

خلاصه
کلید واژه ها:
شاخص مکانی-زمانی سلسله مراتبی ; شبکه های P2P ؛ کدگذاری مشترک اطلاعات مکانی – زمانی ; دانه بندی مکانی-زمانی ; تعیین سطح شاخص بهینه
1. معرفی
-
مطالعات بر بهبود یا گسترش شاخص فضایی سنتی (QuadTree، R-Tree، Grid index، و غیره) برای محیط های توزیع شده متمرکز شده است [ 7 ، 8 ، 9 ، 10 ]. به عنوان مثال، به عنوان یک چارچوب MapReduce توسعه یافته، SpatialHadoop یک الگوریتم نمایه سازی کلی عمومی ارائه می دهد که برای پیاده سازی پارتیشن بندی درختی Grid، R-tree، R+-tree، Quad-tree و k- بعدی (KD) استفاده شد [ 11 ].]. Hadoop فضایی-زمانی (ST) که یک توسعه جامع برای Hadoop و SpatialHadoop است، از مزایای استفاده از تکنیکهای بارگذاری انبوه فضایی فوق الذکر که قبلاً در SpatialHadoop پیادهسازی شدهاند، بهره میبرد و دادهها را به صورت مکانی-زمانی بارگذاری و بین گرههای محاسباتی تقسیم میکند که منجر به دستیابی به سفارش میشود. عملکرد بهتری نسبت به Hadoop و SpatialHadoop [ 4 ] دارد. GeoSpark همچنین شبکه یکنواخت، R-tree، Quad-Tree و KDB-Tree (ترکیبی از KD-tree و B-tree) الگوریتم نمایه سازی داده های فضایی را ارائه می دهد و شاخص های مکانی محلی را روی هر پارتیشن داده Spark ایجاد می کند تا سرعت محلی را افزایش دهد. محاسبه [ 12]. چنین ساختار شاخصی همیشه به زمان ساخت طولانی، هزینه بهروزرسانی بالا نیاز دارد و حفظ ثبات شاخص دشوار است، بنابراین برای دادههای مکانی-زمانی که اغلب در محیطهای توزیعشده بهروزرسانی میشوند، مناسب نیست.
-
مطالعات بر ایجاد یک شاخص بر اساس منحنی های پرکننده فضا (SFCs؛ Z-Order، Hilbert، Google S2 و غیره) متمرکز بود. فاکس و همکاران [ 13 ] یک ساختار شاخص مکانی-زمانی پیشنهاد کرد که از یک رشته GeoHash برای شناسایی اطلاعات مکانی استفاده میکند و رشته ویژگی زمان را برای تشکیل مقدار کلید شاخص به هم میپیوندد. لی و همکاران [ 14 ] یک روش شاخص فضایی با ترکیب R-Tree و Geohash پیشنهاد کرد. گوگل یک شاخص فضایی به نام S2 را با ترکیب یک چهار درخت و منحنی هیلبرت پیادهسازی کرد که امکان بیان عناصر فضایی چند سطحی را فراهم کرد [ 15 ، 16 ]. GeoMesa [ 17 ]، یک پروژه منبع باز محبوب، شامل پیادهسازی یک روش نمایهسازی مکانی-زمانی با ترتیب Z توسعه یافته (XZ-ordering) بر اساس Z-order [18 ]. در این رویکرد، مرتبسازی XZ برای بیان اطلاعات مکانی با وضوح دلخواه مورد استفاده قرار میگیرد و عملکرد پرس و جو با افزایش وضوح بدتر نمیشود [ 19 ، 20 ]. علاوه بر این، Eldawy و همکاران. [ 21 ] شاخص فضایی سنتی را با معرفی تکنیکهای تقسیمبندی منحنی Z و منحنی هیلبرت در SpatialHadoop گسترش میدهد. استراتژی مبتنی بر SFC میتواند ویژگیهای پیوستگی مکانی دادههای مکانی-زمانی را به دلیل ویژگیهای تراکم مکانی آن بهتر توصیف کند [ 22 ، 23]. از این رو، این رویکرد در سالهای اخیر بهطور گسترده در مطالعات شاخصهای مکانی-زمانی مورد استفاده قرار گرفته است. با این حال، در تحقیقات مبتنی بر شاخص SFC موجود، ویژگیهای مکانی و زمانی به طور کلی از هم جدا شدهاند، که در نظر گرفتن کارایی پرسوجوهای زمانی و مکانی به طور همزمان دشوار است. علاوه بر این، برای عناصر خط و چند ضلعی با محدودههای جغرافیایی مختلف، کارایی و دقت پرسوجوها ارتباط نزدیکی با سطح شاخص مورد استفاده دارد و ابزاری برای دستیابی به یک بیان مکانی-زمانی منطقی و تعیین سطح شاخص عملی هنوز شناسایی نشده است. .
