1. مقدمه
منابع زمین به عنوان حامل مادی بقا و توسعه انسان دارای ویژگی های مکان ثابت، تجدید ناپذیر، توزیع نامتعادل منابع و غیره است [ 1 ]. با توسعه سریع جمعیت و سیستم های اقتصادی-اجتماعی، منابع زمین یکبار مصرف باقی مانده روز به روز در حال کاهش است. بنابراین برنامه ریزی کلی و برنامه ریزی منطقی منابع زمین دارای ارزش اجتماعی مهمی است. برای مناطق شهری، بیشتر لندفرم ها از ساختمان ها و جاده ها تشکیل شده اند، تقسیم بندی دقیق ساختمان ها و جاده ها می تواند به تحقق برنامه ریزی کلان شهری کمک کند. بنابراین، تقسیم بندی خودکار ساختمان ها و جاده ها در تصاویر سنجش از دور بسیار ضروری است.
در دهههای گذشته، بسیاری از محققان روشهای بخشبندی تصویر سنجش از دور مهندسی ویژگیهای مؤثر را پیشنهاد کرده بودند. به عنوان مثال، یوان و همکاران. [ 2 ] از هیستوگرام های طیفی محلی برای محاسبه ویژگی های طیفی و بافت تصویر استفاده کرد. هر هیستوگرام طیفی محلی چندین ویژگی نماینده را به صورت خطی ترکیب کرده و در نهایت به تقسیم بندی تصویر سنجش از دور با تخمین وزن پی برد. لی و همکاران [ 3 ] بهبودی را در دو مرحله کلیدی استخراج برچسب و برچسبگذاری پیکسل در فرآیند تقسیمبندی پیشنهاد کرد که میتواند به طور موثر و کارآمدی دقت قطعهبندی لبه تصویر با وضوح بالا را بهبود بخشد. فن و همکاران [ 4] یک روش تقسیم بندی تصویر سنجش از دور بر اساس اطلاعات قبلی پیشنهاد کرد. این روش از الگوریتم خوشهبندی c-means فازی وزندار تک نقطهای برای حل تأثیر توزیع دادهها و مقداردهی اولیه تصادفی مرکز خوشهبندی بر کیفیت خوشهبندی استفاده کرد. روشهای تقسیمبندی مهندسی با ویژگیهای بالا میتوانند به طور موثری تصاویر سنجش از راه دور را تقسیمبندی کنند. با این حال، آنها مشکلاتی مانند مقاومت در برابر نویز ضعیف، سرعت بخشبندی پایین و طراحی پارامترهای مصنوعی دارند و نمیتوانند وظایف تقسیمبندی خودکار مقادیر زیادی داده را انجام دهند.
در سالهای اخیر، شبکههای عصبی کانولوشنال (CNN) در بسیاری از زمینهها مانند مراقبتهای بهداشتی [ 5 ، 6 ]، بازاریابی [ 7 ]، مدیریت توان [ 8 ]، مهندسی عمران [ 9 ]، پایگاه داده توزیعشده [ 10 ] به موفقیتهای زیادی دست یافتهاند . ، امنیت سایبری [ 11 ] و غیره. حوزه تقسیم بندی معنایی بینایی کامپیوتر نیز از این قاعده مستثنی نیست. در بخشبندی معنایی، CNNها نه تنها مقاومت نویز قوی دارند، بلکه میتوانند به تقسیمبندی خودکار تعداد زیادی داده پی ببرند و عملکرد تقسیمبندی عالی را به دست آوردهاند. شبکه کامل کانولوشن (FCN) توسط لانگ و همکاران پیشنهاد شد. [ 12]، و این اولین باری بود که از شبکه عصبی کانولوشنال کامل برای دستیابی به بخش بندی معنایی تصویر استفاده کرد و پایه ای را برای روش های تقسیم بندی بعدی ایجاد کرد. رونبرگر و همکاران [ 13 ] ساختار U شکل (U-Net) را برای تقسیم بندی معنایی پیشنهاد کرد. بر اساس چارچوب FCN، U-Net روش ترکیب ویژگیها را بهبود بخشیده بود و ویژگیهای درجات مختلف برای تحقق استفاده مجدد از ویژگیها ترکیب شدند. ادغام سطوح مختلف نقشه های ویژگی، شبکه را قادر می سازد تا حاوی اطلاعات معنایی چند سطحی باشد و دقت تقسیم بندی را بهبود بخشد. با این حال، در مقایسه با FCN، مقدار محاسبه تا حدی افزایش یافت. ژائو و همکاران [ 14] شبکه تجزیه صحنه هرمی (PSPNet) را با استفاده از ساختار هرمی برای جمعآوری اطلاعات زمینه مناطق مختلف پیشنهاد کرد و میتواند اطلاعات زمینه جهانی را استخراج کند. DeeplabV3+ پیشنهاد شده توسط چن و همکاران. [ 15 ] از کانولوشن آتروس برای ساختن نقشه ویژگی هرم چند مقیاسی استفاده کرد، که نمونهبرداری فرعی را قادر میسازد تا اطلاعات زمینه چند مقیاسی را به دست آورد و میدان دریافتی بزرگتری را بدون وارد کردن سربار محاسباتی به دست آورد.
لیو و همکاران [ 16 ] یک شبکه عصبی پیچیده چند کاناله جدید را پیشنهاد کرد. این شبکه این مشکل را حل کرده بود که ویژگیهای فضایی و مقیاس اشیاء بخشبندی در برخی از تصاویر سنجش از راه دور از بین رفته بود، اما در مورد انسداد سایه به راحتی میتوان اشتباه کرد. Qi و همکاران با هدف وضوح فوق العاده بالا و ویژگی های پیچیده تصاویر سنجش از دور. [ 17 ] یک مدل تقسیم بندی را با استفاده از مکانیسم های پیچیدگی و توجه چند مقیاسی پیشنهاد کرد. با این حال، مکانیسم توجه فقط می تواند میدان دریافت محلی را بگیرد. بنابراین لازم بود از روش توجه به خود برای به دست آوردن اطلاعات مهم از طریق میدان دریافتی جهانی خود استفاده کرد و از آن در تصاویر سنجش از دور استفاده موثر کرد. کائو و همکاران [ 18] یک روش همجوشی ویژگی عمیق مبتنی بر توجه به خود را پیشنهاد کرد که در تصاویر صحنه سنجش از دور، ترکیب ویژگی عمیق را برای اجسام پیچیده انجام داد و بر وزن آنها تأکید کرد. سینها و همکاران [ 19 ] از یک مکانیسم خودتوجه هدایت شده برای ثبت وابستگی های زمینه پیکسل ها در تصویر استفاده کرد. علاوه بر این، از دست دادن اضافی برای تأکید بر همبستگی ویژگی بین ماژولهای مختلف استفاده شد، که مکانیسم توجه را به نادیده گرفتن اطلاعات نامربوط هدایت کرد و بر روی مناطق متمایزتر تصویر متمرکز شد. روش های خود توجهی فوق [ 18 ، 19] به نتایج اولیه در زمینه تصاویر سنجش از دور دست یافته بود، اما هنوز فضای بیشتری برای کاوش وجود داشت، مانند استفاده از مکانیسم خود توجه برای دستیابی به انتقال ویژگی لایه پنهان.
