

خلاصه
کلید واژه ها:
عنصر آدرس چینی شبکه عصبی Bi-GRU ; بخش بندی آدرس ویتربی
1. معرفی
- (1)
-
به دلیل وسعت سرزمین چین، ملیتهای متعدد و تفاوتهای جغرافیایی و فرهنگی زیاد، آدرسهای چینی در وضعیتی بینظم و فاقد استانداردهای یکسان هستند و باعث سردرگمی میشوند. بنابراین، تا به امروز، چین یک استاندارد نامگذاری آدرس یکپارچه چینی معتبر و قابل اعتمادی که کل کشور را پوشش دهد، ایجاد نکرده است. در حال حاضر، با ظهور عصر داده های بزرگ، بیان آدرس چینی پیچیده تر و متنوع تر شده است [ 11 ]. این اختلال و سردرگمی فوق را تشدید می کند. این وضعیت تقسیم بندی عناصر آدرس چینی را پیچیده می کند.
- (2)
-
بر خلاف جملات انگلیسی، که در آن فاصله ها به عنوان خطوط جداکننده طبیعی بین کلمات وجود دارد، جملات چینی را می توان تنها با علائم نگارشی مختلف تعریف کرد. مرحله تقسیمبندی آدرس چینی بسیار دشوارتر از بسیاری از زبانهای دیگر است که فضاها جداکنندههای طبیعی هستند.
- (3)
-
با توجه به سیستم مدیریت نام مکان و آدرس منحصر به فرد چین و تنوع و پیچیدگی آدرس های چینی [ 12]، ادارات دولتی در همه سطوح، ادارات برنامه ریزی و ادارات حمل و نقل برای مدت طولانی فاقد منابع اطلاعاتی آدرس قابل اعتماد، استاندارد و واحد بوده اند. به عنوان مثال، در مدیریت نامگذاری آدرس پکن، نامگذاری بخشهای اداری در تمام سطوح توسط اداره امور عمرانی پکن، نامگذاری جادهها توسط اداره ترافیک و برنامهریزی پکن و پلاکهای نامگذاری خانهها مدیریت میشود. ، ساختمان ها، واحدها و صفحات خانگی (اتاق) توسط اداره امنیت عمومی پکن مدیریت می شود. دستیابی به عبارات آدرس واحد به دلیل استانداردهای مختلف نامگذاری آدرس و نظارت مدیریتی چندین بخش دشوار است [ 13]]. این همچنین مدیریت آدرس ها را دشوارتر می کند و دقت تقسیم بندی برای انواع مختلف عناصر آدرس بسیار متفاوت است.
2. آثار مرتبط
2.1. آثار قبلی
- (1)
-
روش تطبیق رشتهای مبتنی بر فرهنگ لغت، رشتههایی را که قرار است با یک کتابخانه فرهنگ لغت تقسیم شوند، یک به یک مطابق با استراتژی خاصی مطابقت میدهد. با توجه به جهات مختلف تطبیق رشته ها، استراتژی های تطبیق را می توان به سه نوع تقسیم کرد: تطبیق حداکثر رو به جلو، تطبیق حداکثر معکوس و حداکثر تطبیق دو طرفه. اجرای این روش آسان است، دقت قطعه بندی بالایی دارد و سریع است، بنابراین بیشترین استفاده را دارد. بسیاری از محققان عملکرد تقسیم بندی کلمات این روش را با بهبود ساختار فرهنگ لغت بهبود بخشیده اند. به عنوان مثال، وانگ و همکاران. [ 18] از الگوریتم درخت سه آرایهای دوگانه برای پردازش ترجیحی گرهها با گرههای شاخه بیشتر استفاده کرد تا کارایی جستجوی فرهنگ لغت را بهبود بخشد و فضای ذخیرهسازی دادههای لازم را کاهش دهد. لی و همکاران [ 19 ] و مو و همکاران. [ 20 ] از مکانیزم نمایه سازی هش دو کاراکتری برای بهبود دقت تقسیم بندی کلمات و کوتاه کردن زمان تقسیم بندی استفاده کرد. با این حال، روش تطبیق رشته ای مبتنی بر فرهنگ لغت نمی تواند به شناسایی کلمات مبهم و کلمات ثبت نشده بپردازد.
