

کلید واژه ها:
مسیر فرکانس پایین ؛ تطبیق نقشه ; احتمال جامع ; برنامه ریزی کوتاه ترین مسیر
1. مقدمه
- (1)
-
روش های مبتنی بر یادگیری ماشین
- (2)
-
روش های مبتنی بر محاسبه احتمال
- (3)
-
روش های مبتنی بر تعیین وزن
2. روش ها
2.1. مفاهیم اساسی و شرح مسئله
تعریف 1.
تعریف 2.
تعریف 3.
تعریف 4.
تعریف 5.
تعریف 6.
تعریف 7.
تعریف 8.
(زاویه جهت بخش جاده): زاویه ای که از چرخش خلاف جهت عقربه های ساعت جهت بخش جاده به سمت شمال تشکیل می شود به عنوان زاویه جهت بخش جاده تعریف می شود. روش محاسبه در رابطه (1) نشان داده شده است.
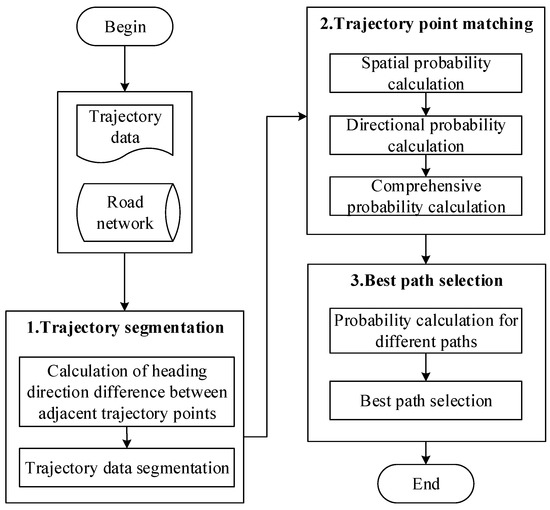
2.2. الگوریتم تطبیق نقشه مسیر فرکانس پایین
2.2.1. بررسی اجمالی الگوریتم
- (1)
-
تقسیم بندی مسیر
- (2)
-
تطبیق نقطه مسیر
- (3)
-
انتخاب بهترین مسیر
2.2.2. تقسیم بندی مسیر
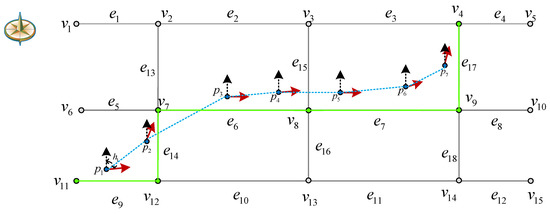
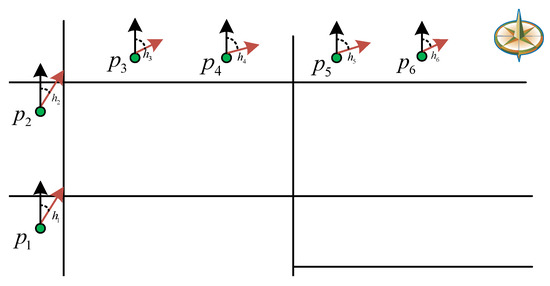
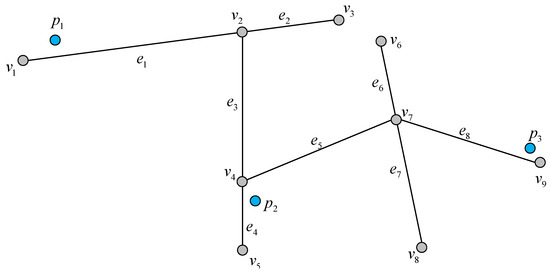
همانطور که در شکل 3 نشان داده شده است، یک قطعه مسیر اولیه وجود دارد τ={p1,p2,p3,p4,p5,p6}�={�1,�2,�3,�4,�5,�6}، p1�1با زاویه جهت حرکت مطابقت دارد h1ℎ1، p2�2با زاویه جهت حرکت مطابقت دارد h2ℎ2، و غیره. در فرآیند تقسیم بندی، تفاوت جهت سفر بین p1�1و p2�2ابتدا محاسبه می شود و نتیجه کمتر از θc��. بنابراین، آنها به یک بخش تعلق دارند. سپس، تفاوت جهت سفر را محاسبه می کنیم p2�2و p3�3و دریابید که بزرگتر از θc��، بنابراین آنها به بخش های مختلف تقسیم می شوند. طبق این قانون، مسیر قطعه بندی می شود و مسیرهای فرعی قطعه بندی شده در نهایت به صورت τ1={p1,p2}�1={�1,�2}و τ2={p2,p3,p4,p5,p6}�2={�2,�3,�4,�5,�6}. برای اطمینان از اتصال بین مسیرهای فرعی تقسیم شده، آخرین نقطه در τ1�1اولین نقطه در است τ2�2. شبه کد برای تقسیم مسیر در الگوریتم 1 نشان داده شده است.
