
فرآیند تعبیه واترمارک اصلاح دادههای اصلی است که در برخی زمینهها، بهویژه در زمینه با وفاداری بالا، مجاز نیست.
-
احراز هویت مبتنی بر واترمارک اساساً یک احراز هویت مبتنی بر حامل است. اگر تبدیل قالب به داده ها بدون تغییر محتوا اعمال شود، اطلاعات واترمارک نیز ممکن است تا حد زیادی تغییر کند.
فناوری هش ادراکی می تواند راه حل های جدیدی برای مشکلات فوق ارائه دهد. هش ادراکی روشی برای نگاشت داده های چندرسانه ای به دنباله هش است که برای عملیات حفظ محتوا قوی است و به عملیات دستکاری محتوا حساس است [ 17 ]. به طور گسترده در بازیابی اطلاعات [ 18 ، 19 ، 20 ]، احراز هویت داده ها [ 21 ، 22 ، 23 ]، تشخیص کپی [ 24 ، 25 ] استفاده می شود.] و زمینه های دیگر. تحقق هش ادراکی به شرح زیر است: فرستنده داده با استخراج ویژگی و فشرده سازی ویژگی، توالی هش را تولید می کند و گیرنده داده با مقایسه شباهت دنباله هش یکپارچگی را تأیید می کند. در مقایسه با روش های مبتنی بر امضای دیجیتال، مهم ترین ویژگی هش ادراکی این است که از نظر ادراکی قوی است، به این معنی که پس از انجام عملیات حفظ محتوا (مانند تبدیل فرمت و جاسازی واترمارک) روی تصویر، توالی هش تغییر قابل توجهی نمی کند. . در مقایسه با واترمارکینگ دیجیتال، هش ادراکی نیازی به جاسازی هیچ اطلاعاتی در داده ها ندارد و توالی هش به شدت به محتوای داده ها وابسته است، که این ضرر را برطرف می کند که واترمارکینگ دیجیتال بیش از حد به حامل اطلاعات متکی است.26 ] و احراز هویت [ 27 ، 28 ، 29 ]. مرجع [ 27 ] از مدل هرمی استفاده کرد که یک مدل احراز هویت تصویر HRRS چند مقیاسی را ساخت. مرجع [ 28 ] از عملگر Canny برای تشخیص لبه، ترکیب DWT و فیلتر Gabor برای ساخت یک روش احراز هویت یکپارچگی هش ادراکی برای تصاویر HRRS استفاده کرد. در مرجع [ 29 ]، یک شبکه U-net برای بهبود روش در [ 28 ] استفاده شد. ویژگیهای لبه استخراجشده توسط اپراتور Canny از طریق یادگیری مستقل شبکه U-net بیشتر اصلاح شد، اما نتایج یادگیری این الگوریتم نیاز به تصحیح دستی زیادی داشت.
با این حال، الگوریتم احراز هویت یکپارچگی تصاویر HRRS همچنان مشکلات زیر را دارد:
-
بسیاری از الگوریتمهای هش ادراکی موجود HRRS بر اساس یک ویژگی برای احراز هویت هستند. تصاویر سنجش از دور دارای ویژگیهای بزرگواری دادهها هستند و عموماً اطلاعات موضوعی واضحی وجود ندارد، بنابراین نتایج احراز هویت براساس یک ویژگی مجزا قانعکننده نیست.
-
الگوریتمهای موجود اساساً فرآیندی از تصمیمگیری دودویی هستند. یعنی فقط دو نتیجه وجود دارد: عبور از احراز هویت یکپارچگی و عدم تصویب احراز هویت یکپارچگی. اطلاعات قابل تفسیر بیشتر توسط این الگوریتم ها قابل ارائه نیست.
برای غلبه بر این مشکلات، یک الگوریتم هش ادراکی HRRS، لحظات Zernike و توصیفگرهای ویژگی FAST را در این مقاله ارائه میکند. علاوه بر این، ویژگی های تصاویر HRRS با دقت بالا و اندازه داده های بزرگ به طور کامل در نظر گرفته شده است. این الگوریتم در حالی که استحکام و قابلیتهای تشخیص دستکاری را بهبود میبخشد، میتواند شواهد قابل تفسیر بیشتری برای احراز هویت یکپارچگی تصاویر HRRS ارائه دهد.
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش 2 پیشرفت تحقیقات مربوطه را تشریح می کند. بخش 3 روش پیشنهادی ما را شرح می دهد. بخش 4 نتایج تجربی را تجزیه و تحلیل و بحث می کند. و بخش 5 نتیجه گیری این مقاله را ارائه می دهد.
2. آثار مرتبط
2.1. هش ادراکی
هش ادراکی ریشه در فناوری امضای دیجیتال دارد. همانطور که در بالا ذکر شد، میتواند دادههای چندرسانهای (مانند تصاویر و ویدئوها) را به دنبالهای از خلاصهها با طول معین نگاشت، یعنی اطلاعات محتوای دادههای چندرسانهای را میتوان با کمترین اطلاعات ممکن نمایش داد.
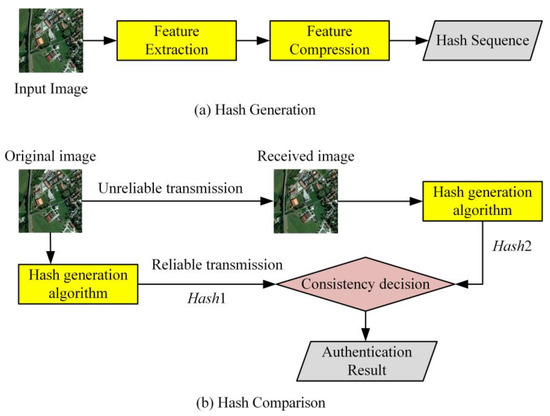
تصاویر HRRS شباهت هایی با تصاویر دیجیتال در سازماندهی داده ها دارند، بنابراین نمی توان تجربیات موفق هش ادراکی تصویر را نادیده گرفت. برای تصاویر دیجیتال، روش هش ادراکی در شکل 1 نشان داده شده است که شامل تولید هش و مقایسه هش [ 30 ] است. شکل 1 a روند تولید هش را نشان می دهد که شامل استخراج ویژگی و فشرده سازی ویژگی است: تصویر دو بعدی به یک آرایه یک بعدی نگاشت می شود و اطلاعات استحکام برای تشکیل توالی هش استخراج می شود. شکل 1b روش مقایسه هش را نشان می دهد: دنباله هش توسط یک کانال قابل اعتماد منتقل می شود و ممکن است تصویر در طول انتقال دستکاری شود. گیرنده از همان الگوریتم فرستنده برای تولید یک دنباله هش Hash2 از تصویر برای احراز هویت استفاده می کند و برای ایجاد نتیجه احراز هویت، مقایسه هش را با هش اصلی Hash1 انجام می دهد.
استخراج ویژگی کلید الگوریتم هش ادراکی است. روشهای استخراج ویژگی عمدتا مبتنی بر تشخیص لبه [ 28 ، 29 ]، تشخیص نقطه کلیدی [ 31 ، 32 ]، DCT (تبدیل کسینوس گسسته) [ 33 ، 34 ]، DWT (تبدیل موجک گسسته) [ 35 ، 36 ] و موارد دیگر است. روش های استخراج ویژگی به عنوان یک کاربرد خاص از هش ادراکی در تصویر HRRS، باید ویژگی های هش ادراکی تصویر را داشته باشد:
-
یک طرفه: توالی هش را می توان از تصویر تولید کرد، اما اطلاعات تصویر را نمی توان از توالی هش تولید کرد.
