1. معرفی
با توسعه سریع نقشه های الکترونیکی و فن آوری های ارتباطات سیار، تقاضا برای خدمات مبتنی بر مکان به تدریج افزایش یافته است [ 1 ]. داده های مکانی جغرافیایی نشان داده شده توسط نقاط مورد علاقه (POI) توجه فزاینده ای را به خود جلب کرده است [ 2 ، 3 ، 4 ، 5 ]. در حال حاضر، بهبود غنا و کیفیت داده با ویژگی های مکمل از طریق ادغام POI از منابع مختلف، به روشی موثر برای به روز رسانی سریع داده های POI تبدیل شده است [ 6 ، 7 ، 8 ]. با این حال، از آنجایی که دادههای POI از منابع مختلف معمولاً مسائلی مانند ناسازگاری، افزونگی، ابهام و تناقض را نشان میدهند [ 9 ]، 10 ]، روش مناسب برای تطبیق دقیق داده های POI از منابع مختلف مهم است [ 11 ]. تطبیق POI از منابع مختلف معمولاً به فرآیند دور انداختن POIهایی اشاره دارد که اشیاء مشابه را نشان می دهند، اما در نظر گرفتن POIهایی که اشیاء مختلف را با مقایسه POI در نقشه های مرجع و کمکی با محدودیت های خاص نشان می دهند. تطبیق POI یک پیش نیاز و بخش کلیدی برای به روز رسانی POI است. تطبیق سریع و دقیق POI از منابع مختلف برای غنیسازی و استانداردسازی پایگاههای اطلاعاتی POI و تحقق استفاده مجدد مؤثر از دادهها حیاتی است [ 12 ، 13 ].
روشهای مطابقت با اشیاء POI چند منبعی عمدتاً شامل سه دسته هستند: روشهای مبتنی بر ویژگیهای فضایی [ 13 ، 14 ]، روشهای مبتنی بر ویژگیهای غیرمکانی، و روشهایی که هر دو ویژگی مکانی و غیر مکانی را ترکیب میکنند [ 15 ، 16 ]]. از آنجا که معمولاً عدم قطعیتهای متعددی در طول تطبیق POI وجود دارد، روشهای مبتنی بر تنها یک نوع ویژگی منجر به نتایج تطبیق ضعیف میشوند. روشی که هر دو ویژگی فضایی و غیرمکانی را ترکیب می کند، دارای مزیت یکپارچه سازی چند ویژگی مانند نام و فاصله مکانی است که معمولاً در تطبیق POI پیاده سازی می شود. McKenzie و همکاران (2014) یک استراتژی چند ویژگی وزنی برای تطبیق POIها پیشنهاد کردند که ویژگی هایی مانند مکان و فاصله مکانی، ویژگی های نام و شباهت موضوعی را ادغام می کند و خاطرنشان کردند که روش های ترکیب چندین ویژگی می توانند به طور موثر مشکل را حل کنند. دقت تطابق پایین ناشی از استفاده از یک ویژگی واحد [ 17]. بر اساس ویژگی های فاصله فضایی، هوانگ و همکاران (2018) یک ویژگی غیرمکانی، به عنوان مثال، شباهت نام را برای افزایش دقت همجوشی داده های POI از منابع مختلف اعمال کردند [ 15 ]. لی و همکاران (2016) و دنگ و همکاران (2019) روشهای تطبیق POI را پیشنهاد کردند که شباهتهای ویژگیهای متعدد و وزنهای مناسب متناظر آنها را با هم ترکیب میکردند و نشان دادند که در بین روشهای موجود [ 18 ، 19 ]، روش یکپارچهسازی فاصله مکانی، نام و کلاس بهترین عملکرد را به دست آوردند.
با این حال، روشهای موجود که ویژگیهای فضایی و غیرمکانی را ترکیب میکنند معمولاً بر محدودیتهای ضعیفی تکیه میکنند، که ممکن است منجر به دقت تطبیق POI پایین شود. به عنوان مثال، تحقیقات قبلی (1) اغلب محدودیتهای معنایی نام ضعیفی را اتخاذ میکردند، که در آن شباهت نامها مستقیماً بر اساس رشتههای کاراکتر محاسبه میشد، و اغلب باعث میشد که اشیاء POI مختلف بهدلیل نامهای بسیار مشابهشان، به اشتباه به عنوان اشیاء یکسان متمایز شوند. (2) مطالعات قبلی معمولاً محدودیتهای فاصله کلاس ضعیف را اتخاذ میکردند، که منجر به تبعیض نادرست اشیاء POI از کلاسهای مختلف با فاصله کلاسی کوچک شد. (3) تحقیقات قبلی ویژگیهای فضایی را به کار میبردند که فقط محدودیتهای فاصله مکان را در نظر میگرفتند، اما عوامل دیگر، مانند توپولوژی فضایی بین اشیاء را نادیده گرفتند. تمام مسائل ذکر شده در بالا منجر به دقت تطبیق POI پایین و نتایج تطبیق ضعیف شد. بنابراین، بر اساس ویژگیهای اشیاء POI، این مقاله یک روش تطبیق POI را پیشنهاد میکند که محدودیتهای تعیین چندگانه را یکپارچه میکند، که توپولوژی فضایی، برچسبگذاری نقش نام، و محدودیتهای کلاس پایین به بالا را در نظر میگیرد. روش پیشنهادی میتواند به طور موثری دقت تطبیق و همجوشی POI را از منابع مختلف افزایش دهد.
مقاله شامل پنج بخش است. بخش 2 روشهای تطبیق POI موجود را معرفی میکند که ویژگیهای فضایی و غیرمکانی را ادغام میکند و کاستیهای آنها. روش تطبیق POI پیشنهادی با محدودیتهای تعیین چندگانه به تفصیل در بخش 3 توضیح داده شده است . بخش 4 آزمایش ها را تشریح می کند و نتایج را ارائه می دهد و به دنبال آن بحث ها و نتیجه گیری ها در بخش 5 ارائه می شود .