| الگوریتم 1: بخش بندی مسیر |
| ورودی: مسیر T , θc, �� خروجی: Segmented trajectory set ΓSegmented trajectory set � 1: Initialize Γ=ϕ1: Initialize �=�, ind = 2, cnt = 1; 2: Γ11=p12: �11=�1; 3: Γ21=p23: �12=�2; 4: برای i = 3 تا | T | انجام 5: اگر |h(pi)−h(pi−1)|<θc|ℎ(��)−ℎ(��−1)|<�� سپس 6: ind = ind + 1; 7: Γindcnt=pi7: �������=��; 8: else 9: cnt = cnt + 1; 10: Γ1cnt=pi−110: ����1=��−1; 11: Γ2cnt=pi11: ����2=��; 12: ind = 2; 13: پایان اگر 14: پایان برای 15: برگردانید Γ�; |
2.2.3. تطبیق نقطه مسیر
تعریف 9.
(احتمال مکانی) [ 19 ] : بگذار Hejpi����� کمترین فاصله از نقطه مسیر باشد pi�� به بخش جاده ej��. ما احتمال فضایی را به عنوان معیاری برای امکان تطبیق فضایی بین pi�� و ej��، نشان داده شده است G1(Hejpi)�1(�����). روش های محاسبه از Hejpi����� و G1(Hejpi)�1(�����) به ترتیب در معادلات (2) و (3) نشان داده شده است:
جایی که c1�1 و c2�2 دو نقطه پایانی بخش جاده هستند ej�� به ترتیب و c3�3 نقطه طرح عمودی از است pi�� به ej��. اگر c3�3 در واقع نیست ej��، سپس disp(pi,c3)����(��,�3) تنظیم شده است +∞+∞; σ1�1 انحراف استاندارد اندازه گیری مکان است که به طور کلی روی 20 متر تنظیم می شود [ 23 ] . به طور کلی، فاصله بین نقطه مسیر و بخش جاده را می توان به عنوان توزیع نرمال فاصله شبیه سازی کرد Hejpi�����.
تعریف 10.
(احتمال جهتی) [ 19 ] : بگذار Aθjhi�ℎ��� تفاوت زاویه ای بین زاویه جهت حرکت باشد pi�� و زاویه جهت بخش جاده. احتمال جهت را به عنوان معیاری برای امکان تطابق جهت بین نقطه مسیر تعریف کنید pi�� و بخش جاده کاندید ej��، نشان داده شده است G2(Aθjhi)�2(�ℎ���). روش های محاسبه از Aθjhi�ℎ��� و G2(Aθjhi)�2(�ℎ���) به ترتیب در معادلات (4) و (5) نشان داده شده است:
جایی که hiℎ� زاویه جهت حرکت را نشان می دهد pi��، θ1j��1 و θ2j��2 زاویه ها را در دو جهت مختلف از بخش جاده نشان می دهد. σ2�2 انحراف استاندارد اندازه گیری جهت است و همچنین روی 20 متر تنظیم شده است.
تعریف 11.
(احتمال جامع) [ 19 ] : این مطالعه با ترکیب احتمال مکانی و احتمال جهتی، احتمال جامع را به صورت تعریف می کند. Gw��که با رابطه (6) محاسبه می شود.