به طور خلاصه، این شبکههای تقسیمبندی معنایی عصبی کانولوشنال [ 12 ، 13 ، 14 ، 15 ، 16 ، 17 ، 18 ، 19 ] سهم قابل توجهی در زمینه تقسیمبندی معنایی در بینایی رایانه داشتند. در مقایسه با روش تقسیمبندی مهندسی ویژگی [ 2 ، 3 ، 4 ]، عملکرد ضد نویز قوی داشت و میتوانست به تقسیمبندی خودکار انبوه سرتاسر عمل کند. FCN [ 12 ] و U-Net [ 13] از طریق ترکیب ویژگی ها در سطوح مختلف و استفاده مکرر از نقشه های ویژگی، به بهبود ویژگی دست یافت. با این حال، هدف تقسیمبندی فاقد درک صحنه است، بنابراین PSPNet [ 14 ] لایه ادغام هرمی ویژگی را ایجاد کرد، از لایههای ادغام با اندازههای مختلف برای اتصال و فیوژن استفاده کرد و در نهایت تجزیه و تحلیل ویژگی را در شبکه انجام داد تا درک صحنه از هدف تقسیمبندی را به دست آورد. در فرآیند تقسیمبندی، اهداف تقسیمبندی در مقیاسهای مختلف وجود داشت، Deeplabv3+ [ 15 ] از پیچیدگی عضلانی نرخهای مختلف دهلیزی برای دستیابی به همجوشی چند مقیاسی استفاده کرد. مدل های شبکه عصبی کانولوشنال فوق [ 12 , 13 , 14 , 15] تجزیه و تحلیلی را برای مشکلات مختلف در فرآیند تقسیمبندی ارائه کرد، از جمله استفاده مجدد از نقشه ویژگی و ادغام سطوح مختلف ویژگیها، لایه ادغام هرم ویژگی برای درک صحنه هدف تقسیمبندی، و ادغام ویژگیهای چند مقیاسی پیچش آتروس با نرخهای آتروس متفاوت. با این حال، در فرآیند ادغام ویژگی این شبکهها، تقریباً تمام نقشههای ویژگی مستقیماً در بعد کانال به هم پیوسته و ادغام شدند و اطلاعات ویژگیهای لایههای پنهان (بعد کانال نقشه ویژگی) به طور مستقل توسعه و استفاده نشد. نادیده گرفتن سطح اهمیت کاوی ویژگیهای لایه پنهان منجر به فقدان اطلاعات دستهبندی پیکسلهای زمینه در طبقهبندی پیکسل شد و در نتیجه مشکلاتی مانند قضاوت نادرست منطقه بزرگ ساختمان و قطع ارتباط جادهها را به همراه داشت. علاوه بر این،12 ، 13 ، 14 ، 15] عبارتند از پیچیدگی بالا، سرعت استدلال کند و هزینه بالای آموزش مدل. برای حل این مشکلات، این مقاله یک شبکه جستجوی ویژگی غیرمحلی (NFSNet) را پیشنهاد میکند. این شبکه میتواند دقت تقسیمبندی ساختمانها و جادهها را از تصاویر سنجش از دور بهبود بخشد و به دستیابی به برنامهریزی شهری دقیق از طریق ساختمانها و استخراج جادهها با دقت بالا کمک کند. به طور کلی، سه مشارکت در کار ما وجود دارد: (1) ماژول انتقال ویژگی خود توجه (SAFT) از طریق روش توجه به خود ساخته شده است تا به طور مؤثر اطلاعات ویژگی لایه پنهان را بررسی کند. یک نقشه ویژگی حاوی اطلاعات دسته بندی هر پیکسل و اطلاعات معنایی دسته پیکسل های زمینه به دست می آید. برای جلوگیری از مشکل قضاوت نادرست مساحت بزرگ ساختمان و قطع جاده. (2) ماژول Global Feature Refinement (GFR) ساخته شده است و اطلاعات ویژگی لایه پنهان استخراج شده از ماژول SAFT به طور موثر با شبکه ستون فقرات یکپارچه می شود. ماژول GFR نقشه ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات ویژگی در بعد فضایی لایه پنهان هدایت می کند و اطلاعات معنایی نقشه ویژگی را افزایش می دهد. این به بازیابی نقشه ویژگی با نمونه برداری دقیق تر کمک می کند و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند. و اطلاعات ویژگی لایه پنهان استخراج شده از ماژول SAFT به طور موثر با شبکه ستون فقرات یکپارچه شده است. ماژول GFR نقشه ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات ویژگی در بعد فضایی لایه پنهان هدایت می کند و اطلاعات معنایی نقشه ویژگی را افزایش می دهد. این به بازیابی نقشه ویژگی با نمونه برداری دقیق تر کمک می کند و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند. و اطلاعات ویژگی لایه پنهان استخراج شده از ماژول SAFT به طور موثر با شبکه ستون فقرات یکپارچه شده است. ماژول GFR نقشه ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات ویژگی در بعد فضایی لایه پنهان هدایت می کند و اطلاعات معنایی نقشه ویژگی را افزایش می دهد. این به بازیابی نقشه ویژگی با نمونه برداری دقیق تر کمک می کند و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند. ماژول GFR نقشه ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات ویژگی در بعد فضایی لایه پنهان هدایت می کند و اطلاعات معنایی نقشه ویژگی را افزایش می دهد. این به بازیابی نقشه ویژگی با نمونه برداری دقیق تر کمک می کند و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند. ماژول GFR نقشه ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات ویژگی در بعد فضایی لایه پنهان هدایت می کند و اطلاعات معنایی نقشه ویژگی را افزایش می دهد. این به بازیابی نقشه ویژگی با نمونه برداری دقیق تر کمک می کند و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند. و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند. و دقت تقسیم بندی را بهبود می بخشد. (3) آزمایشها بر روی مجموعه دادههای تقسیمبندی معنایی تصویر سنجش از راه دور انجام میشوند و میانگین تقاطع 70.54٪ روی اتحاد را به دست میآورند که از مدل موجود بهتر عمل میکند. علاوه بر این، مقدار پارامترهای مدل و پیچیدگی مدل در بین تمام مدلهای مقایسه کمترین مقدار را دارند و باعث صرفهجویی در زمان و هزینه آموزش میشوند.