2. کارهای مرتبط
2.1. روشهای تطبیق POI موجود که ویژگیهای فضایی و غیرمکانی را ادغام میکنند
در حال حاضر، آخرین روشهای تطبیق POI که ویژگیهای فضایی و غیرمکانی را ترکیب میکنند، معمولاً استراتژیهای تطبیق وزنی را با ادغام مکان مکانی و نام، آدرس و ویژگیهای کلاس اجرا میکنند که میتواند به طور قابلتوجهی دقت تطبیق POI و نرخ فراخوان را افزایش دهد. الگوریتم های محاسبات اصلی به شرح زیر است.
(1) محاسبه شباهت فضایی
تشابه مکان مکانی به مجاورت جغرافیایی دو جسم در فضای جغرافیایی اشاره دارد. روش اصلی محاسبه، روش فاصله اقلیدسی است. علاوه بر این، برای از بین بردن اثرات ابعاد، پارامترهای مکان نرمال می شوند. شباهت فضایی اسسپآتیمنآلبه صورت زیر محاسبه می شود:
جایی که اسOمنOjنشان دهنده شباهت مختصات است، Oمن(ایکسمن،yمن)و Oj(ایکسj،yj)دو مجموعه مختصات از اشیاء POI از دو منبع مختلف هستند و منفی یک ثابت آماری است که توسط مجموعه داده آموزشی تعیین می شود. چه زمانی اسسپآتیمنآلبرابر 0 است، دو شی کاملاً مطابقت ندارند، در حالی که مقدار 1 نشان دهنده تطابق کامل است.
(2) محاسبه تشابه نام
روشهای رایج برای محاسبه شباهت نام POI، الگوریتم شباهت Jaro، الگوریتم شباهت Jaro-Winkler و الگوریتم فاصله ویرایشی Levenshtein است. اشتراک آنها بر اساس نمایش کمی تشابه رشته است. به عنوان مثال، الگوریتم فاصله ویرایش لوونشتاین به صورت زیر تعریف شده است:
جایی که نآمن آnد نآjدو نام POI هستند. ED فاصله ویرایش از است نآمنبه نآj; Lنآمنطول نام POI است نآمن; و Lنآjطول نام POI است نآj.
(3) محاسبه شباهت طبقاتی
در محاسبات شباهت کلاس، ابتدا روابط نگاشت گره ریشه متناظر ایجاد می شود. سپس، فاصله کلاس بین دو گره را می توان با توجه به روابط نگاشت گره ریشه تعیین شده و عمق گره ها به گره های ریشه محاسبه کرد.
(4) وزن دهی چند ویژگی
وزن ها بر اساس عملکرد صفات در طول تطبیق تخصیص داده می شوند. شباهت کلی را می توان با اتخاذ شباهت های وزن و صفت به دست آورد. هنگامی که شباهت کلی از یک آستانه خاص فراتر رفت، POI ها یکسان در نظر گرفته می شوند. در غیر این صورت، آنها POI های متفاوتی در نظر گرفته می شوند.
جایی که سشباهت کلی است، سمننشان دهنده تشابه یک صفت واحد است و γمنوزن صفت است.
2.2. کاستی های روش های موجود
در حال حاضر، متدهای تطبیق POI متداول، عمدتاً روشهای تطبیق وزنی هستند که مکان مکانی و نام، آدرس و ویژگیهای کلاس را به طور جامع در نظر میگیرند. همانطور که در بالا ذکر شد، این روش های موجود محدودیت های خاصی از نظر محاسبات چند ویژگی و تنظیم محدودیت دارند. بنابراین، دقت تطبیق POI پایین و حتی نتایج تطبیق نادرست در برخی سناریوها رخ خواهد داد. این سناریوها در زیر نشان داده شده است.
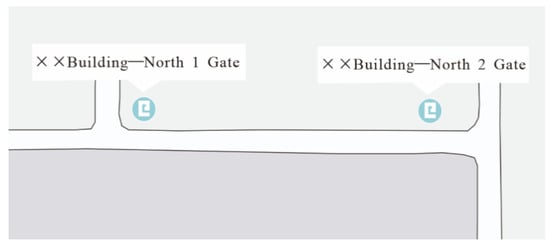
سناریو 1: از آنجایی که محدودیتهای ویژگی نام به اندازه کافی دقیق نیستند، اشیاء POI مجاور با شباهت نامی بالا به اشتباه مطابقت داده میشوند. همانطور که در شکل 1 نشان داده شده است ، دو POI مختلف وجود دارد و نام آنها تنها با یک عدد متفاوت است. هنگامی که یک روش محاسبه شباهت موجود استفاده می شود، شباهت نام این دو POI به 1 نزدیک می شود. علاوه بر این، به دلیل نزدیک بودن این دو شیء به یکدیگر، به احتمال بسیار زیاد در طول تطبیق، یک شی در نظر گرفته می شوند.
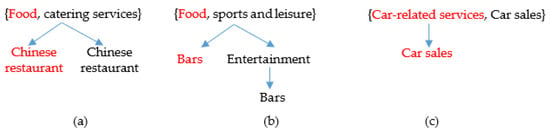
سناریوی 2: از آنجایی که محدودیتهای معنایی کلاس اغلب ضعیف هستند، اگر کلاسهای اولیه دادههای POI از منابع مختلف متفاوت باشند، اشیاء POI یکسان به درستی مطابقت ندارند. در شکل 2 ، طبقه بندی استفاده شده در نقشه بایدو به رنگ قرمز ارائه شده است، در حالی که طبقه بندی استفاده شده در نقشه Gaode به رنگ سیاه نشان داده شده است. در سطح اولیه، میلهها به POIهای «غذا» در نقشه بایدو تعلق دارند، اما به POI «ورزش و اوقات فراغت» در نقشه Gaode تعلق دارند. بر اساس روش های موجود، شباهت کلاس همان POI نوار ∞ با تطبیق POI است. این منجر به شباهت کلاس پایین می شود و بنابراین، یک نوار به عنوان دو شی متفاوت در دو سیستم نقشه در نظر گرفته می شود.
