

خلاصه
بلایای انسانی در مقیاس بزرگ اغلب به طور نامتناسبی به جوامع فقیر آسیب می رساند. این اثر زمانی تشدید میشود که جوامع از راه دور با اتصال محدود و پاسخدهی کند هستند. در حالی که سازمانهای واکنش بشردوستانه به طور فزایندهای از طیف گستردهای از ماهوارهها برای شناسایی مناطق آسیبدیده استفاده میکنند، این تصاویر میتوانند روزها یا هفتهها به تأخیر بیفتند و ممکن است داستان تعداد یا مکانهای آسیب دیده مردم را نشان ندهند. به منظور پرداختن به نیاز به شناسایی جوامع به شدت آسیب دیده به دلیل بلایای انسانی، ما یک رویکرد الگوریتمی برای استفاده از دادههای مکانی نام مستعار جمعآوریشده از تلفنهای همراه شخصی برای شناسایی کاهش جمعیت مناطقی که به شدت تحت تأثیر زلزله پوئبلا در مکزیک سال ۲۰۱۷ قرار گرفتهاند، ارائه میکنیم. این الگوریتم بر ساختن یک الگوی زندگی برای این محلات سرمایه گذاری می کند. ابتدا تعیین هویت مستعار ساکنان آن محل و سپس تعیین چند درصد از ساکنان آن محلات پس از زلزله. با استفاده از مطالعه 15 محل به شدت آسیب دیده و 15 محل کنترلی که تحت تأثیر زلزله قرار نگرفته بودند، این رویکرد با موفقیت 73 درصد از محلات به شدت آسیب دیده را شناسایی کرد. این سیستم متمرکز بر فرد، رویکرد امیدوارکنندهای را برای سازمانها فراهم میکند تا اندازه و شدت یک فاجعه انسانی را درک کنند، تشخیص دهند که کدام مناطق به شدت آسیب دیدهاند، و به آنها در اولویتبندی تلاشهای واکنش و بازسازی کمک کند. با استفاده از مطالعه 15 محل به شدت آسیب دیده و 15 محل کنترلی که تحت تأثیر زلزله قرار نگرفته بودند، این رویکرد با موفقیت 73 درصد از محلات به شدت آسیب دیده را شناسایی کرد. این سیستم متمرکز بر فرد، رویکرد امیدوارکنندهای را برای سازمانها فراهم میکند تا اندازه و شدت یک فاجعه انسانی را درک کنند، تشخیص دهند که کدام مناطق به شدت آسیب دیدهاند، و به آنها در اولویتبندی تلاشهای واکنش و بازسازی کمک کند. با استفاده از مطالعه 15 محل به شدت آسیب دیده و 15 محل کنترلی که تحت تأثیر زلزله قرار نگرفته بودند، این رویکرد با موفقیت 73 درصد از محلات به شدت آسیب دیده را شناسایی کرد. این سیستم متمرکز بر فرد، رویکرد امیدوارکنندهای را برای سازمانها فراهم میکند تا اندازه و شدت یک فاجعه انسانی را درک کنند، تشخیص دهند که کدام مناطق به شدت آسیب دیدهاند، و به آنها در اولویتبندی تلاشهای واکنش و بازسازی کمک کند.
کلید واژه ها:
تجزیه و تحلیل مکان ؛ بشردوستانه ; زلزله ؛ مکزیک
1. معرفی
در 19 سپتامبر 2017، زمین لرزه ای به بزرگی 7.1 ریشتر (M) در پوئبلا، مکزیک [ 1 ] رخ داد. مکزیکو سیتی و ایالت های پوئبلا و مورلوس به دلیل منطقه پرجمعیت، آسیب قابل توجهی به زیرساخت ها و جمعیت وارد کردند [ 1 ]. آژانس توسعه بین المللی ایالات متحده (USAID) و سازمان بهداشت پان آمریکا (PAHO) تخمین زدند که حداقل 43000 ساختمان ویران شده یا آسیب قابل توجهی دیده است، 6100 نفر مجروح شدند، 366 نفر کشته شدند و صدها نفر ناپدید شدند [2] .]. بیشترین مناطق آسیب دیده در بخشهای روستایی منطقه بود که شناسایی و پاسخگویی به جوامعی را که بیشترین نیاز را دارند برای سازمانهای پاسخدهنده دشوار میکرد. مقیاس تخریب قابل توجه بود و از نظر جغرافیایی توزیع شده بود، هزاران نفر از ساکنان بی خانمان شدند و دیگران از ترس پس لرزه ها در خیابان ها خوابیدند [ 2 ].
پس از بلایای انسانی در مقیاس بزرگ، چالش هایی در مورد اولویت بندی واکنش اضطراری و مفاد کمک پدیدار می شود. با بلایای طبیعی، عموماً جمعیت زیادی آواره وجود دارد که به دنبال سرپناه هستند و به کمک نیاز دارند. اغلب غریزی است که افراد پس از مدتی از منطقه آسیب دیده فرار کنند. با این حال، این می تواند تلاش های امدادی را پیچیده کند و احتمال مرگ و میر را افزایش دهد [ 3 ]. روشهای سنتی مانند مصاحبه شاهدان یا تصاویر ماهوارهای معمولاً در بین سازمانهای امدادی برای تعیین وضعیت پس از تخریب و تخمین تعداد تلفات یا افراد گمشده استفاده میشوند [ 3 ]. با این حال، آنها اغلب کند، بالقوه مغرضانه و غیرقابل اعتماد هستند [ 3 ].
با افزایش وقوع بلایای طبیعی در طول زمان، دیدگاه های فضایی و زمین آماری جدیدی اتخاذ شده است. مدلسازی ریسک و آسیب زلزله به طور خاص رشد زیادی داشته است. در سال 2010، سحر، موتوکومار و فرنچ از سیستم های اطلاعات جغرافیایی (GIS) و الگوریتم ها برای استخراج اشکال ساختمان های دو بعدی از تصاویر هوایی برای مدل سازی بهتر ارزیابی خطر زلزله استفاده کردند [4 ] . فنگ و همکاران استفاده ترکیبی از سنجش از دور با دادههای ساختمان GIS را برای تشخیص تخریب سهبعدی ساختمانها و تخمین تعداد تلفات احتمالی نشان داد [ 5]]. تلاشهای جدیدتر توانایی ارزیابی پیشگیرانه آسیبهای مورد انتظار در مناطق شهری را با استفاده از قوانین ساختمانی زلزله نشان دادهاند، که میتواند به کمپهای کمکرسانی کارآمدتر یا مسیرهای تخلیه منجر شود [6 ] . اخیراً تغییری به سمت رویکردهای ژئومحاسباتی بیشتر صورت گرفته است. حسین و همکاران دادههای ساعت هوشمند و فنآوریهای GIS را برای ثبت الگوریتمی ضربان قلب قربانیان زلزله به منظور شناسایی مناطق حیاتی برای جستجو و نجات به کار گرفت [ 7 ]. روشهای یادگیری ماشین و شبکه عصبی برای بهبود مدلهای پیشبینی زلزله قبلی آزمایش میشوند [ 8]. روشهای دیگر دادههای جمعی مانند نقشهبرداری داوطلبانه اضطراری و برچسبهای جغرافیایی رسانههای اجتماعی را برای شناسایی مکانهایی که بیشترین آسیب در شرایط اضطراری بشردوستانه یا صور فلکی ماهوارههای کوچک رخ داده است برای شناسایی روستاهای آسیبدیده قابل توجه به صورت روزانه [9، 10 ، 11 ] ترکیب کردهاند . . آژانس ملی زمین فضایی در تلاش است تا استخراج مناطق نیازمند کمک های بشردوستانه را با استفاده از هوش مصنوعی بر روی تصاویر با وضوح بالا به طور خودکار انجام دهد [ 12 ]. همه این روشها از دادههای موقعیت مکانی فراگیر به جای شخصی برای ارائه بینشی در مورد بلایای انسانی استفاده میکنند.
ادبیات نشان می دهد که سوابق جزئیات تماس (CDRs) در اندازه گیری ویژگی های جمعیت فضایی گسترده و مهاجرت در بخش خصوصی و عمومی مفید بوده است. با استفاده از تکنیکهای مثلثسازی، دادههای CDR میتوانند موقعیت جغرافیایی را در زمان برقراری تماس یا متن ایجاد کنند و تحرک جمعیت و شبکه اجتماعی را ارزیابی کنند، گاهی اوقات تا مقیاس فردی [13] .]. شرکت های مخابراتی به طور مداوم CDR ها را برای نظارت بر نفوذ در بازار و موفقیت اقتصادی خود تجزیه و تحلیل می کنند. محققان همچنان به بررسی این موضوع ادامه میدهند که چگونه دولتها و سازمانهای خصوصی میتوانند با استفاده از CDRها از تخمینهای به موقع جمعیت و مهاجرت بهره ببرند، بهویژه در کشورهای در حال توسعه که چنین دانشی میتواند سیاستگذاری را تعیین کند، اما هزینههای جمعآوری دادهها ممکن است قابل توجه باشد. به عنوان مثال، Salat، Smoreda و Schläpfer روش هایی را برای برون یابی تراکم جمعیت از CDR ها از ردیابی الگوهای هفتگی، ماهانه و سالانه استفاده از تلفن همراه در سنگال توسعه دادند [14] .]. زفیریا و همکاران همچنین از دادههای تلفن همراه سنگال استفاده کرد و دریافت که پروفایلهای تحرک انبوه بر اساس معیشت احتمالی میتواند فعالیتهای اقتصادی، چرخههای کشاورزی، و بارندگی و بنابراین مهاجرت فصلی را روشن کند [15 ] . لای و همکاران بیشتر مستقیماً دادههای CDR را اعمال کرد و دریافت که میتواند آمارهای ملی را، بهویژه در کشورهایی با نرخ بالای مهاجرت داخلی، تکمیل کند تا اطمینان حاصل شود که خدمات عمومی به طور مناسب مستقر شدهاند [ 16 ]. داده های تلفن همراه در شناسایی و به تصویر کشیدن الگوهای زندگی ثابت در یک کشور موثر است.