-
مقاومت در برابر برخورد: تصاویر مختلف توالی هش کاملاً متفاوتی ایجاد می کنند.
-
استحکام ادراکی: توالی هش به طور قابل توجهی پس از عملیات حفظ محتوا تغییر نمی کند.
-
حساسیت به دستکاری: پس از عملیات دستکاری محتوا، مقدار توالی هش می تواند تا حد زیادی تغییر کند.
2.2. تصویر سنجش از راه دور با وضوح بالا
ویژگی اصلی تصاویر HRRS وضوح قوی اشیاء زمینی است. در حال حاضر، وضوح تصاویر HRRS تجاری رایج به سطح زیر متر رسیده است. به عنوان مثال، وضوح ماهواره WorldView-3 به 0.3 متر و وضوح ماهواره تجاری JL-1 توسعه یافته در چین به 0.72 متر رسیده است. در مقایسه با دادههای ماهوارهای با وضوح کم یا متوسط و کم، تصاویر HRRS میتوانند اطلاعات دقیقتری از اجسام زمینی را نشان دهند.
تصاویر HRRS به دقت اندازه گیری بالایی نیاز دارند، در حالی که الگوریتم هش ادراک تصویر نمی تواند الزامات تصاویر HRRS را برآورده کند. تفسیر محتوای تصاویر HRRS دارای تنوع و ابهامی است که دشواری استخراج ویژگی های محتوای تصاویر HRRS توسط الگوریتم هش ادراکی را افزایش می دهد. علاوه بر این، معمولاً هیچ اطلاعات موضوع منحصر به فردی در یک تصویر سنجش از راه دور وجود ندارد، که عدم قطعیت استخراج ویژگی ادراکی تصاویر HRRS را افزایش میدهد. علاوه بر این، با توجه به توسعه فناوری به اشتراک گذاری داده ها، فرآیند احراز هویت باید تا حد امکان سریع باشد. با این حال، کارایی محاسباتی تصاویر با اندازه بزرگ معمولاً در الگوریتمهای هش درک تصویر در نظر گرفته نمیشود.
بنابراین، در حالی که ویژگیهای هش ادراکی تصویر بالا را برآورده میکند، الگوریتمهای هش برای تصاویر HRRS باید ویژگیهای زیر را نیز داشته باشند:
-
قابلیت شناسایی میکرو دستکاری: با تنظیم سطح حفاظت، میکرو دستکاری بالاتر از سطح حفاظت قابل تشخیص است.
-
قابلیت محلیسازی دستکاری: اندازه تصویر سنجش از راه دور معمولاً بزرگ است و الگوریتمهای خوب باید بتوانند مکانهای دستکاری خاصی را ارائه دهند.
-
راندمان محاسبات و دقت احراز هویت باید متعادل باشد.
علاوه بر این، برای برآورده شدن ویژگی های تصاویر HRRS فوق، به برخی از طرح های هدفمند نیاز است. طراحی این الگوریتم برای داده های سنجش از دور شامل موارد زیر است اما محدود به موارد زیر نیست:
-
روش تقسیم شبکه برای استخراج ویژگیهای داده تصاویر HRRS به روشی دقیقتر در مقایسه با الگوریتمهای هش ادراکی تصویر موجود، که الزامات دقت تصاویر HRRS را برآورده میکند، معرفی شده است.
-
توصیف جامعی از محتوای تصویر با ترکیب ویژگیهای جهانی و ویژگیهای محلی ساخته شده است که ویژگیهای تنوع و ابهام تصاویر HRRS را برآورده میکند. از این گذشته، یک ویژگی به سختی می تواند تمام اطلاعات اصلی یک تصویر را منعکس کند.
-
با در نظر گرفتن کارایی محاسباتی، الگوریتم FAST برای استخراج ویژگی های محلی به کار گرفته شده است. در مقایسه با الگوریتم هش ادراکی تصویر دیجیتال موجود، کارایی محاسباتی تا حد زیادی بهبود یافته است.
2.3. لحظه های زرنیک
ویژگی های لحظه ای در چرخش و ترجمه ثابت هستند، بنابراین می توان از آن برای استخراج ویژگی تصویر سراسری استفاده کرد. اخیراً، ویژگیهای لحظهای که برای استخراج ویژگی تصویر سنجش از راه دور استفاده میشوند، عمدتاً شامل ممانهای هیستوگرام، ممانهای Hu و ممانهای زرنیک و غیره است. لحظات زرنیک توسط زرنیک پیشنهاد شد [ 38]. مشابه ویژگیهای گشتاورهای هیستوگرام و گشتاورهای هو، ویژگیهای استخراجشده توسط ممانهای زرنیک دارای تغییرناپذیری چرخش و ترجمه هستند. به طور متفاوت، ویژگی های استخراج شده توسط لحظه های Zernike، مستقل از دو طرف، با افزونگی اطلاعات کم، و غیر حساس به حمله نویز هستند. بنابراین، لحظه Zernike برای استخراج ویژگی های جهانی تصاویر HRRS اعمال می شود.
برای یک تصویر دیجیتال دو بعدی [ خطای پردازش ریاضی ]�(ایکس،�)، لحظات زرنیک آن به ترتیب [ خطای پردازش ریاضی ]�و تکرار [ خطای پردازش ریاضی ]متربه عنوان … تعریف شده است:
جایی که [ خطای پردازش ریاضی ]�،متر∈ن، و [ خطای پردازش ریاضی ]|متر|≤�، * عدد مختلط مزدوج را نشان می دهد. [ خطای پردازش ریاضی ](�، �)مختصات قطبی هستند که تصویر اصلی را عادی می کنند [ خطای پردازش ریاضی ]�(ایکس،�)به (-1,1) و آن را به دایره واحد ترسیم کنید، به عنوان مثال، [ خطای پردازش ریاضی ]�=ایکس2+�2، [ خطای پردازش ریاضی ]�=آرکتان(�/ایکس); [ خطای پردازش ریاضی ]��متر*(�، �)هسته تبدیل گشتاورهای زرنیک را نشان می دهد که شامل مجموعه ای از چند جمله ای های زرنیک است که به صورت زیر بیان می شود:
در این فرمول، [ خطای پردازش ریاضی ]آر�متر(�)یک چند جمله ای شعاعی زرنیک است و [ خطای پردازش ریاضی ]منیک واحد خیالی است
2.4. تشخیص سریع نقطه کلیدی
اخیراً، یک سری از الگوریتمهای استخراج نقاط کلیدی پیشنهاد شدهاند، از جمله هریس [ 39 ]، تبدیل ویژگی تغییرناپذیر مقیاس (SIFT) [ 40 ]، سرعت بالا بردن ویژگیهای قوی (SURF) [ 41 ]، ویژگیهای تست قطعه شتابدهی (FAST) [ 42 ]، و غیره. شکل 2 نتایج حاصل از تشخیص نقاط کلیدی نتایج روش های مختلف را نشان می دهد.