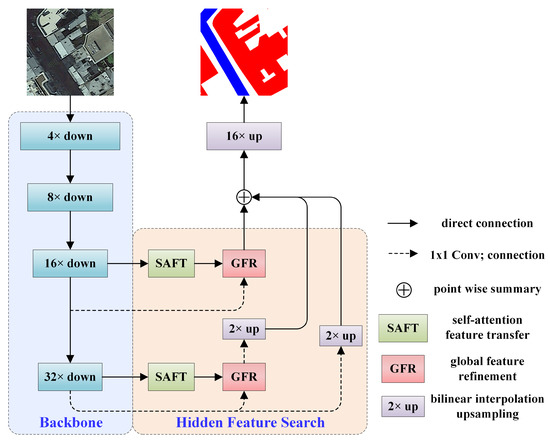
2. روش شناسی
در فرآیند ادغام ویژگی، روشهای تقسیمبندی معنایی موجود به طور کلی از روش اتصال برای ترکیب نقشه ویژگی در بعد کانال استفاده میکنند. اطلاعات معنایی لایه های پنهان (بعد کانال نقشه ویژگی) به طور جداگانه توسعه داده نشده است. با توجه به وضوح بالای تصاویر سنجش از دور و پیچیدگی بالای هدف، پیکسل در تقسیم بندی معنایی تصاویر سنجش از دور موفق به گرفتن دسته پیکسل های زمینه نشد و در نتیجه قضاوت نادرست منطقه بزرگ ساختمان و قطع ارتباط جاده ها را به همراه داشت. در مرحله دوم، مدلهای الگوریتم تقسیمبندی معنایی موجود [ 12 ، 13 ، 14 ، 15] پیچیدگی بالا و هزینه زمان استدلال بالایی داشت. به منظور حل این دو مشکل، این مقاله یک شبکه جستجوی ویژگی غیرمحلی (NFSNet) برای بخشبندی ساختمان و جاده در تصاویر سنجش از دور پیشنهاد میکند. چارچوب کلی NFSNet در شکل 1 نشان داده شده است . NFSNet پیشنهادی در این کار یک مدل آموزشی سرتاسر است و چارچوب کلی به شبکه رمزگذاری و شبکه رمزگشایی تقسیم میشود. ResNet [ 20 ] به عنوان شبکه ستون فقرات برای استخراج ویژگی در شبکه رمزگذاری استفاده می شود، شبکه رمزگشایی ماژول انتقال ویژگی خود توجه (SAFT) و ماژول بهبود ویژگی جهانی (GFR) را می سازد. شبکه رمزگشایی بخش جستجوی ویژگی پنهان در شکل 1 است. ماژول SAFT ارتباط ویژگی ها بین لایه های پنهان را از طریق پرس و جوی خود توجه خود بررسی می کند. اطلاعات معنایی لایه پنهان به نقشه ویژگی اصلی منتقل می شود و یک نقشه ویژگی حاوی اطلاعات دسته بندی خود هر پیکسل و پیکسل های زمینه آن به دست می آید. ماژول GFR به منظور بهبود مشکل طبقهبندی نادرست ناحیه بزرگ ساختمان و قطع ارتباط جادهها در فرآیند تقسیمبندی، به طور موثر نقشه ویژگی شبکه ستون فقرات و اطلاعات معنایی لایه پنهان استخراجشده توسط SAFT را ادغام میکند. ماژول GFR میانگین جهانی ویژگی های استخراج شده توسط SAFT را جمع آوری می کند، به نقشه ویژگی های شبکه ستون فقرات دستور می دهد تا اطلاعات معنایی لایه پنهان در بعد فضایی را به دست آورد و دقت تقسیم بندی را بهبود می بخشد. سرانجام،
2.1. شبکه رمزگذاری
در این مقاله، CNN ها به عنوان شبکه ستون فقرات برای دستیابی به استخراج ویژگی های شبکه استفاده می شوند. در سالهای اخیر، بسیاری از CNNهای عالی مانند VGG [ 21 ]، GoogLeNet [ 22 ] و ResNet [ 20 ] ظهور کردهاند.]. این کار پس از سنجیدن تعداد پارامترهای شبکه و دقت، ResNet را به عنوان شبکه اصلی برای استخراج ویژگی انتخاب می کند. ResNet اولین روشی است که استفاده از اتصالات پرش را برای کاهش تخریب مدل با افزایش عمق شبکه پیشنهاد می کند. ResNet لایه های پیچیدگی مختلفی را برای سناریوهای برنامه های مختلف تنظیم می کند که به ترتیب شامل 18، 34، 50، 101 و 152 لایه می شود. NFSNet پیشنهادی در این مقاله یک شبکه سبک وزن است، بنابراین کمترین تعداد لایه های پیچشی شبکه ResNet-18 به عنوان شبکه ستون فقرات انتخاب می شود. ResNet-18 لایه به لایه نمونه برداری می شود تا نقشه ویژگی با اطلاعات معنایی غنی بدست آید، اندازه نقشه ویژگی آخرین لایه 1/32 تصویر ورودی است. ResNet-18 برای به دست آوردن نقشه ویژگی اندازه 1/16 و نقشه ویژگی 1/32 (از این پس CNN نامیده می شود) نمونه برداری می شود.
2.2. شبکه رمزگشایی
شبکه رمزگشایی وظیفه رمزگشایی اطلاعات رمزگذاری شده و بازیابی اطلاعات ویژگی های معنایی نقشه ویژگی را بر عهده دارد. ورودی شبکه رمزگشایی نقشه ویژگی در اندازه های 16/1 و 32/1 تصویر اصلی است که از شبکه ستون فقرات شبکه رمزگذاری نمونه برداری شده است. شبکه رمزگشایی عمدتاً از ماژول SAFT و ماژول GFR تشکیل شده است. ماژول SAFT از مکانیسم توجه به خود برای استخراج ارتباط بین لایه های پنهان استفاده می کند و اطلاعات ویژگی های لایه های پنهان را به نقشه ویژگی اصلی منتقل می کند. یک نقشه ویژگی حاوی اطلاعات دسته بندی دسته بندی هر پیکسل و پیکسل های زمینه آن به دست می آید. نقشه ویژگی حاوی اطلاعات معنایی لایه پنهان می تواند مشکلات طبقه بندی نادرست ساختمان و قطع ارتباط جاده ها را کاهش دهد. ماژول GFR اطلاعات معنایی استخراج شده از SAFT را اصلاح می کند و آن را با نقشه ویژگی های شبکه ستون فقرات یکپارچه می کند. ماژول GFR می تواند به گراف ویژگی شبکه ستون فقرات برای به دست آوردن اطلاعات معنایی لایه پنهان در بعد فضایی کمک کند و دقت تقسیم بندی را بهبود بخشد.
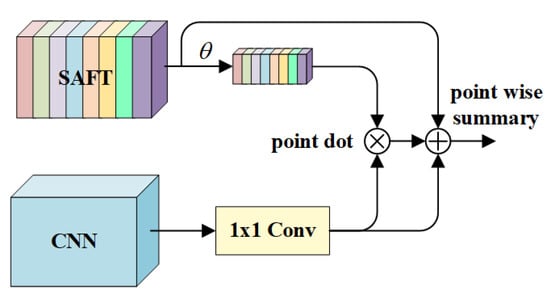
2.2.1. ماژول انتقال ویژگی خود توجه
نمونه اولیه مکانیسم توجه به خود توسط واسوانی [ 23 ] پیشنهاد شد که معمولاً برای استخراج اطلاعات در فرآیند رمزگذاری و رمزگشایی پردازش زبان طبیعی استفاده میشود. هنگامی که یک پیام متنی وارد می شود، رابطه بین هر کاراکتر در متن و زمینه آن استخراج می شود تا درجه اهمیت هر کاراکتر در متن به دست آید [ 24 ].]. با الهام از این ایده، مکانیسم توجه به خود در لایه های پنهان شبکه عصبی کانولوشن تعبیه شده است. ارتباط بین هر لایه پنهان و لایه های پنهان زمینه آن از طریق توجه به خود به دست می آید، به طوری که انتقال اطلاعات ویژگی لایه پنهان به نقشه ویژگی اصلی محقق می شود. هنگامی که نقشههای ویژگی حاوی اطلاعات معنایی لایههای پنهان بهدست میآیند، دستهبندی پیکسل فعلی و پیکسلهای زمینه آن را میتوان در طول طبقهبندی پیکسل ثبت کرد، که میتواند به طور موثر طبقهبندی اشتباه پیکسلها را کاهش دهد و از قضاوت نادرست ساختمان در منطقه بزرگ و قطع ارتباط جاده جلوگیری کند.