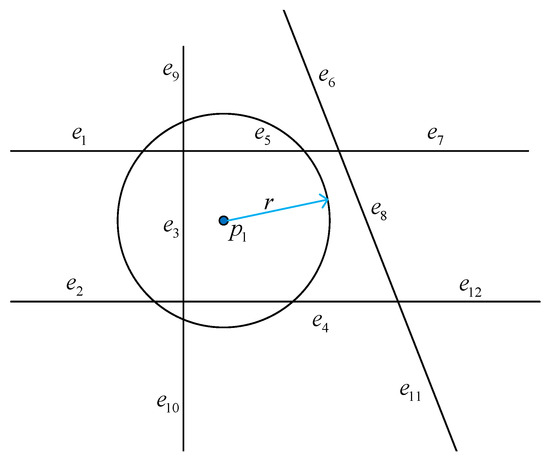
با توجه به محاسبه و بحث فوق، در اطراف هر نقطه مسیر حداقل یک قطعه جاده واجد شرایط وجود دارد، بنابراین حداقل یک احتمال جامع وجود دارد. بر اساس مقدار احتمال جامع، ما بخشهای جاده کاندید m را با بیشترین احتمال برای انتخاب بهترین مسیر بعدی و ارزیابی الگوریتم تطبیق نقشه انتخاب میکنیم. شبه کد تطبیق نقطه مسیر در الگوریتم 2 نشان داده شده است.
| الگوریتم 2: تطبیق نقطه مسیر |
| ورودی: Segmented trajectory set ΓSegmented trajectory set �, شبکه راه G , آستانه شعاع r , مقدار کاندید k خروجی: مجموعه قطعه جاده کاندید Cr , مجموعه احتمال جامع G w 1: مقداردهی اولیه Cr =∅=∅، ن =∅=∅، اچ =∅=∅; 2: برای هر کدام pi∈Γ��∈� انجام 3: یک دایره با C i بسازیدpi��به عنوان مرکز و r به عنوان شعاع. 4: Cr ← Cr ∪∪{بخش های جاده کاندید در اطراف C i }; 5: برای هر کدام cj∈��∈Cr do 6: N ij ← احتمال فضایی cj��محاسبه شده با معادله (3)؛ 7: H ij ← احتمال عنوان از cj��محاسبه شده با معادله (5)؛ 8: G w ij ← احتمال جامع cj��محاسبه شده با معادله (6)؛ 9: پایان برای 10: پایان برای 11: بازگشت G w , Cr ; |
2.2.4. بهترین انتخاب مسیر
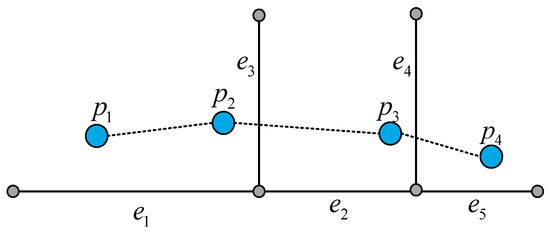
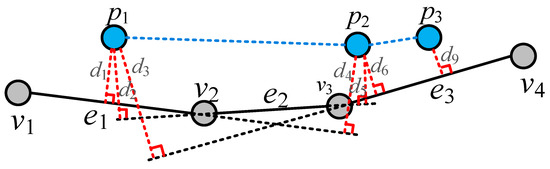
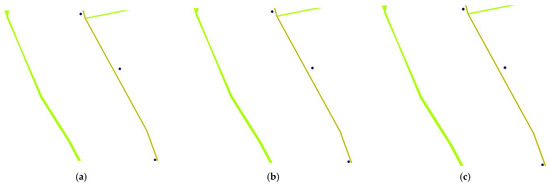
با تجزیه و تحلیل بالا، ما می توانیم k مسیرهای نامزد مربوطه را برای هر زیرمسیر قطعه بندی شده مسیر اصلی پیدا کنیم و مسیرهای نامزد مسیرهای فرعی مختلف را برای بدست آوردن k مسیر نامزد کامل ترکیب کنیم. شکل 9 نقاط مسیر را نشان می دهد p1, p2, p3�1, �2, �3و بخشهای جاده منطبق بر آن e1�1و e3�3. در فرآیند مسیریابی، e1→e2→e3�1→�2→�3یکی از مسیرهای نامزد است. برای یافتن بهترین مسیر منطبق، فاصله بین مسیر اصلی p1→p2→p3�1→�2→�3و هر مسیر نامزد باید محاسبه شود. ابتدا کمترین فاصله را از هر نقطه مسیر تا هر بخش جاده در مسیر محاسبه کنید. یعنی فاصله پیش بینی شده از نقطه مسیر تا قسمت جاده. اگر نقطه پیش بینی شده در قسمت جاده نیست، فاصله بین نقطه مسیر و نقطه پیش بینی شده در خط توسعه یافته قطعه جاده را محاسبه کنید. همانطور که در شکل 9 نشان داده شده است ، فواصل از p1�1به بخش های جاده ای e1�1، e2�2، و e3�3هستند d1�1، d2�2، و d3�3، به ترتیب؛ فواصل از p2�2به بخش های جاده ای e1�1، e2�2، و e3�3هستند d4�4، d5�5، و d6�6، به ترتیب؛ و فواصل از p3�3به بخش های جاده ای e1�1، e2�2، و e3�3هستند d7�7، d8�8، و d9�9به ترتیب. دوم، تمام کوتاه ترین فاصله ها را اضافه کنید تا فاصله بین مسیر و مسیر نامزد فعلی را بدست آورید. از آنجایی که k مسیرهای کاندید وجود دارد که توسط بخشهای جاده با احتمالات مختلف به هم متصل میشوند، فاصله بین هر مسیر و مسیر کاندیدای k- امین آن به صورت نشان داده میشود.Dk (k=1, 2, 3, 4, 5)�� (�=1, 2, 3, 4, 5). با استفاده از معادله (7)، مسیر با بیشترین مقدار احتمال P(Dk)�(��)از k مسیرهای کاندید به عنوان بهترین مسیر منطبق انتخاب شده است.