2. کارهای مرتبط
2.1. شاخص فضایی-زمانی XZ3
- (1)
-
این الگوریتم از یک منحنی Z-order به عنوان SFC استفاده می کند که هنگام بیان فضای دو بعدی مشکل پرش دارد. در نتیجه، دادههای بیانشده توسط کدگذاری مجاورت از نظر مکانی مجاور نیستند و منجر به تعداد زیادی پرسوجوی بیاثر در هنگام جستجو در مناطق پرش میشوند.
- (2)
-
هنگام تقسیم سلسله مراتب فضایی، الگوریتم XZ3 با قضاوت در مورد اینکه آیا تعداد سلول های تقسیم شده در یک سلسله مراتب با آستانه خاصی مطابقت دارد یا خیر، تصمیم می گیرد که آیا بیشتر تقسیم شود یا خیر. با این حال، تنظیم آستانه به طور کامل توزیع فضایی و چگالی همه عناصر در یک لایه را در نظر نمی گیرد.
2.2. شاخص فضایی S2
- مرحله 1
-
مکعبی را با شعاع 1، [-1،1] × [-1،1] × [-1،1] و مرکز زمین به عنوان مبدأ احاطه کرده است. برای یک نقطه یا منطقه معینی از زمین، مختصات طول و عرض جغرافیایی نقطه p در مستطیل حداقل مرزی (MBR) اطراف نقطه یا ناحیه را به مختصات سه بعدی یک مکعب تبدیل کنید، p = ( lat , lng ) => ( x ، y ، z ).
- گام 2
-
نقطه p را بر روی سطح خاصی از مکعب با پیروی از جهت شعاعی، ( x , y , z ) => ( face , u , v ) قرار دهید، جایی که وجه نشان دهنده تعداد سطح مکعب است، وجه = {0، 1، 2، 3، 4، 5}، u و v مختصات طرح ریزی هر سطح را نشان می دهند. سپس مختصات پیش بینی شده u و v را تا بازه [0، 1] نرمال کنید.
- مرحله 3
-
u و v نرمال شده گسسته به ترتیب به i و j ، ( face , u , v ) => ( face , i , j ) که i , j ∈ [0, 2 n − 1] نشان دهنده حداکثر بیت موثر درخت چهارگانه است. سلول، و n ∈ [0, 30] نشان دهنده عمق چهار درخت است که یک سری سلسله مراتبی است.
- مرحله 4
-
سلول چهاردرختی شناسایی شده با صورت ، i و j را به منحنی هیلبرت با یک سطح معین نگاشت، و شناسه سلول مربوطه را محاسبه کنید، ( face , i , j ) => CellId , جایی که CellId یک عدد صحیح 64 بیتی است و می تواند به طور منحصر به فرد نشان دهنده یک نقطه یا منطقه است.
- (1)
-
با توجه به بیان مشترک اطلاعات مکانی-زمانی، S2 فقط اطلاعات مکانی را بیان می کند. برای عناصر هندسی فضایی با سری های زمانی متعدد، ابزار موثری برای ترکیب اطلاعات زمانی و مکانی هنوز مشخص نشده است.
- (2)
-
بیان عناصر غیر نقطه ای. برای عناصر خط و چند ضلعی، مقیاس فضایی بسیار متفاوت است، و برای جستارهای عناصر جغرافیایی، گستره فضایی و حالت پرس و جو فضایی هر دو تصادفی هستند. در نظر گرفتن پرس و جوهای دقیق و سریع در محدوده کوچک و عملیات اسکن در مقیاس بزرگ ضروری است. یک روش معقول از عبارات مکانی-زمانی محدودیت دوم است.
- (3)
-
تعیین دانه بندی زمانی و سلسله مراتب بهینه. در تحقیق بر روی شاخص فضایی سنتی شامل شبکه منظم، شبکه مبتنی بر چهاردرخت و شبکه مبتنی بر درخت R، بلوسی و همکاران. [ 28 ] اشاره کرد که کارایی و دقت پرسوجوها با ویژگی توزیع دادههای مکانی-زمانی مرتبط است. بنابراین، فقدان ابزار معقول برای دستیابی به بیان مکانی-زمانی و تعیین سطح شاخص عملی با توجه به ویژگیهای مکانی و زمانی عناصر برای شاخص مبتنی بر SFC سومین محدودیت است.