ماژول انتقال ویژگی خودتوجهی پیشنهاد شده در این مقاله در شکل 2 نشان داده شده است . در مرحله اول، ماتریس پرس و جو، ماتریس ارزش کلیدی و ماتریس مقدار عددی توسط سه کانولوشن 1 × 1 و توابع نگاشت به دست می آیند. φ، ز، η; در مرحله دوم، پس از ضرب ماتریس پرس و جو و ماتریس مقدار کلید، softmax در بعد کانال اول محاسبه می شود. در نهایت، کانولوشن تفکیک پذیر عمق برای افزایش ویژگی ها استفاده می شود. ورودی این ماژول یک نقشه ویژگی به اندازه 1/32 (یا 1/16) از تصویر اصلی پس از نمونه برداری از شبکه ستون فقرات است. بعد نقشه ویژگی X (CNN در شکل 2 ) است سی”×اچ×دبلیو. با توجه به تعداد کانال ها سی”=512(یا سی”=256) خیلی بزرگ است، مقدار محاسبه در فرآیند انتقال پارامتر نسبتاً زیاد است. به منظور کاهش بار محاسباتی، 1×1پیچیدگی برای کاهش ابعاد ویژگی ها استفاده می شود، نقشه ویژگی را با سی=سی”/2کانال ها سه شعبه می گذرد 1×1پیچیدگی، و نرمال سازی دسته ای (BN) [ 25 ] و فعال سازی ReLU [ 26 ] لایه ها دریافت می شوند ایکس^q،ایکس^ک،ایکس^vبا بعد سی×اچ×دبلیوبه ترتیب. فرآیند محاسبه در معادله ( 1 ) نشان داده شده است:
جایی که سیonv1×1است 1×1پیچیدگی، βBN است، σتابع فعال سازی ReLU است.
در مرحله بعد، باید اطلاعات توجه بین کانالها را محاسبه کنیم، اطلاعات معنایی بین کانالها را استخراج کنیم تا بتوانیم اطلاعات دستهبندی هر پیکسل و پیکسلهای زمینه آن را بگیریم. سه تابع نقشه برداری φ، ز، ηبرای نقشه برداری استفاده می شود ایکس^q،ایکس^ک،ایکس^v∈آرسی×اچ×دبلیوبه ماتریس پرس و جو ایکس^q، ماتریس کلید ایکس^کو ماتریس ارزش ایکس^vبه ترتیب از کانال هدف از نگاشت ویژگی تسهیل ضرب ماتریس است. ضرب ماتریس می تواند اطلاعات ویژگی استخراج شده لایه پنهان را به نقشه ویژگی اصلی [ 27 ] منتقل کند.
از طریق عملکرد صاف کردن افستابع نقشه برداری φدو بعد آخر نقشه ویژگی را صاف می کند ایکس^qبه ایکسq∈آرسی×(اچدبلیو). فرآیند محاسبه در معادله ( 2 ) نشان داده شده است.
جایی که زشبیه است به φ. اول، دو بعد آخر نقشه ویژگی ایکس^کپهن می شوند ایکسک”∈آرسی×(اچدبلیو)با استفاده از تابع صاف کردن افس. سپس انتقال دهید ایکسک”با استفاده از تابع تیسبرای بدست آوردن ایکسک∈آر(اچدبلیو)×سی. عمل جابجایی برای مطابقت با ابعاد در هنگام ضرب است ایکس^qو ایکس^کماتریس ها برای فرآیند محاسبه به معادله ( 3 ) مراجعه کنید.
ماتریس ارزش کانال ایکسvبا تابع نقشه برداری به دست می آید ηمانند ماتریس پرس و جو کانال ایکسq، و معادله ( 4 ) با مراجعه به رابطه ( 2 ) به دست می آید.
ماتریس پرس و جو ایکسq، ماتریس ارزش کلیدی ایکسکو ماتریس ارزش ایکسvبه دست آمده. ماتریس Query برای پرس و جو کردن اطلاعات ویژگی بین کانال ها توسط ماتریس کلید استفاده می شود. ماتریس کلید در ماتریس پرس و جو ضرب می شود که می تواند ماتریس ویژگی بعد را بدست آورد سی×سی. Softmax روی بعد اول ماتریس ویژگی به دست آمده انجام می شود و برای هر کانال امتیازهای نرمال شده برای به دست آوردن ماتریس ویژگی ایجاد می شود. ایکس¯. فرآیند محاسبه در معادله ( 5 ) نشان داده شده است:
که در آن × ضرب ماتریس است، Ωsoftmax در بعد اول محاسبه می شود.
اهمیت هر کانال از ماتریس ویژه ایکس¯متمایز می شود. ماتریس مقدار را ضرب کنید ایکسvبا ماتریس درجه اهمیت کانال ایکس¯، ماتریس ویژه ایکس˜”∈آرسی×(اچدبلیو)می توان به دست آورد. تابع نقشه برداری δبعد دوم ماتریس ویژگی را تجزیه می کند ایکس˜”از طریق عملکرد صاف کردن به دو بعد افس”، یک ماتریس دو بعدی ایکس˜”∈آرسی×(اچدبلیو)نقشه به یک ماتریس سه بعدی ایکس˜∈آرسی×اچ×دبلیو. فرآیند محاسبه در معادله ( 6 ) نشان داده شده است:
که در آن × ضرب ماتریس است، افس”عملکرد صاف کردن است.
اطلاعات توجه بین هر کانال در استخراج می شود ایکس˜، که می تواند دسته پیکسل های زمینه خود را بگیرد و ویژگی های لایه پنهان را جستجو کند. اطلاعات ویژگی لایه پنهان به نقشه ویژگی اصلی منتقل می شود و نقشه ویژگی حاوی اطلاعات دسته بندی هر پیکسل و پیکسل های زمینه آن به دست می آید. بنابراین، مشکلات طبقهبندی نادرست ساختمانها و قطع ارتباط جادهها در فرآیند قطعهبندی قابل بهبود است.
در نهایت، نقشه ویژگی ایکس˜به دست آمده توسط جستجوی ویژگی لایه پنهان، برای استخراج اطلاعات موثر از نقشه ویژگی، ویژگی ها را افزایش می دهد. با در نظر گرفتن کارایی محاسباتی مدل، از کانولوشن قابل تفکیک عمیق برای بهبود ویژگی استفاده میشود و میتوان بدون معرفی پارامترهای محاسباتی بیشتر، به افزایش ویژگی دست یافت. گروه های کانولوشن قابل تفکیک عمق را بر تعداد کانال ها تنظیم می کند [ 28 ]. پس از پیچیدگی قابل تفکیک عمق، اتصال به حالت عادی سازی دسته ای است. انتشار رو به جلو در معادله ( 7 ) نشان داده شده است:
جایی که Dدبلیوسیonv3×3کانولوشن عمقی تفکیک پذیر هسته کانولوشن است 3×3، βعادی سازی دسته ای است، ایکسoتوتی∈آرسی×اچ×دبلیوخروجی است.
2.2.2. ماژول پالایش ویژگی جهانی
پس از اینکه ماژول SAT اطلاعات ویژگی لایه پنهان را بررسی کرد، این کار ماژول GFR را می سازد تا اطلاعات ویژگی لایه پنهان را با نقشه ویژگی شبکه ستون فقرات ترکیب کند. ماژول GFR می تواند نمودار ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات معنایی غنی لایه پنهان راهنمایی کند. نقشه ویژگی با اطلاعات معنایی غنی می تواند به بازیابی بهتر جزئیات در فرآیند نمونه برداری کمک کند. ماژول GFR پیشنهاد شده در این کار در شکل 3 نشان داده شده است . ماژول GFR نقشه ویژگی شبکه ستون فقرات و نقشه ویژگی لایه پنهان استخراج شده توسط ماژول SAFT را ادغام می کند. مشابه ایده SENet [ 29]، نقشه ویژگی لایه پنهان استخراج شده توسط ماژول SAFT به صورت میانگین جهانی برای به دست آوردن اطلاعات ویژگی لایه پنهان در بعد فضایی جمع می شود. ضرب متناظر با نقشه ویژگی شبکه ستون فقرات می تواند نقشه ویژگی شبکه ستون فقرات را برای به دست آوردن اطلاعات معنایی لایه پنهان در بعد فضایی راهنمایی کند [ 30 ، 31 ، 32 ]. در نهایت، نقشه ویژگی شبکه ستون فقرات و نقشه ویژگی استخراج شده توسط ماژول SAFT برای بهبود دقت تقسیم بندی ادغام می شوند.