جایی که σ3�3روی 20 متر تنظیم شده است که نشان دهنده همان معنی است σ1�1و σ2�2. شبه کد برای انتخاب بهترین مسیر در الگوریتم 3 نشان داده شده است.
| الگوریتم 3: انتخاب بهترین مسیر |
| ورودی: مجموعه بخش مسیر Γ�, شبکه جاده G , مقدار کاندید k , مجموعه احتمال جامع G w خروجی: مجموعه مسیر نهایی مسیر 1 : مقداردهی اولیه k ← {1,2,3,4,5}, Path =∅=∅; 2: بخشهای جاده کاندید را بر اساس G w مرتب کنید . 3: dist ← ماتریس مجاورت گره های پیوند در مجموعه مرتب شده از بخش های جاده کاندید. 4: برای هر کدام τi∈Γ��∈� انجام 5: PathtemPath���← کوتاه ترین مسیرهای مختلف که بر اساس مقادیر k و دور بدست می آیند . 6: PathiPath�← بهترین مسیر به دست آمده بر اساس رابطه (7)؛ 7: پایان برای 8: بازگشت مسیر ; |
2.2.5. تحلیل پیچیدگی الگوریتم
3. نتایج
3.1. مجموعه داده ها
3.1.1. مجموعه داده شبکه راه
3.1.2. مجموعه داده مسیر
3.2. شاخص های ارزیابی
3.2.1. دقت تطبیق نقطه مسیر
دقت تطبیق نقطه مسیر، به عنوان نشان داده شده است Rc��، به نسبت بین تعداد نقاط مسیری که به درستی با شبکه جاده تطبیق داده شده اند و تعداد نقاط مسیری که باید مطابقت داده شوند، به شرح زیر محاسبه می شود:
که در آن P تعداد نقاط مسیری را نشان می دهد که به درستی با بخش جاده مطابقت دارند، و R نشان دهنده تعداد نقاط مسیر مورد استفاده برای تطبیق است.
3.2.2. دقت تطبیق بخش جاده
دقت تطابق بخش جاده، نشان داده شده به عنوان Rm��، به نسبت بین تعداد بخش های جاده ای که به درستی با شبکه جاده مطابقت دارند به تعداد کل بخش های جاده واقعی مسیر اشاره دارد که به شرح زیر محاسبه می شود:
که در آن l تعداد بخش های جاده را که به درستی تطبیق داده شده اند، و L نشان دهنده تعداد کل بخش های جاده واقعی مسیر است.
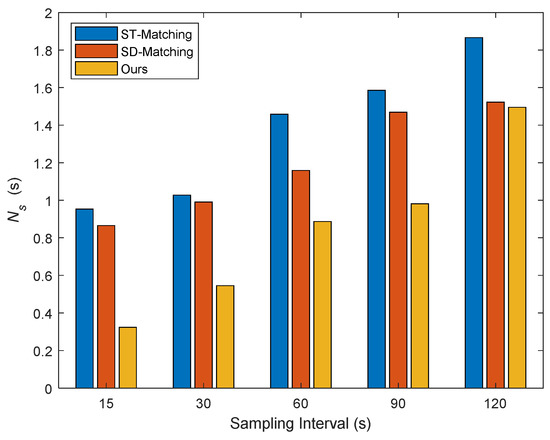
3.2.3. زمان تطبیق نقطه مسیر
استفاده کنید Ns��برای نشان دادن میانگین زمان اجرا مورد نیاز برای هر نقطه مسیر برای تکمیل تطابق.