- (2)
-
روش تقسیم بندی کلمه بر اساس قواعد معنایی است. ایده اصلی این روش استفاده از اصول واژهسازی، ویژگیهای بخشی از گفتار و پایگاههای اطلاعاتی معنایی برای ساخت قوانین خاص بر اساس معناشناسی است. به عنوان مثال، لی و همکاران. [ 21 ] یک روش تقسیم بندی آدرس چینی را بر اساس ترکیبی از قوانین و آمار پیشنهاد کرد. این روش از روش های آماری برای استخراج اطلاعات آدرس از مجموعه آدرس اصلی استفاده می کند و از روش مبتنی بر قانون برای بخش بندی آدرس های چینی استفاده می کند. ژانگ و همکاران [ 22] یک پایگاه داده ویژگی عنصر آدرس را بر اساس انواع مختلف عناصر آدرس ساخت و تقسیم بندی آدرس چینی را بر اساس پایگاه داده ای از این ویژگی های کاراکتر انجام داد. مزیت این روش این است که به شدت با انواع خاصی از کلمات مرتبط است و دقت قطعه بندی بالایی دارد. با این حال، برچسب گذاری مصنوعی و استخراج ویژگی مورد نیاز است و برخی مشکلات مانند ویژگی های پراکنده و سازگاری ضعیف وجود دارد.
- (3)
-
روش تقسیم بندی کلمات بر اساس یادگیری ماشینی مرسوم است. ایده اصلی این روش آموزش مدلی در برچسب گذاری کاراکترها و در نظر گرفتن فراوانی و اطلاعات متنی کلمات است. بنابراین، این روش توانایی یادگیری مطلوبی را ارائه می دهد و در تشخیص کلمات مبهم و کلمات ثبت نشده عملکرد خوبی دارد. از جمله مدل های رایج استفاده شده می توان به مدل حداکثر آنتروپی [ 23 ، 24 ]، مدل مارکوف پنهان (HMM) [ 25 ، 26 ] و مدل میدان تصادفی شرطی (CRF) [ 27 ، 28] اشاره کرد.]. سه مدل بالا برای آموزش به مقادیر زیادی داده برچسبگذاری مصنوعی نیاز دارند و به راحتی تحت تأثیر انتخاب ویژگی دستی قرار میگیرند.
- (4)
-
روش تقسیم بندی کلمه بر اساس یک شبکه عصبی است. ایده اصلی شبیه سازی عملکرد مغز انسان، توزیع پردازش و ایجاد یک مدل محاسبه عددی است. این فرآیند روش ضمنی را برای درک تقسیمبندی کلمات در شبکه عصبی ذخیره میکند و از طریق خودآموزی و آموزش وزنهای داخلی، به نتیجه تقسیمبندی صحیح کلمات دست مییابد. شبکه عصبی می تواند به طور خودکار ویژگی ها را بیاموزد و از محدودیت های استخراج ویژگی های دستی معمولی اجتناب کند. به عنوان مثال، چن و همکاران. [ 29 ] از یک شبکه عصبی حافظه کوتاه مدت (LSTM) استفاده کرد، زیرا یک شبکه عصبی عمومی نمی تواند روابط وابستگی از راه دور را یاد بگیرد. چن و همکاران [ 30] یک شبکه عصبی بازگشتی دروازهای (GRNN) پیشنهاد کرد که ویژگیهای پیچیده شخصیتهای متنی و یک روش آموزش لایهای نظارت شده را برای دستیابی به یک مدل تقسیمبندی کلمات بهتر ترکیب میکند.
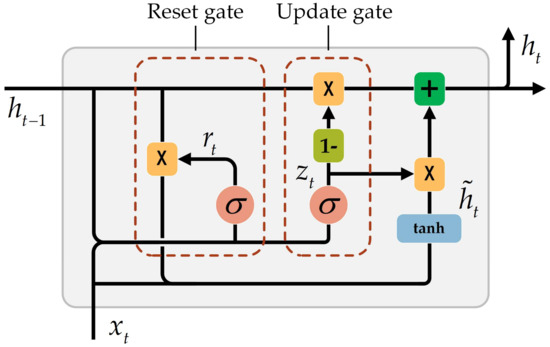
2.2. شبکه عصبی GRU
در شکل 1 ، zتیدروازه به روز رسانی است، rتیدروازه تنظیم مجدد است، ساعت˜تیحالت مخفی نامزد گره پنهان فعلی است، ساعتتیحالت پنهان فعلی است، ایکستیورودی شبکه عصبی فعلی است و ساعتتی-1حالت پنهان در لحظه قبل است. فرمول محاسبه دقیق به شرح زیر است:
جایی که σتابع فعال سازی است سمنgمترoمند، که از 0 تا 1 متغیر است، ⊙حاصلضرب هادامارد ماتریس است، wو توماتریس های وزنی هستند که باید یاد بگیرند و zتیو rتیمحدوده از 0 تا 1. در بخش بندی عنصر آدرس چینی، گیت تنظیم مجدد عمل می کند ساعتتی-1برای ثبت تمام اطلاعات مهم که به عنوان محتوای حافظه نیز شناخته می شود. همانطور که در فرمول (3) نشان داده شده است، دروازه تنظیم مجدد از بردارهایی از 0 تا 1 تشکیل شده است. بنابراین، پس از به دست آمدن محصول هادامارد، گیت تنظیم مجدد تعیین می کند که چه مقدار از حالت پنهان در زمان قبلی باید در حافظه فعلی فراموش شود. محتوا. سپس اطلاعات ورودی فعلی اضافه شده و در عملکرد فعال سازی قرار می گیرد. از این رو، ساعت˜تیتمام اطلاعات مهم را از طریق گیت تنظیم مجدد و اطلاعات ورودی ثبت می کند. گیت به روز رسانی وضعیت پنهان فعلی را تعیین می کند ساعتتیبا عمل کردن ساعتتی-1و ساعت˜تیو آن را به واحد بعدی منتقل می کند. همانطور که در فرمول (4)، اولین ترم از طریق نشان داده شده است 1-zتیتعیین می کند که چه اطلاعاتی باید فراموش شوند و اطلاعات مربوطه در محتوای حافظه در این زمان به روز می شود. عبارت دوم فرمول میزان اطلاعات را تعیین می کند ساعتتی-1در حالت پنهان فعلی حفظ می شود. از این رو، ساعتتیتصمیم به جمع آوری اطلاعات مورد نیاز در ساعت˜تیو ساعتتی-1از طریق گیت آپدیت
2.3. تقسیم بندی کلمات Jieba
2.4. عنصر آدرس چینی
آدرسهای چینی نیازمند روشهای کدگذاری انتزاعی با توصیف موقعیت مکانی از طریق سازماندهی مدلهای زبان طبیعی و بیان آدرس [ 8 ] است. این را می توان به صورت زیر بیان کرد:
جایی که آآدرس چینی است، ایکسمنعنصر آدرس چینی است و پایکسمن،ایکسjرابطه محدودیت مکانی بین عناصر آدرس است و نمی تواند خالی باشد. رابطه محدودیت فضایی به محدودیت توپولوژیکی بین موجودات جغرافیایی مربوط به عناصر آدرس اشاره دارد.
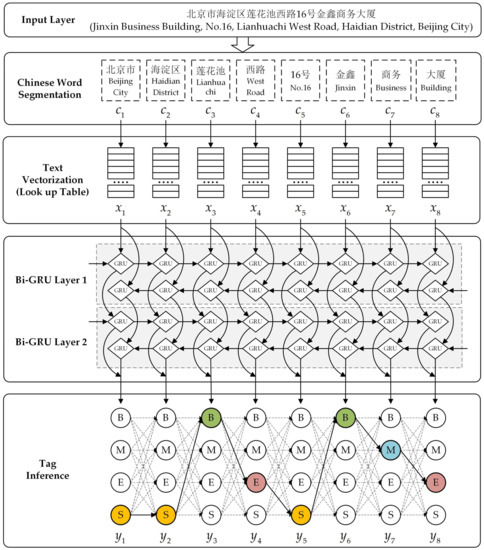
3. بخش بندی عناصر آدرس چینی
- (1)
-
تقسیم بندی کلمات چینی: توالی آدرس چینی با استفاده از ابزار تقسیم بندی کلمات چینی و ویژگی های عناصر آدرس به چندین کلمه مستقل تقسیم می شود. این کلمات مستقل به عنوان ورودی برای برداری متن استفاده می شود.
- (2)
-
بردار سازی متن: نمایش بردار ویژگی هر کلمه از طریق یک جدول جستجو پیدا می شود و این بردارهای ویژگی به عنوان ورودی شبکه عصبی استفاده می شود.
- (3)
-
شبکه عصبی: شبکه عصبی Bi-GRU برای تولید نمایش ویژگی برچسب هر کلمه و به عنوان ورودی استنتاج برچسب استفاده می شود.
- (4)
-
استنتاج برچسب: الگوریتم Viterbi برای یافتن حداکثر ترکیب برچسب ممکن به عنوان دنباله برچسب نهایی استفاده می شود.
3.1. تقسیم بندی کلمات چینی
- (1)
-
اعداد عموماً اطلاعاتی مانند شماره خانه، شماره ساختمان، شماره واحد، شماره طبقه و شماره اتاق را نشان می دهند. روش پردازش عدد را با پیشوند و پسوند ترکیب میکند تا آن را به یک کلمه تغییر دهد، مانند “甲2号 (شماره 2 A)” در “前门大街甲2号 (شماره 2 خیابان کیانمن)” به عنوان یک کلمه. .
- (2)
-
حروف انگلیسی به طور کلی با پیشوندها و پسوندها ترکیب می شوند تا یک موجود جغرافیایی خاص را نشان دهند، مانند “望京SOHO中心 (مرکز Wangjing SOHO)”. روش پردازش تمام حروف انگلیسی مجاور را در یک کلمه ترکیب می کند.