سناریوی 3: از آنجایی که فقط فاصله مکانی در نظر گرفته می شود و روابط توپولوژیکی نادیده گرفته می شود، اشیاء POI در طرفین مقابل یا در همان صفحه به درستی مطابقت ندارند. شکل 3 a دو ایستگاه اتوبوس مجاور را با همین نام اما در طرفین مخالف جاده نشان می دهد. شناسایی POI صحیح برای تطبیق دشوار است. علاوه بر این، شکل 3 ب نشان می دهد که برای یک شی POI، به دلیل منطقه مسکونی بزرگ، مکان این شی POI در منطقه مسکونی به طور متفاوت در نقشه بایدو و نقشه گائود مشخص شده است. فاصله 200 متر است که معمولاً از آستانه فاصله مکانی فراتر می رود و منجر به تشابه فاصله مکانی کم و نتایج تطبیق POI نادرست و از دست رفته می شود.
3. روش تطبیق POI با در نظر گرفتن محدودیت های متعدد
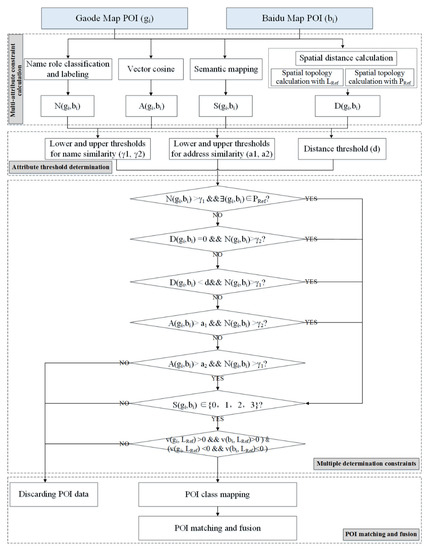
هنگام تطبیق POI از منابع مختلف، محاسبات شباهت باید برای همه ویژگی ها بهبود یابد تا دقت تطبیق برای هر ویژگی افزایش یابد و دقت تطبیق کلی POI افزایش یابد. بنابراین، این مقاله یک روش تطبیق POI با در نظر گرفتن محدودیتهای تعیین چندگانه پیشنهاد میکند. یک تطابق جامعتر و دقیقتر POI با بهبود محاسبه شباهت ویژگیها و ادغام محدودیتهای تعیین مختلف محقق میشود. به طور خاص، برای محدودیتهای ویژگی، علاوه بر نام POI، آدرس و ویژگیهای کلاس، محدودیتهای فضایی مانند روابط توپولوژیکی و فواصل بین اهداف منطبق و ویژگیهای مجاور آنها نیز ثبت میشود. POI ها از Baidu Map و Gaode Map اقتباس شده اند و Gaode Map به عنوان مرجع استفاده می شود. روش پیشنهادی از سه بخش اصلی تشکیل شده است: محاسبه محدودیت چند ویژگی، تعیین آستانه محدودیت، و تعریف محدودیتهای تعیین چندگانه. نمودار جریان در نشان داده شده استشکل 4 .
3.1. محاسبه محدودیت چند ویژگی
3.1.1. محاسبه تشابه نام
ویژگیهای نام عموماً ویژگیهای متمایز برای تشخیص POI در نظر گرفته میشوند. با این حال، نتایج تطبیق POI نادرست و از دست رفته به راحتی با تفاوت های کوچک در اعداد و جهت کلمات در نام POI به دست می آید. برای پرداختن به این موضوع، این مقاله یک روش محاسبه مبتنی بر برچسبگذاری نقش را پیشنهاد میکند. پالایش و محاسبه دقیق برای برچسبگذاری نقش نامهای مناسب و جهت و تعداد کلمات انجام میشود تا دقت تطبیق بهبود یابد.
(1) نام ترکیب نقش
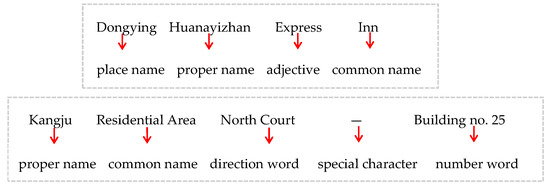
برای نامهای چینی اکثر POI، کلمه ترکیب نسبتاً منظم است. با توجه به عملکرد آنها، کلمات در یک نام POI را می توان به نام مکان (D)، نام خاص (Z)، صفت (X)، کلمات جهت (F)، کلمات عددی (S)، نام های رایج (T) تقسیم کرد. و کاراکترهای خاص (Y). از این رو، مجموعه نقش یک نام POI، NB = {D, Z, X, F, S, T, Y}. شکل 5 ترکیب نقش معنایی نامهای “Dongying Huanayizhan Kuaijie Jiudian (Huanayizhan Express Inn، Dongying)” و “Kangju Xiaoqu Beiqu—25Haolou (ساختمان شماره 25 – دادگاه شمالی، منطقه مسکونی کانجو)” را نشان میدهد.
(2) برچسب گذاری نقش معنایی
ابتدا، عبارات منظم برای شناسایی جهت و تعداد کلمات و کاراکترهای خاص در نام های POI اتخاذ می شوند. پس از آن، بر اساس فرهنگ لغت برچسب نقش، از جمله نام مکان، صفت، و نام مشترک، و مدل پنهان مارکوف مدل (HMM)، نام های POI نشانه گذاری شده، و نقش های مربوطه به کلمات اختصاص داده می شود. ساختار فرهنگ لغت {واژهها، نقشها و زمانها} است. در نهایت، تمام کلمات بدون نقش به عنوان نام های خاص طبقه بندی می شوند و نقش آنها به صورت Z تعریف می شود.
