


7.2.1 سؤال تحقیق 1.1
پیچیدگی کار تصمیمگیری بر انواع ساختارهای اطلاعات جغرافیایی، بهعنوان مثال نقشهها، جداول و نمودارها که توسط شرکتکنندگان اختصاص داده شده است، چگونه تأثیر میگذارد؟ هنگام انجام تجزیه و تحلیل آماری سنتی برای این سؤال تحقیق، ما یک فرضیة صفر به شکل فرموله کردیم: پیچیدگی کار تأثیری بر تخصیص کمکهای نقشه (کدگذاریشده بهعنوان MAPS) و/ یا کمکهای جدول تصمیمگیری (کدگذاریشده بهعنوان MCDM) ندارد. برای تعیین اینکه آیا پیچیدگی کار تأثیری بر تعامل بین تعداد حرکتهای نقشه و تعداد حرکات MCDM دارد یا خیر، از روش آماری مدل خطی عمومی (GLM) استفاده کردیم (SPSS Base 8.0, 1998). روش GLM، تجزیه و تحلیل رگرسیون و تجزیه و تحلیل واریانس متغیر وابسته توسط یک یا چند عامل و/ یا متغیر را فراهم میکند. متغیر وابسته حرکت نقشه و متغیر کمکی حرکت MCDM و عامل پیچیدگی کار بود. پیچیدگی کار از کار 1 (کمترین پیچیدگی: هشت سایت و سه معیار ارزیابی) تا کار 4 (پیچیدهترین: بیست سایت و یازده معیار ارزیابی) متغیر بود. این مدل، تنها 8 از تنوع بین استفاده از کمکهای MAPS و کمکهای MCDM را توضیح میدهد (081/0=R مربع، F=10.682، Sig.=0000) و پیچیدگی کار تأثیر معنیداری در توضیح تغییرپذیری ندارد (F= 1.368، Sig.=.252) استفاده از این کمکهای تصمیمگیری.
ما در بررسی بیشتر استفاده از کمکهای تصمیمگیری MAPS و MCDM، بهویژه به میزان استفادة همزمان نقشهها با کمکهای MCDM علاقهمند شدیم. با این حال، بر اساس این یافتهها میتوانیمنتیجهگیری کنید که شرکتکنندگان بیشتر از نقشهها بهطور مستقل از MCDM استفاده میکردند کمک میکند تا در هماهنگی با کمک MCDM. در طول آزمایش (74 جلسه)، نقشهها همراه با کمکهای MCDM 34.4 زمان (استفاده از نقشة پیوندی) استفاده شد. در بقیة موارد (65.6)، نقشهها بهطور مستقل از کمکهای MCDM (استفاده از نقشة جداکننده) استفاده شد. بهمنظور انجام تجزیه و تحلیل استفادة «همزمان»، دادهها باید پس گرفته میشدند. کدگذاری استفاده از کمک تصمیمگیری، تنها یک ورودی برای تعداد سلول یکدقیقهای ایجاد کرد؛ زیرا کدهای MAPS و MCDM بخشی از سیستم کدگذاری یکسان بودند؛ بنابراین، بهمنظور کدگذاری استفادة همزمان، سلولهای یکدقیقهای به سلولهای دو دقیقهای گسترش یافتند و هر بار که کمک MAPS مشاهده شد، یک کد MCDM را در سلول یکدقیقهای مجاور بررسی کردیم. پاسخ به سؤال همزمانی با اجرای سیستم کدگذاری محدود شد؛ همانطور که در بخش 7.3.2 به آن اشاره شد.
هنگام در نظر گرفتن تجزیه و تحلیل دادههای متوالی، متوجه میشویم که میتوانیم به رابطة بین پیچیدگی کار و استفاده از کمک تصمیمگیری بپردازیم. با این حال، به دلیل محدودیت سیستم کدگذاری که در بالا توضیح داده شد، نمیتوانیم به استفادة همزمان از کمکهای تصمیمگیری بپردازیم. در آن شرایط، فقط میتوان از کد کمک تصمیمگیری در فاصلة شمارش یکدقیقهای استفاده کرد. به یاد داشته باشید که از سه مسیر کدگذاری در کدگذاری دادهها استفاده شده است، با این حال، یک آهنگ تنها یک کد را در آن فاصله ذخیره میکند. ما در تحلیل متوالی تأخیر، از یک کد پایه (F1، بهعنوان مثال برای روابط کاری گروهی در جدول 7.3) به یک کد هدف (T1، بهعنوان مثال برای سیستم کدگذاری کمکهای تصمیمگیری در جدول 7.3) کد میکنیم. تأخیر «0» کدی است که همزمان با کد «F1» رخ میدهد. تأخیرهای «5-1» کدهایی هستند که 5 دقیقه تا 1 دقیقه قبل از کد تأخیر «0» هستند. تأخیرهای «1-5» کدهایی هستند که 1 دقیقه تا 5 دقیقه بعد از کد تأخیر «0» هستند. بهعنوان مثال، در جدول 7.3 در بالای جدول، زمانی که کد «GW» کار گروهی در مجموعة داده ظاهر میشود، درمجموع 46 کد MAP مشاهده میشود؛ به این معنی که 46 دقیقه استفاده از نقشه در طول 46 دقیقه کار گروهی کدگذاری شد؛ یعنی کار بدون تضاد. اطلاعات دیگر در این جدول، این است که 44 مشاهدة یکدقیقهای از کدهای نقشه در یک دقیقه قبل از کد «GW» وجود دارد و 45 مشاهدة یکدقیقهای بعد از کد «GW» ظاهر میشود (سلول برجستهشده را ببینیدـ ورودیهای جدول 7.3). مقدار اطلاعات موجود در جداول متوالی تأخیر، ما را تشویق میکند تا تحلیل را با تمرکز بر تأخیر «0» ساده کنیم.