مشاهده می شود که نقاط مشخصه استخراج شده توسط الگوریتم های مختلف نیز شباهت خاصی در ساختار فضایی دارند. ارزیابی الگوریتم استخراج نقاط کلیدی به شدت به سناریوهای کاربردی عملی وابسته است. الگوریتم SIFT با قابلیت چرخش بیتغییر بالا و قابلیت ضد نویز آن مشخص میشود که برای احراز هویت یکپارچگی تصویر دیجیتال اعمال شده است [ 31 ]. با این حال، کاستی های الگوریتم SIFT آشکار است: پیچیدگی محاسباتی آن به خصوص در تصاویر HRRS با اندازه تصویر بزرگ، که ممکن است زمان زیادی را صرف کند، نسبتاً بالا است. به عنوان یک نسخه بهبود یافته از الگوریتم SIFT، الگوریتم SURF حدود سه برابر در سرعت محاسبه افزایش یافته است [ 32 ]]، اما این بهبود قابل توجه نیست.
فرآیند احراز هویت یکپارچگی باید به طور موثر و راحت پیاده سازی شود، به خصوص در عصر اشتراک داده ها. بر این اساس، الگوریتم FAST برای استخراج ویژگی های محلی در این مقاله اعمال شده است. الگوریتم استخراج نقطه کلید FAST توسط Rosten [ 42 ] در سال 2011 پیشنهاد شد و به دلیل فرآیند محاسبات ساده و سرعت محاسبات سریع شناخته شده است. در مقایسه با SIFT و SURF، الگوریتم FAST در تشخیص نقاط کلیدی بسیار سریعتر است.
2.4.1. ایجاد پنجره تجزیه و تحلیل
ما در اینجا شرح مختصری از اجرای الگوریتم FAST ارائه می دهیم. ابتدا فضای رنگی تصویر از RGB به YCbCr تبدیل می شود. در میان آنها، کانال Y جزء روشنایی تصویر است و می توان از آن برای استخراج نقاط کلیدی FAST استفاده کرد. برای هر پیکسل [ خطای پردازش ریاضی ]پبرای تشخیص در تصویر، یک دایره برسنهام [ 43 ] با مرکز بکشید[ خطای پردازش ریاضی ]پو شعاع [ خطای پردازش ریاضی ]�. این دایره شامل [ خطای پردازش ریاضی ]�پیکسل ها شکل 3 نمودار شماتیک کی را نشان می دهد [ خطای پردازش ریاضی ]�=16و [ خطای پردازش ریاضی ]�=3که FAST-16 نام دارد.
2.4.2. پارتیشن بندی زیر مجموعه
برای هر نقطه [ خطای پردازش ریاضی ]ایکس�در پنجره تحلیلی که در بالا ذکر شد، موقعیت آن نسبت به مرکز [ خطای پردازش ریاضی ]پبه عنوان مشخص می شود [ خطای پردازش ریاضی ]اسپ→ایکس. سپس از فرمول زیر برای تقسیم زیر مجموعه ها استفاده می شود:
در این فرمول، آستانه [ خطای پردازش ریاضی ]تیبستگی به شرایط خاص دارد مقدار معمولی [ خطای پردازش ریاضی ]تی=10در این الگوریتم انتخاب شده است. [ خطای پردازش ریاضی ]مندرخشندگی نقاط را نشان می دهد. [ خطای پردازش ریاضی ]“د”به این معنی که نقطه فعلی تیره تر از نقطه مرکزی است. “s” به این معنی است که نقطه فعلی و نقطه مرکزی درخشندگی مشابهی دارند. “ب” به این معنی است که نقطه فعلی سبک تر از مرکز است. به این ترتیب مجموعه پیکسلی کل تصویر را می توان به سه زیر مجموعه تقسیم کرد.
در اجرای عملی، به منظور بهبود سرعت، به طور کلی دو پیکسل اول در پنجره تجزیه و تحلیل شناسایی می شوند: [ خطای پردازش ریاضی ]اسپ→�1=سو [ خطای پردازش ریاضی ]اسپ→�9=سبه طور همزمان اتفاق می افتد، این نقطه به عنوان یک نقطه کلیدی نامزد انتخاب نمی شود. در غیر این صورت، به شناسایی ادامه دهید [ خطای پردازش ریاضی ]اسپ→�5و [ خطای پردازش ریاضی ]اسپ→�13. اگر سه مقدار از چهار مقدار بالا ” [ خطای پردازش ریاضی ]د” یا ” b ”، این نقطه به عنوان یک نقطه کلیدی نامزد در نظر گرفته می شود و به محاسبه ادامه می دهد [ خطای پردازش ریاضی ]اسپ→��ارزش سایر نقاط در پنجره تحلیل در FAST-16، اگر تعداد نقاط در هر زیر مجموعه از « [ خطای پردازش ریاضی ]د” یا “ b ” کمتر از 9، مرکز نیست [ خطای پردازش ریاضی ]پیک نکته کلیدی محسوب می شود.
2.4.3. سرکوب غیر حداکثری
سرکوب غیر حداکثری برای نقاط کلیدی غربال شده اعمال می شود. از آنجایی که مراحل فوق می تواند نقاط زیادی با ویژگی های مشابه ایجاد کند، مجموعه نقاط کلیدی باید برای به دست آوردن مجموعه نقاط ویژگی نهایی غربال شوند. در اصل، FAST یک الگوریتم تشخیص گوشه است. از نظر تئوری اعتقاد بر این است که مجموع اختلاف خاکستری بین گوشه بهینه و پیکسل های اطراف باید بزرگترین باشد. بنابراین، تابع پاسخ R ایجاد می شود:
پاسخ R به عنوان استحکام نقطه کلیدی در نظر گرفته می شود. تمام نقاط کلیدی که در یک همسایگی 3×3 پاسخ میدهند، طبق رابطه (4) محاسبه میشوند و سپس نقطهای که بیشترین پاسخ را دارد به عنوان نقطه کلیدی نهایی حفظ میشود و سایر نقاط کلیدی در همسایگی حذف میشوند.
الگوریتم FAST در نهایت یک مجموعه نقاط کلیدی ایجاد می کند [ خطای پردازش ریاضی ]افمتشکل از n نکته کلیدی:
برای هر نقطه کلیدی [ خطای پردازش ریاضی ]اف�، ترکیب آن به شرح زیر است:
در این فرمول، [ خطای پردازش ریاضی ](ایکس،�)نشان دهنده موقعیت نقطه کلیدی است. [ خطای پردازش ریاضی ]آرنشان دهنده مقدار پاسخ نقطه کلیدی است.
3. الگوریتم هش ادراکی ترکیبی از لحظات Zernike و FAST
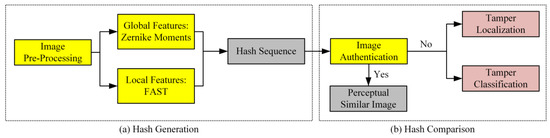
همانطور که در شکل 4 نشان داده شده است، یک الگوریتم هش ادراک تصویر HRRS که لحظات Zernike و FAST را ترکیب می کند، پیشنهاد شده است . لحظه های Zernike برای توصیف ویژگی های جهانی و الگوریتم FAST برای به دست آوردن ویژگی های محلی استفاده می شود. ویژگی های جهانی و ویژگی های محلی برای ایجاد یک توالی هش ترکیب می شوند.