- (3)
-
کاراکترهای ویژه معمولاً به عنوان اطلاعات توصیفی اضافی یا برخی اطلاعات پیش فرض بیان می شوند. در “东城区天坛路1号(天坛公园北门) (شماره 1 جاده تیانتان، منطقه دونگ چنگ (دروازه شمالی معبد پارک بهشت))، اطلاعات داخل پرانتز شرح اضافی اطلاعات آدرس قبلی است. . در روش پردازش، برای کاراکترهای خاصی که اطلاعات براکتی دارند، براکت ها و اطلاعات داخل آن حذف می شوند و نمادهای خاص غیر از براکت ها به عنوان کلمه در نظر گرفته می شوند.
3.2. بردار سازی متن
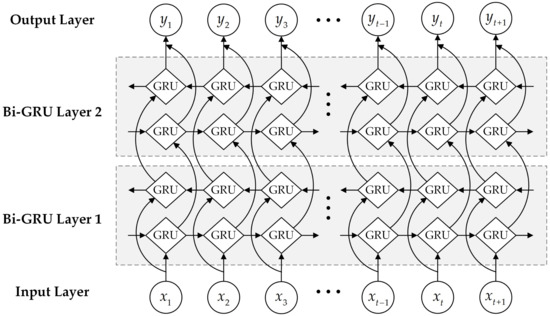
3.3. شبکه عصبی Bi-GRU
از جمله، در شبکه عصبی Bi-GRU هر لایه، لایه جلو خروجی لایه پنهان را در هر زمان از جلو به عقب محاسبه می کند و لایه عقب خروجی لایه پنهان را در هر زمان از عقب به جلو محاسبه می کند. . لایه خروجی نتایج خروجی لایه رو به جلو و لایه عقب را در هر لحظه روی هم قرار داده و عادی می کند:
جایی که ساعتتی1→∈آراچو ساعتتی2→∈آراچبردارهای خروجی لایه پنهان لایه جلویی در لایه های اول و دوم شبکه عصبی Bi-GRU در زمان t هستند، اچتعداد واحدها در سلول GRU است، ساعتتی1←∈آراچو ساعتتی2←∈آراچبردارهای خروجی لایه پنهان لایه عقب در لایه های اول و دوم شبکه های عصبی Bi-GRU در زمان t هستند، yتی∈آرتیامتیاز کلمه مربوطه در هر برچسب در زمان t است، تیتعداد برچسب ها است، ایکستیورودی شبکه عصبی در زمان t است، f⋅پردازش شبکه عصبی GRU است، g⋅تابع فعال سازی است، که در آن gایکسمن=هایکسمن∑ک=1nهایکسک، و wو بماتریس های وزنی هستند که باید یاد بگیرند.
3.4. استنتاج برچسب
چه زمانی تی=1:
چه زمانی 1<تی≤n:
جایی که πمناحتمال آن برچسب است مناولین تگ دنباله است، آjمناحتمال انتقال آن برچسب است jبه برچسب منتقل می کند من، جایی که هر چه مقدار آن بزرگتر باشد آjمنیعنی احتمال آن تگ بیشتر است jبه برچسب منتقل می کند من، و yتی،مننمره کلمه است جتیروی برچسب مندر زمان تی. φتیمنبه یک برچسب خاص اشاره می کند jدر زمان قبلی که تگ بهینه را ایجاد کرد مندر زمان تی.
از این طریق می توان مسیر بهینه تا زمان فعلی را تعیین کرد و اشاره گر را نشان داد. بنابراین، برچسب نهایی منتیدر زمان تیمی توان از احتمال بهینه محلی در آن زمان استنباط کرد n. فرمول استخراج به شرح زیر است:
4. آزمایشات
4.1. مجموعه داده ها
4.2. معیارهای ارزیابی
برای معیارهای ارزیابی تجربی، از روش ارزیابی طبقهبندی یادگیری ماشین استفاده میشود. این روش از سه شاخص دقت (P)، فراخوان (R) و امتیاز F1 (F1) برای ارزیابی نتایج تقسیمبندی استفاده میکند. دقت به نسبت عناصر آدرس به درستی تقسیمبندی شده با توجه به تمام عناصر آدرس تقسیمبندی شده، فراخوان به نسبت عناصر آدرس به درستی تقسیمبندی شده به تمام عناصر آدرس استاندارد، و امتیاز F1 به میانگین وزنی هارمونیک دقت اشاره دارد. و به یاد آورید. فرمول محاسبه هر شاخص به شرح زیر است:
جایی که آمجموعه استاندارد عناصر آدرس است و بمجموعه قطعه بندی شده از عناصر آدرس است.