3. روش شناسی
3.1. کدگذاری مشترک اطلاعات مکانی- زمانی
3.1.1. کدگذاری اطلاعات زمان
3.1.2. کدگذاری اطلاعات مکانی
3.1.3. کدگذاری اطلاعات شناسایی ویژگی
3.1.4. سازماندهی کدگذاری کلید ردیف
3.2. بیان عناصر مکانی-زمانی
3.2.1. بیان مکانی-زمانی عناصر نقطه ای
3.2.2. بیان مکانی-زمانی عناصر غیر نقطه ای
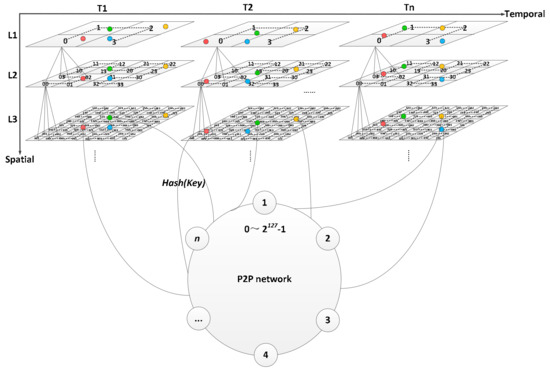
3.3. الگوریتم ساخت شاخص فضایی-زمانی در شبکه همتا به همتا (P2P)
3.3.1. تعیین دانه بندی زمانی
با در نظر گرفتن پایگاه داده Cassandra به عنوان مثال، زمانی که یک پارتیشن از این پایگاه داده بیش از 100 مگابایت باشد، یک پارتیشن بزرگ ایجاد می شود که باعث فشار نسبتاً بزرگ جمع آوری زباله بر روی Cassandra در هنگام فشرده سازی و گسترش خوشه می شود و باعث کاهش عملکرد پایگاه داده می شود. بنابراین، این ویژگی می تواند به عنوان یک محدودیت برای محاسبه دانه بندی زمانی استفاده شود. فاصله نمونه برداری را I (ms)، تعداد حسگرها را N (عدد)، و فضای مورد نیاز برای ذخیره یک رکورد را به صورت S (MB) تعریف کنید. مقدار T (ms) که با معادله زیر محاسبه می شود، می تواند برای تعیین دانه بندی زمان بهینه استفاده شود:
3.3.2. تعیین سلسله مراتب شبکه فضایی
تعریف 1.
تعریف 2.
زمان پرس و جو T k برای k -امین پرس و جو فضایی را می توان به عنوان مجموع زمان مصرف برای i -امین سلول پرس و جو بیان کرد ( تیEffکمن) و j- امین سلول پرس و جو بی اثر ( تیمنnهffکj). برای پایگاه داده NoSQL، زمان مورد نیاز برای پرس و جو از یک منطقه خاص از داده ها عمدتاً توسط مقدار داده تعیین می شود. بنابراین می توان آن را شبیه سازی کرد تیEffکمنو تیمنnهffکjبا تعداد عناصر سلول و زمان مورد نیاز برای پرس و جو هر عنصر تعیین می شود، Eکمنو Eکj، و ΔتیEffکمنو Δتیمنnهffکjزمان مصرف مربوطه را نشان می دهد. سپس، فرض کنید که زمان یکسانی برای پرس و جو از یک عنصر در همان سطح l که به صورت Δ T l بیان می شود، طول می کشد . بنابراین، زمان پرس و جو را می توان به صورت زیر ساده کرد:
تیک=∑من=1مترتیEffکمن+∑j=1nتیمنnهffکj≈∑من=1مترEکمنΔتیEffکمن+∑j=1nEکjΔتیمنnهffکj≈(∑من=1مترEکمن+∑j=1nEکj)Δتیل
که در آن m و n تعداد سلول های پرس و جو موثر و سلول های پرس و جو غیر موثر هستند.
کل زمان مورد نیاز برای به حداقل رساندن k- امین پرس و جو را می توان به صورت زیر بیان کرد:
دقیقه∑ک=1کتیک≈دقیقه∑ک=1ک(∑من=1مترEکمن+∑j=1nEکj)Δتیل
مجموعه سلسله مراتبی اتخاذ شده L i ( L i ∈ L , 1 ≤ l ≤ thresh ) را فرض کنید که تعداد عناصر در هر سلول در L i برابر است و زمان پرس و جو دارای همبستگی خطی با تعداد عناصر موجود در سلول. سپس معادله (3) را می توان به صورت زیر بیان کرد:
دقیقه∑ک=1کتیک≈دقیقه∑ک=1ک∑ل∈LنکلΔEل·Δتیل≈دقیقهΔE¯·Δتی¯·∑ک=1ک∑ل∈Lنکل≈دقیقهλ·اسن1·Δتی¯·∑ک=1ک∑ل∈Lنکل
که در آن N l k تعداد سلول های سطح l را در پرس و جوی k و Δ E l نشان دهنده تعداد عناصر در هر سلول است. ΔE¯و Δتی¯میانگین تعداد عناصر سلول در مجموعه L و میانگین زمان پرس و جو از یک عنصر را به ترتیب نشان می دهد. این مقادیر به صورت خطی با تعداد سلول های سطح 1، N 1 مرتبط هستند و λ یک ضریب همبستگی خطی است، که در آن،
ن1+2·تیساعتrهسساعت≤∑ل∈Lنکل≤4تیساعتrهسساعت·ن1
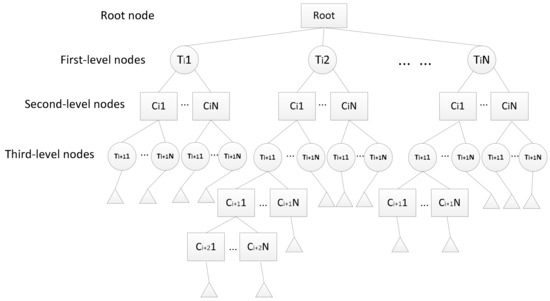
3.3.3. درخت شاخص فضایی-زمانی چند سطحی
- مرحله 1
-
دانه بندی زمانی پارتیشن T ( g i ) مورد استفاده در کلید پارتیشن را تعیین کنید و یک گره سطح اول بسازید، همانطور که با Ti در شکل 9 نشان داده شده است.