سوابق جزئیات تماس همچنین به طور گسترده برای تکمیل درک سازمانهای مختلف از جابجایی جمعیت، زمانی که این الگوهای زندگی در پی بحرانهای خاص محیطی و اپیدمیولوژیک مختل میشوند، استفاده شده است. در مثالی خاص، Bengtsson و همکاران. (2011) داده های موقعیت مکانی از CDR ها را تجزیه و تحلیل کرد تا دریافت که 630000 نفر پورتو پرنس را در یک دوره 19 روزه پس از زلزله 2010 هائیتی ترک کردند [ 3 ]. به طور مشابه، ویلسون و همکاران. (2016) از CDR های متحرک شناسایی نشده و ماتریس های انتقال الگوریتمی برای شناسایی جریان های جمعیتی در داخل و خارج از دره کاتماندو در چند هفته اول پس از زلزله 2015 گورخا در نپال استفاده کرد [17 ]]. کشیش-اسکوردو و همکاران در سال 2009 امکان استفاده از CDRها را برای توصیف اثرات سیل در تاباسکو، مکزیک نشان داد [ 18 ]. آندراد و همکاران در تجزیه و تحلیل خود از زلزله 2016 در منابی، اکوادور نشان دادند که استفاده از فعالیت انبوه از طریق دکلهای تماس میتواند از کاربران فردی در برابر نگرانیهای حفظ حریم خصوصی محافظت کند، در حالی که میزان آسیب زیرساختهای شهری را ارزیابی میکند و بینشی در مورد الگوهای تحرک بسته به نزدیکی کاربر به مرکز زلزله ارائه میکند. از زلزله [ 19 ]. هورانونت و همکاران (2013) از 9.2 میلیارد رکورد موقعیت مکانی، مشتق شده از سرویس سیستم ماهواره ای ناوبری خودکار جهانی (GNSS) از یک شرکت مخابراتی در ژاپن، برای تجزیه و تحلیل الگوهای تحرک انسان پس از زلزله بزرگ ژاپن در سال 2011 استفاده کرد [20 ]]. داده های CDR همچنین در برنامه های کاربردی اپیدمی و کنترل بیماری استفاده شده است. پیک و همکاران (2018) از CDRها برای بررسی الگوریتمی کاهش سفر در طول مداخله اپیدمی ابولا در سیرالئون استفاده کرد [ 21 ]. این مطالعات توانستند الگوهای تحرک و رفتار جمعیت را پس از یک بلای طبیعی در مقیاس بزرگ شناسایی کنند و روشی امیدوارکننده برای آمادهسازی برای ارزیابی آسیب و واکنشهای پس از فاجعه را نشان دهند.
نوع دیگری از داده های مخابراتی که می تواند در کاربردهای مشابه با CDR ها استفاده شود، داده های دستگاه الکترونیکی شخصی (PED) است. با گسترش دسترسی به تلفن همراه در جنوب جهانی، دادههای PED برای کمک به چالشهایی که در شرایط اضطراری بشردوستانه در مقیاس بزرگ با آن روبرو هستند، مورد استفاده قرار گرفتهاند. استفاده از دادههای PED به موازات دادههای CDR توسعه یافته است و به جای آن از سیستمهای ماهوارهای ناوبری جهانی (GNSS) در دستگاههای هوشمند (یعنی تلفنهای همراه، تلفنهای هوشمند، ساعتهای هوشمند، تبلتهای هوشمند و غیره) جمعآوری میشود [22] .]. دادههای PED با دادههای CDR که قبلاً استفاده میشد متفاوت است، زیرا اطلاعات مربوط به یک مکان را بدون وابستگی به انتقال ارتباطات (تماسها و/یا متنها) جمعآوری میکند و بنابراین، سطح بالاتری از دقت را از دقت مکان به دست میدهد. یابه و همکاران (2019) از داده های PED یک میلیون کاربر پس از زلزله کوماموتو برای تخمین نرخ تخلیه نسبت به شدت لرزه استفاده کرد [ 23 ]. چن و همکاران (2020) از داده های PED از نقشه بایدو برای ردیابی تغییرات جریان شهری در شنژن در طول طوفان Mangkhut استفاده کرد [ 24]. اخیراً، با همهگیری COVID-19، از دادههای PED برای ردیابی تحرک، انتقال و موفقیت دستورالعملهای فاصلهگذاری اجتماعی استفاده میشود. Liautaud، Huybers و Santillana (2020) از دادههای PED برای تجزیه و تحلیل کاهش تحرک با بروز تب از دماسنجهای متصل به تلفنهای هوشمند استفاده کردند [ 25 ]. این تایید کرد که فاصله گذاری اجتماعی باعث کاهش انتقال ویروس شده و می تواند به شناسایی شیوع های احتمالی در آینده کمک کند.
دادههای PED دادههای مکانی و زمانی بسیار غنی را در مورد تحرک انسان فراهم میکند و میتواند در بسیاری از کاربردهای چند رشتهای مانند بلایای طبیعی، بهداشت عمومی، تقلب اعتباری، نقض حقوق بشر و غیره استفاده شود [26 ] . شرکتهایی مانند LocationSmart ( www.locationsmart.com )، Foursquare ( www.foursquare.com )، یا Cuebiq ( www.cuebiq.com ) تجزیه و تحلیل موقعیت مکانی آفلاین را برای کسبوکارها میفروشند تا بینش مصرفکننده و بازاریابی ارائه کنند. سازمانهایی مانند یونیسف و بانک جهانی نیز از این دادههای مکانی برای پاسخهای بشردوستانه در زمان واقعی استفاده میکنند [ 27 ] ( شکل 1 ).
این مطالعه روشی را با استفاده از دادههای PED با نام مستعار برای تشخیص کاهش جمعیت محل از زلزله بزرگ سال 2017 در پوئبلا، مکزیک، شرح میدهد. داده ها با استفاده از الگوریتم های پایتون پیش پردازش شده و در پایگاه داده PostgreSQL بارگذاری شدند. سپس این رویکرد از سیستمی از الگوریتمها برای تشخیص زمان ترک محل توسط ساکنان استفاده کرد. الگوریتم ها ابتدا ساکنان محلات را شناسایی کردند، تعداد ساکنان را در هر روز مقایسه کردند و سپس چگونگی تغییر میانگین جمعیت در طول زمان را برای شناسایی جوامعی که در حال کاهش جمعیت بودند، تجزیه و تحلیل کردند. این رویکرد با استفاده از جوامع نزدیک به مرکز زلزله و همچنین جوامع با اندازه مشابه دور از کانون زلزله، به طور دقیق نشان داد که جوامع نزدیک به زلزله به سرعت در نتیجه زلزله خالی از سکنه شدند. در حال حاضر، تحقیقات محدودی در مورد استفاده از تحرک ردیابی داده PED در طول یک بلای طبیعی وجود دارد. با این حال، این مطالعه به دنبال رسیدگی به شکاف موجود است و رویکردی را توصیف میکند که به سازمانهای پاسخدهی بشردوستانه یک رویکرد مقرونبهصرفه، دقیق و خودکار ارائه میکند تا تشخیص دهد کدام جوامع از یک فاجعه انسانی در مقیاس بزرگ بیشترین تأثیر را دارند. چنین رویکردی احتمالاً در مناطقی که فاقد سایر ابزارهای گزارش دهی هستند (فقدان ظرفیت) یا جایی که دولت/مقامات محلی نمی خواهند اطلاعات را با جامعه بین المللی به اشتراک بگذارند (فقدان شفافیت) ارزشمندتر خواهد بود. و رویکرد خودکار برای تشخیص اینکه کدام جوامع از یک فاجعه انسانی در مقیاس بزرگ بیشترین تأثیر را دارند. چنین رویکردی احتمالاً در مناطقی که فاقد سایر ابزارهای گزارش دهی هستند (فقدان ظرفیت) یا جایی که دولت/مقامات محلی نمی خواهند اطلاعات را با جامعه بین المللی به اشتراک بگذارند (فقدان شفافیت) ارزشمندتر خواهد بود. و رویکرد خودکار برای تشخیص اینکه کدام جوامع از یک فاجعه انسانی در مقیاس بزرگ بیشترین تأثیر را دارند. چنین رویکردی احتمالاً در مناطقی که فاقد سایر ابزارهای گزارش دهی هستند (فقدان ظرفیت) یا جایی که دولت/مقامات محلی نمی خواهند اطلاعات را با جامعه بین المللی به اشتراک بگذارند (فقدان شفافیت) ارزشمندتر خواهد بود.
