

خلاصه
از آنجایی که کدگذاری یک سیستم رودخانه دندریتی می تواند برای نشان دادن نظم جریان و ساختار فضایی یک شبکه رودخانه استفاده شود، همیشه در انتخاب رودخانه استفاده می شود که یک مرحله کلیدی در تعمیم نقشه توپوگرافی است. دو دسته از سیستم های کدگذاری هیدرولوژیکی مرسوم وجود دارد، یکی رویکرد از بالا به پایین و دیگری رویکرد از پایین به بالا. با این حال، اولی به طور دقیق سلسله مراتب شبکه رودخانه دندریتی را که توسط روابط حوضه ایجاد می شود منعکس نمی کند و برای انتخاب جریان شبکه های رودخانه با توزیع یکنواخت شاخه ها مناسب نیست. دومی نمی تواند به طور مستقیم عمق زیردرخت یک جریان را نشان دهد، و انتخاب جریان سیستم های رودخانه ای که دارای ساختارهای توپولوژیکی عمیق هستند مطلوب نیست. از این رو، یک روش انتخاب برای شبکههای رودخانهای دندریتیک بر اساس کدگذاری ترکیبی در این مقاله پیشنهاد شدهاست. ابتدا، شبکه رودخانه دندریتی از طریق کدگذاری کلاسیک هورتون از بالا به پایین کدگذاری می شود. دوم، درختان توپولوژی هدایتشده برای سازماندهی دادههای شبکه رودخانه ساخته میشوند و اتصالات ضربهای برای کدگذاری شبکه رودخانه در رویکرد پایین به بالا محاسبه میشوند. سوم، شبکه رودخانه با استفاده ترکیبی از رویکرد از بالا به پایین و رویکرد پایین به بالا مشخص می شود و بر اساس ویژگی های فضایی شبکه رودخانه، شبکه رودخانه به سه نوع زیر درخت تقسیم می شود: شاخه عمیق، شاخه کم عمق و شعبه ساده سپس برای دستیابی به انتخاب رودخانه، کدگذاری مناسب به طور خودکار به زیر درختان مختلف اختصاص داده می شود. سرانجام، داده های نقشه توپوگرافی واقعی یک سیستم رودخانه در منطقه ای از استان هوبی برای اعتبار نسبی سیستم کدگذاری ترکیبی در برابر دو سیستم کدگذاری جدا شده موجود استفاده می شود. نتایج تجربی نشان میدهد که روش کدگذاری ترکیبی برای انتخاب شبکه رودخانه بسیار مؤثر است، نه تنها در برجسته کردن سلسله مراتب تشکیلشده توسط روابط حوضه، بلکه در توزیع یکنواخت شاخهها.
کلید واژه ها:
تعمیم نقشه ; شبکه های رودخانه ای دندریتی ; انتخاب شبکه رودخانه ; سفارش ترکیبی ; طبقه بندی زیردرخت
1. معرفی
شبکه رودخانه عنصر اسکلت در نقشه های توپوگرافی چند مقیاسی است. به دلیل حساسیت مقیاس، داده های هیدروگرافی نیاز به تعمیم مکرر برای حفظ ویژگی های اصلی و معمولی شبکه رودخانه دارند [ 1 ]. به طور کلی، ویژگیهای رودخانه دندریتیک با ویژگیهای سلسله مراتبی و فراکتالی مشخص مشخص میشوند [ 2 ، 3 ]، و کدگذاری یک رویکرد مؤثر برای آشکار ساختن ساختار فضایی ویژگیهای رودخانه و ترتیب هر جریان است. بنابراین، کدگذاری ویژگیهای رودخانه دندریتی همیشه یک نقطه کانونی برای مطالعات تعمیم نقشه [ 4 ، 5 ] بوده است.
هورتون [ 6 ] سیستم کدگذاری کلاسیک هورتون را بر اساس ویژگی رودخانه طبیعی پیشنهاد کرد که در آن آب تحت تأثیر گرانش جریان دارد. سیستم کدگذاری هورتون ترتیب هر جریان را متمایز میکند و بازتابی بصری از عمق زیردرخت جریان را ارائه میدهد که آن را به ابزاری قدرتمند در تحلیلهای کمی ویژگیهای ساختاری شبکههای رودخانه تبدیل میکند. به عنوان مثال، محار و همکاران. [ 7 ] و هاریش و همکاران. [ 8 ] سیستم ترتیب جریان هورتون را با تصاویر سنجش از دور ترکیب کرد تا ویژگی های توپوگرافی حوزه های آبخیز را تجزیه و تحلیل کند. بیشتر از همه، از آنجایی که سیستم کدگذاری هورتون را می توان برای تشخیص ترتیب جریان استفاده کرد، سیستم کدگذاری برای انتخاب جریان در تعمیم سیستم های رودخانه استفاده شد [ 9 ]].
Strahler [ 10 ] نظریه های هورتون را برای ایجاد سیستم کدگذاری Strahler، که بر اساس بخش های رودخانه است، توسعه داد. سیستم کدگذاری Strahler اندازه ها و ویژگی های مورفولوژیکی زیرجریان ها را منعکس می کند و برای برجسته کردن ویژگی های دندریتیک یک شبکه رودخانه مفید است. استانیسلاوسکی و همکاران [ 11 ] از سیستم کدگذاری Strahler به عنوان معیاری برای شناسایی اهمیت دسترسی در طول تعمیم و انتخاب جریان استفاده کرد. از آنجایی که سیستم کدگذاری مبتنی بر دسترسی برای سازماندهی شبکه های رودخانه ای در رایانه ها مناسب تر است، Shreve [ 12 ]، Horsfield و Cumming [ 13 ]] سیستم های کدگذاری هیدرولوژیکی خود را بر اساس سیستم کدگذاری Strahler پیشنهاد کردند تا ویژگی هایی مانند تعداد شاخه ها و تفاوت در تراکم شبکه رودخانه را منعکس کنند. سیستم های کدگذاری فوق به طور گسترده در تجزیه و تحلیل هیدروگرافی و تعمیم رودخانه استفاده می شود. با این حال، این سیستم ها به طور کلی از یک رویکرد از بالا به پایین استفاده می کنند، که در آن جریان ها از انتهای یک سیستم رودخانه (یعنی منبع رودخانه) به سمت ساقه اصلی (یعنی مصب) مرتب می شوند. هنگامی که این سیستم های کدگذاری برای پردازش سیستم های رودخانه دندریتی بزرگ استفاده می شوند، کدهای جریان حاصل برای برجسته کردن سلسله مراتب یک سیستم رودخانه که توسط روابط حوضه آبریز تشکیل می شوند، مناسب نیستند.
Gravelius [ 14 ] و Hack [ 15 ] یک تعریف کلاسیک برای ترتیب جریان با توجه به روابط حوضه ارائه کردند. بر اساس این تعریف، یک سیستم کدگذاری هیدرولوژیکی خودکار از پایین به بالا برای سیستم های رودخانه دندریتیک توسعه داده شد [ 16 ، 17 ]]. در این روش، موجودیتهای رودخانه بهعنوان عناصر در نظر گرفته میشوند و سلسله مراتب جریان در کدگذاری ترتیب جریان در نظر گرفته میشود. در مقایسه با سیستم کدگذاری جریان هورتون، این سیستم کدگذاری نمیتواند مستقیماً عمق زیردرخت یک جریان را نشان دهد، با این حال نشاندهنده بهتری از سلسله مراتب جریان تولید شده توسط روابط حوضه آبریز است. به طور خلاصه، در طول انتخاب و تعمیم جریان، سیستم کدگذاری جریان هورتون برای سیستمهای رودخانه دندریتی که ساختارهای توپولوژیکی عمیقی دارند، مناسبتر است، در حالی که سیستم کدگذاری جریان Gravelius [ 14 ] و Hack [ 15 ] برای سیستمهای رودخانه دندریتی کمعمق توپولوژیکی مناسبتر است. توزیع یکنواخت انشعابات
در روش سنتی انتخاب رودخانه برای تعمیم نقشه توپوگرافی، دو سیستم کدگذاری فوق به صورت جداگانه مورد استفاده قرار گرفتند، محققان یا یک رویکرد از بالا به پایین یا یک رویکرد از پایین به بالا را انتخاب می کنند. با این حال، ساختار توزیع فضایی شبکههای رودخانهای در دادههای واقعی پیچیده و متنوع است، برای یک سیستم کد واحد توصیف اهمیت هر جریان در طول عملیات انتخاب دشوار است. در نتیجه، برخی از زیردرختان رودخانه نمی توانند ویژگی های توزیع فضایی اولیه را پس از انتخاب خودکار حفظ کنند. بنابراین، با ترکیب مزایای هر دوی این روش ها، یک روش انتخاب شبکه رودخانه دندریتی بر اساس کدگذاری ترکیبی در این مقاله پیشنهاد شده است.