که در آن Trt کل زمان مورد نیاز برای کل مسیر برای تکمیل فرآیند تطبیق نقشه را نشان می دهد و R نشان دهنده تعداد نقاط مسیر مورد استفاده برای تطبیق است.
3.3. تنظیم پارامتر
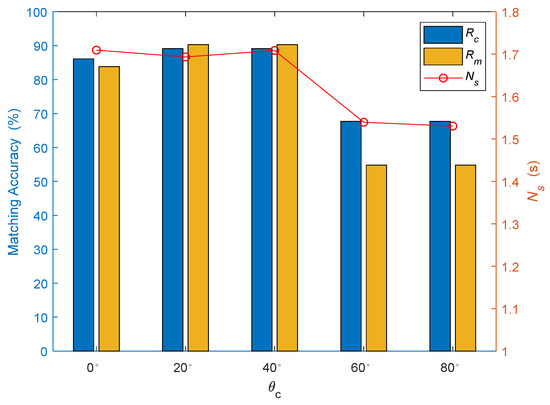
3.3.1. زاویه تقسیم بندی
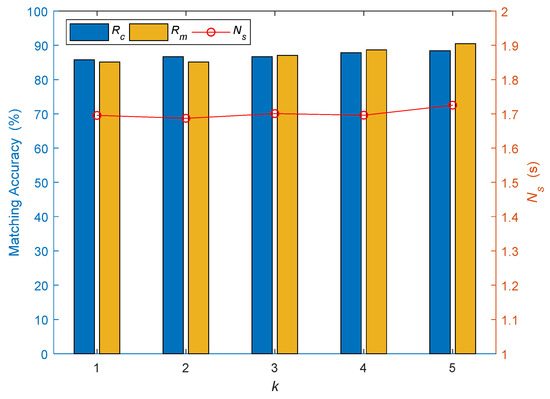
3.3.2. تعداد مسیرهای کاندیدا
3.3.3. فرکانس نمونه برداری
3.4. نتایج تجربی
3.4.1. نتایج مقایسه تجربی بر اساس پارامترهای مختلف
- (1)
-
نتایج تجربی در زوایای تقسیم بندی مختلف
- (2)
-
نتایج تجربی تحت مقادیر مختلف مسیر نامزد
- (3)
-
نتایج تجربی در فرکانس های نمونه برداری مختلف
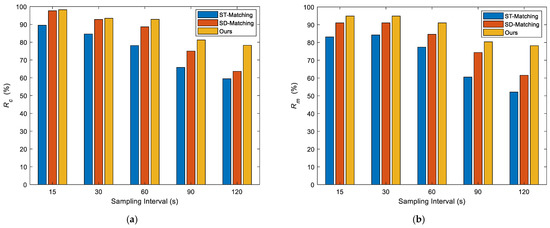
3.4.2. مقایسه نتایج با سایر الگوریتم ها
4. بحث
- (1)
-
یک الگوریتم تطبیق نقشه مسیر فرکانس پایین جدید پیشنهاد شده است، که با تقسیم بندی داده های مسیر مطابق جهت حرکت نقاط مکان و بهبود دقت تطابق.
- (2)
-
روش تطبیق بخشبندی، مدل مارکوف پنهان و الگوریتم کوتاهترین مسیر برای بهبود دقت تطبیق و کارایی تطبیق ترکیب شدهاند.
