1. مقدمه
جنگلهای استوایی که فراوانترین و پیچیدهترین اکوسیستم جنگلی هستند، در تنظیم اقلیم جهانی و ارائه خدمات مختلف اکوسیستمی بسیار مهم هستند. علیرغم اهمیت آنها، این جنگل ها نیز به شدت توسط جنگل زدایی، مزارع و سایر فعالیت های انسانی تهدید می شوند [ 1 ، 2 ]]. به دلیل پیچیدگی و تراکم ذاتی هنگام عبور از جنگلهای استوایی، بررسیهای میدانی بسیار ناکارآمد هستند و لازم است از روش طبقهبندی خودکار برای پایش دینامیکی منابع جنگلی استفاده شود. به عنوان یک فناوری رصدی در مقیاس بزرگ کارآمد، سنجش از دور مزایای آشکاری در پایش منابع جنگلی دارد. با استخراج و تجزیه و تحلیل اطلاعات مکانی با وضوح بالا و اطلاعات طیفی موجود در تصاویر، چنین فناوری قادر به طبقهبندی پوشش زمین در مناطق جنگلی با دقت بالایی است. بسیاری از محققان از فناوری مرتبط با سنجش از دور برای تحقیقات جنگل های استوایی استفاده کرده اند، مانند نقشه برداری کلاس های جنگل های استوایی [ 3 ، 4 ]، نظارت بر جنگل زدایی و تخریب [ 5 ]، و تخمین زیست توده [5]. 6 ] به کار برده اند.] که در این میان طبقه بندی دقیق پوشش زمین مبنای مطالعات مختلف است.
روشهای طبقهبندی سنجش از راه دور سنتی شامل جنگل تصادفی، k-نزدیکترین همسایه، ماشین بردار پشتیبان و سایر الگوریتمهای یادگیری ماشین است. از زمانی که مقاله هینتون منتشر شد [ 7 ]، روش های یادگیری عمیق به یک منطقه تحقیقاتی داغ برای پردازش تصویر تبدیل شده اند و مزایای زیادی نسبت به روش های طبقه بندی سنتی نشان داده اند. در میان روشهای یادگیری عمیق، مدلهای مختلف شبکه عصبی کانولوشنال (CNN) برای طبقهبندی صحنه محبوبیت بالایی کسب کردهاند [ 8 ، 9 ، 10 ، 11 ، 12 ]. شبکههای تقسیمبندی معنایی، که به شبکههای طبقهبندی در زمینههای سنجش از راه دور نیز گفته میشود، از این شبکهها توسعه یافتهاند. شبکه های کاملاً کانولوشنال (FCNs) [13 ، SegNet [ 14 ]، U-Net [ 15 ]، DeepLabv3+ [ 16 ]، و شبکههای مختلف سرتاسری برای بهبود دقت طبقهبندی شبکههای عصبی عمیق پیشنهاد شدهاند. با تعمیق شبکه ها، قابلیت استخراج ویژگی نیز تقویت شده است. بر این اساس، برخی از محققان مکانیسم های توجه را در طبقه بندی تصاویر معرفی کرده اند [ 17 ، 18 ]. ماژول های توجه باعث می شوند که شبکه بر روی مناطق کلیدی تمرکز کند و ویژگی ها و جزئیات را برجسته کند. این شبکههای توسعهیافته به تدریج چارچوبهایی را برای طبقهبندی تصاویر سنجش از دور فراهم میکنند [ 19]. شبکه های تقسیم بندی معنایی، به ویژه شبکه های عصبی کانولوشن، به طور گسترده در طبقه بندی کاربری زمین و پوشش زمین (LULC) [ 20 ، 21 ، 22 ، 23 27 ] استفاده می شود.]، استخراج جاده [ 24 ، 25 ]، استخراج ساختمان [ 26 ،] و غیره در حال حاضر هنوز مشکلات زیادی در طبقه بندی مناطق جنگلی استوایی و اطراف آن بر اساس شبکه های عصبی عمیق وجود دارد. جنگلهای استوایی بزرگ بلند و متراکم هستند و دارای سطوح متعدد از تاجپوش تا درختان زیرزمینی هستند. فراتر از آن، بافت و رنگ بسیاری از درختان کوچک یا مصنوعی کاشته شده کاملاً متفاوت است. با توجه به پیچیدگی پوشش گیاهی جنگل های استوایی، شبکه به توانایی بازنمایی بالایی برای استخراج صحیح جنگل ها نیاز دارد. علاوه بر این، پوشش زمین جنگل های استوایی نامتعادل است. مناطق جنگلی و آبی اکثریت کل مساحت را اشغال می کنند، در حالی که زمین های مصنوعی و زمین های کشاورزی نسبت بسیار کمی را تشکیل می دهند. هنگام استفاده از روش های موجود برای آموزش، اجسام زمینی نامتعادل منجر به نتایج طبقه بندی نامتعادل می شوند. در نتیجه به سمت مقوله هایی با اعداد زیاد گرایش پیدا می کند و دسته های کوچک را حذف می کند. بهینه سازی روش های موجود برای تقویت قابلیت های استخراج ویژگی هنگام استفاده از تصاویر با وضوح بالا و بهبود استحکام الگوریتم برای مجموعه داده های کوچک و نامتعادل ضروری است.
در این مطالعه، ما یک شبکه چندتوجهی باقیمانده جدید را برای طبقهبندی مناطق جنگلهای استوایی و بهبود کارایی و دقت نظارت بر جنگلهای استوایی در مقیاس بزرگ پیشنهاد میکنیم. یک CNN چند مقیاسی برای استخراج ویژگیهای چند مقیاسی از مناظر پیچیده گرمسیری معرفی شده است و یک مکانیسم توجه برای اصلاح نقشه ویژگی برای برجسته کردن اطلاعات فضایی و طیفی ویژگیهای کلیدی در تصاویر سنجش از دور چند طیفی با وضوح بالا استفاده میشود. برای به دست آوردن مرزهای دسته بندی صاف و پیوسته، مدل اطلاعات عمیق و کم عمق را با نمونه برداری چند مرحله ای جذب می کند. ما همچنین یک تابع از دست دادن مشترک ایجاد میکنیم و از یک استراتژی دو مرحلهای برای آموزش شبکه برای کاهش عدم تعادل نمونه در جنگلهای استوایی استفاده میکنیم، که همچنین یک مشکل رایج در مجموعه دادههای کوچک است.
2. مواد و روشها
2.1. منطقه مطالعه
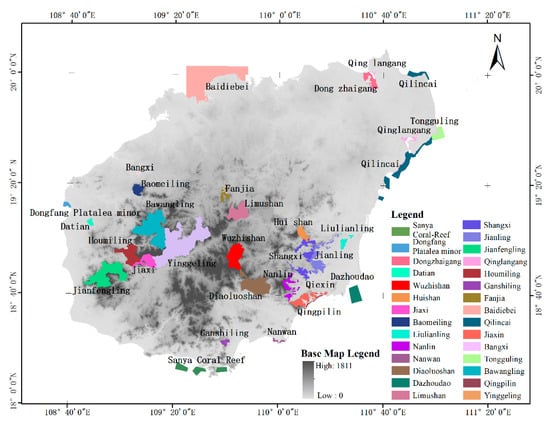
ما ذخایر طبیعی استوایی در جزیره هاینان، چین را به عنوان منطقه مورد مطالعه انتخاب کردیم. جزیره هاینان بزرگترین منطقه جنگل های بارانی استوایی چین و اکوسیستم جنگل های موسمی [ 28 ] را حفظ می کند و تنها جنگل بارانی «جزیره قاره ای» را در جنگل های بارانی استوایی و منطقه انتقال جنگل های پهن برگ همیشه سبز موسمی دارد. این جزیره بین 18°10′-20°10′ شمالی و 108°37′-111°03′ شرقی با مساحت کل تقریباً 33900 کیلومتر واقع شده است. .. محور اصلی جزیره از شمال شرقی به جنوب غربی امتداد دارد و حدود 290 کیلومتر طول دارد، در حالی که طول آن از شمال غربی به جنوب شرقی 180 کیلومتر است. جزیره هاینان پست و مسطح در اطراف است و دارای کوه های بلند در مناطق مرکزی است. کوه ها و تپه ها شکل اصلی جزیره هاینان هستند که بیش از 38 درصد از مساحت جزیره را تشکیل می دهند. کوههای Wuzhishan و Yinggeling هسته مناطق مرتفع را نشان میدهند. در اطراف کوهها و تپهها، سکوها و تراسهایی با عرضهای مختلف به طور گسترده پخش شدهاند. نواحی ساحلی بیشتر دشت های ساحلی و عمدتاً دشت های آبرفتی و دشت های دریایی هستند. توپوگرافی یک لندفرم لایه ای حلقه ای شکل با ساختار آبشاری مشخصی تشکیل می دهد که پهنه بندی ارتفاعی از پوشش گیاهی جنگل های استوایی را ایجاد می کند. جزیره هاینان دارای آب و هوای موسمی گرمسیری با میانگین بارندگی سالانه بالا و پوشش ابری چند ساله است و با فصول خشک و مرطوب مشخص می شود. فصل مرطوب از می تا نوامبر و فصل خشک از نوامبر تا آوریل ادامه دارد.