مقاله شامل پنج بخش است. بخش 2 روش های کدگذاری از بالا به پایین و پایین به بالا را معرفی می کند و به طور همزمان کاستی های آنها را تحلیل می کند. روش انتخاب پیشنهادی برای شبکههای رودخانه دندریتیک بر اساس کدگذاری ترکیبی به تفصیل در بخش 3 توضیح داده شده است . بخش 4 آزمایش ها را توضیح می دهد و سپس نتایج را ارائه و تجزیه و تحلیل می کند و به دنبال آن بحث ها و نتیجه گیری ها در بخش 5 ارائه می شود .
2. آثار مرتبط
2.1. روشهای کدگذاری جریان فعلی
2.1.1. سیستم کدگذاری از بالا به پایین
دو سیستم کدگذاری کلاسیک از بالا به پایین وجود دارد. یکی سیستم کدگذاری جریان هورتون و دیگری سیستم کدگذاری استریم استراهلر است.
هدف سیستم کدگذاری هورتون این است که موجودیتهای رودخانه را در حوضههای آبخیز مختلف که شکلها و ویژگیهای ساختاری مشابهی دارند به یک ترتیب طبقهبندی کند. برای این منظور، شاخههای پایانهای بدون انشعاب در یک ویژگی رودخانه دندریتی، مرتبه یک در سیستم جریان هورتون اختصاص داده میشوند. بر اساس جهت هر جریان، رودخانه هایی که فقط شامل نهرهای درجه یک هستند به عنوان نهرهای مرتبه دوم تعریف می شوند، در حالی که رودخانه هایی که دارای نهرهای درجه یک و دوم هستند به عنوان نهرهای مرتبه سوم تعریف می شوند. به این ترتیب، ساقه اصلی یک سیستم رودخانه ای، که دارای بیشترین تعداد شاخه ها است، به عنوان جریان بالاترین مرتبه ( مرتبه n )، همانطور که در شکل 1 a نشان داده شده است، تعریف می شود.
نظم دهی جریان استرالر بر روی ویژگی های رودخانه دندریتی بر اساس بخش های رودخانه انجام می شود. بخشهای رودخانهای که به گرههای منبع رودخانه متصل میشوند، بهعنوان ورودیهای مرتبه اول تعریف میشوند، در حالی که دسترسیهایی که از همگرایی دو یا چند دهانه مرتبه اول تشکیل میشوند، مرتبه جریانی برابر با 2 دارند. به این ترتیب، هر دستی که توسط دو یا چند n تشکیل میشود. -order reaches دارای ترتیب جریانی n + 1 است. همه دسترسی ها تا زمانی که همه جریان ها کدگذاری شوند پیمایش می شوند. سپس کدهای Strahler یک سیستم رودخانه، همانطور که در شکل 1 b نشان داده شده است، به دست می آید.
2.1.2. سیستم کدگذاری از پایین به بالا
درست مانند سیستم کدگذاری از بالا به پایین، دو نوع سیستم کدگذاری از پایین به بالا وجود دارد. یکی سیستم کدگذاری استریم هک بر اساس جریان های رودخانه و دیگری سیستم کدگذاری استریم مارانی بر اساس بخش های رودخانه است. یک سیستم کدگذاری از پایین به بالا پیشنهاد و اجرا شد [ 14 ، 15 ، 16 ، 17 ] از طریق یک تعریف کلاسیک از نظم جریان، که در آن ساقه اصلی به عنوان یک جریان مرتبه اول تعریف می شود، در حالی که شاخه های فرعی به ساقه اصلی متصل می شوند. جریان های درجه دوم هستند. به این ترتیب، شاخه های بدون انشعاب در انتهای یک سیستم رودخانه به عنوان نهرهای با بالاترین مرتبه تعریف می شوند، همانطور که در شکل 2 نشان داده شده است.آ. این تعریف از نظم جریان به وضوح سلسله مراتبی را که توسط روابط حوضه آبریز در یک سیستم رودخانه تشکیل شده است، تعریف می کند. مارانی و همکاران [ 18 ] یک سیستم کدگذاری مبتنی بر بخش های رودخانه را پیشنهاد کرد که به عنوان روش کدگذاری قطر توپولوژیکی [ 16 ] نیز شناخته می شود، همانطور که در شکل 2 ب نشان داده شده است.
2.2. نارسایی های روش های فعلی
2.2.1. نارسایی های رویکرد بالا به پایین در انتخاب رودخانه
رویکرد کدگذاری از بالا به پایین اغلب در تعمیم رودخانه استفاده می شود تا اهمیت رودخانه را منعکس کند [ 1 ، 11 ]. در مقایسه با سیستم کدگذاری Strahler، سیستم کدگذاری هورتون مزایای بیشتری در بیان اتصال یک رودخانه دارد زیرا واحد در کدگذاری هورتون موجودات رودخانه هستند. شکل 1 a نشان می دهد که سیستم کدگذاری هورتون (که بر اساس موجودیت های رودخانه است) یک روش عالی برای تشخیص ترتیب جریان و توصیف عمق زیردرخت یک جریان است. با این حال، از آنجایی که سیستم کدگذاری هورتون از رویکرد بالا به پایین استفاده میکند، موجودیتهای شاخهای که نظم هورتون یکسانی در سیستمهای رودخانهای بزرگ دارند ممکن است در واقع ترتیب جریان یکسانی نداشته باشند. در شکل 3، جریانهای AB (سبز)، CD (زرد) و EF (قرمز) همگی دارای کد هورتون 1 هستند، علیرغم داشتن ترتیب جریانهای متفاوت در واقعیت. جریان AB به ساقه اصلی متصل است و بنابراین یک جریان مرتبه اول است. سی دی استریم به انشعابات مرتبه اول متصل است و بنابراین یک جریان مرتبه دوم است. و جریان EF به یک انشعابات مرتبه دوم متصل است و بنابراین یک جریان مرتبه سوم است. از این رو، موجودیتهای رودخانهای که ترتیب جریان هورتون یکسانی دارند، نمیتوانند با یکدیگر مقایسه شوند و ترتیبهای تعیینشده توسط این سیستم بهطور دقیق سلسله مراتب جریانهای تشکیلشده توسط روابط حوضه آبریز را منعکس نمیکنند.
2.2.2. نارسایی های رویکرد پایین به بالا در انتخاب رودخانه
ما همچنان بر روی رویکرد کدگذاری مبتنی بر جریانهای رودخانه تمرکز میکنیم، که کدهایی که جریانها در روابط حوضه آبریز هر رودخانه به آن تکیه میکنند [ 15 ، 16 ] در شکل 4 نشان داده شده است. با این حال، از آنجایی که سیستم کدگذاری از یک رویکرد از بالا به پایین استفاده میکند، موجودیتهای شاخهای که ترتیب کدگذاری یکسانی در سیستمهای رودخانهای بزرگ دارند ممکن است در واقع عمق درخت فرعی یک جریان را توصیف نکنند. در شکل 4 ، جریانهای AB (سبز)، CD (زرد) و EF (قرمز) همگی دارای کد دو هستند، علیرغم اینکه ساختارهای عمیق آنها در واقعیت متفاوت است.