(3) محاسبه شباهت
برای نامهای POI واقعی، چون نقشهای D، X، T و Y ممکن است وجود نداشته باشند و معمولاً سهم کمی در شباهت کلی دارند یا حتی منجر به سردرگمی در طول محاسبه شباهت کلی میشوند، در روش پیشنهادی، کلمات با نقشهای D، X، T و Y در محاسبه لحاظ نشده اند. محاسبات شباهت فقط بر اساس کلمات با نقش های زیر است: نام های خاص (Z)، کلمات جهت (F)، و کلمات عددی (S). معادله در زیر آورده شده است:
که در آن N شباهت نام، W i شباهت کلمات با نقش i ، و m تعداد اتحادیههای برچسبهای نقش بین نام دو شی است. علاوه بر این، روشهای محاسبه برای W i برای نقشهای معنایی مختلف متفاوت است. دو سناریو اصلی وجود دارد:
جایی که نآمن آnد نآjدو نام POI هستند، ED فاصله ویرایش از آن است نآمنبه نآj، Lنآمنطول نام POI است نآمن، و Lنآjطول نام POI است نآj.
3.1.2. محاسبه شباهت آدرس
در مقایسه با ویژگی های نام، ویژگی های آدرس قابلیت تطبیق POI کمتری دارند. این امر به این دلیل اتفاق میافتد که در واقعیت، توصیفهای آدرس برای بسیاری از POI استاندارد نشدهاند (به عنوان مثال، توصیفهای خاص شامل بخش اداری هستند در حالی که سایرین چنین نیستند)، که منجر به عدم قطعیتهای بزرگ میشود. در این مقاله، شباهت آدرس بر اساس شباهت کسینوس برای محاسبات شباهت آدرس [ 20 ] استفاده شده است.] که شامل دو مرحله است. ابتدا، توضیحی از بخش اداری باید در توضیحات آدرس گنجانده شود و کاراکترهای خاص بی معنی حذف می شوند. دوم، دو قطعه آدرس با چارچوب پردازش زبان طبیعی منبع باز HanLP متمایز می شوند و دو بردار بر اساس کلمات قطعه به دست آمده ساخته می شوند. سپس شباهت بر اساس مقادیر کسینوس دو بردار محاسبه می شود (معادله 5).
جایی که gمنو بمنبه ترتیب POI در نقشه Gaode و Baidu Map هستند، G و B بردارهای پس از رمزگذاری متن آدرس هستند، و آ(gمن،بمن)∈ (0,1) شباهت دو آدرس است. هنگامی که مقدار به 1 نزدیک می شود، آدرس ها بیشتر شبیه هستند.
3.1.3. محاسبه شباهت کلاس
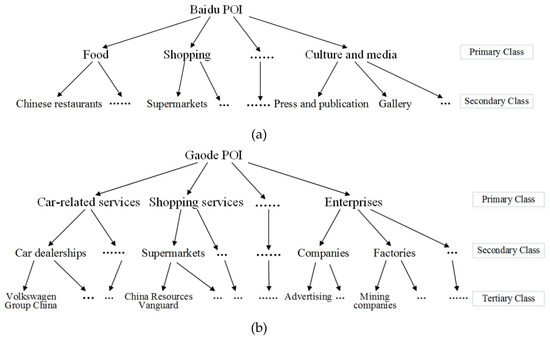
POIهای یک کلاس ممکن است شباهت بیشتری به یکدیگر داشته باشند تا POIهای کلاسهای مختلف. داده های هر نقشه سیستم طبقه بندی خاص خود را دارد و سطوح و حتی نام کلاس ها متفاوت است. نقشه Gaode شامل 23 سطح اولیه، 264 سطح متوسطه و 869 سطح سوم است. Baidu Map دارای 19 سطح اولیه و 138 سطح ثانویه است ( شکل 6 ). برای تطبیق دقیقتر کلاسهای POI از منابع مختلف، این مقاله نگاشت کلاس از پایین به بالا را برای تقویت محدودیتهای کلاس و درک تطابق بسیار دقیق ویژگیهای کلاس ایجاد میکند.
روابط نگاشت معنایی بین گره های کلاس دو سیستم طبقه بندی ایجاد می شود. به طور خاص، روابط نگاشت بین کلاس های والد با پیروی از درخت های سلسله مراتبی به زیر کلاس ها اختصاص داده می شود. در این مقاله سه نوع رابطه نقشه برداری وجود دارد. نوع اول نگاشت معنایی کامل گره های کلاس است و فاصله معنایی آن 0 است. برای نوع دوم، روابط نگاشت گره های کلاس از طریق گره های والد آنها تعیین می شود و فاصله معنایی می تواند 1، 2 یا 3 باشد. دنگ و همکاران، 2019). برای نوع سوم، هیچ رابطه نگاشت کاملی وجود ندارد و فاصله معنایی +∞ است. شکل 7سه شرط اصلی را نشان می دهد که در آنها فاصله معنایی 0 است. آنها شامل (1) رستوران های چینی در سطح ثانویه در نقشه بایدو و رستوران های چینی در سطح ثانویه در نقشه گائود ( شکل 7 a) هستند. (2) میلهها در سطح ثانویه در نقشه بایدو و میلهها در سطح سوم در نقشه گائود ( شکل 7 ب). و (3) نمایندگی های خودرو در سطح ثانویه در نقشه بایدو و آنها در سطح اولیه در نقشه گائود ( شکل 7 ج). در این شکل ها طبقه بندی های موجود در Baidu Map و Gaode Map به ترتیب با رنگ قرمز و مشکی مشخص شده اند.