- (3)
-
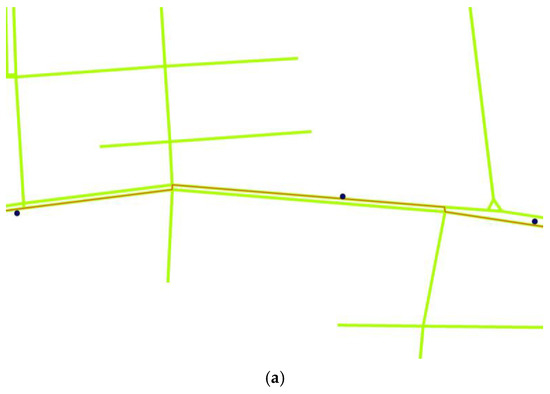
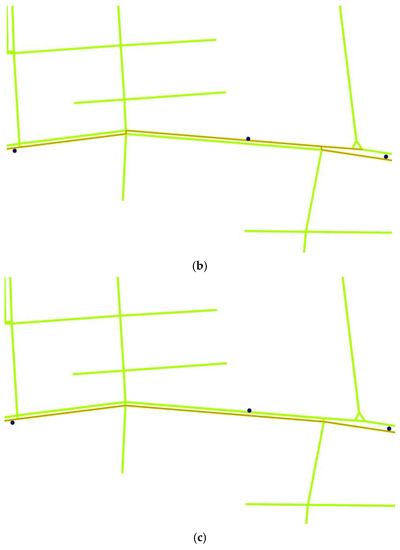
آزمایشها با استفاده از مجموعه دادههای مسیر واقعی و دادههای شبکه جادهای شانگهای انجام میشوند، و نتایج نشان میدهد که الگوریتم تطبیق نقشه مبتنی بر تقسیمبندی جهت خودروی پیشنهادی به دقت بالاتری دست مییابد و به زمان اجرای کمتری نیاز دارد. به طور خاص، روش پیشنهادی زمان اجرا را تقریباً 10-20٪ کوتاه می کند و دقت تطبیق تقریباً 5٪ بهبود می یابد. به طور همزمان، سازگاری خوبی تحت توپولوژی جاده موازی دارد.
منابع
- کیانی، ع. لیو، جی. شی، اچ. خریشا، ع. انصاری، ن. لی، جی. لیو، سی. یک مدل مبتنی بر محاسبات لبه دو لایه برای تشخیص ترافیک پیشرفته. در مجموعه مقالات پنجمین کنفرانس بین المللی اینترنت اشیا: سیستم ها، مدیریت و امنیت، والنسیا، اسپانیا، 15 تا 18 اکتبر 2018؛ ص 208-215. [ Google Scholar ]
- ولی، بی. ختک، ای جی; بوزدوگان، اچ. کامرانی، م. نوسانات رانندگی چگونه با ایمنی تقاطع ارتباط دارد؟ تجزیه و تحلیل مبتنی بر ناهمگونی بیزی از داده های وسایل نقلیه ابزار. ترانسپ Res. قسمت C Emerg. تکنولوژی 2018 ، 92 ، 504-524. [ Google Scholar ] [ CrossRef ]
- عظیمجونوف، ج. Özmen، A. یک سیستم تشخیص بیدرنگ خودرو و یک سیستم ردیابی خودرو جدید برای تخمین و نظارت بر جریان ترافیک در بزرگراهها. Adv. مهندس به اطلاع رساندن. 2021 ، 50 ، 101393. [ Google Scholar ] [ CrossRef ]
- تانگ، جی. بی، دبلیو. لیو، اف. ژانگ، دبلیو. بررسی الگوهای سفر شهری با استفاده از خوشهبندی مبتنی بر تراکم با ویژگیهای چندگانه از مسیرهای وسایل نقلیه در مقیاس بزرگ. فیزیک یک آمار مکانیک. برنامه آن است. 2021 , 561 , 125301. [ Google Scholar ] [ CrossRef ]
- دندالا، تی تی; کریشنامورتی، وی. Alwan, R. اینترنت وسایل نقلیه (IoV) برای مدیریت ترافیک. در مجموعه مقالات کنفرانس بین المللی 2017 کامپیوتر، ارتباطات و پردازش سیگنال، چنای، هند، 10–11 ژانویه 2017؛ صص 1-4. [ Google Scholar ]
- لی، های. هو، HW; Zhou، Y. اجتناب از موانع تک چشمی مبتنی بر یادگیری عمیق برای ناوبری وسایل نقلیه هوایی بدون سرنشین در مزارع درختان. جی. اینتل. ربات. سیستم 2021 ، 101 ، 5. [ Google Scholar ] [ CrossRef ]
- ولاگا، NR; قدوس، م. Bristow, AL در حال توسعه الگوریتم تطبیق نقشه توپولوژیکی مبتنی بر وزن برای سیستم های حمل و نقل هوشمند. ترانسپ Res. قسمت C Emerg. تکنولوژی 2009 ، 17 ، 672-683. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تولدو مورئو، آر. Bétaille، D. Peyret، F. ارائه یکپارچگی در سطح خط برای ناوبری و تطبیق نقشه با GNSS، محاسبه مرده، و نقشه های پیشرفته. IEEE Trans. هوشمند ترانسپ سیستم 2009 ، 11 ، 100-112. [ Google Scholar ] [ CrossRef ]
- Szottka، I. فیلتر ذرات برای تطبیق نقشه سطح خط در دوشاخههای جاده. در مجموعه مقالات شانزدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند، لاهه، هلند، 6 تا 9 اکتبر 2013. صص 154-159. [ Google Scholar ]