3. روش انتخاب برای شبکه های رودخانه دندریتی بر اساس کدگذاری ترکیبی
یک روش انتخاب برای شبکه های رودخانه دندریتی بر اساس کدگذاری ترکیبی پیشنهاد شده است، و از سه بخش تشکیل شده است: (1) شبکه رودخانه دندریتی توسط کدگذاری کلاسیک هورتون از بالا به پایین کدگذاری می شود. (2) درختان توپولوژی هدایت شده برای سازماندهی داده های شبکه رودخانه ساخته می شوند، در حالی که اتصالات سکته مغزی برای کدگذاری شبکه رودخانه در رویکرد پایین به بالا محاسبه می شوند. و (3) شبکه رودخانه از طریق استفاده ترکیبی از رویکرد بالا به پایین و رویکرد پایین به بالا مشخص شده است، پس از آن یک الگوریتم انتخاب برای ویژگیهای رودخانه دندریتیک بر اساس کدگذاری ترکیبی ارائه میشود.
3.1. کدگذاری از بالا به پایین برای ویژگی های رودخانه دندریتیک
اولین مرحله کدگذاری ترکیبی، کدگذاری جریان در شبکه رودخانه دندریتیک با کدگذاری هورتون از بالا به پایین است. به شاخه های پایانی متصل به منابع رودخانه مرتبه 1 اختصاص داده می شود. بر اساس جهت هر نهر، نهرهایی که فقط شامل نهرهای مرتبه اول هستند به عنوان نهرهای مرتبه دوم تعریف می شوند و به آنها مرتبه 2 اختصاص می یابد. به این ترتیب، هر جریانی شامل نهرهای مرتبه n دارای مرتبه n + 1 است. ساقه اصلی سیستم رودخانه ای که بیشترین تعداد شاخه های فرعی را دارد، به عنوان جریان بالاترین مرتبه ( مرتبه n ) تعریف می شود، همانطور که در شکل 5 نشان داده شده است. فرآیند دقیق کدگذاری هورتون در تحقیقات موجود توضیح داده شده است [ 6 ، 9 ، 19]؛ بنابراین، در اینجا پوشش داده نمی شود.
3.2. کدگذاری از پایین به بالا برای ویژگی های رودخانه دندریتیک
در واقع، رودخانه ها معمولاً به عنوان مجموعه ای از عناصر دسترسی در داده های نقشه اصلی ذخیره می شوند. در مورد انتخاب، مهم است که یک جریان به طور کلی پردازش شود. برای کدگذاری یک جریان در یک شبکه رودخانه دندریتی با رویکرد پایین به بالا، درختان توپولوژی هدایت شده برای سازماندهی داده های شبکه رودخانه ساخته می شوند و اتصالات سکته مغزی از مصب برای ردیابی جریان اصلی در این مقاله محاسبه می شوند [ 17 ].
3.2.1. درختان توپولوژی هدایت شده و اتصالات ضربه ای
نمودارهای ساختاری توپولوژیکی ویژگیهای رودخانه دندریتی که حاوی جهتهای جریان هستند نیز به عنوان DTT [ 20 ] شناخته میشوند که مجموعهای از گرهها و کمانها هستند که اطلاعاتی مانند درجه، درجه خارج و درجات هر گره را ثبت میکنند [ 21 ]. جهت هر قوس (لبه) به عنوان جهت از گره منبع به گره پایانه تعریف می شود. علاوه بر این، DTTها همچنین حاوی اطلاعات معنایی (مثلاً نام و نوع) و هندسی (مثلاً طول و عرض) جریان هستند.
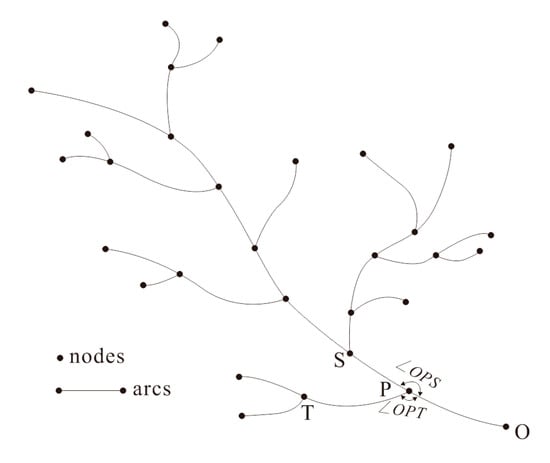
شناخت ساقه های اصلی گام مهمی در کدگذاری سیستم های رودخانه ای است. برخی از محققان پیشنهاد کردهاند که مسیرهای رودخانهای را میتوان برای تشکیل نهادهای رودخانه با استفاده از طول جریان و مناطق حوضه متصل کرد [ 16 ]. با این حال، این روش ها ویژگی های جهت جریان یک جریان را در نظر نمی گیرند. تامسون و همکاران [ 22 ، 23] پیشنهاد کرد که اصل اتصال در روانشناسی گشتالت میتواند برای ساخت سکتههای سیستمهای رودخانهای بر اساس معناشناسی، هندسه، توپولوژی و جهت جریانهای آنها استفاده شود. نتایج عالی با استفاده از این روش به دست آمده است. در روش ما، اتصالات سکته مغزی یک ویژگی رودخانه دندریتی به طور تکراری با استفاده از DTT بر اساس اصول سازگاری معنایی، ثبات جهت و اولویتبندی طول محاسبه میشود (یعنی طولانیتر بهتر است). سپس ساقه اصلی بر این اساس شناسایی می شود. روشهای محاسبه اتصالات ضربهای و شناسایی ساقه اصلی در زیر توضیح داده شده است که شکل 6 به عنوان یک مثال توضیحی استفاده میشود:
مرحله 1: در بیشتر موارد، دستآهن پایین دست یک رودخانه دندریتیک فقط یک مصب دارد. بنابراین، مصب را به عنوان مبدأ (نقطه O) انتخاب کرده ایم که اتصالات سکته از آن ردیابی می شود. قوس مرتبط با خور، قوس ردیابی (Arc OP) و گره دیگر این قوس (نقطه P) گره ردیابی است.
مرحله 2: کمان های مرتبط با P در مجموعه کمان های کاندید برای اتصال ضربه ای R {PS، PT} گنجانده می شوند. زوایای این کمان ها نسبت به OP (یعنی {∠OPS، ∠OPT}، به ترتیب) نیز محاسبه می شود.
مرحله 3: قوس در مجموعه R که یک سکته مغزی را با OP تشکیل می دهد با توجه به اصول سازگاری معنایی، ثبات جهت و اولویت بندی طول انتخاب می شود. در این مورد، S برای تشکیل OS انتخاب می شود و S اکنون گره ردیابی است.
مرحله 4: اتصالات Stroke به طور مداوم طبق روش های مراحل 2 و 3 محاسبه و ردیابی می شوند تا زمانی که جریان به منبع آن ردیابی شود. سپس سکته مغزی حاصل، ساقه اصلی خور است.
مرحله 5: تمام اتصالات ضربه ای به قوس مرتبط با منبع رودخانه برای بدست آوردن شاخه های ساقه اصلی محاسبه می شود.
مرحله 6: تمام اتصالات سکته مغزی مرتبط با شاخه های فوق الذکر تا زمانی که تمام قوس های موجود در DTT محاسبه شود محاسبه می شود. محاسبه اتصالات استروک در این نقطه خاتمه می یابد.
3.2.2. رویه های کدگذاری خودکار از پایین به بالا
رویههای روش کدگذاری خودکار برای ویژگیهای رودخانه دندریتیک در زیر توضیح داده شده است، با سیستم رودخانه نشاندادهشده در شکل 7 به عنوان مثالی گویا:
مرحله 1: اتصالات ضربه ای از خور O تا زمانی که ساقه اصلی سیستم رودخانه محاسبه شود محاسبه می شود. همانطور که در شکل 7 الف نشان داده شده است، به ساقه اصلی یک کد (ترتیب) 1 اختصاص داده شده است .
مرحله 2: تمام اتصالات ضربه ای مرتبط با قوس ساقه اصلی برای بدست آوردن شاخه های ساقه اصلی محاسبه می شود. همانطور که در شکل 7 ب نشان داده شده است، به این انشعابات کد 2 اختصاص داده شده است .