جنگل های طبیعی گرمسیری جزیره هاینان عمدتاً در مناطق کوهستانی بالای 500 متر از سطح دریا در جنوب شرقی، میانه-جنوب، جنوب غربی و وسط جزیره پراکنده شده اند. این انواع عمدتاً شامل جنگل های بارانی کوهستانی، جنگل های همیشه سبز کوهستانی، جنگل های حرا و جنگل های دیگر است. 29 ذخیره گاه طبیعی ملی و استانی بزرگترین و نماینده ترین مناطق جنگل های استوایی هستند. شکل 1).). این ذخایر عمدتاً در نواحی کوهستانی مرکزی و در امتداد ساحل پراکنده شده اند و از جنگل های بارانی استوایی، حرا، حیوانات وحشی نادر و گیاهان محافظت می کنند. در میان آنها، ذخیره گاه طبیعی ملی Yinggeling کامل ترین و متمرکزترین ذخیره گاه جنگل های بارانی استوایی با بیشترین مساحت است. پوشش زمین این ذخیرهگاه تحت سلطه جنگلهاست، از جمله جنگلهای حرا در Dongzhaigang و Qinglangang، جنگلهای Vatica hainanensis در ذخیرهگاه طبیعی Qingpilin، و بسیاری دیگر از گونههای جنگلی مشخص و به دنبال آن آب، با زمینهای کشاورزی و زمینهای مصنوعی که کمترین نسبت را اشغال میکنند.
ما دادههای پوشش زمین هاینان و تصاویر وسایل نقلیه هوایی بدون سرنشین (UAV) را برای کمک به انتخاب نمونه و تأیید نتایج جمعآوری کردیم. با استفاده از این ذخایر استوایی می توانیم درک بهتری از محیط اکولوژیکی جنگل های استوایی داشته باشیم.
2.2. مجموعه داده
از سه مجموعه داده استفاده شد، از جمله دو مجموعه داده هاینان Nature Reserve (مجموعه داده های A و B) که به طور خاص برای این تجزیه و تحلیل ساخته شده بودند و یک مجموعه داده عمومی. مجموعه داده A یک مجموعه داده کوچک است که برای تأیید عملکرد در مورد وضوح فوق العاده بالا و کیفیت های مختلف تصویر استفاده می شود. مجموعه داده B یک مجموعه داده کوچک است که برای تأیید عملکرد در مورد داده های چند طیفی و منابع تصویری متعدد استفاده می شود. تأثیر تغییرات فصلی، مانند رشد محصولات زراعی و علف، در مجموعه داده هاینان در نظر گرفته می شود و تصاویر در فصول مختلف می توانند توانایی نمایش را بهبود بخشند و عملکرد شبکه ها را آزمایش کنند.
2.2.1. مجموعه دادههای ذخیرهگاه طبیعی هاینان با تصاویر رنگی واقعی (مجموعه داده A)
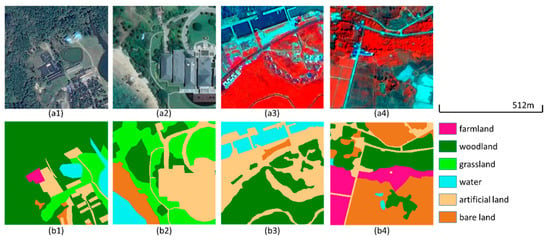
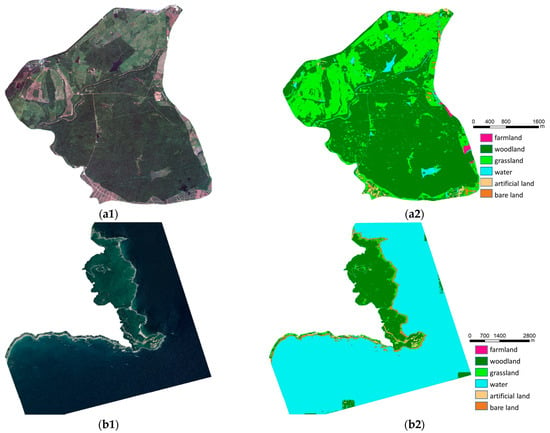
نمونههای رنگ واقعی (قرمز، سبز و آبی) از تصاویر Google Earth با وضوح فضایی 0.5 متر انتخاب شدند. این تصاویر برای سال های 2016 و 2017 به دست آمدند و نسبت فصل مرطوب به خشک آنها 5:4 بود. دو نمونه تصادفی در شکل 2 نشان داده شده است(a1,a2) و مختصات جغرافیایی نقاط مرکزی آنها در حدود (18°43’30″ شمالی، 109°52’5″ شرقی) و (19°38’35” شمالی، 110°59’12” شرقی است. ). بر اساس انواع ویژگیهای اصلی ذخایر طبیعی، ما شش دسته معنایی، یعنی زمینهای کشاورزی (SC1)، جنگلها (SC2)، علفزار (SC3)، آب (SC4)، زمین مصنوعی (SC5) و زمین برهنه (SC6) را تنظیم کردیم. ). ذخایر با مساحت وسیع و ویژگی های سطح غنی یا منحصر به فرد به عنوان مناطق معمولی برای انتخاب نمونه ها انتخاب شدند. اکثر نمونههای انتخابشده توانستند ویژگیهای سطحی منحصربهفرد و فعالیتهای انسانی، مانند جنگلهای حرا در Qinglangang، ساختمانهای مصنوعی در Sanya، و جادهها در Tongguling را برجسته کنند، در حالی که اطمینان حاصل شود که نمونهها از نظر جغرافیایی پراکنده هستند. ما به صورت دستی تصاویر را بر اساس نتایج تحقیقات میدانی، نقشههای پوشش زمین موجود و تصاویر پهپاد برچسبگذاری کردیم. و مجموعه داده A را به یک مجموعه آموزشی و یک مجموعه اعتبار سنجی با نسبت 4:1 مربوطه تقسیم کرد. با توجه به توانایی محدود برچسبگذاری دستی، ما 283 نمونه معرف مانند جنگلها و ساختمانها را انتخاب کردیم و برای افزایش تعداد نمونهها و تعادل در هر طبقه، دادهها را از طریق چرخش و چرخش افزایش دادیم. این پردازش همگرایی را تسریع کرد، تناسب بیش از حد را کاهش داد و توانایی تعمیم مدل را افزایش داد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد. با توجه به توانایی محدود برچسبگذاری دستی، ما 283 نمونه معرف مانند جنگلها و ساختمانها را انتخاب کردیم و برای افزایش تعداد نمونهها و تعادل در هر طبقه، دادهها را از طریق چرخش و چرخش افزایش دادیم. این پردازش همگرایی را تسریع کرد، تناسب بیش از حد را کاهش داد و توانایی تعمیم مدل را افزایش داد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد. با توجه به توانایی محدود برچسبگذاری دستی، ما 283 نمونه معرف مانند جنگلها و ساختمانها را انتخاب کردیم و برای افزایش تعداد نمونهها و تعادل در هر طبقه، دادهها را از طریق چرخش و چرخش افزایش دادیم. این پردازش همگرایی را تسریع کرد، تناسب بیش از حد را کاهش داد و توانایی تعمیم مدل را افزایش داد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد. و افزایش داده ها را از طریق چرخش و چرخش انجام داد تا تعداد نمونه ها افزایش یابد و هر کلاس متعادل شود. این پردازش همگرایی را تسریع کرد، تناسب بیش از حد را کاهش داد و توانایی تعمیم مدل را افزایش داد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد. و افزایش داده ها را از طریق چرخش و چرخش انجام داد تا تعداد نمونه ها افزایش یابد و هر کلاس متعادل شود. این پردازش همگرایی را تسریع کرد، تناسب بیش از حد را کاهش داد و توانایی تعمیم مدل را افزایش داد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد. مجموعه داده تکمیل شده نهایی شامل 1698 بلوک تصویر با اندازه 256 × 256 پیکسل بود. تصاویر با وضوح فوق العاده بالا برای آزمایش توانایی مدل در طبقه بندی دقیق سطوح استفاده شد. استفاده از داده ها با تفاوت کیفیت زیاد، داده های موجود را در عمل افزایش می دهد و توانایی یادگیری و ارزش کاربردی را افزایش می دهد.