- تائو، ز. بونیفیت، پ. فرمونت، وی. Ibanez-Guzman، J. Lane علامت گذاری به محلی سازی وسیله نقلیه کمک کرد. در مجموعه مقالات شانزدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند، لاهه، هلند، 6 تا 9 اکتبر 2013. صفحات 1509-1515. [ Google Scholar ]
- گو، ی. وادا، ی. هسو، ال. Kamijo، S. خود محلی سازی وسیله نقلیه در دره شهری با استفاده از موقعیت یابی GPS و حسگرهای وسیله نقلیه مبتنی بر نقشه سه بعدی. در مجموعه مقالات کنفرانس بین المللی 2014 در مورد وسایل نقلیه متصل و نمایشگاه، وین، اتریش، 3 تا 7 نوامبر 2014. صص 792-798. [ Google Scholar ]
- شونسوکه، ک. یانلی، جی. ادغام دوربین Hsu، LT GNSS/INS/بورد برای مکانیابی خودکار خودرو در دره شهری. در مجموعه مقالات 2015 IEEE هجدهمین کنفرانس بین المللی سیستم های حمل و نقل هوشمند، گران کاناریا، اسپانیا، 15 تا 18 سپتامبر 2015. صص 2533-2538. [ Google Scholar ]
- ژنگ، ی. Hansen، تشخیص تغییر خط JHL از سیگنال فرمان با استفاده از تقسیم بندی طیفی و طبقه بندی مبتنی بر یادگیری. IEEE Trans. هوشمند وه 2017 ، 2 ، 14-24. [ Google Scholar ] [ CrossRef ]
- کاساس، ZZM؛ معارف، م. مورالس، جی جی. خلیف، جی جی. Shamei، K. مکان یابی قوی وسیله نقلیه و تطبیق نقشه در محیط های شهری از طریق سیگنال های IMU، GNSS و سلولی. IEEE Intell. ترانسپ سیستم Mag. 2020 ، 12 ، 36-52. [ Google Scholar ] [ CrossRef ]
- معارف، م. Kassas، ناوبری وسیله نقلیه زمینی ZM در محیط های به چالش کشیده GNSS با استفاده از سیگنال های فرصت و رویکرد تطبیق نقشه حلقه بسته. IEEE Trans. هوشمند ترانسپ سیستم 2019 ، 21 ، 2723-2738. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- نیوزون، پی. Krumm, J. Hidden Markov نقشه مطابق با نویز و پراکندگی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 4-6 نوامبر 2009. صص 336-343. [ Google Scholar ]
- زنگ، ز. ژانگ، تی. لی، کیو. وو، زی. زو، اچ. Gao, C. ویژگی انحنای تطبیق نقشه محدود برای دادههای خودروی کاوشگر فرکانس پایین. بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 660-690. [ Google Scholar ] [ CrossRef ]
- لو، ا. چن، اس. Xv، B. الگوریتم تطبیق نقشه پیشرفته با مدل مارکوف پنهان برای موقعیت یابی تلفن همراه. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 327. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چن، سی. دینگ، ی. Xie، X. ژانگ، اس. یک الگوریتم تطبیق نقشه آنلاین سه مرحله ای با استفاده کامل از جهت حرکت خودرو. J. محیط. هوشمند اومانیز. محاسبه کنید. 2018 ، 9 ، 1623-1633. [ Google Scholar ] [ CrossRef ]
- لین، MC-H. هوانگ، F.-M. لیو، پی.-سی. هوانگ، Y.-H. چانگ، Y.-S. انتخاب مبتنی بر Dijkstra برای تطبیق نقشه چند خط موازی و یک سیستم برچسب گذاری مسیر واقعی. در مجموعه مقالات کنفرانس آسیایی اطلاعات هوشمند و سیستم های پایگاه داده، دا نانگ، ویتنام، 14 تا 16 مارس 2016. صص 499-508. [ Google Scholar ]