مرحله 3: تمام اتصالات ضربه ای به قوس های شاخه ای محاسبه و کدگذاری می شوند. نتایج نهایی فرآیند سفارش جریان در شکل 7 ج نشان داده شده است.
3.3. الگوریتم انتخاب ویژگیهای رودخانه دندریتیک بر اساس کدگذاری ترکیبی
3.3.1. کدگذاری ترکیبی
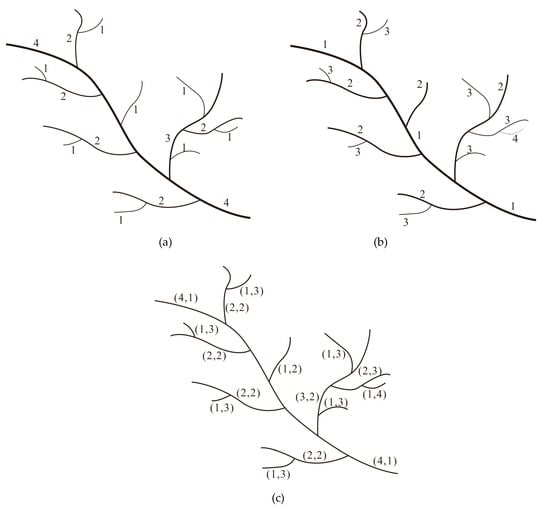
با ترکیب مزایای هر دو روش کدگذاری، کدگذاری ترکیبی برای توصیف ویژگی فضایی شبکههای رودخانه پیشنهاد میشود. ایده اصلی این است که هر جریانی در شبکه رودخانه از طریق استفاده ترکیبی از رویکرد بالا به پایین و رویکرد پایین به بالا مشخص می شود و ساختار کدگذاری به صورت (کدگذاری از بالا به پایین، کدگذاری از پایین به بالا) توصیف می شود. شکل 8 .
همانطور که از شکل 8 مشاهده می شود ، ساختار عمیق و رابطه سلسله مراتبی را می توان همزمان با کدگذاری ترکیبی توصیف کرد.
3.3.2. تعیین آستانه دوگانگی هر جریان
با توجه به تجزیه و تحلیل در بخش 2.1 ، اطلاعات توصیف شده توسط دو روش کدگذاری موجود متفاوت است، که بر قضاوت ساختار فضایی شبکه رودخانه تأثیر می گذارد. برای استفاده کامل از مزایای دو کد، زیردرخت های متصل به جریان اصلی شبکه رودخانه در الگوهای مختلف طبقه بندی می شوند.
ابتدا اطلاعات عمق هر جریان (DS) بر اساس کدگذاری هورتون شناسایی می شود و آستانه عمق (DT) بر اساس واریانس توزیع اطلاعات عمق محاسبه می شود تا جریان ها به دو دسته طبقه بندی شوند. اگر DS > DT باشد، نهر یک جریان عمیق است، به این معنی که جریان برای حفظ خصوصیات عمق کلی شبکه رودخانه بسیار مهم است و اگر DS ≤ DT باشد، نهر یک جریان کم عمق است، به این معنی که اهمیت آن در حفظ مشخصات عمق کلی کمتر است.
آستانه عمق (DT) با روش Otsu [ 24 ] محاسبه می شود که یک الگوریتم موثر برای تقسیم بندی تصویر است و به طور گسترده در کاربردهای میدانی مختلف به کار گرفته شده است. اجازه دهید توزیع عمق یک شبکه رودخانه معین با سطوح L نشان داده شود [1, 2, ,L] . تعداد جریان ها در سطح i با n i نشان داده می شود و تعداد کل جریان ها با N = n 1 + n 2 + + n L نشان داده می شود. سپس، توزیع احتمال هر سطح عمق p i = n i / N است.
حال، فرض کنید که عمق را با یک آستانه در سطح k به دو کلاس C 0 و C 1 تقسیم می کنیم . C 0 نشان دهنده عمق سطوح [1, … , k ] و C 1 نشان دهنده عمق سطوح [ k + 1, … , L ] است. سپس واریانس بین طبقاتی با [ 24 ] داده می شود:
σب2=ω0(تو0-توتی)2+ω1(تو1-توتی)2=ω0ω1(تو1-تو0)2=[توتیω(ک)-μ(ک)]2ω(ک)(1-ω(ک))
جایی که ω0، ω1، تو0، و تو1به ترتیب احتمال وقوع کلاس و سطوح میانگین کلاس، ω(ک)=ω0، توتی=∑من=1Lمنپمن، و μ(ک)=∑من=1کمنپمن.
آستانه بهینه k * [ 24 ] است:
σب2(ک∗)=مترآایکس1≤ک<Lσب2(ک)
3.3.3. طبقه بندی شبکه های رودخانه ای دندریتی
پس از مشخص شدن دوگانگی همه نهرها، هر زیردرخت متصل به جریان اصلی بر اساس توزیع فضایی و رابطه اتصال دو نوع نهر به یکی از سه الگوی زیر طبقه بندی می شود: (1) شاخه عمیق که شامل نهرهای عمیق و نهرهای کم عمق موجود در این نهرهای عمیق. (2) شاخه کم عمق که از نهرهای کم عمق یا فقط از یک نهر عمیق و نهرهای کم عمق موجود در این نهر تشکیل شده است. و (3) انشعاب متوسط، که از نهرهای کم عمق بدون اختلاف عمق تشکیل شده است یا تفاوت بین آنها 1 است. در طول فرآیند تعمیم، شاخه های عمیق با استفاده از رویکرد بالا به پایین کدگذاری می شوند، شاخه های کم عمق از طریق پایین به بالا کدگذاری می شوند. رویکرد، و شاخه های متوسط با یکی از دو رویکرد فوق کدگذاری می شوند.
طبقه بندی بر اساس کدگذاری ترکیبی هر جریان انجام می شود. درختهای فرعی متصل به جریان اصلی را میتوان از طریق کدگذاری از پایین به بالا استخراج کرد و این جریانها با کد 2 کدگذاری میشوند. برای مقایسه با DT از کدگذاری از بالا به پایین برای طبقهبندی جریانها در دستههای عمیق یا کم عمق استفاده میشود، و زیردرختها به انواع مختلف طبقهبندی میشوند. الگوهای مبتنی بر قوانین طبقه بندی فوق الذکر.
3.3.4. الگوریتم انتخاب
انتخاب رودخانه با استفاده از روش انتخاب کلاسیک ارائه شده توسط استانیسلاوسکی و همکاران انجام می شود. [ 11 ]. روش دقیق به شرح زیر است:
مرحله 1: تعداد جریان هایی که باید حفظ شوند با استفاده از مدل “قانون رادیکال” تعیین می شود [ 25 ، 26 ]، nf=nآمآ/مf، جایی که nfتعداد اشیایی است که می توان در مقیاس هدف نشان داد، nآتعداد اشیاء نشان داده شده بر روی نقشه اصلی است، و مآو مfبه ترتیب مخرج مقیاس نقشه های اصلی و هدف هستند.
مرحله 2: شبکه رودخانه برای توصیف عمق و اطلاعات سلسله مراتبی هر جریان کدگذاری ترکیبی می شود و سپس آستانه عمق (DT) با روش Otsu محاسبه می شود.
مرحله 3: نهرها به انواع عمیق یا کم عمق و درختان فرعی جریان اصلی بر اساس ویژگی فضایی و روابط ارتباطی نهرها به الگوهای عمیق، کم عمق و متوسط طبقه بندی می شوند.
مرحله 4: شاخه های عمیق با استفاده از رویکرد بالا به پایین کدگذاری می شوند، شاخه های کم عمق از طریق رویکرد پایین به بالا کدگذاری می شوند و شاخه های متوسط با یکی از دو رویکرد فوق برای آماده سازی انتخاب طبقه بندی می شوند.
مرحله 5: اعداد انتخابی به طور نابرابر به هر زیردرخت بر اساس تعداد جریان ها تخصیص داده می شوند. nمن=nf×نمن/نتی، جایی که nمنتعداد جریان های نشان داده شده در زیر درخت i است، nfتعداد کل جریان های نشان داده شده است، نمنتعداد جریانها در زیر درخت i، و است نتیتعداد کل نهرها در کل شبکه رودخانه است.