GFR می تواند نقشه های ویژگی را در مقیاس های مختلف ترکیب کند. همانطور که در شکل 1 نشان داده شده است ، از GFR برای ترکیب نقشه ویژگی شبکه ستون فقرات به اندازه 1/32 (یا 1/16) تصویر اصلی و نقشه ویژگی SAFT استفاده می شود. نقشههای ویژگی در مقیاسهای مختلف اطلاعات معنایی حوزههای دریافتی مختلف را ارائه میکنند. تعداد کانال های خروجی ماژول SAFT به 1/2 کانال های ورودی آن کاهش می یابد و ورودی ماژول SAFT نقشه ویژگی شبکه ستون فقرات است. بنابراین، قبل از اینکه ماژول GFR نقشه ویژگی ماژول SAFT و نقشه ویژگی شبکه ستون فقرات را ادغام کند، شماره کانال نقشه ویژگی شبکه ستون فقرات و نقشه ویژگی ماژول SAFT باید در همان سطح استاندارد شود [ 33 ]. این کار ابعاد کانال شبکه ستون فقرات نقشه ویژگی X را کاهش می دهد (CNN درشکل 3 ) به 1/2 از ویژگی های اصلی شبکه ستون فقرات نقشه برداری توسط 1×1پیچیدگی، که با بعد کانال نقشه ویژگی ماژول SAFT مطابقت دارد. خروجی ماژول SAFT ایکسoتوتیدر سطح جهان به طور متوسط ادغام شده است θو نقشه ویژگی بعد اصلی سی×اچ×دبلیوبه نقشه برداری می شود سی×1×1که می تواند اطلاعات ابعاد فضایی ماژول های SAFT را بدست آورد. ابعاد کاهش یافته نقشه ویژگی شبکه ستون فقرات با اطلاعات مکانی نقشه ویژگی ماژول SAFT در بعد کانال ضرب می شود و نقشه ویژگی شبکه ستون فقرات برای به دست آوردن اطلاعات معنایی مکانی در بعد کانال هدایت می شود [ 34 ].]. در نهایت، نقشه ویژگی شبکه ستون فقرات حاوی اطلاعات معنایی فضایی لایه پنهان، نقشه ویژگی اصلی شبکه ستون فقرات و نقشه ویژگی ماژول SAFT ترکیب و ترکیب شدهاند. به این ترتیب، نه تنها اطلاعات ویژگی اصلی شبکه اصلی و اطلاعات ویژگی لایه پنهان استخراج شده از ماژول اصلی SAFT حفظ می شود، بلکه نقشه ویژگی شبکه ستون فقرات حاوی اطلاعات معنایی فضایی لایه پنهان نیز اضافه می شود. از طریق ماژول GFR، انواع مختلفی از تصاویر ویژگی را می توان ترکیب کرد [ 35 ]، که می تواند به بهبود بیشتر دقت تقسیم بندی کمک کند. فرآیند محاسبه و استخراج GFR در معادله ( 8 ) نشان داده شده است:
جایی که θمیانگین جهانی ادغام در بعد کانال است، سیonv1×1است 1×1کانولوشن، · ضرب متناظر است، + جمع متناظر است، ایکسoتوتیخروجی ماژول SAFT است، ایکسجیافآرخروجی ماژول GFR است.
3. آزمایش ها و نتایج
به منظور تأیید اثربخشی NFSNet پیشنهادی، آزمایشهایی بر روی مجموعه دادههای باز تقسیمبندی تصویر هوایی (AISD) [ 36 ] و مسابقه برچسبگذاری معنایی ISPRS 2D (ISPRS) [ 37 ] انجام شد. شاخصهای تجزیه و تحلیل کمی آزمایش، میزان دقت کلی (OA)، نرخ فراخوان (Recall)، امتیاز F1 و میانگین تقاطع بیش از اتحادیه (MIoU) را اتخاذ کردند. مدل پیشنهادی در این مقاله با مدلهای تقسیمبندی معنایی عالی فعلی FCN-8S [ 12 ]، U-Net [ 13 ]، DeeplabV3+ [ 15 ] و PSPNet [ 14 ] مقایسه شد.]. نتایج تجربی نشان داد که NFSNet پیشنهادی در این مقاله از مدل مقایسه در شاخصهای ارزیابی چندگانه فراتر رفته است که اثربخشی مدل پیشنهادی در این مقاله را ثابت میکند.
3.1. مجموعه داده ها
3.1.1. مجموعه داده AISD
تصاویر اصلی مجموعه داده AISD از دادههای تصویر سنجش از دور آنلاین OpenStreetMap جمعآوری شد و مجموعه دادههای تقسیمبندی معنایی تصاویر سنجش از دور با وضوح بالا با حاشیهنویسی دستی ساخته شد. AISD شامل داده های تصویری از شش منطقه بود: برلین، شیکاگو، پاریس، پوتسدام و زوریخ. در این مقاله، دادههای منطقهای پوتسدام برای آزمایش انتخاب شدند و مجموعه دادهها Potsdam-A نامگذاری شدند. مجموعه داده Potsdam-A در مجموع شامل 24 تصویر اصلی و برچسب از 3000×3000اندازه متوسط. یک نمودار شماتیک از داده های آموزشی در شکل 4 نشان داده شده است . شکل 4 a تصویر اصلی و شکل 4 b برچسب است. پوتسدام-A از سه دسته تشکیل شده است: ساختمان، جاده و پس زمینه، مربوط به قرمز، آبی و سفید در شکل 4 ب.
از آنجایی که اندازه تصویر اصلی Potsdam-A برای آموزش مدل خیلی بزرگ بود، تصویر را با اندازه بزرگ برش دادیم 3000×3000در اندازه کوچک تصویر از 512×512، و در نهایت 1728 عکس از 512×512اندازه. وقتی مقدار داده کم بود، توانایی یادگیری مدل ضعیف و اثر تعمیم ضعیف بود. برای اینکه مدل قابلیت یادگیری قابل اعتمادی داشته باشد، افزایش داده ضروری بود. ما چرخش های افقی تصادفی، چرخش های عمودی و چرخش های 90 درجه ای را روی مجموعه داده های اصلی انجام دادیم تا به 4307 عکس افزایش یابد. در نهایت مجموعه داده ها به 4000 مجموعه آموزشی و 307 مجموعه تست تقسیم شد.
3.1.2. مجموعه داده ISPRS
مجموعه داده مسابقه برچسبگذاری معنایی ISPRS 2D یک مجموعه داده تصویری هوایی با وضوح بالا با برچسبگذاری معنایی کامل است که توسط انجمن بینالمللی فتوگرامتری و سنجش از دور (ISPRS) منتشر شده است. مجموعه داده ISPRS حاوی تصاویر تقسیم بندی معنایی منطقه پوتسدام در مجموعه داده AISD بود، بنابراین منطقه پوتسدام در مجموعه داده ISPRS برای تأیید عملکرد تعمیم مدل انتخاب شد و این مجموعه داده Potsdam-B نام گرفت. Potsdam-B در مجموع شامل 38 تصویر سنجش از دور با برچسب دقیق بود، پنج نوع پیش زمینه وجود داشت: سطوح غیر قابل نفوذ، ساختمان، پوشش گیاهی کم، درخت و ماشین. نمایش داده ها در شکل 5 نشان داده شده است ، شکل 5 a تصویر اصلی و شکل 5 b برچسب است. در شکل 5ب، در مجموع شش دسته نشان داده شده است، شامل پنج دسته پیش زمینه و یک دسته پس زمینه.