2.2.2. مجموعه دادههای ذخیرهگاه طبیعی هاینان با تصاویر چند طیفی (مجموعه داده B)
ما مجموعه داده چند طیفی را ساختیم تا پوشش گیاهی را برجسته کنیم، که بازتاب آن در باند مادون قرمز نزدیک به سرعت افزایش مییابد. همچنین هدف ما افزایش تمایز بین جنگل، زمین مصنوعی و آب بود. داده ها از تصاویر چند طیفی و پانکروماتیک از ماهواره های Gaofen-1 (GF-1)، Gaofen-2 (GF-2) و Ziyuan-3 (ZY-3) به دست آمد. پارامترهای مربوطه برای سه مجموعه داده خام در جدول 1 نشان داده شده است. این سه ماهواره دارای محدوده طول موج یکسانی در باندهای چند طیفی هستند اما وضوح فضایی متفاوتی دارند. این امر ثبات اطلاعات طیفی را تضمین می کند در حالی که ویژگی های چند مقیاسی را ارائه می دهد، که برای استخراج جنگل های اولیه و مناطق آبی با ویژگی های فضایی کمی مفید است. پس از نمونه برداری مجدد باند پانکروماتیک GF-2 برای مطابقت با باندهای دیگر (با وضوح 2 متر)، باند پانکروماتیک دارای طول موج های کمی متفاوت اما وضوح فضایی برابر است. پس از کالیبراسیون رادیومتریک و تصحیح جوی سریع (QUAC)، تصاویر پانکروماتیک و چند طیفی با وضوح پانکروماتیک Gram-Schmidt برای به دست آوردن تصاویر چند طیفی با وضوح فضایی 2 متر × 2 متر ترکیب شدند.
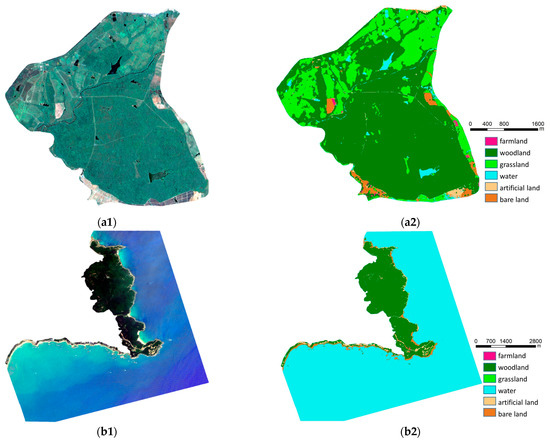
نمونه ها بر اساس همان اصل مجموعه داده A انتخاب شدند. تصاویر در سال 2018 به دست آمدند و نسبت تصاویر در فصول خشک و مرطوب حدود 1:3 بود. ما به صورت دستی تصاویر را بر اساس نتایج تحقیقات میدانی و نقشههای پوشش زمین موجود برچسبگذاری کردیم و مجموعه داده B را به یک مجموعه آموزشی و یک مجموعه اعتبار سنجی بر اساس نسبت 4:1 تقسیم کردیم. نمونهها پراکنده شدند، و هزینههای کار و زمان برای پردازش پیشپردازش تصاویر چند طیفی نسبتاً بالا بود، که منجر به نمونههای کمتری نسبت به مجموعه داده A شد. ما از چرخش و چرخش برای تقویت 125 نمونه انتخابشده استفاده کردیم. مجموعه داده تکمیل شده نهایی شامل 750 بلوک تصویر با اندازه 256 × 256 پیکسل بود و دو نمونه داده تصادفی در شکل 2 نشان داده شده است.(a3,a4) و مختصات جغرافیایی نقاط مرکزی آنها در حدود (18°13’54” شمالی، 109°29’39” شرقی) و (18°21’18” شمالی، 109°41’41” شرقی است. ). مجموعه داده چند طیفی برای تأیید توانایی شبکه برای استخراج اطلاعات طیفی و قابلیت کاربرد با داده های چند منبعی استفاده شد که همچنین میزان داده های موجود را برای کارهای واقعی افزایش داد.
2.2.3. مجموعه داده های عمومی
برای تأیید کاربرد مدل بهبودیافته، مجموعه دادههای عمومی را از مجموعه داده UC Merced Land Use [ 29 ] و مجموعه داده سنجش از دور برچسبگذاری متراکم (DLRSD) [ 30 ، 31 ] انتخاب کردیم.] برای تمرین. مجموعه داده UC Merced Land Use (یک مجموعه داده عمومی) یک مجموعه داده طبقه بندی صحنه با تصاویر کاربری زمین برای 21 کلاس با 100 تصویر برای هر کلاس است. ابعاد هر تصویر 256 × 256 پیکسل و وضوح فضایی 1 فوت است. مطابق با مجموعه داده UC Merced Land Use، DLRSD هر تصویر را با 17 کلاس معنایی تقسیم می کند. 17 برچسب کلاس زیر در این مجموعه داده در نظر گرفته شد: هواپیما، خاک برهنه، ساختمانها، ماشینها، چاپارال، دادگاه، اسکله، مزارع، چمن، خانههای متحرک، پیادهرو، شن، دریا، کشتیها، مخازن، درختان و آب. ما داده ها را با چرخش، چرخش، تبدیل گاما و روش های دیگر برای تصاویر تقویت کردیم. مجموعه داده نهایی شامل 16448 تصویر بود.شکل 3چهار تصویر را با نتایج برچسبگذاری پیکسلی مربوطه نشان میدهد که همه 17 کلاس را نشان نمیدهند. ما به طور تصادفی 80 درصد از تصاویر را به مجموعه آموزشی و 20 درصد را به مجموعه اعتبار سنجی اختصاص دادیم. تصاویر با وضوح بسیار بالا (VHR) برای تأیید توانایی مدل در طبقهبندی دقیق مناطق زمینی و 17 دسته معنایی برای تأیید عملکرد طبقهبندی مدل برای کارهای پیچیده با دستههای معنایی چندگانه استفاده شد.