2. مواد و روشها
2.1. داده ها
داده های دستگاه الکترونیکی شخصی (PED).
شرکت تجزیه و تحلیل موقعیت مکانی Cuebiq Inc. دسترسی به نمونهای از دادههای مکان PED با نام مستعار مکزیک مرکزی و حفظ حریم خصوصی را از ۴ سپتامبر تا ۱۰ اکتبر ۲۰۱۷ فراهم کرد. دادهها در هر دو حالت آنلاین و آفلاین جمعآوری شدند، بنابراین اگر ارتباط با برج های سلولی نزدیک، مکان ها همچنان ثبت می شوند و بعداً در مجموعه داده گنجانده می شوند. دستگاههای منفرد، بر اساس هویت بینالمللی تجهیزات تلفن همراه (IMEI)، نام مستعار داشتند، و مکانهای آنها را میتوان برای یک روز ترسیم کرد، که نشاندهنده الگوهایی مانند سفر در طول زمان است ( شکل 2)). دادههای موقعیتیابی توسط سرویسهای مکان هر برنامه با استفاده از روشهای مختلف برای جمعآوری مکان IMEI جمعآوری شد. داده ها در یک مرکز تحقیقات محاسباتی با امنیت فیزیکی در پشت فایروال ها قرار گرفتند. تجزیه و تحلیل بر روی این سرور از راه دور با ورود به لپ تاپ های شخصی انجام شد. داده های شخص اول جمع آوری شده توسط Cuebiq شامل 8 ستون مختلف بود: شناسه، نوع دستگاه، نوع نویز، طول جغرافیایی، طول جغرافیایی، فاصله از نقطه داده قبلی، مهر زمانی و دقت. با اطلاعات بالقوه حریم خصوصی در دادههای PED، Cuebiq رویههایی را برای اطمینان از حریم خصوصی و لایههای مختلف حفاظت برای همه کاربران اعمال میکند. برای این مجموعه داده، دادهها با هش کردن و رمزگذاری شناسه شناسایی شدند و نویز 600 متری برای مکانهای خانه (در یک شبکه geohash) و بین 20 تا 100 متر برای همه مکانهای دیگر اضافه شد. این نویز به مجموعه داده اضافه شد تا کاربران خاص را ناشناس بیشتر کند. برای هر نوع مکان، روش حفظ حریم خصوصی متفاوتی اعمال شد. مکانهای خانه و محل کار در بلوکهای سرشماری تصادفی شدند، که امکان تخمین جمعیتشناختی را بدون افشای مکانهای واقعی کاربران فراهم میکرد. نقاط حساس حساس (POI) مانند مدارس ابتدایی، کلینیک های سلامت جنسی/باروری، مکان های عبادت و غیره به طور کامل از مجموعه داده حذف شدند. POIهای لیست سفید (نقاط مورد علاقه تجاری و عمومی) بدون تغییر باقی ماندند. و POIهای بدون تطابق (همه نقاط داده دیگر) نویز 20-100 متر بر اساس تراکم نقاط داده در منطقه داشتند. مکانهای خانه و محل کار در بلوکهای سرشماری تصادفی شدند، که امکان تخمین جمعیتشناختی را بدون افشای مکانهای واقعی کاربران فراهم میکرد. نقاط حساس حساس (POI) مانند مدارس ابتدایی، کلینیک های سلامت جنسی/باروری، مکان های عبادت و غیره به طور کامل از مجموعه داده حذف شدند. POIهای لیست سفید (نقاط مورد علاقه تجاری و عمومی) بدون تغییر باقی ماندند. و POIهای بدون تطابق (همه نقاط داده دیگر) نویز 20-100 متر بر اساس تراکم نقاط داده در منطقه داشتند. مکانهای خانه و محل کار در بلوکهای سرشماری تصادفی شدند، که امکان تخمین جمعیتشناختی را بدون افشای مکانهای واقعی کاربران فراهم میکرد. نقاط حساس حساس (POI) مانند مدارس ابتدایی، کلینیک های سلامت جنسی/باروری، مکان های عبادت و غیره به طور کامل از مجموعه داده حذف شدند. POIهای لیست سفید (نقاط مورد علاقه تجاری و عمومی) بدون تغییر باقی ماندند. و POIهای بدون تطابق (همه نقاط داده دیگر) نویز 20-100 متر بر اساس تراکم نقاط داده در منطقه داشتند. POIهای لیست سفید (نقاط مورد علاقه تجاری و عمومی) بدون تغییر باقی ماندند. و POIهای بدون تطابق (همه نقاط داده دیگر) نویز 20-100 متر بر اساس تراکم نقاط داده در منطقه داشتند. POIهای لیست سفید (نقاط مورد علاقه تجاری و عمومی) بدون تغییر باقی ماندند. و POIهای بدون تطابق (همه نقاط داده دیگر) نویز 20-100 متر بر اساس تراکم نقاط داده در منطقه داشتند.
2.2. لایه زلزله
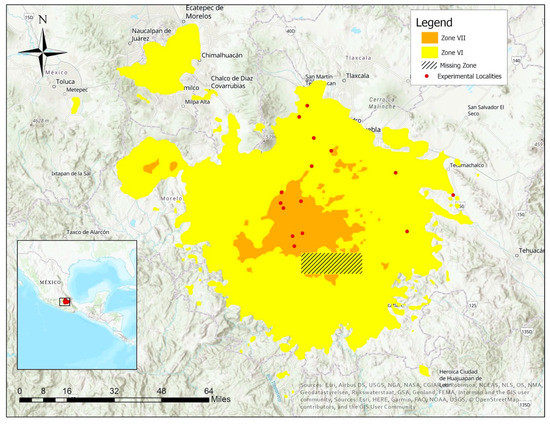
پس از زلزله، مرکز هماهنگی واکنش اضطراری کمیسیون اروپا (ERCC) یک نقشه دقیق تهیه کرد که شدت نسبی زمین لرزه را در سراسر و فراتر از ایالت پوئبلا نشان می داد [ 29 ]. با استفاده از مقیاس مرکالی اصلاح شده، ERCC مناطقی را که لرزش «بسیار قوی» (VII)، «قوی» (VI)، «متوسط» (V) و «سبک» (IV) را تجربه کردهاند، برجسته کرد. از این اطلاعات، ما 15 محل آزمایشی یا آسیب دیده را انتخاب کردیم که در مناطق “بسیار قوی” (VII) یا “قوی” (VI) قرار داشتند. برای مناطق کنترل، ما 15 محل را انتخاب کردیم که کاملاً خارج از وسیع ترین مناطق “نور” (IV) بودند ( شکل 3).). این نقشه شدت بهعنوان دادههای مرجع زمینی ما عمل کرد و روستاهایی را که به شدت تحت تأثیر قرار گرفتهاند و روستاهایی که تحت تأثیر قرار نگرفتهاند را مشخص میکند.
2.3. منطقه مطالعه
ایالت پوئبلا تقریباً 13000 مایل مربع وسعت دارد که توسط ایالت های مورلوس، وراکروز، گوئررو، اواکساکا، هیدالگو و تلاکسکالا احاطه شده است. این ایالت به دلیل جغرافیای کوهستانی خود شناخته شده است و از خاک غنی آتشفشانی برای کشاورزی بهره برده است. در حالی که پایتخت پوئبلا، شهر پوئبلا (سیوداد د پوئبلا)، توسعه یافته تر است، تفاوت های ثروت در مناطق روستایی در داخل ایالت وجود دارد. این رویکرد تحلیلی بر هر دو مکان کنترلی و آزمایشی متکی است که تعداد قابل توجهی از ساکنان به طور مداوم از برنامههایی استفاده میکنند که دادههای مکانی آنها توسط Cuebiq به اشتراک گذاشته شده و در دسترس است. نفوذ فعال گوشی های هوشمند مکزیک، محدود به افرادی است که حداقل یک بار در ماه از تلفن خود استفاده می کنند، تنها به 40.7 درصد از جمعیت گسترش می یابد [ 30]]. از آنجایی که استفاده از برنامههای اشتراکگذاری مکان احتمالاً در سال 2017 کمتر رایج بود، بهویژه در مناطق روستایی، 38 نامزد محل آزمایشی از منطقه مورد مطالعه انتخاب شدند تا احتمالاً در مطالعه مورد استفاده قرار گیرند. در انتخاب محل های آزمایشی، کاندیداها بر اساس اندازه جمعیت بین 2000 تا 6000 نفر از سرشماری سال 2010 و نزدیکی آنها به کانون زلزله انتخاب شدند [ 29 ، 31 ].
هشتاد و دو محل کاندیدای کنترل نیز بر اساس معیارهای جمعیتی مشابه مجموعه داده های تجربی بودند، اما از دیگر ایالت های مکزیک که در محدوده زلزله نبودند (پوئبلا، اوآخاکا و گوئررو) انتخاب شدند. به منظور تعیین ساکنان یک محل خاص، و همچنین تعیین درصد ساکنانی که آن محل را در یک روز معین ترک کردند، یک بافر هندسی به صورت دستی در اطراف هر محل ایجاد شد. این «جغرافیههای جغرافیایی» بهصورت بصری از تصاویر ماهوارهای در Google Earth ایجاد شدهاند تا تقریباً تمام مناطق مسکونی را به تصویر بکشند و در عین حال تا آنجا که ممکن است مناطق دور از سکنه را حذف کنند. وسعت روستا در نظر گرفته نشد، فقط منطقه بصری توسعه یافته در نظر گرفته شد. با توجه به ناهمگونی اندازه جمعیت و شکل محلی، به هر منطقه یک بافر منحصر به فرد اختصاص داده شد.شکل 3 ). از این کاندیداها، 15 محل کنترل و 15 محل آزمایشی در تجزیه و تحلیل نهایی ( شکل 4 ) پس از ارزیابی نفوذ در بازار مورد استفاده قرار گرفتند.