اندازه متوسط تصاویر در مجموعه داده Potsdam-B بود 6000×6000، و همان استراتژی کشت مجموعه داده Potsdam-A برای به دست آوردن 5184 عکس اتخاذ شد. 512×512اندازه. در نهایت مجموعه داده ها به 4684 مجموعه آموزشی و 500 مجموعه تست تقسیم شد.
3.2. جزئیات پیاده سازی
این کار از میزان دقت کلی (OA)، نرخ فراخوان (Recall)، امتیاز F1 و تقاطع روی اتحادیه (IoU) به عنوان شاخصهای ارزیابی مدل برای تأیید تأثیر یادگیری مدل استفاده کرد، فرآیند محاسبه در معادلات نشان داده شده است. 9) – (13). OA نسبت پیکسل های صحیح پیش بینی شده در همه پیکسل ها است. یادآوری به نسبت پیکسل ها در نمونه مثبت واقعی پیش بینی شده به عنوان نمونه مثبت به پیکسل در نمونه مثبت اولیه اشاره دارد. امتیاز F1 میانگین هارمونیک یادآوری و دقت است. در میان آنها، دقت نسبت پیکسل های پیش بینی شده به عنوان نمونه های مثبت به پیکسل های پیش بینی شده به عنوان نمونه های مثبت است. IoU نسبت پیکسل هایی است که پیش بینی می شود نمونه های مثبت به همه پیکسل ها باشند. MIoU میانگین تجمعی IoU همه دسته ها است.
مدل در این کار یک روش یادگیری نظارت شده بود. در پایان مدل، برای ارزیابی شکاف بین مقدار پیشبینیشده و مقدار واقعی، باید یک تابع ضرر تنظیم شود. آنتروپی متقاطع عمدتاً برای اندازهگیری تفاوت بین دو توزیع احتمال در تئوری اطلاعات مورد استفاده قرار میگرفت و اغلب به عنوان تابع ضرر در یادگیری عمیق استفاده میشد. در این مقاله، تابع از دست دادن آنتروپی متقاطع ( سیEلoسس) برای اندازه گیری تفاوت بین مقدار پیش بینی شده و مقدار واقعی استفاده شد و از مقدار اختلاف برای هدایت مدل برای انجام انتشار مجدد و یادگیری پارامترهای بهینه استفاده شد. فرآیند اشتقاق از سیEلoسسدر معادله ( 14 ) نشان داده شده است:
که در آن m تعداد نمونه ها است، n نشان دهنده تعداد دسته ها است، پ(ایکسمنj)متغیر است (اگر دسته j و نمونه i یکسان هستند، 1 است، در غیر این صورت 0 است) q(ایکسمنj)نمونه احتمالی است که i کلاس j پیشبینی میشود .
پارامترهای آموزش شبکه به شرح زیر بود: استفاده از یک کارت گرافیک GTX1080TI برای محاسبه استنتاج در پلت فرم Ubuntu16.04. مدل با استفاده از چارچوب یادگیری عمیق Pytorch ساخته شد، مدل با 300 دوره همگرا شد، نرخ یادگیری اولیه 0.001 بود و هر 10 دوره در ضریب تضعیف 0.85 ضرب شد. با استفاده از adam به عنوان بهینه ساز برای بهینه سازی مدل، وزن_decay از بهینه ساز adam را 0.0001 و سایر پارامترها را به عنوان مقادیر پیش فرض قرار می دهیم.
3.3. تجزیه و تحلیل نتایج پیاده سازی
3.3.1. مقایسه شاخص ارزیابی آزمون مدل و اثر تجسم
- (1)
-
داده های تجربی اصلی نتایج تجربی Potsdam-A
به منظور تأیید اثربخشی مدل پیشنهادی ما، این کار آزمایشهای جامعی را روی مجموعه داده Potsdam-A انجام داد و شاخصهای مختلف در مجموعه آزمایشی از مدل موجود فراتر رفت. نتایج تجربی کمی خاص در جدول 1 نشان داده شده است ، و اثر مقایسه بصری در شکل 6 نشان داده شده است.. مدلهای مقایسه U-Net، FCN-8S، DeeplabV3+ و PSPNet بودند که شبکههای ستون فقرات تا حد ممکن با مقاله اصلی سازگار بودند. شبکه های ستون فقرات FCN-8S، DeeplabV3+ و PSPNet به ترتیب VGG16، ResNet-50 و ResNet-50 بودند. به منظور بررسی اثربخشی ماژول GFR پیشنهادی، آزمایشهای فرسایشی انجام شد. شبکه بدون ماژول GFR مورد آزمایش قرار گرفت و شبکه با ماژول sat NFSNet-1 نام گرفت.
همانطور که از جدول 1 مشاهده می شود ، شبکه NFSNet پیشنهاد شده در این مقاله، فراخوان، F1، OA و MIoU به ترتیب 86.96، 86.31، 82.43 و 70.54 درصد به دست آمد. شبکه پیشنهادی در این کار جستجوی اهمیت بین کانالهای لایه پنهان را تقویت کرد، به طور موثر اطلاعات ویژگی لایه پنهان را با نقشه ویژگی شبکه ستون فقرات یکپارچه کرد، و قضاوت نادرست منطقه بزرگ از قطع ارتباط ساختمان و جاده در تصاویر سنجش از دور را کاهش داد. هر چهار شاخص از شبکه های مقایسه فراتر رفتند [ 12 , 13 , 14 , 15 .]. شبکه U-Net با کمترین شاخص ها، OA و MIoU به ترتیب 77.35% و 63.61% را به دست آورد. FCN-8S که از VGG16 به عنوان شبکه اصلی استفاده می کرد، اندیکاتورهای کمی بهبود یافته بود، با 79.90٪ OA و 66.99٪ MIoU. DeeplabV3+، که از پیچش گشاد شده برای به دست آوردن یک میدان پذیرنده بزرگتر استفاده می کرد، در مقایسه با FCN-8S، با OA و MIoU به ترتیب 81.12% و 68.61% در دقت تقسیم بندی بهبود خاصی داشت. در مقایسه با Deeplabv3+، PSPNet از شبکه کانولوشن عمیق برای استخراج اطلاعات ویژگی های سطح بالا استفاده کرد و ماژول هرمی ویژگی برای همجوشی چند مقیاسی، 0.29 بیشتر از OA و 0.5 بالاتر از MIoU بود. شبکه تقسیم بندی معنایی پیشرفته فوق به دقت تقسیم بندی رضایت بخشی دست یافت. با این حال، در فرآیند ادغام ویژگی این شبکه ها، تقریباً تمام نقشههای ویژگی مستقیماً در بعد کانال به هم پیوسته و ادغام شدند و اطلاعات ویژگیهای لایههای پنهان (بعد کانال نقشه ویژگی) به طور مستقل توسعه و استفاده نشد که منجر به نادیده گرفتن دسته پیکسلهای زمینه در طبقهبندی پیکسل شد. ، منجر به مشکلاتی مانند قضاوت نادرست ساختمان و قطع ارتباط جاده ها می شود. در مقایسه با PSPNet با بالاترین شاخص در شبکه مقایسه، NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، بهتر از PSPNet در هر دو OA و MIoU عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد. و اطلاعات ویژگی های لایه های پنهان (بعد کانال نقشه ویژگی) به طور مستقل توسعه و استفاده نشده است که منجر به نادیده گرفتن مقوله پیکسل های زمینه در طبقه بندی پیکسل شده و در نتیجه مشکلاتی مانند قضاوت نادرست منطقه بزرگ ساختمان و قطع ارتباط جاده ها را به همراه دارد. . در مقایسه با PSPNet با بالاترین شاخص در شبکه مقایسه، NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، بهتر از