مرحله 6: اصل انتخابی حفظ جریان های اصلی و حذف انشعابات است. به طور خاص، برای یک زیردرخت، انتخاب از جریان اصلی درخت فرعی شروع می شود و تا شاخه های فرعی گسترش می یابد. جریان ها به ترتیب مشابه با توجه به اطلاعات طول آنها انتخاب می شوند و جریان های طولانی تر حفظ می شوند.
مرحله 7: به دلیل ساختار خاص شاخه های متوسط با کد عمق 1، آنها در کنار هم قرار گرفته و به عنوان یک کل انتخاب می شوند.
مرحله 8: مراحل 6 و 7 تکرار می شوند تا تعداد کافی جریان (مطابق با مدل ریشه دوم) انتخاب شوند و سپس الگوریتم انتخاب به پایان می رسد.
4. آزمایش ها و تجزیه و تحلیل
4.1. داده های تجربی و محیط
روش کدگذاری ترکیبی در ایستگاه کاری نقشه برداری WJ-III که توسط آکادمی نقشه برداری و نقشه برداری چین توسعه داده شده است، تعبیه شده است. روش کدگذاری جریان جدید به صورت تجربی از طریق مقایسه با روش کدگذاری کلاسیک از بالا به پایین و روش از پایین به بالا تأیید شد. داده های تجربی مربوط به بخشی از ویژگی رودخانه دندریتی در شهری از استان هوبی در چین است. مقیاس اصلی این داده ها 1:100000 است و در مجموع 108 رودخانه در این مجموعه داده وجود دارد. فضای ذخیره سازی داده های آزمایشی 55 کیلوبایت است. محیط سخت افزاری این آزمایش بر روی یک سیستم عامل 64 بیتی مایکروسافت ویندوز 7 مجهز به Intel Core i7-3770 با فرکانس 3.2 گیگاهرتز، با 16 گیگابایت رم و 1024 گیگابایت درایو حالت جامد اجرا می شود.
این آزمایش شامل دو بخش بود: اول، کدگذاری رودخانهها در یک منطقه آزمایشی با استفاده از سه روش کدگذاری مختلف برای تجزیه و تحلیل تفاوتها و ویژگیهای آنها. دوم، مقایسه اثر انتخاب تحت سه روش مختلف کدگذاری از طریق طبقهبندی درختان فرعی رودخانه در سه منطقه معمولی.
زمان مصرف شده توسط روش انتخاب مبتنی بر کدگذاری رودخانه عمدتاً شامل سه بخش است: زمان آمادهسازی داده، زمان کدگذاری رودخانه و زمان انتخاب رودخانه. برای همان منطقه آزمایشی، کل زمان تکمیل سه عملیات فوق برای هر سیستم کدگذاری کلاسیک 8 ثانیه و کل زمان بر اساس روش پیشنهادی 10 ثانیه است.
4.2. تحلیل مقایسه ای هر روش کدگذاری
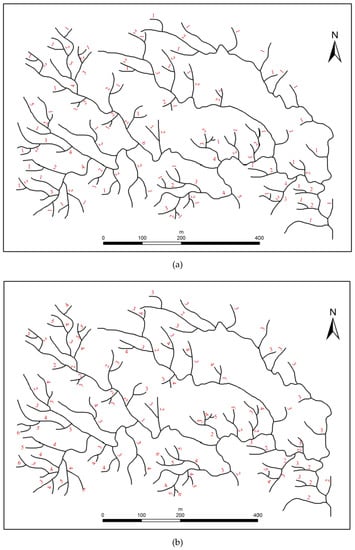
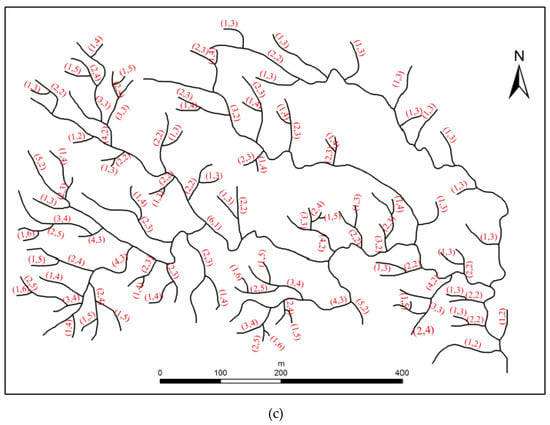
شکل 9 نتایج کدگذاری شبکه آزمایشی رودخانه را نشان می دهد که با استفاده از سه روش کدگذاری مختلف به دست آمده است، از جمله (الف) روش کدگذاری هورتون از بالا به پایین، (ب) روش کدگذاری از پایین به بالا و (ج) روش کدگذاری ترکیبی. همانطور که در شکل 9 نشان داده شده استمحدوده ترتیبات جریان داده شده توسط این سه روش یکسان است، یعنی از 1 تا 6. با این حال، ویژگی های ساختاری فضایی که آنها توصیف می کنند متفاوت است. (1) کدگذاری هورتون شبکه رودخانه را از منبع تا مصب کدگذاری کرد، بنابراین اطلاعات عمق ثبت شد. به عنوان مثال، جریانی که مرتبه جریان هورتون 3 دارد باید دارای انشعاب از شاخه های مرتبه اول و دوم باشد و عمق درخت فرعی این جریان 3 باشد. (2) رویکرد پایین به بالا شبکه رودخانه را از مصب به منبع، بنابراین سلسله مراتب تشکیل شده توسط روابط حوضه ثبت شد. به عنوان مثال، جریانی که دارای کد 2 است باید به جریان اصلی متصل شود که با 1 کدگذاری شده است.
برای تجزیه و تحلیل بیشتر ویژگی ها و تفاوت های روش های مختلف کدگذاری، تعداد جریان های مربوط به هر ترتیب جریان در جدول 1 نشان داده شده است .
همانطور که در جدول 1 نشان داده شده است ، اگرچه محدوده کدگذاری این دو روش کدگذاری یکسان است، اما تفاوت های قابل توجهی در تعداد جریان های مربوط به هر ترتیب جریان وجود دارد. در روش هورتون تعداد جریان ها با ترتیب جریان کاهش می یابد. رودخانه هایی با کدهای 1 و 2 در مرز 82.4 درصد را به خود اختصاص می دهند که به این معنی است که اهمیت این نهرها را می توان با کدگذاری دقیق تشخیص داد. توزیع جریان های مربوط به روش کدگذاری ما یک الگوی نوع n را نشان می دهد، به عنوان مثال، جریان های مرتبه پایین تر و بالاتر از نظر تعداد کمتر هستند، در حالی که جریان های مرتبه متوسط از نظر تعداد بیشتر هستند، که قضاوت در مورد اهمیت را آسان می کند. نهرها در اطراف خارج از شبکه رودخانه هستند اما قضاوت در مورد نهرها در وسط دشوار است.
علاوه بر این، یک تحلیل متقاطع در این مقاله انجام شد. با در نظر گرفتن کدگذاری هورتون به عنوان کد مرجع، تعداد جریانهای با کدهای معکوس و کدهای غیر معکوس در کدگذاری از پایین به بالا ثبت شد. همانطور که در جدول 1 نشان داده شده است ، تنها 16.67 درصد از رودخانه ها نهرهایی با کدهای معکوس هستند، که به این معنی است که استفاده جامع از این دو روش از طریق تبدیل جبری ساده امکان پذیر نیست، بلکه نیاز به تجزیه و تحلیل عمیق از عملکردهای این دو دارد. روشهای بیان ساختارهای فضایی مختلف
4.3. تحلیل کارایی هر سیستم کدگذاری در انتخاب و تعمیم رودخانه
مقیاس هدف تعمیم شبکه رودخانه 1:500000 است. بنابراین، 52 جریان را می توان در مقیاس هدف بر اساس مدل ریشه مربع نشان داد. علاوه بر این، بر اساس روش Otsu [ 24 ]، برای هر سطح عمق، واریانس بین کلاس محاسبه شد. نتایج به شرح زیر بود. σب2(1)= 206.21، σب2(2)= 222.25، σب2(3)= 112.53، σب2(4)= 41.84، σب2(5)= 14.59 و σب2(2)حداکثر مقدار بود، بنابراین آستانه عمق (DT) روی 2 تنظیم شد. بر اساس DT، 6 شاخه عمیق، 12 شاخه کم عمق و 4 شاخه متوسط به دست آمد.