- گام 2
-
با توجه به ایده شاخص S2، MBR یک محدوده مکانی خاص را به صورت Rect تعریف کنید و مختصات چهار گوشه عرض و طول جغرافیایی آن ( Rect k , k = 0, 1, 2, 3) را به مختصات سه بعدی تبدیل کنید. محدوده فضایی مستطیلی Rect به عنوان گره ریشه درخت شاخص استفاده می شود.
- مرحله 3
-
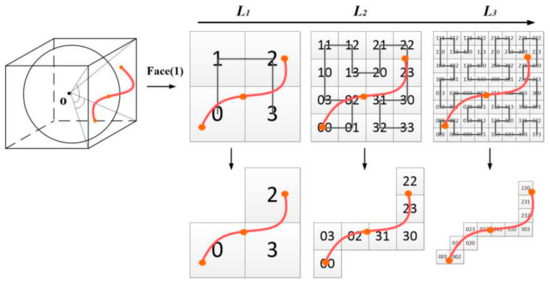
مختصات چهار گوشه پیش بینی شده را به سطوح مختلف n , n ∈ [0, 30] تقسیم کنید. محدوده مقدار n توسط محدوده فضایی سلول در هر سطح از شاخص S2 تعیین می شود، همانطور که در جدول 2 نشان داده شده است [ 15 ]، حداقل مساحتی که یک شبکه می تواند در سطح 30 توصیف کند 0.43 سانتی متر مربع است که به معنای هر سانتی متر است. 2 را می توان با استفاده از یک عدد صحیح 64 بیتی نشان داد و این برای سناریوهای رایج مدیریت داده های مکانی به اندازه کافی خوب است [ 30 ، 31 ]. با شروع از سطح n = 0، منطقه فعلی ( صورت ، i k، j k ) را می توان با سلول های m پوشش داد ، اگر m > آستانه ( N 1 )، سطح فعلی سطح مورد نظر است و به عنوان گره سطح دوم C i استفاده می شود.
- مرحله 4
-
اطلاعات دانه بندی زمانی را در کلید مرتب سازی، به عنوان مثال، مرتب سازی T ( g i )، به عنوان یک گره سطح سوم، همانطور که توسط T i +1 در شکل 9 نشان داده شده است، بسازید .
- مرحله 5
-
عناصر موجود در کل لایه را نمونه برداری کنید و تعداد عناصر موجود در سلول را بشمارید. اگر عدد بزرگتر از آستانه تقسیم آستانه باشد ، C i بیشتر تقسیم می شود. آستانه تقسیم آستانه یک مقدار تجربی است که ما از طریق تعداد زیادی آزمایش داده های واقعی به دست آوردیم. در این مقاله آن را 30 درصد از کل عناصر قرار می دهیم. متفاوت از تقسیم چهار درختی از چهار سلول، تنها سلول فرعی که تقسیم می شود این است که عنصر را به عنوان گره های درخت فرعی گره سطح سوم T i+ 1 می پوشاند.و حداکثر تعداد سلول های فرعی 4 است. سپس مرحله 5 برای سلول های فرعی تکرار می شود تا زمانی که تعداد عناصر از آستانه کمتر شود یا عمق درخت فرعی به آستانه عمق برسد Height thresh ( thresh ). سطح به عنوان زیرسطح تنظیم می شود و تقسیم متوقف می شود.
- مرحله 6
-
با نگاشت سلول های واحد چهاردرخت m- امین شناسایی شده توسط ( face , i k , j k ) به منحنی هیلبرت زیرسطح ، سلول S مجموعه ID سلول مربوطه محاسبه می شود. سلول S می تواند به طور منحصر به فرد ناحیه پرس و جو را نشان دهد، جایی که هر شناسه سلولی سلول S نشان دهنده زیر ناحیه یک پرس و جو است. تمام شناسه های سلولی در سلول S به عنوان گره های سطح استفاده می شوند و به عنوان رمزگذاری اطلاعات مکانی در کلید مرتب سازی عمل می کنند.
- مرحله 7
-
با توجه به گره های سطح اول و دوم، تابع Murmur Hash برای محاسبه محل پارتیشن مربوطه جایگزین می شود و مکان های گره سطح سوم و گره برگ درخت فرعی آن با توجه به شناسه سلول تعیین می شود.