هنگامی که روابط نگاشت بین گره های کلاس بر اساس کلاس های اصلی آنها تعیین می شود، فاصله ها با استفاده از معادله زیر محاسبه می شوند:
که در آن A ( g i ,b i ) فاصله معنایی بین یک POI در نقشه Gaode و آن در نقشه بایدو است، و مرحله P ( g i ) و P stepl ( b i ) تعداد مراحل از گره ها تا والد آنها هستند. گره ها برای تعیین روابط نگاشت بر اساس گره های والد در نقشه Gaode و Baidu Map به ترتیب.
3.1.4. محاسبه محدودیت فضایی با در نظر گرفتن روابط توپولوژیکی فضایی
به طور کلی، هر چه دو POI نزدیکتر باشند، احتمال تطابق آنها بیشتر می شود. با این حال، اگر فقط محدودیت های فاصله در نظر گرفته شود، عدم قطعیت های زیادی وجود دارد. از یک طرف، تعیین آستانه های محدودیت فاصله نسبتاً چالش برانگیز است. اگر آستانه ها خیلی بالا تنظیم شوند، ممکن است برخی از اشیاء POI مطابقت نداشته باشند یا برخی دیگر در طول تطبیق حذف شوند، در حالی که آستانه های بسیار پایین منجر به عدم تطابق بیشتر می شود. از سوی دیگر، حتی زمانی که دو POI نزدیک به یکدیگر هستند، ممکن است خطاهای تطبیق به دلیل روابط توپولوژیکی فضایی ناسازگار باشد. از این رو، این مقاله یک روش محاسبه محدودیت فضایی را با در نظر گرفتن روابط توپولوژیکی فضایی بین POI و سایر ویژگیها پیشنهاد میکند. روش پیشنهادی عمدتاً از سه جزء تشکیل شده است: محاسبه فاصله فضایی،
(1) محاسبه فاصله فضایی
این مقاله فاصله مسطح بین دو POI را برای اندازه گیری شباهت آنها اتخاذ می کند. معادله در زیر آورده شده است:
جایی که d فاصله مسطح بین دو نقطه، R شعاع تقریبی زمین، و x i و y i به ترتیب مختصات طول و عرض جغرافیایی دو نقطه هستند.
(2) محاسبه محدودیت های توپولوژیکی فضایی بین POI و ویژگی های خط
یک ویژگی خط (L Ref ) به عنوان یک ویژگی مرجع انتخاب می شود، مانند یک جاده، و زمانی که یک POI در امتداد L Ref یا در فاصله آستانه از L Ref قرار دارد، یک رابطه محدودیت مکانی بین POI و L Ref وجود دارد ، که است، POI متعلق به L Ref است. معادله محاسبه در زیر ارائه شده است:
جایی که پ∈Lمنnهنشان می دهد که نقطه p متعلق به خط شی خطی است، ∃نشان دهنده وجود است، خط [ i ] پاره معینی از خط است ، فاصله ( p، خط [ i ]) فاصله اقلیدسی بین نقطه p و پاره خط خط [ i ] و M آستانه است. مقدار M به کلاس های جاده در شهر بستگی دارد.
پس از تعیین اینکه آیا یک POI به یک شی خطی تعلق دارد، لازم است ارزیابی شود که آیا POI در سمت چپ یا راست شی خطی قرار دارد. معادله به صورت زیر ارائه شده است:
که در آن x و y مختصات طول و عرض جغرافیایی، به ترتیب، POI و ( x 1 , y 1 ) و ( x 2 , y 2 ) مختصات نقاط انتهایی پاره خط Line[i] هستند. وقتی v > 0 باشد، POI در سمت چپ شی خطی قرار دارد. برعکس، وقتی v < 0، در سمت راست شی خطی قرار دارد.
(3) محاسبه محدودیت های توپولوژیکی فضایی بین POI و ویژگی های چند ضلعی
یک ویژگی چند ضلعی (P Ref ) به عنوان یک ویژگی مرجع انتخاب می شود، مانند یک منطقه مسکونی، و زمانی که یک POI در یا در امتداد مرز P Ref قرار دارد، یک رابطه محدودیت فضایی بین POI و P Ref وجود دارد ، به عنوان مثال، POI متعلق به P Ref است. مجموع تمام زوایای بین لبه های P Ref و POI برای تعیین اینکه آیا POI متعلق به P Ref است محاسبه می شود . معادله به صورت زیر است:
جایی که پ∈حوزهنشان میدهد که نقطه p متعلق به ناحیه شی مسطح است و زاویه ( p, Area ( i )) زاویه بین نقطه p و ناحیه لبه i ( منطقه ( i )) جسم مسطح است. معادله زاویه ( p، مساحت ( i )) به صورت زیر است:
که در آن x و y مختصات طول و عرض جغرافیایی، به ترتیب، POI و ( x 1 , y 1 ) و ( x 2 , y 2 ) مختصات طول و عرض جغرافیایی نقاط انتهایی یال Area(i) هستند.
3.2. تعیین آستانه محدودیت
دقت، فراخوانی و امتیاز F1 برای تطبیق POI زمانی محاسبه می شود که ویژگی های نام و آدرس و فاصله مکانی به طور جداگانه استفاده شود. پس از آن، آستانه های بهینه برای شباهت نام و آدرس و فاصله مکانی انتخاب می شوند. دقت به نسبت تعداد منطبقات صحیح مورد انتظار به تعداد کل مورد انتظار مطابقت اشاره دارد (معادله 12). فراخوان به نسبت تعداد منطبقات صحیح مورد انتظار به تعداد کل واقعی منطبقات مثبت اشاره دارد (معادله 13). امتیاز F1 تعادل بین دقت و یادآوری را ارزیابی می کند (معادله 14). F1 میانگین هارمونیک فراخوان و دقت است. به منظور اطمینان از علمی بودن و قابل اعتماد بودن آستانه ها، 3552 POI از Gaode Map و 1350 POI از Baidu Map که 15 کلاس اولیه را پوشش می دهد برای تست های انجام شده استفاده می شود. این کلاس ها شامل خدمات مربوط به خودرو، خدمات پذیرایی، خدمات خرید، خدمات زندگی، خدمات تسهیلات حمل و نقل، شرکت ها، مدارس، خدمات پزشکی (بیمارستان ها)، سازمان های دولتی، شماره ساختمان و بلوک و غیره می باشد.