2.4. روش شناسی
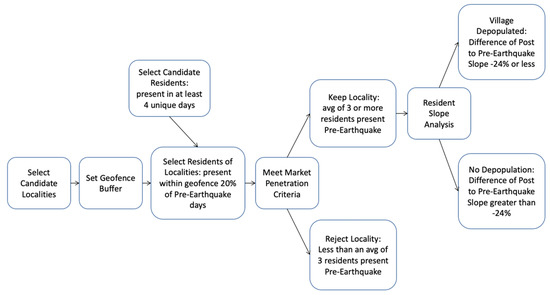
گردش کار تحلیلی هر محل نامزد را از طریق یک سری از اسکریپت ها پردازش کرد. اگر آن محل با الزامات زیر مطابقت داشت، در مجموعه داده نهایی استفاده شد ( شکل 5 ).
2.4.1. آماده سازی پایگاه داده
برای 14.4 گیگابایت داده مکان، مناسب بودن PostgreSQL برای داده های ساختاریافته، قوی تر و جدولی برای پایگاه داده انتخابی ما ساخته شده است. تهیه داده ها شامل موارد زیر بود:
(1) تبدیل داده های ارائه شده به یک فایل csv قابل خواندن با اجرای یک اسکریپت تبدیل پایتون. این کد فایل های csv روزانه را از حالت فشرده خارج می کند، نام ستون های مربوطه را درج می کند و سپس داده ها را در یک فایل csv جدید ذخیره می کند. هر روز داده برای 37 روز شامل بیش از صد فایل csv بسته به میزان داده آن روز بود.
(2) بارگذاری داده ها در پایگاه داده با استفاده از یک الگوریتم پایتون سفارشی شده. اسکریپت به پایگاه داده PostgreSQL متصل می شود، از طریق فایل های csv تکرار می شود و سپس داده ها را با استفاده از بسته pyscopg2 Anaconda وارد جدول می کند. تقریباً 6.5 ساعت طول کشید تا 225,962,016 ردیف اولیه بارگیری شود که نشان دهنده داده های 37 روزه است.
(3) ایجاد یک اسکریپت پایتون که پایگاه داده را به یک نوت بوک Jupyter به منظور انجام عملیات در مقیاس بزرگ روی داده ها متصل می کند.
2.4.2. پیش پردازش
به منظور بهبود زمان اجرای کد و حذف نویز در مجموعه داده، یک الگوریتم پیش پردازش زمانی (TP) توسعه و پیاده سازی شد. مجموعه داده اولیه شامل 774343 شناسه منحصر به فرد بود. پیش پردازش تنها برای تجزیه و تحلیل شناسه هایی ایجاد شد که در آن تجزیه و تحلیل الگوی زندگی انجام شود.
این الگوریتم برای حذف شناسهها و تمام «بازدیدها» یا رکوردهای مرتبط با آنها طراحی شده است که در کل مجموعه داده حضور چشمگیری نداشتند ( شکل 6)). ابتدا، الگوریتم مهر زمانی هر رکورد را به فرمت YYYY-MM-DD HH:MM تبدیل کرد (مثلاً: 2018-10-12 11:33)، که سپس برای نمایش فقط روز ماه (مثلا: 12) کوتاه شد. . سپس الگوریتم بررسی کرد که هر ID چند روز مجزا در مجموعه داده وجود دارد. اگر یک شناسه حداقل برای 4 روز متمایز از 37 روز کامل (از 4 سپتامبر تا 11 اکتبر) موجود در مجموعه داده شناسایی شده بود)، سوابق مرتبط با شناسه حفظ می شد. در غیر این صورت، رکوردهای مرتبط با آن شناسه از مجموعه داده حذف می شوند. چهار روز به عنوان حداقل تعداد روز انتخاب شد تا مشخص شود که یک شناسه در یک روستای خاص زندگی می کند اما تا آنجا که ممکن است شناسه های منحصر به فرد را نگه می دارد. این مجموعه داده را با 8,271,655 ردیف کاهش داد و به مجموع 217,690,361 ردیف کاهش داد که در کل کاهش 3.6٪ را نشان می دهد.
حذف شناسهها بدون حضور مداوم در مجموعه داده تضمین میکند که مطالعه ما میتواند روندهای معناداری را از تعداد معقولی از نقاط داده استخراج کند. قبل از پیش پردازش، شناسه ها به طور متوسط 7.86 روز با رکورد داشتند. پیش پردازش بسیاری از شناسه ها را با 1 یا 2 رکورد حذف کرد و میانگین روزهای حضور یک شناسه را به 13.48 رساند ( جدول A1 ( شکل 7 ).
2.4.3. الگوریتم تعیین مقیم
الگوریتم تعیین ساکن شاخصی را برای سکونت در یک محل ایجاد کرد. ساکن یک محل خاص به عنوان یک شناسه منحصربهفرد تعریف میشود که حداقل 3 روز مختلف قبل از زلزله (4 سپتامبر تا 18 سپتامبر) در بافر آن منطقه وجود داشته باشد. این اسکریپت پردازش ابتدا دادههای پیشپردازش شده قبلی را با 3 ستون اضافه کرد. اولین نقطه از نوع جغرافیایی ایجاد شد که مربوط به طول و عرض جغرافیایی است که در ابتدا با هر رکورد ارائه شده بود. دوم و سوم به ترتیب روز سال و ساعت روز مربوط به هر رکورد را استخراج کردند. سپس زیر مجموعه داده های ثبت شده قبل از زلزله در جدول دوم کپی شد.
برای هر محل کنترل و آزمایش، نسخههای جدیدی از پیشزلزله و دادههای پیشپردازششده زمانی ایجاد شد. تمام نقاط درون هر دو زیرمجموعه که با یک بافر فضایی که به صورت دستی برای اندازه فیزیکی شهر مرتبط کالیبره شده بود تلاقی نداشتند، کنار گذاشته شدند. این ژئوفنس برای ماهیت درهم مختصات مختصات ارائه شده توسط Cuebiq تنظیم شد و یک حاشیه 610 متری برای محاسبه نقاط پرتاب شده به خارج از بافر که در غیر این صورت در داخل بافر شناسایی می شدند، اضافه کرد.
این الگوریتم سعی در ایجاد تعادل بین سرکوب موارد مثبت کاذب و استخراج هر چه بیشتر ساکنان از دادهها داشت. با محدودیتهای زمانی دادهها که از ایجاد یک محل اقامت پایه جلوگیری میکند، هدف الگوریتم این بود که تا حد امکان افراد با سطوح بالای فعالیت و فعالیت ثابت در سرتاسر مجموعه داده را با تعریف یک شناسه بهعنوان مقیم در صورتی که در محدوده جغرافیایی ثبت شده بودند، جذب کند. حداقل 20 درصد از روزهای منحصر به فرد قبل از زلزله (3 روز). از آنجایی که ساکنان ممکن است برای مدت کوتاهی شهر را ترک کنند، آستانه 20 درصدی الگوریتم شناسایی افرادی را که دارای ارتباطات جغرافیایی قوی با محل مورد نظر هستند، تضمین می کند. شناسه های تعریف شده به عنوان ساکنان یک محل سپس در یک جدول جداگانه ذخیره می شوند.
2.4.4. معیارهای نفوذ در بازار
هنگامی که ساکنان هر منطقه ایجاد شدند، گردش کار بعدی تضمین کرد که هر محل آزمایشی و کنترلی استاندارد نفوذ بازار را برای تجزیه و تحلیل بیشتر برآورده میکند. این آستانه برای فیلتر کردن مناطق با کمتر از 3 ساکن شناسایی شده تنظیم شده است.
برای به دست آوردن 15 محل کنترل و 15 محل آزمایشی، این مطالعه 82 نامزد کنترل و 38 محل کاندید آزمایشی را مورد بررسی قرار داد. از آنجایی که ضریب نفوذ گوشی های هوشمند در مکزیک در مناطق روستایی نسبتاً کمتر است، ما انتظار داریم که تجزیه و تحلیل مشابهی که بر روی داده های فعلی بیشتر انجام می شود، تعداد بیشتری از مناطق واجد شرایط را به دست آورد.
2.4.5. تجزیه و تحلیل شیب ساکن
برای 15 محل تجربی و 15 محل کنترل، رویکرد ما به دنبال شناسایی محلاتی بود که پس از زلزله کاهش ساکنان را تجربه کردند. در پاسخ، تحلیل شیب ساکنان قبل و بعد از زلزله انجام شد. تجزیه و تحلیل شیب کاهش ساکنان در هر محل را از طریق تفاوت بین شیبها نشان داد و به این دلیل انتخاب شد که این روش ابزار بهتری برای محاسبه مهاجرت تدریجیتر به خارج از یک محل ارائه میدهد. این تفاوت شیب برای هر محل با استفاده از تابع LINEST در Microsoft Excel محاسبه شد. مناطقی که از قبل از زلزله تا بعد از زلزله بیش از 24 درصد کاهش جمعیت را تجربه کردهاند، بهسرعت تخلیه شدهاند ( جدول A3)). این آستانه 24 درصد برای به حداکثر رساندن دقت کلی برای 30 روستا تعیین شده است.