3.1. پیش پردازش تصاویر HRRS
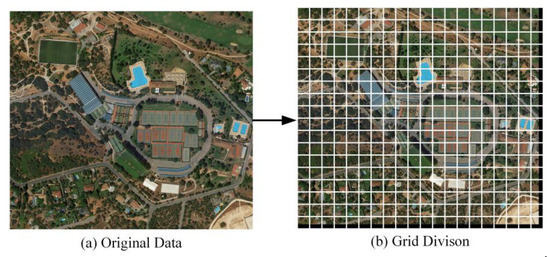
برای تصاویر سنجش از راه دور معمولی، الگوریتم های ترکیبی تصویر برای پیش پردازش استفاده می شود. برای تصاویر سنجش از راه دور چند باند، داده ها را می توان به طور جداگانه برای احراز هویت مستقل استخراج کرد. الگوریتم هش ادراکی تصویر معمولاً تصویر اصلی را به اندازه یکنواخت برای احراز هویت عادی می کند. با توجه به اینکه تصویر HRRS دارای ویژگی های اندازه تصویر بزرگ و جزئیات غنی است، ما تصویر اصلی را پیش پردازش می کنیم. [ خطای پردازش ریاضی ]�با استفاده از تقسیم شبکه و تقسیم تصویر اصلی به بلوک های فرعی اندازه [ خطای پردازش ریاضی ]متر×متر. در تصاویر HRRS توصیه می شود از اندازه واحد شبکه 256 × 256 برای تقسیم شبکه استفاده شود و تحلیل حساسیت این اندازه بعداً ارائه خواهد شد. برای ناحیه ای با کمتر از m پیکسل در مرز، مقدار 0 برای تکمیل استفاده می شود.
داده های اصلی [ خطای پردازش ریاضی ]�را می توان به مساحت واحد شبکه تقسیم کرد [ خطای پردازش ریاضی ]دبلیو×اچ، و واحدهای شبکه تقسیم شده به عنوان نشان داده می شود [ خطای پردازش ریاضی ]��ساعت(�=1،2،…،دبلیو;ساعت=1،2،…،اچ)، جایی که w و h نشان دهنده مکان واحدهای شبکه هستند. شکل 5 نتیجه تقسیم شبکه 256 × 256 را بر روی یک تصویر HRRS با اندازه 5031 × 4516 نشان می دهد. فرآیندهای تولید هش و تمایز هش زیر در سطح واحد شبکه انجام می شود.
3.2. تولید هش تصویر HRRS
3.2.1. استخراج ویژگی های جهانی
همانطور که در بالا ذکر شد، ویژگی های کلی واحد شبکه با محاسبه ممان زرنیک داده های واحد شبکه به دست می آید. از آنجایی که ممانهای مرتبه پایین Zernike میتوانند اطلاعات بافت تصویر را به خوبی نشان دهند، نیازی نیست ترتیب لحظههای Zernike خیلی زیاد باشد. در این مقاله، دستور [ خطای پردازش ریاضی ]�لحظه انتخاب شده است [ خطای پردازش ریاضی ]�=5 که برای نمایش اطلاعات بافت تصویر کافی است [ 44 ].
همانطور که در جدول 1 نشان داده شده است ، تمام عناصر ممان پنج مرتبه زرنیک به دست می آیند و در نهایت می توان 12 ممان زرنیک را به دست آورد. بزرگی یک گشتاور زرنیک به عنوان مقدار ویژه a ثبت می شود ، بنابراین برای یک واحد شبکه [ خطای پردازش ریاضی ]��ساعت، بردار a در ممان های 5 مرتبه ای زرنیک یک فضای ویژگی 12 بعدی است که به صورت ثبت شده است. [ خطای پردازش ریاضی ]ز�ساعت=(آ1،آ2 ،…،آ12).
3.2.2. استخراج ویژگی های محلی
الگوریتم FAST برای استخراج ویژگی های محلی واحدهای شبکه استفاده می شود. الگوریتم FAST می تواند یک سری نکات کلیدی را استخراج کند [ خطای پردازش ریاضی ]افواحد شبکه، به عنوان مثال، [ خطای پردازش ریاضی ]اف={اف1،اف2،…،اف�}. به منظور قویتر کردن ویژگی استخراجشده و کاهش طول توالی هش، نکات کلیدی استخراجشده توسط FAST به صورت زیر بررسی میشوند:
-
همه نقاط ویژگی را بر اساس پاسخ از بزرگ به کوچک مرتب کنید [ خطای پردازش ریاضی ]آر، و مجموعه نقطه ویژگی مرتب شده را به عنوان تعریف کنید [ خطای پردازش ریاضی ]اف�ه�. مجموعه نقاط کلیدی جدید به عنوان تعریف می شود [ خطای پردازش ریاضی ]اسو یک مجموعه دایره کمکی [ خطای پردازش ریاضی ]سی”تعریف شده است.
-
الگوریتم غربالگری از [ خطای پردازش ریاضی ]اف1. بگذارید نقطه فعلی باشد [ خطای پردازش ریاضی ]افایکس(0<ایکس<�)، یک دایره بکشید [ خطای پردازش ریاضی ]سیایکسبا مختصات [ خطای پردازش ریاضی ]افایکسبه عنوان مرکز، و پاسخ [ خطای پردازش ریاضی ]آربه عنوان شعاع اگر [ خطای پردازش ریاضی ]سیایکسهیچ دایره ای را قطع نمی کند [ خطای پردازش ریاضی ]سی”، سپس [ خطای پردازش ریاضی ]افایکسبه اضافه می شود [ خطای پردازش ریاضی ]اس، و [ خطای پردازش ریاضی ]سیایکسبه اضافه می شود [ خطای پردازش ریاضی ]سی”.
-
مرحله 2 به ترتیب انجام می شود تا زمانی که 10 نقطه وجود داشته باشد [ خطای پردازش ریاضی ]اس، و غربالگری به پایان رسید.
-
برای هر نقطه در [ خطای پردازش ریاضی ]اف�ه�، ویژگی روشنایی متوسط به توضیحات نقطه کلیدی اضافه می شود. روشنایی متوسط A به عنوان مقدار میانگین پیکسل در مربع با پاسخ تعریف می شود [ خطای پردازش ریاضی ]آربه عنوان طول ضلع و نقطه کلیدی مختصات [ خطای پردازش ریاضی ](ایکس،�)به عنوان مرکز
طبق اصل FAST، هر چه پاسخ بزرگتر باشد، تفاوت بین نقطه کلیدی و نقاط اطراف بیشتر است. اگر عملیات حفظ محتوا (مانند فیلتر گاوسی) روی تصویر اعمال شود، ویژگیهای پاسخ بزرگ به راحتی پاک نمیشوند. بنابراین، نقاط کلیدی FAST با پاسخ بزرگتر، پایدارتر از نقاط با پاسخ کم هستند، و نقاط کلیدی که از طریق غربالگری به دست می آیند، قوی تر خواهند بود. غربالگری با استفاده از تقاطع دایره ها می تواند نقاط کلیدی را تا حد امکان به طور یکنواخت در سراسر واحد شبکه توزیع کند و طول توالی هش را تا حد امکان کوتاه کند. از آنجایی که نقاط کلیدی در سطح واحد شبکه استخراج می شوند که در یک منطقه کوچک است، تعداد نقاط انتخاب شده نباید خیلی زیاد باشد. در این صفحه، [ خطای پردازش ریاضی ]�=10با در نظر گرفتن طول توالی هش و کارایی محاسبه. بنابراین، مجموعه نهایی از نکات کلیدی است [ خطای پردازش ریاضی ]اس�ساعت={اس1،اس2،…،اس10}. شکل 6 نقاط کلیدی یک واحد شبکه را پس از غربالگری نشان می دهد.