3.2.1. تعیین آستانه تشابه نام
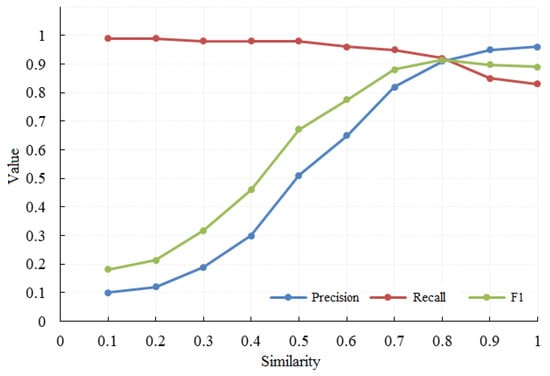
آستانه محدودیت بالا بر اساس امتیاز F1 انتخاب می شود. همانطور که در شکل 8 نشان داده شده است ، زمانی که شباهت نام 0.8 باشد، دقت، فراخوانی و امتیاز F1 منطبق است. در این مرحله، امتیاز F1 به اوج خود می رسد. بنابراین، شباهت نام 0.8 به عنوان آستانه بالایی γ1 انتخاب می شود. هنگامی که شباهت نام برابر با 0.5 شود، فراخوان به طور قابل توجهی کاهش می یابد. برای اطمینان از فراخوان نسبتاً بالا، آستانه تشابه نام پایین γ2 روی 0.5 تنظیم شده است.
3.2.2. تعیین آستانه تشابه آدرس
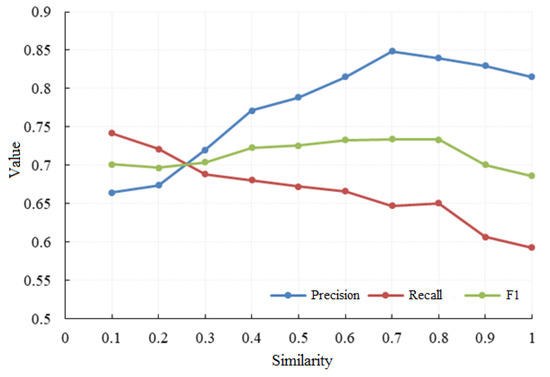
به طور مشابه، امتیاز F1 نیز در هنگام تعیین آستانه آدرس بالا در نظر گرفته می شود. همانطور که در شکل 9 نشان داده شده است ، امتیاز F1 در ابتدا افزایش می یابد اما در مرحله بعدی به سرعت کاهش می یابد و زمانی که شباهت آدرس 0.8 باشد به حداکثر می رسد. از این رو، آستانه تشابه آدرس بالایی a1 به عنوان 0.8 تعریف می شود. علاوه بر این، زمانی که شباهت آدرس برابر با 0.4 باشد، دقت و امتیاز F1 به طور همزمان به طور قابل توجهی افزایش می یابد. برای اطمینان از فراخوان نسبتاً بالا، آستانه آدرس پایینتر a2 برابر با 0.4 انتخاب میشود.
3.2.3. تعیین آستانه فاصله فضایی
شکل 10 نشان می دهد که وقتی فاصله مکانی کمتر از 10 متر باشد، دقت به بالاترین مقدار خود می رسد، اما با افزایش فاصله، دقت به تدریج کاهش می یابد. در مقابل، روند معکوس برای فراخوان مشاهده می شود. یادآوری به تدریج با افزایش فاصله افزایش می یابد. هنگامی که فاصله از 30 متر بیشتر شود، امتیاز F1 تثبیت می شود. با در نظر گرفتن هر سه شاخص، به دلیل اینکه امتیاز F1 به حداکثر خود می رسد و دقت و فراخوانی هر دو نسبتاً بالا هستند وقتی فاصله مکانی 50 متر است، آستانه فاصله فضایی “d” روی 50 متر تنظیم می شود.
3.3. محدودیت های تعیین چندگانه
برای تطبیق دقیقتر POI، این مقاله محدودیتهای تعیین چندگانه را بر اساس نتایج محاسبه محدودیت چند ویژگی تعریف میکند. اول، تا آنجا که ممکن است مجموعه های تطبیق اولیه انتخاب می شوند. دوم، مجموعههای تطبیق اولیه در معرض فیلتر ثانویه قرار میگیرند تا اشیایی را که شرایط تنظیم شده را برآورده نمیکنند حذف کنند. در نهایت، POI هایی که محدودیت های تعیین چندگانه را برآورده می کنند، مطابقت داده و ترکیب می شوند.
(1) انتخاب مجموعه تطبیق اولیه
ترکیبهای مختلفی از محدودیتهای ویژگی برای انتخاب هر چه بیشتر هدف برای تطبیق استفاده میشود، که هدف آن به حداکثر رساندن فراخوان است. POI هایی که هر یک از محدودیت های زیر را برآورده می کنند برای فیلتر ثانویه گنجانده شده اند. محدودیت ها در زیر آورده شده است:
که در آن g i و b i دو نوع POI هستند که باید مطابقت داده شوند، N(g i ,b i ) شباهت نام است، D(g i ,b i ) فاصله بین POI ها است، A(g i ,b i ) شباهت آدرس است، γ 1 و γ 2 به ترتیب آستانه تشابه نام بالایی و پایینی هستند، “d” آستانه فاصله است، و a 1 و a 2 به ترتیب آستانه تشابه آدرس بالا و پایین هستند.