4.3. فراپارامترها
برای به دست آوردن عملکرد مطلوب از یک شبکه عصبی، تنظیم فراپارامترها بسیار مهم است. هایپرپارامترهای اصلی این آزمایش در جدول 5 نشان داده شده است . در لایه برداری متن مدل، اندازه پنجره تعداد کاراکترهای موجود در طولانی ترین آدرس در مجموعه داده های آدرس است. کلمه بعد برداری یک بعد تعبیه کاراکتر رایج است [ 38 ، 39 ]. در لایه شبکه عصبی، تعداد واحدهای پنهان و تعداد لایه های شبکه عصبی نشان دهنده سازش بین سرعت آموزش مدل و عملکرد مدل است [ 40]]. نرخ ترک تحصیل و اندازه دسته از طریق آزمایش های مقایسه ای برای تعیین مقدار بهینه انتخاب می شوند. در لایه استنتاج برچسب، پس از به دست آوردن آمار برچسب برای مجموعه داده آموزش کاراکتر و مجموعه داده آموزش کلمه، ماتریس انتقال برچسب آو بردار اولیه سازی برداری πهمانطور که در معادلات (18) و (19) نشان داده شده است، به دست می آیند.
جایی که آ1و π1هنگامی که کاراکترهای منفرد ورودی هستند، ماتریس انتقال برچسب و بردار اولیه هستند. آ2و π2هنگامی که کلمات ورودی هستند، ماتریس انتقال برچسب و بردار مقداردهی اولیه هستند.
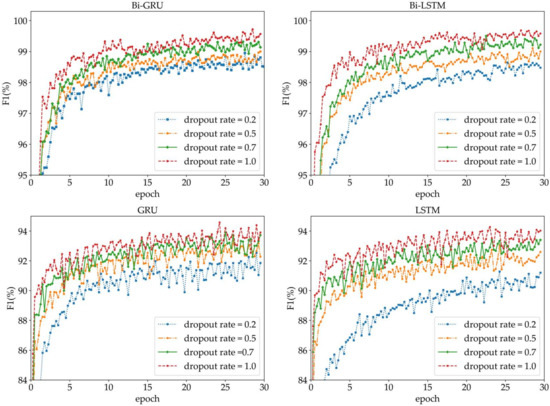
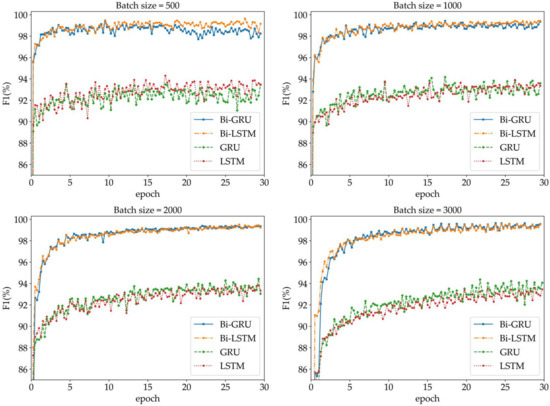
4.4. نتایج
-
ورودی تک کاراکتری
-
ورودی کلمه
-
مقایسه
5. بحث
5.1. تجزیه و تحلیل نتایج تجربی
- (1)
-
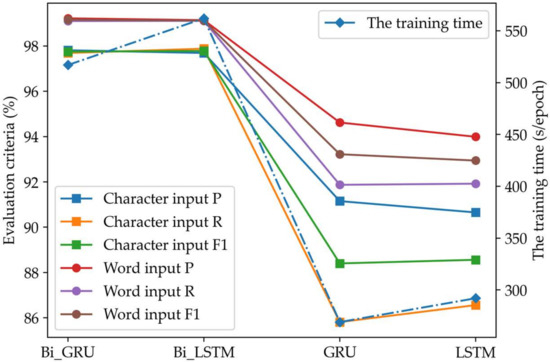
صرف نظر از اینکه مدل های شبکه از ورودی تک کاراکتری یا ورودی کلمه استفاده می کنند، شبکه های عصبی دو طرفه Bi-GRU و Bi-LSTM عملکرد بخش بندی بهتری نسبت به شبکه های عصبی یک طرفه GRU و LSTM ارائه می دهند، زیرا یک شبکه عصبی دو طرفه می تواند حالت را قبل از و بعد از هر لحظه به ترتیب از جهت جلو و عقب. بنابراین این نوع شبکه بهتر می تواند اطلاعات گذشته و اطلاعات آینده دنباله آدرس را در نظر بگیرد.
- (2)
-
مدلهای شبکه با ورودی کلمه چهار نوع شبکه عصبی فوق، عملکرد بخشبندی بهتری را نسبت به مدلهای شبکه مربوطه با ورودیهای تک کاراکتری نشان میدهند. عناصر آدرس چینی از کلمات تشکیل شده اند و نتایج تقسیم بندی کلمات چینی هستند. بنابراین، استفاده از کلمات به عنوان ورودی مدل شبکه عصبی با قوانین کلمهسازی عناصر آدرس چینی مطابقت دارد.