3.3.4. به روز رسانی پویا و نگهداری از چند سطح کره 3 (MLS3)
-
عملیات درج: برای داده های جدید اضافه شده، ابتدا شناسه سلول محاسبه می شود. اگر اطلاعات زمان متعلق به درخت شاخص فعلی نباشد، یک گره سطح اول جدید و یک شاخه درخت شاخص جدید اضافه می شود. در غیر این صورت، گره سطح اول داده های جدید را با توجه به شناسه سلول تعیین کنید و سپس لایه به لایه زیر درخت را از گره سطح اول به گره برگ پیمایش کنید تا پیدا کنید که آیا گره حاوی داده های جدید وجود دارد یا خیر. اگر نه، داده های جدید را به عنوان یک گره برگ جدید وارد کنید. اگر وجود داشته باشد، گره دیگر نیازی به درج [ 4 ، 6 ] ندارد.
-
عملیات حذف: اگر گره حذف شده یک گره برگ باشد، می توان آن را مستقیماً حذف کرد. در غیر این صورت نمی توان آن را حذف کرد. اگر گره برگ حذف شده دارای همان گره باشد، عملیات حذف خاتمه می یابد و اگر گره دیگری در همان سطح گره برگ وجود نداشته باشد، گره والد حذف می شود. درخت فرعی را به نوبت طی کنید و مرحله بالا را تکرار کنید [ 4 ، 6 ].
-
عملیات تقسیم: اگر تعداد عناصر یک سلول از آستانه تقسیم آستانه بزرگتر باشد ، این سلول بیشتر تقسیم می شود. با تقسیم چهار درختی از چهار سلول، تنها سلول فرعی که عنصر را به عنوان گره های درخت فرعی گره سطح سوم T i +1 پوشش می دهد، تقسیم می شود و حداکثر تعداد سلول های فرعی 4 است. عملیات تقسیم برای سلول های فرعی تکرار می شود تا زمانی که تعداد عناصر کمتر از آستانه باشد یا عمق درخت فرعی به آستانه عمق برسد Height thresh ( thresh ).
4. نتایج و بحث
4.1. داده های تجربی و محیط
4.2. تایید عقلانیت تعیین سلسله مراتب
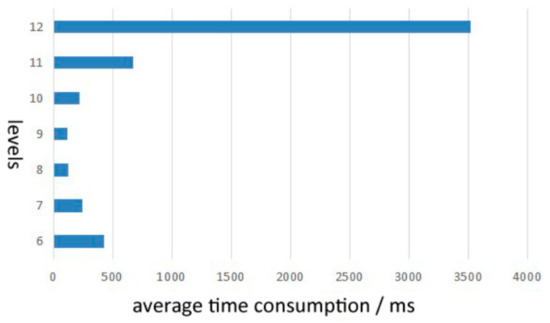
مقدار مرجع آستانه تعداد سلول ها در سطح اول به صورت زیر محاسبه می شود: برای محیط آزمایش در این مقاله، ما از یک CPU با 16 هسته استفاده کردیم که می تواند 16 رشته همزمان قابلیت محاسبات موازی را ارائه دهد. به طور کلی، زمان قابل قبول یک پاسخ پرس و جو در پایگاه داده کمتر از 5 ثانیه است [ 36 ، 37 ]. همانطور که در آزمایش در این مقاله می بینیم، برای پرس و جوهای مکانی-زمانی رایج ( جدول 3)، زمان پرس و جو از یک رشته حدود 400-500 میلی ثانیه است. از این رو، حد بالایی و پایینی زمان های پرس و جو در 5 ثانیه 5 ثانیه × 1000/400 میلی ثانیه × 16 ≈ 200 و 5 ثانیه × 1000/500 میلی ثانیه × 16 ≈ 160 است که به عنوان سطح بهینه آستانه شماره سلول در نظر گرفته می شود. کاغذ. علاوه بر این، با توجه به اینکه هر پرس و جوی مکانی-زمانی نیازی به عبور از تمام سلول ها ندارد، بنابراین مقدار آستانه در این مقاله روی 200 تنظیم شده است، و این مقدار نیز در مجموعه داده TDrive فوق الذکر پکن تأیید شده است، نتایج تجربی نشان می دهد که این مقدار موجود است. برای دادههای ورودی جدید، میتوانیم به سرعت سطح شاخص بهینه را با توجه به محدوده مکانی دادهها و مقدار تجربی 200 تعیین کنیم. با فرض اینکه منطقه فضایی S باشد، ناحیه MBR متناظر S MBR است.، میانگین مساحت سلول در هر سطح AS level(i) است، سپس حداقل مقدار تفاوت بین اسمبآر/200و آاسلهvهلمنمطابق فرمول زیر (6). سطح مربوط به حداقل مقدار به عنوان مناسب ترین سطح برای داده های جدید در نظر گرفته می شود.
مترمنn(اسمبآر200-آاسلهvهل1،اسمبآر200-آاسلهvهل2،…،اسمبآر200-آاسلهvهلمن،…،اسمبآر200-آاسلهvهل30)
4.3. مقایسه عملکرد شاخص
4.3.1. کارایی جستجوی شاخص
4.3.2. راندمان ساخت و ساز و نسبت مصرف فضا
5. نتیجه گیری ها
- (1)
-
برای تعیین سلسله مراتب بهینه، توزیع فضایی و چگالی کل لایه عناصر در نظر گرفته شد. مناسب ترین سطح برای لایه ملی 4-5، برای لایه استانی 7-8 و برای لایه شهرستان 9-10 است.