2.5. اعتبار سنجی
از 15 محل آزمایشی، هر منطقه ای با کاهش جمعیت بیش از 24٪ “هشدار” شد که به دلیل زلزله به سرعت از جمعیت خالی می شود. هر محلی که با این معیار مطابقت نداشت، خطای حذف تلقی می شد. به همین ترتیب، 15 محل خارج از منطقه زلزله و بین اندازه های مشابه با مجموعه داده تجربی به صورت تصادفی برای ارزیابی خطاهای کمیسیون انتخاب شدند. اگر هر یک از مناطق کنترل کاهش جمعیت بیش از 24٪ (-0.24) را ثبت کند، آنها “هشدار” یا یک خطای کمیسیون در نظر گرفته می شوند ( شکل 8 ).
3. نتایج
این رویکرد منجر به دقت کلی 73 درصد در تشخیص کاهش جمعیت محلات پس از زلزله شد. از 15 محل کنترل، 12 محل خالی از سکنه یا کاهش ناچیز ساکنان پس از زلزله شناسایی شد که خطای کمیسیون 20٪ را به همراه داشت ( جدول A3 ). از 15 محل آزمایشی، 10 محل با کاهش بیش از 24٪ یا بیشتر از جمعیت پس از زلزله شناسایی شدند که خطای حذف 33٪ را به همراه داشت ( جدول A3 ).
همه نامزدهای محلی برای کنترل ها به طور تصادفی از 21 ایالت از 32 ایالت مکزیک انتخاب شدند. حداقل دو محل از هر ایالت در بین اندازه جمعیت 1000 تا 6000 نفر انتخاب شدند. همه 15 محل آزمایشی در ایالت پوئبلا، از نظر جغرافیایی نزدیک به مرکز زلزله بودند ( شکل 9). به نظر میرسد هیچ ارتباط فضایی بین منفیهای کاذب یا مکانهای آزمایشی که نتوانستهاند هشدار دهند، وجود ندارد. پنج محل آزمایشی که هشدار ندادند در مجاورت جغرافیایی مشابه با 10 محل آزمایشی بودند که به درستی هشدار داده بودند. شش منطقه از 15 محل کنترل از ایالت مکزیک، دو نفر از هیدالگو، دو نفر از یوکاتان، دو نفر از گوئررو، یکی از میچوآکان، یکی از چیاپیاس و یکی از کولیما بودند. علاوه بر این، در حالی که به نظر میرسد هیچ ارتباط مکانی قطعی بین کنترلها وجود ندارد، بیشتر موارد مثبت کاذب در ایالتهای نزدیک به منطقه مرکزی کشور، غرب زمینلرزه بود.
جمعیت کلی یک محل با دقت برای مکانهای کنترل یا تجربی همبستگی نداشت. به عنوان مثال، منطقه کنترل سن میگل ایکستاپان دارای 1251 نفر با کاهش جزئی 1.36٪ از ساکنان بود، در حالی که منطقه کنترل Huamuxtitlán دارای 6063 نفر جمعیت بود اما افزایش 3.15٪ (جدول A2 ) . به طور مشابه، منطقه آزمایشی Domingas Arenas دارای جمعیت 5864 نفر و کاهش 47.86٪ از ساکنان پس از زلزله بود، اما منطقه آزمایشی San Felix Hidalgo دارای جمعیت 1628 نفر و کاهش 53.73٪ بود (جدول A3 ) .
در نهایت، از بین مکانهای آزمایشی، همبستگی قوی بین شدت ناحیه زلزله و دقت الگوریتم وجود نداشت. از هفت محل واقع در منطقه VI، دو منطقه هشدار ندادند، در حالی که از هشت محل در منطقه VII، سه منطقه هشدار ندادند ( شکل 4 ) ( جدول A4 ) ( جدول A5 ).
4. بحث
این رویکرد از دادههای PED مستعار Cuebiq برای شناسایی و تجزیه و تحلیل الگوهای حرکت پس از یک بلای طبیعی استفاده کرد. روشهای مورد استفاده در این مطالعه جریان کاری را ارائه میکنند که میتواند بهطور بالقوه به عنوان چارچوبی برای سایر بلایای طبیعی یا حوادث مشابه (مانند خشونت) که باعث مهاجرت میشوند، استفاده شود. توزیع فضایی و نفوذ بازار دادههای 2017 هنگام کار با دادههای Cuebiq PED چالشهایی را ایجاد کرد. ایجاد تعادل بین بررسی مکانهایی با ژئوفنس محکمتر و مطمئنتر و مکانهایی که ساکنان کافی برای تجزیه و تحلیل طولی داشتند دشوار بود. 15 محل کنترل و 15 محل آزمایشی تنها پس از بررسی 82 داوطلب کنترل و 38 داوطلب آزمایشی و بررسی نفوذ آنها در بازار برای دیدن اینکه آیا تأثیرات آنها قابل اندازهگیری و تجزیه و تحلیل است یا خیر، انتخاب شدند. کار با مناطق کوچکتر و روستایی بیشتر (معمولا با جمعیت کمتر از 2000 نفر) به معنای استفاده از بافرهای کوچکتر با ویژگی بیشتر در شناسایی ساکنان است – احتمال کمتری وجود داشت که افراد مثبت کاذب از افرادی که در منطقه در حال رفت و آمد به محل کار هستند و غیره مشاهده شود. ، به طور کلی ساکنان کمتری در آن مناطق وجود داشت، زیرا ضریب نفوذ تلفن همراه در مناطق روستایی کم بود. این احتمالاً در هنگام تکرار آزمایش بر روی دادههای جدیدتر مشکلی ایجاد نخواهد کرد، زیرا نشان داده است که نفوذ PED به طور مداوم در طول زمان افزایش مییابد. در سال 2019، ضریب نفوذ گوشی های هوشمند مکزیک طی سه سال 10 درصد افزایش یافت و 49.5 درصد از جمعیت را به خود اختصاص داد. بیشتر مناطق روستایی (معمولاً با جمعیت کمتر از 2000 نفر) به معنای استفاده از بافرهای کوچکتر با ویژگی بیشتر در شناسایی ساکنان است – احتمال کمتری وجود دارد که افراد مثبت کاذب از افرادی که در منطقه در حال رفت و آمد به محل کار هستند و غیره مشاهده شود. ساکنان آن مناطق به طور کلی، زیرا ضریب نفوذ تلفن همراه در مناطق روستایی کم بود. این احتمالاً در هنگام تکرار آزمایش بر روی دادههای جدیدتر مشکلی ایجاد نخواهد کرد، زیرا نشان داده است که نفوذ PED به طور مداوم در طول زمان افزایش مییابد. در سال 2019، ضریب نفوذ گوشی های هوشمند مکزیک طی سه سال 10 درصد افزایش یافت و 49.5 درصد از جمعیت را به خود اختصاص داد. بیشتر مناطق روستایی (معمولاً با جمعیت کمتر از 2000 نفر) به معنای استفاده از بافرهای کوچکتر با ویژگی بیشتر در شناسایی ساکنان است – احتمال کمتری وجود دارد که افراد مثبت کاذب از افرادی که در منطقه در حال رفت و آمد به محل کار هستند و غیره مشاهده شود. ساکنان آن مناطق به طور کلی، زیرا ضریب نفوذ تلفن همراه در مناطق روستایی کم بود. این احتمالاً در هنگام تکرار آزمایش بر روی دادههای جدیدتر مشکلی ایجاد نخواهد کرد، زیرا نشان داده است که نفوذ PED به طور مداوم در طول زمان افزایش مییابد. در سال 2019، ضریب نفوذ گوشی های هوشمند مکزیک طی سه سال 10 درصد افزایش یافت و 49.5 درصد از جمعیت را به خود اختصاص داد. زیرا ضریب نفوذ تلفن همراه در مناطق روستایی کم بود. این احتمالاً در هنگام تکرار آزمایش بر روی دادههای جدیدتر مشکلی ایجاد نخواهد کرد، زیرا نشان داده است که نفوذ PED به طور مداوم در طول زمان افزایش مییابد. در سال 2019، ضریب نفوذ گوشی های هوشمند مکزیک طی سه سال 10 درصد افزایش یافت و 49.5 درصد از جمعیت را به خود اختصاص داد. زیرا ضریب نفوذ تلفن همراه در مناطق روستایی کم بود. این احتمالاً در هنگام تکرار آزمایش بر روی دادههای جدیدتر مشکلی ایجاد نخواهد کرد، زیرا نشان داده است که نفوذ PED به طور مداوم در طول زمان افزایش مییابد. در سال 2019، ضریب نفوذ گوشی های هوشمند مکزیک طی سه سال 10 درصد افزایش یافت و 49.5 درصد از جمعیت را به خود اختصاص داد.32 ].