PSPNet در هر دو OA و MIoU عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد. و اطلاعات ویژگی های لایه های پنهان (بعد کانال نقشه ویژگی) به طور مستقل توسعه و استفاده نشده است که منجر به نادیده گرفتن مقوله پیکسل های زمینه در طبقه بندی پیکسل شده و در نتیجه مشکلاتی مانند قضاوت نادرست منطقه بزرگ ساختمان و قطع ارتباط جاده ها را به همراه دارد. . در مقایسه با PSPNet با بالاترین شاخص در شبکه مقایسه، NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، بهتر از PSPNet در هر دو OA و MIoU عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد. منجر به نادیده گرفتن مقوله پیکسلهای زمینه در طبقهبندی پیکسل میشود و در نتیجه مشکلاتی مانند قضاوت نادرست ساختمان و قطع ارتباط جادهها به وجود میآید. در مقایسه با PSPNet با بالاترین شاخص در شبکه مقایسه، NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، بهتر از PSPNet در هر دو OA و MIoU عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد. منجر به نادیده گرفتن مقوله پیکسلهای زمینه در طبقهبندی پیکسل میشود و در نتیجه مشکلاتی مانند قضاوت نادرست ساختمان و قطع ارتباط جادهها به وجود میآید. در مقایسه با PSPNet با بالاترین شاخص در شبکه مقایسه، NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، بهتر از PSPNet در هر دو OA و MIoU عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد. NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، در هر دو OA و MIoU بهتر از PSPNet عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد. NFSNet ارائه شده در این مقاله با استفاده کامل از ویژگی های لایه پنهان، 1.02 بالاتر در OA و 1.43 بالاتر در MIOU، در هر دو OA و MIoU بهتر از PSPNet عمل کرد. NFSNet-1 بدون ماژول GFR بالاترین دقت را به جز NFSNet به دست آورد، با OA به 82.25٪ و MIOU به 70.17٪، اثربخشی ماژول پیشنهادی تأیید شد.
نتایج IOU دسته های مختلف مدل در مجموعه تست پوتسدام-A در جدول 2 نشان داده شده است. شاخصهای IOU مقولههای ساختمان، جاده و پسزمینه پیشنهاد شده توسط NFSNet در مجموعه آزمایشی به ترتیب 59.50٪، 71.19٪ و 80.91٪ بود که از چهار مقایسه عالی موجود بیشتر بود [ 12 ، 13 ، 14 ، 15 ].]. NFSNet با مدلهای دیگر مقایسه شد، IoU پسزمینه رده 2.02 بالاتر از بالاترین DeeplabV3+ بود، IoU رده جاده 1.74 بالاتر از بالاترین PSPNet بود، IoU ساختمان رده 0.73 بالاتر از بالاترین PSPNet بود. از نتایج تجربی می توان دریافت که NFSNet پیشنهاد شده در این کار به طور موثری دقت تقسیم بندی جاده ها و ساختمان ها را بهبود بخشیده است. بهبود دقت بخشبندی میتواند به طور موثر ساختمانها و جادهها را در تصاویر سنجش از دور شناسایی کند، که برای تحقق برنامهریزی دقیق شهری اهمیت زیادی دارد.
به منظور تسهیل مقایسه شهودی نتایج پیشبینی مدل، این کار نتایج پیشبینی مدلهای مختلف را تجسم کرد و شکل 6 را به دست آورد . شکل 6 مجموعاً پنج نقشه پیش بینی را نشان می دهد و هر ردیف در شکل 6 نقشه مقایسه ای یک تصویر را نشان می دهد. شکل 6 به شش ستون تقسیم شده است، ستون (a) برهم نهی تصویر اصلی و برچسب است، در حالی که ستون (b)-(f) به ترتیب با نمودار تجسم نتایج پیشبینیشده U-Net، FCN-8S مطابقت دارد. ، DeeplabV3+، PSPNet و NFSNet. کادرهای سبز در ستون (a) ناحیه جلوه برجسته NFSNet هستند. از ردیف اول در شکل 6مشاهده می شود که NFSNet پیشنهادی در این مقاله بهترین عملکرد را در کنترل نویز تقسیم بندی دارد. نتیجه تقسیمبندی، استخراج دقیق جادهها را محقق کرد و طبقهبندی اشتباه ساختمانها را تا حد زیادی کاهش داد. این دستاورد به NFSNet پیشنهاد شده در این کار نسبت داده شد، که شبکه موجود را نادیده گرفت استفاده از اطلاعات ویژگی لایه پنهان، و به طور کامل اطلاعات ویژگی لایه پنهان را کاوش کرد. نقشه ویژگی شامل دسته پیکسل های زمینه آن در طول طبقه بندی بود که به دستیابی به طبقه بندی دقیق کمک می کرد. از ردیف دوم شکل 6، مشاهده می شود که مناطق زیادی از پس زمینه به اشتباه به عنوان ساختمان از ستون (ب) تا ستون (ه) طبقه بندی شده است. شبکه ستون f که این کار پیشنهاد میکند میتواند بر این مشکل غلبه کند و با کاوش ویژگیهای معنایی لایه پنهان، پسزمینه را به دقت طبقهبندی کند. ردیف سوم و ردیف چهارم در شکل 6منعکس کننده وضعیت استخراج قطع ارتباط از جاده های شبکه مقایسه است. ستون های (ب) تا (و) اثر کاهش قطع ارتباط جاده را به ترتیب نشان می دهد. NFSNet پیشنهادی ما اساساً میتوانست طرح کلی جاده را استخراج کند، که نتیجه ادغام اطلاعات ویژگی لایه پنهان استخراج شده توسط ماژول SAFT از طریق ماژول GFR و نقشه ویژگی شبکه ستون فقرات بود. نقشه ویژگی ذوب شده نه تنها حاوی اطلاعات مکانی غنی از شبکه ستون فقرات بلکه اطلاعات ابعاد فضایی نقشه ویژگی لایه پنهان است که به طور موثر مشکل قطع ارتباط جاده را حل می کند. آخرین خط در شکل 6مشکل نامشخص بودن خطوط کلی ساختمان ها را نشان می دهد. شبکه ستون f که در این مقاله پیشنهاد شد، اطلاعات ویژگی لایه پنهان را به طور کامل بررسی کرد، نقشههای ویژگی اطلاعات معنایی غنی را ارائه کرد و به استخراج مؤثر طرح کلی ساختمانها دست یافت.
- (2)
-
تعمیم داده های تجربی نتایج تجربی Potsdam-B
از آنجایی که بازتاب عملکرد تعمیم مدل برای یک مجموعه داده مشکل بود، این کار از مجموعه داده Potsdam-B برای آزمایش عملکرد تعمیم مدل استفاده کرد. نتایج آزمایش پیش زمینه روی مجموعه تست پوتسدام-بی در جدول 3 نشان داده شده است. از جدول 3 مشاهده می شود که فراخوان، F1، OA و MIoU NFSNet به ترتیب به 89.12، 87.41، 87.52 درصد و 78.09 درصد رسیده است. همه شاخص ها بالاترین مقدار را به دست آوردند که می تواند اثربخشی و عملکرد تعمیم خوب مدل ارائه شده در این مقاله را اثبات کند.