همانطور که در شکل 10 ، شکل 11 و شکل 12 نشان داده شده است، برای هر الگو، درختان فرعی با بیشترین تعداد جریان به عنوان مناطق معمولی برای تجزیه و تحلیل بصری نتایج انتخاب انتخاب می شوند. شکل 10 یک شاخه متوسط را نشان می دهد که در آن همه شاخه های متصل به ساقه اصلی درخت فرعی دارای عمق توپولوژیکی یکسانی هستند. شکل 11 شاخه ای کم عمق با شاخه های پراکنده یکنواخت را نشان می دهد که در آن شاخه های ساقه اصلی از نظر عمق توپولوژیکی نسبتاً کم عمق هستند و عمق آنها تغییر چندانی ندارد. شکل 12یک شاخه عمیق توپولوژیکی را نشان می دهد که در آن شاخه های متصل به ساقه اصلی تفاوت های بسیار زیادی در عمق توپولوژیکی دارند.
11 جریان در شاخه متوسط نشان داده شده در شکل 10 وجود دارد. بر اساس مدل ریشه مربع، 5 جریان باید حفظ شود، در حالی که 6 جریان باید حذف شود. خصوصیات توزیع فضایی نهرها نشان می دهد که سلسله مراتب و عمق هر شاخه به جز جریان اصلی در این شاخه یکسان است. از این رو، کدهای آنها فرقی ندارد، صرف نظر از اینکه از کدام روش کدگذاری استفاده می شود. در طی فرآیند تعمیم، کدگذاری هورتون به عنوان روش کدگذاری در این مقاله انتخاب شد. نتایج انتخاب برای هر روش در شکل 10 a-c نشان داده شده است، و سه روش ترتیب دادن به نتایج انتخاب یکسانی در این سناریو منجر شدند.
شکل 11 نشان می دهد که 13 نهر در شاخه کم عمق وجود دارد. با توجه به مدل ریشه مربع، 6 جریان حفظ می شود، در حالی که 7 جریان باید حذف شود. این نهرها به طور یکنواخت در اطراف جریان اصلی این شاخه پراکنده شده اند، اما سلسله مراتب و اعماق هر یک از شاخه ها تفاوت های جزئی دارند. برای این الگو، کدگذاری از پایین به بالا به عنوان روش کدگذاری در این مقاله انتخاب شد. نتایج انتخاب برای هر روش در شکل 11 a-c نشان داده شده است. نتایج به دست آمده با استفاده از روش کدگذاری هورتون جریان b را حفظ و جریان a را حذف می کند. برعکس، نتایج بهدستآمده با استفاده از کدگذاری از پایین به بالا، جریان b را حذف کرده و جریان a را حفظ میکند. همانطور که از شکل 11 مشاهده می شوداگرچه جریان b دارای عمق دو است، اما ساختار عمق در این شاخه به اندازه ساختار سلسله مراتبی مهم نیست، که می تواند ساختار فضایی اصلی این شاخه را بهتر منعکس کند، همانطور که در جریان a نشان داده شده است. از این رو، روش کدگذاری از پایین به بالا و روش پیشنهادی می توانند ساختارهای فضایی نقشه اصلی را به طور موثر حفظ کنند.
27 نهر در شاخه عمیق نشان داده شده در شکل 12 وجود دارد. بر اساس مدل ریشه مربع، 13 جریان باید حفظ شود، در حالی که 14 جریان باید حذف شود. این رودخانه ها ساختاری عمیقا تو در تو را تشکیل می دهند و سلسله مراتب و اعماق هر شاخه با هم تفاوت های آشکاری دارند. برای این الگو، کدگذاری از بالا به پایین به عنوان روش کدگذاری در این مقاله انتخاب شد. نتایج انتخاب برای هر روش در شکل 12 a-c نشان داده شده است. نتایج بهدستآمده با استفاده از روش کدگذاری هورتون، جریانهای a، b و d را حفظ کرده و جریانهای c، e و f را حذف میکند. برعکس، نتایج بهدستآمده با استفاده از کدگذاری از پایین به بالا، جریانهای a، b و d را حذف کرده و جریانهای c، e و f را حفظ میکنند. همانطور که از شکل 12 مشاهده می شودنهرهای a، b و d با ساختارهای عمیق تر از جریان های c، e و f در انعکاس ساختار فضایی اصلی این شاخه اهمیت بیشتری دارند. حذف جریان های a و b منجر به از بین رفتن آشکار ساختار درخت می شود. از این رو، روش کدگذاری از بالا به پایین و روش پیشنهادی می توانند ساختار فضایی نقشه اصلی را به طور موثر حفظ کنند.
5. نتیجه گیری ها
کدگذاری رودخانه نقش مهمی در انتخاب شبکه رودخانه برای تعمیم نقشه توپوگرافی دارد. دو روش کدگذاری کلاسیک موجود ویژگیهای متفاوتی را نشان میدهند – روش کدگذاری از بالا به پایین برای انتخاب جریان شبکههای رودخانهای با توزیع یکنواخت شاخهها مناسب نیست، و روش کدگذاری از پایین به بالا برای انتخاب جریان سیستمهای رودخانهای مطلوب نیست. ساختارهای عمیق توپولوژیکی دو سیستم کدگذاری فوق به صورت جداگانه در روش سنتی انتخاب رودخانه مورد استفاده قرار گرفتند، که منجر به این میشود که نتایج انتخاب برخی از زیردرختهای رودخانه نمیتواند ویژگیهای توزیع فضایی اولیه را حفظ کند. بنابراین، یک روش انتخاب برای شبکه های رودخانه دندریتی بر اساس کدگذاری ترکیبی در این مقاله پیشنهاد شده است. که مزیت های دو روش فوق را با هم ترکیب می کند و می تواند با انتخاب حالت کدگذاری مناسب با توجه به ساختار فضایی زیردرختان رودخانه، ویژگی های ساختاری فضایی شبکه های رودخانه ای را به خوبی حفظ کند. نتایج زیر از اعتبار سنجی تجربی با استفاده از داده های واقعی استخراج شد:
(1) تنها 16.67 درصد از رودخانه ها دارای کد معکوس هستند، که به این معنی است که استفاده جامع از این دو روش از طریق تبدیل جبری ساده امکان پذیر نیست. روش کدگذاری ترکیبی پیشنهاد شده در این مقاله موثر است و اطلاعات عمق و سلسله مراتب یک جریان را می توان همزمان خواند.
(2) ساختار توزیع فضایی شبکه های رودخانه بر اساس کدگذاری ترکیبی تعیین می شود. ابتدا، جریان ها بر اساس رویکرد کدگذاری از بالا به پایین، که اطلاعات عمق را منعکس می کند، به جریان های عمیق یا کم عمق طبقه بندی شدند. دوم، درختان فرعی رودخانه بر اساس رویکرد کدگذاری پایین به بالا، که اطلاعات سلسله مراتبی را منعکس می کند، شناسایی شدند. در نهایت بر اساس ویژگی های توزیع و رابطه اتصال نهرها به سه نوع الگو طبقه بندی شد که شاخه عمیق، شاخه کم عمق و انشعاب متوسط است.
(3) برای الگوهای مختلف، حالت کدگذاری مناسب به طور خودکار در این مقاله انتخاب شد، که اطمینان حاصل کرد که نتایج انتخاب ساختارهای فضایی مختلف منطقی است. برای شاخه متوسط، یکی از دو رویکرد کدگذاری خودسرانه استفاده شد، زیرا نتیجه انتخاب یکسان بود. برای شاخه کم عمق و شاخه عمیق به ترتیب روش کدگذاری از پایین به بالا و روش کدگذاری از بالا به پایین انتخاب شد.