3.2.3. هش ساخت و ساز
مقدار هش [ خطای پردازش ریاضی ]اچ�ساعتاز یک واحد شبکه [ خطای پردازش ریاضی ]��ساعتتشکیل شده است از [ خطای پردازش ریاضی ]ز�ساعتو [ خطای پردازش ریاضی ]اس�ساعت، یعنی [ خطای پردازش ریاضی ]اچ�ساعت={ز�ساعت، اس�ساعت}که به آن هش واحد می گویند. برای هر عنصر در یک هش واحد، روش برش عدد صحیح برای پردازش داده ها به منظور کوتاه کردن بیشتر طول هش استفاده می شود. طول هش واحد نهایی (12 + (4 × 10)) × 8 بیت = 416 بیت است. برای یک تصویر HRRS، دنباله هش مجموعه هش های هر واحد است، به عنوان مثال، [ خطای پردازش ریاضی ]اچ(�)={اچ(�)11، …،اچ(�)�ساعت}(�=1،2،…،دبلیو;ساعت=1،2،…،اچ). طول توالی هش ادراک نهایی تصویر به اندازه تصویر بستگی دارد. در همین حال، به منظور اطمینان از امنیت احراز هویت، از روش تبدیل لجستیک [ 45 ] برای انجام درهمسازی شبه تصادفی هش اصلی استفاده میشود. [ خطای پردازش ریاضی ]اچ(�)، و کلید درهم به عنوان K تنظیم می شود .
3.3. مقایسه هش
همانطور که در بالا ذکر شد، در یک مورد به اشتراک گذاری داده معمولی، انتقال داده ها به طور کلی در یک کانال غیر قابل اعتماد اجرا می شود و دنباله هش [ خطای پردازش ریاضی ]اچ(�)تولید شده از داده های اصلی همراه با کلید K باید از طریق کانال قابل اعتماد به گیرنده منتقل شود. گیرنده از همان الگوریتم تولید هش به عنوان داده های اصلی برای تولید دنباله هش استفاده می کند [ خطای پردازش ریاضی ]اچ(�”)از داده هایی که باید احراز هویت شوند، و دنباله هش اصلی را رمزگشایی می کند [ خطای پردازش ریاضی ]اچ(�)با کلید K .
3.3.1. تبعیض ویژگی های جهانی
از آنجایی که لحظه Zernike توانایی کافی برای توصیف اطلاعات بافت تصویر [ 39 ] را دارد، احراز هویت یکپارچگی را می توان توسط لحظه های Zernike پیاده سازی کرد. در همین حال، بر اساس توانایی تشخیص ویژگی جزئیات خوب FAST، برای محلی سازی دستکاری اعمال می شود. شباهت را محاسبه کنید [ خطای پردازش ریاضی ]اسمنمتر(�،ساعت)از ویژگی های گشتاور Zernike واحد شبکه در همان موقعیت از [ خطای پردازش ریاضی ]اچ(�)و [ خطای پردازش ریاضی ]اچ(�”)یکی یکی. روش اندازه گیری شباهت برای محاسبه فاصله اقلیدسی آنها است، همانطور که در فرمول (7) نشان داده شده است:
با ترکیب آستانه های قضاوت [ خطای پردازش ریاضی ]تی1و [ خطای پردازش ریاضی ]تی2(0<تی1<تی2)، نتایج احراز هویت به سه دسته تقسیم می شود:
-
[ خطای پردازش ریاضی ]0≤اسمنمتر(�،ساعت)<تی1: گروه 1، مطابق با ادراک داده های اصلی و تأیید اعتبار.
-
[ خطای پردازش ریاضی ]تی1≤اسمنمتر(�،ساعت)<تی2: گروه 2، واحد شبکه دستکاری شده است و احراز هویت را انجام نمی دهد، که باید محلی سازی شود.
-
[ خطای پردازش ریاضی ]اسمنمتر(�،ساعت)≥تی2: گروه 3، داده های محتوای کاملاً متفاوتی در واحد شبکه وجود دارد که نمی توانند احراز هویت را پاس کنند. کل واحد شبکه به عنوان دستکاری شده مشخص شده است.
تعیین آستانه ها [ خطای پردازش ریاضی ]تی1و [ خطای پردازش ریاضی ]تی2در بخش تجربی مورد بحث قرار خواهد گرفت.
3.3.2. تبعیض ویژگی های محلی
از دیدگاه احراز هویت، اگر یک واحد شبکه نتواند احراز هویت را تصویب کند، نشان میدهد که کل تصویر HRRS «یکپارچگی» خود را از دست نداده است. با این حال، با توجه به نیاز محلی سازی دستکاری، لازم است شباهت همه واحدهای شبکه تعیین شود تا به یک نتیجه توضیحی تر برسیم. همانطور که در بالا ذکر شد برای واحدهای شبکه در گروه 2، نکات کلیدی FAST باید بیشتر پردازش شوند.
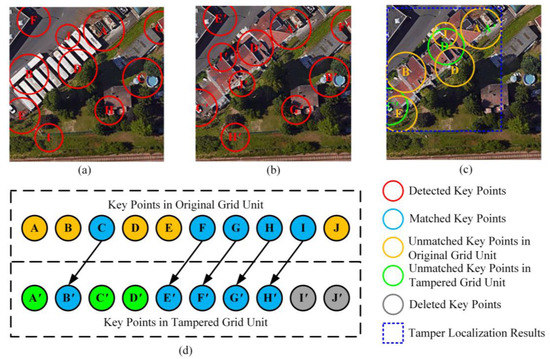
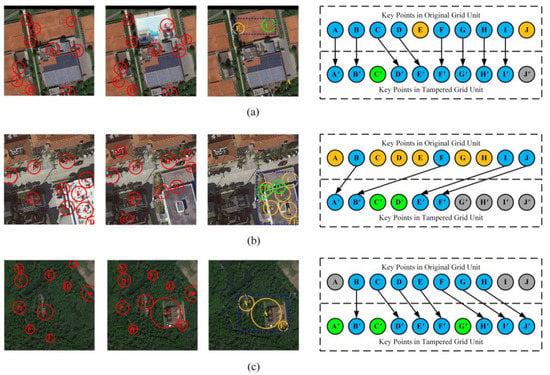
روش پردازش با مثال هایی نشان داده شده است، همانطور که در شکل 7 نشان داده شده است. توالی هش شکل 7 در پیوست A ارائه شده است. روش پردازش به شرح زیر است:
-
استفاده از روش Fast Library for Approximate Nearest Neighbors (FLANN) برای مجموعه نقاط کلیدی [ خطای پردازش ریاضی ]اس(�)�ساعتواحد شبکه اصلی و مجموعه نقطه ویژگی [ خطای پردازش ریاضی ]اس(�”)�ساعتبرای اینکه واحد برای ساخت یک مسابقه احراز هویت شود. FLANN یک روش تطبیق نقطه کلیدی کارآمد است که باید آستانه تطبیق را در نظر بگیرد. آستانه تطابق را روی 0.8 قرار دادیم، که آستانه ای است که موجا [ 46 ] در مقاله خود توصیه می کند. همانطور که در شکل 7 d نشان داده شده است، نقاط آبی پنج جفت نقطه کلیدی هستند که با موفقیت مطابقت داشتند.