این کار هر دسته را در مجموعه تست پوتسدام-بی کمیت کرد. از طریق آزمایشها، NFSNet پیشنهادی در این مقاله میتواند به اثر بخشبندی خوبی در دستههای مختلف دست یابد. در این میان، شاخص IoU سطوح غیرقابل نفوذ (Imp_sur)، ساختمان، پوشش گیاهی کم (Low_veg)، درخت و ماشین بالاترین مقادیر در مدل مقایسه بودند که میتواند ثابت کند NFSNet پیشنهادی ما دارای قابلیت تعمیم خوبی است. نتایج IoU برای هر دسته در مجموعه تست Potsdam-B در جدول 4 نشان داده شده است.
به منظور مقایسه بصری اثر تقسیم بندی مدل، این مقاله سه رندر را در شکل 7 نشان می دهد . از طریق مقایسه، می توان دریافت که به دلیل کاوی عمیق اطلاعات معنایی پنهان در شبکه ارائه شده توسط ما، نقشه ویژگی طبقه بندی شامل دسته پیکسل های زمینه آن است که وضعیت طبقه بندی نادرست منطقه بزرگ و دسته بندی پیوسته را بسیار کاهش می دهد. قطع ارتباط خطوط دوم و سوم شکل 7 به خوبی مزایای مدل پیشنهادی ما را نشان می دهد.
3.3.2. پارامترهای مدل و آزمایش های پیچیدگی
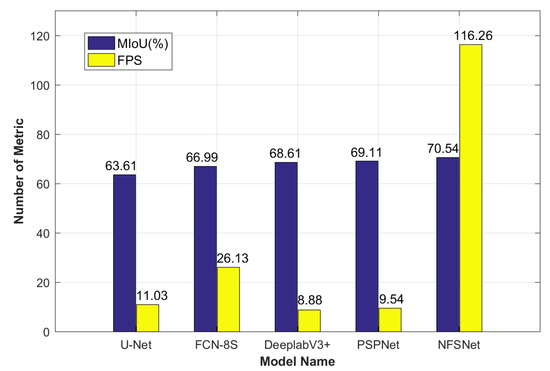
NFSNet پیشنهادی این مقاله نه تنها دارای سطح بالایی از دقت تقسیم بندی است، بلکه دارای مزایای خوبی در پارامترهای مدل، پیچیدگی مدل و سرعت استنتاج است. تعداد پارامترها، پیچیدگی مدل و سرعت استنتاج شبکه های مختلف در جدول 5 نشان داده شده است. به طور کلی، عملیات ممیز شناور (FLOPs، GFLOPs برابر است با 109از FLOPs) برای اندازه گیری پیچیدگی مدل و فریم در ثانیه (FPS) برای اندازه گیری سرعت استدلال استفاده شد. تجهیزات تست سرعت استنتاج یک GTX1080TI تک بود، ورودی یک تصویر اندازه سه کانال، در مجموع سه دسته است. وقتی NFSNet از ResNet-18 به عنوان شبکه اصلی استفاده کرد، کمترین پارامتر و GFLOP را داشت و سرعت استنتاج مدل سریعترین بود. مقدار پارامتر مدل 11.91 M بود که تنها 24% از PSPNet بود. پیچیدگی مدل 9.82 GFLOP بود که تنها 0.05٪ U-Net بود. سرعت استنتاج 116.26 FPS بود که 17.43 برابر PSPNet بود.
به منظور مشاهده مقایسه دقت تقسیم بندی مدل (MIoU) و سرعت استنتاج (FPS)، این مقاله نمودار مقایسه بصری مدل های مختلف در مجموعه داده Potsdam-A را ارائه می دهد، همانطور که در شکل 8 نشان داده شده است. ابسیسا شکل 8 نام مدل است و مختصات دقت تقسیم بندی MIoU و FPS است. به طور مستقیم از شکل 8 می توان دریافت که NFSNet با بالاترین دقت و سریع ترین سرعت استنتاج در رتبه اول قرار دارد.
3.3.3. آزمایش کمی سازی شبکه ستون فقرات
از آنجایی که شبکه اصلی مدل مقایسه از ResNet-50 استفاده میکرد، به منظور منصفانه بودن آزمایش، شبکه اصلی با ResNet-50 با لایه ResNet عمیقتر برای آزمایشهای مقایسه جایگزین شد و شبکه NFSNet* نام گرفت. نتایج مقایسه کمی شبکه ستون فقرات در جدول 6 نشان داده شده است. اگرچه NFSNet* OA و MIoU هر دو 0.24 بالاتر از NFSNet بودند، پارامترهای مدل 35.08M و پیچیدگی مدل 26.25 GFLOP حدود سه برابر NFSNet بود. علاوه بر این، NFSNet سرعت استنتاج 116.26 FPS داشت که 80 FPS سریعتر از NFSNet* بود.
این نشان دهنده مزیت استفاده از ResNet-18 به عنوان شبکه اصلی است. بدون از دست دادن دقت زیاد، NFSNet پیشنهادی ما با پیچیدگی مدل و مقدار پارامتر کمتر، هزینههای آموزشی زیادی را صرفهجویی کرد و عملکرد سرعت خوبی در استنتاج پیشبینی داشت.
4. نتیجه گیری
در این مقاله، NFSNet برای ساخت و تقسیم جاده تصاویر سنجش از دور با وضوح بالا پیشنهاد شده است. در مقایسه با شبکههای تقسیمبندی معنایی موجود، NFSNet دارای مزایای زیر است: (1) ماژول SAFT برای افزایش جستجوی اهمیت بین کانالهای لایه پنهان و به دست آوردن همبستگی بین کانالها ساخته شده است. اطلاعات معنایی لایه پنهان به نقشه ویژگی اصلی منتقل می شود که حاوی اطلاعات معنایی دسته هر پیکسل و پیکسل های زمینه آن است. بنابراین، مشکلات طبقهبندی نادرست ساختمانها و قطع ارتباط جادهها در فرآیند قطعهبندی قابل بهبود است. (2) با استفاده از ماژول GFR، اطلاعات ویژگی لایه پنهان استخراج شده از ماژول SAFT به طور موثر با نقشه ویژگی شبکه ستون فقرات ترکیب می شود. به این ترتیب، شبکه ستون فقرات می تواند اطلاعات ویژگی لایه پنهان را در بعد فضایی به دست آورد، اطلاعات ویژگی نمونه برداری بالا را افزایش دهد و دقت تقسیم بندی را بهبود بخشد. (3) مدل کمترین پیچیدگی را دارد اما به بالاترین شاخص دقت دست می یابد.
با این حال، هنوز برخی از نقص ها در بخش بندی ساختمان و جاده وجود دارد: (1) در دقت تقسیم بندی لبه ساختمان و جاده جا برای بهبود وجود دارد. (2) هنگامی که نویز زیادی در تصویر سنجش از راه دور وجود دارد، دقت تقسیم بندی کاهش می یابد. ما به بهینه سازی NFSNet ادامه خواهیم داد تا دقت تقسیم بندی لبه ساختمان و جاده را بهبود بخشیم و بر کاهش دقت تقسیم بندی ناشی از مقادیر زیاد نویز در تصاویر سنجش از دور غلبه کنیم. (3) ساختار ماژول ارائه شده در این مقاله را می توان به راحتی به مدل های دیگر پیوند داد، و ما روی شبکه های معیار بیشتری برای گسترش سناریوهای کاربردی غنی تر آزمایش خواهیم کرد.









بدون دیدگاه