فقط در مورد تأخیر «0»، یعنی زمانی که یک کد در سیستم کدگذاری (F1) همزمان با یک کد در سیستم کدگذاری دیگر (T1) رخ میدهد، میتوانیم جدول بسیار سادهشدهای مانند جدول 7.4 ایجاد کنیم. ترکیب استفاده از کمک تصمیم «GW» با استفاده از کمک تصمیم «GWC»، اطلاعات جدول 7.4 را به ما میدهد؛ این تفاوت در زمان برای همة گروههایی است که از کمکهای تصمیمگیری در کار 1 و کار 4 استفاده کردهاند. از این پس، یافتهها با استفاده از نسخة سادهتر جداول ایجاد میشوند؛
بهعنوان مثال، تأخیر «0» در جدول 7.4. جالب اینجاست که نقشهها به صورت کدگذاریشده توسط نقشهها در کار ساده، تقریباً دو برابر بیشتر استفاده میشود. با این حال، جداول تصمیم به صورت کدگذاریشده توسط
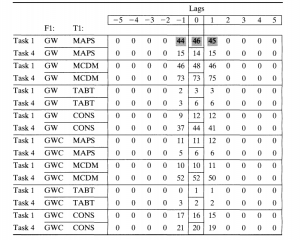
جدول 7.3 تحلیل متوالی تأخیر از روابط کاری گروهی (F1) تا کمکهای تصمیمگیری (T1) در مقایسه بین پیچیدگی کار- وظیفة 1: ساده و کار 4: پیچیده (برای توضیح کدها به متن مراجعه کنید.)
MCDM در کارهای پیچیده، بیش از دو برابر در کارهای ساده استفاده شده است. از جداول برای نمایش دادهها در هر دو کار، بسیار کم استفاده شده و از کمکهای اجماع در کارهای پیچیدهتر، بیشتر از کارهای ساده استفاده شده است.
بحث در مورد یافتهها و ارزیابی استراتژی روشی که در آن کدگذاری انجام شد، هر دو تحلیل را محدود میکند. با توجه به تجزیه و تحلیل آماری سنتی، پردازش فواصل یکدقیقهای کاهشیافته با استفاده از فواصل دو دقیقهای، بهگونهای که گویی دومی نشاندهندة استفادة همزمان از کمکهای تصمیمگیری است، میتواند با موفقیتـ هم موافق و هم مخالفـ مورد بحث قرار گیرد. فاصلة زمانی دو دقیقهای بهقدری کوتاه است که اکثر مردم قبول دارند که استفاده در این فاصله میتواند «همزمان مؤثر» باشد. درنهایت، چرا یک دقیقه آنقدر خاص است که از دو دقیقه مؤثرتر باشد؟ یک دقیقه بهتر است؛ زیرا واقعاً باید فعالیت را در بازههای سی و دوم کدگذاری میکردیم. فرصت را از دست دادیم. در کدنویسی و تحلیلهای بعدی زمانی که از کدهای اولیه و ثانویه در نرمافزار کدنویسی استفاده نکردیم؛ یعنی MacSHAPA درواقع اجازه میدهد تا دو کد در یک زمان اختصاص داده شود، یعنی یک کد اصلی
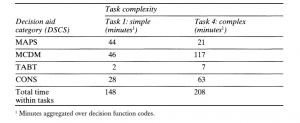
جدول 7.4استفاده از کمک تصمیمگیری (در چند دقیقه اندازهگیری میشود) که با پیچیدگی کار مشخص میشود.
1 دقایق جمعآوریشده روی کدهای تابع تصمیمگیری و یک کد ثانویه
این کدها را میتوان به شیوهای انتخابشده توسط یک محقق تفسیر کرد. این به ما امکان میدهد که MCDM و MAPS را در بازة کدگذاری یکدقیقهای بیان کنیم.