2.3. مواد و روش ها
2.3.1. ساختار ResMANet
شبکه چندتوجهی باقیمانده (ResMANet) که در اینجا پیشنهاد شده است، ساختار رمزگذار – رمزگشا را اتخاذ می کند. رمزگذار ویژگی های تصویر را لایه به لایه استخراج می کند. رمزگشا نقشه ویژگی را نمونه برداری می کند و آن را با ویژگی های کم عمق ترکیب می کند تا به تدریج اندازه اصلی را بازیابی کند. نتیجه طبقه بندی سطح پیکسل از طریق یک تابع softmax به دست می آید. معماری کلی ResMANet در شکل 4 نشان داده شده است .
ماژول رمزگذار به ResNet-50 اشاره دارد و شامل 5 مرحله پیچیدگی است. بخش استخراج ویژگی شامل دو ساختار باقیمانده، یعنی “conv_block” و “identity_block” است ( شکل 5 ). ما هسته کانولوشن 3 × 3 conv_block را به هسته های کانولوشن 1 × 1، 3 × 3، 5 × 5 و 7 × 7 جایگزین کردیم و نقشه ویژگی به دست آمده توسط چهار هسته کانولوشن را به هم الحاق کردیم، که فیلد گیرنده را گسترش داد و استخراج کرد. ویژگی های فضایی چند مقیاسی اشیاء زمینی به منظور بهبود تشخیص مناظر مختلف.
ماژول توجه ترکیبی متوالی از توجه کانال و توجه فضایی را اتخاذ می کند [ 17 ]، و ساختارهای خاص در شکل 6 نشان داده شده است.. ماژول توجه کانال ابتدا اطلاعات مکانی یک نقشه ویژگی را با استفاده از هر دو عملیات ادغام میانگین جهانی (avg(c)) و ادغام حداکثر جهانی (max(c)) جمعآوری میکند و دو ویژگی متفاوت با کانالهای 1×1 ایجاد میکند. سپس هر دو ویژگی به دو لایه مشترک متراکم ارسال می شوند. پس از اعمال شبکه مشترک، دو بردار ویژگی را برای هر عنصر اضافه کردیم و نتیجه در ورودی اصلی ضرب شد تا نقشه توجه کانال نهایی به دست آید. این ماژول نوارهای طیفی کلیدی را برجسته می کند و برای داده های چند طیفی می تواند به طور قابل توجهی تمایز بین آب، پوشش گیاهی و زمین در ذخایر طبیعی را بهبود بخشد. ماژول توجه فضایی ابتدا اطلاعات یک نقشه ویژگی را با استفاده از ادغام متوسط (میانگین(ها)) و حداکثر ادغام (حداکثر(ها)) در امتداد محور کانال جمع می کند. ایجاد دو ویژگی مختلف که تعداد کانالهای آنها به 1 تبدیل میشود. پس از به هم پیوستن دو نقشه ویژگی، نتیجه به یک لایه کانولوشن با تابع فعالسازی ارسال میشود. نتیجه در ورودی اصلی ضرب می شود تا نقشه توجه فضایی نهایی به دست آید. این ماژول بر اشیاء و کانال های کلیدی تأکید می کند، اطلاعات تکراری را سرکوب می کند و با تمرکز بر اطلاعات مکان، مرز کلاس را بهینه می کند.
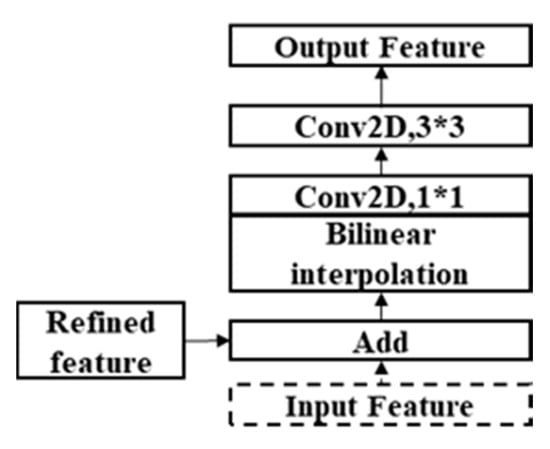
ماژول رمزگشا شامل لایههای upsampling، جمعبندی و کانولوشن است ( شکل 7). پس از الحاق نقشه ویژگی ورودی و نقشه ویژگی تصفیه شده به دست آمده با ماژول توجه، نتیجه به لایه upsampling با درون یابی دوخطی و کانولوشن 1×1 و سپس به لایه کانولوشن 3×3 ارسال می شود. ویژگی ورودی ماژول خروجی مرحله قبل است و ورودی اولین ماژول نمونه برداری فقط ویژگی تصفیه شده است. ماژول فوق تکرار می شود تا به تدریج نقشه ویژگی به اندازه اصلی بازیابی شود و در نهایت لایه softmax برای پیش بینی احتمال وارد شود. رمزگشا ویژگیهای کم عمق چند لایه را برای جبران اطلاعات موقعیت از دست رفته در ویژگیهای عمیق ادغام میکند و دقت مرز را برای اجسام کوچک بهبود میبخشد.
2.3.2. چهار شبکه SOTA Semantic Segmentation
ما چهار ساختار شبکه تقسیم بندی معنایی را به عنوان شبکه های مقایسه، U-Net، PSPNet (ResNet-50) انتخاب کردیم [ 32]، DeepLabv3+ (ResNet-50) و U-Net (ResNet-50). همه آنها ساختارهای رمزگذار-رمزگشا هستند، اما سه مورد آخر دارای ستون فقرات ResNet-50 هستند. U-Net اصلی شامل چهار لایه maxpooling متقارن و لایه های upsampling برای تشکیل یک ساختار U شکل است. رمزگذار ویژگی ها را استخراج کرده و به رمزگشا ارسال می کند. از طریق لایههای پیوسته، پیچیدگی و نمونهبرداری، ویژگیهای مقیاسهای مختلف ادغام شده و به اندازه ورودی بازیابی میشوند. ما رمزگشای U-Net را با ResNet-50 جایگزین کردیم تا U-Net (ResNet-50) را دریافت کنیم. PSPNet (ResNet-50) دارای یک ماژول ادغام هرمی برای استخراج زمینه جهانی در بالای ResNet-50 است و اندازه هسته ماژول 1 × 1، 2 × 2، 3 × 3، 6 × 6 است. DeepLabv3+ ( ResNet-50) شامل شبکه استخراج ویژگی، ماژول ادغام هرم فضایی آتروس (ASPP) و رمزگشا است. شبکه استخراج ویژگی یک ویژگی کم عمق و یک ویژگی عمیق را خروجی می دهد. پس از پالایش توسط ASPP، ویژگی عمیق با ویژگی کم عمق الحاق می شود و سپس به اندازه ورودی در رمزگشا بازیابی می شود.
2.3.3. عملکرد از دست دادن مشترک
عدم تعادل نمونه یک مشکل رایج است که هنگام استفاده از روش های یادگیری عمیق در عمل با آن مواجه می شود. به دلیل تفاوت های زیاد در نسبت اشیاء مختلف زمینی، این مشکل برای مجموعه داده های Hainan با برچسب دستی نیز ظاهر شد. برای حل این مشکل، یک تابع از دست دادن مفصل ساخته شد و یک استراتژی آموزشی دو مرحلهای برای کاهش عدم تعادل، کاهش بیشبرازندگی و بهبود دقت استخراج برای دستههایی با تعداد کم اعمال شد. مرحله اول تابع از دست دادن مشترک است که توسط از دست دادن آنتروپی متقاطع (CEL) و از دست دادن تاس تعمیم یافته (GDL) [ 33 ] (معادله (4)) ایجاد می شود. مرحله دوم از از دست دادن کانونی استفاده می کند [ 34] برای تنظیم دقیق وزن ها و تمایل مدل به سمت اشیایی که طبقه بندی آنها دشوار است. GDL از از دست دادن تاس ایجاد شده است، و تاس یک تابع اندازه گیری است که برای محاسبه شباهت دو نمونه استفاده می شود [ 35 ] (معادله (1)). اگر نمونه متعادل نباشد، از دست دادن تاس در تمرین ناپایدار است و منجر به تغییرات شیب سریع می شود. GDL می تواند این مشکل را تا حدی حل کند. هنگام انجام طبقهبندی چند کلاسه، هر کلاس دارای یک مقدار از دست دادن تاس است و این مقادیر وزن شده و ادغام میشوند تا یک افت تاس تعمیمیافته را تشکیل دهند (معادله (2)).
|الف| و |B| به ترتیب نشان دهنده پیش بینی و برچسب هستند. از آنجایی که عناصر مشترک بین A و B دو بار در مخرج محاسبه می شوند، عدد ضریب 2 دارد. مترتعداد کلاس ها است؛ نتعداد پیکسل ها است. rلnنشان دهنده حقیقت پایه مقوله است لدر پیکسل n ام، در حالی که پلnنشان دهنده احتمال پیش بینی شده مربوطه است. و wلوزن هر کلاس را نشان می دهد.