- (2)
-
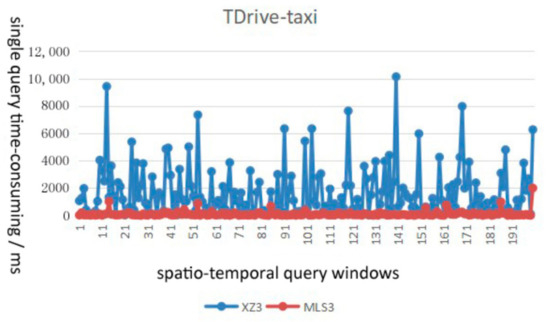
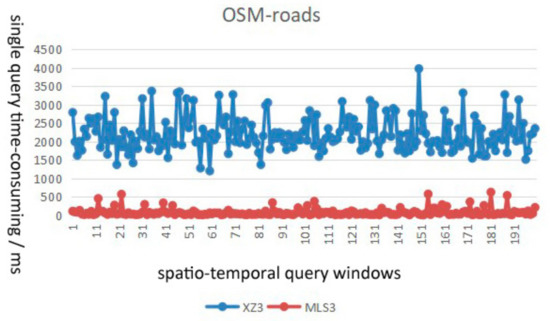
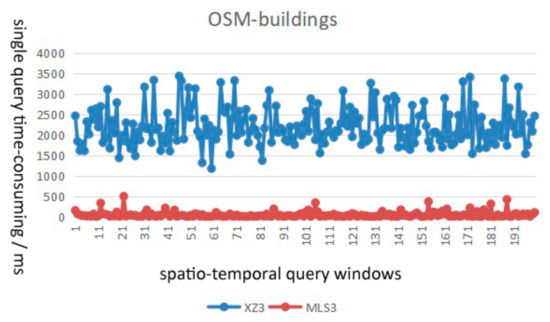
از نظر کارایی پرس و جو، میانگین زمان مصرف الگوریتم MLS3 پیشنهادی حدود 1/7-1/2 از الگوریتم XZ3 با پارامترهای یکسان است، و کارایی پرس و جو شاخص MLS3 را می توان با 4-7 بهبود داد. بارها پس از بهینه سازی پارامتر
- (3)
-
از نظر ثبات پرس و جو، شاخص MLS3 با منحنی پرکننده هیلبرت می تواند تداوم داده های مکانی-زمانی را بهتر از شاخص XZ3 با منحنی پرکننده مرتبه Z توصیف کند. شاخص MLS3 عملکرد پرس و جو با ثبات تری را نشان می دهد و برای مدیریت ذخیره سازی توزیع شده داده های عظیم چند مقیاسی مناسب تر است.
- (4)
-
از نظر نسبت مصرف فضا، روش ما بخشی از فضای ذخیره سازی را قربانی یک جستجوی کارآمد می کند. با این حال، فضای ذخیره سازی شاخص حدود 0.5٪ از کل فضای ذخیره سازی سخت افزاری را تشکیل می دهد که برای ذخیره سازی و مدیریت داده های بزرگ مکانی-زمانی قابل قبول است.
منابع
- کورنلی، اف. دامیانی، ای. دی ویمرکاتی، SDC; پارابوسچی، اس. سامراتی، ص. انتخاب سرویس های معتبر در یک شبکه P2P. در مجموعه مقالات یازدهمین کنفرانس بین المللی وب جهانی، هونولولو، HI، ایالات متحده آمریکا، 7-11 مه 2002; صص 376-386. [ Google Scholar ]
- کوستاکیس، وی. باونز، ام. نیاروس، V. پیکربندی مجدد شهری پس از ظهور زیرساخت های همتا به همتا: چهار سناریوی آینده با تأثیر بر شهرهای هوشمند. در شهرهای هوشمند به عنوان زیست بوم های دموکراتیک ; پالگریو مک میلان: لندن، بریتانیا، 2015; صص 116-124. [ Google Scholar ]
- سانتوس، جی. واترز، تی. Volckaert، B. De Turck, F. Fog computing: امکان مدیریت و هماهنگ سازی برنامه های کاربردی شهر هوشمند در شبکه های 5g. Entropy 2018 , 20 , 4. [ Google Scholar ] [ CrossRef ]
- اعرابی، ل. موکبل، MF; Musleh, M. St-hadoop: یک چارچوب کاهش نقشه برای داده های مکانی-زمانی. GeoInformatica 2018 ، 22 ، 785-813. [ Google Scholar ] [ CrossRef ]
- شن، دی. یو، جی. وانگ، ایکس. نی، تی. Kou, Y. بررسی در NoSQL برای مدیریت داده های بزرگ. جی. سافتو. 2013 ، 24 ، 1786-1803. (به زبان چینی) [ Google Scholar ] [ CrossRef ]
- جان، ا. سوگوماران، م. تکنیک های راجش، RS نمایه سازی و پردازش پرس و جو در داده های مکانی-زمانی. ICTACT J. Soft Comput. 2016 ، 6 . [ Google Scholar ] [ CrossRef ]
- آگیلرا، MK; گلاب، دبلیو. شاه، MA یک درخت B توزیع شده مقیاس پذیر عملی. در مجموعه مقالات VLDB. مورگان کافمن، اوکلند، نیوزلند، 24 تا 30 اوت 2008. [ Google Scholar ]
- کری، ا. سان، ز. هریستیدیس، وی. Rishe, N. تجربیات در پردازش داده های مکانی با MapReduce. در مجموعه مقالات مدیریت پایگاه داده های علمی و آماری، کنفرانس بین المللی (SSDBM 2009)، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 2-4 ژوئن 2009. صص 302-319. [ Google Scholar ]
- موزا، سی. لیتوین، دبلیو. Rigaux، P. نمایه سازی در مقیاس بزرگ داده های مکانی در مخازن توزیع شده: SD-Rtree. VLDB J. 2009 ، 18 ، 933-958. [ Google Scholar ] [ CrossRef ]
- وو، اس. جیانگ، DW; Ooi، BC; Wu، KL شاخصسازی مبتنی بر درخت B کارآمد برای پردازش دادههای ابری. Proc. VLDB Enddow. 2010 ، 3 ، 1207-1218. [ Google Scholar ] [ CrossRef ]