-
نقاطی را حذف کنید که میانگین روشنایی آنها تغییر قابل توجهی نداشته است. برای نقاط کلیدی بی همتا در واحدهای شبکه اصلی، اگر میانگین روشنایی آنها در مقایسه با واحد شبکه دستکاری شده تغییر قابل توجهی نداشته باشد، باید حذف شوند. در غیر این صورت، نکات کلیدی باید حفظ شود. از آنجایی که میانگین درخشندگی نقاط کلیدی در واحد شبکه اصلی مشخص است، متوسط روشنایی واحد شبکه دستکاری شده را می توان در همان موقعیت محاسبه کرد، بنابراین میانگین تغییر روشنایی این نقاط کلیدی را می توان به دست آورد. یعنی وقتی:
-
نکته را حذف کنید برای افزایش استحکام، آستانه روشنایی متوسط روی تنظیم شده است [ خطای پردازش ریاضی ]تی�=2. همانطور که در شکل 7 ج نشان داده شده است، نقاط “A”، “B”، “D”، “E” و “J” همگی حفظ می شوند زیرا میانگین روشنایی اطراف آنها تغییر کرده است. در پایان هر ست، نکات کلیدی بی همتا را حذف کنید. پس از تطبیق، اگر هنوز یک نقطه کلیدی بی همتا در پایان وجود دارد [ خطای پردازش ریاضی ]اس(�”)�ساعتو [ خطای پردازش ریاضی ]اس(�)�ساعت، آن را حذف کنید. اما اگر مشخص شود که هر یک از این نقاط در مرحله قبل تغییر در روشنایی متوسط داشته است، حذف نمی شود. از آنجایی که تعداد یک مجموعه امتیاز کلیدی روی 10 ثابت است، نقطه ای در پایان که مطابقت ندارد به این معنی نیست که در آن دستکاری شده است، بلکه ممکن است نقطه تطبیق مربوطه آن پس از رتبه دهم یک مجموعه دیگر رتبه بندی شود. به عنوان مثال، “I” و “J” در این مثال حذف شده اند. میتوانیم متوجه شویم که اگرچه آنها مطابقت ندارند، اما مناطق آنها دستکاری نشده است.
-
برای دایره ای که توسط تمام نقاط مشخصه باقی مانده تشکیل شده است، حداقل مستطیل خارجی ساخته شده است که ناحیه دستکاری است. همانطور که در شکل 7 ج نشان داده شده است، نقاط کلیدی باقی مانده عبارتند از “A”، “B”، “D”، “E”، “J”، “A”، “C”، و “D”، و مستطیل آبی نتیجه محلی سازی دستکاری است.
-
سه مورد خاص در نظر گرفته می شود: اگر همه نکات کلیدی با موفقیت مطابقت نداشته باشند به این معنی است که واحد شبکه به اشتباه به “گروه 2” تقسیم شده است. بنابراین، این واحد شبکه باید دوباره به “گروه 3” تقسیم شود، زیرا تمام نکات کلیدی دستکاری شده اند. اگر همه نکات کلیدی با موفقیت مطابقت داشته باشند، به این معنی است که میکرو دستکاری شناسایی نشده است. در موارد شدید، اگر تعداد نقاط کلیدی پس از غربالگری کمتر از 10 باشد، روش فوق همچنان میتواند برای تطبیق نقاط کلیدی و محلیسازی دستکاری استفاده شود – البته با دقت کمتر.
4. آزمایش و تجزیه و تحلیل
به منظور تأیید اعتبار و جهانی بودن الگوریتم، این مقاله 100 تصویر را از پایگاه داده تصویر DOTA [ 47 ] HRRS برای ساخت یک مجموعه داده انتخاب می کند که اندازه آن از 7568 × 5619 تا 1444 × 1727 متغیر است. مجموعه داده DOTA از مجموعه داده های DOTA تشکیل شده است. سه منبع داده: Google Earth، GF-2 و JL-1. این داده ها همگی تصاویر سنجش از دور با وضوح زیر متر هستند که در میان آنها وضوح تصویر Google Earth 0.5 متر، وضوح تصویر GF-2 0.8 متر و وضوح تصویر JL-1 0.72 متر است.
4.1. تجزیه و تحلیل حساسیت اندازه واحد شبکه
اندازه تقسیم شبکه [ خطای پردازش ریاضی ]مترمی تواند به عنوان سطح حفاظتی در نظر گرفته شود که کاربر می خواهد به الگوریتم اختصاص دهد. اندازه واحدهای شبکه ممکن است مستقیماً بر جزئیات احراز هویت تأثیر بگذارد. اگر [ خطای پردازش ریاضی ]مترخیلی بزرگ است، بسیاری از جزئیات تصویر HRRS از بین خواهد رفت، در حالی که اگر [ خطای پردازش ریاضی ]متربسیار کوچک است، پیچیدگی محاسباتی تا حد زیادی افزایش خواهد یافت.
جدول 2 زمان محاسبه گشتاور زرنیک را در اندازه های مختلف شبکه و فاصله اقلیدسی بین واحدهای شبکه مشابه و واحدهای شبکه متفاوت نشان می دهد. داده های جدول، مقادیر میانگین داده های آزمایش شده روی 20 تصویر HRRS است. زمان محاسبه مجموع زمان تقسیم شبکه و زمان محاسبه لحظه زرنیک است. زمان محاسبه بر روی پلتفرم های رایانه شخصی با Anaconda3 (Python3.7)، پردازنده دوگانه i5-3230m و رم 12G آزمایش شد.
همانطور که از جدول مشاهده می شود، اگرچه تقسیم شبکه 512 × 512 کوتاه ترین زمان محاسبه را دارد، اما تبعیض ضعیفی برای داده ها دارد. انتخاب یک واحد شبکه 256 × 256 برای احراز هویت می تواند راه حل بهینه را بین پیچیدگی الگوریتم و قابلیت تشخیص محتوا به دست آورد.
علاوه بر این، آزمایشی در مورد مقایسه توانایی محلی سازی دستکاری تحت اندازه های مختلف شبکه در شکل 8 آورده شده است. سه تصویر دستکاری شده با اندازه های شبکه متفاوت برای تست های محلی سازی دستکاری چند مقیاسی انتخاب شده اند که همان ناحیه دستکاری شده را منعکس می کنند. نتایج نشان میدهد که الگوریتم پیشنهادی ما میتواند مکان دستکاری را به طور موثر در اندازههای شبکه مختلف تشخیص دهد. لازم به ذکر است که ناحیه دستکاری در شکل 8 a اکثر مناطق در واحد شبکه را پوشش می دهد، بنابراین محل دستکاری نسبتا بزرگ است. که در شکل 8ج، ممکن است به دلیل گسترش دامنه شبکه، دستکاری جزئی در داده ها قابل شناسایی نباشد (اگرچه این ناحیه دستکاری در مثال ما مشخص شده است). بنابراین، از این جنبه، استفاده از اندازه 256 × 256 برای تقسیم شبکه نیز توصیه می شود.
4.2. تجزیه و تحلیل آستانه ویژگی های جهانی
به منظور ارائه یک آستانه معقول برای استخراج ویژگی های جهانی، مقدار زیادی از داده ها باید آزمایش شوند.