همچنین مسائل مربوط به جمع آوری داده ها در این رویکرد ارائه شده است. اگر یک فاجعه شدید باشد، احتمالا شبکه های مخابراتی و برق را از بین می برد. از آنجایی که PED های فعلی به شبکه مخابراتی زمینی متکی هستند، هیچ راهی برای آپلود اطلاعات خود نخواهند داشت. با ظهور صور فلکی ماهواره های ارتباطی در پایین زمین، مانند استارلینک اسپیس ایکس (starlink.com)، می توان این مشکل را کاهش داد، اما دستگاه ها همچنان بدون شبکه برق ظرف چند روز شارژ خود را از دست خواهند داد. این را می توان با منابع انرژی پراکنده مانند ژنراتورهای دیزل، پانل های خورشیدی یا ژنراتورهای بادی در مقیاس کوچک حل کرد، اما این موارد به طور گسترده در برخی مناطق کمتر توسعه یافته در دسترس نیستند.
یکی دیگر از اشکالات این مطالعه، توزیع زمانی داده ها است. از آنجایی که دادهها کمی بیش از یک ماه – 15 روز قبل از زلزله و 21 روز پس از زلزله – به طول انجامید، استفاده از یک مجموعه داده با محدوده زمانی بزرگتر احتمالاً نتایج الگوی تحلیل زندگی مورد استفاده برای شناسایی صحیح ساکنان را بهبود میبخشد. کسانی که ممکن است در سفر باشند، به طور موقت در جای دیگری کار کنند یا فقط به طور متناوب از تلفن هوشمند خود استفاده کنند. با استفاده از رویکردی که در اینجا توضیح داده شد، به طور متوسط تنها 2٪ از جمعیت یک منطقه در سال 2010 به عنوان ساکنان ردیابی شدند [ 31 ].
پس از بررسی، عناصر آینده این تحقیق می تواند شامل، اما نه محدود به، بررسی عوامل زمین شناسی و جغرافیایی باشد که می تواند در عدم نفوذ بازار نقش داشته باشد، تجزیه و تحلیل استفاده از انواع مختلف برنامه های کاربردی دستگاه های هوشمند که با Cuebiq همکاری می کنند. و معمولاً در مکزیک مورد استفاده قرار میگیرند، برای درک جمعیتشناسی کل منطقه در ارتباط با استفاده از تلفن هوشمند، و سایر شرایط موقعیتی که بر تحرک جمعیت تأثیر میگذارد اما قبلاً شناسایی نشده بود. این دلایل، فرضیههای برتر در مورد اینکه چرا الگوریتم در برخی مکانها بهتر از سایرین عمل میکند، بودند، و بررسی بیشتر میتواند بینشی بالقوه در مورد عدم نفوذ بازار و تنظیمات دقیقتری برای الگوریتم ارائه دهد.
رویکرد ارائه شده در اینجا می تواند تا امروز گسترش یابد و بر مناطق دست نخورده فعلی در مناطق در معرض خطر بلایای انسانی نظارت شود. هنگام دانلود، بارگیری در پایگاه داده و پیش پردازش داده های این ماه در منطقه مورد مطالعه ما تقریباً سه روز در سرور ویندوز 10 طول کشید. خودکارسازی فرآیند برای حذف ناکارآمدیهای ناشی از بهینهسازی گردش کار برای خروجی مجموعه دادههای موازی متفاوت در پارامترهای تجربی میتواند این فرآیند را به صورت هفتگی امکانپذیر کند. در طول عواقب یک فاجعه انسانی، دادهها میتوانند مکانهایی را که بیشترین آسیب را متحمل شدهاند مشخص کنند. علاوه بر این، این رویکرد می تواند برای عملکرد از یک دوره چند ساعته به جای یک دوره 24 ساعته اصلاح شود تا به عنوان یک مکانیسم هشدار اولیه در مورد یک فاجعه انسانی و مهاجرت دسته جمعی که ممکن است منجر شود، عمل کند. در حالی که موانعی وجود دارد، این رویکرد مقیاس پذیر است. یک تلاش مبتنی بر ابر میتواند به راحتی همه مکانها را در یک منطقه نظارت کند، مانند این مورد در مکزیک، و هر زمان که گروهبندی مکانی از محلها کاهش جمعیت سریع را تجربه کند، به کاربران هشدار میدهد.
سازمان های علاقه مند به این رویکرد می توانند حساسیت الگوریتم را متناسب با اهداف خود تغییر دهند. به عنوان مثال، در شرایطی مانند نظارت بر یک منطقه خاص در معرض خطر فاجعه، اختلاف شیب 24-٪ را می توان به -15٪ درصد تغییر داد، که این احتمال کاهش جمعیت یک منطقه را کاهش می دهد. این باعث کاهش نرخ حذف اما افزایش نرخ کمیسیون می شود. برعکس، اگر سازمانی نگران تعداد کل افراد فراری باشد، سطح هشدار را می توان به 30 درصد تغییر داد تا خطاهای کمیسیون کاهش یابد.
5. نتیجه گیری ها
در مطالعات آتی، ایجاد یک خط پایه بهتر از الگوهای زندگی محلی میتواند تغییرات هفتگی، ماهانه و سالانه را به همراه داشته باشد و دقت را به طور قابل توجهی بهبود بخشد. این با افزایش قابل توجه نفوذ بازار PED مکان و محاسبات مقیاس پذیر امکان پذیر است. علاوه بر این، با یک دوره طولانیتر داده، میتوان یک بافر سفارشی برای هر ID بر اساس حرکات معمول آنها ایجاد کرد. هنگامی که ID از آن بافر خارج می شود، به عنوان یک حرکت غیرعادی ثبت می شود. شناسه های کافی با حرکات غیرعادی در یک روز خاص می تواند نشان دهنده یک رویداد محیطی یا سیاسی غیرعادی باشد. مزیتی که این الگوریتم دارد این است که می تواند در شهرهای بزرگتر برای زمانی که ممکن است یک محله ویران شود و ساکنان به محله همسایه تغییر مکان دهند، استفاده شود. یک عیب این است که مثبت کاذب ممکن است به دلایل دیگر رخ دهد،
با در دسترس قرار گرفتن سالهای بیشتر دادهها، تعداد بیشتری از حوادث مانند موارد اضطراری بشردوستانه «برچسبهایی» برای آموزش هوش مصنوعی یا الگوریتمهای یادگیری ماشینی ارائه میدهند. این الگوریتمها موقعیتهای غیرعادی مورد علاقه را با دقت بیشتری شناسایی میکنند، مانند مکانهایی که شدیداً تحت تأثیر یک فاجعه انسانی قرار گرفتهاند. عملیاتی شدن این رویکرد احتمالاً در آینده نزدیک با افزایش جمع آوری و در دسترس بودن داده ها، بهبود پردازش کامپیوتری و زمان تقریباً واقعی امکان پذیر خواهد بود. با این حال، عملیاتی سازی مستلزم این است که داده های مکان از PED ها منتقل شوند و به یک شبکه مخابراتی فعال یا یک شبکه ارتباطی مبتنی بر فضا مانند Starlink نیاز دارد. عملیاتی شدن همچنین مستلزم آن است که PED ها بتوانند از طریق یک شبکه برق فعال یا
با افزایش ظرفیت محاسباتی و پایگاه داده رو به رشد PED در مقیاس جهانی، رویکردهایی مانند این امکان فراهم کردن روشی را برای محققان و متخصصان برای نظارت بر مناطق بزرگ در معرض خطر فاجعه انسانی فراهم می کند. قابل درک است که این رویکرد هرگز جایگزین شاهدان روی زمین نخواهد شد، بلکه به عنوان یک سیستم هشدار کم هزینه قادر به ارائه اطلاعات اضافی در مناطق فاقد اتصال است. چنین رویکردی در مناطقی که فاقد سایر ابزارهای گزارش دهی هستند (فقدان ظرفیت) یا دولت/مقامات محلی نمی خواهند اطلاعات را با جامعه بین المللی به اشتراک بگذارند (فقدان شفافیت) ارزش بیشتری خواهد داشت. امید ما این است که این تحقیق به سازمانهایی که متعهد به ارائه پاسخهای بشردوستانه اضطراری هستند کمک کند راهی برای اقدام قاطع از طریق آگاهانه،
پیوست اول

جدول A1. قبل از پیش پردازش، شناسه ها به طور متوسط 7.86 روز با رکورد داشتند. پیش پردازش بسیاری از شناسهها را با یک یا دو رکورد حذف کرد و میانگین روزهایی که شناسهها موفق شدند به 13.48 رسید.
جدول A2. در تجزیه و تحلیل نهایی از پانزده محل کنترل استفاده شد. در پردازش، 610 متر اضافی به این شعاع بافر اضافه شد تا غربالگری داده های حریم خصوصی توسط ارائه دهنده داده را در نظر بگیرد.
جدول A3. در تجزیه و تحلیل نهایی از پانزده محل آزمایشی استفاده شد که همگی از مناطق کلاس زلزله VI/VII یا بالاتر بودند. در پردازش، 610 متر اضافی به این شعاع بافر اضافه شد تا غربالگری داده های حریم خصوصی توسط ارائه دهنده داده را در نظر بگیرد.
جدول A4. شمارش ساکنان برای 30 محل برای هر یک از 37 روز مورد استفاده برای محاسبه شیب آنها قبل و بعد از زلزله ( جدول A5 ).
جدول A5. در صورتی که شیب ساکنان قبل از زلزله 24 درصد کمتر از شیب ساکنان پس از زلزله باشد، محلی خالی از سکنه تعیین شد.