- الدوی، ا. Mokbel، MF Spatialhadoop: یک چارچوب کاهش نقشه برای داده های مکانی. در مجموعه مقالات سی و یکمین کنفرانس بین المللی IEEE 2015 در زمینه مهندسی داده، سئول، کره، 13 تا 17 آوریل 2015؛ صص 1352–1363. [ Google Scholar ]
- یو، جی. ژانگ، ز. Sarwat، M. مدیریت داده های فضایی در اسپارک آپاچی: چشم انداز geospark و فراتر از آن. Geoinformatica 2019 ، 23 ، 37–78. [ Google Scholar ] [ CrossRef ]
- فاکس، ا. آیکلبرگر، سی. هیوز، جی. لیون، S. نمایه سازی مکانی-زمانی در پایگاه های داده توزیع شده غیر رابطه ای. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد داده های بزرگ، سیلیکون ولی، CA، ایالات متحده آمریکا، 6-9 اکتبر 2013. ص 291-299. [ Google Scholar ]
- Le، HV; آتسوهیرو، تی. یک شاخص توزیع شده کارآمد برای پایگاههای اطلاعاتی جغرافیایی. در پایگاه داده و برنامه های کاربردی سیستم های خبره ; Springer: Cham, Switzerland, 2015; ص 28-42. [ Google Scholar ]
- شرکت گوگل کتابخانه هندسه S2. 2015. در دسترس آنلاین: https://s2geometry.io/ (در 6 آوریل 2019 قابل دسترسی است).
- Procopiuc، O. هندسه در کره: کتابخانه S2 Google. 2011. در دسترس آنلاین: https://docs.google.com/presentation/d/1Hl4KapfAENAOf4gv-pSngKwvS_jwNVHRPZTTDzXXn6Q/view#slide=id.i22 (در 7 آوریل 2019 قابل دسترسی است).
- هیوز، JN; پیوست، الف. Eichelberger، CN; فاکس، ا. هالبرت، ا. Ronquest، M. GeoMesa: A Distributed Architecture for Spatio-Temporal Fusion. در انفورماتیک جغرافیایی، فیوژن، و تجزیه و تحلیل ویدئو حرکت V ; انجمن بین المللی اپتیک و فوتونیک: بالتیمور، MD، ایالات متحده آمریکا، 20 آوریل 2015. [ Google Scholar ]
- بوکسم، سی. کلمپ، جی. کریگل، HP XZ-Ordering: منحنی پرکننده فضا برای اشیاء با گسترش فضایی. در سمپوزیوم بین المللی پیشرفت در پایگاه داده های فضایی ; Springer: برلین، آلمان، 1999. [ Google Scholar ]
- ژانگ، آر. چی، جی. استرادلینگ، ام. Huang, J. به سمت یک شاخص بدون درد برای اشیاء فضایی. ACM Trans. سیستم پایگاه داده 2014 ، 39 ، 19. [ Google Scholar ] [ CrossRef ]
- فچر، آر. Whitby، MA بهینه سازی تجزیه و تحلیل مکانی-زمانی با استفاده از نمایه سازی چند بعدی با GeoWave. نرم افزار منبع باز رایگان. ژئوسپات. Conf. Proc. 2017 ، 17 ، 12. [ Google Scholar ]
- الدوی، ا. اعرابی، ل. Mokbel، MF تکنیک های پارتیشن بندی فضایی در SpatialHadoop. Proc. VLDB Enddow. 2015 ، 8 ، 1602-1605. [ Google Scholar ] [ CrossRef ]
- Eldawy، A. SpatialHadoop: به سمت پردازش فضایی انعطاف پذیر و مقیاس پذیر با استفاده از MapReduce. در مجموعه مقالات سمپوزیوم دکترای Sigmod، Snowbird، UT، ایالات متحده آمریکا، 22 ژوئن 2014; صص 46-50. [ Google Scholar ]
- ویتمن، RT; پارک، مگابایت؛ Ambrose، SM; Hoel، EG نمایه سازی فضایی و تجزیه و تحلیل در Hadoop. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، 4 تا 7 نوامبر 2014. صص 73-82. [ Google Scholar ]
- لاکشمن، ا. Malik, P. Cassandra: یک سیستم ذخیره سازی ساختار یافته در یک شبکه P2P. در مجموعه مقالات سمپوزیوم ACM در مورد موازی سازی در الگوریتم ها و معماری ها، کلگری، AB، کانادا، 10-12 اوت 2009. پ. 47. [ Google Scholar ]
- لاکشمن، ا. Malik, P. Cassandra: یک سیستم ذخیره سازی ساختاریافته غیرمتمرکز. ACM SIGOPS Oper. سیستم Rev. 2010 , 44 , 35-40. [ Google Scholar ] [ CrossRef ]
- Brahim, MB; دریرا، دبلیو. فیلالی، ف. حمدی، N. پسوند داده های فضایی برای پایگاه داده NoSQL Cassandra. J. Big Data 2016 ، 3 ، 1-16. [ Google Scholar ] [ CrossRef ]
- چبوتکو، ا. کشلو، ا. Lu, S. یک روش مدل سازی کلان داده برای آپاچی کاساندرا. در مجموعه مقالات کنگره بین المللی IEEE در مورد داده های بزرگ، نیویورک، نیویورک، ایالات متحده آمریکا، 27 ژوئن تا 2 ژوئیه 2015. صص 238-245. [ Google Scholar ]
- بلوسی، ا. میگلیورینی، اس. Eldawy، A. تشخیص چولگی داده های فضایی بزرگ در SpatialHadoop. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 6-9 نوامبر 2018؛ صص 432-435. [ Google Scholar ]
- گونزالس، آر. مونوز، ا. هرناندز، جی. Cuevas, R. در مورد فرآیند ورود توییت در توییتر: تجزیه و تحلیل و برنامه های کاربردی. ترانس. ظهور. مخابرات تکنولوژی 2014 ، 25 ، 273-282. [ Google Scholar ] [ CrossRef ]
- شاو، بی. شی، جی. سینها، س. Hogue, A. یادگیری رتبه بندی برای جستجوی مکانی و زمانی. در مجموعه مقالات ششمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، رم، ایتالیا، 4 تا 8 فوریه 2013. صص 717-726. [ Google Scholar ]
- ویاند، تی. کوستریکوف، آی. فیلبین، جی. پلانت – موقعیت جغرافیایی عکس با شبکه های عصبی کانولوشن. در کنفرانس اروپایی بینایی کامپیوتر ; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds. Springer: Cham، Switzerland، 2016. [ Google Scholar ]
- یوان، جی. ژنگ، ی. ژانگ، سی. زی، دبلیو. Xie، X. سان، جی. Huang, Y. Tdrive: مسیرهای رانندگی بر اساس مسیرهای تاکسی. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در زمینه پیشرفت در سیستم های اطلاعات جغرافیایی، GIS’10، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010. صص 99-108. [ Google Scholar ]
- یوان، جی. ژنگ، ی. Xie، X. Sun, G. رانندگی با دانش از دنیای فیزیکی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، KDD’11، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 21 تا 24 اوت 2011. صص 316-324. [ Google Scholar ]
- کوران، ک. فیشر، جی. Crumlish، J. OpenStreetMap. بین المللی J. تعامل. اشتراک. سیستم تکنولوژی 2012 ، 2 ، 69-78. [ Google Scholar ] [ CrossRef ]
- هاکلی، م. Weber, P. OpenStreetMap: نقشه های خیابانی تولید شده توسط کاربر. محاسبات فراگیر IEEE 2008 ، 7 ، 12-18. [ Google Scholar ] [ CrossRef ]
- شائو، جی. لیو، ایکس. لی، ی. Liu, J. بهینه سازی عملکرد پایگاه داده برای SQL Server بر اساس مدل شبکه صف سلسله مراتبی. بین المللی J. Database Theory Appl. 2015 ، 8 ، 187-196. [ Google Scholar ] [ CrossRef ]
- کائو، ی. ریتز، سی. رعد، ر. چقدر دیگر باید برود؟ تأثیر زمان انتظار و شاخصهای پیشرفت بر کیفیت تجربه جستجوی بصری موبایل که در رسانههای چاپی اعمال میشود. در مجموعه مقالات پنجمین کارگاه بین المللی 2013 در مورد کیفیت تجربه چند رسانه ای (QoMEX)، کلاگنفورت آم وورترزی، اتریش، 3 تا 5 ژوئیه 2013. صص 112-117. [ Google Scholar ]










بدون دیدگاه