100 تصویر در “داده داده اصلی” بدون تغییر محتوا پردازش شدند تا یک “مجموعه داده مشابه” متشکل از 700 تصویر تولید شود. این عملیات که محتوا را تغییر نمی دهد شامل تعبیه واترمارک LSB، تبدیل فرمت به BMP، تبدیل فرمت به PNG، فیلتر گاوسی ( [ خطای پردازش ریاضی ]�2=0.1، �2=1و فشرده سازی JPEG ( [ خطای پردازش ریاضی ]س=99%،س=90%). پس از تقسیم شبکه، 6337 واحد شبکه در مجموعه داده اصلی و 44359 واحد شبکه در مجموعه داده مشابه وجود دارد. بنابراین می توان 44359 جفت واحد شبکه با محتویات مشابه تولید کرد.
حمله دستکاری به واحدهای شبکه در مجموعه داده اصلی اعمال می شود تا یک «داده دستکاری شده» متشکل از 6337 واحد شبکه به دست آید. روش دستکاری به این صورت است که به طور تصادفی مناطقی از 15٪ تا 25٪ از واحد شبکه اصلی جایگزین می شود که می تواند 6337 جفت واحد شبکه را ایجاد کند که محتوای آنها دستکاری شده است. برای رسیدن به این هدف، ما 40 الگوی دستکاری در اندازه های 100 × 100 تا 128 × 128 ساخته ایم. 10 در اندازه 128 × 128. این الگوها به طور تصادفی به هر یک از سلولهای شبکه اصلی اختصاص داده میشوند تا بخشی از دادههای اصلی را جایگزین کنند.
با جایگزینی کامل واحدهای شبکه در پایگاه داده اصلی، می توان یک “داده داده متفاوت” به دست آورد و 6337 جفت جفت واحد شبکه با محتویات مختلف تولید کرد.
فاصله اقلیدسی بین 44359 جفت واحد مشابه، 6337 جفت واحد دستکاری شده و 6337 جفت واحد مختلف برای بدست آوردن نمودار توزیع احتمال فاصله اقلیدسی محاسبه می شود، همانطور که در شکل 9 نشان داده شده است. همانطور که از شکل مشاهده می شود، زمانی که آستانه [ خطای پردازش ریاضی ]تی1=1.75و آستانه [ خطای پردازش ریاضی ]تی2=6.50، بهترین تمایز مجموعه داده های مختلف را می توان به دست آورد. علاوه بر این، تمام آستانه های استفاده شده در این الگوریتم در پیوست B ارائه شده است.
4.3. تست های استحکام
یک الگوریتم هش ادراکی خوب باید برای عملیات حفظ محتوا قوی باشد. همانطور که در بخش 4.2 توضیح داده شد ، 44359 واحد شبکه در “داده داده مشابه” همه داده هایی هستند که تحت عملیات حفظ محتوا قرار گرفته اند. آنها از نظر تئوری باید احراز هویت یکپارچگی را بگذرانند. همانطور که در جدول 3 نشان داده شده است، میتوان دقت الگوریتم را از طریق تست احراز هویت یکپارچگی مجموعه داده مشابه به دست آورد .
با توجه به دادههای جدول، الگوریتم پیشنهادی تقریباً 100% برای تعبیه واترمارک LSB، تبدیل فرمت، فشردهسازی JPEG و فیلتر گاوسی قوی است. [ خطای پردازش ریاضی ]�2=0.1، در حالی که یک نتیجه نسبتا ضعیف را برای فیلتر گاوسی نشان می دهد ( [ خطای پردازش ریاضی ]�2=1). دلیل آن این است که فیلتر گاوسی یک فیلتر کل نگر است. چه زمانی [ خطای پردازش ریاضی ]�2=1، اطلاعات تصویر ممکن است تا حد زیادی تغییر کند. به طور کلی، الگوریتم هنوز برای انواع عملیات حفظ محتوا قوی است.4.4. تست های تشخیص دستکاری
ضمن حفظ حساسیت به «عملیات حفظ محتوا»، حساسیت به «عملیات دستکاری محتوا» نیز باید در نظر گرفته شود. یک الگوریتم احراز هویت خوب باید تمایز خوبی بین عملیات حفظ محتوا و عملیات دستکاری محتوا داشته باشد. علاوه بر این، تمایز بین “مجموعه داده های دستکاری شده” و “مجموعه داده های مختلف” نیز لازم است. به منظور تأیید عملکرد جامع الگوریتم، ماتریس سردرگمی در سه مجموعه داده (مجموعه داده مشابه، مجموعه داده دستکاری شده و مجموعه داده های مختلف) در جدول 4 آورده شده است.
نرخ مثبت واقعی ( [ خطای پردازش ریاضی ]تیپآر) و نرخ مثبت کاذب ( [ خطای پردازش ریاضی ]افپآر) معمولا برای تعیین عملکرد جامع الگوریتم ها استفاده می شود. تعریف TPR و FPR در فرمول (9) آورده شده است:
در این فرمول، [ خطای پردازش ریاضی ]تیپبه مثبت واقعی اشاره دارد، [ خطای پردازش ریاضی ]افپبه مثبت کاذب اشاره دارد، [ خطای پردازش ریاضی ]افناشاره به ارجاع به منفی کاذب، و [ خطای پردازش ریاضی ]تینبه منفی واقعی اشاره دارد. TPR نشاندهنده نسبت نمونههای مثبت شناساییشده توسط الگوریتم به تمام نمونههای مثبت است و TFR نشاندهنده نسبت نمونههای منفی است که توسط الگوریتم به همه موارد منفی طبقهبندی شدهاند. جدول 5 مقدار TPR و FPR هر مجموعه داده را نشان می دهد.
[ خطای پردازش ریاضی ]تیپآراسنشاندهنده استحکام الگوریتم است، یعنی احتمال اینکه دادهها بتوانند پس از عملیات حفظ محتوا، احراز هویت یکپارچگی را پاس کنند. [ خطای پردازش ریاضی ]افپآراساین احتمال را نشان می دهد که پس از عملیات دستکاری محتوا، داده ها به اشتباه به عنوان “تأیید اعتبار یکپارچگی” علامت گذاری شده اند. در این آزمایش، [ خطای پردازش ریاضی ]تیپآراس=97.98%، و [ خطای پردازش ریاضی ]افپآراس=3.19%. مشاهده می شود که الگوریتم برای عملیات حفظ محتوا بسیار قوی است و به گزینه های دستکاری محتوا بسیار حساس است. به عبارت دیگر، الگوریتم توانایی تمایز قوی بین عملیات حفظ محتوا و عملیات دستکاری محتوا دارد.
با این حال، مقادیر TPR T و TPR D خیلی ایده آل نیستند. همانطور که از جدول 4 مشاهده می شود، برخی از واحدهای Tamper واحدهای مختلف و برخی از واحدهای مختلف به عنوان واحدهای Tamper در نظر گرفته می شوند. دلیل آن این است که اندازه ناحیه دستکاری شده نمی تواند به صورت خطی بر شدت دستکاری تأثیر بگذارد. به عنوان مثال، تعبیه یک ناحیه دستکاری سیاه در یک تصویر سفید تأثیر زیادی بر لحظات زرنیک دارد، در حالی که جایگزینی یک چمن با چمنزار دیگر تأثیر نسبتاً کمی بر لحظات زرنیک دارد. در اصل، توانایی تمایز بین واحدهای Tamper و Different Units تنها بر نتیجه محلی سازی Tamper تأثیر می گذارد. از آنجایی که مکان یابی دستکاری در مقیاس واحد شبکه اجرا می شود، نتایج به شدت تحت تأثیر قرار نمی گیرند.