- (3)
-
در مورد عملکرد تقسیمبندی یکسان، شبکه عصبی Bi-GRU از نظر بازده قطعهبندی سریعتر از شبکه عصبی Bi-LSTM است، زیرا واحد عصبی Bi-GRU مستقیماً حالت پنهان را به واحد عصبی بعدی منتقل میکند، در حالی که Bi- واحد عصبی LSTM باید از حالت سلول حافظه برای بسته بندی حالت پنهان و انتقال آن به واحد عصبی بعدی استفاده کند. علاوه بر این، هنگام محاسبه مقدار حالت پنهان فعلی، واحد عصبی Bi-GRU باید علاوه بر ورودی فعلی، تنها مقدار یک پارامتر را در زمان قبلی خروجی دهد، در حالی که واحد عصبی Bi-LSTM به دو پارامتر، سلول حافظه نیاز دارد. مقدار حالت، و مقدار خروجی گره پنهان در لحظه قبل.
- (4)
-
مدلهای شبکه با ورودیهای کلمه چهار نوع شبکه عصبی فوق عملکرد بخشبندی بهتر و کارایی تقسیمبندی مشابه مدلهای شبکه مربوطه با ورودیهای تک کاراکتری دارند، زیرا صرف نظر از اینکه از ورودی تکنویسه یا ورودی کلمه استفاده میشود، محاسبه در شبکه عصبی یک بردار ویژگی است که پس از بردارسازی متن ایجاد می شود. بنابراین، ابعاد بردار بر کارایی تقسیم بندی تأثیر می گذارد، نه کاراکترها و کلمات ورودی.
5.2. مسائل بخش بندی
6. نتیجه گیری
منابع
- دار، س. Varshney، U. چالش ها و مدل های کسب و کار برای خدمات و تبلیغات مبتنی بر مکان تلفن همراه. اشتراک. ACM 2011 ، 54 ، 121-128. [ Google Scholar ] [ CrossRef ]
- کنگ، جی. Jensen، CS Querying Geo-Textual Data: Spatial Keyword Queries and Beyond. در مجموعه مقالات کنفرانس بین المللی مدیریت داده ها در سال 2016، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 26 ژوئن تا 1 ژوئیه 2016؛ ص 2207–2212. [ Google Scholar ]
- ملو، اف. مارتینز، بی. ژئوکدینگ خودکار اسناد متنی: بررسی رویکردهای فعلی. ترانس. GIS 2017 ، 21 ، 3-38. [ Google Scholar ] [ CrossRef ]
- دیویس، کالیفرنیا؛ Fonseca، FT ارزیابی قطعیت مکان های تولید شده توسط یک سیستم کدگذاری آدرس. Geoinformatica 2007 ، 11 ، 103-129. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیلوی، ف. رجبی فرد، ع. کلانتری، م. رویکرد چند عنصری به استنتاج مکان توییتر: موردی برای واکنش اضطراری. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 56. [ Google Scholar ] [ CrossRef ]
- راشتون، جی. آرمسترانگ، نماینده مجلس؛ گیتلر، جی. گرین، BR; پاولیک، م. غرب، MM; Zimmerman، DL Geocoding در تحقیقات سرطان: مروری. صبح. J. قبلی پزشکی 2006 ، 30 ، S16–S24. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ratcliffe، JH Geocoding جنایات و اولین برآورد از حداقل نرخ ضربه قابل قبول. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 61-72. [ Google Scholar ] [ CrossRef ]
- Zandbergen، PA مقایسه تکنیکهای ژئوکدینگ نقطه آدرس، بسته و خیابان. محاسبه کنید. محیط زیست سیستم شهری 2008 ، 32 ، 214-232. [ Google Scholar ] [ CrossRef ]
- آهنگ، Z. الگوریتم تطبیق آدرس بر اساس درک زبان طبیعی چینی. J. Remote Sens. 2013 ، 17 ، 788-801. [ Google Scholar ]
- کوای، ایکس. گوا، آر. ژانگ، ز. او، بی. ژائو، ز. Guo، H. استخراج نام محلی مبتنی بر زمینه فضایی و بخش بندی آدرس نوشتاری چینی از داده های POI شهری. ISPRS Int. Geo-Inf. 2020 ، 9 ، 147. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شان، اس. لی، ز. یانگ، کیو. لیو، ا. ژائو، ال. لیو، جی. Chen, Z. آموزش نمایش نشانی جغرافیایی برای تطبیق آدرس. شبکه جهانی وب 2020 ، 23 ، 1-18. [ Google Scholar ] [ CrossRef ]