(2) فیلتر کردن مجموعه تطبیق اولیه
محدودیتهایی بر طبقات و روابط توپولوژیکی فضایی مجموعههای تطبیق اولیه اعمال میشود تا دقت تطبیق را بیشتر افزایش دهد. محدودیت کلاس در زیر آورده شده است:
که در آن S(g i ,b i ) فاصله معنایی کلاس بین دو POI است.
محدودیت در رابطه توپولوژیکی فضایی POI با سایر ویژگی های خط به شرح زیر ارائه می شود:
اگر ∃(g i ,b i ) ∈ L Ref , سپس (v(g i , L Ref ) >0 && v(b i , L Ref )>0) یا (v(g i , L Ref ) <0 && v( b i ، L Ref )<0) باید برآورده شود، جایی که L Ref همان شی خطی است که دو POI به آن تعلق دارند، و v(g i/ b i ، L Ref ) مقدار جهت POI و شی خط
4. آزمایش و تجزیه و تحلیل
4.1. داده های تجربی
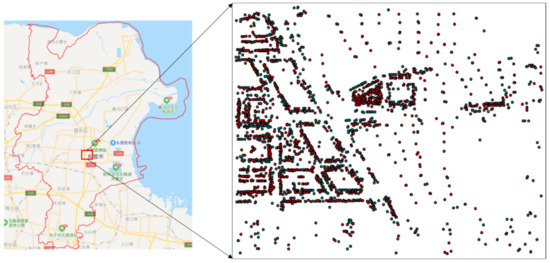
دادههای POI در Dongying، استان شاندونگ، برای تأیید صحت و اثربخشی روش پیشنهادی استفاده میشوند. داده ها از نقشه Gaode و نقشه بایدو گرفته شده اند و داده های نقشه Gaode به عنوان مرجع در نظر گرفته می شوند. دادههای POI منطقهای که بهطور خودسرانه انتخاب شده است که 1000 (m) × 1200 (m) در شهر Dongying را پوشش میدهد، به عنوان دادههای تجربی انتخاب میشوند. 2220 و 1350 POI به ترتیب از Gaode Map و Baidu Map وجود دارد ( شکل 11 ). طبقات داده های POI شامل شماره ساختمان و بلوک، خدمات پذیرایی، شرکت ها، مدارس، بیمارستان ها، خدمات خرید و سازمان های دولتی است.
4.2. تجزیه و تحلیل دقت کلی
برای تأیید صحت روش پیشنهادی، نتایج مبتنی بر روشهای تطبیق POI پیشنهادی و موجود با در نظر گرفتن ویژگیهای متعدد با استفاده از مجموعه دادههای مشابه Dongying مقایسه و تجزیه و تحلیل میشوند. نقشه Baidu و نقشه Gaode به ترتیب از سیستم مختصات BD-09 و GCJ-02 استفاده می کنند که هر دو با رمزگذاری WGS-84 به دست آمده اند. قبل از تطبیق، همه مجموعههای داده تحت تبدیل مختصات WGS84 و پاکسازی دادهها قرار گرفتهاند. نتایج تطبیق POI با استفاده از شاخصهای دقت، یادآوری و امتیاز F1 ارزیابی میشوند. جدول 1 صحت کلی روش های پیشنهادی و موجود و تبعیض دستی را خلاصه می کند.
از جدول 1 و شکل 12، تعداد موارد منطبق نادرست و گمشده برای روش پیشنهادی کمتر از روش موجود است. به طور خاص، تعداد مطابقت های نادرست 76.7٪ کاهش می یابد. دقت تطبیق POI برای هر دو روش پیشنهادی و موجود با در نظر گرفتن ویژگیهای چندگانه تقریباً 96٪ است که نشان میدهد هر دو روش میتوانند به خوبی با POI مطابقت داشته باشند. روش پیشنهادی کمی بهتر از روش های دیگر است. با این حال، فراخوانی روش تطبیق POI پیشنهادی 7.1 درصد بیشتر از روش موجود است، که نشان میدهد روش پیشنهادی توصیفهای POI دقیقتری دارد و احتمال بالایی برای طبقهبندی POI برای مطابقت با کلاس صحیح دارد. علاوه بر این، امتیاز F1 روش پیشنهادی به طور قابلتوجهی بالاتر از روش موجود است.
اگرچه روش پیشنهادی میتواند به طور موثری تطابقهای نادرست و از دست رفته را کاهش دهد، اما هنوز زمانی که روش پیشنهادی استفاده میشود، وجود دارند (همانطور که در جدول 1 نشان داده شده است). این ممکن است نتیجه دلایل زیر باشد. اول، همان POI، با تلفظ یکسان، ممکن است با کلمات مختلف توصیف شود. دوم، برای همان POI، نام کامل آن در یکی از منابع استفاده شده است، اما در منبع دیگری از مخفف استفاده شده است که منجر به تشابه نام کم می شود. ثالثاً، ترتیب کلمات در نام همان POI در منابع مختلف متفاوت است. به عنوان مثال، «جاده بینژو/خیابان فوقیان (تقاطع)» و «تقاطع خیابان فوقیان و جاده بینژو» در واقع به همان POI اشاره دارد. چهارم، اطلاعات ویژگی خود POI نادرست است.