روش ارائه شده در این مقاله می تواند به طور مستقیم در تعمیم نقشه رودخانه مورد استفاده قرار گیرد و همچنین در تعیین مناطق حوضه آبریز رودخانه مفید باشد. تحقیقات آینده بر روی (1) کلیت روش پیشنهادی در انتخاب رودخانه مجموعه دادههای شبکه رودخانه چند مقیاسی و وسیع فضایی تمرکز خواهد کرد. (2) بررسی گسترده کاربردهای روش پیشنهادی در زمینههایی مانند آنالیزهای هیدروگرافی، سیل، فعالیتهای نگهداری و غیره. در حال حاضر، روش پیشنهادی تعبیهشده در ایستگاه نقشه WJ-III در پنج استان چین برای انجام چندگانه استفاده شده است. نمایش مقیاس دادههای شبکههای رودخانهای در سرشماری نشنال جئوگرافیک، مانند گوئیژو، گانسو، گوانگدونگ، و غیره. نتایج تحقیق در انتخاب رودخانه مجموعه دادههای شبکه رودخانهای چند مقیاسی و وسیع فضایی نیاز به خلاصهسازی بیشتری دارد.
منابع
- باتنفیلد، BP; استانیسلاوسکی، LV; اندرسون تارور، سی. Gleason، MJ روشهای جایگزین برای انتخاب خودکار مسیرهای اولیه از طریق شبکههای هیدروگرافی بافته شده. در مجموعه مقالات شانزدهمین کارگاه ICA در مورد تعمیم و بازنمایی های چندگانه، درسدن، آلمان، 23 تا 24 اوت 2013. [ Google Scholar ]
- تاربتون، دی جی; سوتین، RL; Rodriguez-Iturbe, I. ماهیت فراکتال شبکه های رودخانه. منبع آب Res. 1988 ، 24 ، 1317-1322. [ Google Scholar ] [ CrossRef ]
- او، ز. اصل و روش مدل دادهپردازی نقشه ; انتشارات دانشگاه ووهان: ووهان، چین، 2004. (به زبان چینی) [ Google Scholar ]
- ژانگ، ال. وانگ، جی کیو؛ دای، BX; Li، TJ طبقه بندی و روش های کدگذاری شبکه جریان در حوضه رودخانه، بررسی. محیط زیست آگاه کردن. قوس. 2007 ، 5 ، 364-372. [ Google Scholar ]
- Gülgen, F. یک رویکرد سفارش جریان بر اساس عملیات تجزیه و تحلیل شبکه. Geocarto Int. 2017 ، 32 ، 322-333. [ Google Scholar ] [ CrossRef ]
- Horton، RE توسعه فرسایشی نهرها و حوضه های زهکشی آنها. رویکرد هیدروفیزیکی به مورفولوژی کمی جئول Soc. صبح. گاو نر 1945 ، 56 ، 275-370. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- محرر، KN; Pande، CB تجزیه و تحلیل پارامترهای مورفومتریک با استفاده از تکنیکهای سنجش از دور و GIS در نالا لونار در منطقه آکولا ماهاراشترا هند. بین المللی J. Tech. Res. مهندس 2014 ، 1 ، 1034-1040. [ Google Scholar ]
- هاریش، ن. کومار، ص. رجا، ام اس; لوکش، وی. ردی، ام جی اس؛ شالیساد، س. Sazid, S. سنجش از دور و GIS در تجزیه و تحلیل مورفومتریک حوضه های کلان برای ارزیابی سناریو هیدرولوژیکی و توصیف – مطالعه بر روی زیرحوضه رودخانه پنا. ناحیه SPSR Nellore، هند. بین المللی Res. J. Eng. تکنولوژی 2016 ، 3 ، 1579-1583. [ Google Scholar ]
- سن، ا. Gokgoz، T. یک رویکرد تجربی برای انتخاب / حذف در تعمیم شبکه جریان با استفاده از ماشینهای بردار پشتیبانی. Geocarto Int. 2015 ، 30 ، 311-329. [ Google Scholar ] [ CrossRef ]
- Strahler، AN تحلیل کمی ژئومورفولوژی حوزه آبخیز. Eos Trans. صبح. ژئوفیز. اتحادیه 1957 ، 38 ، 913-920. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- استانیسلاوسکی، LV; ساوینو، اس. هرس شبکه های هیدروگرافی: مقایسه دو رویکرد. در مجموعه مقالات چهاردهمین کارگاه ICA در مورد تعمیم و بازنمایی چندگانه، که به طور مشترک با گروه کاری ISPRS کمیسیون II/2 در زمینه نمایش چند مقیاسی داده های فضایی، پاریس، فرانسه، 3 تا 8 ژوئیه 2011 سازماندهی شد. [ Google Scholar ]
- شرو، RL قانون آماری اعداد جریان. جی. جئول. 1966 ، 74 ، 17-37. [ Google Scholar ] [ CrossRef ]
- هورسفیلد، ک. کامین، جی. مورفولوژی درخت برونش در انسان. J. Appl. فیزیول. 1968 ، 24 ، 373-383. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Gravelius ، H. Flusskunde ; Goschen’sche Verlagshandlung: برلین، آلمان، 1914. [ Google Scholar ]
- Hack, J. مطالعات پروفیل جریان طولی در ویرجینیا و مریلند. جیول آمریکا Surv. پروفسور پاپ 1957 ، 294B ، 45-95. [ Google Scholar ]
- Jasiewicz، J.Ł. Metz, M. یک ابزار جدید GRASS GIS برای تجزیه و تحلیل Hortonian شبکه های زهکشی. محاسبه کنید. Geosci. 2011 ، 37 ، 1162-1173. [ Google Scholar ] [ CrossRef ]
- دای، ZX; لی، سی ام؛ Wu, PD یک سیستم کدگذاری خودکار از پایین به بالا برای سیستم رودخانه دندریتیک. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2019 ، XLII-4/W16 ، 169–175. [ Google Scholar ]
- مارانی، ع. ریگون، آر. رینالدو، A. یادداشتی در مورد شبکه کانال فراکتال. منبع آب Res. 1991 ، 27 ، 3041-3049. [ Google Scholar ] [ CrossRef ]
- ویتاکر، اس. استانیسلاوسکی، ال. هامان، ام. تسطیح خودکار جریان برای مجموعه داده ملی هیدروگرافی با وضوح بالا. در مجموعه مقالات بیست و دومین کنفرانس سالانه کاربران بین المللی ESRI، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 8 تا 12 ژوئیه 2002. صص 8-12. [ Google Scholar ]
- وو، جی. دنگ، م. لیو، اچ. یک مدل یکپارچه برای نشان دادن رابطه توپولوژیکی و رابطه جهتی بین اجسام خط جهت دار. Geomat. Inf. علمی دانشگاه ووهان 2013 ، 11 ، 1358–1363. (به زبان چینی) [ Google Scholar ]
- ژانگ، ی. لی، ال. جین، ی. Zhu، HH طراحی ساختاری شبکه های رودخانه دندریتیک بر اساس نمودار. Geomat. Inf. علمی دانشگاه ووهان 2004 ، 29 ، 537-539. (به زبان چینی) [ Google Scholar ]
- تامسون، آرسی بروکس، آر. تعمیم و انتزاع کارآمد داده های شبکه با استفاده از گروه بندی ادراکی. در مجموعه مقالات پنجمین کنفرانس بین المللی محاسبات جغرافیایی، چتم، انگلستان، 23 تا 25 اوت 2000. ص 23-25. [ Google Scholar ]
- تامسون، آرسی بروکس، آر. بهرهبرداری از گروهبندی ادراکی برای تحلیل، درک و تعمیم نقشه: مورد شبکههای جاده و رودخانه. در کارگاه بین المللی تشخیص گرافیک ; Springer: برلین/هایدلبرگ، آلمان، 2001; صص 148-157. [ Google Scholar ]
- Otsu، N. روش انتخاب آستانه از هیستوگرام های سطح خاکستری. IEEE Trans. سیستم مرد سایبرن. 1979 ، 9 ، 62-66. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Töpfer, F. مطالعه کاربرد اصل ریشه مربع در تعمیم نقشه کشی . مطبوعات نقشه برداری و نقشه برداری: پکن، چین، 1963. [ Google Scholar ]
- تاپفر، اف. Pillewizer, W. اصول انتخاب، وسیله ای برای تعمیم نقشه برداری. کارتوگر. J. 1966 ، 3 ، 10-16. [ Google Scholar ] [ CrossRef ]
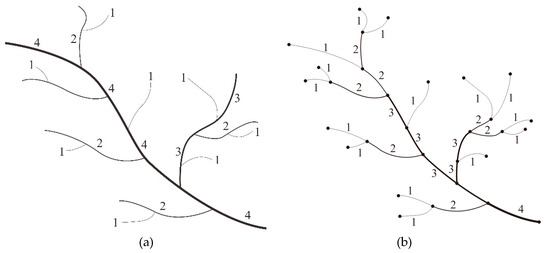
شکل 1. دو سیستم کدگذاری کلاسیک جریان برای ویژگیهای رودخانه دندریتیک: ( الف ) کدگذاری هورتون بر اساس جریانهای رودخانه و ( ب ) کدگذاری استرالر بر اساس بخشهای رودخانه.