منابع
- آلبرتو، ی. اوتسوبو، ام. کیوکاوا، اچ. کیوتا، تی. Towhata، I. شناسایی زلزله 2017 پوئبلا، مکزیک. خاک های یافت شده 2018 ، 58 ، 1073-1092. [ Google Scholar ] [ CrossRef ]
- زمین لرزه قدرتمند مرکز مکزیک را ویران کرد و بیش از 200 کشته بر جای گذاشت. در دسترس آنلاین: https://www.npr.org/sections/thetwo-way/2017/09/19/552141609/at-least-42-people-kiled-as-powerful-earthquake-convulses-central-mexico (دسترسی در 5 دسامبر 2019).
- بنگتسسون، ال. لو، ایکس. تورسون، ا. گارفیلد، آر. Von Schreeb, J. بهبود پاسخ به بلایا و شیوع با ردیابی جابجایی جمعیت با داده های شبکه تلفن همراه: یک مطالعه جغرافیایی پس از زلزله در هائیتی. PLoS Med. 2011 ، 8 ، e1001083. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- سحر، ل. موتوکومار، اس. فرانسوی، SP با استفاده از تصاویر هوایی و GIS در استخراج خودکار ردپای ساختمان و تشخیص شکل برای ارزیابی خطر زلزله موجودیهای شهری. IEEE Trans. Geosci. Remote Sens. 2010 , 48 , 3511–3520. [ Google Scholar ] [ CrossRef ]
- فنگ، تی. هنگ، ز. وو، اچ. فو، س. وانگ، سی. جیانگ، سی. تانگ، X. برآورد تلفات زلزله با استفاده از سنجش از دور با وضوح بالا: مطالعه موردی شهر دوجیانگیان در زلزله ونچوان می 2008. نات خطرات 2013 ، 69 ، 1577-1595. [ Google Scholar ] [ CrossRef ]
- رودناس، جی ال. گارسیا-آیلون، اس. توماس، الف. برآورد آسیب پذیری لرزه ای ساختمان ها: پیشنهاد روش شناختی برای برنامه ریزی سناریوهای ضد زلزله در مناطق شهری. Appl. علمی 2018 ، 8 ، 1208. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- حسین، ام اس; گاداگاما، CK; باتاچاریا، ی. نومادا، م. موریمورا، ن. Meguro، K. ادغام ساعت هوشمند و سیستم اطلاعات جغرافیایی (GIS) برای شناسایی بخش نجات بحرانی پس از زلزله. I. توسعه سیستم. Prog. فاجعه علمی. 2020 ، 7 ، 100116. [ Google Scholar ] [ CrossRef ]
- ینا، ر. پرادان، بی. الامری، ع. لی، سی دبلیو; پارک، اچ. ارزیابی احتمال زلزله برای شبه قاره هند با استفاده از یادگیری عمیق. چند رشته ای. رقم. انتشار Inst. Sens. 2020 , 20 , 4369. [ Google Scholar ] [ CrossRef ]
- مولدر، اف. فرگوسن، جی. Groenewegen، P. بوئرسما، ک. وولبرز، جی. پرسش از داده های بزرگ: جمع سپاری داده های بحران به سمت یک پاسخ بشردوستانه فراگیر. Big Data Soc. 2016 . [ Google Scholar ] [ CrossRef ]
- پالن، ال. هیوز، AL رسانه های اجتماعی در ارتباطات فاجعه. In Handbook of Disaster Research Handbooks of Sociology and Social Research ; Springer International Publishing AG: Cham, Switzerland, 2017; صص 497-518. [ Google Scholar ] [ CrossRef ]
- مارکس، آ. ویندیش، آر. کیم، جی اس در حال شناسایی آتشسوزیهای دهکده با صندلیهای کوچک با سرعت بالا: مطالعه موردی در ایالت راخین میانمار. Remote Sens. Appl. Soc. محیط زیست 2019 ، 14 ، 119-125. [ Google Scholar ] [ CrossRef ]
- خودکارسازی امداد در بلایای طبیعی در دسترس آنلاین: https://trajectorymagazine.com/automating-disaster-relief/ (در 2 دسامبر 2019 قابل دسترسی است).
- یو، م. یانگ، سی. لی، ی. داده های بزرگ در مدیریت بلایای طبیعی: بررسی. Geosciences 2018 , 8 , 165. [ Google Scholar ] [ CrossRef ][ Green Version ]
- صلات، ح. اسموردا، ز. Schläpfer, M. روشی برای تخمین تراکم جمعیت و مصرف برق از داده های تلفن همراه و تلفن در کشورهای در حال توسعه. PLoS ONE 2020 , 15 , e0235224. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- زفیریا، پی جی؛ کشیش-اسکوردو، دی. ابدا- مدینه، ال. هرناندز مدینه، م. Barriales-Valbuena، I.; مورالس، ای جی. ژاک، دی سی; انکوامبی، دبلیو. دیوپ، مگابایت؛ کوین، جی. و همکاران شناسایی پروفایل های تحرک فصلی از داده های تلفن همراه ناشناس و انباشته شده. کاربرد در امنیت غذایی PLoS ONE 2018 , 13 , e0195714. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لای، اس. زو ارباخ-شونبرگ، ای. پزولو، سی. روکتانونچای، ن. سوریچتا، ا. استیل، جی. لی، تی. دولی، سی. Tatem، A. بررسی استفاده از داده های تلفن همراه برای آمار مهاجرت ملی. کمون پالگریو 2019 ، 5 ، 1-10. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ویلسون، آر. زو ارباخ-شونبرگ، ای. آلبرت، ام. پاور، دی. تاج، اس. گونزالس، م. گاتری، اس. چمبرلین، اچ. بروکس، سی. هیوز، سی. و همکاران ارزیابی سریع و نزدیک به زمان واقعی جابجایی جمعیت با استفاده از داده های تلفن همراه پس از بلایا: زلزله 2015 نپال. PLoS Curr. 2016 ، 8 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کشیش-اسکوردو، دی. مورالس گوزمن، آ. تورس-فرناندز، ی. بائر، J.-M. وادهوا، ا. کاسترو کوریا، سی. رومانوف، ال. لی، جی جی; رادرفورد، ا. فریاس مارتینز، وی. و همکاران سیل از دریچه فعالیت تلفن همراه. در مجموعه مقالات کنفرانس فناوری بشردوستانه جهانی IEEE (GHTC 2014)، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 10 تا 13 اکتبر 2014. صص 279-286. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آندراد، ایکس. لایدرا، اف. واکا، سی. Cruz, E. RiSC: کمی سازی تغییرات پس از بلایای طبیعی برای برآورد آسیب زیرساخت با داده های تلفن همراه. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در مورد داده های بزرگ، سیاتل، WA، ایالات متحده، 10-13 دسامبر 2018؛ صص 3383-3391. [ Google Scholar ]
- هورانونت، تی. ویتایانگ کورن، آ. سکیموتو، ی. Shibasaki، R. تجزیه و تحلیل خودکار GPS در مقیاس بزرگ برای تغییر رفتار مشخص در طول بحران. IEEE Intell. سیستم 2013 ، 28 ، 26-34. [ Google Scholar ] [ CrossRef ]
- اوج، CM؛ وسولوفسکی، آ. زو ارباخ-شونبرگ، ای. تاتم، ای جی. وتر، ای. لو، ایکس. پاور، دی. ویدمن-گرونوالد، ای. راموس، اس. موریتز، اس. و همکاران کاهش تحرک جمعیت مرتبط با محدودیتهای سفر در طول اپیدمی ابولا در سیرالئون: استفاده از دادههای تلفن همراه. بین المللی J. Epidemiol. 2018 ، 47 ، 1562-1570. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دیده بان حقوق بشر. داده های مکان تلفن همراه و کووید-19: پرسش و پاسخ. در دسترس آنلاین: https://www.hrw.org/news/2020/05/13/mobile-location-data-and-covid-19-qa# (در 2 دسامبر 2019 قابل دسترسی است).
- یابه، تی. سکیموتو، ی. سوبوچی، ک. Ikemoto، S. تجزیه و تحلیل متقابل مقایسه ای رفتار تخلیه پس از زلزله با استفاده از داده های تلفن همراه. PLoS ONE 2019 , 14 , e0211375. [ Google Scholar ] [ CrossRef ]
- چن، ز. گونگ، ز. یانگ، اس. ما، س. کان، سی. تأثیر رویدادهای آب و هوایی شدید بر جریان انسانی شهری: چشم اندازی از داده های خدمات مبتنی بر مکان. محاسبه کنید. محیط زیست شهری. سیستم 2020 ، 83 ، 101520. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیوتو، پی. هایبرز، پی. Santillana، M. Fever و داده های تحرک نشان می دهد که فاصله گذاری اجتماعی باعث کاهش بروز بیماری های واگیر در ایالات متحده شده است. arXiv 2020 ، arXiv:2004.09911. در دسترس آنلاین: https://arxiv.org/pdf/2004.09911.pdf (دسترسی در 25 مه 2020).
- تامپسون، SA; Warzel، C. دوازده میلیون تلفن، یک مجموعه داده، حریم خصوصی صفر. 2019. در دسترس آنلاین: https://www.nytimes.com/interactive/2019/12/19/opinion/location-tracking-cell-phone.html (در 2 دسامبر 2019 قابل دسترسی است).
- برنامه Cuebiq’s Data for Good به یونیسف دادههای تحرک انسانی با دقت بالا را برای پاسخدهی بلادرنگ به اقدامات بشردوستانه ارائه میدهد. در دسترس آنلاین: https://www.bloomberg.com/press-releases/2019-09-10/cuebiq-s-data-for-good-program-provides-unicef-with-high-precision-human-mobility-data -برای پاسخگویی به انسان دوستانه در زمان واقعی (در 2 دسامبر 2019 قابل دسترسی است).
- زلزله صدها کشته برجای گذاشت، خدمه از میان آوار در مکزیک عبور کردند. در دسترس آنلاین: https://www.citynews1130.com/2017/09/20/earthquake-leaves-hundreds-dead-crews-combing-rubble-mexico/ (دسترسی در 5 اکتبر 2020).
- مرکز هماهنگی واکنش اضطراری (ERCC) – نقشه روزانه DG ECHO. در دسترس آنلاین: https://erccportal.jrc.ec.europa.eu/ercmaps/ECDM_20170920_Mexico_EQ.pdf (در 25 مه 2020 قابل دسترسی است).
- گزارش بازار جهانی موبایل Newzoo نسخه سبک. 2017. در دسترس آنلاین: https://resources.newzoo.com/hubfs/Reports/Newzoo_2017_Global_Mobile_Market_Report_Free.pdf (در 2 دسامبر 2019 قابل دسترسی است).
- Censos y Conteeos de Poblaación y Vivienda. در دسترس آنلاین: https://www.inegi.org.mx/programas/ccpv/2010/default.html#Microdatos (در 2 دسامبر 2019 قابل دسترسی است).
- گزارش بازار جهانی موبایل Newzoo 2019: نسخه سبک. Available online: https://resources.newzoo.com/hubfs/Reports/2019_Free_Global_Mobile_Market_Report.pdf?utm_campaign=Mobile%20Report%20Launch%202019&utm_medium=email&_hsmi=76926953&_hsenc=p2ANqtz-_O72fQKM2ds9C0e-CuL4yhUoFzrQCAirctfPQYeB6ab0u_Qx998l6SSv0rf4SlGCKGX3DCWTTE-lCCUesAC9RsQqXGJg&utm_content=76926953&utm_source=hs_automation (accessed on 25 می 2020).

شکل 1. تصویری از یک ساختمان ویران شده در جوجوتلا، مورلوس، یک شهر روستایی نزدیک به مرکز زلزله 2017 پوئبلا [ 28 ].
شکل 2. مسیر یک شناسه منحصربهفرد در ایالت گوئررو، مکزیک در 22 سپتامبر 2017. رنگهای روشنتر نشاندهنده نقاط مکان از اوایل روز است. این تعداد پینگ در یک روز غیرعادی است اما گویای غنای مکانی و زمانی داده ها است.
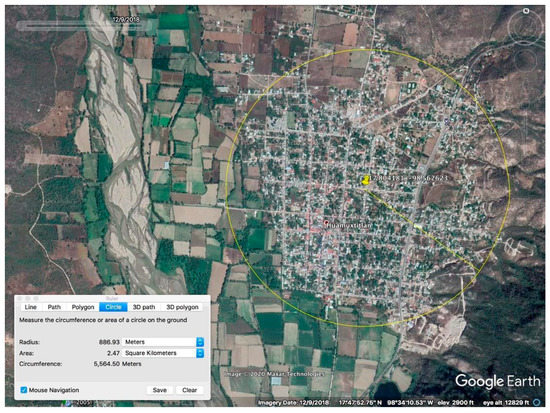
شکل 3. ژئوفنس های منحصر به فرد به صورت دستی در اطراف جوامع کنترلی و آزمایشی، مانند بافر 867 متری در اطراف Huamuxtitlán، Guerrero از Huamuxtitlán ساخته شدند.
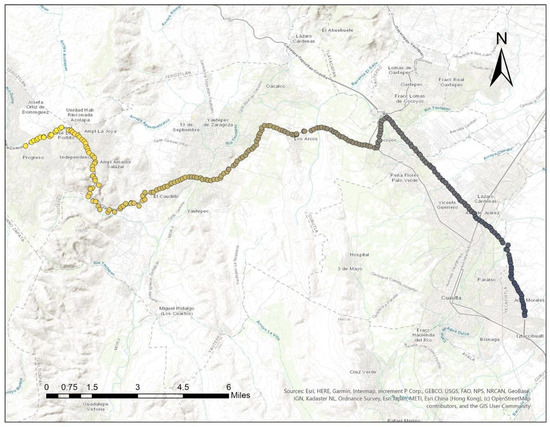
شکل 4. نقشه 15 محل آزمایشی نهایی، در دو منطقه قویترین زلزله، که در تجزیه و تحلیل نهایی برای شناسایی مکانهایی که در نتیجه زمینلرزه پوئبلا 2017 از جمعیت خالی شدهاند استفاده شد [29 ] .
شکل 5. در گردش کار تحلیلی، به دنبال geofence ( بخش 2.3 )، ساکنان روستاها ایجاد شدند ( بخش 2.4.3 ). فقط روستاهایی با حداقل 3 ساکن ( بخش 2.4.4 ) برای تشخیص اینکه آیا پس از زلزله کاهش جمعیت را تجربه کردهاند ( بخش 2.4.5 ) تجزیه و تحلیل شدند.
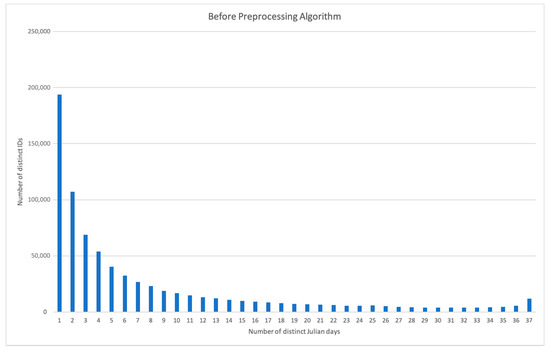
شکل 6. توزیع شناسه های منحصر به فرد و تعداد روزهایی که آنها به عنوان موجود در پایگاه داده ثبت شده اند.
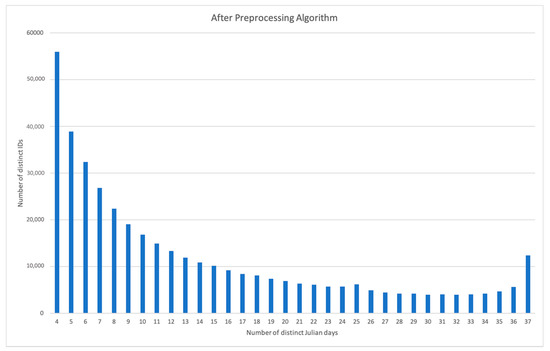
شکل 7. پیش پردازش داده ها، 369839 شناسه منحصر به فرد را حذف کرد که حداقل یک رکورد برای چهار روز منحصر به فرد قبل از زلزله نداشتند. مجموع 774343 شناسه منحصربه فرد اولیه ( شکل 6 ) به 404504 کاهش یافت.
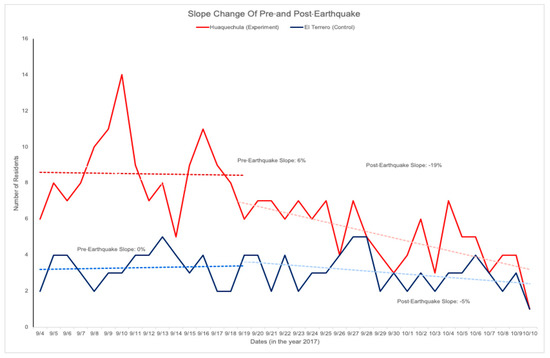
شکل 8. اگر شیب ساکنان قبل از زلزله 24 درصد کمتر از شیب ساکنان پس از زلزله باشد، این رویکرد محلی را خالی از سکنه تشخیص داد. در این شکل، منطقه آزمایشی Huaquechula دارای درصد ثابتی از ساکنان (6٪ شیب) قبل از زلزله بود، اما شاهد کاهش مداوم ساکنان پس از زلزله (-19٪) بود، در حالی که محل کنترل El Terrero درصد ثابتی از خود را حفظ کرد. ساکنین قبل از (0٪) و پس از (-5٪).
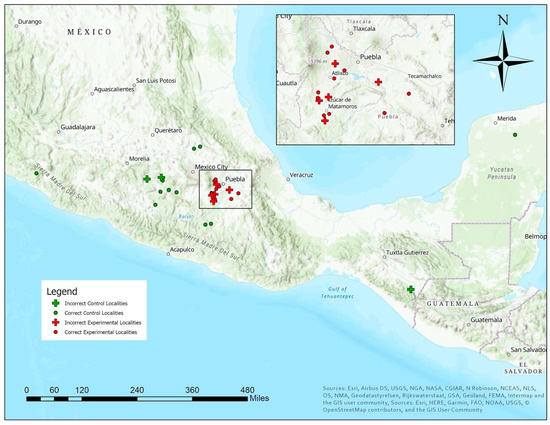
شکل 9. نقشه 15 محل کنترل و 15 محل تجربی. نماد بعلاوه کنترل نادرست یا مکان های آزمایشی را نشان می دهد.


بدون دیدگاه