کدگذاری و تحلیل مربوط به تحلیل ترتیبی تأخیر نیز خالی از اشکال نیست. با مقایسة اطلاعات تفسیرشده از ارائة کد خام تحلیل دادههای متوالی تأخیر (LSA) (در جدول 7.3) با اطلاعات تفسیرشده از کدهای انبوه LSA (جدول 7.4)، بهطور قطع میتوان گفت که اطلاعات جدول 7.3 نسبت به نتایج تفسیرشده از کدهای تجمیعشده در جدول 7.4 نسبت به دادهها صادقتر است. با این حال، نتایج تفسیرشده در جدول 7.4، سادهتر و کلیتر از نتایج خام هستند: آیا چنین ارائهای به اطلاعات بیشتری دلالت دارد؟ توالی، بخش اساسی از روابط دادههای خام در جدول 7.3 است.
به دلیل تجمیع کدها برای «سادهسازی» تعداد سازههای گزارششده، موقتی سازهها (که توسط مشاهدات دادههای خام نشان داده میشوند) در سطح دقیقی در یک کار خاص میتوانند از بین بروند؛ اگرچه کلیت سازهها افزایش مییابد.
اکنون که میدانیم هر دو استراتژی تحلیل، مزایا و معایب خود را دارند، علاقهمند شدیم تا آنها را به روشی سیستماتیک با هم مقایسه کنیم. ارزیابی کنار هم از راهبردهای تحلیل را میتوان با استفاده از ده ویژگی تحلیل روابط معرفیشده در فصل 4 (دربارة روشهای تحقیق اجتماعی- رفتاری) و فهرستشده در ستون سمت چپ جدول 7.5 انجام داد. ویژگیهای رابطه به ترتیبِ «به دست آوردن اطلاعات» که توسط برینبرگ و مک گراث (1985) ارائه شده است، فهرست شدهاند. به یاد داشته باشید که هر رابطه بین دو متغیر ij، به معنای مطابقت با رابطة بین دو عنصر از حوزة ماهوی (در این مورد، نقشهها و جداول تصمیم) و همچنین، رابطة بین دو عنصر در حوزة مفهومی (در این مورد، دو دسته از کمکهای تصمیمگیری: «کمکهای نقشه» و «کمکهای تصمیمگیری MCDM») است. به این معنا که باید با رابطة بین تعداد هر کمکی که در حوزة روششناسی کدگذاری شده است، مطابقت داشته باشد. از آنجا که متغیرهای شمارش و دادههای زیربنایی که استفاده میکنیم، در هر دو تحلیل سنتی و متوالی، یعنی حوزة روششناختی ما یکسان هستند، میتوانیم این دو تحلیل را به روشی سیستماتیک مقایسه کنیم. برای انجام این کار، بهسادگی از طریق روابط ویژگیهای 1-10 عبور میکنیم؛ یعنی ستونهای دوم و سوم را از نظر کسب اطلاعات آنها برای هر تجزیه و تحلیل مقایسه میکنیم. اطلاعات جدول 7.5 با ورودی سلولهای ستونهای 2 و 3 از ویژگی مربوطه در ستون 1 نشان داده شده است. در گام برداشتن در روابط، توجه میکنیم که تکنیک تحلیل سنتی دادهها (مدل خطی عمومی، GLM) ارائه میکند.
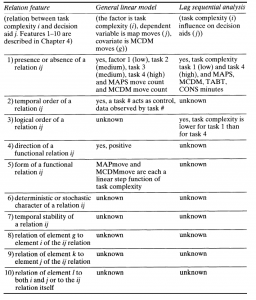
جدول 7.5تحلیل ویژگیهای رابطة مقایسهای برای سؤال تحقیق 1.1 (وظیفة تأثیر پیچیدگی بر انواع مختلف کمکهای تصمیمگیری)
بینش بیشتر به رابطة بین پیچیدگی کار (درمان من) و کمک تصمیمگیری (j) نسبت به روش تجزیه و تحلیل دادههای متوالی اکتشافی (تحلیل متوالی تأخیر، LSA)؛ زیرا ستون GLM حاوی اطلاعات بیشتری نسبت به ستون LSA است. چهار سلول در ستون «مدل خطی عمومی» تحلیل سنتی حاوی اطلاعات است. «ناشناخته» هیچ اطلاعاتی ندارد. تنها دو سلول در ستون تحلیل متوالی حاوی اطلاعات هستند. ذکر این نکته مفید است که ورود «ناشناخته» در سلولهای اساسیتر، یعنی ویژگیهای 1-3، درواقع آنچه را که در سلولهای 4-10 شناخته شده است، به خطر میاندازد.





بدون دیدگاه