- کانگ، م. دو، س. وانگ، ام. روشی جدید برای استخراج آدرس چینی بر اساس مدل درخت آدرس. Acta Geod. کارتوگر. گناه 2015 ، 44 ، 99-107. [ Google Scholar ]
- تیان، کیو. رن، اف. هو، تی. لیو، جی. لی، آر. Du، Q. استفاده از یک روش تطبیق آدرس چینی بهینه برای توسعه یک سرویس رمزگذاری جغرافیایی: مطالعه موردی شنژن، چین. ISPRS Int. Geo-Inf. 2016 ، 5 ، 65. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یائو، ی. Huang, Z. شبکه عصبی بازگشتی LSTM دو جهته برای تقسیم بندی کلمات چینی. در مجموعه مقالات کنفرانس بین المللی پردازش اطلاعات عصبی، کیوتو، ژاپن، 16 تا 21 اکتبر 2016. صص 345-353. [ Google Scholar ]
- لی، ایکس. دوان، اچ. Xu, M. یک شبکه عصبی واحد بازگشتی دردار برای تقسیم بندی کلمات چینی. J. Xiamen Univ. 2017 ، 56 ، 237-243. [ Google Scholar ]
- لو، کیو. زو، ز. خو، اف. ژانگ، دی. Guo، Q. Bi-GRU طبقه بندی احساسات برای چینی بر اساس قوانین گرامر و BERT. بین المللی جی. کامپیوتر. هوشمند سیستم 2020 ، 13 ، 538. [ Google Scholar ] [ CrossRef ]
- ژانگ، ام. یو، ن. Fu، G. یک مدل عصبی ساده و موثر برای تقسیمبندی کلمات مشترک و برچسبگذاری POS. IEEE/ACM Trans. زبان گفتار صوتی. روند. 2018 ، 26 ، 1528-1538. [ Google Scholar ] [ CrossRef ]
- وانگ، اس. ژانگ، اچ. وانگ، بی. تحقیق بهینه سازی در دو آرایه آزمایشی و کاربرد آن. جی. چین. Inf. Proc. 2006 ، 20 ، 24-30. [ Google Scholar ]
- لی، کیو. چن، ی. Sun, J. مکانیزم دیکشنری جدید برای تقسیم بندی کلمات چینی. جی. چین. Inf. Proc. 2003 ، 4 ، 13-18. [ Google Scholar ]
- مو، ج. ژنگ، ی. شو، ز. Zhang، S. بهبود روش تقسیم بندی کلمات چینی بر اساس فرهنگ لغت. محاسبه کنید. مهندس طراحی 2013 ، 34 ، 1802-1807. [ Google Scholar ]
- لی، ال. وانگ، دبلیو. او، بی. Zhang، Y. یک روش ترکیبی برای بخشبندی آدرس چینی. بین المللی جی. جئوگر. Inf. علمی 2018 ، 32 ، 30-48. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. Lv، G. لی، بی. رویکرد مبتنی بر قانون به تفکیک معنایی آدرسهای چینی. J. Geo-Inf. علمی 2010 ، 1 ، 9-16. [ Google Scholar ] [ CrossRef ]
- کم، JK; Ng، HT؛ Guo, W. رویکرد حداکثر آنتروپی به بخش بندی کلمات چینی. در مجموعه مقالات چهارمین کارگاه آموزشی SIGHAN در مورد پردازش زبان چینی، جزیره ججو، کره، 14 تا 15 اکتبر 2005. صص 161-164. [ Google Scholar ]
- ژانگ، ال. کین، ام. ژانگ، ایکس. Ma, H. یک الگوریتم تقسیم بندی کلمات چینی بر اساس حداکثر آنتروپی. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین و سایبرنتیک، چینگدائو، چین، 11 تا 14 ژوئیه 2010. ص 1264–1267. [ Google Scholar ]
- ژانگ، اچ. لیو، کیو. چنگ، ایکس. ژانگ، اچ. Yu, H. تحلیل واژگانی چینی با استفاده از مدل مارکوف پنهان سلسله مراتبی. در مجموعه مقالات دومین کارگاه SIGHAN در مورد پردازش زبان چینی، ساپورو، ژاپن، 11-12 ژوئیه 2003. صص 63-70. [ Google Scholar ]
- آسهارا، م. گوه، CL; وانگ، ایکس. ماتسوموتو، ی. ترکیب قطعهساز و قطعهکننده برای تقسیمبندی کلمات چینی. در مجموعه مقالات دومین کارگاه SIGHAN در مورد پردازش زبان چینی، ساپورو، ژاپن، 11-12 ژوئیه 2003. صص 144-147. [ Google Scholar ]
- پنگ، اف. فنگ، اف. McCallum، A. بخشبندی چینی و تشخیص کلمه جدید با استفاده از فیلدهای تصادفی شرطی. در مجموعه مقالات بیستمین کنفرانس بین المللی زبان شناسی محاسباتی، ژنو، سوئیس، 23 تا 27 اوت 2004. صص 562-568. [ Google Scholar ]