- پتوشک، وی. راپنت، ال. Martinovič, J. تطبیق نقشه داده های خودرو شناور با استفاده از الگوریتم Dijkstra. در مدیریت داده، تجزیه و تحلیل و نوآوری ؛ اسپرینگر: سنگاپور، 2020؛ صص 115-130. [ Google Scholar ]
- کولر، اچ. ویدهام، پی. دراگاشنیگ، م. Graser, A. تطبیق سریع مدل مارکوف پنهان برای مسیرهای پراکنده و پر سر و صدا. در مجموعه مقالات 2015 IEEE هجدهمین کنفرانس بین المللی سیستم های حمل و نقل هوشمند، گران کاناریا، اسپانیا، 15 تا 18 سپتامبر 2015. صص 2557–2561. [ Google Scholar ]
- لو، ی. ژانگ، سی. ژنگ، ی. Xie، X. وانگ، دبلیو. Huang, Y. تطبیق نقشه برای مسیرهای GPS با نرخ نمونه برداری پایین. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 4-6 نوامبر 2009. صص 352-361. [ Google Scholar ]
- کاردونی، ع. کرمانشاه، ع. Derrible، S. پروتکلی برای تبدیل داده های چند خطی فضایی به فرمت های شبکه و برنامه های کاربردی به شبکه های جاده های شهری جهانی. علمی داده 2016 ، 3 ، 160046. [ Google Scholar ] [ CrossRef ]
- نیکولیچ، م. Jović, J. پیاده سازی الگوریتم عمومی در مدل تطبیق نقشه. سیستم خبره Appl. 2017 ، 72 ، 283-292. [ Google Scholar ] [ CrossRef ]
- یو، جی. یانگ، کیو. لو، جی. هان، جی. پنگ، اچ. الگوریتمهای تطبیق نقشه پیشرفته: نظرسنجی و روندها. Acta Electron. گناه 2021 ، 49 ، 1818-1829. [ Google Scholar ]
- هوانگ، ز. کیائو، اس. هان، ن. یوان، کالیفرنیا؛ آهنگ، X. Xiao, Y. بررسی تکنیک های تطبیق نقشه خودرو. CAAI Trans. هوشمند تکنولوژی 2021 ، 6 ، 55-71. [ Google Scholar ] [ CrossRef ]
- چائو، پی. خو، ی. هوآ، دبلیو. ژو، ایکس. نظرسنجی در مورد الگوریتم های تطبیق نقشه. در مجموعه مقالات کنفرانس پایگاه داده استرالیا، ملبورن، VIC، استرالیا، 3 تا 7 فوریه 2020؛ Springer: Cham، سوئیس، 2020؛ صص 121-133. [ Google Scholar ]
- یو، کیو. هو، اف. بله، ز. چن، سی. سان، ال. Luo, Y. الگوریتم تطبیق نقشه مسیر فرکانس بالا بر اساس توپولوژی شبکه جاده. IEEE Trans. هوشمند ترانسپ سیستم 2022 ، 3 ، 1-16. [ Google Scholar ] [ CrossRef ]
- Hsueh، YL; تطبیق نقشه Chen، HC برای مسیرهای GPS با نرخ نمونهبرداری پایین با کاوش جهتهای حرکت در زمان واقعی. Inf. علمی 2018 ، 433 ، 55-69. [ Google Scholar ] [ CrossRef ]
- تاناکا، ا. تاتیوا، ن. هاتا، ن. یوشیدا، ا. واکاماتسو، تی. اوزافون، اس. Fujisawa، K. تطبیق نقشه آفلاین با استفاده از نمودار توسعه یافته زمان برای داده های فرکانس پایین. ترانسپ Res. قسمت C Emerg. تکنولوژی 2021 ، 130 ، 103265. [ Google Scholar ] [ CrossRef ]
- چن، آر. یوان، اس. مک.؛ ژائو، اچ. فنگ، Z.-Y. THMM: یک مدل مارکوف پنهان طراحی شده که برای تطبیق نقشه مبتنی بر سلولی بهینه شده است. IEEE Trans. الکترون صنعتی 2021 ، 12 ، 1-10. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه