

خلاصه
کلید واژه ها:
پیش بینی مکان داخلی تشابه توالی ; خوشه بندی کاربران مشابه مسیر حرکت داخل ساختمان
1. معرفی
- (1)
-
یک روش شباهت مکانی- معنایی جدید (SSS) تعریف شده است. این اطلاعات مکانی و معنایی را برای محاسبه شباهت بین دنباله های مکان و یافتن گروه های شباهت کاربران داخلی ترکیب می کند.
- (2)
-
حافظه کوتاه مدت بلند مدت (LSTM) برای مدل سازی هر گروه از کاربران به منظور بهبود دقت پیش بینی مکان داخلی استفاده می شود.
- (3)
-
عملکرد Indoor-WhereNext با استفاده از مسیرهای داخلی واقعی ارزیابی می شود. نتایج نشاندهنده مزایای رویکرد ما در مقایسه با خطوط پایه است.
2. کارهای مرتبط
3. روش شناسی
3.1. روش تشخیص توالی مکان
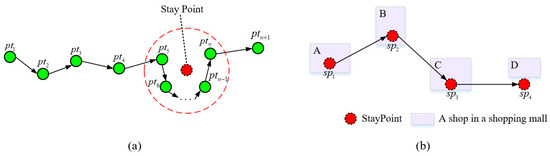
3.1.1. تشخیص نقطه ماندن
| الگوریتم 1. الگوریتم تشخیص نقطه اقامت در مسیر داخلی. |
| نیاز: مسیر فردی: تی�آ�={پتیمن}من=1� شعاع: �1 پنجره زمان: �2 آستانه تراکم همسایگی: ممن�پتیس اطمینان حاصل کنید: دنباله نقطه اقامت فردی: اسمند={سپمنمند} 1: تابع Indoor-STDBSCAN ( تی�آ�، �1، �2، ممن�پتیس) 2: جلتوستیه�مند=0; ستیآ�تی=0 3: برای پردازش نشده بعدی پتی∈تی�آ� انجام 4: اگر پتی.من�دهایکس<ستیآ�تی سپس 5: ادامه 6: ن=�هتینهمن�ساعتب��س (پتی، �1، �2) 7: اگر |ن|>ممن�پتیس سپس 8: پتی.پ��جهسسهد=تی�توه;پتی.جلتوستیه�مند=جلتوستیه�مند 9: اسههدس=[] 10: آدد تو�پ��جهسسهد پ∈ن تی� اسههدس 11: برای بعدی �∈اسههدس انجام 12: ن”=�هتینهمن�ساعتب��س(�، �1، �2) 13: �.پ��جهسسهد=تی�توه;�.جلتوستیه�مند=جلتوستیه�مند 14: اگر |ن”|>ممن�پتیس سپس 15: آدد تو�پ��جهسسهد پ∈ن” تی� اسههدس 16: ستیآ�تی=تی�آ�.�من�د(پ.جلتوستیه�مند==جلتوستیه�مند)[-1].من�دهایکس 17: جلتوستیه�مند=جلتوستیه�مند+1 18: برای بعدی من∈[0، 1، …، جلتوستیه�مند-1] انجام 19: پتیآ�� = تی�آ�.�من�د(پ.جلتوستیه�مند==من) 20: سپمند.آ��تی=پتیآ��[0].تی;سپمند.له�تی=پتیآ��[له�(پتیآ��)-1].تی 21: سپمند.ایکس،سپمند.� = ج�مترپتوتیهمهآ�سی���د (پتیآ��);سپمند.�=پتیآ��[0].� 22: اسمند.آدد (سپمند) 23: بازگشت اسمند |
3.1.2. تبدیل توالی مکان
3.2. روش محاسبه تشابه توالی مکان
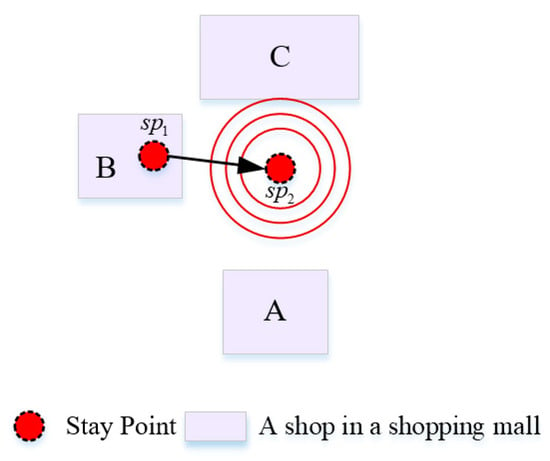
شباهت فضایی عمدتاً شباهت اطلاعات مکانی ضمنی در توالی مکان را محاسبه می کند و شباهت مسیر حرکت دو دنباله را در فضای جغرافیایی توصیف می کند. وقتی کاربران در یک فروشگاه می مانند، درجه خاصی از شباهت فضایی را نشان می دهند. هر چه تعداد مغازه ها بین توالی های مکان بیشتر باشد، شباهت فضایی بیشتر می شود. بنابراین، طولانی ترین زیر دنباله مشترک (LCSS) [ 46 ] برای محاسبه شباهت فضایی بین دنباله های مکان استفاده می شود. شباهت فضایی بین کاربر توو کاربر �مطابق با فرمول های (1) و (2) محاسبه می شود.
جایی که {سساعت�پمنتو}من=1�و {سساعت�پ��}�=1مترنشان دهنده توالی مکان کاربران است توو �، به ترتیب؛ �و مترنشان دهنده تعداد مغازه های بازدید شده توسط کاربران؛ مترآایکس(ایکس،�)تابعی برای به دست آوردن حداکثر مقادیر است ایکسو �; اسمسپآماتریس شباهت فضایی است. و اسمتو�سپآنشان دهنده شباهت فضایی بین کاربران است توو �.
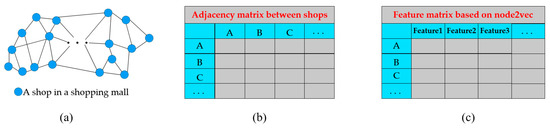
شباهت معنایی عمدتاً شباهت اطلاعات معنایی ضمنی در توالی مکان را محاسبه می کند و میزان شباهت بین دو کاربر را در علایق و رفتارها توصیف می کند. در این مقاله، اطلاعات معنایی یک ویژگی طبقهبندی مغازهها نیست، زیرا معتقدیم اطلاعات ویژگیهای آنها بهطور مصنوعی مشخص و ذهنی است. اطلاعات معنایی که به آن اشاره می کنیم یک پیام ضمنی است که از طریق رفتار کاربر بیان می شود. به طور کلی، کاربران بیشتر بین انواع مشابهی از فروشگاه ها (مصرف هدفمند) پرش می کنند، که نشان دهنده شباهت معنایی بین آن مغازه ها است. با توجه به این موضوع، توالی های مکان همه کاربران در یک شبکه وزن دار ساخته می شوند جی(�،�،دبلیو)، جایی که �نشان دهنده مجموعه فروشگاهی است، �نشان دهنده مجموعه انتقال بین مغازه ها و دبلیوزمان انتقال بین مغازه ها را نشان می دهد. با افزایش تعداد توالی های مکان، وزن بین مغازه ها می تواند شباهت بین آنها را منعکس کند. یعنی هر چه شباهت بیشتر باشد وزن آن بیشتر می شود. بر اساس این ویژگی ها، از روش node2vec [ 47 ] برای بردارسازی مغازه ها استفاده می شود. همانطور که در شکل 4 نشان داده شده است ، هنگامی که وزن بین مغازه ها بزرگتر است، فاصله بین بردارهای مربوطه مغازه ها کمتر است. پس از برداری توسط node2vec، هر فروشگاه به طور منحصربهفردی با یک بردار مطابقت دارد و شباهت معنایی بین دنبالههای مکان را میتوان توسط دنبالههای برداری مربوطه محاسبه کرد. در این کار، تاب خوردگی زمانی پویا (DTW) [ 48 ، 49 ، 50الگوریتم ] برای محاسبه شباهت معنایی بین دنباله های مکان استفاده می شود. شباهت معنایی بین کاربر توو کاربر �مطابق با فرمول های (3) و (4) محاسبه می شود.
جایی که {سساعت�پمنتو}من=1�و {سساعت�پ��}�=1مترنشان دهنده توالی مکان کاربران است توو �، به ترتیب؛ �و مترنشان دهنده تعداد مغازه های بازدید شده توسط کاربران؛ دمنستیبرای محاسبه فاصله اقلیدسی بین بردارهای مربوطه مغازه ها استفاده می شود سساعت�پ�توو سساعت�پمتر�; مترمن�(ایکس،�،�)تابعی برای به دست آوردن حداقل مقادیر است ایکس، �، و �; اسمسهمترماتریس تشابه معنایی است. و اسمتو�سهمترنشان دهنده شباهت معنایی بین کاربران توو �.
پس از محاسبه شباهت های معنایی و فضایی بین توالی ها، شباهت توالی مکان نهایی توسط دو بخش، همانطور که در فرمول (5) تعریف شده است، قرار می گیرد.
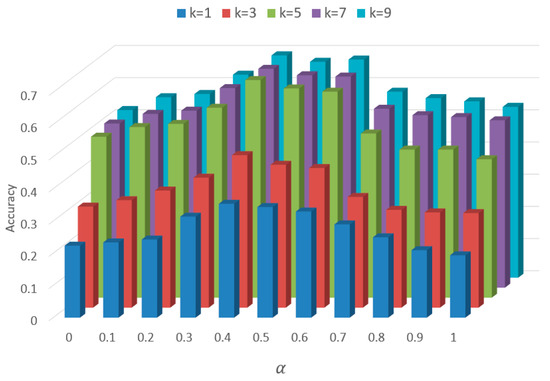
جایی که اسمسپآ, اسمسهمترو اساسمبه ترتیب ماتریس شباهت فضایی، ماتریس شباهت معنایی و ماتریس شباهت فضایی- معنایی را نشان می دهد. مترمن�(ایکس)و مترآایکس(ایکس)توابعی برای به دست آوردن حداقل و حداکثر مقادیر به ترتیب در ماتریس ایکس; و �یک ضریب وزنی است که سهم شباهت فضایی را در تشابه توالی مکان نشان می دهد. مقدار پیش فرض �0.5 است – یعنی سهم تشابه معنایی و شباهت مکانی به شباهت توالی مکان برابر است.
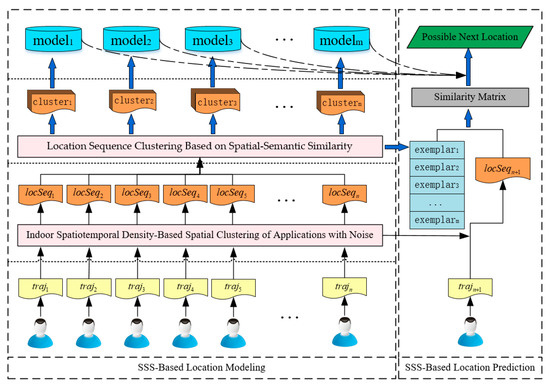
3.3. چارچوب پیشبینی موقعیت مکانی کاربر داخلی
3.3.1. مدلسازی مکان مبتنی بر SSS
| الگوریتم 2. فرآیند آموزش چارچوب Indoor-WhereNext. |
| نیاز: مسیرهای همه کاربران: تی�آ�آ��={تی�آ�من} فراپارامترهای Indoor-STDBSCAN: �1،�2،ممن�پتیس ضریب وزن: � اطمینان حاصل کنید: مدلهای پیشبینی: {متر�دهلمن} مراکز خوشه: {هایکسهمترپلآ�من} 1: برای بعدی تی�آ�∈تی�آ�آ�� انجام 2: {سپمنمند}=من�د���-استی�باسسیآن(تی�آ�،�1،�2،ممن�پتیس) 3: ل�جاسه�مند=سی���ه�سمن��({سپمنمند}) 4: ل�جاسه�آ��.آدد(ل�جاسه�مند) 5: اساسم=اساساس(ل�جاسه�آ��،�) 6: {ل�جاسه�استوبآ��من}،{هایکسهمترپلآ�من}=آ��من�منتی�پ��پآ�آتیمن��(اساسم) 7: برای ل�جاسه�استوبآ��∈{ل�جاسه�استوبآ��من} انجام 8: متر�دهل=�استیم(ل�جاسه�استوبآ��) 9: متر�دهلس.آدد(متر�دهل) 10: بازگشت متر�دهلس،{هایکسهمترپلآ�من} |
3.3.2. پیش بینی مکان مبتنی بر SSS
| الگوریتم 3. فرآیند پیش بینی چارچوب Indoor-WhereNext. |
| مورد نیاز: مسیر کاربر جدید: تی�آ�={پتیمن} فراپارامترهای Indoor-STDBSCAN: �1،�2،ممن�پتیس ضریب وزن: α مدل های پیش بینی: {متر�دهلمن} مراکز خوشه: {هایکسهمترپلآ�من} اطمینان حاصل کنید: اسهتی �� پ�هدمنجتیهد ل�جآتیمن��س 1: {سپمنمند}=من�د���-استی�باسسیآن (تی�آ�،�1،�2،ممن�پتیس) 2: ل�جاسه�مند=سی���ه�سمن�� ({سپمنمند}) 3: اساسم=اساساس(ل�جاسه�مند،{هایکسهمترپلآ�من}،�) 4: مندایکس=آ��مترآایکس(اساسم) 5: متر�دهل=متر�دهلس[مندایکس] 6: اسهتی �� پ�هدمنجتیهد ل�جآتیمن��س=متر�دهل (ل�جاسه�مند) 7: بازگشت اسهتی �� پ�هدمنجتیهد ل�جآتیمن��س |
4. نتایج تجربی و تجزیه و تحلیل
4.1. آماده سازی داده ها
4.1.1. منابع اطلاعات
4.1.2. پیش پردازش داده ها
- (1)
-
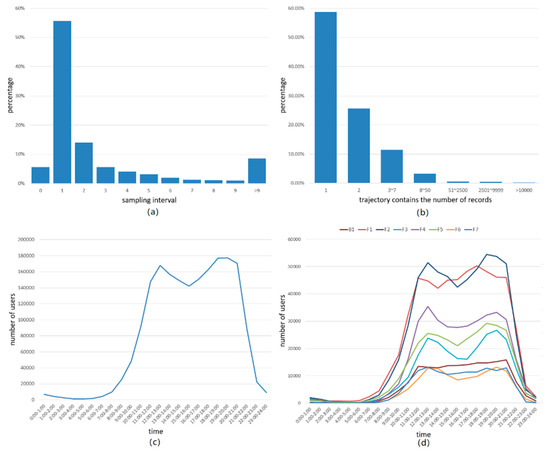
فاصله نمونه برداری برای نقاط مسیر عمدتاً بین 1 تا 5 ثانیه متمرکز بود که تقریباً 82.5٪ را شامل می شود، اما هنوز داده های غیرعادی با فواصل نمونه برداری زیاد و فواصل نمونه برداری 0 ثانیه وجود دارد. به عنوان مثال، نقاط مسیر با فواصل نمونه برداری 0 ثانیه حدود 7.3٪ را تشکیل می دهند.
- (2)
-
تعداد نقاط مسیر موجود در یک مسیر بین 1 تا 7 در اکثر مجموعه ها بود که بیش از 97٪ را شامل می شود. به عبارت دیگر، تعداد زیادی از مسیرها فقط حاوی چند نقطه مسیر بودند و نمی توانستند برای آموزش مدل از آنها استفاده کنند. در کار ما، مسیرهایی که تعداد نقاط مسیر کمتر از 50 بود حذف شدند.
- (3)
-
بازه زمانی نقاط مسیر ثبتشده در مرکز خرید 24 ساعت بود، یعنی رکوردهایی حتی در ساعات غیر اداری برای مرکز خرید ایجاد میشد و رکوردهای ایجاد شده در این فرآیند نامعتبر بود.
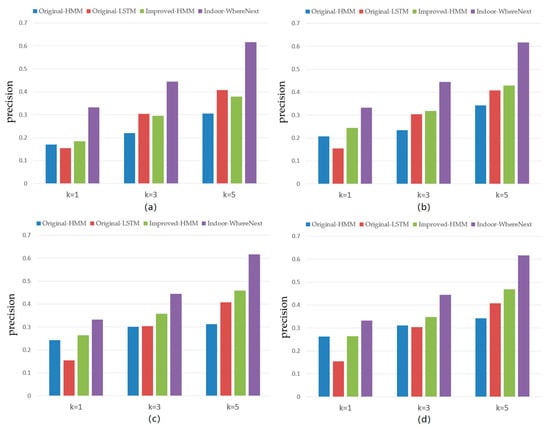
4.2. معیارهای ارزیابی
در این کار آججتو�آج�@کو پ�هجمنسمن��@ک (بالا ک مکان ها)به عنوان شاخص های کمی مدل ارزیابی استفاده شد. آججتو�آج�@کبرای ارزیابی مکانهای پیشبینی بالای k ، برای تعیین اینکه آیا مکانهای واقعی را نشان میدهند یا خیر، استفاده میشود. پ�هجمنسمن��@ایکساز میانگینگیری کلان برای ارزیابی عملکرد مدلها از منظر طبقهبندیهای متعدد استفاده میکند – یعنی مشکلات پیشبینی مکان داخلی. آججتو�آج�@کو پ�هجمنسمن��@کدر معادلات (6) و (7) تعریف شده است.
جایی که نتعداد کل مکان ها و تعداد مغازه ها را نشان می دهد. تیپمنتعداد نمونه هایی را نشان می دهد که در آنها مدل به درستی پیش بینی می کند که کاربر از مکان بازدید می کند سساعت�پمن; افنمنتعداد نمونه هایی را نشان می دهد که در آنها مدل به اشتباه پیش بینی می کند که کاربر از مکان بازدید نمی کند سساعت�پمن.
4.3. تخمین متغیر
4.3.1. کالیبره کردن پارامترهای Indoor-STDBSCAN
4.3.2. کالیبره کردن ضریب وزن
4.4. عملکرد Indoor-WhereNext
- (1)
-
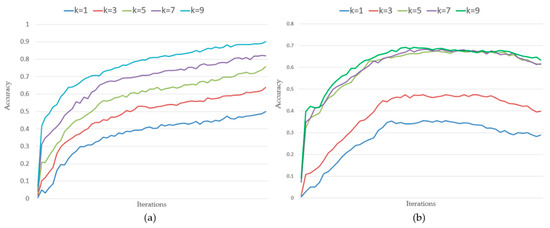
برای مجموعه داده آموزشی، دقت پیشبینی یک روند صعودی پیوسته با افزایش تعداد تکرارها نشان داد.
- (2)
-
برای مجموعه داده آزمایشی، دقت پیشبینی ابتدا افزایش یافت، سپس ثابت ماند و در نهایت با افزایش تعداد تکرارها کاهش یافت. با افزایش تعداد تکرارها، چارچوب تمایل بیشتری به تناسب داشت و دقت پیشبینی مدل را در مجموعه داده آموزشی بهبود بخشید و در عین حال دقت پیشبینی را در مجموعه داده آزمایش بدتر کرد.
- (3)
-
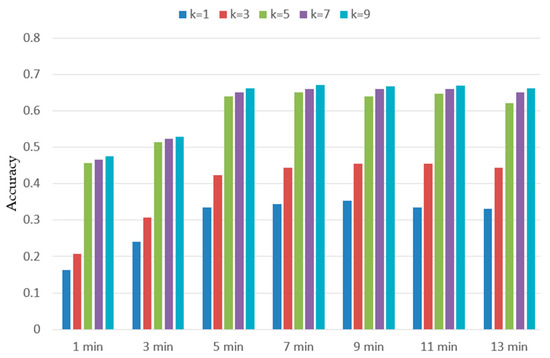
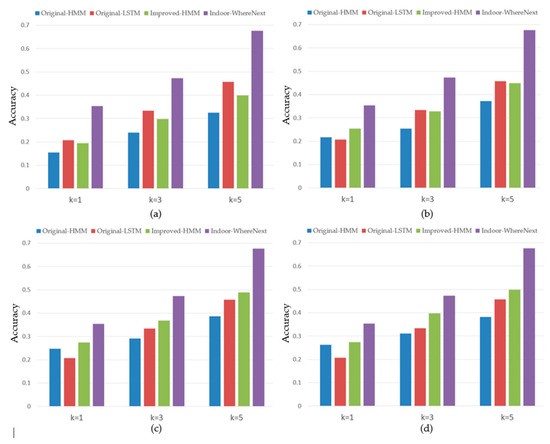
مقایسه آججتو�آج�@کدر مجموعه داده آزمایشی، زمانی که ک∈{1، 3، 5}دقت پیشبینی مدل بسیار بهبود یافته است. در آججتو�آج�@5دقت پیشبینی 67.6 درصد بود. در مقایسه با آججتو�آج�@1و آججتو�آج�@3دقت پیشبینی به ترتیب 32.5% و 22.1% افزایش یافت. با این حال، به عنوان کبا ادامه افزایش، دقت پیشبینی مدل به آرامی افزایش یافت. در مقایسه با آججتو�آج�@5, آججتو�آج�@7و آججتو�آج�@9تنها به ترتیب 0.9% و 1.5% افزایش یافته است، زیرا فروشگاهی که کاربر بعدی در مرکز خرید از آن بازدید می کند، اغلب مجموعه ای از مغازه ها است تا یک فروشگاه خاص. در مجموعه فروشگاه های پیش بینی شده، مقصد کاربر تصادفی خاصی دارد.
4.5. مقایسه با خطوط پایه
5. نتیجه گیری و کار آینده
منابع
- وانگ، Y.-S. لین، اس.-جی. لی، سی.-ر. Tseng، T. لی، H.-T. لی، جی.-ای. توسعه و اعتبارسنجی یک مدل موفقیت سیستم های باطله الکترونیکی محصول فیزیکی Inf. تکنولوژی مدیریت 2018 ، 19 ، 245-257. [ Google Scholar ] [ CrossRef ]
- حاجلی، ن. Featherman، MS تجارت اجتماعی و توسعه جدید در فناوری های تجارت الکترونیک. بین المللی J. Inf. مدیریت 2017 ، 37 ، 177-178. [ Google Scholar ] [ CrossRef ]
- لیو، ی. چنگ، دی. پی، تی. شو، اچ. Ge، X. ما، تی. دو، ی. او، ی. وانگ، ام. Xu, L. استنباط جنسیت و سن مشتریان در مراکز خرید از طریق داده های موقعیت یابی داخلی. محیط زیست طرح. مقعد شهری. علوم شهر 2019 . [ Google Scholar ] [ CrossRef ]
- ژانگ، اچ. وانگ، ز. چن، اس. Guo, C. توصیه محصول در جوامع آنلاین شبکه های اجتماعی: یک مطالعه تجربی از سوابق و یک واسطه. Inf. مدیریت 2018 , 56 . [ Google Scholar ] [ CrossRef ]
- Dixit، VS; گوپتا، اس. جین، پی. یک رویکرد ترکیبی قوی برای توصیههای محصول آنلاین شخصیشده. Appl. آرتیف. هوشمند 2018 ، 32 ، 785–801. [ Google Scholar ] [ CrossRef ]
- چان، NN; گالول، دبلیو. تاتا، اس. یک سیستم توصیهکننده بر اساس دادههای استفاده تاریخی برای کشف سرویس وب. خدمت محاسبات گرا Appl. 2012 ، 6 ، 51-63. [ Google Scholar ] [ CrossRef ]
- تومازیک، اس. دوزان، د. Škrjanc، I. محلی سازی فضای داخلی مبتنی بر مدل فازی-فاصله اطمینان. IEEE Trans. الکترون صنعتی 2018 ، 66 ، 2015–2024. [ Google Scholar ] [ CrossRef ]
- لی، اچ. لو، اچ. شو، ال. چن، جی. چن، ک. در جستجوی مناطق متراکم داخلی: رویکردی با استفاده از داده های موقعیت یابی داخلی. IEEE Trans. دانستن مهندسی داده 2018 ، 30 ، 1481-1495. [ Google Scholar ] [ CrossRef ]
- گوا، اس. شیونگ، اچ. ژنگ، ایکس. ژو، ی. شناسایی فعالیت و توصیف معنایی برای محلیسازی موبایل داخلی. Sensors 2017 , 17 , 649. [ Google Scholar ] [ CrossRef ]
- کوهلر، سی. بانوویچ، ن. اوکلی، آی. منکف، جی. Dey، AK Indoor-ALPS: یک سیستم پیشبینی مکان داخلی تطبیقی. در مجموعه مقالات کنفرانس مشترک بین المللی ACM 2014 در محاسبات فراگیر و همه جا حاضر، سیاتل، WA، ایالات متحده، 13-17 سپتامبر 2014. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2014; صص 171-181. [ Google Scholar ] [ CrossRef ]
- آهنگ، سی. Qu، Z. بلوم، ن. باراباسی، ع.-ال. محدودیت های قابل پیش بینی در تحرک انسان. Science 2010 ، 327 ، 1018-1021. [ Google Scholar ] [ CrossRef ]
- لو، ایکس. وتر، ای. بهارتی، ن. تاتم، ای جی. Bengtsson، L. نزدیک شدن به حد قابل پیش بینی در تحرک انسان. علمی Rep. 2013 , 3 , 2923. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- مینگ شیائو، ال. آهنگ، جی. فنگ، ال. Hengcai, Z. بازسازی مسیر حرکت انسان از داده های تلفن همراه با فرکانس پایین در مقیاس بزرگ. محاسبه کنید. محیط زیست سیستم شهری 2019 ، 77 ، 101346. [ Google Scholar ] [ CrossRef ]
- بله، م. یین، پی. لی، دبلیو.-سی. توصیه مکان برای شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2-5 نوامبر 2010. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2010; ص 458-461. [ Google Scholar ] [ CrossRef ]
- کوانگ، ال. یو، ال. هوانگ، ال. وانگ، ی. ما، پ. لی، سی. Zhu, Y. یک رویکرد پیش بینی QoS شخصی برای توصیه خدمات CPS بر اساس شهرت و فیلتر مشارکتی آگاه از مکان. Sensors 2018 , 18 , 1556. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بائو، جی. ژنگ، ی. Mokbel، MF توصیه مبتنی بر موقعیت و اولویت آگاه با استفاده از داده های شبکه های جغرافیایی-اجتماعی پراکنده. در GIS: مجموعه مقالات سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی . ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2012; ص 199-208. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. ژائو، ز. ژنگ، ی. لی، جی. پیشبینی مقاصد تاکسی با استفاده از روش جدید جاسازی دادهها و یادگیری گروهی. IEEE Trans. هوشمند ترانسپ سیستم 2019 ، 1–11. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. لی، ام. گونگ، ی.-جی. ژانگ، X.-L. Yin, J. T-DesP: پیش بینی مقصد بر اساس داده های مسیر بزرگ. IEEE Trans. هوشمند ترانسپ سیستم 2016 ، 17 ، 2344-2354. [ Google Scholar ] [ CrossRef ]
- بوگومولوف، آ. لپری، بی. استایانو، جی. الیور، ن. پیانسی، اف. Pentland، A. Once Upon a Crime: Towards Crime Prediction from Demographics and Mobile Data. در مجموعه مقالات شانزدهمین کنفرانس بین المللی تعامل چندوجهی، استانبول، ترکیه، 12 تا 16 نوامبر 2014. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- ژائو، ز. کوتسوپولوس، HN; ژائو، جی. پیشبینی تحرک فردی با استفاده از دادههای کارت هوشمند حملونقل. ترانسپ Res. قسمت ظهور. تکنولوژی 2018 ، 89 ، 19-34. [ Google Scholar ] [ CrossRef ]
- مونریال، آ. پینلی، اف. تراسارتی، ر. Giannotti، F. WhereNext: پیشبینیکننده مکان در استخراج الگوی مسیر. در مجموعه مقالات کنفرانس بین المللی Acm Sigkdd در مورد کشف دانش و داده کاوی، پاریس، فرانسه، 28 ژوئن تا 1 ژوئیه 2009. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2009; صص 637-646. [ Google Scholar ] [ CrossRef ]
- لی، اس. لیم، جی. پارک، جی. Kim, K. پیشبینی مکان بعدی براساس الگوی مکانی-زمانی استخراج گزارشهای دستگاه تلفن همراه. Sensors 2016 , 16 , 145. [ Google Scholar ] [ CrossRef ]
- یینگ، جی سی. لی، WC; Tseng، در مقابل الگوهای جغرافیایی-زمانی- معنایی معدن در مسیرها برای پیشبینی مکان. ACM Trans. هوشمند سیستم تکنولوژی 2014 ، 5 ، 1-33. [ Google Scholar ] [ CrossRef ]
- وو، آر. لو، جی. یانگ، کیو. شائو، جی. یادگیری ترجیحات حرکتی و تعامل اجتماعی برای پیشبینی مکان. دسترسی IEEE 2018 ، 6 ، 10675–10687. [ Google Scholar ] [ CrossRef ]
- Gambs، S. کیلیجیان، م.-او. del Prado Cortez، MN پیشبینی مکان بعدی با استفاده از زنجیره مارکوف تحرک. در مجموعه مقالات اولین کارگاه در مورد اندازه گیری، حریم خصوصی و تحرک، MPM’12، برن، سوئیس، 10 آوریل 2012. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2012. [ Google Scholar ] [ CrossRef ]
- هاولکا، بی. سیتکو، آی. کازاکوپولوس، پ. Beinat, E. پیشبینی جمعی ردپای تحرک فردی برای کاربران با تاریخچه دادههای کوتاه. PLoS ONE 2017 , 12 , e0170907. [ Google Scholar ] [ CrossRef ]
- Keles، TI; اوزر، م. توروسلو، آی. کاراگوز، ص. پیشبینی مکان کاربران تلفن همراه با استفاده از کاوش دنبالهای مبتنی بر پیشینه با پشتیبانی چندگانه. در یادداشت های سخنرانی در هوش مصنوعی (زیر مجموعه یادداشت های سخنرانی در علوم کامپیوتر) ; Springer: برلین/هایدلبرگ، آلمان، 2014; جلد 8983، صص 179–193. [ Google Scholar ] [ CrossRef ]
- Morzy, M. پیشبینی مکان شی متحرک بر اساس مسیرهای مکرر . Springer: برلین/هایدلبرگ، آلمان، 2006; صص 583-592. [ Google Scholar ] [ CrossRef ]
- متیو، دبلیو. راپوسو، آر. مارتینز، بی. پیشبینی مکانهای آینده با مدلهای پنهان مارکوف. در مجموعه مقالات کنفرانس UbiComp’12-2012 ACM در مورد محاسبات همه جا، پیتسبورگ، پنسیلوانیا، 5 تا 8 سپتامبر 2012. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2012; ص 911-918. [ Google Scholar ] [ CrossRef ]
- کیانگ، ال. شو، دبلیو. لیانگ، دبلیو. Tan, T. پیشبینی مکان بعدی: مدلی تکرارشونده با زمینههای مکانی و زمانی. در مجموعه مقالات سی امین کنفرانس AAAI در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; مطبوعات AAAI: پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، 2016؛ صص 194–200. [ Google Scholar ]
- دی، ی. چائو، ز. هوانگ، جی. Bi, J. SERM: مدلی تکرارشونده برای پیشبینی مکان بعدی در مسیرهای معنایی . ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2017؛ ص 2411-2414. [ Google Scholar ] [ CrossRef ]
- بله، ی. ژنگ، ی. چن، ی. فنگ، جی. Xie، X. الگوی زندگی فردی معدن بر اساس تاریخچه مکان. در مجموعه مقالات کنفرانس بین المللی IEEE در مدیریت داده های تلفن همراه، تایپه، تایوان، 18-21 مه 2009. صص 1-10. [ Google Scholar ]
- Vu، L. انجام، س. Nahrstedt، K. Jyotish: رویکرد سازنده برای پیشبینی زمینه حرکت افراد از ردیابی مشترک Wifi/Bluetooth. اوباش فراگیر. محاسبه کنید. 2011 ، 7 ، 690-704. [ Google Scholar ] [ CrossRef ]
- Vu، L. نگوین، پی. Nahrstedt، K. Richerzhagen, B. مشخص کردن و مدلسازی حرکت افراد از روی ردیابیهای حسگر تلفن همراه. اوباش فراگیر. محاسبه کنید. 2015 ، 17 ، 220-235. [ Google Scholar ] [ CrossRef ]
- انجام دهید، TMT; دوسه، او. میتینن، ام. Gatica-Perez, D. A Probabilistic Kernel Method for Human Mobility Prediction with Smartphones. محاسبات موبایلی فراگیر 2014 ، 20 ، 13-28. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وو، اف. فو، ک. وانگ، ی. شیائو، ز. فو، ایکس. الگوریتم شبکه عصبی مکانی-زمانی-معنای برای پیشبینی مکان روی اجسام متحرک. الگوریتمها 2017 ، 10 ، 37. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژو، ی. سان، اچ. هوانگ، جی. جیا، ایکس. ژائو، زی. پیشبینی کارآمد مقصد بر اساس انتخاب مسیر با بهینهسازی ماتریس انتقال. IEEE Trans. دانستن مهندسی داده 2018 , 14 . [ Google Scholar ] [ CrossRef ]
- Ang، B.-K. Dahlmeier، D. لین، ز. هوانگ، جی. سیتو، ام.-ال. Shi, H. پیشبینی موقعیت مکانی بعدی داخلی با Wi-Fi. در مجموعه مقالات چهارمین کنفرانس بین المللی پردازش اطلاعات دیجیتال و ارتباطات، کوالالامپور، مالزی، 18 تا 20 مارس 2014. [ Google Scholar ]
- سپهکار، م. خیام باشی، MR رویکرد مشترک جدید برای پیش بینی مکان در شبکه های تلفن همراه. سیم. شبکه 2018 ، 24 ، 283-294. [ Google Scholar ] [ CrossRef ]
- ژانگ، دی. ژانگ، دی. شیونگ، اچ. یانگ، LT; Gauthier, V. NextCell: پیشبینی موقعیت مکانی با استفاده از تعامل اجتماعی از ردیابی تلفن همراه. IEEE Trans. محاسبه کنید. 2015 ، 64 ، 452-463. [ Google Scholar ] [ CrossRef ]
- ون، ال. شی-زیونگ، ایکس. فنگ، ال. Lei, Z. بهبود پیشبینی مکان با کاوش پیوندهای مکانی-زمانی-اجتماعی. ریاضی. مشکل مهندس 2014 ، 2014 ، 1-7. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، جی. بروگر، آی. زیبارت، بی. برگرولف، تی. کروفوت، ام. Farine, D. اطلاعات اجتماعی پیش بینی مکان را در طبیعت بهبود می بخشد. در مجموعه مقالات کارگاه های بیست و نهمین کنفرانس AAAI در مورد هوش مصنوعی، آستین، TX، ایالات متحده، 25 تا 30 ژانویه 2015. [ Google Scholar ] [ CrossRef ]
- اسپاکاپیترا، اس. پدر و مادر، سی. دامیانی، ام.ال. De Macedo، JA; پورتو، اف. وانگنوت، سی. دیدگاه مفهومی در مسیرها. دانستن داده ها مهندس 2008 ، 65 ، 126-146. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- استر، ام. کریگل، اچ پی؛ ساندر، جی. Xu, X. الگوریتم مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز. در مجموعه مقالات کنفرانس بین المللی کشف دانش و داده کاوی، پورتلند، OR، ایالات متحده آمریکا، 2 تا 4 اوت 1996. جلد 96، ص 226–231. [ Google Scholar ]
- بیرانت، دی. Kut، A. ST-DBSCAN: الگوریتمی برای خوشه بندی داده های مکانی-زمانی. دانستن داده ها مهندس 2007 ، 60 ، 208-221. [ Google Scholar ] [ CrossRef ]
- ایلیوپولوس، CS; رحمان، MS یک الگوریتم کارآمد جدید برای محاسبه طولانی ترین دنباله متداول. محاسبات تئوری. سیستم 2009 ، 45 ، 355-371. [ Google Scholar ] [ CrossRef ]
- گروور، ا. Leskovec, J. node2vec: آموزش ویژگی مقیاس پذیر برای شبکه ها. در مجموعه مقالات KDD: کنفرانس بین المللی کشف دانش و داده کاوی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 13 تا 17 اوت 2016. صص 855-864. [ Google Scholar ]
- یوان، جی. سان، پ. ژائو، جی. لی، دی. وانگ، سی. مروری بر الگوریتمهای خوشهبندی مسیر جسم متحرک. آرتیف. هوشمند Rev. 2016 , 47 , 123-144. [ Google Scholar ] [ CrossRef ]
- چن، ال. اوزسو، MT; Oria، V. جستجوی شباهت قوی و سریع برای مسیر حرکت جسم متحرک. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2005، بالتیمور، MD، ایالات متحده آمریکا، 14-16 ژوئن 2005. پ. 491. [ Google Scholar ]
- Sankoff، BD; Kruskal، JB Time Warps، String Edits، و Macromolecules: Theory and Practice of Sequence Comparison. ریدینگ، MA: ادیسون-وسلی. J. محاسبات منطقی. 1983 ، 11 ، 356. [ Google Scholar ]
- فری، بی جی؛ Dueck, D. خوشه بندی با ارسال پیام بین نقاط داده. Science 2007 ، 315 ، 972-976. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- سپ، اچ. یورگن، اس. حافظه کوتاه مدت طولانی. محاسبات عصبی 1997 ، 9 ، 1735-1780. [ Google Scholar ] [ CrossRef ]


بدون دیدگاه