از دست دادن کانونی بهبود CEL برای وظایف تشخیص اشیای متراکم است. عمدتاً برای اندازه گیری تفاوت اطلاعات بین دو توزیع احتمال استفاده می شود. در مسائل چند طبقهبندی، مجموعه دادههای نامتعادل دو مشکل ایجاد میکنند، یعنی بسیاری از نمونهها اطلاعات بیفایده را در اختیار مدل قرار میدهند و تسلط نوع خاصی از نمونه، عملکرد مدل را کاهش میدهد. هدف از دست دادن کانونی حل مشکل با کاهش وزن نمونه های ساده و غالب است به طوری که مدل بر تمرین با نمونه های پراکنده و دشوار تمرکز می کند. زمانی که مقدار تلفات کانونی کوچک باشد، برای تنظیم دقیق مدل در مرحله دوم مناسب است. فرمول محاسبه به شرح زیر است:
جایی که γروی 2 تنظیم شده است، تیحقیقت زمین است و پتینشان دهنده احتمال پیش بینی شده است.
3. نتایج و بحث
در این بخش، تنظیمات دقیق آزمایشی و نتایج تجربی را همراه با تحلیل و مقایسه معقول ارائه میکنیم. آزمایشهای ما روی Python 3.5 و Keras 2.2 با کارت گرافیک NVIDIA GeForce GTX 1080 با 8 گیگابایت حافظه و CPU E5-2637 v4 با 16 گیگابایت رم انجام شد. ما از چهار شاخص دقت برای ارزیابی دقت طبقهبندی شبکه آموزشدیده استفاده کردیم، یعنی دقت تولیدکننده (PA)، دقت کاربر (UA)، دقت کلی (OA)، و میانگین تقاطع روی اتحادیه (MIoU). PA و UA میانگین هر دسته هستند. MIoU میانگین امتیاز IoU هر دسته است، در حالی که امتیاز IoU یک معیار عملکرد استاندارد برای مشکل تقسیم بندی دسته بندی اشیا است [ 36 ].
3.1. آزمایشات روی مجموعه داده A
لایه های کانولوشن روش اولیه سازی توزیع نرمال [ 37 ] را اتخاذ کردند، که به خوبی با توابع واحد خطی اصلاح شده (ReLU) کار می کند و سرعت همگرایی را بهبود می بخشد. نرخ یادگیری یک فراپارامتر است که فرآیند همگرایی را کنترل می کند. پس از تست های مکرر، میزان یادگیری مرحله اول 2 × 10-4 ، نرخ کاهش یادگیری 2 × 10-5 تنظیم شد.و اندازه دسته روی 8 تنظیم شد. برای اطمینان از نزدیکترین زمان ممکن به بهترین نقطه در طول تمرین، تعداد دورهها روی 100 تنظیم شد. میتوان آموزش را به صورت دستی قطع کرد یا دورهها را میتوان با توجه به دقت افزایش داد. در حین تمرین تغییر می کند وزن بهینه به عنوان وزن اولیه برای مرحله دوم انتخاب شد، میزان یادگیری بر روی 2 × 10-4 ، و نرخ فروپاشی یادگیری 2 × 10-5 تنظیم شد. زمانی که دقت بعد از تقریباً 5 تا 10 دوره دیگر بهبود نیافت، آموزش را پایان دادیم.
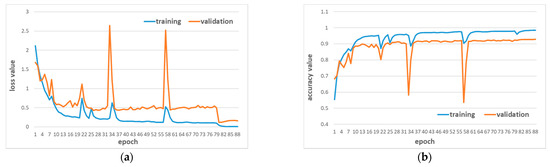
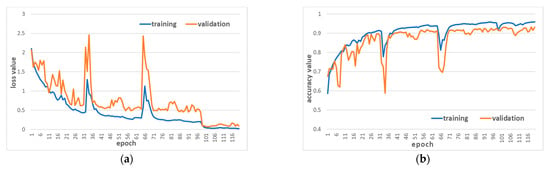
فرآیند آموزش مجموعه داده هاینان A در شکل 8 نشان داده شده است . از دست دادن آموزش و اعتبارسنجی از نظر نوسانات که ناشی از به روز رسانی وزن لایه های کم عمق بود، کاهش یافت و دقت اعتبارسنجی از 68.21 درصد به 92.39 درصد افزایش یافت. وزن بهینه مرحله اول (نتیجه صدک 79) به عنوان وزن اولیه مرحله دوم استفاده شد. توالی ورودی به هم ریخته شد و سپس وارد مرحله دوم یادگیری شد. هنگامی که دقت مجموعه اعتبار سنجی دیگر افزایش نیافته بود، آموزش متوقف شد و دقتی تا 92.81٪ پیدا کرد.
به منظور تأیید عملکرد الگوریتمها، کارایی آموزش و پیشبینی پنج شبکه را مقایسه کردیم ( جدول 2)). اگرچه شبکه ما بیشترین لایه ها را دارد، اما بازده آموزشی بهتر از PSPNet (ResNet-50) و U-Net است که نزدیک به DeepLabv3 + (ResNet-50) است و راندمان پیش بینی بهتر از DeepLabv3 + (ResNet-50) و نزدیک به PSPNet (ResNet-50). فراتر از آن، پنج مدل نیز برای پیشبینی دو تصویر در مجموعه اعتبارسنجی استفاده شد و پیشبینیها با حقایق پایه مقایسه شدند. هدف از طبقهبندی سطح، پایش منابع جنگلی و شناسایی فعالیتهای انسانی در مناطق جنگلی است. تشخیص دقیق فعالیت های انسانی مانند ساختمان ها، امکانات حمل و نقل و زمین های کشاورزی ضروری است. بنابراین، ما این دو تصویر را بر اساس دو اصل انتخاب کردیم، یعنی شامل هرچه بیشتر دسته بندی ها و نشان دهنده فعالیت های انسانی.شکل 9. پیش بینی های به دست آمده توسط شبکه های مختلف کاملاً متفاوت بود. اطلاعات کم عمق یکپارچه U-Net و عملکرد طبقهبندی برای اشیاء زمینی و بازیابی مرز خوب بود، اما عمق کم شبکه بر توانایی استخراج ویژگی تأثیر گذاشت و منجر به خطاهای طبقهبندی بین دستهها شد. PSPNet (ResNet-50) بر استخراج اطلاعات زمینه جهانی متمرکز شد و اطلاعات ویژگی های کم عمق را استخراج نکرد، که منجر به نادیده گرفتن ویژگی های کوچک و ایجاد مرزهای مبهم شد. DeepLabv3+ (ResNet-50) اطلاعات سطح عمیق را از طریق ماژول ادغام هرم فضایی atrous (ASPP) استخراج کرد و خروجی مرحله دوم رمزگذار را در طول فرآیند بازیابی ادغام کرد. سر و صدای داخلی کمی در هر کلاس وجود داشت و مرزها کمی بهبود یافته بودند. U-Net (ResNet-50) عملیات زیادی را با ویژگی های عمیق انجام نداد و ویژگی ها را با روش لایه به لایه بازیابی کرد تا به یک نقشه طبقه بندی خوب دست یابد. مشابه DeepLabv3+، خطاهای کمی وجود داشت، اگرچه یک مرز ناهموار ظاهر شد. روش ResMANet از پیچیدگی چند مقیاسی برای استخراج اطلاعات ویژگی های غنی تر استفاده می کند. دو ماژول توجه، کانال و اطلاعات فضایی اشیاء برجسته را حفظ میکنند تا مدل به خوبی بین انواع مختلف پوشش زمین تمایز قائل شود. در بین این مدل ها، مدل ما کمترین خطای طبقه بندی و بهترین بازیابی مرز را داشت. روش ResMANet از پیچیدگی چند مقیاسی برای استخراج اطلاعات ویژگی های غنی تر استفاده می کند. دو ماژول توجه، کانال و اطلاعات فضایی اشیاء برجسته را حفظ میکنند تا مدل به خوبی بین انواع مختلف پوشش زمین تمایز قائل شود. در بین این مدل ها، مدل ما کمترین خطای طبقه بندی و بهترین بازیابی مرز را داشت. روش ResMANet از پیچیدگی چند مقیاسی برای استخراج اطلاعات ویژگی های غنی تر استفاده می کند. دو ماژول توجه، کانال و اطلاعات فضایی اشیاء برجسته را حفظ میکنند تا مدل به خوبی بین انواع مختلف پوشش زمین تمایز قائل شود. در بین این مدل ها، مدل ما کمترین خطای طبقه بندی و بهترین بازیابی مرز را داشت.