شکل 2. سیستم کدگذاری از پایین به بالا برای ویژگیهای رودخانه دندریتیک: ( الف ) کدگذاری هک بر اساس جریانهای رودخانه و ( ب ) کدگذاری مارانی بر اساس بخشهای رودخانه.
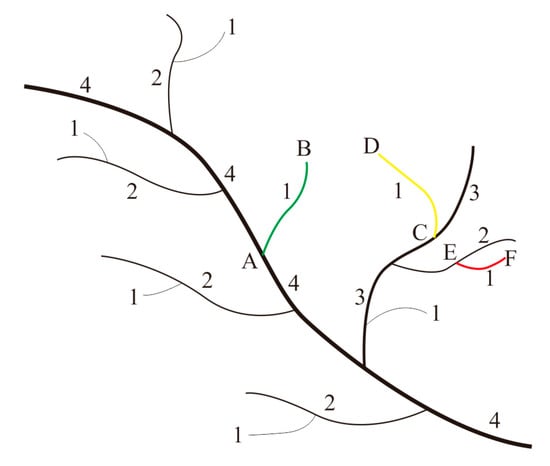
شکل 3. نارسایی روش های کدگذاری از بالا به پایین: سه جریان (AB، CD و EF) با سطوح مختلف دارای کد یکسانی هستند.
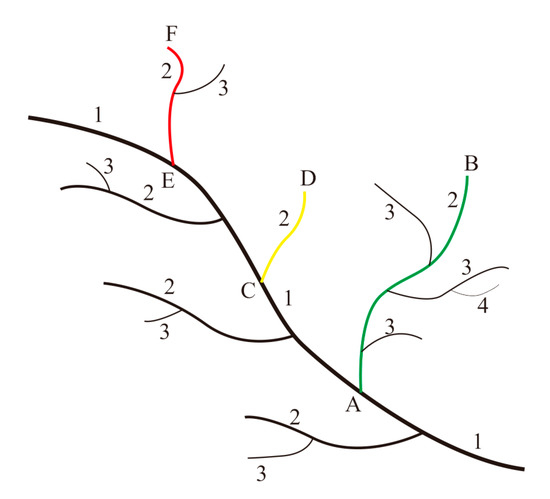
شکل 4. نارسایی روش های کدگذاری از پایین به بالا: سه جریان (AB، CD و EF) با عمق های مختلف دارای کد دو برابر هستند.
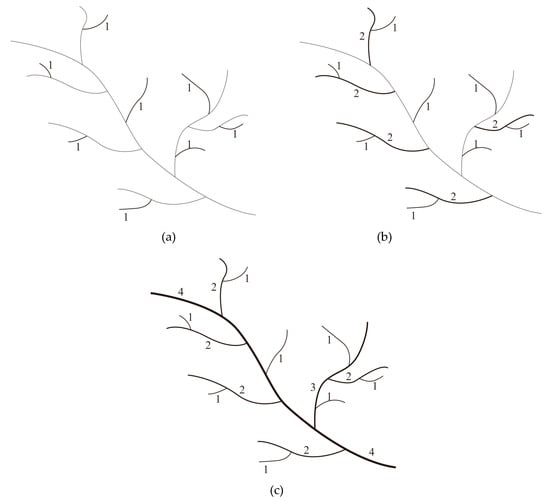
شکل 5. رویههای روش کدگذاری خودکار برای ویژگیهای رودخانه دندریتیک: ( الف ) کدگذاری شاخههای انتهایی، ( ب ) کدگذاری جریانهای مرتبه دوم و ( ج ) نتایج نهایی کدگذاری جریان.
شکل 6. ساخت اتصالات ضربه ای: نقطه شروع O، گره ردیابی P در مرحله اول، گره ردیابی S و T در مرحله دوم.

شکل 7. رویه های روش رمزگذاری خودکار برای ویژگی های رودخانه دندریتیک: ( الف ) کدگذاری ساقه اصلی، ( ب ) کدگذاری شاخه ها و ( ج ) نتایج نهایی کدگذاری جریان.
شکل 8. سه روش کدگذاری مختلف: ( الف ) روش کدگذاری از بالا به پایین، ( ب ) روش کدگذاری از پایین به بالا و ( ج ) روش کدگذاری ترکیبی.
شکل 9. مقایسه سیستم های کدگذاری جریان: ( الف ) روش کدگذاری از بالا به پایین، ( ب ) روش کدگذاری از پایین به بالا و ( ج ) روش کدگذاری ترکیبی.

شکل 10. مقایسه انتخاب ها در یک شاخه متوسط: ( الف ) نتیجه انتخاب بر اساس روش کدگذاری از بالا به پایین، ( ب ) نتیجه انتخاب بر اساس روش کدگذاری از پایین به بالا و ( ج ) نتیجه انتخاب بر اساس کدگذاری ترکیبی روش (نتایج انتخاب به صورت خطوط قرمز و رودخانه های اصلی به صورت خطوط سیاه نشان داده می شوند).
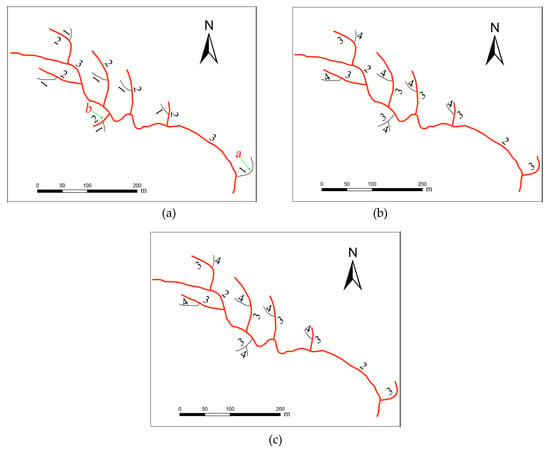
شکل 11. مقایسه انتخاب ها در یک شاخه کم عمق: ( الف ) نتیجه انتخاب بر اساس روش کدگذاری از بالا به پایین، ( ب ) نتیجه انتخاب بر اساس روش کدگذاری از پایین به بالا و ( ج ) انتخاب بر اساس روش کدگذاری ترکیبی. نتایج انتخاب به صورت خطوط قرمز و رودخانه های اصلی به صورت خطوط سیاه نشان داده می شوند.

شکل 12. مقایسه انتخاب ها در یک شاخه عمیق: ( الف ) نتیجه انتخاب بر اساس روش کدگذاری از بالا به پایین، ( ب ) نتیجه انتخاب بر اساس روش کدگذاری از پایین به بالا و ( ج ) نتیجه انتخاب بر اساس روش کدگذاری ترکیبی (نتایج انتخاب به صورت خطوط قرمز و رودخانه های اصلی به صورت خطوط سیاه نشان داده شده اند).


بدون دیدگاه