- لافرتی، جی. مک کالوم، ا. Pereira، F. زمینه های تصادفی شرطی: مدل های احتمالی برای بخش بندی و برچسب گذاری داده های توالی. در مجموعه مقالات هجدهمین کنفرانس بین المللی یادگیری ماشین، ویلیامزتاون، MA، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2001. صص 282-289. [ Google Scholar ]
- چن، ایکس. کیو، ایکس. زو، سی. لیو، پی. Huang، X. شبکه های عصبی حافظه کوتاه مدت برای تقسیم بندی کلمات چینی. در مجموعه مقالات کنفرانس 2015 در مورد روشهای تجربی در پردازش زبان طبیعی، لیسبون، پرتغال، 17-21 سپتامبر 2015. صص 1197–1206. [ Google Scholar ]
- چن، ایکس. کیو، ایکس. زو، سی. Huang, X. شبکه عصبی بازگشتی دردار برای تقسیم بندی کلمات چینی. در مجموعه مقالات نشست سالانه انجمن زبانشناسی محاسباتی، پکن، چین، 26 تا 31 ژوئیه 2015. صفحات 1744-1753. [ Google Scholar ]
- هوانگ، CR; چن، کی جی. چن، مالی؛ Chang، استاندارد تقسیم بندی LL برای پردازش زبان طبیعی چینی. در مجموعه مقالات کنفرانس بین المللی زبانشناسی محاسباتی، تایپه، تایوان، 1-4 اوت 1997; صص 47-62. [ Google Scholar ]
- هوکرایتر، اس. Schmidhuber, J. حافظه کوتاه مدت طولانی. محاسبات عصبی 1997 ، 9 ، 1735-1780. [ Google Scholar ] [ CrossRef ]
- چو، ک. ون مرینبور، بی. گلچهره، سی. بهداناو، د. بوگارس، اف. شونک، اچ. Bengio، Y. آموزش نمایش عبارات با استفاده از رمزگذار-رمزگشا RNN برای ترجمه ماشینی آماری. در مجموعه مقالات کنفرانس 2014 در مورد روشهای تجربی در پردازش زبان طبیعی، دوحه، قطر، 25-29 اکتبر 2014. صفحات 1724-1734. [ Google Scholar ]
- ژنگ، ایکس. چن، اچ. Xu, T. یادگیری عمیق برای تقسیم بندی کلمات چینی و برچسب گذاری POS. در مجموعه مقالات کنفرانس 2013 در مورد روشهای تجربی در پردازش زبان طبیعی، سیاتل، WA، ایالات متحده آمریکا، 18-21 اکتبر 2013. صص 647-657. [ Google Scholar ]
- یو، سی. وانگ، اس. Guo, J. آموزش تقسیم بندی کلمات چینی بر اساس مدل دوطرفه GRU-CRF و شبکه CNN. IJTHI 2019 ، 15 ، 47–62. [ Google Scholar ] [ CrossRef ]
- لیو، ز. دینگ، دی. لی، سی. روش تقسیم بندی کلمات چینی برای متن کوتاه چینی بر اساس فیلدهای تصادفی شرطی. J. Tsinghua Univ. نات علمی اد. 2015 ، 55 ، 906-910. [ Google Scholar ]
- دولین، جی. چانگ، مگاوات؛ تره فرنگی.؛ Toutanova، K. BERT: پیش آموزش ترانسفورماتورهای عمیق دو جهته برای درک زبان. در مجموعه مقالات کنفرانس 2019 بخش آمریکای شمالی انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، مینیاپولیس، MN، ایالات متحده آمریکا، 8 ژوئن 2019؛ جلد 1، ص 4171–4186. [ Google Scholar ]
- چن، ایکس. خو، ال. لیو، ز. سان، م. لوان، اچ. یادگیری مشترک تعبیه شخصیت و کلمه. در مجموعه مقالات بیست و چهارمین کنفرانس مشترک بین المللی هوش مصنوعی، بوئنوس آیرس، آرژانتین، 25 تا 31 ژوئیه 2015؛ ص 1236-1242. [ Google Scholar ]
- لو، ی. ژانگ، ی. جی، DH چند نمونه اولیه تعبیه نویسه چینی. در مجموعه مقالات دهمین کنفرانس بین المللی منابع و ارزشیابی زبان، پورتوروژ، اسلوونی، 23 تا 28 مه 2016; صص 855-859. [ Google Scholar ]
- فن، تی. ژو، جی. چنگ، ی. لی، کیو. ژو، دی. Munnoch، R. یک رویکرد جدید تقسیمبندی صدای قلب مستقیم با استفاده از GRU دو جهته. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی اتوماسیون و محاسبات 2018، نیوکاسل، انگلستان، 6 تا 7 سپتامبر 2018؛ صص 1-5. [ Google Scholar ]
- سوتسکور، آی. وینیالز، او. Le، QV توالی برای یادگیری توالی با شبکه های عصبی. در مجموعه مقالات کنفرانس سیستم های پردازش اطلاعات عصبی، مونترال، QC، کانادا، 8-13 دسامبر 2014. صص 3104–3112. [ Google Scholar ]


بدون دیدگاه