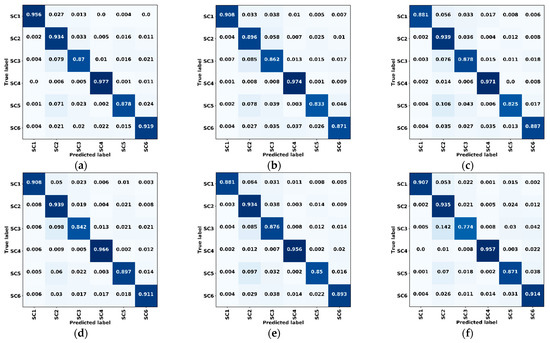
بر اساس مجموعه اعتبارسنجی، ماتریس های سردرگمی پنج شبکه محاسبه شد و در شکل 10 نشان داده شده است.، که در آن (الف) تا (ه) نتایج استفاده از تابع تلفات مشترک و (f) نتیجه استفاده از تلفات آنتروپی متقاطع است. به دلیل مزیت در اندازه نمونه، نتایج طبقهبندی عموماً به سمت دستههای جنگلی (SC2) و آب (SC4) متمایل شدند و بسیاری از پیکسلها به اشتباه در این دو دسته طبقهبندی شدند. شبکه ما بالاترین دقت را برای زمین های کشاورزی، آب و زمین های بایر داشت و در سایر رده ها نزدیک به بهترین بود. مقایسه بین نتایج بهدستآمده توسط تابع تلفات مشترک و نتایج بهدستآمده از تلفات متقاطع آنتروپی ثابت کرد که تابع ضرر مشترک که ما ساختهایم دقت طبقهبندی را برای دستههایی با تعداد کم، مانند زمینهای کشاورزی بهبود میبخشد و تأثیر عدم تعادل نمونه را کاهش میدهد.
از ماتریس های سردرگمی برای محاسبه شاخص های دقت کلی نشان داده شده در جدول 3 استفاده شد. دقت تولید کننده نشان دهنده این احتمال است که پوشش زمین معینی از یک منطقه روی زمین به این صورت طبقه بندی می شود و دقت کاربر به عنوان قابلیت اطمینان نامیده می شود. این دو شاخص مقادیر متوسط هستند. دقت کلی نسبت صحیح نتیجه را نشان می دهد. ما 0.50-3.22٪، 1.18-3.18٪ و 0.70-2.78٪ بهبودهایی برای این سه شاخص به دست آوردیم. به عنوان یک شاخص مهم در بینایی کامپیوتر، MIoU نشان دهنده نسبت تقاطع و اتحاد حقیقت زمین و پیش بینی ها است. با توجه به مجموعه داده های کوچک و تفاوت های کوچک با تصاویر رنگی واقعی، دقت تمام شبکه ها به طور کلی بالا بود. با این حال، بهبود 2.39-5.27٪ برای MIoU توسط شبکه پیشنهادی به دست آمد که عملکرد عالی شبکه را ثابت می کند.
ما از شبکه آموزش دیده برای طبقه بندی ذخایر طبیعی Datian و Tongguling استفاده کردیم که از نظر موقعیت جغرافیایی و نوع ویژگی متفاوت هستند. ذخیرهگاه طبیعی داتیان در شمال غربی جزیره هاینان، دور از ساحل واقع شده است و سطح آن بیشتر از جنگلها و مراتع پوشیده شده است. ذخیرهگاه طبیعی Tongguling در شرق جزیره Hainan قرار دارد و پوشیده از جنگلها و آب و برخی زمینهای مصنوعی در امتداد ساحل است. برای ورود به شبکه و ایجاد موزاییکی از پیشبینیها در یک مرز 30 پیکسلی، تصویر را به بلوکهای 256 × 256 پیکسل برش دادیم. نقشه های طبقه بندی نهایی دو ذخیره گاه طبیعی در شکل 11 نشان داده شده است.
هیچ طبقه بندی اشتباه در مقیاس بزرگ برای این دو ذخیره معمولی وجود نداشت. تشخیص زمین های مصنوعی، جنگل های بزرگ، و مناطق مرتع در منطقه حفاظت شده طبیعی داتیان دقیق بود. تعداد کمی از ویژگی های کوچک مانند رودخانه ها و جاده های سخت نشده با اشیاء مجاور اشتباه گرفته شد و در نتیجه ویژگی های ناپیوسته ایجاد شد. عملکرد طبقهبندی برای ذخیرهگاه طبیعی Tongguling بهتر بود و طبقهبندی زمینهای برهنه در امتداد ساحل، جنگلها و بیشتر جادههای آسفالتشده دقیق بود، در حالی که برخی از جادههای سختنشده با زمینهای لخت اشتباه گرفته میشدند. به دلیل وضوح بالای تصاویر و ویژگی های ترکیبی زمین، برخی از اشیاء تکه تکه می شدند و گاهی اوقات تشخیص دقیق کلاس آنها غیرممکن بود. با توجه به انتخاب تنها بخش کوچکی از منطقه معمولی، اکثر ذخایر درگیر آموزش نبودند. در این مورد، نتایج کلی عالی نیز عملکرد عالی مدل ارائه شده در اینجا را ثابت می کند. اگرچه مشکلات مربوط به ویژگیهای فضایی نامشخص و تفاوت زیاد بین جنگل و آب کاهش یافته است، اما همچنان سروصدا در مناطق جنگلی و حاشیه آب وجود دارد. با افزودن اطلاعات طیفی (مثلاً اطلاعات باند مادون قرمز نزدیک)، خطاهای مربوطه ممکن است بیشتر کاهش یابد.
3.2. آزمایشات روی مجموعه داده B
تنظیمات فراپارامتر مانند نرخ یادگیری مانند آزمایش قبلی بود. آموزش می تواند به صورت دستی قطع شود یا تعداد دوره ها با توجه به دقت مورد نظر افزایش یابد. فرآیند آموزش مجموعه داده هاینان B در شکل 12 نشان داده شده است . ضرر در طول آموزش و اعتبارسنجی با نوسان کاهش یافت و دقت اعتبارسنجی از 67.55% به 92.57% افزایش یافت. وزن بهینه در مرحله اول (نتیجه 97) به عنوان وزن اولیه در مرحله دوم استفاده شد. توالی ورودی به هم ریخته و سپس وارد مرحله دوم یادگیری شد. آموزش زمانی متوقف شد که دقت مجموعه اعتبار سنجی دیگر افزایش نیافته و به 93.20% رسید.