4.4. تست های محلی سازی دستکاری
به منظور بررسی اثربخشی الگوریتم برای محلیسازی دستکاری، آزمایشهای محلیسازی دستکاری را به ترتیب در مقیاس واحد شبکه و مقیاس کل تصویر انجام دادیم.
4.4.1. تست های محلی سازی دستکاری در واحدهای شبکه
در این آزمایش، نتایج محلی سازی دستکاری سه واحد شبکه دستکاری شده نشان داده شده است. روش تطبیق نقاط کلیدی که در بالا توضیح داده شد برای بومی سازی ناحیه دستکاری شده اجرا می شود. همانطور که در شکل 10 نشان داده شده است، مناطق دستکاری شده در این واحدهای شبکه پیدا و شناسایی شدند. این نشان میدهد که روش محلیسازی دستکاری که ما طراحی کردهایم میتواند نتایج موقعیتیابی دستکاری نسبتاً دقیقی را در عین حفظ انتزاع توالی هش ارائه دهد. در اصل، اگر تعداد زیادی از نقاط کلیدی انتخاب شوند، می توان ناحیه دستکاری شده را با دقت بیشتری به تصویر کشید. با این حال، با توجه به الزامات انتزاع هش، هنوز هم تنها با استفاده از 10 نکته کلیدی می توان به یک نتیجه نسبتا معقول دست یافت.
4.4.2. تست های محلی سازی دستکاری در کل تصاویر
از آنجایی که ساختن یک تصویر دستکاری شده متقاعد کننده دشوار است، ما شش تصویر HRRS را برای تست محلی سازی دستکاری در مقیاس کل تصویر انتخاب کردیم. همانطور که در جدول 6 نشان داده شده است ، نتایج محلی سازی دستکاری شش تصویر دستکاری به دست آمده است. در مجموع 71 واحد شبکه تحت تأثیر “حمله دستکاری” قرار گرفتند که از این تعداد 68 واحد دستکاری شده توسط این الگوریتم شناسایی شدند، با نرخ تشخیص دستکاری 95.77%. سه واحد شبکه دستکاری شده شناسایی نشدند زیرا شامل یک منطقه بسیار کوچک بود. همانطور که در بخش 4.3 توضیح داده شد، توانایی تمایز بین واحدهای Tamper و Different Units نسبتاً کم است و برخی از واحدهای شبکه به اشتباه طبقه بندی می شوند. از نظر تئوری، به دلیل اینکه نتایج بومی سازی دستکاری ارتباط فضایی دارند، یعنی برخی از مناطق دستکاری شده به هم مرتبط هستند. بنابراین، یک بدنه محدب می تواند برای شبیه سازی بیشتر موقعیت دستکاری ساخته شود. با این حال، با توجه به تصادفی بودن دستکاری، تعیین اینکه آیا این مفاهیم دستکاری دارای همبستگی فضایی هستند، مشکل است، بنابراین این روش اتخاذ نشد. با این حال، در مقیاس کل تصویر، دقت محلی سازی دستکاری هنوز دقیق است و بیشتر مناطق دستکاری شده را می توان شناسایی و مکان یابی کرد.
4.5. تحلیل امنیت الگوریتم
امنیت الگوریتم هش ادراکی عمدتاً به یک جهتی بودن توالی هش اشاره دارد، یعنی اطلاعات تصویر را نمی توان با توالی هش استنتاج کرد. از آنجایی که ما از تبدیل لجستیک برای رمزگذاری دنباله هش استفاده کردیم، میتوان از یک جهتی بودن دنباله هش اطمینان حاصل کرد. در اصل، اطلاعات تصویر به یک رشته بی معنی تبدیل می شود که امنیت الگوریتم را تضمین می کند. البته در فرآیند پیاده سازی خاص، DES و AES و سایر الگوریتم های رمزگذاری را نیز می توان به عنوان روش رمزگذاری دنباله هش در نظر گرفت. با این حال، این موضوع مورد توجه این مقاله نیست و در اینجا به تفصیل توضیح داده نخواهد شد.
4.6. مقایسه با الگوریتم های موجود
ما این الگوریتم را با الگوریتم هش ادراکی موجود مقایسه می کنیم که شامل هر دو الگوریتم هش ادراکی تصویر دیجیتال [ 31 ، 33 ، 34 ، 35 ، 36 ، 37 ] و الگوریتم هش ادراکی تصویر HRRS [ 28 ، 29 ] است. جدول 7 نتایج مقایسه این الگوریتم ها را نشان می دهد.
با توجه به استفاده از الگوریتم FAST برای استخراج ویژگی، سرعت اجرای الگوریتم در مقایسه با الگوریتم تشخیص نقطه کلیدی SIFT بسیار بهبود یافته است. در همین حال، به دلیل ترکیب ویژگیهای جهانی و محلی، الگوریتم میتواند نتایج موقعیتیابی را تا سطح زیرشبکه اصلاح کند. به عبارت دیگر، شبکه تنها مبنای مکان یابی دستکاری است و دقت مکان یابی دستکاری نهایی بالاتر از اندازه شبکه خواهد بود.
5. نتیجه گیری ها
در این مقاله، با ترکیب توانایی لحظه زرنیک برای تشخیص محتوای تصویر و الگوریتم FAST برای شناسایی نقاط کلیدی، یک الگوریتم هش ادراکی تصویر HRRS پیشنهاد شد. این الگوریتم دارای استحکام قوی برای عملیات حفظ محتوا، توانایی تشخیص موثر برای عملیات دستکاری محتوا، و می تواند به محلی سازی دستکاری دست یابد. مشارکت های این مقاله به شرح زیر است:
-
با استفاده از ایده ترکیب چند ویژگی برای احراز هویت تصاویر HRRS قابلیت اطمینان در مقایسه با الگوریتمهای احراز هویت تصویر HRRS موجود افزایش یافته است.
-
در مقایسه با الگوریتمهای هش ادراکی تصویر دیجیتال موجود، معرفی الگوریتم FAST کارایی استخراج نقاط کلیدی را تا حد زیادی بهبود میبخشد. این برای تصاویر HRRS با اندازه تصویر بزرگ عملی تر است.
-
یک سری پایگاه داده برای تجزیه و تحلیل آستانه قضاوت ساخته شد. در مقایسه با الگوریتمهای موجود، قضاوت بر اساس آستانه تجربی است که تفسیرپذیری و دقت را بهبود میبخشد.
در تحقیقات آینده، درک دقیقتر و استفاده از توصیفگرهای FAST به منظور دستیابی به دقت محلیسازی دستکاری بالاتر در نظر گرفته خواهد شد. از آنجایی که روش تقسیم شبکه برای بهبود دقت احراز هویت استفاده می شود، طول کل توالی هش به اندازه تصویر بستگی دارد، که به ناچار منجر به توالی هش تصویر بسیار طولانی می شود. همچنین کشف راه برای فشرده سازی بیشتر توالی هش در تحقیقات آینده موضوع مهمی است. در حالت ایده آل، تعداد نقاط کلیدی را می توان به صورت تطبیقی با توجه به محتوای تصویر تغییر داد، اما این ممکن است به استفاده از روش های یادگیری ماشین نیاز داشته باشد، که همچنین مشکلات زیادی در مورد تجزیه و تحلیل معنایی تصویر به همراه خواهد داشت. امیدواریم در آینده تحقیقات بیشتری در مورد آن داشته باشیم.









بدون دیدگاه