4.3. تجزیه و تحلیل برتری
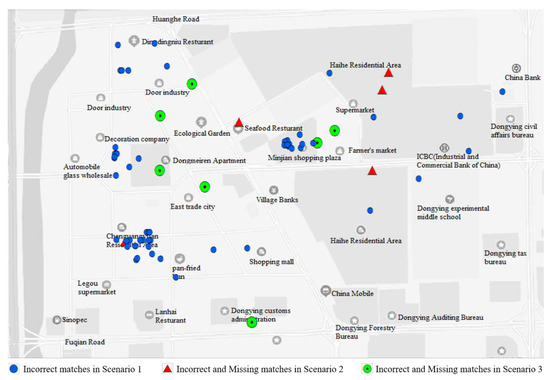
برای تایید برتری روش پیشنهادی در تطبیق POI، عملکرد تطبیق در سناریوهای مختلف ارزیابی و تجزیه و تحلیل می شود ( جدول 2 و شکل 13 ). همانطور که در جدول 2 نشان داده شده است، روش پیشنهادی به طور موثر تطبیق POI را در سه سناریو، که در بخش 2.2 ذکر و تعریف شده اند، انجام می دهد .
به طور دقیق تر، در سناریوی 1، تعداد تطابقات نادرست با روش موجود بالاترین است، در حالی که هیچ تطابق نادرستی با روش پیشنهادی وجود ندارد. این نشان می دهد که روش پیشنهادی می تواند به طور قابل توجهی تطابق نادرست POI هایی را که به یکدیگر نزدیک هستند اما دارای شباهت نامی بالایی هستند، کاهش دهد. POI ها در سناریوی 1 بیشتر در مناطق مسکونی و تجاری قرار دارند. در سناریوی 2، روش پیشنهادی به طور موثری از عدم تطابق اشیاء POI یکسان حتی اگر از کلاسهای اولیه متفاوت باشند جلوگیری میکند. POIها در سناریوی 2 مستعد عدم تطابق زمانی هستند که طبقات اولیه اشیاء POI امکانات حمل و نقل یا تفریحات ورزشی باشند. در سناریوی 3، روش پیشنهادی دارای منطبقات نادرست و گمشده صفر است. این تأیید می کند که روش پیشنهادی با محدودیت های فضایی می تواند به طور قابل توجهی دقت تطبیق و یادآوری را افزایش دهد زیرا روابط توپولوژیکی فضایی را نیز در نظر می گیرد. در Dongying، POI در سناریوی 3 بیشتر در امتداد دو طرف جاده ها و در مناطق تجاری بزرگ قرار دارند.
4.4. اعتبار سنجی در سطح شهر
آزمایشها در کل شهر Dongying (با مساحت 7923 کیلومتر مربع ) بیشتر برای تأیید روش تطبیق POI پیشنهادی انجام میشود. در مجموع 138.376 و 80.167 POI به ترتیب از Gaode Map و Baidu Map گرفته شده است. با روش پیشنهادی، در مجموع 149.276 POI با 10.900 افزایش POI ترکیب و مطابقت داده می شود. علاوه بر این، فراخوانی POIهای منطبق در آزمایش در سطح شهر اساساً با دادههای آزمایشی یکسان است و نتایج تطبیق کاملاً الزامات کیفیت استانی را به دست آورد، که دوباره دقت، استحکام و تطبیق پذیری روش پیشنهادی را نشان میدهد.
5. نتیجه گیری و بحث
تطبیق POI یک پیش نیاز و بخش کلیدی ادغام و به روز رسانی POI با استفاده از منابع مختلف نقشه است. دقت تطبیق POI برای بهبود و استانداردسازی پایگاه های داده POI مهم است. با این حال، تحقیقات موجود در مورد تطبیق POI معمولاً محدودیتهای ضعیفی را اتخاذ میکند که منجر به دقت تطبیق POI پایین میشود. بنابراین، این مقاله یک روش تطبیق POI را پیشنهاد میکند که توپولوژی فضایی و کلاس پایین به بالا و محدودیتهای نقش دقیق نام و محدودیتهای تعیین چندگانه را در نظر میگیرد. این به طور موثر ترکیب POI و دقت تطبیق دادههای Gaode Map و Baidu Map را افزایش میدهد. روش پیشنهادی با استفاده از دادههای POI واقعی در Dongying، استان شاندونگ تأیید میشود. نتایج اصلی به شرح زیر است:
(1) با توجه به دقت کلی، تعداد تطابقات POI نادرست و گمشده توسط روش پیشنهادی هر دو کوچکتر از روش موجود است. به طور خاص، تعداد مسابقات نادرست 76.7٪ کاهش می یابد. دقت تطبیق POI هر دو روش پیشنهادی و موجود تقریباً 96٪ است. با این حال، از نظر امتیاز فراخوان و F1، روش پیشنهادی به طور موثر مقادیر آنها را به ترتیب 7.1% و 0.3 افزایش میدهد، که به خوبی نشان میدهد که روش پیشنهادی به طور قابلتوجهی از روش موجود از نظر دقت تطبیق POI بهتر عمل میکند.
(2) از نظر برتری، در هیچ یک از سه سناریو در نظر گرفته شده با روش پیشنهادی، هیچ مسابقه نادرست و مفقودی وجود ندارد که نشان دهنده برتری آن است.
(3) در اعتبار سنجی در سطح شهر، فراخوانی اساساً با داده های تجربی مشابه است و نتایج تطبیق کاملاً الزامات کیفیت استانی را به دست آورد. این به شدت از استحکام و تطبیق پذیری روش پیشنهادی حمایت می کند.
روش پیشنهادی در درجه اول به صورت تجربی با استفاده از دادههای Baidu Map و Gaode Map تأیید میشود، که برای تطبیق POI از منابع داده دیگر نیز قابل استفاده است، اما این نتایج تطبیق نیاز به تأیید بیشتری دارد. در تحقیقات آتی، توجه بیشتری به تکمیل متقابل و کالیبراسیون اطلاعات POI از منابع داده های متعدد داده خواهد شد.








بدون دیدگاه