ما همچنین کارایی آموزش و پیشبینی پنج شبکه را مقایسه کردیم ( جدول 4 )، و ResMANet به کارایی بالایی در پردازش دادههای چند طیفی دست یافت. راندمان آموزشی بهتر از PSPNet (ResNet-50)، DeepLabv3+ (ResNet-50) و U-Net است و راندمان پیشبینی بهتر از DeepLabv3+ (ResNet-50) و PSPNet (ResNet-50) است. نزدیک به U-Net است. دقت چهار شبکه کلاسیک نیز با مجموعه اعتبارسنجی ارزیابی شد و نتایج از نظر عملکرد آنها در برابر ResMANet مقایسه شد ( شکل 13).). با توجه به هدف این مطالعه، ما دو تصویر اعتبارسنجی را انتخاب کردیم که حاوی فعالیتهای انسانی و تا حد امکان دستهبندی بودند تا عملکرد طبقهبندی شبکههای مختلف را ارائه کنیم. ما همچنین برای نشان دادن خطاهای طبقه بندی که عمدتاً در مرزهای بین دسته ها متمرکز بودند، نقشه های تفاوت ایجاد کردیم. پیشبینیها و نقشههای تفاوت بهدستآمده با شبکههای مختلف، تفاوتهای زیادی را نشان دادند. نتایج برای U-Net بیشترین خطاهای طبقه بندی و طبقه بندی اشیاء زمینی ناپیوسته را داشتند. همچنین بین زمین مصنوعی و زمین برهنه سردرگمی وجود داشت. بدون هیچ اطلاعات سطحی، PSPNet (ResNet-50) جدی ترین از دست دادن اطلاعات مرزی را نشان داد و مرزهای ناهموار ظاهر شد. DeepLabv3+ (ResNet-50) و U-Net (ResNet-50) نسبت به دو مدل قبلی، لایههای پیچیدهتری برای استخراج و بازیابی ویژگیها داشتند که باعث کاهش نویز داخلی برای دستهها و افزایش اطلاعات برای ویژگیهای کوچک میشد. شبکه ما اطلاعات باند مادون قرمز نزدیک را به طور کامل استخراج کرد به طوری که لکه های پوشش گیاهی و زمین مصنوعی به طور نادرست به طور قابل توجهی کمتر از سایر شبکه ها طبقه بندی شدند. شبکه پیشنهادی نه تنها سازگاری خوبی در کلاسها داشت، بلکه صافترین مرزها را نیز داشت که برای تمایز بین ویژگیهای داخلی اشیاء بزرگ و تشخیص اجسام کوچک و باریک مفید بود. شبکه ما اطلاعات باند مادون قرمز نزدیک را به طور کامل استخراج کرد به طوری که لکه های پوشش گیاهی و زمین مصنوعی به طور نادرست به طور قابل توجهی کمتر از سایر شبکه ها طبقه بندی شدند. شبکه پیشنهادی نه تنها سازگاری خوبی در کلاسها داشت، بلکه صافترین مرزها را نیز داشت که برای تمایز بین ویژگیهای داخلی اشیاء بزرگ و تشخیص اجسام کوچک و باریک مفید بود. شبکه ما اطلاعات باند مادون قرمز نزدیک را به طور کامل استخراج کرد به طوری که لکه های پوشش گیاهی و زمین مصنوعی به طور نادرست به طور قابل توجهی کمتر از سایر شبکه ها طبقه بندی شدند. شبکه پیشنهادی نه تنها سازگاری خوبی در کلاسها داشت، بلکه صافترین مرزها را نیز داشت که برای تمایز بین ویژگیهای داخلی اشیاء بزرگ و تشخیص اجسام کوچک و باریک مفید بود.
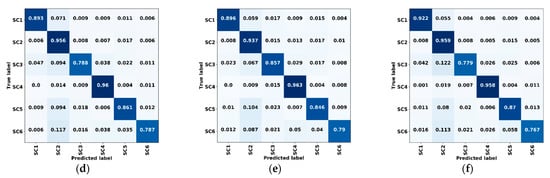
بر اساس مجموعه اعتبارسنجی، ماتریس های سردرگمی پنج شبکه محاسبه شد و در شکل 14 نشان داده شده است.، که در آن (الف) تا (ه) نتایج استفاده از تابع تلفات مشترک و (f) نتیجه استفاده از تلفات آنتروپی متقاطع است. با مزیت در اندازه نمونه، نتایج طبقهبندی نیز به سمت مناطق جنگلی (SC2) و آب (SC4) متمایل شد و بسیاری از پیکسلها در مناطق علفزار (SC3)، زمین مصنوعی (SC5) و زمینهای بایر (SC6) به اشتباه در این مناطق طبقهبندی شدند. دو دسته ResMANet کمترین درصد طبقهبندیهای غلط را داشت و بهترین دقت طبقهبندی را بین پنج دسته بهویژه برای علفزار، زمین مصنوعی و زمینهای بایر به دست آورد. استفاده از یک تابع از دست دادن مشترک به طور قابل توجهی دقت طبقه بندی را برای دسته هایی با تعداد کم، مانند علفزار و زمین های برهنه بهبود بخشید و نتایج را متعادل تر کرد. ماتریس های سردرگمی برای محاسبه شاخص های دقت کلی نشان داده شده در استفاده شدجدول 5 . ما به ترتیب 1.6-2.82٪، 1.86-6.8٪ و 1.34-3.17٪ بهبودهایی را برای PA، UA و OA به دست آوردیم. بهبود قابل توجه MIoU (3.25-7.38٪ بهبود) سازگاری بالا بین پیشبینیهای روش پیشنهادی و حقیقت پایه را ثابت میکند.
با شبکه آموزش داده شده بر روی مجموعه داده B، ما از همان روش های پیش بینی و موزاییک برای ارائه نقشه های طبقه بندی نهایی برای دو ذخیره استفاده کردیم ( شکل 15).). دادههای چند طیفی با وضوح 2 متر نسبت به دادههای رنگی واقعی تارتر بودند و تکه تکه شدن وصله کمتری داشتند. ماژول توجه کانال ResMANet اطلاعات باند مادون قرمز نزدیک را به طور کامل استخراج کرد و لکه های داخلی پوشش گیاهی و مناطق آبی را کاهش داد. مناطق جنگلی و علفزار در ذخیرهگاه طبیعی داتیان به خوبی متمایز بودند و مناطق آبی بهطور دقیق استخراج شدند. بین زمین برهنه و زمین کشاورزی با مناطق کوچک پوشش گیاهی سردرگمی وجود داشت. تقریباً هیچ خطای طبقه بندی برای مناطق آبی در ذخیره گاه طبیعی Tongguling وجود نداشت. یکنواختی مناطق جنگلی بسیار خوب بود، و نقشه طبقه بندی برای زمین های باریک باریک در ساحل قابل قبول بود، در حالی که جاده های سخت نشده و خاک برهنه تا حدی اشتباه شده بودند.
3.3. آزمایش بر روی مجموعه داده های عمومی
علاوه بر ذخایر استوایی، ما همچنین کاربرد مدل خود را با مجموعه دادههای UC Merced Land Use و مجموعه دادههای عمومی DLRSD تأیید کردیم. همان استراتژی آموزشی و تابع ضرر اعمال شد. مجموعه داده های عمومی شامل 17 کلاس معنایی با وضوح فوق العاده بالا است که نیازهای بالاتری برای مدل دارد. در حالی که مجموعه داده هاینان فقط شامل ذخایر طبیعی و مناطق مجاور بود، این مجموعه داده ها دارای منطقه اکتسابی وسیع تری هستند و بنابراین می توان از آنها برای تأیید کاربرد مدل برای وظایف طبقه بندی پیچیده استفاده کرد. ما همچنین دو تصویر اعتبار سنجی را انتخاب کردیم که تا حد ممکن دارای دسته بندی بودند تا عملکرد طبقه بندی شبکه های مختلف را ارائه دهیم. با استفاده از شبکه آموزش دیده برای پیش بینی دو تصویر در مجموعه داده اعتبارسنجی، نتایج و نقشه های تفاوت درشکل 16 .
از شکل می توان دریافت که توانایی بازنمایی شبکه های کم عمق ضعیف بوده است. برخی از دسته بندی های ترکیبی با U-Net وجود داشت، اگرچه اطلاعات مرزی به دلیل افزودن ویژگی های کم عمق چند مرحله ای به خوبی حفظ شد. شبکههای عمیق تواناییهای نمایش قویتر و عملکرد طبقهبندی بالاتری داشتند، اما برخی از خطاها هنوز به دلیل پیچیدگی ویژگی زمین رخ میدادند. مشابه آزمایشهای قبلی، نتایج شبکههای مبتنی بر ResNet-50 دارای خطاهای داخلی کمتری در دستهها بود. با این حال، تفاوت در استخراج اطلاعات عمیق و استفاده از اطلاعات سطحی منجر به تفاوت های زیادی در نتایج شد. مرزهای PSPNet (ResNet-50) به ویژه برای خاک و ساختمانها ناهموار بود. مرزهای DeepLabv3+ (ResNet-50) و U-Net (ResNet-50) واضح تر بودند، اگرچه با خطاهای طبقهبندی شدید، مانند طبقهبندی اشتباه روسازی به چمن (c3) و طبقهبندی اشتباه خاک برهنه به روسازی (e4). با توجه به مزایای ماژول های کانولوشنال و توجه چند مقیاسی، مدل ما بهترین قابلیت استخراج ویژگی های چند مقیاسی و دقیق ترین نتایج را داشت. مرزهای خاک برهنه، ساختمانها و درختان به شدت با حقایق زمین سازگار بود. با این حال، طبقه بندی اشتباه خاک لخت به روسازی نیز رخ داد (e5). دقت کلی در نشان داده شده است مرزهای خاک برهنه، ساختمانها و درختان به شدت با حقایق زمین سازگار بود. با این حال، طبقه بندی اشتباه خاک لخت به روسازی نیز رخ داد (e5). دقت کلی در نشان داده شده است مرزهای خاک برهنه، ساختمانها و درختان به شدت با حقایق زمین سازگار بود. با این حال، طبقه بندی اشتباه خاک لخت به روسازی نیز رخ داد (e5). دقت کلی در نشان داده شده استجدول 6 . شاخصهای دقت U-Net نسبت به سایر شبکههای عمیق کمتر بود که با لایههای کانولوشنی کمتر آن مشخص شد. عملکرد U-Net (ResNet-50) بهتر از U-Net بود، اما بدتر از دو شبکه دیگر با ResNet-50 بود که به دلیل توانایی ناکافی برای استخراج اطلاعات جهانی با U-Net است. تفاوت دقت بین DeepLabv3+ (ResNet-50) و PSPNet (ResNet-50) معنیدار نبود. شبکه ما بهترین عملکرد و بهترین دقت را بهویژه از نظر بهبود MIoU به دست آورد که نشاندهنده توانایی تمایز زیادی برای 17 دسته معنایی است.
این نتایج تصویر و شاخصهای دقت ثابت میکنند که شبکه ما برای انجام وظایف بخشبندی معنایی پیچیده کافی است و کاربرد وسیعتری دارد.
4. نتیجه گیری
جنگلها و محیطهای استوایی در جزیره هاینان دارای موقعیتهای جغرافیایی بیولوژیکی غیرعادی در بافت چین و ویژگیهای منطقهای خاص هستند. مطالعه عمیق جنگل ها و محیط های استوایی مستلزم طبقه بندی دقیق پوشش زمین است. برای به دست آوردن خودکار اطلاعات کاربری و پوشش زمین برای جنگلهای استوایی و مناطق اطراف، یک مدل طبقهبندی بهبودیافته بر اساس یک شبکه پیچیده عمیق، ساخت یک مدل سرتاسر، و گسترش دامنه کاربرد فناوریهای مرتبط پیشنهاد کردهایم. این مدل طبقه بندی می تواند کارهای دستی مانند تفسیر بصری و ترسیم دستی را کاهش دهد. با اعمال پیچیدگی چند مقیاسی، یک ماژول توجه، و نمونهبرداری لایه به لایه برای بهبود شبکه اصلی، مدل ما میدان دریافت را گسترش میدهد. قابلیت های استخراج ویژگی را افزایش می دهد و اطلاعات عمیق و کم عمق را به طور کامل یکپارچه می کند. استراتژی آموزشی چند مرحله ای، وزنه های شبکه را قادر می سازد تا به سرعت بدون تطبیق بیش از حد همگرا شوند. با این توابع از دست دادن، مدل تمایل به استخراج اطلاعات ویژگیهای سطح زمین برهنه و زمین مصنوعی دارد و تأثیر نمونههای غالب مانند جنگلها را متعادل میکند.
ما بهصورت دستی مجموعهدادههای رنگ واقعی و چند طیفی Hainan را مشخص کردیم تا عملکرد ResMANet را با شرایط وضوح فوقالعاده بالا و کیفیتهای مختلف تصویر، و همچنین اطلاعات چند طیفی و منابع تصویری متعدد تأیید کنیم. در مقایسه با چهار مدل پیشرفته، مدل پیشنهادی دقیقتر بود و دقت کلی 92.80% و 93.17% را برای دو مجموعه اعتبارسنجی به دست آورد. این نه تنها سازگاری خوبی در کلاس ها داشت، بلکه صاف ترین مرزها را نیز داشت. نوار مادون قرمز نزدیک به طور کامل استخراج شد تا یکنواختی را بهبود بخشد و خطاها را در مناطق پوشش گیاهی و آبی و برخی از طبقات زمین مصنوعی کاهش دهد. نقشههای طبقهبندی تصفیهشده کلی برای ذخایر نیز بهطور شهودی عملکرد عالی مدل برای ذخایر استوایی Hainan و چشمانداز کاربرد در سایر مناطق جنگلهای استوایی را نشان میدهد. علاوه بر مجموعه داده هاینان، ResMANet به دقت کلی 91.52% با مجموعه داده عمومی دست یافت که توانایی خوب خود را برای مشکلات پیچیده چند کلاسه و چشم انداز کاربردی گسترده آن ثابت کرد. از طریق استفاده از یک تابع از دست دادن مشترک و یک استراتژی آموزشی دو مرحله ای، اثر عدم تعادل نمونه در سه مجموعه داده به طور قابل توجهی کاهش یافت.
افزودن اطلاعات نزدیک به مادون قرمز به داده های آموزشی، عملکرد شبکه را برای طبقه بندی کاربری زمین و پوشش زمین بهبود بخشید. در مراحل بعدی بهینه سازی الگوریتم را از دو جنبه ادامه خواهیم داد. جنبه اول افزایش غنای اطلاعاتی برای ورودیها است، مانند افزودن اطلاعات مدل سطح دیجیتال و اطلاعات فراطیفی برای گیاهان گرمسیری. دوم بهبود بیشتر قابلیت استخراج و بازیابی ویژگی های شبکه برای استفاده کامل از نمونه های آموزشی است. در عین حال، ما امیدواریم که دامنه کاربرد الگوریتم را بر اساس مجموعه داده های کوچک و نیازهای سخت افزاری کم گسترش دهیم.












بدون دیدگاه